AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605575398
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [
FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse,
product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and
`CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
> Can we describe the behavior with documents instead of examples? We
can also take a look at how other databases document this feature.
Oracle document
https://docs.oracle.com/cd/E11882_01/server.112/e25554/aggreg.htm#DWHSG8612
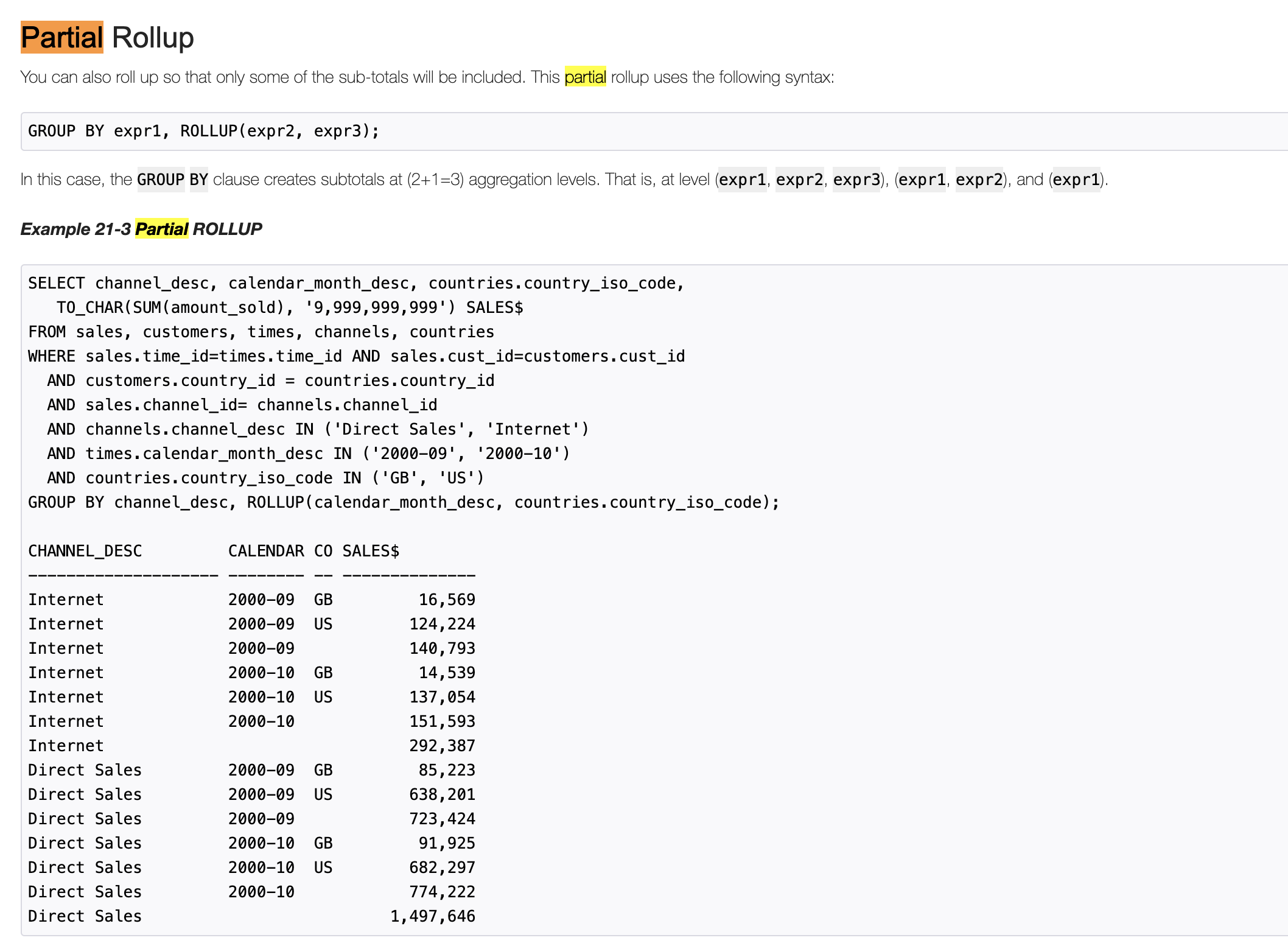
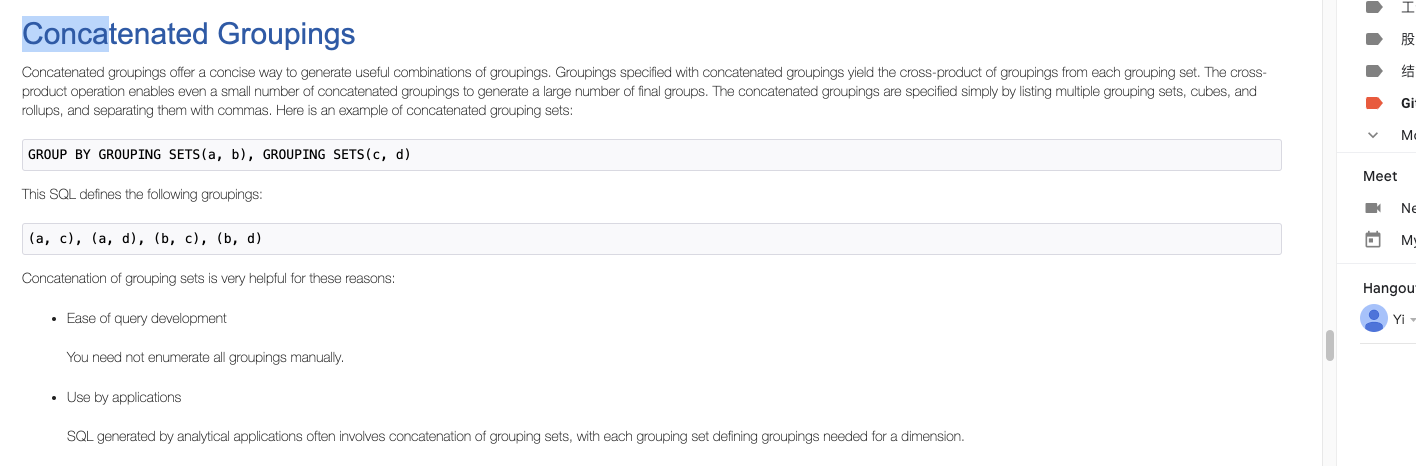
All have an example data then demo sql and result.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}