thomasg19930417 commented on PR #34542: URL: https://github.com/apache/spark/pull/34542#issuecomment-1481097597
When using this optimization to insert hive dynamic partitions, it is found that when the spark.sql.shuffle.partitions setting is very large, some result files are particularly large and this part of the task will take time and length. These files are not in accordance with the self-adaptive Target size to split,But there is no problem when spark.sql.shuffle.partitions is set very small config: spark.sql.adaptive.enabled true spark.sql.adaptive.coalescePartitions.enabled true spark.sql.adaptive.skewedJoin.enabled true spark.sql.optimizer.dynamicPartitionPruning.enabled false spark.sql.adaptive.advisoryPartitionSizeInBytes 128M spark.sql.adaptive.coalescePartitions.minPartitionSize 20M celeborn.shuffle.rangeReadFilter.enabled true celeborn.shuffle.partitionSplit.mode hard 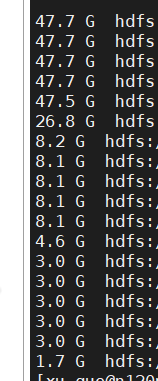 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}