LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
28643411").show
```
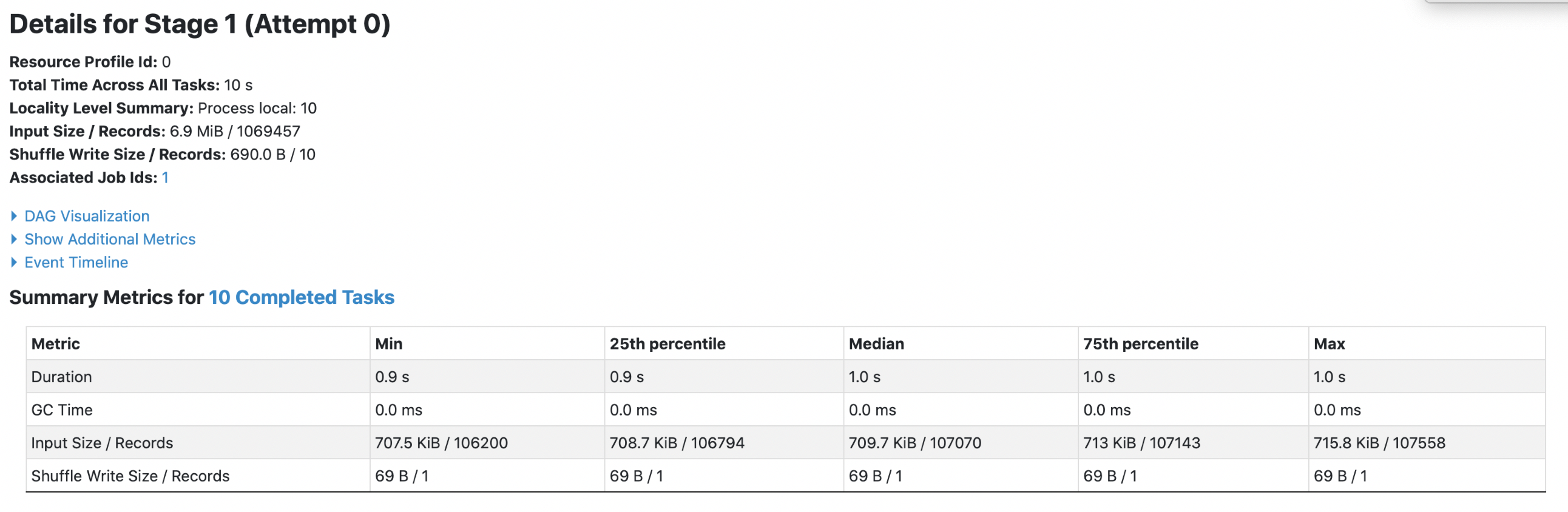
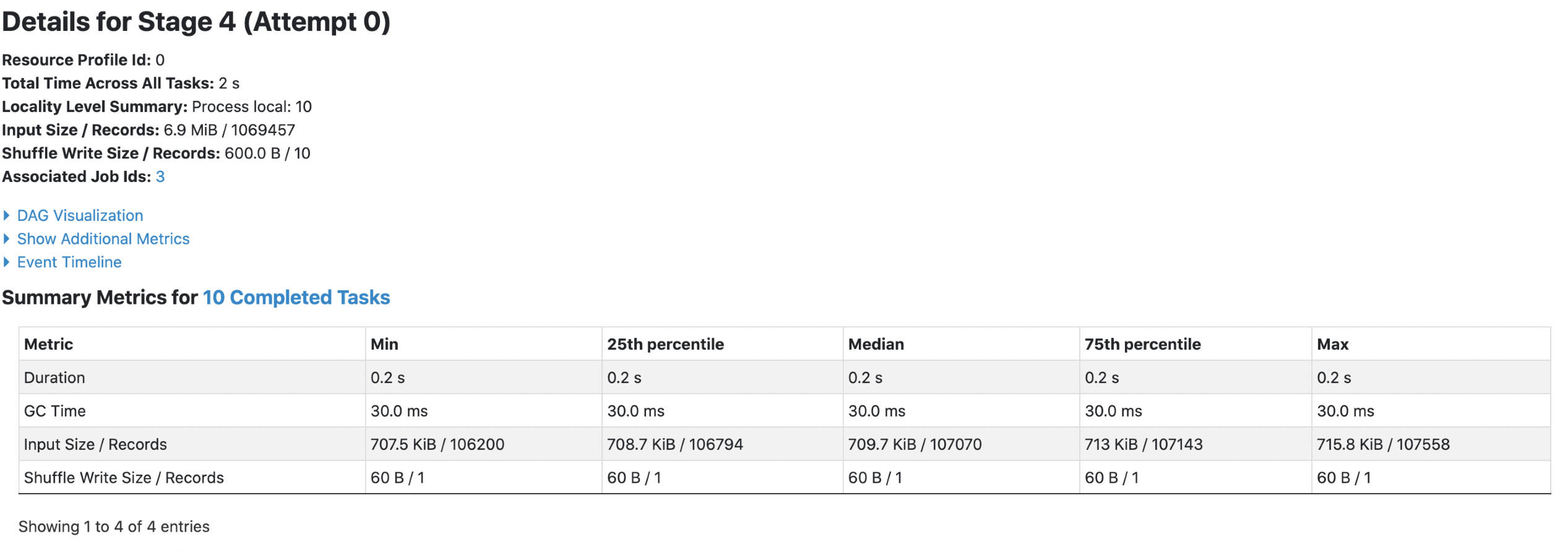
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`
**Each footer was read 4 times, both queries read 6.9m data.**
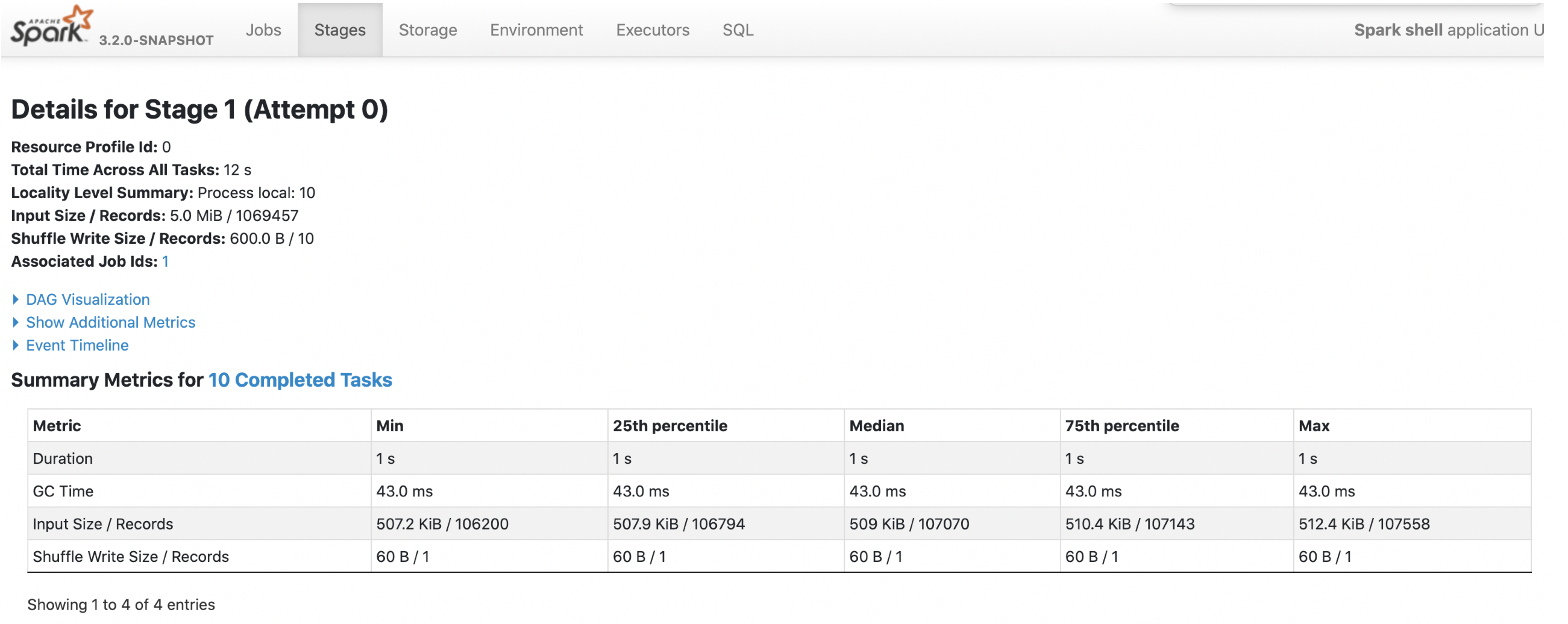
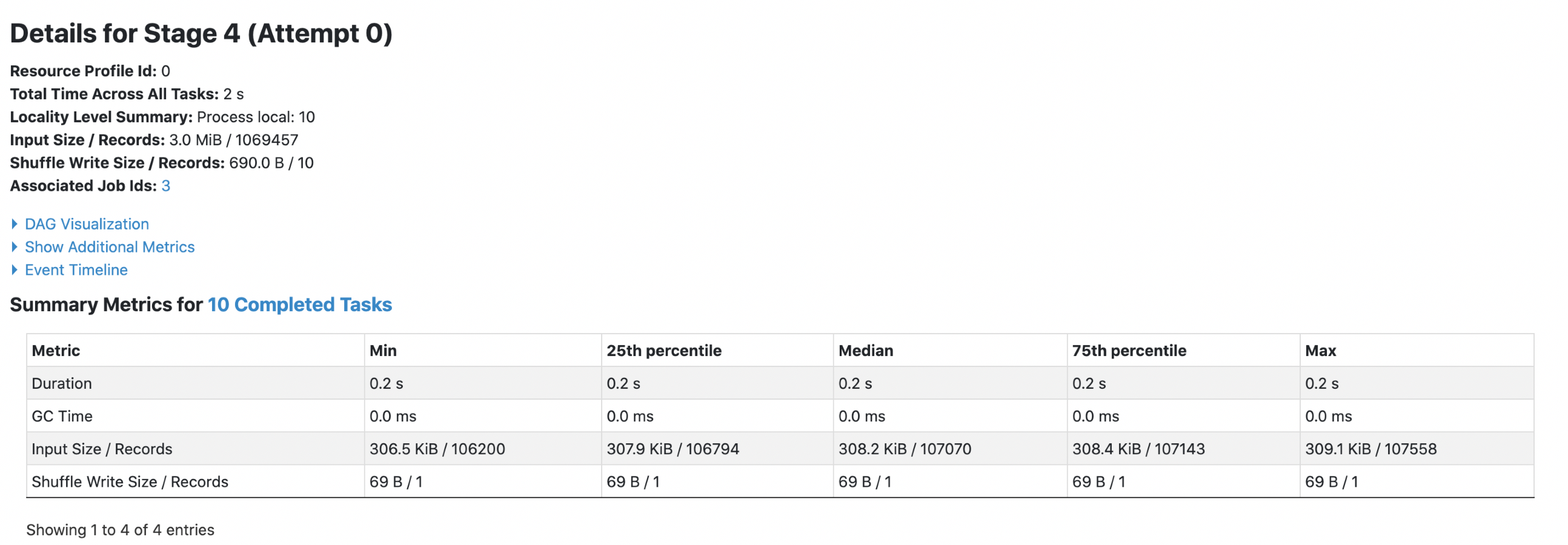
2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`
**Each footer was read 1 times, 1st query read 5m data and 2nd query read 3m
data.**
3. orc with `spark.sql.fileMetaCache.orc.enabled =false`
**Each footer was read 4 times, both queries read 52.3m data.**
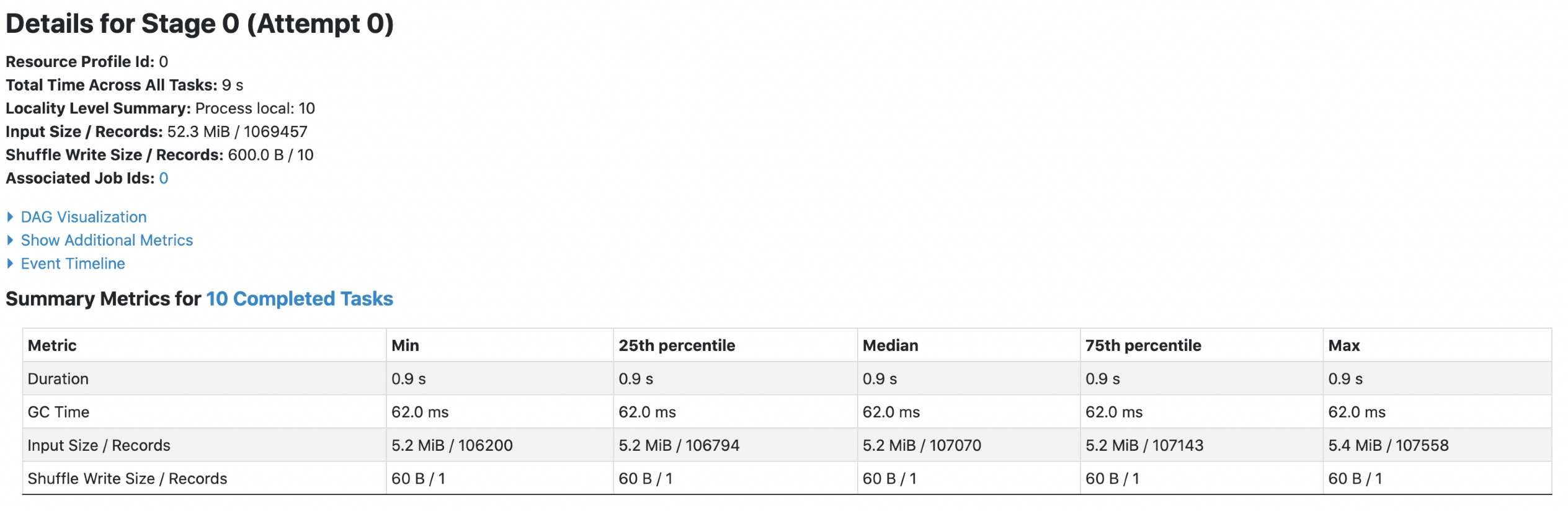
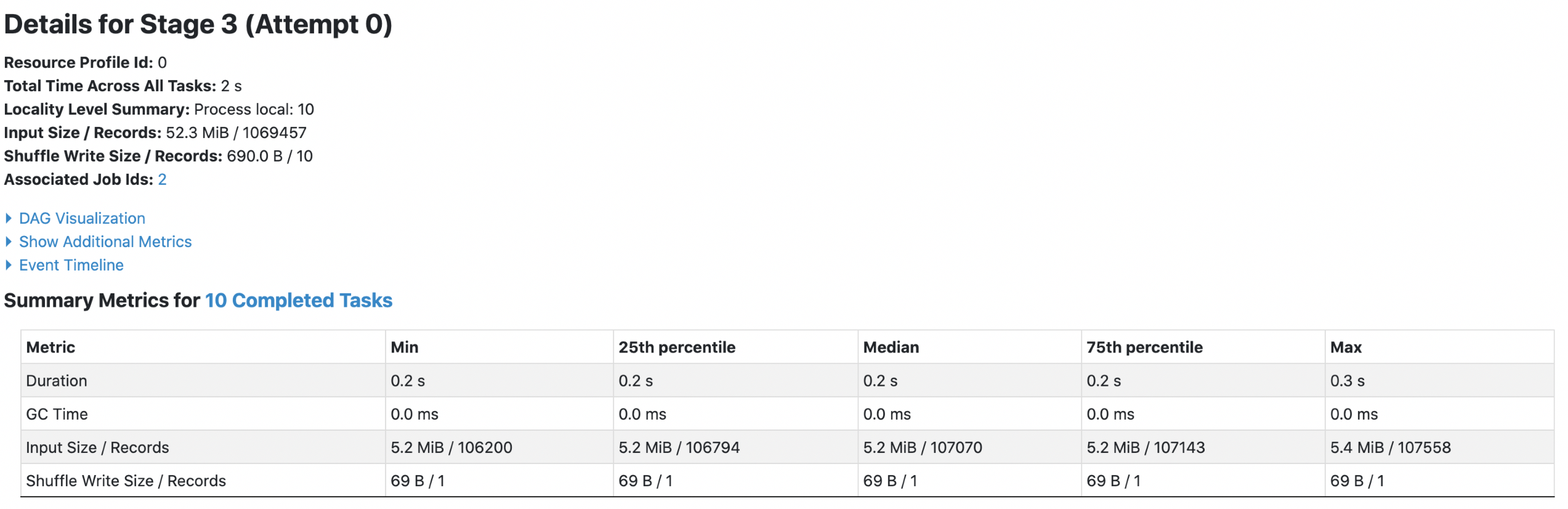
4. orc with `spark.sql.fileMetaCache.orc.enabled =true`
**Each footer was read 1 times, 1st query read 45.5m data and 2nd query read
38.7m data.**
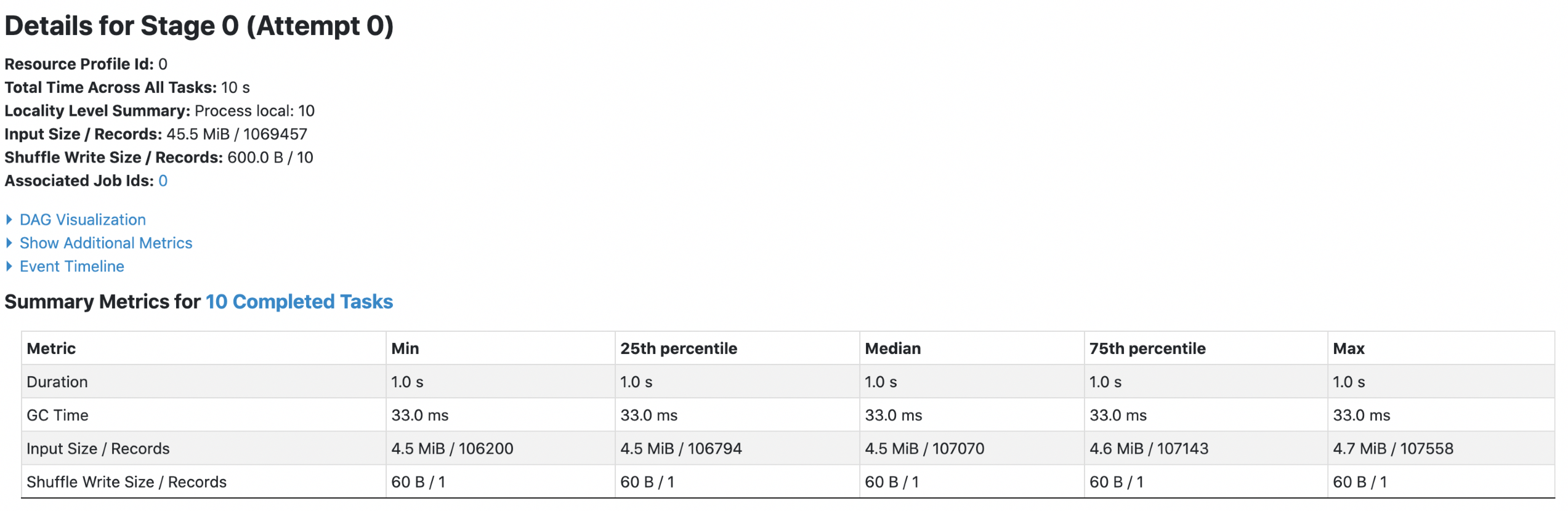
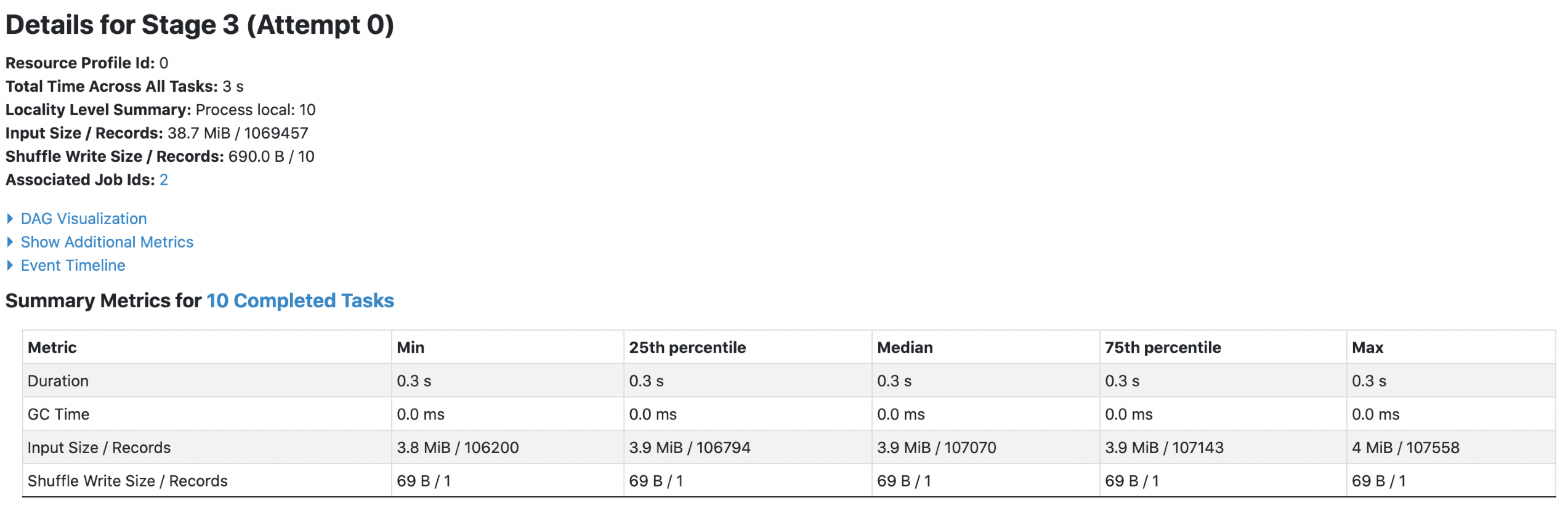
DataSource V2 API has similar results.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}