[GitHub] r39132 closed pull request #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
r39132 closed pull request #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879 This is a PR merged from a forked repository. As GitHub hides the original diff on merge, it is displayed below for the sake of provenance: As this is a foreign pull request (from a fork), the diff is supplied below (as it won't show otherwise due to GitHub magic): diff --git a/README.md b/README.md index 16fb2f4250..5b1b6b7d4e 100644 --- a/README.md +++ b/README.md @@ -116,6 +116,7 @@ Currently **officially** using Airflow: 1. [Bluecore](https://www.bluecore.com) [[@JLDLaughlin](https://github.com/JLDLaughlin)] 1. [Boda Telecom Suite - CE](https://github.com/bodastage/bts-ce) [[@erssebaggala](https://github.com/erssebaggala), [@bodastage](https://github.com/bodastage)] 1. [Bodastage Solutions](http://bodastage.com) [[@erssebaggala](https://github.com/erssebaggala), [@bodastage](https://github.com/bodastage)] +1. [Bombora Inc](https://bombora.com/) [[@jeffkpayne](https://github.com/jeffkpayne), [@TheOriginalAlex](https://github.com/TheOriginalAlex)] 1. [Bonnier Broadcasting](http://www.bonnierbroadcasting.com) [[@wileeam](https://github.com/wileeam)] 1. [BounceX](http://www.bouncex.com) [[@JoshFerge](https://github.com/JoshFerge), [@hudsonrio](https://github.com/hudsonrio), [@ronniekritou](https://github.com/ronniekritou)] 1. [Branch](https://branch.io) [[@sdebarshi](https://github.com/sdebarshi), [@dmitrig01](https://github.com/dmitrig01)] This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] codecov-io edited a comment on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
codecov-io edited a comment on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879#issuecomment-420147353 # [Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=h1) Report > Merging [#3879](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=desc) into [master](https://codecov.io/gh/apache/incubator-airflow/commit/2318cea74d4f71fba353eaca9bb3c4fd3cdb06c0?src=pr=desc) will **increase** coverage by `<.01%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=tree) ```diff @@Coverage Diff @@ ## master#3879 +/- ## == + Coverage 77.47% 77.48% +<.01% == Files 200 200 Lines 1585015850 == + Hits1228012281 +1 + Misses 3570 3569 -1 ``` | [Impacted Files](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/models.py](https://codecov.io/gh/apache/incubator-airflow/pull/3879/diff?src=pr=tree#diff-YWlyZmxvdy9tb2RlbHMucHk=) | `88.79% <0%> (+0.04%)` | :arrow_up: | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=footer). Last update [2318cea...5959b61](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] codecov-io commented on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
codecov-io commented on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879#issuecomment-420147353 # [Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=h1) Report > Merging [#3879](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=desc) into [master](https://codecov.io/gh/apache/incubator-airflow/commit/2318cea74d4f71fba353eaca9bb3c4fd3cdb06c0?src=pr=desc) will **increase** coverage by `<.01%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=tree) ```diff @@Coverage Diff @@ ## master#3879 +/- ## == + Coverage 77.47% 77.48% +<.01% == Files 200 200 Lines 1585015850 == + Hits1228012281 +1 + Misses 3570 3569 -1 ``` | [Impacted Files](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/models.py](https://codecov.io/gh/apache/incubator-airflow/pull/3879/diff?src=pr=tree#diff-YWlyZmxvdy9tb2RlbHMucHk=) | `88.79% <0%> (+0.04%)` | :arrow_up: | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=footer). Last update [2318cea...5959b61](https://codecov.io/gh/apache/incubator-airflow/pull/3879?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] jeffkpayne commented on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
jeffkpayne commented on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879#issuecomment-420142299 @r39132 Gah... Sorry about that... This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-3001) Accumulative tis slow allocation of new schedule
[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16610026#comment-16610026
]
ASF GitHub Bot commented on AIRFLOW-3001:
-
ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table
index 'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
[ Description ]
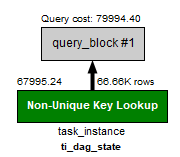
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ]
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)

### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Accumulative tis slow allocation of new schedule
>
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 1.10.0
>Reporter: Jason Kim
>Assignee: Jason Kim
>Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (AIRFLOW-3001) Accumulative tis slow allocation of new schedule
[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16610025#comment-16610025
]
ASF GitHub Bot commented on AIRFLOW-3001:
-
ubermen closed pull request #3874: [AIRFLOW-3001] Add task_instance table index
'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
new file mode 100644
index 00..2f89181bb5
--- /dev/null
+++ b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
@@ -0,0 +1,42 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""add index to taskinstance
+
+Revision ID: 82c452539eeb
+Revises: 9635ae0956e7
+Create Date: 2018-09-10 17:04:32.058103
+
+"""
+
+# revision identifiers, used by Alembic.
+revision = '82c452539eeb'
+down_revision = '9635ae0956e7'
+branch_labels = None
+depends_on = None
+
+from alembic import op
+import sqlalchemy as sa
+
+
+def upgrade():
+op.create_index('ti_dag_date', 'task_instance', ['dag_id',
'execution_date'], unique=False)
+
+
+def downgrade():
+op.drop_index('ti_dag_date', table_name='task_instance')
diff --git a/airflow/models.py b/airflow/models.py
index 2096785b41..c41f2a9dbe 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -880,6 +880,7 @@ class TaskInstance(Base, LoggingMixin):
__table_args__ = (
Index('ti_dag_state', dag_id, state),
+Index('ti_dag_date', dag_id, execution_date),
Index('ti_state', state),
Index('ti_state_lkp', dag_id, task_id, execution_date, state),
Index('ti_pool', pool, state, priority_weight),
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Accumulative tis slow allocation of new schedule
>
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 1.10.0
>Reporter: Jason Kim
>Assignee: Jason Kim
>Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table
index 'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
[ Description ]
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ]
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)


### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] ubermen closed pull request #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen closed pull request #3874: [AIRFLOW-3001] Add task_instance table index
'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
new file mode 100644
index 00..2f89181bb5
--- /dev/null
+++ b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
@@ -0,0 +1,42 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""add index to taskinstance
+
+Revision ID: 82c452539eeb
+Revises: 9635ae0956e7
+Create Date: 2018-09-10 17:04:32.058103
+
+"""
+
+# revision identifiers, used by Alembic.
+revision = '82c452539eeb'
+down_revision = '9635ae0956e7'
+branch_labels = None
+depends_on = None
+
+from alembic import op
+import sqlalchemy as sa
+
+
+def upgrade():
+op.create_index('ti_dag_date', 'task_instance', ['dag_id',
'execution_date'], unique=False)
+
+
+def downgrade():
+op.drop_index('ti_dag_date', table_name='task_instance')
diff --git a/airflow/models.py b/airflow/models.py
index 2096785b41..c41f2a9dbe 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -880,6 +880,7 @@ class TaskInstance(Base, LoggingMixin):
__table_args__ = (
Index('ti_dag_state', dag_id, state),
+Index('ti_dag_date', dag_id, execution_date),
Index('ti_state', state),
Index('ti_state_lkp', dag_id, task_id, execution_date, state),
Index('ti_pool', pool, state, priority_weight),
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] r39132 commented on a change in pull request #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
r39132 commented on a change in pull request #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879#discussion_r216525697 ## File path: README.md ## @@ -117,6 +117,7 @@ Currently **officially** using Airflow: 1. [Boda Telecom Suite - CE](https://github.com/bodastage/bts-ce) [[@erssebaggala](https://github.com/erssebaggala), [@bodastage](https://github.com/bodastage)] 1. [Bodastage Solutions](http://bodastage.com) [[@erssebaggala](https://github.com/erssebaggala), [@bodastage](https://github.com/bodastage)] 1. [Bonnier Broadcasting](http://www.bonnierbroadcasting.com) [[@wileeam](https://github.com/wileeam)] +1. [Bombora Inc](https://bombora.com/) [[@jeffkpayne](https://github.com/jeffkpayne), [@TheOriginalAlex](https://github.com/TheOriginalAlex)] Review comment: @jeffkpayne Bombora should go above Bonnier per alphabetic ordering! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 commented on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
r39132 commented on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879#issuecomment-420119747 @jeffkpayne Bombara should go above Bonnier per alphabetic ordering! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 removed a comment on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
r39132 removed a comment on issue #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow URL: https://github.com/apache/incubator-airflow/pull/3879#issuecomment-420119747 @jeffkpayne Bombara should go above Bonnier per alphabetic ordering! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] XD-DENG edited a comment on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
XD-DENG edited a comment on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime URL: https://github.com/apache/incubator-airflow/pull/3834#issuecomment-420113869 Sure! But I may only start to look into that later, since I got ideas for a few other potential PR to work on at this moment, which may be prioritized. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] XD-DENG commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
XD-DENG commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime URL: https://github.com/apache/incubator-airflow/pull/3834#issuecomment-420113869 Sure! But I may only start to look into that later, since I got ideas for a few other potential PR to work on at this moment, which may prioritized. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (AIRFLOW-3036) Upgrading to Airflow 1.10 not possible using GCP Cloud SQL for MYSQL
[
https://issues.apache.org/jira/browse/AIRFLOW-3036?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Smith Mathieu updated AIRFLOW-3036:
---
Description:
The upgrade path to airflow 1.10 seems impossible for users of MySQL in
Google's Cloud SQL service given new mysql requirements for 1.10.
When executing "airflow upgradedb"
```
INFO [alembic.runtime.migration] Running upgrade d2ae31099d61 -> 0e2a74e0fc9f,
Add time zone awareness
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 32, in
args.func(args)
File "/usr/local/lib/python3.6/site-packages/airflow/bin/cli.py", line 1002,
in initdb
db_utils.initdb(settings.RBAC)
File "/usr/local/lib/python3.6/site-packages/airflow/utils/db.py", line 92, in
initdb
upgradedb()
File "/usr/local/lib/python3.6/site-packages/airflow/utils/db.py", line 346,
in upgradedb
command.upgrade(config, 'heads')
File "/usr/local/lib/python3.6/site-packages/alembic/command.py", line 174, in
upgrade
script.run_env()
File "/usr/local/lib/python3.6/site-packages/alembic/script/base.py", line
416, in run_env
util.load_python_file(self.dir, 'env.py')
File "/usr/local/lib/python3.6/site-packages/alembic/util/pyfiles.py", line
93, in load_python_file
module = load_module_py(module_id, path)
File "/usr/local/lib/python3.6/site-packages/alembic/util/compat.py", line 68,
in load_module_py
module_id, path).load_module(module_id)
File "", line 399, in _check_name_wrapper
File "", line 823, in load_module
File "", line 682, in load_module
File "", line 265, in _load_module_shim
File "", line 684, in _load
File "", line 665, in _load_unlocked
File "", line 678, in exec_module
File "", line 219, in _call_with_frames_removed
File "/usr/local/lib/python3.6/site-packages/airflow/migrations/env.py", line
91, in
run_migrations_online()
File "/usr/local/lib/python3.6/site-packages/airflow/migrations/env.py", line
86, in run_migrations_online
context.run_migrations()
File "", line 8, in run_migrations
File "/usr/local/lib/python3.6/site-packages/alembic/runtime/environment.py",
line 807, in run_migrations
self.get_context().run_migrations(**kw)
File "/usr/local/lib/python3.6/site-packages/alembic/runtime/migration.py",
line 321, in run_migrations
step.migration_fn(**kw)
File
"/usr/local/lib/python3.6/site-packages/airflow/migrations/versions/0e2a74e0fc9f_add_time_zone_awareness.py",
line 46, in upgrade
raise Exception("Global variable explicit_defaults_for_timestamp needs to be
on (1) for mysql")
Exception: Global variable explicit_defaults_for_timestamp needs to be on (1)
for mysql
```
Reading documentation for upgrading to airflow 1.10, it seems the requirement
for explicit_defaults_for_timestamp=1 was intentional.
However, MySQL on Google Cloud SQL does not support configuring this variable
and it is off by default. Users of MySQL and Cloud SQL do not have an upgrade
path to 1.10. Alas, so close to the mythical Kubernetes Executor.
In GCP, Cloud SQL is _the_ hosted MySQL solution.
[https://cloud.google.com/sql/docs/mysql/flags]
was:
The upgrade path to airflow 1.10 seems impossible for users of MySQL in
Google's Cloud SQL service given new mysql requirements for 1.10.
When executing "airflow upgradedb"
```
INFO [alembic.runtime.migration] Running upgrade d2ae31099d61 -
0e2a74e0fc9f, Add time zone awareness
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 32, in module
args.func(args)
File "/usr/local/lib/python3.6/site-packages/airflow/bin/cli.py", line 1002,
in initdb
db_utils.initdb(settings.RBAC)
File "/usr/local/lib/python3.6/site-packages/airflow/utils/db.py", line 92, in
initdb
upgradedb()
File "/usr/local/lib/python3.6/site-packages/airflow/utils/db.py", line 346,
in upgradedb
command.upgrade(config, 'heads')
File "/usr/local/lib/python3.6/site-packages/alembic/command.py", line 174, in
upgrade
script.run_env()
File "/usr/local/lib/python3.6/site-packages/alembic/script/base.py", line
416, in run_env
util.load_python_file(self.dir, 'env.py')
File "/usr/local/lib/python3.6/site-packages/alembic/util/pyfiles.py", line
93, in load_python_file
module = load_module_py(module_id, path)
File "/usr/local/lib/python3.6/site-packages/alembic/util/compat.py", line 68,
in load_module_py
module_id, path).load_module(module_id)
File "frozen importlib._bootstrap_external", line 399, in
_check_name_wrapper
File "frozen importlib._bootstrap_external", line 823, in load_module
File "frozen importlib._bootstrap_external", line 682, in load_module
File "frozen importlib._bootstrap", line 265, in _load_module_shim
File "frozen importlib._bootstrap", line 684, in _load
File "frozen importlib._bootstrap", line 665, in _load_unlocked
File "frozen importlib._bootstrap_external", line 678, in exec_module
File "frozen importlib._bootstrap", line 219, in
_call_with_frames_removed
File
[jira] [Created] (AIRFLOW-3036) Upgrading to Airflow 1.10 not possible using GCP Cloud SQL for MYSQL
Smith Mathieu created AIRFLOW-3036:
--
Summary: Upgrading to Airflow 1.10 not possible using GCP Cloud
SQL for MYSQL
Key: AIRFLOW-3036
URL: https://issues.apache.org/jira/browse/AIRFLOW-3036
Project: Apache Airflow
Issue Type: Bug
Components: core, db
Affects Versions: 1.10.0
Environment: Google Cloud Platform, Google Kubernetes Engine, Airflow
1.10 on Debian Stretch, Google Cloud SQL MySQL
Reporter: Smith Mathieu
The upgrade path to airflow 1.10 seems impossible for users of MySQL in
Google's Cloud SQL service given new mysql requirements for 1.10.
When executing "airflow upgradedb"
```
INFO [alembic.runtime.migration] Running upgrade d2ae31099d61 -
0e2a74e0fc9f, Add time zone awareness
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 32, in module
args.func(args)
File "/usr/local/lib/python3.6/site-packages/airflow/bin/cli.py", line 1002,
in initdb
db_utils.initdb(settings.RBAC)
File "/usr/local/lib/python3.6/site-packages/airflow/utils/db.py", line 92, in
initdb
upgradedb()
File "/usr/local/lib/python3.6/site-packages/airflow/utils/db.py", line 346,
in upgradedb
command.upgrade(config, 'heads')
File "/usr/local/lib/python3.6/site-packages/alembic/command.py", line 174, in
upgrade
script.run_env()
File "/usr/local/lib/python3.6/site-packages/alembic/script/base.py", line
416, in run_env
util.load_python_file(self.dir, 'env.py')
File "/usr/local/lib/python3.6/site-packages/alembic/util/pyfiles.py", line
93, in load_python_file
module = load_module_py(module_id, path)
File "/usr/local/lib/python3.6/site-packages/alembic/util/compat.py", line 68,
in load_module_py
module_id, path).load_module(module_id)
File "frozen importlib._bootstrap_external", line 399, in
_check_name_wrapper
File "frozen importlib._bootstrap_external", line 823, in load_module
File "frozen importlib._bootstrap_external", line 682, in load_module
File "frozen importlib._bootstrap", line 265, in _load_module_shim
File "frozen importlib._bootstrap", line 684, in _load
File "frozen importlib._bootstrap", line 665, in _load_unlocked
File "frozen importlib._bootstrap_external", line 678, in exec_module
File "frozen importlib._bootstrap", line 219, in
_call_with_frames_removed
File "/usr/local/lib/python3.6/site-packages/airflow/migrations/env.py", line
91, in module
run_migrations_online()
File "/usr/local/lib/python3.6/site-packages/airflow/migrations/env.py", line
86, in run_migrations_online
context.run_migrations()
File "string", line 8, in run_migrations
File "/usr/local/lib/python3.6/site-packages/alembic/runtime/environment.py",
line 807, in run_migrations
self.get_context().run_migrations(**kw)
File "/usr/local/lib/python3.6/site-packages/alembic/runtime/migration.py",
line 321, in run_migrations
step.migration_fn(**kw)
File
"/usr/local/lib/python3.6/site-packages/airflow/migrations/versions/0e2a74e0fc9f_add_time_zone_awareness.py",
line 46, in upgrade
raise Exception("Global variable explicit_defaults_for_timestamp needs to be
on (1) for mysql")
Exception: Global variable explicit_defaults_for_timestamp needs to be on (1)
for mysql
```
Reading documentation for upgrading to airflow 1.10, it seems the requirement
for explicit_defaults_for_timestamp=1 was intentional.
However, MySQL on Google Cloud SQL does not support configuring this variable
and it is off by default. Users of MySQL and Cloud SQL do not have an upgrade
path to 1.10
In GCP, Cloud SQL is _the_ hosted MySQL solution.
https://cloud.google.com/sql/docs/mysql/flags
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jeffrey Payne updated AIRFLOW-3035:
---
Priority: Minor (was: Major)
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Assignee: Jeffrey Payne
>Priority: Minor
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
> Another, perhaps better, option would be to have the dataproc job operators
> accept a list of {{error_states}} that could be passed into
> {{raise_error()}}, allowing the caller to determine which states should
> result in "failure" of the task. I would lean towards that option.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jeffrey Payne updated AIRFLOW-3035:
---
Issue Type: Improvement (was: Bug)
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Improvement
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Assignee: Jeffrey Payne
>Priority: Minor
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
> Another, perhaps better, option would be to have the dataproc job operators
> accept a list of {{error_states}} that could be passed into
> {{raise_error()}}, allowing the caller to determine which states should
> result in "failure" of the task. I would lean towards that option.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] jeffkpayne opened a new pull request #3879: [AIRFLOW-XXX] Add Bombora Inc using Airflow
jeffkpayne opened a new pull request #3879: [AIRFLOW-XXX] Add Bombora Inc using
Airflow
URL: https://github.com/apache/incubator-airflow/pull/3879
Make sure you have checked _all_ steps below.
### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] r39132 commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
r39132 commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime URL: https://github.com/apache/incubator-airflow/pull/3834#issuecomment-420104265 That's a fair point. If you can think of a treatment that makes good use of the real-estate (e.g. on hover, show the next run), that might work around this constraint. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] feng-tao commented on issue #3878: [AIRFLOW-3034]: Update Readme : Add slack link, remove Gitter
feng-tao commented on issue #3878: [AIRFLOW-3034]: Update Readme : Add slack link, remove Gitter URL: https://github.com/apache/incubator-airflow/pull/3878#issuecomment-420100410 hey @r39132 , there are some -1 on the vote thread you started. Have we decided the final decision of retiring gitter? If that's the case, the pr lgtm. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 commented on issue #1906: [AIRFLOW-536] Schedule all pending DAG runs in a single scheduler loop
r39132 commented on issue #1906: [AIRFLOW-536] Schedule all pending DAG runs in a single scheduler loop URL: https://github.com/apache/incubator-airflow/pull/1906#issuecomment-420099175 @vijaysbhat Please rebase and let me know if you still want a review! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 commented on issue #2055: [AIRFLOW-417] Show useful error message for missing DAG in URL
r39132 commented on issue #2055: [AIRFLOW-417] Show useful error message for missing DAG in URL URL: https://github.com/apache/incubator-airflow/pull/2055#issuecomment-420099102 @vijaysbhat Please rebase and let me know if you still want a review! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] XD-DENG edited a comment on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
XD-DENG edited a comment on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime URL: https://github.com/apache/incubator-airflow/pull/3834#issuecomment-420097902 Thanks @r39132 . I’ll follow up on the documentation should necessary. Regarding adding this to UI->DAG List, I’m conservative about this idea since: - it may make the interface too crowded - it’s not really necessary as we already have “ last run” and “schedule” in the table. It is very straightforward for us to refer the next execution in UI scenario. “Next_execution” feature is only necessary in command line interface in my opinion, as information in command line is much less visual. May you let me know your thought? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 commented on issue #2129: [AIRFLOW-952] Allow deleting extra field in connection UI
r39132 commented on issue #2129: [AIRFLOW-952] Allow deleting extra field in connection UI URL: https://github.com/apache/incubator-airflow/pull/2129#issuecomment-420099031 @vijaysbhat Please rebase and let me know if you still want a review! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 closed pull request #2140: WIP - Waiting endpoint
r39132 closed pull request #2140: WIP - Waiting endpoint
URL: https://github.com/apache/incubator-airflow/pull/2140
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/models.py b/airflow/models.py
index 37f88230a0..7eeaae6ee5 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -1019,7 +1019,7 @@ def key(self):
"""
return self.dag_id, self.task_id, self.execution_date
-def set_state(self, state, session):
+def set_state(self, state, session):
self.state = state
self.start_date = datetime.now()
self.end_date = datetime.now()
@@ -1393,13 +1393,17 @@ def signal_handler(signum, frame):
Stats.incr('operator_successes_{}'.format(
self.task.__class__.__name__), 1, 1)
self.state = State.SUCCESS
+if (task.on_success_set_state_to
+and task.on_success_set_state_to in State.hold()):
+self.state = task.on_success_set_state_to
+
except AirflowSkipException:
self.state = State.SKIPPED
except (Exception, KeyboardInterrupt) as e:
self.handle_failure(e, test_mode, context)
raise
-# Recording SUCCESS
+# Recording SUCCESS or on_success_set_state_to
self.end_date = datetime.now()
self.set_duration()
if not test_mode:
@@ -1883,6 +1887,12 @@ class derived from this one results in the creation of a
task object,
:type resources: dict
:param run_as_user: unix username to impersonate while running the task
:type run_as_user: str
+:param on_success_set_state_to: sets the exit state of the operator to this
+state. Can be used to allow an external event to trigger continuation
+:type on_success_set_state_to: str
+:param on_standby_timeout: the amount of time the scheduler waits on the
+external trigger. Will be converted to seconds.
+:type on_standby_timeout: timedelta
"""
# For derived classes to define which fields will get jinjaified
@@ -1925,6 +1935,8 @@ def __init__(
trigger_rule=TriggerRule.ALL_SUCCESS,
resources=None,
run_as_user=None,
+on_success_set_state_to=None,
+on_standby_timeout=timedelta(3600),
*args,
**kwargs):
@@ -1976,6 +1988,11 @@ def __init__(
self.execution_timeout = execution_timeout
self.on_failure_callback = on_failure_callback
self.on_success_callback = on_success_callback
+self.on_success_set_state_to = on_success_set_state_to
+if isinstance(on_standby_timeout, timedelta):
+self.on_standby_timeout = on_standby_timeout
+else:
+self.on_standby_timeout = timedelta(seconds=retry_delay)
self.on_retry_callback = on_retry_callback
if isinstance(retry_delay, timedelta):
self.retry_delay = retry_delay
@@ -2019,6 +2036,7 @@ def __init__(
'on_failure_callback',
'on_success_callback',
'on_retry_callback',
+'on_success_set_state',
}
def __eq__(self, other):
diff --git a/airflow/ti_deps/deps/onstandby_dep.py
b/airflow/ti_deps/deps/onstandby_dep.py
new file mode 100644
index 00..ad8c579d65
--- /dev/null
+++ b/airflow/ti_deps/deps/onstandby_dep.py
@@ -0,0 +1,57 @@
+# -*- coding: utf-8 -*-
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from datetime import datetime
+
+from airflow.ti_deps.deps.base_ti_dep import BaseTIDep
+from airflow.utils.db import provide_session
+from airflow.utils.state import State
+
+
+class OnStandByDep(BaseTIDep):
+"""
+Determines if a task's upstream tasks are in a state that allows a given
task instance
+to run.
+"""
+NAME = "On Standby"
+IGNOREABLE = True
+IS_TASK_DEP = True
+
+@provide_session
+def _get_dep_statuses(self, ti, session, dep_context):
+if dep_context.ignore_ti_state:
+yield self._passing_status(
+reason="Context specified that state should be ignored.")
+return
+
+if ti.state is not State.ON_STANDBY:
+yield self._passing_status(
+reason="The
[GitHub] r39132 commented on issue #2140: WIP - Waiting endpoint
r39132 commented on issue #2140: WIP - Waiting endpoint URL: https://github.com/apache/incubator-airflow/pull/2140#issuecomment-420098512 @bolkedebruin I'm closing this PR for now. Please reopen when you start actively working on it again. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] XD-DENG commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
XD-DENG commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime URL: https://github.com/apache/incubator-airflow/pull/3834#issuecomment-420097902 Thanks @r39132 . Regarding adding this to UI->DAG List, I’m conservative about this idea since: - it may make the interface too crowded - it’s not really necessary as we already have “ last run” and “schedule” in the table. It is very straightforward for us to refer the next execution in UI scenario. “Next_execution” feature is only necessary in command line interface in my opinion, as information in command line is much less visual. May you let me know your thought? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (AIRFLOW-2965) Add CLI command to find the next dag run.
[
https://issues.apache.org/jira/browse/AIRFLOW-2965?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Siddharth Anand closed AIRFLOW-2965.
Resolution: Fixed
> Add CLI command to find the next dag run.
> -
>
> Key: AIRFLOW-2965
> URL: https://issues.apache.org/jira/browse/AIRFLOW-2965
> Project: Apache Airflow
> Issue Type: Task
>Affects Versions: 1.10.0
>Reporter: jack
>Assignee: Xiaodong DENG
>Priority: Minor
>
> I have a dag with the following properties:
> {code:java}
> dag = DAG(
> dag_id='mydag',
> default_args=args,
> schedule_interval='0 1 * * *',
> max_active_runs=1,
> catchup=False){code}
>
>
> This runs great.
> Last run is: 2018-08-26 01:00 (start date is 2018-08-27 01:00)
>
> Now it's 2018-08-27 17:55 I decided to change my dag to:
>
> {code:java}
> dag = DAG(
> dag_id='mydag',
> default_args=args,
> schedule_interval='0 23 * * *',
> max_active_runs=1,
> catchup=False){code}
>
> Now, I have no idea when will be the next dag run.
> Will it be today at 23:00? I can't be sure when the cycle is complete. I'm
> not even sure that this change will do what I wish.
> I'm sure you guys are expert and you can answer this question but most of us
> wouldn't know.
>
> The scheduler has the knowledge when the dag is available for running. All
> I'm asking is to take that knowledge and create a CLI command that I will
> give the dag_id and it will tell me the next date/hour which my dag will be
> runnable.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (AIRFLOW-2965) Add CLI command to find the next dag run.
[
https://issues.apache.org/jira/browse/AIRFLOW-2965?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609889#comment-16609889
]
ASF GitHub Bot commented on AIRFLOW-2965:
-
r39132 closed pull request #3834: [AIRFLOW-2965] CLI tool to show the next
execution datetime
URL: https://github.com/apache/incubator-airflow/pull/3834
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/bin/cli.py b/airflow/bin/cli.py
index e22427cf40..c38116e6c0 100644
--- a/airflow/bin/cli.py
+++ b/airflow/bin/cli.py
@@ -551,6 +551,31 @@ def dag_state(args):
print(dr[0].state if len(dr) > 0 else None)
+@cli_utils.action_logging
+def next_execution(args):
+"""
+Returns the next execution datetime of a DAG at the command line.
+>>> airflow next_execution tutorial
+2018-08-31 10:38:00
+"""
+dag = get_dag(args)
+
+if dag.is_paused:
+print("[INFO] Please be reminded this DAG is PAUSED now.")
+
+if dag.latest_execution_date:
+next_execution_dttm = dag.following_schedule(dag.latest_execution_date)
+
+if next_execution_dttm is None:
+print("[WARN] No following schedule can be found. " +
+ "This DAG may have schedule interval '@once' or `None`.")
+
+print(next_execution_dttm)
+else:
+print("[WARN] Only applicable when there is execution record found for
the DAG.")
+print(None)
+
+
@cli_utils.action_logging
def list_dags(args):
dagbag = DagBag(process_subdir(args.subdir))
@@ -1986,6 +2011,11 @@ class CLIFactory(object):
'func': sync_perm,
'help': "Update existing role's permissions.",
'args': tuple(),
+},
+{
+'func': next_execution,
+'help': "Get the next execution datetime of a DAG.",
+'args': ('dag_id', 'subdir')
}
)
subparsers_dict = {sp['func'].__name__: sp for sp in subparsers}
diff --git a/tests/cli/test_cli.py b/tests/cli/test_cli.py
index 616b9a0f16..93ec0576e6 100644
--- a/tests/cli/test_cli.py
+++ b/tests/cli/test_cli.py
@@ -20,9 +20,12 @@
import unittest
+from datetime import datetime, timedelta, time
from mock import patch, Mock, MagicMock
from time import sleep
import psutil
+import pytz
+import subprocess
from argparse import Namespace
from airflow import settings
from airflow.bin.cli import get_num_ready_workers_running, run, get_dag
@@ -165,3 +168,80 @@ def test_local_run(self):
ti.refresh_from_db()
state = ti.current_state()
self.assertEqual(state, State.SUCCESS)
+
+def test_next_execution(self):
+# A scaffolding function
+def reset_dr_db(dag_id):
+session = Session()
+dr = session.query(models.DagRun).filter_by(dag_id=dag_id)
+dr.delete()
+session.commit()
+session.close()
+
+EXAMPLE_DAGS_FOLDER = os.path.join(
+os.path.dirname(
+os.path.dirname(
+os.path.dirname(os.path.realpath(__file__))
+)
+),
+"airflow/example_dags"
+)
+
+dagbag = models.DagBag(dag_folder=EXAMPLE_DAGS_FOLDER,
+ include_examples=False)
+dag_ids = ['example_bash_operator', # schedule_interval is '0 0 * * *'
+ 'latest_only', # schedule_interval is timedelta(hours=4)
+ 'example_python_operator', # schedule_interval=None
+ 'example_xcom'] # schedule_interval="@once"
+
+# The details below is determined by the schedule_interval of example
DAGs
+now = timezone.utcnow()
+next_execution_time_for_dag1 = pytz.utc.localize(
+datetime.combine(
+now.date() + timedelta(days=1),
+time(0)
+)
+)
+next_execution_time_for_dag2 = now + timedelta(hours=4)
+expected_output = [str(next_execution_time_for_dag1),
+ str(next_execution_time_for_dag2),
+ "None",
+ "None"]
+
+for i in range(len(dag_ids)):
+dag_id = dag_ids[i]
+
+# Clear dag run so no execution history fo each DAG
+reset_dr_db(dag_id)
+
+p = subprocess.Popen(["airflow", "next_execution", dag_id,
+ "--subdir", EXAMPLE_DAGS_FOLDER],
+ stdout=subprocess.PIPE)
+p.wait()
+stdout = []
+for line in p.stdout:
+stdout.append(str(line.decode("utf-8").rstrip()))
+
+# `next_execution`
[GitHub] r39132 closed pull request #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
r39132 closed pull request #3834: [AIRFLOW-2965] CLI tool to show the next
execution datetime
URL: https://github.com/apache/incubator-airflow/pull/3834
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/bin/cli.py b/airflow/bin/cli.py
index e22427cf40..c38116e6c0 100644
--- a/airflow/bin/cli.py
+++ b/airflow/bin/cli.py
@@ -551,6 +551,31 @@ def dag_state(args):
print(dr[0].state if len(dr) > 0 else None)
+@cli_utils.action_logging
+def next_execution(args):
+"""
+Returns the next execution datetime of a DAG at the command line.
+>>> airflow next_execution tutorial
+2018-08-31 10:38:00
+"""
+dag = get_dag(args)
+
+if dag.is_paused:
+print("[INFO] Please be reminded this DAG is PAUSED now.")
+
+if dag.latest_execution_date:
+next_execution_dttm = dag.following_schedule(dag.latest_execution_date)
+
+if next_execution_dttm is None:
+print("[WARN] No following schedule can be found. " +
+ "This DAG may have schedule interval '@once' or `None`.")
+
+print(next_execution_dttm)
+else:
+print("[WARN] Only applicable when there is execution record found for
the DAG.")
+print(None)
+
+
@cli_utils.action_logging
def list_dags(args):
dagbag = DagBag(process_subdir(args.subdir))
@@ -1986,6 +2011,11 @@ class CLIFactory(object):
'func': sync_perm,
'help': "Update existing role's permissions.",
'args': tuple(),
+},
+{
+'func': next_execution,
+'help': "Get the next execution datetime of a DAG.",
+'args': ('dag_id', 'subdir')
}
)
subparsers_dict = {sp['func'].__name__: sp for sp in subparsers}
diff --git a/tests/cli/test_cli.py b/tests/cli/test_cli.py
index 616b9a0f16..93ec0576e6 100644
--- a/tests/cli/test_cli.py
+++ b/tests/cli/test_cli.py
@@ -20,9 +20,12 @@
import unittest
+from datetime import datetime, timedelta, time
from mock import patch, Mock, MagicMock
from time import sleep
import psutil
+import pytz
+import subprocess
from argparse import Namespace
from airflow import settings
from airflow.bin.cli import get_num_ready_workers_running, run, get_dag
@@ -165,3 +168,80 @@ def test_local_run(self):
ti.refresh_from_db()
state = ti.current_state()
self.assertEqual(state, State.SUCCESS)
+
+def test_next_execution(self):
+# A scaffolding function
+def reset_dr_db(dag_id):
+session = Session()
+dr = session.query(models.DagRun).filter_by(dag_id=dag_id)
+dr.delete()
+session.commit()
+session.close()
+
+EXAMPLE_DAGS_FOLDER = os.path.join(
+os.path.dirname(
+os.path.dirname(
+os.path.dirname(os.path.realpath(__file__))
+)
+),
+"airflow/example_dags"
+)
+
+dagbag = models.DagBag(dag_folder=EXAMPLE_DAGS_FOLDER,
+ include_examples=False)
+dag_ids = ['example_bash_operator', # schedule_interval is '0 0 * * *'
+ 'latest_only', # schedule_interval is timedelta(hours=4)
+ 'example_python_operator', # schedule_interval=None
+ 'example_xcom'] # schedule_interval="@once"
+
+# The details below is determined by the schedule_interval of example
DAGs
+now = timezone.utcnow()
+next_execution_time_for_dag1 = pytz.utc.localize(
+datetime.combine(
+now.date() + timedelta(days=1),
+time(0)
+)
+)
+next_execution_time_for_dag2 = now + timedelta(hours=4)
+expected_output = [str(next_execution_time_for_dag1),
+ str(next_execution_time_for_dag2),
+ "None",
+ "None"]
+
+for i in range(len(dag_ids)):
+dag_id = dag_ids[i]
+
+# Clear dag run so no execution history fo each DAG
+reset_dr_db(dag_id)
+
+p = subprocess.Popen(["airflow", "next_execution", dag_id,
+ "--subdir", EXAMPLE_DAGS_FOLDER],
+ stdout=subprocess.PIPE)
+p.wait()
+stdout = []
+for line in p.stdout:
+stdout.append(str(line.decode("utf-8").rstrip()))
+
+# `next_execution` function is inapplicable if no execution record
found
+# It prints `None` in such cases
+self.assertEqual(stdout[-1], "None")
+
+dag = dagbag.dags[dag_id]
+# Create a DagRun for each DAG, to prepare
[GitHub] r39132 commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime
r39132 commented on issue #3834: [AIRFLOW-2965] CLI tool to show the next execution datetime URL: https://github.com/apache/incubator-airflow/pull/3834#issuecomment-420089890 @XD-DENG This works great. It may be worth documenting that the next execution is based on the last execution which was started, but not necessarily completed or completed successfully. Happy to look at that documentation as a follow-on PR if folks agree it's not obvious. Also, you may want to update the UI (the dags list) with a next execution column! So, add a `Next Run` similar to the `Last Run` that exists today. https://user-images.githubusercontent.com/581734/45328997-2dab3080-b513-11e8-91fe-32d40c3b7757.png;> This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609884#comment-16609884
]
Jeffrey Payne commented on AIRFLOW-3035:
One other nitpick, the message passed into {{raise_error()}} from {{submit()}}
on line references "DataProcTask", which is inconsistent with the rest of the
naming in the {{gcp_dataproc_hook.py}}.
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Assignee: Jeffrey Payne
>Priority: Major
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
> Another, perhaps better, option would be to have the dataproc job operators
> accept a list of {{error_states}} that could be passed into
> {{raise_error()}}, allowing the caller to determine which states should
> result in "failure" of the task. I would lean towards that option.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jeffrey Payne updated AIRFLOW-3035:
---
Description:
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
{code}
would fix both of these...
Another, perhaps better, option would be to have the dataproc job operators
accept a list of {{error_states}} that could be passed into {{raise_error()}},
allowing the caller to determine which states should result in "failure" of the
task. I would lean towards that option.
was:
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
{code}
would fix both of these...
Another, perhaps better, option would be to have the dataproc job operators
accept a list of {{error_states}} that would result in {{raise_error()}} being
called, allowing the caller to determine which states should result in
"failure" of the task. I would lean towards that option.
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Assignee: Jeffrey Payne
>Priority: Major
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
> Another, perhaps better, option would be to have the dataproc job operators
> accept a list of {{error_states}} that could be passed into
> {{raise_error()}}, allowing the caller to determine which states should
> result in "failure" of the task. I would lean towards that option.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jeffrey Payne updated AIRFLOW-3035:
---
Description:
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
{code}
would fix both of these...
Another, perhaps better, option would be to have the dataproc job operators
accept a list of {{error_states}} that would result in {{raise_error()}} being
called, allowing the caller to determine which states should result in
"failure" of the task. I would lean towards that option.
was:
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
{code}
would fix both of these...
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Assignee: Jeffrey Payne
>Priority: Major
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
> Another, perhaps better, option would be to have the dataproc job operators
> accept a list of {{error_states}} that would result in {{raise_error()}}
> being called, allowing the caller to determine which states should result in
> "failure" of the task. I would lean towards that option.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jeffrey Payne reassigned AIRFLOW-3035:
--
Assignee: Jeffrey Payne
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Assignee: Jeffrey Payne
>Priority: Major
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
[
https://issues.apache.org/jira/browse/AIRFLOW-3035?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jeffrey Payne updated AIRFLOW-3035:
---
Description:
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
{code}
would fix both of these...
was:
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CENCELLED'):
{code}
would fix both of these...
> gcp_dataproc_hook should treat CANCELLED job state consistently
> ---
>
> Key: AIRFLOW-3035
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib
>Affects Versions: 1.10.0, 2.0.0, 1.10.1
>Reporter: Jeffrey Payne
>Priority: Major
> Labels: dataproc
>
> When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
> {{CENCELLED}} state in a consistent and non-intuitive manner:
> # The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
> {{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
> for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the
> job state is {{ERROR}}.
> # The end result from the perspective of the {{dataproc_operator.py}} for a
> cancelled job is that the job succeeded, which results in the success
> callback being called. This seems strange to me, as a "cancelled" job is
> rarely considered successful, in my experience.
> Simply changing {{raise_error()}} from:
> {code:python}
> if 'ERROR' == self.job['status']['state']:
> {code}
> to
> {code:python}
> if self.job['status']['state'] in ('ERROR', 'CANCELLED'):
> {code}
> would fix both of these...
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (AIRFLOW-3035) gcp_dataproc_hook should treat CANCELLED job state consistently
Jeffrey Payne created AIRFLOW-3035:
--
Summary: gcp_dataproc_hook should treat CANCELLED job state
consistently
Key: AIRFLOW-3035
URL: https://issues.apache.org/jira/browse/AIRFLOW-3035
Project: Apache Airflow
Issue Type: Bug
Components: contrib
Affects Versions: 1.10.0, 2.0.0, 1.10.1
Reporter: Jeffrey Payne
When a DP job is cancelled, {{gcp_dataproc_hook.py}} does not treat the
{{CENCELLED}} state in a consistent and non-intuitive manner:
# The API internal to {{gcp_dataproc_hook.py}} returns {{False}} from
{{_DataProcJob.wait_for_done()}}, resulting in {{raise_error()}} being called
for cancelled jobs, yet {{raise_error()}} only raises {{Exception}} if the job
state is {{ERROR}}.
# The end result from the perspective of the {{dataproc_operator.py}} for a
cancelled job is that the job succeeded, which results in the success callback
being called. This seems strange to me, as a "cancelled" job is rarely
considered successful, in my experience.
Simply changing {{raise_error()}} from:
{code:python}
if 'ERROR' == self.job['status']['state']:
{code}
to
{code:python}
if self.job['status']['state'] in ('ERROR', 'CENCELLED'):
{code}
would fix both of these...
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] codecov-io commented on issue #3878: [AIRFLOW-3034]: Update Readme : Add slack link, remove Gitter
codecov-io commented on issue #3878: [AIRFLOW-3034]: Update Readme : Add slack link, remove Gitter URL: https://github.com/apache/incubator-airflow/pull/3878#issuecomment-420078393 # [Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=h1) Report > Merging [#3878](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=desc) into [master](https://codecov.io/gh/apache/incubator-airflow/commit/d0efeabc654000793eacf1abeb1c74deba3959a9?src=pr=desc) will **decrease** coverage by `0.49%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=tree) ```diff @@Coverage Diff@@ ## master#3878 +/- ## = - Coverage 77.52% 77.03% -0.5% = Files 200 200 Lines 1583915839 = - Hits1227912201 -78 - Misses 3560 3638 +78 ``` | [Impacted Files](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/hooks/hdfs\_hook.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9oZGZzX2hvb2sucHk=) | `27.5% <0%> (-65%)` | :arrow_down: | | [airflow/executors/sequential\_executor.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy9leGVjdXRvcnMvc2VxdWVudGlhbF9leGVjdXRvci5weQ==) | `50% <0%> (-50%)` | :arrow_down: | | [airflow/utils/sqlalchemy.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy91dGlscy9zcWxhbGNoZW15LnB5) | `74.28% <0%> (-7.15%)` | :arrow_down: | | [airflow/utils/decorators.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy91dGlscy9kZWNvcmF0b3JzLnB5) | `85.41% <0%> (-6.25%)` | :arrow_down: | | [airflow/executors/\_\_init\_\_.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy9leGVjdXRvcnMvX19pbml0X18ucHk=) | `59.61% <0%> (-3.85%)` | :arrow_down: | | [airflow/hooks/dbapi\_hook.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9kYmFwaV9ob29rLnB5) | `79.67% <0%> (-3.26%)` | :arrow_down: | | [airflow/task/task\_runner/base\_task\_runner.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy90YXNrL3Rhc2tfcnVubmVyL2Jhc2VfdGFza19ydW5uZXIucHk=) | `77.96% <0%> (-1.7%)` | :arrow_down: | | [airflow/utils/dag\_processing.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy91dGlscy9kYWdfcHJvY2Vzc2luZy5weQ==) | `87.71% <0%> (-1.32%)` | :arrow_down: | | [airflow/operators/docker\_operator.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy9vcGVyYXRvcnMvZG9ja2VyX29wZXJhdG9yLnB5) | `96.51% <0%> (-1.17%)` | :arrow_down: | | [airflow/www\_rbac/app.py](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree#diff-YWlyZmxvdy93d3dfcmJhYy9hcHAucHk=) | `96.66% <0%> (-1.12%)` | :arrow_down: | | ... and [6 more](https://codecov.io/gh/apache/incubator-airflow/pull/3878/diff?src=pr=tree-more) | | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=footer). Last update [d0efeab...e88abc1](https://codecov.io/gh/apache/incubator-airflow/pull/3878?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (AIRFLOW-3034) Update Readme : Add slack link, remove Gitter
[ https://issues.apache.org/jira/browse/AIRFLOW-3034?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Siddharth Anand updated AIRFLOW-3034: - External issue URL: https://github.com/apache/incubator-airflow/pull/3878 > Update Readme : Add slack link, remove Gitter > - > > Key: AIRFLOW-3034 > URL: https://issues.apache.org/jira/browse/AIRFLOW-3034 > Project: Apache Airflow > Issue Type: Improvement >Reporter: Siddharth Anand >Assignee: Siddharth Anand >Priority: Minor > > * Remove the Gitter badge > * Replace the gitter link with one for slack -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (AIRFLOW-3034) Update Readme : Add slack link, remove Gitter
[
https://issues.apache.org/jira/browse/AIRFLOW-3034?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609822#comment-16609822
]
ASF GitHub Bot commented on AIRFLOW-3034:
-
r39132 opened a new pull request #3878: [AIRFLOW-3034]: Update Readme : Add
slack link, remove Gitter
URL: https://github.com/apache/incubator-airflow/pull/3878
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-3034
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [x] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [x] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
N/A.
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [x] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [x] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Update Readme : Add slack link, remove Gitter
> -
>
> Key: AIRFLOW-3034
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3034
> Project: Apache Airflow
> Issue Type: Improvement
>Reporter: Siddharth Anand
>Assignee: Siddharth Anand
>Priority: Minor
>
> * Remove the Gitter badge
> * Replace the gitter link with one for slack
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] r39132 opened a new pull request #3878: [AIRFLOW-3034]: Update Readme : Add slack link, remove Gitter
r39132 opened a new pull request #3878: [AIRFLOW-3034]: Update Readme : Add
slack link, remove Gitter
URL: https://github.com/apache/incubator-airflow/pull/3878
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-3034
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [x] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [x] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
N/A.
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [x] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [x] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (AIRFLOW-3034) Update Readme : Add slack link, remove Gitter
Siddharth Anand created AIRFLOW-3034: Summary: Update Readme : Add slack link, remove Gitter Key: AIRFLOW-3034 URL: https://issues.apache.org/jira/browse/AIRFLOW-3034 Project: Apache Airflow Issue Type: Improvement Reporter: Siddharth Anand Assignee: Siddharth Anand * Remove the Gitter badge * Replace the gitter link with one for slack -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] r39132 closed pull request #3877: [AIRFLOW-XXX] Add Enigma to list of companies
r39132 closed pull request #3877: [AIRFLOW-XXX] Add Enigma to list of companies URL: https://github.com/apache/incubator-airflow/pull/3877 This is a PR merged from a forked repository. As GitHub hides the original diff on merge, it is displayed below for the sake of provenance: As this is a foreign pull request (from a fork), the diff is supplied below (as it won't show otherwise due to GitHub magic): diff --git a/README.md b/README.md index 1c0cd13f59..16fb2f4250 100644 --- a/README.md +++ b/README.md @@ -147,6 +147,7 @@ Currently **officially** using Airflow: 1. [Dotmodus](http://dotmodus.com) [[@dannylee12](https://github.com/dannylee12)] 1. [Drivy](https://www.drivy.com) [[@AntoineAugusti](https://github.com/AntoineAugusti)] 1. [Easy Taxi](http://www.easytaxi.com/) [[@caique-lima](https://github.com/caique-lima) & [@WesleyBatista](https://github.com/WesleyBatista) & [@diraol](https://github.com/diraol)] +1. [Enigma](https://www.enigma.com) [[@hydrosquall](https://github.com/hydrosquall)] 1. [eRevalue](https://www.datamaran.com) [[@hamedhsn](https://github.com/hamedhsn)] 1. [evo.company](https://evo.company/) [[@orhideous](https://github.com/orhideous)] 1. [Flipp](https://www.flipp.com) [[@sethwilsonwishabi](https://github.com/sethwilsonwishabi)] This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] r39132 commented on issue #3877: [AIRFLOW-XXX] Add Enigma to list of companies
r39132 commented on issue #3877: [AIRFLOW-XXX] Add Enigma to list of companies URL: https://github.com/apache/incubator-airflow/pull/3877#issuecomment-420059847 @hydrosquall Welcome to the Airflow community! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] hydrosquall opened a new pull request #3877: [AIRFLOW-XXX] Add Enigma to list of companies
hydrosquall opened a new pull request #3877: [AIRFLOW-XXX] Add Enigma to list
of companies
URL: https://github.com/apache/incubator-airflow/pull/3877
### Jira
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
Adds Enigma to the list of companies using Airflow
### Tests
N/A
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
N/A
### Code Quality
N/A
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (AIRFLOW-461) BigQuery: Support autodetection of schemas
[ https://issues.apache.org/jira/browse/AIRFLOW-461?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609739#comment-16609739 ] Siddharth Anand commented on AIRFLOW-461: - [~xnuinside]Thanks for picking this up. Feel free to update the External Issue URL with a new Pull Request URL when ready. > BigQuery: Support autodetection of schemas > -- > > Key: AIRFLOW-461 > URL: https://issues.apache.org/jira/browse/AIRFLOW-461 > Project: Apache Airflow > Issue Type: Improvement > Components: contrib, gcp >Reporter: Jeremiah Lowin >Assignee: Iuliia Volkova >Priority: Major > > Add support for autodetecting schemas. Autodetect behavior is described in > the documentation for federated data sources here: > https://cloud.google.com/bigquery/federated-data-sources#auto-detect but is > actually available when loading any CSV or JSON data (not just for federated > tables). See the API: > https://cloud.google.com/bigquery/docs/reference/v2/jobs#configuration.load.autodetect -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] feng-tao edited a comment on issue #3830: [AIRFLOW-2156] Parallelize Celery Executor task state fetching
feng-tao edited a comment on issue #3830: [AIRFLOW-2156] Parallelize Celery Executor task state fetching URL: https://github.com/apache/incubator-airflow/pull/3830#issuecomment-420036693 @yrqls21 , sorry, didn't see you change the default from 16 to a value depending on numbers of cores. I am +1 for the current way of setting the default value. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Assigned] (AIRFLOW-461) BigQuery: Support autodetection of schemas
[ https://issues.apache.org/jira/browse/AIRFLOW-461?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Iuliia Volkova reassigned AIRFLOW-461: -- Assignee: Iuliia Volkova (was: Jeremiah Lowin) > BigQuery: Support autodetection of schemas > -- > > Key: AIRFLOW-461 > URL: https://issues.apache.org/jira/browse/AIRFLOW-461 > Project: Apache Airflow > Issue Type: Improvement > Components: contrib, gcp >Reporter: Jeremiah Lowin >Assignee: Iuliia Volkova >Priority: Major > > Add support for autodetecting schemas. Autodetect behavior is described in > the documentation for federated data sources here: > https://cloud.google.com/bigquery/federated-data-sources#auto-detect but is > actually available when loading any CSV or JSON data (not just for federated > tables). See the API: > https://cloud.google.com/bigquery/docs/reference/v2/jobs#configuration.load.autodetect -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] yrqls21 commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop
yrqls21 commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop URL: https://github.com/apache/incubator-airflow/pull/3873#issuecomment-420029489 @kaxil Thank you! This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] kaxil commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop
kaxil commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop URL: https://github.com/apache/incubator-airflow/pull/3873#issuecomment-420025101 @yrqls21 https://github.com/apache/incubator-airflow/blob/master/docs/scheduler.rst This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] yrqls21 commented on issue #3830: [AIRFLOW-2156] Parallelize Celery Executor task state fetching
yrqls21 commented on issue #3830: [AIRFLOW-2156] Parallelize Celery Executor task state fetching URL: https://github.com/apache/incubator-airflow/pull/3830#issuecomment-420024359 @feng-tao Would you elaborate a bit more on the reason please? It feels weird to introduce a new performance improvement with no improvement by default. As mentioned by @Fokko, there might have already been too many config people need to tune. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] kaxil commented on issue #3869: [AIRFLOW-3012] Fix Bug when passing emails for SLA
kaxil commented on issue #3869: [AIRFLOW-3012] Fix Bug when passing emails for SLA URL: https://github.com/apache/incubator-airflow/pull/3869#issuecomment-420018479 cc @fokko @ashb This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] TheOriginalAlex commented on issue #3871: [AIRFLOW-2797] Create Google Dataproc cluster with custom image
TheOriginalAlex commented on issue #3871: [AIRFLOW-2797] Create Google Dataproc cluster with custom image URL: https://github.com/apache/incubator-airflow/pull/3871#issuecomment-420006157 Also for sanity sake, might be a good idea to unset `cluster_data['config']['softwareConfig']['imageVersion']` if a custom image is passed in. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-2887) Add to BigQueryBaseCursor methods for creating insert dataset
[
https://issues.apache.org/jira/browse/AIRFLOW-2887?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609537#comment-16609537
]
ASF GitHub Bot commented on AIRFLOW-2887:
-
xnuinside opened a new pull request #3876: WIP: [AIRFLOW-2887] Add to
BigQueryBaseCursor methods for insert dataset
URL: https://github.com/apache/incubator-airflow/pull/3876
Make sure you have checked _all_ steps below.
### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add to BigQueryBaseCursor methods for creating insert dataset
> -
>
> Key: AIRFLOW-2887
> URL: https://issues.apache.org/jira/browse/AIRFLOW-2887
> Project: Apache Airflow
> Issue Type: New Feature
>Reporter: Iuliia Volkova
>Assignee: Iuliia Volkova
>Priority: Minor
>
> In BigQueryBaseCursor exist only:
> def delete_dataset(self, project_id, dataset_id)
> And there are no hook to
> create([https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/insert)]
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] xnuinside opened a new pull request #3876: WIP: [AIRFLOW-2887] Add to BigQueryBaseCursor methods for insert dataset
xnuinside opened a new pull request #3876: WIP: [AIRFLOW-2887] Add to
BigQueryBaseCursor methods for insert dataset
URL: https://github.com/apache/incubator-airflow/pull/3876
Make sure you have checked _all_ steps below.
### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Work started] (AIRFLOW-2797) Add ability to create Google Dataproc cluster with custom image
[ https://issues.apache.org/jira/browse/AIRFLOW-2797?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on AIRFLOW-2797 started by Jarosław Śmietanka. --- > Add ability to create Google Dataproc cluster with custom image > --- > > Key: AIRFLOW-2797 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2797 > Project: Apache Airflow > Issue Type: Improvement > Components: contrib, gcp, operators >Affects Versions: 2.0.0 >Reporter: Jarosław Śmietanka >Assignee: Jarosław Śmietanka >Priority: Minor > > In GCP, it is possible to create Dataproc cluster with a [custom > image|https://cloud.google.com/dataproc/docs/guides/dataproc-images] that > includes user's pre-installed packages. It significantly reduces the startup > time of the cluster. > > Since I already have a code which does that, I volunteer to bring it to the > community :) > This improvement won't change many components and should not require > groundbreaking changes to DataprocClusterCreateOperator. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work started] (AIRFLOW-2797) Add ability to create Google Dataproc cluster with custom image
[ https://issues.apache.org/jira/browse/AIRFLOW-2797?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on AIRFLOW-2797 started by Jarosław Śmietanka. --- > Add ability to create Google Dataproc cluster with custom image > --- > > Key: AIRFLOW-2797 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2797 > Project: Apache Airflow > Issue Type: Improvement > Components: contrib, gcp, operators >Affects Versions: 2.0.0 >Reporter: Jarosław Śmietanka >Assignee: Jarosław Śmietanka >Priority: Minor > > In GCP, it is possible to create Dataproc cluster with a [custom > image|https://cloud.google.com/dataproc/docs/guides/dataproc-images] that > includes user's pre-installed packages. It significantly reduces the startup > time of the cluster. > > Since I already have a code which does that, I volunteer to bring it to the > community :) > This improvement won't change many components and should not require > groundbreaking changes to DataprocClusterCreateOperator. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] TheOriginalAlex commented on issue #3871: [AIRFLOW-2797] Create Google Dataproc cluster with custom image
TheOriginalAlex commented on issue #3871: [AIRFLOW-2797] Create Google Dataproc cluster with custom image URL: https://github.com/apache/incubator-airflow/pull/3871#issuecomment-419964270 Would it be useful to allow the ability to have distinct images for master and worker nodes? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (AIRFLOW-2904) Clean an unnecessary line in airflow/executors/celery_executor.py
[ https://issues.apache.org/jira/browse/AIRFLOW-2904?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaodong DENG updated AIRFLOW-2904: --- Fix Version/s: (was: 2.0.0) 1.10.1 > Clean an unnecessary line in airflow/executors/celery_executor.py > - > > Key: AIRFLOW-2904 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2904 > Project: Apache Airflow > Issue Type: Improvement > Components: executor >Reporter: Xiaodong DENG >Assignee: Xiaodong DENG >Priority: Trivial > Fix For: 1.10.1 > > Attachments: Screen Shot 2018-08-15 at 10.23.05 PM.png > > > Line > [https://github.com/apache/incubator-airflow/blob/00adade4163197fcff799168398edc629f989d34/airflow/executors/celery_executor.py#L34] > is unnecessary. Variable *PARALLELISM* is defined here but never used later. > !Screen Shot 2018-08-15 at 10.23.05 PM.png! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (AIRFLOW-2855) Need to Check Validity of Cron Expression When Process DAG File/Zip File
[ https://issues.apache.org/jira/browse/AIRFLOW-2855?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaodong DENG updated AIRFLOW-2855: --- Fix Version/s: 1.10.1 > Need to Check Validity of Cron Expression When Process DAG File/Zip File > > > Key: AIRFLOW-2855 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2855 > Project: Apache Airflow > Issue Type: Improvement > Components: DAG >Reporter: Xiaodong DENG >Assignee: Xiaodong DENG >Priority: Critical > Fix For: 1.10.1 > > > *schedule_interval* of DAGs can either be *timedelta* or a *Cron expression*. > When it's a Cron expression, there is no mechanism to check its validity at > this moment. If there is anything wrong with the Cron expression itself, it > will cause issues when methods _*following_schedule(**)*_ and > _*previous_schedule()*_ are invoked (will affect scheduling). However, > exceptions will only be written into logs. From Web UI, it’s hard for users > to identify this issue & the source while no new task can be initiated > (especially for users who’re not very familiar with Cron). > It may be good to show error messages in web UI when a DAG's Cron expression > (as schedule_interval) can not be parsed by *croniter* properly. > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (AIRFLOW-2797) Add ability to create Google Dataproc cluster with custom image
[ https://issues.apache.org/jira/browse/AIRFLOW-2797?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609323#comment-16609323 ] Jarosław Śmietanka commented on AIRFLOW-2797: - [~jeffkpa...@gmail.com] Code is in PR. > Add ability to create Google Dataproc cluster with custom image > --- > > Key: AIRFLOW-2797 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2797 > Project: Apache Airflow > Issue Type: Improvement > Components: contrib, gcp, operators >Affects Versions: 2.0.0 >Reporter: Jarosław Śmietanka >Assignee: Jarosław Śmietanka >Priority: Minor > > In GCP, it is possible to create Dataproc cluster with a [custom > image|https://cloud.google.com/dataproc/docs/guides/dataproc-images] that > includes user's pre-installed packages. It significantly reduces the startup > time of the cluster. > > Since I already have a code which does that, I volunteer to bring it to the > community :) > This improvement won't change many components and should not require > groundbreaking changes to DataprocClusterCreateOperator. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (AIRFLOW-2895) Prevent scheduler from spamming heartbeats/logs
[ https://issues.apache.org/jira/browse/AIRFLOW-2895?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ash Berlin-Taylor resolved AIRFLOW-2895. Resolution: Fixed Fix Version/s: 1.10.1 > Prevent scheduler from spamming heartbeats/logs > --- > > Key: AIRFLOW-2895 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2895 > Project: Apache Airflow > Issue Type: Bug > Components: scheduler >Reporter: Dan Davydov >Assignee: Dan Davydov >Priority: Major > Fix For: 1.10.1 > > > There seems to be a couple of problems with > [https://github.com/apache/incubator-airflow/pull/2986] that cause the sleep > to not trigger and Scheduler heartbeating/logs to be spammed: > # If all of the files are being processed in the queue, there is no sleep > (can be fixed by sleeping for min_sleep even if there are no files) > # I have heard reports that some files can return a parsing time that is > monotonically increasing for some reason (e.g. file actually parses in 1s > each loop, but the reported duration seems to use the very time the file was > parsed as the start time instead of the last time), I haven't confirmed this > but it sounds problematic. > To unblock the release I'm reverting this PR for now. It should be re-added > with tests/mocking. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (AIRFLOW-2895) Prevent scheduler from spamming heartbeats/logs
[ https://issues.apache.org/jira/browse/AIRFLOW-2895?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609222#comment-16609222 ] Fabrice Dossin commented on AIRFLOW-2895: - Hello, This one should also be cherry picked to 1.10.1 please. > Prevent scheduler from spamming heartbeats/logs > --- > > Key: AIRFLOW-2895 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2895 > Project: Apache Airflow > Issue Type: Bug > Components: scheduler >Reporter: Dan Davydov >Assignee: Dan Davydov >Priority: Major > > There seems to be a couple of problems with > [https://github.com/apache/incubator-airflow/pull/2986] that cause the sleep > to not trigger and Scheduler heartbeating/logs to be spammed: > # If all of the files are being processed in the queue, there is no sleep > (can be fixed by sleeping for min_sleep even if there are no files) > # I have heard reports that some files can return a parsing time that is > monotonically increasing for some reason (e.g. file actually parses in 1s > each loop, but the reported duration seems to use the very time the file was > parsed as the start time instead of the last time), I haven't confirmed this > but it sounds problematic. > To unblock the release I'm reverting this PR for now. It should be re-added > with tests/mocking. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (AIRFLOW-2895) Prevent scheduler from spamming heartbeats/logs
[ https://issues.apache.org/jira/browse/AIRFLOW-2895?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16609221#comment-16609221 ] Fabrice Dossin commented on AIRFLOW-2895: - Hello, This one should also be cherry picked to 1.10.1 please. > Prevent scheduler from spamming heartbeats/logs > --- > > Key: AIRFLOW-2895 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2895 > Project: Apache Airflow > Issue Type: Bug > Components: scheduler >Reporter: Dan Davydov >Assignee: Dan Davydov >Priority: Major > > There seems to be a couple of problems with > [https://github.com/apache/incubator-airflow/pull/2986] that cause the sleep > to not trigger and Scheduler heartbeating/logs to be spammed: > # If all of the files are being processed in the queue, there is no sleep > (can be fixed by sleeping for min_sleep even if there are no files) > # I have heard reports that some files can return a parsing time that is > monotonically increasing for some reason (e.g. file actually parses in 1s > each loop, but the reported duration seems to use the very time the file was > parsed as the start time instead of the last time), I haven't confirmed this > but it sounds problematic. > To unblock the release I'm reverting this PR for now. It should be re-added > with tests/mocking. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (AIRFLOW-3033) `airflow upgradedb` should create FAB user tables always.
Ash Berlin-Taylor created AIRFLOW-3033:
--
Summary: `airflow upgradedb` should create FAB user tables always.
Key: AIRFLOW-3033
URL: https://issues.apache.org/jira/browse/AIRFLOW-3033
Project: Apache Airflow
Issue Type: Bug
Affects Versions: 1.10.0
Reporter: Ash Berlin-Taylor
Fix For: 1.10.1
Right now the FAB user tables are only created on running {{airflow initdb}},
and only when the rbac option is already set.
I think we should
1) create the table un-conditinallly, and
2) create the tables as part of {{upgradedb}}, not just initdb. (I don't ever
run initdb on my production clusters - I don't want all the example connections
created.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] Fokko commented on issue #3875: Update kubernetes.rst with correct KubernetesPodOperator inputs
Fokko commented on issue #3875: Update kubernetes.rst with correct KubernetesPodOperator inputs URL: https://github.com/apache/incubator-airflow/pull/3875#issuecomment-419907005 Thanks @thejasbabu This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] thejasbabu opened a new pull request #3875: Update kubernetes.rst with correct KubernetesPodOperator inputs
thejasbabu opened a new pull request #3875: Update kubernetes.rst with correct
KubernetesPodOperator inputs
URL: https://github.com/apache/incubator-airflow/pull/3875
Make sure you have checked _all_ steps below.
### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (AIRFLOW-3032) _pickle.UnpicklingError with using remote MySQL Server
[ https://issues.apache.org/jira/browse/AIRFLOW-3032?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Max Richter updated AIRFLOW-3032: - Description: Hello, I am running Airflow 1.9.0 successfully with a localhost MySQL database, version 5.7.23. I switched sql_alchemy_conn = mysql://airflow:@:3306/airflow in order to use the proper MySQL server - same version 5.7.23. I created a dump from my local instance to the remote one. Issue: * When tasks are executed by the scheduler everything runs fine, tasks are executed and DB updated * When manually triggering a task via the webserver, I am getting "_pickle.UnpicklingError" please see error__log.txt for full log In the end, I only changed this one line in airflow.cfg which is causing that I can not use it with a remote MySQL server. Best, Max was: Hello, I am running Airflow 1.9.0 successfully with a localhost MySQL database, version 5.7.23. I switched sql_alchemy_conn = mysql://airflow:@:3306/airflow in order to use the proper MySQL server - same version 5.7.23. I created a dump from my local instance to the remote one. Issue: * When tasks are executed by the scheduler everything runs fine, tasks are executed and DB upadted * When manually triggering a task via the webserver, I am getting "_pickle.UnpicklingError" please see error__log.txt for full log In the end, I only changed this one line in airflow.cfg which is causing that I can not use it with a remote MySQL server. Best, Max > _pickle.UnpicklingError with using remote MySQL Server > -- > > Key: AIRFLOW-3032 > URL: https://issues.apache.org/jira/browse/AIRFLOW-3032 > Project: Apache Airflow > Issue Type: Bug > Components: database >Affects Versions: 1.9.0 >Reporter: Max Richter >Priority: Blocker > Attachments: error_log.txt, pip_list.txt > > > Hello, > I am running Airflow 1.9.0 successfully with a localhost MySQL database, > version 5.7.23. > I switched sql_alchemy_conn = > mysql://airflow:@:3306/airflow in order to use the > proper MySQL server - same version 5.7.23. > I created a dump from my local instance to the remote one. > Issue: > * When tasks are executed by the scheduler everything runs fine, tasks are > executed and DB updated > * When manually triggering a task via the webserver, I am getting > "_pickle.UnpicklingError" please see error__log.txt for full log > In the end, I only changed this one line in airflow.cfg which is causing that > I can not use it with a remote MySQL server. > > Best, > Max -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (AIRFLOW-2825) S3ToHiveTransfer operator may not may able to handle GZIP file with uppercase ext in S3
[ https://issues.apache.org/jira/browse/AIRFLOW-2825?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaodong DENG updated AIRFLOW-2825: --- Fix Version/s: (was: 2.0.0) 1.10.1 > S3ToHiveTransfer operator may not may able to handle GZIP file with uppercase > ext in S3 > --- > > Key: AIRFLOW-2825 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2825 > Project: Apache Airflow > Issue Type: Bug > Components: operators >Reporter: Xiaodong DENG >Assignee: Xiaodong DENG >Priority: Critical > Fix For: 1.10.1 > > > Because upper/lower case was not considered in the extension check, > S3ToHiveTransfer operator may think a GZIP file with uppercase ext `.GZ` is > not a GZIP file and raise exception. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] ashb commented on a change in pull request #3830: [AIRFLOW-2156] Parallelize Celery Executor task state fetching
ashb commented on a change in pull request #3830: [AIRFLOW-2156] Parallelize Celery Executor task state fetching URL: https://github.com/apache/incubator-airflow/pull/3830#discussion_r216255773 ## File path: airflow/executors/celery_executor.py ## @@ -72,10 +112,24 @@ class CeleryExecutor(BaseExecutor): vast amounts of messages, while providing operations with the tools required to maintain such a system. """ -def start(self): + +def __init__(self): +super(CeleryExecutor, self).__init__() + +# Parallelize Celery requests here since Celery does not support parallelization. Review comment: `# Celery doesn't support querying the state of multiple tasks in parallel (which can become a bottleneck on bigger clusters) so we use a multiprocessing pool to speed this up` This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Resolved] (AIRFLOW-3030) Command Line docs incorrect subdir
[ https://issues.apache.org/jira/browse/AIRFLOW-3030?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kaxil Naik resolved AIRFLOW-3030. - Resolution: Fixed Resolved by https://github.com/apache/incubator-airflow/pull/3872 > Command Line docs incorrect subdir > -- > > Key: AIRFLOW-3030 > URL: https://issues.apache.org/jira/browse/AIRFLOW-3030 > Project: Apache Airflow > Issue Type: Improvement > Components: docs, Documentation >Affects Versions: 1.8.2, 1.9.0, 1.10.0 >Reporter: Kaxil Naik >Assignee: Kaxil Naik >Priority: Minor > Fix For: 1.10.1 > > Attachments: image-2018-09-09-20-53-10-766.png > > > There are two issues found in documentation of command line interface > Issue 1 > !image-2018-09-09-20-53-10-766.png! > The default value of --subdir is generated dynamically, so Kaxil's Dag Folder > during compiling is used in the final documentation (this appeared 14 times > in https://airflow.apache.org/cli.html). I believe this should be "hardcoded" > into [AIRFLOW_HOME]/dags. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (AIRFLOW-3030) Command Line docs incorrect subdir
[
https://issues.apache.org/jira/browse/AIRFLOW-3030?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608923#comment-16608923
]
ASF GitHub Bot commented on AIRFLOW-3030:
-
kaxil closed pull request #3872: [AIRFLOW-3030] Fix doc of command line
interface
URL: https://github.com/apache/incubator-airflow/pull/3872
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/bin/cli.py b/airflow/bin/cli.py
index 4ff1ae3679..a3f5c7300d 100644
--- a/airflow/bin/cli.py
+++ b/airflow/bin/cli.py
@@ -80,6 +80,11 @@
log = LoggingMixin().log
+DAGS_FOLDER = settings.DAGS_FOLDER
+
+if "BUILDING_AIRFLOW_DOCS" in os.environ:
+DAGS_FOLDER = '[AIRFLOW_HOME]/dags'
+
def sigint_handler(sig, frame):
sys.exit(0)
@@ -133,7 +138,7 @@ def setup_locations(process, pid=None, stdout=None,
stderr=None, log=None):
def process_subdir(subdir):
if subdir:
-subdir = subdir.replace('DAGS_FOLDER', settings.DAGS_FOLDER)
+subdir = subdir.replace('DAGS_FOLDER', DAGS_FOLDER)
subdir = os.path.abspath(os.path.expanduser(subdir))
return subdir
@@ -1456,8 +1461,10 @@ class CLIFactory(object):
"The regex to filter specific task_ids to backfill (optional)"),
'subdir': Arg(
("-sd", "--subdir"),
-"File location or directory from which to look for the dag",
-default=settings.DAGS_FOLDER),
+"File location or directory from which to look for the dag. "
+"Defaults to '[AIRFLOW_HOME]/dags' where [AIRFLOW_HOME] is the "
+"value you set for 'AIRFLOW_HOME' config you set in 'airflow.cfg'
",
+default=DAGS_FOLDER),
'start_date': Arg(
("-s", "--start_date"), "Override start_date -MM-DD",
type=parsedate),
@@ -1874,7 +1881,7 @@ class CLIFactory(object):
"If reset_dag_run option is used,"
" backfill will first prompt users whether airflow "
"should clear all the previous dag_run and task_instances "
-"within the backfill date range."
+"within the backfill date range. "
"If rerun_failed_tasks is used, backfill "
"will auto re-run the previous failed task instances"
" within the backfill date range.",
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Command Line docs incorrect subdir
> --
>
> Key: AIRFLOW-3030
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3030
> Project: Apache Airflow
> Issue Type: Improvement
> Components: docs, Documentation
>Affects Versions: 1.8.2, 1.9.0, 1.10.0
>Reporter: Kaxil Naik
>Assignee: Kaxil Naik
>Priority: Minor
> Fix For: 1.10.1
>
> Attachments: image-2018-09-09-20-53-10-766.png
>
>
> There are two issues found in documentation of command line interface
> Issue 1
> !image-2018-09-09-20-53-10-766.png!
> The default value of --subdir is generated dynamically, so Kaxil's Dag Folder
> during compiling is used in the final documentation (this appeared 14 times
> in https://airflow.apache.org/cli.html). I believe this should be "hardcoded"
> into [AIRFLOW_HOME]/dags.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] kaxil closed pull request #3872: [AIRFLOW-3030] Fix doc of command line interface
kaxil closed pull request #3872: [AIRFLOW-3030] Fix doc of command line
interface
URL: https://github.com/apache/incubator-airflow/pull/3872
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/bin/cli.py b/airflow/bin/cli.py
index 4ff1ae3679..a3f5c7300d 100644
--- a/airflow/bin/cli.py
+++ b/airflow/bin/cli.py
@@ -80,6 +80,11 @@
log = LoggingMixin().log
+DAGS_FOLDER = settings.DAGS_FOLDER
+
+if "BUILDING_AIRFLOW_DOCS" in os.environ:
+DAGS_FOLDER = '[AIRFLOW_HOME]/dags'
+
def sigint_handler(sig, frame):
sys.exit(0)
@@ -133,7 +138,7 @@ def setup_locations(process, pid=None, stdout=None,
stderr=None, log=None):
def process_subdir(subdir):
if subdir:
-subdir = subdir.replace('DAGS_FOLDER', settings.DAGS_FOLDER)
+subdir = subdir.replace('DAGS_FOLDER', DAGS_FOLDER)
subdir = os.path.abspath(os.path.expanduser(subdir))
return subdir
@@ -1456,8 +1461,10 @@ class CLIFactory(object):
"The regex to filter specific task_ids to backfill (optional)"),
'subdir': Arg(
("-sd", "--subdir"),
-"File location or directory from which to look for the dag",
-default=settings.DAGS_FOLDER),
+"File location or directory from which to look for the dag. "
+"Defaults to '[AIRFLOW_HOME]/dags' where [AIRFLOW_HOME] is the "
+"value you set for 'AIRFLOW_HOME' config you set in 'airflow.cfg'
",
+default=DAGS_FOLDER),
'start_date': Arg(
("-s", "--start_date"), "Override start_date -MM-DD",
type=parsedate),
@@ -1874,7 +1881,7 @@ class CLIFactory(object):
"If reset_dag_run option is used,"
" backfill will first prompt users whether airflow "
"should clear all the previous dag_run and task_instances "
-"within the backfill date range."
+"within the backfill date range. "
"If rerun_failed_tasks is used, backfill "
"will auto re-run the previous failed task instances"
" within the backfill date range.",
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] ashb commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop
ashb commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop URL: https://github.com/apache/incubator-airflow/pull/3873#issuecomment-419845976 First thought: this sounds like a good thing, but could put some of the description of this PR into the docs too??https://airflow.apache.org/scheduler.html seems like a likely place to put them. (I haven't looked at the code for this PR yet) This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] XD-DENG commented on issue #3823: [AIRFLOW-2985] Operators for S3 object copying/deleting
XD-DENG commented on issue #3823: [AIRFLOW-2985] Operators for S3 object copying/deleting URL: https://github.com/apache/incubator-airflow/pull/3823#issuecomment-419844342 Thanks @ashb This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (AIRFLOW-3032) _pickle.UnpicklingError with using remote MySQL Server
Max Richter created AIRFLOW-3032: Summary: _pickle.UnpicklingError with using remote MySQL Server Key: AIRFLOW-3032 URL: https://issues.apache.org/jira/browse/AIRFLOW-3032 Project: Apache Airflow Issue Type: Bug Components: database Affects Versions: 1.9.0 Reporter: Max Richter Attachments: error_log.txt, pip_list.txt Hello, I am running Airflow 1.9.0 successfully with a localhost MySQL database, version 5.7.23. I switched sql_alchemy_conn = mysql://airflow:l@:3306/airflow in order to use the proper MySQL server - same version 5.7.23. I created a dump from my local instance to the remote one. Issue: * When tasks are executed by the scheduler everything runs fine, tasks are executed and DB upadted * When manually triggering a task via the webserver, I am getting "_pickle.UnpicklingError" please see error__log.txt for full log In the end, I only changed this one line in airflow.cfg which is causing that I can not use it with a remote MySQL server. Best, Max -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (AIRFLOW-2818) Cant' identify DAG .py files with capital case extension ('.PY', '.Py', '.pY')
[
https://issues.apache.org/jira/browse/AIRFLOW-2818?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Xiaodong DENG closed AIRFLOW-2818.
--
Resolution: Won't Fix
> Cant' identify DAG .py files with capital case extension ('.PY', '.Py', '.pY')
> --
>
> Key: AIRFLOW-2818
> URL: https://issues.apache.org/jira/browse/AIRFLOW-2818
> Project: Apache Airflow
> Issue Type: Bug
> Components: DAG
>Reporter: Xiaodong DENG
>Assignee: Xiaodong DENG
>Priority: Major
>
> This bug is quite simple.
> In multiple scripts in which we try to identify and list python files, the
> capital case extension was not considered. For example, if I have a DAG file
> with file name "dag.py", it will be identified. However, if I change the name
> into "dag.PY", it will be missed by Airflow.
> This is because simply using function *os.path.splitext()* can not handle
> case issue.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (AIRFLOW-3032) _pickle.UnpicklingError with using remote MySQL Server
[ https://issues.apache.org/jira/browse/AIRFLOW-3032?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Max Richter updated AIRFLOW-3032: - Description: Hello, I am running Airflow 1.9.0 successfully with a localhost MySQL database, version 5.7.23. I switched sql_alchemy_conn = mysql://airflow:@:3306/airflow in order to use the proper MySQL server - same version 5.7.23. I created a dump from my local instance to the remote one. Issue: * When tasks are executed by the scheduler everything runs fine, tasks are executed and DB upadted * When manually triggering a task via the webserver, I am getting "_pickle.UnpicklingError" please see error__log.txt for full log In the end, I only changed this one line in airflow.cfg which is causing that I can not use it with a remote MySQL server. Best, Max was: Hello, I am running Airflow 1.9.0 successfully with a localhost MySQL database, version 5.7.23. I switched sql_alchemy_conn = mysql://airflow:l@:3306/airflow in order to use the proper MySQL server - same version 5.7.23. I created a dump from my local instance to the remote one. Issue: * When tasks are executed by the scheduler everything runs fine, tasks are executed and DB upadted * When manually triggering a task via the webserver, I am getting "_pickle.UnpicklingError" please see error__log.txt for full log In the end, I only changed this one line in airflow.cfg which is causing that I can not use it with a remote MySQL server. Best, Max > _pickle.UnpicklingError with using remote MySQL Server > -- > > Key: AIRFLOW-3032 > URL: https://issues.apache.org/jira/browse/AIRFLOW-3032 > Project: Apache Airflow > Issue Type: Bug > Components: database >Affects Versions: 1.9.0 >Reporter: Max Richter >Priority: Blocker > Attachments: error_log.txt, pip_list.txt > > > Hello, > I am running Airflow 1.9.0 successfully with a localhost MySQL database, > version 5.7.23. > I switched sql_alchemy_conn = > mysql://airflow:@:3306/airflow in order to use the > proper MySQL server - same version 5.7.23. > I created a dump from my local instance to the remote one. > Issue: > * When tasks are executed by the scheduler everything runs fine, tasks are > executed and DB upadted > * When manually triggering a task via the webserver, I am getting > "_pickle.UnpicklingError" please see error__log.txt for full log > In the end, I only changed this one line in airflow.cfg which is causing that > I can not use it with a remote MySQL server. > > Best, > Max -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (AIRFLOW-2985) Operators for S3 object copying/deleting [boto3.client.copy_object()/delete_object()]
[ https://issues.apache.org/jira/browse/AIRFLOW-2985?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ash Berlin-Taylor resolved AIRFLOW-2985. Resolution: Fixed Fix Version/s: 2.0.0 > Operators for S3 object copying/deleting > [boto3.client.copy_object()/delete_object()] > - > > Key: AIRFLOW-2985 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2985 > Project: Apache Airflow > Issue Type: Improvement > Components: operators >Reporter: Xiaodong DENG >Assignee: Xiaodong DENG >Priority: Minor > Fix For: 2.0.0 > > > Currently we don't have an operator in Airflow to help copy/delete objects > within S3, while they may be quite common use case when we deal with the data > in S3. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (AIRFLOW-2818) Cant' identify DAG .py files with capital case extension ('.PY', '.Py', '.pY')
[
https://issues.apache.org/jira/browse/AIRFLOW-2818?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608911#comment-16608911
]
ASF GitHub Bot commented on AIRFLOW-2818:
-
XD-DENG closed pull request #3662: [AIRFLOW-2818] Handle DAG File with Upper
Case Extension
URL: https://github.com/apache/incubator-airflow/pull/3662
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/models.py b/airflow/models.py
index cf7eb0a64f..ecdd5420ba 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -372,7 +372,7 @@ def process_file(self, filepath, only_if_updated=True,
safe_mode=True):
for mod in zip_file.infolist():
head, _ = os.path.split(mod.filename)
mod_name, ext = os.path.splitext(mod.filename)
-if not head and (ext == '.py' or ext == '.pyc'):
+if not head and (ext.lower() == '.py' or ext.lower() ==
'.pyc'):
if mod_name == '__init__':
self.log.warning("Found __init__.%s at root of %s",
ext, filepath)
if safe_mode:
diff --git a/airflow/plugins_manager.py b/airflow/plugins_manager.py
index 735f2de1e8..8f7c8f99d9 100644
--- a/airflow/plugins_manager.py
+++ b/airflow/plugins_manager.py
@@ -76,7 +76,7 @@ def validate(cls):
continue
mod_name, file_ext = os.path.splitext(
os.path.split(filepath)[-1])
-if file_ext != '.py':
+if file_ext.lower() != '.py':
continue
log.debug('Importing plugin module %s', filepath)
diff --git a/airflow/utils/dag_processing.py b/airflow/utils/dag_processing.py
index e236397da0..b21bbe7883 100644
--- a/airflow/utils/dag_processing.py
+++ b/airflow/utils/dag_processing.py
@@ -208,7 +208,7 @@ def list_py_file_paths(directory, safe_mode=True):
continue
mod_name, file_ext = os.path.splitext(
os.path.split(file_path)[-1])
-if file_ext != '.py' and not zipfile.is_zipfile(file_path):
+if file_ext.lower() != '.py' and not
zipfile.is_zipfile(file_path):
continue
if any([re.findall(p, file_path) for p in patterns]):
continue
diff --git a/tests/jobs.py b/tests/jobs.py
index 93f6574df4..0e038aa490 100644
--- a/tests/jobs.py
+++ b/tests/jobs.py
@@ -3167,7 +3167,7 @@ def test_list_py_file_paths(self):
detected_files = []
expected_files = []
for file_name in os.listdir(TEST_DAGS_FOLDER):
-if file_name.endswith('.py') or file_name.endswith('.zip'):
+if file_name.lower().endswith('.py') or
file_name.lower().endswith('.zip'):
if file_name not in ['no_dags.py']:
expected_files.append(
'{}/{}'.format(TEST_DAGS_FOLDER, file_name))
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Cant' identify DAG .py files with capital case extension ('.PY', '.Py', '.pY')
> --
>
> Key: AIRFLOW-2818
> URL: https://issues.apache.org/jira/browse/AIRFLOW-2818
> Project: Apache Airflow
> Issue Type: Bug
> Components: DAG
>Reporter: Xiaodong DENG
>Assignee: Xiaodong DENG
>Priority: Major
>
> This bug is quite simple.
> In multiple scripts in which we try to identify and list python files, the
> capital case extension was not considered. For example, if I have a DAG file
> with file name "dag.py", it will be identified. However, if I change the name
> into "dag.PY", it will be missed by Airflow.
> This is because simply using function *os.path.splitext()* can not handle
> case issue.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (AIRFLOW-2985) Operators for S3 object copying/deleting [boto3.client.copy_object()/delete_object()]
[ https://issues.apache.org/jira/browse/AIRFLOW-2985?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608910#comment-16608910 ] ASF GitHub Bot commented on AIRFLOW-2985: - ashb closed pull request #3823: [AIRFLOW-2985] Operators for S3 object copying/deleting URL: https://github.com/apache/incubator-airflow/pull/3823 This is a PR merged from a forked repository. As GitHub hides the original diff on merge, it is displayed below for the sake of provenance: As this is a foreign pull request (from a fork), the diff is supplied below (as it won't show otherwise due to GitHub magic): diff --git a/airflow/contrib/operators/s3_copy_object_operator.py b/airflow/contrib/operators/s3_copy_object_operator.py new file mode 100644 index 00..330138ed27 --- /dev/null +++ b/airflow/contrib/operators/s3_copy_object_operator.py @@ -0,0 +1,93 @@ +# -*- coding: utf-8 -*- +# +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. + +from airflow.hooks.S3_hook import S3Hook +from airflow.models import BaseOperator +from airflow.utils.decorators import apply_defaults + + +class S3CopyObjectOperator(BaseOperator): +""" +Creates a copy of an object that is already stored in S3. + +Note: the S3 connection used here needs to have access to both +source and destination bucket/key. + +:param source_bucket_key: The key of the source object. + +It can be either full s3:// style url or relative path from root level. + +When it's specified as a full s3:// url, please omit source_bucket_name. +:type source_bucket_key: str +:param dest_bucket_key: The key of the object to copy to. + +The convention to specify `dest_bucket_key` is the same as `source_bucket_key`. +:type dest_bucket_key: str +:param source_bucket_name: Name of the S3 bucket where the source object is in. + +It should be omitted when `source_bucket_key` is provided as a full s3:// url. +:type source_bucket_name: str +:param dest_bucket_name: Name of the S3 bucket to where the object is copied. + +It should be omitted when `dest_bucket_key` is provided as a full s3:// url. +:type dest_bucket_name: str +:param source_version_id: Version ID of the source object (OPTIONAL) +:type source_version_id: str +:param aws_conn_id: Connection id of the S3 connection to use +:type aws_conn_id: str +:param verify: Whether or not to verify SSL certificates for S3 connection. +By default SSL certificates are verified. + +You can provide the following values: + +- False: do not validate SSL certificates. SSL will still be used, + but SSL certificates will not be + verified. +- path/to/cert/bundle.pem: A filename of the CA cert bundle to uses. + You can specify this argument if you want to use a different + CA cert bundle than the one used by botocore. +:type verify: bool or str +""" + +@apply_defaults +def __init__( +self, +source_bucket_key, +dest_bucket_key, +source_bucket_name=None, +dest_bucket_name=None, +source_version_id=None, +aws_conn_id='aws_default', +verify=None, +*args, **kwargs): +super(S3CopyObjectOperator, self).__init__(*args, **kwargs) + +self.source_bucket_key = source_bucket_key +self.dest_bucket_key = dest_bucket_key +self.source_bucket_name = source_bucket_name +self.dest_bucket_name = dest_bucket_name +self.source_version_id = source_version_id +self.aws_conn_id = aws_conn_id +self.verify = verify + +def execute(self, context): +s3_hook = S3Hook(aws_conn_id=self.aws_conn_id, verify=self.verify) +s3_hook.copy_object(self.source_bucket_key, self.dest_bucket_key, +self.source_bucket_name, self.dest_bucket_name, +self.source_version_id) diff --git a/airflow/contrib/operators/s3_delete_objects_operator.py b/airflow/contrib/operators/s3_delete_objects_operator.py new file mode 100644
[GitHub] ashb closed pull request #3823: [AIRFLOW-2985] Operators for S3 object copying/deleting
ashb closed pull request #3823: [AIRFLOW-2985] Operators for S3 object copying/deleting URL: https://github.com/apache/incubator-airflow/pull/3823 This is a PR merged from a forked repository. As GitHub hides the original diff on merge, it is displayed below for the sake of provenance: As this is a foreign pull request (from a fork), the diff is supplied below (as it won't show otherwise due to GitHub magic): diff --git a/airflow/contrib/operators/s3_copy_object_operator.py b/airflow/contrib/operators/s3_copy_object_operator.py new file mode 100644 index 00..330138ed27 --- /dev/null +++ b/airflow/contrib/operators/s3_copy_object_operator.py @@ -0,0 +1,93 @@ +# -*- coding: utf-8 -*- +# +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. + +from airflow.hooks.S3_hook import S3Hook +from airflow.models import BaseOperator +from airflow.utils.decorators import apply_defaults + + +class S3CopyObjectOperator(BaseOperator): +""" +Creates a copy of an object that is already stored in S3. + +Note: the S3 connection used here needs to have access to both +source and destination bucket/key. + +:param source_bucket_key: The key of the source object. + +It can be either full s3:// style url or relative path from root level. + +When it's specified as a full s3:// url, please omit source_bucket_name. +:type source_bucket_key: str +:param dest_bucket_key: The key of the object to copy to. + +The convention to specify `dest_bucket_key` is the same as `source_bucket_key`. +:type dest_bucket_key: str +:param source_bucket_name: Name of the S3 bucket where the source object is in. + +It should be omitted when `source_bucket_key` is provided as a full s3:// url. +:type source_bucket_name: str +:param dest_bucket_name: Name of the S3 bucket to where the object is copied. + +It should be omitted when `dest_bucket_key` is provided as a full s3:// url. +:type dest_bucket_name: str +:param source_version_id: Version ID of the source object (OPTIONAL) +:type source_version_id: str +:param aws_conn_id: Connection id of the S3 connection to use +:type aws_conn_id: str +:param verify: Whether or not to verify SSL certificates for S3 connection. +By default SSL certificates are verified. + +You can provide the following values: + +- False: do not validate SSL certificates. SSL will still be used, + but SSL certificates will not be + verified. +- path/to/cert/bundle.pem: A filename of the CA cert bundle to uses. + You can specify this argument if you want to use a different + CA cert bundle than the one used by botocore. +:type verify: bool or str +""" + +@apply_defaults +def __init__( +self, +source_bucket_key, +dest_bucket_key, +source_bucket_name=None, +dest_bucket_name=None, +source_version_id=None, +aws_conn_id='aws_default', +verify=None, +*args, **kwargs): +super(S3CopyObjectOperator, self).__init__(*args, **kwargs) + +self.source_bucket_key = source_bucket_key +self.dest_bucket_key = dest_bucket_key +self.source_bucket_name = source_bucket_name +self.dest_bucket_name = dest_bucket_name +self.source_version_id = source_version_id +self.aws_conn_id = aws_conn_id +self.verify = verify + +def execute(self, context): +s3_hook = S3Hook(aws_conn_id=self.aws_conn_id, verify=self.verify) +s3_hook.copy_object(self.source_bucket_key, self.dest_bucket_key, +self.source_bucket_name, self.dest_bucket_name, +self.source_version_id) diff --git a/airflow/contrib/operators/s3_delete_objects_operator.py b/airflow/contrib/operators/s3_delete_objects_operator.py new file mode 100644 index 00..1aa1b3901e --- /dev/null +++ b/airflow/contrib/operators/s3_delete_objects_operator.py @@ -0,0 +1,85 @@ +# -*- coding: utf-8 -*- +# +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license
[GitHub] ashb commented on a change in pull request #3823: [AIRFLOW-2985] Operators for S3 object copying/deleting
ashb commented on a change in pull request #3823: [AIRFLOW-2985] Operators for
S3 object copying/deleting
URL: https://github.com/apache/incubator-airflow/pull/3823#discussion_r216246069
##
File path: tests/contrib/operators/test_s3_delete_objects_operator.py
##
@@ -0,0 +1,85 @@
+# -*- coding: utf-8 -*-
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import io
+import unittest
+
+import boto3
+from moto import mock_s3
+
+from airflow.contrib.operators.s3_delete_objects_operator import
S3DeleteObjectsOperator
+
+
+class TestS3DeleteObjectsOperator(unittest.TestCase):
+
+@mock_s3
+def test_s3_delete_single_object(self):
+bucket = "testbucket"
+key = "path/data.txt"
+
+conn = boto3.client('s3')
+conn.create_bucket(Bucket=bucket)
+conn.upload_fileobj(Bucket=bucket,
+Key=key,
+Fileobj=io.BytesIO(b"input"))
+
+# The object should be detected before the DELETE action is taken
+objects_in_dest_bucket = conn.list_objects(Bucket=bucket,
+ Prefix=key)
+self.assertEqual(len(objects_in_dest_bucket['Contents']), 1)
+self.assertEqual(objects_in_dest_bucket['Contents'][0]['Key'], key)
+
+t =
S3DeleteObjectsOperator(task_id="test_task_s3_delete_single_object",
+bucket=bucket,
+keys=key)
+t.execute(None)
+
+# There should be no object found in the bucket created earlier
+self.assertFalse('Contents' in conn.list_objects(Bucket=bucket,
+ Prefix=key))
+
+@mock_s3
+def test_s3_delete_multiple_objects(self):
+bucket = "testbucket"
+key_pattern = "path/data"
+n_keys = 3
+keys = [key_pattern + str(i) for i in range(n_keys)]
+
+conn = boto3.client('s3')
+conn.create_bucket(Bucket=bucket)
+for k in keys:
+conn.upload_fileobj(Bucket=bucket,
+Key=k,
+Fileobj=io.BytesIO(b"input"))
+
+# The objects should be detected before the DELETE action is taken
+objects_in_dest_bucket = conn.list_objects(Bucket=bucket,
+ Prefix=key_pattern)
+self.assertEqual(len(objects_in_dest_bucket['Contents']), n_keys)
+self.assertEqual(sorted([x['Key'] for x in
objects_in_dest_bucket['Contents']]),
+ sorted(keys))
+
+t =
S3DeleteObjectsOperator(task_id="test_task_s3_delete_multiple_objects",
+bucket=bucket,
+keys=keys)
+t.execute(None)
+
+# There should be no object found in the bucket created earlier
+self.assertFalse('Contents' in conn.list_objects(Bucket=bucket,
+ Prefix=key_pattern))
Review comment:
Confirmed, sounds good.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (AIRFLOW-3001) Accumulative tis slow allocation of new schedule
[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608861#comment-16608861
]
ASF GitHub Bot commented on AIRFLOW-3001:
-
ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table
index 'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
[ Description ]
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ]
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)


### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Accumulative tis slow allocation of new schedule
>
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 1.10.0
>Reporter: Jason Kim
>Assignee: Jason Kim
>Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (AIRFLOW-3001) Accumulative tis slow allocation of new schedule
[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608860#comment-16608860
]
ASF GitHub Bot commented on AIRFLOW-3001:
-
ubermen closed pull request #3874: [AIRFLOW-3001] Add task_instance table index
'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
new file mode 100644
index 00..2f89181bb5
--- /dev/null
+++ b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
@@ -0,0 +1,42 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""add index to taskinstance
+
+Revision ID: 82c452539eeb
+Revises: 9635ae0956e7
+Create Date: 2018-09-10 17:04:32.058103
+
+"""
+
+# revision identifiers, used by Alembic.
+revision = '82c452539eeb'
+down_revision = '9635ae0956e7'
+branch_labels = None
+depends_on = None
+
+from alembic import op
+import sqlalchemy as sa
+
+
+def upgrade():
+op.create_index('ti_dag_date', 'task_instance', ['dag_id',
'execution_date'], unique=False)
+
+
+def downgrade():
+op.drop_index('ti_dag_date', table_name='task_instance')
diff --git a/airflow/models.py b/airflow/models.py
index 2096785b41..c41f2a9dbe 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -880,6 +880,7 @@ class TaskInstance(Base, LoggingMixin):
__table_args__ = (
Index('ti_dag_state', dag_id, state),
+Index('ti_dag_date', dag_id, execution_date),
Index('ti_state', state),
Index('ti_state_lkp', dag_id, task_id, execution_date, state),
Index('ti_pool', pool, state, priority_weight),
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Accumulative tis slow allocation of new schedule
>
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 1.10.0
>Reporter: Jason Kim
>Assignee: Jason Kim
>Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] ubermen closed pull request #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen closed pull request #3874: [AIRFLOW-3001] Add task_instance table index
'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
new file mode 100644
index 00..2f89181bb5
--- /dev/null
+++ b/airflow/migrations/versions/82c452539eeb_add_index_to_taskinstance.py
@@ -0,0 +1,42 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""add index to taskinstance
+
+Revision ID: 82c452539eeb
+Revises: 9635ae0956e7
+Create Date: 2018-09-10 17:04:32.058103
+
+"""
+
+# revision identifiers, used by Alembic.
+revision = '82c452539eeb'
+down_revision = '9635ae0956e7'
+branch_labels = None
+depends_on = None
+
+from alembic import op
+import sqlalchemy as sa
+
+
+def upgrade():
+op.create_index('ti_dag_date', 'task_instance', ['dag_id',
'execution_date'], unique=False)
+
+
+def downgrade():
+op.drop_index('ti_dag_date', table_name='task_instance')
diff --git a/airflow/models.py b/airflow/models.py
index 2096785b41..c41f2a9dbe 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -880,6 +880,7 @@ class TaskInstance(Base, LoggingMixin):
__table_args__ = (
Index('ti_dag_state', dag_id, state),
+Index('ti_dag_date', dag_id, execution_date),
Index('ti_state', state),
Index('ti_state_lkp', dag_id, task_id, execution_date, state),
Index('ti_pool', pool, state, priority_weight),
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table
index 'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
[ Description ]
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ]
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)


### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] ubermen commented on issue #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen commented on issue #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date' URL: https://github.com/apache/incubator-airflow/pull/3874#issuecomment-419827604 This PR is recreated from https://github.com/apache/incubator-airflow/pull/3840 as feng-tao's feedback reflected version. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] ubermen commented on issue #3840: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen commented on issue #3840: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date' URL: https://github.com/apache/incubator-airflow/pull/3840#issuecomment-419827367 I have closed this pr (for clean commit log) and then create new pr reflected from feedback of feng-tao. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] ubermen closed pull request #3840: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen closed pull request #3840: [AIRFLOW-3001] Add task_instance table index
'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3840
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/migrations/versions/e3a246e0dc1_current_schema.py
b/airflow/migrations/versions/e3a246e0dc1_current_schema.py
index 6c63d0a9dd..22624a4c8d 100644
--- a/airflow/migrations/versions/e3a246e0dc1_current_schema.py
+++ b/airflow/migrations/versions/e3a246e0dc1_current_schema.py
@@ -7,9 +7,9 @@
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
-#
+#
# http://www.apache.org/licenses/LICENSE-2.0
-#
+#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
@@ -176,6 +176,12 @@ def upgrade():
['dag_id', 'state'],
unique=False
)
+op.create_index(
+'ti_dag_date',
+'task_instance',
+['dag_id', 'execution_date'],
+unique=False
+)
op.create_index(
'ti_pool',
'task_instance',
@@ -269,6 +275,7 @@ def downgrade():
op.drop_index('ti_state_lkp', table_name='task_instance')
op.drop_index('ti_pool', table_name='task_instance')
op.drop_index('ti_dag_state', table_name='task_instance')
+op.drop_index('ti_dag_date', table_name='task_instance')
op.drop_table('task_instance')
op.drop_table('slot_pool')
op.drop_table('sla_miss')
diff --git a/airflow/models.py b/airflow/models.py
index 2096785b41..c41f2a9dbe 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -880,6 +880,7 @@ class TaskInstance(Base, LoggingMixin):
__table_args__ = (
Index('ti_dag_state', dag_id, state),
+Index('ti_dag_date', dag_id, execution_date),
Index('ti_state', state),
Index('ti_state_lkp', dag_id, task_id, execution_date, state),
Index('ti_pool', pool, state, priority_weight),
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (AIRFLOW-3001) Accumulative tis slow allocation of new schedule
[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608853#comment-16608853
]
ASF GitHub Bot commented on AIRFLOW-3001:
-
ubermen closed pull request #3840: [AIRFLOW-3001] Add task_instance table index
'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3840
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/airflow/migrations/versions/e3a246e0dc1_current_schema.py
b/airflow/migrations/versions/e3a246e0dc1_current_schema.py
index 6c63d0a9dd..22624a4c8d 100644
--- a/airflow/migrations/versions/e3a246e0dc1_current_schema.py
+++ b/airflow/migrations/versions/e3a246e0dc1_current_schema.py
@@ -7,9 +7,9 @@
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
-#
+#
# http://www.apache.org/licenses/LICENSE-2.0
-#
+#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
@@ -176,6 +176,12 @@ def upgrade():
['dag_id', 'state'],
unique=False
)
+op.create_index(
+'ti_dag_date',
+'task_instance',
+['dag_id', 'execution_date'],
+unique=False
+)
op.create_index(
'ti_pool',
'task_instance',
@@ -269,6 +275,7 @@ def downgrade():
op.drop_index('ti_state_lkp', table_name='task_instance')
op.drop_index('ti_pool', table_name='task_instance')
op.drop_index('ti_dag_state', table_name='task_instance')
+op.drop_index('ti_dag_date', table_name='task_instance')
op.drop_table('task_instance')
op.drop_table('slot_pool')
op.drop_table('sla_miss')
diff --git a/airflow/models.py b/airflow/models.py
index 2096785b41..c41f2a9dbe 100755
--- a/airflow/models.py
+++ b/airflow/models.py
@@ -880,6 +880,7 @@ class TaskInstance(Base, LoggingMixin):
__table_args__ = (
Index('ti_dag_state', dag_id, state),
+Index('ti_dag_date', dag_id, execution_date),
Index('ti_state', state),
Index('ti_state_lkp', dag_id, task_id, execution_date, state),
Index('ti_pool', pool, state, priority_weight),
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Accumulative tis slow allocation of new schedule
>
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 1.10.0
>Reporter: Jason Kim
>Assignee: Jason Kim
>Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (AIRFLOW-3001) Accumulative tis slow allocation of new schedule
[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16608851#comment-16608851
]
ASF GitHub Bot commented on AIRFLOW-3001:
-
ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table
index 'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
[ Description ]
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ]
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)


### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Accumulative tis slow allocation of new schedule
>
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 1.10.0
>Reporter: Jason Kim
>Assignee: Jason Kim
>Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table index 'ti_dag_date'
ubermen opened a new pull request #3874: [AIRFLOW-3001] Add task_instance table
index 'ti_dag_date'
URL: https://github.com/apache/incubator-airflow/pull/3874
[ Description ]
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ]
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)


### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] yrqls21 commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop
yrqls21 commented on issue #3873: [Airflow-2760] Decouple DAG parsing loop from scheduler loop URL: https://github.com/apache/incubator-airflow/pull/3873#issuecomment-419824971 @aoen @Fokko @bolkedebruin @mistercrunch @kaxil @ashb @saguziel @feng-tao @afernandez @YingboWang PTAL This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (AIRFLOW-2887) Add to BigQueryBaseCursor methods for creating insert dataset
[ https://issues.apache.org/jira/browse/AIRFLOW-2887?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Iuliia Volkova updated AIRFLOW-2887: Summary: Add to BigQueryBaseCursor methods for creating insert dataset (was: Add to BigQueryBaseCursor methods for creating and updating datasets) > Add to BigQueryBaseCursor methods for creating insert dataset > - > > Key: AIRFLOW-2887 > URL: https://issues.apache.org/jira/browse/AIRFLOW-2887 > Project: Apache Airflow > Issue Type: New Feature >Reporter: Iuliia Volkova >Assignee: Iuliia Volkova >Priority: Minor > > In BigQueryBaseCursor exist only: > def delete_dataset(self, project_id, dataset_id) > And there are no hook to > create([https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/insert)] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] yrqls21 opened a new pull request #3873: [WIP][Airflow-2760] Decouple DAG parsing loop from scheduler loop
yrqls21 opened a new pull request #3873: [WIP][Airflow-2760] Decouple DAG
parsing loop from scheduler loop
URL: https://github.com/apache/incubator-airflow/pull/3873
Make sure you have checked _all_ steps below.
### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services