[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user shahidki31 commented on the issue: https://github.com/apache/spark/pull/22645 Hi @felixcheung , I will update the code --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22656: [SPARK-25669][SQL] Check CSV header only when it ...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22656 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22674 **[Test build #97145 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97145/testReport)** for PR 22674 at commit [`436197b`](https://github.com/apache/spark/commit/436197b4a395323a5ea26d194389d1c0c41cb578). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22674 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3813/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22674 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user kiszk commented on the issue: https://github.com/apache/spark/pull/22630 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21710#discussion_r223574367
--- Diff: R/pkg/R/mllib_fpm.R ---
@@ -154,3 +160,74 @@ setMethod("write.ml", signature(object =
"FPGrowthModel", path = "character"),
function(object, path, overwrite = FALSE) {
write_internal(object, path, overwrite)
})
+
+#' PrefixSpan
+#'
+#' A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+#' \code{spark.prefixSpan} returns an instance of PrefixSpan.
+#' \code{spark.findFrequentSequentialPatterns} returns a complete set of
frequent sequential
+#' patterns.
+#' For more details, see
+#'
\href{https://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html#prefixspan}{
+#' PrefixSpan}.
+#'
+#' @param minSupport Minimal support level.
+#' @param maxPatternLength Maximal pattern length.
+#' @param maxLocalProjDBSize Maximum number of items (including delimiters
used in the internal
+#' storage format) allowed in a projected
database before local
+#' processing.
+#' @param sequenceCol name of the sequence column in dataset.
+#' @param ... additional argument(s) passed to the method.
+#' @return \code{spark.prefixSpan} returns an instance of PrefixSpan
+#' @rdname spark.prefixSpan
+#' @name spark.prefixSpan
+#' @aliases spark.prefixSpan,ANY-method
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(list(list(list(list(1L, 2L), list(3L))),
+#' list(list(list(1L), list(3L, 2L), list(1L, 2L))),
+#' list(list(list(1L, 2L), list(5L))),
+#' list(list(list(6L, schema = c("sequence"))
+#' prefix_Span <- spark.prefixSpan(minSupport = 0.5, maxPatternLength = 5L,
+#' maxLocalProjDBSize = 3200L)
+#' frequency <- spark.findFrequentSequentialPatterns(prefix_Span, df)
+#' showDF(frequency)
+#' }
+#' @note spark.prefixSpan since 3.0.0
+setMethod("spark.prefixSpan", signature(),
+ function(minSupport=0.1, maxPatternLength=10L,
+ maxLocalProjDBSize=3200L, sequenceCol="sequence") {
+if (!is.numeric(minSupport) || minSupport < 0) {
+ stop("minSupport should be a number with value >= 0.")
+}
+if (!is.integer(maxPatternLength) || maxPatternLength <= 0) {
+ stop("maxPatternLength should be a number with value > 0.")
+}
+if (!is.numeric(maxLocalProjDBSize) || maxLocalProjDBSize <=
0) {
+ stop("maxLocalProjDBSize should be a number with value > 0.")
+}
+
+jobj <- callJStatic("org.apache.spark.ml.r.PrefixSpanWrapper",
"getPrefixSpan",
+as.numeric(minSupport),
as.integer(maxPatternLength),
+as.numeric(maxLocalProjDBSize),
as.character(sequenceCol))
+new("PrefixSpan", jobj = jobj)
+ })
+
+# Find frequent sequential patterns.
+
+#' @param object a PrefixSpan object.
+#' @param data A SparkDataFrame.
+#' @return A complete set of frequent sequential patterns in the input
sequences of itemsets.
+#' The returned \code{SparkDataFrame} contains columns of sequence
and corresponding
+#' frequency. The schema of it will be:
+#' \code{sequence: ArrayType(ArrayType(T))} (T is the item type)
+#' \code{freq: Long}
+#' @rdname spark.prefixSpan
+#' @aliases findFrequentSequentialPatterns,PrefixSpan,SparkDataFrame-method
+#' @note spark.findFrequentSequentialPatterns(PrefixSpan, SparkDataFrame)
since 3.0.0
+
+setMethod("spark.findFrequentSequentialPatterns",
+ signature(object = "PrefixSpan", data = "SparkDataFrame"),
--- End diff --
nm, see the other comment instead
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97139/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21710#discussion_r223574019
--- Diff: R/pkg/R/mllib_fpm.R ---
@@ -154,3 +160,74 @@ setMethod("write.ml", signature(object =
"FPGrowthModel", path = "character"),
function(object, path, overwrite = FALSE) {
write_internal(object, path, overwrite)
})
+
+#' PrefixSpan
+#'
+#' A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+#' \code{spark.prefixSpan} returns an instance of PrefixSpan.
+#' \code{spark.findFrequentSequentialPatterns} returns a complete set of
frequent sequential
+#' patterns.
+#' For more details, see
+#'
\href{https://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html#prefixspan}{
+#' PrefixSpan}.
+#'
+#' @param minSupport Minimal support level.
+#' @param maxPatternLength Maximal pattern length.
+#' @param maxLocalProjDBSize Maximum number of items (including delimiters
used in the internal
+#' storage format) allowed in a projected
database before local
+#' processing.
+#' @param sequenceCol name of the sequence column in dataset.
+#' @param ... additional argument(s) passed to the method.
+#' @return \code{spark.prefixSpan} returns an instance of PrefixSpan
+#' @rdname spark.prefixSpan
+#' @name spark.prefixSpan
+#' @aliases spark.prefixSpan,ANY-method
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(list(list(list(list(1L, 2L), list(3L))),
+#' list(list(list(1L), list(3L, 2L), list(1L, 2L))),
+#' list(list(list(1L, 2L), list(5L))),
+#' list(list(list(6L, schema = c("sequence"))
+#' prefix_Span <- spark.prefixSpan(minSupport = 0.5, maxPatternLength = 5L,
+#' maxLocalProjDBSize = 3200L)
+#' frequency <- spark.findFrequentSequentialPatterns(prefix_Span, df)
+#' showDF(frequency)
+#' }
+#' @note spark.prefixSpan since 3.0.0
+setMethod("spark.prefixSpan", signature(),
+ function(minSupport=0.1, maxPatternLength=10L,
+ maxLocalProjDBSize=3200L, sequenceCol="sequence") {
+if (!is.numeric(minSupport) || minSupport < 0) {
+ stop("minSupport should be a number with value >= 0.")
+}
+if (!is.integer(maxPatternLength) || maxPatternLength <= 0) {
+ stop("maxPatternLength should be a number with value > 0.")
+}
+if (!is.numeric(maxLocalProjDBSize) || maxLocalProjDBSize <=
0) {
+ stop("maxLocalProjDBSize should be a number with value > 0.")
+}
+
+jobj <- callJStatic("org.apache.spark.ml.r.PrefixSpanWrapper",
"getPrefixSpan",
+as.numeric(minSupport),
as.integer(maxPatternLength),
+as.numeric(maxLocalProjDBSize),
as.character(sequenceCol))
+new("PrefixSpan", jobj = jobj)
+ })
+
+# Find frequent sequential patterns.
+
+#' @param object a PrefixSpan object.
+#' @param data A SparkDataFrame.
+#' @return A complete set of frequent sequential patterns in the input
sequences of itemsets.
+#' The returned \code{SparkDataFrame} contains columns of sequence
and corresponding
+#' frequency. The schema of it will be:
+#' \code{sequence: ArrayType(ArrayType(T))} (T is the item type)
+#' \code{freq: Long}
+#' @rdname spark.prefixSpan
+#' @aliases findFrequentSequentialPatterns,PrefixSpan,SparkDataFrame-method
+#' @note spark.findFrequentSequentialPatterns(PrefixSpan, SparkDataFrame)
since 3.0.0
+
+setMethod("spark.findFrequentSequentialPatterns",
+ signature(object = "PrefixSpan", data = "SparkDataFrame"),
--- End diff --
hmm, another one - why isn't `data` the first param? should also be called
`x` (the convention in R API)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 **[Test build #97139 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97139/testReport)** for PR 21669 at commit [`2108154`](https://github.com/apache/spark/commit/210815496cc2e5ecf8a0e7f86572733994e2f671). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21710#discussion_r223573856
--- Diff: R/pkg/R/mllib_fpm.R ---
@@ -154,3 +160,74 @@ setMethod("write.ml", signature(object =
"FPGrowthModel", path = "character"),
function(object, path, overwrite = FALSE) {
write_internal(object, path, overwrite)
})
+
+#' PrefixSpan
+#'
+#' A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+#' \code{spark.prefixSpan} returns an instance of PrefixSpan.
+#' \code{spark.findFrequentSequentialPatterns} returns a complete set of
frequent sequential
+#' patterns.
+#' For more details, see
+#'
\href{https://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html#prefixspan}{
+#' PrefixSpan}.
+#'
+#' @param minSupport Minimal support level.
+#' @param maxPatternLength Maximal pattern length.
+#' @param maxLocalProjDBSize Maximum number of items (including delimiters
used in the internal
+#' storage format) allowed in a projected
database before local
+#' processing.
+#' @param sequenceCol name of the sequence column in dataset.
+#' @param ... additional argument(s) passed to the method.
+#' @return \code{spark.prefixSpan} returns an instance of PrefixSpan
+#' @rdname spark.prefixSpan
+#' @name spark.prefixSpan
+#' @aliases spark.prefixSpan,ANY-method
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(list(list(list(list(1L, 2L), list(3L))),
+#' list(list(list(1L), list(3L, 2L), list(1L, 2L))),
+#' list(list(list(1L, 2L), list(5L))),
+#' list(list(list(6L, schema = c("sequence"))
+#' prefix_Span <- spark.prefixSpan(minSupport = 0.5, maxPatternLength = 5L,
+#' maxLocalProjDBSize = 3200L)
+#' frequency <- spark.findFrequentSequentialPatterns(prefix_Span, df)
+#' showDF(frequency)
+#' }
+#' @note spark.prefixSpan since 3.0.0
+setMethod("spark.prefixSpan", signature(),
--- End diff --
sorry, I didn't see this before - an empty `signature()` is a bit usual
should we either
1) put one of these param as required (if they are required?) and its type
into the signature, eg. `signature(minSupport = "numeric")`
2) instead of having `spark.prefixSpan`, take all of these param into
`spark.findFrequentSequentialPatterns`
ie.
```
setMethod("spark.findFrequentSequentialPatterns",
signature(object = "PrefixSpan", data = "SparkDataFrame"),
function(object, data, minSupport = 0.1, maxPatternLength = 10L,
maxLocalProjDBSize = 3200L, sequenceCol =
"sequence") {
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22567: [SPARK-25550][WEBUI]Environment Page of Spark Job Histor...
Github user shivusondur commented on the issue: https://github.com/apache/spark/pull/22567 @vanzin I modified according to your suggestion and updated the code. Now History properties will come as seperate tab in the EnvironmentPage as shown below snap. 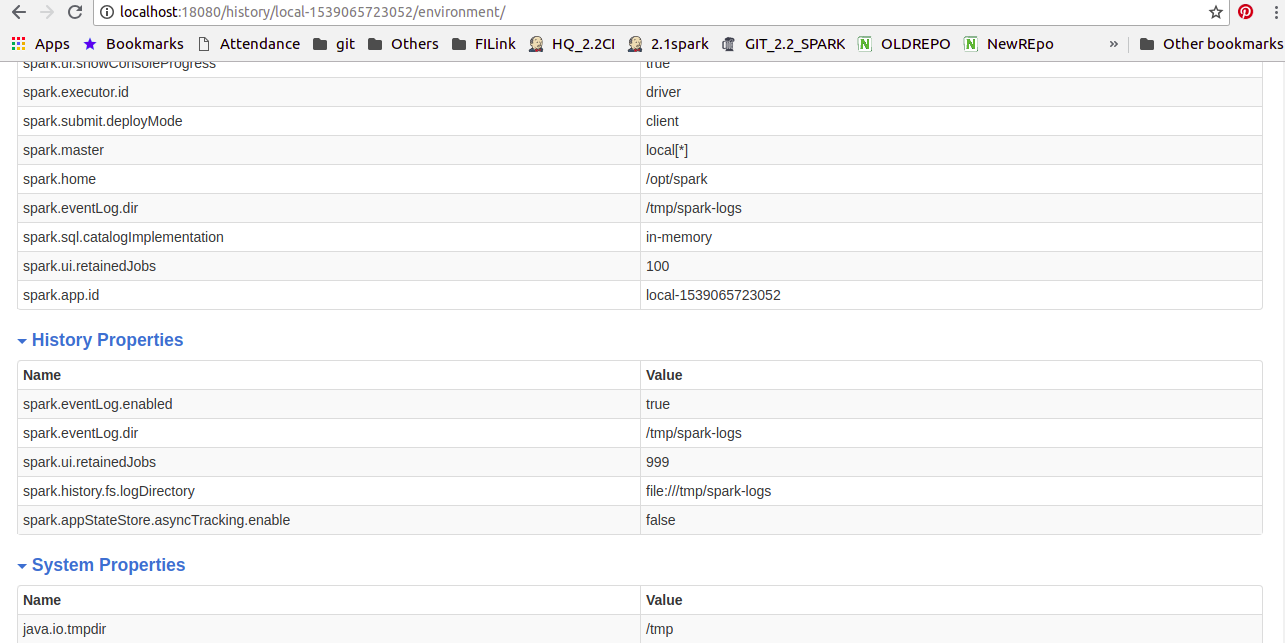 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21710#discussion_r223572974
--- Diff: R/pkg/R/mllib_fpm.R ---
@@ -154,3 +160,74 @@ setMethod("write.ml", signature(object =
"FPGrowthModel", path = "character"),
function(object, path, overwrite = FALSE) {
write_internal(object, path, overwrite)
})
+
+#' PrefixSpan
+#'
+#' A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+#' \code{spark.prefixSpan} returns an instance of PrefixSpan.
+#' \code{spark.findFrequentSequentialPatterns} returns a complete set of
frequent sequential
+#' patterns.
+#' For more details, see
+#'
\href{https://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html#prefixspan}{
+#' PrefixSpan}.
+#'
+#' @param minSupport Minimal support level.
+#' @param maxPatternLength Maximal pattern length.
+#' @param maxLocalProjDBSize Maximum number of items (including delimiters
used in the internal
+#' storage format) allowed in a projected
database before local
+#' processing.
+#' @param sequenceCol name of the sequence column in dataset.
+#' @param ... additional argument(s) passed to the method.
+#' @return \code{spark.prefixSpan} returns an instance of PrefixSpan
+#' @rdname spark.prefixSpan
+#' @name spark.prefixSpan
+#' @aliases spark.prefixSpan,ANY-method
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(list(list(list(list(1L, 2L), list(3L))),
+#' list(list(list(1L), list(3L, 2L), list(1L, 2L))),
+#' list(list(list(1L, 2L), list(5L))),
+#' list(list(list(6L, schema = c("sequence"))
+#' prefix_Span <- spark.prefixSpan(minSupport = 0.5, maxPatternLength = 5L,
+#' maxLocalProjDBSize = 3200L)
+#' frequency <- spark.findFrequentSequentialPatterns(prefix_Span, df)
+#' showDF(frequency)
+#' }
+#' @note spark.prefixSpan since 3.0.0
+setMethod("spark.prefixSpan", signature(),
+ function(minSupport=0.1, maxPatternLength=10L,
+ maxLocalProjDBSize=3200L, sequenceCol="sequence") {
--- End diff --
nit: I think R style we put space around `=`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21710#discussion_r223572694
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/r/PrefixSpanWrapper.scala ---
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.r
+
+import org.apache.spark.ml.fpm.PrefixSpan
+
+private[r] object PrefixSpanWrapper {
+ def getPrefixSpan(
+ minSupport: Double,
+ maxPatternLength: Int,
+ maxLocalProjDBSize: Double,
--- End diff --
no native 64 bit int support in R. double is ok
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22645 @shahidki31 ^^ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22615: [SPARK-25016][BUILD][CORE] Remove support for Had...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/22615#discussion_r223571584
--- Diff: docs/index.md ---
@@ -30,9 +30,6 @@ Spark runs on Java 8+, Python 2.7+/3.4+ and R 3.1+. For
the Scala API, Spark {{s
uses Scala {{site.SCALA_BINARY_VERSION}}. You will need to use a
compatible Scala version
({{site.SCALA_BINARY_VERSION}}.x).
-Note that support for Java 7, Python 2.6 and old Hadoop versions before
2.6.5 were removed as of Spark 2.2.0.
-Support for Scala 2.10 was removed as of 2.3.0.
--- End diff --
so we are not going to mention supported hadoop version?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22615: [SPARK-25016][BUILD][CORE] Remove support for Had...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/22615#discussion_r223571106 --- Diff: sql/hive/src/main/scala/org/apache/spark/sql/hive/TableReader.scala --- @@ -71,7 +71,7 @@ class HadoopTableReader( // Hadoop honors "mapreduce.job.maps" as hint, // but will ignore when mapreduce.jobtracker.address is "local". - // https://hadoop.apache.org/docs/r2.6.5/hadoop-mapreduce-client/hadoop-mapreduce-client-core/ + // https://hadoop.apache.org/docs/r2.7.6/hadoop-mapreduce-client/hadoop-mapreduce-client-core/ --- End diff -- how come this is 2.7.6 and not 2.7.3 like others? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22615: [SPARK-25016][BUILD][CORE] Remove support for Had...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/22615#discussion_r223570946
--- Diff: dev/create-release/release-build.sh ---
@@ -191,9 +191,17 @@ if [[ "$1" == "package" ]]; then
make_binary_release() {
NAME=$1
FLAGS="$MVN_EXTRA_OPTS -B $BASE_RELEASE_PROFILES $2"
+# BUILD_PACKAGE can be "withpip", "withr", or both as "withpip,withr"
BUILD_PACKAGE=$3
SCALA_VERSION=$4
+if [[ $BUILD_PACKAGE == *"withpip"* ]]; then
--- End diff --
one caveat is I'm not sure we have tested building both python and R in
"one build".
this could be a good thing but if I recall the R build changes some of the
binary files under R that gets shipped in the "source release" (these are
required R object file)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97138/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 **[Test build #97138 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97138/testReport)** for PR 21669 at commit [`69840a8`](https://github.com/apache/spark/commit/69840a8026d1f8a72eed9a3e6c7073e8bdbf04b0). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22466: [SPARK-25464][SQL] Create Database to the location,only ...
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/22466 The major comments are in the test cases. Could you help clean up the existing test cases? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22615 I think we all know enough to not to make changes (merge changes) to these config, should be safe. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22645 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97144/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22645 **[Test build #97144 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97144/testReport)** for PR 22645 at commit [`e6af675`](https://github.com/apache/spark/commit/e6af675dddec44dcdc3f5060ac6b3db6fbef5f20). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22645 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22466: [SPARK-25464][SQL] Create Database to the locatio...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22466#discussion_r223570144
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -207,6 +207,16 @@ class SessionCatalog(
"you cannot create a database with this name.")
}
validateName(dbName)
+// SPARK-25464 fail if DB location exists and is not empty
+val dbPath = new Path(dbDefinition.locationUri)
+val fs = dbPath.getFileSystem(hadoopConf)
+if (fs.exists(dbPath)) {
+ val fileStatus = fs.listStatus(dbPath)
+ if (fileStatus.nonEmpty) {
--- End diff --
if (fs.exists(dbPath) && fs.listStatus(dbPath).nonEmpty) {
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22645 **[Test build #97144 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97144/testReport)** for PR 22645 at commit [`e6af675`](https://github.com/apache/spark/commit/e6af675dddec44dcdc3f5060ac6b3db6fbef5f20). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22645: [SPARK-25566][SPARK-25567][WEBUI][SQL]Support pagination...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22645 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22466: [SPARK-25464][SQL] Create Database to the locatio...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22466#discussion_r223569270
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala
---
@@ -407,6 +407,7 @@ abstract class DDLSuite extends QueryTest with
SQLTestUtils {
test("create a managed table with the existing non-empty directory") {
withTable("tab1") {
+ Utils.createDirectory(spark.sessionState.conf.warehousePath)
--- End diff --
If we do not delete the directory for each test case, this line is not
needed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22675 we need this for 2.4? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22466: [SPARK-25464][SQL] Create Database to the locatio...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22466#discussion_r223569182
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveDDLSuite.scala
---
@@ -53,6 +53,7 @@ class HiveCatalogedDDLSuite extends DDLSuite with
TestHiveSingleton with BeforeA
// drop all databases, tables and functions after each test
spark.sessionState.catalog.reset()
} finally {
+ Utils.deleteRecursively(new
File(spark.sessionState.conf.warehousePath))
--- End diff --
We dropped all the database in line 54, right? Could you fix the test cases
instead of delete the directory here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21710#discussion_r223568243
--- Diff: R/pkg/R/mllib_fpm.R ---
@@ -154,3 +160,74 @@ setMethod("write.ml", signature(object =
"FPGrowthModel", path = "character"),
function(object, path, overwrite = FALSE) {
write_internal(object, path, overwrite)
})
+
+#' PrefixSpan
+#'
+#' A parallel PrefixSpan algorithm to mine frequent sequential patterns.
+#' \code{spark.prefixSpan} returns an instance of PrefixSpan.
+#' \code{spark.findFrequentSequentialPatterns} returns a complete set of
frequent sequential
+#' patterns.
+#' For more details, see
+#'
\href{https://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html#prefixspan}{
+#' PrefixSpan}.
+#'
+#' @param minSupport Minimal support level.
+#' @param maxPatternLength Maximal pattern length.
+#' @param maxLocalProjDBSize Maximum number of items (including delimiters
used in the internal
+#' storage format) allowed in a projected
database before local
+#' processing.
+#' @param sequenceCol name of the sequence column in dataset.
+#' @param ... additional argument(s) passed to the method.
+#' @return \code{spark.prefixSpan} returns an instance of PrefixSpan
+#' @rdname spark.prefixSpan
+#' @name spark.prefixSpan
+#' @aliases spark.prefixSpan,ANY-method
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(list(list(list(list(1L, 2L), list(3L))),
+#' list(list(list(1L), list(3L, 2L), list(1L, 2L))),
+#' list(list(list(1L, 2L), list(5L))),
+#' list(list(list(6L, schema = c("sequence"))
+#' prefix_Span <- spark.prefixSpan(minSupport = 0.5, maxPatternLength = 5L,
+#' maxLocalProjDBSize = 3200L)
+#' frequency <- spark.findFrequentSequentialPatterns(prefix_Span, df)
+#' showDF(frequency)
+#' }
+#' @note spark.prefixSpan since 3.0.0
+setMethod("spark.prefixSpan", signature(),
+ function(minSupport=0.1, maxPatternLength=10L,
+ maxLocalProjDBSize=3200L, sequenceCol="sequence") {
+if (!is.numeric(minSupport) || minSupport < 0) {
+ stop("minSupport should be a number with value >= 0.")
+}
+if (!is.integer(maxPatternLength) || maxPatternLength <= 0) {
+ stop("maxPatternLength should be a number with value > 0.")
+}
+if (!is.numeric(maxLocalProjDBSize) || maxLocalProjDBSize <=
0) {
+ stop("maxLocalProjDBSize should be a number with value > 0.")
+}
+
+jobj <- callJStatic("org.apache.spark.ml.r.PrefixSpanWrapper",
"getPrefixSpan",
+as.numeric(minSupport),
as.integer(maxPatternLength),
+as.numeric(maxLocalProjDBSize),
as.character(sequenceCol))
+new("PrefixSpan", jobj = jobj)
+ })
+
+# Find frequent sequential patterns.
+
+#' @param object a PrefixSpan object.
+#' @param data A SparkDataFrame.
+#' @return A complete set of frequent sequential patterns in the input
sequences of itemsets.
+#' The returned \code{SparkDataFrame} contains columns of sequence
and corresponding
+#' frequency. The schema of it will be:
+#' \code{sequence: ArrayType(ArrayType(T))} (T is the item type)
+#' \code{freq: Long}
+#' @rdname spark.prefixSpan
+#' @aliases findFrequentSequentialPatterns,PrefixSpan,SparkDataFrame-method
+#' @note spark.findFrequentSequentialPatterns(PrefixSpan, SparkDataFrame)
since 3.0.0
+
--- End diff --
remove extra line - note this might break doc generation
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/21710#discussion_r223568592 --- Diff: docs/ml-frequent-pattern-mining.md --- @@ -85,3 +85,56 @@ Refer to the [R API docs](api/R/spark.fpGrowth.html) for more details. + +## PrefixSpan --- End diff -- is this not in the doc for branch-2.4? we might need a quick fix on the branch then before the next RC, I think --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21710: [SPARK-24207][R]add R API for PrefixSpan
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/21710#discussion_r223568708 --- Diff: examples/src/main/python/ml/prefixspan_example.py --- @@ -0,0 +1,48 @@ +# --- End diff -- ditto for java and scala and python example --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22466: [SPARK-25464][SQL] Create Database to the locatio...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22466#discussion_r223568531
--- Diff: python/pyspark/sql/tests.py ---
@@ -351,7 +351,7 @@ def tearDown(self):
super(SQLTests, self).tearDown()
# tear down test_bucketed_write state
-self.spark.sql("DROP TABLE IF EXISTS pyspark_bucket")
+self.spark.sql("DROP DATABASE IF EXISTS some_db CASCADE")
--- End diff --
Could you update the corresponding test cases instead of dropping the
database here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22674 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22674 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97140/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22674 **[Test build #97140 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97140/testReport)** for PR 22674 at commit [`a456226`](https://github.com/apache/spark/commit/a4562264c45c24a88f4d508c2d34d4e7aed50631). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22656: [SPARK-25669][SQL] Check CSV header only when it ...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22656#discussion_r223566522
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala ---
@@ -505,7 +505,8 @@ class DataFrameReader private[sql](sparkSession:
SparkSession) extends Logging {
val actualSchema =
StructType(schema.filterNot(_.name ==
parsedOptions.columnNameOfCorruptRecord))
-val linesWithoutHeader: RDD[String] = maybeFirstLine.map { firstLine =>
+val linesWithoutHeader = if (parsedOptions.headerFlag &&
maybeFirstLine.isDefined) {
--- End diff --
LGTM but it really needs some refactoring. Let me give a shot
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/22675#discussion_r223566032
--- Diff: docs/ml-datasource.md ---
@@ -0,0 +1,51 @@
+---
+layout: global
+title: Data sources
+displayTitle: Data sources
+---
+
+In this section, we introduce how to use data source in ML to load data.
+Beside some general data sources "parquat", "csv", "json", "jdbc", we also
provide some specific data source for ML.
+
+**Table of Contents**
+
+* This will become a table of contents (this text will be scraped).
+{:toc}
+
+## Image data source
+
+This image data source is used to load libsvm data files from directory.
+
+
+
+[`ImageDataSource`](api/scala/index.html#org.apache.spark.ml.source.image.ImageDataSource)
+implements Spark SQL data source API for loading image data as DataFrame.
+The loaded DataFrame has one StructType column: "image". containing image
data stored as image schema.
+
+{% highlight scala %}
+scala> spark.read.format("image").load("data/mllib/images/origin")
+res1: org.apache.spark.sql.DataFrame = [image: struct]
+{% endhighlight %}
+
+
+
+[`ImageDataSource`](api/java/org/apache/spark/ml/source/image/ImageDataSource.html)
--- End diff --
Usually it depends on how important the use case is. For example, CSV was
created as an external data source and later merged into Spark. See
https://issues.apache.org/jira/browse/SPARK-21866?focusedCommentId=16148268&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16148268.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22623: [SPARK-25636][CORE] spark-submit cuts off the failure re...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22623 **[Test build #97143 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97143/testReport)** for PR 22623 at commit [`131b3af`](https://github.com/apache/spark/commit/131b3af7ab286d2f001cbf0638cd5dbe7653a420). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22661: [SPARK-25664][SQL][TEST] Refactor JoinBenchmark to use m...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/22661 cc @dongjoon-hyun --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22663: [SPARK-25490][SQL][TEST] Refactor KryoBenchmark to use m...
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/22663 @dongjoon-hyun Is the changes OK to you? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request: https://github.com/apache/spark/pull/21669#discussion_r223560424 --- Diff: resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/KubernetesConf.scala --- @@ -47,6 +50,13 @@ private[spark] case class KubernetesExecutorSpecificConf( driverPod: Option[Pod]) extends KubernetesRoleSpecificConf +/* + * Structure containing metadata for HADOOP_CONF_DIR customization + */ +private[spark] case class HadoopConfSpecConf( --- End diff -- Let's just call it `HadoopConfSpec`. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223560209
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/hadooputils/HadoopBootstrapUtil.scala
---
@@ -0,0 +1,260 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.deploy.k8s.features.hadooputils
+
+import java.io.File
+import java.nio.charset.StandardCharsets
+
+import scala.collection.JavaConverters._
+
+import com.google.common.io.Files
+import io.fabric8.kubernetes.api.model._
+
+import org.apache.spark.deploy.k8s.Constants._
+import org.apache.spark.deploy.k8s.SparkPod
+
+private[spark] object HadoopBootstrapUtil {
+
+ /**
+* Mounting the DT secret for both the Driver and the executors
+*
+* @param dtSecretName Name of the secret that stores the Delegation
Token
+* @param dtSecretItemKey Name of the Item Key storing the Delegation
Token
+* @param userName Name of the SparkUser to set SPARK_USER
+* @param maybeFileLocation Optional Location of the krb5 file
+* @param newKrb5ConfName Optional location of the ConfigMap for Krb5
+* @param maybeKrb5ConfName Optional name of ConfigMap for Krb5
+* @param pod Input pod to be appended to
+* @return a modified SparkPod
+*/
+ def bootstrapKerberosPod(
+dtSecretName: String,
+dtSecretItemKey: String,
+userName: String,
+maybeFileLocation: Option[String],
+newKrb5ConfName: Option[String],
+maybeKrb5ConfName: Option[String],
--- End diff --
Rename this to `existingKrb5ConfName`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223557398
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/KubernetesConf.scala
---
@@ -61,7 +71,16 @@ private[spark] case class KubernetesConf[T <:
KubernetesRoleSpecificConf](
roleSecretEnvNamesToKeyRefs: Map[String, String],
roleEnvs: Map[String, String],
roleVolumes: Iterable[KubernetesVolumeSpec[_ <:
KubernetesVolumeSpecificConf]],
-sparkFiles: Seq[String]) {
+sparkFiles: Seq[String],
+hadoopConfDir: Option[HadoopConfSpecConf]) {
--- End diff --
Can you rename this parameter to `hadoopConfSpec`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223561140
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/KerberosConfDriverFeatureStep.scala
---
@@ -0,0 +1,182 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.deploy.k8s.features
+
+import io.fabric8.kubernetes.api.model.HasMetadata
+
+import org.apache.spark.deploy.SparkHadoopUtil
+import org.apache.spark.deploy.k8s.{KubernetesConf, KubernetesUtils,
SparkPod}
+import org.apache.spark.deploy.k8s.Config._
+import org.apache.spark.deploy.k8s.Constants._
+import org.apache.spark.deploy.k8s.KubernetesDriverSpecificConf
+import org.apache.spark.deploy.k8s.features.hadooputils._
+import org.apache.spark.internal.Logging
+
+ /**
+ * Runs the necessary Hadoop-based logic based on Kerberos configs and
the presence of the
+ * HADOOP_CONF_DIR. This runs various bootstrap methods defined in
HadoopBootstrapUtil.
+ */
+private[spark] class KerberosConfDriverFeatureStep(
+ kubernetesConf: KubernetesConf[KubernetesDriverSpecificConf])
+ extends KubernetesFeatureConfigStep with Logging {
+
+ require(kubernetesConf.hadoopConfDir.isDefined,
+ "Ensure that HADOOP_CONF_DIR is defined either via env or a
pre-defined ConfigMap")
+ private val hadoopConfDirSpec = kubernetesConf.hadoopConfDir.get
+ private val conf = kubernetesConf.sparkConf
+ private val maybePrincipal =
conf.get(org.apache.spark.internal.config.PRINCIPAL)
+ private val maybeKeytab =
conf.get(org.apache.spark.internal.config.KEYTAB)
+ private val maybeExistingSecretName =
conf.get(KUBERNETES_KERBEROS_DT_SECRET_NAME)
+ private val maybeExistingSecretItemKey =
+ conf.get(KUBERNETES_KERBEROS_DT_SECRET_ITEM_KEY)
+ private val maybeKrb5File =
+ conf.get(KUBERNETES_KERBEROS_KRB5_FILE)
+ private val maybeKrb5CMap =
--- End diff --
Can we call this `existingKrb5ConfigMap`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request: https://github.com/apache/spark/pull/21669#discussion_r223560748 --- Diff: resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/KubernetesConf.scala --- @@ -47,6 +50,13 @@ private[spark] case class KubernetesExecutorSpecificConf( driverPod: Option[Pod]) extends KubernetesRoleSpecificConf +/* + * Structure containing metadata for HADOOP_CONF_DIR customization + */ +private[spark] case class HadoopConfSpecConf( --- End diff -- Can you create a similar one for krb5 and call it `Krb5ConfSpec`, which contains an optional krb5 file location or the name of a pre-defined krb5 ConfigMap? Then you can use that `Krb5ConfSpec` in places where you use both the file location and ConfigMap as parameters. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223558019
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/hadooputils/HadoopBootstrapUtil.scala
---
@@ -0,0 +1,260 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.deploy.k8s.features.hadooputils
+
+import java.io.File
+import java.nio.charset.StandardCharsets
+
+import scala.collection.JavaConverters._
+
+import com.google.common.io.Files
+import io.fabric8.kubernetes.api.model._
+
+import org.apache.spark.deploy.k8s.Constants._
+import org.apache.spark.deploy.k8s.SparkPod
+
+private[spark] object HadoopBootstrapUtil {
+
+ /**
+* Mounting the DT secret for both the Driver and the executors
+*
+* @param dtSecretName Name of the secret that stores the Delegation
Token
+* @param dtSecretItemKey Name of the Item Key storing the Delegation
Token
+* @param userName Name of the SparkUser to set SPARK_USER
+* @param maybeFileLocation Optional Location of the krb5 file
+* @param newKrb5ConfName Optional location of the ConfigMap for Krb5
+* @param maybeKrb5ConfName Optional name of ConfigMap for Krb5
+* @param pod Input pod to be appended to
+* @return a modified SparkPod
+*/
+ def bootstrapKerberosPod(
+dtSecretName: String,
+dtSecretItemKey: String,
+userName: String,
+maybeFileLocation: Option[String],
+newKrb5ConfName: Option[String],
+maybeKrb5ConfName: Option[String],
+pod: SparkPod) : SparkPod = {
+
+val maybePreConfigMapVolume = maybeKrb5ConfName.map { kconf =>
+ new VolumeBuilder()
+.withName(KRB_FILE_VOLUME)
+.withNewConfigMap()
+ .withName(kconf)
+ .endConfigMap()
+.build() }
+
+val maybeCreateConfigMapVolume = for {
+ fileLocation <- maybeFileLocation
+ krb5ConfName <- newKrb5ConfName
+ } yield {
+ val krb5File = new File(fileLocation)
+ val fileStringPath = krb5File.toPath.getFileName.toString
+ new VolumeBuilder()
+.withName(KRB_FILE_VOLUME)
+.withNewConfigMap()
+.withName(krb5ConfName)
+.withItems(new KeyToPathBuilder()
+ .withKey(fileStringPath)
+ .withPath(fileStringPath)
+ .build())
+.endConfigMap()
+.build()
+}
+
+ // Breaking up Volume Creation for clarity
+ val configMapVolume = maybePreConfigMapVolume.getOrElse(
+ maybeCreateConfigMapVolume.get)
+
+ val kerberizedPod = new PodBuilder(pod.pod)
+ .editOrNewSpec()
+.addNewVolume()
+ .withName(SPARK_APP_HADOOP_SECRET_VOLUME_NAME)
+ .withNewSecret()
+.withSecretName(dtSecretName)
+.endSecret()
+ .endVolume()
+.addNewVolumeLike(configMapVolume)
+ .endVolume()
+.endSpec()
+.build()
+
+ val kerberizedContainer = new ContainerBuilder(pod.container)
+ .addNewVolumeMount()
+.withName(SPARK_APP_HADOOP_SECRET_VOLUME_NAME)
+.withMountPath(SPARK_APP_HADOOP_CREDENTIALS_BASE_DIR)
+.endVolumeMount()
+ .addNewVolumeMount()
+.withName(KRB_FILE_VOLUME)
+.withMountPath(KRB_FILE_DIR_PATH + "/krb5.conf")
+.withSubPath("krb5.conf")
+.endVolumeMount()
+ .addNewEnv()
+.withName(ENV_HADOOP_TOKEN_FILE_LOCATION)
+
.withValue(s"$SPARK_APP_HADOOP_CREDENTIALS_BASE_DIR/$dtSecretItemKey")
+.endEnv()
+ .addNewEnv()
+.withName(ENV_SPARK_USER)
+.withValue(userName)
+.endEnv()
+ .build()
+ SparkPod(kerberizedPod, kerberizedContainer)
+ }
+
+ /**
+* setting ENV
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223558932
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Constants.scala
---
@@ -78,4 +80,29 @@ private[spark] object Constants {
val KUBERNETES_MASTER_INTERNAL_URL = "https://kubernetes.default.svc";
val DRIVER_CONTAINER_NAME = "spark-kubernetes-driver"
val MEMORY_OVERHEAD_MIN_MIB = 384L
+
+ // Hadoop Configuration
+ val HADOOP_FILE_VOLUME = "hadoop-properties"
+ val KRB_FILE_VOLUME = "krb5-file"
+ val HADOOP_CONF_DIR_PATH = "/opt/hadoop/conf"
+ val KRB_FILE_DIR_PATH = "/etc"
+ val ENV_HADOOP_CONF_DIR = "HADOOP_CONF_DIR"
+ val HADOOP_CONFIG_MAP_NAME =
+"spark.kubernetes.executor.hadoopConfigMapName"
+ val KRB5_CONFIG_MAP_NAME =
+"spark.kubernetes.executor.krb5ConfigMapName"
+
+ // Kerberos Configuration
+ val KERBEROS_DELEGEGATION_TOKEN_SECRET_NAME = "delegation-tokens"
+ val KERBEROS_KEYTAB_SECRET_NAME =
--- End diff --
Looks like this is used as the name of the secret storing the DT, not the
keytab. So please rename it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223561204
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/KerberosConfDriverFeatureStep.scala
---
@@ -0,0 +1,182 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.deploy.k8s.features
+
+import io.fabric8.kubernetes.api.model.HasMetadata
+
+import org.apache.spark.deploy.SparkHadoopUtil
+import org.apache.spark.deploy.k8s.{KubernetesConf, KubernetesUtils,
SparkPod}
+import org.apache.spark.deploy.k8s.Config._
+import org.apache.spark.deploy.k8s.Constants._
+import org.apache.spark.deploy.k8s.KubernetesDriverSpecificConf
+import org.apache.spark.deploy.k8s.features.hadooputils._
+import org.apache.spark.internal.Logging
+
+ /**
+ * Runs the necessary Hadoop-based logic based on Kerberos configs and
the presence of the
+ * HADOOP_CONF_DIR. This runs various bootstrap methods defined in
HadoopBootstrapUtil.
+ */
+private[spark] class KerberosConfDriverFeatureStep(
+ kubernetesConf: KubernetesConf[KubernetesDriverSpecificConf])
+ extends KubernetesFeatureConfigStep with Logging {
+
+ require(kubernetesConf.hadoopConfDir.isDefined,
+ "Ensure that HADOOP_CONF_DIR is defined either via env or a
pre-defined ConfigMap")
+ private val hadoopConfDirSpec = kubernetesConf.hadoopConfDir.get
+ private val conf = kubernetesConf.sparkConf
+ private val maybePrincipal =
conf.get(org.apache.spark.internal.config.PRINCIPAL)
--- End diff --
Can we avoid adding the prefix `maybe` to the variable names? They make the
variables unnecessarily longer without really improving readability much.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21669: [SPARK-23257][K8S] Kerberos Support for Spark on ...
Github user liyinan926 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21669#discussion_r223561016
--- Diff:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/KerberosConfDriverFeatureStep.scala
---
@@ -0,0 +1,182 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.deploy.k8s.features
+
+import io.fabric8.kubernetes.api.model.HasMetadata
+
+import org.apache.spark.deploy.SparkHadoopUtil
+import org.apache.spark.deploy.k8s.{KubernetesConf, KubernetesUtils,
SparkPod}
+import org.apache.spark.deploy.k8s.Config._
+import org.apache.spark.deploy.k8s.Constants._
+import org.apache.spark.deploy.k8s.KubernetesDriverSpecificConf
+import org.apache.spark.deploy.k8s.features.hadooputils._
+import org.apache.spark.internal.Logging
+
+ /**
+ * Runs the necessary Hadoop-based logic based on Kerberos configs and
the presence of the
+ * HADOOP_CONF_DIR. This runs various bootstrap methods defined in
HadoopBootstrapUtil.
+ */
+private[spark] class KerberosConfDriverFeatureStep(
+ kubernetesConf: KubernetesConf[KubernetesDriverSpecificConf])
+ extends KubernetesFeatureConfigStep with Logging {
+
+ require(kubernetesConf.hadoopConfDir.isDefined,
+ "Ensure that HADOOP_CONF_DIR is defined either via env or a
pre-defined ConfigMap")
+ private val hadoopConfDirSpec = kubernetesConf.hadoopConfDir.get
+ private val conf = kubernetesConf.sparkConf
+ private val maybePrincipal =
conf.get(org.apache.spark.internal.config.PRINCIPAL)
+ private val maybeKeytab =
conf.get(org.apache.spark.internal.config.KEYTAB)
+ private val maybeExistingSecretName =
conf.get(KUBERNETES_KERBEROS_DT_SECRET_NAME)
+ private val maybeExistingSecretItemKey =
+ conf.get(KUBERNETES_KERBEROS_DT_SECRET_ITEM_KEY)
+ private val maybeKrb5File =
+ conf.get(KUBERNETES_KERBEROS_KRB5_FILE)
+ private val maybeKrb5CMap =
+ conf.get(KUBERNETES_KERBEROS_KRB5_CONFIG_MAP)
+ private val kubeTokenManager = kubernetesConf.tokenManager(conf,
+ SparkHadoopUtil.get.newConfiguration(conf))
+ private val isKerberosEnabled =
+ (hadoopConfDirSpec.hadoopConfDir.isDefined &&
kubeTokenManager.isSecurityEnabled) ||
+ (hadoopConfDirSpec.hadoopConfigMapName.isDefined &&
+ (maybeKrb5File.isDefined || maybeKrb5CMap.isDefined))
+
+ require(maybeKeytab.isEmpty || isKerberosEnabled,
+ "You must enable Kerberos support if you are specifying a Kerberos
Keytab")
+
+ require(maybeExistingSecretName.isEmpty || isKerberosEnabled,
+ "You must enable Kerberos support if you are specifying a Kerberos
Secret")
+
+ require((maybeKrb5File.isEmpty || maybeKrb5CMap.isEmpty) ||
isKerberosEnabled,
+ "You must specify either a krb5 file location or a ConfigMap with a
krb5 file")
+
+ KubernetesUtils.requireNandDefined(
+ maybeKrb5File,
+ maybeKrb5CMap,
+ "Do not specify both a Krb5 local file and the ConfigMap as the
creation " +
+ "of an additional ConfigMap, when one is already specified, is
extraneous")
+
+ KubernetesUtils.requireBothOrNeitherDefined(
+ maybeKeytab,
+ maybePrincipal,
+ "If a Kerberos principal is specified you must also specify a
Kerberos keytab",
+ "If a Kerberos keytab is specified you must also specify a Kerberos
principal")
+
+ KubernetesUtils.requireBothOrNeitherDefined(
+ maybeExistingSecretName,
+ maybeExistingSecretItemKey,
+ "If a secret data item-key where the data of the Kerberos Delegation
Token is specified" +
+" you must also specify the name of the secret",
+ "If a secret storing a Kerberos Delegation Token is specified you
must also" +
+" specify the item-key where the data is stored")
+
+ private val hadoopConfigurationFiles =
hadoopConfDirSpec.hadoopConfDir.map { hConfDir =>
+ HadoopBootstrapU
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22615 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22615 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97137/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22615 **[Test build #97137 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97137/testReport)** for PR 22615 at commit [`7392cf0`](https://github.com/apache/spark/commit/7392cf00c31d48790d1235330c2fe18f7f850624). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22466: [SPARK-25464][SQL] Create Database to the location,only ...
Github user sandeep-katta commented on the issue: https://github.com/apache/spark/pull/22466 @cloud-fan @gatorsmile if everything is okay,can you please merge this PR --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22583: [SPARK-10816][SS] SessionWindow support for Structure St...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22583 **[Test build #97142 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97142/testReport)** for PR 22583 at commit [`0a27efd`](https://github.com/apache/spark/commit/0a27efdbcd5d7612cdeb9fc2618e1c76e70a586c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22583: [SPARK-10816][SS] SessionWindow support for Structure St...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22583 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3812/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22583: [SPARK-10816][SS] SessionWindow support for Structure St...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22583 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22675#discussion_r223552437
--- Diff: docs/ml-datasource.md ---
@@ -0,0 +1,51 @@
+---
+layout: global
+title: Data sources
+displayTitle: Data sources
+---
+
+In this section, we introduce how to use data source in ML to load data.
+Beside some general data sources "parquat", "csv", "json", "jdbc", we also
provide some specific data source for ML.
+
+**Table of Contents**
+
+* This will become a table of contents (this text will be scraped).
+{:toc}
+
+## Image data source
+
+This image data source is used to load libsvm data files from directory.
+
+
+
+[`ImageDataSource`](api/scala/index.html#org.apache.spark.ml.source.image.ImageDataSource)
+implements Spark SQL data source API for loading image data as DataFrame.
+The loaded DataFrame has one StructType column: "image". containing image
data stored as image schema.
+
+{% highlight scala %}
+scala> spark.read.format("image").load("data/mllib/images/origin")
+res1: org.apache.spark.sql.DataFrame = [image: struct]
+{% endhighlight %}
+
+
+
+[`ImageDataSource`](api/java/org/apache/spark/ml/source/image/ImageDataSource.html)
--- End diff --
cc @mengxr as well
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22675#discussion_r223552386
--- Diff: docs/ml-datasource.md ---
@@ -0,0 +1,51 @@
+---
+layout: global
+title: Data sources
+displayTitle: Data sources
+---
+
+In this section, we introduce how to use data source in ML to load data.
+Beside some general data sources "parquat", "csv", "json", "jdbc", we also
provide some specific data source for ML.
+
+**Table of Contents**
+
+* This will become a table of contents (this text will be scraped).
+{:toc}
+
+## Image data source
+
+This image data source is used to load libsvm data files from directory.
+
+
+
+[`ImageDataSource`](api/scala/index.html#org.apache.spark.ml.source.image.ImageDataSource)
+implements Spark SQL data source API for loading image data as DataFrame.
+The loaded DataFrame has one StructType column: "image". containing image
data stored as image schema.
+
+{% highlight scala %}
+scala> spark.read.format("image").load("data/mllib/images/origin")
+res1: org.apache.spark.sql.DataFrame = [image: struct]
+{% endhighlight %}
+
+
+
+[`ImageDataSource`](api/java/org/apache/spark/ml/source/image/ImageDataSource.html)
--- End diff --
Out of curiosity, why did we put the image source inside of Spark, rather
then a separate module? (see also
https://github.com/apache/spark/pull/21742#discussion_r201552008). Avro was put
as a separate module.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22653: [SPARK-25659][PYTHON][TEST] Test type inference s...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22653#discussion_r223552056
--- Diff: python/pyspark/sql/tests.py ---
@@ -1149,6 +1149,75 @@ def test_infer_schema(self):
result = self.spark.sql("SELECT l[0].a from test2 where d['key'].d
= '2'")
self.assertEqual(1, result.head()[0])
+def test_infer_schema_specification(self):
+from decimal import Decimal
+
+class A(object):
+def __init__(self):
+self.a = 1
+
+data = [
+True,
+1,
+"a",
+u"a",
--- End diff --
Fair point. Will change when I fix some codes around here.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22615 I want to see the configurations .. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22237: [SPARK-25243][SQL] Use FailureSafeParser in from_...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22237#discussion_r223550790
--- Diff: docs/sql-programming-guide.md ---
@@ -1890,6 +1890,10 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
# Migration Guide
+## Upgrading From Spark SQL 2.4 to 3.0
+
+ - Since Spark 3.0, the `from_json` functions supports two modes -
`PERMISSIVE` and `FAILFAST`. The modes can be set via the `mode` option. The
default mode became `PERMISSIVE`. In previous versions, behavior of `from_json`
did not conform to either `PERMISSIVE` nor `FAILFAST`, especially in processing
of malformed JSON records. For example, the JSON string `{"a" 1}` with the
schema `a INT` is converted to `null` by previous versions but Spark 3.0
converts it to `Row(null)`. In version 2.4 and earlier, arrays of JSON objects
are considered as invalid and converted to `null` if specified schema is
`StructType`. Since Spark 3.0, the input is considered as a valid JSON array
and only its first element is parsed if it conforms to the specified
`StructType`.
--- End diff --
Last option sounds better to me but can we fill the corrupt row when the
corrupt field name is specified in the schema?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22675 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22675 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97141/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22675 **[Test build #97141 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97141/testReport)** for PR 22675 at commit [`887f528`](https://github.com/apache/spark/commit/887f5282fba8a8a0bcbb9242eb87b27bf94d0210). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97136/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22630 **[Test build #97136 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97136/testReport)** for PR 22630 at commit [`4fc4301`](https://github.com/apache/spark/commit/4fc43010c7c466e7a3db6a08c554adc78719db76). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22675 **[Test build #97141 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97141/testReport)** for PR 22675 at commit [`887f528`](https://github.com/apache/spark/commit/887f5282fba8a8a0bcbb9242eb87b27bf94d0210). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22675 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3811/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22675: [SPARK-25347][ML][DOC] Spark datasource for image/libsvm...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22675 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22675: [SPARK-25347][ML][DOC] Spark datasource for image...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/22675 [SPARK-25347][ML][DOC] Spark datasource for image/libsvm user guide ## What changes were proposed in this pull request? Spark datasource for image/libsvm user guide ## How was this patch tested? Scala: 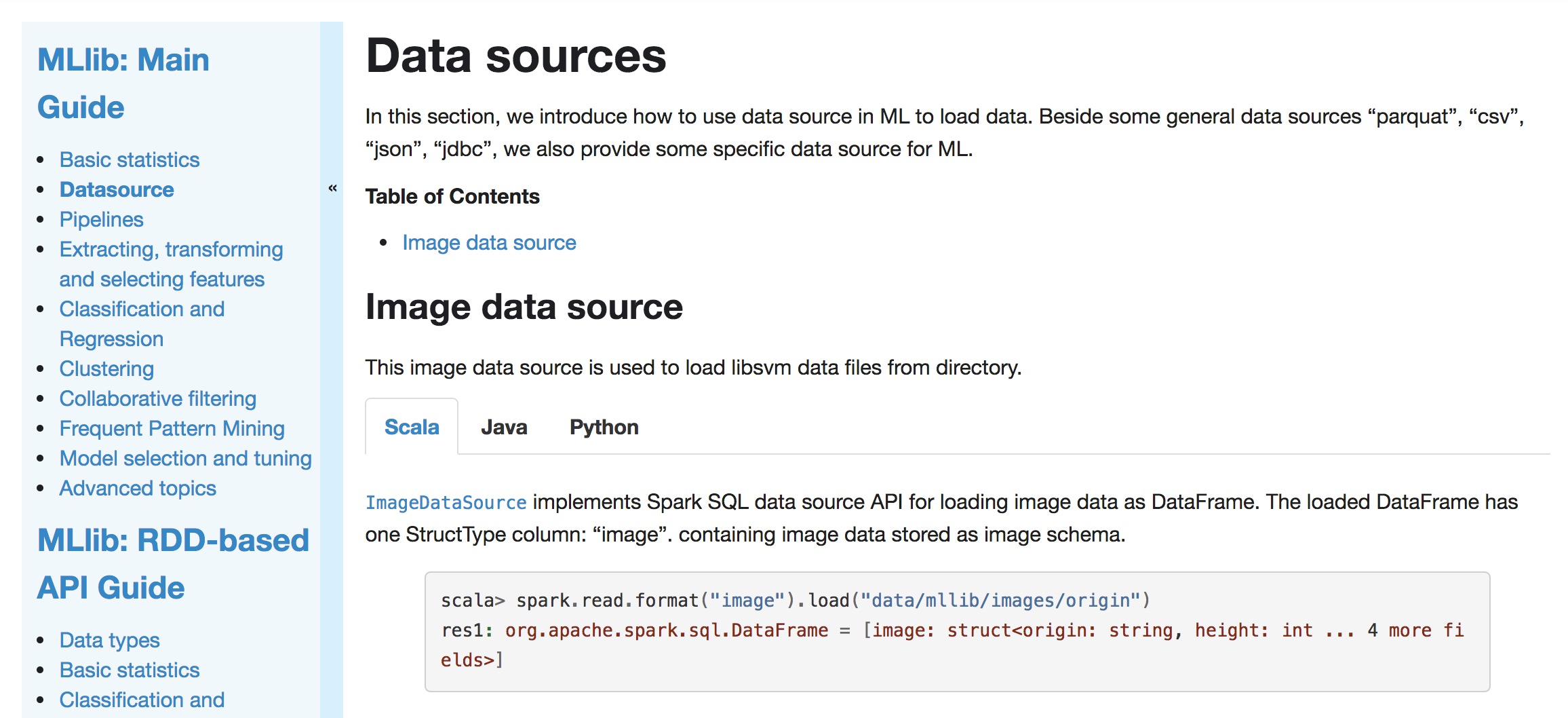 Java: 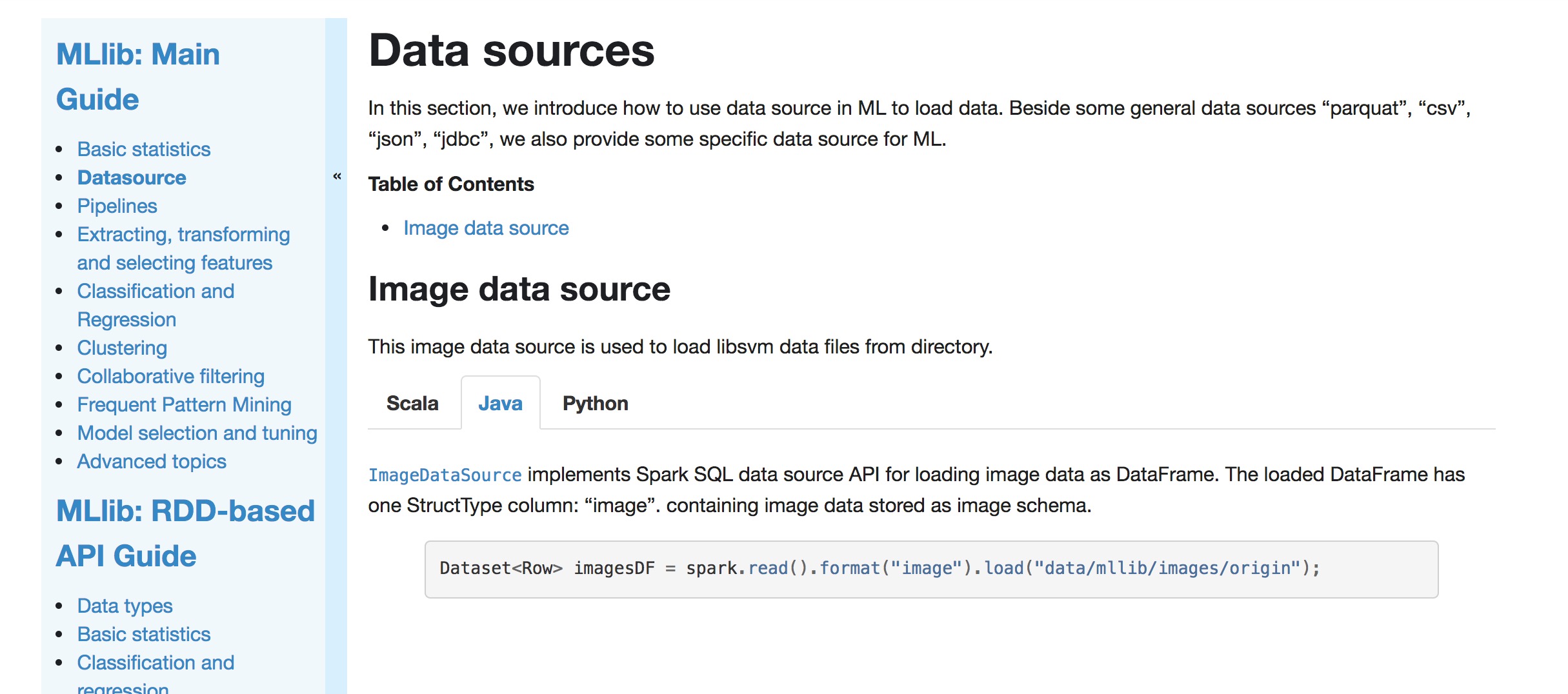 Python: 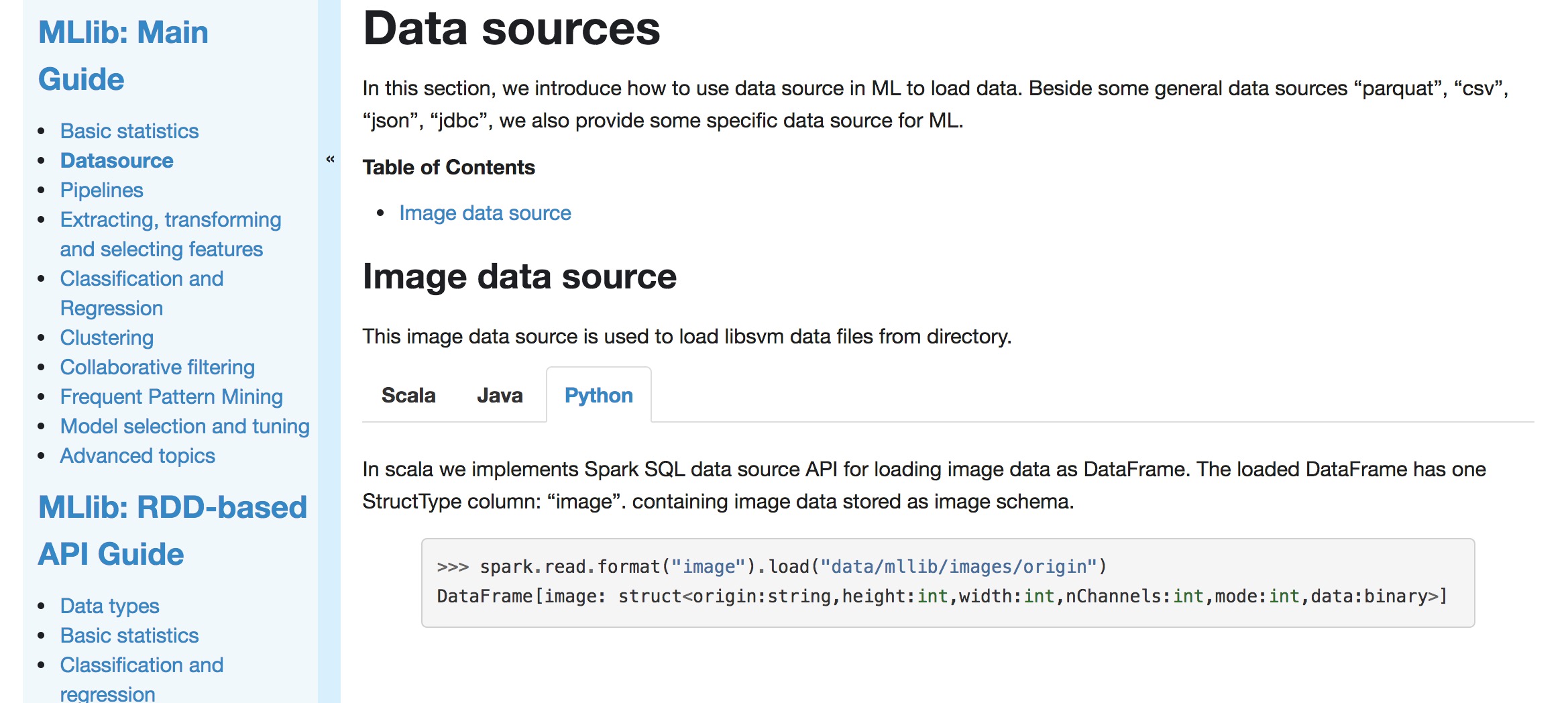 You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark add_image_source_doc Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22675.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22675 commit 887f5282fba8a8a0bcbb9242eb87b27bf94d0210 Author: WeichenXu Date: 2018-10-09T02:54:09Z init --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21156: [SPARK-24087][SQL] Avoid shuffle when join keys are a su...
Github user wangshisan commented on the issue: https://github.com/apache/spark/pull/21156 What is the status now? I think this is of great value, since this gives users more possibility to leverage bucket join, all joins which take the bucket key as the prefix of join keys will benefit from this. And we have a further optimization here: 1. Table A(a1, a2, a3) is bucketed by a1, a2 2. Table B(b1, b2, b3) is bucketed by b1. 3. A join B on (a1=b1, a2=b2, a3=b3) In this case, only table B needs extra shuffle, and shuffle keys are (b1, b2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22674 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-make-spark-distribution-unified/3809/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3809/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22674 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3810/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-make-spark-distribution-unified/3809/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22237: [SPARK-25243][SQL] Use FailureSafeParser in from_...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22237#discussion_r223545341
--- Diff: docs/sql-programming-guide.md ---
@@ -1890,6 +1890,10 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
# Migration Guide
+## Upgrading From Spark SQL 2.4 to 3.0
+
+ - Since Spark 3.0, the `from_json` functions supports two modes -
`PERMISSIVE` and `FAILFAST`. The modes can be set via the `mode` option. The
default mode became `PERMISSIVE`. In previous versions, behavior of `from_json`
did not conform to either `PERMISSIVE` nor `FAILFAST`, especially in processing
of malformed JSON records. For example, the JSON string `{"a" 1}` with the
schema `a INT` is converted to `null` by previous versions but Spark 3.0
converts it to `Row(null)`. In version 2.4 and earlier, arrays of JSON objects
are considered as invalid and converted to `null` if specified schema is
`StructType`. Since Spark 3.0, the input is considered as a valid JSON array
and only its first element is parsed if it conforms to the specified
`StructType`.
--- End diff --
the last option LGTM
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-make-spark-distribution-unified/3808/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21669 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3808/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22674: [SPARK-25680][SQL] SQL execution listener shouldn't happ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22674 **[Test build #97140 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97140/testReport)** for PR 22674 at commit [`a456226`](https://github.com/apache/spark/commit/a4562264c45c24a88f4d508c2d34d4e7aed50631). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-make-spark-distribution-unified/3808/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22659: [SPARK-25623][SPARK-25624][SPARK-25625][TEST] Reduce tes...
Github user shahidki31 commented on the issue: https://github.com/apache/spark/pull/22659 Thank you @srowen for merging. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 **[Test build #97139 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97139/testReport)** for PR 21669 at commit [`2108154`](https://github.com/apache/spark/commit/210815496cc2e5ecf8a0e7f86572733994e2f671). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21669 **[Test build #97138 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97138/testReport)** for PR 21669 at commit [`69840a8`](https://github.com/apache/spark/commit/69840a8026d1f8a72eed9a3e6c7073e8bdbf04b0). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22482 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97135/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22482 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22482 **[Test build #97135 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97135/testReport)** for PR 22482 at commit [`94e9859`](https://github.com/apache/spark/commit/94e9859b4bef01a9c08da0ce444167dd0d25e3ba). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22623: [SPARK-25636][CORE] spark-submit cuts off the failure re...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22623 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97134/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22623: [SPARK-25636][CORE] spark-submit cuts off the failure re...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22623 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22623: [SPARK-25636][CORE] spark-submit cuts off the failure re...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22623 **[Test build #97134 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97134/testReport)** for PR 22623 at commit [`71e3e30`](https://github.com/apache/spark/commit/71e3e30aaf94dfb638eca7e2edfc5feddccc0d3d). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22623: [SPARK-25636][CORE] spark-submit cuts off the failure re...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22623 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22623: [SPARK-25636][CORE] spark-submit cuts off the failure re...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22623 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97133/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org