yeskarthik opened a new pull request #35547:
URL: https://github.com/apache/spark/pull/35547
<!--
Thanks for sending a pull request! Here are some tips for you:
1. If this is your first time, please read our contributor guidelines:
https://spark.apache.org/contributing.html
2. Ensure you have added or run the appropriate tests for your PR:
https://spark.apache.org/developer-tools.html
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g.,
'[WIP][SPARK-XXXX] Your PR title ...'.
4. Be sure to keep the PR description updated to reflect all changes.
5. Please write your PR title to summarize what this PR proposes.
6. If possible, provide a concise example to reproduce the issue for a
faster review.
7. If you want to add a new configuration, please read the guideline first
for naming configurations in
'core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala'.
8. If you want to add or modify an error type or message, please read the
guideline first in
'core/src/main/resources/error/README.md'.
-->
### What changes were proposed in this pull request?
<!--
Please clarify what changes you are proposing. The purpose of this section
is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster
reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class
hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other
DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
Add two monitoring REST API endpoints under SQL that provides details about
the structured streaming queries. Even though a store exists for it and the
data is presented in the UI under the "Structured Streaming" tab, this data is
not exposed as a REST API.
#### Summary API
Returns the summary of all existing streaming queries.
GET `/{appId}/sql/streamingqueries`
Response is list of `StreamingQueryData`.
#### Progress API
Returns the progress events of a specific streaming query by `runId`. User
can also specify how many of the most recent events needs to be retrieved by
using the `last `query parameter. By default, we return the most recent
progress event i.e. last is set to 1.
GET `/{appId}/sql/streamingqueries/{runId}/progress?last={N}`
Response is list of `StreamingQueryProgress`.
Note: We are not introducing new object definitions for the response since
we are just returning the data from the store without aggregation, these are
existing event structures - `StreamingQueryData` and `StreamingQueryProgress`.
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
This data can be used for monitoring, detecting streaming and to build
custom dashboards. This monitoring API will be similar to the monitoring APIs
that are present for DStreams - refer
[SPARK-18470](https://issues.apache.org/jira/browse/SPARK-18470).
### Does this PR introduce _any_ user-facing change?
<!--
Note that it means *any* user-facing change including all aspects such as
the documentation fix.
If yes, please clarify the previous behavior and the change this PR proposes
- provide the console output, description and/or an example to show the
behavior difference if possible.
If possible, please also clarify if this is a user-facing change compared to
the released Spark versions or within the unreleased branches such as master.
If no, write 'No'.
-->
No
### How was this patch tested?
<!--
If tests were added, say they were added here. Please make sure to add some
test cases that check the changes thoroughly including negative and positive
cases if possible.
If it was tested in a way different from regular unit tests, please clarify
how you tested step by step, ideally copy and paste-able, so that other
reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why
it was difficult to add.
If benchmark tests were added, please run the benchmarks in GitHub Actions
for the consistent environment, and the instructions could accord to:
https://spark.apache.org/developer-tools.html#github-workflow-benchmarks.
-->
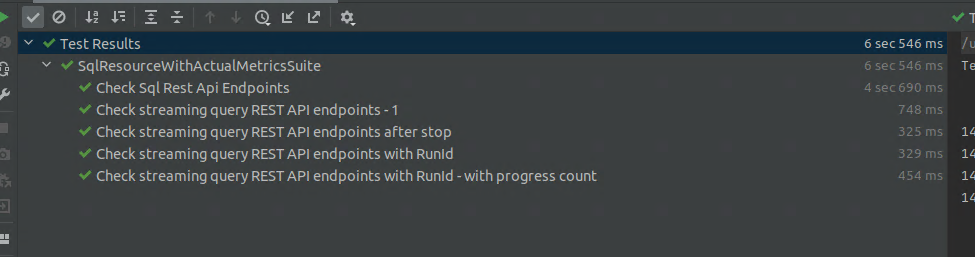
* Added 4 tests under `SqlResourceWithActualMetricsSuite` to test the
endpoints when streaming code is executed. Tested various cases, parameters,
boundary conditions
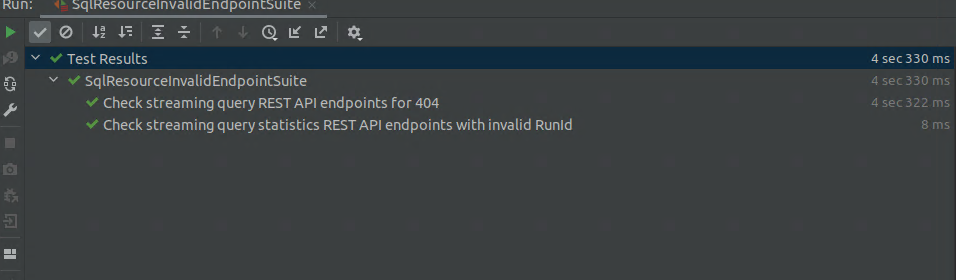
* Added 2 tests under `SqlResourceInvalidEndpointSuite.scala` to test the
endpoints when no streaming code is running.
* As mentioned earlier, since we are just returning the objects from the
store, there is no need to test them individually.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}