wangyum commented on a change in pull request #34291:
URL: https://github.com/apache/spark/pull/34291#discussion_r736584812
##########
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2ScanRelationPushDown.scala
##########
@@ -225,6 +225,37 @@ object V2ScanRelationPushDown extends Rule[LogicalPlan]
with PredicateHelper {
withProjection
}
+ def applyLimit(plan: LogicalPlan): LogicalPlan = plan.transform {
+ case globalLimit @ GlobalLimit(_, l @
LocalLimit(IntegerLiteral(limitValue), child)) =>
Review comment:
It seems`fetchsize=-2147483648` means enable streaming mode:
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-implementation-notes.html
```shell
bin/spark-shell --queue default --conf
spark.sql.catalog.mysql=org.apache.spark.sql.execution.datasources.v2.jdbc.JDBCTableCatalog
--conf spark.sql.catalog.mysql.driver=com.mysql.jdbc.Driver --conf
"spark.sql.catalog.mysql.url=jdbc:mysql://ipToMySQL:3306/mydb?user=userName&password=mypasswd"
--conf spark.sql.catalog.mysql.pushDownLimit=false --conf
spark.sql.catalog.mysql.fetchsize=-2147483648
```
This is benchmark result:
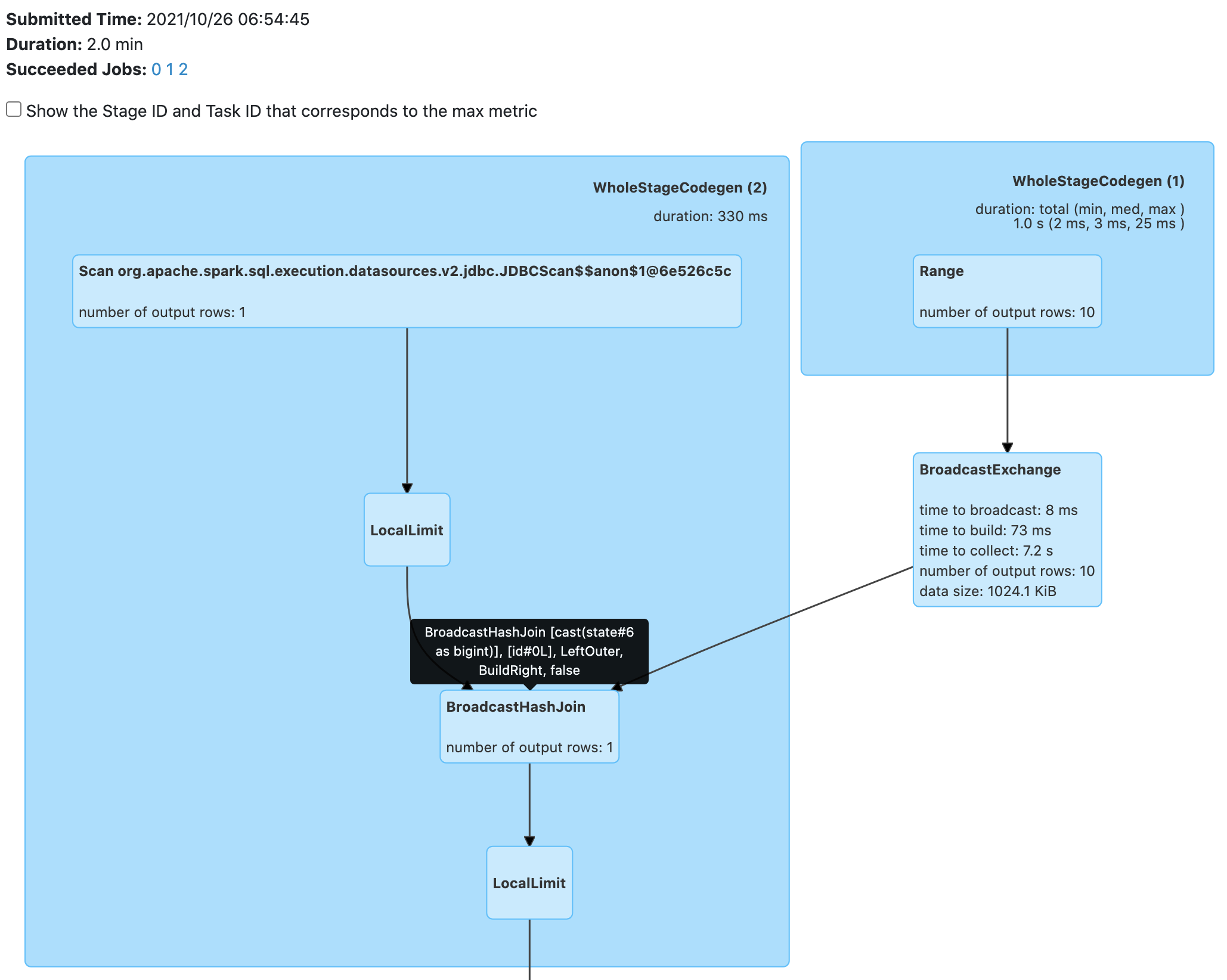
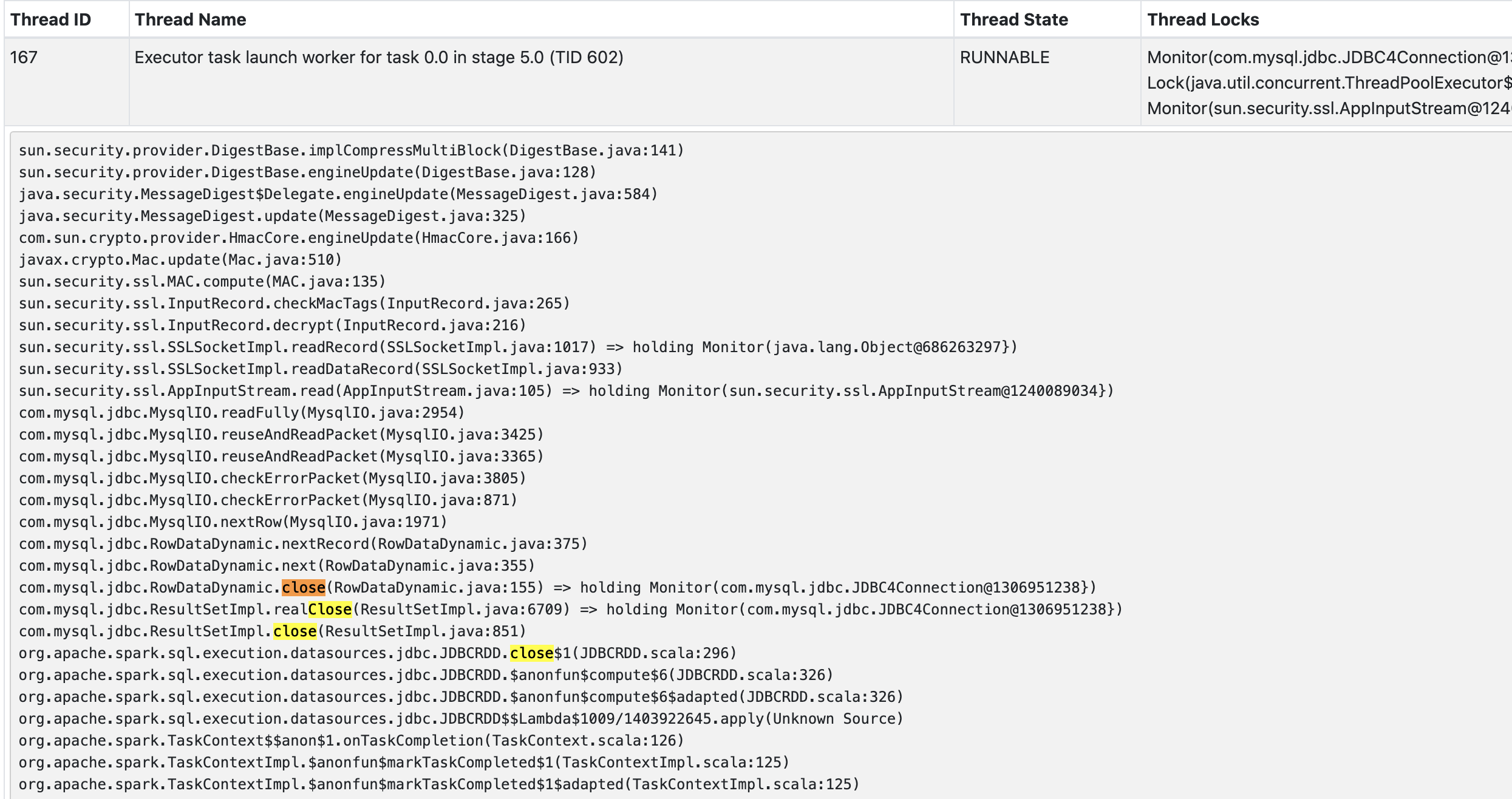
`close()` took lot of time.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}