[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17077007#comment-17077007 ] ASF GitHub Bot commented on BAHIR-85: - eskabetxe commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-610225699 @lresende I help you This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17076861#comment-17076861 ] ASF GitHub Bot commented on BAHIR-85: - lresende commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-610154539 Any volunteers to help with a release ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17076852#comment-17076852 ] ASF GitHub Bot commented on BAHIR-85: - Zentopia commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-610145753 It has been merged. But the version in maven central is still 1.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17076847#comment-17076847 ] ASF GitHub Bot commented on BAHIR-85: - Zentopia commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-610145753 Any updates on this? We need it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-220) Add redis descriptor to make redis connection as a table
[
https://issues.apache.org/jira/browse/BAHIR-220?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17059135#comment-17059135
]
ASF GitHub Bot commented on BAHIR-220:
--
lresende commented on pull request #72: [BAHIR-220] Add redis descriptor to
make redis connection as a table
URL: https://github.com/apache/bahir-flink/pull/72
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add redis descriptor to make redis connection as a table
>
>
> Key: BAHIR-220
> URL: https://issues.apache.org/jira/browse/BAHIR-220
> Project: Bahir
> Issue Type: Improvement
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: yuemeng
>Priority: Major
>
> currently, for Flink-1.9.0, we can use the catalog to store our stream table
> source and sink
> for Redis connector, it should exist a Redis table sink so we can register it
> to catalog, and use Redis as a table in SQL environment
> {code}
> Redis redis = new Redis()
> .mode(RedisVadidator.REDIS_CLUSTER)
> .command(RedisCommand.INCRBY_EX.name())
> .ttl(10)
> .property(RedisVadidator.REDIS_NODES, REDIS_HOST+ ":" +
> REDIS_PORT);
> tableEnvironment
> .connect(redis).withSchema(new Schema()
> .field("k", TypeInformation.of(String.class))
> .field("v", TypeInformation.of(Long.class)))
> .registerTableSink("redis");
> tableEnvironment.sqlUpdate("insert into redis select k, v from t1");
> env.execute("Test Redis Table");
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-220) Add redis descriptor to make redis connection as a table
[
https://issues.apache.org/jira/browse/BAHIR-220?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17052388#comment-17052388
]
ASF GitHub Bot commented on BAHIR-220:
--
eskabetxe commented on issue #72: [BAHIR-220] Add redis descriptor to make
redis connection as a table
URL: https://github.com/apache/bahir-flink/pull/72#issuecomment-595364359
@lresende LGTM
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add redis descriptor to make redis connection as a table
>
>
> Key: BAHIR-220
> URL: https://issues.apache.org/jira/browse/BAHIR-220
> Project: Bahir
> Issue Type: Improvement
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: yuemeng
>Priority: Major
>
> currently, for Flink-1.9.0, we can use the catalog to store our stream table
> source and sink
> for Redis connector, it should exist a Redis table sink so we can register it
> to catalog, and use Redis as a table in SQL environment
> {code}
> Redis redis = new Redis()
> .mode(RedisVadidator.REDIS_CLUSTER)
> .command(RedisCommand.INCRBY_EX.name())
> .ttl(10)
> .property(RedisVadidator.REDIS_NODES, REDIS_HOST+ ":" +
> REDIS_PORT);
> tableEnvironment
> .connect(redis).withSchema(new Schema()
> .field("k", TypeInformation.of(String.class))
> .field("v", TypeInformation.of(Long.class)))
> .registerTableSink("redis");
> tableEnvironment.sqlUpdate("insert into redis select k, v from t1");
> env.execute("Test Redis Table");
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-222) Update Readme with details of SQL Streaming SQS connector
[ https://issues.apache.org/jira/browse/BAHIR-222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17006589#comment-17006589 ] ASF GitHub Bot commented on BAHIR-222: -- abhishekd0907 commented on issue #96: [BAHIR-222] Update Readme with details of SQL Streaming SQS connector URL: https://github.com/apache/bahir/pull/96#issuecomment-570117872 sure will do @lresende. just wanted to confirm if the code changes required will be similar to these 2 commits: [Update doc script with newly added extensions](https://github.com/apache/bahir-website/commit/0995f1ef61f0ad7c10e44bf3fd5beb661c09f3af) [Add template for new pubnub spark extension](https://github.com/apache/bahir-website/commit/a4e3d3d356bba45faf8c120be999339470d40178) Is that all or am I missing out something? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Update Readme with details of SQL Streaming SQS connector > - > > Key: BAHIR-222 > URL: https://issues.apache.org/jira/browse/BAHIR-222 > Project: Bahir > Issue Type: Task > Components: Spark Structured Streaming Connectors >Affects Versions: Not Applicable >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Spark-2.4.0 > > > Adding link to SQL Streaming SQS connector in BAHIR Readme. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-222) Update Readme with details of SQL Streaming SQS connector
[ https://issues.apache.org/jira/browse/BAHIR-222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17005817#comment-17005817 ] ASF GitHub Bot commented on BAHIR-222: -- lresende commented on pull request #96: [BAHIR-222] Update Readme with details of SQL Streaming SQS connector URL: https://github.com/apache/bahir/pull/96 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Update Readme with details of SQL Streaming SQS connector > - > > Key: BAHIR-222 > URL: https://issues.apache.org/jira/browse/BAHIR-222 > Project: Bahir > Issue Type: Task > Components: Spark Structured Streaming Connectors >Affects Versions: Not Applicable >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Not Applicable > > > Adding link to SQL Streaming SQS connector in BAHIR Readme. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-222) Update Readme with details of SQL Streaming SQS connector
[ https://issues.apache.org/jira/browse/BAHIR-222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17005815#comment-17005815 ] ASF GitHub Bot commented on BAHIR-222: -- lresende commented on issue #96: [BAHIR-222] Update Readme with details of SQL Streaming SQS connector URL: https://github.com/apache/bahir/pull/96#issuecomment-569800815 Could you please also update the website (github.com/apache/bahir-website) and add correspondent links to the SQS connector. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Update Readme with details of SQL Streaming SQS connector > - > > Key: BAHIR-222 > URL: https://issues.apache.org/jira/browse/BAHIR-222 > Project: Bahir > Issue Type: Task > Components: Spark Structured Streaming Connectors >Affects Versions: Not Applicable >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Not Applicable > > > Adding link to SQL Streaming SQS connector in BAHIR Readme. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17005128#comment-17005128 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569581591 Thanks @lresende This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Spark-2.4.0 > > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17005127#comment-17005127 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569581591 Thank @lresende This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Spark-2.4.0 > > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-222) Update Readme with details of SQL Streaming SQS connector
[ https://issues.apache.org/jira/browse/BAHIR-222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17004734#comment-17004734 ] ASF GitHub Bot commented on BAHIR-222: -- abhishekd0907 commented on pull request #96: [BAHIR-222] Update Readme with details of SQL Streaming SQS connector URL: https://github.com/apache/bahir/pull/96 Adding link to SQL Streaming SQS connector in BAHIR README.md This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Update Readme with details of SQL Streaming SQS connector > - > > Key: BAHIR-222 > URL: https://issues.apache.org/jira/browse/BAHIR-222 > Project: Bahir > Issue Type: Task > Components: Spark Structured Streaming Connectors >Affects Versions: Not Applicable >Reporter: Abhishek Dixit >Assignee: Abhishek Dixit >Priority: Major > Fix For: Not Applicable > > > Adding link to SQL Streaming SQS connector in BAHIR Readme. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17004573#comment-17004573 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on pull request #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17004075#comment-17004075 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-569241249 @abhishekd0907 Thanks, I will wait a day or so in case @steveloughran can say something, otherwise, I will go ahead and merge this and we can iterate on master when @steveloughran is better and available. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16987877#comment-16987877 ] ASF GitHub Bot commented on BAHIR-213: -- steveloughran commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-561650867 I'm not directly ignoring you, just some problems are stop me doing much coding right now. I had hoped to do a PoC what this would look like against hadoop-3.2.1 I'm so drive whatever changes needed to be done there to help this (e.g delegation tokens to support the SQS), plus some tests. But its not going to happen this year -sorry. Similarly, I'm cutting back on approximately all my reviews. Anything involving typing basically. I do think it's important -and I also think somebody needs to look at spark streaming checkpointing -against S3 put-with-overwrite works the way rename doesn't. Just not going to be me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16986278#comment-16986278 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-560538377 > @abhishekd0907 could you please rebase to latest master to make sure we get a green build. Otherwise, looks ok to me. @lresende i see that master build is also failing https://travis-ci.org/apache/bahir/builds/584684002?utm_source=github_status_medium=notification probably due to this `Detected Maven Version: 3.5.2 is not in the allowed range 3.5.4. ` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16985188#comment-16985188 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-559875628 @abhishekd0907 could you please rebase to latest master to make sure we get a green build. Otherwise, looks ok to me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-220) Add redis descriptor to make redis connection as a table
[
https://issues.apache.org/jira/browse/BAHIR-220?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16977300#comment-16977300
]
ASF GitHub Bot commented on BAHIR-220:
--
hzyuemeng1 commented on pull request #72: [BAHIR-220] Add redis descriptor to
make redis connection as a table
URL: https://github.com/apache/bahir-flink/pull/72
currently, for Flink-1.9.0, we can use the catalog to store our stream table
source and sink meta.
for Redis connector, it should exist a Redis table sink so we can register
it to catalog, and use Redis as a table in SQL environment
```
Redis redis = new Redis()
.mode(RedisVadidator.REDIS_CLUSTER)
.command(RedisCommand.INCRBY_EX.name())
.ttl(10)
.property(RedisVadidator.REDIS_NODES, REDIS_HOST+ ":" +
REDIS_PORT);
tableEnvironment
.connect(redis).withSchema(new Schema()
.field("k", TypeInformation.of(String.class))
.field("v", TypeInformation.of(Long.class)))
.registerTableSink("redis");
tableEnvironment.sqlUpdate("insert into redis select k, v from t1");
env.execute("Test Redis Table");
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add redis descriptor to make redis connection as a table
>
>
> Key: BAHIR-220
> URL: https://issues.apache.org/jira/browse/BAHIR-220
> Project: Bahir
> Issue Type: Improvement
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: yuemeng
>Priority: Major
>
> currently, for Flink-1.9.0, we can use the catalog to store our stream table
> source and sink meta.
> for Redis connector, it should exist a Redis table sink so we can register it
> to catalog, and use Redis as a table in SQL environment
> {code}
> Redis redis = new Redis()
> .mode(RedisVadidator.REDIS_CLUSTER)
> .command(RedisCommand.INCRBY_EX.name())
> .ttl(10)
> .property(RedisVadidator.REDIS_NODES, REDIS_HOST+ ":" +
> REDIS_PORT);
> tableEnvironment
> .connect(redis).withSchema(new Schema()
> .field("k", TypeInformation.of(String.class))
> .field("v", TypeInformation.of(Long.class)))
> .registerTableSink("redis");
> tableEnvironment.sqlUpdate("insert into redis select k, v from t1");
> env.execute("Test Redis Table");
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16966315#comment-16966315 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-549194053 ping @steveloughran This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (BAHIR-155) Add expire to redis sink
[
https://issues.apache.org/jira/browse/BAHIR-155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16949646#comment-16949646
]
ASF GitHub Bot commented on BAHIR-155:
--
tutss commented on issue #66: [BAHIR-155] TTL to HSET and SETEX command
URL: https://github.com/apache/bahir-flink/pull/66#issuecomment-541148390
my apache jira username is **tutss**
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add expire to redis sink
> -
>
> Key: BAHIR-155
> URL: https://issues.apache.org/jira/browse/BAHIR-155
> Project: Bahir
> Issue Type: Wish
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: miki haiat
>Priority: Major
> Labels: features
> Fix For: Flink-Next
>
>
> I have a scenario that im collection some MD and aggregate the result by
> time .
> for example Each HSET of each window can create different values
> by adding expiry i can guarantee that the key is holding only the current
> window values
> im thinking to change the the interface signuter
>
> {code:java}
> void hset(String key, String hashField, String value);
> void set(String key, String value);
> //to this
> void hset(String key, String hashField, String value,int expire);
> void set(String key, String value,int expire);
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-155) Add expire to redis sink
[
https://issues.apache.org/jira/browse/BAHIR-155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16949520#comment-16949520
]
ASF GitHub Bot commented on BAHIR-155:
--
lresende commented on issue #66: [BAHIR-155] TTL to HSET and SETEX command
URL: https://github.com/apache/bahir-flink/pull/66#issuecomment-541097293
@tutss , please let me know your apache jira account so I can assign the
jira as resolved by you.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add expire to redis sink
> -
>
> Key: BAHIR-155
> URL: https://issues.apache.org/jira/browse/BAHIR-155
> Project: Bahir
> Issue Type: Wish
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: miki haiat
>Priority: Major
> Labels: features
> Fix For: Flink-1.0
>
>
> I have a scenario that im collection some MD and aggregate the result by
> time .
> for example Each HSET of each window can create different values
> by adding expiry i can guarantee that the key is holding only the current
> window values
> im thinking to change the the interface signuter
>
> {code:java}
> void hset(String key, String hashField, String value);
> void set(String key, String value);
> //to this
> void hset(String key, String hashField, String value,int expire);
> void set(String key, String value,int expire);
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-155) Add expire to redis sink
[
https://issues.apache.org/jira/browse/BAHIR-155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16949515#comment-16949515
]
ASF GitHub Bot commented on BAHIR-155:
--
lresende commented on pull request #66: [BAHIR-155] TTL to HSET and SETEX
command
URL: https://github.com/apache/bahir-flink/pull/66
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add expire to redis sink
> -
>
> Key: BAHIR-155
> URL: https://issues.apache.org/jira/browse/BAHIR-155
> Project: Bahir
> Issue Type: Wish
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: miki haiat
>Priority: Major
> Labels: features
> Fix For: Flink-1.0
>
>
> I have a scenario that im collection some MD and aggregate the result by
> time .
> for example Each HSET of each window can create different values
> by adding expiry i can guarantee that the key is holding only the current
> window values
> im thinking to change the the interface signuter
>
> {code:java}
> void hset(String key, String hashField, String value);
> void set(String key, String value);
> //to this
> void hset(String key, String hashField, String value,int expire);
> void set(String key, String value,int expire);
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-155) Add expire to redis sink
[
https://issues.apache.org/jira/browse/BAHIR-155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16949482#comment-16949482
]
ASF GitHub Bot commented on BAHIR-155:
--
eskabetxe commented on issue #66: [BAHIR-155] TTL to HSET and SETEX command
URL: https://github.com/apache/bahir-flink/pull/66#issuecomment-541078180
LGTM @lresende
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add expire to redis sink
> -
>
> Key: BAHIR-155
> URL: https://issues.apache.org/jira/browse/BAHIR-155
> Project: Bahir
> Issue Type: Wish
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: miki haiat
>Priority: Major
> Labels: features
> Fix For: Flink-1.0
>
>
> I have a scenario that im collection some MD and aggregate the result by
> time .
> for example Each HSET of each window can create different values
> by adding expiry i can guarantee that the key is holding only the current
> window values
> im thinking to change the the interface signuter
>
> {code:java}
> void hset(String key, String hashField, String value);
> void set(String key, String value);
> //to this
> void hset(String key, String hashField, String value,int expire);
> void set(String key, String value,int expire);
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-155) Add expire to redis sink
[
https://issues.apache.org/jira/browse/BAHIR-155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16949035#comment-16949035
]
ASF GitHub Bot commented on BAHIR-155:
--
lresende commented on issue #66: [BAHIR-155] TTL to HSET and SETEX command
URL: https://github.com/apache/bahir-flink/pull/66#issuecomment-540858385
Looks good, @eskabetxe do you want to take a quick look at this?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add expire to redis sink
> -
>
> Key: BAHIR-155
> URL: https://issues.apache.org/jira/browse/BAHIR-155
> Project: Bahir
> Issue Type: Wish
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: miki haiat
>Priority: Major
> Labels: features
> Fix For: Flink-1.0
>
>
> I have a scenario that im collection some MD and aggregate the result by
> time .
> for example Each HSET of each window can create different values
> by adding expiry i can guarantee that the key is holding only the current
> window values
> im thinking to change the the interface signuter
>
> {code:java}
> void hset(String key, String hashField, String value);
> void set(String key, String value);
> //to this
> void hset(String key, String hashField, String value,int expire);
> void set(String key, String value,int expire);
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-155) Add expire to redis sink
[
https://issues.apache.org/jira/browse/BAHIR-155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16948026#comment-16948026
]
ASF GitHub Bot commented on BAHIR-155:
--
tutss commented on pull request #66: [BAHIR-155] TTL to HSET and SETEX command
URL: https://github.com/apache/bahir-flink/pull/66
This PR introduces some new functionality, following [BAHIR-155 Jira
discussion](https://issues.apache.org/jira/projects/BAHIR/issues/BAHIR-155?filter=allopenissues):
- Possibility to include TTL to a HASH in HSET operation.
- SETEX command.
Tests for each respective change were included.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Add expire to redis sink
> -
>
> Key: BAHIR-155
> URL: https://issues.apache.org/jira/browse/BAHIR-155
> Project: Bahir
> Issue Type: Wish
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: miki haiat
>Priority: Major
> Labels: features
> Fix For: Flink-1.0
>
>
> I have a scenario that im collection some MD and aggregate the result by
> time .
> for example Each HSET of each window can create different values
> by adding expiry i can guarantee that the key is holding only the current
> window values
> im thinking to change the the interface signuter
>
> {code:java}
> void hset(String key, String hashField, String value);
> void set(String key, String value);
> //to this
> void hset(String key, String hashField, String value,int expire);
> void set(String key, String value,int expire);
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (BAHIR-107) Build and test Bahir against Scala 2.12
[ https://issues.apache.org/jira/browse/BAHIR-107?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16926406#comment-16926406 ] ASF GitHub Bot commented on BAHIR-107: -- mahtuog commented on issue #76: [BAHIR-107] Upgrade to Scala 2.12 and Spark 2.4.0 URL: https://github.com/apache/bahir/pull/76#issuecomment-529823908 Any info on when the sql-streaming-mqtt for Spark 2.4 will be released ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Build and test Bahir against Scala 2.12 > --- > > Key: BAHIR-107 > URL: https://issues.apache.org/jira/browse/BAHIR-107 > Project: Bahir > Issue Type: Improvement >Reporter: Ted Yu >Assignee: Lukasz Antoniak >Priority: Major > Fix For: Spark-2.4.0 > > > Spark has started effort for accommodating Scala 2.12 > See SPARK-14220 . > This JIRA is to track requirements for building Bahir on Scala 2.12.7 -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-214) Improve KuduConnector speed
[ https://issues.apache.org/jira/browse/BAHIR-214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921088#comment-16921088 ] ASF GitHub Bot commented on BAHIR-214: -- lresende commented on pull request #64: [BAHIR-214]: improve speed and solve issues on eventual consistence URL: https://github.com/apache/bahir-flink/pull/64 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Improve KuduConnector speed > --- > > Key: BAHIR-214 > URL: https://issues.apache.org/jira/browse/BAHIR-214 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > kudu connector has some issues on kudu sink with some flush modes that kill > sink over time > > this is a refactor to resolve that issues and improve speed on eventual > consistence -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-172) Avoid FileInputStream/FileOutputStream
[
https://issues.apache.org/jira/browse/BAHIR-172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921085#comment-16921085
]
ASF GitHub Bot commented on BAHIR-172:
--
lresende commented on pull request #92: [BAHIR-172 ] Create input stream and
output stream of file with Files
URL: https://github.com/apache/bahir/pull/92
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Avoid FileInputStream/FileOutputStream
> --
>
> Key: BAHIR-172
> URL: https://issues.apache.org/jira/browse/BAHIR-172
> Project: Bahir
> Issue Type: Bug
>Reporter: Ted Yu
>Priority: Minor
>
> They rely on finalizers (before Java 11), which create unnecessary GC load.
> The alternatives, {{Files.newInputStream}}, are as easy to use and don't have
> this issue.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16921083#comment-16921083 ] ASF GitHub Bot commented on BAHIR-213: -- lresende commented on issue #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91#issuecomment-527259701 @steveloughran could you please review this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-217) Install of Oracle JDK 8 Failing in Travis CI
[
https://issues.apache.org/jira/browse/BAHIR-217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16919823#comment-16919823
]
ASF GitHub Bot commented on BAHIR-217:
--
lresende commented on pull request #93: [BAHIR-217] Install of Oracle JDK 8
Failing in Travis CI
URL: https://github.com/apache/bahir/pull/93
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Install of Oracle JDK 8 Failing in Travis CI
>
>
> Key: BAHIR-217
> URL: https://issues.apache.org/jira/browse/BAHIR-217
> Project: Bahir
> Issue Type: Bug
> Components: Build
>Reporter: Abhishek Dixit
>Priority: Major
> Labels: build, easyfix
>
> Install of Oracle JDK 8 Failing in Travis CI. As a result, build is failing
> for new pull requests.
> We need to make a small fix in _ __ .travis.yml_ file as mentioned in the
> issue here:
> https://travis-ci.community/t/install-of-oracle-jdk-8-failing/3038
> We just need to add
> {code:java}
> dist: trusty{code}
> in the .travis.yml file as mentioned in the issue above.
> I can raise a PR for this fix if required.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (BAHIR-217) Install of Oracle JDK 8 Failing in Travis CI
[
https://issues.apache.org/jira/browse/BAHIR-217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16919821#comment-16919821
]
ASF GitHub Bot commented on BAHIR-217:
--
lresende commented on issue #93: [BAHIR-217] Install of Oracle JDK 8 Failing in
Travis CI
URL: https://github.com/apache/bahir/pull/93#issuecomment-526706426
Thanks for the clarification. LGTM
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Install of Oracle JDK 8 Failing in Travis CI
>
>
> Key: BAHIR-217
> URL: https://issues.apache.org/jira/browse/BAHIR-217
> Project: Bahir
> Issue Type: Bug
> Components: Build
>Reporter: Abhishek Dixit
>Priority: Major
> Labels: build, easyfix
>
> Install of Oracle JDK 8 Failing in Travis CI. As a result, build is failing
> for new pull requests.
> We need to make a small fix in _ __ .travis.yml_ file as mentioned in the
> issue here:
> https://travis-ci.community/t/install-of-oracle-jdk-8-failing/3038
> We just need to add
> {code:java}
> dist: trusty{code}
> in the .travis.yml file as mentioned in the issue above.
> I can raise a PR for this fix if required.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (BAHIR-217) Install of Oracle JDK 8 Failing in Travis CI
[
https://issues.apache.org/jira/browse/BAHIR-217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16919811#comment-16919811
]
ASF GitHub Bot commented on BAHIR-217:
--
abhishekd0907 commented on issue #93: [BAHIR-217] Install of Oracle JDK 8
Failing in Travis CI
URL: https://github.com/apache/bahir/pull/93#issuecomment-526698979
> Just out of curiosity, I [build master on
travis](https://travis-ci.org/apache/bahir/builds/544930279) without a problem.
How are you seeing the issue requiring trusty distro for travis builds.
@lresende I had raised another PR in BHAIR regarding sql-streaming SQS
connector #91
and its travis build is failing due to install jdk error. You can see the
details below:
[Travis Job log](https://travis-ci.org/apache/bahir/jobs/573750572)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Install of Oracle JDK 8 Failing in Travis CI
>
>
> Key: BAHIR-217
> URL: https://issues.apache.org/jira/browse/BAHIR-217
> Project: Bahir
> Issue Type: Bug
> Components: Build
>Reporter: Abhishek Dixit
>Priority: Major
> Labels: build, easyfix
>
> Install of Oracle JDK 8 Failing in Travis CI. As a result, build is failing
> for new pull requests.
> We need to make a small fix in _ __ .travis.yml_ file as mentioned in the
> issue here:
> https://travis-ci.community/t/install-of-oracle-jdk-8-failing/3038
> We just need to add
> {code:java}
> dist: trusty{code}
> in the .travis.yml file as mentioned in the issue above.
> I can raise a PR for this fix if required.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (BAHIR-217) Install of Oracle JDK 8 Failing in Travis CI
[
https://issues.apache.org/jira/browse/BAHIR-217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16919736#comment-16919736
]
ASF GitHub Bot commented on BAHIR-217:
--
lresende commented on issue #93: [BAHIR-217] Install of Oracle JDK 8 Failing in
Travis CI
URL: https://github.com/apache/bahir/pull/93#issuecomment-526678080
Just out of curiosity, I [build master on
travis](https://travis-ci.org/apache/bahir/builds/544930279) without a problem.
How are you seeing the issue requiring trusty distro for travis builds.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Install of Oracle JDK 8 Failing in Travis CI
>
>
> Key: BAHIR-217
> URL: https://issues.apache.org/jira/browse/BAHIR-217
> Project: Bahir
> Issue Type: Bug
> Components: Build
>Reporter: Abhishek Dixit
>Priority: Major
> Labels: build, easyfix
>
> Install of Oracle JDK 8 Failing in Travis CI. As a result, build is failing
> for new pull requests.
> We need to make a small fix in _ __ .travis.yml_ file as mentioned in the
> issue here:
> https://travis-ci.community/t/install-of-oracle-jdk-8-failing/3038
> We just need to add
> {code:java}
> dist: trusty{code}
> in the .travis.yml file as mentioned in the issue above.
> I can raise a PR for this fix if required.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (BAHIR-217) Install of Oracle JDK 8 Failing in Travis CI
[
https://issues.apache.org/jira/browse/BAHIR-217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16919359#comment-16919359
]
ASF GitHub Bot commented on BAHIR-217:
--
abhishekd0907 commented on pull request #93: [BAHIR-217] Install of Oracle JDK
8 Failing in Travis CI
URL: https://github.com/apache/bahir/pull/93
## What changes were proposed in this pull request?
Install of Oracle JDK 8 Failing in Travis CI. As a result, build is failing
for new pull requests.
We need to make a small fix in _.travis.yml_ file as mentioned in the
issue here:
https://travis-ci.community/t/install-of-oracle-jdk-8-failing/3038
We just need to add
`dist: trusty`
in the _.travis.yml_ file as mentioned in the issue above.
## How will these changes be tested?
Travis Build should successfully pass for this PR, thus testing the changes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Install of Oracle JDK 8 Failing in Travis CI
>
>
> Key: BAHIR-217
> URL: https://issues.apache.org/jira/browse/BAHIR-217
> Project: Bahir
> Issue Type: Bug
> Components: Build
>Reporter: Abhishek Dixit
>Priority: Major
> Labels: build, easyfix
>
> Install of Oracle JDK 8 Failing in Travis CI. As a result, build is failing
> for new pull requests.
> We need to make a small fix in _ __ .travis.yml_ file as mentioned in the
> issue here:
> https://travis-ci.community/t/install-of-oracle-jdk-8-failing/3038
> We just need to add
> {code:java}
> dist: trusty{code}
> in the .travis.yml file as mentioned in the issue above.
> I can raise a PR for this fix if required.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (BAHIR-215) bump flink to 1.9.0
[ https://issues.apache.org/jira/browse/BAHIR-215?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16915865#comment-16915865 ] ASF GitHub Bot commented on BAHIR-215: -- lresende commented on pull request #65: [BAHIR-215]: bump flink version to 1.9.0 URL: https://github.com/apache/bahir-flink/pull/65 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink to 1.9.0 > --- > > Key: BAHIR-215 > URL: https://issues.apache.org/jira/browse/BAHIR-215 > Project: Bahir > Issue Type: Improvement >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-215) bump flink to 1.9.0
[ https://issues.apache.org/jira/browse/BAHIR-215?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16915732#comment-16915732 ] ASF GitHub Bot commented on BAHIR-215: -- eskabetxe commented on issue #65: [BAHIR-215]: bump flink version to 1.9.0 URL: https://github.com/apache/bahir-flink/pull/65#issuecomment-524824774 @lresende could you check this This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink to 1.9.0 > --- > > Key: BAHIR-215 > URL: https://issues.apache.org/jira/browse/BAHIR-215 > Project: Bahir > Issue Type: Improvement >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-215) bump flink to 1.9.0
[ https://issues.apache.org/jira/browse/BAHIR-215?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16915701#comment-16915701 ] ASF GitHub Bot commented on BAHIR-215: -- eskabetxe commented on pull request #65: [BAHIR-215]: bump flink version to 1.9.0 URL: https://github.com/apache/bahir-flink/pull/65 bump flink version to 1.9.0 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink to 1.9.0 > --- > > Key: BAHIR-215 > URL: https://issues.apache.org/jira/browse/BAHIR-215 > Project: Bahir > Issue Type: Improvement >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-210) bump flink version to 1.8.1
[ https://issues.apache.org/jira/browse/BAHIR-210?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16911934#comment-16911934 ] ASF GitHub Bot commented on BAHIR-210: -- lresende commented on pull request #62: [BAHIR-210] upgrade flink to 1.8.1 URL: https://github.com/apache/bahir-flink/pull/62 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink version to 1.8.1 > --- > > Key: BAHIR-210 > URL: https://issues.apache.org/jira/browse/BAHIR-210 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Commented] (BAHIR-214) Improve KuduConnector speed
[ https://issues.apache.org/jira/browse/BAHIR-214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16906072#comment-16906072 ] ASF GitHub Bot commented on BAHIR-214: -- eskabetxe commented on issue #64: [BAHIR-214]: improve speed and solve issues on eventual consistence URL: https://github.com/apache/bahir-flink/pull/64#issuecomment-520786266 @lresende this is falling for the same reason BAHIR-210 fails.. this is the error "The job exceeded the maximum log length, and has been terminated." its resolved on that PR, could yo merge that first? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Improve KuduConnector speed > --- > > Key: BAHIR-214 > URL: https://issues.apache.org/jira/browse/BAHIR-214 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > kudu connector has some issues on kudu sink with some flush modes that kill > sink over time > > this is a refactor to resolve that issues and improve speed on eventual > consistence -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-214) Improve KuduConnector speed
[ https://issues.apache.org/jira/browse/BAHIR-214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16906054#comment-16906054 ] ASF GitHub Bot commented on BAHIR-214: -- eskabetxe commented on issue #64: [BAHIR-214]: improve speed and solve issues on eventual consistence URL: https://github.com/apache/bahir-flink/pull/64#issuecomment-520779750 @lresende could you check This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Improve KuduConnector speed > --- > > Key: BAHIR-214 > URL: https://issues.apache.org/jira/browse/BAHIR-214 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > kudu connector has some issues on kudu sink with some flush modes that kill > sink over time > > this is a refactor to resolve that issues and improve speed on eventual > consistence -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-214) Improve KuduConnector speed
[ https://issues.apache.org/jira/browse/BAHIR-214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16906053#comment-16906053 ] ASF GitHub Bot commented on BAHIR-214: -- eskabetxe commented on pull request #64: [BAHIR-214]: improve speed and solve issues on eventual consistence URL: https://github.com/apache/bahir-flink/pull/64 - resolve eventual consistence issues - improve speed special on eventual consistence stream - actualized Readme This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Improve KuduConnector speed > --- > > Key: BAHIR-214 > URL: https://issues.apache.org/jira/browse/BAHIR-214 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > kudu connector has some issues on kudu sink with some flush modes that kill > sink over time > > this is a refactor to resolve that issues and improve speed on eventual > consistence -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[ https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16902384#comment-16902384 ] ASF GitHub Bot commented on BAHIR-213: -- abhishekd0907 commented on pull request #91: [BAHIR-213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Faster S3 file Source for Structured Streaming with SQS > --- > > Key: BAHIR-213 > URL: https://issues.apache.org/jira/browse/BAHIR-213 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.4.0 >Reporter: Abhishek Dixit >Priority: Major > > Using FileStreamSource to read files from a S3 bucket has problems both in > terms of costs and latency: > * *Latency:* Listing all the files in S3 buckets every microbatch can be > both slow and resource intensive. > * *Costs:* Making List API requests to S3 every microbatch can be costly. > The solution is to use Amazon Simple Queue Service (SQS) which lets you find > new files written to S3 bucket without the need to list all the files every > microbatch. > S3 buckets can be configured to send notification to an Amazon SQS Queue on > Object Create / Object Delete events. For details see AWS documentation here > [Configuring S3 Event > Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html] > > Spark can leverage this to find new files written to S3 bucket by reading > notifications from SQS queue instead of listing files every microbatch. > I hope to contribute changes proposed in [this pull > request|https://github.com/apache/spark/pull/24934] to Apache Bahir as > suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi] > [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130] -- This message was sent by Atlassian JIRA (v7.6.14#76016)
[jira] [Commented] (BAHIR-213) Faster S3 file Source for Structured Streaming with SQS
[
https://issues.apache.org/jira/browse/BAHIR-213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16902385#comment-16902385
]
ASF GitHub Bot commented on BAHIR-213:
--
abhishekd0907 commented on pull request #91: [BAHIR-213] Faster S3 file Source
for Structured Streaming with SQS
URL: https://github.com/apache/bahir/pull/91
## What changes were proposed in this pull request?
Using FileStreamSource to read files from a S3 bucket has problems both in
terms of costs and latency:
- **Latency**: Listing all the files in S3 buckets every microbatch can be
both slow and resource intensive.
- **Costs**: Making List API requests to S3 every microbatch can be costly.
The solution is to use Amazon Simple Queue Service (SQS) which lets you find
new files written to S3 bucket without the need to list all the files every
microbatch.
S3 buckets can be configured to send notification to an Amazon SQS Queue on
Object Create / Object Delete events. For details see AWS documentation here
[Configuring S3 Event
Notifications](https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html)
Spark can leverage this to find new files written to S3 bucket by reading
notifications from SQS queue instead of listing files every microbatch.
This PR adds a new SQSSource which uses Amazon SQS queue to find new files
every microbatch.
## Usage
`val inputDf = spark
.readStream
.format("s3-sqs")
.schema(schema)
.option("fileFormat", "json")
.option("sqsUrl", "https://QUEUE_URL;)
.option("region", "us-east-1")
.load()`
## Implementation Details
We create a scheduled thread which runs asynchronously with the streaming
query thread and periodically fetches messages from the SQS Queue. Key
information related to file path & timestamp is extracted from the SQS messages
and the new files are stored in a thread safe SQS file cache.
Streaming Query thread gets the files from SQS File Cache and filters out
the new files. Based on the maxFilesPerTrigger condition, all or a part of the
new files are added to the offset log and marked as processed in the SQS File
Cache. The corresponding SQS messages for the processed files are deleted from
the Amazon SQS Queue and the offset value is incremented and returned.
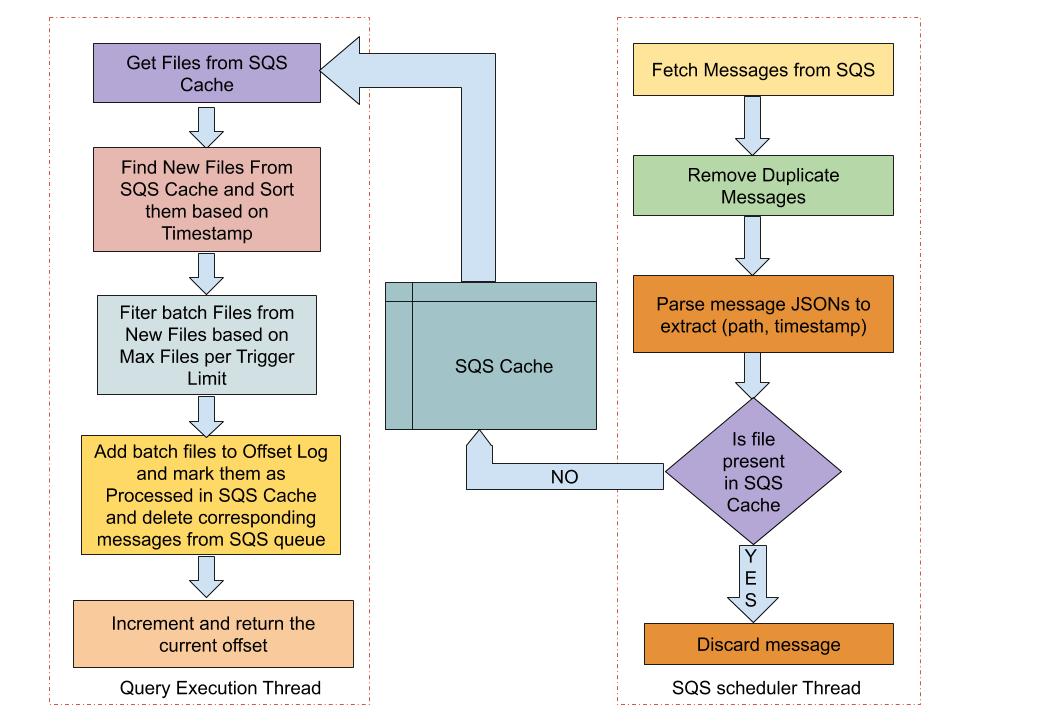
## How was this patch tested?
Added new unit tests in SqsSourceOptionsSuite which test various
SqsSourceOptions. Will add more tests after some initial feedback on design
approach and functionality.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Faster S3 file Source for Structured Streaming with SQS
> ---
>
> Key: BAHIR-213
> URL: https://issues.apache.org/jira/browse/BAHIR-213
> Project: Bahir
> Issue Type: New Feature
> Components: Spark Structured Streaming Connectors
>Affects Versions: Spark-2.4.0
>Reporter: Abhishek Dixit
>Priority: Major
>
> Using FileStreamSource to read files from a S3 bucket has problems both in
> terms of costs and latency:
> * *Latency:* Listing all the files in S3 buckets every microbatch can be
> both slow and resource intensive.
> * *Costs:* Making List API requests to S3 every microbatch can be costly.
> The solution is to use Amazon Simple Queue Service (SQS) which lets you find
> new files written to S3 bucket without the need to list all the files every
> microbatch.
> S3 buckets can be configured to send notification to an Amazon SQS Queue on
> Object Create / Object Delete events. For details see AWS documentation here
> [Configuring S3 Event
> Notifications|https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html]
>
> Spark can leverage this to find new files written to S3 bucket by reading
> notifications from SQS queue instead of listing files every microbatch.
> I hope to contribute changes proposed in [this pull
> request|https://github.com/apache/spark/pull/24934] to Apache Bahir as
> suggested by [gaborgsomogyi|https://github.com/gaborgsomogyi]
> [here|https://github.com/apache/spark/pull/24934#issuecomment-511389130]
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (BAHIR-172) Avoid FileInputStream/FileOutputStream
[
https://issues.apache.org/jira/browse/BAHIR-172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16894620#comment-16894620
]
ASF GitHub Bot commented on BAHIR-172:
--
liketic commented on issue #92: [BAHIR-172 ] Create input stream and output
stream of file with Files
URL: https://github.com/apache/bahir/pull/92#issuecomment-515732686
@lresende Please review again.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Avoid FileInputStream/FileOutputStream
> --
>
> Key: BAHIR-172
> URL: https://issues.apache.org/jira/browse/BAHIR-172
> Project: Bahir
> Issue Type: Bug
>Reporter: Ted Yu
>Priority: Minor
>
> They rely on finalizers (before Java 11), which create unnecessary GC load.
> The alternatives, {{Files.newInputStream}}, are as easy to use and don't have
> this issue.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (BAHIR-172) Avoid FileInputStream/FileOutputStream
[
https://issues.apache.org/jira/browse/BAHIR-172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16894615#comment-16894615
]
ASF GitHub Bot commented on BAHIR-172:
--
lresende commented on issue #92: [BAHIR-172 ]Replace FileInputStream with
Files.newInputStream
URL: https://github.com/apache/bahir/pull/92#issuecomment-515731144
There are some usage of outputstream on `streaming-pubsub` as well. Are you
planning to also fix that as part of bahir-172 ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Avoid FileInputStream/FileOutputStream
> --
>
> Key: BAHIR-172
> URL: https://issues.apache.org/jira/browse/BAHIR-172
> Project: Bahir
> Issue Type: Bug
>Reporter: Ted Yu
>Priority: Minor
>
> They rely on finalizers (before Java 11), which create unnecessary GC load.
> The alternatives, {{Files.newInputStream}}, are as easy to use and don't have
> this issue.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (BAHIR-172) Avoid FileInputStream/FileOutputStream
[
https://issues.apache.org/jira/browse/BAHIR-172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16894352#comment-16894352
]
ASF GitHub Bot commented on BAHIR-172:
--
liketic commented on pull request #92: [BAHIR-172 ]Replace FileInputStream with
Files.newInputStream
URL: https://github.com/apache/bahir/pull/92
Replace FileInputStream with Files.newInputStream in MQTTTestUtils.
Related to JIRA:
https://issues.apache.org/jira/projects/BAHIR/issues/BAHIR-172
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Avoid FileInputStream/FileOutputStream
> --
>
> Key: BAHIR-172
> URL: https://issues.apache.org/jira/browse/BAHIR-172
> Project: Bahir
> Issue Type: Bug
>Reporter: Ted Yu
>Priority: Minor
>
> They rely on finalizers (before Java 11), which create unnecessary GC load.
> The alternatives, {{Files.newInputStream}}, are as easy to use and don't have
> this issue.
--
This message was sent by Atlassian JIRA
(v7.6.14#76016)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16880755#comment-16880755 ] ASF GitHub Bot commented on BAHIR-85: - lresende commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-509412323 I don't think I can do it before OSCON which is next week, any volunteers ? @eskabetxe or @lukasz-antoniak This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16880327#comment-16880327 ] ASF GitHub Bot commented on BAHIR-85: - marcosschroh commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-509219449 hi @lresende , When the a new version is going to be released with the new change? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-210) bump flink version to 1.8.1
[ https://issues.apache.org/jira/browse/BAHIR-210?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878515#comment-16878515 ] ASF GitHub Bot commented on BAHIR-210: -- eskabetxe commented on issue #62: [BAHIR-210] upgrade flink to 1.8.1 URL: https://github.com/apache/bahir-flink/pull/62#issuecomment-508424431 @lresende i added a -quiet option to mvn command.. that way only logs the errors... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink version to 1.8.1 > --- > > Key: BAHIR-210 > URL: https://issues.apache.org/jira/browse/BAHIR-210 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-210) bump flink version to 1.8.1
[ https://issues.apache.org/jira/browse/BAHIR-210?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878405#comment-16878405 ] ASF GitHub Bot commented on BAHIR-210: -- eskabetxe commented on issue #62: [BAHIR-210] upgrade flink to 1.8.1 URL: https://github.com/apache/bahir-flink/pull/62#issuecomment-508377386 this is the error "The job exceeded the maximum log length, and has been terminated." i have pending to check all the warnings.. i will see if there are some easy error to solve This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink version to 1.8.1 > --- > > Key: BAHIR-210 > URL: https://issues.apache.org/jira/browse/BAHIR-210 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-210) bump flink version to 1.8.1
[ https://issues.apache.org/jira/browse/BAHIR-210?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878227#comment-16878227 ] ASF GitHub Bot commented on BAHIR-210: -- lresende commented on issue #62: [BAHIR-210] upgrade flink to 1.8.1 URL: https://github.com/apache/bahir-flink/pull/62#issuecomment-508285988 @eskabetxe could you check the build failures, it might be related to Travis load, but it usually passes so it might also be a side effect of the upgrade? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink version to 1.8.1 > --- > > Key: BAHIR-210 > URL: https://issues.apache.org/jira/browse/BAHIR-210 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-210) bump flink version to 1.8.1
[ https://issues.apache.org/jira/browse/BAHIR-210?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878200#comment-16878200 ] ASF GitHub Bot commented on BAHIR-210: -- eskabetxe commented on pull request #62: [BAHIR-210] upgrade flink to 1.8.1 URL: https://github.com/apache/bahir-flink/pull/62 upgrade flink to 1.8.1 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink version to 1.8.1 > --- > > Key: BAHIR-210 > URL: https://issues.apache.org/jira/browse/BAHIR-210 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-210) bump flink version to 1.8.1
[ https://issues.apache.org/jira/browse/BAHIR-210?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878201#comment-16878201 ] ASF GitHub Bot commented on BAHIR-210: -- eskabetxe commented on issue #62: [BAHIR-210] upgrade flink to 1.8.1 URL: https://github.com/apache/bahir-flink/pull/62#issuecomment-508274200 @lresende could you check This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink version to 1.8.1 > --- > > Key: BAHIR-210 > URL: https://issues.apache.org/jira/browse/BAHIR-210 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878196#comment-16878196 ] ASF GitHub Bot commented on BAHIR-207: -- lresende commented on pull request #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-209) bump kudu version to 1.10.0
[ https://issues.apache.org/jira/browse/BAHIR-209?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878191#comment-16878191 ] ASF GitHub Bot commented on BAHIR-209: -- lresende commented on pull request #61: [BAHIR-209] upgrade kudu version to 1.10.0 URL: https://github.com/apache/bahir-flink/pull/61 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump kudu version to 1.10.0 > --- > > Key: BAHIR-209 > URL: https://issues.apache.org/jira/browse/BAHIR-209 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878187#comment-16878187 ] ASF GitHub Bot commented on BAHIR-85: - lresende commented on pull request #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878053#comment-16878053 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on issue #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#issuecomment-508202111 @lresende could you check this This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16878050#comment-16878050 ] ASF GitHub Bot commented on BAHIR-85: - eskabetxe commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-508201780 @lresende LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16877793#comment-16877793 ] ASF GitHub Bot commented on BAHIR-85: - marcosschroh commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-508069809 Hi, Any update on this? :smiley: This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16877792#comment-16877792 ] ASF GitHub Bot commented on BAHIR-85: - marcosschroh commented on issue #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60#issuecomment-508069809 Hi, Any update in this? :smiley: This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-85) Redis Sink Connector should allow update of command without reinstatiation
[ https://issues.apache.org/jira/browse/BAHIR-85?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16876480#comment-16876480 ] ASF GitHub Bot commented on BAHIR-85: - tonvanbart commented on pull request #60: BAHIR-85: make it possible to change additional key without restarting URL: https://github.com/apache/bahir-flink/pull/60 We have a use case where we want to sink data to Redis as hashes, but have the hashes stored under different keys which are also extracted from the data. This change makes this possible in a backward compatible manner (see my comment in BAHIR-85 for details). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Redis Sink Connector should allow update of command without reinstatiation > --- > > Key: BAHIR-85 > URL: https://issues.apache.org/jira/browse/BAHIR-85 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Atharva Inamdar >Priority: Major > > ref: FLINK-5478 > `getCommandDescription()` gets called when RedisSink is instantiated. This > happens only once and thus doesn't allow the command to be updated during run > time. > Use Case: > As a dev I want to store some data by day. So each key will have some date > specified. this will change over course of time. for example: > `counts_for_148426560` for 2017-01-13. This is not limited to any > particular command. > connector: > https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.java#L114 > I wish `getCommandDescription()` could be called in `invoke()` so that the > key can be updated without having to restart. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-183) Using HDFS for saving message for mqtt source
[ https://issues.apache.org/jira/browse/BAHIR-183?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16870500#comment-16870500 ] ASF GitHub Bot commented on BAHIR-183: -- yanlin-Lynn commented on issue #84: [BAHIR-183] [WIP] HDFS based MQTT client persistence URL: https://github.com/apache/bahir/pull/84#issuecomment-504732887 And, I think we should better keep the ability to do flow-control, eg, control max number of message in each batch. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Using HDFS for saving message for mqtt source > - > > Key: BAHIR-183 > URL: https://issues.apache.org/jira/browse/BAHIR-183 > Project: Bahir > Issue Type: Improvement > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.2.0 >Reporter: Wang Yanlin >Assignee: Wang Yanlin >Priority: Major > Fix For: Spark-2.4.0 > > > Currently in spark-sql-streaming-mqtt, the received mqtt message is saved in > a local file by driver, this will have the risks of losing data for cluster > mode when application master failover occurs. So saving in-coming mqtt > messages using a director in checkpoint will solve this problem. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-183) Using HDFS for saving message for mqtt source
[
https://issues.apache.org/jira/browse/BAHIR-183?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16870495#comment-16870495
]
ASF GitHub Bot commented on BAHIR-183:
--
yanlin-Lynn commented on pull request #84: [BAHIR-183] [WIP] HDFS based MQTT
client persistence
URL: https://github.com/apache/bahir/pull/84#discussion_r296471045
##
File path:
sql-streaming-mqtt/src/main/scala/org/apache/bahir/sql/streaming/mqtt/MessageStore.scala
##
@@ -148,3 +141,113 @@ private[mqtt] class LocalMessageStore(val
persistentStore: MqttClientPersistence
}
}
+
+private[mqtt] class HdfsMqttClientPersistence(config: Configuration)
+extends MqttClientPersistence {
+
+ var rootPath: Path = _
+ var fileSystem: FileSystem = _
+
+ override def open(clientId: String, serverURI: String): Unit = {
+try {
+ rootPath = new Path("mqtt/" + clientId + "/" +
serverURI.replaceAll("[^a-zA-Z0-9]", "_"))
+ fileSystem = FileSystem.get(config)
+ if (!fileSystem.exists(rootPath)) {
+fileSystem.mkdirs(rootPath)
+ }
+}
+catch {
+ case e: Exception => throw new MqttPersistenceException(e)
+}
+ }
+
+ override def close(): Unit = {
+try {
+ fileSystem.close()
+}
+catch {
+ case e: Exception => throw new MqttPersistenceException(e)
+}
+ }
+
+ override def put(key: String, persistable: MqttPersistable): Unit = {
+try {
+ val path = getPath(key)
Review comment:
I just worry about the performance of creating a file for each coming
message.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Using HDFS for saving message for mqtt source
> -
>
> Key: BAHIR-183
> URL: https://issues.apache.org/jira/browse/BAHIR-183
> Project: Bahir
> Issue Type: Improvement
> Components: Spark Structured Streaming Connectors
>Affects Versions: Spark-2.2.0
>Reporter: Wang Yanlin
>Assignee: Wang Yanlin
>Priority: Major
> Fix For: Spark-2.4.0
>
>
> Currently in spark-sql-streaming-mqtt, the received mqtt message is saved in
> a local file by driver, this will have the risks of losing data for cluster
> mode when application master failover occurs. So saving in-coming mqtt
> messages using a director in checkpoint will solve this problem.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-192) Add jdbc sink support for Structured Streaming
[ https://issues.apache.org/jira/browse/BAHIR-192?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16860930#comment-16860930 ] ASF GitHub Bot commented on BAHIR-192: -- lresende commented on pull request #81: [BAHIR-192]add jdbc sink for structured streaming. URL: https://github.com/apache/bahir/pull/81 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Add jdbc sink support for Structured Streaming > -- > > Key: BAHIR-192 > URL: https://issues.apache.org/jira/browse/BAHIR-192 > Project: Bahir > Issue Type: New Feature > Components: Spark Structured Streaming Connectors >Reporter: Wang Yanlin >Priority: Major > > Currently, spark sql support read and write to jdbc in batch mode, but do not > support for Structured Streaming. During work, even thought we can write to > jdbc using foreach sink, but providing a more easier way for writing to jdbc > would be helpful. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16860144#comment-16860144 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on issue #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#issuecomment-500491064 solved the problems with travis.. akka connector and siddhi library have a lot of warnings and logs This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859981#comment-16859981 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on issue #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#issuecomment-500387221 > What are the benefits of breaking the builds per project? none.. travis was giving me a bad day.. it ends with a "The job exceeded the maximum log length, and has been terminated." the only way to fix this is breaking the builds This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859980#comment-16859980 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on pull request #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#discussion_r291999346 ## File path: pom.xml ## @@ -703,7 +703,7 @@ scala-2.11 - !scala-2.12 + scala-2.11 Review comment: on travis is mandarory because of change-scala-version.sh on local machine it works as scala version is defined on properties.. (version 2.11) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859943#comment-16859943 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on issue #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#issuecomment-500387221 > What are the benefits of breaking the builds per project? none.. travis was giving me a bad day.. its fixed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-183) Using HDFS for saving message for mqtt source
[ https://issues.apache.org/jira/browse/BAHIR-183?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859146#comment-16859146 ] ASF GitHub Bot commented on BAHIR-183: -- lresende commented on issue #84: [BAHIR-183] [WIP] HDFS based MQTT client persistence URL: https://github.com/apache/bahir/pull/84#issuecomment-500106395 @lukasz-antoniak what's the status of this pr, is this ready for final review/merge? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Using HDFS for saving message for mqtt source > - > > Key: BAHIR-183 > URL: https://issues.apache.org/jira/browse/BAHIR-183 > Project: Bahir > Issue Type: Improvement > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.2.0 >Reporter: Wang Yanlin >Assignee: Wang Yanlin >Priority: Major > Fix For: Spark-2.4.0 > > > Currently in spark-sql-streaming-mqtt, the received mqtt message is saved in > a local file by driver, this will have the risks of losing data for cluster > mode when application master failover occurs. So saving in-coming mqtt > messages using a director in checkpoint will solve this problem. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859144#comment-16859144 ] ASF GitHub Bot commented on BAHIR-207: -- lresende commented on pull request #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#discussion_r291798761 ## File path: pom.xml ## @@ -703,7 +703,7 @@ scala-2.11 - !scala-2.12 + scala-2.11 Review comment: If we don't specify a profile on the command line, does the build pickup a default one and build it properly? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859143#comment-16859143 ] ASF GitHub Bot commented on BAHIR-207: -- lresende commented on issue #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59#issuecomment-500106068 What are the benefits of breaking the builds per project? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-205) add password support for flink sink of redis cluster
[ https://issues.apache.org/jira/browse/BAHIR-205?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16859142#comment-16859142 ] ASF GitHub Bot commented on BAHIR-205: -- lresende commented on pull request #57: [BAHIR-205] Support configure password for redis cluster URL: https://github.com/apache/bahir-flink/pull/57 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add password support for flink sink of redis cluster > - > > Key: BAHIR-205 > URL: https://issues.apache.org/jira/browse/BAHIR-205 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Affects Versions: Not Applicable >Reporter: yanfeng >Priority: Major > Labels: features > Fix For: Not Applicable > > Original Estimate: 24h > Remaining Estimate: 24h > > redis cluster with password protect is not supported in > flink-connector-redis_2.11 version 1.1-SNAPSHOT, because the related jedis > 2.8.0 doesn't support the feature, so uprade jedis to 2.9.0 and some code > will fulfill it -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-205) add password support for flink sink of redis cluster
[ https://issues.apache.org/jira/browse/BAHIR-205?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858749#comment-16858749 ] ASF GitHub Bot commented on BAHIR-205: -- eskabetxe commented on issue #57: [BAHIR-205] Support configure password for redis cluster URL: https://github.com/apache/bahir-flink/pull/57#issuecomment-499937632 @lresende LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add password support for flink sink of redis cluster > - > > Key: BAHIR-205 > URL: https://issues.apache.org/jira/browse/BAHIR-205 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Affects Versions: Not Applicable >Reporter: yanfeng >Priority: Major > Labels: features > Fix For: Not Applicable > > Original Estimate: 24h > Remaining Estimate: 24h > > redis cluster with password protect is not supported in > flink-connector-redis_2.11 version 1.1-SNAPSHOT, because the related jedis > 2.8.0 doesn't support the feature, so uprade jedis to 2.9.0 and some code > will fulfill it -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-205) add password support for flink sink of redis cluster
[
https://issues.apache.org/jira/browse/BAHIR-205?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858690#comment-16858690
]
ASF GitHub Bot commented on BAHIR-205:
--
liketic commented on pull request #57: [BAHIR-205] Support configure password
for redis cluster
URL: https://github.com/apache/bahir-flink/pull/57#discussion_r291611667
##
File path:
flink-connector-redis/src/test/java/org/apache/flink/streaming/connectors/redis/common/config/JedisClusterConfigTest.java
##
@@ -46,4 +48,20 @@ public void
shouldThrowIllegalArgumentExceptionIfNodeValuesAreEmpty(){
.setNodes(set)
.build();
}
+
+@Test
+public void shouldSetPasswordSuccessfully() {
Review comment:
I added the test.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> add password support for flink sink of redis cluster
> -
>
> Key: BAHIR-205
> URL: https://issues.apache.org/jira/browse/BAHIR-205
> Project: Bahir
> Issue Type: Improvement
> Components: Flink Streaming Connectors
>Affects Versions: Not Applicable
>Reporter: yanfeng
>Priority: Major
> Labels: features
> Fix For: Not Applicable
>
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> redis cluster with password protect is not supported in
> flink-connector-redis_2.11 version 1.1-SNAPSHOT, because the related jedis
> 2.8.0 doesn't support the feature, so uprade jedis to 2.9.0 and some code
> will fulfill it
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858620#comment-16858620 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on pull request #59: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/59 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858615#comment-16858615 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on pull request #58: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/58 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858590#comment-16858590 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on issue #58: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/58#issuecomment-499870536 @lresende could you check This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-207) add suport for scala 2.12 on travis
[ https://issues.apache.org/jira/browse/BAHIR-207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858588#comment-16858588 ] ASF GitHub Bot commented on BAHIR-207: -- eskabetxe commented on pull request #58: [BAHIR-207] added tests for scala 2.12 on travis URL: https://github.com/apache/bahir-flink/pull/58 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add suport for scala 2.12 on travis > --- > > Key: BAHIR-207 > URL: https://issues.apache.org/jira/browse/BAHIR-207 > Project: Bahir > Issue Type: Test > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-205) add password support for flink sink of redis cluster
[
https://issues.apache.org/jira/browse/BAHIR-205?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16858575#comment-16858575
]
ASF GitHub Bot commented on BAHIR-205:
--
eskabetxe commented on pull request #57: [BAHIR-205] Support configure password
for redis cluster
URL: https://github.com/apache/bahir-flink/pull/57#discussion_r291568219
##
File path:
flink-connector-redis/src/test/java/org/apache/flink/streaming/connectors/redis/common/config/JedisClusterConfigTest.java
##
@@ -46,4 +48,20 @@ public void
shouldThrowIllegalArgumentExceptionIfNodeValuesAreEmpty(){
.setNodes(set)
.build();
}
+
+@Test
+public void shouldSetPasswordSuccessfully() {
Review comment:
could you add a test with no password setted.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> add password support for flink sink of redis cluster
> -
>
> Key: BAHIR-205
> URL: https://issues.apache.org/jira/browse/BAHIR-205
> Project: Bahir
> Issue Type: Improvement
> Components: Flink Streaming Connectors
>Affects Versions: Not Applicable
>Reporter: yanfeng
>Priority: Major
> Labels: features
> Fix For: Not Applicable
>
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> redis cluster with password protect is not supported in
> flink-connector-redis_2.11 version 1.1-SNAPSHOT, because the related jedis
> 2.8.0 doesn't support the feature, so uprade jedis to 2.9.0 and some code
> will fulfill it
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-107) Build and test Bahir against Scala 2.12
[ https://issues.apache.org/jira/browse/BAHIR-107?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16853193#comment-16853193 ] ASF GitHub Bot commented on BAHIR-107: -- jacek-rzrz commented on issue #76: [BAHIR-107] Upgrade to Scala 2.12 and Spark 2.4.0 URL: https://github.com/apache/bahir/pull/76#issuecomment-497775256 I cannot find the Scala 2.12 / Spark 2.4 version of spark-streaming-pubsub in Maven central yet. Is there a chance it will be released soon? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Build and test Bahir against Scala 2.12 > --- > > Key: BAHIR-107 > URL: https://issues.apache.org/jira/browse/BAHIR-107 > Project: Bahir > Issue Type: Improvement >Reporter: Ted Yu >Assignee: Lukasz Antoniak >Priority: Major > Fix For: Spark-2.4.0 > > > Spark has started effort for accommodating Scala 2.12 > See SPARK-14220 . > This JIRA is to track requirements for building Bahir on Scala 2.12.7 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-190) ActiveMQ connector stops on empty queue
[
https://issues.apache.org/jira/browse/BAHIR-190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16851345#comment-16851345
]
ASF GitHub Bot commented on BAHIR-190:
--
lresende commented on issue #53: [BAHIR-190] [activemq] Fixed premature exit on
empty queue
URL: https://github.com/apache/bahir-flink/pull/53#issuecomment-497126213
@Krystex Nothing wrong, your PR has been merged (manually) and you can see
the info above: `asfgit closed this in e5b1cae 12 days ago`. Github sometimes
displays `closed` versus `merged` particularly when using some local way for
merging.
Also, if you want to create a jira account, so I can assign the issue to
yourself, that might be useful towards committership in the project.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> ActiveMQ connector stops on empty queue
> ---
>
> Key: BAHIR-190
> URL: https://issues.apache.org/jira/browse/BAHIR-190
> Project: Bahir
> Issue Type: Bug
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: Stephan Brosinski
>Priority: Critical
> Fix For: Flink-Next
>
>
> I tried the ActiveMQ Flink Connector. Reading from an ActiveMQ queue, it
> seems to connector exits once there are no more messages in the queue. This
> ends the Flink job processing the stream.
> To me it seems, that the while loop inside the run method (AMQSource.java,
> line 222) should not do a return, but a continue if the message is no
> instance of ByteMessage, e.g. null.
> If I'm right, I can create a pull request showing the change.
> To reproduce:
>
> {code:java}
> ActiveMQConnectionFactory connectionFactory = new
> ActiveMQConnectionFactory("xxx", "xxx",
> "tcp://localhost:61616?jms.redeliveryPolicy.maximumRedeliveries=1");
> AMQSourceConfig amqConfig = new
> AMQSourceConfig.AMQSourceConfigBuilder()
> .setConnectionFactory(connectionFactory)
> .setDestinationName("test")
> .setDestinationType(DestinationType.QUEUE)
> .setDeserializationSchema(new SimpleStringSchema())
> .build();
> AMQSource amqSource = new AMQSource<>(amqConfig);
> env.addSource(amqSource).print()
> env.setParallelism(1).execute("ActiveMQ Consumer");{code}
> Then point the Flink job at an empty ActiveMQ queue.
>
> Not sure if this is a bug, but it's not what I expected when I used the
> connector.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-190) ActiveMQ connector stops on empty queue
[
https://issues.apache.org/jira/browse/BAHIR-190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16850717#comment-16850717
]
ASF GitHub Bot commented on BAHIR-190:
--
Krystex commented on issue #53: [BAHIR-190] [activemq] Fixed premature exit on
empty queue
URL: https://github.com/apache/bahir-flink/pull/53#issuecomment-496872475
Sorry, I don't have an jira account.
I'm kind of a newcomer to open source contributions, so please forgive my
next question:
Why was the pull request closed? What did I do wrong?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> ActiveMQ connector stops on empty queue
> ---
>
> Key: BAHIR-190
> URL: https://issues.apache.org/jira/browse/BAHIR-190
> Project: Bahir
> Issue Type: Bug
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: Stephan Brosinski
>Priority: Critical
> Fix For: Flink-Next
>
>
> I tried the ActiveMQ Flink Connector. Reading from an ActiveMQ queue, it
> seems to connector exits once there are no more messages in the queue. This
> ends the Flink job processing the stream.
> To me it seems, that the while loop inside the run method (AMQSource.java,
> line 222) should not do a return, but a continue if the message is no
> instance of ByteMessage, e.g. null.
> If I'm right, I can create a pull request showing the change.
> To reproduce:
>
> {code:java}
> ActiveMQConnectionFactory connectionFactory = new
> ActiveMQConnectionFactory("xxx", "xxx",
> "tcp://localhost:61616?jms.redeliveryPolicy.maximumRedeliveries=1");
> AMQSourceConfig amqConfig = new
> AMQSourceConfig.AMQSourceConfigBuilder()
> .setConnectionFactory(connectionFactory)
> .setDestinationName("test")
> .setDestinationType(DestinationType.QUEUE)
> .setDeserializationSchema(new SimpleStringSchema())
> .build();
> AMQSource amqSource = new AMQSource<>(amqConfig);
> env.addSource(amqSource).print()
> env.setParallelism(1).execute("ActiveMQ Consumer");{code}
> Then point the Flink job at an empty ActiveMQ queue.
>
> Not sure if this is a bug, but it's not what I expected when I used the
> connector.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-200) change from docker tests to kudu-test-utils
[ https://issues.apache.org/jira/browse/BAHIR-200?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16848309#comment-16848309 ] ASF GitHub Bot commented on BAHIR-200: -- lresende commented on pull request #49: [BAHIR-200] change test from docker to kudu-test-utils URL: https://github.com/apache/bahir-flink/pull/49 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > change from docker tests to kudu-test-utils > --- > > Key: BAHIR-200 > URL: https://issues.apache.org/jira/browse/BAHIR-200 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > As of version 1.9.0, Kudu ships with an experimental feature called the > binary test JAR. This feature gives people who want to test against Kudu the > capability to start a Kudu "mini cluster" from Java or another JVM-based > language without having to first build Kudu locally > > https://kudu.apache.org/docs/developing.html#_jvm_based_integration_testing -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-205) add password support for flink sink of redis cluster
[ https://issues.apache.org/jira/browse/BAHIR-205?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16848220#comment-16848220 ] ASF GitHub Bot commented on BAHIR-205: -- liketic commented on pull request #57: [BAHIR-205] Support configure password for redis cluster URL: https://github.com/apache/bahir-flink/pull/57 Upgrade jedis to 2.9.0 and add password for redis cluster sink. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > add password support for flink sink of redis cluster > - > > Key: BAHIR-205 > URL: https://issues.apache.org/jira/browse/BAHIR-205 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Affects Versions: Not Applicable >Reporter: yanfeng >Priority: Major > Labels: features > Fix For: Not Applicable > > Original Estimate: 24h > Remaining Estimate: 24h > > redis cluster with password protect is not supported in > flink-connector-redis_2.11 version 1.1-SNAPSHOT, because the related jedis > 2.8.0 doesn't support the feature, so uprade jedis to 2.9.0 and some code > will fulfill it -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-183) Using HDFS for saving message for mqtt source
[ https://issues.apache.org/jira/browse/BAHIR-183?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16843911#comment-16843911 ] ASF GitHub Bot commented on BAHIR-183: -- Brahim13brahim commented on issue #84: [BAHIR-183] [WIP] HDFS based MQTT client persistence URL: https://github.com/apache/bahir/pull/84#issuecomment-493959752 yes This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Using HDFS for saving message for mqtt source > - > > Key: BAHIR-183 > URL: https://issues.apache.org/jira/browse/BAHIR-183 > Project: Bahir > Issue Type: Improvement > Components: Spark Structured Streaming Connectors >Affects Versions: Spark-2.2.0 >Reporter: Wang Yanlin >Assignee: Wang Yanlin >Priority: Major > Fix For: Spark-2.4.0 > > > Currently in spark-sql-streaming-mqtt, the received mqtt message is saved in > a local file by driver, this will have the risks of losing data for cluster > mode when application master failover occurs. So saving in-coming mqtt > messages using a director in checkpoint will solve this problem. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-200) change from docker tests to kudu-test-utils
[ https://issues.apache.org/jira/browse/BAHIR-200?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16843555#comment-16843555 ] ASF GitHub Bot commented on BAHIR-200: -- eskabetxe commented on issue #49: [BAHIR-200] change test from docker to kudu-test-utils URL: https://github.com/apache/bahir-flink/pull/49#issuecomment-493796109 @lresende its fixed.. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > change from docker tests to kudu-test-utils > --- > > Key: BAHIR-200 > URL: https://issues.apache.org/jira/browse/BAHIR-200 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > As of version 1.9.0, Kudu ships with an experimental feature called the > binary test JAR. This feature gives people who want to test against Kudu the > capability to start a Kudu "mini cluster" from Java or another JVM-based > language without having to first build Kudu locally > > https://kudu.apache.org/docs/developing.html#_jvm_based_integration_testing -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-200) change from docker tests to kudu-test-utils
[ https://issues.apache.org/jira/browse/BAHIR-200?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16843549#comment-16843549 ] ASF GitHub Bot commented on BAHIR-200: -- lresende commented on issue #49: [BAHIR-200] change test from docker to kudu-test-utils URL: https://github.com/apache/bahir-flink/pull/49#issuecomment-493792861 Suggestion for the future, once a different PR get's merged into master, update your master, rebase the pr branch to master, and push (--force). to the repo... this avoids increasing the number of commits showing in this PR and also makes the "changed files" exactly what is being added to the PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > change from docker tests to kudu-test-utils > --- > > Key: BAHIR-200 > URL: https://issues.apache.org/jira/browse/BAHIR-200 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > As of version 1.9.0, Kudu ships with an experimental feature called the > binary test JAR. This feature gives people who want to test against Kudu the > capability to start a Kudu "mini cluster" from Java or another JVM-based > language without having to first build Kudu locally > > https://kudu.apache.org/docs/developing.html#_jvm_based_integration_testing -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-206) bump flink to 1.8.0
[ https://issues.apache.org/jira/browse/BAHIR-206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16843547#comment-16843547 ] ASF GitHub Bot commented on BAHIR-206: -- asfgit commented on pull request #54: [BAHIR-206] bump flink version to 1.8.0 URL: https://github.com/apache/bahir-flink/pull/54 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink to 1.8.0 > --- > > Key: BAHIR-206 > URL: https://issues.apache.org/jira/browse/BAHIR-206 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > bump flink version to 1.8.0 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-206) bump flink to 1.8.0
[ https://issues.apache.org/jira/browse/BAHIR-206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16843469#comment-16843469 ] ASF GitHub Bot commented on BAHIR-206: -- eskabetxe commented on issue #54: [BAHIR-206] bump flink version to 1.8.0 URL: https://github.com/apache/bahir-flink/pull/54#issuecomment-493769386 @lresende its fixed upgrated flink version on travis file to This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink to 1.8.0 > --- > > Key: BAHIR-206 > URL: https://issues.apache.org/jira/browse/BAHIR-206 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > bump flink version to 1.8.0 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-190) ActiveMQ connector stops on empty queue
[
https://issues.apache.org/jira/browse/BAHIR-190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16843415#comment-16843415
]
ASF GitHub Bot commented on BAHIR-190:
--
lresende commented on issue #53: [BAHIR-190] [activemq] Fixed premature exit on
empty queue
URL: https://github.com/apache/bahir-flink/pull/53#issuecomment-493753758
@Krystex ^^^
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> ActiveMQ connector stops on empty queue
> ---
>
> Key: BAHIR-190
> URL: https://issues.apache.org/jira/browse/BAHIR-190
> Project: Bahir
> Issue Type: Bug
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: Stephan Brosinski
>Priority: Critical
> Fix For: Flink-Next
>
>
> I tried the ActiveMQ Flink Connector. Reading from an ActiveMQ queue, it
> seems to connector exits once there are no more messages in the queue. This
> ends the Flink job processing the stream.
> To me it seems, that the while loop inside the run method (AMQSource.java,
> line 222) should not do a return, but a continue if the message is no
> instance of ByteMessage, e.g. null.
> If I'm right, I can create a pull request showing the change.
> To reproduce:
>
> {code:java}
> ActiveMQConnectionFactory connectionFactory = new
> ActiveMQConnectionFactory("xxx", "xxx",
> "tcp://localhost:61616?jms.redeliveryPolicy.maximumRedeliveries=1");
> AMQSourceConfig amqConfig = new
> AMQSourceConfig.AMQSourceConfigBuilder()
> .setConnectionFactory(connectionFactory)
> .setDestinationName("test")
> .setDestinationType(DestinationType.QUEUE)
> .setDeserializationSchema(new SimpleStringSchema())
> .build();
> AMQSource amqSource = new AMQSource<>(amqConfig);
> env.addSource(amqSource).print()
> env.setParallelism(1).execute("ActiveMQ Consumer");{code}
> Then point the Flink job at an empty ActiveMQ queue.
>
> Not sure if this is a bug, but it's not what I expected when I used the
> connector.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-203) Pubsub manual acknowledgement
[
https://issues.apache.org/jira/browse/BAHIR-203?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842785#comment-16842785
]
ASF GitHub Bot commented on BAHIR-203:
--
lresende commented on pull request #85: [BAHIR-203] Manual acknowledge PubSub
messages
URL: https://github.com/apache/bahir/pull/85
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Pubsub manual acknowledgement
> --
>
> Key: BAHIR-203
> URL: https://issues.apache.org/jira/browse/BAHIR-203
> Project: Bahir
> Issue Type: Improvement
> Components: Spark Streaming Connectors
>Reporter: Danny Tachev
>Priority: Minor
> Fix For: Spark-2.3.0, Spark-2.4.0
>
>
> Hi,
> We have a use case where acknowledgement has to be sent at a later stage when
> streaming data from google pubsub. Any chance for the acknowledgement in
> PubsubReceiver to be made optional and ackId to be included in the
> SparkPubsubMessage model?
> Example:
> {code:java}
> store(receivedMessages
> .map(x => {
> val sm = new SparkPubsubMessage
> sm.message = x.getMessage
> sm.ackId = x.getAckId
> sm
> })
> .iterator)
> if ( ... ) {
> val ackRequest = new AcknowledgeRequest()
> ackRequest.setAckIds(receivedMessages.map(x => x.getAckId).asJava)
> client.projects().subscriptions().acknowledge(subscriptionFullName,
> ackRequest).execute()
> }{code}
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-202) Improve KuduSink throughput by using async FlushMode
[ https://issues.apache.org/jira/browse/BAHIR-202?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842648#comment-16842648 ] ASF GitHub Bot commented on BAHIR-202: -- asfgit commented on pull request #50: [BAHIR-202] Improve KuduSink throughput by using async FlushMode URL: https://github.com/apache/bahir-flink/pull/50 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Improve KuduSink throughput by using async FlushMode > > > Key: BAHIR-202 > URL: https://issues.apache.org/jira/browse/BAHIR-202 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Affects Versions: Flink-1.0 >Reporter: Suxing Lee >Priority: Major > Fix For: Flink-Next > > > Improve KuduSink throughput by using async FlushMode. > And using checkpoint to ensure at-least-once in async flush mode. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-177) Siddhi Library state recovery causes an Exception
[ https://issues.apache.org/jira/browse/BAHIR-177?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842628#comment-16842628 ] ASF GitHub Bot commented on BAHIR-177: -- asfgit commented on pull request #51: [BAHIR-177] Fixed state recovery for Flink and fixed size of the reco… URL: https://github.com/apache/bahir-flink/pull/51 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Siddhi Library state recovery causes an Exception > - > > Key: BAHIR-177 > URL: https://issues.apache.org/jira/browse/BAHIR-177 > Project: Bahir > Issue Type: Bug >Reporter: Dominik Wosiński >Assignee: Dominik Wosiński >Priority: Blocker > > Currently, Flink offers a way to store state and this is utilized for Siddhi > Library. The problem is that Siddhi internally bases on operators IDs that > are generated automatically when the _SiddhiAppRuntime_ is initialized. This > means that if the job is restarted and new operators IDs are assigned for > Siddhi, yet the Flink stores states with old ID's. > Siddhi uses an operator ID to get state from Map : > _snapshotable.restoreState(snapshots.get(snapshotable.getElementId()));_ > Siddhi does not make a null-check on the retrieved values, thus > _restoreState_ throws an NPE which is caught and > _CannotRestoreSiddhiAppStateException_ is thrown instead. Any flink job will > go into infinite loop of restarting after facing this issue. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-190) ActiveMQ connector stops on empty queue
[
https://issues.apache.org/jira/browse/BAHIR-190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842623#comment-16842623
]
ASF GitHub Bot commented on BAHIR-190:
--
lresende commented on issue #53: [BAHIR-190] [activemq] Fixed premature exit on
empty queue
URL: https://github.com/apache/bahir-flink/pull/53#issuecomment-493607417
Could you please provide your jira account so I can assign the jira to
yourself
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> ActiveMQ connector stops on empty queue
> ---
>
> Key: BAHIR-190
> URL: https://issues.apache.org/jira/browse/BAHIR-190
> Project: Bahir
> Issue Type: Bug
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: Stephan Brosinski
>Priority: Critical
>
> I tried the ActiveMQ Flink Connector. Reading from an ActiveMQ queue, it
> seems to connector exits once there are no more messages in the queue. This
> ends the Flink job processing the stream.
> To me it seems, that the while loop inside the run method (AMQSource.java,
> line 222) should not do a return, but a continue if the message is no
> instance of ByteMessage, e.g. null.
> If I'm right, I can create a pull request showing the change.
> To reproduce:
>
> {code:java}
> ActiveMQConnectionFactory connectionFactory = new
> ActiveMQConnectionFactory("xxx", "xxx",
> "tcp://localhost:61616?jms.redeliveryPolicy.maximumRedeliveries=1");
> AMQSourceConfig amqConfig = new
> AMQSourceConfig.AMQSourceConfigBuilder()
> .setConnectionFactory(connectionFactory)
> .setDestinationName("test")
> .setDestinationType(DestinationType.QUEUE)
> .setDeserializationSchema(new SimpleStringSchema())
> .build();
> AMQSource amqSource = new AMQSource<>(amqConfig);
> env.addSource(amqSource).print()
> env.setParallelism(1).execute("ActiveMQ Consumer");{code}
> Then point the Flink job at an empty ActiveMQ queue.
>
> Not sure if this is a bug, but it's not what I expected when I used the
> connector.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-190) ActiveMQ connector stops on empty queue
[
https://issues.apache.org/jira/browse/BAHIR-190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842622#comment-16842622
]
ASF GitHub Bot commented on BAHIR-190:
--
asfgit commented on pull request #53: [BAHIR-190] [activemq] Fixed premature
exit on empty queue
URL: https://github.com/apache/bahir-flink/pull/53
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> ActiveMQ connector stops on empty queue
> ---
>
> Key: BAHIR-190
> URL: https://issues.apache.org/jira/browse/BAHIR-190
> Project: Bahir
> Issue Type: Bug
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: Stephan Brosinski
>Priority: Critical
>
> I tried the ActiveMQ Flink Connector. Reading from an ActiveMQ queue, it
> seems to connector exits once there are no more messages in the queue. This
> ends the Flink job processing the stream.
> To me it seems, that the while loop inside the run method (AMQSource.java,
> line 222) should not do a return, but a continue if the message is no
> instance of ByteMessage, e.g. null.
> If I'm right, I can create a pull request showing the change.
> To reproduce:
>
> {code:java}
> ActiveMQConnectionFactory connectionFactory = new
> ActiveMQConnectionFactory("xxx", "xxx",
> "tcp://localhost:61616?jms.redeliveryPolicy.maximumRedeliveries=1");
> AMQSourceConfig amqConfig = new
> AMQSourceConfig.AMQSourceConfigBuilder()
> .setConnectionFactory(connectionFactory)
> .setDestinationName("test")
> .setDestinationType(DestinationType.QUEUE)
> .setDeserializationSchema(new SimpleStringSchema())
> .build();
> AMQSource amqSource = new AMQSource<>(amqConfig);
> env.addSource(amqSource).print()
> env.setParallelism(1).execute("ActiveMQ Consumer");{code}
> Then point the Flink job at an empty ActiveMQ queue.
>
> Not sure if this is a bug, but it's not what I expected when I used the
> connector.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-206) bump flink to 1.8.0
[
https://issues.apache.org/jira/browse/BAHIR-206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842618#comment-16842618
]
ASF GitHub Bot commented on BAHIR-206:
--
lresende commented on issue #54: [BAHIR-206] bump flink version to 1.8.0
URL: https://github.com/apache/bahir-flink/pull/54#issuecomment-493604796
Looks like I went too aggressive on approving the PR based on the Travis ci
build status. This PR needs to update Travis to see that Flink 1.8.0 will bring
some errors. Building it locally would also have exposed the error.
```
[INFO] Compiling 4 Java sources to
/Users/lresende/opensource/apache/bahir/bahir-flink/flink-connector-activemq/target/test-classes...
[ERROR] Picked up _JAVA_OPTIONS: -Dfile.encoding=UTF-8
[ERROR]
/Users/lresende/opensource/apache/bahir/bahir-flink/flink-connector-activemq/src/test/java/org/apache/flink/streaming/connectors/activemq/ActiveMQConnectorITCase.java:27:
error: cannot find symbol
[ERROR] import org.apache.flink.runtime.minicluster.LocalFlinkMiniCluster;
[ERROR]^
[ERROR] symbol: class LocalFlinkMiniCluster
[ERROR] location: package org.apache.flink.runtime.minicluster
[ERROR]
/Users/lresende/opensource/apache/bahir/bahir-flink/flink-connector-activemq/src/test/java/org/apache/flink/streaming/connectors/activemq/ActiveMQConnectorITCase.java:58:
error: cannot find symbol
[ERROR] private static LocalFlinkMiniCluster flink;
[ERROR]^
[ERROR] symbol: class LocalFlinkMiniCluster
[ERROR] location: class ActiveMQConnectorITCase
[ERROR]
/Users/lresende/opensource/apache/bahir/bahir-flink/flink-connector-activemq/src/test/java/org/apache/flink/streaming/connectors/activemq/ActiveMQConnectorITCase.java:70:
error: cannot find symbol
[ERROR] flink = new LocalFlinkMiniCluster(flinkConfig, false);
[ERROR] ^
[ERROR] symbol: class LocalFlinkMiniCluster
[ERROR] location: class ActiveMQConnectorITCase
[ERROR]
/Users/lresende/opensource/apache/bahir/bahir-flink/flink-connector-activemq/src/test/java/org/apache/flink/streaming/connectors/activemq/ActiveMQConnectorITCase.java:164:
warning: [rawtypes] found raw type: Context
[ERROR] public void invoke(String value, Context context)
throws Exception {
[ERROR] ^
[ERROR] missing type arguments for generic class Context
[ERROR] where T is a type-variable:
[ERROR] T extends Object declared in interface Context
[ERROR] 3 errors
[ERROR] 1 warning
[INFO]
[INFO] Reactor Summary for Apache Bahir for Apache Flink - Parent POM
1.1-SNAPSHOT:
[INFO]
[INFO] Apache Bahir for Apache Flink - Parent POM . SUCCESS [ 4.269
s]
[INFO] flink-connector-activemq ... FAILURE [ 5.445
s]
[INFO] flink-connector-akka ... SKIPPED
[INFO] flink-connector-flume .. SKIPPED
[INFO] flink-connector-influxdb ... SKIPPED
[INFO] flink-connector-kudu ... SKIPPED
[INFO] flink-connector-netty .. SKIPPED
[INFO] flink-connector-redis .. SKIPPED
[INFO] flink-library-siddhi ... SKIPPED
[INFO]
[INFO] BUILD FAILURE
[INFO]
[INFO] Total time: 10.946 s
[INFO] Finished at: 2019-05-17T23:21:50+02:00
[INFO]
[ERROR] Failed to execute goal
net.alchim31.maven:scala-maven-plugin:3.4.6:testCompile
(scala-test-compile-first) on project flink-connector-activemq_2.11: Execution
scala-test-compile-first of goal
net.alchim31.maven:scala-maven-plugin:3.4.6:testCompile failed.: CompileFailed
-> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e
switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please
read the following articles:
[ERROR] [Help 1]
http://cwiki.apache.org/confluence/display/MAVEN/PluginExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the
command
[ERROR] mvn -rf :flink-connector-activemq_2.11
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For
[jira] [Commented] (BAHIR-206) bump flink to 1.8.0
[ https://issues.apache.org/jira/browse/BAHIR-206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16842576#comment-16842576 ] ASF GitHub Bot commented on BAHIR-206: -- asfgit commented on pull request #54: [BAHIR-206] bump flink version to 1.8.0 URL: https://github.com/apache/bahir-flink/pull/54 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > bump flink to 1.8.0 > --- > > Key: BAHIR-206 > URL: https://issues.apache.org/jira/browse/BAHIR-206 > Project: Bahir > Issue Type: Improvement > Components: Flink Streaming Connectors >Reporter: Joao Boto >Assignee: Joao Boto >Priority: Major > > bump flink version to 1.8.0 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BAHIR-190) ActiveMQ connector stops on empty queue
[
https://issues.apache.org/jira/browse/BAHIR-190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16836306#comment-16836306
]
ASF GitHub Bot commented on BAHIR-190:
--
Krystex commented on pull request #53: [BAHIR-190] [activemq] Fixed premature
exit on empty queue
URL: https://github.com/apache/bahir-flink/pull/53
**Fixes**: When the source queue has no more messages, the job doesn't exit
anymore. This was a problem with ActiveMQ.
Note: The [original JIRA
issue](https://issues.apache.org/jira/browse/BAHIR-190) wasn't created by me.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> ActiveMQ connector stops on empty queue
> ---
>
> Key: BAHIR-190
> URL: https://issues.apache.org/jira/browse/BAHIR-190
> Project: Bahir
> Issue Type: Bug
> Components: Flink Streaming Connectors
>Affects Versions: Flink-1.0
>Reporter: Stephan Brosinski
>Priority: Critical
>
> I tried the ActiveMQ Flink Connector. Reading from an ActiveMQ queue, it
> seems to connector exits once there are no more messages in the queue. This
> ends the Flink job processing the stream.
> To me it seems, that the while loop inside the run method (AMQSource.java,
> line 222) should not do a return, but a continue if the message is no
> instance of ByteMessage, e.g. null.
> If I'm right, I can create a pull request showing the change.
> To reproduce:
>
> {code:java}
> ActiveMQConnectionFactory connectionFactory = new
> ActiveMQConnectionFactory("xxx", "xxx",
> "tcp://localhost:61616?jms.redeliveryPolicy.maximumRedeliveries=1");
> AMQSourceConfig amqConfig = new
> AMQSourceConfig.AMQSourceConfigBuilder()
> .setConnectionFactory(connectionFactory)
> .setDestinationName("test")
> .setDestinationType(DestinationType.QUEUE)
> .setDeserializationSchema(new SimpleStringSchema())
> .build();
> AMQSource amqSource = new AMQSource<>(amqConfig);
> env.addSource(amqSource).print()
> env.setParallelism(1).execute("ActiveMQ Consumer");{code}
> Then point the Flink job at an empty ActiveMQ queue.
>
> Not sure if this is a bug, but it's not what I expected when I used the
> connector.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-204) AMQSource is not at-least-once
[
https://issues.apache.org/jira/browse/BAHIR-204?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16817379#comment-16817379
]
ASF GitHub Bot commented on BAHIR-204:
--
rmetzger commented on pull request #52: [BAHIR-204] [activemq] ActiveMQ Source
only emits previously unproce…
URL: https://github.com/apache/bahir-flink/pull/52
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> AMQSource is not at-least-once
> --
>
> Key: BAHIR-204
> URL: https://issues.apache.org/jira/browse/BAHIR-204
> Project: Bahir
> Issue Type: Bug
>Reporter: Konstantin Knauf
>Priority: Major
>
> The {{AMQSource}} should only emit records, for which addIds(..) returned
> "true" in order to play along in checkpointing.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BAHIR-204) AMQSource is not at-least-once
[
https://issues.apache.org/jira/browse/BAHIR-204?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16817381#comment-16817381
]
ASF GitHub Bot commented on BAHIR-204:
--
rmetzger commented on issue #52: [BAHIR-204] [activemq] ActiveMQ Source only
emits previously unproce…
URL: https://github.com/apache/bahir-flink/pull/52#issuecomment-483036390
Thank you!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> AMQSource is not at-least-once
> --
>
> Key: BAHIR-204
> URL: https://issues.apache.org/jira/browse/BAHIR-204
> Project: Bahir
> Issue Type: Bug
>Reporter: Konstantin Knauf
>Priority: Major
>
> The {{AMQSource}} should only emit records, for which addIds(..) returned
> "true" in order to play along in checkpointing.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)