Github user yuchenhuo commented on a diff in the pull request:
https://github.com/apache/spark/pull/20953#discussion_r181306071
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileScanRDD.scala
---
@@ -179,7 +182,23 @@ class FileScanRDD(
currentIterator = readCurrentFile()
}
- hasNext
+ try {
+ hasNext
+ } catch {
+ case e: SchemaColumnConvertNotSupportedException =>
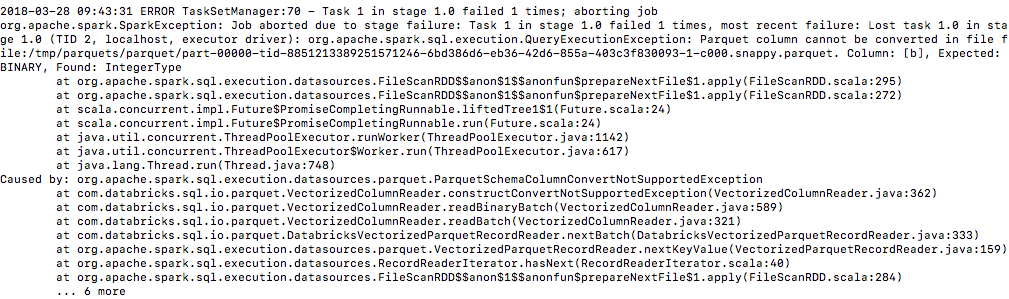
+ val message = "Parquet column cannot be converted in " +
+ s"file ${currentFile.filePath}. Column: ${e.getColumn}, " +
+ s"Expected: ${e.getLogicalType}, Found:
${e.getPhysicalType}"
+ throw new QueryExecutionException(message, e)
--- End diff --
Yes, you are right. Sorry, I shouldn't say "use QueryExecutionException
instead of the original SparkException". The final exception would still be
wrapped with a SparkException. Inside the SparkException would be
QueryExecutionException. But the reason is still the same, they don't want to
throw too many different Exceptions which might be hard to capture and display.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}