[GitHub] carbondata issue #2575: [WIP] fixed for ModularPlan exception during update ...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2575 fixed in #2579 ---
[GitHub] carbondata pull request #2575: [WIP] fixed for ModularPlan exception during ...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2575 ---
[GitHub] carbondata issue #2575: [WIP] fixed for ModularPlan exception during update ...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2575 retest this please ---
[GitHub] carbondata issue #2575: [WIP] fixed for ModularPlan exception during update ...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2575 retest this please ---
[GitHub] carbondata pull request #2575: [WIP] fixed for ModularPlan exception during ...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2575#discussion_r205969751
--- Diff:
datamap/mv/core/src/main/scala/org/apache/carbondata/mv/datamap/MVAnalyzerRule.scala
---
@@ -80,7 +80,7 @@ class MVAnalyzerRule(sparkSession: SparkSession) extends
Rule[LogicalPlan] {
}
def isValidPlan(plan: LogicalPlan, catalog: SummaryDatasetCatalog):
Boolean = {
-!plan.isInstanceOf[Command] && !isDataMapExists(plan,
catalog.listAllSchema()) &&
+!plan.isInstanceOf[Command] && isDataMapExists(plan,
catalog.listAllSchema()) &&
--- End diff --
simply i have created a table in spark-2.2 cluster and after load ,
updating the record it goes to rewrite the plan. even no datamap created on the
same table.
---
[GitHub] carbondata pull request #2575: [WIP] fixed for ModularPlan exception during ...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2575 [WIP] fixed for ModularPlan exception during update query update query is failing in spark-2.2 cluster if mv jars are available because catalogs are not empty if datamap are created for other table also and returns true from isValidPlan() inside MVAnalyzerRule. - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata mv_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2575.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2575 commit 043898b523ed26a4de04b18af257223a0a918d6b Author: rahul Date: 2018-07-28T10:55:07Z fixed for ModularPlan exception during update query ---
[GitHub] carbondata issue #2441: [CARBONDATA-2625] optimize CarbonReader performance
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2441 retest this please ---
[GitHub] carbondata issue #2441: [CARBONDATA-2625] optimize CarbonReader performance
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2441 retest this please ---
[GitHub] carbondata issue #2513: [CARBONDATA-2748] blocking concurrent load if any co...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2513 retest sdv please ---
[GitHub] carbondata pull request #2518: [WIP] fixing testcase for if HiveMetastore is...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2518 [WIP] fixing testcase for if HiveMetastore is enabled Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata hivemetastore_test Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2518.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2518 commit 9129092ca883e30a92a7450edd98bbd5f637897c Author: rahul Date: 2018-07-17T13:49:27Z fixing testcase for if HiveMetastore is enabled ---
[GitHub] carbondata pull request #2513: [WIP] blocking concurrent load if any column ...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2513 [WIP] blocking concurrent load if any column included as dictionary Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata concur_load Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2513.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2513 commit bf294519ea67f5c9b4ae89a5ee5188ea6f9662c3 Author: rahul Date: 2018-07-16T17:40:22Z [WIP] blocking concurrent load if any column included as dictionary ---
[GitHub] carbondata pull request #2434: [CARBONDATA-2625] Optimize the performance of...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2434 ---
[GitHub] carbondata issue #2441: [WIP] optimize CarbonReader performance
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2441 retest this please ---
[GitHub] carbondata issue #2441: [WIP] optimize CarbonReader performance
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2441 retest sdv please ---
[GitHub] carbondata issue #2441: [WIP] optimize CarbonReader performance
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2441 retest this please ---
[GitHub] carbondata pull request #2441: [WIP] optimize CarbonReader performance
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2441 [WIP] optimize CarbonReader performance Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata carbon_performance Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2441.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2441 commit 224f48e1e922e7f92425892a96c2fea1e87eb78a Author: rahul Date: 2018-07-03T15:49:57Z [WIP] optimize CarbonReader performance ---
[GitHub] carbondata pull request #2434: [CARBONDATA-2625] Optimize the performance of...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2434 [CARBONDATA-2625] Optimize the performance of CarbonReader read many files REf : https://github.com/apache/carbondata/pull/2391 About the issue: it's timeout and no result in 8 minutes when read more than 10 million data with 140 files, Even though increase 20 rows for each carbon Writer and it can reduce the index files and data files when the number of rows is 1300, but when there are more than 1 billion or more, the number of files still still many. I check the code and find read more 140 files can be optimize: In the cache.getAll, the IO is more than 140 if there are 140 carbon files, in fact, the IO are more than 70 * 140 times, it's slow and can be optimized Secondly, there are some duplicate operate in getDataMaps and can be optimized Thirdly, SDK need much time to create multiple carbonRecorderReader, it need more than 8 minutes by testing 150 files and 15million rows data when create more than 16 carbonReorederReader if the machine has 8 cores . It can be optimized By optimizing the three points,including cache.getAll, getDatamaps and create carbonRecordReader, now SDK can work for reading 150 files and 15million rows data in 8 minutes, it need about 340 seconds by testing. One case: 150 files , each file has 20 rows, total rows is 1500 Finished write data time: 449.102 s Finished build reader time:192.596 s Read first row time: 192.597 s, including build reader Read time:341.556 s, including build reader Another case: 15 files , each file has 200 rows, total rows is 1500 Finished write data time: 286.907 s Finished build reader time: 134.665 s Read first row time: 134.666 s, including build reader Finished read, the count of rows is:1500 Read time:156.427 s, including build reader Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: Any interfaces changed? Yes, add new one for optimizing performance Any backward compatibility impacted? NA Document update required? NO Testing done add example for it For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NO You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata xuboPRsynch2391 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2434.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2434 commit 28a0b0f40c45967e586d7a5e703dce3cfaa48c99 Author: xubo245 <601450868@...> Date: 2018-06-21T04:25:27Z [CARBONDATA-2625] Optimize the performance of CarbonReader read many files optimize the build process, including cache.getAll, getDatamaps and create carbonRecordReader fix CI error add config to change the carbonreader thread number for SDKDetailQueryExecutor optimize optimize try to fix sdv error optimize optimize fix fix again optimize commit 9d1c825768cce1ca7e5d0f0aa9eb354ef166e2c9 Author: xubo245 Date: 2018-06-30T02:40:45Z optimize commit 69210f8ac7e64ed8a5c6a0c0a586e0cf8fc95812 Author: xubo245 Date: 2018-06-30T02:53:31Z remove unused import commit ac3f70c081171eaab0163f6b89901117759d9fdf Author: xubo245 Date: 2018-06-30T08:33:52Z optimize commit 9306daea8be158a6cdfed2387fd94100ceca13ca Author: rahul Date: 2018-07-02T05:37:51Z removed unnecessary properties ---
[GitHub] carbondata issue #2398: [CARBONDATA-2627] removed the dependency of tech.all...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2398 done ---
[GitHub] carbondata pull request #2398: [CARBONDATA-2627] removed the dependency of t...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2398#discussion_r197852117
--- Diff:
store/sdk/src/test/java/org/apache/carbondata/sdk/file/TestUtil.java ---
@@ -17,20 +17,58 @@
package org.apache.carbondata.sdk.file;
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.DataInputStream;
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;
+import java.io.InputStream;
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.constants.CarbonCommonConstants;
import org.apache.carbondata.core.datastore.impl.FileFactory;
import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.core.util.path.CarbonTablePath;
+import org.apache.avro.file.DataFileWriter;
+import org.apache.avro.generic.GenericData;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.JsonDecoder;
import org.junit.Assert;
public class TestUtil {
+ public static GenericData.Record jsonToAvro(String json, String
avroSchema) throws IOException {
+InputStream input = null;
+DataFileWriter writer = null;
+Encoder encoder = null;
+ByteArrayOutputStream output = null;
+try {
--- End diff --
test-cases are from two different packages , so we should write the util
class separately.
---
[GitHub] carbondata pull request #2398: [CARBONDATA-2627] removed the dependency of t...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2398#discussion_r197852069
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/createTable/TestNonTransactionalCarbonTable.scala
---
@@ -2301,3 +2292,29 @@ class TestNonTransactionalCarbonTable extends
QueryTest with BeforeAndAfterAll {
checkAnswer(sql("select * from sdkOutputTable"),
Seq(Row(Timestamp.valueOf("1970-01-02 16:00:00"),
Row(Timestamp.valueOf("1970-01-02 16:00:00")
}
}
+
+
+object avroUtil{
+
+ def jsonToAvro(json: String, avroSchema: String): GenericRecord = {
+var input: InputStream = null
+var writer: DataFileWriter[GenericRecord] = null
+var encoder: Encoder = null
+var output: ByteArrayOutputStream = null
+try {
+ val schema = new org.apache.avro.Schema.Parser().parse(avroSchema)
+ val reader = new GenericDatumReader[GenericRecord](schema)
+ input = new ByteArrayInputStream(json.getBytes())
--- End diff --
test-cases are from two different packages , so we should write the util
class separately.
---
[GitHub] carbondata pull request #2398: [CARBONDATA-2627] removed the dependency of t...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2398#discussion_r197826528
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/createTable/TestNonTransactionalCarbonTable.scala
---
@@ -1460,8 +1459,13 @@ class TestNonTransactionalCarbonTable extends
QueryTest with BeforeAndAfterAll {
}
test("Read sdk writer Avro output Array Type with Default value") {
-buildAvroTestDataSingleFileArrayDefaultType()
-assert(new File(writerPath).exists())
+// avro1.8.x Parser donot handles default value , this willbe fixed in
1.9.x. So for now this
+// will throw exception. After upgradation of Avro we can change this
test case.
--- End diff --
community knows this issue , they said this will be fixed in 2.x version
---
[GitHub] carbondata pull request #2398: [CARBONDATA-2627] removed the dependency of t...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2398 [CARBONDATA-2627] removed the dependency of tech.allegro.schema.json2avro Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata jsonconverter Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2398.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2398 commit b44ba0474d715d35f73e2553d49c1d5220a7c8a5 Author: rahul Date: 2018-06-22T06:35:32Z [CARBONDATA-2627] removed the dependency of tech.allegro.schema.json2avro ---
[GitHub] carbondata pull request #2392: [HOTFIX] spark restricts to give the length o...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2392 [HOTFIX] spark restricts to give the length of char always and so carbon also behaves likely - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata spark-2.1_test Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2392.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2392 commit 44842bdc98fb6c3596d82e891d2a97eae6e1ced1 Author: rahul Date: 2018-06-21T05:59:37Z [HOTFIX] spark restricts to give the length of char always and so carbon also behaves likely ---
[GitHub] carbondata pull request #2385: [wip]invalid tuple-id and block id getting fo...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2385 [wip]invalid tuple-id and block id getting formed for partition table Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata block_id_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2385.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2385 commit 811e611fda3ceef5e9c2e3470ded2bd6f656b770 Author: rahul Date: 2018-06-19T13:53:26Z invalid tuple-id and block id getting formed for partition table ---
[GitHub] carbondata issue #2369: [CARBONDATA-2604] getting ArrayIndexOutOfBoundExcept...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2369 retest sdv please ---
[GitHub] carbondata pull request #2369: [CARBONDATA-2604] getting ArrayIndexOutOfBoun...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2369 [CARBONDATA-2604] getting ArrayIndexOutOfBoundException during compaction after IUD in cluster is fixed - [ ] Any interfaces changed? No - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done => Yes, tested on cluster - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata compaction_issue Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2369.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2369 commit 9bb2aa97995a21b0ac36026b01fc02e885205399 Author: rahul Date: 2018-06-12T13:56:40Z [CARBONDATA-2604] getting ArrayIndexOutOfBoundException during compaction after IUD in cluster is fixed ---
[GitHub] carbondata pull request #2362: [CARBONDATA-2578] fixed memory leak inside Ca...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2362#discussion_r193963265
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/createTable/TestNonTransactionalCarbonTable.scala
---
@@ -401,7 +402,7 @@ class TestNonTransactionalCarbonTable extends QueryTest
with BeforeAndAfterAll {
intercept[RuntimeException] {
buildTestDataWithSortColumns(List(""))
}
-
+
--- End diff --
it improves readability of test-cases. like that only rest of test-cases
added.
---
[GitHub] carbondata pull request #2362: [CARBONDATA-2578] fixed memory leak inside Ca...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2362#discussion_r193962103
--- Diff:
store/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonReader.java ---
@@ -74,6 +74,8 @@ public boolean hasNext() throws IOException,
InterruptedException {
return false;
} else {
index++;
+// current reader is closed
+currentReader.close();
--- End diff --
@sujith71955 this we cant do in finally block because if we will do it in
finally it wiill close immendiately currentReader . currentReader we are using
to iterate rows. so its better to close last currentReader before getting new
currentReader.
---
[GitHub] carbondata pull request #2362: [CARBONDATA-2578] RowBatch is closed when rea...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2362 [CARBONDATA-2578] RowBatch is closed when reader is iterated Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata CARBONDATA-2578 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2362.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2362 commit bbb9481cfe6e6502764c4eae4b33d4ab0211b297 Author: rahul Date: 2018-06-05T07:39:36Z [CARBONDATA-2578] RowBatch is closed when reader is iterated ---
[GitHub] carbondata pull request #2351: [CARBONDATA-2559] task id set for each carbon...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2351 ---
[GitHub] carbondata issue #2351: [CARBONDATA-2559] task id set for each carbonReader ...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2351 @kumarvishal09 done ---
[GitHub] carbondata issue #2351: [CARBONDATA-2559] task id set for each carbonReader ...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2351 retest this please ---
[GitHub] carbondata pull request #1412: [CARBONDATA-1510] UDF test case added
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/1412 ---
[GitHub] carbondata pull request #2351: [WIP] task id set for each carbonReader in th...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2351 [WIP] task id set for each carbonReader in threadlocal Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata mem_analyzer_sdk Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2351.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2351 commit c46d21a6aad0a3f0c4abbefed4bd16c457420da9 Author: rahulforallp Date: 2018-05-29T04:53:46Z task id set for each carbonReader in threadlocal ---
[GitHub] carbondata issue #2333: [WIP] Change the query flow while selecting the carb...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2333 retest this please ---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189778890
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false while executing the main to use offheap memory or
not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if (args.length > 0 && args[0] != null) {
+ testSdkWriter(args[0]);
+ } else {
+ testSdkWriter("true");
+ }
}
- public static void testSdkWriter() throws IOException,
InvalidLoadOptionException {
- String path = "/home/root1/Documents/ab/temp";
+ public static void testSdkWriter(String enableOffheap) throws
IOException, InvalidLoadOptionException {
+ String path = "./target/testCSVSdkWriter";
Field[] fields = new Field[2];
fields[0] = new Field("name", DataTypes.STRING);
fields[1] = new Field("age", DataTypes.INT);
Schema schema = new Schema(fields);
+
+ CarbonProperties.getInstance().addProperty("enable.offheap.sort",
enableOffheap);
--- End diff --
@xubo245 if args[0] is specified as any other value except true or false
then it will log warning message and will set default value.
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189604495
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false while executing the main to use offheap memory or
not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
+ testSdkWriter(args[0]);
+ } else {
+ testSdkWriter("true");
+ }
}
- public static void testSdkWriter() throws IOException,
InvalidLoadOptionException {
+ public static void testSdkWriter(String enableOffheap) throws
IOException, InvalidLoadOptionException {
String path = "/home/root1/Documents/ab/temp";
--- End diff --
done
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189588715
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false while executing the main to use offheap memory or
not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
--- End diff --
it may be failing because of invalid path given in testSdkWriter().
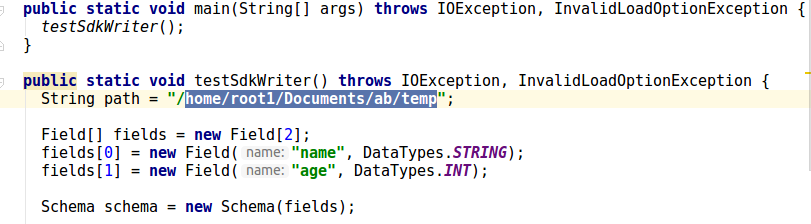
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189588091
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false while executing the main to use offheap memory or
not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
+ testSdkWriter(args[0]);
+ } else {
+ testSdkWriter("true");
+ }
}
- public static void testSdkWriter() throws IOException,
InvalidLoadOptionException {
+ public static void testSdkWriter(String enableOffheap) throws
IOException, InvalidLoadOptionException {
String path = "/home/root1/Documents/ab/temp";
Field[] fields = new Field[2];
fields[0] = new Field("name", DataTypes.STRING);
fields[1] = new Field("age", DataTypes.INT);
Schema schema = new Schema(fields);
+
+ CarbonProperties.getInstance().addProperty("enable.offheap.sort",
enableOffheap);
CarbonWriterBuilder builder =
CarbonWriter.builder().withSchema(schema).outputPath(path);
--- End diff --
it may be failing because of invalid path given in testSdkWriter().
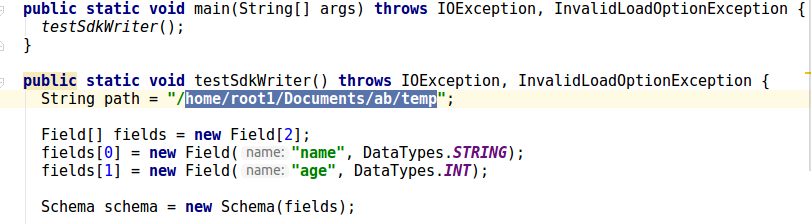
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189579501
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false while executing the main to use offheap memory or
not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
--- End diff --
BufferedReader reader =
new BufferedReader(new InputStreamReader(System.in));
String enableOffheapSortVal = reader.readLine();
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189576886
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false whle executing the main to use offheap memory or not
--- End diff --
done
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189576859
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false whle executing the main to use offheap memory or not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
+ testSdkWriter(args[0]);
+ } else {
+ testSdkWriter("true");
--- End diff --
done
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189576814
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false whle executing the main to use offheap memory or not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
+ testSdkWriter(args[0]);
--- End diff --
done
---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] doc updated to set the prop...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r189575742
--- Diff: docs/sdk-writer-guide.md ---
@@ -13,25 +13,33 @@ These SDK writer output contains just a carbondata and
carbonindex files. No met
import
org.apache.carbondata.common.exceptions.sql.InvalidLoadOptionException;
import org.apache.carbondata.core.metadata.datatype.DataTypes;
+ import org.apache.carbondata.core.util.CarbonProperties;
import org.apache.carbondata.sdk.file.CarbonWriter;
import org.apache.carbondata.sdk.file.CarbonWriterBuilder;
import org.apache.carbondata.sdk.file.Field;
import org.apache.carbondata.sdk.file.Schema;
public class TestSdk {
-
+
+ // pass true or false whle executing the main to use offheap memory or not
public static void main(String[] args) throws IOException,
InvalidLoadOptionException {
- testSdkWriter();
+ if(args[0] != null) {
+ testSdkWriter(args[0]);
--- End diff --
that is already handled in CarbonProperties validation.
---
[GitHub] carbondata pull request #2326: [WIP] sortColumn with empty gives exception
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2326 [WIP] sortColumn with empty gives exception Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata sort_col_sdk_emptyVal Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2326.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2326 commit 4ac783289913c267e04bf2cfc558791e4caabd6b Author: rahulforallp <rahul.kumar@...> Date: 2018-05-21T09:47:10Z sortColumn with empty gives exception is fixed commit 4c2e32ec0df62aec94384d21ee1b6edccf072a54 Author: dhatchayani <dhatcha.official@...> Date: 2018-05-21T09:19:37Z Update issue on select query ---
[GitHub] carbondata issue #2274: [CARBONDATA-2440] doc updated to set the property fo...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2274 @xubo245 review comments resolved . ---
[GitHub] carbondata issue #2292: [CARBONDATA-2467] sdk writer log shouldnot print nul...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2292 retest this please ---
[GitHub] carbondata pull request #2292: [CARBONDATA-2467] sdk writer log shouldnot pr...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2292#discussion_r187847932
--- Diff:
store/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonWriterBuilder.java
---
@@ -413,8 +413,8 @@ private CarbonTable buildCarbonTable() {
tableName = "_tempTable";
dbName = "_tempDB";
} else {
- dbName = null;
- tableName = null;
+ dbName = "";
+ tableName = String.valueOf(UUID);
--- End diff --
done
---
[GitHub] carbondata issue #2293: [CARBONDATA-2468] addition of column to default sort...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2293 retest this please ---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] default value of ENABLE_OFF...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r187533693
--- Diff:
store/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonWriterBuilder.java
---
@@ -340,7 +342,13 @@ private CarbonLoadModel createLoadModel() throws
IOException, InvalidLoadOptionE
// we are still using the traditional carbon table folder structure
persistSchemaFile(table, CarbonTablePath.getSchemaFilePath(path));
}
-
+if (!table.isTransactionalTable()) {
+ CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.ENABLE_OFFHEAP_SORT, "false");
--- End diff --
@kunal642 if we are updating the doc to set the properties then no need of
this code. same PR we can use to update the doc.
---
[GitHub] carbondata pull request #2293: [CARBONDATA-2468] addition of column to defau...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2293#discussion_r187533373
--- Diff:
store/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonWriterBuilder.java
---
@@ -481,9 +482,13 @@ private void buildTableSchema(Field[] fields,
TableSchemaBuilder tableSchemaBuil
ColumnSchema columnSchema = tableSchemaBuilder
.addColumn(new StructField(field.getFieldName(),
field.getDataType()),
valIndex, isSortColumn > -1);
- columnSchema.setSortColumn(true);
if (isSortColumn > -1) {
+columnSchema.setSortColumn(true);
sortColumnsSchemaList[isSortColumn] = columnSchema;
+ } else if (sortColumnsList.isEmpty() &&
columnSchema.isDimensionColumn()) {
--- End diff --
complex check is already handled above.
---
[GitHub] carbondata issue #2262: [CARBONDATA-2431] Incremental data added after exter...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2262 retest this please ---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] default value of ENABLE_OFF...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2274#discussion_r187368858
--- Diff:
store/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonWriterBuilder.java
---
@@ -340,7 +342,13 @@ private CarbonLoadModel createLoadModel() throws
IOException, InvalidLoadOptionE
// we are still using the traditional carbon table folder structure
persistSchemaFile(table, CarbonTablePath.getSchemaFilePath(path));
}
-
+if (!table.isTransactionalTable()) {
+ CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.ENABLE_OFFHEAP_SORT, "false");
--- End diff --
Intention was to prevent 'unsafe' property from being used by SDK user by
default. Otherwise they have to configure memory for unsafe also. So making it
simple to use.
Any way we will update the doc how SDK user can set the property by
following code:
CarbonProperties.getInstance() .addProperty("property", "value");
---
[GitHub] carbondata pull request #2293: [CARBONDATA-2468] addition of default sort_co...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2293 [CARBONDATA-2468] addition of default sort_column handled **issue :** default sort_column handling was missing **solution :** condition added for default sort_columns - [ ] Any interfaces changed? NO - [ ] Any backward compatibility impacted?No - [ ] Document update required?NO - [ ] Testing done==> UT added - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata CARBONDATA-2468 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2293.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2293 commit 33985d350001b8b8d4cd4bf1d79405c934bcc824 Author: rahulforallp <rahul.kumar@...> Date: 2018-05-10T10:47:39Z addition of default sort_column handled ---
[GitHub] carbondata issue #2262: [CARBONDATA-2431] Incremental data added after exter...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2262 retest this please ---
[GitHub] carbondata pull request #2262: [CARBONDATA-2431] Incremental data added afte...
GitHub user rahulforallp reopened a pull request: https://github.com/apache/carbondata/pull/2262 [CARBONDATA-2431] Incremental data added after external table creation is not reflecting while doing select query issue is fixed. - [x] Any interfaces changed? NO - [x] Any backward compatibility impacted? NO - [x] Document update required? NO - [x] Testing done ==> UT added - [x] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata inc_load_sdk Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2262.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2262 commit ee429388cee55bed5aa2876548c645037860ba2c Author: rahulforallp <rahul.kumar@...> Date: 2018-05-03T08:41:12Z [CARBONDATA-2431] Incremental data added after table creation is not reflecting while doing select query issue is fixed. ---
[GitHub] carbondata pull request #2262: [CARBONDATA-2431] Incremental data added afte...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2262 ---
[GitHub] carbondata pull request #2284: [WIP] concurrent insert requires separtate te...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2284 [WIP] concurrent insert requires separtate temp path which is differentiated with seg_id only Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata concurrent_insert_external_tab Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2284.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2284 commit b5eb975f60b909b96bf0228d5ab81dfe46252b26 Author: rahulforallp <rahul.kumar@...> Date: 2018-05-08T11:41:41Z concurrent insert requires separtate temp path which is differentiated with seg_id only ---
[GitHub] carbondata issue #2262: [CARBONDATA-2431] Incremental data added after exter...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2262 retest this please ---
[GitHub] carbondata issue #2274: [CARBONDATA-2440] default value of ENABLE_OFFHEAP_SO...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2274 retest this please ---
[GitHub] carbondata pull request #2274: [CARBONDATA-2440] default value of ENABLE_OFF...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2274 [CARBONDATA-2440] default value of ENABLE_OFFHEAP_SORT for sdk set as false Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata unsafe_mem_sdk Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2274.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2274 commit 3d67d58737d099458fbfd050bb256918573b8610 Author: rahulforallp <rahul.kumar@...> Date: 2018-05-04T14:09:58Z [CARBONDATA-2440] false set as default value of ENABLE_OFFHEAP_SORT for sdk ---
[GitHub] carbondata pull request #1680: [WIP] fixing text parsing exception
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/1680 ---
[GitHub] carbondata pull request #2262: [CARBONDATA-2431] Incremental data added afte...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2262 [CARBONDATA-2431] Incremental data added after table creation is not reflecting while doing select query issue is fixed. - [ ] Any interfaces changed? NO - [ ] Any backward compatibility impacted? NO - [ ] Document update required? NO - [ ] Testing done ==> UT added - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata inc_load_sdk Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2262.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2262 commit c53522ad376885b308f50077700dabfd9fed7217 Author: rahulforallp <rahul.kumar@...> Date: 2018-05-03T08:41:12Z [CARBONDATA-2431] Incremental data added after table creation is not reflecting while doing select query issue is fixed. ---
[GitHub] carbondata pull request #2249: [WIP]sortColumns Order we are getting wrong a...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2249 [WIP]sortColumns Order we are getting wrong as we set for external table is fixed Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata sort_col_sdk Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2249.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2249 ---
[GitHub] carbondata issue #2223: [CARBONDATA-2394] [WIP] Setting segments in thread l...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2223 retest this please ---
[GitHub] carbondata pull request #2223: [CARBONDATA-2394] [WIP] Setting segments in t...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2223 [CARBONDATA-2394] [WIP] Setting segments in thread local space but was not ⦠â¦getting reflected in the driver is fixed Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata thread_local_issue Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2223.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2223 commit 38c09f086aeacf1d4d7e7414bf76eff16ac5a02a Author: rahulforallp <rahul.kumar@...> Date: 2018-04-24T12:38:41Z [CARBONDATA-2394] Setting segments in thread local space but was not getting reflected in the driver is fixed ---
[GitHub] carbondata pull request #2159: [CARBONDATA-2303] clean files issue resolved ...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2159 ---
[GitHub] carbondata pull request #2158: [CARBONDATA-2316] Executor task is failed but...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2158 ---
[GitHub] carbondata issue #2128: [CARBONDATA-2303] If dataload is failed for parition...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2128 retest this please ---
[GitHub] carbondata pull request #2159: [CARBONDATA-2303] clean files issue resolved ...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2159 [CARBONDATA-2303] clean files issue resolved for partition folder Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? No - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done NA - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata synch_part_tab_clean Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2159.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2159 commit 506f274e57bf0c57b65ccd869e960e88c6824db0 Author: rahulforallp <rahul.kumar@...> Date: 2018-04-01T12:08:51Z [CARBONDATA-2303] clean files issue resolved for partition folder ---
[GitHub] carbondata pull request #2156: [CARBONDATA-2317] Concurrent datamap with sam...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2156 ---
[GitHub] carbondata pull request #2156: [CARBONDATA-2317] Concurrent datamap with sam...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2156 [CARBONDATA-2317] Concurrent datamap with same name and schema creation throws exception - [ ] Any interfaces changed? No - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done UT added - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata synch_CARBONDATA-2238 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2156.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2156 commit a2f85e49f45b095f541312ef915a0bc4dfc6c699 Author: rahulforallp <rahul.kumar@...> Date: 2018-04-06T09:47:54Z [CARBONDATA-2317] Concurrent datamap with same name and schema creation throws exception ---
[GitHub] carbondata pull request #2128: [CARBONDATA-2303] If dataload is failed for p...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2128#discussion_r180156407
--- Diff:
core/src/main/java/org/apache/carbondata/core/datastore/filesystem/LocalCarbonFile.java
---
@@ -156,6 +158,25 @@ public boolean delete() {
}
+ @Override
+ public CarbonFile[] listFiles(Boolean recurssive) {
+if (!file.isDirectory()) {
+ return new CarbonFile[0];
+}
+String[] filter = null;
+Collection fileCollection = FileUtils.listFiles(file, null,
true);
+File[] files = fileCollection.toArray(new File[fileCollection.size()]);
+if (files == null) {
+ return new CarbonFile[0];
+}
+CarbonFile[] carbonFiles = new CarbonFile[files.length];
--- End diff --
done
---
[GitHub] carbondata pull request #2128: [CARBONDATA-2303] If dataload is failed for p...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2128#discussion_r180156365
--- Diff:
integration/spark-common/src/main/scala/org/apache/carbondata/api/CarbonStore.scala
---
@@ -151,13 +153,82 @@ object CarbonStore {
}
}
} finally {
+ if (currentTablePartitions.equals(None)) {
+cleanUpPartitionFoldersRecurssively(carbonTable,
List.empty[PartitionSpec])
+ } else {
+cleanUpPartitionFoldersRecurssively(carbonTable,
currentTablePartitions.get.toList)
+ }
+
if (carbonCleanFilesLock != null) {
CarbonLockUtil.fileUnlock(carbonCleanFilesLock,
LockUsage.CLEAN_FILES_LOCK)
}
}
LOGGER.audit(s"Clean files operation is success for
$dbName.$tableName.")
}
+ /**
+ * delete partition folders recurssively
+ *
+ * @param carbonTable
+ * @param partitionSpecList
+ */
+ def cleanUpPartitionFoldersRecurssively(carbonTable: CarbonTable,
+ partitionSpecList: List[PartitionSpec]): Unit = {
+if (carbonTable != null) {
+ val loadMetadataDetails = SegmentStatusManager
+.readLoadMetadata(carbonTable.getMetadataPath)
+
+ val fileType = FileFactory.getFileType(carbonTable.getTablePath)
+ val carbonFile = FileFactory.getCarbonFile(carbonTable.getTablePath,
fileType)
+
+ // list all files from table path
+ val listOfDefaultPartFilesIterator = carbonFile.listFiles(true)
+ loadMetadataDetails.foreach { metadataDetail =>
+if
(metadataDetail.getSegmentStatus.equals(SegmentStatus.MARKED_FOR_DELETE) &&
+metadataDetail.getSegmentFile == null) {
+ val loadStartTime: Long = metadataDetail.getLoadStartTime
+ // delete all files of @loadStartTime from tablepath
+ cleanPartitionFolder(listOfDefaultPartFilesIterator,
loadStartTime)
+ partitionSpecList.foreach {
+partitionSpec =>
+ val partitionLocation = partitionSpec.getLocation
+ // For partition folder outside the tablePath
+ if
(!partitionLocation.toString.startsWith(carbonTable.getTablePath)) {
+val fileType =
FileFactory.getFileType(partitionLocation.toString)
+val partitionCarbonFile = FileFactory
+ .getCarbonFile(partitionLocation.toString, fileType)
+// list all files from partitionLoacation
+val listOfExternalPartFilesIterator =
partitionCarbonFile.listFiles(true)
+// delete all files of @loadStartTime from externalPath
+cleanPartitionFolder(listOfExternalPartFilesIterator,
loadStartTime)
+ }
+ }
+}
+ }
+}
+ }
+
+ /**
+ *
+ * @param carbonFiles
+ * @param timestamp
+ */
+ private def cleanPartitionFolder(carbonFiles: Array[CarbonFile],
+ timestamp: Long): Unit = {
+carbonFiles.foreach {
+ carbonFile =>
+val filePath = carbonFile.getPath
+val fileName = carbonFile.getName
+if (fileName.lastIndexOf("-") > 0 && fileName.lastIndexOf(".") >
0) {
+ if (fileName.substring(fileName.lastIndexOf("-") + 1,
fileName.lastIndexOf("."))
--- End diff --
done
---
[GitHub] carbondata pull request #2128: [CARBONDATA-2303] If dataload is failed for p...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2128#discussion_r180079486
--- Diff:
integration/spark-common/src/main/scala/org/apache/carbondata/api/CarbonStore.scala
---
@@ -151,13 +152,88 @@ object CarbonStore {
}
}
} finally {
+ if (currentTablePartitions.equals(None)) {
+cleanUpPartitionFoldersRecurssively(carbonTable,
List.empty[PartitionSpec])
+ } else {
+cleanUpPartitionFoldersRecurssively(carbonTable,
currentTablePartitions.get.toList)
+ }
+
if (carbonCleanFilesLock != null) {
CarbonLockUtil.fileUnlock(carbonCleanFilesLock,
LockUsage.CLEAN_FILES_LOCK)
}
}
LOGGER.audit(s"Clean files operation is success for
$dbName.$tableName.")
}
+ /**
+ * delete partition folders recurssively
+ *
+ * @param carbonTable
+ * @param partitionSpecList
+ */
+ def cleanUpPartitionFoldersRecurssively(carbonTable: CarbonTable,
+ partitionSpecList: List[PartitionSpec]): Unit = {
+if (carbonTable != null) {
+ val loadMetadataDetails = SegmentStatusManager
--- End diff --
1. partition folders cannot be deleted, as there is no way to check if new
dataload is using them. ==> Done
2. Shouldnot take multiple snapshots of file system during clean files. ==>
earlier we are not taking snapshot recurssively . so it required here for
partition folders.
3. Partition location will be valid for partitions inside table path also,
those folders should not be scanned twice. ==> Done
4. CarbonFile interface should be used for filesystem operations. ==> Done
---
[GitHub] carbondata pull request #2143: [CARBONDATA-2317] oncurrent datamap with same...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2143 [CARBONDATA-2317] oncurrent datamap with same name and schema creation throws exception â¦n throws exception Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata concur_preagg Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2143.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2143 commit c82a046849562dc61b761f3aaefff1653f585a0f Author: rahulforallp <rahul.kumar@...> Date: 2018-04-06T09:47:54Z [CARBONDATA-2317] oncurrent datamap with same name and schema creation throws exception ---
[GitHub] carbondata pull request #2142: [CARBONDATA-2316] [WIP] Executor task is fail...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2142 [CARBONDATA-2316] [WIP] Executor task is failed but UI shows success issue is fixed ⦠- [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata compact_task_faail_issue Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2142.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2142 commit 1ac4d350c4b405b0ff65cb04909b02e3a43d7737 Author: rahulforallp <rahul.kumar@...> Date: 2018-04-06T08:46:06Z [CARBONDATA-2316] Executor task is failed but UI shows success issue fixed ---
[GitHub] carbondata issue #2128: [CARBONDATA-2303] [WIP] If dataload is failed for pa...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2128 retest sdv please ---
[GitHub] carbondata issue #2128: [WIP] partition table clean files fixed
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2128 retest this please ---
[GitHub] carbondata pull request #2128: [WIP] partition table clean files fixed
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2128 [WIP] partition table clean files fixed Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata part_tab_cleanFile Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2128.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2128 commit 8044edb5afa858fa72ae7b2d0d1cf0685cf92597 Author: rahulforallp <rahul.kumar@...> Date: 2018-04-01T12:08:51Z partition table clean files fixed ---
[GitHub] carbondata pull request #2119: [CARBONDATA-2287] [CARBONDATA-2274] sync defe...
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2119 ---
[GitHub] carbondata pull request #2120: [HOTFIX] scalaStyle fixed
Github user rahulforallp closed the pull request at: https://github.com/apache/carbondata/pull/2120 ---
[GitHub] carbondata pull request #2120: [HOTFIX] scalaStyle fixed
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2120 [HOTFIX] scalaStyle fixed Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata style Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2120.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2120 commit 33beaa156d7a197e06752860c62041f31e7fe595 Author: rahulforallp <rahul.kumar@...> Date: 2018-03-30T15:01:16Z scalastyle fixed ---
[GitHub] carbondata pull request #2119: [CARBONDATA-2287] [CARBONDATA-2274] sync defe...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2119 [CARBONDATA-2287] [CARBONDATA-2274] sync defects to branch-1.3 Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata synchTo1.3 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2119.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2119 commit 29ed172944888e2d4524b2560946fd0f7f616252 Author: rahulforallp <rahul.kumar@...> Date: 2018-03-23T14:49:43Z [CARBONDATA-2274]fixed Partition table having more than 4 column giving zero record commit 144889b848c102ded82747f79b030f6e4f7204d1 Author: rahulforallp <rahul.kumar@...> Date: 2018-03-27T06:50:04Z [CARBONDATA-2287] events added for alter hive partition table ---
[GitHub] carbondata pull request #2096: [CARBONDATA-2274] fix for Partition table hav...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2096#discussion_r177721541
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/standardpartition/StandardPartitionTableLoadingTestCase.scala
---
@@ -135,6 +135,23 @@ class StandardPartitionTableLoadingTestCase extends
QueryTest with BeforeAndAfte
sql("select empno, empname, designation, doj, workgroupcategory,
workgroupcategoryname, deptno, deptname, projectcode, projectjoindate,
projectenddate, attendance, utilization, salary from originTable order by
empno"))
}
+ test("data loading for partition table for five partition column") {
+sql(
+ """
+| CREATE TABLE partitionfive (empno int, doj Timestamp,
+| workgroupcategoryname String, deptno int, deptname String,
+| projectcode int, projectjoindate Timestamp, projectenddate
Timestamp,attendance int)
+| PARTITIONED BY (utilization int,salary int,workgroupcategory
int, empname String,
+| designation String)
+| STORED BY 'org.apache.carbondata.format'
+ """.stripMargin)
+sql(s"""LOAD DATA local inpath '$resourcesPath/data.csv' INTO TABLE
partitionfive OPTIONS('DELIMITER'= ',', 'QUOTECHAR'= '"')""")
+
+validateDataFiles("default_partitionfive", "0", 10)
+
+checkAnswer(sql("select empno, empname, designation, doj,
workgroupcategory, workgroupcategoryname, deptno, deptname, projectcode,
projectjoindate, projectenddate, attendance, utilization, salary from
partitionfive order by empno"),
--- End diff --
filter test case also added
---
[GitHub] carbondata pull request #2096: [CARBONDATA-2274] fix for Partition table hav...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2096#discussion_r177720898
--- Diff:
integration/spark-common/src/main/scala/org/apache/carbondata/spark/util/CarbonScalaUtil.scala
---
@@ -340,12 +342,12 @@ object CarbonScalaUtil {
* @return updated partition spec
*/
def updatePartitions(
- partitionSpec: Map[String, String],
- table: CarbonTable): Map[String, String] = {
+ partitionSpec: mutable.LinkedHashMap[String, String],
+ table: CarbonTable): mutable.LinkedHashMap[String, String] = {
--- End diff --
formatting done
---
[GitHub] carbondata pull request #2096: [CARBONDATA-2274] fix for Partition table hav...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2096#discussion_r177705701
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/standardpartition/StandardPartitionTableLoadingTestCase.scala
---
@@ -135,6 +135,23 @@ class StandardPartitionTableLoadingTestCase extends
QueryTest with BeforeAndAfte
sql("select empno, empname, designation, doj, workgroupcategory,
workgroupcategoryname, deptno, deptname, projectcode, projectjoindate,
projectenddate, attendance, utilization, salary from originTable order by
empno"))
}
+ test("data loading for partition table for five partition column") {
+sql(
+ """
+| CREATE TABLE partitionfive (empno int, doj Timestamp,
+| workgroupcategoryname String, deptno int, deptname String,
+| projectcode int, projectjoindate Timestamp, projectenddate
Timestamp,attendance int)
+| PARTITIONED BY (utilization int,salary int,workgroupcategory
int, empname String,
+| designation String)
+| STORED BY 'org.apache.carbondata.format'
+ """.stripMargin)
+sql(s"""LOAD DATA local inpath '$resourcesPath/data.csv' INTO TABLE
partitionfive OPTIONS('DELIMITER'= ',', 'QUOTECHAR'= '"')""")
+
+validateDataFiles("default_partitionfive", "0", 10)
+
+checkAnswer(sql("select empno, empname, designation, doj,
workgroupcategory, workgroupcategoryname, deptno, deptname, projectcode,
projectjoindate, projectenddate, attendance, utilization, salary from
partitionfive order by empno"),
--- End diff --
@ravipesala you mean i should add filter query also in test case?
without filter also i was able to reproduce it.
---
[GitHub] carbondata issue #2107: [CARBONDATA-2287] events added for alter hive partit...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2107 retest sdv please ---
[GitHub] carbondata issue #2107: [CARBONDATA-2287] events added for alter hive partit...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2107 retest sdv please ---
[GitHub] carbondata pull request #2107: [CARBONDATA-2287] events added for alter hive...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2107 [CARBONDATA-2287] events added for alter hive partition table Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? No - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done NR, All UT and SDV pass report is enough. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata CARBONDATA-2287 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2107.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2107 commit 7f46f86e2fcaaf385dfe426ecc0617155401cca7 Author: rahulforallp <rahul.kumar@...> Date: 2018-03-27T06:50:04Z [CARBONDATA-2287] events added for alter hive partition table ---
[GitHub] carbondata issue #2096: [CARBONDATA-2274] fix for Partition table having mor...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2096 retest sdv please ---
[GitHub] carbondata issue #2096: [CARBONDATA-2274] fix for Partition table having mor...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/2096 retest sdv please ---
[GitHub] carbondata pull request #2096: [CARBONDATA-2274] fix for Partition table hav...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2096 [CARBONDATA-2274] fix for Partition table having more than 4 column giving zero record - [X] Any interfaces changed? NO - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done **UT added** - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata CARBONDATA-2274 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2096.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2096 commit cee1e90f3e94c67a14209551f4d08eee9c525797 Author: rahulforallp <rahul.kumar@...> Date: 2018-03-23T14:49:43Z [CARBONDATA-2274]fixed Partition table having more than 4 column giving zero record ---
[GitHub] carbondata pull request #1991: [CARBONDATA-2196]carbontable should be taken ...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1991#discussion_r171489212
--- Diff:
processing/src/main/java/org/apache/carbondata/processing/util/CarbonDataProcessorUtil.java
---
@@ -117,22 +117,25 @@ public static void createLocations(String[]
locations) {
}
}
}
+
/**
+ *
* This method will form the local data folder store location
*
- * @param databaseName
- * @param tableName
+ * @param carbonTable
* @param taskId
* @param partitionId
* @param segmentId
+ * @param isCompactionFlow
+ * @param isAltPartitionFlow
* @return
*/
- public static String[] getLocalDataFolderLocation(String databaseName,
String tableName,
+ public static String[] getLocalDataFolderLocation(CarbonTable
carbonTable, String tableName,
--- End diff --
in case of Pre aggregate table, table name can be of child even though
carbonTable object is for main table.
---
[GitHub] carbondata pull request #2008: [CARBONDATA-2211] in case of DDL HndOff shoul...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2008#discussion_r171465697
--- Diff:
streaming/src/main/scala/org/apache/carbondata/streaming/StreamHandoffRDD.scala
---
@@ -277,15 +277,21 @@ object StreamHandoffRDD {
*/
def startStreamingHandoffThread(
carbonLoadModel: CarbonLoadModel,
- sparkSession: SparkSession
+ sparkSession: SparkSession,
+ isDDL: Boolean
): Unit = {
// start a new thread to execute streaming segment handoff
val handoffThread = new Thread() {
--- End diff --
Done
---
[GitHub] carbondata pull request #2008: [CARBONDATA-2211] in case of DDL HndOff shoul...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/2008 [CARBONDATA-2211] in case of DDL HndOff should not be execute in thread If handoff triggered from DDL it should not execute in thread. - [ ] Any interfaces changed? No - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done Manual testing Done - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata CARBONDATA-2211 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2008.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2008 commit eb3a536e88b6550d9e004aa6eeddc992168c16b9 Author: rahulforallp <rahul.kumar@...> Date: 2018-02-27T16:20:20Z [CARBONDATA-2211] in case of DDL HndOff should not be execute in thread ---
[GitHub] carbondata pull request #1997: [CARBONDATA-2201] NPE fixed while triggering ...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1997#discussion_r170452321
--- Diff:
streaming/src/main/scala/org/apache/carbondata/streaming/StreamSinkFactory.scala
---
@@ -67,7 +67,7 @@ object StreamSinkFactory {
carbonLoadModel.getFactFilePath,
false,
parameters.asJava,
- null,
+ parameters.asJava,
--- End diff --
while triggering the LoadTablePreExecutionEvent we reuire options provided
by user and the finalOptions . In case of streaming both are same
---
[GitHub] carbondata pull request #1997: [CARBONDATA-2201] NPE fixed for Streaming eve...
GitHub user rahulforallp opened a pull request: https://github.com/apache/carbondata/pull/1997 [CARBONDATA-2201] NPE fixed for Streaming event Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rahulforallp/incubator-carbondata stream_npe Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1997.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1997 commit b94ae7c86f67b6d4eedfc9ed56ca2f7bde2a2ea9 Author: rahulforallp <rahul.kumar@...> Date: 2018-02-25T09:55:26Z NPE fixed for Streaming event ---
[GitHub] carbondata pull request #1991: [CARBONDATA-2196]carbontable should be taken ...
Github user rahulforallp commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1991#discussion_r170417245
--- Diff:
processing/src/main/java/org/apache/carbondata/processing/util/CarbonDataProcessorUtil.java
---
@@ -117,22 +117,25 @@ public static void createLocations(String[]
locations) {
}
}
}
+
/**
+ *
* This method will form the local data folder store location
*
- * @param databaseName
- * @param tableName
+ * @param carbonTable
* @param taskId
* @param partitionId
* @param segmentId
+ * @param isCompactionFlow
+ * @param isAltPartitionFlow
* @return
*/
- public static String[] getLocalDataFolderLocation(String databaseName,
String tableName,
+ public static String[] getLocalDataFolderLocation(CarbonTable
carbonTable,
--- End diff --
done
---
[GitHub] carbondata issue #1991: [CARBONDATA-2196]carbontable should be taken from lo...
Github user rahulforallp commented on the issue: https://github.com/apache/carbondata/pull/1991 retest this please ---