xingchaozh opened a new pull request, #38330: URL: https://github.com/apache/spark/pull/38330
### What changes were proposed in this pull request? For bucket tables with huge size, lots of partitions maybe generated if bucketed scan disabled by sql planner. We can add one limit(default as BUCKETING_MAX_BUCKETS) to reduce the partitions for non-bucketed scan. ### Why are the changes needed? Avoid too many tasks introduced in single stage. Before 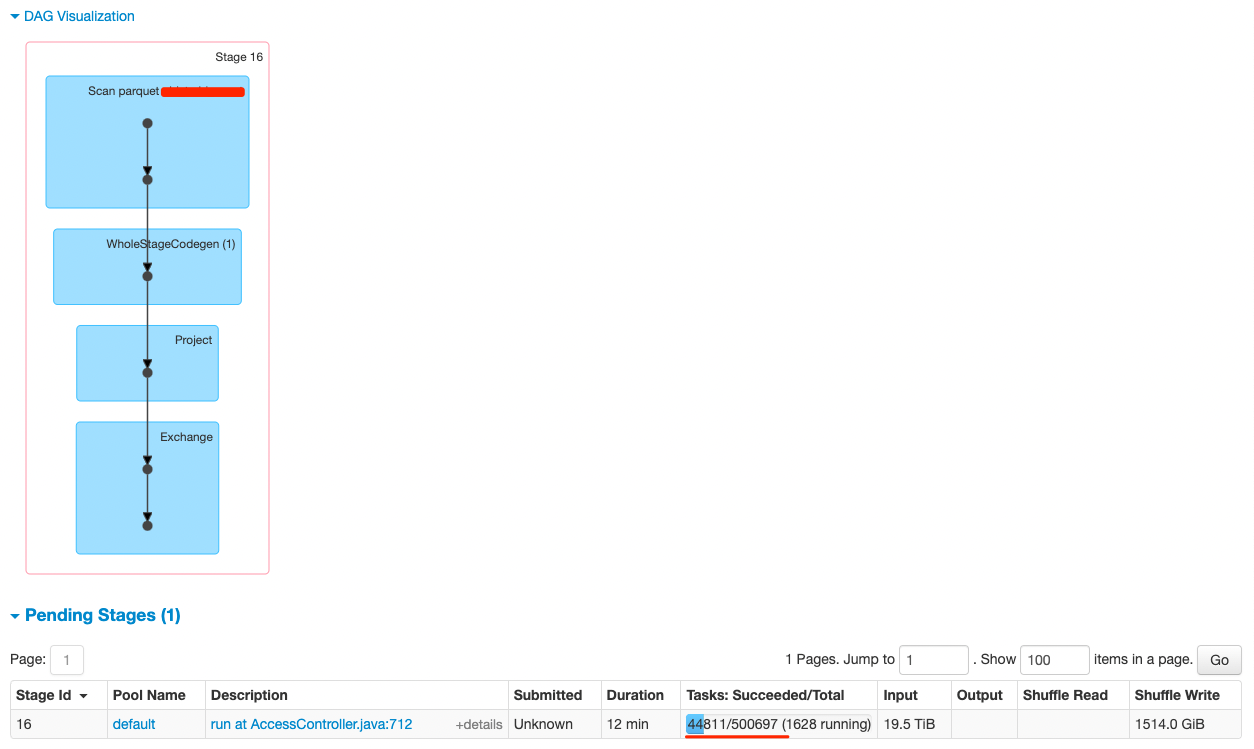 After 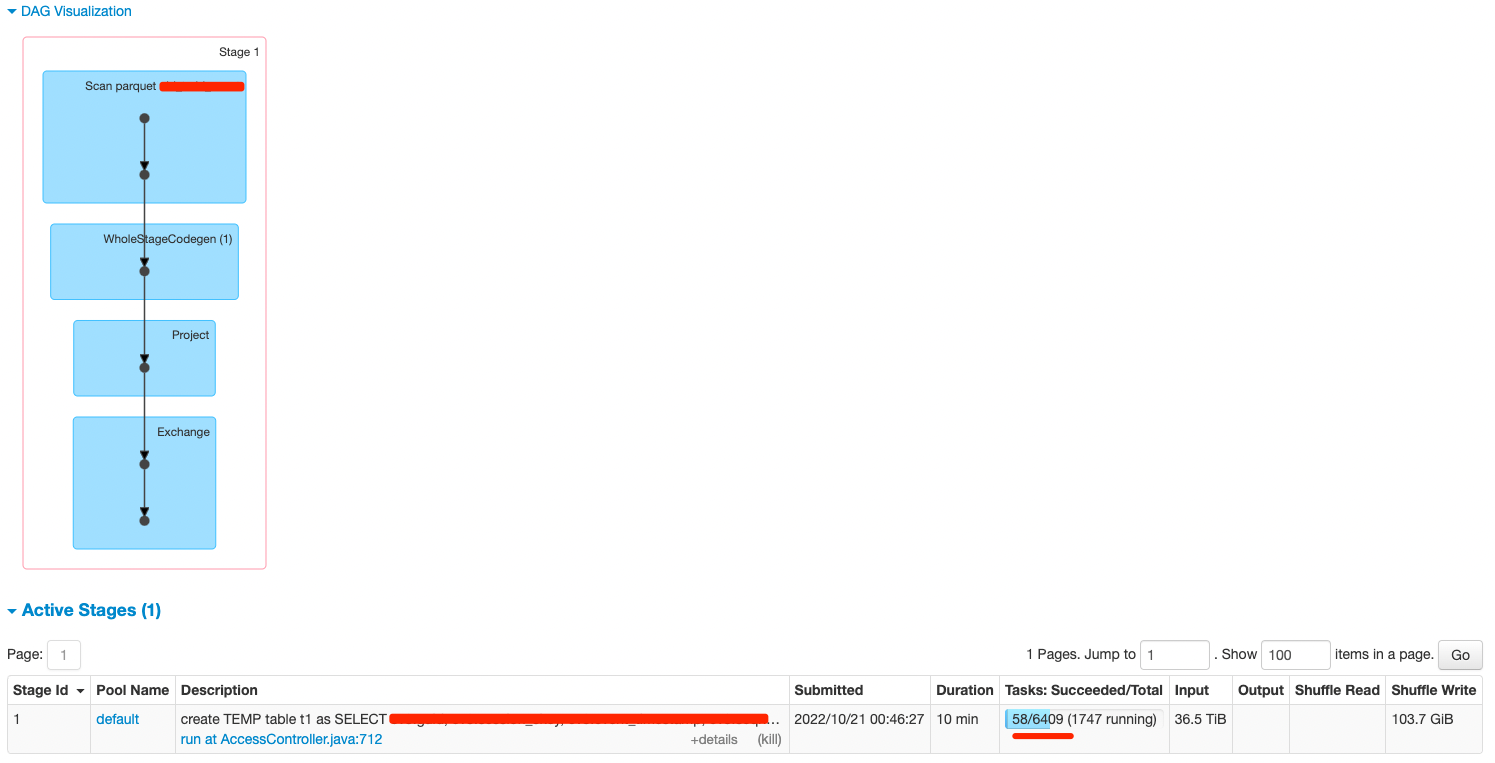 ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}