Github user sujith71955 commented on the issue:
https://github.com/apache/spark/pull/20611
As above changes are applicable only for hdfs related paths, i did testing
manually, please find the attached test report
Usecase 1: Load data by specifying wild card character in the hdfs file path
HDFS path details

load command output file level

Usecase 2: Load data by specifying wild card character in the hdfs folder
path
HDFS path details
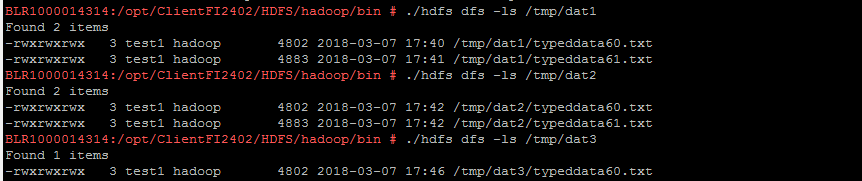
load command output folder level

Usecase 3: Negative case - Load data by specifying wild card character in
the wrong hdfs file path

Usecase 4: Negative case - Load data by specifying wild card character in
the wrong hdfs folder path

---
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}