JoshRosen commented on PR #43640: URL: https://github.com/apache/spark/pull/43640#issuecomment-1791732011
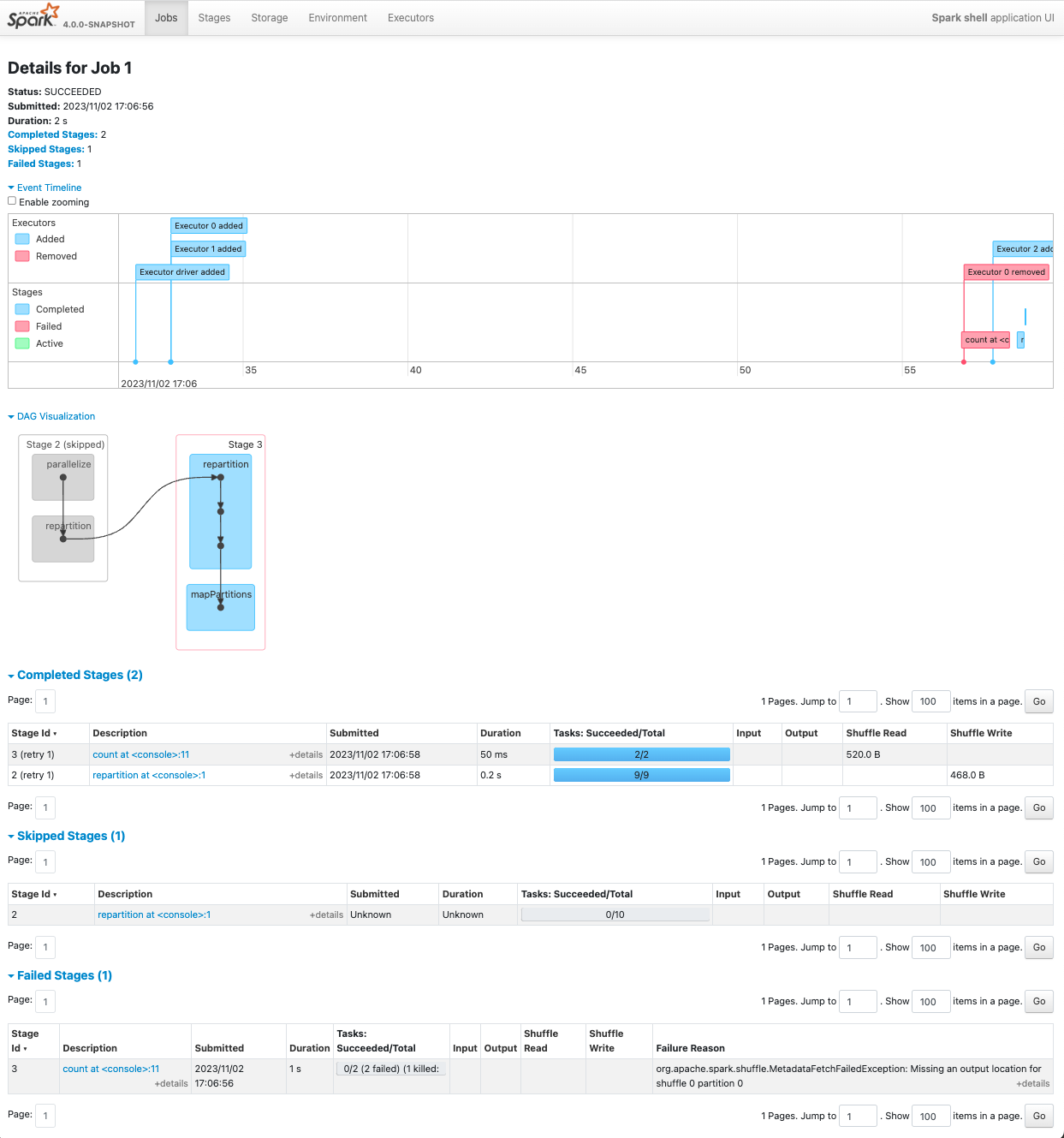
This is an attempt at fixing a nearly nine year old Spark UI nit (https://issues.apache.org/jira/browse/SPARK-4836). I'm opening this draft PR early to get feedback on a couple of design questions: 1. Should this be configuration-flaggable? 2. How should we handle sorting of the stage table? It looks like stage sorting is done server-side and can only be sorted on a single column. By default the table is sorted on Stage ID. 3. Will the "initially-skipped-but-subsequently-retried" stages semantic be confusing to users? - See [the screenshot](https://user-images.githubusercontent.com/50748/280157322-90abb73a-c8f0-41fc-98ba-71de2300b349.png) for an example: in that case, I'm running a job that re-uses the shuffle output of a previous job and hits a fetch failure, causing a recomputation of that initially-skipped stage. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}