[GitHub] [incubator-druid] alonshoshani commented on issue #8058: Graphite Emitter Issue Druid 0.14
alonshoshani commented on issue #8058: Graphite Emitter Issue Druid 0.14 URL: https://github.com/apache/incubator-druid/issues/8058#issuecomment-512113264 @vogievetsk Hi Vadim, I opened the issues 6 days ago and no response yet. I didn't find someone which the graphite metrics worked for him with druid 0.14. Is this a known issue? By the way, when changing druid.emitter to logging, it writes the metrics to log but bit able to send them. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm opened a new issue #8091: groupBy with subtotalsSpec doesn't fully group each set
gianm opened a new issue #8091: groupBy with subtotalsSpec doesn't fully group
each set
URL: https://github.com/apache/incubator-druid/issues/8091
These two queries (if posed in GroupByQueryRunnerTest) return different
results, but I think they should return the same results. The only difference
between query 1 and query 2 is that query 2 has an additional dimension that is
_not_ referenced in the subtotalsSpec.
I believe the issue is that `GroupByStrategyV2.processSubtotalsSpec` calls
`mergeResults` on rows returned by `GroupByRowProcessor.getRowsFromGrouper` for
each subtotal dimension list, but this isn't enough to fully group them. The
result rows from the grouper are sorted based on the original dimension set,
and `mergeResults` only merges adjacent rows.
i.e. Imagine you have two dimensions and they each have values A, B, and C.
The original grouper might have rows like this:
AA
AB
BA
BB
Passing "dimsToInclude" with just the second dim would yield these rows from
the Grouper:
A
B
A
B
Which cannot be merged by `mergeResults`.
I can think of a couple of fixes:
1. Re-sorting the Grouper rows each time they are pulled out. However, not
all Groupers support re-sorting (e.g. SpillingGrouper cannot change its sort
order once it has spilled to disk) so it might not always be possible.
2. Using _two_ Groupers (with two merge buffers), one to store the initially
grouped rows and one to store subtotal groupings. The act of adding results to
the subtotal Grouper will properly and fully group them. Takes more memory but
should work in all cases.
Query 1:
```java
GroupByQuery query = makeQueryBuilder()
.setDataSource(QueryRunnerTestHelper.dataSource)
.setQuerySegmentSpec(QueryRunnerTestHelper.firstToThird)
.setDimensions(
ImmutableList.of(
new DefaultDimensionSpec("market", "market")
)
)
.setAggregatorSpecs(Collections.singletonList(QueryRunnerTestHelper.rowsCount))
.setGranularity(QueryRunnerTestHelper.allGran)
.setSubtotalsSpec(ImmutableList.of(ImmutableList.of("market")))
.build();
```
Query 2:
```java
GroupByQuery query = makeQueryBuilder()
.setDataSource(QueryRunnerTestHelper.dataSource)
.setQuerySegmentSpec(QueryRunnerTestHelper.firstToThird)
.setDimensions(
ImmutableList.of(
new DefaultDimensionSpec("quality", "quality"),
new DefaultDimensionSpec("market", "market")
)
)
.setAggregatorSpecs(Collections.singletonList(QueryRunnerTestHelper.rowsCount))
.setGranularity(QueryRunnerTestHelper.allGran)
.setSubtotalsSpec(ImmutableList.of(ImmutableList.of("market")))
.build();
```
/cc @himanshug
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] JackyYangPassion commented on issue #7594: [for master] general exactly count distinct support in Druid
JackyYangPassion commented on issue #7594: [for master] general exactly count distinct support in Druid URL: https://github.com/apache/incubator-druid/pull/7594#issuecomment-512086460 > > From the error message ,i think there is must be an error in built dictionary stage ! so when in the ingestion stage there is a key can't find in the dictionary! > > do you have the same error when use wikiticker-2015-09-12-sampled.json data? @pzhdfy > > Yes, this is a know issue, non-ascii char may not be encoded correctly in BuildDictJob. > We fix it in our internal version, I will commit it later Thank you for your attention This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8088: Add intermediary data server for shuffle
clintropolis commented on a change in pull request #8088: Add intermediary data server for shuffle URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304204101 ## File path: server/src/main/java/org/apache/druid/server/http/security/TaskShuffleResourceFilter.java ## @@ -0,0 +1,72 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, + * software distributed under the License is distributed on an + * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY + * KIND, either express or implied. See the License for the + * specific language governing permissions and limitations + * under the License. + */ + +package org.apache.druid.server.http.security; + +import com.google.common.base.Preconditions; +import com.google.inject.Inject; +import com.sun.jersey.spi.container.ContainerRequest; +import org.apache.druid.server.security.Access; +import org.apache.druid.server.security.AuthorizationUtils; +import org.apache.druid.server.security.AuthorizerMapper; +import org.apache.druid.server.security.ForbiddenException; +import org.apache.druid.server.security.Resource; +import org.apache.druid.server.security.ResourceAction; +import org.apache.druid.server.security.ResourceType; + +/** + * This resource filter is used for data shuffle between native parallel index tasks. See ShuffleResource for details. + * + * It currently performs the authorization check for DATASOURCE, but ideally, it should be the authorization check + * for task data. This issue should be addressed in the future. Review comment: Could you clarify in these javadocs that I think you are referring to this should be doing what `TaskResourceFilter` is doing? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8088: Add intermediary data server for shuffle
clintropolis commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304182914
##
File path:
indexing-service/src/test/java/org/apache/druid/indexing/worker/IntermediaryDataManagerManualAddAndDeleteTest.java
##
@@ -0,0 +1,147 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.amazonaws.util.StringUtils;
+import com.google.common.collect.ImmutableList;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.NoopIndexingServiceClient;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.Intervals;
+import org.apache.druid.segment.loading.StorageLocationConfig;
+import org.apache.druid.timeline.DataSegment;
+import org.apache.druid.timeline.partition.NumberedShardSpec;
+import org.joda.time.Interval;
+import org.junit.After;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Comparator;
+import java.util.List;
+
+public class IntermediaryDataManagerManualAddAndDeleteTest
+{
+ @Rule
+ public TemporaryFolder tempDir = new TemporaryFolder();
+
+ private IntermediaryDataManager intermediaryDataManager;
+
+ @Before
+ public void setup() throws IOException
+ {
+final WorkerConfig workerConfig = new WorkerConfig();
+final TaskConfig taskConfig = new TaskConfig(
+null,
+null,
+null,
+null,
+null,
+false,
+null,
+null,
+ImmutableList.of(new StorageLocationConfig(tempDir.newFolder(), null,
null))
+);
+final IndexingServiceClient indexingServiceClient = new
NoopIndexingServiceClient();
+intermediaryDataManager = new IntermediaryDataManager(workerConfig,
taskConfig, indexingServiceClient);
+intermediaryDataManager.start();
+ }
+
+ @After
+ public void teardown() throws InterruptedException
+ {
+intermediaryDataManager.stop();
+ }
+
+ @Test
+ public void testAddSegment() throws IOException
Review comment:
nit: is this test worth having since it is also implicitly tested by the
other 2 tests?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] pzhdfy commented on issue #7594: [for master] general exactly count distinct support in Druid
pzhdfy commented on issue #7594: [for master] general exactly count distinct support in Druid URL: https://github.com/apache/incubator-druid/pull/7594#issuecomment-512074338 > From the error message ,i think there is must be an error in built dictionary stage ! so when in the ingestion stage there is a key can't find in the dictionary! > > do you have the same error when use wikiticker-2015-09-12-sampled.json data? @pzhdfy Yes, this is a know issue, non-ascii char may not be encoded correctly in BuildDictJob. We fix it in our internal version, I will commit it later This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] pzhdfy commented on issue #6988: [Improvement] historical fast restart by lazy load columns metadata(20X faster)
pzhdfy commented on issue #6988: [Improvement] historical fast restart by lazy load columns metadata(20X faster) URL: https://github.com/apache/incubator-druid/pull/6988#issuecomment-512068329 > I apply it to 0.12.3, but inoperative. I just apply and restart on one historical node of cluster. > Need I apply it on all nodes and restart? Just on historical. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on issue #7866: Moving project to Gradle
ccaominh commented on issue #7866: Moving project to Gradle URL: https://github.com/apache/incubator-druid/issues/7866#issuecomment-512060236 My earlier measurements for maven were unfair as I have not converted most of the maven plugins to their gradle equivalents. The adjusted numbers for maven: - **Non-parallel:**`mvn install -DskipTests -Dcheckstyle.skip=true -Dforbiddenapis.skip=true -Dpmd.skip=true -Danimal.sniffer.skip=true -Denforcer.skip=true -Dspotbugs.skip=true `(3m 15s): https://scans.gradle.com/s/uetcuf7p57utq - **Parallel:**`mvn install -DskipTests -Dcheckstyle.skip=true -Dforbiddenapis.skip=true -Dpmd.skip=true -Danimal.sniffer.skip=true -Denforcer.skip=true -Dspotbugs.skip=true -T8` (1m 51s): https://scans.gradle.com/s/nbxz5xiwqtloa The build for `druid-console` takes 33-34 seconds (mostly front-end related compilation) and needs to be subtracted when comparing against gradle, as I have not translated that yet. After that is taken into account, **gradle 5.5 is 2x faster than maven 3.6.1 for clean builds**. I was also able to fix the test runtime errors for gradle, but did not measure a significant difference in the test execution time between gradle and maven. **Probably the biggest performance advantage of using gradle over maven, is that gradle is very good at doing incremental builds.** This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: add missing dynamic coordinator configs (#8090)
This is an automated email from the ASF dual-hosted git repository.
cwylie pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-druid.git
The following commit(s) were added to refs/heads/master by this push:
new b80f20f add missing dynamic coordinator configs (#8090)
b80f20f is described below
commit b80f20f7694716e94a40ad8826e78d3fd0d659f9
Author: Vadim Ogievetsky
AuthorDate: Tue Jul 16 17:40:41 2019 -0700
add missing dynamic coordinator configs (#8090)
---
web-console/src/console-application.tsx| 12 ---
.../coordinator-dynamic-config-dialog.tsx | 105 -
web-console/src/entry.ts | 17 +++-
.../src/views/load-data-view/load-data-view.tsx| 1 +
4 files changed, 119 insertions(+), 16 deletions(-)
diff --git a/web-console/src/console-application.tsx
b/web-console/src/console-application.tsx
index 268fb92..636c706 100644
--- a/web-console/src/console-application.tsx
+++ b/web-console/src/console-application.tsx
@@ -25,7 +25,6 @@ import { HashRouter, Route, Switch } from 'react-router-dom';
import { ExternalLink, HeaderActiveTab, HeaderBar, Loader } from
'./components';
import { AppToaster } from './singletons/toaster';
-import { UrlBaser } from './singletons/url-baser';
import { QueryManager } from './utils';
import { DRUID_DOCS_API, DRUID_DOCS_SQL } from './variables';
import {
@@ -45,9 +44,6 @@ type Capabilities = 'working-with-sql' |
'working-without-sql' | 'broken';
export interface ConsoleApplicationProps {
hideLegacy: boolean;
- baseURL?: string;
- customHeaderName?: string;
- customHeaderValue?: string;
}
export interface ConsoleApplicationState {
@@ -125,14 +121,6 @@ export class ConsoleApplication extends
React.PureComponent<
capabilitiesLoading: true,
};
-if (props.baseURL) {
- axios.defaults.baseURL = props.baseURL;
- UrlBaser.baseURL = props.baseURL;
-}
-if (props.customHeaderName && props.customHeaderValue) {
- axios.defaults.headers.common[props.customHeaderName] =
props.customHeaderValue;
-}
-
this.capabilitiesQueryManager = new QueryManager({
processQuery: async () => {
const capabilities = await ConsoleApplication.discoverCapabilities();
diff --git
a/web-console/src/dialogs/coordinator-dynamic-config-dialog/coordinator-dynamic-config-dialog.tsx
b/web-console/src/dialogs/coordinator-dynamic-config-dialog/coordinator-dynamic-config-dialog.tsx
index 233d532..7d70487 100644
---
a/web-console/src/dialogs/coordinator-dynamic-config-dialog/coordinator-dynamic-config-dialog.tsx
+++
b/web-console/src/dialogs/coordinator-dynamic-config-dialog/coordinator-dynamic-config-dialog.tsx
@@ -16,7 +16,7 @@
* limitations under the License.
*/
-import { Intent } from '@blueprintjs/core';
+import { Code, Intent } from '@blueprintjs/core';
import { IconNames } from '@blueprintjs/icons';
import axios from 'axios';
import React from 'react';
@@ -138,50 +138,153 @@ export class CoordinatorDynamicConfigDialog extends
React.PureComponent<
{
name: 'balancerComputeThreads',
type: 'number',
+ defaultValue: 1,
+ info: (
+<>
+ Thread pool size for computing moving cost of segments in
segment balancing.
+ Consider increasing this if you have a lot of segments and
moving segments starts
+ to get stuck.
+
+ ),
},
{
name: 'emitBalancingStats',
type: 'boolean',
+ info: (
+<>
+ Boolean flag for whether or not we should emit balancing
stats. This is an
+ expensive operation.
+
+ ),
},
{
name: 'killAllDataSources',
type: 'boolean',
+ info: (
+<>
+ Send kill tasks for ALL dataSources if property{' '}
+ druid.coordinator.kill.on is true. If this is
set to true then{' '}
+ killDataSourceWhitelist must not be specified
or be empty list.
+
+ ),
},
{
name: 'killDataSourceWhitelist',
type: 'string-array',
+ info: (
+<>
+ List of dataSources for which kill tasks are sent if
property{' '}
+ druid.coordinator.kill.on is true. This can be
a list of
+ comma-separated dataSources or a JSON array.
+
+ ),
},
{
name: 'killPendingSegmentsSkipList',
type: 'string-array',
+ info: (
+<>
+ List of dataSources for which pendingSegments are NOT
cleaned up if property{' '}
+
[GitHub] [incubator-druid] clintropolis merged pull request #8090: Web console: add missing dynamic coordinator configs
clintropolis merged pull request #8090: Web console: add missing dynamic coordinator configs URL: https://github.com/apache/incubator-druid/pull/8090 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky opened a new pull request #8090: Web console: add missing dynamic coordinator configs
vogievetsky opened a new pull request #8090: Web console: add missing dynamic coordinator configs URL: https://github.com/apache/incubator-druid/pull/8090 Added `decommissioningNodes` and `decommissioningMaxPercentOfMaxSegmentsToMove` were missing from the dynamic config dialog.  Also: - Refactored the default config setting - Added icon to submit button This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated: add Class.getCanonicalName to forbidden-apis (#8086)
This is an automated email from the ASF dual-hosted git repository. himanshug pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git The following commit(s) were added to refs/heads/master by this push: new 15fbf59 add Class.getCanonicalName to forbidden-apis (#8086) 15fbf59 is described below commit 15fbf5983d9d6abaeda54296f97fe65f1d6bba98 Author: Clint Wylie AuthorDate: Tue Jul 16 15:21:50 2019 -0700 add Class.getCanonicalName to forbidden-apis (#8086) * add checkstyle to forbid unecessary use of Class.getCanonicalName * use forbiddin-api instead of checkstyle * add space --- codestyle/druid-forbidden-apis.txt | 3 ++- .../java/org/apache/druid/guice/GuiceInjectableValues.java | 2 +- .../apache/druid/java/util/common/lifecycle/Lifecycle.java | 6 ++ .../org/apache/druid/metadata/DefaultPasswordProvider.java | 2 +- .../druid/query/lookup/NamespaceLookupExtractorFactory.java | 2 +- .../cache/OffHeapNamespaceExtractionCacheManager.java| 2 +- .../query/lookup/namespace/UriExtractionNamespaceTest.java | 8 .../druid/indexing/overlord/http/OverlordResource.java | 2 +- .../seekablestream/SeekableStreamDataSourceMetadata.java | 8 .../seekablestream/SeekableStreamEndSequenceNumbers.java | 8 .../seekablestream/SeekableStreamStartSequenceNumbers.java | 8 .../apache/druid/indexing/worker/http/WorkerResource.java| 2 +- .../apache/druid/collections/bitmap/WrappedBitSetBitmap.java | 12 ++-- .../druid/query/aggregation/first/StringFirstAggregator.java | 2 +- .../query/aggregation/first/StringFirstBufferAggregator.java | 2 +- .../druid/query/aggregation/last/StringLastAggregator.java | 2 +- .../query/aggregation/last/StringLastBufferAggregator.java | 2 +- .../DataSourceMetadataQueryRunnerFactory.java| 2 +- .../druid/query/lookup/RegisteredLookupExtractionFn.java | 2 +- .../java/org/apache/druid/query/search/SearchStrategy.java | 2 +- .../org/apache/druid/granularity/QueryGranularityTest.java | 2 +- .../test/java/org/apache/druid/segment/CloserRuleTest.java | 2 +- .../apache/druid/segment/data/BitmapCreationBenchmark.java | 2 +- .../java/org/apache/druid/initialization/Initialization.java | 4 ++-- .../druid/initialization/Log4jShutterDownerModule.java | 8 .../main/java/org/apache/druid/server/StatusResource.java| 3 +-- .../apache/druid/server/coordinator/DruidCoordinator.java| 2 +- .../org/apache/druid/initialization/InitializationTest.java | 5 ++--- .../java/org/apache/druid/server/StatusResourceTest.java | 2 +- 29 files changed, 53 insertions(+), 56 deletions(-) diff --git a/codestyle/druid-forbidden-apis.txt b/codestyle/druid-forbidden-apis.txt index b06e502..c7f38fb 100644 --- a/codestyle/druid-forbidden-apis.txt +++ b/codestyle/druid-forbidden-apis.txt @@ -34,6 +34,7 @@ java.util.Random#() @ Use ThreadLocalRandom.current() or the constructor w java.lang.Math#random() @ Use ThreadLocalRandom.current() java.util.regex.Pattern#matches(java.lang.String,java.lang.CharSequence) @ Use String.startsWith(), endsWith(), contains(), or compile and cache a Pattern explicitly org.apache.commons.io.FileUtils#getTempDirectory() @ Use org.junit.rules.TemporaryFolder for tests instead +java.lang.Class#getCanonicalName() @ Class.getCanonicalName can return null for anonymous types, use Class.getName instead. @defaultMessage Use Locale.ENGLISH com.ibm.icu.text.DateFormatSymbols#() @@ -45,4 +46,4 @@ org.apache.commons.codec.binary.Base64 com.google.common.io.BaseEncoding.base64 @defaultMessage Use com.google.errorprone.annotations.concurrent.GuardedBy -javax.annotations.concurrent.GuardedBy \ No newline at end of file +javax.annotations.concurrent.GuardedBy diff --git a/core/src/main/java/org/apache/druid/guice/GuiceInjectableValues.java b/core/src/main/java/org/apache/druid/guice/GuiceInjectableValues.java index f7071c9..d12497e 100644 --- a/core/src/main/java/org/apache/druid/guice/GuiceInjectableValues.java +++ b/core/src/main/java/org/apache/druid/guice/GuiceInjectableValues.java @@ -54,7 +54,7 @@ public class GuiceInjectableValues extends InjectableValues } throw new IAE( "Unknown class type [%s] for valueId [%s]", -valueId.getClass().getCanonicalName(), +valueId.getClass().getName(), valueId.toString() ); } diff --git a/core/src/main/java/org/apache/druid/java/util/common/lifecycle/Lifecycle.java b/core/src/main/java/org/apache/druid/java/util/common/lifecycle/Lifecycle.java index 2cc897b..413f4ba 100644 --- a/core/src/main/java/org/apache/druid/java/util/common/lifecycle/Lifecycle.java +++ b/core/src/main/java/org/apache/druid/java/util/common/lifecycle/Lifecycle.java @@ -432,8 +432,7 @@ public class Lifecycle for (Method method :
[GitHub] [incubator-druid] himanshug merged pull request #8086: add Class.getCanonicalName to forbidden-apis
himanshug merged pull request #8086: add Class.getCanonicalName to forbidden-apis URL: https://github.com/apache/incubator-druid/pull/8086 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8089: add CachingClusteredClient benchmark, refactor some stuff
jihoonson commented on issue #8089: add CachingClusteredClient benchmark, refactor some stuff URL: https://github.com/apache/incubator-druid/pull/8089#issuecomment-512006804 LGTM overall. Would you fix the Line 198 of BrokerServerView? It should be `QueryableDruidServer retVal = new QueryableDruidServer<>(server, makeDirectClient(server));` now. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8088: Add intermediary data server for shuffle
jihoonson commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304107124
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/IntermediaryDataManager.java
##
@@ -0,0 +1,270 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.google.common.collect.Iterators;
+import com.google.common.io.Files;
+import com.google.inject.Inject;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.TaskStatus;
+import org.apache.druid.guice.ManageLifecycle;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.IOE;
+import org.apache.druid.java.util.common.concurrent.Execs;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStart;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStop;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.segment.loading.StorageLocation;
+import org.apache.druid.timeline.DataSegment;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+import org.joda.time.Period;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ScheduledExecutorService;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+/**
+ * This class manages intermediary segments for data shuffle between native
parallel index tasks.
+ * In native parallel indexing, phase 1 tasks store segment files in local
storage of middleManagers
+ * and phase 2 tasks read those files via HTTP.
+ *
+ * The directory where segment files are placed is structured as
+ * {@link
StorageLocation#path}/supervisorTaskId/startTimeOfSegment/endTimeOfSegment/partitionIdOfSegment.
+ *
+ * This class provides interfaces to store, find, and remove segment files.
+ * It also has a self-cleanup mechanism to clean up stale segment files. It
periodically checks the last access time
+ * per supervisorTask and removes its all segment files if the supervisorTask
is not running anymore.
+ */
+@ManageLifecycle
+public class IntermediaryDataManager
+{
+ private static final Logger log = new Logger(IntermediaryDataManager.class);
+
+ private final long intermediaryPartitionDiscoveryPeriodSec;
+ private final long intermediaryPartitionCleanupPeriodSec;
+ private final Period intermediaryPartitionTimeout;
+ private final List intermediarySegmentsLocations;
+ private final IndexingServiceClient indexingServiceClient;
+
+ // supervisorTaskId -> time to check supervisorTask status
+ // This time is initialized when a new supervisorTask is found and updated
whenever a partition is accessed for
+ // the supervisor.
+ private final ConcurrentHashMap supervisorTaskCheckTimes =
new ConcurrentHashMap<>();
+
+ // supervisorTaskId -> cyclic iterator of storage locations
+ private final Map> locationIterators = new
HashMap<>();
+
+ // The overlord is supposed to send a cleanup request as soon as the
supervisorTask is finished in parallel indexing,
+ // but middleManager or indexer could miss the request. This executor is to
automatically clean up unused intermediary
+ // partitions.
+ private ScheduledExecutorService supervisorTaskChecker;
+
+ @Inject
+ public IntermediaryDataManager(
+ WorkerConfig workerConfig,
+ TaskConfig taskConfig,
+ IndexingServiceClient indexingServiceClient
+ )
+ {
+this.intermediaryPartitionDiscoveryPeriodSec =
workerConfig.getIntermediaryPartitionDiscoveryPeriodSec();
+this.intermediaryPartitionCleanupPeriodSec =
workerConfig.getIntermediaryPartitionCleanupPeriodSec();
+
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8088: Add intermediary data server for shuffle
jihoonson commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304107095
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/IntermediaryDataManager.java
##
@@ -0,0 +1,270 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.google.common.collect.Iterators;
+import com.google.common.io.Files;
+import com.google.inject.Inject;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.TaskStatus;
+import org.apache.druid.guice.ManageLifecycle;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.IOE;
+import org.apache.druid.java.util.common.concurrent.Execs;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStart;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStop;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.segment.loading.StorageLocation;
+import org.apache.druid.timeline.DataSegment;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+import org.joda.time.Period;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ScheduledExecutorService;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+/**
+ * This class manages intermediary segments for data shuffle between native
parallel index tasks.
+ * In native parallel indexing, phase 1 tasks store segment files in local
storage of middleManagers
+ * and phase 2 tasks read those files via HTTP.
+ *
+ * The directory where segment files are placed is structured as
+ * {@link
StorageLocation#path}/supervisorTaskId/startTimeOfSegment/endTimeOfSegment/partitionIdOfSegment.
+ *
+ * This class provides interfaces to store, find, and remove segment files.
+ * It also has a self-cleanup mechanism to clean up stale segment files. It
periodically checks the last access time
+ * per supervisorTask and removes its all segment files if the supervisorTask
is not running anymore.
+ */
+@ManageLifecycle
+public class IntermediaryDataManager
+{
+ private static final Logger log = new Logger(IntermediaryDataManager.class);
+
+ private final long intermediaryPartitionDiscoveryPeriodSec;
+ private final long intermediaryPartitionCleanupPeriodSec;
+ private final Period intermediaryPartitionTimeout;
+ private final List intermediarySegmentsLocations;
+ private final IndexingServiceClient indexingServiceClient;
+
+ // supervisorTaskId -> time to check supervisorTask status
+ // This time is initialized when a new supervisorTask is found and updated
whenever a partition is accessed for
+ // the supervisor.
+ private final ConcurrentHashMap supervisorTaskCheckTimes =
new ConcurrentHashMap<>();
+
+ // supervisorTaskId -> cyclic iterator of storage locations
+ private final Map> locationIterators = new
HashMap<>();
+
+ // The overlord is supposed to send a cleanup request as soon as the
supervisorTask is finished in parallel indexing,
+ // but middleManager or indexer could miss the request. This executor is to
automatically clean up unused intermediary
+ // partitions.
+ private ScheduledExecutorService supervisorTaskChecker;
+
+ @Inject
+ public IntermediaryDataManager(
+ WorkerConfig workerConfig,
+ TaskConfig taskConfig,
+ IndexingServiceClient indexingServiceClient
+ )
+ {
+this.intermediaryPartitionDiscoveryPeriodSec =
workerConfig.getIntermediaryPartitionDiscoveryPeriodSec();
+this.intermediaryPartitionCleanupPeriodSec =
workerConfig.getIntermediaryPartitionCleanupPeriodSec();
+
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8088: Add intermediary data server for shuffle
jihoonson commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304107143
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/http/ShuffleResource.java
##
@@ -0,0 +1,116 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker.http;
+
+import com.google.common.io.ByteStreams;
+import com.google.inject.Inject;
+import com.sun.jersey.spi.container.ResourceFilters;
+import org.apache.druid.indexing.worker.IntermediaryDataManager;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.StringUtils;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.server.http.security.TaskShuffleResourceFilter;
+import org.joda.time.Interval;
+
+import javax.ws.rs.DELETE;
+import javax.ws.rs.GET;
+import javax.ws.rs.Path;
+import javax.ws.rs.PathParam;
+import javax.ws.rs.Produces;
+import javax.ws.rs.QueryParam;
+import javax.ws.rs.core.MediaType;
+import javax.ws.rs.core.Response;
+import javax.ws.rs.core.Response.Status;
+import javax.ws.rs.core.StreamingOutput;
+import java.io.File;
+import java.io.FileInputStream;
+import java.io.IOException;
+import java.util.List;
+
+@Path("/druid/worker/v1/shuffle")
+@ResourceFilters(TaskShuffleResourceFilter.class)
+public class ShuffleResource
+{
+ private static final Logger log = new Logger(ShuffleResource.class);
+
+ private final IntermediaryDataManager intermediaryDataManager;
+
+ @Inject
+ public ShuffleResource(IntermediaryDataManager intermediaryDataManager)
+ {
+this.intermediaryDataManager = intermediaryDataManager;
+ }
+
+ @GET
+ @Path("/task/{supervisorTaskId}/partition")
+ @Produces(MediaType.APPLICATION_OCTET_STREAM)
+ public Response getPartition(
+ @PathParam("supervisorTaskId") String supervisorTaskId,
+ @QueryParam("dataSource") String dataSource,
+ @QueryParam("startTime") String startTime,
+ @QueryParam("endTime") String endTime,
+ @QueryParam("partitionId") int partitionId
+ )
+ {
+final Interval interval = new Interval(DateTimes.of(startTime),
DateTimes.of(endTime));
+final List partitionFiles =
intermediaryDataManager.findPartitionFiles(
+supervisorTaskId,
+interval,
+partitionId
+);
+
+if (partitionFiles.isEmpty()) {
+ final String errorMessage = StringUtils.format(
+ "Can't find the partition for supervisor[%s], interval[%s], and
partitionId[%s]",
+ supervisorTaskId,
+ interval,
+ partitionId
+ );
+ return Response.status(Status.NOT_FOUND).entity(errorMessage).build();
+} else {
+ return Response.ok(
+ (StreamingOutput) output -> {
+for (File partitionFile : partitionFiles) {
+ try (final FileInputStream fileInputStream = new
FileInputStream(partitionFile)) {
+ByteStreams.copy(fileInputStream, output);
+ }
+}
+ }
+ ).build();
+}
+ }
+
+ @DELETE
+ @Path("/task/{supervisorTaskId}")
+ public Response deletePartitions(
+ @PathParam("supervisorTaskId") String supervisorTaskId,
+ @QueryParam("dataSource") String dataSource
Review comment:
It's.. used in `TaskShuffleResourceFilter` to check authorization. I know
this is weird and, ideally, the resourceFilter should check authorization for
task data instead of dataSource. However, the current security system only
supports dataSource-level authorization. Added a comment.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8088: Add intermediary data server for shuffle
jihoonson commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304107048
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/common/config/TaskConfig.java
##
@@ -89,6 +94,13 @@ public TaskConfig(
this.directoryLockTimeout = directoryLockTimeout == null
? DEFAULT_DIRECTORY_LOCK_TIMEOUT
: directoryLockTimeout;
+if (intermediarySegmentsLocations == null) {
+ this.intermediarySegmentsLocations = Collections.singletonList(
+ new StorageLocationConfig(new
File(System.getProperty("java.io.tmpdir"), "intermediary-segments"), null, null)
Review comment:
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8088: Add intermediary data server for shuffle
jihoonson commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304107067
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/IntermediaryDataManager.java
##
@@ -0,0 +1,270 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.google.common.collect.Iterators;
+import com.google.common.io.Files;
+import com.google.inject.Inject;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.TaskStatus;
+import org.apache.druid.guice.ManageLifecycle;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.IOE;
+import org.apache.druid.java.util.common.concurrent.Execs;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStart;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStop;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.segment.loading.StorageLocation;
+import org.apache.druid.timeline.DataSegment;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+import org.joda.time.Period;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ScheduledExecutorService;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+/**
+ * This class manages intermediary segments for data shuffle between native
parallel index tasks.
+ * In native parallel indexing, phase 1 tasks store segment files in local
storage of middleManagers
+ * and phase 2 tasks read those files via HTTP.
+ *
+ * The directory where segment files are placed is structured as
+ * {@link
StorageLocation#path}/supervisorTaskId/startTimeOfSegment/endTimeOfSegment/partitionIdOfSegment.
+ *
+ * This class provides interfaces to store, find, and remove segment files.
+ * It also has a self-cleanup mechanism to clean up stale segment files. It
periodically checks the last access time
+ * per supervisorTask and removes its all segment files if the supervisorTask
is not running anymore.
+ */
+@ManageLifecycle
+public class IntermediaryDataManager
+{
+ private static final Logger log = new Logger(IntermediaryDataManager.class);
+
+ private final long intermediaryPartitionDiscoveryPeriodSec;
+ private final long intermediaryPartitionCleanupPeriodSec;
+ private final Period intermediaryPartitionTimeout;
+ private final List intermediarySegmentsLocations;
+ private final IndexingServiceClient indexingServiceClient;
+
+ // supervisorTaskId -> time to check supervisorTask status
+ // This time is initialized when a new supervisorTask is found and updated
whenever a partition is accessed for
+ // the supervisor.
+ private final ConcurrentHashMap supervisorTaskCheckTimes =
new ConcurrentHashMap<>();
+
+ // supervisorTaskId -> cyclic iterator of storage locations
+ private final Map> locationIterators = new
HashMap<>();
+
+ // The overlord is supposed to send a cleanup request as soon as the
supervisorTask is finished in parallel indexing,
+ // but middleManager or indexer could miss the request. This executor is to
automatically clean up unused intermediary
+ // partitions.
+ private ScheduledExecutorService supervisorTaskChecker;
+
+ @Inject
+ public IntermediaryDataManager(
+ WorkerConfig workerConfig,
+ TaskConfig taskConfig,
+ IndexingServiceClient indexingServiceClient
+ )
+ {
+this.intermediaryPartitionDiscoveryPeriodSec =
workerConfig.getIntermediaryPartitionDiscoveryPeriodSec();
+this.intermediaryPartitionCleanupPeriodSec =
workerConfig.getIntermediaryPartitionCleanupPeriodSec();
+
[GitHub] [incubator-druid] jihoonson commented on issue #7547: Add support minor compaction with segment locking
jihoonson commented on issue #7547: Add support minor compaction with segment
locking
URL: https://github.com/apache/incubator-druid/pull/7547#issuecomment-511966275
@clintropolis I ran some benchmark and here are some results. The benchmark
code is available in [my
branch](https://github.com/jihoonson/druid/blob/minor-compaction-benchmark/benchmarks/src/main/java/org/apache/druid/timeline/VersionedIntervalTimelineBenchmark.java)
and will raise another pr for it after this PR is merged. Please note that
this benchmark doesn't compare the performance of `VersionedIntervalTimeline`
of this PR with that of the master branch. The primary purpose of this
benchmark is to measure how slow `VersionedIntervalTimeline` is with
segmentLock after this PR. (When timeChunk lock is used,
`VersionedIntervalTimeline` performs a bit more operations such as creating an
`OvershadowableManager` of a single partitionChunk than that of master.
However, the overall performance wouldn't be much different.)
TL;DR `VersionedIntervalTimeline` is slower with segment lock than that with
timeChunk lock, but it's still acceptable.
### Data setup
A synthetic segments were created to emulate the usual compaction scenario
where initial segments are created and then they got compacted while new
segments are appended. The benchmark first generates
`numInitialRootGenSegmentsPerInterval` segments per interval. Then, it
generates `numInitialRootGenSegmentsPerInterval *
COMPACTED_SEGMENTS_RATIO_TO_INITIAL_SEGMENTS` compacted segments which
overwrites the segments of the previous generation. It also generates new
appending segments. This can be repeated more than once based on
`numNonRootGenerations`.
Here, I pasted only some of results, e.g., when segmentGranularity = MONTH
or # of non-root generations = 5, because they look similar. In every graph,
blue and red represent throughput when using timeChunk lock and segment lock,
respectively. Line charts show the throughput with varying # of total segments
(including overshadowed ones). The _log scale_ is used for y axis of all line
charts. The bar charts just show the one data point in line charts where # of
segments = 160 which is the number Druid dataSources usually have per timeChunk.
Lookup
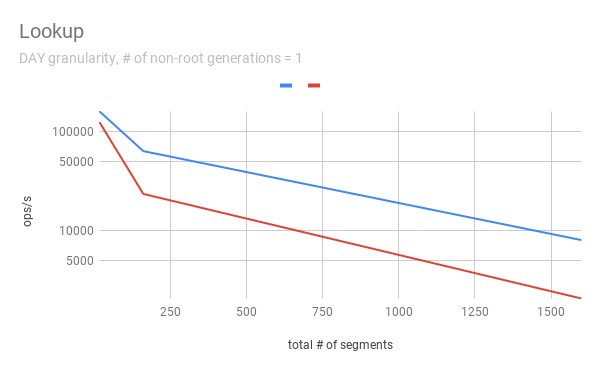
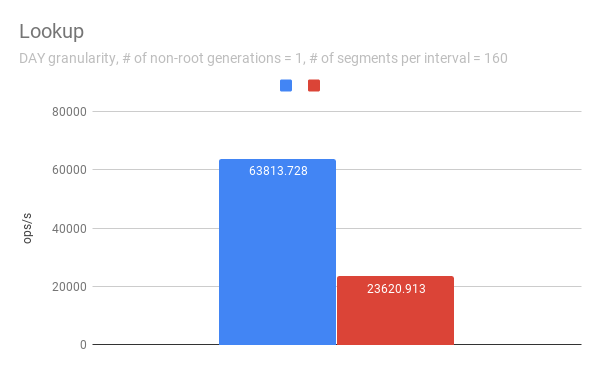
To measure the throughput of the `lookup` method, the benchmark picks up a
random interval which spans 3 time chunks based on segmentGranularity. This
result says the timeline is pretty faster with timeChunk lock than using
segment lock. But 23620.913 ops/s is still fast. Regarding peak CPU usage,
there's no big difference between using timeChunk lock and segment lock.
FindFullyOvershadowed
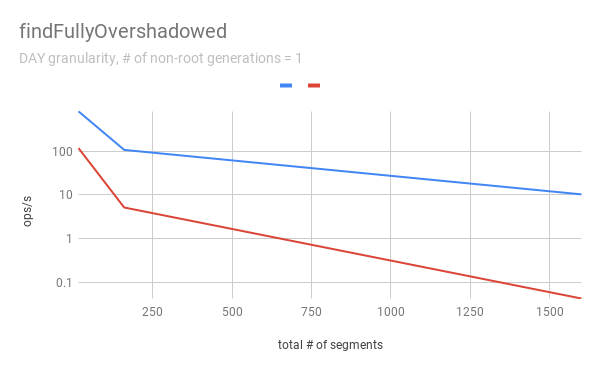
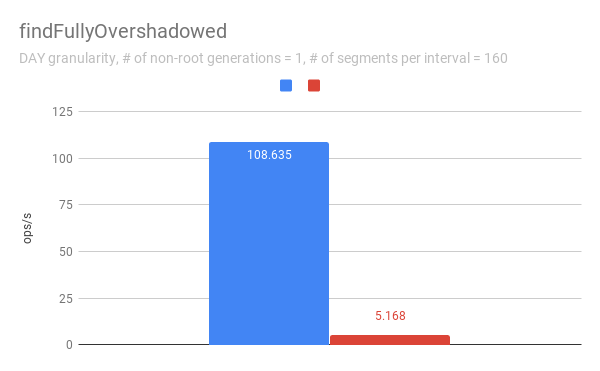
`findFullyOvershadowed` is very slow with segmentLock. This is because the
implementation is not very optimized, especially the constructor of
`PartitionHolder`. Here is the code snippet.
```java
public PartitionHolder(List> initialChunks)
{
this.overshadowableManager = new OvershadowableManager<>();
for (PartitionChunk chunk : initialChunks) {
add(chunk);
}
}
```
This could be improved by adding a bulk construction of
OvershadowableManager, but `findFullyOvershadowed` is called only one place in
production code, i.e., `ParallelSubIndexTask`. I think it could be done later
rather than in this PR.
IsOvershadowed
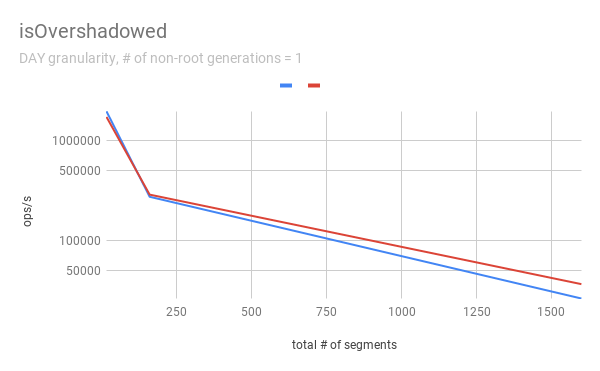
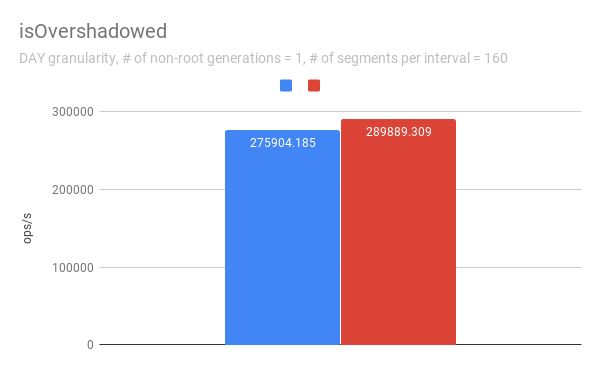
`isOvershadowed` shows a pretty similar throughput. The benchmark chooses a
random one among timeChunks populated based on segmentGranularity. As a result,
the benchmark always executes the below part in `isOvershadowed` method.
```java
TimelineEntry entry = completePartitionsTimeline.get(interval);
if (entry != null) {
final int majorVersionCompare = versionComparator.compare(version,
entry.getVersion());
if (majorVersionCompare == 0) {
for (PartitionChunk chunk : entry.partitionHolder) {
if (chunk.getObject().isOvershadow(object)) {
return true;
}
}
[GitHub] [incubator-druid] mihai-cazacu-adswizz commented on issue #8063: The compaction task fails without errors
mihai-cazacu-adswizz commented on issue #8063: The compaction task fails without errors URL: https://github.com/apache/incubator-druid/issues/8063#issuecomment-511942787 I have solved this by changing the value of `Xmx` and `MaxDirectMemorySize` for Peons. Even so, it would be nice to have an error message in the log for this kind of issue. Thank you! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8088: Add intermediary data server for shuffle
himanshug commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304067921
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/IntermediaryDataManager.java
##
@@ -0,0 +1,270 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.google.common.collect.Iterators;
+import com.google.common.io.Files;
+import com.google.inject.Inject;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.TaskStatus;
+import org.apache.druid.guice.ManageLifecycle;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.IOE;
+import org.apache.druid.java.util.common.concurrent.Execs;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStart;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStop;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.segment.loading.StorageLocation;
+import org.apache.druid.timeline.DataSegment;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+import org.joda.time.Period;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ScheduledExecutorService;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+/**
+ * This class manages intermediary segments for data shuffle between native
parallel index tasks.
+ * In native parallel indexing, phase 1 tasks store segment files in local
storage of middleManagers
+ * and phase 2 tasks read those files via HTTP.
+ *
+ * The directory where segment files are placed is structured as
+ * {@link
StorageLocation#path}/supervisorTaskId/startTimeOfSegment/endTimeOfSegment/partitionIdOfSegment.
+ *
+ * This class provides interfaces to store, find, and remove segment files.
+ * It also has a self-cleanup mechanism to clean up stale segment files. It
periodically checks the last access time
+ * per supervisorTask and removes its all segment files if the supervisorTask
is not running anymore.
+ */
+@ManageLifecycle
+public class IntermediaryDataManager
+{
+ private static final Logger log = new Logger(IntermediaryDataManager.class);
+
+ private final long intermediaryPartitionDiscoveryPeriodSec;
+ private final long intermediaryPartitionCleanupPeriodSec;
+ private final Period intermediaryPartitionTimeout;
+ private final List intermediarySegmentsLocations;
+ private final IndexingServiceClient indexingServiceClient;
+
+ // supervisorTaskId -> time to check supervisorTask status
+ // This time is initialized when a new supervisorTask is found and updated
whenever a partition is accessed for
+ // the supervisor.
+ private final ConcurrentHashMap supervisorTaskCheckTimes =
new ConcurrentHashMap<>();
+
+ // supervisorTaskId -> cyclic iterator of storage locations
+ private final Map> locationIterators = new
HashMap<>();
+
+ // The overlord is supposed to send a cleanup request as soon as the
supervisorTask is finished in parallel indexing,
+ // but middleManager or indexer could miss the request. This executor is to
automatically clean up unused intermediary
+ // partitions.
+ private ScheduledExecutorService supervisorTaskChecker;
+
+ @Inject
+ public IntermediaryDataManager(
+ WorkerConfig workerConfig,
+ TaskConfig taskConfig,
+ IndexingServiceClient indexingServiceClient
+ )
+ {
+this.intermediaryPartitionDiscoveryPeriodSec =
workerConfig.getIntermediaryPartitionDiscoveryPeriodSec();
+this.intermediaryPartitionCleanupPeriodSec =
workerConfig.getIntermediaryPartitionCleanupPeriodSec();
+
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8088: Add intermediary data server for shuffle
himanshug commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304065976
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/IntermediaryDataManager.java
##
@@ -0,0 +1,270 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.google.common.collect.Iterators;
+import com.google.common.io.Files;
+import com.google.inject.Inject;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.TaskStatus;
+import org.apache.druid.guice.ManageLifecycle;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.IOE;
+import org.apache.druid.java.util.common.concurrent.Execs;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStart;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStop;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.segment.loading.StorageLocation;
+import org.apache.druid.timeline.DataSegment;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+import org.joda.time.Period;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ScheduledExecutorService;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+/**
+ * This class manages intermediary segments for data shuffle between native
parallel index tasks.
+ * In native parallel indexing, phase 1 tasks store segment files in local
storage of middleManagers
+ * and phase 2 tasks read those files via HTTP.
+ *
+ * The directory where segment files are placed is structured as
+ * {@link
StorageLocation#path}/supervisorTaskId/startTimeOfSegment/endTimeOfSegment/partitionIdOfSegment.
+ *
+ * This class provides interfaces to store, find, and remove segment files.
+ * It also has a self-cleanup mechanism to clean up stale segment files. It
periodically checks the last access time
+ * per supervisorTask and removes its all segment files if the supervisorTask
is not running anymore.
+ */
+@ManageLifecycle
+public class IntermediaryDataManager
+{
+ private static final Logger log = new Logger(IntermediaryDataManager.class);
+
+ private final long intermediaryPartitionDiscoveryPeriodSec;
+ private final long intermediaryPartitionCleanupPeriodSec;
+ private final Period intermediaryPartitionTimeout;
+ private final List intermediarySegmentsLocations;
+ private final IndexingServiceClient indexingServiceClient;
+
+ // supervisorTaskId -> time to check supervisorTask status
+ // This time is initialized when a new supervisorTask is found and updated
whenever a partition is accessed for
+ // the supervisor.
+ private final ConcurrentHashMap supervisorTaskCheckTimes =
new ConcurrentHashMap<>();
+
+ // supervisorTaskId -> cyclic iterator of storage locations
+ private final Map> locationIterators = new
HashMap<>();
+
+ // The overlord is supposed to send a cleanup request as soon as the
supervisorTask is finished in parallel indexing,
+ // but middleManager or indexer could miss the request. This executor is to
automatically clean up unused intermediary
+ // partitions.
+ private ScheduledExecutorService supervisorTaskChecker;
+
+ @Inject
+ public IntermediaryDataManager(
+ WorkerConfig workerConfig,
+ TaskConfig taskConfig,
+ IndexingServiceClient indexingServiceClient
+ )
+ {
+this.intermediaryPartitionDiscoveryPeriodSec =
workerConfig.getIntermediaryPartitionDiscoveryPeriodSec();
+this.intermediaryPartitionCleanupPeriodSec =
workerConfig.getIntermediaryPartitionCleanupPeriodSec();
+
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8088: Add intermediary data server for shuffle
himanshug commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304063075
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/common/config/TaskConfig.java
##
@@ -89,6 +94,13 @@ public TaskConfig(
this.directoryLockTimeout = directoryLockTimeout == null
? DEFAULT_DIRECTORY_LOCK_TIMEOUT
: directoryLockTimeout;
+if (intermediarySegmentsLocations == null) {
+ this.intermediarySegmentsLocations = Collections.singletonList(
+ new StorageLocationConfig(new
File(System.getProperty("java.io.tmpdir"), "intermediary-segments"), null, null)
Review comment:
```suggestion
new StorageLocationConfig(new File(defaultDir(null,
"intermediary-segments")), null, null)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8088: Add intermediary data server for shuffle
himanshug commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304066400
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/IntermediaryDataManager.java
##
@@ -0,0 +1,270 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker;
+
+import com.google.common.collect.Iterators;
+import com.google.common.io.Files;
+import com.google.inject.Inject;
+import org.apache.commons.io.FileUtils;
+import org.apache.druid.client.indexing.IndexingServiceClient;
+import org.apache.druid.client.indexing.TaskStatus;
+import org.apache.druid.guice.ManageLifecycle;
+import org.apache.druid.indexing.common.config.TaskConfig;
+import org.apache.druid.indexing.worker.config.WorkerConfig;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.IOE;
+import org.apache.druid.java.util.common.concurrent.Execs;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStart;
+import org.apache.druid.java.util.common.lifecycle.LifecycleStop;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.segment.loading.StorageLocation;
+import org.apache.druid.timeline.DataSegment;
+import org.joda.time.DateTime;
+import org.joda.time.Interval;
+import org.joda.time.Period;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.ScheduledExecutorService;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+/**
+ * This class manages intermediary segments for data shuffle between native
parallel index tasks.
+ * In native parallel indexing, phase 1 tasks store segment files in local
storage of middleManagers
+ * and phase 2 tasks read those files via HTTP.
+ *
+ * The directory where segment files are placed is structured as
+ * {@link
StorageLocation#path}/supervisorTaskId/startTimeOfSegment/endTimeOfSegment/partitionIdOfSegment.
+ *
+ * This class provides interfaces to store, find, and remove segment files.
+ * It also has a self-cleanup mechanism to clean up stale segment files. It
periodically checks the last access time
+ * per supervisorTask and removes its all segment files if the supervisorTask
is not running anymore.
+ */
+@ManageLifecycle
+public class IntermediaryDataManager
+{
+ private static final Logger log = new Logger(IntermediaryDataManager.class);
+
+ private final long intermediaryPartitionDiscoveryPeriodSec;
+ private final long intermediaryPartitionCleanupPeriodSec;
+ private final Period intermediaryPartitionTimeout;
+ private final List intermediarySegmentsLocations;
+ private final IndexingServiceClient indexingServiceClient;
+
+ // supervisorTaskId -> time to check supervisorTask status
+ // This time is initialized when a new supervisorTask is found and updated
whenever a partition is accessed for
+ // the supervisor.
+ private final ConcurrentHashMap supervisorTaskCheckTimes =
new ConcurrentHashMap<>();
+
+ // supervisorTaskId -> cyclic iterator of storage locations
+ private final Map> locationIterators = new
HashMap<>();
+
+ // The overlord is supposed to send a cleanup request as soon as the
supervisorTask is finished in parallel indexing,
+ // but middleManager or indexer could miss the request. This executor is to
automatically clean up unused intermediary
+ // partitions.
+ private ScheduledExecutorService supervisorTaskChecker;
+
+ @Inject
+ public IntermediaryDataManager(
+ WorkerConfig workerConfig,
+ TaskConfig taskConfig,
+ IndexingServiceClient indexingServiceClient
+ )
+ {
+this.intermediaryPartitionDiscoveryPeriodSec =
workerConfig.getIntermediaryPartitionDiscoveryPeriodSec();
+this.intermediaryPartitionCleanupPeriodSec =
workerConfig.getIntermediaryPartitionCleanupPeriodSec();
+
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8088: Add intermediary data server for shuffle
himanshug commented on a change in pull request #8088: Add intermediary data
server for shuffle
URL: https://github.com/apache/incubator-druid/pull/8088#discussion_r304068750
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/worker/http/ShuffleResource.java
##
@@ -0,0 +1,116 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.worker.http;
+
+import com.google.common.io.ByteStreams;
+import com.google.inject.Inject;
+import com.sun.jersey.spi.container.ResourceFilters;
+import org.apache.druid.indexing.worker.IntermediaryDataManager;
+import org.apache.druid.java.util.common.DateTimes;
+import org.apache.druid.java.util.common.StringUtils;
+import org.apache.druid.java.util.common.logger.Logger;
+import org.apache.druid.server.http.security.TaskShuffleResourceFilter;
+import org.joda.time.Interval;
+
+import javax.ws.rs.DELETE;
+import javax.ws.rs.GET;
+import javax.ws.rs.Path;
+import javax.ws.rs.PathParam;
+import javax.ws.rs.Produces;
+import javax.ws.rs.QueryParam;
+import javax.ws.rs.core.MediaType;
+import javax.ws.rs.core.Response;
+import javax.ws.rs.core.Response.Status;
+import javax.ws.rs.core.StreamingOutput;
+import java.io.File;
+import java.io.FileInputStream;
+import java.io.IOException;
+import java.util.List;
+
+@Path("/druid/worker/v1/shuffle")
+@ResourceFilters(TaskShuffleResourceFilter.class)
+public class ShuffleResource
+{
+ private static final Logger log = new Logger(ShuffleResource.class);
+
+ private final IntermediaryDataManager intermediaryDataManager;
+
+ @Inject
+ public ShuffleResource(IntermediaryDataManager intermediaryDataManager)
+ {
+this.intermediaryDataManager = intermediaryDataManager;
+ }
+
+ @GET
+ @Path("/task/{supervisorTaskId}/partition")
+ @Produces(MediaType.APPLICATION_OCTET_STREAM)
+ public Response getPartition(
+ @PathParam("supervisorTaskId") String supervisorTaskId,
+ @QueryParam("dataSource") String dataSource,
+ @QueryParam("startTime") String startTime,
+ @QueryParam("endTime") String endTime,
+ @QueryParam("partitionId") int partitionId
+ )
+ {
+final Interval interval = new Interval(DateTimes.of(startTime),
DateTimes.of(endTime));
+final List partitionFiles =
intermediaryDataManager.findPartitionFiles(
+supervisorTaskId,
+interval,
+partitionId
+);
+
+if (partitionFiles.isEmpty()) {
+ final String errorMessage = StringUtils.format(
+ "Can't find the partition for supervisor[%s], interval[%s], and
partitionId[%s]",
+ supervisorTaskId,
+ interval,
+ partitionId
+ );
+ return Response.status(Status.NOT_FOUND).entity(errorMessage).build();
+} else {
+ return Response.ok(
+ (StreamingOutput) output -> {
+for (File partitionFile : partitionFiles) {
+ try (final FileInputStream fileInputStream = new
FileInputStream(partitionFile)) {
+ByteStreams.copy(fileInputStream, output);
+ }
+}
+ }
+ ).build();
+}
+ }
+
+ @DELETE
+ @Path("/task/{supervisorTaskId}")
+ public Response deletePartitions(
+ @PathParam("supervisorTaskId") String supervisorTaskId,
+ @QueryParam("dataSource") String dataSource
Review comment:
unused ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] capistrant commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off
capistrant commented on issue #7562: Enable ability to toggle SegmentMetadata request logging on/off URL: https://github.com/apache/incubator-druid/pull/7562#issuecomment-511932914 Thanks all for the tips and info! I'll be cleaning this up this week following all the feedback This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8086: add Class.getCanonicalName to forbidden-api
himanshug commented on a change in pull request #8086: add Class.getCanonicalName to forbidden-api URL: https://github.com/apache/incubator-druid/pull/8086#discussion_r304047609 ## File path: codestyle/druid-forbidden-apis.txt ## @@ -34,6 +34,7 @@ java.util.Random#() @ Use ThreadLocalRandom.current() or the constructor w java.lang.Math#random() @ Use ThreadLocalRandom.current() java.util.regex.Pattern#matches(java.lang.String,java.lang.CharSequence) @ Use String.startsWith(), endsWith(), contains(), or compile and cache a Pattern explicitly org.apache.commons.io.FileUtils#getTempDirectory() @ Use org.junit.rules.TemporaryFolder for tests instead +java.lang.Class#getCanonicalName() @Class.getCanonicalName can return null for anonymous types, use Class.getName instead. Review comment: on other lines I see a space between '@' and message start , it might or might not be important but we could that space just to be consistent . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] himanshug commented on a change in pull request #8086: add Class.getCanonicalName to forbidden-api
himanshug commented on a change in pull request #8086: add Class.getCanonicalName to forbidden-api URL: https://github.com/apache/incubator-druid/pull/8086#discussion_r304047609 ## File path: codestyle/druid-forbidden-apis.txt ## @@ -34,6 +34,7 @@ java.util.Random#() @ Use ThreadLocalRandom.current() or the constructor w java.lang.Math#random() @ Use ThreadLocalRandom.current() java.util.regex.Pattern#matches(java.lang.String,java.lang.CharSequence) @ Use String.startsWith(), endsWith(), contains(), or compile and cache a Pattern explicitly org.apache.commons.io.FileUtils#getTempDirectory() @ Use org.junit.rules.TemporaryFolder for tests instead +java.lang.Class#getCanonicalName() @Class.getCanonicalName can return null for anonymous types, use Class.getName instead. Review comment: on other lines I see a space between '@' and message start , it might or might not be important but we could add that space just to be consistent . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8086: add checkstyle to forbid unecessary use of Class.getCanonicalName
clintropolis commented on a change in pull request #8086: add checkstyle to forbid unecessary use of Class.getCanonicalName URL: https://github.com/apache/incubator-druid/pull/8086#discussion_r304040441 ## File path: codestyle/checkstyle.xml ## @@ -319,5 +319,11 @@ codestyle/checkstyle.xml."/> + + Review comment: Oops, yeah will fix :+1: This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #8084: Add more excempt tags for stalebot; Make stalebot to close PRs/issues in 21 days rather than in 7/14 days
leventov commented on issue #8084: Add more excempt tags for stalebot; Make stalebot to close PRs/issues in 21 days rather than in 7/14 days URL: https://github.com/apache/incubator-druid/pull/8084#issuecomment-511896406 I overlooked the PR/issue distinction. Indeed, I also don't see the point of having exempt labels for PRs - even `Bug`/`Security`/`Proposal` which used to be exempt for PRs before. I've updated the PR. I've also added `Uncategorized problem report` label discussed in the thread in the mailing list to "Problem report" template. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] surekhasaharan commented on a change in pull request #8059: Refactoring to use `CollectionUtils.mapValues`
surekhasaharan commented on a change in pull request #8059: Refactoring to use
`CollectionUtils.mapValues`
URL: https://github.com/apache/incubator-druid/pull/8059#discussion_r304007145
##
File path: core/src/main/java/org/apache/druid/utils/CollectionUtils.java
##
@@ -88,12 +89,22 @@ public int size()
/**
* Returns a transformed map from the given input map where the key is
modified based on the given keyMapper
- * function.
+ * function. This method fails if keys collide after applying the given
keyMapper function and
+ * throws a IllegalStateException.
+ *
+ * @throws ISE if key collisions occur while applying specified keyMapper
*/
+
public static Map mapKeys(Map map, Function
keyMapper)
{
final Map result = Maps.newHashMapWithExpectedSize(map.size());
-map.forEach((k, v) -> result.put(keyMapper.apply(k), v));
+map.forEach((k, v) -> {
+ final K2 k2 = keyMapper.apply(k);
+ if (result.containsKey(k2)) {
Review comment:
i see, fixed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy closed issue #8074: Unified console broken: resizeSensor.js unexpected token { on line 88
fjy closed issue #8074: Unified console broken: resizeSensor.js unexpected
token { on line 88
URL: https://github.com/apache/incubator-druid/issues/8074
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy merged pull request #8007: Web console: update dependencies
fjy merged pull request #8007: Web console: update dependencies URL: https://github.com/apache/incubator-druid/pull/8007 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7842: The instruction for running integration tests from integration-tests/README.md doesn't work
leventov commented on issue #7842: The instruction for running integration tests from integration-tests/README.md doesn't work URL: https://github.com/apache/incubator-druid/issues/7842#issuecomment-511874813 @jon-wei thank you, yes, the cert generation step failed because of the following problems: ``` ../docker/tls/generate-expired-client-cert.sh: line 18: resolveip: command not found ``` and ``` Error Loading request extension section req_ext 4681430636:error:22FFF076:X509 V3 routines:func(4095):bad ip address:/BuildRoot/Library/Caches/com.apple.xbs/Sources/libressl/libressl-22.260.1/libressl-2.6/crypto/x509v3/v3_alt.c:529:value= 4681430636:error:22FFF080:X509 V3 routines:func(4095):error in extension:/BuildRoot/Library/Caches/com.apple.xbs/Sources/libressl/libressl-22.260.1/libressl-2.6/crypto/x509v3/v3_conf.c:96:name=subjectAltName, value=@alt_names ``` I'm going to look for the root cause and a solution later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8086: add checkstyle to forbid unecessary use of Class.getCanonicalName
leventov commented on a change in pull request #8086: add checkstyle to forbid unecessary use of Class.getCanonicalName URL: https://github.com/apache/incubator-druid/pull/8086#discussion_r303959138 ## File path: codestyle/checkstyle.xml ## @@ -319,5 +319,11 @@ codestyle/checkstyle.xml."/> + + Review comment: Could you use [forbidden-apis](https://github.com/apache/incubator-druid/blob/master/codestyle/druid-forbidden-apis.txt) which is a native tool for this type of prohibition? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov edited a comment on issue #7991: Add development principles
leventov edited a comment on issue #7991: Add development principles URL: https://github.com/apache/incubator-druid/pull/7991#issuecomment-511830784 @gianm I don't see how to make the document significantly shorter without cutting important (in my opinion) content. The document already skips almost all justifications and therefore looks somewhat unsubstantiated, but including explanations for each principle would make the document several times longer. I also don't see a value in creating a "poster form" of this document consisting of only headers, for example, because it is *not* a checklist and is *not* expected to be used (let alone read in full) frequently. I can include the "table of contents" in the beginning of the document itself but would do it after the contents and the structure is agreed upon. Finally, note that the target audience of this document are only regular Druid contributors. Many of them spend several hours every day developing Druid. I believe 45 minutes is a tiny investment for getting to the same page with the community and would pay off manyfold for them and the community as a whole. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7991: Add development principles
leventov commented on issue #7991: Add development principles URL: https://github.com/apache/incubator-druid/pull/7991#issuecomment-511830784 @gianm I don't see how to make the document significantly shorter without cutting important (in my opinion) content. The document already skips almost all justifications and therefore looks somewhat unsubstantiated, but including explanations for each principle would make it several times longer. I also don't see a value in creating a "poster form" of this document consisting of only headers, for example, because it is *not* a checklist and is *not* expected to be used (let alone read in full) frequently. I can include the "table of contents" in the beginning of the document itself but would do it after the contents and the structure is agreed upon. Finally, note that the target audience of this document are only regular Druid contributors. Many of them spend several hours every day developing Druid. I believe 45 minutes is a tiny investment for getting to the same page with the community and would pay off manyfold for them and the community as a whole. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch leventov-patch-1 deleted (was e8ef50b)
This is an automated email from the ASF dual-hosted git repository. leventov pushed a change to branch leventov-patch-1 in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. was e8ef50b Add instruction about skipping up-to-date checks when running integration tests The revisions that were on this branch are still contained in other references; therefore, this change does not discard any commits from the repository. - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8059: Refactoring to use `CollectionUtils.mapValues`
leventov commented on a change in pull request #8059: Refactoring to use
`CollectionUtils.mapValues`
URL: https://github.com/apache/incubator-druid/pull/8059#discussion_r303901726
##
File path: core/src/main/java/org/apache/druid/utils/CollectionUtils.java
##
@@ -88,12 +89,22 @@ public int size()
/**
* Returns a transformed map from the given input map where the key is
modified based on the given keyMapper
- * function.
+ * function. This method fails if keys collide after applying the given
keyMapper function and
+ * throws a IllegalStateException.
+ *
+ * @throws ISE if key collisions occur while applying specified keyMapper
*/
+
public static Map mapKeys(Map map, Function
keyMapper)
{
final Map result = Maps.newHashMapWithExpectedSize(map.size());
-map.forEach((k, v) -> result.put(keyMapper.apply(k), v));
+map.forEach((k, v) -> {
+ final K2 k2 = keyMapper.apply(k);
+ if (result.containsKey(k2)) {
Review comment:
@surekhasaharan the idea of this replacement was to get rid of
`containsKey()` call, so that only one lookup operation (`putIfAbsent()`
itself) is done on each iteration instead of two (`containsKey()` and `put()`):
```java
if (result.putIfAbsent(k2, v) != null) {
throw new ISE("Conflicting key[%s] calculated via keyMapper for original
key[%s]", k2, k);
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8060: 6855 add Checkstyle for constant name static final
leventov commented on a change in pull request #8060: 6855 add Checkstyle for constant name static final URL: https://github.com/apache/incubator-druid/pull/8060#discussion_r303900541 ## File path: extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTuningConfigTest.java ## @@ -24,7 +24,6 @@ import org.apache.druid.indexing.kafka.KafkaIndexTaskModule; import org.apache.druid.jackson.DefaultObjectMapper; import org.apache.druid.segment.IndexSpec; -import org.apache.druid.segment.data.CompressionStrategy; Review comment: @SandishKumarHN please reconcile with the upstream master and get your branch to the state when there are no changes which appear as unrelated to the purpose of this PR (for example the one to which this comment thread is attached). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7653: Refactor SQLMetadataSegmentManager; Change contract of REST methods in DataSourcesResource
leventov commented on issue #7653: Refactor SQLMetadataSegmentManager; Change contract of REST methods in DataSourcesResource URL: https://github.com/apache/incubator-druid/pull/7653#issuecomment-511808804 @egor-ryashin could you please check this PR again? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] JackyYangPassion edited a comment on issue #7594: [for master] general exactly count distinct support in Druid
JackyYangPassion edited a comment on issue #7594: [for master] general exactly count distinct support in Druid URL: https://github.com/apache/incubator-druid/pull/7594#issuecomment-511800536 From the error message ,i think there is must be an error in built dictionary stage ! so when in the ingestion stage there is a key can't find in the dictionary! do you have the same error when use wikiticker-2015-09-12-sampled.json data? @pzhdfy This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] JackyYangPassion commented on issue #7594: [for master] general exactly count distinct support in Druid
JackyYangPassion commented on issue #7594: [for master] general exactly count distinct support in Druid URL: https://github.com/apache/incubator-druid/pull/7594#issuecomment-511800536 from the error message ,i think there is must be an error in built dictionary stage ! so when in the ingestion stage there is a key can't find in the dictionary This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] JackyYangPassion edited a comment on issue #7594: [for master] general exactly count distinct support in Druid
JackyYangPassion edited a comment on issue #7594: [for master] general exactly
count distinct support in Druid
URL: https://github.com/apache/incubator-druid/pull/7594#issuecomment-511795351
when i use quickstart example wikiticker-2015-09-12-sampled.json with unique
user:
### record:
`{"time":"2015-09-12T00:47:44.963Z","channel":"#ru.wikipedia","cityName":null,"comment":"/*
Донецкая Народная Республика
*/","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Караман,
Александр Акимович","regionIsoCode":null,"regionName":null,"user":"Камарад
Че","delta":0,"added":0,"deleted":0}`
### Error:
`java.lang.Exception: io.druid.java.util.common.RE: Failure on
row[{"time":"2015-09-12T00:47:44.963Z","channel":"#ru.wikipedia","cityName":null,"comment":"/*
Ð”Ð¾Ð½ÐµÑ†ÐºÐ°Ñ ÐÐ°Ñ€Ð¾Ð´Ð½Ð°Ñ Ð ÐµÑпублика
*/","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Караман,
ÐлекÑандр
Ðкимович","regionIsoCode":null,"regionName":null,"user":"Камарад
Че","delta":0,"added":0,"deleted":0}]
at
org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
~[hadoop-mapreduce-client-common-2.7.3.jar:?]
at
org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
[hadoop-mapreduce-client-common-2.7.3.jar:?]
Caused by: io.druid.java.util.common.RE: Failure on
row[{"time":"2015-09-12T00:47:44.963Z","channel":"#ru.wikipedia","cityName":null,"comment":"/*
Ð”Ð¾Ð½ÐµÑ†ÐºÐ°Ñ ÐÐ°Ñ€Ð¾Ð´Ð½Ð°Ñ Ð ÐµÑпублика
*/","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Караман,
ÐлекÑандр
Ðкимович","regionIsoCode":null,"regionName":null,"user":"Камарад
Че","delta":0,"added":0,"deleted":0}]
at
io.druid.indexer.HadoopDruidIndexerMapper.map(HadoopDruidIndexerMapper.java:93)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
~[hadoop-mapreduce-client-core-2.7.3.jar:?]
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
~[hadoop-mapreduce-client-core-2.7.3.jar:?]
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
~[hadoop-mapreduce-client-core-2.7.3.jar:?]
at
org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
~[hadoop-mapreduce-client-common-2.7.3.jar:?]
at
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
~[?:1.8.0_171]
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
~[?:1.8.0_171]
at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
~[?:1.8.0_171]
at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
~[?:1.8.0_171]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_171]
Caused by: java.lang.IllegalArgumentException: Value : Камарад Че
not exists
at
org.apache.kylin.common.util.Dictionary.getIdFromValue(Dictionary.java:107)
~[kylin-core-common-2.5.2.jar:2.5.2]
at
org.apache.kylin.common.util.Dictionary.getIdFromValue(Dictionary.java:85)
~[kylin-core-common-2.5.2.jar:2.5.2]
at
io.druid.segment.incremental.IncrementalIndex$1InputRowDictWrap.getDimension(IncrementalIndex.java:180)
~[druid-processing-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.query.aggregation.unique.RoaringBitmapComplexMetricSerde$1.extractValue(RoaringBitmapComplexMetricSerde.java:70)
~[druid-uniq-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.query.aggregation.unique.RoaringBitmapComplexMetricSerde$1.extractValue(RoaringBitmapComplexMetricSerde.java:52)
~[druid-uniq-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.segment.incremental.IncrementalIndex$1IncrementalIndexInputRowColumnSelectorFactory$1.getObject(IncrementalIndex.java:264)
~[druid-processing-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.query.aggregation.unique.UniqueBuildAggregator.aggregate(UniqueBuildAggregator.java:53)
~[druid-uniq-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at io.druid.indexer.InputRowSerde.toBytes(InputRowSerde.java:281)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.indexer.IndexGeneratorJob$IndexGeneratorMapper.innerMap(IndexGeneratorJob.java:371)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.indexer.HadoopDruidIndexerMapper.map(HadoopDruidIndexerMapper.java:88)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
[GitHub] [incubator-druid] JackyYangPassion commented on issue #7594: [for master] general exactly count distinct support in Druid
JackyYangPassion commented on issue #7594: [for master] general exactly count
distinct support in Druid
URL: https://github.com/apache/incubator-druid/pull/7594#issuecomment-511795351
when i use quickstart example wikiticker-2015-09-12-sampled.json with unique
user:
record:
`{"time":"2015-09-12T00:47:44.963Z","channel":"#ru.wikipedia","cityName":null,"comment":"/*
Донецкая Народная Республика
*/","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Караман,
Александр Акимович","regionIsoCode":null,"regionName":null,"user":"Камарад
Че","delta":0,"added":0,"deleted":0}`
Error:
`java.lang.Exception: io.druid.java.util.common.RE: Failure on
row[{"time":"2015-09-12T00:47:44.963Z","channel":"#ru.wikipedia","cityName":null,"comment":"/*
Ð”Ð¾Ð½ÐµÑ†ÐºÐ°Ñ ÐÐ°Ñ€Ð¾Ð´Ð½Ð°Ñ Ð ÐµÑпублика
*/","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Караман,
ÐлекÑандр
Ðкимович","regionIsoCode":null,"regionName":null,"user":"Камарад
Че","delta":0,"added":0,"deleted":0}]
at
org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
~[hadoop-mapreduce-client-common-2.7.3.jar:?]
at
org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
[hadoop-mapreduce-client-common-2.7.3.jar:?]
Caused by: io.druid.java.util.common.RE: Failure on
row[{"time":"2015-09-12T00:47:44.963Z","channel":"#ru.wikipedia","cityName":null,"comment":"/*
Ð”Ð¾Ð½ÐµÑ†ÐºÐ°Ñ ÐÐ°Ñ€Ð¾Ð´Ð½Ð°Ñ Ð ÐµÑпублика
*/","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Караман,
ÐлекÑандр
Ðкимович","regionIsoCode":null,"regionName":null,"user":"Камарад
Че","delta":0,"added":0,"deleted":0}]
at
io.druid.indexer.HadoopDruidIndexerMapper.map(HadoopDruidIndexerMapper.java:93)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
~[hadoop-mapreduce-client-core-2.7.3.jar:?]
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
~[hadoop-mapreduce-client-core-2.7.3.jar:?]
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
~[hadoop-mapreduce-client-core-2.7.3.jar:?]
at
org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
~[hadoop-mapreduce-client-common-2.7.3.jar:?]
at
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
~[?:1.8.0_171]
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
~[?:1.8.0_171]
at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
~[?:1.8.0_171]
at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
~[?:1.8.0_171]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_171]
Caused by: java.lang.IllegalArgumentException: Value : Камарад Че
not exists
at
org.apache.kylin.common.util.Dictionary.getIdFromValue(Dictionary.java:107)
~[kylin-core-common-2.5.2.jar:2.5.2]
at
org.apache.kylin.common.util.Dictionary.getIdFromValue(Dictionary.java:85)
~[kylin-core-common-2.5.2.jar:2.5.2]
at
io.druid.segment.incremental.IncrementalIndex$1InputRowDictWrap.getDimension(IncrementalIndex.java:180)
~[druid-processing-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.query.aggregation.unique.RoaringBitmapComplexMetricSerde$1.extractValue(RoaringBitmapComplexMetricSerde.java:70)
~[druid-uniq-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.query.aggregation.unique.RoaringBitmapComplexMetricSerde$1.extractValue(RoaringBitmapComplexMetricSerde.java:52)
~[druid-uniq-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.segment.incremental.IncrementalIndex$1IncrementalIndexInputRowColumnSelectorFactory$1.getObject(IncrementalIndex.java:264)
~[druid-processing-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.query.aggregation.unique.UniqueBuildAggregator.aggregate(UniqueBuildAggregator.java:53)
~[druid-uniq-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at io.druid.indexer.InputRowSerde.toBytes(InputRowSerde.java:281)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.indexer.IndexGeneratorJob$IndexGeneratorMapper.innerMap(IndexGeneratorJob.java:371)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at
io.druid.indexer.HadoopDruidIndexerMapper.map(HadoopDruidIndexerMapper.java:88)
~[druid-indexing-hadoop-0.12.4-SNAPSHOT.jar:0.12.4-SNAPSHOT]
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
[GitHub] [incubator-druid] clintropolis opened a new pull request #8089: add CachingClusteredClient benchmark, refactor some stuff
clintropolis opened a new pull request #8089: add CachingClusteredClient
benchmark, refactor some stuff
URL: https://github.com/apache/incubator-druid/pull/8089
### Description
This PR adds a benchmark for `CachingClusteredClient` and some refactoring
of the query processing pipeline to provide the foundation for testing
approaches to parallel broker merges.
Benchmarks can be run with a command like the following:
```
java -Ddruid.benchmark.cacheDir=./tmp/benches/ -jar
benchmarks/target/benchmarks.jar
org.apache.druid.benchmark.query.CachingClusteredClientBenchmark
```
Substituting benchmark cache directory as appropriate.
Background
I'm having a go at parallel broker merges, making another attempt to achieve
the goals of #5913 and #6629, eventually planning to attempt the `ForkJoinPool`
in `asyncMode` approach suggested by @leventov in [this
thread](https://github.com/apache/incubator-druid/pull/6629#discussion_r241089247).
Before that, in order to untangle things a bit, I've taken the benchmarks from
#6629 (credit to @jihoonson) and updated/simplified them to take advantage of
some of the changes to `SegmentGenerator` from #6794, to allow a persistent
cache for the generated benchmark segments for much faster benchmarking. I've
also extracted some of the useful refactorings and got a bit more adventurous.
This should help isolate these supporting changes from any future PR which adds
parallel merging, reducing review overhead.
Refactoring
# `CombiningFunction`
Added `CombiningFunction`, a new `@FunctionalInterface` to replace
`BinaryFn`, since all actual usages were of the form
`BinaryFn` and being strictly used in merging
sequences/iterators/iterables, etc.
# `QueryToolChest` and `ResultMergeQueryRunner`
In order to split out the mechanisms useful during merge from the merge
implementation, `QueryToolChest` now has 2 additional functions:
```
CombiningFunction createMergeFn(Query query)
```
and
```
Ordering createOrderingFn(Query query)
```
For group-by queries, `GroupByStrategy` also has these method signatures,
since `GroupByQueryToolchest` is delegating these things to the strategy.
These methods are passed into a refactored, non-abstract
`ResultMergeQueryRunner`, as function generators, that given a `Query` produce
either a `CombiningFunction` or `Ordering` respectively.
# `ConnectionCountServerSelectorStrategy` is now
`WeightedServerSelectorStrategy`
I did not refactor `QueryableDruidServer` in quite the same manner as #6629,
but I did still modify `QueryableDruidServer` and `QueryRunner` to add a
`getWeight` method, as suggested by @drcrallen in [this comment
thread](https://github.com/apache/incubator-druid/pull/6629#discussion_r240789022)
to make the selector strategy a bit more generic instead of hard casting
`QueryRunner` to a `DirectDruidClient` to get the number of connections.
Removed
`OrderedMergingIterator`, `OrderedMergingSequence`, and
`SortingMergeIterator` have been removed, since they were strictly used by
their tests.
This PR has:
- [ ] been self-reviewed.
- [x] added Javadocs for most classes and all non-trivial methods. Linked
related entities via Javadoc links.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] sanastas commented on issue #5698: Oak: New Concurrent Key-Value Map
sanastas commented on issue #5698: Oak: New Concurrent Key-Value Map URL: https://github.com/apache/incubator-druid/issues/5698#issuecomment-511734712 @gianm , @jon-wei , @jihoonson and everyone! Oak has a great ability to scan forward ***and backward*** with the same speed! As Java's ConcurrentSkipListMap backward scan steps are in O(logN) each, Oak performs almost ten time faster in backward scans. Can you think about any scenario in Druid where the scan (iterator) goes forward and backward or only backward? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] satybald commented on issue #8078: Upgrade Kafka library for kafka-lookup module
satybald commented on issue #8078: Upgrade Kafka library for kafka-lookup module URL: https://github.com/apache/incubator-druid/pull/8078#issuecomment-511715093 thanks @jihoonson for review. I've updated the licenses doc. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org