[GitHub] spark issue #21199: [SPARK-24127][SS] Continuous text socket source
Github user jerryshao commented on the issue: https://github.com/apache/spark/pull/21199 I was thinking if it is too overkill to receive data in the driver side and publish them to the executors via RPC? This might give user a wrong impression that data should be received in the driver side and published to the executors again. Just my two cents. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21222: [SPARK-24161][SS] Enable debug package feature on struct...
Github user HeartSaVioR commented on the issue: https://github.com/apache/spark/pull/21222 Kindly ping. I guess debugging last batch might not be attractive that much, but printing codegen would be helpful to someone who want to investigate or debug in detail. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21290: [SPARK-24241][Submit]Do not fail fast when dynamic resou...
Github user jerryshao commented on the issue: https://github.com/apache/spark/pull/21290 LGTM, just some minor comments. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21290: [SPARK-24241][Submit]Do not fail fast when dynami...
Github user jerryshao commented on a diff in the pull request: https://github.com/apache/spark/pull/21290#discussion_r187847736 --- Diff: core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala --- @@ -76,6 +75,7 @@ private[deploy] class SparkSubmitArguments(args: Seq[String], env: Map[String, S var proxyUser: String = null var principal: String = null var keytab: String = null + var dynamicAllocationEnabled: String = null --- End diff -- Add `private` since this variable is never used out of this class. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21290: [SPARK-24241][Submit]Do not fail fast when dynami...
Github user jerryshao commented on a diff in the pull request:
https://github.com/apache/spark/pull/21290#discussion_r187847656
--- Diff:
core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala ---
@@ -180,6 +180,25 @@ class SparkSubmitSuite
appArgs.toString should include ("thequeue")
}
+ test("SPARK-24241: not fail fast when executor num is 0 and dynamic
allocation enabled") {
--- End diff --
nit: "do not fail fast x when dynamic allocation is enabled"
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user BryanCutler commented on the issue: https://github.com/apache/spark/pull/21312 Thanks for catching this @viirya! Looks good from a first glance, but my only concern is that `clear()` will release the vector buffers, where `reset()` just zeros them out. Let me look into that a little further tomorrow and make sure it won't cause a problem. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21318 @rxin, should we maybe we mention that SQL functions are usually added to match other DBMSs (unlike functions.scala)? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21318: [minor] Update docs for functions.scala to make i...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21318#discussion_r187843889
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -39,7 +39,21 @@ import org.apache.spark.util.Utils
/**
- * Functions available for DataFrame operations.
+ * Commonly used functions available for DataFrame operations. Using
functions defined here provides
+ * a little bit more compile-time safety to make sure the function exists.
+ *
+ * Spark also includes more built-in functions that are less common and
are not defined here.
+ * You can still access them (and all the functions defined here) using
the [[functions.expr()]] API
+ * and calling them through a SQL expression string. You can find the
entire list of functions for
+ * the latest version of Spark at
[[https://spark.apache.org/docs/latest/api/sql/index.html]].
+ *
+ * As an example, `isnan` is a function that is defined here. You can use
`isnan(col("myCol"))`
+ * to invoke the isnan function. This way the programming language's
compiler ensures isnan exists
--- End diff --
nit: `isnan` -> `` `isnan` ``
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21318: [minor] Update docs for functions.scala to make i...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/21318#discussion_r187843283 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala --- @@ -39,7 +39,21 @@ import org.apache.spark.util.Utils /** - * Functions available for DataFrame operations. + * Commonly used functions available for DataFrame operations. Using functions defined here provides --- End diff -- Maybe I am too much caring about this but I hope we don't have arguments too much if it's common or not ... --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21318: [minor] Update docs for functions.scala to make i...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/21318#discussion_r187843125 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala --- @@ -39,7 +39,21 @@ import org.apache.spark.util.Utils /** - * Functions available for DataFrame operations. + * Commonly used functions available for DataFrame operations. Using functions defined here provides + * a little bit more compile-time safety to make sure the function exists. + * + * Spark also includes more built-in functions that are less common and are not defined here. + * You can still access them (and all the functions defined here) using the [[functions.expr()]] API + * and calling them through a SQL expression string. You can find the entire list of functions for + * the latest version of Spark at [[https://spark.apache.org/docs/latest/api/sql/index.html]]. --- End diff -- @rxin, it's rather a nit but shouldn't we always update the link for each release since it always points the latest? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3188/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21299 **[Test build #90568 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90568/testReport)** for PR 21299 at commit [`a100dea`](https://github.com/apache/spark/commit/a100dea9573e9b43b993516c817e306d80f72d29). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21318: [minor] Update docs for functions.scala to make i...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21318#discussion_r187842050
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -39,7 +39,21 @@ import org.apache.spark.util.Utils
/**
- * Functions available for DataFrame operations.
+ * Commonly used functions available for DataFrame operations. Using
functions defined here provides
+ * a little bit more compile-time safety to make sure the function exists.
+ *
+ * Spark also includes more built-in functions that are less common and
are not defined here.
+ * You can still access them (and all the functions defined here) using
the [[functions.expr()]] API
--- End diff --
```
[error]
/home/jenkins/workspace/SparkPullRequestBuilder/sql/core/target/java/org/apache/spark/sql/functions.java:7:
error: unexpected text
[error] * You can still access them (and all the functions defined here)
using the {@link functions.expr()} API
[error]
^
[error]
/home/jenkins/workspace/SparkPullRequestBuilder/sql/core/target/java/org/apache/spark/sql/functions.java:9:
error: unexpected text
[error] * the latest version of Spark at {@link
https://spark.apache.org/docs/latest/api/sql/index.html}.
[error] ^
```
Seems both links are the problem in Javadoc. Shall we just use ``
`functions.expr() ` `` and leave the
`https://spark.apache.org/docs/latest/api/sql/index.html` like without
`[[...]]`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187841313
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SQLExecution.scala ---
@@ -90,13 +92,33 @@ object SQLExecution {
* thread from the original one, this method can be used to connect the
Spark jobs in this action
* with the known executionId, e.g.,
`BroadcastExchangeExec.relationFuture`.
*/
- def withExecutionId[T](sc: SparkContext, executionId: String)(body: =>
T): T = {
+ def withExecutionId[T](sparkSession: SparkSession, executionId:
String)(body: => T): T = {
+val sc = sparkSession.sparkContext
val oldExecutionId = sc.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
+withSQLConfPropagated(sparkSession) {
+ try {
+sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, executionId)
+body
+ } finally {
+sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, oldExecutionId)
+ }
+}
+ }
+
+ def withSQLConfPropagated[T](sparkSession: SparkSession)(body: => T): T
= {
+// Set all the specified SQL configs to local properties, so that they
can be available at
+// the executor side.
+val allConfigs = sparkSession.sessionState.conf.getAllConfs
+for ((key, value) <- allConfigs) {
+ // Excludes external configs defined by users.
+ if (key.startsWith("spark"))
sparkSession.sparkContext.setLocalProperty(key, value)
+}
try {
- sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, executionId)
body
} finally {
- sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, oldExecutionId)
+ allConfigs.foreach {
+case (key, _) => sparkSession.sparkContext.setLocalProperty(key,
null)
--- End diff --
good point, although it's very unlikely that users set some sql configs to
local property. let me change it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user rxin commented on the issue: https://github.com/apache/spark/pull/21318 Hm the failure doesn't look like it's caused by this PR. Do you guys know what's going on? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21318 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187837123
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/maskExpressions.scala
---
@@ -0,0 +1,569 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.commons.codec.digest.DigestUtils
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.MaskExpressionsUtils._
+import org.apache.spark.sql.catalyst.expressions.MaskLike._
+import org.apache.spark.sql.catalyst.expressions.codegen.{CodegenContext,
CodeGenerator, ExprCode}
+import org.apache.spark.sql.types._
+import org.apache.spark.unsafe.types.UTF8String
+
+
+trait MaskLike {
+ def upper: String
+ def lower: String
+ def digit: String
+
+ protected lazy val upperReplacement: Int = getReplacementChar(upper,
defaultMaskedUppercase)
+ protected lazy val lowerReplacement: Int = getReplacementChar(lower,
defaultMaskedLowercase)
+ protected lazy val digitReplacement: Int = getReplacementChar(digit,
defaultMaskedDigit)
+
+ protected val maskUtilsClassName: String =
classOf[MaskExpressionsUtils].getName
+
+ def inputStringLengthCode(inputString: String, length: String): String =
{
+s"${CodeGenerator.JAVA_INT} $length = $inputString.codePointCount(0,
$inputString.length());"
+ }
+
+ def appendMaskedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($maskUtilsClassName.transformChar($codePoint,
+ |$upperReplacement, $lowerReplacement,
+ |$digitReplacement, $defaultMaskedOther));
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendUnchangedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($codePoint);
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendMaskedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(transformChar(
+codePoint,
+upperReplacement,
+lowerReplacement,
+digitReplacement,
+defaultMaskedOther))
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+
+ def appendUnchangedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(codePoint)
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+}
+
+trait MaskLikeWithN extends MaskLike {
+ def n: Int
+ protected lazy val charCount: Int = if (n < 0) 0 else n
+}
+
+/**
+ * Utils for mask oper
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187835032
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/maskExpressions.scala
---
@@ -0,0 +1,569 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.commons.codec.digest.DigestUtils
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.MaskExpressionsUtils._
+import org.apache.spark.sql.catalyst.expressions.MaskLike._
+import org.apache.spark.sql.catalyst.expressions.codegen.{CodegenContext,
CodeGenerator, ExprCode}
+import org.apache.spark.sql.types._
+import org.apache.spark.unsafe.types.UTF8String
+
+
+trait MaskLike {
+ def upper: String
+ def lower: String
+ def digit: String
+
+ protected lazy val upperReplacement: Int = getReplacementChar(upper,
defaultMaskedUppercase)
+ protected lazy val lowerReplacement: Int = getReplacementChar(lower,
defaultMaskedLowercase)
+ protected lazy val digitReplacement: Int = getReplacementChar(digit,
defaultMaskedDigit)
+
+ protected val maskUtilsClassName: String =
classOf[MaskExpressionsUtils].getName
+
+ def inputStringLengthCode(inputString: String, length: String): String =
{
+s"${CodeGenerator.JAVA_INT} $length = $inputString.codePointCount(0,
$inputString.length());"
+ }
+
+ def appendMaskedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($maskUtilsClassName.transformChar($codePoint,
+ |$upperReplacement, $lowerReplacement,
+ |$digitReplacement, $defaultMaskedOther));
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendUnchangedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($codePoint);
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendMaskedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(transformChar(
+codePoint,
+upperReplacement,
+lowerReplacement,
+digitReplacement,
+defaultMaskedOther))
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+
+ def appendUnchangedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(codePoint)
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+}
+
+trait MaskLikeWithN extends MaskLike {
+ def n: Int
+ protected lazy val charCount: Int = if (n < 0) 0 else n
+}
+
+/**
+ * Utils for mask oper
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187839186
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/MaskExpressionsSuite.scala
---
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.spark.SparkFunSuite
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.types.{IntegerType, StringType}
+
+class MaskExpressionsSuite extends SparkFunSuite with ExpressionEvalHelper
{
+
+ test("mask") {
+checkEvaluation(Mask(Literal("abcd-EFGH-8765-4321"), "U", "l", "#"),
"---")
+checkEvaluation(
+ new Mask(Literal("abcd-EFGH-8765-4321"), Literal("U"), Literal("l"),
Literal("#")),
+ "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"), Literal("U"),
Literal("l")),
+ "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"),
Literal("U")), "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321")),
"---")
+checkEvaluation(new Mask(Literal(null, StringType)), null)
+checkEvaluation(Mask(Literal("abcd-EFGH-8765-4321"), null, "l", "#"),
"---")
+checkEvaluation(new Mask(
+ Literal("abcd-EFGH-8765-4321"),
+ Literal(null, StringType),
+ Literal(null, StringType),
+ Literal(null, StringType)), "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"),
Literal("Upper")),
+ "---")
+checkEvaluation(new Mask(Literal("")), "")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"), Literal("")),
"---")
+checkEvaluation(Mask(Literal("abcd-EFGH-8765-4321"), "", "", ""),
"---")
+// scalastyle:off nonascii
+checkEvaluation(Mask(Literal("Ul9U"), "\u2200", null, null),
"\u2200xn\u2200")
+checkEvaluation(new Mask(Literal("Hello World, ããã«ã¡ã¯, ð
"), Literal("ã"), Literal("ð¡½")),
+ "ãð¡½ð¡½ð¡½ð¡½ ãð¡½ð¡½ð¡½ð¡½, ããã«ã¡ã¯, ð ")
+// scalastyle:on nonascii
+intercept[AnalysisException] {
+ checkEvaluation(new Mask(Literal(""), Literal(1)), "")
+}
+ }
+
+ test("mask_first_n") {
+checkEvaluation(MaskFirstN(Literal("abcd-EFGH-8765-4321"), 6, "U",
"l", "#"),
--- End diff --
Can you include upper/lower/number/other letters in the first N letters to
check the mask is working?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187835331
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/MaskExpressionsUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions;
+
+/**
+ * Contains all the Utils methods used in the masking expressions.
+ */
+public class MaskExpressionsUtils {
--- End diff --
Why is this implemented in Java?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187835834
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/maskExpressions.scala
---
@@ -0,0 +1,569 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.commons.codec.digest.DigestUtils
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.MaskExpressionsUtils._
+import org.apache.spark.sql.catalyst.expressions.MaskLike._
+import org.apache.spark.sql.catalyst.expressions.codegen.{CodegenContext,
CodeGenerator, ExprCode}
+import org.apache.spark.sql.types._
+import org.apache.spark.unsafe.types.UTF8String
+
+
+trait MaskLike {
+ def upper: String
+ def lower: String
+ def digit: String
+
+ protected lazy val upperReplacement: Int = getReplacementChar(upper,
defaultMaskedUppercase)
+ protected lazy val lowerReplacement: Int = getReplacementChar(lower,
defaultMaskedLowercase)
+ protected lazy val digitReplacement: Int = getReplacementChar(digit,
defaultMaskedDigit)
+
+ protected val maskUtilsClassName: String =
classOf[MaskExpressionsUtils].getName
+
+ def inputStringLengthCode(inputString: String, length: String): String =
{
+s"${CodeGenerator.JAVA_INT} $length = $inputString.codePointCount(0,
$inputString.length());"
+ }
+
+ def appendMaskedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($maskUtilsClassName.transformChar($codePoint,
+ |$upperReplacement, $lowerReplacement,
+ |$digitReplacement, $defaultMaskedOther));
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendUnchangedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($codePoint);
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendMaskedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(transformChar(
+codePoint,
+upperReplacement,
+lowerReplacement,
+digitReplacement,
+defaultMaskedOther))
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+
+ def appendUnchangedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(codePoint)
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+}
+
+trait MaskLikeWithN extends MaskLike {
+ def n: Int
+ protected lazy val charCount: Int = if (n < 0) 0 else n
+}
+
+/**
+ * Utils for mask oper
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21318 **[Test build #90567 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90567/testReport)** for PR 21318 at commit [`83c191f`](https://github.com/apache/spark/commit/83c191fbbe82bf49c81a860f4f1ebde7a4076f00). * This patch **fails to generate documentation**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187839605
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/MaskExpressionsSuite.scala
---
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.spark.SparkFunSuite
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.types.{IntegerType, StringType}
+
+class MaskExpressionsSuite extends SparkFunSuite with ExpressionEvalHelper
{
+
+ test("mask") {
+checkEvaluation(Mask(Literal("abcd-EFGH-8765-4321"), "U", "l", "#"),
"---")
+checkEvaluation(
+ new Mask(Literal("abcd-EFGH-8765-4321"), Literal("U"), Literal("l"),
Literal("#")),
+ "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"), Literal("U"),
Literal("l")),
+ "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"),
Literal("U")), "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321")),
"---")
+checkEvaluation(new Mask(Literal(null, StringType)), null)
+checkEvaluation(Mask(Literal("abcd-EFGH-8765-4321"), null, "l", "#"),
"---")
+checkEvaluation(new Mask(
+ Literal("abcd-EFGH-8765-4321"),
+ Literal(null, StringType),
+ Literal(null, StringType),
+ Literal(null, StringType)), "---")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"),
Literal("Upper")),
+ "---")
+checkEvaluation(new Mask(Literal("")), "")
+checkEvaluation(new Mask(Literal("abcd-EFGH-8765-4321"), Literal("")),
"---")
+checkEvaluation(Mask(Literal("abcd-EFGH-8765-4321"), "", "", ""),
"---")
+// scalastyle:off nonascii
+checkEvaluation(Mask(Literal("Ul9U"), "\u2200", null, null),
"\u2200xn\u2200")
+checkEvaluation(new Mask(Literal("Hello World, ããã«ã¡ã¯, ð
"), Literal("ã"), Literal("ð¡½")),
+ "ãð¡½ð¡½ð¡½ð¡½ ãð¡½ð¡½ð¡½ð¡½, ããã«ã¡ã¯, ð ")
+// scalastyle:on nonascii
+intercept[AnalysisException] {
+ checkEvaluation(new Mask(Literal(""), Literal(1)), "")
+}
+ }
+
+ test("mask_first_n") {
+checkEvaluation(MaskFirstN(Literal("abcd-EFGH-8765-4321"), 6, "U",
"l", "#"),
+ "-UFGH-8765-4321")
+checkEvaluation(new MaskFirstN(
+ Literal("abcd-EFGH-8765-4321"), Literal(6), Literal("U"),
Literal("l"), Literal("#")),
+ "-UFGH-8765-4321")
+checkEvaluation(
+ new MaskFirstN(Literal("abcd-EFGH-8765-4321"), Literal(6),
Literal("U"), Literal("l")),
+ "-UFGH-8765-4321")
+checkEvaluation(new MaskFirstN(Literal("abcd-EFGH-8765-4321"),
Literal(6), Literal("U")),
+ "-UFGH-8765-4321")
+checkEvaluation(new MaskFirstN(Literal("abcd-EFGH-8765-4321"),
Literal(6)),
+ "-XFGH-8765-4321")
+intercept[AnalysisException] {
+ checkEvaluation(new MaskFirstN(Literal("abcd-EFGH-8765-4321"),
Literal("U")), "")
+}
+checkEvaluation(new MaskFirstN(Literal("abcd-EFGH-8765-4321")),
"-EFGH-8765-4321")
+checkEvaluation(new MaskFirstN(Literal(null, StringType)), null)
+checkEvaluation(MaskFirstN(Literal("abcd-EFGH-8765-4321"), 4, "U",
"l", null),
+ "-EFGH-8765-4321")
+checkEvaluation(new MaskFirstN(
+ Literal("abcd-EFGH-8765-4321"),
+ Literal(null, IntegerType),
+ Literal(null, StringType),
+ Literal(null, StringType),
+ Literal(null, StringType)), "-EFGH-8765-4321")
+checkEvaluation(new MaskFirstN(Literal("abcd-EFGH-8765-4321"),
Literal(6), Literal("Upper")),
+ "-UFGH-8765-4321")
+checkEvaluation(new MaskFirstN(Literal("")), "")
+checkEvaluation(new MaskFir
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187836985
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/maskExpressions.scala
---
@@ -0,0 +1,569 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.commons.codec.digest.DigestUtils
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.MaskExpressionsUtils._
+import org.apache.spark.sql.catalyst.expressions.MaskLike._
+import org.apache.spark.sql.catalyst.expressions.codegen.{CodegenContext,
CodeGenerator, ExprCode}
+import org.apache.spark.sql.types._
+import org.apache.spark.unsafe.types.UTF8String
+
+
+trait MaskLike {
+ def upper: String
+ def lower: String
+ def digit: String
+
+ protected lazy val upperReplacement: Int = getReplacementChar(upper,
defaultMaskedUppercase)
+ protected lazy val lowerReplacement: Int = getReplacementChar(lower,
defaultMaskedLowercase)
+ protected lazy val digitReplacement: Int = getReplacementChar(digit,
defaultMaskedDigit)
+
+ protected val maskUtilsClassName: String =
classOf[MaskExpressionsUtils].getName
+
+ def inputStringLengthCode(inputString: String, length: String): String =
{
+s"${CodeGenerator.JAVA_INT} $length = $inputString.codePointCount(0,
$inputString.length());"
+ }
+
+ def appendMaskedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($maskUtilsClassName.transformChar($codePoint,
+ |$upperReplacement, $lowerReplacement,
+ |$digitReplacement, $defaultMaskedOther));
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendUnchangedToStringBuilderCode(
+ ctx: CodegenContext,
+ sb: String,
+ inputString: String,
+ offset: String,
+ numChars: String): String = {
+val i = ctx.freshName("i")
+val codePoint = ctx.freshName("codePoint")
+s"""
+ |for (${CodeGenerator.JAVA_INT} $i = 0; $i < $numChars; $i++) {
+ | ${CodeGenerator.JAVA_INT} $codePoint =
$inputString.codePointAt($offset);
+ | $sb.appendCodePoint($codePoint);
+ | $offset += Character.charCount($codePoint);
+ |}
+ """.stripMargin
+ }
+
+ def appendMaskedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(transformChar(
+codePoint,
+upperReplacement,
+lowerReplacement,
+digitReplacement,
+defaultMaskedOther))
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+
+ def appendUnchangedToStringBuffer(
+ sb: StringBuffer,
+ inputString: String,
+ startOffset: Int,
+ numChars: Int): Int = {
+var offset = startOffset
+(1 to numChars) foreach { _ =>
+ val codePoint = inputString.codePointAt(offset)
+ sb.appendCodePoint(codePoint)
+ offset += Character.charCount(codePoint)
+}
+offset
+ }
+}
+
+trait MaskLikeWithN extends MaskLike {
+ def n: Int
+ protected lazy val charCount: Int = if (n < 0) 0 else n
+}
+
+/**
+ * Utils for mask oper
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21318 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90567/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21246: [SPARK-23901][SQL] Add masking functions
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21246#discussion_r187835126
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/MaskExpressionsUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions;
+
+/**
+ * Contains all the Utils methods used in the masking expressions.
+ */
+public class MaskExpressionsUtils {
+ final static int UNMASKED_VAL = -1;
+
+ /**
+ *
--- End diff --
Can you add a description?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21318 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3187/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21318 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21318 **[Test build #90567 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90567/testReport)** for PR 21318 at commit [`83c191f`](https://github.com/apache/spark/commit/83c191fbbe82bf49c81a860f4f1ebde7a4076f00). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21318: [minor] Update docs for functions.scala to make it clear...
Github user rxin commented on the issue: https://github.com/apache/spark/pull/21318 cc @gatorsmile @HyukjinKwon --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21318: [minor] Update docs for functions.scala to make i...
GitHub user rxin opened a pull request: https://github.com/apache/spark/pull/21318 [minor] Update docs for functions.scala to make it clear not all the built-in functions are defined there The title summarizes the change. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rxin/spark functions Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21318.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21318 commit 83c191fbbe82bf49c81a860f4f1ebde7a4076f00 Author: Reynold Xin Date: 2018-05-14T05:15:56Z [minor] Update docs for functions.scala --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21316: [SPARK-20538][SQL] Wrap Dataset.reduce with withN...
Github user rxin commented on a diff in the pull request:
https://github.com/apache/spark/pull/21316#discussion_r187838099
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -1607,7 +1607,9 @@ class Dataset[T] private[sql](
*/
@Experimental
@InterfaceStability.Evolving
- def reduce(func: (T, T) => T): T = rdd.reduce(func)
+ def reduce(func: (T, T) => T): T = withNewExecutionId {
--- End diff --
cc @zsxwing
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21092 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-spark-integration/3091/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21092 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-spark-integration/3091/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21092 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21092 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3186/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user ifilonenko commented on the issue: https://github.com/apache/spark/pull/21092 jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user jiangxb1987 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187833760
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SQLExecution.scala ---
@@ -90,13 +92,33 @@ object SQLExecution {
* thread from the original one, this method can be used to connect the
Spark jobs in this action
* with the known executionId, e.g.,
`BroadcastExchangeExec.relationFuture`.
*/
- def withExecutionId[T](sc: SparkContext, executionId: String)(body: =>
T): T = {
+ def withExecutionId[T](sparkSession: SparkSession, executionId:
String)(body: => T): T = {
+val sc = sparkSession.sparkContext
val oldExecutionId = sc.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
+withSQLConfPropagated(sparkSession) {
+ try {
+sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, executionId)
+body
+ } finally {
+sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, oldExecutionId)
+ }
+}
+ }
+
+ def withSQLConfPropagated[T](sparkSession: SparkSession)(body: => T): T
= {
+// Set all the specified SQL configs to local properties, so that they
can be available at
+// the executor side.
+val allConfigs = sparkSession.sessionState.conf.getAllConfs
+for ((key, value) <- allConfigs) {
+ // Excludes external configs defined by users.
+ if (key.startsWith("spark"))
sparkSession.sparkContext.setLocalProperty(key, value)
+}
try {
- sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, executionId)
body
} finally {
- sc.setLocalProperty(SQLExecution.EXECUTION_ID_KEY, oldExecutionId)
+ allConfigs.foreach {
+case (key, _) => sparkSession.sparkContext.setLocalProperty(key,
null)
--- End diff --
Shouldn't this be set back to the original value?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21316: [SPARK-20538][SQL] Wrap Dataset.reduce with withN...
Github user sohama4 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21316#discussion_r187832727
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -1607,7 +1607,9 @@ class Dataset[T] private[sql](
*/
@Experimental
@InterfaceStability.Evolving
- def reduce(func: (T, T) => T): T = rdd.reduce(func)
+ def reduce(func: (T, T) => T): T = withNewExecutionId {
--- End diff --
I believe so.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21296: [SPARK-24244][SQL] Passing only required columns ...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/21296#discussion_r187832513
--- Diff: docs/sql-programming-guide.md ---
@@ -1814,6 +1814,7 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
- In version 2.3 and earlier, `to_utc_timestamp` and
`from_utc_timestamp` respect the timezone in the input timestamp string, which
breaks the assumption that the input timestamp is in a specific timezone.
Therefore, these 2 functions can return unexpected results. In version 2.4 and
later, this problem has been fixed. `to_utc_timestamp` and `from_utc_timestamp`
will return null if the input timestamp string contains timezone. As an
example, `from_utc_timestamp('2000-10-10 00:00:00', 'GMT+1')` will return
`2000-10-10 01:00:00` in both Spark 2.3 and 2.4. However,
`from_utc_timestamp('2000-10-10 00:00:00+00:00', 'GMT+1')`, assuming a local
timezone of GMT+8, will return `2000-10-10 09:00:00` in Spark 2.3 but `null` in
2.4. For people who don't care about this problem and want to retain the
previous behaivor to keep their query unchanged, you can set
`spark.sql.function.rejectTimezoneInString` to false. This option will be
removed in Spark 3.0 and should only be used as a tempora
ry workaround.
- In version 2.3 and earlier, Spark converts Parquet Hive tables by
default but ignores table properties like `TBLPROPERTIES (parquet.compression
'NONE')`. This happens for ORC Hive table properties like `TBLPROPERTIES
(orc.compress 'NONE')` in case of `spark.sql.hive.convertMetastoreOrc=true`,
too. Since Spark 2.4, Spark respects Parquet/ORC specific table properties
while converting Parquet/ORC Hive tables. As an example, `CREATE TABLE t(id
int) STORED AS PARQUET TBLPROPERTIES (parquet.compression 'NONE')` would
generate Snappy parquet files during insertion in Spark 2.3, and in Spark 2.4,
the result would be uncompressed parquet files.
- Since Spark 2.0, Spark converts Parquet Hive tables by default for
better performance. Since Spark 2.4, Spark converts ORC Hive tables by default,
too. It means Spark uses its own ORC support by default instead of Hive SerDe.
As an example, `CREATE TABLE t(id int) STORED AS ORC` would be handled with
Hive SerDe in Spark 2.3, and in Spark 2.4, it would be converted into Spark's
ORC data source table and ORC vectorization would be applied. To set `false` to
`spark.sql.hive.convertMetastoreOrc` restores the previous behavior.
+ - Since Spark 2.4, handling of malformed rows in CSV files was changed.
Previously, all column values of every row are parsed independently of its
future usage. A row was considered as malformed if the CSV parser wasn't able
to handle any column value in the row even if the value wasn't requested.
Starting from version 2.4, only requested column values are parsed, and other
values can be ignored. In such way, correct column values that were considered
as malformed in previous Spark version only because of other malformed values
become correct in Spark version 2.4.
--- End diff --
can we follow the style of other migration guides?
```
In version 2.3 and earlier, . Since Spark 2.4, . As an example,
. (and talk about the flag to restore the previous behavior)
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20800: [SPARK-23627][SQL] Provide isEmpty in Dataset
Github user cloud-fan commented on a diff in the pull request: https://github.com/apache/spark/pull/20800#discussion_r187831971 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala --- @@ -511,6 +511,14 @@ class Dataset[T] private[sql]( */ def isLocal: Boolean = logicalPlan.isInstanceOf[LocalRelation] + /** + * Returns true if the `Dataset` is empty. + * + * @group basic + * @since 2.4.0 + */ + def isEmpty: Boolean = rdd.isEmpty() --- End diff -- `RDD#isEmpty` is pretty effective, it just checks if all the partitions are empty, without loading the data. The problem is how to build an RDD from `Dataset`, which minimize the cost of building the `Iterator`. It seems `Dataset#rdd` is not good enough, e.g., if we have a `Filter` in the query, we may do a full scan(no column pruning) for the underlying files. Doing a count is not perfect either. Ideally we can stop as soon as we see one record. I'd suggest doing a `limit 1` first and then count. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21317 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90566/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21317 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21317 **[Test build #90566 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90566/testReport)** for PR 21317 at commit [`24832c5`](https://github.com/apache/spark/commit/24832c55e42cd768c191ba895ba054bd44d5905c). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21317 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3185/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21208: [SPARK-23925][SQL] Add array_repeat collection function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21208 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90563/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21301: [SPARK-24228][SQL] Fix Java lint errors
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/21301 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21317 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21208: [SPARK-23925][SQL] Add array_repeat collection function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21208 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21208: [SPARK-23925][SQL] Add array_repeat collection function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21208 **[Test build #90563 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90563/testReport)** for PR 21208 at commit [`471597a`](https://github.com/apache/spark/commit/471597aed1beeca2268c50feff0a30383945bd59). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21317 **[Test build #90566 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90566/testReport)** for PR 21317 at commit [`24832c5`](https://github.com/apache/spark/commit/24832c55e42cd768c191ba895ba054bd44d5905c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21317: [SPARK-24232][k8s] Add support for secret env vars
Github user skonto commented on the issue: https://github.com/apache/spark/pull/21317 @liyinan926 @dharmeshkakadia pls review. Hope its close to what we discussed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21301: [SPARK-24228][SQL] Fix Java lint errors
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21301 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21317: [SPARK-24232][Kubernetes] Add support for secret ...
GitHub user skonto opened a pull request: https://github.com/apache/spark/pull/21317 [SPARK-24232][Kubernetes] Add support for secret env vars ## What changes were proposed in this pull request? * Allows to refer a secret as an env var. * Introduces new properties in the form described in the ticket. * Updates docs. * Adds required unit tests. ## How was this patch tested? Manually tested and confirmed that the secrets exist in driver's and executor's container env. First created a secret with the following yaml: ``` apiVersion: v1 kind: Secret metadata: name: test-secret data: username: c3RhdnJvcwo= password: Mzk1MjgkdmRnN0pi --- $ echo -n 'stavros' | base64 c3RhdnJvcw== $ echo -n '1f2d1e2e67df' | base64 MWYyZDFlMmU2N2Rm ``` Run a job as follows: ```./bin/spark-submit \ --master k8s://http://localhost:9000 \ --deploy-mode cluster \ --name spark-pi \ --class org.apache.spark.examples.SparkPi \ --conf spark.executor.instances=1 \ --conf spark.kubernetes.container.image=skonto/spark:k8envs2 \ --conf spark.kubernetes.driver.secretKeyRef.test-secret=username \ --conf spark.kubernetes.executor.secretKeyRef.test-secret=username \ --conf spark.kubernetes.container.image.pullPolicy=Always \ local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar 1 ``` Secret loaded correctly at the driver container: 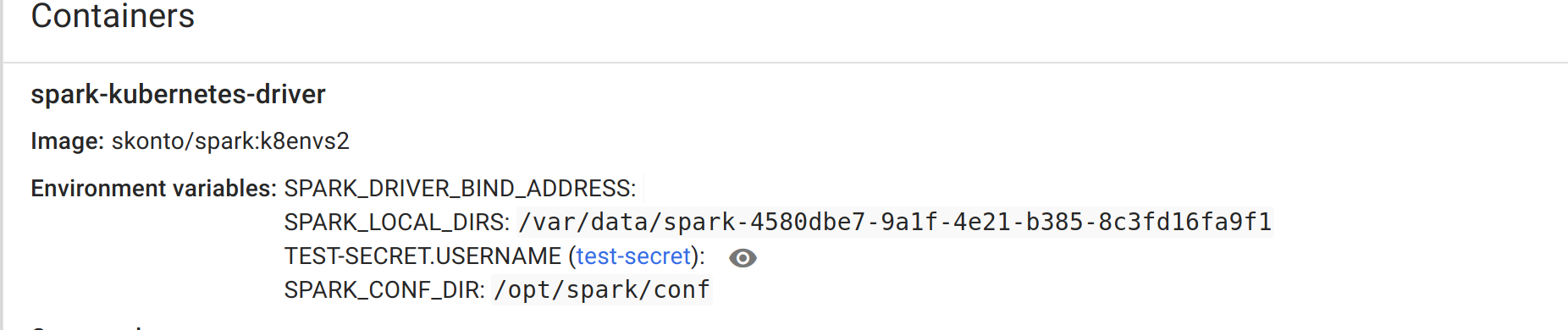 Also if I log into the exec container: ``` kubectl exec -it spark-pi-1526265507716-exec-1 bash bash-4.4# env SPARK_EXECUTOR_MEMORY=1g SPARK_EXECUTOR_CORES=1 LANG=C.UTF-8 HOSTNAME=spark-pi-1526265507716-exec-1 SPARK_APPLICATION_ID=spark-application-1526265518652 JAVA_HOME=/usr/lib/jvm/java-1.8-openjdk KUBERNETES_PORT_443_TCP_PROTO=tcp KUBERNETES_PORT_443_TCP_ADDR=10.100.0.1 **TEST-SECRET.USERNAME=stavros** ... ``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/skonto/spark k8s-fix-env-secrets Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21317.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21317 commit 24832c55e42cd768c191ba895ba054bd44d5905c Author: Stavros Kontopoulos Date: 2018-05-14T02:41:20Z add support for secret env vars --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21301: [SPARK-24228][SQL] Fix Java lint errors
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21301 **[Test build #4177 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4177/testReport)** for PR 21301 at commit [`5403bae`](https://github.com/apache/spark/commit/5403bae783515b868046df6fbee40effbe64a2e6). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21267 **[Test build #90565 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90565/testReport)** for PR 21267 at commit [`68be3ba`](https://github.com/apache/spark/commit/68be3baef22d8b7aa58a432cb5bd12437c07feb7). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21267 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21267 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90565/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21221: [SPARK-23429][CORE] Add executor memory metrics t...
Github user Ngone51 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21221#discussion_r187825561
--- Diff: core/src/main/scala/org/apache/spark/Heartbeater.scala ---
@@ -0,0 +1,52 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark
+
+import java.util.concurrent.TimeUnit
+
+import org.apache.spark.util.{ThreadUtils, Utils}
+
+/**
+ * Creates a heartbeat thread which will call the specified
reportHeartbeat function at
+ * intervals of intervalMs.
+ *
+ * @param reportHeartbeat the heartbeat reporting function to call.
+ * @param intervalMs the interval between heartbeats.
+ */
+private[spark] class Heartbeater(reportHeartbeat: () => Unit, intervalMs:
Long) {
+ // Executor for the heartbeat task
+ private val heartbeater =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("driver-heartbeater")
--- End diff --
"pass in the name to the constructor" is better(if we do need to do this
for the driver)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21208: [SPARK-23925][SQL] Add array_repeat collection function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21208 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21221: [SPARK-23429][CORE] Add executor memory metrics t...
Github user Ngone51 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21221#discussion_r187824094
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
---
@@ -1753,9 +1766,21 @@ class DAGScheduler(
messageScheduler.shutdownNow()
eventProcessLoop.stop()
taskScheduler.stop()
+heartbeater.stop()
+ }
+
+ /** Reports heartbeat metrics for the driver. */
+ private def reportHeartBeat(): Unit = {
--- End diff --
> With cluster mode, including YARN, there isn't a local executor, so the
metrics for the driver would not be collected.
Yes. But the problem is can we use `executor`'s
`getCurrentExecutorMetrics()` method for collecting memory metrics for `driver`
? IIRC, `driver` do not acqurie memory from execution memory pool at least.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21208: [SPARK-23925][SQL] Add array_repeat collection function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21208 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90562/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21221: [SPARK-23429][CORE] Add executor memory metrics t...
Github user Ngone51 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21221#discussion_r187823298
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/EventLoggingListener.scala ---
@@ -169,6 +179,27 @@ private[spark] class EventLoggingListener(
// Events that trigger a flush
override def onStageCompleted(event: SparkListenerStageCompleted): Unit
= {
+// log the peak executor metrics for the stage, for each executor
+val accumUpdates = new ArrayBuffer[(Long, Int, Int,
Seq[AccumulableInfo])]()
+val executorMap = liveStageExecutorMetrics.remove(
+ (event.stageInfo.stageId, event.stageInfo.attemptNumber()))
+executorMap.foreach {
+ executorEntry => {
+for ((executorId, peakExecutorMetrics) <- executorEntry) {
--- End diff --
I revisited the code, I think you're right. My mistake, sorry.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21208: [SPARK-23925][SQL] Add array_repeat collection function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21208 **[Test build #90562 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90562/testReport)** for PR 21208 at commit [`5381ac0`](https://github.com/apache/spark/commit/5381ac0f4700c5e1dbf9d9ee1fef131765e32452). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21296: [SPARK-24244][SQL] Passing only required columns ...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21296#discussion_r187823861
--- Diff: docs/sql-programming-guide.md ---
@@ -1814,6 +1814,7 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
- In version 2.3 and earlier, `to_utc_timestamp` and
`from_utc_timestamp` respect the timezone in the input timestamp string, which
breaks the assumption that the input timestamp is in a specific timezone.
Therefore, these 2 functions can return unexpected results. In version 2.4 and
later, this problem has been fixed. `to_utc_timestamp` and `from_utc_timestamp`
will return null if the input timestamp string contains timezone. As an
example, `from_utc_timestamp('2000-10-10 00:00:00', 'GMT+1')` will return
`2000-10-10 01:00:00` in both Spark 2.3 and 2.4. However,
`from_utc_timestamp('2000-10-10 00:00:00+00:00', 'GMT+1')`, assuming a local
timezone of GMT+8, will return `2000-10-10 09:00:00` in Spark 2.3 but `null` in
2.4. For people who don't care about this problem and want to retain the
previous behaivor to keep their query unchanged, you can set
`spark.sql.function.rejectTimezoneInString` to false. This option will be
removed in Spark 3.0 and should only be used as a tempora
ry workaround.
- In version 2.3 and earlier, Spark converts Parquet Hive tables by
default but ignores table properties like `TBLPROPERTIES (parquet.compression
'NONE')`. This happens for ORC Hive table properties like `TBLPROPERTIES
(orc.compress 'NONE')` in case of `spark.sql.hive.convertMetastoreOrc=true`,
too. Since Spark 2.4, Spark respects Parquet/ORC specific table properties
while converting Parquet/ORC Hive tables. As an example, `CREATE TABLE t(id
int) STORED AS PARQUET TBLPROPERTIES (parquet.compression 'NONE')` would
generate Snappy parquet files during insertion in Spark 2.3, and in Spark 2.4,
the result would be uncompressed parquet files.
- Since Spark 2.0, Spark converts Parquet Hive tables by default for
better performance. Since Spark 2.4, Spark converts ORC Hive tables by default,
too. It means Spark uses its own ORC support by default instead of Hive SerDe.
As an example, `CREATE TABLE t(id int) STORED AS ORC` would be handled with
Hive SerDe in Spark 2.3, and in Spark 2.4, it would be converted into Spark's
ORC data source table and ORC vectorization would be applied. To set `false` to
`spark.sql.hive.convertMetastoreOrc` restores the previous behavior.
+ - Since Spark 2.4, handling of malformed rows in CSV files was changed.
Previously, all column values of every row are parsed independently of its
future usage. A row was considered as malformed if the CSV parser wasn't able
to handle any column value in the row even if the value wasn't requested.
Starting from version 2.4, only requested column values are parsed, and other
values can be ignored. In such way, correct column values that were considered
as malformed in previous Spark version only because of other malformed values
become correct in Spark version 2.4.
--- End diff --
Do we really wanna this behaviour change @cloud-fan and @gatorsmile?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21296: [SPARK-24244][SQL] Passing only required columns ...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21296#discussion_r187823801
--- Diff: docs/sql-programming-guide.md ---
@@ -1814,6 +1814,7 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
- In version 2.3 and earlier, `to_utc_timestamp` and
`from_utc_timestamp` respect the timezone in the input timestamp string, which
breaks the assumption that the input timestamp is in a specific timezone.
Therefore, these 2 functions can return unexpected results. In version 2.4 and
later, this problem has been fixed. `to_utc_timestamp` and `from_utc_timestamp`
will return null if the input timestamp string contains timezone. As an
example, `from_utc_timestamp('2000-10-10 00:00:00', 'GMT+1')` will return
`2000-10-10 01:00:00` in both Spark 2.3 and 2.4. However,
`from_utc_timestamp('2000-10-10 00:00:00+00:00', 'GMT+1')`, assuming a local
timezone of GMT+8, will return `2000-10-10 09:00:00` in Spark 2.3 but `null` in
2.4. For people who don't care about this problem and want to retain the
previous behaivor to keep their query unchanged, you can set
`spark.sql.function.rejectTimezoneInString` to false. This option will be
removed in Spark 3.0 and should only be used as a tempora
ry workaround.
- In version 2.3 and earlier, Spark converts Parquet Hive tables by
default but ignores table properties like `TBLPROPERTIES (parquet.compression
'NONE')`. This happens for ORC Hive table properties like `TBLPROPERTIES
(orc.compress 'NONE')` in case of `spark.sql.hive.convertMetastoreOrc=true`,
too. Since Spark 2.4, Spark respects Parquet/ORC specific table properties
while converting Parquet/ORC Hive tables. As an example, `CREATE TABLE t(id
int) STORED AS PARQUET TBLPROPERTIES (parquet.compression 'NONE')` would
generate Snappy parquet files during insertion in Spark 2.3, and in Spark 2.4,
the result would be uncompressed parquet files.
- Since Spark 2.0, Spark converts Parquet Hive tables by default for
better performance. Since Spark 2.4, Spark converts ORC Hive tables by default,
too. It means Spark uses its own ORC support by default instead of Hive SerDe.
As an example, `CREATE TABLE t(id int) STORED AS ORC` would be handled with
Hive SerDe in Spark 2.3, and in Spark 2.4, it would be converted into Spark's
ORC data source table and ORC vectorization would be applied. To set `false` to
`spark.sql.hive.convertMetastoreOrc` restores the previous behavior.
+ - Since Spark 2.4, handling of malformed rows in CSV files was changed.
Previously, all column values of every row are parsed independently of its
future usage. A row was considered as malformed if the CSV parser wasn't able
to handle any column value in the row even if the value wasn't requested.
Starting from version 2.4, only requested column values are parsed, and other
values can be ignored. In such way, correct column values that were considered
as malformed in previous Spark version only because of other malformed values
become correct in Spark version 2.4.
--- End diff --
Shall we add some more examples? I guess now df.count() with dropmalformed
give a different number too.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21311: [SPARK-24257][SQL]LongToUnsafeRowMap calculate the new s...
Github user maropu commented on the issue: https://github.com/apache/spark/pull/21311 @gatorsmile @hvanhovell Could you trigger tests? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21114: [SPARK-22371][CORE] Return None instead of throwing an e...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21114 cc @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21273: [SPARK-17916][SQL] Fix empty string being parsed ...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/21273 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20068: [SPARK-17916][SQL] Fix empty string being parsed ...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20068 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21310: [SPARK-24256][SQL] SPARK-24256: ExpressionEncoder should...
Github user maropu commented on the issue: https://github.com/apache/spark/pull/21310 You need to add tests first. Could you? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187823469
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -237,6 +236,65 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
acc.merge("kindness")
assert(acc.value === "kindness")
}
+
+ test("updating garbage collected accumulators") {
+// Simulate FetchFailedException in the first attempt to force a retry.
+// Then complete remaining task from the first attempt after the second
+// attempt started, but before it completes. Completion event for the
first
+// attempt will try to update garbage collected accumulators.
+val numPartitions = 2
+sc = new SparkContext("local[2]", "test")
+
+val attempt0Latch = new TestLatch("attempt0")
+val attempt1Latch = new TestLatch("attempt1")
+
+val x = sc.parallelize(1 to 100, numPartitions).groupBy(identity)
+val sid = x.dependencies.head.asInstanceOf[ShuffleDependency[_, _,
_]].shuffleHandle.shuffleId
+val rdd = x.mapPartitionsWithIndex { case (i, iter) =>
+ val taskContext = TaskContext.get()
+ if (taskContext.stageAttemptNumber() == 0) {
+if (i == 0) {
+ // Fail the first task in the first stage attempt to force retry.
+ throw new FetchFailedException(
+SparkEnv.get.blockManager.blockManagerId,
+sid,
+taskContext.partitionId(),
+taskContext.partitionId(),
+"simulated fetch failure")
+} else {
+ // Wait till the second attempt starts.
+ attempt0Latch.await()
+ iter
+}
+ } else {
+if (i == 0) {
+ // Wait till the first attempt completes.
+ attempt1Latch.await()
+}
+iter
+ }
+}
+
+sc.addSparkListener(new SparkListener {
+ override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = {
+if (taskStart.stageId == 1 && taskStart.stageAttemptId == 1) {
--- End diff --
Got it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21267 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21092 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21092 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90561/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21267 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3184/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21092: [SPARK-23984][K8S] Initial Python Bindings for PySpark o...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21092 **[Test build #90561 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90561/testReport)** for PR 21092 at commit [`72953a3`](https://github.com/apache/spark/commit/72953a3ef42ce0aa0d4b55c0f213198b4b468907). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21273 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21267 **[Test build #90565 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90565/testReport)** for PR 21267 at commit [`68be3ba`](https://github.com/apache/spark/commit/68be3baef22d8b7aa58a432cb5bd12437c07feb7). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user maropu commented on the issue: https://github.com/apache/spark/pull/21273 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21307: [SPARK-24186][R][SQL]change reverse and concat to...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/21307 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21288: [SPARK-24206][SQL] Improve FilterPushdownBenchmar...
Github user maropu commented on a diff in the pull request:
https://github.com/apache/spark/pull/21288#discussion_r187822729
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/FilterPushdownBenchmark.scala ---
@@ -32,14 +32,14 @@ import org.apache.spark.util.{Benchmark, Utils}
*/
object FilterPushdownBenchmark {
val conf = new SparkConf()
- conf.set("orc.compression", "snappy")
- conf.set("spark.sql.parquet.compression.codec", "snappy")
+.setMaster("local[1]")
+.setAppName("FilterPushdownBenchmark")
+.set("spark.driver.memory", "3g")
--- End diff --
aha, ok. Looks good to me.
I just added this along with other benchmark code, e.g.,
`TPCDSQueryBenchmark`.
If no problem, I'll fix the other places in follow-up.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21267: [SPARK-21945][YARN][PYTHON] Make --py-files work with Py...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21267 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21307 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21307: [SPARK-24186][R][SQL]change reverse and concat to...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21307#discussion_r187822362
--- Diff: R/pkg/R/functions.R ---
@@ -2055,20 +2058,10 @@ setMethod("countDistinct",
#' @details
#' \code{concat}: Concatenates multiple input columns together into a
single column.
-#' If all inputs are binary, concat returns an output as binary.
Otherwise, it returns as string.
+#' The function works with strings, binary and compatible array columns.
--- End diff --
I think it basically mean the arrays of elements are compatibile and
castable for a wider type. (e.g. array array -> array)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21114: [SPARK-22371][CORE] Return None instead of throwing an e...
Github user artemrd commented on the issue: https://github.com/apache/spark/pull/21114 Yes, this is correct. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user artemrd commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187821160
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -237,6 +236,65 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
acc.merge("kindness")
assert(acc.value === "kindness")
}
+
+ test("updating garbage collected accumulators") {
+// Simulate FetchFailedException in the first attempt to force a retry.
+// Then complete remaining task from the first attempt after the second
+// attempt started, but before it completes. Completion event for the
first
+// attempt will try to update garbage collected accumulators.
+val numPartitions = 2
+sc = new SparkContext("local[2]", "test")
+
+val attempt0Latch = new TestLatch("attempt0")
+val attempt1Latch = new TestLatch("attempt1")
+
+val x = sc.parallelize(1 to 100, numPartitions).groupBy(identity)
+val sid = x.dependencies.head.asInstanceOf[ShuffleDependency[_, _,
_]].shuffleHandle.shuffleId
+val rdd = x.mapPartitionsWithIndex { case (i, iter) =>
+ val taskContext = TaskContext.get()
+ if (taskContext.stageAttemptNumber() == 0) {
+if (i == 0) {
+ // Fail the first task in the first stage attempt to force retry.
+ throw new FetchFailedException(
+SparkEnv.get.blockManager.blockManagerId,
+sid,
+taskContext.partitionId(),
+taskContext.partitionId(),
+"simulated fetch failure")
+} else {
+ // Wait till the second attempt starts.
+ attempt0Latch.await()
+ iter
+}
+ } else {
+if (i == 0) {
+ // Wait till the first attempt completes.
+ attempt1Latch.await()
+}
+iter
+ }
+}
+
+sc.addSparkListener(new SparkListener {
+ override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = {
+if (taskStart.stageId == 1 && taskStart.stageAttemptId == 1) {
--- End diff --
It actually doesn't matter, we just need to wait till second attempt is
started, this will update Stage._latestInfo and first attempt accumulators can
be garbage collected.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20800: [SPARK-23627][SQL] Provide isEmpty in Dataset
Github user maropu commented on a diff in the pull request: https://github.com/apache/spark/pull/20800#discussion_r187820731 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala --- @@ -511,6 +511,14 @@ class Dataset[T] private[sql]( */ def isLocal: Boolean = logicalPlan.isInstanceOf[LocalRelation] + /** + * Returns true if the `Dataset` is empty. + * + * @group basic + * @since 2.4.0 + */ + def isEmpty: Boolean = rdd.isEmpty() --- End diff -- If it's worth doing, I'll take (if nobody does this...) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18903: [SPARK-21590][SS]Window start time should support negati...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/18903 **[Test build #4178 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4178/testReport)** for PR 18903 at commit [`07e98e7`](https://github.com/apache/spark/commit/07e98e7d0903d72e66d0688dde11d481b41a63df). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21316: [SPARK-20538][SQL] Wrap Dataset.reduce with withN...
Github user maropu commented on a diff in the pull request:
https://github.com/apache/spark/pull/21316#discussion_r187820636
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -1607,7 +1607,9 @@ class Dataset[T] private[sql](
*/
@Experimental
@InterfaceStability.Evolving
- def reduce(func: (T, T) => T): T = rdd.reduce(func)
+ def reduce(func: (T, T) => T): T = withNewExecutionId {
--- End diff --
Only a place to need this wrapper in this file?
@gatorsmile btw, this api is still useful? Or, this intends to be
deprecated in v3.0+?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21236: [SPARK-23935][SQL] Adding map_entries function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21236 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90557/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21236: [SPARK-23935][SQL] Adding map_entries function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21236 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21236: [SPARK-23935][SQL] Adding map_entries function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21236 **[Test build #90557 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90557/testReport)** for PR 21236 at commit [`56ff20a`](https://github.com/apache/spark/commit/56ff20ac977ca1a305e96a7582789e2e75e6718c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21162: shaded guava is not used anywhere, seems guava is...
Github user yileic closed the pull request at: https://github.com/apache/spark/pull/21162 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21314: [SPARK-24263][R] SparkR java check breaks with op...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21314#discussion_r187817762
--- Diff: R/pkg/R/client.R ---
@@ -82,7 +82,7 @@ checkJavaVersion <- function() {
})
javaVersionFilter <- Filter(
function(x) {
-grepl("java version", x)
+grepl(" version", x)
--- End diff --
great! interesting it's only broken on openjdk then
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20274: [SPARK-20120][SQL][FOLLOW-UP] Better way to support spar...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20274 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20274: [SPARK-20120][SQL][FOLLOW-UP] Better way to support spar...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20274 **[Test build #90564 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90564/testReport)** for PR 20274 at commit [`0501653`](https://github.com/apache/spark/commit/050165302062aeddbe1c9c598ecc29abf8858c55). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20274: [SPARK-20120][SQL][FOLLOW-UP] Better way to support spar...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20274 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90564/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20274: [SPARK-20120][SQL][FOLLOW-UP] Better way to support spar...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20274 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3183/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org