akpatnam25 opened a new pull request #33643:
URL: https://github.com/apache/spark/pull/33643
### What changes were proposed in this pull request?
1. Move final iteration of aggregation of RDD.treeAggregate to an executor
with one partition and fetch that result to the driver
### Why are the changes needed?
1. RDD.fold pulls all shuffle partitions to the driver to merge the result
a. Driver becomes a single point of failure in the case that there are a
lot of partitions to do the final aggregation on
2. Shuffle machinery at executors is much more robust/fault tolerant
compared to fetching results to driver.
### Does this PR introduce _any_ user-facing change?
The previous behavior always did the final aggregation in the driver. The
user can now (optionally) provide a boolean config (default = false)
`ENABLE_EXECUTOR_TREE_AGGREGATE` to do that final aggregation in a single
partition executor before fetching the results to the driver. The only
additional cost is that the user will see an extra stage in their job.
### How was this patch tested?
<!--
This patch was tested via unit tests, and also tested on a cluster.
The screenshots showing the extra stage on a cluster are attached below
(before vs after).
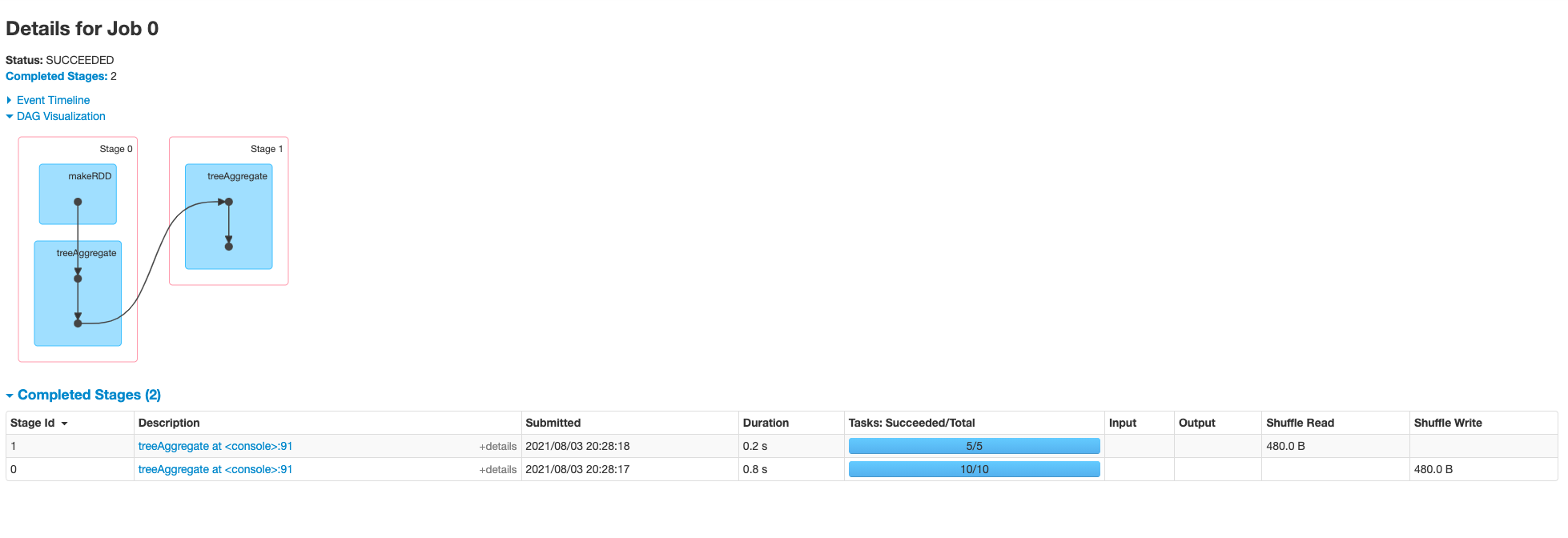
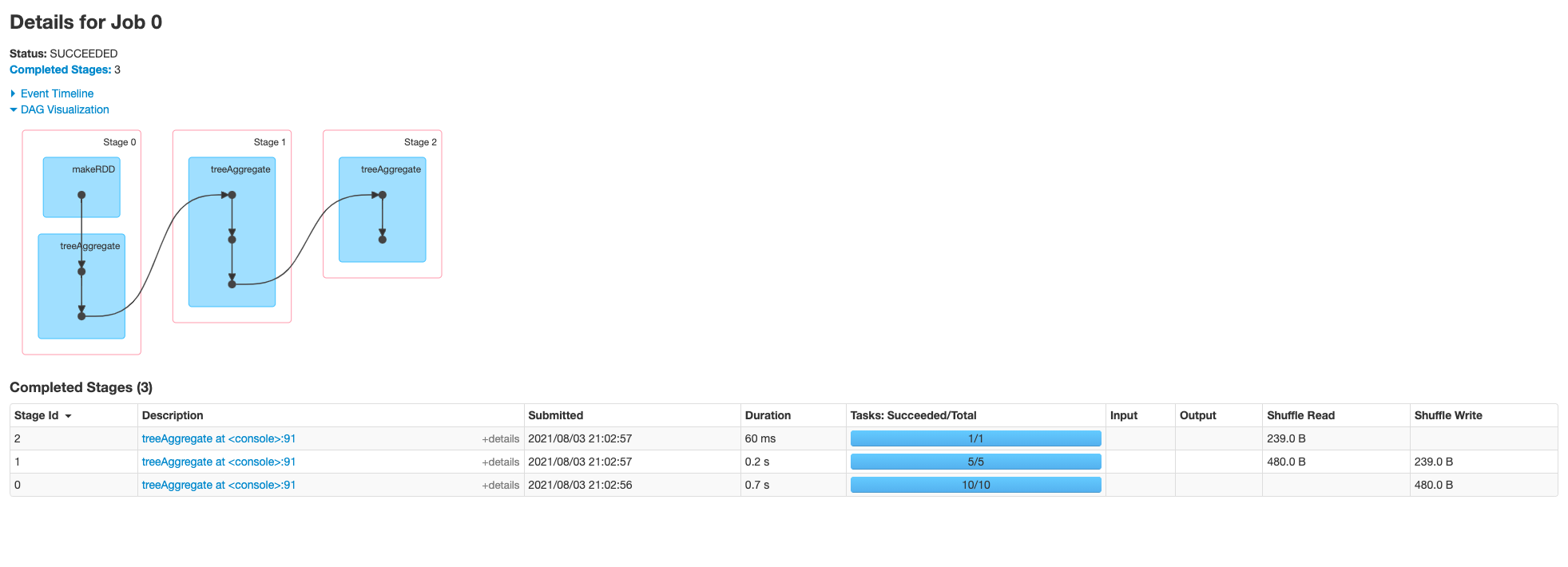
-->
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}