WangGuangxin opened a new pull request #24660: [SPARK-27789]Use stopEarly in codegen of ColumnarBatchScan URL: https://github.com/apache/spark/pull/24660 ## What changes were proposed in this pull request? Suppose that we have a hive table created like this ```create table parquet_test (id int) using parquet```, and our query sql is `select id from parquet_test limit 10`. With `spark.sql.hive.convertMetastoreParquet` set to false, the sql execution will go into `InputAdapter`, in its codegen, it can use `stopEarly` to accelerate local limit. But if we set `spark.sql.hive.convertMetastoreParquet` to true, the sql exectuion will go into `ColumnarBatchScan`, which didn't optimize local limit. In this patch, We use `stopEarly` in `ColumnarBatchScan` as well to accelerate local limit. ## How was this patch tested? Test manually by codegen. For sql `select id from parquet_test limit 10`, the code generated before patch 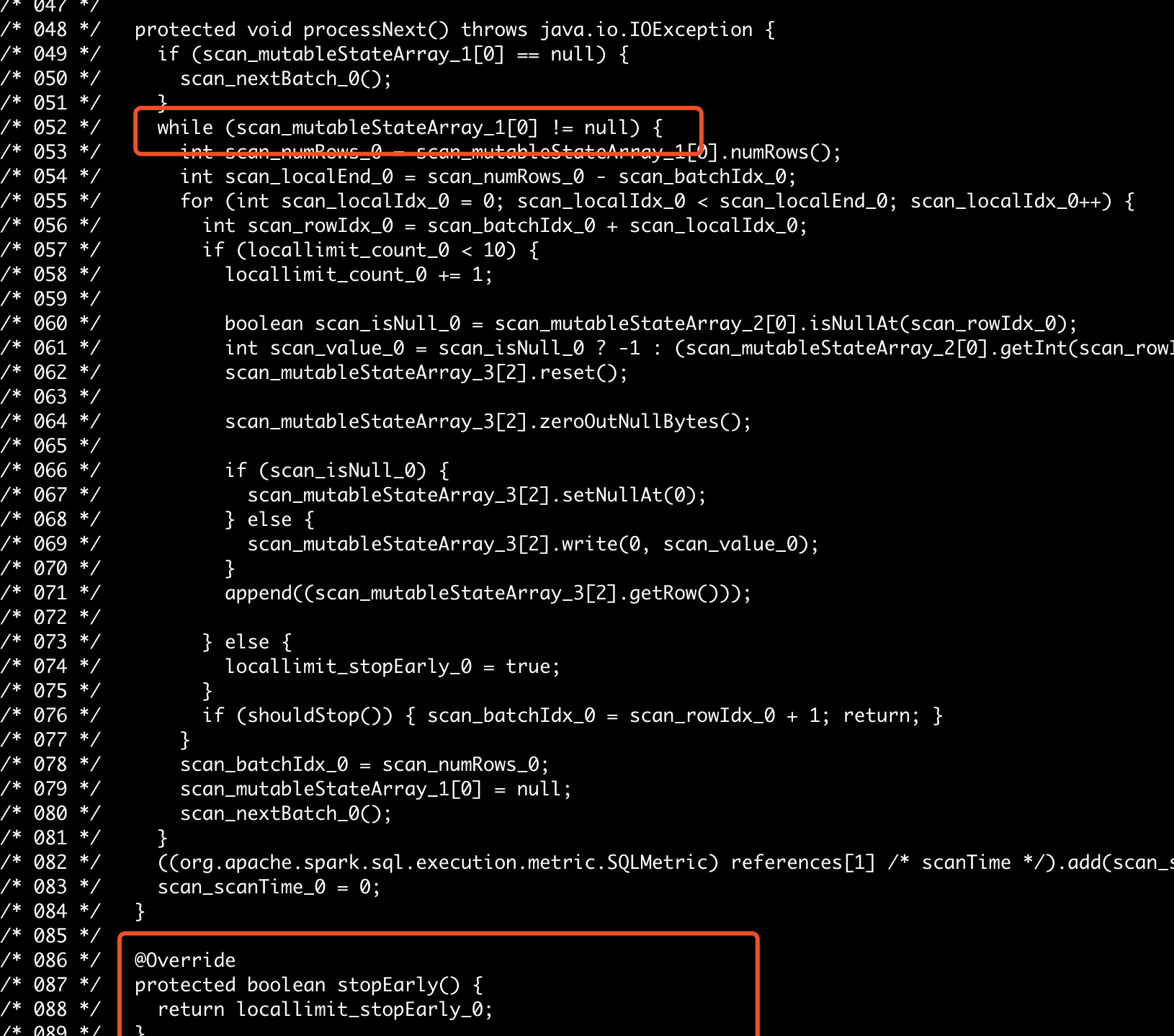 the code generated after patch 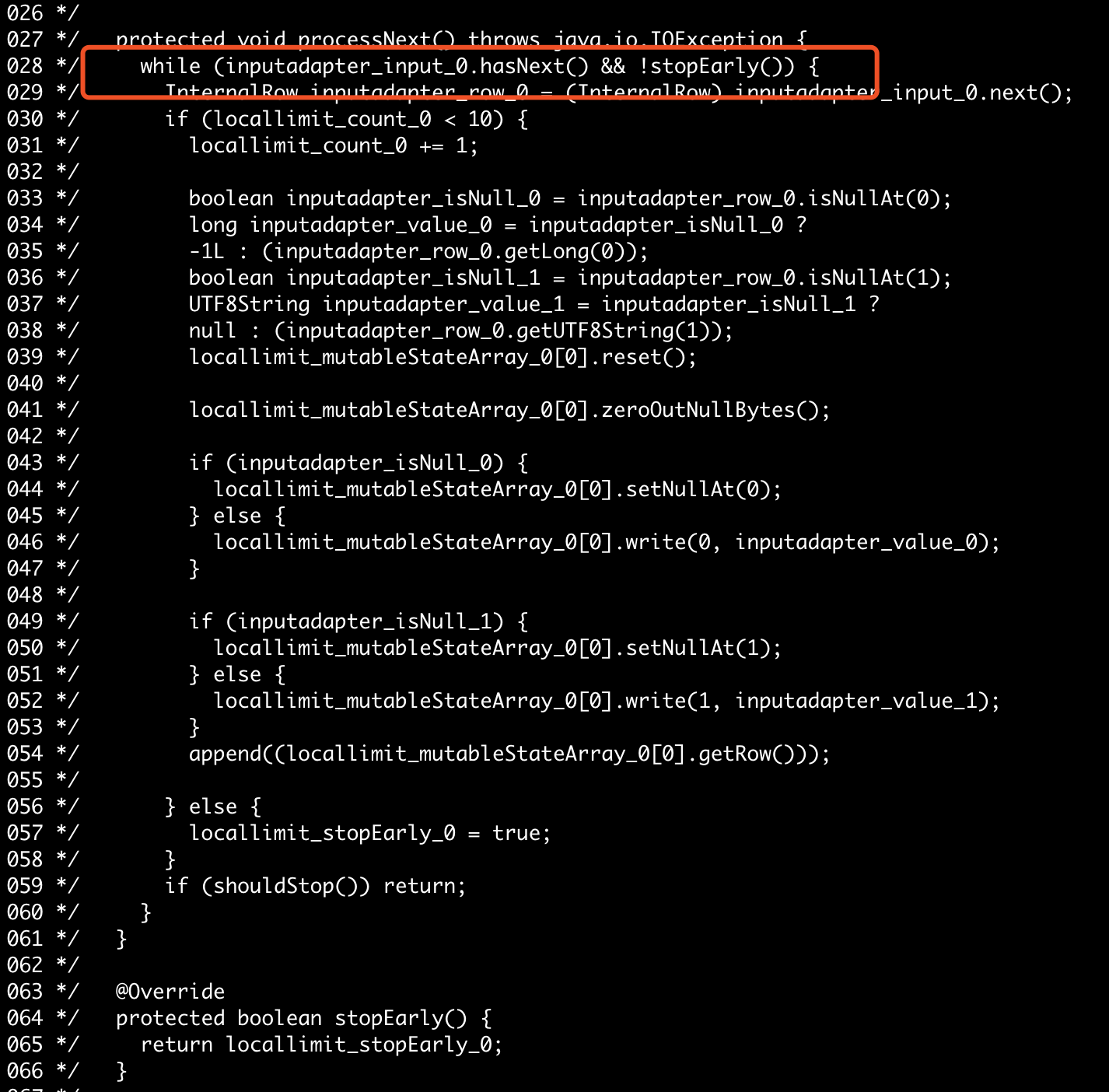
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]