anthonywainer commented on code in PR #38285:
URL: https://github.com/apache/spark/pull/38285#discussion_r999115515
##########
python/pyspark/sql/types.py:
##########
@@ -653,8 +653,8 @@ def fromJson(cls, json: Dict[str, Any]) -> "StructField":
return StructField(
json["name"],
_parse_datatype_json_value(json["type"]),
- json["nullable"],
- json["metadata"],
+ json.get("nullable", True),
+ json.get("metadata"),
Review Comment:
Here an example, many dataframes are being created from a schema, this
schema is created from a Json.
The input parameters to create a schema is StructType.fromJson(json), this
internally uses StructField.fromJson().
The issue is when the StructField parses the Json, which forces to define
the nullable and metadata attributes inside.
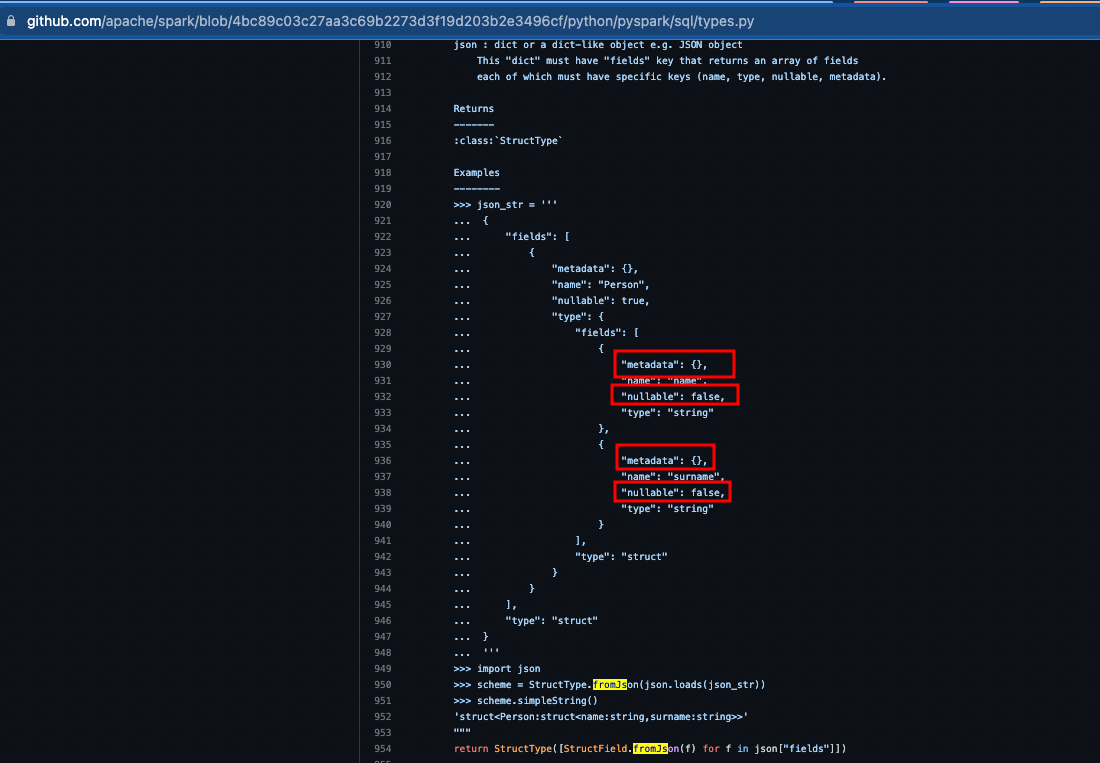
it is understandable that name and type are mandatory, but the others should
be optional.
The current parsing does not allow this. If more than 1000 fields are
defined, this would be a headache and unnecessary metadata.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}