[GitHub] [spark] cloud-fan commented on a change in pull request #25601: [SPARK-28856][SQL] Implement SHOW DATABASES for Data Source V2 Tables
cloud-fan commented on a change in pull request #25601: [SPARK-28856][SQL]
Implement SHOW DATABASES for Data Source V2 Tables
URL: https://github.com/apache/spark/pull/25601#discussion_r319379649
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/ShowDatabasesExec.scala
##
@@ -0,0 +1,62 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.v2
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalog.v2.CatalogV2Implicits.NamespaceHelper
+import org.apache.spark.sql.catalog.v2.SupportsNamespaces
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.encoders.RowEncoder
+import org.apache.spark.sql.catalyst.expressions.{Attribute,
GenericRowWithSchema}
+import org.apache.spark.sql.catalyst.util.StringUtils
+import org.apache.spark.sql.execution.LeafExecNode
+
+/**
+ * Physical plan node for showing databases.
+ */
+case class ShowDatabasesExec(
+output: Seq[Attribute],
+catalog: SupportsNamespaces,
+pattern: Option[String])
+extends LeafExecNode {
+ override protected def doExecute(): RDD[InternalRow] = {
+val namespaces = catalog.listNamespaces().flatMap(getNamespaces(catalog,
_))
Review comment:
> Add SHOW NAMESPACES that behaves differently than SHOW DATABASES
I prefer this.
Another idea is: `SHOW NAMESPACES` should list the root namespaces of the
current catalog, no matter what the current namespace is.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill
AmplabJenkins commented on issue #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill URL: https://github.com/apache/spark/pull/25628#issuecomment-526482818 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] PavithraRamachandran opened a new pull request #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill
PavithraRamachandran opened a new pull request #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill URL: https://github.com/apache/spark/pull/25628 ### What changes were proposed in this pull request? **Root Cause:** When a dataframe is created using select statement (using **spark.sql.parser.quotedRegexColumnNames=true**) dataframe fill is called- the _fillCol_ in DataFrameNaFunctions, **``(backtick)** are added explicitly to the **columnNames**, the column name is misunderstood to be a regex and it is set as an unresolvedregex, which makes the coalesce resolving to fail. _Observation_ When we create the dataframe from the select statement using a regex, valid columns names are returned after applying the filter(regex). So adding _backticks_ to column name in this flow was not needed. To check the impact, select statement with regex were used, there was no impact while executing without the _backticks_. **After Fix** While passing the columnname to the dataframe column method, **``(backtick)** are not added, as the value that is received is not a regular expression, but a valid column name. ### Why are the changes needed? By doing this change column name is not considered as regex and the proper Column function is derived. And does not fail to resolve the expression. ### Does this PR introduce any user-facing change? No ### How was this patch tested? The patch was tested by adding UT cases. And testing in spark shell using various select statement .(with and without regex) Before Fix: 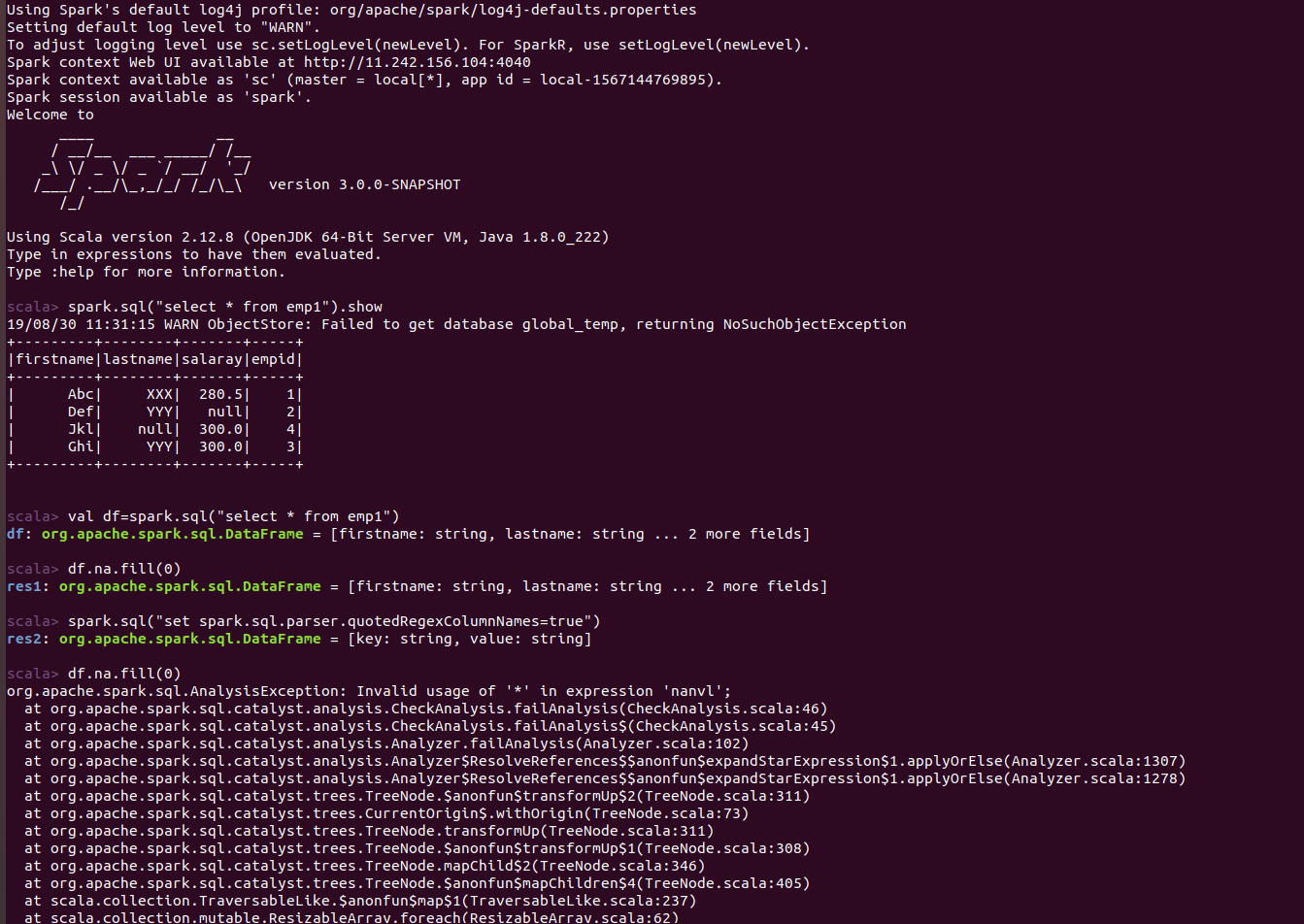 After Fix: 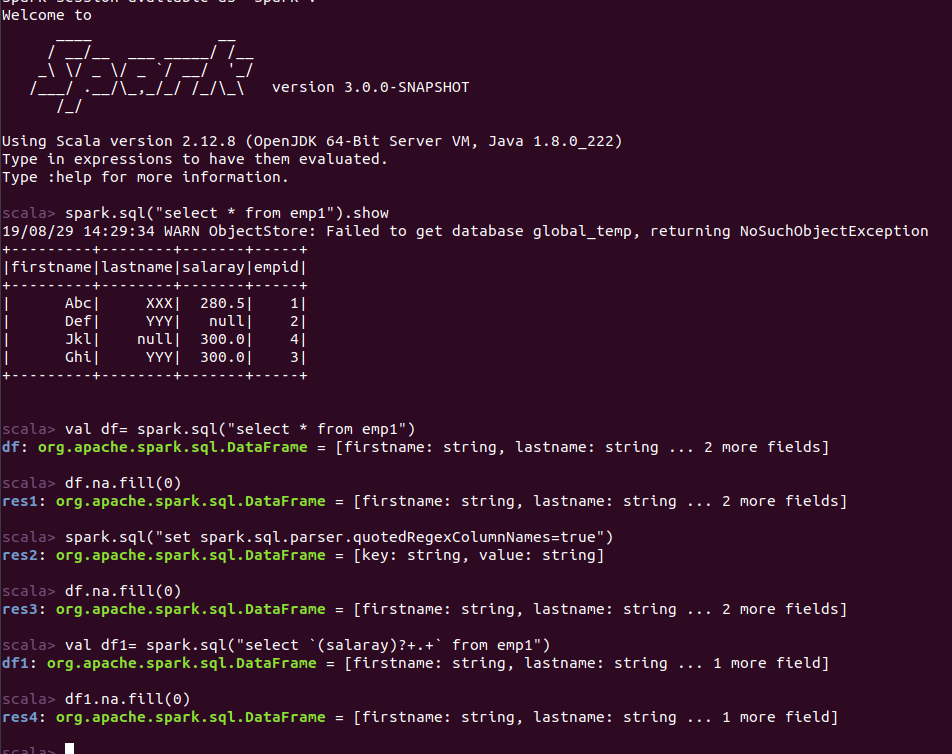 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LucaCanali commented on a change in pull request #24901: [SPARK-28091[CORE] Extend Spark metrics system with user-defined metrics using executor plugins
LucaCanali commented on a change in pull request #24901: [SPARK-28091[CORE]
Extend Spark metrics system with user-defined metrics using executor plugins
URL: https://github.com/apache/spark/pull/24901#discussion_r319376590
##
File path: core/src/main/java/org/apache/spark/ExecutorPlugin.java
##
@@ -47,6 +48,17 @@
*/
default void init() {}
+ /**
+ * Initialize the executor plugins used to extend the Spark/Dropwizard
metrics system.
+ *
+ * Each executor will, during its initialization, invoke this method on
each
+ * plugin provided in the spark.executor.metrics.plugins configuration.
+ *
+ * Plugins should register the data sources using the Dropwizard/codahale
API
+ *
+ */
+ default void init(MetricRegistry sourceMetricsRegistry) {}
Review comment:
Thanks @vanzin for looking at this. I'll be interested to know about your
use case for using this (executor plugins for extending the metrics system) .
BTW I take the occasion to add that over the summer we have used this code a
few times for workload and performance measurements/tests, and found it quite
useful, in particular in the context of measuring I/O access time with some
custom plugins we worte ( https://github.com/cerndb/SparkExecutorPlugins ) +
custom I/O instrumentation for S3, HDFS. I have been thinking also at adding
some additional instrumentation for CPU counters or network metrics, but not
yet worked on that.
I agree that using one config for "normal" plugins and for metrics plugins
would reduce complexity and in general be preferrable. I'll appreciate a few
more deatils on your proposed changes. I guess what could be a very simple way
to merge the two plugin types, is just to pass sourceMetricsregistry to all
plugins init code. This would be a breaking change from 2.4, but maybe
acceptable for Spark 3.0? I guess there are just a few people using executor
plugins in their current form? /cc @squito
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wenxuanguan commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
wenxuanguan commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526481232 > Spark doesn't have semantics of 2PC natively as you've seen DSv2 API - If I understand correctly, Spark HDFS sink doesn't leverage 2PC. > > Previously it used temporal directory - let all tasks write to that directory, and driver move that directory to final destination only when all tasks succeed to write. It leverages the fact that "rename" is atomic, so it didn't support "exactly-once" if underlying filesystem doesn't support atomic renaming. > > Now it leverages metadata - let all tasks write files, and pass the list of files (path) written to driver. When driver receives all list of written files from all tasks, driver writes overall list of files to metadata. So exactly-once for HDFS is only guaranteed when "Spark" reads the output which is aware of metadata information. Sorry for late reply. In my understand that is the procedure of 2PC. The voting phase every task write data and return commit message to driver. In the commit phase, when all tasks completed successfully, the driver commit job with rename, or abort job if any task failed to commit or job commit failed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] advancedxy commented on a change in pull request #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
advancedxy commented on a change in pull request #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#discussion_r319373447 ## File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/HadoopFileWholeTextReader.scala ## @@ -45,6 +45,7 @@ class HadoopFileWholeTextReader(file: PartitionedFile, conf: Configuration) val attemptId = new TaskAttemptID(new TaskID(new JobID(), TaskType.MAP, 0), 0) val hadoopAttemptContext = new TaskAttemptContextImpl(conf, attemptId) val reader = new WholeTextFileRecordReader(fileSplit, hadoopAttemptContext, 0) +reader.setConf(hadoopAttemptContext.getConfiguration) Review comment: `WholeTextFileRecordReader` is `Configurable`, `setConf` should be called after creation. This is why tests are failing before this patch. However, I am wondering for `org.apache.spark.input.WholeTextFileRecordReader` and `org.apache.spark.input.ConfigurableCombineFileRecordReader`, we can already retrieve config from `org.apache.hadoop.mapreduce.TaskAttemptContext`. There is no need to make these class `Configurable` I am wondering if we should remove `Configurable` trait for the related classes all at once. what do you think @gatorsmile This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526477986 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14964/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526477981 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526477981 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526477986 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14964/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
SparkQA commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526476375 **[Test build #109937 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109937/testReport)** for PR 25616 at commit [`149de72`](https://github.com/apache/spark/commit/149de72c220cbc094f0b8756c535cf1bd796a48e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean d
cloud-fan commented on a change in pull request #25458: [SPARK-27931][SQL]
Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and
trim input for the boolean data type.
URL: https://github.com/apache/spark/pull/25458#discussion_r319370632
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
##
@@ -819,19 +819,32 @@ class CastSuite extends SparkFunSuite with
ExpressionEvalHelper {
}
test("cast string to boolean") {
-checkCast("t", true)
+
checkCast("true", true)
+checkCast("tru", true)
+checkCast("tr", true)
+checkCast("t", true)
checkCast("tRUe", true)
-checkCast("y", true)
+checkCast("tRue ", true)
+checkCast("tRu ", true)
checkCast("yes", true)
+checkCast("ye", true)
+checkCast("y", true)
checkCast("1", true)
+checkCast("on", true)
-checkCast("f", false)
checkCast("false", false)
-checkCast("FAlsE", false)
-checkCast("n", false)
+checkCast("fals", false)
+checkCast("fal", false)
+checkCast("fa", false)
+checkCast("f", false)
+checkCast("fAlse", false)
+checkCast("fAls", false)
checkCast("no", false)
+checkCast("n", false)
checkCast("0", false)
+checkCast("off", false)
+checkCast("of", false)
Review comment:
SGTM
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
AmplabJenkins commented on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-526474166 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
AmplabJenkins removed a comment on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-526474166 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
AmplabJenkins commented on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-526474173 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109935/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
AmplabJenkins removed a comment on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-526474173 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109935/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
SparkQA removed a comment on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-526431556 **[Test build #109935 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109935/testReport)** for PR 25512 at commit [`1ad57a1`](https://github.com/apache/spark/commit/1ad57a1ea038445d14e37de31c6732237f2d6b5a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions
SparkQA commented on issue #25512: [SPARK-28782][SQL] Generator support in aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-526473775 **[Test build #109935 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109935/testReport)** for PR 25512 at commit [`1ad57a1`](https://github.com/apache/spark/commit/1ad57a1ea038445d14e37de31c6732237f2d6b5a). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
cloud-fan commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526473042 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
cloud-fan closed pull request #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526471995 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109933/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data typ
AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526471995 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109933/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data typ
AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526471988 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526471988 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
SparkQA removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526429921 **[Test build #109933 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109933/testReport)** for PR 25458 at commit [`2ea551c`](https://github.com/apache/spark/commit/2ea551c728396881cfb05ed01f6179497bd3ceb5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
SparkQA commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526471499 **[Test build #109933 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109933/testReport)** for PR 25458 at commit [`2ea551c`](https://github.com/apache/spark/commit/2ea551c728396881cfb05ed01f6179497bd3ceb5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
cloud-fan commented on a change in pull request #25502: [SPARK-28668][SQL]
Support V2SessionCatalog for ALTER TABLE
URL: https://github.com/apache/spark/pull/25502#discussion_r319366124
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -922,51 +916,51 @@ class Analyzer(
TableChange.updateColumnComment(colName.toArray, newComment)
}
-AlterTable(
- v2Catalog.asTableCatalog, ident,
- UnresolvedRelation(alter.tableName),
- typeChange.toSeq ++ commentChange.toSeq)
+resolveV2Alter(tableName, typeChange.toSeq ++
commentChange.toSeq).getOrElse(alter)
- case alter @ AlterTableRenameColumnStatement(
- CatalogObjectIdentifier(Some(v2Catalog), ident), col, newName) =>
-AlterTable(
- v2Catalog.asTableCatalog, ident,
- UnresolvedRelation(alter.tableName),
- Seq(TableChange.renameColumn(col.toArray, newName)))
+ case alter @ AlterTableRenameColumnStatement(tableName, col, newName) =>
+val changes = Seq(TableChange.renameColumn(col.toArray, newName))
+resolveV2Alter(tableName, changes).getOrElse(alter)
- case alter @ AlterTableDropColumnsStatement(
- CatalogObjectIdentifier(Some(v2Catalog), ident), cols) =>
+ case alter @ AlterTableDropColumnsStatement(tableName, cols) =>
val changes = cols.map(col => TableChange.deleteColumn(col.toArray))
-AlterTable(
- v2Catalog.asTableCatalog, ident,
- UnresolvedRelation(alter.tableName),
- changes)
-
- case alter @ AlterTableSetPropertiesStatement(
- CatalogObjectIdentifier(Some(v2Catalog), ident), props) =>
-val changes = props.map {
- case (key, value) =>
-TableChange.setProperty(key, value)
+resolveV2Alter(tableName, changes).getOrElse(alter)
+
+ case alter @ AlterTableSetPropertiesStatement(tableName, props) =>
+val changes = props.map { case (key, value) =>
+ TableChange.setProperty(key, value)
}
-AlterTable(
- v2Catalog.asTableCatalog, ident,
- UnresolvedRelation(alter.tableName),
- changes.toSeq)
-
- case alter @ AlterTableUnsetPropertiesStatement(
- CatalogObjectIdentifier(Some(v2Catalog), ident), keys, _) =>
-AlterTable(
- v2Catalog.asTableCatalog, ident,
- UnresolvedRelation(alter.tableName),
- keys.map(key => TableChange.removeProperty(key)))
-
- case alter @ AlterTableSetLocationStatement(
- CatalogObjectIdentifier(Some(v2Catalog), ident), newLoc) =>
-AlterTable(
- v2Catalog.asTableCatalog, ident,
- UnresolvedRelation(alter.tableName),
- Seq(TableChange.setProperty("location", newLoc)))
+resolveV2Alter(tableName, changes.toSeq).getOrElse(alter)
+
+ case alter @ AlterTableUnsetPropertiesStatement(tableName, keys, _) =>
+resolveV2Alter(tableName, keys.map(key =>
TableChange.removeProperty(key))).getOrElse(alter)
+
+ case alter @ AlterTableSetLocationStatement(tableName, newLoc) =>
+resolveV2Alter(tableName, Seq(TableChange.setProperty("location",
newLoc))).getOrElse(alter)
+}
+
+private def resolveV2Alter(
+tableName: Seq[String],
+changes: Seq[TableChange]): Option[AlterTable] = {
Review comment:
I also thought about it before. I think the ideal resolution process is:
1. rules like `ResolveAlterTable` are only responsible for converting
XYZStatement to v1 or v2 command
2. `ResolveTables` and `ResolveRelations` are responsible for resolving
`UnresolvedRelation` to v1 or v2 relations
However, some commands like ALTER TABLE also need to get the catalog
instance, which can't be done by `ResolveTables` or `ResolveRelations`. Unlike
table resolution which replaces `UnresolvedRelation` with v1/v2 relation and
can be done by a rule separately. Catalog resolution needs to be done during
the converting from XYZStatement to v1/v2 command and we can't do it in a
separated rule.
I don't have a good idea now but we should definitely revisit it later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data typ
AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526462894 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data typ
AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526462899 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109931/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526462894 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526462899 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109931/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
SparkQA removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526425369 **[Test build #109931 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109931/testReport)** for PR 25458 at commit [`abe9a84`](https://github.com/apache/spark/commit/abe9a8431f0b7f5cd403e54b31834aecce66c524). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
SparkQA commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526462461 **[Test build #109931 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109931/testReport)** for PR 25458 at commit [`abe9a84`](https://github.com/apache/spark/commit/abe9a8431f0b7f5cd403e54b31834aecce66c524). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq'
AmplabJenkins removed a comment on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq' URL: https://github.com/apache/spark/pull/25627#issuecomment-526458347 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq'
AmplabJenkins commented on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq' URL: https://github.com/apache/spark/pull/25627#issuecomment-526459457 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526458256 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109936/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526458253 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq'
AmplabJenkins commented on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq' URL: https://github.com/apache/spark/pull/25627#issuecomment-526458347 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq'
AmplabJenkins removed a comment on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq' URL: https://github.com/apache/spark/pull/25627#issuecomment-526457930 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526458256 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109936/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
SparkQA removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526433143 **[Test build #109936 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109936/testReport)** for PR 20965 at commit [`17706c3`](https://github.com/apache/spark/commit/17706c3b5d62ac30ac004aebaf5c0c118243e116). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526458253 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
SparkQA commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526458143 **[Test build #109936 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109936/testReport)** for PR 20965 at commit [`17706c3`](https://github.com/apache/spark/commit/17706c3b5d62ac30ac004aebaf5c0c118243e116). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq'
AmplabJenkins commented on issue #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq' URL: https://github.com/apache/spark/pull/25627#issuecomment-526457930 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin opened a new pull request #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq'
xianyinxin opened a new pull request #25627: [SPARK-28923][SQL] Deduplicate the codes 'multipartIdentifier' and 'identifierSeq' URL: https://github.com/apache/spark/pull/25627 ### What changes were proposed in this pull request? In `sqlbase.g4`, `multipartIdentifier` and `identifierSeq` have the same functionality. We'd better deduplicate them. ### Why are the changes needed? Deduplicate the codes which have the same function. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Existing tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tnachen commented on a change in pull request #25614: [WIP][SPARK-28887][K8S] Executor pod status fix
tnachen commented on a change in pull request #25614: [WIP][SPARK-28887][K8S]
Executor pod status fix
URL: https://github.com/apache/spark/pull/25614#discussion_r319357937
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshot.scala
##
@@ -42,32 +43,47 @@ object ExecutorPodsSnapshot extends Logging {
ExecutorPodsSnapshot(toStatesByExecutorId(executorPods))
}
- def apply(): ExecutorPodsSnapshot = ExecutorPodsSnapshot(Map.empty[Long,
ExecutorPodState])
+ def apply(): ExecutorPodsSnapshot = ExecutorPodsSnapshot(Map.empty[Long,
ExecutorState])
- private def toStatesByExecutorId(executorPods: Seq[Pod]): Map[Long,
ExecutorPodState] = {
+ private def toStatesByExecutorId(executorPods: Seq[Pod]): Map[Long,
ExecutorState] = {
executorPods.map { pod =>
(pod.getMetadata.getLabels.get(SPARK_EXECUTOR_ID_LABEL).toLong,
toState(pod))
}.toMap
}
- private def toState(pod: Pod): ExecutorPodState = {
+ private def toState(pod: Pod): ExecutorState = {
if (isDeleted(pod)) {
- PodDeleted(pod)
+ ExecutorPodDeleted(pod)
} else {
val phase = pod.getStatus.getPhase.toLowerCase(Locale.ROOT)
phase match {
case "pending" =>
- PodPending(pod)
+ ExecutorPending(pod)
case "running" =>
- PodRunning(pod)
+ // Checking executor container status is not terminated
Review comment:
Can we add a test for this?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data typ
AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526453076 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109927/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data typ
AmplabJenkins removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526453071 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526453076 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109927/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
AmplabJenkins commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526453071 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
SparkQA removed a comment on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526414104 **[Test build #109927 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109927/testReport)** for PR 25458 at commit [`dacd46b`](https://github.com/apache/spark/commit/dacd46b3856060ba1792779815d3e938468abc5a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
SparkQA commented on issue #25458: [SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. URL: https://github.com/apache/spark/pull/25458#issuecomment-526452793 **[Test build #109927 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109927/testReport)** for PR 25458 at commit [`dacd46b`](https://github.com/apache/spark/commit/dacd46b3856060ba1792779815d3e938468abc5a). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on issue #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on issue #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI URL: https://github.com/apache/spark/pull/25611#issuecomment-526449905 @juliuszsompolski There are some conflicts in the process. Changed a lot to cover all problems you have mentioned, include call ` close() `before setState `FINISHED`, Thanks for review again. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25588: [SPARK-28000][SQL][TEST] Port comments.sql
dongjoon-hyun commented on a change in pull request #25588: [SPARK-28000][SQL][TEST] Port comments.sql URL: https://github.com/apache/spark/pull/25588#discussion_r319351993 ## File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/comments.sql ## @@ -0,0 +1,48 @@ +-- +-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group +-- +-- +-- COMMENTS +-- https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/comments.sql Review comment: Shall we use `BETA3` from now? I believe it will be the same with `BETA2`. - https://github.com/postgres/postgres/blob/REL_12_BETA3/src/test/regress/sql/comments.sql This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25614: [WIP][SPARK-28887][K8S] Executor pod status fix
dongjoon-hyun commented on a change in pull request #25614:
[WIP][SPARK-28887][K8S] Executor pod status fix
URL: https://github.com/apache/spark/pull/25614#discussion_r319351543
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodStates.scala
##
@@ -18,20 +18,20 @@ package org.apache.spark.scheduler.cluster.k8s
import io.fabric8.kubernetes.api.model.Pod
-sealed trait ExecutorPodState {
+sealed trait ExecutorState {
Review comment:
@jinxingwang . Could you make another PR for this renaming?
This PR seems to have two orthogonal themes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25614: [WIP][SPARK-28887][K8S] Executor pod status fix
dongjoon-hyun commented on a change in pull request #25614:
[WIP][SPARK-28887][K8S] Executor pod status fix
URL: https://github.com/apache/spark/pull/25614#discussion_r319351543
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodStates.scala
##
@@ -18,20 +18,20 @@ package org.apache.spark.scheduler.cluster.k8s
import io.fabric8.kubernetes.api.model.Pod
-sealed trait ExecutorPodState {
+sealed trait ExecutorState {
Review comment:
Hi, @jinxingwang . Could you make another PR for this renaming?
This PR seems to have two orthogonal themes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25614: [WIP][SPARK-28887][K8S] Executor pod status fix
dongjoon-hyun commented on issue #25614: [WIP][SPARK-28887][K8S] Executor pod status fix URL: https://github.com/apache/spark/pull/25614#issuecomment-526449061 Thank you for making a PR, @jinxingwang . Could you fix the scala style? You can check with `dev/scalastyle`. ``` [error] /home/jenkins/workspace/SparkPullRequestBuilder/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshot.scala:25:18: Instead of importing implicits in scala.collection.JavaConversions._, import [error] scala.collection.JavaConverters._ and use .asScala / .asJava methods [error] /home/jenkins/workspace/SparkPullRequestBuilder/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshot.scala:25:0: collection.JavaConversions._ should be in group 3rdParty, not spark. ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
viirya commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526447635 No problem at all! thanks @dongjoon-hyun This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
dongjoon-hyun commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526446430 Oh.. Resovling conflicts seem not good. It removes the PR template and shows me as a co-author. Sorry about that, @viirya . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526446039 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109929/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526446035 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526446039 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109929/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25625: [SPARK-28920][INFRA] Set up java version for github workflow
dongjoon-hyun closed pull request #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
SparkQA removed a comment on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526415595 **[Test build #109929 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109929/testReport)** for PR 20965 at commit [`67673db`](https://github.com/apache/spark/commit/67673db1349bb59d4a4917a249170b821ee02041). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526446035 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions
SparkQA commented on issue #20965: [SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-526445912 **[Test build #109929 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109929/testReport)** for PR 20965 at commit [`67673db`](https://github.com/apache/spark/commit/67673db1349bb59d4a4917a249170b821ee02041). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
AmplabJenkins removed a comment on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526445262 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109930/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
AmplabJenkins removed a comment on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526445255 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
AmplabJenkins commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526445262 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109930/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
AmplabJenkins commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526445255 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
SparkQA removed a comment on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526417252 **[Test build #109930 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109930/testReport)** for PR 25625 at commit [`4fe4854`](https://github.com/apache/spark/commit/4fe4854dd5eb217b60783a1ed8cb8af0ec4e3424). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow
SparkQA commented on issue #25625: [SPARK-28920][INFRA] Set up java version for github workflow URL: https://github.com/apache/spark/pull/25625#issuecomment-526444966 **[Test build #109930 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109930/testReport)** for PR 25625 at commit [`4fe4854`](https://github.com/apache/spark/commit/4fe4854dd5eb217b60783a1ed8cb8af0ec4e3424). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r319345622
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2.scala
##
@@ -239,6 +239,15 @@ object HiveThriftServer2 extends Logging {
executionList(id).state = ExecutionState.COMPILED
}
+def onStatementCanceled(id: String): Unit = {
+ synchronized {
+executionList(id).finishTimestamp = System.currentTimeMillis
+executionList(id).state = ExecutionState.CANCELED
+totalRunning -= 1
Review comment:
@juliuszsompolski if we call close() before FINISH, onOperationClose()
won't do
`totalRunning -= 1`, also a bug.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25610: [SPARK-28899][SQL][TEST] merge the testing in-memory v2 catalogs from catalyst and core
cloud-fan commented on issue #25610: [SPARK-28899][SQL][TEST] merge the testing in-memory v2 catalogs from catalyst and core URL: https://github.com/apache/spark/pull/25610#issuecomment-526441695 @rdblue congrats and thanks for merging my PR! Hopefully this is your first Spark PR merging :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wenxuanguan commented on a change in pull request #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
wenxuanguan commented on a change in pull request #25618:
[SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
URL: https://github.com/apache/spark/pull/25618#discussion_r319342797
##
File path:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataWriter.scala
##
@@ -18,16 +18,160 @@
package org.apache.spark.sql.kafka010
import java.{util => ju}
+import java.util.concurrent.atomic.AtomicInteger
+
+import com.google.common.cache._
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions.Attribute
import org.apache.spark.sql.sources.v2.writer._
+import org.apache.spark.util.Utils
+
+/**
+ * A [[WriterCommitMessage]] for Kafka commit message.
+ * @param transactionalId Unique transactionalId for each producer.
+ * @param epoch Transactional epoch.
+ * @param producerId Transactional producerId for producer, got when init
transaction.
+ */
+private[kafka010] case class ProducerTransactionMetaData(
+transactionalId: String,
+epoch: Short,
+producerId: Long)
+ extends WriterCommitMessage
+
+/**
+ * Emtpy commit message for resume transaction.
+ */
+private case object EmptyCommitMessage extends WriterCommitMessage
+
+private[kafka010] case object ProducerTransactionMetaData {
+ val VERSION = 1
+
+ def toTransactionId(
+ executorId: String,
+ taskIndex: String,
+ transactionalIdSuffix: String): String = {
+toTransactionId(toProducerIdentity(executorId, taskIndex),
transactionalIdSuffix)
+ }
+
+ def toTransactionId(producerIdentity: String, transactionalIdSuffix:
String): String = {
+s"$producerIdentity||$transactionalIdSuffix"
+ }
+
+ def toTransactionalIdSuffix(transactionalId: String): String = {
+transactionalId.split("\\|\\|", 2)(1)
+ }
+
+ def toProducerIdentity(transactionalId: String): String = {
+transactionalId.split("\\|\\|", 2)(0)
+ }
+
+ def toExecutorId(transactionalId: String): String = {
+val producerIdentity = toProducerIdentity(transactionalId)
+producerIdentity.split("-", 2)(0)
+ }
+
+ def toTaskIndex(transactionalId: String): String = {
+val producerIdentity = toProducerIdentity(transactionalId)
+producerIdentity.split("-", 2)(1)
+ }
+
+ def toProducerIdentity(executorId: String, taskIndex: String): String = {
+s"$executorId-$taskIndex"
+ }
+}
+
+/**
+ * A [[DataWriter]] for Kafka transactional writing. One data writer will be
created
+ * in each partition to process incoming rows.
+ *
+ * @param targetTopic The topic that this data writer is targeting. If None,
topic will be inferred
+ *from a `topic` field in the incoming data.
+ * @param producerParams Parameters to use for the Kafka producer.
+ * @param inputSchema The attributes in the input data.
+ */
+private[kafka010] class KafkaTransactionDataWriter(
+targetTopic: Option[String],
+producerParams: ju.Map[String, Object],
+inputSchema: Seq[Attribute])
+ extends KafkaRowWriter(inputSchema, targetTopic) with
DataWriter[InternalRow] {
+
+ private lazy val producer = {
+val kafkaProducer = CachedKafkaProducer.getOrCreate(producerParams)
Review comment:
I think caching logic is ok and we can control producer creation per task,
and also failover with transactional.id in producerParams.
Transaction producer is not thread safe, so what I do is one producer per
task in one micro-batch, and in next batch reused the created producer instead
of recreate one since transaction is complete in every micro-batch. With
producerParams, transactional.id is different between tasks in one micro-batch,
but same in the next micro-batch.
And if task number is same for every executor in every micro-batch, no more
producer will be created except the first micro-batch.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
AmplabJenkins commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526438195 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
AmplabJenkins removed a comment on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526438195 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
AmplabJenkins commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526438201 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109922/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
AmplabJenkins removed a comment on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526438201 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109922/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
SparkQA commented on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526437869 **[Test build #109922 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109922/testReport)** for PR 25502 at commit [`1f82198`](https://github.com/apache/spark/commit/1f821986e7458ca4b87c898d6c3c6d73b0ac78ad). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE
SparkQA removed a comment on issue #25502: [SPARK-28668][SQL] Support V2SessionCatalog for ALTER TABLE URL: https://github.com/apache/spark/pull/25502#issuecomment-526397155 **[Test build #109922 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109922/testReport)** for PR 25502 at commit [`1f82198`](https://github.com/apache/spark/commit/1f821986e7458ca4b87c898d6c3c6d73b0ac78ad). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r319341975
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -275,6 +279,7 @@ private[hive] class SparkExecuteStatementOperation(
override def cancel(): Unit = {
logInfo(s"Cancel '$statement' with $statementId")
cleanup(OperationState.CANCELED)
+HiveThriftServer2.listener.onStatementCanceled(statementId)
Review comment:
> This can call `onStatementCanceled()` before the thread launching
`execute()` gets to `onStatementStarted()`, which will result in the listener
throwing an NoSuchElementException on executionList(id).
> `onStatementStarted()` could be moved to `runInternal()` in the main
thread to prevent that, but then the `catch` block there has to add
`onStatementError()`. It then would also be good to extend the `try` block to
the start of `execute()`
add a new status ExecutionState.PREPARED to fix this problem, call
onStatementPrepared in runInternal().
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r319341975
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -275,6 +279,7 @@ private[hive] class SparkExecuteStatementOperation(
override def cancel(): Unit = {
logInfo(s"Cancel '$statement' with $statementId")
cleanup(OperationState.CANCELED)
+HiveThriftServer2.listener.onStatementCanceled(statementId)
Review comment:
add a new status ExecutionState.PREPARED to fix this problem, call
onStatementPrepared in runInternal().
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
HeartSaVioR edited a comment on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526436430 Spark doesn't have semantics of 2PC natively as you've seen DSv2 API - If I understand correctly, Spark HDFS sink doesn't leverage 2PC. Previously it used temporal directory - let all tasks write to that directory, and driver move that directory to final destination only when all tasks succeed to write. It leverages the fact that "rename" is atomic, so it didn't support "exactly-once" if underlying filesystem doesn't support atomic renaming. Now it leverages metadata - let all tasks write files, and pass the list of files (path) written to driver. When driver receives all list of written files from all tasks, driver writes overall list of files to metadata. So exactly-once for HDFS is only guaranteed when "Spark" reads the output which is aware of metadata information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
HeartSaVioR edited a comment on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526436430 Spark doesn't have semantics of 2PC natively as you've seen DSv2 API - Spark HDFS sink doesn't leverage 2PC. If I understand correctly, previously it used temporal directory - let all tasks write to that directory, and driver move that directory to final destination only when all tasks succeed to write. It leverages the fact that "rename" is atomic, so it didn't support "exactly-once" if underlying filesystem doesn't support atomic renaming. Now it leverages metadata - let all tasks write files, and pass the list of files (path) written to driver. When driver receives all list of written files from all tasks, driver writes overall list of files to metadata. So exactly-once for HDFS is only guaranteed when "Spark" reads the output which is aware of metadata information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25622: [SPARK-28915][CORE]The new keyword is not used when instantiating the WorkerOffer.
HyukjinKwon commented on a change in pull request #25622:
[SPARK-28915][CORE]The new keyword is not used when instantiating the
WorkerOffer.
URL: https://github.com/apache/spark/pull/25622#discussion_r319341164
##
File path:
core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala
##
@@ -270,7 +270,7 @@ class CoarseGrainedSchedulerBackend(scheduler:
TaskSchedulerImpl, val rpcEnv: Rp
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
-new WorkerOffer(id, executorData.executorHost,
executorData.freeCores,
+WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Review comment:
I think we don't have to change this - it's going to cause a lot of
conflicts when we backport but the gain here is virtually nothing. Either way
is legitimate.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526435912 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109928/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
HeartSaVioR commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526436430 Spark doesn't have semantics of 2PC natively as you've seen DSv2 API - Spark HDFS sink doesn't leverage 2PC. If I understand correctly, previously it used temporal directory - let all tasks write to that directory, and driver move that directory to final destination only when all tasks succeed to write. Now it leverages metadata - let all tasks write files, and pass the list of files (path) written to driver. When driver receives all list of written files from all tasks, driver writes overall list of files to metadata. So exactly-once for HDFS is only guaranteed when "Spark" reads the output which is aware of metadata information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526435907 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
SparkQA removed a comment on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526415600 **[Test build #109928 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109928/testReport)** for PR 25616 at commit [`50d6d75`](https://github.com/apache/spark/commit/50d6d7558d098a8423de0ae7570b4863c778dd14). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25611: [SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
AngersZh commented on a change in pull request #25611: [SPARK-28901][SQL]
SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI
URL: https://github.com/apache/spark/pull/25611#discussion_r319341101
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
##
@@ -275,6 +279,7 @@ private[hive] class SparkExecuteStatementOperation(
override def cancel(): Unit = {
logInfo(s"Cancel '$statement' with $statementId")
cleanup(OperationState.CANCELED)
+HiveThriftServer2.listener.onStatementCanceled(statementId)
Review comment:
This can truly happen, especially when running SQL asynchronously, I add a
new STATUS of ExecutStatus.PREPARED in runInternal(), then onStatementStart
just change status, this can fix this problem.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on issue #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
xianyinxin commented on issue #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2 URL: https://github.com/apache/spark/pull/25626#issuecomment-526436021 cc @cloud-fan @rdblue This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25619: [SPARK-28911][SS]unify kafka source option pattern
HyukjinKwon commented on issue #25619: [SPARK-28911][SS]unify kafka source option pattern URL: https://github.com/apache/spark/pull/25619#issuecomment-526436037 Yea, let's don't change. You gotta also keep the compatibility and the namespace-like convention seems fine. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526435912 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109928/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
AmplabJenkins commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526435907 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration()
SparkQA commented on issue #25616: [SPARK-28907][CORE] Review invalid usage of new Configuration() URL: https://github.com/apache/spark/pull/25616#issuecomment-526435727 **[Test build #109928 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109928/testReport)** for PR 25616 at commit [`50d6d75`](https://github.com/apache/spark/commit/50d6d7558d098a8423de0ae7570b4863c778dd14). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow
AmplabJenkins removed a comment on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow URL: https://github.com/apache/spark/pull/25624#issuecomment-526434565 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109924/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow
AmplabJenkins removed a comment on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow URL: https://github.com/apache/spark/pull/25624#issuecomment-526434558 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow
AmplabJenkins commented on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow URL: https://github.com/apache/spark/pull/25624#issuecomment-526434565 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109924/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow
AmplabJenkins commented on issue #25624: [SPARK-28919][INFRA] Add more profiles for JDK8/11 build test for Github workflow URL: https://github.com/apache/spark/pull/25624#issuecomment-526434558 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org