[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=416307=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-416307
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 06/Apr/20 01:30
Start Date: 06/Apr/20 01:30
Worklog Time Spent: 10m
Work Description: lukecwik commented on pull request #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#discussion_r403789265
##
File path:
runners/spark/src/main/java/org/apache/beam/runners/spark/translation/TransformTranslator.java
##
@@ -695,8 +695,10 @@ public void evaluate(Reshuffle transform,
EvaluationContext context) {
final WindowedValue.WindowedValueCoder> wvCoder =
WindowedValue.FullWindowedValueCoder.of(coder,
windowFn.windowCoder());
+int numPartitions =
+Math.max(context.getSparkContext().defaultParallelism(),
inRDD.getNumPartitions());
Review comment:
I believe we should do the same thing in the streaming and batch portable
pipeline translators as well.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 416307)
Time Spent: 3h 20m (was: 3h 10m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 3h 20m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=416306=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-416306
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 06/Apr/20 01:29
Start Date: 06/Apr/20 01:29
Worklog Time Spent: 10m
Work Description: lukecwik commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-609522569
Thanks for the follow-up. I also have been adjusting to the new WFH
lifestyle.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 416306)
Time Spent: 3h 10m (was: 3h)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 3h 10m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=416288=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-416288
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 05/Apr/20 23:43
Start Date: 05/Apr/20 23:43
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-609504865
> Sorry about the long delay
My time to apology @lukecwik. I was busy on something else as well as trying
to settling in this new life of working from home due to the virus
> It looks like the spark translation is copying the number of partitions
from the upstream transform for the reshuffle translation and in your case this
is likely 1
Gotcha. And yes, I can confirm that the value for the partitions is 1, not
only in my case. Fact of the matter, the number of partitions is calculated (in
a bizarre way) only for the root RDD (Create), containing only the pattern for
the s3 files -- a string like `s3://my-bucket-name/*.avro`. From that moment
onwards it is copied all the way through. So with one pattern is always one.
This confirms my initial impression when I wrote:
> The impression I have is that when the physical plan is created, there is
only one task detected that is bound to do the entire reading on one executor
I have changed the PR, reverting the original one and now - after your
analysis - I am setting the number of the partitions in the reshuffle transform
translator.
I am using the value of the default parallelism for Spark, already available
in the Spark configuration options for Beam.
So essentially with this PR the Spark configuration:
`--conf spark.default.parallelism=10` is the replacement for the hint I
wrote initially.
I have tested this PR with the same configuration as the initial one, and
the performance is identical. I can now see all the executors and nodes
processing a partition of the read, as one expects. I also did a back-to-back
run with the vanilla Beam and I can confirm the problem is still there.
I deem this implementation is superior to the first one. Let me have your
opinions on it. Also paging in @iemejia
I have seen the previous build failing, I think the failing tests were
unrelated to the changes; keen to see a new build with these code changes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 416288)
Time Spent: 3h (was: 2h 50m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 3h
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=410790=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-410790
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 27/Mar/20 02:40
Start Date: 27/Mar/20 02:40
Worklog Time Spent: 10m
Work Description: lukecwik commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-604785112
Sorry about the long delay but **Reshuffle** should produce as many
partitions as the runner thinks is optimal. It is effectively a
**redistribute** operation.
It looks like the spark translation is copying the number of partitions from
the upstream transform for the reshuffle translation and in your case this is
likely 1.
Translation:
https://github.com/apache/beam/blob/f5a4a5afcd9425c0ddb9ec9c70067a5d5c0bc769/runners/spark/src/main/java/org/apache/beam/runners/spark/translation/TransformTranslator.java#L681
Copying partitions:
https://github.com/apache/beam/blob/f5a4a5afcd9425c0ddb9ec9c70067a5d5c0bc769/runners/spark/src/main/java/org/apache/beam/runners/spark/translation/GroupCombineFunctions.java#L191
@iemejia Shouldn't we be using a much larger value for partitions, e.g. the
number of nodes?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 410790)
Time Spent: 2h 50m (was: 2h 40m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 2h 50m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=401417=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-401417
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 11/Mar/20 13:09
Start Date: 11/Mar/20 13:09
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-597622075
Any thoughts on the above @lukecwik @iemejia ? I did not hear back from you
in a couple of days.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 401417)
Time Spent: 2h 40m (was: 2.5h)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 2h 40m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=400436=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-400436
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 09/Mar/20 23:10
Start Date: 09/Mar/20 23:10
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596822153
Unfortunately the problem happens for me, that is why this work started.
Let's see if we can understand the root cause for it.
> Reshuffle should ensure that there is a repartition between MatchAll and
ReadMatches, is it missing (it is difficult to tell from your screenshots)? If
it isn't missing, they why is the following stage only executing on a single
machine (since repartition shouldn't be restricting output to only a single
machine)
It's clearly not missing as in the base case I'm using
withHintMatchesManyFiles().
Still what happens is that the entire reading is on one machine (see second
last screenshot "summary metrics for 2 completed tasks"). The impression I have
is that when the physical plan is created, there is only one task detected that
is bound to do the entire reading on one executor. Consider that, I am doing
something really plain, just reading from two buckets, joining the records and
writing them back to S3. Did you try this yourself to see if you can reproduce
the issue?
I had a look at the code of Reshuffle.expand() and Reshuffle.ViaRandomKey,
but I have some doubts on what is the expected behaviour in terms of machines /
partitions.
How many different partitions shall Reshuffle create? Will there be 1 task
per partition? and how are the tasks ultimately assigned to the executors?
Maybe you can help me understand the above / point me to the relevant
documentation. That should hopefully help me troubleshoot this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 400436)
Time Spent: 2.5h (was: 2h 20m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 2.5h
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=400245=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-400245
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 09/Mar/20 17:30
Start Date: 09/Mar/20 17:30
Worklog Time Spent: 10m
Work Description: lukecwik commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596669808
I understand what your saying and how your solution resolves the problem.
I'm trying to say that the problem shouldn't occur in the first place
because
[AvroIO.read](https://github.com/apache/beam/blob/a4ab76881d843a17906d866f0d6225def82ea6d0/sdks/java/core/src/main/java/org/apache/beam/sdk/io/AvroIO.java#L1030)
should expand to
[MatchAll](https://github.com/apache/beam/blob/060d0874e0c831a71ca6b240c66c04d367c8793d/sdks/java/core/src/main/java/org/apache/beam/sdk/io/FileIO.java#L622)
that contains a
[Reshuffle](https://github.com/apache/beam/blob/060d0874e0c831a71ca6b240c66c04d367c8793d/sdks/java/core/src/main/java/org/apache/beam/sdk/io/FileIO.java#L641)
followed by
[ReadMatches](https://github.com/apache/beam/blob/060d0874e0c831a71ca6b240c66c04d367c8793d/sdks/java/core/src/main/java/org/apache/beam/sdk/io/FileIO.java#L690)
Reshuffle should ensure that there is a repartition between MatchAll and
ReadMatches, is it missing (it is difficult to tell from your screenshots)? If
it isn't missing, they why is the following stage only executing on a single
machine (since repartition shouldn't be restricting output to only a single
machine)?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 400245)
Time Spent: 2h 20m (was: 2h 10m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 2h 20m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=400244=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-400244
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 09/Mar/20 17:29
Start Date: 09/Mar/20 17:29
Worklog Time Spent: 10m
Work Description: lukecwik commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596669808
I understand what your saying and how your solution resolves the problem.
I'm trying to say that the problem shouldn't occur in the first place
because
[AvroIO.read](https://github.com/apache/beam/blob/a4ab76881d843a17906d866f0d6225def82ea6d0/sdks/java/core/src/main/java/org/apache/beam/sdk/io/AvroIO.java#L1030)
should expand to
[MatchAll](https://github.com/apache/beam/blob/060d0874e0c831a71ca6b240c66c04d367c8793d/sdks/java/core/src/main/java/org/apache/beam/sdk/io/FileIO.java#L622)
that contains a
[Reshuffle](https://github.com/apache/beam/blob/060d0874e0c831a71ca6b240c66c04d367c8793d/sdks/java/core/src/main/java/org/apache/beam/sdk/io/FileIO.java#L641)
followed by
[ReadMatches](https://github.com/apache/beam/blob/060d0874e0c831a71ca6b240c66c04d367c8793d/sdks/java/core/src/main/java/org/apache/beam/sdk/io/FileIO.java#L690)
Reshuffle should ensure that there is either a repartition between MatchAll
and ReadMatches, is it missing? If it isn't missing, they why is the following
stage only executing on a single machine?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 400244)
Time Spent: 2h 10m (was: 2h)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399765=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399765
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 07/Mar/20 22:10
Start Date: 07/Mar/20 22:10
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596045046
> The expansion for withHintManyFiles uses a reshuffle between the match and
the actual reading of the file. The reshuffle allows for the runner to balance
the amount of work across as many nodes as it wants. The only thing being
reshuffled is file metadata so after that reshuffle the file reading should be
distributed to several nodes.
>
> In your reference run, when you say that "the entire reading taking place
in a single task/node", was it that the match all happened on a single node or
was it that the "read" happened all on a single node?
Both.
Reading the metadata wouldn't be a problem, it also happens on every node in
the proposed PR.
But the actual reading also happens on one node with unacceptably high
reading times.
Maybe what you say applies possibly to the case of "bulky" files.
However, my solution particularly applies to the case where there is a high
number of tiny files (I think I explained better in the Jira ticket).
In this latter case, the latency of reading each file from S3 dominates, but
no chunking / shuffling happens with the standard Beam.
When I look at the DAG in Spark, I can see only one task there, and if I
look at the executors they are all idle, spare the one where all the readings
happen.
This is true for both the stage where you read the metadata, and for the
stage where you read the data.
With the proposed PR instead the number of tasks and parallel executors in
the DAG is the one that you pass in the hint.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399765)
Time Spent: 2h (was: 1h 50m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 2h
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399637=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399637
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 07/Mar/20 10:36
Start Date: 07/Mar/20 10:36
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596073078
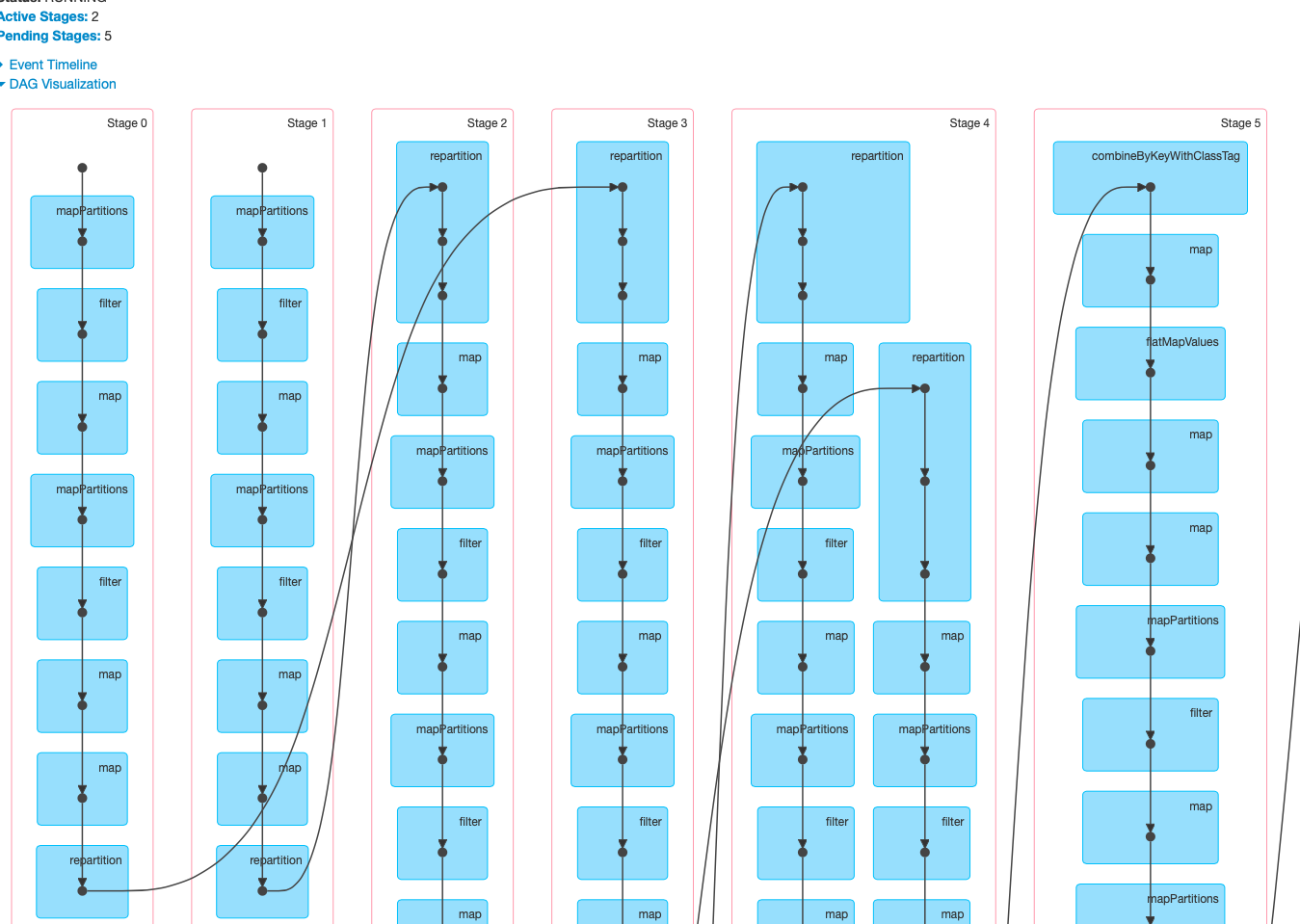
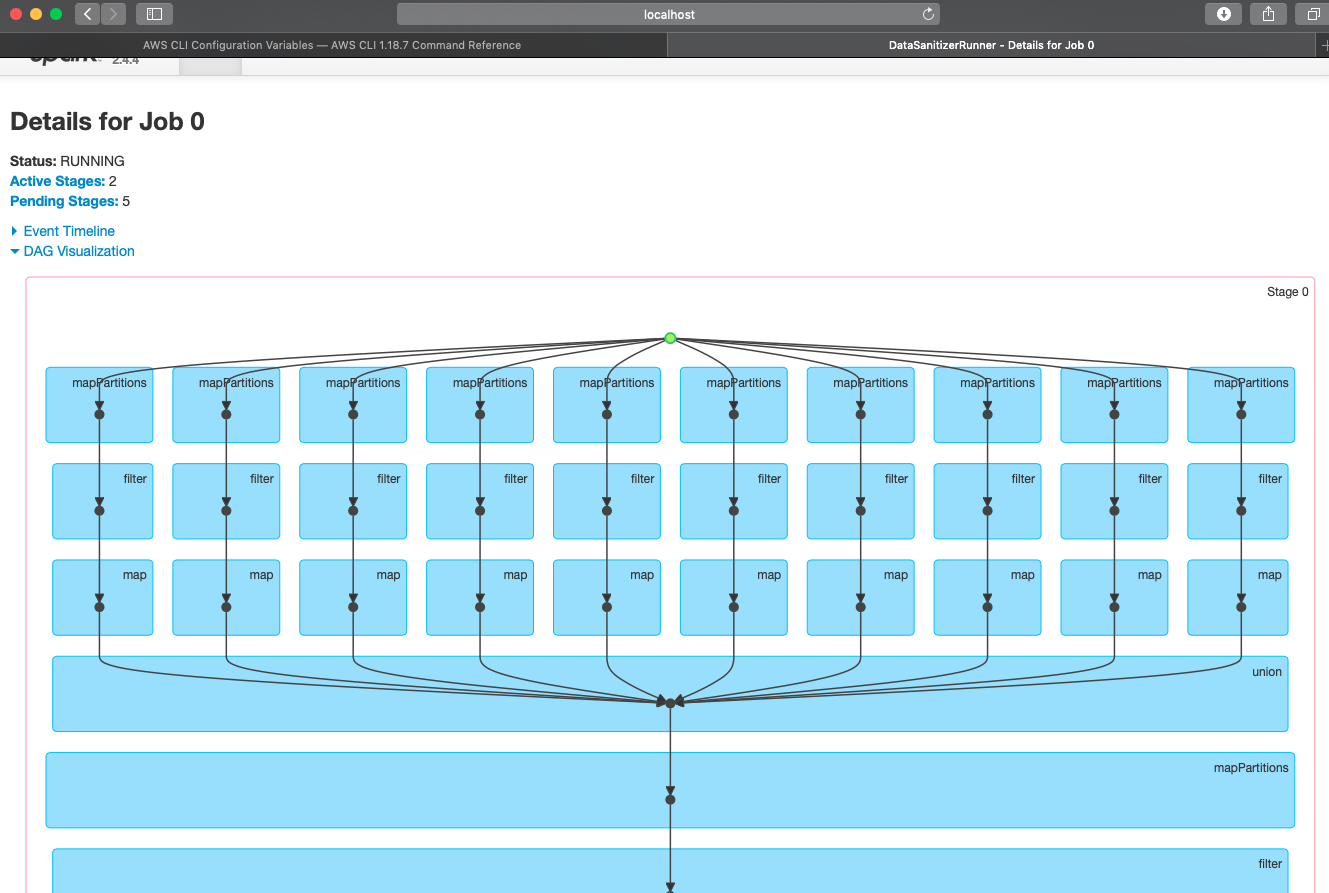
This is the fundamental difference between the base and the current PR.
Notice, in the base case there's only 2 tasks (the entire job is a join of two
independent readings) whereas when using 10 partitions there are 20 tasks for
doing the same work (the image is a detail of one of the two independent
readings, showing its 10 parallel partitions).
This is reflected in the executors being used and in the time to complete
(16 minutes with 2 tasks, 2.3 minutes with 20).
See below the comparison of execution data.
https://user-images.githubusercontent.com/8372724/76141746-24931500-605f-11ea-8c98-7b99587ae2a4.png;>
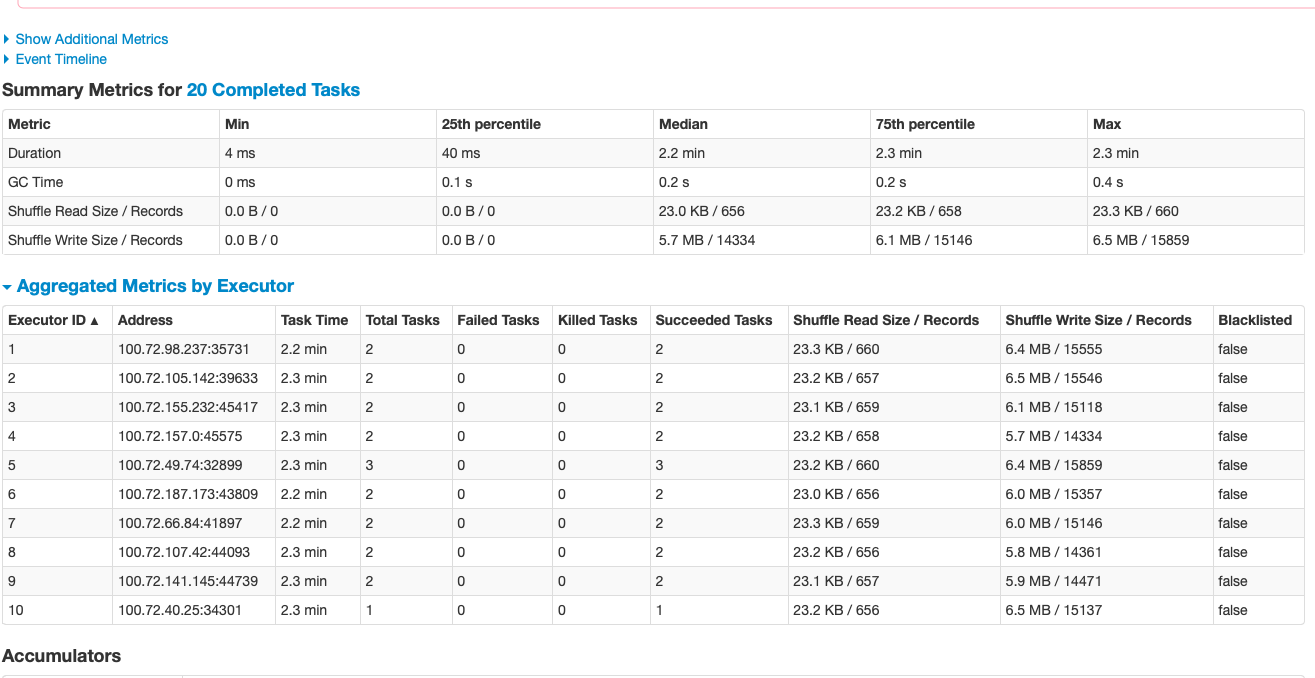
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399637)
Time Spent: 1h 50m (was: 1h 40m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399636=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399636
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 07/Mar/20 10:34
Start Date: 07/Mar/20 10:34
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596073078


This is the fundamental difference between the base and the current PR.
Notice, in the base case there's only 2 tasks (the entire job is a join of two
independent readings) whereas when using 10 partitions there are 20 tasks for
doing the same work.
This is reflected in the executors being used and in the time to complete
(16 minutes with 2 tasks, 2.3 minutes with 20).
See below the comparison of execution data.
https://user-images.githubusercontent.com/8372724/76141746-24931500-605f-11ea-8c98-7b99587ae2a4.png;>

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399636)
Time Spent: 1h 40m (was: 1.5h)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 1h 40m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399628=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399628
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 07/Mar/20 09:31
Start Date: 07/Mar/20 09:31
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596045046
> The expansion for withHintManyFiles uses a reshuffle between the match and
the actual reading of the file. The reshuffle allows for the runner to balance
the amount of work across as many nodes as it wants. The only thing being
reshuffled is file metadata so after that reshuffle the file reading should be
distributed to several nodes.
>
> In your reference run, when you say that "the entire reading taking place
in a single task/node", was it that the match all happened on a single node or
was it that the "read" happened all on a single node?
Both.
Reading the metadata wouldn't be a problem, it also happens on every node in
the proposed PR.
But the actual reading also happens on one node with unacceptably high
reading times.
Maybe what you say applies possibly to the case of "bulky" files.
However, my solution particularly applies to the case where there is a high
number of tiny files (I think I explained better in the Jira ticket).
In this latter case, the latency of reading each file from S3 dominates, but
no chunking / shuffling happens with the standard Beam.
When I look at the DAG in Spark, I can see only one task there, and if I
look at the executors they are all idle spare the one when all the reading
happens.
This is true for both the stage where you read the metadata, and the stage
where you read the data.
With the proposed PR instead the number of tasks and parallel executors in
the DAG is the one that you pass in the hint.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399628)
Time Spent: 1.5h (was: 1h 20m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 1.5h
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399535=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399535
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 07/Mar/20 04:24
Start Date: 07/Mar/20 04:24
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596045046
> The expansion for withHintManyFiles uses a reshuffle between the match and
the actual reading of the file. The reshuffle allows for the runner to balance
the amount of work across as many nodes as it wants. The only thing being
reshuffled is file metadata so after that reshuffle the file reading should be
distributed to several nodes.
>
> In your reference run, when you say that "the entire reading taking place
in a single task/node", was it that the match all happened on a single node or
was it that the "read" happened all on a single node?
Both.
Reading the metadata wouldn't be a problem, it also happens on every node in
the proposed PR.
But the actual reading also happens on one node with unacceptably high
reading times.
What you say applies to the case of "bulky" files. For those, the shuffling
stage chunks the files and shuffle reading of each chunk.
However, my solution particularly applies to the case where there is a high
number of tiny files (I think I explained better in the Jira ticket).
In this latter case, the latency of reading each file from S3 dominates, but
no chunking / shuffling happens with the standard Beam.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399535)
Time Spent: 1h 20m (was: 1h 10m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 1h 20m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399332=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399332
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 06/Mar/20 19:49
Start Date: 06/Mar/20 19:49
Worklog Time Spent: 10m
Work Description: lukecwik commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-595935705
Adding a filesystem API that all filesystems need to implement is going to
raise some questions in the Apache Beam community. Asked some follow-ups on
BEAM-9434 to see if the issue is localized to Spark.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399332)
Time Spent: 50m (was: 40m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 50m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399383=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399383
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 06/Mar/20 21:59
Start Date: 06/Mar/20 21:59
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-595982928
> Adding a filesystem API that all filesystems need to implement is going to
raise some questions in the Apache Beam community. Asked some follow-ups on
BEAM-9434 to see if the issue is localized to Spark.
@lukecwik Ok I see.
Technically speaking, it is not *mandatory* to implement in every
filesystem, but effectively in order to properly support the hint in every
filesystem it is.
I considered a few alternatives:
- the current one, throwing an UnsupportedOperationException if a filesystem
does not support it
- a default implementation that does a wasteful filtering before returning
the results (not scalable)
- implementing it for all filesystem
The reality is, I haven't got a mean of testing the last option on anything
else than S3, otherwise the last option is the best approach imho.
Let me know what are the opinions.
Also, looks like to me that the filesystems classes are internal to the
framework, not supposed to be used directly by end users. In which case *maybe*
another option is viable, which is renaming appropriately the new hint, and
don't make it mandatory by means of the framework to consider the hint.
In other words, I'm saying that we can hint to use N partitions, but the
runtime can just ignore the hint if that's not supported by the underlying
filesystem.
I can modify the code in this way if that's viable.
Happy to hear back from you guys, and thanks for the feedback.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399383)
Time Spent: 1h (was: 50m)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 1h
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399410=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399410
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 06/Mar/20 22:44
Start Date: 06/Mar/20 22:44
Worklog Time Spent: 10m
Work Description: lukecwik commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-595996288
The expansion for withHintManyFiles uses a reshuffle between the match and
the actual reading of the file. The reshuffle allows for the runner to balance
the amount of work across as many nodes as it wants. The only thing being
reshuffled is file metadata so after that reshuffle the file reading should be
distributed to several nodes.
In your reference run, when you say that "the entire reading taking place in
a single task/node", was it that the match all happened on a single node or was
it that the "read" happened all on a single node?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 399410)
Time Spent: 1h 10m (was: 1h)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Work logged] (BEAM-9434) Performance improvements processing a large number of Avro files in S3+Spark
[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=398717=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-398717
]
ASF GitHub Bot logged work on BEAM-9434:
Author: ASF GitHub Bot
Created on: 05/Mar/20 21:44
Start Date: 05/Mar/20 21:44
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-595462888
R: @lukecwik do you mind having a look and giving me feedback on this PR?
Thanks I look forward to hearing from you
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 398717)
Time Spent: 40m (was: 0.5h)
> Performance improvements processing a large number of Avro files in S3+Spark
>
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
>Affects Versions: 2.19.0
>Reporter: Emiliano Capoccia
>Assignee: Emiliano Capoccia
>Priority: Minor
> Time Spent: 40m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)