wang-zhun opened a new pull request, #37406: URL: https://github.com/apache/spark/pull/37406
### What changes were proposed in this pull request? Solve the data skew on the stream side in `BroadcastHashJoin` - When data skew needs to introduce additional shuffle, support forcibly solve the data skew problem through `spark.sql.adaptive.forceOptimizeSkewedJoin` - If data skew optimization is performed, `LocalShuffle` optimization will not be performed, otherwise the skew optimization will not take effect. ### Why are the changes needed? In the actual production environment, data skew will slow down the task execution time 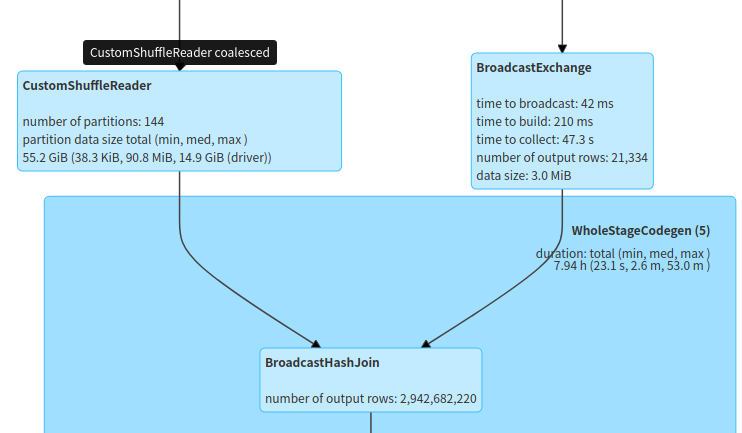  After solving the data skew 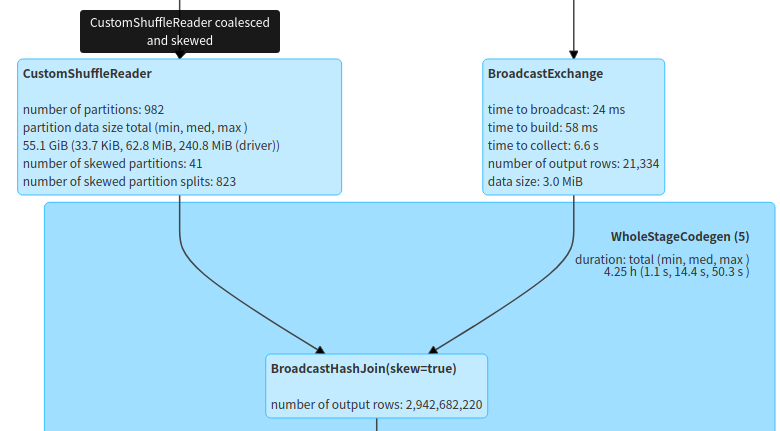  ### How was this patch tested? UTs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}