Yikun opened a new pull request #34456: URL: https://github.com/apache/spark/pull/34456
### What changes were proposed in this pull request? `PodGroup` is a group of pods with strong association and is mainly used in batch scheduling, is of a Custom Resource Definition (CRD) type in Kubernetes, PodGroup concept which was approved by Kuberentes community in [KEP-583 Coscheduling](https://github.com/kubernetes/enhancements/tree/master/keps/sig-scheduling/583-coscheduling). 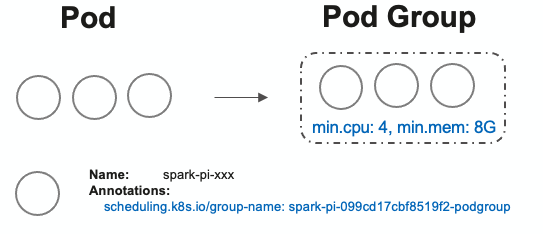 This patch adds the PodGroup support for Kuberentes: - Add PodGroup configuration: Introduce configurations to enable PodGroup support: `spark.kubernetes.enablePodGroup`, and also adds two configurations (`spark.kubernetes.podgroup.min.[cpu|memory]`) to helps user specifing min CPU and min Memory for a PodGroup. - Add Volcano implementaions: if user specify the spark k8s scheduler as `volcano`, will create the PodGroup with minReousrce requirement in Volcano automically, If available resources in the cluster cannot satisfy the requirement, no pod in the PodGroup will be scheduled. - Driver/Executor pod would be labeled with `scheduling.k8s.io/group-name` key and value s"${kubernetesConf.resourceNamePrefix}-podgroup". Such as, user can use below configuration to request a group of pods with 4 CPU/ 8G Mem as min requirement, the volcano will help user create these pods if the meet the min requirement (4 CPUU, 8G Mem), If available resources in the cluster cannot satisfy the requirement, no pod in the PodGroup will be scheduled. ``` --conf spark.kubernetes.driver.scheduler.name=volcano \ --conf spark.kubernetes.enablePodGroup=true \ --conf spark.kubernetes.podgroup.min.cpu=4 \ --conf spark.kubernetes.podgroup.min.cpu=8G \ ``` ### Why are the changes needed? Provide feature to request minimum resources before scheduling jobs. ### Does this PR introduce _any_ user-facing change? Yes, add podgroup related configuration. ### How was this patch tested? - UT - e2e test: ```shell # Setup K8S minikube start --cpus 3 --memory 4096 kubectl create serviceaccount spark kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark:spark --namespace=spark # Setup Volcano kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml # Submit job bin/spark-submit \ --master k8s://https://127.0.0.1:6443 \ --deploy-mode cluster \ --conf spark.kubernetes.driver.scheduler.name=volcano \ --conf spark.kubernetes.enablePodGroup=true \ --conf spark.executor.instances=1 \ --conf spark.kubernetes.namespace=default \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.kubernetes.container.image=spark:latest \ --class org.apache.spark.examples.SparkPi \ --name spark-pi \ local:///opt/spark/examples/jars/spark-examples_2.12-3.3.0-SNAPSHOT.jar ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}