zhengruifeng commented on PR #36063: URL: https://github.com/apache/spark/pull/36063#issuecomment-1089929408
this PR is still WIP, but a basic funcation was implemented. I personaly thought it is not feasible to efficiently compute `ewm` for each x_t with existing window functions 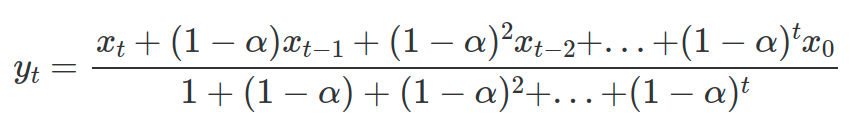 so a new window function is added to compute ewm.mean. However, I found that I should add a `public` api in the SQL side, otherwise, the PySpark side can not find it. Are there some methods to work around it? I think we should not expose it to end users of SparkSQL. @HyukjinKwon @ueshin could you please take a glance? Am I on the right way? Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
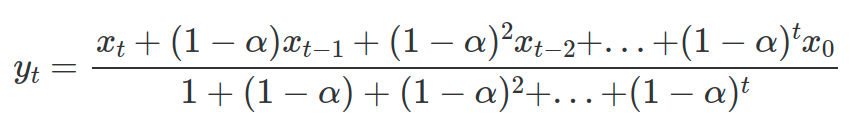{kind=link}