wangyum commented on a change in pull request #25373: [SPARK-28527][SQL][TEST] Directly re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25373#discussion_r313330383
########## File path: sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/ThriftServerQueryTestSuite.scala ########## @@ -0,0 +1,359 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.sql.hive.thriftserver + +import java.io.File +import java.sql.{DriverManager, SQLException, Statement, Timestamp} +import java.util.Locale + +import scala.util.{Random, Try} +import scala.util.control.NonFatal + +import org.apache.hadoop.hive.conf.HiveConf.ConfVars +import org.apache.hive.service.cli.HiveSQLException + +import org.apache.spark.sql.{AnalysisException, SQLQueryTestSuite} +import org.apache.spark.sql.catalyst.util.fileToString +import org.apache.spark.sql.execution.HiveResult +import org.apache.spark.sql.internal.SQLConf +import org.apache.spark.sql.types._ + +/** + * Directly re-run all the tests in SQLQueryTestSuite via Thrift Server + * + * TODO: + * 1. Support UDF testing. + * 2. Support DESC command. + * 3. Support SHOW command. + */ +class ThriftServerQueryTestSuite extends SQLQueryTestSuite { + + private var hiveServer2: HiveThriftServer2 = _ + + override def beforeEach(): Unit = { + // Chooses a random port between 10000 and 19999 + var listeningPort = 10000 + Random.nextInt(10000) + + // Retries up to 3 times with different port numbers if the server fails to start + (1 to 3).foldLeft(Try(startThriftServer(listeningPort, 0))) { case (started, attempt) => + started.orElse { + listeningPort += 1 + Try(startThriftServer(listeningPort, attempt)) + } + }.recover { + case cause: Throwable => + throw cause + }.get + logInfo(s"HiveThriftServer2 started successfully") + } + + override def afterEach(): Unit = { + hiveServer2.stop() + hiveServer2 = null + } + + override val isTestWithConfigSets = false + + /** List of test cases to ignore, in lower cases. */ + override def blackList: Set[String] = Set( + "blacklist.sql", // Do NOT remove this one. It is here to test the blacklist functionality. + // Missing UDF + "pgSQL/boolean.sql", + "pgSQL/case.sql", + // SPARK-28624 + "date.sql", + // SPARK-28619 + "pgSQL/aggregates_part1.sql", + "group-by.sql", + // SPARK-28620 + "pgSQL/float4.sql", + // SPARK-28636 + "decimalArithmeticOperations.sql", + "literals.sql", + "subquery/scalar-subquery/scalar-subquery-predicate.sql", + "subquery/in-subquery/in-limit.sql", + "subquery/in-subquery/simple-in.sql", + "subquery/in-subquery/in-order-by.sql", + "subquery/in-subquery/in-set-operations.sql", + // SPARK-28637 + "cast.sql", + "ansi/interval.sql" + ) + + override def runQueries( + queries: Seq[String], + testCase: TestCase, + configSet: Option[Seq[(String, String)]]): Unit = { + // We do not test with configSet. + withJdbcStatement { statement => + + loadTestData(statement) + + testCase match { + case _: PgSQLTest => + // PostgreSQL enabled cartesian product by default. + statement.execute(s"SET ${SQLConf.CROSS_JOINS_ENABLED.key} = true") + statement.execute(s"SET ${SQLConf.ANSI_SQL_PARSER.key} = true") + statement.execute(s"SET ${SQLConf.PREFER_INTEGRAL_DIVISION.key} = true") + case _ => + } + + // Run the SQL queries preparing them for comparison. + val outputs: Seq[QueryOutput] = queries.map { sql => + val output = getNormalizedResult(statement, sql) + // We might need to do some query canonicalization in the future. + QueryOutput( + sql = sql, + schema = "", + output = output.mkString("\n").replaceAll("\\s+$", "")) + } + + // Read back the golden file. + val expectedOutputs: Seq[QueryOutput] = { + val goldenOutput = fileToString(new File(testCase.resultFile)) + val segments = goldenOutput.split("-- !query.+\n") + + // each query has 3 segments, plus the header + assert(segments.size == outputs.size * 3 + 1, + s"Expected ${outputs.size * 3 + 1} blocks in result file but got ${segments.size}. " + + s"Try regenerate the result files.") + Seq.tabulate(outputs.size) { i => + val sql = segments(i * 3 + 1).trim + val originalOut = segments(i * 3 + 3) + val output = if (isNeedSort(sql)) { + originalOut.split("\n").sorted.mkString("\n") + } else { + originalOut + } + QueryOutput( + sql = sql, + schema = "", + output = output.replaceAll("\\s+$", "") + ) + } + } + + // Compare results. + assertResult(expectedOutputs.size, s"Number of queries should be ${expectedOutputs.size}") { + outputs.size + } + + outputs.zip(expectedOutputs).zipWithIndex.foreach { case ((output, expected), i) => + assertResult(expected.sql, s"SQL query did not match for query #$i\n${expected.sql}") { + output.sql + } + + expected match { + // Skip desc command, see HiveResult.hiveResultString + case d if d.sql.toUpperCase(Locale.ROOT).startsWith("DESC ") + || d.sql.toUpperCase(Locale.ROOT).startsWith("DESC\n") + || d.sql.toUpperCase(Locale.ROOT).startsWith("DESCRIBE ") + || d.sql.toUpperCase(Locale.ROOT).startsWith("DESCRIBE\n") => + // Skip show command, see HiveResult.hiveResultString + case s if s.sql.toUpperCase(Locale.ROOT).startsWith("SHOW ") + || s.sql.toUpperCase(Locale.ROOT).startsWith("SHOW\n") => + // AnalysisException should exactly match. + // SQLException should not exactly match. We only assert the result contains Exception. + case _ if output.output.startsWith(classOf[SQLException].getName) => + assert(expected.output.contains("Exception"), + s"Exception did not match for query #$i\n${expected.sql}, " + + s"expected: ${expected.output}, but got: ${output.output}") + // HiveSQLException is usually a feature that our ThriftServer cannot support. + // Please add SQL to blackList. + case _ if output.output.startsWith(classOf[HiveSQLException].getName) => + assert(false, s"${output.output} for query #$i\n${expected.sql}") + case _ => + assertResult(expected.output, s"Result did not match for query #$i\n${expected.sql}") { + output.output + } + } + } + } + } + + override def createScalaTestCase(testCase: TestCase): Unit = { + if (blackList.exists(t => + testCase.name.toLowerCase(Locale.ROOT).contains(t.toLowerCase(Locale.ROOT)))) { + // Create a test case to ignore this case. + ignore(testCase.name) { /* Do nothing */ } + } else { + // Create a test case to run this case. + test(testCase.name) { + runTest(testCase) + } + } + } + + override def listTestCases(): Seq[TestCase] = { + listFilesRecursively(new File(inputFilePath)).flatMap { file => + val resultFile = file.getAbsolutePath.replace(inputFilePath, goldenFilePath) + ".out" + val absPath = file.getAbsolutePath + val testCaseName = absPath.stripPrefix(inputFilePath).stripPrefix(File.separator) + + if (file.getAbsolutePath.startsWith(s"$inputFilePath${File.separator}udf")) { + Seq.empty + } else if (file.getAbsolutePath.startsWith(s"$inputFilePath${File.separator}pgSQL")) { + PgSQLTestCase(testCaseName, absPath, resultFile) :: Nil + } else { + RegularTestCase(testCaseName, absPath, resultFile) :: Nil + } + } + } + + test("Check if ThriftServer can work") { + withJdbcStatement { statement => + val rs = statement.executeQuery("select 1L") + rs.next() + assert(rs.getLong(1) === 1L) + } + } + + private def getNormalizedResult(statement: Statement, sql: String): Seq[String] = { + try { + val rs = statement.executeQuery(sql) + val cols = rs.getMetaData.getColumnCount + val buildStr = () => (for (i <- 1 to cols) yield { + getHiveResult(rs.getObject(i)) + }).mkString("\t") + + val answer = Iterator.continually(rs.next()).takeWhile(identity).map(_ => buildStr()).toSeq + .map(replaceNotIncludedMsg) + if (isNeedSort(sql)) { + answer.sorted + } else { + answer + } + } catch { + case a: AnalysisException => + // Do not output the logical plan tree which contains expression IDs. + // Also implement a crude way of masking expression IDs in the error message + // with a generic pattern "###". + val msg = if (a.plan.nonEmpty) a.getSimpleMessage else a.getMessage + Seq(a.getClass.getName, msg.replaceAll("#\\d+", "#x")).sorted + case NonFatal(e) => + // If there is an exception, put the exception class followed by the message. + Seq(e.getClass.getName, e.getMessage) + } + } + + private def startThriftServer(port: Int, attempt: Int): Unit = { + logInfo(s"Trying to start HiveThriftServer2: port=$port, attempt=$attempt") + val localSparkSession = spark.newSession() + val sqlContext = localSparkSession.sqlContext + sqlContext.setConf(ConfVars.HIVE_SERVER2_THRIFT_PORT.varname, port.toString) + hiveServer2 = HiveThriftServer2.startWithContext(sqlContext) + } + + private def withJdbcStatement(fs: (Statement => Unit)*) { Review comment: If move `loadTestData` to `beforeAll`. Some tests will fail: 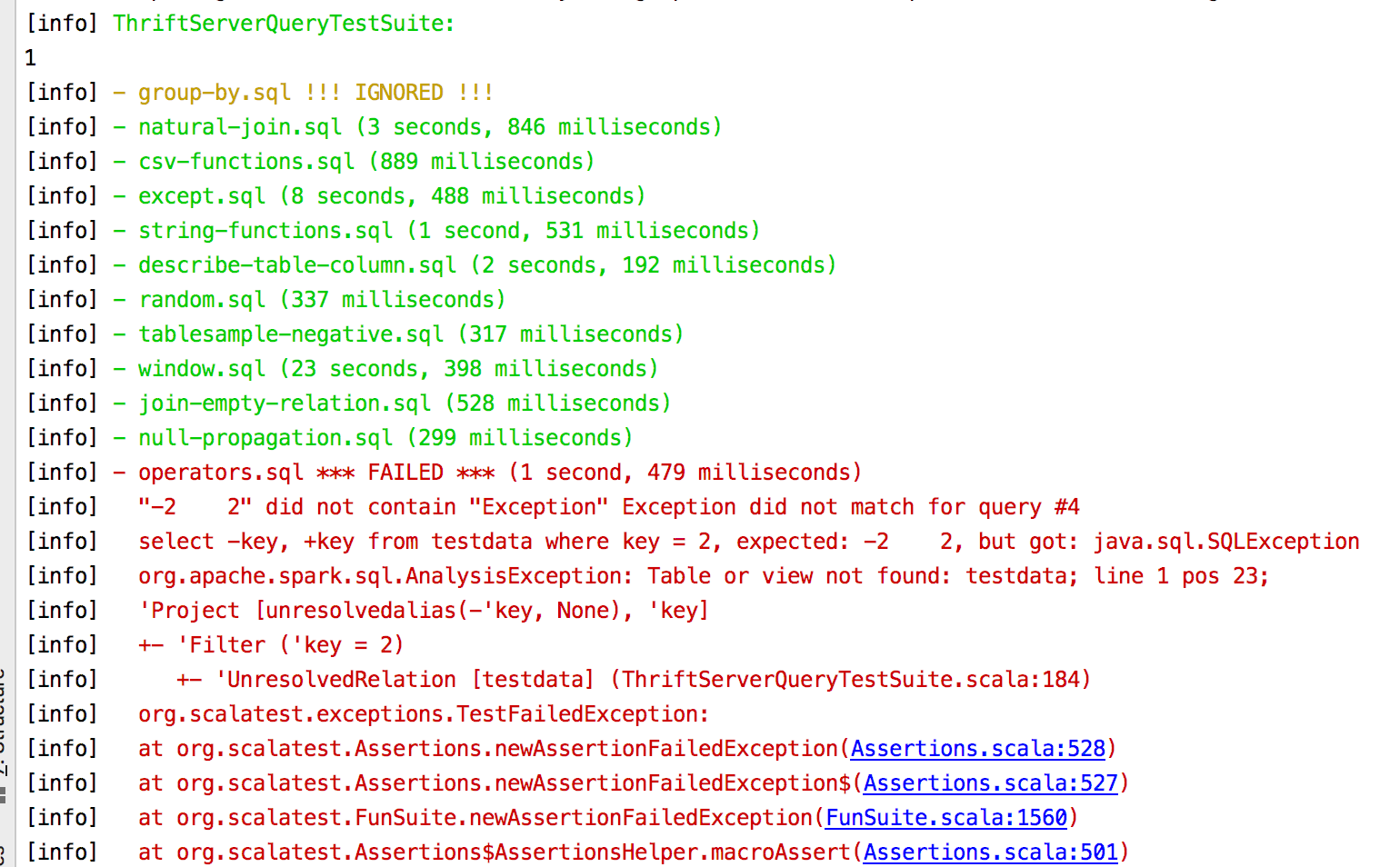 ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}