mcdull-zhang commented on code in PR #38703:
URL: https://github.com/apache/spark/pull/38703#discussion_r1027906540
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/subquery.scala:
##########
@@ -355,7 +355,7 @@ case class ListQuery(
plan.canonicalized,
outerAttrs.map(_.canonicalized),
ExprId(0),
- childOutputs.map(_.canonicalized.asInstanceOf[Attribute]),
+ plan.canonicalized.output,
Review Comment:
The premise of using cache is that `canonicalized` of two plans is equals.
`canonicalized` of `plan` of two `ListQuery` is equals, but `canonicalized`
of childOutputs is different because their exprIds are different.
In the end, the cache did not take effect.
plan to be executed:
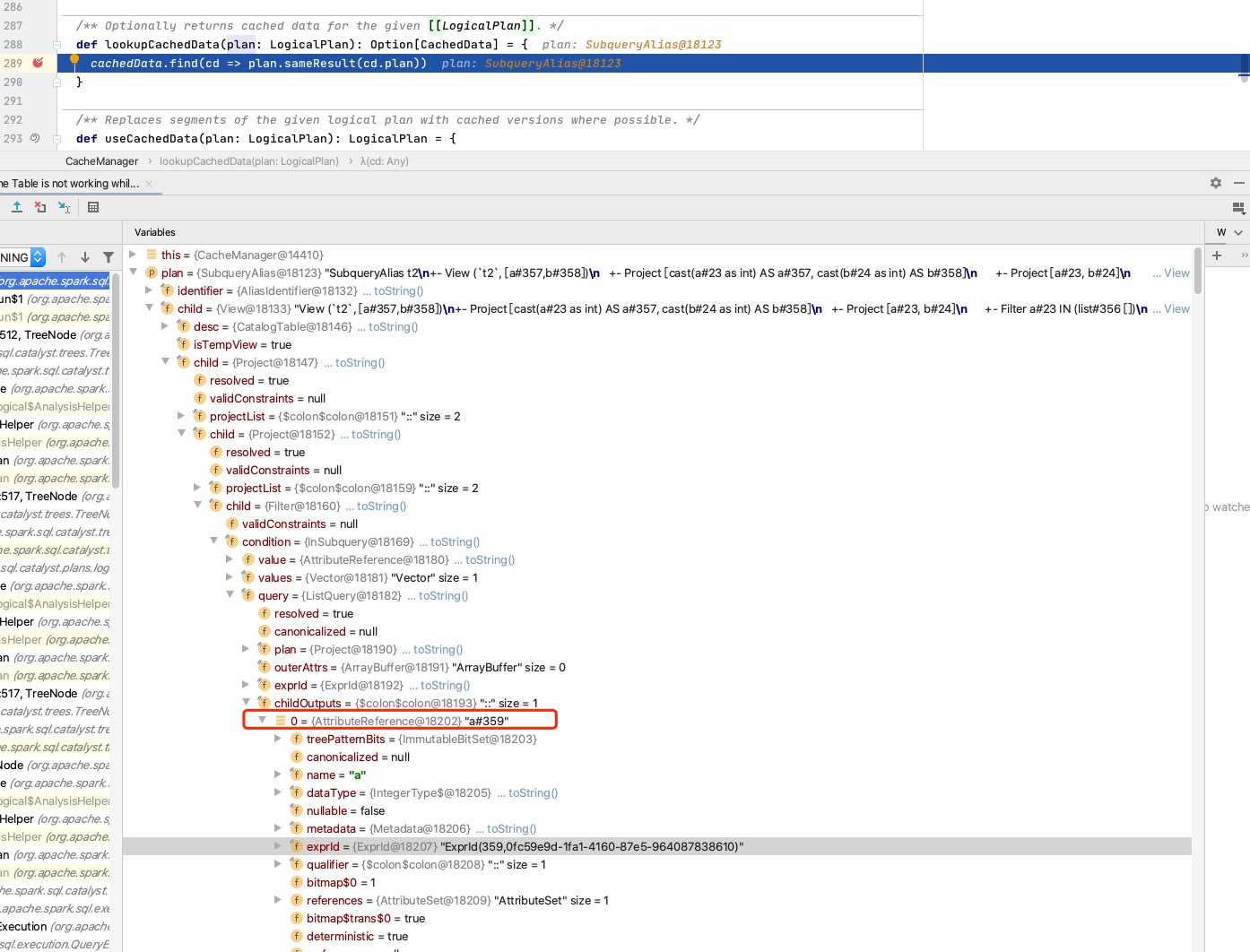
Plan that have been cached:
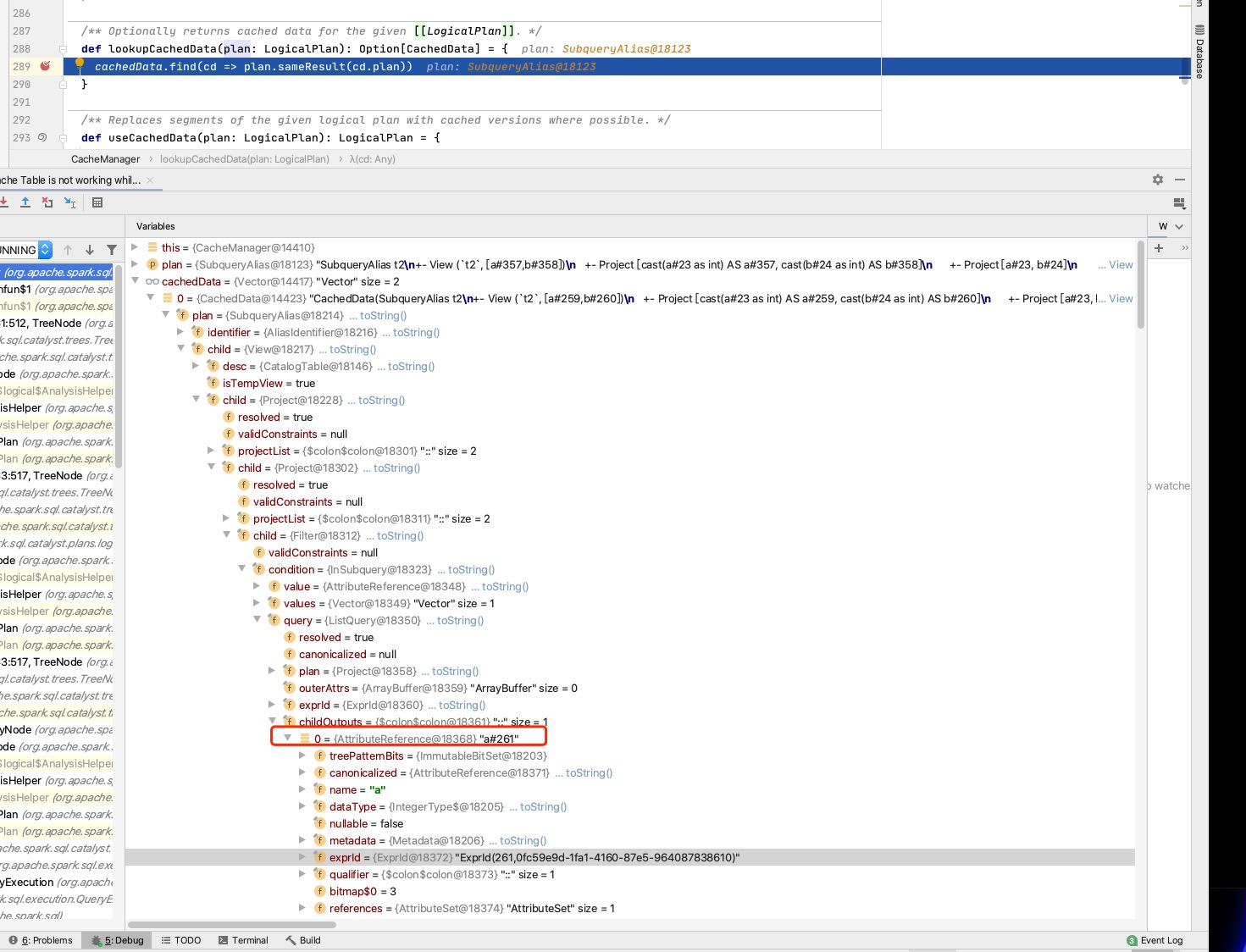
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}