[GitHub] [hudi] nsivabalan edited a comment on issue #2839: HIVE_SKIP_RO_SUFFIX config not working
nsivabalan edited a comment on issue #2839: URL: https://github.com/apache/hudi/issues/2839#issuecomment-821765589 thanks for reporting it. looks like its a bug, have filed a [jira](https://issues.apache.org/jira/browse/HUDI-1806). Feel free to put in a patch if interested :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan closed issue #2839: HIVE_SKIP_RO_SUFFIX config not working
nsivabalan closed issue #2839: URL: https://github.com/apache/hudi/issues/2839 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2839: HIVE_SKIP_RO_SUFFIX config not working
nsivabalan commented on issue #2839: URL: https://github.com/apache/hudi/issues/2839#issuecomment-821765589 looks like its a bug, have filed a [jira](https://issues.apache.org/jira/browse/HUDI-1806). Feel free to put in a patch if interested :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (HUDI-1805) Honor "skipROSuffix" in spark ds
[ https://issues.apache.org/jira/browse/HUDI-1805?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan closed HUDI-1805. - Resolution: Duplicate > Honor "skipROSuffix" in spark ds > > > Key: HUDI-1805 > URL: https://issues.apache.org/jira/browse/HUDI-1805 > Project: Apache Hudi > Issue Type: Bug > Components: Hive Integration >Reporter: sivabalan narayanan >Priority: Major > Labels: sev:high > Fix For: 0.9.0 > > Original Estimate: 1m > Remaining Estimate: 1m > > In HoodieSparkSqlWriter#buildSyncConfig(), we don't set skipROSuffix based on > configs. This needs fixing. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-1806) Honor "skipROSuffix" in spark ds
sivabalan narayanan created HUDI-1806: - Summary: Honor "skipROSuffix" in spark ds Key: HUDI-1806 URL: https://issues.apache.org/jira/browse/HUDI-1806 Project: Apache Hudi Issue Type: Bug Components: Hive Integration Reporter: sivabalan narayanan Fix For: 0.9.0 In HoodieSparkSqlWriter#buildSyncConfig(), we don't set skipROSuffix based on configs. This needs fixing. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] rubenssoto commented on issue #2588: [SUPPORT] Cannot create hive connection
rubenssoto commented on issue #2588: URL: https://github.com/apache/hudi/issues/2588#issuecomment-821765451 @nsivabalan I really tried, our migration to hudi was late more than 2 months, we have a 2 months ticket with AWS and no solution was gave to us. We will create a file on table folder with all table columns, when the new dataframe have different columns comparing to that file, we will enable hudi hive sync. I think it could solve the problem for now, until aws gave to us a better solution. Another approach that we want to try, is to sync hive table through metastore, disabling jdbc -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-1805) Honor "skipROSuffix" in spark ds
sivabalan narayanan created HUDI-1805: - Summary: Honor "skipROSuffix" in spark ds Key: HUDI-1805 URL: https://issues.apache.org/jira/browse/HUDI-1805 Project: Apache Hudi Issue Type: Bug Components: Hive Integration Reporter: sivabalan narayanan Fix For: 0.9.0 In HoodieSparkSqlWriter#buildSyncConfig(), we don't set skipROSuffix based on configs. This needs fixing. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] nsivabalan commented on issue #2838: [SUPPORT]User class threw exception: org.apache.hudi.exception.HoodieMetadataException: Error syncing to metadata table
nsivabalan commented on issue #2838: URL: https://github.com/apache/hudi/issues/2838#issuecomment-821764890 @prashantwason : can you assist here. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2834: [SUPPORT] Help~~~org.apache.hudi.exception.TableNotFoundException
nsivabalan commented on issue #2834: URL: https://github.com/apache/hudi/issues/2834#issuecomment-821764795 @yanghua : related to Flink. can you (or loop in someone to) assist here. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan edited a comment on issue #2830: [SUPPORT]same _hoodie_record_key has duplicates data
nsivabalan edited a comment on issue #2830: URL: https://github.com/apache/hudi/issues/2830#issuecomment-821764581 @wsxGit: Is it possible to give us some reproducible code snippet. also, can you clarify if you are seeing duplicates in both spark ds/spark sql and hive or just in hive. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2830: [SUPPORT]same _hoodie_record_key has duplicates data
nsivabalan commented on issue #2830: URL: https://github.com/apache/hudi/issues/2830#issuecomment-821764581 Is it possible to give us some reproducible code snippet. also, can you clarify if you are seeing duplicates in both spark ds/spark sql and hive or just in hive. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2829: Getting an Exception Property hoodie.deltastreamer.schemaprovider.registry.baseUrl not found
nsivabalan commented on issue #2829: URL: https://github.com/apache/hudi/issues/2829#issuecomment-821764391 @pratyakshsharma : can you take this up. related to HoodieMultiTableDeltaStreamer -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2588: [SUPPORT] Cannot create hive connection
nsivabalan commented on issue #2588: URL: https://github.com/apache/hudi/issues/2588#issuecomment-821761181 and wrt your point about syncing hive only when required: we might have to establish hive connection to get the schema and compare w/ latest hudi schema and to find differences in partitions. so not sure how we can avoid creating hive connections if no changes are done to schema and partitions. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2588: [SUPPORT] Cannot create hive connection
nsivabalan commented on issue #2588: URL: https://github.com/apache/hudi/issues/2588#issuecomment-821760500 Did you file a ticket w/ EMR then? if you know the actual root cause and the fix, would be good to bring it up w/ EMR folks so that EMR can patch the fix and others can benefit. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1769) websites updates for 0.8.0 release
[ https://issues.apache.org/jira/browse/HUDI-1769?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-1769: -- Description: Dumping all changes required to be done in our website wrt 0.8.0 release. # fix min spark supported version. 2.4.3 and 3.* # talk about diff bundles we have (Hudi-spark-bundles) and when to use which one. # configurations ## bulk insert row writer. ## [https://github.com/apache/hudi/issues/2760] ## hoodie.merge.allow.duplicate.on.inserts # migration guide # doc updates : moving all docs to 0.8.0 dir etc. regular release guide. was: Dumping all changes required to be done in our website wrt 0.8.0 release. # fix min spark supported version. 2.4.3 and 3.* # talk about diff bundles we have (Hudi-spark-bundles) and when to use which one. # configurations ## bulk insert row writer. ## https://github.com/apache/hudi/issues/2760 # migration guide # doc updates : moving all docs to 0.8.0 dir etc. regular release guide. > websites updates for 0.8.0 release > -- > > Key: HUDI-1769 > URL: https://issues.apache.org/jira/browse/HUDI-1769 > Project: Apache Hudi > Issue Type: Improvement > Components: Docs >Reporter: sivabalan narayanan >Assignee: Gary Li >Priority: Major > > Dumping all changes required to be done in our website wrt 0.8.0 release. > # fix min spark supported version. 2.4.3 and 3.* > # talk about diff bundles we have (Hudi-spark-bundles) and when to use which > one. > # configurations > ## bulk insert row writer. > ## [https://github.com/apache/hudi/issues/2760] > ## hoodie.merge.allow.duplicate.on.inserts > # migration guide > # doc updates : moving all docs to 0.8.0 dir etc. regular release guide. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] nsivabalan closed issue #2656: HUDI insert operation is working same as upsert
nsivabalan closed issue #2656: URL: https://github.com/apache/hudi/issues/2656 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2656: HUDI insert operation is working same as upsert
nsivabalan commented on issue #2656: URL: https://github.com/apache/hudi/issues/2656#issuecomment-821758611 my bad. In latest release, we added support for allowing duplicates w/ INSERTs btw. forgot about it when I posted earlier. ensure you set "hoodie.merge.allow.duplicate.on.inserts" to true and your operation is "insert". you should see duplicates if you try to ingest same batch of records again. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2656: HUDI insert operation is working same as upsert
nsivabalan commented on issue #2656: URL: https://github.com/apache/hudi/issues/2656#issuecomment-821757914 I guess I understand what's happening. in COW, when creating a new data file, hudi reads existing data and merges w/ incoming data. From merging standpoint, partition path and record key pairs are considered unique. And so even if we insert the same batch again, new data file will not have duplicated data. One option is to create unique keys for every record as suggested by @pengzhiwei2018. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2787: [SUPPORT] Error upserting bucketType UPDATE for partition
nsivabalan commented on issue #2787: URL: https://github.com/apache/hudi/issues/2787#issuecomment-821755784 Can you try enabling schema validation and we can go from there. ``` hoodie.avro.schema.validate ``` set this property to true. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-commenter edited a comment on pull request #2843: [HUDI-1804] Continue to write when Flink write task restart because o…
codecov-commenter edited a comment on pull request #2843: URL: https://github.com/apache/hudi/pull/2843#issuecomment-821748199 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=h1_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) Report > Merging [#2843](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (dc3e5c2) into [master](https://codecov.io/gh/apache/hudi/commit/b6d949b48a649acac27d5d9b91677bf2e25e9342?el=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (b6d949b) will **decrease** coverage by `0.01%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master#2843 +/- ## - Coverage 52.60% 52.58% -0.02% + Complexity 3709 3708 -1 Files 485 485 Lines 2322423227 +3 Branches 2465 2466 +1 - Hits 1221612214 -2 - Misses 9929 9934 +5 Partials 1079 1079 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `40.29% <ø> (ø)` | `215.00 <ø> (ø)` | | | hudiclient | `∅ <ø> (∅)` | `0.00 <ø> (ø)` | | | hudicommon | `50.66% <ø> (-0.03%)` | `1976.00 <ø> (-1.00)` | | | hudiflink | `56.51% <ø> (-0.04%)` | `516.00 <ø> (ø)` | | | hudihadoopmr | `33.33% <ø> (ø)` | `198.00 <ø> (ø)` | | | hudisparkdatasource | `72.06% <ø> (ø)` | `237.00 <ø> (ø)` | | | hudisync | `45.70% <ø> (ø)` | `131.00 <ø> (ø)` | | | huditimelineservice | `64.36% <ø> (ø)` | `62.00 <ø> (ø)` | | | hudiutilities | `69.79% <ø> (ø)` | `373.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...ache/hudi/common/fs/inline/InMemoryFileSystem.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL2ZzL2lubGluZS9Jbk1lbW9yeUZpbGVTeXN0ZW0uamF2YQ==) | `79.31% <0.00%> (-10.35%)` | `15.00% <0.00%> (-1.00%)` | | | [.../hudi/table/format/cow/CopyOnWriteInputFormat.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1mbGluay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS90YWJsZS9mb3JtYXQvY293L0NvcHlPbldyaXRlSW5wdXRGb3JtYXQuamF2YQ==) | `55.33% <0.00%> (-0.75%)` | `20.00% <0.00%> (ø%)` | | | [...java/org/apache/hudi/common/fs/StorageSchemes.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL2ZzL1N0b3JhZ2VTY2hlbWVzLmphdmE=) | `100.00% <0.00%> (ø)` | `10.00% <0.00%> (ø%)` | | -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-commenter edited a comment on pull request #2843: [HUDI-1804] Continue to write when Flink write task restart because o…
codecov-commenter edited a comment on pull request #2843: URL: https://github.com/apache/hudi/pull/2843#issuecomment-821748199 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-commenter commented on pull request #2843: [HUDI-1804] Continue to write when Flink write task restart because o…
codecov-commenter commented on pull request #2843: URL: https://github.com/apache/hudi/pull/2843#issuecomment-821748199 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=h1_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) Report > Merging [#2843](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (dc3e5c2) into [master](https://codecov.io/gh/apache/hudi/commit/b6d949b48a649acac27d5d9b91677bf2e25e9342?el=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (b6d949b) will **increase** coverage by `17.19%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master#2843 +/- ## = + Coverage 52.60% 69.79% +17.19% + Complexity 3709 373 -3336 = Files 485 54 -431 Lines 23224 1993-21231 Branches 2465 235 -2230 = - Hits 12216 1391-10825 + Misses 9929 471 -9458 + Partials 1079 131 -948 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `?` | `?` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `69.79% <ø> (ø)` | `373.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2843?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...hadoop/realtime/RealtimeCompactedRecordReader.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1oYWRvb3AtbXIvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvaGFkb29wL3JlYWx0aW1lL1JlYWx0aW1lQ29tcGFjdGVkUmVjb3JkUmVhZGVyLmphdmE=) | | | | | [...ache/hudi/common/util/collection/DiskBasedMap.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3V0aWwvY29sbGVjdGlvbi9EaXNrQmFzZWRNYXAuamF2YQ==) | | | | | [...a/org/apache/hudi/common/util/ClusteringUtils.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3V0aWwvQ2x1c3RlcmluZ1V0aWxzLmphdmE=) | | | | | [...va/org/apache/hudi/metadata/BaseTableMetadata.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvbWV0YWRhdGEvQmFzZVRhYmxlTWV0YWRhdGEuamF2YQ==) | | | | | [.../apache/hudi/common/bootstrap/FileStatusUtils.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL2Jvb3RzdHJhcC9GaWxlU3RhdHVzVXRpbHMuamF2YQ==) | | | | | [...mmon/table/log/block/HoodieDeleteBlockVersion.java](https://codecov.io/gh/apache/hudi/pull/2843/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL2xvZy9ibG9jay9Ib29kaWVEZWxldGVCbG9ja1ZlcnNpb24uamF2YQ==) | | | | |
[jira] [Updated] (HUDI-1765) disabling auto commit does not work with spark ds
[ https://issues.apache.org/jira/browse/HUDI-1765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-1765: -- Description: commitAndPerformPostOperations in HoodieSparkSqlWriter commits all operations w/o checking for autoCommitProp. So, this prop is not being honored at spark ds layer. Added below test to TestCOWDataSource and it fails. [https://gist.github.com/nsivabalan/479320351bec95ba3e0c0dfa5abb2b06] was:commitAndPerformPostOperations in HoodieSparkSqlWriter commits all operations w/o checking for autoCommitProp. So, this prop is not being honored at spark ds layer. > disabling auto commit does not work with spark ds > - > > Key: HUDI-1765 > URL: https://issues.apache.org/jira/browse/HUDI-1765 > Project: Apache Hudi > Issue Type: Bug > Components: Spark Integration >Reporter: sivabalan narayanan >Priority: Major > Labels: sev:critical > Fix For: 0.9.0 > > > commitAndPerformPostOperations in HoodieSparkSqlWriter commits all operations > w/o checking for autoCommitProp. So, this prop is not being honored at spark > ds layer. > > Added below test to TestCOWDataSource and it fails. > [https://gist.github.com/nsivabalan/479320351bec95ba3e0c0dfa5abb2b06] > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1765) disabling auto commit does not work with spark ds
[ https://issues.apache.org/jira/browse/HUDI-1765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-1765: -- Description: commitAndPerformPostOperations in HoodieSparkSqlWriter commits all operations w/o checking for autoCommitProp. So, this prop is not being honored at spark ds layer. (was: looks like when delete operation auto commits even if auto commit config is set to false. ) > disabling auto commit does not work with spark ds > - > > Key: HUDI-1765 > URL: https://issues.apache.org/jira/browse/HUDI-1765 > Project: Apache Hudi > Issue Type: Bug > Components: Spark Integration >Reporter: sivabalan narayanan >Priority: Major > Labels: sev:critical > Fix For: 0.9.0 > > > commitAndPerformPostOperations in HoodieSparkSqlWriter commits all operations > w/o checking for autoCommitProp. So, this prop is not being honored at spark > ds layer. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1765) disabling auto commit does not work with spark ds
[ https://issues.apache.org/jira/browse/HUDI-1765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-1765: -- Summary: disabling auto commit does not work with spark ds (was: disabling auto commit does not work for delete operation) > disabling auto commit does not work with spark ds > - > > Key: HUDI-1765 > URL: https://issues.apache.org/jira/browse/HUDI-1765 > Project: Apache Hudi > Issue Type: Bug > Components: Spark Integration >Reporter: sivabalan narayanan >Priority: Major > Labels: sev:critical > Fix For: 0.9.0 > > > looks like when delete operation auto commits even if auto commit config is > set to false. > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1765) disabling auto commit does not work for delete operation
[ https://issues.apache.org/jira/browse/HUDI-1765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-1765: -- Labels: sev:critical (was: sev:normal) > disabling auto commit does not work for delete operation > > > Key: HUDI-1765 > URL: https://issues.apache.org/jira/browse/HUDI-1765 > Project: Apache Hudi > Issue Type: Bug > Components: Spark Integration >Reporter: sivabalan narayanan >Priority: Major > Labels: sev:critical > Fix For: 0.9.0 > > > looks like when delete operation auto commits even if auto commit config is > set to false. > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] jtmzheng commented on issue #2566: [SUPPORT] Unable to read Hudi MOR data set in a test on 0.7
jtmzheng commented on issue #2566: URL: https://github.com/apache/hudi/issues/2566#issuecomment-821583643 @nsivabalan I tried bumping to 0.8.0 in the Dockerfile provided above but I'm running into same errors. Can you reprod on your end? Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-commenter commented on pull request #2842: Added metric reporter Prometheus to HoodieBackedTableMetadataWriter
codecov-commenter commented on pull request #2842: URL: https://github.com/apache/hudi/pull/2842#issuecomment-821311104 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2842?src=pr=h1_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) Report > Merging [#2842](https://codecov.io/gh/apache/hudi/pull/2842?src=pr=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (cb8c4a9) into [master](https://codecov.io/gh/apache/hudi/commit/1d53d6e6c2d3ff967d333d87b308406c8cd6917a?el=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (1d53d6e) will **increase** coverage by `17.25%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2842?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master#2842 +/- ## = + Coverage 52.58% 69.84% +17.25% + Complexity 3709 374 -3335 = Files 485 54 -431 Lines 23227 1993-21234 Branches 2466 235 -2231 = - Hits 12215 1392-10823 + Misses 9934 471 -9463 + Partials 1078 130 -948 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `?` | `?` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `69.84% <ø> (ø)` | `374.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2842?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [.../common/table/log/block/HoodieLogBlockVersion.java](https://codecov.io/gh/apache/hudi/pull/2842/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL2xvZy9ibG9jay9Ib29kaWVMb2dCbG9ja1ZlcnNpb24uamF2YQ==) | | | | | [...in/java/org/apache/hudi/common/model/BaseFile.java](https://codecov.io/gh/apache/hudi/pull/2842/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL21vZGVsL0Jhc2VGaWxlLmphdmE=) | | | | | [.../org/apache/hudi/sink/utils/NonThrownExecutor.java](https://codecov.io/gh/apache/hudi/pull/2842/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1mbGluay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9zaW5rL3V0aWxzL05vblRocm93bkV4ZWN1dG9yLmphdmE=) | | | | | [...g/apache/hudi/sink/partitioner/BucketAssigner.java](https://codecov.io/gh/apache/hudi/pull/2842/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1mbGluay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9zaW5rL3BhcnRpdGlvbmVyL0J1Y2tldEFzc2lnbmVyLmphdmE=) | | | | | [...che/hudi/common/table/timeline/dto/InstantDTO.java](https://codecov.io/gh/apache/hudi/pull/2842/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL3RpbWVsaW5lL2R0by9JbnN0YW50RFRPLmphdmE=) | | | | | [.../apache/hudi/sink/compact/CompactionPlanEvent.java](https://codecov.io/gh/apache/hudi/pull/2842/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1mbGluay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9zaW5rL2NvbXBhY3QvQ29tcGFjdGlvblBsYW5FdmVudC5qYXZh) | | | | |
[jira] [Updated] (HUDI-765) Implement OrcReaderIterator
[ https://issues.apache.org/jira/browse/HUDI-765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Teresa Kang updated HUDI-765: - Status: In Progress (was: Open) > Implement OrcReaderIterator > --- > > Key: HUDI-765 > URL: https://issues.apache.org/jira/browse/HUDI-765 > Project: Apache Hudi > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: Teresa Kang >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-765) Implement OrcReaderIterator
[ https://issues.apache.org/jira/browse/HUDI-765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Teresa Kang updated HUDI-765: - Status: Patch Available (was: In Progress) > Implement OrcReaderIterator > --- > > Key: HUDI-765 > URL: https://issues.apache.org/jira/browse/HUDI-765 > Project: Apache Hudi > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: Teresa Kang >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614929242
##
File path:
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestDelete.scala
##
@@ -0,0 +1,67 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+class TestDelete extends TestHoodieSqlBase {
+
+ test("Test Delete Table") {
+withTempDir { tmp =>
+ Seq("cow", "mor").foreach {tableType =>
+val tableName = generateTableName
+// create table
+spark.sql(
+ s"""
+ |create table $tableName (
+ | id int,
+ | name string,
+ | price double,
+ | ts long
+ |) using hudi
+ | location '${tmp.getCanonicalPath}/$tableName'
+ | options (
+ | type = '$tableType',
+ | primaryKey = 'id',
+ | versionColumn = 'ts'
+ | )
+ """.stripMargin)
+// insert data to table
+spark.sql(s"insert into $tableName select 1, 'a1', 10, 1000")
+checkAnswer(s"select id, name, price, ts from $tableName")(
+ Seq(1, "a1", 10.0, 1000)
+)
+
+// delete table
Review comment:
Fixed
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] lw309637554 commented on pull request #2784: [HUDI-1740] Fix insert-overwrite API archival
lw309637554 commented on pull request #2784: URL: https://github.com/apache/hudi/pull/2784#issuecomment-821230101 > @lw309637554 I reviewed this PR but just want to get another set of eyes. do you mind taking a pass on this? okay -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] lw309637554 commented on pull request #2722: [HUDI-1722]hive beeline/spark-sql query specified field on mor table occur NPE
lw309637554 commented on pull request #2722: URL: https://github.com/apache/hudi/pull/2722#issuecomment-821228266 @xiarixiaoyao hello , will review it this weekend -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1804) Continue to write when Flink write task restart because of container killing
[
https://issues.apache.org/jira/browse/HUDI-1804?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-1804:
-
Labels: pull-request-available (was: )
> Continue to write when Flink write task restart because of container killing
>
>
> Key: HUDI-1804
> URL: https://issues.apache.org/jira/browse/HUDI-1804
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Reporter: Danny Chen
>Assignee: Danny Chen
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> The {{FlinkMergeHande}} creates a marker file under the metadata path each
> time it initializes, when a write task restarts from killing, it tries to
> create the existing file and reports error.
> To solve this problem, skip the creation and use the original data file as
> base file to merge.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] danny0405 opened a new pull request #2843: [HUDI-1804] Continue to write when Flink write task restart because o…
danny0405 opened a new pull request #2843: URL: https://github.com/apache/hudi/pull/2843 …f container killing The `FlinkMergeHande` creates a marker file under the metadata path each time it initializes, when a write task restarts from killing, it tries to create the existing file and reports error. To solve this problem, skip the creation and use the original data file as base file to merge. ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contributing.html before opening a pull request.* ## What is the purpose of the pull request *(For example: This pull request adds quick-start document.)* ## Brief change log *(for example:)* - *Modify AnnotationLocation checkstyle rule in checkstyle.xml* ## Verify this pull request *(Please pick either of the following options)* This pull request is a trivial rework / code cleanup without any test coverage. *(or)* This pull request is already covered by existing tests, such as *(please describe tests)*. (or) This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end.* - *Added HoodieClientWriteTest to verify the change.* - *Manually verified the change by running a job locally.* ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] sbernauer opened a new pull request #2842: Added metric reporter Prometheus to HoodieBackedTableMetadataWriter
sbernauer opened a new pull request #2842: URL: https://github.com/apache/hudi/pull/2842 ## What is the purpose of the pull request Add support for metric reporter type Prometheus inside HoodieBackedTableMetadataWriter ## Brief change log - Added case statement for Prometheus metric reporter - I removed the existing TODO marker since it had no description and i personally cant see a TODO here. But im also fine to leave it here ## Verify this pull request - Sadly i cant run the Deltastream with metadata enabled because of the hbase dependency of Hudi and our Hadoop 3.3.0 containing a to new guava version (21 vs 27). I will open an Issue for this. But i think change is trivial ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] AkshayChan opened a new issue #2841: hoodie.cleaner.commits.retained max value?
AkshayChan opened a new issue #2841: URL: https://github.com/apache/hudi/issues/2841 1. Is there a greatest value possible for the number of commits the hudi cleaner can retain? 2. What about the greatest possible value for `hoodie.keep.min.commits` and `hoodie.keep.max.commits`? 3. What is the difference between `hoodie.cleaner.commits.retained` and `hoodie.keep.min.commits`? If I understand correctly, the cleaner commits is the maximum number of commits we can query incrementally/point in time from, keep min commits is the least number of commits stored (for example in S3) and keep max commits is the maximum number of commits stored. 4. Are any commits between the keep min commits and kee[ max commits thresholds archived as log files? 5. Are any commits that exceed the max commit threshold deleted? 6. Are there performance issues if I set these values very large? For example: `hoodie.cleaner.commits.retained: 2, hoodie.keep.min.commits: 20001, hoodie.keep.max.commits: 3` Thanks in advance -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-io edited a comment on pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
codecov-io edited a comment on pull request #2645: URL: https://github.com/apache/hudi/pull/2645#issuecomment-792430670 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=h1_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) Report > Merging [#2645](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (0c0dbee) into [master](https://codecov.io/gh/apache/hudi/commit/18459d4045ec4a85081c227893b226a4d759f84b?el=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (18459d4) will **increase** coverage by `0.46%`. > The diff coverage is `54.75%`. [](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master#2645 +/- ## + Coverage 52.26% 52.73% +0.46% - Complexity 3682 3822 +140 Files 484 509 +25 Lines 2309424656+1562 Branches 2456 2774 +318 + Hits 1207013002 +932 - Misses 995910380 +421 - Partials 1065 1274 +209 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `40.29% <ø> (+3.35%)` | `215.00 <ø> (+20.00)` | | | hudiclient | `∅ <ø> (∅)` | `0.00 <ø> (ø)` | | | hudicommon | `50.57% <11.11%> (-0.20%)` | `1979.00 <2.00> (+3.00)` | :arrow_down: | | hudiflink | `56.51% <ø> (-0.07%)` | `516.00 <ø> (+2.00)` | :arrow_down: | | hudihadoopmr | `33.33% <ø> (-0.12%)` | `198.00 <ø> (+1.00)` | :arrow_down: | | hudisparkdatasource | `65.00% <56.21%> (-6.34%)` | `348.00 <109.00> (+111.00)` | :arrow_down: | | hudisync | `45.62% <0.00%> (+0.15%)` | `131.00 <1.00> (+3.00)` | | | huditimelineservice | `64.36% <ø> (ø)` | `62.00 <ø> (ø)` | | | hudiutilities | `69.79% <ø> (+0.06%)` | `373.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...rg/apache/hudi/common/table/HoodieTableConfig.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL0hvb2RpZVRhYmxlQ29uZmlnLmphdmE=) | `41.66% <0.00%> (-1.55%)` | `17.00 <0.00> (ø)` | | | [...pache/hudi/common/table/HoodieTableMetaClient.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL0hvb2RpZVRhYmxlTWV0YUNsaWVudC5qYXZh) | `63.35% <0.00%> (-3.31%)` | `43.00 <0.00> (ø)` | | | [.../apache/hudi/common/table/TableSchemaResolver.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL1RhYmxlU2NoZW1hUmVzb2x2ZXIuamF2YQ==) | `0.00% <0.00%> (ø)` | `0.00 <0.00> (ø)` | | | [...he/hudi/exception/HoodieDuplicateKeyException.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvZXhjZXB0aW9uL0hvb2RpZUR1cGxpY2F0ZUtleUV4Y2VwdGlvbi5qYXZh) | `0.00% <0.00%> (ø)` | `0.00 <0.00> (?)` | | |
[GitHub] [hudi] codecov-io edited a comment on pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
codecov-io edited a comment on pull request #2645: URL: https://github.com/apache/hudi/pull/2645#issuecomment-792430670 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=h1_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) Report > Merging [#2645](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (0c0dbee) into [master](https://codecov.io/gh/apache/hudi/commit/18459d4045ec4a85081c227893b226a4d759f84b?el=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (18459d4) will **increase** coverage by `0.25%`. > The diff coverage is `54.75%`. [](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master#2645 +/- ## + Coverage 52.26% 52.51% +0.25% - Complexity 3682 3760 +78 Files 484 503 +19 Lines 2309424207+1113 Branches 2456 2750 +294 + Hits 1207012713 +643 - Misses 995910239 +280 - Partials 1065 1255 +190 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `40.29% <ø> (+3.35%)` | `215.00 <ø> (+20.00)` | | | hudiclient | `∅ <ø> (∅)` | `0.00 <ø> (ø)` | | | hudicommon | `50.57% <11.11%> (-0.20%)` | `1979.00 <2.00> (+3.00)` | :arrow_down: | | hudiflink | `56.51% <ø> (-0.07%)` | `516.00 <ø> (+2.00)` | :arrow_down: | | hudihadoopmr | `33.33% <ø> (-0.12%)` | `198.00 <ø> (+1.00)` | :arrow_down: | | hudisparkdatasource | `65.00% <56.21%> (-6.34%)` | `348.00 <109.00> (+111.00)` | :arrow_down: | | hudisync | `45.62% <0.00%> (+0.15%)` | `131.00 <1.00> (+3.00)` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `69.79% <ø> (+0.06%)` | `373.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2645?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...rg/apache/hudi/common/table/HoodieTableConfig.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL0hvb2RpZVRhYmxlQ29uZmlnLmphdmE=) | `41.66% <0.00%> (-1.55%)` | `17.00 <0.00> (ø)` | | | [...pache/hudi/common/table/HoodieTableMetaClient.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL0hvb2RpZVRhYmxlTWV0YUNsaWVudC5qYXZh) | `63.35% <0.00%> (-3.31%)` | `43.00 <0.00> (ø)` | | | [.../apache/hudi/common/table/TableSchemaResolver.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL1RhYmxlU2NoZW1hUmVzb2x2ZXIuamF2YQ==) | `0.00% <0.00%> (ø)` | `0.00 <0.00> (ø)` | | | [...he/hudi/exception/HoodieDuplicateKeyException.java](https://codecov.io/gh/apache/hudi/pull/2645/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvZXhjZXB0aW9uL0hvb2RpZUR1cGxpY2F0ZUtleUV4Y2VwdGlvbi5qYXZh) | `0.00% <0.00%> (ø)` | `0.00 <0.00> (?)` | | |
[jira] [Created] (HUDI-1804) Continue to write when Flink write task restart because of container killing
Danny Chen created HUDI-1804:
Summary: Continue to write when Flink write task restart because
of container killing
Key: HUDI-1804
URL: https://issues.apache.org/jira/browse/HUDI-1804
Project: Apache Hudi
Issue Type: Bug
Components: Flink Integration
Reporter: Danny Chen
Assignee: Danny Chen
Fix For: 0.9.0
The {{FlinkMergeHande}} creates a marker file under the metadata path each time
it initializes, when a write task restarts from killing, it tries to create the
existing file and reports error.
To solve this problem, skip the creation and use the original data file as base
file to merge.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614781917
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/test/scala/org/apache/spark/sql/hudi/TestDelete.scala
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+import org.apache.hadoop.fs.Path
+
+class TestDelete extends TestHoodieSqlBase {
+
+ test("Test Delete Table") {
+withTempDir { tmp =>
+ val tablePath = new Path(tmp.toString, "deleteTable").toUri.toString
+ spark.sql("set spark.hoodie.shuffle.parallelism=4")
+ spark.sql(
+s"""create table deleteTable (
+ |keyid int,
+ |name string,
+ |price double,
+ |col1 long,
+ |p string,
+ |p1 string,
+ |p2 string) using hudi
+ |partitioned by (p,p1,p2)
+ |options('hoodie.datasource.write.table.type'='MERGE_ON_READ',
+ |'hoodie.datasource.write.precombine.field'='col1',
Review comment:
here in base sql implement, it called `versionColumn`, should align with
this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614780712
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/hudi/execution/MergeIntoHudiTable.scala
##
@@ -0,0 +1,332 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.execution
+
+import org.apache.hudi.DataSourceWriteOptions.{DEFAULT_PAYLOAD_OPT_VAL,
PAYLOAD_CLASS_OPT_KEY, RECORDKEY_FIELD_OPT_KEY}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
WriteOperationType}
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql._
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.encoders.{ExpressionEncoder, RowEncoder}
+import org.apache.spark.sql.catalyst.expressions.codegen.GeneratePredicate
+import org.apache.spark.sql.catalyst.merge._
+import org.apache.spark.sql.catalyst.expressions.{And, Attribute,
BasePredicate, Expression, Literal, PredicateHelper, UnsafeProjection}
+import org.apache.spark.sql.functions.{col, lit, when}
+import org.apache.spark.sql.catalyst.merge.{HudiMergeClause,
HudiMergeInsertClause}
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation,
LogicalPlan, Project}
+import org.apache.spark.sql.execution.command.RunnableCommand
+import org.apache.spark.sql.internal.StaticSQLConf
+import org.apache.spark.sql.types.{StringType, StructType}
+
+import scala.collection.mutable.ArrayBuffer
+
+/**
+ * merge command, execute merge operation for hudi
+ */
+case class MergeIntoHudiTable(
+target: LogicalPlan,
+source: LogicalPlan,
+joinCondition: Expression,
+matchedClauses: Seq[HudiMergeClause],
+noMatchedClause: Seq[HudiMergeInsertClause],
+finalSchema: StructType,
+trimmedSchema: StructType) extends RunnableCommand with Logging with
PredicateHelper {
+
+ var tableMeta: Map[String, String] = null
+
+ lazy val isRecordKeyJoin = {
+val recordKeyFields =
tableMeta.get(RECORDKEY_FIELD_OPT_KEY).get.split(",").map(_.trim).filter(!_.isEmpty)
+val intersect = joinCondition.references.intersect(target.outputSet).toSeq
+if (recordKeyFields.size == 1 && intersect.size ==1 &&
intersect(0).name.equalsIgnoreCase(recordKeyFields(0))) {
+ true
+} else {
+ false
+}
+ }
+
+ override def run(sparkSession: SparkSession): Seq[Row] = {
+tableMeta = HudiSQLUtils.getHoodiePropsFromRelation(target, sparkSession)
+val enableHive = "hive" ==
sparkSession.sessionState.conf.getConf(StaticSQLConf.CATALOG_IMPLEMENTATION)
Review comment:
here please the logic put into a method called
`hiveCatalogImplementaion`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614780712
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/hudi/execution/MergeIntoHudiTable.scala
##
@@ -0,0 +1,332 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.execution
+
+import org.apache.hudi.DataSourceWriteOptions.{DEFAULT_PAYLOAD_OPT_VAL,
PAYLOAD_CLASS_OPT_KEY, RECORDKEY_FIELD_OPT_KEY}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
WriteOperationType}
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql._
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.encoders.{ExpressionEncoder, RowEncoder}
+import org.apache.spark.sql.catalyst.expressions.codegen.GeneratePredicate
+import org.apache.spark.sql.catalyst.merge._
+import org.apache.spark.sql.catalyst.expressions.{And, Attribute,
BasePredicate, Expression, Literal, PredicateHelper, UnsafeProjection}
+import org.apache.spark.sql.functions.{col, lit, when}
+import org.apache.spark.sql.catalyst.merge.{HudiMergeClause,
HudiMergeInsertClause}
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation,
LogicalPlan, Project}
+import org.apache.spark.sql.execution.command.RunnableCommand
+import org.apache.spark.sql.internal.StaticSQLConf
+import org.apache.spark.sql.types.{StringType, StructType}
+
+import scala.collection.mutable.ArrayBuffer
+
+/**
+ * merge command, execute merge operation for hudi
+ */
+case class MergeIntoHudiTable(
+target: LogicalPlan,
+source: LogicalPlan,
+joinCondition: Expression,
+matchedClauses: Seq[HudiMergeClause],
+noMatchedClause: Seq[HudiMergeInsertClause],
+finalSchema: StructType,
+trimmedSchema: StructType) extends RunnableCommand with Logging with
PredicateHelper {
+
+ var tableMeta: Map[String, String] = null
+
+ lazy val isRecordKeyJoin = {
+val recordKeyFields =
tableMeta.get(RECORDKEY_FIELD_OPT_KEY).get.split(",").map(_.trim).filter(!_.isEmpty)
+val intersect = joinCondition.references.intersect(target.outputSet).toSeq
+if (recordKeyFields.size == 1 && intersect.size ==1 &&
intersect(0).name.equalsIgnoreCase(recordKeyFields(0))) {
+ true
+} else {
+ false
+}
+ }
+
+ override def run(sparkSession: SparkSession): Seq[Row] = {
+tableMeta = HudiSQLUtils.getHoodiePropsFromRelation(target, sparkSession)
+val enableHive = "hive" ==
sparkSession.sessionState.conf.getConf(StaticSQLConf.CATALOG_IMPLEMENTATION)
Review comment:
here please the logic put into a method called
`hiveCatalogImplementaion`to be reused
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614779858
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/hudi/execution/CreateHudiTableCommand.scala
##
@@ -0,0 +1,326 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.execution
+
+import java.util.Properties
+
+import org.apache.hadoop.fs.{FSDataInputStream, FSDataOutputStream,
FileSystem, Path}
+import org.apache.hudi.DataSourceWriteOptions
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.common.model.{HoodieFileFormat, HoodieRecord}
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient,
TableSchemaResolver}
+import org.apache.hudi.config.HoodieWriteConfig.KEYGENERATOR_CLASS_PROP
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.hudi.hadoop.HoodieParquetInputFormat
+import org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
+import org.apache.hudi.hadoop.utils.HoodieInputFormatUtils
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.avro.SchemaConverters
+import org.apache.spark.sql.catalyst.analysis.{NoSuchDatabaseException,
TableAlreadyExistsException}
+import org.apache.spark.sql.{Row, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogStorageFormat,
CatalogTable, CatalogTableType}
+import org.apache.spark.sql.execution.command.RunnableCommand
+import org.apache.spark.sql.hive.SparkfunctionWrapper
+import org.apache.spark.sql.internal.StaticSQLConf
+import org.apache.spark.sql.types.{StringType, StructField, StructType}
+
+import scala.collection.JavaConverters._
+
+/**
+ * Command for create hoodie table
+ */
+case class CreateHudiTableCommand(table: CatalogTable, ignoreIfExists:
Boolean) extends RunnableCommand {
+
+ override def run(sparkSession: SparkSession): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+
+val tableName = table.identifier.unquotedString
+val sessionState = sparkSession.sessionState
+val tableIsExists = sessionState.catalog.tableExists(table.identifier)
+if (tableIsExists) {
+ if (ignoreIfExists) {
+// scalastyle:off
+return Seq.empty[Row]
+// scalastyle:on
+ } else {
+throw new IllegalArgumentException(s"Table
${table.identifier.quotedString} already exists")
+ }
+}
+
+val enableHive = "hive" ==
sparkSession.sessionState.conf.getConf(StaticSQLConf.CATALOG_IMPLEMENTATION)
+val path = HudiSQLUtils.getTablePath(sparkSession, table)
+val conf = sparkSession.sessionState.newHadoopConf()
+val isTableExists = HudiSQLUtils.tableExists(path, conf)
+val (newSchema, tableOptions) = if (table.tableType ==
CatalogTableType.EXTERNAL && isTableExists) {
+ // if this is an external table & the table has already exists in the
location,
+ // infer schema from the table meta
+ assert(table.schema.isEmpty, s"Should not specified table schema " +
+s"for an exists hoodie table: ${table.identifier.unquotedString}")
+ // get Schema from the external table
+ val metaClient =
HoodieTableMetaClient.builder().setBasePath(path).setConf(conf).build()
+ val schemaResolver = new TableSchemaResolver(metaClient)
+ val avroSchema = schemaResolver.getTableAvroSchema(true)
+ val tableSchema =
SchemaConverters.toSqlType(avroSchema).dataType.asInstanceOf[StructType]
+ (tableSchema, table.storage.properties ++
metaClient.getTableConfig.getProps.asScala)
+} else {
+ // Add the meta fields to the scheme if this is a managed table or an
empty external table
+ val fullSchema: StructType = {
+val metaFields = HoodieRecord.HOODIE_META_COLUMNS.asScala
+val dataFields = table.schema.fields.filterNot(f =>
metaFields.contains(f.name))
+val fields = metaFields.map(StructField(_, StringType)) ++ dataFields
+StructType(fields)
+ }
+ (fullSchema, table.storage.properties)
+}
+
+// Append * to tablePath if create dataSourceV1 hudi table
+val newPath = if
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614779619
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/hudi/execution/CreateHudiTableCommand.scala
##
@@ -0,0 +1,326 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.execution
+
+import java.util.Properties
+
+import org.apache.hadoop.fs.{FSDataInputStream, FSDataOutputStream,
FileSystem, Path}
+import org.apache.hudi.DataSourceWriteOptions
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.common.model.{HoodieFileFormat, HoodieRecord}
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient,
TableSchemaResolver}
+import org.apache.hudi.config.HoodieWriteConfig.KEYGENERATOR_CLASS_PROP
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.hudi.hadoop.HoodieParquetInputFormat
+import org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
+import org.apache.hudi.hadoop.utils.HoodieInputFormatUtils
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.avro.SchemaConverters
+import org.apache.spark.sql.catalyst.analysis.{NoSuchDatabaseException,
TableAlreadyExistsException}
+import org.apache.spark.sql.{Row, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogStorageFormat,
CatalogTable, CatalogTableType}
+import org.apache.spark.sql.execution.command.RunnableCommand
+import org.apache.spark.sql.hive.SparkfunctionWrapper
+import org.apache.spark.sql.internal.StaticSQLConf
+import org.apache.spark.sql.types.{StringType, StructField, StructType}
+
+import scala.collection.JavaConverters._
+
+/**
+ * Command for create hoodie table
+ */
+case class CreateHudiTableCommand(table: CatalogTable, ignoreIfExists:
Boolean) extends RunnableCommand {
+
+ override def run(sparkSession: SparkSession): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+
+val tableName = table.identifier.unquotedString
+val sessionState = sparkSession.sessionState
+val tableIsExists = sessionState.catalog.tableExists(table.identifier)
+if (tableIsExists) {
+ if (ignoreIfExists) {
+// scalastyle:off
+return Seq.empty[Row]
+// scalastyle:on
+ } else {
+throw new IllegalArgumentException(s"Table
${table.identifier.quotedString} already exists")
+ }
+}
+
+val enableHive = "hive" ==
sparkSession.sessionState.conf.getConf(StaticSQLConf.CATALOG_IMPLEMENTATION)
+val path = HudiSQLUtils.getTablePath(sparkSession, table)
+val conf = sparkSession.sessionState.newHadoopConf()
+val isTableExists = HudiSQLUtils.tableExists(path, conf)
+val (newSchema, tableOptions) = if (table.tableType ==
CatalogTableType.EXTERNAL && isTableExists) {
+ // if this is an external table & the table has already exists in the
location,
+ // infer schema from the table meta
+ assert(table.schema.isEmpty, s"Should not specified table schema " +
+s"for an exists hoodie table: ${table.identifier.unquotedString}")
+ // get Schema from the external table
+ val metaClient =
HoodieTableMetaClient.builder().setBasePath(path).setConf(conf).build()
+ val schemaResolver = new TableSchemaResolver(metaClient)
+ val avroSchema = schemaResolver.getTableAvroSchema(true)
+ val tableSchema =
SchemaConverters.toSqlType(avroSchema).dataType.asInstanceOf[StructType]
+ (tableSchema, table.storage.properties ++
metaClient.getTableConfig.getProps.asScala)
+} else {
+ // Add the meta fields to the scheme if this is a managed table or an
empty external table
+ val fullSchema: StructType = {
+val metaFields = HoodieRecord.HOODIE_META_COLUMNS.asScala
+val dataFields = table.schema.fields.filterNot(f =>
metaFields.contains(f.name))
+val fields = metaFields.map(StructField(_, StringType)) ++ dataFields
+StructType(fields)
+ }
+ (fullSchema, table.storage.properties)
+}
+
+// Append * to tablePath if create dataSourceV1 hudi table
+val newPath = if
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614779342
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/hudi/execution/CreateHudiTableAsSelectCommand.scala
##
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.execution
+
+import java.util.Properties
+
+import org.apache.hadoop.fs.{FileSystem, Path}
+import org.apache.hudi.DataSourceWriteOptions
+import org.apache.hudi.DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.config.HoodieWriteConfig.BULKINSERT_PARALLELISM
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.spark.sql._
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.command.RunnableCommand
+import org.apache.spark.sql.internal.StaticSQLConf
+
+import scala.collection.JavaConverters._
+
+/**
+ * Command for ctas
+ */
+case class CreateHudiTableAsSelectCommand(
+table: CatalogTable,
+mode: SaveMode,
+query: LogicalPlan,
+outputColumnNames: Seq[String]) extends RunnableCommand {
+ override def run(sparkSession: SparkSession): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+val sessionState = sparkSession.sessionState
+var fs: FileSystem = null
+val conf = sessionState.newHadoopConf()
+
+val db =
table.identifier.database.getOrElse(sessionState.catalog.getCurrentDatabase)
+val tableIdentWithDB = table.identifier.copy(database = Some(db))
+val tableName = tableIdentWithDB.unquotedString
+val enableHive = "hive" ==
sparkSession.sessionState.conf.getConf(StaticSQLConf.CATALOG_IMPLEMENTATION)
+val path = HudiSQLUtils.getTablePath(sparkSession, table)
+
+if (sessionState.catalog.tableExists(tableIdentWithDB)) {
+ assert(mode != SaveMode.Overwrite, s"Expect the table $tableName has
been dropped when the save mode is OverWrite")
+ if (mode == SaveMode.ErrorIfExists) {
+throw new AnalysisException(s"Table $tableName already exists. You eed
to drop it first.")
+ }
+ if (mode == SaveMode.Ignore) {
+// scalastyle:off
+return Seq.empty
+// scalastyle:on
+ }
+ // append table
+ saveDataIntoHudiTable(sparkSession, table, path,
table.storage.properties, enableHive)
+} else {
+ val properties = table.storage.properties
+ assert(table.schema.isEmpty)
+ sparkSession.sessionState.catalog.validateTableLocation(table)
+ // create table
+ if (!enableHive) {
+val newTable = if (!HudiSQLUtils.tableExists(path, conf)) {
+ table.copy(schema = query.schema)
+} else {
+ table
+}
+CreateHudiTableCommand(newTable, true).run(sparkSession)
+ }
+ saveDataIntoHudiTable(sparkSession, table, path, properties, enableHive,
"bulk_insert")
+}
+
+// save necessary parameter in hoodie.properties
+val newProperties = new Properties()
+newProperties.putAll(table.storage.properties.asJava)
+// add table partition
+newProperties.put(PARTITIONPATH_FIELD_OPT_KEY,
table.partitionColumnNames.mkString(","))
+val metaPath = new Path(path, HoodieTableMetaClient.METAFOLDER_NAME)
+val propertyPath = new Path(metaPath,
HoodieTableConfig.HOODIE_PROPERTIES_FILE)
+
CreateHudiTableCommand.saveNeededPropertiesIntoHoodie(propertyPath.getFileSystem(conf),
propertyPath, newProperties)
+Seq.empty[Row]
+ }
+
+ private def saveDataIntoHudiTable(
+ session: SparkSession,
+ table: CatalogTable,
+ tablePath: String,
+ tableOptions: Map[String, String],
+ enableHive: Boolean,
+ operationType: String = "upsert"): Unit = {
+val mode = if (operationType.equals("upsert")) {
+ "append"
+} else {
+ "overwrite"
+}
+val newTableOptions = if (enableHive) {
+ // add hive sync properties
+ val extraOptions =
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614776987
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/catalyst/analysis/HudiAnalysis.scala
##
@@ -0,0 +1,240 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.analysis
+
+import org.apache.hudi.common.model.HoodieRecord
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.hudi.execution.HudiSQLUtils.HoodieV1Relation
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, HiveTableRelation}
+import org.apache.spark.sql.{AnalysisException, SparkSession}
+import org.apache.spark.sql.catalyst.expressions.{Alias, Literal}
+import org.apache.spark.sql.catalyst.merge.HudiMergeIntoUtils
+import org.apache.spark.sql.catalyst.plans.logical._
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.LogicalRelation
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.hudi.execution.InsertIntoHudiTable
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{StructField, StructType}
+
+import scala.collection.mutable
+
+/**
+ * Analysis rules for hudi. deal with * in merge clause and insert into clause
+ */
+class HudiAnalysis(session: SparkSession, conf: SQLConf) extends
Rule[LogicalPlan] {
+ override def apply(plan: LogicalPlan): LogicalPlan =
plan.resolveOperatorsDown {
+case dsv2 @ DataSourceV2Relation(d: HoodieDataSourceInternalTable, _, _,
_, options) =>
+ HoodieV1Relation.fromV2Relation(dsv2, d, options)
+
+// ResolveReferences rule will resolve * in merge, but the resolve result
is not what we expected
+// so if source is not resolved, we add a special placeholder to prevert
ResolveReferences rule to resolve * in mergeIntoTable
+case m @ MergeIntoTable(target, source, _, _, _) =>
+ if (source.resolved) {
+dealWithStarAction(m)
+ } else {
+placeHolderStarAction(m)
+ }
+// we should deal with Meta columns in hudi, it will be safe to deal
insertIntoStatement here.
+case i @ InsertIntoStatement(table, _, query, overwrite, _)
+ if table.resolved && query.resolved &&
HudiSQLUtils.isHudiRelation(table) =>
+ table match {
+case relation: HiveTableRelation =>
+ val metadata = relation.tableMeta
+ preprocess(i, metadata.identifier.quotedString,
metadata.partitionSchema, Some(metadata), query, overwrite)
+case dsv2 @ DataSourceV2Relation(d: HoodieDataSourceInternalTable, _,
_, _, _) =>
+ preprocessV2(i, d, query)
+case l: LogicalRelation =>
+ val catalogTable = l.catalogTable
+ val tblName =
catalogTable.map(_.identifier.quotedString).getOrElse("unknown")
+ preprocess(i, tblName, catalogTable.get.partitionSchema,
catalogTable, query, overwrite)
+case _ => i
+ }
+ }
+
+ /**
+ * do align hoodie metacols, hoodie tablehave metaCols which are hidden by
default, we try our best to fill those cols auto
Review comment:
table has
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614778297
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/hudi/execution/CreateHudiTableAsSelectCommand.scala
##
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.execution
+
+import java.util.Properties
+
+import org.apache.hadoop.fs.{FileSystem, Path}
+import org.apache.hudi.DataSourceWriteOptions
+import org.apache.hudi.DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.config.HoodieWriteConfig.BULKINSERT_PARALLELISM
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.spark.sql._
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.command.RunnableCommand
+import org.apache.spark.sql.internal.StaticSQLConf
+
+import scala.collection.JavaConverters._
+
+/**
+ * Command for ctas
+ */
+case class CreateHudiTableAsSelectCommand(
+table: CatalogTable,
+mode: SaveMode,
+query: LogicalPlan,
+outputColumnNames: Seq[String]) extends RunnableCommand {
+ override def run(sparkSession: SparkSession): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+val sessionState = sparkSession.sessionState
+var fs: FileSystem = null
+val conf = sessionState.newHadoopConf()
+
+val db =
table.identifier.database.getOrElse(sessionState.catalog.getCurrentDatabase)
+val tableIdentWithDB = table.identifier.copy(database = Some(db))
+val tableName = tableIdentWithDB.unquotedString
+val enableHive = "hive" ==
sparkSession.sessionState.conf.getConf(StaticSQLConf.CATALOG_IMPLEMENTATION)
+val path = HudiSQLUtils.getTablePath(sparkSession, table)
+
+if (sessionState.catalog.tableExists(tableIdentWithDB)) {
+ assert(mode != SaveMode.Overwrite, s"Expect the table $tableName has
been dropped when the save mode is OverWrite")
+ if (mode == SaveMode.ErrorIfExists) {
+throw new AnalysisException(s"Table $tableName already exists. You eed
to drop it first.")
+ }
+ if (mode == SaveMode.Ignore) {
+// scalastyle:off
+return Seq.empty
+// scalastyle:on
+ }
+ // append table
+ saveDataIntoHudiTable(sparkSession, table, path,
table.storage.properties, enableHive)
+} else {
+ val properties = table.storage.properties
+ assert(table.schema.isEmpty)
+ sparkSession.sessionState.catalog.validateTableLocation(table)
+ // create table
+ if (!enableHive) {
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614777699
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/spark/sql/catalyst/analysis/HudiOperationsCheck.scala
##
@@ -0,0 +1,125 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.analysis
+
+import org.apache.hudi.execution.HudiSQLUtils
+import org.apache.spark.sql.{AnalysisException, SparkSession}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.expressions.{Expression, InSubquery,
Literal, Not}
+import org.apache.spark.sql.catalyst.merge.HudiMergeIntoTable
+import org.apache.spark.sql.catalyst.plans.logical.{DeleteFromTable,
LogicalPlan}
+import org.apache.spark.sql.execution.command._
+
+/**
+ * check rule which can intercept unSupportOperation for hudi
+ */
+class HudiOperationsCheck(spark: SparkSession) extends (LogicalPlan => Unit) {
+ val catalog = spark.sessionState.catalog
+
+ override def apply(plan: LogicalPlan): Unit = {
+plan foreach {
+ case AlterTableAddPartitionCommand(tableName, _, _) if
(checkHudiTable(tableName)) =>
+throw new AnalysisException("AlterTableAddPartitionCommand are not
currently supported in HUDI")
+
+ case a: AlterTableDropPartitionCommand if (checkHudiTable(a.tableName))
=>
+throw new AnalysisException("AlterTableDropPartitionCommand are not
currently supported in HUDI")
+
+ case AlterTableChangeColumnCommand(tableName, _, _) if
(checkHudiTable(tableName)) =>
+throw new AnalysisException("AlterTableChangeColumnCommand are not
currently supported in HUDI")
+
+ case AlterTableRenamePartitionCommand(tableName, _, _) if
(checkHudiTable(tableName)) =>
+throw new AnalysisException("AlterTableRenamePartitionCommand are not
currently supported in HUDI")
+
+ case AlterTableRecoverPartitionsCommand(tableName, _) if
(checkHudiTable(tableName)) =>
+throw new AnalysisException("AlterTableRecoverPartitionsCommand are
not currently supported in HUDI")
+
+ case AlterTableSetLocationCommand(tableName, _, _) if
(checkHudiTable(tableName)) =>
+throw new AnalysisException("AlterTableSetLocationCommand are not
currently supported in HUDI")
+
+ case DeleteFromTable(target, Some(condition)) if
(hasNullAwarePredicateWithNot(condition) && checkHudiTable(target)) =>
+throw new AnalysisException("Null-aware predicate sub-squeries a are
not currently supported for DELETE")
+
+ case HudiMergeIntoTable(target, _, _, _, noMatchedClauses, _) =>
+noMatchedClauses.map { m =>
+ m.resolvedActions.foreach { action =>
+if (action.targetColNameParts.size > 1) {
+ throw new AnalysisException(s"cannot insert nested values:
${action.targetColNameParts.mkString("<") }")
Review comment:
would you please describe why would not insert nested values?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614772168
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614776570
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614773873
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614772279
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614771176
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614774065
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614768558
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/SparkUpsertCommitActionExecutor.java
##
@@ -44,6 +44,7 @@ public
SparkUpsertCommitActionExecutor(HoodieSparkEngineContext context,
@Override
public HoodieWriteMetadata> execute() {
return SparkWriteHelper.newInstance().write(instantTime, inputRecordsRDD,
context, table,
-config.shouldCombineBeforeUpsert(),
config.getUpsertShuffleParallelism(), this, true);
+config.shouldCombineBeforeUpsert(),
config.getUpsertShuffleParallelism(),
+this,
Boolean.parseBoolean(config.getProps().getProperty("hoodie.tagging.before.insert",
"true")));
Review comment:
would you please move `hoodie.tagging.before.insert` and default value
to HoodieWriteConfig?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614770493
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
Review comment:
log.warn?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614771646
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614768558
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/SparkUpsertCommitActionExecutor.java
##
@@ -44,6 +44,7 @@ public
SparkUpsertCommitActionExecutor(HoodieSparkEngineContext context,
@Override
public HoodieWriteMetadata> execute() {
return SparkWriteHelper.newInstance().write(instantTime, inputRecordsRDD,
context, table,
-config.shouldCombineBeforeUpsert(),
config.getUpsertShuffleParallelism(), this, true);
+config.shouldCombineBeforeUpsert(),
config.getUpsertShuffleParallelism(),
+this,
Boolean.parseBoolean(config.getProps().getProperty("hoodie.tagging.before.insert",
"true")));
Review comment:
would you move `hoodie.tagging.before.insert` and default value to
HoodieWriteConfig?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] sbernauer opened a new pull request #2840: Fixed typo in documentation for configurations
sbernauer opened a new pull request #2840: URL: https://github.com/apache/hudi/pull/2840 ## What is the purpose of the pull request Fixed typo in documentation for configurations -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614772540
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
+ val OVERWRITEWITHLATESTVROAYLOAD =
classOf[OverwriteWithLatestAvroPayload].getName
+ val OVERWRITENONDEFAULTSWITHLATESTAVROPAYLOAD =
classOf[OverwriteNonDefaultsWithLatestAvroPayload].getName
+ val MERGE_MARKER = "_hoodie_merge_marker"
+
+ private val log = LogManager.getLogger(getClass)
+
+ private val tableConfigCache = CacheBuilder
+.newBuilder()
+.maximumSize(1000)
+.build(new CacheLoader[String, Properties] {
+ override def load(k: String): Properties = {
+try {
+
HoodieTableMetaClient.builder().setConf(SparkSession.active.sparkContext.hadoopConfiguration)
+.setBasePath(k).build().getTableConfig.getProperties
+} catch {
+ // we catch expected error here
+ case e: HoodieIOException =>
+log.error(e.getMessage)
+new Properties()
+ case t: Throwable =>
+throw t
+}
+ }
+})
+
+ def getPropertiesFromTableConfigCache(path: String): Properties = {
+if (path.isEmpty) {
+ throw new HoodieIOException("unexpected empty hoodie table basePath")
+}
+tableConfigCache.get(path)
+ }
+
+ private def matchHoodieRelation(relation:
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614770205
##
File path:
hudi-spark-datasource/hudi-spark3-extensions_2.12/src/main/scala/org/apache/hudi/execution/HudiSQLUtils.scala
##
@@ -0,0 +1,553 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution
+
+import java.io.File
+import java.util
+import java.util.{Locale, Properties}
+
+import com.google.common.cache.{CacheBuilder, CacheLoader}
+import org.apache.avro.generic.GenericRecord
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
+import org.apache.hudi.DataSourceReadOptions.{QUERY_TYPE_OPT_KEY,
QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_SNAPSHOT_OPT_VAL}
+import org.apache.hudi.DataSourceWriteOptions._
+import org.apache.hudi.HoodieSparkSqlWriter.{TableInstantInfo, toProperties}
+import org.apache.hudi.{AvroConversionUtils, DataSourceReadOptions,
DataSourceUtils, DataSourceWriteOptions, DefaultSource,
HoodieBootstrapPartition, HoodieBootstrapRelation, HoodieSparkSqlWriter,
HoodieSparkUtils, HoodieWriterUtils, MergeOnReadSnapshotRelation}
+import
org.apache.hudi.common.model.{OverwriteNonDefaultsWithLatestAvroPayload,
OverwriteWithLatestAvroPayload}
+import org.apache.hudi.avro.HoodieAvroUtils
+import org.apache.hudi.client.{HoodieWriteResult, SparkRDDWriteClient}
+import org.apache.hudi.common.config.TypedProperties
+import org.apache.hudi.common.model._
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient}
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline
+import org.apache.hudi.config.HoodieWriteConfig._
+import org.apache.hudi.exception.{HoodieException, HoodieIOException}
+import org.apache.hudi.hive.{HiveSyncConfig, HiveSyncTool}
+import org.apache.hudi.keygen.constant.KeyGeneratorOptions
+import org.apache.hudi.payload.AWSDmsAvroPayload
+import org.apache.hudi.spark3.internal.HoodieDataSourceInternalTable
+import org.apache.log4j.LogManager
+import org.apache.spark.api.java.JavaSparkContext
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType,
HiveTableRelation}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.functions.{col, udf}
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.sources.BaseRelation
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable.ListBuffer
+
+
+
+/**
+ * hudi IUD utils
+ */
+object HudiSQLUtils {
+
+ val AWSDMSAVROPAYLOAD = classOf[AWSDmsAvroPayload].getName
Review comment:
not quietly understand why specify AWSDMSAVROPAYLOAD here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2761: [HUDI-1676] Support SQL with spark3
leesf commented on a change in pull request #2761:
URL: https://github.com/apache/hudi/pull/2761#discussion_r614768775
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/deltacommit/SparkUpsertDeltaCommitActionExecutor.java
##
@@ -44,6 +44,7 @@ public
SparkUpsertDeltaCommitActionExecutor(HoodieSparkEngineContext context,
@Override
public HoodieWriteMetadata execute() {
return SparkWriteHelper.newInstance().write(instantTime, inputRecordsRDD,
context, table,
-config.shouldCombineBeforeUpsert(),
config.getUpsertShuffleParallelism(),this, true);
+config.shouldCombineBeforeUpsert(),
config.getUpsertShuffleParallelism(),
+this,
Boolean.parseBoolean(config.getProps().getProperty("hoodie.tagging.before.insert",
"true")));
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] RocMarshal closed pull request #2822: [Hotfix][hudi-sync] Refactor method up to parent-class
RocMarshal closed pull request #2822: URL: https://github.com/apache/hudi/pull/2822 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] luopuya opened a new issue #2839: HIVE_SKIP_RO_SUFFIX config not working
luopuya opened a new issue #2839:
URL: https://github.com/apache/hudi/issues/2839
How to produce:
```Scala
dataFrame.write
.format("org.apache.hudi")
.option(HIVE_SKIP_RO_SUFFIX, true)
```
It seems that it is not working.
buildSyncConfig (in HoodieSparkSqlWriter) did not set skipROSuffix from
parameters
https://github.com/apache/hudi/blob/master/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/HoodieSparkSqlWriter.scala#L398
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] RocMarshal commented on pull request #2822: [Hotfix][hudi-sync] Refactor method up to parent-class
RocMarshal commented on pull request #2822: URL: https://github.com/apache/hudi/pull/2822#issuecomment-821076075 @codecov-io rerun tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] RocMarshal removed a comment on pull request #2822: [Hotfix][hudi-sync] Refactor method up to parent-class
RocMarshal removed a comment on pull request #2822: URL: https://github.com/apache/hudi/pull/2822#issuecomment-821070142 rerun tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] RocMarshal commented on pull request #2822: [Hotfix][hudi-sync] Refactor method up to parent-class
RocMarshal commented on pull request #2822: URL: https://github.com/apache/hudi/pull/2822#issuecomment-821072166 rerun tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] RocMarshal commented on pull request #2822: [Hotfix][hudi-sync] Refactor method up to parent-class
RocMarshal commented on pull request #2822: URL: https://github.com/apache/hudi/pull/2822#issuecomment-821070142 rerun tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] GaruGaru commented on issue #2609: [SUPPORT] Presto hudi query slow when compared to parquet
GaruGaru commented on issue #2609: URL: https://github.com/apache/hudi/issues/2609#issuecomment-821065195 It can be a nice idea to port changes to trinodb(prestosql) but there may be some differences in the `hive-connector` implementation -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] 410680876f1 opened a new issue #2838: [SUPPORT]User class threw exception: org.apache.hudi.exception.HoodieMetadataException: Error syncing to metadata table
410680876f1 opened a new issue #2838: URL: https://github.com/apache/hudi/issues/2838 I tried to upgrade hudi to version 0.8.0 with set "hoodie.metadata.enable" true,but i throw an error when spark writting data to hudi 2021/04/16 14:49:03,837 [WARN][Class->HoodieBackedTableMetadataWriter][Method->bootstrapIfNeeded]: Metadata Table will need to be re-bootstrapped as no instants were found 2021/04/16 14:49:04,047 [ERROR][Class->ApplicationMaster][Method->logError]: User class threw exception: org.apache.hudi.exception.HoodieMetadataException: Error syncing to metadata table. org.apache.hudi.exception.HoodieMetadataException: Error syncing to metadata table. at org.apache.hudi.client.SparkRDDWriteClient.syncTableMetadata(SparkRDDWriteClient.java:447) at org.apache.hudi.client.AbstractHoodieWriteClient.preWrite(AbstractHoodieWriteClient.java:400) at org.apache.hudi.client.SparkRDDWriteClient.upsert(SparkRDDWriteClient.java:153) at org.apache.hudi.DataSourceUtils.doWriteOperation(DataSourceUtils.java:214) at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:186) at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:145) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:83) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:81) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:696) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:696) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:127) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:75) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:696) at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:305) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:291) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:249) at com.leqee.sparktool.hoodie.HoodieData.saveData(HoodieData.scala:184) at com.leqee.sparktool.hoodie.HoodieData.upsert(HoodieData.scala:96) at com.leqee.sparktool.hoodie.Hoodie$class.upsert(Hoodie.scala:160) at com.leqee.sparktool.hoodie.HoodieData.upsert(HoodieData.scala:13) at com.leqee.datasync.synctool.sync.SyncTask.setLastSync(SyncTask.scala:235) at com.leqee.datasync.synctool.sync.SyncTask.batchSyncing(SyncTask.scala:159) at com.leqee.datasync.synctool.sync.DateTimeSync.syncAnalyze(DateTimeSync.scala:49) at com.leqee.datasync.synctool.sync.SyncTask.sync(SyncTask.scala:66) at com.leqee.datasync.synctool.sync.SyncProxy.com$leqee$datasync$synctool$sync$SyncProxy$$runSync(SyncProxy.scala:49) at com.leqee.datasync.synctool.sync.SyncProxy$$anonfun$workFunc$1.apply(SyncProxy.scala:55) at com.leqee.datasync.synctool.sync.SyncProxy$$anonfun$workFunc$1.apply(SyncProxy.scala:55) at com.leqee.datasync.synctool.sync.SyncProxy$$anonfun$runGroup$1.apply(SyncProxy.scala:81) at com.leqee.datasync.synctool.sync.SyncProxy$$anonfun$runGroup$1.apply(SyncProxy.scala:80) at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186) at com.leqee.datasync.synctool.sync.SyncProxy.runGroup(SyncProxy.scala:80) at com.leqee.datasync.synctool.SyncApp$.main(SyncApp.scala:61) at com.leqee.datasync.synctool.SyncApp.main(SyncApp.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614680980
##
File path:
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestCreateTable.scala
##
@@ -0,0 +1,230 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+import scala.collection.JavaConverters._
+import org.apache.hudi.common.model.HoodieRecord
+import org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType,
StringType, StructField}
+
+class TestCreateTable extends TestHoodieSqlBase {
+
+ test("Test Create Managed Hoodie Table") {
+val tableName = generateTableName
+// Create a managed table
+spark.sql(
+ s"""
+ | create table $tableName (
+ | id int,
+ | name string,
+ | price double,
+ | ts long
+ | ) using hudi
+ | options (
+ | primaryKey = 'id',
+ | versionColumn = 'ts'
Review comment:
There is a check for the versionColumn when create table in
`CreateHoodieTableCommand#validateTable`. So the `versionColumn` must be a
field defined in the table columns. I will also add test for other column name
as the `versionColumn`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614680980
##
File path:
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestCreateTable.scala
##
@@ -0,0 +1,230 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+import scala.collection.JavaConverters._
+import org.apache.hudi.common.model.HoodieRecord
+import org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType,
StringType, StructField}
+
+class TestCreateTable extends TestHoodieSqlBase {
+
+ test("Test Create Managed Hoodie Table") {
+val tableName = generateTableName
+// Create a managed table
+spark.sql(
+ s"""
+ | create table $tableName (
+ | id int,
+ | name string,
+ | price double,
+ | ts long
+ | ) using hudi
+ | options (
+ | primaryKey = 'id',
+ | versionColumn = 'ts'
Review comment:
There is a check for the versionColumn when create table in
`CreateHoodieTableCommand#validateTable`. So the `versionColumn` must be a
field defined in the table columns. I think we should not define a default
value for the versionColumn.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] tooptoop4 commented on issue #2609: [SUPPORT] Presto hudi query slow when compared to parquet
tooptoop4 commented on issue #2609: URL: https://github.com/apache/hudi/issues/2609#issuecomment-821029965 u can raise the PR @njalan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xglv1985 commented on a change in pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
xglv1985 commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614664439
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
> @xglv1985 Would you please also add an entry here
http://hudi.apache.org/docs/cloud.html and a page like this
http://hudi.apache.org/docs/ibm_cos_hoodie.html to describe how to use AFS?
Hello, Baidu AFS is currently only open to its staff. As if the way to use
afs, it is highly similar to HDFS. Actually, AFS do some optimization from the
base level, but does not change the main user api. The users can not perceive
their difference. But if the document is mandatory, could I update the doc once
AFS is open to all users?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614669121
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/CreateHoodieTableAsSelectCommand.scala
##
@@ -0,0 +1,69 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command
+
+import org.apache.spark.sql.{Row, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
+import org.apache.spark.sql.execution.command.DataWritingCommand
+
+/**
+ * Command for create table as query statement.
+ */
+case class CreateHoodieTableAsSelectCommand(
+ table: CatalogTable,
+ mode: SaveMode,
+ query: LogicalPlan) extends DataWritingCommand {
+
+ override def run(sparkSession: SparkSession, child: SparkPlan): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+
+val sessionState = sparkSession.sessionState
+val db =
table.identifier.database.getOrElse(sessionState.catalog.getCurrentDatabase)
+val tableIdentWithDB = table.identifier.copy(database = Some(db))
+val tableName = tableIdentWithDB.unquotedString
+
+if (sessionState.catalog.tableExists(tableIdentWithDB)) {
+ assert(mode != SaveMode.Overwrite,
+s"Expect the table $tableName has been dropped when the save mode is
Overwrite")
+
+ if (mode == SaveMode.ErrorIfExists) {
+throw new RuntimeException(s"Table $tableName already exists. You need
to drop it first.")
+ }
+ if (mode == SaveMode.Ignore) {
+// Since the table already exists and the save mode is Ignore, we will
just return.
+// scalastyle:off
+return Seq.empty
+// scalastyle:on
Review comment:
The scala style check will fail for the `return` statement, So we should
turn it off it here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (HUDI-1803) Support BAIDU AFS storage format in hudi
[ https://issues.apache.org/jira/browse/HUDI-1803?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang updated HUDI-1803: --- Fix Version/s: 0.9.0 > Support BAIDU AFS storage format in hudi > > > Key: HUDI-1803 > URL: https://issues.apache.org/jira/browse/HUDI-1803 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Xu Guang Lv >Assignee: Xu Guang Lv >Priority: Minor > Labels: pull-request-available > Fix For: 0.9.0 > > > The storage format of BAIDU Advanced File System(AFS) can naturally be > supported by Hudi each time after I checkout hudi source code and modify the > related code. Hopefully Hudi will officially support it, for convenience -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (HUDI-1803) Support BAIDU AFS storage format in hudi
[ https://issues.apache.org/jira/browse/HUDI-1803?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang closed HUDI-1803. -- Resolution: Done 1d53d6e6c2d3ff967d333d87b308406c8cd6917a > Support BAIDU AFS storage format in hudi > > > Key: HUDI-1803 > URL: https://issues.apache.org/jira/browse/HUDI-1803 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Xu Guang Lv >Assignee: Xu Guang Lv >Priority: Minor > Labels: pull-request-available > Fix For: 0.9.0 > > > The storage format of BAIDU Advanced File System(AFS) can naturally be > supported by Hudi each time after I checkout hudi source code and modify the > related code. Hopefully Hudi will officially support it, for convenience -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] yanghua commented on a change in pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
yanghua commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614667438
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
OK, sounds good.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] yanghua merged pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
yanghua merged pull request #2836: URL: https://github.com/apache/hudi/pull/2836 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (62b8a34 -> 1d53d6e)
This is an automated email from the ASF dual-hosted git repository. vinoyang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git. from 62b8a34 [HUDI-1792] flink-client query error when processing files larger than 128mb (#2814) add 1d53d6e [HUDI-1803] Support BAIDU AFS storage format in hudi (#2836) No new revisions were added by this update. Summary of changes: hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java | 2 ++ .../src/test/java/org/apache/hudi/common/fs/TestStorageSchemes.java | 1 + 2 files changed, 3 insertions(+)
[GitHub] [hudi] xglv1985 commented on a change in pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
xglv1985 commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614664439
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
> @xglv1985 Would you please also add an entry here
http://hudi.apache.org/docs/cloud.html and a page like this
http://hudi.apache.org/docs/ibm_cos_hoodie.html to describe how to use AFS?
Hello, Baidu AFS is currently just open to its staff. As if the way to use
afs, it is highly similar to HDFS. Actually, AFS do some optimization from the
base level, but does not change the main user api. The users can not perceive
their difference. But if the document is mandatory, could I update the doc once
AFS is open to all users?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614665177
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/analysis/HoodieAnalysis.scala
##
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.analysis
+
+import org.apache.hudi.SparkSqlAdapterSupport
+
+import scala.collection.JavaConverters._
+import org.apache.hudi.common.model.HoodieRecord
+import org.apache.spark.SPARK_VERSION
+import org.apache.spark.sql.{AnalysisException, SparkSession}
+import org.apache.spark.sql.catalyst.analysis.UnresolvedStar
+import org.apache.spark.sql.catalyst.expressions.AttributeReference
+import org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute
+import org.apache.spark.sql.catalyst.expressions.{Alias, Expression, Literal,
NamedExpression}
+import org.apache.spark.sql.catalyst.plans.Inner
+import org.apache.spark.sql.catalyst.plans.logical.{Assignment, DeleteAction,
DeleteFromTable, InsertAction, LogicalPlan, MergeIntoTable, Project,
UpdateAction, UpdateTable}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.command.CreateDataSourceTableCommand
+import org.apache.spark.sql.execution.datasources.{CreateTable,
LogicalRelation}
+import org.apache.spark.sql.hudi.HoodieSqlUtils._
+import org.apache.spark.sql.hudi.command.{CreateHoodieTableAsSelectCommand,
CreateHoodieTableCommand, DeleteHoodieTableCommand,
InsertIntoHoodieTableCommand, MergeIntoHoodieTableCommand,
UpdateHoodieTableCommand}
+import org.apache.spark.sql.types.StringType
+
+object HoodieAnalysis {
+ def customResolutionRules(): Seq[SparkSession => Rule[LogicalPlan]] =
+Seq(
+ session => HoodieResolveReferences(session),
+ session => HoodieAnalysis(session)
+)
+
+ def customPostHocResolutionRules(): Seq[SparkSession => Rule[LogicalPlan]] =
+Seq(
+ session => HoodiePostAnalysisRule(session)
+)
+}
+
+/**
+ * Rule for convert the logical plan to command.
+ * @param sparkSession
+ */
+case class HoodieAnalysis(sparkSession: SparkSession) extends Rule[LogicalPlan]
+ with SparkSqlAdapterSupport {
+
+ override def apply(plan: LogicalPlan): LogicalPlan = {
+plan match {
+ // Convert to MergeIntoHoodieTableCommand
+ case m @ MergeIntoTable(target, _, _, _, _)
+if m.resolved && isHoodieTable(target, sparkSession) =>
+ MergeIntoHoodieTableCommand(m)
+
+ // Convert to UpdateHoodieTableCommand
+ case u @ UpdateTable(table, _, _)
+if u.resolved && isHoodieTable(table, sparkSession) =>
+ UpdateHoodieTableCommand(u)
+
+ // Convert to DeleteHoodieTableCommand
+ case d @ DeleteFromTable(table, _)
+if d.resolved && isHoodieTable(table, sparkSession) =>
+ DeleteHoodieTableCommand(d)
+
+ // Convert to InsertIntoHoodieTableCommand
+ case l if sparkSqlAdapter.isInsertInto(l) =>
+val (table, partition, query, overwrite, _) =
sparkSqlAdapter.getInsertIntoChildren(l).get
+table match {
+ case relation: LogicalRelation if isHoodieTable(relation,
sparkSession) =>
+new InsertIntoHoodieTableCommand(relation, query, partition,
overwrite)
+ case _ =>
+l
+}
+ // Convert to CreateHoodieTableAsSelectCommand
+ case CreateTable(table, mode, Some(query))
+if query.resolved && isHoodieTable(table) =>
+ CreateHoodieTableAsSelectCommand(table, mode, query)
+ case _=> plan
+}
+ }
+}
+
+/**
+ * Rule for resolve hoodie's extended syntax or rewrite some logical plan.
+ * @param sparkSession
+ */
+case class HoodieResolveReferences(sparkSession: SparkSession) extends
Rule[LogicalPlan]
+ with SparkSqlAdapterSupport {
+ private lazy val analyzer = sparkSession.sessionState.analyzer
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+plan match {
+ // Resolve merge into
+ case MergeIntoTable(target, source, mergeCondition, matchedActions,
notMatchedActions)
+if isHoodieTable(target, sparkSession) && target.resolved &&
source.resolved =>
+
+def
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614664550
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/SparkSqlAdapterSupport.scala
##
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi
+
+import org.apache.spark.SPARK_VERSION
+import org.apache.spark.sql.hudi.SparkSqlAdapter
+
+trait SparkSqlAdapterSupport {
+
+ lazy val sparkSqlAdapter: SparkSqlAdapter = {
+val adapterClass = if (SPARK_VERSION.startsWith("2.")) {
+ "org.apache.spark.sql.adapter.Spark2SqlAdapter"
Review comment:
Yes, because the `hudi-spark` project only include the `hudi-spark2` or
`hudi-spark3`, we cannot include the spark2 dependency and spark3 dependency in
the project at the same time.
So we cannot get the `Spark2SqlAdapter` and `Spark3SqlAdapter` at the same
time when compile. Here we use the string name instead of the class to avoid
compile error.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xglv1985 commented on a change in pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
xglv1985 commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614664439
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
> @xglv1985 Would you please also add an entry here
http://hudi.apache.org/docs/cloud.html and a page like this
http://hudi.apache.org/docs/ibm_cos_hoodie.html to describe how to use AFS?
Hello, Baidu AFS is currently just open to its staff. As if the way to use
afs, it is highly similar to HDFS. Actually, AFS do some optimization from the
base level, and does not change the main user api. The users can not perceive
their difference. But if the document is mandatory, could I update the doc once
AFS is open to all users?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614664550
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/SparkSqlAdapterSupport.scala
##
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi
+
+import org.apache.spark.SPARK_VERSION
+import org.apache.spark.sql.hudi.SparkSqlAdapter
+
+trait SparkSqlAdapterSupport {
+
+ lazy val sparkSqlAdapter: SparkSqlAdapter = {
+val adapterClass = if (SPARK_VERSION.startsWith("2.")) {
+ "org.apache.spark.sql.adapter.Spark2SqlAdapter"
Review comment:
Yes, because the `hudi-spark` project only include the `hudi-spark2` or
`hudi-spark3`, we cannot include the spark2 dependency and spark3 dependency in
the project at the same time.
So we cannot get the `Spark2SqlAdapter` and `Spark3SqlAdapter` at the same
time in compile time. Here we use the string name instead of the class to avoid
compile error.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xglv1985 commented on a change in pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
xglv1985 commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614664439
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
> @xglv1985 Would you please also add an entry here
http://hudi.apache.org/docs/cloud.html and a page like this
http://hudi.apache.org/docs/ibm_cos_hoodie.html to describe how to use AFS?
Hello, Baidu AFS is currently just open to its staff. As if the way to use
afs, it is highly similar to HDFS. Actually, AFS
do some optimization from the base level, and does not change the main user
api. The users can not perceive their difference. But if the document is
mandatory, could I update the doc once AFS is open to all users?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645: URL: https://github.com/apache/hudi/pull/2645#discussion_r614658039 ## File path: hudi-common/src/main/java/org/apache/hudi/common/model/HoodiePayloadProps.java ## @@ -40,4 +40,12 @@ */ public static final String PAYLOAD_EVENT_TIME_FIELD_PROP = "hoodie.payload.event.time.field"; public static String DEFAULT_PAYLOAD_EVENT_TIME_FIELD_VAL = "ts"; + + public static final String PAYLOAD_DELETE_CONDITION = "hoodie.payload.delete.condition"; Review comment: ok -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-io commented on pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
codecov-io commented on pull request #2836: URL: https://github.com/apache/hudi/pull/2836#issuecomment-821007767 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2836?src=pr=h1_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) Report > Merging [#2836](https://codecov.io/gh/apache/hudi/pull/2836?src=pr=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (f1319af) into [master](https://codecov.io/gh/apache/hudi/commit/b6d949b48a649acac27d5d9b91677bf2e25e9342?el=desc_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) (b6d949b) will **decrease** coverage by `0.00%`. > The diff coverage is `100.00%`. [](https://codecov.io/gh/apache/hudi/pull/2836?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master#2836 +/- ## - Coverage 52.60% 52.59% -0.01% + Complexity 3709 3708 -1 Files 485 485 Lines 2322423227 +3 Branches 2465 2466 +1 Hits 1221612216 - Misses 9929 9933 +4 + Partials 1079 1078 -1 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `40.29% <ø> (ø)` | `215.00 <ø> (ø)` | | | hudiclient | `∅ <ø> (∅)` | `0.00 <ø> (ø)` | | | hudicommon | `50.68% <100.00%> (-0.01%)` | `1976.00 <0.00> (-1.00)` | | | hudiflink | `56.51% <ø> (-0.04%)` | `516.00 <ø> (ø)` | | | hudihadoopmr | `33.33% <ø> (ø)` | `198.00 <ø> (ø)` | | | hudisparkdatasource | `72.06% <ø> (ø)` | `237.00 <ø> (ø)` | | | hudisync | `45.70% <ø> (ø)` | `131.00 <ø> (ø)` | | | huditimelineservice | `64.36% <ø> (ø)` | `62.00 <ø> (ø)` | | | hudiutilities | `69.79% <ø> (ø)` | `373.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2836?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...java/org/apache/hudi/common/fs/StorageSchemes.java](https://codecov.io/gh/apache/hudi/pull/2836/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL2ZzL1N0b3JhZ2VTY2hlbWVzLmphdmE=) | `100.00% <100.00%> (ø)` | `10.00 <0.00> (ø)` | | | [...ache/hudi/common/fs/inline/InMemoryFileSystem.java](https://codecov.io/gh/apache/hudi/pull/2836/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL2ZzL2lubGluZS9Jbk1lbW9yeUZpbGVTeXN0ZW0uamF2YQ==) | `79.31% <0.00%> (-10.35%)` | `15.00% <0.00%> (-1.00%)` | | | [.../hudi/table/format/cow/CopyOnWriteInputFormat.java](https://codecov.io/gh/apache/hudi/pull/2836/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1mbGluay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS90YWJsZS9mb3JtYXQvY293L0NvcHlPbldyaXRlSW5wdXRGb3JtYXQuamF2YQ==) | `55.33% <0.00%> (-0.75%)` | `20.00% <0.00%> (ø%)` | | | [...e/hudi/common/table/log/HoodieLogFormatWriter.java](https://codecov.io/gh/apache/hudi/pull/2836/diff?src=pr=tree_medium=referral_source=github_content=comment_campaign=pr+comments_term=The+Apache+Software+Foundation#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL2xvZy9Ib29kaWVMb2dGb3JtYXRXcml0ZXIuamF2YQ==) | `79.68% <0.00%> (+1.56%)` | `26.00% <0.00%> (ø%)` | | -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] pengzhiwei2018 commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
pengzhiwei2018 commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614649396
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/model/DefaultHoodieRecordPayload.java
##
@@ -97,4 +86,20 @@ public DefaultHoodieRecordPayload(Option
record) {
}
return metadata.isEmpty() ? Option.empty() : Option.of(metadata);
}
+
+ protected boolean noNeedUpdatePersistedRecord(IndexedRecord currentValue,
Review comment:
Yeah, needUpdatePersistedRecord looks more read able
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #2836: [HUDI-1803] Support BAIDU AFS storage format in hudi
yanghua commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614643725
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
@xglv1985 Would you please also add an entry here
http://hudi.apache.org/docs/cloud.html and a page like this
http://hudi.apache.org/docs/ibm_cos_hoodie.html to describe how to use AFS?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (HUDI-1803) Support BAIDU AFS storage format in hudi
[ https://issues.apache.org/jira/browse/HUDI-1803?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang updated HUDI-1803: --- Summary: Support BAIDU AFS storage format in hudi (was: Hopefully Hudi will officially support BAIDU AFS storage format) > Support BAIDU AFS storage format in hudi > > > Key: HUDI-1803 > URL: https://issues.apache.org/jira/browse/HUDI-1803 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Xu Guang Lv >Assignee: Xu Guang Lv >Priority: Minor > Labels: pull-request-available > > The storage format of BAIDU Advanced File System(AFS) can naturally be > supported by Hudi each time after I checkout hudi source code and modify the > related code. Hopefully Hudi will officially support it, for convenience -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] yanghua commented on a change in pull request #2836: [MINOR] support BAIDU afs. jira id: HUDI-1803
yanghua commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614639114
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
Yes. Baidu: the biggest search engine in China.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zherenyu831 commented on pull request #2784: [HUDI-1740] Fix insert-overwrite API archival
zherenyu831 commented on pull request #2784: URL: https://github.com/apache/hudi/pull/2784#issuecomment-820994344 There is one solution: always enable cleaner, which will help you refresh timeline -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] liijiankang commented on issue #2837: [SUPPORT]How to measure the performance of upsert
liijiankang commented on issue #2837: URL: https://github.com/apache/hudi/issues/2837#issuecomment-820987025 @zherenyu831 thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] liijiankang closed issue #2837: [SUPPORT]How to measure the performance of upsert
liijiankang closed issue #2837: URL: https://github.com/apache/hudi/issues/2837 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2836: [MINOR] support BAIDU afs. jira id: HUDI-1803
vinothchandar commented on a change in pull request #2836:
URL: https://github.com/apache/hudi/pull/2836#discussion_r614623290
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -28,6 +28,8 @@
FILE("file", false),
// Hadoop File System
HDFS("hdfs", true),
+ // Baidu Advanced File System
+ AFS("afs", true),
Review comment:
supports append? nice!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zherenyu831 commented on issue #2837: [SUPPORT]How to measure the performance of upsert
zherenyu831 commented on issue #2837: URL: https://github.com/apache/hudi/issues/2837#issuecomment-820956020 It dependent on count of cores, configuration, ratio of insert/update, storage type IMO, it is not slow -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] liijiankang opened a new issue #2837: [SUPPORT]How to measure the performance of upsert
liijiankang opened a new issue #2837: URL: https://github.com/apache/hudi/issues/2837 **Describe the problem you faced** I am a novice and would appreciate your help. We use Structured Streaming to consume the data in Kafka, and then write the data to the cow table of hudi.I want to know whether the performance of this program is high or low 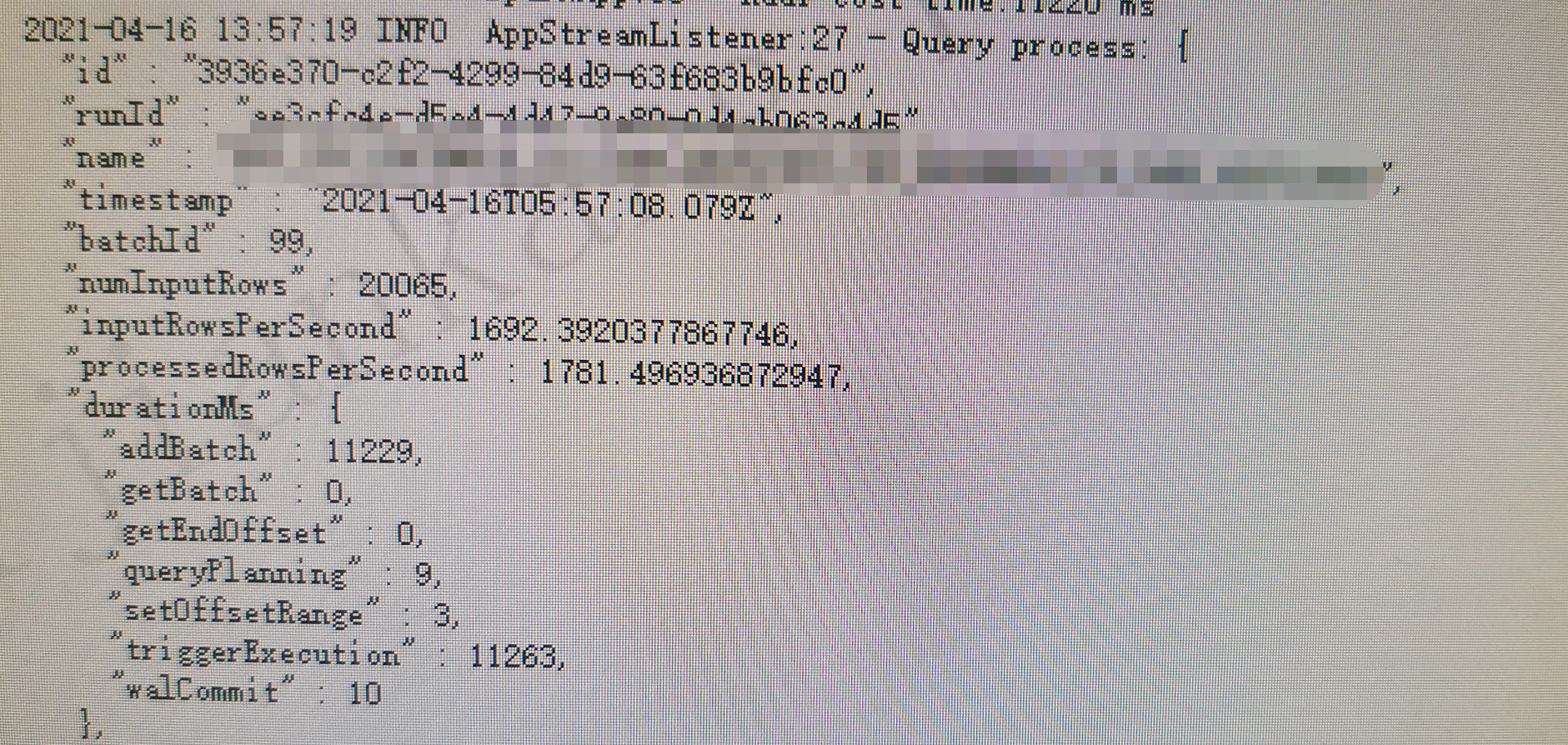  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1803) Hopefully Hudi will officially support BAIDU AFS storage format
[ https://issues.apache.org/jira/browse/HUDI-1803?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-1803: - Labels: pull-request-available (was: ) > Hopefully Hudi will officially support BAIDU AFS storage format > --- > > Key: HUDI-1803 > URL: https://issues.apache.org/jira/browse/HUDI-1803 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Xu Guang Lv >Assignee: Xu Guang Lv >Priority: Minor > Labels: pull-request-available > > The storage format of BAIDU Advanced File System(AFS) can naturally be > supported by Hudi each time after I checkout hudi source code and modify the > related code. Hopefully Hudi will officially support it, for convenience -- This message was sent by Atlassian Jira (v8.3.4#803005)