GitHub user HyukjinKwon opened a pull request:
https://github.com/apache/spark/pull/22329
[SPARK-25328][PYTHON] Add an example for having two columns as the grouping
key in group aggregate pandas UDF
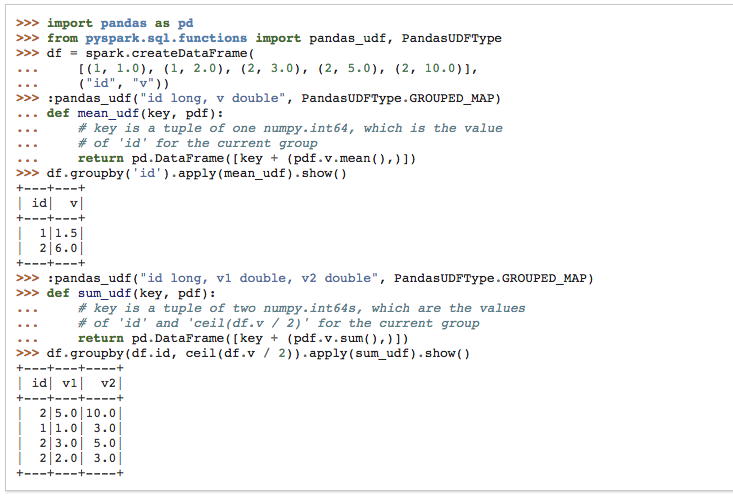
## What changes were proposed in this pull request?
This PR proposes to add another example for multiple grouping key in group
aggregate pandas UDF since this feature could make users still confused.
## How was this patch tested?
Manually tested and documentation built:
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/HyukjinKwon/spark SPARK-25328
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22329.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22329
----
commit 36a7ccc37374a42a2c9cf67f3f1748df638eb937
Author: hyukjinkwon <gurwls223@...>
Date: 2018-09-04T10:00:34Z
Add an example for having two columns as the grouping key in group
aggregate pandas UDF
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}