atronchi commented on a change in pull request #26197: [SPARK-29577] Implement
p-value simulation and unit tests for chi2 test
URL: https://github.com/apache/spark/pull/26197#discussion_r341742483
##########
File path:
mllib/src/main/scala/org/apache/spark/mllib/stat/test/ChiSqTest.scala
##########
@@ -195,7 +200,15 @@ private[spark] object ChiSqTest extends Logging {
}
}
val df = size - 1
- val pValue = 1.0 - new
ChiSquaredDistribution(df).cumulativeProbability(statistic)
+ val pValue = if (simulatePValue && !expArr.isEmpty) {
+ val spark =
SparkSession.getActiveSession.getOrElse(SparkSession.getDefaultSession.get)
+ val exp: BDV[Double] = BDV(expArr.map(_ * scale))
+ val digest = getChi2Digest(spark, exp, numDraw = numDraw)
+
+ 1.0 - digest.cdf(statistic)
+ } else {
+ 1.0 - new ChiSquaredDistribution(df).cumulativeProbability(statistic)
+ }
Review comment:
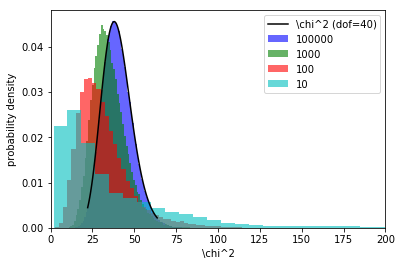
For small N (<5-10 depending on who you talk to) in any bucket of the array
of expected values, the theoretical chi2 distribution is not valid so we cannot
use it in the goodness of fit test. In such cases, we can use MC to empirically
compute the distribution of the chi2 metric, and use this distribution in lieu
of the theoretical one.
Here's an image depicting the deviation of this empirical distribution from
the theoretical one as we scan the total number of points (note that this
number in the legend is not the "N in any bucket" I referred to above, but
think of it as a proxy).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}