[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r182309137
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
---
@@ -1266,6 +1266,9 @@ class DAGScheduler(
}
if (failedEpoch.contains(execId) && smt.epoch <=
failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from
executor $execId")
+} else if (failedStages.contains(shuffleStage)) {
--- End diff --
This also confuse me before, as far as I'm concerned, the result task in
such scenario(speculative task fail but original task success) is ok because it
has no child stage, we can use the success task's result and
`markStageAsFinished`. But for shuffle map task, it will cause inconformity
between mapOutputTracker and stage's pendingPartitions, it must fix.
I'm not sure of ResultTask's behavior, can you give some advice?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r182307786
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,50 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("[SPARK-23811] FetchFailed comes before Success of same task will
cause child stage" +
+" never succeed") {
--- End diff --
Thanks, I'll change it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r182307728
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,50 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("[SPARK-23811] FetchFailed comes before Success of same task will
cause child stage" +
+" never succeed") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
--- End diff --
Here we only need to mock the speculative task failed event came before
success event, `makeCompletionEvent` with same taskSets's task can achieve such
goal. This also use in `task events always posted in speculation / when stage
is killed`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 @Ngone51 Thanks for your review. > Does stage 2 is correspond to the never success stage in PR description ? Stage 3 is the never success stage, stage 2 is its parent stage. > So, why stage 2 retry 4 times when there's no more missing tasks? Stage 2 retry 4 times triggered by Stage 3's fetch failed event. Actually in this scenario, stage 3 will always failed by fetch fail. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r182296297
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -750,6 +752,10 @@ private[spark] class TaskSetManager(
if (tasksSuccessful == numTasks) {
isZombie = true
}
+} else if (fetchFailedTaskIndexSet.contains(index)) {
+ logInfo("Ignoring task-finished event for " + info.id + " in stage "
+ taskSet.id +
+" because task " + index + " has already failed by FetchFailed")
+ return
--- End diff --
Yep, as @cloud-fan 's suggestion, handle this in `DAGScheduler` is a better
choice.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r182294068
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -750,6 +752,10 @@ private[spark] class TaskSetManager(
if (tasksSuccessful == numTasks) {
isZombie = true
}
+} else if (fetchFailedTaskIndexSet.contains(index)) {
--- End diff --
Great thanks for you two's guidance guidance, that's more clear and the UT
add for reproducing this problem can also used for checking it!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 @cloud-fan @jiangxb1987 Sorry for late reply, delete the useless code as our discussion before. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r181674151
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -750,6 +752,10 @@ private[spark] class TaskSetManager(
if (tasksSuccessful == numTasks) {
isZombie = true
}
+} else if (fetchFailedTaskIndexSet.contains(index)) {
--- End diff --
The change of `fetchFailedTaskIndexSet` is to ignore the task success event
if the stage is marked as failed, as Wenchen's suggestion in before comment.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r181673508
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -794,6 +794,19 @@ private[spark] class TaskSetManager(
fetchFailed.bmAddress.host, fetchFailed.bmAddress.executorId))
}
+// Kill any other attempts for this FetchFailed task
+for (attemptInfo <- taskAttempts(index) if attemptInfo.running) {
+ logInfo(s"Killing attempt ${attemptInfo.attemptNumber} for task
${attemptInfo.id} " +
+s"in stage ${taskSet.id} (TID ${attemptInfo.taskId}) on
${attemptInfo.host} " +
+s"as the attempt ${info.attemptNumber} failed because
FetchFailed")
+ killedByOtherAttempt(index) = true
+ sched.backend.killTask(
--- End diff --
Got it, I remove the code and UT in next commit.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r178500184
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -794,6 +794,19 @@ private[spark] class TaskSetManager(
fetchFailed.bmAddress.host, fetchFailed.bmAddress.executorId))
}
+// Kill any other attempts for this FetchFailed task
+for (attemptInfo <- taskAttempts(index) if attemptInfo.running) {
+ logInfo(s"Killing attempt ${attemptInfo.attemptNumber} for task
${attemptInfo.id} " +
+s"in stage ${taskSet.id} (TID ${attemptInfo.taskId}) on
${attemptInfo.host} " +
+s"as the attempt ${info.attemptNumber} failed because
FetchFailed")
+ killedByOtherAttempt(index) = true
+ sched.backend.killTask(
--- End diff --
@jiangxb1987 Yes, ignore the finished event is necessary, maybe it's also
needed to kill useless task?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r178499952
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -794,6 +794,19 @@ private[spark] class TaskSetManager(
fetchFailed.bmAddress.host, fetchFailed.bmAddress.executorId))
}
+// Kill any other attempts for this FetchFailed task
+for (attemptInfo <- taskAttempts(index) if attemptInfo.running) {
+ logInfo(s"Killing attempt ${attemptInfo.attemptNumber} for task
${attemptInfo.id} " +
+s"in stage ${taskSet.id} (TID ${attemptInfo.taskId}) on
${attemptInfo.host} " +
+s"as the attempt ${info.attemptNumber} failed because
FetchFailed")
+ killedByOtherAttempt(index) = true
+ sched.backend.killTask(
--- End diff --
@cloud-fan Yes you're right, I should guarantee this in TaskSetManager.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 > What's your proposed fix? I fix this by killing other attempts while receive a FetchFailed in `TaskSetManager`. If we finally ignore the success event of other attempts, might as well stop the task. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 Yeah, the stage resubmitted, but there's no missing task for this stage and actually no task will be resubmitted. This mainly because the `ShuffleMapTask 1.0` triggered `shuffleStage.addOutputLoc`. The screenshot I attached in Jira maybe help to explain this scenario. 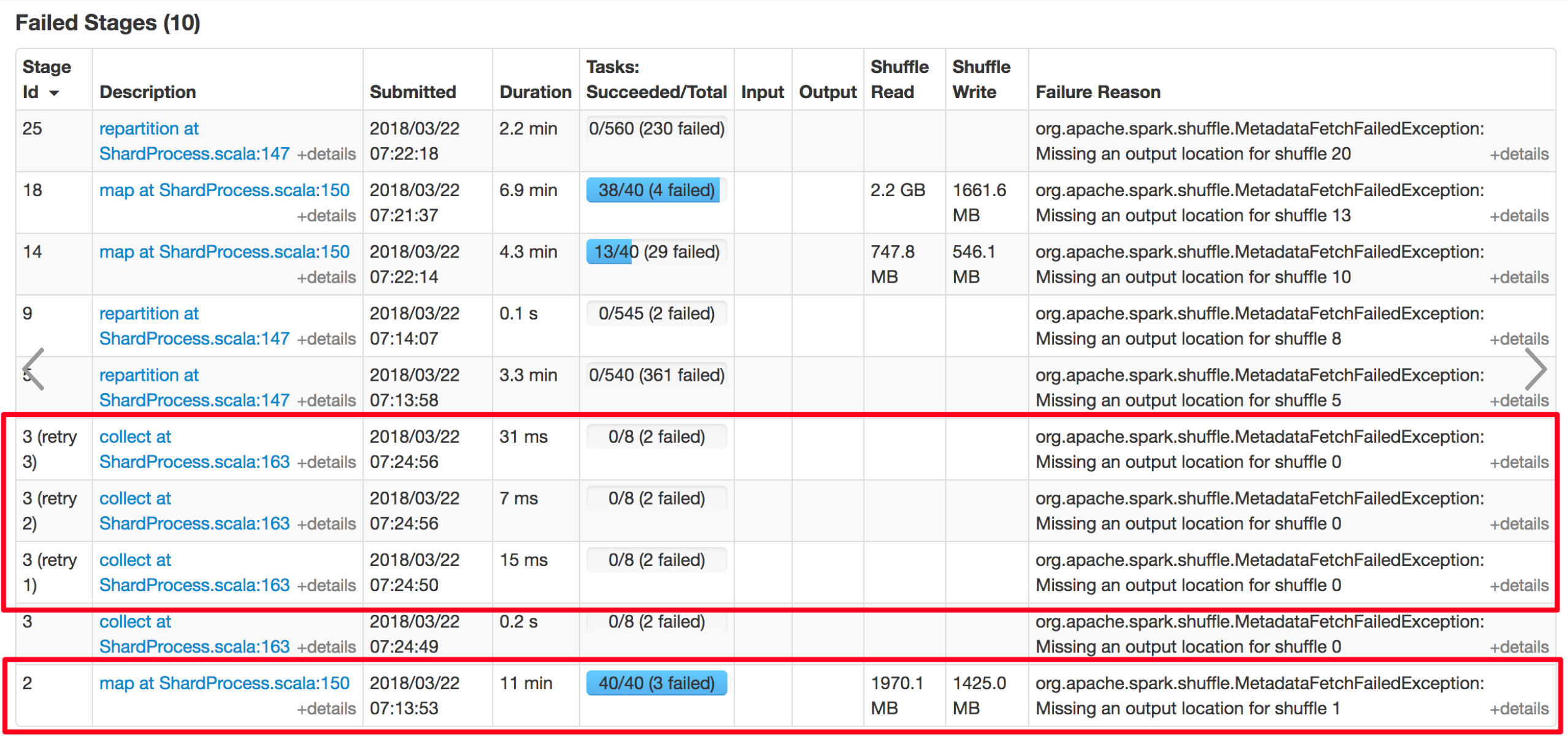 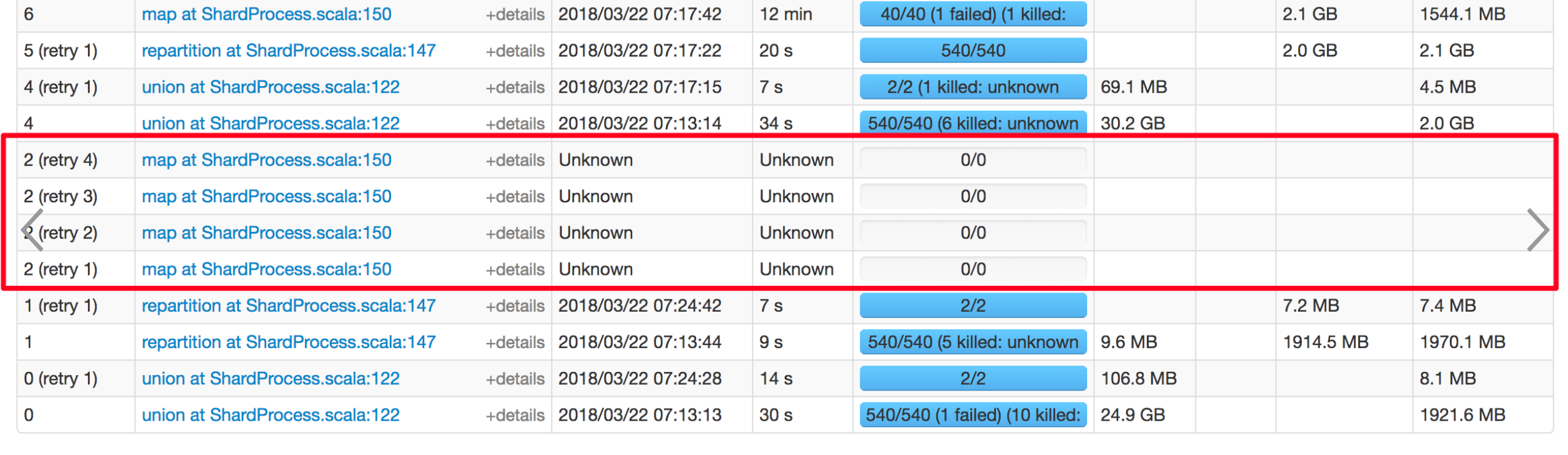 You can see the empty ShuffleMapStage 2 retry 4 times, finally its child stage 3 failed with FetchFailed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 The first case, the stage is marked as failed, but not be resubmitted yet. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] FetchFailed comes before Success of ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 `ShuffleMapTask 1.0` succeed after its speculative task failed by FetchFailed. Thanks for your checking, I will modify the PR description. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] Same tasks' FetchFailed event comes ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 cc @jerryshao @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] Same tasks' FetchFailed event comes ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20930 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20930: [SPARK-23811][Core] Same tasks' FetchFailed event comes ...
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/20930
The scenario can be reproduced by below test case added in
`DAGSchedulerSuite`
```scala
/**
* This tests the case where origin task success after speculative task
got FetchFailed
* before.
*/
test("[SPARK-23811] Fetch failed task should kill other attempt") {
// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
val rddA = new MyRDD(sc, 2, Nil)
val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
val shuffleIdA = shuffleDepA.shuffleId
val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
submit(rddC, Array(0, 1))
// Complete both tasks in rddA.
assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
complete(taskSets(0), Seq(
(Success, makeMapStatus("hostA", 2)),
(Success, makeMapStatus("hostB", 2
// The first task success
runEvent(makeCompletionEvent(
taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
// The second task's speculative attempt fails first, but task self
still running.
// This may caused by ExecutorLost.
runEvent(makeCompletionEvent(
taskSets(1).tasks(1),
FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0, "ignored"),
null))
// Check currently missing partition
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
val missingPartition =
mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get(0)
// The second result task self success soon
runEvent(makeCompletionEvent(
taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
// No missing partitions here, this will cause child stage never succeed
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 0)
}
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] Same tasks' FetchFailed event...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/20930 [SPARK-23811][Core] Same tasks' FetchFailed event comes before Success will cause child stage never succeed ## What changes were proposed in this pull request? This is a bug caused by abnormal scenario describe below: ShuffleMapTask 1.0 running, this task will fetch data from ExecutorA ExecutorA Lost, trigger `mapOutputTracker.removeOutputsOnExecutor(execId)` , shuffleStatus changed. Speculative ShuffleMapTask 1.1 start, got a FetchFailed immediately. ShuffleMapTask 1 is the last task of its stage, so this stage will never succeed because of there's no missing task DAGScheduler can get. I apply the detailed screenshots in jira comments. ## How was this patch tested? Add a new UT in `TaskSetManagerSuite` You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-23811 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20930.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20930 commit 2907075b43eac26c7efbe4aca5f2c037bb5934c2 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-03-29T04:50:16Z [SPARK-23811][Core] Same tasks' FetchFailed event comes before Success will cause child stage never succeed --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20689: [SPARK-23533][SS] Add support for changing Contin...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20689#discussion_r174667490
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaContinuousReader.scala
---
@@ -164,7 +164,15 @@ case class KafkaContinuousDataReaderFactory(
startOffset: Long,
kafkaParams: ju.Map[String, Object],
pollTimeoutMs: Long,
-failOnDataLoss: Boolean) extends DataReaderFactory[UnsafeRow] {
+failOnDataLoss: Boolean) extends
ContinuousDataReaderFactory[UnsafeRow] {
+
+ override def createDataReaderWithOffset(offset: PartitionOffset):
DataReader[UnsafeRow] = {
+val kafkaOffset = offset.asInstanceOf[KafkaSourcePartitionOffset]
+assert(kafkaOffset.topicPartition == topicPartition)
--- End diff --
Got it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20689: [SPARK-23533][SS] Add support for changing ContinuousDat...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20689 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 > it just means that for very long-running streams task restarts will eventually run out. Ah, I know your means. Yeah, if we support task level retry we should also set the task retry number unlimited. > But if you're worried that the current implementation of task restart will become incorrect as more complex scenarios are supported, I'd definitely lean towards deferring it until continuous processing is more feature-complete. Yep, the "complex scenarios" I mentioned mainly including shuffle and aggregation scenario like comments in https://issues.apache.org/jira/browse/SPARK-20928?focusedCommentId=16245556=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16245556, in those scenario maybe task level retry should consider epoch align, but current implementation of task restart is completed for map-only continuous processing I think. Agree with you about deferring it, so I just leave a comment in SPARK-23033 and close this or you think this should reviewed by others? > Do you want to spin that off into a separate PR? (I can handle it otherwise.) Of cause, #20689 added a new interface `ContinuousDataReaderFactory` as our comments. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20675: [SPARK-23033][SS][Follow Up] Task level retry for...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20675#discussion_r171161352
--- Diff:
sql/core/src/main/java/org/apache/spark/sql/sources/v2/reader/streaming/ContinuousDataReader.java
---
@@ -33,4 +33,16 @@
* as a restart checkpoint.
*/
PartitionOffset getOffset();
+
+/**
+ * Set the start offset for the current record, only used in task
retry. If setOffset keep
+ * default implementation, it means current ContinuousDataReader can't
support task level retry.
+ *
+ * @param offset last offset before task retry.
+ */
+default void setOffset(PartitionOffset offset) {
--- End diff --
Cool, that's more clearer.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20689: [SPARK-23533][SS] Add support for changing Contin...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/20689 [SPARK-23533][SS] Add support for changing ContinuousDataReader's startOffset ## What changes were proposed in this pull request? As discussion in #20675, we need add a new interface `ContinuousDataReaderFactory` to support the requirements of setting start offset in Continuous Processing. ## How was this patch tested? Existing UT. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-23533 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20689.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20689 commit 59cef98868586a4f039b04e74c32c94eaff965c0 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-02-28T07:29:57Z [SPARK-23533][SS] Add support for changing ContinousDataReader's startOffset --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20675: [SPARK-23033][SS][Follow Up] Task level retry for...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20675#discussion_r170830121
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/continuous/ContinuousSuite.scala
---
@@ -219,18 +219,59 @@ class ContinuousSuite extends ContinuousSuiteBase {
spark.sparkContext.addSparkListener(listener)
try {
testStream(df, useV2Sink = true)(
-StartStream(Trigger.Continuous(100)),
+StartStream(longContinuousTrigger),
+AwaitEpoch(0),
Execute(waitForRateSourceTriggers(_, 2)),
+IncrementEpoch(),
Execute { _ =>
// Wait until a task is started, then kill its first attempt.
eventually(timeout(streamingTimeout)) {
assert(taskId != -1)
}
spark.sparkContext.killTaskAttempt(taskId)
},
-ExpectFailure[SparkException] { e =>
- e.getCause != null &&
e.getCause.getCause.isInstanceOf[ContinuousTaskRetryException]
-})
+Execute(waitForRateSourceTriggers(_, 4)),
+IncrementEpoch(),
+// Check the answer exactly, if there's duplicated result,
CheckAnserRowsContains
+// will also return true.
+CheckAnswerRowsContainsOnlyOnce(scala.Range(0, 20).map(Row(_))),
--- End diff --
Actually I firstly use `CheckAnswer(0 to 19: _*)` here, but I found the
test case failure probably because the CP maybe not stop between Range(0, 20)
every time. See the logs below:
```
== Plan ==
== Parsed Logical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- Project [value#13L]
+- StreamingDataSourceV2Relation [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
== Analyzed Logical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- Project [value#13L]
+- StreamingDataSourceV2Relation [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
== Optimized Logical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- Project [value#13L]
+- StreamingDataSourceV2Relation [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
== Physical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- *(1) Project [value#13L]
+- *(1) DataSourceV2Scan [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
ScalaTestFailureLocation: org.apache.spark.sql.streaming.StreamTest$class
at (StreamTest.scala:436)
org.scalatest.exceptions.TestFailedException:
== Results ==
!== Correct Answer - 20 == == Spark Answer - 25 ==
!struct struct
[0] [0]
[10][10]
[11][11]
[12][12]
[13][13]
[14][14]
[15][15]
[16][16]
[17][17]
[18][18]
[19][19]
[1] [1]
![2] [20]
![3] [21]
![4] [22]
![5] [23]
![6] [24]
![7] [2]
![8] [3]
![9] [4]
![5]
![6]
![7]
![8]
![9]
== Progress ==
StartStream(ContinuousTrigger(360),org.apache.spark.util.SystemClock@343e225a,Map(),null)
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
=> CheckAnswer:
[0],[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17],[18],[19]
StopStream
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 Great thanks for your detailed reply! > The semantics aren't quite right. Task-level retry can happen a fixed number of times for the lifetime of the task, which is the lifetime of the query - even if it runs for days after, the attempt number will never be reset. - I think the attempt number never be reset is not a problem, as long as the task start with right epoch and offset. Maybe I don't understand the meaning of the semantics, could you please give more explain? - As far as I'm concerned, while we have a larger parallel number, whole stage restart is a too heavy operation and will lead a data shaking. - Also want to leave a further thinking, after CP support shuffle and more complex scenario, task level retry need more work to do in order to ensure data is correct. But it maybe still a useful feature? I just want to leave this patch and initiate a discussion about this :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 cc @tdas and @jose-torres #20225 gives a quickly fix for task level retry, this is just an attempt for a maybe better implementation. Please let me know if I do something wrong or have misunderstandings of Continuous Processing. Thanks :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20675: [SPARK-23033][SS][Follow Up] Task level retry for...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/20675 [SPARK-23033][SS][Follow Up] Task level retry for continuous processing ## What changes were proposed in this pull request? Here we want to reimplement the task level retry for continuous processing, changes include: 1. Add a new `EpochCoordinatorMessage` named `GetLastEpochAndOffset`, it is used for getting last epoch and offset of particular partition while task restarted. 2. Add function setOffset for `ContinuousDataReader`, it supported BaseReader can restart from given offset. ## How was this patch tested? Add new UT in `ContinuousSuite` and new `StreamAction` named `CheckAnswerRowsContainsOnlyOnce` for more accurate result checking. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-23033 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20675.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20675 commit 21f574e2a3ad3c8e68b92776d2a141d7fcb90502 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-02-26T07:27:10Z [SPARK-23033][SS][Follow Up] Task level retry for continuous processing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 ping @vanzin --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/17702#discussion_r163156332
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -668,4 +672,31 @@ object DataSource extends Logging {
}
globPath
}
+
+ /**
+ * Return all paths represented by the wildcard string.
+ * Follow [[InMemoryFileIndex]].bulkListLeafFile and reuse the conf.
+ */
+ private def getGlobbedPaths(
+ sparkSession: SparkSession,
+ fs: FileSystem,
+ hadoopConf: SerializableConfiguration,
+ qualified: Path): Seq[Path] = {
+val paths = SparkHadoopUtil.get.expandGlobPath(fs, qualified)
+if (paths.size <=
sparkSession.sessionState.conf.parallelPartitionDiscoveryThreshold) {
+ SparkHadoopUtil.get.globPathIfNecessary(fs, qualified)
+} else {
+ val parallelPartitionDiscoveryParallelism =
+
sparkSession.sessionState.conf.parallelPartitionDiscoveryParallelism
+ val numParallelism = Math.min(paths.size,
parallelPartitionDiscoveryParallelism)
+ val expanded = sparkSession.sparkContext
--- End diff --
Sorry for the late reply, finished in next commit.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 Thanks for your review! Shixiong --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20150#discussion_r161426641
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
---
@@ -122,6 +122,11 @@ case class MemoryStream[A : Encoder](id: Int,
sqlContext: SQLContext)
batches.slice(sliceStart, sliceEnd)
}
+if (newBlocks.isEmpty) {
--- End diff --
DONE
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20150#discussion_r161426622
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
---
@@ -318,6 +318,84 @@ class KafkaSourceSuite extends KafkaSourceTest {
)
}
+ test("union bug in failover") {
+def getSpecificDF(range: Range.Inclusive):
org.apache.spark.sql.Dataset[Int] = {
+ val topic = newTopic()
+ testUtils.createTopic(topic, partitions = 1)
+ testUtils.sendMessages(topic, range.map(_.toString).toArray, Some(0))
+
+ val reader = spark
+.readStream
+.format("kafka")
+.option("kafka.bootstrap.servers", testUtils.brokerAddress)
+.option("kafka.metadata.max.age.ms", "1")
+.option("maxOffsetsPerTrigger", 5)
+.option("subscribe", topic)
+.option("startingOffsets", "earliest")
+
+ reader.load()
+.selectExpr("CAST(value AS STRING)")
+.as[String]
+.map(k => k.toInt)
+}
+
+val df1 = getSpecificDF(0 to 9)
+val df2 = getSpecificDF(100 to 199)
+
+val kafka = df1.union(df2)
+
+val clock = new StreamManualClock
+
+val waitUntilBatchProcessed = AssertOnQuery { q =>
+ eventually(Timeout(streamingTimeout)) {
+if (!q.exception.isDefined) {
+ assert(clock.isStreamWaitingAt(clock.getTimeMillis()))
+}
+ }
+ if (q.exception.isDefined) {
+throw q.exception.get
+ }
+ true
+}
+
+testStream(kafka)(
+ StartStream(ProcessingTime(100), clock),
+ waitUntilBatchProcessed,
+ // 5 from smaller topic, 5 from bigger one
+ CheckAnswer(0, 1, 2, 3, 4, 100, 101, 102, 103, 104),
--- End diff --
Cool, this made the code more cleaner.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20150#discussion_r161426632
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
---
@@ -318,6 +318,84 @@ class KafkaSourceSuite extends KafkaSourceTest {
)
}
+ test("union bug in failover") {
--- End diff --
DONE
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 @ivoson Tengfei, please post the full stack trace of the `ClassCastException`. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 test this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20244: [SPARK-23053][CORE] taskBinarySerialization and t...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20244#discussion_r161141879
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2417,93 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * In this test, we simply simulate the scene in concurrent jobs using
the same
+ * rdd which is marked to do checkpoint:
+ * Job one has already finished the spark job, and start the process of
doCheckpoint;
+ * Job two is submitted, and submitMissingTasks is called.
+ * In submitMissingTasks, if taskSerialization is called before
doCheckpoint is done,
+ * while part calculates from stage.rdd.partitions is called after
doCheckpoint is done,
+ * we may get a ClassCastException when execute the task because of some
rdd will do
+ * Partition cast.
+ *
+ * With this test case, just want to indicate that we should do
taskSerialization and
+ * part calculate in submitMissingTasks with the same rdd checkpoint
status.
+ */
+ test("task part misType with checkpoint rdd in concurrent execution
scenes") {
--- End diff --
maybe "SPARK-23053: avoid CastException in concurrent execution with
checkpoint" better?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20244: [SPARK-23053][CORE] taskBinarySerialization and t...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20244#discussion_r161141499
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -96,6 +98,22 @@ class MyRDD(
override def toString: String = "DAGSchedulerSuiteRDD " + id
}
+/** Wrapped rdd partition. */
+class WrappedPartition(val partition: Partition) extends Partition {
+ def index: Int = partition.index
+}
+
+/** Wrapped rdd with WrappedPartition. */
+class WrappedRDD(parent: RDD[Int]) extends RDD[Int](parent) {
+ protected def getPartitions: Array[Partition] = {
+parent.partitions.map(p => new WrappedPartition(p))
+ }
+
+ def compute(split: Partition, context: TaskContext): Iterator[Int] = {
+parent.compute(split.asInstanceOf[WrappedPartition].partition, context)
--- End diff --
I think this line is the key point for `WrppedPartition` and `WrappedRDD`,
please give comments for explaining your intention.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20244: [SPARK-23053][CORE] taskBinarySerialization and t...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20244#discussion_r161144809
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2417,93 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * In this test, we simply simulate the scene in concurrent jobs using
the same
+ * rdd which is marked to do checkpoint:
+ * Job one has already finished the spark job, and start the process of
doCheckpoint;
+ * Job two is submitted, and submitMissingTasks is called.
+ * In submitMissingTasks, if taskSerialization is called before
doCheckpoint is done,
+ * while part calculates from stage.rdd.partitions is called after
doCheckpoint is done,
+ * we may get a ClassCastException when execute the task because of some
rdd will do
+ * Partition cast.
+ *
+ * With this test case, just want to indicate that we should do
taskSerialization and
+ * part calculate in submitMissingTasks with the same rdd checkpoint
status.
+ */
+ test("task part misType with checkpoint rdd in concurrent execution
scenes") {
+// set checkpointDir.
+val tempDir = Utils.createTempDir()
+val checkpointDir = File.createTempFile("temp", "", tempDir)
+checkpointDir.delete()
+sc.setCheckpointDir(checkpointDir.toString)
+
+val latch = new CountDownLatch(2)
+val semaphore1 = new Semaphore(0)
+val semaphore2 = new Semaphore(0)
+
+val rdd = new WrappedRDD(sc.makeRDD(1 to 100, 4))
+rdd.checkpoint()
+
+val checkpointRunnable = new Runnable {
+ override def run() = {
+// Simply simulate what RDD.doCheckpoint() do here.
+rdd.doCheckpointCalled = true
+val checkpointData = rdd.checkpointData.get
+RDDCheckpointData.synchronized {
+ if (checkpointData.cpState == CheckpointState.Initialized) {
+checkpointData.cpState =
CheckpointState.CheckpointingInProgress
+ }
+}
+
+val newRDD = checkpointData.doCheckpoint()
+
+// Release semaphore1 after job triggered in checkpoint finished.
+semaphore1.release()
+semaphore2.acquire()
+// Update our state and truncate the RDD lineage.
+RDDCheckpointData.synchronized {
+ checkpointData.cpRDD = Some(newRDD)
+ checkpointData.cpState = CheckpointState.Checkpointed
+ rdd.markCheckpointed()
+}
+semaphore1.release()
+
+latch.countDown()
+ }
+}
+
+val submitMissingTasksRunnable = new Runnable {
+ override def run() = {
+// Simply simulate the process of submitMissingTasks.
+val ser = SparkEnv.get.closureSerializer.newInstance()
+semaphore1.acquire()
+// Simulate task serialization while submitMissingTasks.
+// Task serialized with rdd checkpoint not finished.
+val cleanedFunc = sc.clean(Utils.getIteratorSize _)
+val func = (ctx: TaskContext, it: Iterator[Int]) => cleanedFunc(it)
+val taskBinaryBytes = JavaUtils.bufferToArray(
+ ser.serialize((rdd, func): AnyRef))
+semaphore2.release()
+semaphore1.acquire()
+// Part calculated with rdd checkpoint already finished.
+val (taskRdd, taskFunc) = ser.deserialize[(RDD[Int], (TaskContext,
Iterator[Int]) => Unit)](
+ ByteBuffer.wrap(taskBinaryBytes),
Thread.currentThread.getContextClassLoader)
+val part = rdd.partitions(0)
+intercept[ClassCastException] {
--- End diff --
I think this not a "test", this just a "reproduce" for the problem you want
to fix. We should prove your code added in `DAGScheduler.scala` can fix that
problem and with the original code base, a `ClassCastException` raised.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 reopen this... --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 Hi Shixiong, thanks a lot for your reply. The full stack below can reproduce by running the added UT based on original code base. ``` Assert on query failed: : Query [id = 3421db21-652e-47af-9d54-2b74a222abed, runId = cd8d7c94-1286-44a5-b000-a8d870aef6fa] terminated with exception: Partition topic-0-0's offset was changed from 10 to 5, some data may have been missed. Some data may have been lost because they are not available in Kafka any more; either the data was aged out by Kafka or the topic may have been deleted before all the data in the topic was processed. If you don't want your streaming query to fail on such cases, set the source option "failOnDataLoss" to "false". org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:295) org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:189) Caused by: Partition topic-0-0's offset was changed from 10 to 5, some data may have been missed. Some data may have been lost because they are not available in Kafka any more; either the data was aged out by Kafka or the topic may have been deleted before all the data in the topic was processed. If you don't want your streaming query to fail on such cases, set the source option "failOnDataLoss" to "false". org.apache.spark.sql.kafka010.KafkaSource.org$apache$spark$sql$kafka010$KafkaSource$$reportDataLoss(KafkaSource.scala:332) org.apache.spark.sql.kafka010.KafkaSource$$anonfun$8.apply(KafkaSource.scala:291) org.apache.spark.sql.kafka010.KafkaSource$$anonfun$8.apply(KafkaSource.scala:289) scala.collection.TraversableLike$$anonfun$filterImpl$1.apply(TraversableLike.scala:248) scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) scala.collection.TraversableLike$class.filterImpl(TraversableLike.scala:247) scala.collection.TraversableLike$class.filter(TraversableLike.scala:259) scala.collection.AbstractTraversable.filter(Traversable.scala:104) org.apache.spark.sql.kafka010.KafkaSource.getBatch(KafkaSource.scala:289) ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 cc @gatorsmile @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 cc @zsxwing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/20150 [SPARK-22956][SS] Bug fix for 2 streams union failover scenario ## What changes were proposed in this pull request? This problem reported by @yanlin-Lynn @ivoson and @LiangchangZ. Thanks! When we union 2 streams from kafka or other sources, while one of them have no continues data coming and in the same time task restart, this will cause an `IllegalStateException`. This mainly cause because the code in [MicroBatchExecution](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala#L190) , while one stream has no continues data, its comittedOffset same with availableOffset during `populateStartOffsets`, and `currentPartitionOffsets` not properly handled in KafkaSource. Also, maybe we should also consider this scenario in other Source. ## How was this patch tested? Add a UT in KafkaSourceSuite.scala You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-22956 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20150.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20150 commit aa3d7b73ed5221bdc2aee9dea1f6db45b4a626d7 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-01-04T11:52:23Z SPARK-22956: Bug fix for 2 streams union failover scenario --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19773: [SPARK-22546][SQL] Supporting for changing column dataTy...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19773 gental ping @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19941#discussion_r157118985
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/InsertIntoDataSourceDirCommand.scala
---
@@ -67,8 +67,9 @@ case class InsertIntoDataSourceDirCommand(
val saveMode = if (overwrite) SaveMode.Overwrite else
SaveMode.ErrorIfExists
try {
-
sparkSession.sessionState.executePlan(dataSource.planForWriting(saveMode,
query))
- dataSource.writeAndRead(saveMode, query)
--- End diff --
Revert done.
Sorry, maybe I misunderstand your words of 'get rid of
dataSource.writeAndRead'. Like you and Wenchen's discussion in
https://github.com/apache/spark/pull/16481, shouldn't we make `writeAndRead`
just return a BaseRelation without write to the destination? Thank you for your
patient reply.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19941#discussion_r156960449
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -490,20 +489,19 @@ case class DataSource(
}
/**
- * Writes the given [[LogicalPlan]] out to this [[DataSource]] and
returns a [[BaseRelation]] for
- * the following reading.
+ * Returns a [[BaseRelation]] for creating table after `planForWriting`.
Only use
+ * in `CreateDataSourceTableAsSelectCommand` while saving data to
non-existing table.
*/
- def writeAndRead(mode: SaveMode, data: LogicalPlan): BaseRelation = {
+ def getRelation(mode: SaveMode, data: LogicalPlan): BaseRelation = {
if
(data.schema.map(_.dataType).exists(_.isInstanceOf[CalendarIntervalType])) {
throw new AnalysisException("Cannot save interval data type into
external storage.")
}
providingClass.newInstance() match {
- case dataSource: CreatableRelationProvider =>
+ case dataSource: RelationProvider =>
--- End diff --
Ah, I see.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19941#discussion_r156958793
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/InsertIntoDataSourceDirCommand.scala
---
@@ -67,8 +67,9 @@ case class InsertIntoDataSourceDirCommand(
val saveMode = if (overwrite) SaveMode.Overwrite else
SaveMode.ErrorIfExists
try {
-
sparkSession.sessionState.executePlan(dataSource.planForWriting(saveMode,
query))
- dataSource.writeAndRead(saveMode, query)
--- End diff --
You're right, test the query "INSERT OVERWRITE DIRECTORY
'/home/liyuanjian/tmp' USING json SELECT 1 AS a, 'c' as b;".
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19941#discussion_r156661304
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -490,20 +489,19 @@ case class DataSource(
}
/**
- * Writes the given [[LogicalPlan]] out to this [[DataSource]] and
returns a [[BaseRelation]] for
- * the following reading.
+ * Returns a [[BaseRelation]] for creating table after `planForWriting`.
Only use
+ * in `CreateDataSourceTableAsSelectCommand` while saving data to
non-existing table.
*/
- def writeAndRead(mode: SaveMode, data: LogicalPlan): BaseRelation = {
+ def getRelation(mode: SaveMode, data: LogicalPlan): BaseRelation = {
if
(data.schema.map(_.dataType).exists(_.isInstanceOf[CalendarIntervalType])) {
throw new AnalysisException("Cannot save interval data type into
external storage.")
}
providingClass.newInstance() match {
- case dataSource: CreatableRelationProvider =>
+ case dataSource: RelationProvider =>
--- End diff --
If here use `CreatableRelationProvider.createRelation`, will it write to
destination one more time?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19941#discussion_r156659744
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/InsertIntoDataSourceDirCommand.scala
---
@@ -67,8 +67,9 @@ case class InsertIntoDataSourceDirCommand(
val saveMode = if (overwrite) SaveMode.Overwrite else
SaveMode.ErrorIfExists
try {
-
sparkSession.sessionState.executePlan(dataSource.planForWriting(saveMode,
query))
- dataSource.writeAndRead(saveMode, query)
--- End diff --
I implemented like this at first, but after checking this patch
(https://github.com/apache/spark/pull/18064/files), I changed to current
implementation, is the wrapping of execution id unnecessary here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/17702#discussion_r156658524
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -668,4 +672,31 @@ object DataSource extends Logging {
}
globPath
}
+
+ /**
+ * Return all paths represented by the wildcard string.
+ * Follow [[InMemoryFileIndex]].bulkListLeafFile and reuse the conf.
+ */
+ private def getGlobbedPaths(
+ sparkSession: SparkSession,
+ fs: FileSystem,
+ hadoopConf: SerializableConfiguration,
+ qualified: Path): Seq[Path] = {
+val paths = SparkHadoopUtil.get.expandGlobPath(fs, qualified)
+if (paths.size <=
sparkSession.sessionState.conf.parallelPartitionDiscoveryThreshold) {
+ SparkHadoopUtil.get.globPathIfNecessary(fs, qualified)
+} else {
+ val parallelPartitionDiscoveryParallelism =
+
sparkSession.sessionState.conf.parallelPartitionDiscoveryParallelism
+ val numParallelism = Math.min(paths.size,
parallelPartitionDiscoveryParallelism)
+ val expanded = sparkSession.sparkContext
--- End diff --
Thanks for your suggestion and detailed explanation, I'll reimplement this
to local thread pool.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18760: [SPARK-21560][Core] Add hold mode for the LiveListenerBu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/18760 The porting work of SPARK-18838 is in progress based on Spark 2.1 in our product, I'll close this now and open another PR if needed. Thanks @cloud-fan @vanzin --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18760: [SPARK-21560][Core] Add hold mode for the LiveLis...
Github user xuanyuanking closed the pull request at: https://github.com/apache/spark/pull/18760 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAndRead
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19941 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAndRead
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19941 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/17702#discussion_r156265041
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -668,4 +672,31 @@ object DataSource extends Logging {
}
globPath
}
+
+ /**
+ * Return all paths represented by the wildcard string.
+ * Follow [[InMemoryFileIndex]].bulkListLeafFile and reuse the conf.
+ */
+ private def getGlobbedPaths(
+ sparkSession: SparkSession,
+ fs: FileSystem,
+ hadoopConf: SerializableConfiguration,
+ qualified: Path): Seq[Path] = {
+val paths = SparkHadoopUtil.get.expandGlobPath(fs, qualified)
+if (paths.size <=
sparkSession.sessionState.conf.parallelPartitionDiscoveryThreshold) {
+ SparkHadoopUtil.get.globPathIfNecessary(fs, qualified)
+} else {
+ val parallelPartitionDiscoveryParallelism =
+
sparkSession.sessionState.conf.parallelPartitionDiscoveryParallelism
+ val numParallelism = Math.min(paths.size,
parallelPartitionDiscoveryParallelism)
+ val expanded = sparkSession.sparkContext
--- End diff --
Yep, I means YARN and HDFS always deploy in same region, but driver we
can't control because it's our customer's machine in client mode like spark sql
or shell.
For example we deploy YARN and HDFS in Beijing CN, user use spark sql on
Shanghai CN.
Maybe this scenario shouldn't consider in this patch? What's your opinion
@vanzin
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19941#discussion_r156258956
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -490,20 +489,19 @@ case class DataSource(
}
/**
- * Writes the given [[LogicalPlan]] out to this [[DataSource]] and
returns a [[BaseRelation]] for
- * the following reading.
+ * Returns a [[BaseRelation]] for creating table after `planForWriting`.
Only use
+ * in `CreateDataSourceTableAsSelectCommand` while saving data to
non-existing table.
*/
- def writeAndRead(mode: SaveMode, data: LogicalPlan): BaseRelation = {
+ def getRelation(mode: SaveMode, data: LogicalPlan): BaseRelation = {
if
(data.schema.map(_.dataType).exists(_.isInstanceOf[CalendarIntervalType])) {
throw new AnalysisException("Cannot save interval data type into
external storage.")
}
providingClass.newInstance() match {
- case dataSource: CreatableRelationProvider =>
+ case dataSource: RelationProvider =>
--- End diff --
To the reviewers, current implementation here made datasource should both
inherit `RelationProvider` and `CreatableRelationProvider`([like the
UT](https://github.com/apache/spark/pull/19941/files#diff-d15c669bd62aabde751ae6c54f768d36R28)),
because here just want get the relation by using
`RelationProvider.createRelation` but not save a DF to a destination by using
`CreatableRelationProvider.createRelation`. I need more advise to do better.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/17702#discussion_r156256317
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -668,4 +672,31 @@ object DataSource extends Logging {
}
globPath
}
+
+ /**
+ * Return all paths represented by the wildcard string.
+ * Follow [[InMemoryFileIndex]].bulkListLeafFile and reuse the conf.
+ */
+ private def getGlobbedPaths(
+ sparkSession: SparkSession,
+ fs: FileSystem,
+ hadoopConf: SerializableConfiguration,
+ qualified: Path): Seq[Path] = {
+val paths = SparkHadoopUtil.get.expandGlobPath(fs, qualified)
+if (paths.size <=
sparkSession.sessionState.conf.parallelPartitionDiscoveryThreshold) {
+ SparkHadoopUtil.get.globPathIfNecessary(fs, qualified)
+} else {
+ val parallelPartitionDiscoveryParallelism =
+
sparkSession.sessionState.conf.parallelPartitionDiscoveryParallelism
+ val numParallelism = Math.min(paths.size,
parallelPartitionDiscoveryParallelism)
+ val expanded = sparkSession.sparkContext
--- End diff --
@vanzin Thanks for you reply.
```
Why do this using a Spark job, instead of just a local thread pool?
```
As the DFS generally deployed together with NodeManagers for better data
locality, while using client mode and driver in different region with cluster,
using a Spark job will resolve the problem of cross region interaction in our
scenario.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #16135: [SPARK-18700][SQL] Add StripedLock for each table...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/16135#discussion_r156254083
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/PartitionedTablePerfStatsSuite.scala
---
@@ -352,4 +353,34 @@ class PartitionedTablePerfStatsSuite
}
}
}
+
+ test("SPARK-18700: table loaded only once even when resolved
concurrently") {
+withSQLConf(SQLConf.HIVE_MANAGE_FILESOURCE_PARTITIONS.key -> "false") {
+ withTable("test") {
+withTempDir { dir =>
+ HiveCatalogMetrics.reset()
+ setupPartitionedHiveTable("test", dir, 50)
+ // select the table in multi-threads
+ val executorPool = Executors.newFixedThreadPool(10)
+ (1 to 10).map(threadId => {
+val runnable = new Runnable {
+ override def run(): Unit = {
+spark.sql("select * from test where partCol1 =
999").count()
+ }
+}
+executorPool.execute(runnable)
+None
+ })
+ executorPool.shutdown()
+ executorPool.awaitTermination(30, TimeUnit.SECONDS)
+ // check the cache hit, we use the metric of
METRIC_FILES_DISCOVERED and
+ // METRIC_PARALLEL_LISTING_JOB_COUNT to check this, while the
lock take effect,
+ // only one thread can really do the build, so the listing job
count is 2, the other
+ // one is cache.load func. Also METRIC_FILES_DISCOVERED is
$partition_num * 2
--- End diff --
@gatorsmile Xiao fixed this in https://github.com/apache/spark/pull/16481
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAndRead
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19941 Maybe something wrong with the Jenkins env? I found the build from 84707 to 84733 failed in same reason: ``` [error] running /home/jenkins/workspace/SparkPullRequestBuilder@2/R/run-tests.sh ; received return code 255 ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19941: [SPARK-22753][SQL] Get rid of dataSource.writeAnd...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/19941 [SPARK-22753][SQL] Get rid of dataSource.writeAndRead ## What changes were proposed in this pull request? As the discussion in https://github.com/apache/spark/pull/16481 and https://github.com/apache/spark/pull/18975#discussion_r155454606 Currently the BaseRelation returned by `dataSource.writeAndRead` only used in `CreateDataSourceTableAsSelect`, planForWriting and writeAndRead has some common code paths. In this patch I removed the writeAndRead function and added the getRelation function which only use in `CreateDataSourceTableAsSelectCommand` while saving data to non-existing table. ## How was this patch tested? Existing UT You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-22753 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19941.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19941 commit 14811636692810809033bc7caf03fcecb6939aa3 Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-12-11T12:12:45Z Get rid of dataSource.writeAndRead --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18975: [SPARK-4131] Support "Writing data into the files...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/18975#discussion_r155518105
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/InsertIntoDataSourceDirCommand.scala
---
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command
+
+import org.apache.spark.SparkException
+import org.apache.spark.sql._
+import org.apache.spark.sql.catalyst.catalog._
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
+import org.apache.spark.sql.execution.datasources._
+
+/**
+ * A command used to write the result of a query to a directory.
+ *
+ * The syntax of using this command in SQL is:
+ * {{{
+ * INSERT OVERWRITE DIRECTORY (path=STRING)?
+ * USING format OPTIONS ([option1_name "option1_value", option2_name
"option2_value", ...])
+ * SELECT ...
+ * }}}
+ *
+ * @param storage storage format used to describe how the query result is
stored.
+ * @param provider the data source type to be used
+ * @param query the logical plan representing data to write to
+ * @param overwrite whthere overwrites existing directory
+ */
+case class InsertIntoDataSourceDirCommand(
+storage: CatalogStorageFormat,
+provider: String,
+query: LogicalPlan,
+overwrite: Boolean) extends RunnableCommand {
+
+ override def children: Seq[LogicalPlan] = Seq(query)
+
+ override def run(sparkSession: SparkSession, children: Seq[SparkPlan]):
Seq[Row] = {
+assert(children.length == 1)
+assert(storage.locationUri.nonEmpty, "Directory path is required")
+assert(provider.nonEmpty, "Data source is required")
+
+// Create the relation based on the input logical plan: `query`.
+val pathOption = storage.locationUri.map("path" ->
CatalogUtils.URIToString(_))
+
+val dataSource = DataSource(
+ sparkSession,
+ className = provider,
+ options = storage.properties ++ pathOption,
+ catalogTable = None)
+
+val isFileFormat =
classOf[FileFormat].isAssignableFrom(dataSource.providingClass)
+if (!isFileFormat) {
+ throw new SparkException(
+"Only Data Sources providing FileFormat are supported: " +
dataSource.providingClass)
+}
+
+val saveMode = if (overwrite) SaveMode.Overwrite else
SaveMode.ErrorIfExists
+try {
+
sparkSession.sessionState.executePlan(dataSource.planForWriting(saveMode,
query))
+ dataSource.writeAndRead(saveMode, query)
--- End diff --
@gatorsmile Thanks for you reply, I'll try to fix this.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18975: [SPARK-4131] Support "Writing data into the files...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/18975#discussion_r155185768
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/InsertIntoDataSourceDirCommand.scala
---
@@ -0,0 +1,82 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command
+
+import org.apache.spark.SparkException
+import org.apache.spark.sql._
+import org.apache.spark.sql.catalyst.catalog._
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
+import org.apache.spark.sql.execution.datasources._
+
+/**
+ * A command used to write the result of a query to a directory.
+ *
+ * The syntax of using this command in SQL is:
+ * {{{
+ * INSERT OVERWRITE DIRECTORY (path=STRING)?
+ * USING format OPTIONS ([option1_name "option1_value", option2_name
"option2_value", ...])
+ * SELECT ...
+ * }}}
+ *
+ * @param storage storage format used to describe how the query result is
stored.
+ * @param provider the data source type to be used
+ * @param query the logical plan representing data to write to
+ * @param overwrite whthere overwrites existing directory
+ */
+case class InsertIntoDataSourceDirCommand(
+storage: CatalogStorageFormat,
+provider: String,
+query: LogicalPlan,
+overwrite: Boolean) extends RunnableCommand {
+
+ override def children: Seq[LogicalPlan] = Seq(query)
+
+ override def run(sparkSession: SparkSession, children: Seq[SparkPlan]):
Seq[Row] = {
+assert(children.length == 1)
+assert(storage.locationUri.nonEmpty, "Directory path is required")
+assert(provider.nonEmpty, "Data source is required")
+
+// Create the relation based on the input logical plan: `query`.
+val pathOption = storage.locationUri.map("path" ->
CatalogUtils.URIToString(_))
+
+val dataSource = DataSource(
+ sparkSession,
+ className = provider,
+ options = storage.properties ++ pathOption,
+ catalogTable = None)
+
+val isFileFormat =
classOf[FileFormat].isAssignableFrom(dataSource.providingClass)
+if (!isFileFormat) {
+ throw new SparkException(
+"Only Data Sources providing FileFormat are supported: " +
dataSource.providingClass)
+}
+
+val saveMode = if (overwrite) SaveMode.Overwrite else
SaveMode.ErrorIfExists
+try {
+
sparkSession.sessionState.executePlan(dataSource.planForWriting(saveMode,
query))
+ dataSource.writeAndRead(saveMode, query)
--- End diff --
The implementation here confused me, just want to leave a question here why
we should call both `writeAndRead` and `planForWriting`?
@janewangfb @gatorsmile @cloud-fan
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 gental ping @zsxwing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19773: [SPARK-22546][SQL] Supporting for changing column dataTy...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19773 gental ping @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19773: [SPARK-22546][SQL] Supporting for changing column...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19773#discussion_r152957444
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala ---
@@ -318,16 +318,26 @@ case class AlterTableChangeColumnCommand(
s"'${newColumn.name}' with type '${newColumn.dataType}'")
}
-val newSchema = table.schema.fields.map { field =>
+val typeChanged = originColumn.dataType != newColumn.dataType
+val newDataSchema = table.dataSchema.fields.map { field =>
if (field.name == originColumn.name) {
-// Create a new column from the origin column with the new comment.
-addComment(field, newColumn.getComment)
+// Add the comment to a column, if comment is empty, return the
original column.
+val newField =
newColumn.getComment.map(field.withComment(_)).getOrElse(field)
+if (typeChanged) {
+ newField.copy(dataType = newColumn.dataType)
+} else {
+ newField
+}
} else {
field
}
}
-val newTable = table.copy(schema = StructType(newSchema))
-catalog.alterTable(newTable)
+val newTable = table.copy(schema = StructType(newDataSchema ++
table.partitionSchema))
+if (typeChanged) {
+ catalog.alterTableDataSchema(tableName, StructType(newDataSchema))
--- End diff --
I add the checking logic in next commit and fix bug for changing comment of
partition column.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19773: [SPARK-22546][SQL] Supporting for changing column...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19773#discussion_r152753785
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala ---
@@ -318,16 +318,26 @@ case class AlterTableChangeColumnCommand(
s"'${newColumn.name}' with type '${newColumn.dataType}'")
}
-val newSchema = table.schema.fields.map { field =>
+val typeChanged = originColumn.dataType != newColumn.dataType
+val newDataSchema = table.dataSchema.fields.map { field =>
if (field.name == originColumn.name) {
-// Create a new column from the origin column with the new comment.
-addComment(field, newColumn.getComment)
+// Add the comment to a column, if comment is empty, return the
original column.
+val newField =
newColumn.getComment.map(field.withComment(_)).getOrElse(field)
+if (typeChanged) {
+ newField.copy(dataType = newColumn.dataType)
+} else {
+ newField
+}
} else {
field
}
}
-val newTable = table.copy(schema = StructType(newSchema))
-catalog.alterTable(newTable)
+val newTable = table.copy(schema = StructType(newDataSchema ++
table.partitionSchema))
+if (typeChanged) {
+ catalog.alterTableDataSchema(tableName, StructType(newDataSchema))
--- End diff --
[HIVE-3672](https://issues.apache.org/jira/browse/HIVE-3672) Hive support
this by adding new command of `ALTER TABLE PARTITION COLUMN
( )`.
So here maybe I should throw an AnalysisException while user change the
type of partition column?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19773: [SPARK-22546][SQL] Supporting for changing column...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19773#discussion_r151990044
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala ---
@@ -318,16 +318,28 @@ case class AlterTableChangeColumnCommand(
s"'${newColumn.name}' with type '${newColumn.dataType}'")
}
+val changeSchema = originColumn.dataType != newColumn.dataType
val newSchema = table.schema.fields.map { field =>
if (field.name == originColumn.name) {
-// Create a new column from the origin column with the new comment.
-addComment(field, newColumn.getComment)
+var newField = field
--- End diff --
More clear for getting rid of var, pls check next patch. If we implement
rename or others meta change feature here, may still need some code rework.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19773: [SPARK-22546][SQL] Supporting for changing column dataTy...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19773 @jaceklaskowski Thanks for your review and comments, I rebased the branch and addressed all comments, this patch is now ready for next reviewing. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19773: Supporting for changing column dataType
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/19773 Supporting for changing column dataType ## What changes were proposed in this pull request? Support user to change column dataType in hive table and datasource table, here also want to make a further discuss for other ddl requirement. ## How was this patch tested? Add test case in `DDLSuite.scala` and `SQLQueryTestSuite.scala` You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-22546 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19773.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19773 commit 1bcd74fae9cb6595e04eab6ecaf621739644102f Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-11-17T12:11:33Z Support change column dataType --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19745: [SPARK-2926][Core][Follow Up] Sort shuffle reader...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/19745 [SPARK-2926][Core][Follow Up] Sort shuffle reader for Spark 2.x ## What changes were proposed in this pull request? As comment in [SPARK-2926][https://issues.apache.org/jira/browse/SPARK-2926], this is the follow up work for the old patch on Spark 2.x version. Also this is a preview PR and will add more UT after community think it still worth to follow up. Detailed benchmark attached in jira and this patch mainly to the work below: 1. For support Spark Streaming, Class `ShuffleBlockFetcherIterator` added some wrapping work for ManageBuffer, so here I changes ShuffleBlockFetcherIterator to get the ManagerBuffer, and do the wrapping work out of ShuffleBlockFetcherIterator 2. Class `ShuffleMmeoryManager` has been replaced by `TaskMemoryManager`, so I write a new class named ExternalMergerinherits from `Spillable[ArrayBuffer[MemoryShuffleBlock]]`, this class manage all files and in memory block during `SortShuffleReader.read()` 3. Add a tag named `canUseSortShuffleWriter` in `SortShuffleManager`, for the bug fix of Spark UT error in the scenario of using `UnsafeShuffleWriter` in shuffle write stage but using `SortShuffleReader` in shuffle read stage. 4. Add shuffle metrics of peakMemoryUsedBytes. 5. A Bug fix of datainconsistency in old patch. [Code Link][https://github.com/xuanyuanking/spark/blob/f07c939a25839a5b0f69c504afb9aa008b1b3c5d/core/src/main/scala/org/apache/spark/util/collection/ExternalMerger.scala#L97] ## How was this patch tested? Like the doc described, running a benchmark test vs current spark master and has no data output diff. I will add more UT and complete this PR follow community's advise. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark sort-shuffle-read-master Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19745.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19745 commit b0f1f247cfee8fc7419c6fd3a831f54d1c9d4d63 Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-10-19T06:39:53Z Reimplementation for SPARK-2045 over branch 2.1 commit 1c07650d82f5c85189d4a5758722c3178caa0a3c Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-10-26T05:12:42Z Code clean, include BlockManager and EmternalSorter reuse commit dac1bf9662f1945df0efb5740df84980baa03d8e Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-10-26T05:35:22Z Move ExternalMerger outside commit 33418cae4c4eb80d12ff3bb7b0b4ee3f0a85575e Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-10-26T07:57:01Z fix code style commit f07c939a25839a5b0f69c504afb9aa008b1b3c5d Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-11-10T12:55:27Z Bug fix for data inconsistency and more comments commit ca43f1b44a41b68c2a9a83ced269c3ed644fef69 Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-11-14T14:11:35Z Fix unreasoning var name --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 @zsxwing Thanks for your comments, ready for review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/17702#discussion_r150484788
--- Diff: core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala
---
@@ -246,6 +246,18 @@ class SparkHadoopUtil extends Logging {
if (isGlobPath(pattern)) globPath(fs, pattern) else Seq(pattern)
}
+ def expandGlobPath(fs: FileSystem, pattern: Path): Seq[String] = {
--- End diff --
Add UT in SparkHadoopUtilSuite.scala
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/17702#discussion_r150484715 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala --- @@ -432,6 +433,32 @@ case class DataSource( } /** + * Return all paths represented by the wildcard string. + * Follow [[InMemoryFileIndex]].bulkListLeafFile and reuse the conf. + */ + private def getGlobbedPaths( --- End diff -- Done in next commit. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19287: [SPARK-22074][Core] Task killed by other attempt task sh...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19287 Thanks all reviewers! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19287: [SPARK-22074][Core] Task killed by other attempt task sh...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19287 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19287: [SPARK-22074][Core] Task killed by other attempt task sh...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19287 @squito Hi Rashid, thanks for you review and advise. In the last commit I moved `killedByOtherAttempt` into `TaskSetManager ` as you say and added more asserts in UT. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18760: [SPARK-21560][Core] Add hold mode for the LiveListenerBu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/18760 @vanzin Hi Vanzin, thanks a lot for your comments. Firstly answer your question about `Why isn't hold mode just calling queue.put (blocking) instead of queue.offer (non-blocking)?` In general scenario of the queue is full, we need a time that hold all events push into the queue, here I use offer to control the `empty rate` in the configuration. If here use `put(blocking)`, this will not relief the queue blocking, and just hanging each post events. Actually this patch is a internal fix patch for the event dropping problem in Baidu internal env as I described in [jira](https://issues.apache.org/jira/browse/SPARK-21560), glad to see SPARK-18838 has been merged. Here I had another thought -- how about I port SPARK-18838 to our product env which solved the event dropping by the current patch, if it works well I just close this. What do you two think about this? @cloud-fan @vanzin :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19287: [SPARK-22074][Core] Task killed by other attempt ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/19287#discussion_r141784872 --- Diff: core/src/main/scala/org/apache/spark/scheduler/TaskInfo.scala --- @@ -66,6 +66,13 @@ class TaskInfo( */ var finishTime: Long = 0 + /** + * Set this var when the current task killed by other attempt tasks, this happened while we + * set the `spark.speculation` to true. The task killed by others should not resubmit + * while executor lost. + */ + var killedByOtherAttempt = false --- End diff -- Thanks to point out the `TaskInfo` is DeveloperApi, I address this as your second comment, add this totally private to TaskSetManager --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19287: [SPARK-22074][Core] Task killed by other attempt ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19287#discussion_r141784812
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/TaskSetManagerSuite.scala ---
@@ -744,6 +744,100 @@ class TaskSetManagerSuite extends SparkFunSuite with
LocalSparkContext with Logg
assert(resubmittedTasks === 0)
}
+
+ test("[SPARK-22074] Task killed by other attempt task should not be
resubmitted") {
+val conf = new SparkConf().set("spark.speculation", "true")
+sc = new SparkContext("local", "test", conf)
+// Set the speculation multiplier to be 0 so speculative tasks are
launched immediately
+sc.conf.set("spark.speculation.multiplier", "0.0")
+sc.conf.set("spark.speculation.quantile", "0.5")
+sc.conf.set("spark.speculation", "true")
+
+val sched = new FakeTaskScheduler(sc, ("exec1", "host1"),
+ ("exec2", "host2"), ("exec3", "host3"))
+sched.initialize(new FakeSchedulerBackend() {
+ override def killTask(
+ taskId: Long,
+ executorId: String,
+ interruptThread: Boolean,
+ reason: String): Unit = {}
+})
+
+// Keep track of the number of tasks that are resubmitted,
+// so that the test can check that no tasks were resubmitted.
+var resubmittedTasks = 0
+val dagScheduler = new FakeDAGScheduler(sc, sched) {
+ override def taskEnded(
+ task: Task[_],
+ reason: TaskEndReason,
+ result: Any,
+ accumUpdates: Seq[AccumulatorV2[_, _]],
+ taskInfo: TaskInfo): Unit = {
+super.taskEnded(task, reason, result, accumUpdates, taskInfo)
+reason match {
+ case Resubmitted => resubmittedTasks += 1
+ case _ =>
+}
+ }
+}
+sched.setDAGScheduler(dagScheduler)
+
+val taskSet = FakeTask.createShuffleMapTaskSet(4, 0, 0,
+ Seq(TaskLocation("host1", "exec1")),
+ Seq(TaskLocation("host1", "exec1")),
+ Seq(TaskLocation("host3", "exec3")),
+ Seq(TaskLocation("host2", "exec2")))
+
+val clock = new ManualClock()
+val manager = new TaskSetManager(sched, taskSet, MAX_TASK_FAILURES,
clock = clock)
+val accumUpdatesByTask: Array[Seq[AccumulatorV2[_, _]]] =
taskSet.tasks.map { task =>
+ task.metrics.internalAccums
+}
+// Offer resources for 4 tasks to start
+for ((k, v) <- List(
+ "exec1" -> "host1",
+ "exec1" -> "host1",
+ "exec3" -> "host3",
+ "exec2" -> "host2")) {
+ val taskOption = manager.resourceOffer(k, v, NO_PREF)
+ assert(taskOption.isDefined)
+ val task = taskOption.get
+ assert(task.executorId === k)
+}
+assert(sched.startedTasks.toSet === Set(0, 1, 2, 3))
--- End diff --
OK, I add the assert while get the `taskOption`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19287: [SPARK-22074][Core] Task killed by other attempt ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19287#discussion_r141784747
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/TaskSetManagerSuite.scala ---
@@ -744,6 +744,100 @@ class TaskSetManagerSuite extends SparkFunSuite with
LocalSparkContext with Logg
assert(resubmittedTasks === 0)
}
+
+ test("[SPARK-22074] Task killed by other attempt task should not be
resubmitted") {
+val conf = new SparkConf().set("spark.speculation", "true")
+sc = new SparkContext("local", "test", conf)
+// Set the speculation multiplier to be 0 so speculative tasks are
launched immediately
+sc.conf.set("spark.speculation.multiplier", "0.0")
+sc.conf.set("spark.speculation.quantile", "0.5")
+sc.conf.set("spark.speculation", "true")
+
+val sched = new FakeTaskScheduler(sc, ("exec1", "host1"),
+ ("exec2", "host2"), ("exec3", "host3"))
+sched.initialize(new FakeSchedulerBackend() {
+ override def killTask(
+ taskId: Long,
+ executorId: String,
+ interruptThread: Boolean,
+ reason: String): Unit = {}
+})
+
+// Keep track of the number of tasks that are resubmitted,
+// so that the test can check that no tasks were resubmitted.
+var resubmittedTasks = 0
+val dagScheduler = new FakeDAGScheduler(sc, sched) {
+ override def taskEnded(
+ task: Task[_],
+ reason: TaskEndReason,
+ result: Any,
+ accumUpdates: Seq[AccumulatorV2[_, _]],
+ taskInfo: TaskInfo): Unit = {
+super.taskEnded(task, reason, result, accumUpdates, taskInfo)
+reason match {
+ case Resubmitted => resubmittedTasks += 1
+ case _ =>
+}
+ }
+}
+sched.setDAGScheduler(dagScheduler)
+
+val taskSet = FakeTask.createShuffleMapTaskSet(4, 0, 0,
+ Seq(TaskLocation("host1", "exec1")),
+ Seq(TaskLocation("host1", "exec1")),
+ Seq(TaskLocation("host3", "exec3")),
+ Seq(TaskLocation("host2", "exec2")))
+
+val clock = new ManualClock()
+val manager = new TaskSetManager(sched, taskSet, MAX_TASK_FAILURES,
clock = clock)
+val accumUpdatesByTask: Array[Seq[AccumulatorV2[_, _]]] =
taskSet.tasks.map { task =>
+ task.metrics.internalAccums
+}
+// Offer resources for 4 tasks to start
+for ((k, v) <- List(
+ "exec1" -> "host1",
+ "exec1" -> "host1",
+ "exec3" -> "host3",
+ "exec2" -> "host2")) {
+ val taskOption = manager.resourceOffer(k, v, NO_PREF)
+ assert(taskOption.isDefined)
+ val task = taskOption.get
+ assert(task.executorId === k)
+}
+assert(sched.startedTasks.toSet === Set(0, 1, 2, 3))
+clock.advance(1)
+// Complete the 2 tasks and leave 2 task in running
+for (id <- Set(0, 1)) {
+ manager.handleSuccessfulTask(id, createTaskResult(id,
accumUpdatesByTask(id)))
+ assert(sched.endedTasks(id) === Success)
+}
+
+// checkSpeculatableTasks checks that the task runtime is greater than
the threshold for
+// speculating. Since we use a threshold of 0 for speculation, tasks
need to be running for
+// > 0ms, so advance the clock by 1ms here.
+clock.advance(1)
+assert(manager.checkSpeculatableTasks(0))
+assert(sched.speculativeTasks.toSet === Set(2, 3))
+
+// Offer resource to start the speculative attempt for the running
task 2.0
+val taskOption = manager.resourceOffer("exec2", "host2", ANY)
+assert(taskOption.isDefined)
+val task4 = taskOption.get
+assert(task4.index === 2)
+assert(task4.taskId === 4)
+assert(task4.executorId === "exec2")
+assert(task4.attemptNumber === 1)
+sched.backend = mock(classOf[SchedulerBackend])
--- End diff --
Yep, in this case there's only one `killTask` check, fixed this in next
patch.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19287: [SPARK-22074][Core] Task killed by other attempt task sh...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19287 @jerryshao Thanks for you review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19287: [SPARK-22074][Core] Task killed by other attempt ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/19287#discussion_r141513379
--- Diff: core/src/main/scala/org/apache/spark/scheduler/TaskInfo.scala ---
@@ -74,6 +81,10 @@ class TaskInfo(
gettingResultTime = time
}
+ private[spark] def markKilledAttempt: Unit = {
--- End diff --
Sorry for the missing, I change it right now.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18760: [SPARK-21560][Core] Add hold mode for the LiveListenerBu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/18760 The hold mode is still valid, I resolved the conflict and add the logic into `AsyncEventQueue`, it can confirm by the test case added in this [patch](https://github.com/apache/spark/pull/18760/files#diff-6ddec7f06d0cf5392943ecdb80fcea24R515). `Now LiveListenerBus have multiple queue` Yep, glad to see SPARK-18838 finally merged and it may resolve the event drop problem. But as you say, `it's very unlikely` but may be a hold mode is more safety? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19287: [SPARK-22074][Core] Task killed by other attempt task sh...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19287 ping @cloud-fan @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19287: [SPARK-22074][Core] Task killed by other attempt ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/19287#discussion_r140143293 --- Diff: core/src/main/scala/org/apache/spark/scheduler/TaskInfo.scala --- @@ -66,6 +66,12 @@ class TaskInfo( */ var finishTime: Long = 0 + /** + * Set this tag when this task killed by other attempt. This kind of task should not resubmit + * while executor lost. + */ --- End diff -- Thanks for reviewing, rewrite this comment. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19287: [SPARK-22074][Core] Task killed by other attempt task sh...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19287 `signal 9` retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19287: [SPARK-22074][Core] Task killed by other attempt ...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/19287 [SPARK-22074][Core] Task killed by other attempt task should not be resubmitted ## What changes were proposed in this pull request? As the detail scenario described in [SPARK-22074](https://issues.apache.org/jira/browse/SPARK-22074), unnecessary resubmitted may cause stage hanging in currently release versions. This patch add a new var in TaskInfo to mark this task killed by other attempt or not. ## How was this patch tested? Add a new UT `[SPARK-22074] Task killed by other attempt task should not be resubmitted` in TaskSetManagerSuite, this UT recreate the scenario in JIRA description, it failed without the changes in this PR and passed conversely. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-22074 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19287.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19287 commit a28daa2c3283ad31659f840e6d401ab48a42ad88 Author: Yuanjian Li <xyliyuanj...@gmail.com> Date: 2017-09-20T05:35:35Z [SPARK-22074][Core] Task killed by other attempt task should not be resubmitted --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18760: [SPARK-21560][Core] Add hold mode for the LiveListenerBu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/18760 @jiangxb1987 Hi xingbo, can you give me some advise about this? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18760: [SPARK-21560][Core] Add hold mode for the LiveListenerBu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/18760 ping @gatorsmile @cloud-fan , can you review about this? Thanks :) --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org