GitHub user skonto opened a pull request:
https://github.com/apache/spark/pull/18705
[SPARK-21502][Mesos] fix --supervise for mesos in cluster mode
## What changes were proposed in this pull request?
With supervise enabled for a driver so far re-launching it was failing
because the driver had the same framework Id. This patch creates a new driver
framework id every time we re-launch a driver, but we keep the driver
submission id the same since that is the same with the task id the driver was
launched with on mesos and retry state and other info within Dispatcher's data
structures uses that as a key.
We append a "-retry-%4d" string as a suffix to the framework id passed by
the dispatcher to the driver and the same value to the app_id created by each
driver, except the first time where we dont need the retry suffix.
The previous format for the frameworkId was
'DispactherFId-DriverSubmissionId'.
We also detect the case where we have multiple spark contexts started from
within the same driver and we do set proper names to their corresponding
app-ids. The old practice was to unset the framework id passed from the
dispatcher after the driver framework was started for the first time and let
mesos decide the framework ID for subsequent spark contexts. The decided fId
was passed as an appID.
This patch affects heavily the history server. Btw we dont have the issues
of the standalone case where driver id must be different since the dispatcher
will re-launch a driver(mesos task) only if it gets an update that it is dead
and this is verified by mesos implicitly. We also dont fix the fine grained
mode which deprecated and of no use.
## How was this patch tested?
This task was manually tested on dc/os. Launched a driver, stops its
container and verified the expected behavior.
Initial retry of the driver, driver in pending state:

Driver re-launched:
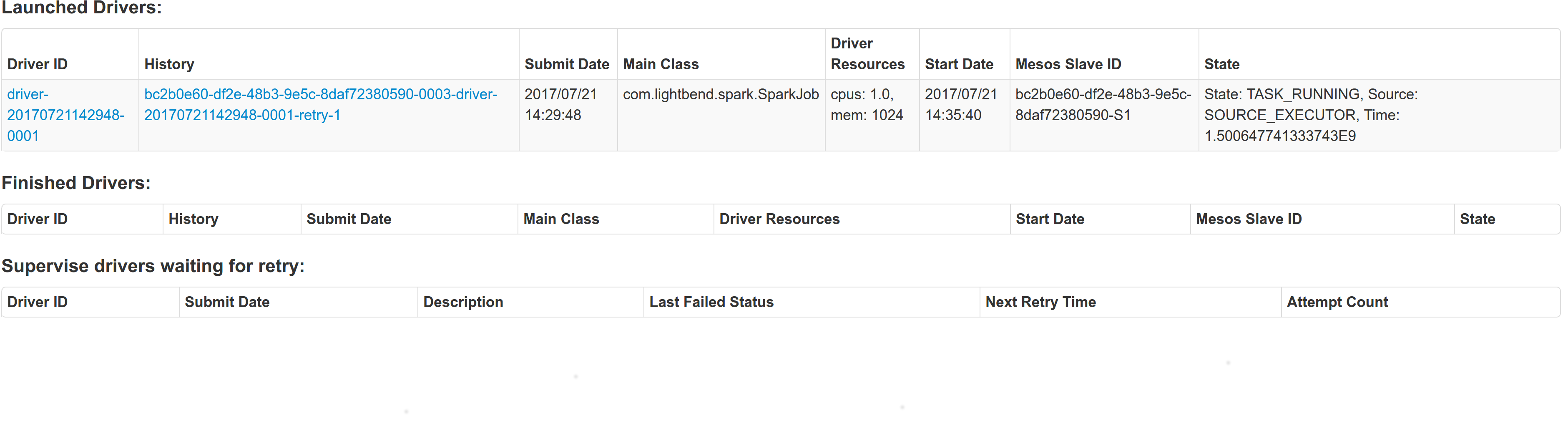
Another re-try:

The resulted entries in history server at the bottom:
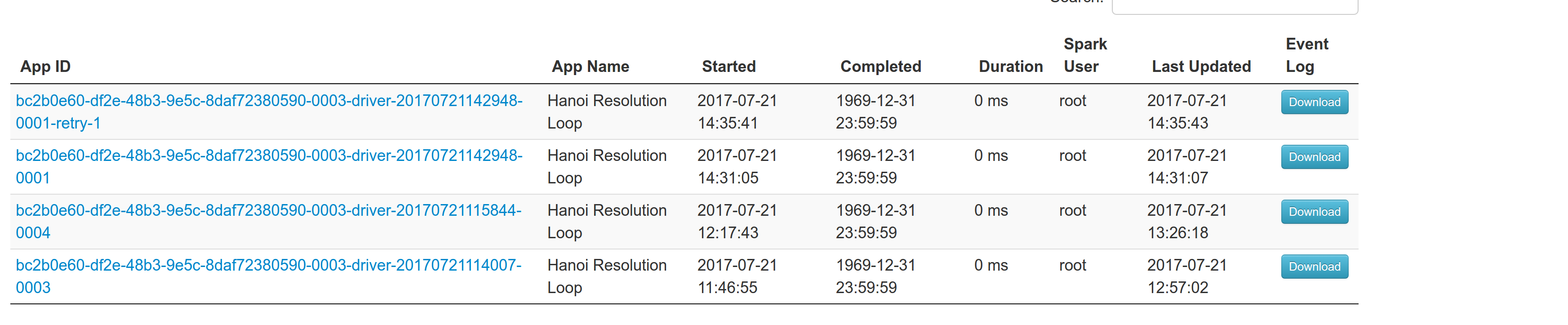
Regarding multiple spark contexts here is the end result regarding the
spark history server:

You can merge this pull request into a Git repository by running:
$ git pull https://github.com/skonto/spark fix_supervise_flag
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/18705.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #18705
----
commit b987c4b28c3aa96f39e78dcc74da570226c6bdba
Author: Stavros Kontopoulos <[email protected]>
Date: 2017-07-21T00:18:34Z
fix supervise for mesos in cluster mode
----
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at [email protected] or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}