guiyanakuang commented on a change in pull request #34743:
URL: https://github.com/apache/spark/pull/34743#discussion_r762424949
##########
File path: core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
##########
@@ -259,21 +259,29 @@ private[spark] class TaskSetManager(
loc match {
case e: ExecutorCacheTaskLocation =>
pendingTaskSetToAddTo.forExecutor.getOrElseUpdate(e.executorId, new
ArrayBuffer) += index
+ pendingTaskSetToAddTo.forHost.getOrElseUpdate(loc.host, new
ArrayBuffer) += index
case e: HDFSCacheTaskLocation =>
val exe = sched.getExecutorsAliveOnHost(loc.host)
exe match {
case Some(set) =>
for (e <- set) {
pendingTaskSetToAddTo.forExecutor.getOrElseUpdate(e, new
ArrayBuffer) += index
}
+ pendingTaskSetToAddTo.forHost.getOrElseUpdate(loc.host, new
ArrayBuffer) += index
logInfo(s"Pending task $index has a cached location at ${e.host}
" +
", where there are executors " + set.mkString(","))
case None => logDebug(s"Pending task $index has a cached location
at ${e.host} " +
", but there are no executors alive there.")
}
- case _ =>
+ case _: HostTaskLocation =>
+ val exe = sched.getExecutorsAliveOnHost(loc.host)
+ exe match {
+ case Some(_) =>
+ pendingTaskSetToAddTo.forHost.getOrElseUpdate(loc.host, new
ArrayBuffer) += index
+ case _ => logDebug(s"Pending task $index has a location at
${loc.host} " +
+ ", but there are no executors alive there.")
+ }
}
- pendingTaskSetToAddTo.forHost.getOrElseUpdate(loc.host, new ArrayBuffer)
+= index
Review comment:
> b) If a task is not run at one level, it would at the next level -
after a modest delay which is configurable.
It does not result in task never getting executed.
Add some spark ui screenshots, I reproduce the situation, The task is very
light, 100,000 rows of data computing count
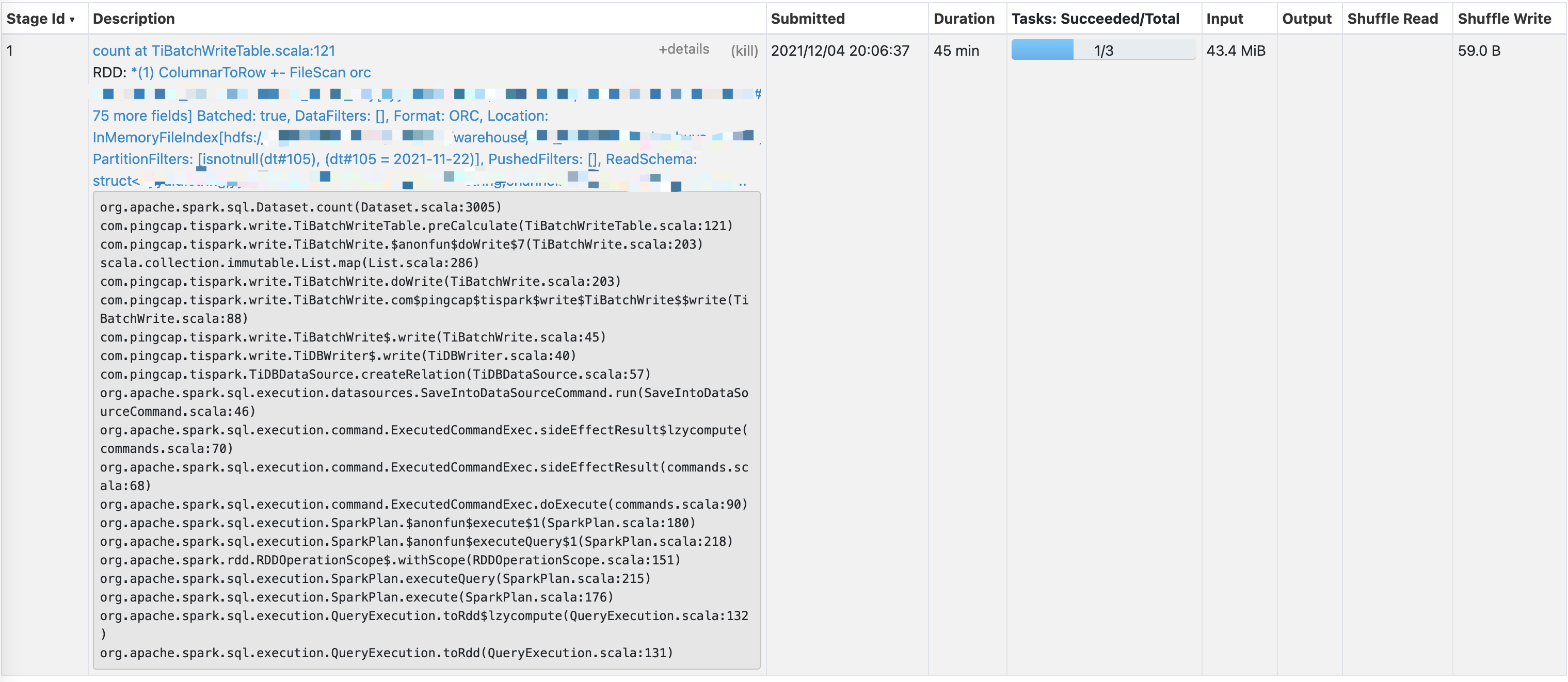

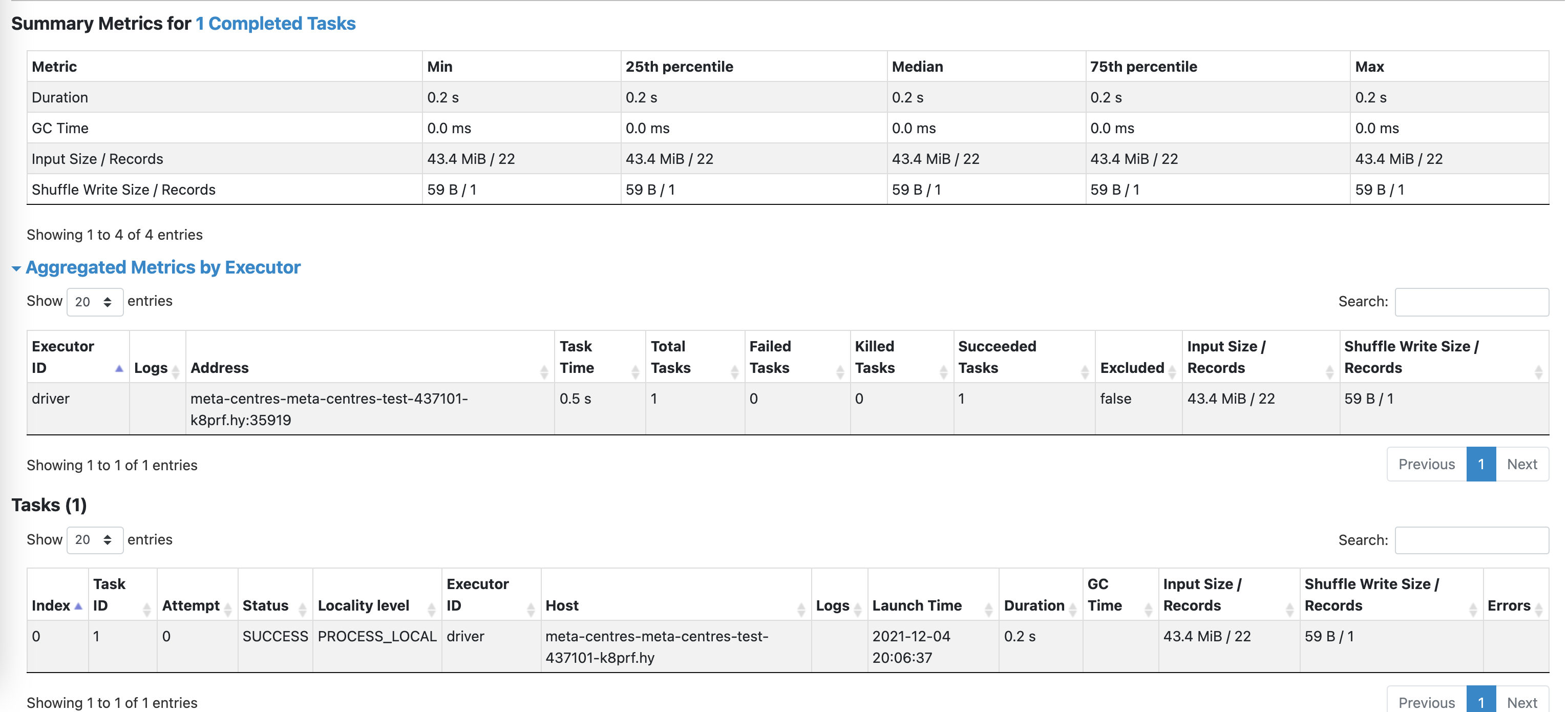
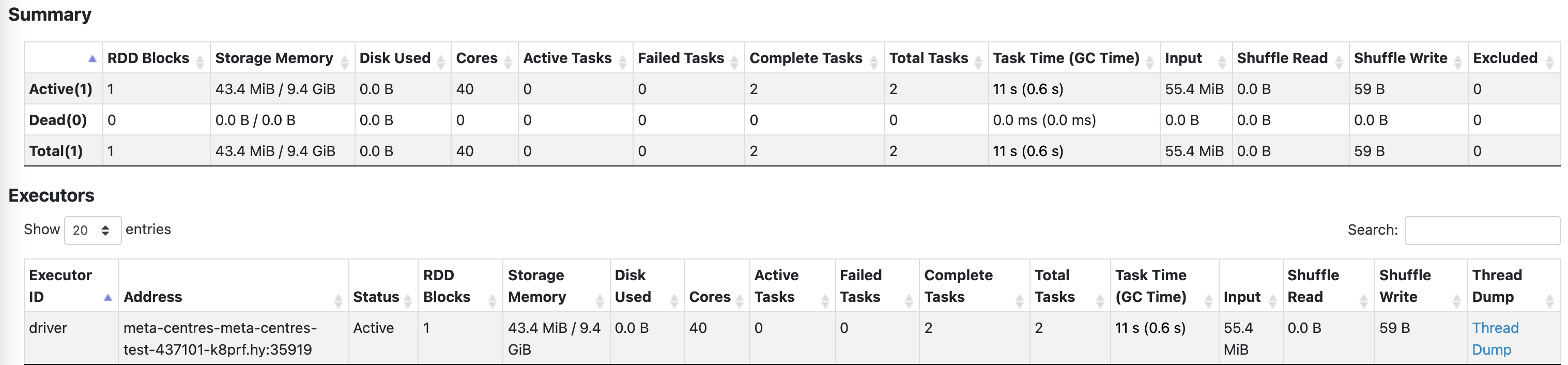
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}