Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
So by running `sc.parallelize(1.to(1000)).map(x => (x % 10,
x)).sortByKey().distinct().count()` in 2.3.0 and my PR we can see the
difference:
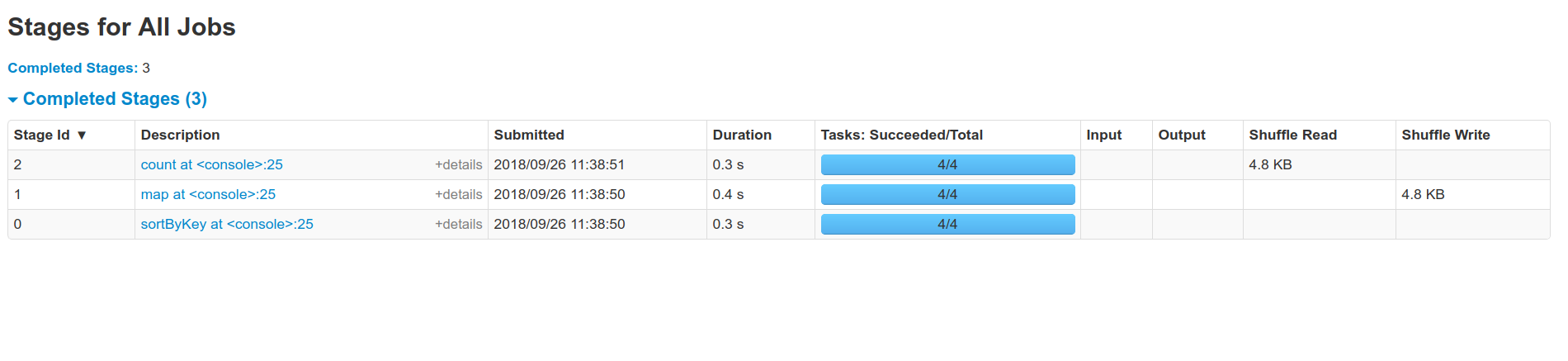
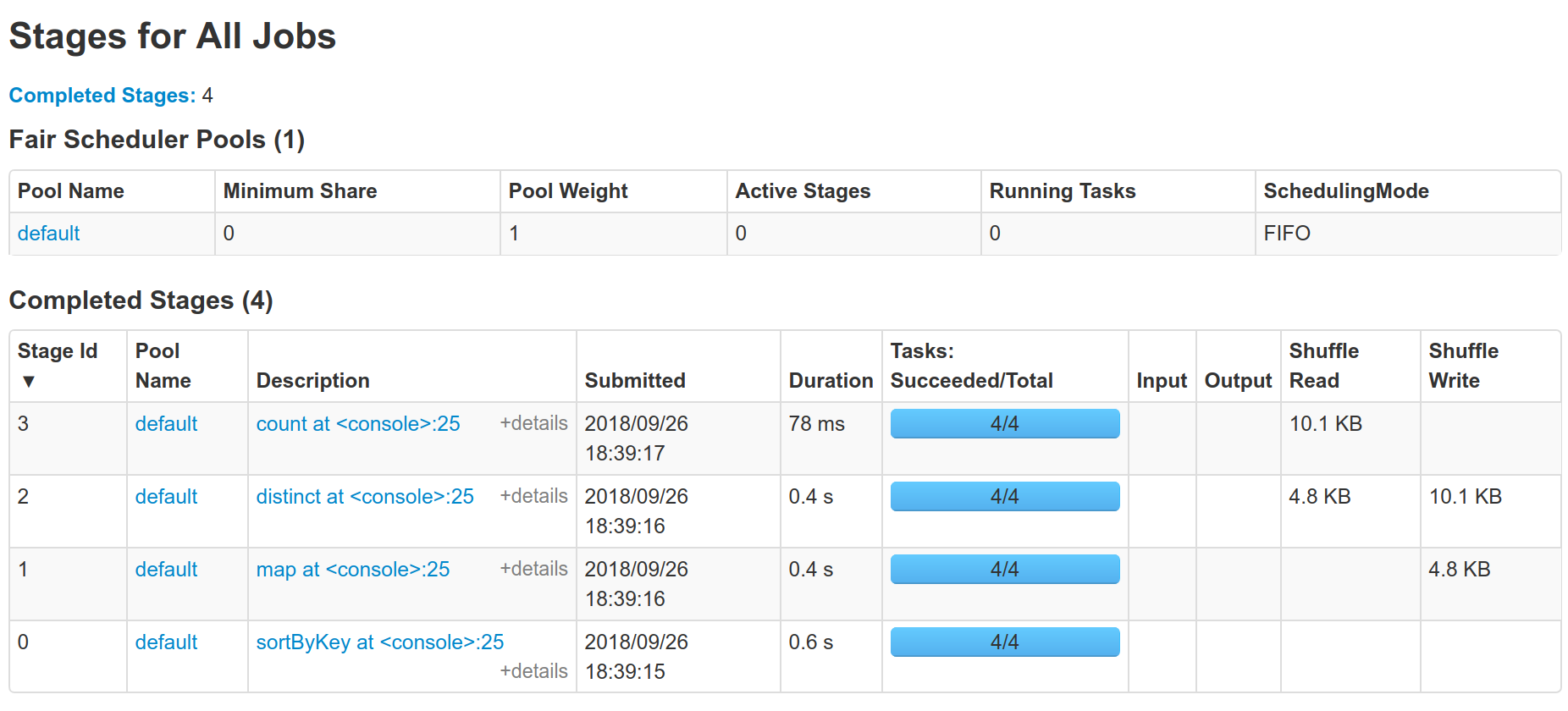
And see one less shuffle.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}