zhengruifeng commented on a change in pull request #33893:
URL: https://github.com/apache/spark/pull/33893#discussion_r805618329
##########
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala
##########
@@ -2476,11 +2703,10 @@ class AdaptiveQueryExecSuite
"UNION ALL SELECT key2 FROM skewData2 GROUP BY key2", 1, 1)
// skewJoin1 union (skewJoin2 join aggregate)
- // skewJoin2 will lead to extra shuffles, but skew1 cannot be optimized
checkSkewJoin(
"SELECT key1 FROM skewData1 JOIN skewData2 ON key1 = key2 UNION ALL
" +
"SELECT key1 from (SELECT key1 FROM skewData1 JOIN skewData2 ON
key1 = key2) tmp1 " +
- "JOIN (SELECT key2 FROM skewData2 GROUP BY key2) tmp2 ON key1 =
key2", 3, 0)
+ "JOIN (SELECT key2 FROM skewData2 GROUP BY key2) tmp2 ON key1 =
key2", 3, 3)
Review comment:
this newly added skew test case can be optimized by this PR without
extra shuffle:
Master | this PR
--- | ---
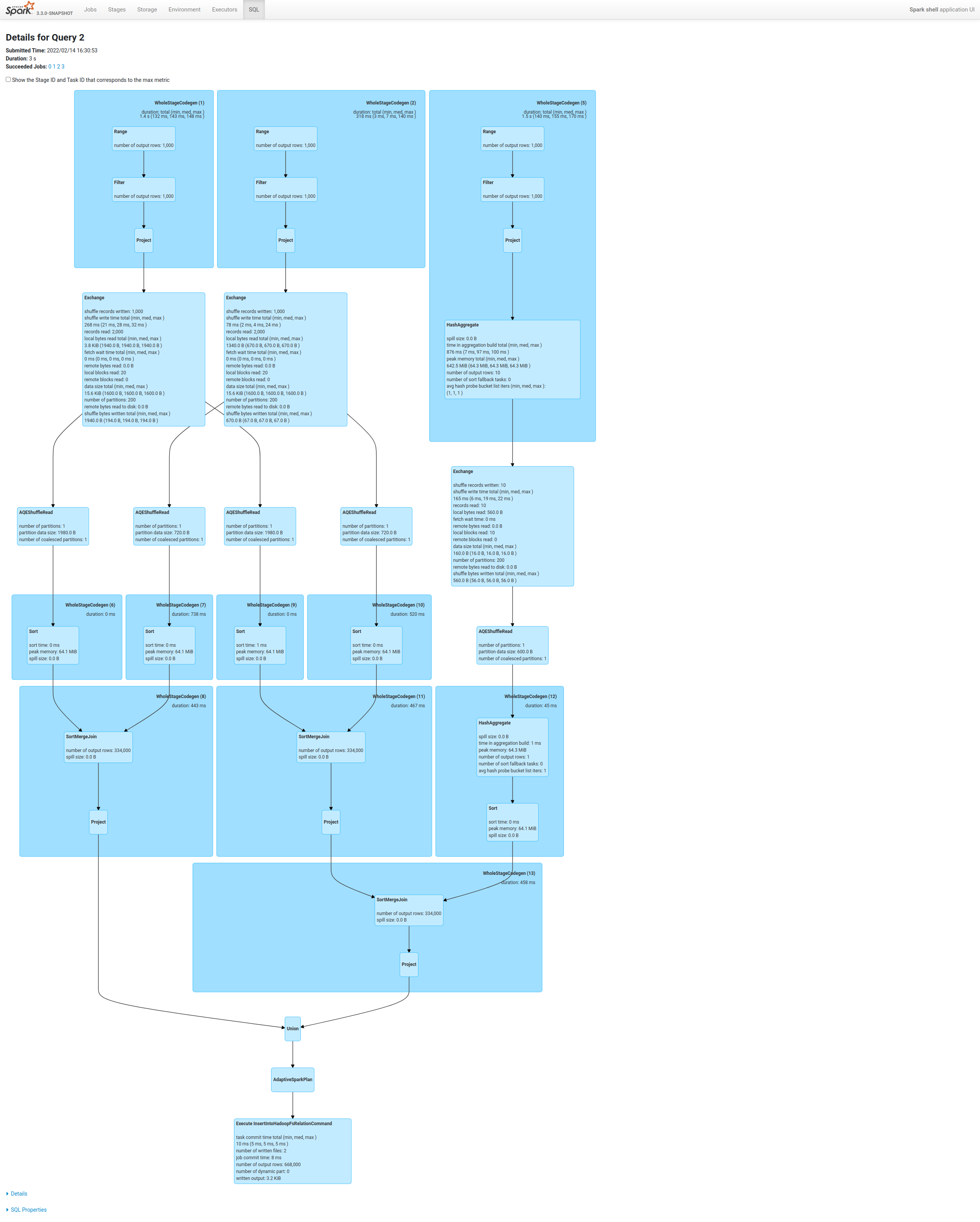
|
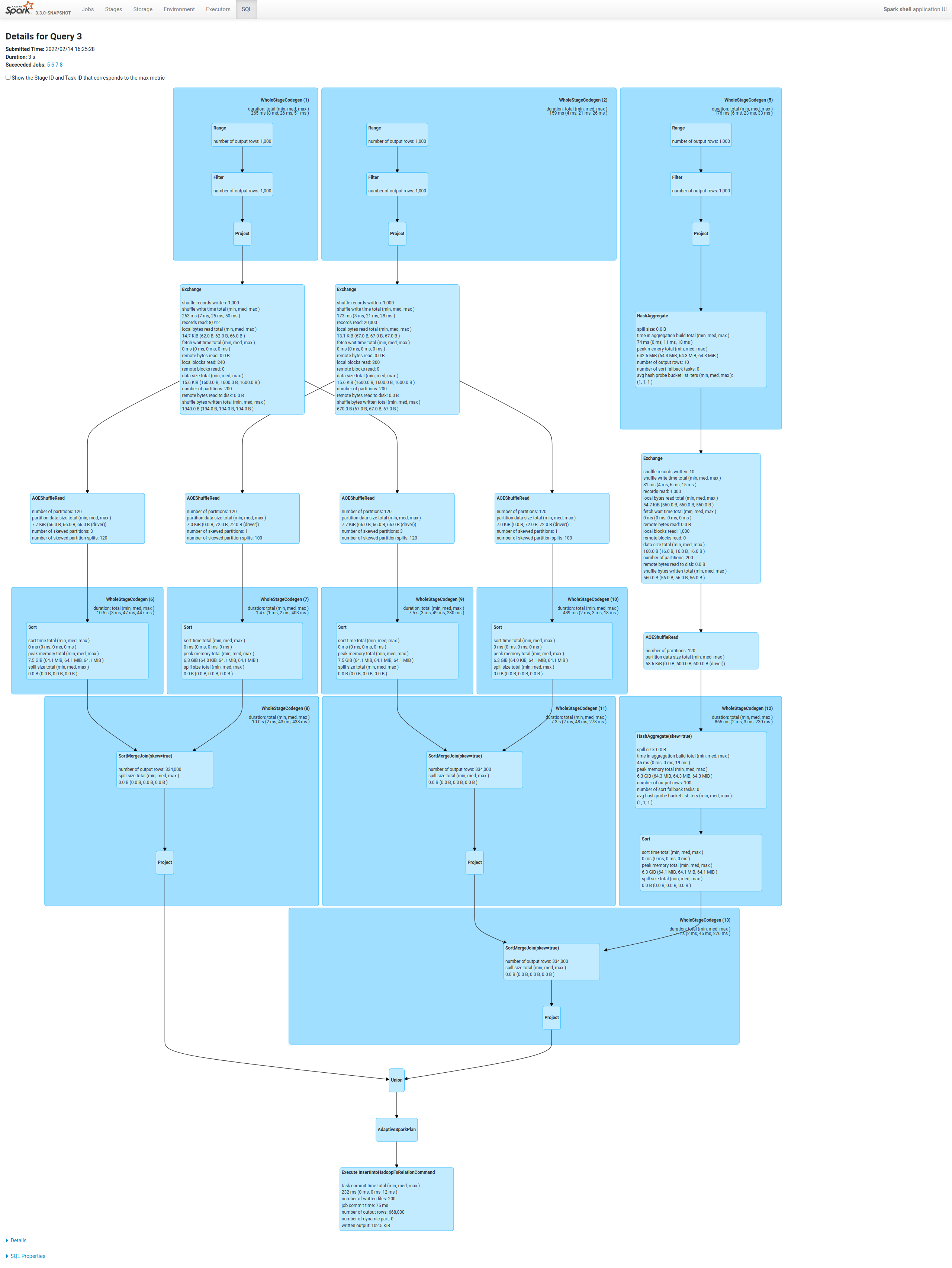
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}