[GitHub] spark pull request #19959: [SPARK-22766] Install R linter package in spark l...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19959#discussion_r177661344
--- Diff: dev/lint-r.R ---
@@ -27,10 +27,11 @@ if (! library(SparkR, lib.loc = LOCAL_LIB_LOC,
logical.return = TRUE)) {
# Installs lintr from Github in a local directory.
# NOTE: The CRAN's version is too old to adapt to our rules.
if ("lintr" %in% row.names(installed.packages()) == FALSE) {
--- End diff --
does `export R_LIBS_USER=~/Rlib` work for installing Rcpp?
`devtools` `install_version` can fetch a specific version of lintr I think
https://www.rdocumentation.org/packages/devtools/versions/1.13.3/topics/install_version
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20907: [WIP][SPARK-11237][ML] Add pmml export for k-mean...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20907#discussion_r177322828
--- Diff: mllib/src/main/scala/org/apache/spark/ml/clustering/KMeans.scala
---
@@ -185,6 +187,47 @@ class KMeansModel private[ml] (
}
}
+/** Helper class for storing model data */
+private case class ClusterData(clusterIdx: Int, clusterCenter: Vector)
+
+
+/** A writer for KMeans that handles the "internal" (or default) format */
+private class InternalKMeansModelWriter extends MLWriterFormat with
MLFormatRegister {
+
+ override def format(): String = "internal"
+ override def stageName(): String =
"org.apache.spark.ml.clustering.KMeansModel"
+
+ override def write(path: String, sparkSession: SparkSession,
+optionMap: mutable.Map[String, String], stage: PipelineStage): Unit = {
+val instance = stage.asInstanceOf[KMeansModel]
+val sc = sparkSession.sparkContext
+// Save metadata and Params
+DefaultParamsWriter.saveMetadata(instance, path, sc)
+// Save model data: cluster centers
+val data: Array[ClusterData] =
instance.clusterCenters.zipWithIndex.map {
+ case (center, idx) =>
+ClusterData(idx, center)
--- End diff --
doesn't this type change `Data` -> `ClusterData` change the schema of the
output parquet file?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20902: [SPARK-23770][R] Exposes repartitionByRange in Sp...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20902#discussion_r177317996
--- Diff: R/pkg/R/DataFrame.R ---
@@ -759,6 +759,67 @@ setMethod("repartition",
dataFrame(sdf)
})
+
+#' Repartition by range
+#'
+#' The following options for repartition by range are possible:
+#' \itemize{
+#' \item{1.} {Return a new SparkDataFrame range partitioned by
+#' the given columns into \code{numPartitions}.}
+#' \item{2.} {Return a new SparkDataFrame range partitioned by the given
column(s),
+#' using \code{spark.sql.shuffle.partitions} as
number of partitions.}
+#'}
+#'
+#' @param x a SparkDataFrame.
+#' @param numPartitions the number of partitions to use.
+#' @param col the column by which the range partitioning will be performed.
+#' @param ... additional column(s) to be used in the range partitioning.
+#'
+#' @family SparkDataFrame functions
+#' @rdname repartitionByRange
+#' @name repartitionByRange
+#' @aliases repartitionByRange,SparkDataFrame-method
+#' @seealso \link{repartition}, \link{coalesce}
+#' @examples
+#'\dontrun{
+#' sparkR.session()
+#' path <- "path/to/file.json"
+#' df <- read.json(path)
+#' newDF <- repartitionByRange(df, col = df$col1, df$col2)
+#' newDF <- repartitionByRange(df, 3L, col = df$col1, df$col2)
+#'}
+#' @note repartitionByRange since 2.4.0
+setMethod("repartitionByRange",
+ signature(x = "SparkDataFrame"),
+ function(x, numPartitions = NULL, col = NULL, ...) {
+if (!is.null(numPartitions) && !is.null(col)) {
+ # number of partitions and columns both are specified
+ if (is.numeric(numPartitions) && class(col) == "Column") {
+cols <- list(col, ...)
+jcol <- lapply(cols, function(c) { c@jc })
+sdf <- callJMethod(x@sdf, "repartitionByRange",
numToInt(numPartitions), jcol)
+ } else {
+stop(paste("numPartitions and col must be numeric and
Column; however, got",
+ class(numPartitions), "and", class(col)))
+ }
+} else if (!is.null(col)) {
+ # only columns are specified
+ if (class(col) == "Column") {
+cols <- list(col, ...)
+jcol <- lapply(cols, function(c) { c@jc })
+sdf <- callJMethod(x@sdf, "repartitionByRange", jcol)
--- End diff --
cool, some duplication but I think unavoidable for clarity
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2871: ZEPPELIN-3337. Add more test to SparkRInterpreter
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2871 Agreed. This is a bit uncomfortablely long to be hard coded. ---
[GitHub] zeppelin issue #2891: ZEPPELIN-1070: Inject Credentials in any Interpreter-C...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2891 Curly braces From: pellmont Sent: Monday, March 26, 2018 1:45:06 PM To: apache/zeppelin Cc: Felix Cheung; Manual Subject: Re: [apache/zeppelin] ZEPPELIN-1070: Inject Credentials in any Interpreter-Code (#2891) nice if I can contribute :-) I think the current API for the credentials makes sense, of course it would be nice if the credentials could be shared across users without exposing the underlying passwords. But I think as long as there are different interpreters (especially those with "free-form-connections" like spark, livy, etc) it's impossible without implementing quite some code for each of the interpreters. Ending up with limited possibilities to cpnnect to a datasource. What do you exactly mean by "match the other way"? Using the same syntax? Curly braces to be replaced and double-curly-braces to escape? Or do you mean by the configuration option(s)? Or both? â You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub<https://github.com/apache/zeppelin/pull/2891#issuecomment-376305551>, or mute the thread<https://github.com/notifications/unsubscribe-auth/AIjc-yypcBR_cbJS2lfRELnOdkQY_uH5ks5tiVNRgaJpZM4S5aTm>. ---
[GitHub] zeppelin issue #2831: ZEPPELIN-3281. Apply getRelativePath when it is LocalC...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2831 .. and I've reviewed all PRs and left one or two comments. ---
[GitHub] spark issue #20893: [SPARK-23785][LAUNCHER] LauncherBackend doesn't check st...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20893 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2891: ZEPPELIN-1070: Inject Credentials in any Interpreter-C...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2891 thanks, sounds like that could be useful. what do you think about "secret" management? also for template I think we should match the other way, where we have a longer discussion: #2834 ---
[GitHub] zeppelin issue #2831: ZEPPELIN-3281. Apply getRelativePath when it is LocalC...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2831 of course, let's do the right thing. feel free to ping me in all PR, but generally I should get to it within a day, at least for the next few months. :) ---
[GitHub] zeppelin issue #2587: [ZEPPELIN-2909]. Support shared SparkContext across la...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2587 ok thanks, didn't realize it's been 7 months... :) ---
[GitHub] zeppelin issue #2892: ZEPPELIN-3162. Fixed Checkstyle issues in neo4j module
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2892 seems like test fail for unrelated reason - is it out of date or something? ``` [WARNING] The requested profile "hadoop2" could not be activated because it does not exist. [ERROR] Failed to execute goal com.github.eirslett:frontend-maven-plugin:1.3:npm (npm test) on project zeppelin-web: Failed to run task: 'npm run test' failed. (error code 1) -> [Help 1] ``` ---
[GitHub] zeppelin issue #2893: ZEPPELIN-3161. Fixed Checkstyle issues in lens module
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2893 merging if no more comment ---
[GitHub] spark issue #20900: [SPARK-23645][MINOR][DOCS][PYTHON] Add docs RE `pandas_u...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20900 > One general question: how do we tend to think about the py2/3 split for api quirks/features? Must everything that is added for py3 also be functional in py2? ideally, is there something you have in mind that would not work in py2? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2587: [ZEPPELIN-2909]. Support shared SparkContext across la...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2587 still, I think this feature is distinctive enough that we should document and bring some visibility (even if it just works) ---
[GitHub] zeppelin issue #2793: ZEPPELIN-3226. Fail to launch IPySparkInterpreter in e...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2793 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2831: ZEPPELIN-3281. Apply getRelativePath when it is LocalC...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2831 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2837: ZEPPELIN-3279. [FlakyTest] NotebookTest.testPerSession...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2837 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2836: ZEPPELIN-3291. Throw exception instead of return null ...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2836 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2843: ZEPPELIN-3299. Combine spark integration test with its...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2843 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2838: ZEPPELIN-3277. NotebookServerTest.testMakeSureNoAngula...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2838 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2844: ZEPPELIN-3296. Reorg livy integration test to minimize...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2844 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2861: ZEPPELIN-3322. Update interpreterBind when restarting ...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2861 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2846: ZEPPELIN-3302. Update SparkVersion.java to support Spa...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2846 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2847: ZEPPELIN-3303. Avoid download spark for travis build
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2847 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2865: [HOTFIX] More proper error message when interpreter is...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2865 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2866: ZEPPELIN-3328. Add plotting test for LivyInterpreter
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2866 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2869: ZEPPELIN-3330. Add more test for RemoteInterpreterServ...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2869 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2874: ZEPPELIN-3339. Add more test for ZeppelinContext
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2874 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2871: ZEPPELIN-3337. Add more test to SparkRInterpreter
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2871 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2875: ZEPPELIN-3343. Interpreter Hook is broken
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2875 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2877: ZEPPELIN-3345. Don't load interpreter setting when it ...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2877 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2878: ZEPPELIN-3331. Use NullLifecycleManager by default
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2878 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2882: ZEPPELIN-3290. Unnecessary message 'IPython is availab...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2882 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] zeppelin issue #2887: ZEPPELIN-3357. Livy security mode is broken
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2887 hey @zjffdu thanks for making all these improvements, could we make sure there is at least one review before merging? @Leemoonsoo ---
[GitHub] spark pull request #20267: [SPARK-23068][BUILD][RELEASE][WIP] doc build erro...
Github user felixcheung closed the pull request at: https://github.com/apache/spark/pull/20267 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2834: [ZEPPELIN-1967] Passing Z variables to Shell and SQL I...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2834 @zjffdu do we still merge commits to branch-0.8? ---
[GitHub] spark pull request #20787: [MINOR][DOCS] Documenting months_between directio...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20787#discussion_r176925831
--- Diff: R/pkg/R/functions.R ---
@@ -1957,8 +1958,12 @@ setMethod("levenshtein", signature(y = "Column"),
})
#' @details
-#' \code{months_between}: Returns number of months between dates \code{y}
and \code{x}.
-#'
+#' \code{months_between}: Returns number of months between dates \code{y}
and \code{x}.
+#' If \code{y} is later than \code{x}, then the result is positive.
+#' If \code{y} and \code{x} are on the same day of month, or both are the
last day of month,
+#' time of day will be ignored.
+#' Otherwise, the difference is calculated based on 31 days per month, and
rounded to
+#' 8 digits.
#' @rdname column_datetime_diff_functions
--- End diff --
you should leave a line `#'` before this
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20787: [MINOR][DOCS] Documenting months_between directio...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20787#discussion_r176925842
--- Diff: R/pkg/R/functions.R ---
@@ -1957,8 +1958,12 @@ setMethod("levenshtein", signature(y = "Column"),
})
#' @details
-#' \code{months_between}: Returns number of months between dates \code{y}
and \code{x}.
-#'
+#' \code{months_between}: Returns number of months between dates \code{y}
and \code{x}.
+#' If \code{y} is later than \code{x}, then the result is positive.
+#' If \code{y} and \code{x} are on the same day of month, or both are the
last day of month,
+#' time of day will be ignored.
+#' Otherwise, the difference is calculated based on 31 days per month, and
rounded to
+#' 8 digits.
#' @rdname column_datetime_diff_functions
--- End diff --
also just as reference, the whitespace/newline will be stripped
```
time of day will be ignored.
Otherwise
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20897: [MINOR][DOC] Fix a few markdown typos
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20897 jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20896: [SPARK-23788][SS] Fix race in StreamingQuerySuite
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20896#discussion_r176902181
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamingQuerySuite.scala
---
@@ -550,22 +550,22 @@ class StreamingQuerySuite extends StreamTest with
BeforeAndAfter with Logging wi
.start()
}
-val input = MemoryStream[Int]
-val q1 = startQuery(input.toDS, "stream_serializable_test_1")
-val q2 = startQuery(input.toDS.map { i =>
+val input = MemoryStream[Int] :: MemoryStream[Int] ::
MemoryStream[Int] :: Nil
--- End diff --
why build a list and not use 3 separate variables?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20003: [SPARK-22817][R] Use fixed testthat version for SparkR t...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20003 yea, I started doing some work but was staled, let me check.. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20889: [MINOR][DOC] Fix ml-guide markdown typos
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20889 @Lemonjing you need to close the PR from github.com - we don't have access to close it --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20897: [MINOR][DOC] Fix a few markdown typos
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20897 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20889: [MINOR][DOC] Fix ml-guide markdown typos
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20889 can you check if we have other typo in the md file? or similar type of typo in other md files? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20864: [SPARK-23745][SQL]Remove the directories of the âhive....
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20864 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20860: [SPARK-23743][SQL] Changed a comparison logic fro...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20860#discussion_r176646535
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/IsolatedClientLoader.scala
---
@@ -179,7 +179,7 @@ private[hive] class IsolatedClientLoader(
val isHadoopClass =
name.startsWith("org.apache.hadoop.") &&
!name.startsWith("org.apache.hadoop.hive.")
-name.contains("slf4j") ||
+name.startsWith("org.slf4j") ||
name.contains("log4j") ||
--- End diff --
do we need the same for "log4j"?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20879: [MINOR][R] Fix R lint failure
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20879 thanks! those are on me then. are we not running lintr? or these checks are on the newer version only? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2880: [ZEPPELIN-3351] Fix to build for spark 2.3
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2880 I think we should try to fix the build profile as in this PR. But we must fix the download source - otherwise given what Iâve seen recently, we cannot release (its not up to me) ---
[GitHub] zeppelin issue #2854: ZEPPELIN-3310. Scio interpreter layout is broken
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2854 thanks - sorry about the delay ---
zeppelin git commit: ZEPPELIN-3310. Scio interpreter layout is broken
Repository: zeppelin
Updated Branches:
refs/heads/master 7dc4dbea5 -> 2a5960bd5
ZEPPELIN-3310. Scio interpreter layout is broken
### What is this PR for?
Fix scio interpreter layout. The current scio interpreter layout is broken
because there is not a newline between %table part and %text part in this
interpreter output.
### What type of PR is it?
[Bug Fix]
### What is the Jira issue?
[ZEPPELIN-3310](https://issues.apache.org/jira/browse/ZEPPELIN-3310)
### How should this be tested?
* CI should pass
* View the snapshot
### Screenshots (if appropriate)
[Before applied this change]
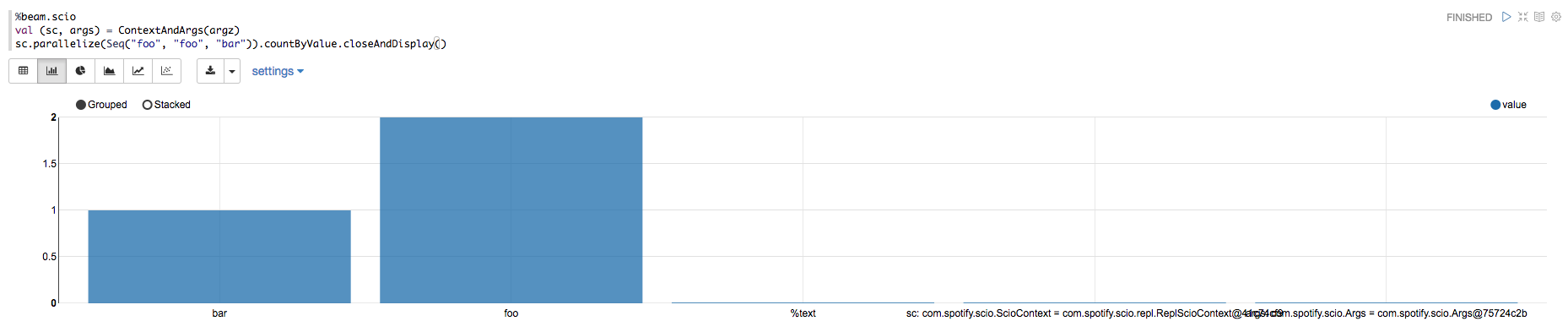
[Ater applied this change]
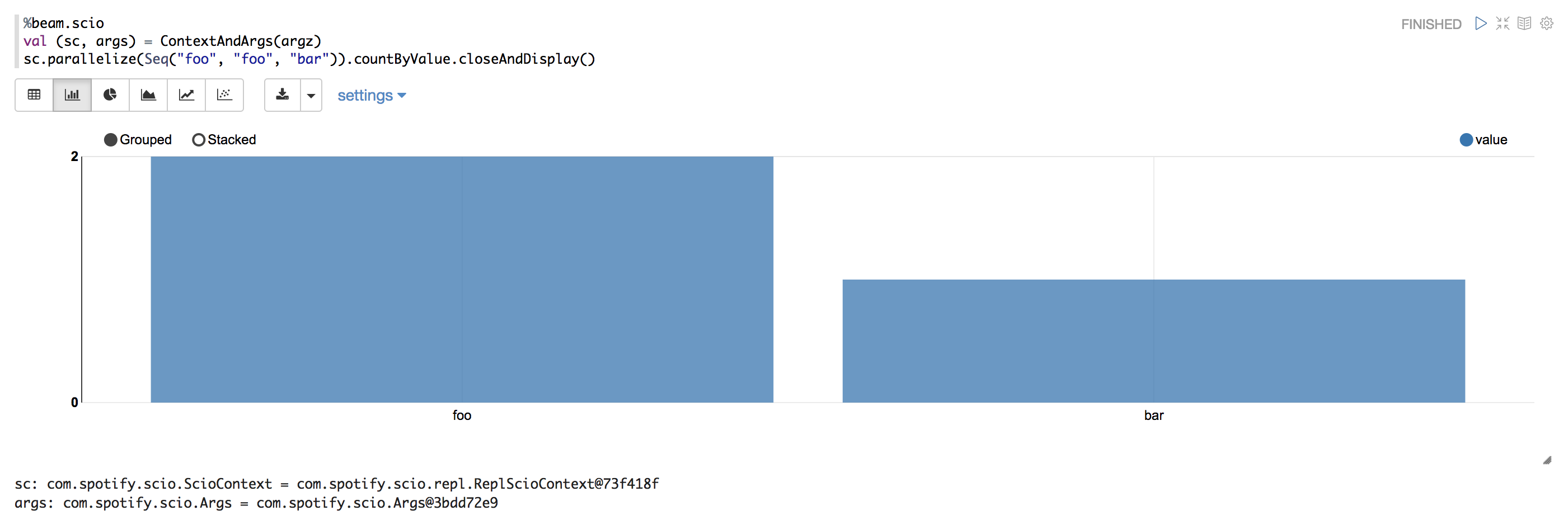
### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
Author: iijima_satoshi
Closes #2854 from iijima-satoshi/fix-scio-interpreter-layout and squashes the
following commits:
2b4fd68 [iijima_satoshi] ZEPPELIN-3310. Scio interpreter layout is broken
Project: http://git-wip-us.apache.org/repos/asf/zeppelin/repo
Commit: http://git-wip-us.apache.org/repos/asf/zeppelin/commit/2a5960bd
Tree: http://git-wip-us.apache.org/repos/asf/zeppelin/tree/2a5960bd
Diff: http://git-wip-us.apache.org/repos/asf/zeppelin/diff/2a5960bd
Branch: refs/heads/master
Commit: 2a5960bd50ea29ce7b925a6ac3288c0fd5ae7ddd
Parents: 7dc4dbe
Author: iijima_satoshi
Authored: Fri Mar 9 19:15:24 2018 +0900
Committer: Felix Cheung
Committed: Mon Mar 19 10:24:44 2018 -0700
--
.../apache/zeppelin/scio/DisplayHelpers.scala | 2 +-
.../zeppelin/scio/DisplayHelpersTest.scala | 103 +--
2 files changed, 47 insertions(+), 58 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/zeppelin/blob/2a5960bd/scio/src/main/scala/org/apache/zeppelin/scio/DisplayHelpers.scala
--
diff --git a/scio/src/main/scala/org/apache/zeppelin/scio/DisplayHelpers.scala
b/scio/src/main/scala/org/apache/zeppelin/scio/DisplayHelpers.scala
index 8dee3ab..bfb4f9c 100644
--- a/scio/src/main/scala/org/apache/zeppelin/scio/DisplayHelpers.scala
+++ b/scio/src/main/scala/org/apache/zeppelin/scio/DisplayHelpers.scala
@@ -35,7 +35,7 @@ private[scio] object DisplayHelpers {
private[scio] val tab = "\t"
private[scio] val newline = "\n"
private[scio] val table = "%table"
- private[scio] val endTable = "%text"
+ private[scio] val endTable = "\n%text"
private[scio] val rowLimitReachedMsg =
s"$newlineResults are limited to " + maxResults + s"
rows.$newline"
private[scio] val bQSchemaIncomplete =
http://git-wip-us.apache.org/repos/asf/zeppelin/blob/2a5960bd/scio/src/test/scala/org/apache/zeppelin/scio/DisplayHelpersTest.scala
--
diff --git
a/scio/src/test/scala/org/apache/zeppelin/scio/DisplayHelpersTest.scala
b/scio/src/test/scala/org/apache/zeppelin/scio/DisplayHelpersTest.scala
index 6dd05ab..a197faf 100644
--- a/scio/src/test/scala/org/apache/zeppelin/scio/DisplayHelpersTest.scala
+++ b/scio/src/test/scala/org/apache/zeppelin/scio/DisplayHelpersTest.scala
@@ -48,7 +48,8 @@ class DisplayHelpersTest extends FlatSpec with Matchers {
//
---
private val anyValHeader = s"$table value"
- private val endTable = DisplayHelpers.endTable
+ private val endTableFooter = DisplayHelpers.endTable.split("\\n").last
+ private val endTableSeq = Seq("", endTableFooter)
"DisplayHelpers" should "support Integer SCollection via AnyVal" in {
import
org.apache.zeppelin.scio.DisplaySCollectionImplicits.ZeppelinSCollection
@@ -60,10 +61,9 @@ class DisplayHelpersTest extends FlatSpec with Matchers {
o should contain theSameElementsAs Seq(anyValHeader,
"1",
"2",
- "3",
- endTable)
+ "3") ++ endTableSeq
o.head should be(anyValHeader)
-o.last should be(endTable)
+o.last should be(endTableFooter)
}
it should "support Long SCollection via AnyVal" in {
@@ -76,10 +76,9 @@ class DisplayHelpersTest extends FlatSpec with Matchers {
o should contain theSameElementsAs Seq(anyValHeader,
"1",
"2",
- "3",
- endTable)
+
[GitHub] zeppelin issue #2867: ZEPPELIN-3332
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2867 @herval @Leemoonsoo ---
[GitHub] zeppelin issue #2870: [ZEPPELIN-3335] trim property name of interpreter sett...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2870 can you check https://travis-ci.org/rockiee281/zeppelin/builds/353672192 ---
[GitHub] spark issue #20788: [SPARK-23647][PYTHON][SQL] Adds more types for hint in p...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20788 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20788: [SPARK-23647][PYTHON][SQL] Adds more types for hi...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20788#discussion_r175008195
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -437,10 +437,11 @@ def hint(self, name, *parameters):
if not isinstance(name, str):
raise TypeError("name should be provided as str, got
{0}".format(type(name)))
+allowed_types = (basestring, list, float, int)
--- End diff --
yap ok -
https://github.com/DylanGuedes/spark/blob/f5de3b8fce22a2d0c55b86066471579c5720ec97/python/pyspark/sql/dataframe.py#L22
no, this should be good
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20822: [SPARK-23680] Fix entrypoint.sh to properly support Arbi...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20822 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2412: [ZEPPELIN-2641] Change encoding to UTF-8 when sending ...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2412 Should this be fixed in Livy? ---
[GitHub] spark issue #17774: [SPARK-18371][Streaming] Spark Streaming backpressure ge...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/17774 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20791: [SPARK-23618][K8s][BUILD] Initialize BUILD_ARGS in docke...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20791 Hi @jooseong do you have a ASF JIRA user account? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20754: [SPARK-23287][CORE] Spark scheduler does not remove init...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20754 Jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20788: [SPARK-23647][PYTHON][SQL] Adds more types for hi...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20788#discussion_r174367197
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -437,10 +437,11 @@ def hint(self, name, *parameters):
if not isinstance(name, str):
raise TypeError("name should be provided as str, got
{0}".format(type(name)))
+allowed_types = (basestring, list, float, int)
--- End diff --
I think the point is that `basestring` is in python2
https://docs.python.org/2/library/functions.html#basestring
but not in python 3
https://docs.python.org/3.0/whatsnew/3.0.html#text-vs-data-instead-of-unicode-vs-8-bit
we should test this
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20807: SPARK-23660: Fix exception in yarn cluster mode w...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20807#discussion_r174027869 --- Diff: resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala --- @@ -496,7 +497,7 @@ private[yarn] class YarnAllocator( executorIdCounter += 1 val executorHostname = container.getNodeId.getHost val containerId = container.getId - val executorId = executorIdCounter.toString + val executorId = (initialExecutorIdCounter + executorIdCounter).toString --- End diff -- it seems a bit strange to me to "add" the Ids? @vanzin @jerryshao --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2854: ZEPPELIN-3310. Scio interpreter layout is broken
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2854 merging if no more comment ---
[GitHub] spark issue #20791: [SPARK-23618][BUILD] Initialize BUILD_ARGS in docker-ima...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20791 @foxish --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20791: [SPARK-23618][BUILD] Initialize BUILD_ARGS in docker-ima...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20791 could you add [K8s] into PR title --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20791: [SPARK-23618][BUILD] Initialize BUILD_ARGS in docker-ima...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20791 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20793: [SPARK-23643] Shrinking the buffer in hashSeed up to siz...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20793 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20788: [WIP][SPARK-21030][PYTHON][SQL] Adds more types f...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20788#discussion_r173612651
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -437,10 +437,11 @@ def hint(self, name, *parameters):
if not isinstance(name, str):
raise TypeError("name should be provided as str, got
{0}".format(type(name)))
+allowed = [str, list, float, int]
for p in parameters:
-if not isinstance(p, str):
+if not type(p) in allowed:
--- End diff --
I think isinstance is preferred, string can be str or unicode etc..
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20754: [SPARK-23287][CORE] Spark scheduler does not remove init...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20754 Jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20759: Added description of checkpointInterval parameter
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20759#discussion_r173379554 --- Diff: docs/ml-collaborative-filtering.md --- @@ -19,6 +19,7 @@ by a small set of latent factors that can be used to predict missing entries. algorithm to learn these latent factors. The implementation in `spark.ml` has the following parameters: +* *checkpointInterval* helps with recovery when nodes fail and StackOverflow exceptions caused by long lineage. **Will be silently ignored if *SparkContext.CheckpointDir* is not set.** (defaults to 10). --- End diff -- the wording is a bit severe... do we have to say node failure or stackoverflow (latter should be rare anyway?) also is this list of param sorted in any way? perhaps add checkpointInterval to the end? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
zeppelin git commit: [ZEPPELIN-3180] BUGFIX - save operation on interpreter add whitespace to permissions
Repository: zeppelin
Updated Branches:
refs/heads/branch-0.8 5f2a69a5f -> bea86c650
[ZEPPELIN-3180] BUGFIX - save operation on interpreter add whitespace to
permissions
### What is this PR for?
This PR fixes a bug when unnecessary spaces are added to the permissions.
### What type of PR is it?
[Bug Fix]
### What is the Jira issue?
[ZEPPELIN-3180](https://issues.apache.org/jira/browse/ZEPPELIN-3180)
### Questions:
* Does the licenses files need update? no
* Is there breaking changes for older versions? no
* Does this needs documentation? no
Author: Savalek
Closes #2749 from Savalek/ZEPPELIN-3180 and squashes the following commits:
b24f1d4 [Savalek] Merge branch 'master' into ZEPPELIN-3180
b2f58fb [Savalek] Merge remote-tracking branch 'upstream/master' into
ZEPPELIN-3180
84ee2cb [Savalek] Merge remote-tracking branch 'upstream/master' into
ZEPPELIN-3180
28c537e [Savalek] [ZEPPELIN-3212] add test
0d4a900 [Savalek] [ZEPPELIN-3180] FIX - interpreter add whitespace to
permissions
(cherry picked from commit 4fc0482385a150ab6712d7f44e00e37d16cd4bdf)
Signed-off-by: Felix Cheung
Project: http://git-wip-us.apache.org/repos/asf/zeppelin/repo
Commit: http://git-wip-us.apache.org/repos/asf/zeppelin/commit/bea86c65
Tree: http://git-wip-us.apache.org/repos/asf/zeppelin/tree/bea86c65
Diff: http://git-wip-us.apache.org/repos/asf/zeppelin/diff/bea86c65
Branch: refs/heads/branch-0.8
Commit: bea86c65093602bda6ce240a4d35b8fbde64d1d8
Parents: 5f2a69a
Author: Savalek
Authored: Tue Feb 27 14:08:18 2018 +0300
Committer: Felix Cheung
Committed: Thu Mar 8 23:09:14 2018 -0800
--
zeppelin-web/e2e/home.spec.js | 48
.../app/interpreter/interpreter.controller.js | 3 ++
2 files changed, 51 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/zeppelin/blob/bea86c65/zeppelin-web/e2e/home.spec.js
--
diff --git a/zeppelin-web/e2e/home.spec.js b/zeppelin-web/e2e/home.spec.js
index 7fc9499..299fbb5 100644
--- a/zeppelin-web/e2e/home.spec.js
+++ b/zeppelin-web/e2e/home.spec.js
@@ -1,4 +1,26 @@
describe('Home e2e Test', function() {
+ /*Common methods for interact with elements*/
+ let clickOn = function(elem) {
+browser.actions().mouseMove(elem).click().perform()
+ }
+
+ let sendKeysToInput = function(input, keys) {
+cleanInput(input)
+input.sendKeys(keys)
+ }
+
+ let cleanInput = function(inputElem) {
+inputElem.sendKeys(protractor.Key.chord(protractor.Key.CONTROL, "a"))
+inputElem.sendKeys(protractor.Key.BACK_SPACE)
+ }
+
+ let scrollToElementAndClick = function(elem) {
+browser.executeScript("arguments[0].scrollIntoView(false);",
elem.getWebElement())
+browser.sleep(100)
+clickOn(elem)
+ }
+
+ //tests
it('should have a welcome message', function() {
browser.get('http://localhost:8080');
var welcomeElem = element(by.id('welcome'))
@@ -15,4 +37,30 @@ describe('Home e2e Test', function() {
var btn = element(by.cssContainingText('a', 'Create new note'))
expect(btn.isPresent()).toBe(true)
})
+
+ it('correct save permission in interpreter', function() {
+var ownerName = 'admin'
+var interpreterName = 'interpreter_e2e_test'
+clickOn(element(by.xpath('//span[@class="username ng-binding"]')))
+clickOn(element(by.xpath('//a[@href="#/interpreter"]')))
+clickOn(element(by.xpath('//button[@ng-click="showAddNewSetting =
!showAddNewSetting"]')))
+
sendKeysToInput(element(by.xpath('//input[@id="newInterpreterSettingName"]')),
interpreterName)
+
clickOn(element(by.xpath('//select[@ng-model="newInterpreterSetting.group"]')))
+browser.sleep(500)
+browser.actions().sendKeys(protractor.Key.ARROW_DOWN).perform()
+browser.actions().sendKeys(protractor.Key.ENTER).perform()
+
clickOn(element(by.xpath('//div[@ng-show="showAddNewSetting"]//input[@id="idShowPermission"]')))
+
sendKeysToInput(element(by.xpath('//div[@ng-show="showAddNewSetting"]//input[@class="select2-search__field"]')),
ownerName)
+browser.sleep(500)
+browser.actions().sendKeys(protractor.Key.ENTER).perform()
+
scrollToElementAndClick(element(by.xpath('//span[@ng-click="addNewInterpreterSetting()"]')))
+scrollToElementAndClick(element(by.xpath('//*[@id="' + interpreterName +
'"]//span[@class="fa fa-pencil"]')))
+scrollToElementAndClick(element(by.xpath('//*[@id="' + interpreterName +
'"]//button[@type="submit"]')))
+
clickOn(element(by.xpath('//div[@class="bootstrap-dialog-footer-buttons"]//button[contains(text(),
\'OK\')]')))
+browser.get('http://localhost:8080/#/interpreter');
+var text = element(by.xpath('//*[@id="' + interpreterName +
'"]//li[contains(text(), \'admin\')]')).getText()
+scrollToElementAndClick(element(by.xpath('//*[@id="' + interpreterName +
'"]//span/
zeppelin git commit: [ZEPPELIN-3180] BUGFIX - save operation on interpreter add whitespace to permissions
Repository: zeppelin
Updated Branches:
refs/heads/master 0267ecf76 -> 4fc048238
[ZEPPELIN-3180] BUGFIX - save operation on interpreter add whitespace to
permissions
### What is this PR for?
This PR fixes a bug when unnecessary spaces are added to the permissions.
### What type of PR is it?
[Bug Fix]
### What is the Jira issue?
[ZEPPELIN-3180](https://issues.apache.org/jira/browse/ZEPPELIN-3180)
### Questions:
* Does the licenses files need update? no
* Is there breaking changes for older versions? no
* Does this needs documentation? no
Author: Savalek
Closes #2749 from Savalek/ZEPPELIN-3180 and squashes the following commits:
b24f1d4 [Savalek] Merge branch 'master' into ZEPPELIN-3180
b2f58fb [Savalek] Merge remote-tracking branch 'upstream/master' into
ZEPPELIN-3180
84ee2cb [Savalek] Merge remote-tracking branch 'upstream/master' into
ZEPPELIN-3180
28c537e [Savalek] [ZEPPELIN-3212] add test
0d4a900 [Savalek] [ZEPPELIN-3180] FIX - interpreter add whitespace to
permissions
Project: http://git-wip-us.apache.org/repos/asf/zeppelin/repo
Commit: http://git-wip-us.apache.org/repos/asf/zeppelin/commit/4fc04823
Tree: http://git-wip-us.apache.org/repos/asf/zeppelin/tree/4fc04823
Diff: http://git-wip-us.apache.org/repos/asf/zeppelin/diff/4fc04823
Branch: refs/heads/master
Commit: 4fc0482385a150ab6712d7f44e00e37d16cd4bdf
Parents: 0267ecf
Author: Savalek
Authored: Tue Feb 27 14:08:18 2018 +0300
Committer: Felix Cheung
Committed: Thu Mar 8 23:08:46 2018 -0800
--
zeppelin-web/e2e/home.spec.js | 48
.../app/interpreter/interpreter.controller.js | 3 ++
2 files changed, 51 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/zeppelin/blob/4fc04823/zeppelin-web/e2e/home.spec.js
--
diff --git a/zeppelin-web/e2e/home.spec.js b/zeppelin-web/e2e/home.spec.js
index 7fc9499..299fbb5 100644
--- a/zeppelin-web/e2e/home.spec.js
+++ b/zeppelin-web/e2e/home.spec.js
@@ -1,4 +1,26 @@
describe('Home e2e Test', function() {
+ /*Common methods for interact with elements*/
+ let clickOn = function(elem) {
+browser.actions().mouseMove(elem).click().perform()
+ }
+
+ let sendKeysToInput = function(input, keys) {
+cleanInput(input)
+input.sendKeys(keys)
+ }
+
+ let cleanInput = function(inputElem) {
+inputElem.sendKeys(protractor.Key.chord(protractor.Key.CONTROL, "a"))
+inputElem.sendKeys(protractor.Key.BACK_SPACE)
+ }
+
+ let scrollToElementAndClick = function(elem) {
+browser.executeScript("arguments[0].scrollIntoView(false);",
elem.getWebElement())
+browser.sleep(100)
+clickOn(elem)
+ }
+
+ //tests
it('should have a welcome message', function() {
browser.get('http://localhost:8080');
var welcomeElem = element(by.id('welcome'))
@@ -15,4 +37,30 @@ describe('Home e2e Test', function() {
var btn = element(by.cssContainingText('a', 'Create new note'))
expect(btn.isPresent()).toBe(true)
})
+
+ it('correct save permission in interpreter', function() {
+var ownerName = 'admin'
+var interpreterName = 'interpreter_e2e_test'
+clickOn(element(by.xpath('//span[@class="username ng-binding"]')))
+clickOn(element(by.xpath('//a[@href="#/interpreter"]')))
+clickOn(element(by.xpath('//button[@ng-click="showAddNewSetting =
!showAddNewSetting"]')))
+
sendKeysToInput(element(by.xpath('//input[@id="newInterpreterSettingName"]')),
interpreterName)
+
clickOn(element(by.xpath('//select[@ng-model="newInterpreterSetting.group"]')))
+browser.sleep(500)
+browser.actions().sendKeys(protractor.Key.ARROW_DOWN).perform()
+browser.actions().sendKeys(protractor.Key.ENTER).perform()
+
clickOn(element(by.xpath('//div[@ng-show="showAddNewSetting"]//input[@id="idShowPermission"]')))
+
sendKeysToInput(element(by.xpath('//div[@ng-show="showAddNewSetting"]//input[@class="select2-search__field"]')),
ownerName)
+browser.sleep(500)
+browser.actions().sendKeys(protractor.Key.ENTER).perform()
+
scrollToElementAndClick(element(by.xpath('//span[@ng-click="addNewInterpreterSetting()"]')))
+scrollToElementAndClick(element(by.xpath('//*[@id="' + interpreterName +
'"]//span[@class="fa fa-pencil"]')))
+scrollToElementAndClick(element(by.xpath('//*[@id="' + interpreterName +
'"]//button[@type="submit"]')))
+
clickOn(element(by.xpath('//div[@class="bootstrap-dialog-footer-buttons"]//button[contains(text(),
\'OK\')]')))
+browser.get('http://localhost:8080/#/interpreter');
+var text = element(by.xpath('//*[@id="' + interpreterName +
'"]//li[contains(text(), \'admin\')]')).getText()
+scrollToElementAndClick(element(by.xpath('//*[@id="' + interpreterName +
'"]//span//span[@class="fa fa-trash"]')))
+
clickOn(element(by.xpath('//div[@class="bootstrap-dialog-footer-butto
[GitHub] spark issue #20754: [SPARK-23287][CORE] Spark scheduler does not remove init...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20754 Jenkins, ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20464: [SPARK-23291][SQL][R] R's substr should not reduce start...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20464 merged to master, thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
spark git commit: [SPARK-23291][SQL][R] R's substr should not reduce starting position by 1 when calling Scala API
Repository: spark
Updated Branches:
refs/heads/master aff7d81cb -> 53561d27c
[SPARK-23291][SQL][R] R's substr should not reduce starting position by 1 when
calling Scala API
## What changes were proposed in this pull request?
Seems R's substr API treats Scala substr API as zero based and so subtracts the
given starting position by 1.
Because Scala's substr API also accepts zero-based starting position (treated
as the first element), so the current R's substr test results are correct as
they all use 1 as starting positions.
## How was this patch tested?
Modified tests.
Author: Liang-Chi Hsieh
Closes #20464 from viirya/SPARK-23291.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/53561d27
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/53561d27
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/53561d27
Branch: refs/heads/master
Commit: 53561d27c45db31893bcabd4aca2387fde869b72
Parents: aff7d81
Author: Liang-Chi Hsieh
Authored: Wed Mar 7 09:37:42 2018 -0800
Committer: Felix Cheung
Committed: Wed Mar 7 09:37:42 2018 -0800
--
R/pkg/R/column.R | 10 --
R/pkg/tests/fulltests/test_sparkSQL.R | 1 +
docs/sparkr.md| 4
3 files changed, 13 insertions(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/53561d27/R/pkg/R/column.R
--
diff --git a/R/pkg/R/column.R b/R/pkg/R/column.R
index 9727efc..7926a9a 100644
--- a/R/pkg/R/column.R
+++ b/R/pkg/R/column.R
@@ -161,12 +161,18 @@ setMethod("alias",
#' @aliases substr,Column-method
#'
#' @param x a Column.
-#' @param start starting position.
+#' @param start starting position. It should be 1-base.
#' @param stop ending position.
+#' @examples
+#' \dontrun{
+#' df <- createDataFrame(list(list(a="abcdef")))
+#' collect(select(df, substr(df$a, 1, 4))) # the result is `abcd`.
+#' collect(select(df, substr(df$a, 2, 4))) # the result is `bcd`.
+#' }
#' @note substr since 1.4.0
setMethod("substr", signature(x = "Column"),
function(x, start, stop) {
-jc <- callJMethod(x@jc, "substr", as.integer(start - 1),
as.integer(stop - start + 1))
+jc <- callJMethod(x@jc, "substr", as.integer(start),
as.integer(stop - start + 1))
column(jc)
})
http://git-wip-us.apache.org/repos/asf/spark/blob/53561d27/R/pkg/tests/fulltests/test_sparkSQL.R
--
diff --git a/R/pkg/tests/fulltests/test_sparkSQL.R
b/R/pkg/tests/fulltests/test_sparkSQL.R
index bd0a0dc..439191a 100644
--- a/R/pkg/tests/fulltests/test_sparkSQL.R
+++ b/R/pkg/tests/fulltests/test_sparkSQL.R
@@ -1651,6 +1651,7 @@ test_that("string operators", {
expect_false(first(select(df, startsWith(df$name, "m")))[[1]])
expect_true(first(select(df, endsWith(df$name, "el")))[[1]])
expect_equal(first(select(df, substr(df$name, 1, 2)))[[1]], "Mi")
+ expect_equal(first(select(df, substr(df$name, 4, 6)))[[1]], "hae")
if (as.numeric(R.version$major) >= 3 && as.numeric(R.version$minor) >= 3) {
expect_true(startsWith("Hello World", "Hello"))
expect_false(endsWith("Hello World", "a"))
http://git-wip-us.apache.org/repos/asf/spark/blob/53561d27/docs/sparkr.md
--
diff --git a/docs/sparkr.md b/docs/sparkr.md
index 6685b58..2909247 100644
--- a/docs/sparkr.md
+++ b/docs/sparkr.md
@@ -663,3 +663,7 @@ You can inspect the search path in R with
[`search()`](https://stat.ethz.ch/R-ma
- The `stringsAsFactors` parameter was previously ignored with `collect`, for
example, in `collect(createDataFrame(iris), stringsAsFactors = TRUE))`. It has
been corrected.
- For `summary`, option for statistics to compute has been added. Its output
is changed from that from `describe`.
- A warning can be raised if versions of SparkR package and the Spark JVM do
not match.
+
+## Upgrading to Spark 2.4.0
+
+ - The `start` parameter of `substr` method was wrongly subtracted by one,
previously. In other words, the index specified by `start` parameter was
considered as 0-base. This can lead to inconsistent substring results and also
does not match with the behaviour with `substr` in R. It has been fixed so the
`start` parameter of `substr` method is now 1-base, e.g., therefore to get the
same result as `substr(df$a, 2, 5)`, it should be changed to `substr(df$a, 1,
4)`.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] spark issue #20754: [SPARK-23287][MESOS] Spark scheduler does not remove ini...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20754 @devaraj-kavali can you add test for this? cc @susanxhuynh --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20678: [SPARK-23380][PYTHON] Adds a conf for Arrow fallb...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20678#discussion_r172751054 --- Diff: docs/sql-programming-guide.md --- @@ -1689,6 +1689,10 @@ using the call `toPandas()` and when creating a Spark DataFrame from a Pandas Da `createDataFrame(pandas_df)`. To use Arrow when executing these calls, users need to first set the Spark configuration 'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default. +In addition, optimizations enabled by 'spark.sql.execution.arrow.enabled' could fallback automatically +to non-optimized implementations if an error occurs before the actual computation within Spark. --- End diff -- very minor nit: `non-optimized implementations` --> `non-Arrow optimization implementation` this matches the description in the paragraph below --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20678: [SPARK-23380][PYTHON] Adds a conf for Arrow fallb...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20678#discussion_r172751164 --- Diff: docs/sql-programming-guide.md --- @@ -1800,6 +1800,7 @@ working with timestamps in `pandas_udf`s to get the best performance, see ## Upgrading From Spark SQL 2.3 to 2.4 - Since Spark 2.4, Spark maximizes the usage of a vectorized ORC reader for ORC files by default. To do that, `spark.sql.orc.impl` and `spark.sql.orc.filterPushdown` change their default values to `native` and `true` respectively. + - In PySpark, when Arrow optimization is enabled, previously `toPandas` just failed when Arrow optimization is unabled to be used whereas `createDataFrame` from Pandas DataFrame allowed the fallback to non-optimization. Now, both `toPandas` and `createDataFrame` from Pandas DataFrame allow the fallback by default, which can be switched by `spark.sql.execution.arrow.fallback.enabled`. --- End diff -- `which can be switched by` -> `which can be switched on by` or `which can be switched on with` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20464: [SPARK-23291][SQL][R] R's substr should not reduc...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20464#discussion_r172750404 --- Diff: docs/sparkr.md --- @@ -663,3 +663,7 @@ You can inspect the search path in R with [`search()`](https://stat.ethz.ch/R-ma - The `stringsAsFactors` parameter was previously ignored with `collect`, for example, in `collect(createDataFrame(iris), stringsAsFactors = TRUE))`. It has been corrected. - For `summary`, option for statistics to compute has been added. Its output is changed from that from `describe`. - A warning can be raised if versions of SparkR package and the Spark JVM do not match. + +## Upgrading to Spark 2.4.0 + + - The `start` parameter of `substr` method was wrongly subtracted by one, previously. In other words, the index specified by `start` parameter was considered as 0-base. This can lead to inconsistent substring results and also does not match with the behaviour with `substr` in R. It has been fixed so the `start` parameter of `substr` method is now 1-base, e.g., `substr(df$a, 2, 5)` should be changed to `substr(df$a, 1, 4)`. --- End diff -- could you add `method is now 1-base, e.g., therefore to get the same result as substr(df$a, 2, 5), it should be changed to substr(df$a, 1, 4)` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20464: [SPARK-23291][SQL][R] R's substr should not reduce start...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20464 appveyor tests failed, could you close and reopen this PR to trigger it. strange, I haven't seen anything like this on appveyor a long time. ``` 1. Error: create DataFrame with complex types (@test_sparkSQL.R#535) --- 8712org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 114.0 failed 1 times, most recent failure: Lost task 0.0 in stage 114.0 (TID 116, localhost, executor driver): java.net.SocketTimeoutException: Accept timed out ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20742: [SPARK-23572][docs] Bring "security.md" up to dat...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20742#discussion_r172409490 --- Diff: R/pkg/DESCRIPTION --- @@ -57,6 +57,6 @@ Collate: 'types.R' 'utils.R' 'window.R' -RoxygenNote: 5.0.1 +RoxygenNote: 6.0.1 --- End diff -- pls revert this --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[2/3] spark git commit: [SPARK-22430][R][DOCS] Unknown tag warnings when building R docs with Roxygen 6.0.1
http://git-wip-us.apache.org/repos/asf/spark/blob/4586eada/R/pkg/R/generics.R
--
diff --git a/R/pkg/R/generics.R b/R/pkg/R/generics.R
index e0dde33..6fba4b6 100644
--- a/R/pkg/R/generics.R
+++ b/R/pkg/R/generics.R
@@ -19,7 +19,6 @@
# @rdname aggregateRDD
# @seealso reduce
-# @export
setGeneric("aggregateRDD",
function(x, zeroValue, seqOp, combOp) {
standardGeneric("aggregateRDD") })
@@ -27,21 +26,17 @@ setGeneric("cacheRDD", function(x) {
standardGeneric("cacheRDD") })
# @rdname coalesce
# @seealso repartition
-# @export
setGeneric("coalesceRDD", function(x, numPartitions, ...) {
standardGeneric("coalesceRDD") })
# @rdname checkpoint-methods
-# @export
setGeneric("checkpointRDD", function(x) { standardGeneric("checkpointRDD") })
setGeneric("collectRDD", function(x, ...) { standardGeneric("collectRDD") })
# @rdname collect-methods
-# @export
setGeneric("collectAsMap", function(x) { standardGeneric("collectAsMap") })
# @rdname collect-methods
-# @export
setGeneric("collectPartition",
function(x, partitionId) {
standardGeneric("collectPartition")
@@ -52,19 +47,15 @@ setGeneric("countRDD", function(x) {
standardGeneric("countRDD") })
setGeneric("lengthRDD", function(x) { standardGeneric("lengthRDD") })
# @rdname countByValue
-# @export
setGeneric("countByValue", function(x) { standardGeneric("countByValue") })
# @rdname crosstab
-# @export
setGeneric("crosstab", function(x, col1, col2) { standardGeneric("crosstab") })
# @rdname freqItems
-# @export
setGeneric("freqItems", function(x, cols, support = 0.01) {
standardGeneric("freqItems") })
# @rdname approxQuantile
-# @export
setGeneric("approxQuantile",
function(x, cols, probabilities, relativeError) {
standardGeneric("approxQuantile")
@@ -73,18 +64,15 @@ setGeneric("approxQuantile",
setGeneric("distinctRDD", function(x, numPartitions = 1) {
standardGeneric("distinctRDD") })
# @rdname filterRDD
-# @export
setGeneric("filterRDD", function(x, f) { standardGeneric("filterRDD") })
setGeneric("firstRDD", function(x, ...) { standardGeneric("firstRDD") })
# @rdname flatMap
-# @export
setGeneric("flatMap", function(X, FUN) { standardGeneric("flatMap") })
# @rdname fold
# @seealso reduce
-# @export
setGeneric("fold", function(x, zeroValue, op) { standardGeneric("fold") })
setGeneric("foreach", function(x, func) { standardGeneric("foreach") })
@@ -95,17 +83,14 @@ setGeneric("foreachPartition", function(x, func) {
standardGeneric("foreachParti
setGeneric("getJRDD", function(rdd, ...) { standardGeneric("getJRDD") })
# @rdname glom
-# @export
setGeneric("glom", function(x) { standardGeneric("glom") })
# @rdname histogram
-# @export
setGeneric("histogram", function(df, col, nbins=10) {
standardGeneric("histogram") })
setGeneric("joinRDD", function(x, y, ...) { standardGeneric("joinRDD") })
# @rdname keyBy
-# @export
setGeneric("keyBy", function(x, func) { standardGeneric("keyBy") })
setGeneric("lapplyPartition", function(X, FUN) {
standardGeneric("lapplyPartition") })
@@ -123,47 +108,37 @@ setGeneric("mapPartitionsWithIndex",
function(X, FUN) { standardGeneric("mapPartitionsWithIndex") })
# @rdname maximum
-# @export
setGeneric("maximum", function(x) { standardGeneric("maximum") })
# @rdname minimum
-# @export
setGeneric("minimum", function(x) { standardGeneric("minimum") })
# @rdname sumRDD
-# @export
setGeneric("sumRDD", function(x) { standardGeneric("sumRDD") })
# @rdname name
-# @export
setGeneric("name", function(x) { standardGeneric("name") })
# @rdname getNumPartitionsRDD
-# @export
setGeneric("getNumPartitionsRDD", function(x) {
standardGeneric("getNumPartitionsRDD") })
# @rdname getNumPartitions
-# @export
setGeneric("numPartitions", function(x) { standardGeneric("numPartitions") })
setGeneric("persistRDD", function(x, newLevel) { standardGeneric("persistRDD")
})
# @rdname pipeRDD
-# @export
setGeneric("pipeRDD", function(x, command, env = list()) {
standardGeneric("pipeRDD")})
# @rdname pivot
-# @export
setGeneric("pivot", function(x, colname, values = list()) {
standardGeneric("pivot") })
# @rdname reduce
-# @export
setGeneric("reduce", function(x, func) { standardGeneric("reduce") })
setGeneric("repartitionRDD", function(x, ...) {
standardGeneric("repartitionRDD") })
# @rdname sampleRDD
-# @export
setGeneric("sampleRDD",
function(x, withReplacement, fraction, seed) {
standardGeneric("sampleRDD")
@@ -171,21 +146,17 @@ setGeneric("sampleRDD",
# @rdname saveAsObjectFile
# @seealso objectFile
-# @export
setGeneric("saveAsObjectFile", function(x, path) {
standardGeneric("saveAsObjectFile") })
# @rdname saveAsTextFile
-# @export
setGeneric("saveAsTextFile", function(x, path) {
standardGeneric("saveAsTextFile") })
# @rdname setName
-# @export
setGe
[GitHub] spark issue #20501: [SPARK-22430][R][Docs] Unknown tag warnings when buildin...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20501 merged to master --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[1/3] spark git commit: [SPARK-22430][R][DOCS] Unknown tag warnings when building R docs with Roxygen 6.0.1
Repository: spark
Updated Branches:
refs/heads/master 947b4e6f0 -> 4586eada4
http://git-wip-us.apache.org/repos/asf/spark/blob/4586eada/R/pkg/R/mllib_tree.R
--
diff --git a/R/pkg/R/mllib_tree.R b/R/pkg/R/mllib_tree.R
index 4e5ddf2..6769be0 100644
--- a/R/pkg/R/mllib_tree.R
+++ b/R/pkg/R/mllib_tree.R
@@ -20,42 +20,36 @@
#' S4 class that represents a GBTRegressionModel
#'
#' @param jobj a Java object reference to the backing Scala GBTRegressionModel
-#' @export
#' @note GBTRegressionModel since 2.1.0
setClass("GBTRegressionModel", representation(jobj = "jobj"))
#' S4 class that represents a GBTClassificationModel
#'
#' @param jobj a Java object reference to the backing Scala
GBTClassificationModel
-#' @export
#' @note GBTClassificationModel since 2.1.0
setClass("GBTClassificationModel", representation(jobj = "jobj"))
#' S4 class that represents a RandomForestRegressionModel
#'
#' @param jobj a Java object reference to the backing Scala
RandomForestRegressionModel
-#' @export
#' @note RandomForestRegressionModel since 2.1.0
setClass("RandomForestRegressionModel", representation(jobj = "jobj"))
#' S4 class that represents a RandomForestClassificationModel
#'
#' @param jobj a Java object reference to the backing Scala
RandomForestClassificationModel
-#' @export
#' @note RandomForestClassificationModel since 2.1.0
setClass("RandomForestClassificationModel", representation(jobj = "jobj"))
#' S4 class that represents a DecisionTreeRegressionModel
#'
#' @param jobj a Java object reference to the backing Scala
DecisionTreeRegressionModel
-#' @export
#' @note DecisionTreeRegressionModel since 2.3.0
setClass("DecisionTreeRegressionModel", representation(jobj = "jobj"))
#' S4 class that represents a DecisionTreeClassificationModel
#'
#' @param jobj a Java object reference to the backing Scala
DecisionTreeClassificationModel
-#' @export
#' @note DecisionTreeClassificationModel since 2.3.0
setClass("DecisionTreeClassificationModel", representation(jobj = "jobj"))
@@ -179,7 +173,6 @@ print.summary.decisionTree <- function(x) {
#' @return \code{spark.gbt} returns a fitted Gradient Boosted Tree model.
#' @rdname spark.gbt
#' @name spark.gbt
-#' @export
#' @examples
#' \dontrun{
#' # fit a Gradient Boosted Tree Regression Model
@@ -261,7 +254,6 @@ setMethod("spark.gbt", signature(data = "SparkDataFrame",
formula = "formula"),
#' \code{numTrees} (number of trees), and \code{treeWeights} (tree
weights).
#' @rdname spark.gbt
#' @aliases summary,GBTRegressionModel-method
-#' @export
#' @note summary(GBTRegressionModel) since 2.1.0
setMethod("summary", signature(object = "GBTRegressionModel"),
function(object) {
@@ -275,7 +267,6 @@ setMethod("summary", signature(object =
"GBTRegressionModel"),
#' @param x summary object of Gradient Boosted Tree regression model or
classification model
#' returned by \code{summary}.
#' @rdname spark.gbt
-#' @export
#' @note print.summary.GBTRegressionModel since 2.1.0
print.summary.GBTRegressionModel <- function(x, ...) {
print.summary.treeEnsemble(x)
@@ -285,7 +276,6 @@ print.summary.GBTRegressionModel <- function(x, ...) {
#' @rdname spark.gbt
#' @aliases summary,GBTClassificationModel-method
-#' @export
#' @note summary(GBTClassificationModel) since 2.1.0
setMethod("summary", signature(object = "GBTClassificationModel"),
function(object) {
@@ -297,7 +287,6 @@ setMethod("summary", signature(object =
"GBTClassificationModel"),
# Prints the summary of Gradient Boosted Tree Classification Model
#' @rdname spark.gbt
-#' @export
#' @note print.summary.GBTClassificationModel since 2.1.0
print.summary.GBTClassificationModel <- function(x, ...) {
print.summary.treeEnsemble(x)
@@ -310,7 +299,6 @@ print.summary.GBTClassificationModel <- function(x, ...) {
#' "prediction".
#' @rdname spark.gbt
#' @aliases predict,GBTRegressionModel-method
-#' @export
#' @note predict(GBTRegressionModel) since 2.1.0
setMethod("predict", signature(object = "GBTRegressionModel"),
function(object, newData) {
@@ -319,7 +307,6 @@ setMethod("predict", signature(object =
"GBTRegressionModel"),
#' @rdname spark.gbt
#' @aliases predict,GBTClassificationModel-method
-#' @export
#' @note predict(GBTClassificationModel) since 2.1.0
setMethod("predict", signature(object = "GBTClassificationModel"),
function(object, newData) {
@@ -334,7 +321,6 @@ setMethod("predict", signature(object =
"GBTClassificationModel"),
#' which means throw exception if the output path exists.
#' @aliases write.ml,GBTRegressionModel,character-method
#' @rdname spark.gbt
-#' @export
#' @note write.ml(GBTRegressionModel, character) since 2.1.0
setMethod("write.ml", signature(object = "GBTRegressionModel", path =
"character"),
function(object, path, overwrite = FALSE) {
@@ -343,7 +329,6 @@ setMe
[3/3] spark git commit: [SPARK-22430][R][DOCS] Unknown tag warnings when building R docs with Roxygen 6.0.1
[SPARK-22430][R][DOCS] Unknown tag warnings when building R docs with Roxygen
6.0.1
## What changes were proposed in this pull request?
Removed export tag to get rid of unknown tag warnings
## How was this patch tested?
Existing tests
Author: Rekha Joshi
Author: rjoshi2
Closes #20501 from rekhajoshm/SPARK-22430.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/4586eada
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/4586eada
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/4586eada
Branch: refs/heads/master
Commit: 4586eada42d6a16bb78d1650d145531c51fa747f
Parents: 947b4e6
Author: Rekha Joshi
Authored: Mon Mar 5 09:30:49 2018 -0800
Committer: Felix Cheung
Committed: Mon Mar 5 09:30:49 2018 -0800
--
R/pkg/R/DataFrame.R| 92 --
R/pkg/R/SQLContext.R | 16 --
R/pkg/R/WindowSpec.R | 8 -
R/pkg/R/broadcast.R| 3 -
R/pkg/R/catalog.R | 18 --
R/pkg/R/column.R | 7 -
R/pkg/R/context.R | 6 -
R/pkg/R/functions.R| 181 ---
R/pkg/R/generics.R | 343
R/pkg/R/group.R| 7 -
R/pkg/R/install.R | 1 -
R/pkg/R/jvm.R | 3 -
R/pkg/R/mllib_classification.R | 20 ---
R/pkg/R/mllib_clustering.R | 23 ---
R/pkg/R/mllib_fpm.R| 6 -
R/pkg/R/mllib_recommendation.R | 5 -
R/pkg/R/mllib_regression.R | 17 --
R/pkg/R/mllib_stat.R | 4 -
R/pkg/R/mllib_tree.R | 33
R/pkg/R/mllib_utils.R | 3 -
R/pkg/R/schema.R | 7 -
R/pkg/R/sparkR.R | 7 -
R/pkg/R/stats.R| 6 -
R/pkg/R/streaming.R| 9 -
R/pkg/R/utils.R| 1 -
R/pkg/R/window.R | 4 -
26 files changed, 830 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/4586eada/R/pkg/R/DataFrame.R
--
diff --git a/R/pkg/R/DataFrame.R b/R/pkg/R/DataFrame.R
index 41c3c3a..c485202 100644
--- a/R/pkg/R/DataFrame.R
+++ b/R/pkg/R/DataFrame.R
@@ -36,7 +36,6 @@ setOldClass("structType")
#' @slot sdf A Java object reference to the backing Scala DataFrame
#' @seealso \link{createDataFrame}, \link{read.json}, \link{table}
#' @seealso
\url{https://spark.apache.org/docs/latest/sparkr.html#sparkr-dataframes}
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -77,7 +76,6 @@ setWriteMode <- function(write, mode) {
write
}
-#' @export
#' @param sdf A Java object reference to the backing Scala DataFrame
#' @param isCached TRUE if the SparkDataFrame is cached
#' @noRd
@@ -97,7 +95,6 @@ dataFrame <- function(sdf, isCached = FALSE) {
#' @rdname printSchema
#' @name printSchema
#' @aliases printSchema,SparkDataFrame-method
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -123,7 +120,6 @@ setMethod("printSchema",
#' @rdname schema
#' @name schema
#' @aliases schema,SparkDataFrame-method
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -146,7 +142,6 @@ setMethod("schema",
#' @aliases explain,SparkDataFrame-method
#' @rdname explain
#' @name explain
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -178,7 +173,6 @@ setMethod("explain",
#' @rdname isLocal
#' @name isLocal
#' @aliases isLocal,SparkDataFrame-method
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -209,7 +203,6 @@ setMethod("isLocal",
#' @aliases showDF,SparkDataFrame-method
#' @rdname showDF
#' @name showDF
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -241,7 +234,6 @@ setMethod("showDF",
#' @rdname show
#' @aliases show,SparkDataFrame-method
#' @name show
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -269,7 +261,6 @@ setMethod("show", "SparkDataFrame",
#' @rdname dtypes
#' @name dtypes
#' @aliases dtypes,SparkDataFrame-method
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -296,7 +287,6 @@ setMethod("dtypes",
#' @rdname columns
#' @name columns
#' @aliases columns,SparkDataFrame-method
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -388,7 +378,6 @@ setMethod("colnames<-",
#' @aliases coltypes,SparkDataFrame-method
#' @name coltypes
#' @family SparkDataFrame functions
-#' @export
#' @examples
#'\dontrun{
#' irisDF <- createDataFrame(iris)
@@ -445,7 +434,6 @@ setMethod("coltypes",
#' @rdname coltypes
#' @name coltypes<-
#' @aliases coltypes<-,SparkDataFrame,character-method
-#' @export
#' @examples
#'\dontrun{
#' sparkR.session()
@@ -494,7 +482,6 @@ setMethod("coltypes<-",
#' @rdname createOrReplaceTempView
#' @name createOrReplaceTempView
#' @aliases createOrReplaceTempView,SparkData
spark-website git commit: update committer
Repository: spark-website Updated Branches: refs/heads/asf-site 32ff6fa97 -> 8bd24fb6d update committer Author: Felix Cheung Closes #103 from felixcheung/fc. Project: http://git-wip-us.apache.org/repos/asf/spark-website/repo Commit: http://git-wip-us.apache.org/repos/asf/spark-website/commit/8bd24fb6 Tree: http://git-wip-us.apache.org/repos/asf/spark-website/tree/8bd24fb6 Diff: http://git-wip-us.apache.org/repos/asf/spark-website/diff/8bd24fb6 Branch: refs/heads/asf-site Commit: 8bd24fb6d1a78a13e741f63a5ad6935f3a572ed2 Parents: 32ff6fa Author: Felix Cheung Authored: Mon Mar 5 09:22:44 2018 -0800 Committer: Felix Cheung Committed: Mon Mar 5 09:22:44 2018 -0800 -- committers.md| 2 +- site/committers.html | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark-website/blob/8bd24fb6/committers.md -- diff --git a/committers.md b/committers.md index 5d7a3d0..38fb3b0 100644 --- a/committers.md +++ b/committers.md @@ -14,7 +14,7 @@ navigation: |Michael Armbrust|Databricks| |Joseph Bradley|Databricks| |Matthew Cheah|Palantir| -|Felix Cheung|Microsoft| +|Felix Cheung|Uber| |Mosharaf Chowdhury|University of Michigan, Ann Arbor| |Bryan Cutler|IBM| |Jason Dai|Intel| http://git-wip-us.apache.org/repos/asf/spark-website/blob/8bd24fb6/site/committers.html -- diff --git a/site/committers.html b/site/committers.html index 1f02da2..bd691ba 100644 --- a/site/committers.html +++ b/site/committers.html @@ -222,7 +222,7 @@ Felix Cheung - Microsoft + Uber Mosharaf Chowdhury - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] spark issue #20737: [SPARK-23601][BUILD] Remove .md5 files from release
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20737 The last part with publishing to staging repo (âpublish-releaseâ) might not work? When I did I added a new file .sha512 and it failed the publish, so I wonder if it is specifically looking for certain file extensions. Although I have not tried publishing without the .md5 file or that might have changed now also. LGTM otherwise --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2749: [ZEPPELIN-3180] BUGFIX - save operation on interpreter...
Github user felixcheung commented on the issue: https://github.com/apache/zeppelin/pull/2749 merging if no more comment ---
[GitHub] spark issue #20501: [SPARK-22430][Docs] Unknown tag warnings when building R...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20501 ping @rekhajoshm ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] zeppelin issue #2811: [ZEPPELIN-3252] Update the Apache Flink version to 1.4...
Github user felixcheung commented on the issue:
https://github.com/apache/zeppelin/pull/2811
that's because of the references to `${scala.binary.version}` in the pom
file?
---
[GitHub] spark pull request #20464: [SPARK-23291][SQL][R] R's substr should not reduc...
Github user felixcheung commented on a diff in the pull request: https://github.com/apache/spark/pull/20464#discussion_r172033037 --- Diff: docs/sparkr.md --- @@ -663,3 +663,7 @@ You can inspect the search path in R with [`search()`](https://stat.ethz.ch/R-ma - The `stringsAsFactors` parameter was previously ignored with `collect`, for example, in `collect(createDataFrame(iris), stringsAsFactors = TRUE))`. It has been corrected. - For `summary`, option for statistics to compute has been added. Its output is changed from that from `describe`. - A warning can be raised if versions of SparkR package and the Spark JVM do not match. + +## Upgrading to Spark 2.4.0 + + - The `start` parameter of `substr` method was wrongly subtracted by one, previously. This can lead to inconsistent substring results and also does not match with the behaviour with `substr` in R. It has been corrected. --- End diff -- 2. in the migration guide we should give a concrete example with non-0 start index, eg. `substr(df$a, 1, 6)` should be changed to `substr(df$a, 0, 5)` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20464: [SPARK-23291][SQL][R] R's substr should not reduc...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20464#discussion_r172033021
--- Diff: R/pkg/R/column.R ---
@@ -169,7 +169,7 @@ setMethod("alias",
#' @note substr since 1.4.0
setMethod("substr", signature(x = "Column"),
function(x, start, stop) {
-jc <- callJMethod(x@jc, "substr", as.integer(start - 1),
as.integer(stop - start + 1))
+jc <- callJMethod(x@jc, "substr", as.integer(start),
as.integer(stop - start + 1))
--- End diff --
I think we should do two things:
1. add to the func doc that the `start` param should be 0-base and to add
to the example with the result
`collect(select(df, substr(df$a, 0, 5))) # this should give you...`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20681: [SPARK-23518][SQL] Avoid metastore access when th...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20681#discussion_r171910649
--- Diff: R/pkg/tests/fulltests/test_sparkSQL.R ---
@@ -67,6 +67,8 @@ sparkSession <- if (windows_with_hadoop()) {
sparkR.session(master = sparkRTestMaster, enableHiveSupport = FALSE)
}
sc <- callJStatic("org.apache.spark.sql.api.r.SQLUtils",
"getJavaSparkContext", sparkSession)
+# materialize the catalog implementation
+listTables()
--- End diff --
ok
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
spark git commit: [SPARKR][DOC] fix link in vignettes
Repository: spark
Updated Branches:
refs/heads/branch-2.3 56cfbd932 -> 8fe20e151
[SPARKR][DOC] fix link in vignettes
## What changes were proposed in this pull request?
Fix doc link that was changed in 2.3
shivaram
Author: Felix Cheung
Closes #20711 from felixcheung/rvigmean.
(cherry picked from commit 0b6ceadeb563205cbd6bd03bc88e608086273b5b)
Signed-off-by: Felix Cheung
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/8fe20e15
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/8fe20e15
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/8fe20e15
Branch: refs/heads/branch-2.3
Commit: 8fe20e15196b4ddbd80828ad3a91cf06c5dbea84
Parents: 56cfbd9
Author: Felix Cheung
Authored: Fri Mar 2 09:23:39 2018 -0800
Committer: Felix Cheung
Committed: Fri Mar 2 09:24:10 2018 -0800
--
R/pkg/vignettes/sparkr-vignettes.Rmd | 20 ++--
1 file changed, 10 insertions(+), 10 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/8fe20e15/R/pkg/vignettes/sparkr-vignettes.Rmd
--
diff --git a/R/pkg/vignettes/sparkr-vignettes.Rmd
b/R/pkg/vignettes/sparkr-vignettes.Rmd
index feca617..d4713de 100644
--- a/R/pkg/vignettes/sparkr-vignettes.Rmd
+++ b/R/pkg/vignettes/sparkr-vignettes.Rmd
@@ -46,7 +46,7 @@ Sys.setenv("_JAVA_OPTIONS" = paste("-XX:-UsePerfData",
old_java_opt, sep = " "))
## Overview
-SparkR is an R package that provides a light-weight frontend to use Apache
Spark from R. With Spark `r packageVersion("SparkR")`, SparkR provides a
distributed data frame implementation that supports data processing operations
like selection, filtering, aggregation etc. and distributed machine learning
using [MLlib](http://spark.apache.org/mllib/).
+SparkR is an R package that provides a light-weight frontend to use Apache
Spark from R. With Spark `r packageVersion("SparkR")`, SparkR provides a
distributed data frame implementation that supports data processing operations
like selection, filtering, aggregation etc. and distributed machine learning
using [MLlib](https://spark.apache.org/mllib/).
## Getting Started
@@ -132,7 +132,7 @@ sparkR.session.stop()
Different from many other R packages, to use SparkR, you need an additional
installation of Apache Spark. The Spark installation will be used to run a
backend process that will compile and execute SparkR programs.
-After installing the SparkR package, you can call `sparkR.session` as
explained in the previous section to start and it will check for the Spark
installation. If you are working with SparkR from an interactive shell (eg. R,
RStudio) then Spark is downloaded and cached automatically if it is not found.
Alternatively, we provide an easy-to-use function `install.spark` for running
this manually. If you don't have Spark installed on the computer, you may
download it from [Apache Spark Website](http://spark.apache.org/downloads.html).
+After installing the SparkR package, you can call `sparkR.session` as
explained in the previous section to start and it will check for the Spark
installation. If you are working with SparkR from an interactive shell (eg. R,
RStudio) then Spark is downloaded and cached automatically if it is not found.
Alternatively, we provide an easy-to-use function `install.spark` for running
this manually. If you don't have Spark installed on the computer, you may
download it from [Apache Spark
Website](https://spark.apache.org/downloads.html).
```{r, eval=FALSE}
install.spark()
@@ -147,7 +147,7 @@ sparkR.session(sparkHome = "/HOME/spark")
### Spark Session {#SetupSparkSession}
-In addition to `sparkHome`, many other options can be specified in
`sparkR.session`. For a complete list, see [Starting up:
SparkSession](http://spark.apache.org/docs/latest/sparkr.html#starting-up-sparksession)
and [SparkR API
doc](http://spark.apache.org/docs/latest/api/R/sparkR.session.html).
+In addition to `sparkHome`, many other options can be specified in
`sparkR.session`. For a complete list, see [Starting up:
SparkSession](https://spark.apache.org/docs/latest/sparkr.html#starting-up-sparksession)
and [SparkR API
doc](https://spark.apache.org/docs/latest/api/R/sparkR.session.html).
In particular, the following Spark driver properties can be set in
`sparkConfig`.
@@ -169,7 +169,7 @@ sparkR.session(spark.sql.warehouse.dir =
spark_warehouse_path)
Cluster Mode
-SparkR can connect to remote Spark clusters. [Cluster Mode
Overview](http://spark.apache.org/docs/latest/cluster-overview.html) is a good
introduction to different Spark cluster modes.
+SparkR can connect to remote Spark clusters. [Cluster Mode
Overview](https://sp
spark git commit: [SPARKR][DOC] fix link in vignettes
Repository: spark
Updated Branches:
refs/heads/master 119f6a0e4 -> 0b6ceadeb
[SPARKR][DOC] fix link in vignettes
## What changes were proposed in this pull request?
Fix doc link that was changed in 2.3
shivaram
Author: Felix Cheung
Closes #20711 from felixcheung/rvigmean.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/0b6ceade
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/0b6ceade
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/0b6ceade
Branch: refs/heads/master
Commit: 0b6ceadeb563205cbd6bd03bc88e608086273b5b
Parents: 119f6a0
Author: Felix Cheung
Authored: Fri Mar 2 09:23:39 2018 -0800
Committer: Felix Cheung
Committed: Fri Mar 2 09:23:39 2018 -0800
--
R/pkg/vignettes/sparkr-vignettes.Rmd | 20 ++--
1 file changed, 10 insertions(+), 10 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/0b6ceade/R/pkg/vignettes/sparkr-vignettes.Rmd
--
diff --git a/R/pkg/vignettes/sparkr-vignettes.Rmd
b/R/pkg/vignettes/sparkr-vignettes.Rmd
index feca617..d4713de 100644
--- a/R/pkg/vignettes/sparkr-vignettes.Rmd
+++ b/R/pkg/vignettes/sparkr-vignettes.Rmd
@@ -46,7 +46,7 @@ Sys.setenv("_JAVA_OPTIONS" = paste("-XX:-UsePerfData",
old_java_opt, sep = " "))
## Overview
-SparkR is an R package that provides a light-weight frontend to use Apache
Spark from R. With Spark `r packageVersion("SparkR")`, SparkR provides a
distributed data frame implementation that supports data processing operations
like selection, filtering, aggregation etc. and distributed machine learning
using [MLlib](http://spark.apache.org/mllib/).
+SparkR is an R package that provides a light-weight frontend to use Apache
Spark from R. With Spark `r packageVersion("SparkR")`, SparkR provides a
distributed data frame implementation that supports data processing operations
like selection, filtering, aggregation etc. and distributed machine learning
using [MLlib](https://spark.apache.org/mllib/).
## Getting Started
@@ -132,7 +132,7 @@ sparkR.session.stop()
Different from many other R packages, to use SparkR, you need an additional
installation of Apache Spark. The Spark installation will be used to run a
backend process that will compile and execute SparkR programs.
-After installing the SparkR package, you can call `sparkR.session` as
explained in the previous section to start and it will check for the Spark
installation. If you are working with SparkR from an interactive shell (eg. R,
RStudio) then Spark is downloaded and cached automatically if it is not found.
Alternatively, we provide an easy-to-use function `install.spark` for running
this manually. If you don't have Spark installed on the computer, you may
download it from [Apache Spark Website](http://spark.apache.org/downloads.html).
+After installing the SparkR package, you can call `sparkR.session` as
explained in the previous section to start and it will check for the Spark
installation. If you are working with SparkR from an interactive shell (eg. R,
RStudio) then Spark is downloaded and cached automatically if it is not found.
Alternatively, we provide an easy-to-use function `install.spark` for running
this manually. If you don't have Spark installed on the computer, you may
download it from [Apache Spark
Website](https://spark.apache.org/downloads.html).
```{r, eval=FALSE}
install.spark()
@@ -147,7 +147,7 @@ sparkR.session(sparkHome = "/HOME/spark")
### Spark Session {#SetupSparkSession}
-In addition to `sparkHome`, many other options can be specified in
`sparkR.session`. For a complete list, see [Starting up:
SparkSession](http://spark.apache.org/docs/latest/sparkr.html#starting-up-sparksession)
and [SparkR API
doc](http://spark.apache.org/docs/latest/api/R/sparkR.session.html).
+In addition to `sparkHome`, many other options can be specified in
`sparkR.session`. For a complete list, see [Starting up:
SparkSession](https://spark.apache.org/docs/latest/sparkr.html#starting-up-sparksession)
and [SparkR API
doc](https://spark.apache.org/docs/latest/api/R/sparkR.session.html).
In particular, the following Spark driver properties can be set in
`sparkConfig`.
@@ -169,7 +169,7 @@ sparkR.session(spark.sql.warehouse.dir =
spark_warehouse_path)
Cluster Mode
-SparkR can connect to remote Spark clusters. [Cluster Mode
Overview](http://spark.apache.org/docs/latest/cluster-overview.html) is a good
introduction to different Spark cluster modes.
+SparkR can connect to remote Spark clusters. [Cluster Mode
Overview](https://spark.apache.org/docs/latest/cluster-overview.html) is a good
introduction to different Spark cluster modes
[GitHub] spark pull request #20711: [SPARKR][DOC] fix link in vignettes
GitHub user felixcheung opened a pull request: https://github.com/apache/spark/pull/20711 [SPARKR][DOC] fix link in vignettes ## What changes were proposed in this pull request? Fix doc link that was changed in 2.3 @shivaram You can merge this pull request into a Git repository by running: $ git pull https://github.com/felixcheung/spark rvigmean Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20711.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20711 commit d09a8043291241e87910ea67263e0318bbe1ad14 Author: Felix Cheung Date: 2018-03-02T02:16:02Z fix link --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20681: [SPARK-23518][SQL] Avoid metastore access when th...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20681#discussion_r171750940
--- Diff: R/pkg/tests/fulltests/test_sparkSQL.R ---
@@ -67,6 +67,8 @@ sparkSession <- if (windows_with_hadoop()) {
sparkR.session(master = sparkRTestMaster, enableHiveSupport = FALSE)
}
sc <- callJStatic("org.apache.spark.sql.api.r.SQLUtils",
"getJavaSparkContext", sparkSession)
+# materialize the catalog implementation
+listTables()
--- End diff --
we are calling `sparkR.session(master = sparkRTestMaster, enableHiveSupport
= FALSE)` is almost every other test files - does the same apply in those other
places?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20681: [SPARK-23518][SQL] Avoid metastore access when the users...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20681 looks like test failures are related? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20295: [SPARK-23011] Support alternative function form w...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20295#discussion_r171466325
--- Diff: python/pyspark/sql/types.py ---
@@ -1725,6 +1737,29 @@ def _get_local_timezone():
return os.environ.get('TZ', 'dateutil/:')
+def _check_series_localize_timestamps(s, timezone):
+"""
+Convert timezone aware timestamps to timezone-naive in the specified
timezone or local timezone.
+
+If the input series is not a timestamp series, then the same series is
returned. If the input
+series is a timestamp series, then a converted series is returned.
+
+:param s: pandas.Series
+:param timezone: the timezone to convert. if None then use local
timezone
+:return pandas.Series that have been converted to tz-naive
+"""
+from pyspark.sql.utils import require_minimum_pandas_version
+require_minimum_pandas_version()
+
+from pandas.api.types import is_datetime64tz_dtype
--- End diff --
do we have tests for tese in tests.py?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20295: [SPARK-23011] Support alternative function form w...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20295#discussion_r171465908
--- Diff: python/pyspark/sql/functions.py ---
@@ -2253,6 +2253,30 @@ def pandas_udf(f=None, returnType=None,
functionType=None):
| 2| 1.1094003924504583|
+---+---+
+ Alternatively, the user can define a function that takes two
arguments.
+ In this case, the grouping key will be passed as the first argument
and the data will
+ be passed as the second argument. The grouping key will be passed
as a tuple of numpy
+ data types, e.g., `numpy.int32` and `numpy.float64`. The data will
still be passed in
+ as a `pandas.DataFrame` containing all columns from the original
Spark DataFrame.
+ This is useful when the user doesn't want to hardcode grouping key
in the function.
+
+ >>> from pyspark.sql.functions import pandas_udf, PandasUDFType
+ >>> df = spark.createDataFrame(
+ ... [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
+ ... ("id", "v")) # doctest: +SKIP
+ >>> @pandas_udf("id long, v double", PandasUDFType.GROUP_MAP) #
doctest: +SKIP
+ ... def mean_udf(key, pdf):
+ ... # key is a tuple of one numpy.int64, which is the value
+ ... # of 'id' for the current group
+ ... return pd.DataFrame([key + (pdf.v.mean(),)])
+ >>> df.groupby('id').apply(mean_udf).show() #doctest: +SKIP
--- End diff --
why skip all of these btw? why not run them so they can be tested?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20695 2.4.0? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org