JkSelf commented on a change in pull request #31756:
URL: https://github.com/apache/spark/pull/31756#discussion_r629918664
##########
File path:
sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
##########
@@ -1463,6 +1474,37 @@ abstract class DynamicPartitionPruningSuiteBase
}
}
}
+
+ test("SPARK-34637: test DPP side broadcast query stage is created firstly") {
+ withSQLConf(SQLConf.DYNAMIC_PARTITION_PRUNING_REUSE_BROADCAST_ONLY.key ->
"true") {
+ val df = sql(
+ """ WITH view1 as (
+ | SELECT f.store_id FROM fact_stats f WHERE f.units_sold = 70
group by f.store_id
+ | )
+ |
+ | SELECT * FROM view1 v1 join view1 v2 WHERE v1.store_id =
v2.store_id
+ """.stripMargin)
+
+ // A possible resulting query plan:
+ // BroadcastHashJoin
+ // +- HashAggregate
+ // +- ShuffleQueryStage
+ // +- Exchange
+ // +- HashAggregate
+ // +- Filter
+ // +- FileScan
+ // Dynamicpruning Subquery
Review comment:
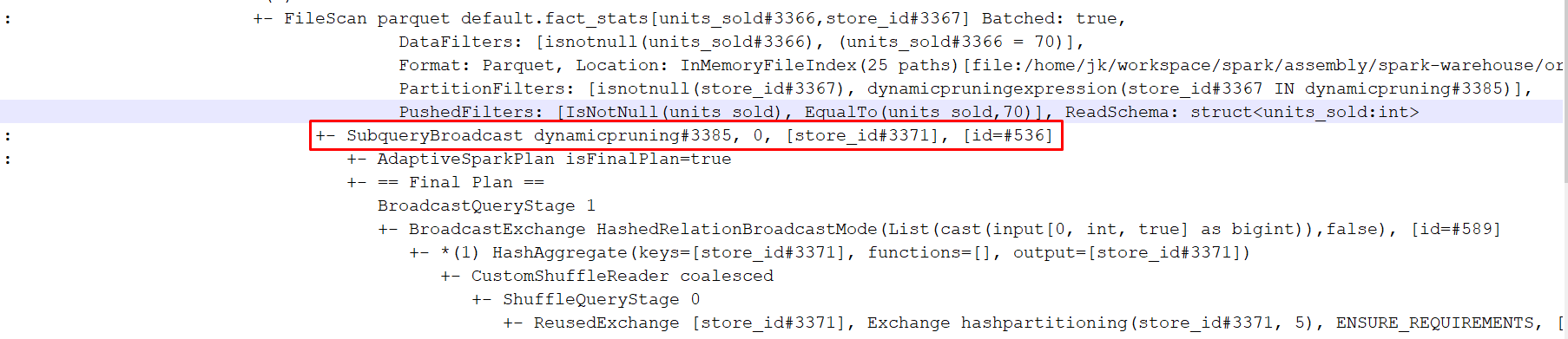
Yes. In this case, it looks like the following:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}