LuciferYang commented on a change in pull request #29542:
URL: https://github.com/apache/spark/pull/29542#discussion_r581690994
##########
File path:
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -92,67 +88,23 @@
public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
- ParquetInputSplit split = (ParquetInputSplit)inputSplit;
+ FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
- long[] rowGroupOffsets = split.getRowGroupOffsets();
-
- ParquetMetadata footer;
- List<BlockMetaData> blocks;
- // if task.side.metadata is set, rowGroupOffsets is null
- if (rowGroupOffsets == null) {
- // then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(),
split.getEnd()));
- MessageType fileSchema = footer.getFileMetaData().getSchema();
- FilterCompat.Filter filter = getFilter(configuration);
- blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
- } else {
- // SPARK-33532: After SPARK-13883 and SPARK-13989, the parquet read
process will
- // no longer enter this branch because `ParquetInputSplit` only be
constructed in
- // `ParquetFileFormat.buildReaderWithPartitionValues` and
- // `ParquetPartitionReaderFactory.buildReaderBase` method,
- // and the `rowGroupOffsets` in `ParquetInputSplit` set to null
explicitly.
- // We didn't delete this branch because PARQUET-131 wanted to move this
to the
- // parquet-mr project.
- // otherwise we find the row groups that were selected on the client
- footer = readFooter(configuration, file, NO_FILTER);
- Set<Long> offsets = new HashSet<>();
- for (long offset : rowGroupOffsets) {
- offsets.add(offset);
- }
- blocks = new ArrayList<>();
- for (BlockMetaData block : footer.getBlocks()) {
- if (offsets.contains(block.getStartingPos())) {
- blocks.add(block);
- }
- }
- // verify we found them all
- if (blocks.size() != rowGroupOffsets.length) {
- long[] foundRowGroupOffsets = new long[footer.getBlocks().size()];
- for (int i = 0; i < foundRowGroupOffsets.length; i++) {
- foundRowGroupOffsets[i] = footer.getBlocks().get(i).getStartingPos();
- }
- // this should never happen.
- // provide a good error message in case there's a bug
- throw new IllegalStateException(
- "All the offsets listed in the split should be found in the file."
- + " expected: " + Arrays.toString(rowGroupOffsets)
- + " found: " + blocks
- + " out of: " + Arrays.toString(foundRowGroupOffsets)
- + " in range " + split.getStart() + ", " + split.getEnd());
- }
- }
- this.fileSchema = footer.getFileMetaData().getSchema();
- Map<String, String> fileMetadata =
footer.getFileMetaData().getKeyValueMetaData();
+ ParquetReadOptions options = HadoopReadOptions
+ .builder(configuration)
+ .withRange(split.getStart(), split.getStart() + split.getLength())
Review comment:
@sunchao @HyukjinKwon I think build `ParquetReadOptions` should add
`.withRecordFilter(ParquetInputFormat.getFilter(configuration))` to ensure that
the filter is pushed down because `recordFilter` is obtained from
`ParquetReadOptions` in `ParquetFileReader#filterRowGroups` method in Parquet
1.11.
```
ParquetReadOptions options = HadoopReadOptions
.builder(configuration)
.withRecordFilter(ParquetInputFormat.getFilter(configuration))
.withRange(split.getStart(), split.getStart() + split.getLength())
.build();
```
1.11.1:
https://github.com/apache/parquet-mr/blob/765bd5cd7fdef2af1cecd0755000694b992bfadd/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L784-L802
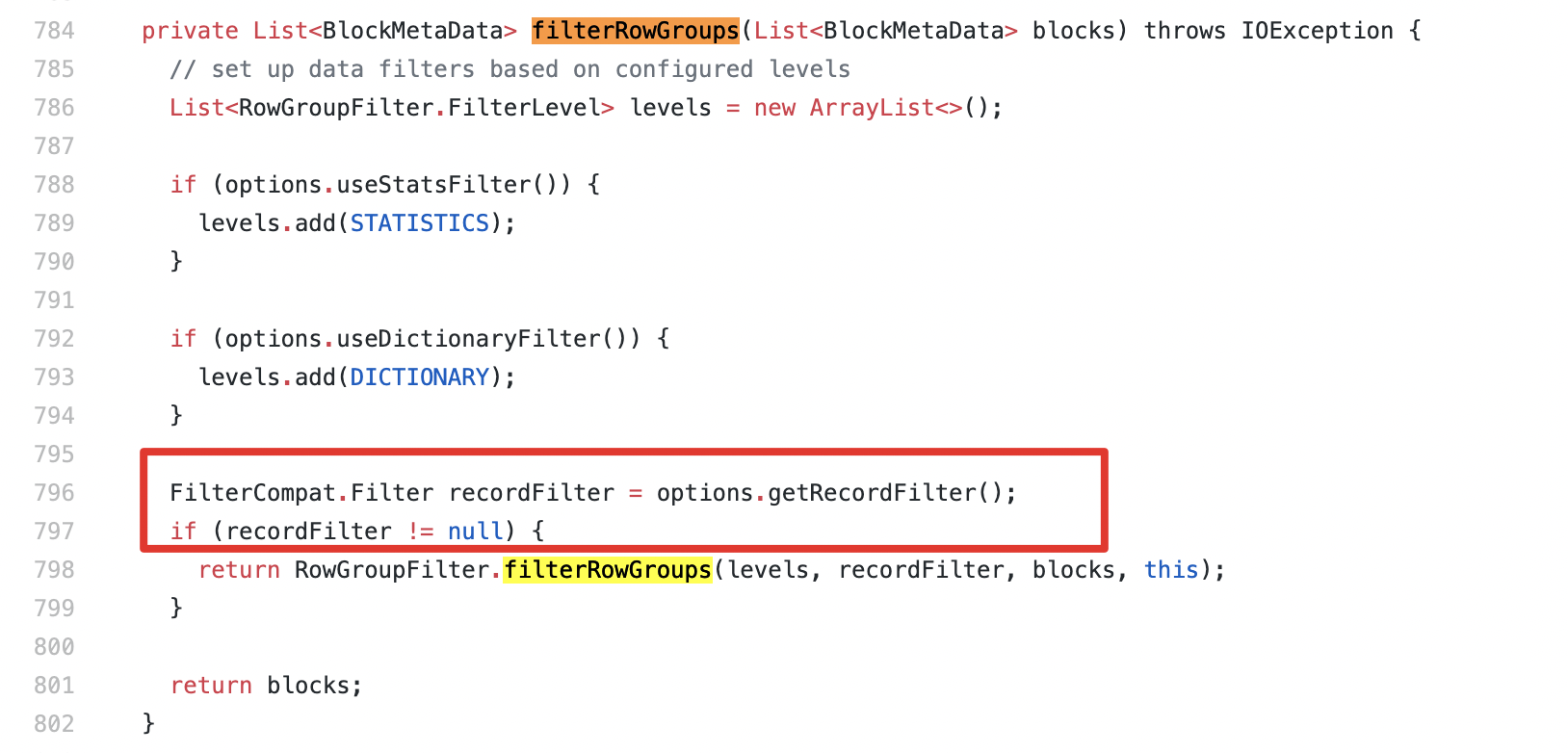
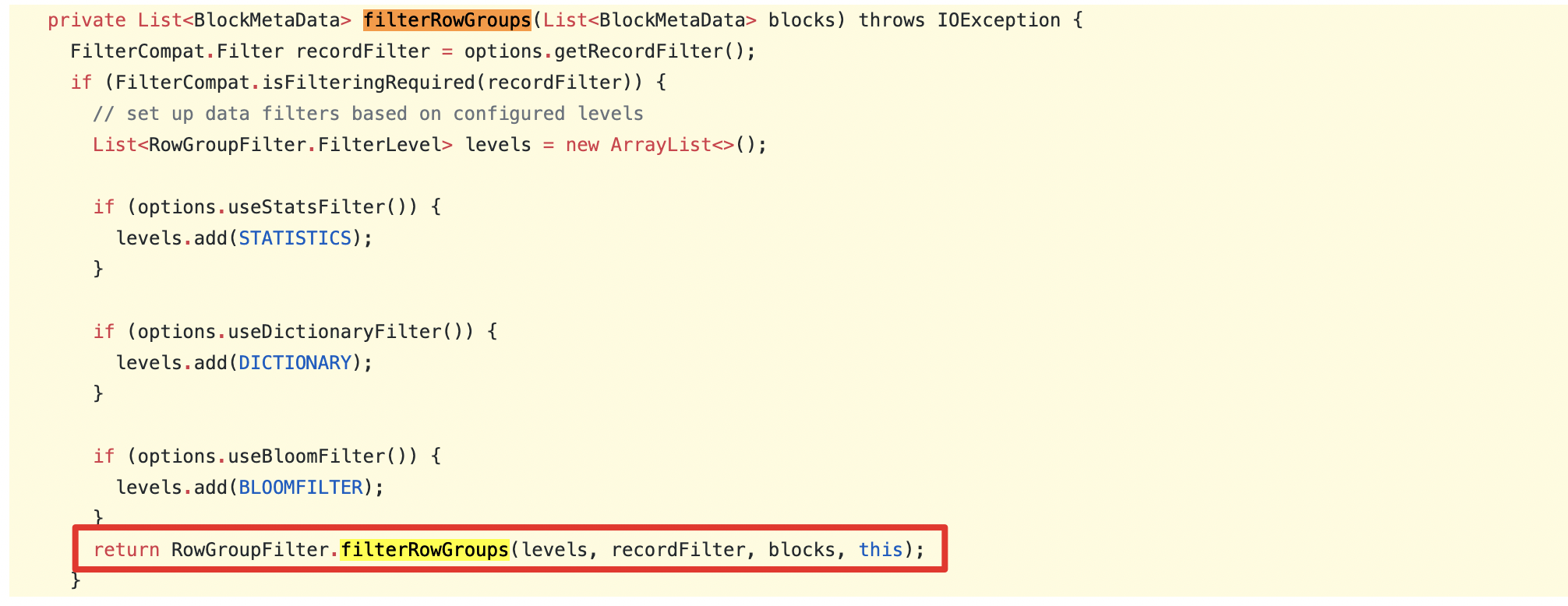
This logic is different from the master code of Apache Parquet:
https://github.com/apache/parquet-mr/blob/ab402f84e956d17ab67b63f91d01c63a92e7ae1e/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L853-L871
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}