ulysses-you commented on pull request #32683: URL: https://github.com/apache/spark/pull/32683#issuecomment-852188051
@maropu After taking a deep look, I think it's about compression ratio that the extreme case @JkSelf metioned above. Here is some pictures of `q72`. We can see the 60MB data contains 4.9million rows. 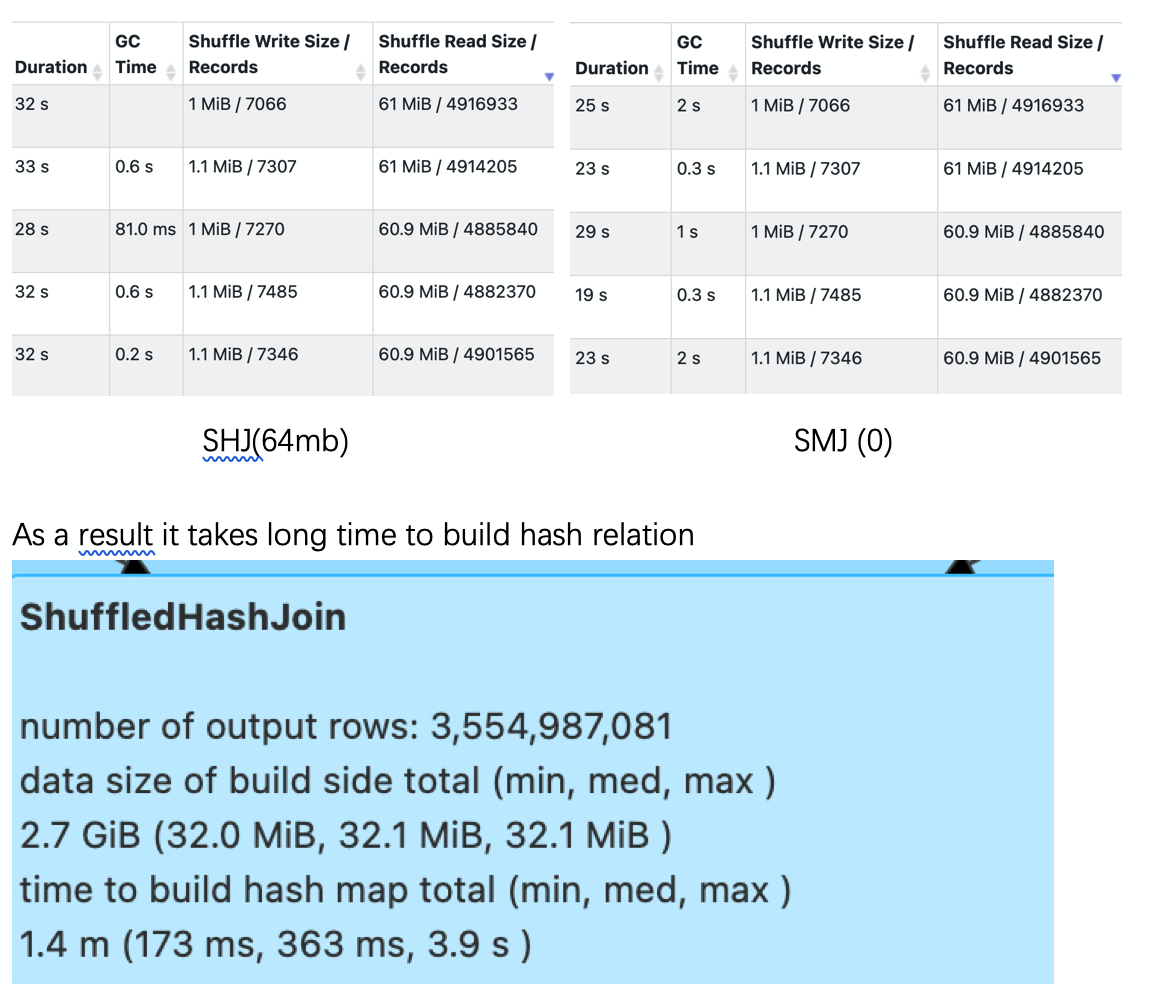 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}