[jira] [Commented] (FLINK-6019) Some log4j messages do not have a loglevel field set, so they can't be suppressed
[
https://issues.apache.org/jira/browse/FLINK-6019?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497586#comment-16497586
]
Luke Hutchison commented on FLINK-6019:
---
[~StephanEwen] I updated to Flink 1.5 and log4j2, and I am seeing this problem
again. Now {{env.getConfig().disableSysoutLogging()}} no longer suppresses
output from Flink.
I have log4j2 configured using {{src/main/resources/log4j2.xml}}, and logging
works correctly for my own log output in my program. However, Flink does not
reuse the same log4j logger. I have even tried adding a {{log4j.properties}}
file in the same directory, in case Flink needs configuration in the older
format, but that does not help.
Log output from my own logging commands appears on stdout, and log output from
Flink appears on stderr, with a different log line format. So it is clear that
Flink is starting up its own instance of log4j.
How do I get Flink to simply use the log4j instance that I have included on the
classpath?
> Some log4j messages do not have a loglevel field set, so they can't be
> suppressed
> -
>
> Key: FLINK-6019
> URL: https://issues.apache.org/jira/browse/FLINK-6019
> Project: Flink
> Issue Type: Bug
> Components: Core
>Affects Versions: 1.2.0
> Environment: Linux
>Reporter: Luke Hutchison
>Priority: Major
>
> Some of the log messages do not appear to have a loglevel value set, so they
> can't be suppressed by setting the log4j level to WARN. There's this line at
> the beginning which doesn't even have a timestamp:
> {noformat}
> Connected to JobManager at Actor[akka://flink/user/jobmanager_1#1844933939]
> {noformat}
> And then there are numerous lines like this, missing an "INFO" field:
> {noformat}
> 03/10/2017 00:01:14 Job execution switched to status RUNNING.
> 03/10/2017 00:01:14 DataSource (at readTable(DBTableReader.java:165)
> (org.apache.flink.api.java.io.PojoCsvInputFormat))(1/8) switched to SCHEDULED
> 03/10/2017 00:01:14 DataSink (count())(1/8) switched to SCHEDULED
> 03/10/2017 00:01:14 DataSink (count())(3/8) switched to DEPLOYING
> 03/10/2017 00:01:15 DataSink (count())(3/8) switched to RUNNING
> 03/10/2017 00:01:17 DataSink (count())(6/8) switched to FINISHED
> 03/10/2017 00:01:17 DataSource (at readTable(DBTableReader.java:165)
> (org.apache.flink.api.java.io.PojoCsvInputFormat))(6/8) switched to FINISHED
> 03/10/2017 00:01:17 Job execution switched to status FINISHED.
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-9367) Truncate() in BucketingSink is only allowed after hadoop2.7
[ https://issues.apache.org/jira/browse/FLINK-9367?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497540#comment-16497540 ] ASF GitHub Bot commented on FLINK-9367: --- Github user zhangxinyu1 commented on the issue: https://github.com/apache/flink/pull/6108 @kl0u @joshfg @StephanEwen Could you please take a look at this pr? > Truncate() in BucketingSink is only allowed after hadoop2.7 > --- > > Key: FLINK-9367 > URL: https://issues.apache.org/jira/browse/FLINK-9367 > Project: Flink > Issue Type: Improvement > Components: Streaming Connectors >Affects Versions: 1.5.0 >Reporter: zhangxinyu >Priority: Major > > When output to HDFS using BucketingSink, truncate() is only allowed after > hadoop2.7. > If some tasks failed, the ".valid-length" file is created for the lower > version hadoop. > The problem is, if other people want to use the data in HDFS, they must know > how to deal with the ".valid-length" file, otherwise, the data may be not > exactly-once. > I think it's not convenient for other people to use the data. Why not just > read the in-progress file and write a new file when restoring instead of > writing a ".valid-length" file. > In this way, others who use the data in HDFS don't need to know how to deal > with the ".valid-length" file. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #6108: [FLINK-9367] [Streaming Connectors] Allow to do truncate(...
Github user zhangxinyu1 commented on the issue: https://github.com/apache/flink/pull/6108 @kl0u @joshfg @StephanEwen Could you please take a look at this pr? ---
[jira] [Commented] (FLINK-9444) KafkaAvroTableSource failed to work for map and array fields
[ https://issues.apache.org/jira/browse/FLINK-9444?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497530#comment-16497530 ] ASF GitHub Bot commented on FLINK-9444: --- Github user suez1224 commented on the issue: https://github.com/apache/flink/pull/6082 Thanks for the PR, @tragicjun. I will take a look in the next few days. > KafkaAvroTableSource failed to work for map and array fields > > > Key: FLINK-9444 > URL: https://issues.apache.org/jira/browse/FLINK-9444 > Project: Flink > Issue Type: Bug > Components: Kafka Connector, Table API SQL >Affects Versions: 1.6.0 >Reporter: Jun Zhang >Priority: Blocker > Labels: patch > Fix For: 1.6.0 > > Attachments: flink-9444.patch > > > When some Avro schema has map/array fields and the corresponding TableSchema > declares *MapTypeInfo/ListTypeInfo* for these fields, an exception will be > thrown when registering the *KafkaAvroTableSource*, complaining like: > Exception in thread "main" org.apache.flink.table.api.ValidationException: > Type Map of table field 'event' does not match with type > GenericType of the field 'event' of the TableSource return > type. > at org.apache.flink.table.api.ValidationException$.apply(exceptions.scala:74) > at > org.apache.flink.table.sources.TableSourceUtil$$anonfun$validateTableSource$1.apply(TableSourceUtil.scala:92) > at > org.apache.flink.table.sources.TableSourceUtil$$anonfun$validateTableSource$1.apply(TableSourceUtil.scala:71) > at > scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33) > at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186) > at > org.apache.flink.table.sources.TableSourceUtil$.validateTableSource(TableSourceUtil.scala:71) > at > org.apache.flink.table.plan.schema.StreamTableSourceTable.(StreamTableSourceTable.scala:33) > at > org.apache.flink.table.api.StreamTableEnvironment.registerTableSourceInternal(StreamTableEnvironment.scala:124) > at > org.apache.flink.table.api.TableEnvironment.registerTableSource(TableEnvironment.scala:438) -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #6082: [FLINK-9444][table] KafkaAvroTableSource failed to work f...
Github user suez1224 commented on the issue: https://github.com/apache/flink/pull/6082 Thanks for the PR, @tragicjun. I will take a look in the next few days. ---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[ https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497469#comment-16497469 ] ASF GitHub Bot commented on FLINK-8790: --- Github user sihuazhou commented on the issue: https://github.com/apache/flink/pull/5582 @StefanRRichter Thanks for your nice review, addressed your comments, could you please have a look again? > Improve performance for recovery from incremental checkpoint > > > Key: FLINK-8790 > URL: https://issues.apache.org/jira/browse/FLINK-8790 > Project: Flink > Issue Type: Improvement > Components: State Backends, Checkpointing >Affects Versions: 1.5.0 >Reporter: Sihua Zhou >Assignee: Sihua Zhou >Priority: Major > Fix For: 1.6.0 > > > When there are multi state handle to be restored, we can improve the > performance as follow: > 1. Choose the best state handle to init the target db > 2. Use the other state handles to create temp db, and clip the db according > to the target key group range (via rocksdb.deleteRange()), this can help use > get rid of the `key group check` in > `data insertion loop` and also help us get rid of traversing the useless > record. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #5582: [FLINK-8790][State] Improve performance for recovery from...
Github user sihuazhou commented on the issue: https://github.com/apache/flink/pull/5582 @StefanRRichter Thanks for your nice review, addressed your comments, could you please have a look again? ---
[jira] [Updated] (FLINK-9468) get outputLimit of LimitedConnectionsFileSystem incorrectly
[
https://issues.apache.org/jira/browse/FLINK-9468?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sihua Zhou updated FLINK-9468:
--
Priority: Critical (was: Blocker)
> get outputLimit of LimitedConnectionsFileSystem incorrectly
> ---
>
> Key: FLINK-9468
> URL: https://issues.apache.org/jira/browse/FLINK-9468
> Project: Flink
> Issue Type: Bug
> Components: FileSystem
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Critical
> Fix For: 1.6.0, 1.5.1
>
>
> In {{LimitedConnectionsFileSystem#createStream}}, we get the outputLimit
> incorrectly.
> {code:java}
> private T createStream(
> final SupplierWithException streamOpener,
> final HashSet openStreams,
> final boolean output) throws IOException {
> final int outputLimit = output && maxNumOpenInputStreams > 0 ?
> maxNumOpenOutputStreams : Integer.MAX_VALUE;
> /**/
> }
> {code}
> should be
> {code:java}
> private T createStream(
> final SupplierWithException streamOpener,
> final HashSet openStreams,
> final boolean output) throws IOException {
> final int outputLimit = output && maxNumOpenOutputStreams > 0 ?
> maxNumOpenOutputStreams : Integer.MAX_VALUE;
> /**/
> }
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-9294) Improve type inference for UDFs with composite parameter or result type
[
https://issues.apache.org/jira/browse/FLINK-9294?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Rong Rong updated FLINK-9294:
-
Issue Type: Sub-task (was: Improvement)
Parent: FLINK-9484
> Improve type inference for UDFs with composite parameter or result type
>
>
> Key: FLINK-9294
> URL: https://issues.apache.org/jira/browse/FLINK-9294
> Project: Flink
> Issue Type: Sub-task
> Components: Table API SQL
>Reporter: Rong Rong
>Assignee: Rong Rong
>Priority: Major
>
> Most of the UDF function signatures that includes composite types such as
> *{{MAP}}*, *{{ARRAY}}*, etc would require user to override
> *{{getParameterType}}* or *{{getResultType}}* method explicitly.
> It should be able to resolve the composite type based on the function
> signature, such as:
> {code:java}
> public List eval(Map mapArg) {
> //...
> }
> {code}
> should automatically resolve that:
> - *{{ObjectArrayTypeInfo}}* to be the result type.
> - *{{MapTypeInfo}}* to be the
> parameter type.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (FLINK-9484) Improve generic type inference for User-Defined Functions
Rong Rong created FLINK-9484: Summary: Improve generic type inference for User-Defined Functions Key: FLINK-9484 URL: https://issues.apache.org/jira/browse/FLINK-9484 Project: Flink Issue Type: Improvement Components: Table API SQL Reporter: Rong Rong Assignee: Rong Rong User-defined function has been a great extension for Flink SQL API to support much complex logics. We experienced many inconvenience when dealing with UDF with generic types and are summarized in the following [doc|https://docs.google.com/document/d/1zKSY1z0lvtQdfOgwcLnCMSRHew3weeJ6QfQjSD0zWas/edit?usp=sharing]. We are planning to implement the generic type inference / functioncatalog look up in multiple phases. Detail tickets will be created. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-9483) "Building Flink" doc doesn't highlight quick build command
[ https://issues.apache.org/jira/browse/FLINK-9483?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497311#comment-16497311 ] ASF GitHub Bot commented on FLINK-9483: --- GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/6109 [FLINK-9483] 'Building Flink' doc doesn't highlight quick build command ## What is the purpose of the change The blue part isn't corrected highlighted as the red ones 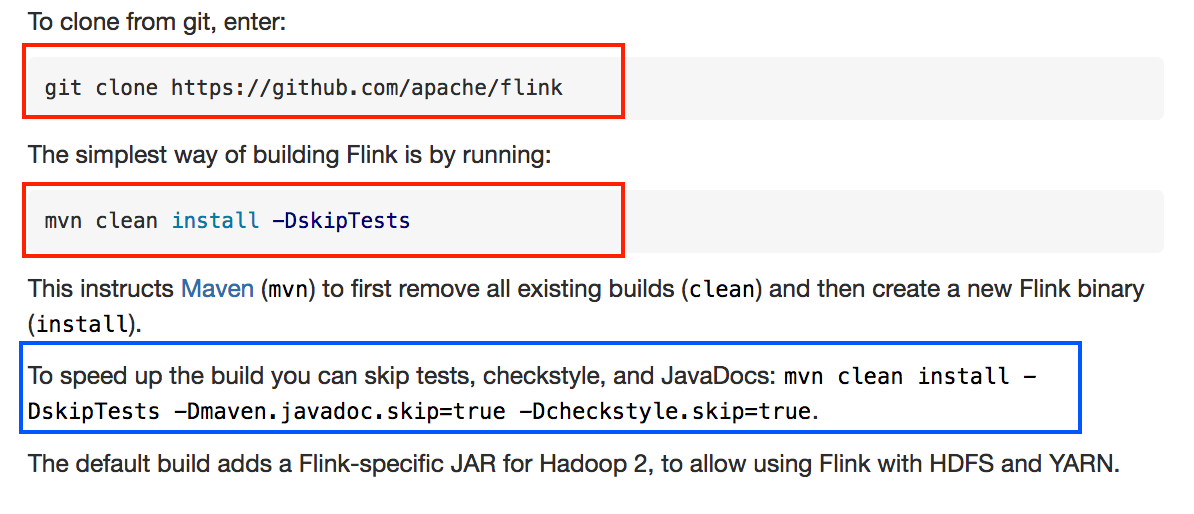 ## Brief change log Highlight quick build command ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-9483 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6109.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6109 commit 8ea6f791de0266f481c45d03731d15ed999ea753 Author: Bowen Li Date: 2018-05-31T23:15:41Z [FLINK-9483] 'Building Flink' doc doesn't highlight quick build command > "Building Flink" doc doesn't highlight quick build command > -- > > Key: FLINK-9483 > URL: https://issues.apache.org/jira/browse/FLINK-9483 > Project: Flink > Issue Type: Improvement > Components: Documentation >Affects Versions: 1.6.0 > Environment: see difference between red and blue parts >Reporter: Bowen Li >Assignee: Bowen Li >Priority: Minor > Fix For: 1.6.0 > > Attachments: Screen Shot 2018-05-31 at 4.12.32 PM.png > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #6109: [FLINK-9483] 'Building Flink' doc doesn't highligh...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/6109 [FLINK-9483] 'Building Flink' doc doesn't highlight quick build command ## What is the purpose of the change The blue part isn't corrected highlighted as the red ones  ## Brief change log Highlight quick build command ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-9483 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6109.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6109 commit 8ea6f791de0266f481c45d03731d15ed999ea753 Author: Bowen Li Date: 2018-05-31T23:15:41Z [FLINK-9483] 'Building Flink' doc doesn't highlight quick build command ---
[jira] [Created] (FLINK-9483) "Building Flink" doc doesn't highlight quick build command
Bowen Li created FLINK-9483: --- Summary: "Building Flink" doc doesn't highlight quick build command Key: FLINK-9483 URL: https://issues.apache.org/jira/browse/FLINK-9483 Project: Flink Issue Type: Improvement Components: Documentation Affects Versions: 1.6.0 Environment: see difference between red and blue parts Reporter: Bowen Li Assignee: Bowen Li Fix For: 1.6.0 Attachments: Screen Shot 2018-05-31 at 4.12.32 PM.png -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #6107: [FLINK-9366] DistributedCache works with Distribut...
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/6107#discussion_r192234433
--- Diff:
flink-fs-tests/src/test/java/org/apache/flink/hdfstests/DistributedCacheDfsTest.java
---
@@ -0,0 +1,166 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.hdfstests;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.core.fs.FileStatus;
+import org.apache.flink.core.fs.FileSystem;
+import org.apache.flink.core.fs.Path;
+import
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.test.util.MiniClusterResource;
+import org.apache.flink.util.NetUtils;
+
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.hdfs.MiniDFSCluster;
+import org.junit.AfterClass;
+import org.junit.BeforeClass;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+
+import java.io.DataInputStream;
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.net.URI;
+
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.assertTrue;
+
+/**
+ * Tests for distributing files with {@link
org.apache.flink.api.common.cache.DistributedCache} via HDFS.
+ */
+public class DistributedCacheDfsTest {
+
+ private static final String testFileContent = "Goethe - Faust: Der
Tragoedie erster Teil\n" + "Prolog im Himmel.\n"
+ + "Der Herr. Die himmlischen Heerscharen. Nachher
Mephistopheles. Die drei\n" + "Erzengel treten vor.\n"
+ + "RAPHAEL: Die Sonne toent, nach alter Weise, In
Brudersphaeren Wettgesang,\n"
+ + "Und ihre vorgeschriebne Reise Vollendet sie mit Donnergang.
Ihr Anblick\n"
+ + "gibt den Engeln Staerke, Wenn keiner Sie ergruenden mag; die
unbegreiflich\n"
+ + "hohen Werke Sind herrlich wie am ersten Tag.\n"
+ + "GABRIEL: Und schnell und unbegreiflich schnelle Dreht sich
umher der Erde\n"
+ + "Pracht; Es wechselt Paradieseshelle Mit tiefer,
schauervoller Nacht. Es\n"
+ + "schaeumt das Meer in breiten Fluessen Am tiefen Grund der
Felsen auf, Und\n"
+ + "Fels und Meer wird fortgerissen Im ewig schnellem
Sphaerenlauf.\n"
+ + "MICHAEL: Und Stuerme brausen um die Wette Vom Meer aufs
Land, vom Land\n"
+ + "aufs Meer, und bilden wuetend eine Kette Der tiefsten
Wirkung rings umher.\n"
+ + "Da flammt ein blitzendes Verheeren Dem Pfade vor des
Donnerschlags. Doch\n"
+ + "deine Boten, Herr, verehren Das sanfte Wandeln deines Tags.";
+
+ @ClassRule
+ public static TemporaryFolder tempFolder = new TemporaryFolder();
+
+ private static MiniClusterResource miniClusterResource;
+ private static MiniDFSCluster hdfsCluster;
+ private static Configuration conf = new Configuration();
+
+ private static Path testFile;
+ private static Path testDir;
+
+ @BeforeClass
+ public static void setup() throws Exception {
+ File dataDir = tempFolder.newFolder();
+
+ conf.set(MiniDFSCluster.HDFS_MINIDFS_BASEDIR,
dataDir.getAbsolutePath());
+ MiniDFSCluster.Builder builder = new
MiniDFSCluster.Builder(conf);
+ hdfsCluster = builder.build();
+
+ String hdfsURI = "hdfs://"
+ +
NetUtils.hostAndPortToUrlString(hdfsCluster.getURI().getHost(),
hdfsCluster.getNameNodePort())
+ + "/";
+
+ miniClusterResource = new MiniClusterResource(
--- End diff --
is it necessary that the flink cluster is started afte rthe dfs cluster?
Otherwise you could use this as a JUnit `Rule`,
---
[jira] [Commented] (FLINK-9366) Distribute Cache only works for client-accessible files
[
https://issues.apache.org/jira/browse/FLINK-9366?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497162#comment-16497162
]
ASF GitHub Bot commented on FLINK-9366:
---
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/6107#discussion_r192234433
--- Diff:
flink-fs-tests/src/test/java/org/apache/flink/hdfstests/DistributedCacheDfsTest.java
---
@@ -0,0 +1,166 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.hdfstests;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.core.fs.FileStatus;
+import org.apache.flink.core.fs.FileSystem;
+import org.apache.flink.core.fs.Path;
+import
org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.test.util.MiniClusterResource;
+import org.apache.flink.util.NetUtils;
+
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.hdfs.MiniDFSCluster;
+import org.junit.AfterClass;
+import org.junit.BeforeClass;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+
+import java.io.DataInputStream;
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.net.URI;
+
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.assertTrue;
+
+/**
+ * Tests for distributing files with {@link
org.apache.flink.api.common.cache.DistributedCache} via HDFS.
+ */
+public class DistributedCacheDfsTest {
+
+ private static final String testFileContent = "Goethe - Faust: Der
Tragoedie erster Teil\n" + "Prolog im Himmel.\n"
+ + "Der Herr. Die himmlischen Heerscharen. Nachher
Mephistopheles. Die drei\n" + "Erzengel treten vor.\n"
+ + "RAPHAEL: Die Sonne toent, nach alter Weise, In
Brudersphaeren Wettgesang,\n"
+ + "Und ihre vorgeschriebne Reise Vollendet sie mit Donnergang.
Ihr Anblick\n"
+ + "gibt den Engeln Staerke, Wenn keiner Sie ergruenden mag; die
unbegreiflich\n"
+ + "hohen Werke Sind herrlich wie am ersten Tag.\n"
+ + "GABRIEL: Und schnell und unbegreiflich schnelle Dreht sich
umher der Erde\n"
+ + "Pracht; Es wechselt Paradieseshelle Mit tiefer,
schauervoller Nacht. Es\n"
+ + "schaeumt das Meer in breiten Fluessen Am tiefen Grund der
Felsen auf, Und\n"
+ + "Fels und Meer wird fortgerissen Im ewig schnellem
Sphaerenlauf.\n"
+ + "MICHAEL: Und Stuerme brausen um die Wette Vom Meer aufs
Land, vom Land\n"
+ + "aufs Meer, und bilden wuetend eine Kette Der tiefsten
Wirkung rings umher.\n"
+ + "Da flammt ein blitzendes Verheeren Dem Pfade vor des
Donnerschlags. Doch\n"
+ + "deine Boten, Herr, verehren Das sanfte Wandeln deines Tags.";
+
+ @ClassRule
+ public static TemporaryFolder tempFolder = new TemporaryFolder();
+
+ private static MiniClusterResource miniClusterResource;
+ private static MiniDFSCluster hdfsCluster;
+ private static Configuration conf = new Configuration();
+
+ private static Path testFile;
+ private static Path testDir;
+
+ @BeforeClass
+ public static void setup() throws Exception {
+ File dataDir = tempFolder.newFolder();
+
+ conf.set(MiniDFSCluster.HDFS_MINIDFS_BASEDIR,
dataDir.getAbsolutePath());
+ MiniDFSCluster.Builder builder = new
MiniDFSCluster.Builder(conf);
+ hdfsCluster = builder.build();
+
+ String hdfsURI = "hdfs://"
+ +
NetUtils.hostAndPortToUrlString(hdfsCluster.getURI().getHost(),
hdfsCluster.getNameNodePort())
+ + "/";
+
+ miniClusterResource = new MiniClusterResource(
--- End diff --
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[
https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497114#comment-16497114
]
ASF GitHub Bot commented on FLINK-7689:
---
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r19854
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -41,6 +46,11 @@
public class JDBCOutputFormat extends RichOutputFormat {
private static final long serialVersionUID = 1L;
static final int DEFAULT_BATCH_INTERVAL = 5000;
+ static final String FLUSH_SCOPE = "flush";
+ static final String FLUSH_RATE_METER_NAME = "rate";
--- End diff --
I'm not convinced of the naming scheme. I would replace `FLUSH_SCOPE` with
"jdbc", and explicitly prefix the rate and duration metrics with "flush".
> Instrument the Flink JDBC sink
> --
>
> Key: FLINK-7689
> URL: https://issues.apache.org/jira/browse/FLINK-7689
> Project: Flink
> Issue Type: Improvement
> Components: Streaming Connectors
>Affects Versions: 1.4.0
>Reporter: Martin Eden
>Priority: Minor
> Labels: jdbc, metrics
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> As confirmed by the Flink community in the following mailing list
> [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html]
> using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra
> sink etc does not expose any sink specific metrics.
> The purpose of this ticket is to add some relevant metrics to the
> JDBCOutputFormat:
> - Meters for when a flush is made.
> - Histograms for the jdbc batch count and batch execution latency.
> These would allow deeper understanding of the runtime behaviour of
> performance critical jobs writing to external databases using this generic
> interface.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r192223629
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -207,13 +238,18 @@ public void writeRecord(Row row) throws IOException {
if (batchCount >= batchInterval) {
// execute batch
+ batchLimitReachedMeter.markEvent();
--- End diff --
this seems redundant given that `flushMeter` exists. While the job is
running `batchLimit == flushMeter`, and at the end `batchLimit == flushMeter
-1` except in the exceedingly rare case that the total number of rows fits
perfectly into the batches.
---
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[ https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497110#comment-16497110 ] ASF GitHub Bot commented on FLINK-7689: --- Github user zentol commented on a diff in the pull request: https://github.com/apache/flink/pull/4725#discussion_r19532 --- Diff: flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java --- @@ -58,6 +68,11 @@ private int[] typesArray; + private Meter batchLimitReachedMeter; + private Meter flushMeter; --- End diff -- These could be initialized in the constructor and made final. > Instrument the Flink JDBC sink > -- > > Key: FLINK-7689 > URL: https://issues.apache.org/jira/browse/FLINK-7689 > Project: Flink > Issue Type: Improvement > Components: Streaming Connectors >Affects Versions: 1.4.0 >Reporter: Martin Eden >Priority: Minor > Labels: jdbc, metrics > Original Estimate: 24h > Remaining Estimate: 24h > > As confirmed by the Flink community in the following mailing list > [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html] > using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra > sink etc does not expose any sink specific metrics. > The purpose of this ticket is to add some relevant metrics to the > JDBCOutputFormat: > - Meters for when a flush is made. > - Histograms for the jdbc batch count and batch execution latency. > These would allow deeper understanding of the runtime behaviour of > performance critical jobs writing to external databases using this generic > interface. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[
https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497115#comment-16497115
]
ASF GitHub Bot commented on FLINK-7689:
---
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r192224177
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -207,13 +238,18 @@ public void writeRecord(Row row) throws IOException {
if (batchCount >= batchInterval) {
// execute batch
+ batchLimitReachedMeter.markEvent();
flush();
}
}
void flush() {
try {
+ flushMeter.markEvent();
+ flushBatchCountHisto.update(batchCount);
+ long before = System.currentTimeMillis();
upload.executeBatch();
+ flushDurationMsHisto.update(System.currentTimeMillis()
- before);
--- End diff --
This may result in a negative duration.
> Instrument the Flink JDBC sink
> --
>
> Key: FLINK-7689
> URL: https://issues.apache.org/jira/browse/FLINK-7689
> Project: Flink
> Issue Type: Improvement
> Components: Streaming Connectors
>Affects Versions: 1.4.0
>Reporter: Martin Eden
>Priority: Minor
> Labels: jdbc, metrics
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> As confirmed by the Flink community in the following mailing list
> [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html]
> using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra
> sink etc does not expose any sink specific metrics.
> The purpose of this ticket is to add some relevant metrics to the
> JDBCOutputFormat:
> - Meters for when a flush is made.
> - Histograms for the jdbc batch count and batch execution latency.
> These would allow deeper understanding of the runtime behaviour of
> performance critical jobs writing to external databases using this generic
> interface.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r19445
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -82,6 +97,22 @@ public void open(int taskNumber, int numTasks) throws
IOException {
} catch (ClassNotFoundException cnfe) {
throw new IllegalArgumentException("JDBC driver class
not found.", cnfe);
}
+ this.flushMeter = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .meter(FLUSH_RATE_METER_NAME, new
DropwizardMeterWrapper(new com.codahale.metrics.Meter()));
--- End diff --
These could be replaced with the built-in `MeterView`.
---
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r192224177
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -207,13 +238,18 @@ public void writeRecord(Row row) throws IOException {
if (batchCount >= batchInterval) {
// execute batch
+ batchLimitReachedMeter.markEvent();
flush();
}
}
void flush() {
try {
+ flushMeter.markEvent();
+ flushBatchCountHisto.update(batchCount);
+ long before = System.currentTimeMillis();
upload.executeBatch();
+ flushDurationMsHisto.update(System.currentTimeMillis()
- before);
--- End diff --
This may result in a negative duration.
---
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r19854
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -41,6 +46,11 @@
public class JDBCOutputFormat extends RichOutputFormat {
private static final long serialVersionUID = 1L;
static final int DEFAULT_BATCH_INTERVAL = 5000;
+ static final String FLUSH_SCOPE = "flush";
+ static final String FLUSH_RATE_METER_NAME = "rate";
--- End diff --
I'm not convinced of the naming scheme. I would replace `FLUSH_SCOPE` with
"jdbc", and explicitly prefix the rate and duration metrics with "flush".
---
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request: https://github.com/apache/flink/pull/4725#discussion_r19532 --- Diff: flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java --- @@ -58,6 +68,11 @@ private int[] typesArray; + private Meter batchLimitReachedMeter; + private Meter flushMeter; --- End diff -- These could be initialized in the constructor and made final. ---
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[ https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497112#comment-16497112 ] ASF GitHub Bot commented on FLINK-7689: --- Github user zentol commented on a diff in the pull request: https://github.com/apache/flink/pull/4725#discussion_r19079 --- Diff: flink-connectors/flink-jdbc/pom.xml --- @@ -59,5 +59,11 @@ under the License. 10.10.1.1 test + + + org.apache.flink + flink-metrics-dropwizard --- End diff -- We should exclusively rely on built-in metrics. > Instrument the Flink JDBC sink > -- > > Key: FLINK-7689 > URL: https://issues.apache.org/jira/browse/FLINK-7689 > Project: Flink > Issue Type: Improvement > Components: Streaming Connectors >Affects Versions: 1.4.0 >Reporter: Martin Eden >Priority: Minor > Labels: jdbc, metrics > Original Estimate: 24h > Remaining Estimate: 24h > > As confirmed by the Flink community in the following mailing list > [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html] > using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra > sink etc does not expose any sink specific metrics. > The purpose of this ticket is to add some relevant metrics to the > JDBCOutputFormat: > - Meters for when a flush is made. > - Histograms for the jdbc batch count and batch execution latency. > These would allow deeper understanding of the runtime behaviour of > performance critical jobs writing to external databases using this generic > interface. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r19379
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -82,6 +97,22 @@ public void open(int taskNumber, int numTasks) throws
IOException {
} catch (ClassNotFoundException cnfe) {
throw new IllegalArgumentException("JDBC driver class
not found.", cnfe);
}
+ this.flushMeter = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .meter(FLUSH_RATE_METER_NAME, new
DropwizardMeterWrapper(new com.codahale.metrics.Meter()));
+ this.batchLimitReachedMeter = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .meter(BATCH_LIMIT_REACHED_RATE_METER_NAME, new
DropwizardMeterWrapper(new com.codahale.metrics.Meter()));
+ this.flushDurationMsHisto = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .histogram(FLUSH_DURATION_HISTO_NAME, new
DropwizardHistogramWrapper(new com.codahale.metrics.Histogram(new
ExponentiallyDecayingReservoir(;
--- End diff --
I recommend staying away form histograms as long as possible. Most metric
backends recommend to _not_ build histograms in the application, but let the
backend handle it.
---
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[
https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497113#comment-16497113
]
ASF GitHub Bot commented on FLINK-7689:
---
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r192223629
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -207,13 +238,18 @@ public void writeRecord(Row row) throws IOException {
if (batchCount >= batchInterval) {
// execute batch
+ batchLimitReachedMeter.markEvent();
--- End diff --
this seems redundant given that `flushMeter` exists. While the job is
running `batchLimit == flushMeter`, and at the end `batchLimit == flushMeter
-1` except in the exceedingly rare case that the total number of rows fits
perfectly into the batches.
> Instrument the Flink JDBC sink
> --
>
> Key: FLINK-7689
> URL: https://issues.apache.org/jira/browse/FLINK-7689
> Project: Flink
> Issue Type: Improvement
> Components: Streaming Connectors
>Affects Versions: 1.4.0
>Reporter: Martin Eden
>Priority: Minor
> Labels: jdbc, metrics
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> As confirmed by the Flink community in the following mailing list
> [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html]
> using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra
> sink etc does not expose any sink specific metrics.
> The purpose of this ticket is to add some relevant metrics to the
> JDBCOutputFormat:
> - Meters for when a flush is made.
> - Histograms for the jdbc batch count and batch execution latency.
> These would allow deeper understanding of the runtime behaviour of
> performance critical jobs writing to external databases using this generic
> interface.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[
https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497109#comment-16497109
]
ASF GitHub Bot commented on FLINK-7689:
---
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r19445
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -82,6 +97,22 @@ public void open(int taskNumber, int numTasks) throws
IOException {
} catch (ClassNotFoundException cnfe) {
throw new IllegalArgumentException("JDBC driver class
not found.", cnfe);
}
+ this.flushMeter = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .meter(FLUSH_RATE_METER_NAME, new
DropwizardMeterWrapper(new com.codahale.metrics.Meter()));
--- End diff --
These could be replaced with the built-in `MeterView`.
> Instrument the Flink JDBC sink
> --
>
> Key: FLINK-7689
> URL: https://issues.apache.org/jira/browse/FLINK-7689
> Project: Flink
> Issue Type: Improvement
> Components: Streaming Connectors
>Affects Versions: 1.4.0
>Reporter: Martin Eden
>Priority: Minor
> Labels: jdbc, metrics
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> As confirmed by the Flink community in the following mailing list
> [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html]
> using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra
> sink etc does not expose any sink specific metrics.
> The purpose of this ticket is to add some relevant metrics to the
> JDBCOutputFormat:
> - Meters for when a flush is made.
> - Histograms for the jdbc batch count and batch execution latency.
> These would allow deeper understanding of the runtime behaviour of
> performance critical jobs writing to external databases using this generic
> interface.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-7689) Instrument the Flink JDBC sink
[
https://issues.apache.org/jira/browse/FLINK-7689?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497111#comment-16497111
]
ASF GitHub Bot commented on FLINK-7689:
---
Github user zentol commented on a diff in the pull request:
https://github.com/apache/flink/pull/4725#discussion_r19379
--- Diff:
flink-connectors/flink-jdbc/src/main/java/org/apache/flink/api/java/io/jdbc/JDBCOutputFormat.java
---
@@ -82,6 +97,22 @@ public void open(int taskNumber, int numTasks) throws
IOException {
} catch (ClassNotFoundException cnfe) {
throw new IllegalArgumentException("JDBC driver class
not found.", cnfe);
}
+ this.flushMeter = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .meter(FLUSH_RATE_METER_NAME, new
DropwizardMeterWrapper(new com.codahale.metrics.Meter()));
+ this.batchLimitReachedMeter = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .meter(BATCH_LIMIT_REACHED_RATE_METER_NAME, new
DropwizardMeterWrapper(new com.codahale.metrics.Meter()));
+ this.flushDurationMsHisto = getRuntimeContext()
+ .getMetricGroup()
+ .addGroup(FLUSH_SCOPE)
+ .histogram(FLUSH_DURATION_HISTO_NAME, new
DropwizardHistogramWrapper(new com.codahale.metrics.Histogram(new
ExponentiallyDecayingReservoir(;
--- End diff --
I recommend staying away form histograms as long as possible. Most metric
backends recommend to _not_ build histograms in the application, but let the
backend handle it.
> Instrument the Flink JDBC sink
> --
>
> Key: FLINK-7689
> URL: https://issues.apache.org/jira/browse/FLINK-7689
> Project: Flink
> Issue Type: Improvement
> Components: Streaming Connectors
>Affects Versions: 1.4.0
>Reporter: Martin Eden
>Priority: Minor
> Labels: jdbc, metrics
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> As confirmed by the Flink community in the following mailing list
> [message|http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/metrics-for-Flink-sinks-td15200.html]
> using off the shelf Flink sinks like the JDBC sink, Redis sink or Cassandra
> sink etc does not expose any sink specific metrics.
> The purpose of this ticket is to add some relevant metrics to the
> JDBCOutputFormat:
> - Meters for when a flush is made.
> - Histograms for the jdbc batch count and batch execution latency.
> These would allow deeper understanding of the runtime behaviour of
> performance critical jobs writing to external databases using this generic
> interface.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #4725: [FLINK-7689] [Streaming Connectors] Added metrics ...
Github user zentol commented on a diff in the pull request: https://github.com/apache/flink/pull/4725#discussion_r19079 --- Diff: flink-connectors/flink-jdbc/pom.xml --- @@ -59,5 +59,11 @@ under the License. 10.10.1.1 test + + + org.apache.flink + flink-metrics-dropwizard --- End diff -- We should exclusively rely on built-in metrics. ---
[jira] [Commented] (FLINK-8873) move unit tests of KeyedStream from DataStreamTest to KeyedStreamTest
[ https://issues.apache.org/jira/browse/FLINK-8873?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16497038#comment-16497038 ] ASF GitHub Bot commented on FLINK-8873: --- Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/5649 > move unit tests of KeyedStream from DataStreamTest to KeyedStreamTest > - > > Key: FLINK-8873 > URL: https://issues.apache.org/jira/browse/FLINK-8873 > Project: Flink > Issue Type: Improvement > Components: DataStream API, Tests >Affects Versions: 1.5.0 >Reporter: Bowen Li >Assignee: Bowen Li >Priority: Minor > Fix For: 1.6.0 > > > move unit tests of KeyedStream.scala from DataStreamTest.scala to > KeyedStreamTest.scala, in order to have clearer separation -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5649: [FLINK-8873] [DataStream API] [Tests] move unit te...
Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/5649 ---
[jira] [Commented] (FLINK-9458) Unable to recover from job failure on YARN with NPE
[
https://issues.apache.org/jira/browse/FLINK-9458?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496954#comment-16496954
]
ASF GitHub Bot commented on FLINK-9458:
---
Github user kkrugler commented on the issue:
https://github.com/apache/flink/pull/6101
One other note - I ran into this problem, but it wasn't on YARN. It was
running locally (via unit test triggered in Eclipse).
> Unable to recover from job failure on YARN with NPE
> ---
>
> Key: FLINK-9458
> URL: https://issues.apache.org/jira/browse/FLINK-9458
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.5.0
> Environment: Ambari HDP 2.6.3
> Hadoop 2.7.3
>
> Job configuration:
> 120 Task Managers x 1 slots
>
>
>Reporter: Truong Duc Kien
>Assignee: vinoyang
>Priority: Blocker
> Fix For: 1.6.0, 1.5.1
>
>
> After upgrading our job to Flink 1.5, they are unable to recover from failure
> with the following exception appears repeatedly
> {noformat}
> 2018-05-29 04:56:06,086 [ jobmanager-future-thread-36] INFO
> o.a.f.r.e.ExecutionGraph Try to restart or fail the job xxx
> (23d9e87bf43ce163ff7db8afb062fb1d) if no longer possible.
> 2018-05-29 04:56:06,086 [ jobmanager-future-thread-36] INFO
> o.a.f.r.e.ExecutionGraph Job xxx (23d9e87bf43ce163ff7db8afb062fb1d) switched
> from state RESTARTING to RESTARTING.
> 2018-05-29 04:56:06,086 [ jobmanager-future-thread-36] INFO
> o.a.f.r.e.ExecutionGraph Restarting the job xxx
> (23d9e87bf43ce163ff7db8afb062fb1d).
> 2018-05-29 04:57:06,086 [ jobmanager-future-thread-36] WARN
> o.a.f.r.e.ExecutionGraph Failed to restart the job.
> java.lang.NullPointerException at
> org.apache.flink.runtime.jobmanager.scheduler.CoLocationConstraint.isAssignedAndAlive(CoLocationConstraint.java:104)
> at
> org.apache.flink.runtime.jobmanager.scheduler.CoLocationGroup.resetConstraints(CoLocationGroup.java:119)
> at
> org.apache.flink.runtime.executiongraph.ExecutionGraph.restart(ExecutionGraph.java:1247)
> at
> org.apache.flink.runtime.executiongraph.restart.ExecutionGraphRestartCallback.triggerFullRecovery(ExecutionGraphRestartCallback.java:59)
> at
> org.apache.flink.runtime.executiongraph.restart.FixedDelayRestartStrategy$1.run(FixedDelayRestartStrategy.java:68)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at
> java.util.concurrent.FutureTask.run(FutureTask.java:266) at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #6101: [FLINK-9458] Unable to recover from job failure on YARN w...
Github user kkrugler commented on the issue: https://github.com/apache/flink/pull/6101 One other note - I ran into this problem, but it wasn't on YARN. It was running locally (via unit test triggered in Eclipse). ---
[jira] [Commented] (FLINK-9458) Unable to recover from job failure on YARN with NPE
[
https://issues.apache.org/jira/browse/FLINK-9458?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496952#comment-16496952
]
ASF GitHub Bot commented on FLINK-9458:
---
Github user kkrugler commented on the issue:
https://github.com/apache/flink/pull/6101
I'm wondering why, now, we're encountering cases where the `sharedSlot`
value is null? Seems like this could be caused by a deeper problem somewhere,
so just adding the null check is masking something else that should be fixed.
Also, seems like we'd want a test case to verify the failure (pre-fix) and
then appropriate behavior with the fix.
> Unable to recover from job failure on YARN with NPE
> ---
>
> Key: FLINK-9458
> URL: https://issues.apache.org/jira/browse/FLINK-9458
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.5.0
> Environment: Ambari HDP 2.6.3
> Hadoop 2.7.3
>
> Job configuration:
> 120 Task Managers x 1 slots
>
>
>Reporter: Truong Duc Kien
>Assignee: vinoyang
>Priority: Blocker
> Fix For: 1.6.0, 1.5.1
>
>
> After upgrading our job to Flink 1.5, they are unable to recover from failure
> with the following exception appears repeatedly
> {noformat}
> 2018-05-29 04:56:06,086 [ jobmanager-future-thread-36] INFO
> o.a.f.r.e.ExecutionGraph Try to restart or fail the job xxx
> (23d9e87bf43ce163ff7db8afb062fb1d) if no longer possible.
> 2018-05-29 04:56:06,086 [ jobmanager-future-thread-36] INFO
> o.a.f.r.e.ExecutionGraph Job xxx (23d9e87bf43ce163ff7db8afb062fb1d) switched
> from state RESTARTING to RESTARTING.
> 2018-05-29 04:56:06,086 [ jobmanager-future-thread-36] INFO
> o.a.f.r.e.ExecutionGraph Restarting the job xxx
> (23d9e87bf43ce163ff7db8afb062fb1d).
> 2018-05-29 04:57:06,086 [ jobmanager-future-thread-36] WARN
> o.a.f.r.e.ExecutionGraph Failed to restart the job.
> java.lang.NullPointerException at
> org.apache.flink.runtime.jobmanager.scheduler.CoLocationConstraint.isAssignedAndAlive(CoLocationConstraint.java:104)
> at
> org.apache.flink.runtime.jobmanager.scheduler.CoLocationGroup.resetConstraints(CoLocationGroup.java:119)
> at
> org.apache.flink.runtime.executiongraph.ExecutionGraph.restart(ExecutionGraph.java:1247)
> at
> org.apache.flink.runtime.executiongraph.restart.ExecutionGraphRestartCallback.triggerFullRecovery(ExecutionGraphRestartCallback.java:59)
> at
> org.apache.flink.runtime.executiongraph.restart.FixedDelayRestartStrategy$1.run(FixedDelayRestartStrategy.java:68)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at
> java.util.concurrent.FutureTask.run(FutureTask.java:266) at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #6101: [FLINK-9458] Unable to recover from job failure on YARN w...
Github user kkrugler commented on the issue: https://github.com/apache/flink/pull/6101 I'm wondering why, now, we're encountering cases where the `sharedSlot` value is null? Seems like this could be caused by a deeper problem somewhere, so just adding the null check is masking something else that should be fixed. Also, seems like we'd want a test case to verify the failure (pre-fix) and then appropriate behavior with the fix. ---
[jira] [Commented] (FLINK-7789) Add handler for Async IO operator timeouts
[
https://issues.apache.org/jira/browse/FLINK-7789?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496871#comment-16496871
]
ASF GitHub Bot commented on FLINK-7789:
---
Github user kisimple commented on a diff in the pull request:
https://github.com/apache/flink/pull/6091#discussion_r192171522
--- Diff:
flink-streaming-scala/src/main/scala/org/apache/flink/streaming/api/scala/AsyncDataStream.scala
---
@@ -71,6 +71,9 @@ object AsyncDataStream {
override def asyncInvoke(input: IN, resultFuture:
JavaResultFuture[OUT]): Unit = {
asyncFunction.asyncInvoke(input, new
JavaResultFutureWrapper(resultFuture))
}
+ override def timeout(input: IN, resultFuture:
JavaResultFuture[OUT]): Unit = {
--- End diff --
I have added a test for `AsyncDataStream.scala`, plz review and see if it
is sufficient :)
> Add handler for Async IO operator timeouts
> ---
>
> Key: FLINK-7789
> URL: https://issues.apache.org/jira/browse/FLINK-7789
> Project: Flink
> Issue Type: Improvement
> Components: DataStream API
>Reporter: Karthik Deivasigamani
>Assignee: blues zheng
>Priority: Major
>
> Currently Async IO operator does not provide a mechanism to handle timeouts.
> When a request times out it an exception is thrown and job is restarted. It
> would be good to pass a AsyncIOTimeoutHandler which can be implemented by the
> user and passed in the constructor.
> Here is the discussion from apache flink users mailing list
> http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/async-io-operator-timeouts-tt16068.html
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #6091: [FLINK-7789][DataStream API] Add handler for Async...
Github user kisimple commented on a diff in the pull request:
https://github.com/apache/flink/pull/6091#discussion_r192171522
--- Diff:
flink-streaming-scala/src/main/scala/org/apache/flink/streaming/api/scala/AsyncDataStream.scala
---
@@ -71,6 +71,9 @@ object AsyncDataStream {
override def asyncInvoke(input: IN, resultFuture:
JavaResultFuture[OUT]): Unit = {
asyncFunction.asyncInvoke(input, new
JavaResultFutureWrapper(resultFuture))
}
+ override def timeout(input: IN, resultFuture:
JavaResultFuture[OUT]): Unit = {
--- End diff --
I have added a test for `AsyncDataStream.scala`, plz review and see if it
is sufficient :)
---
[jira] [Commented] (FLINK-9444) KafkaAvroTableSource failed to work for map and array fields
[ https://issues.apache.org/jira/browse/FLINK-9444?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496732#comment-16496732 ] ASF GitHub Bot commented on FLINK-9444: --- Github user tragicjun commented on the issue: https://github.com/apache/flink/pull/6082 @twalthr @suez1224 would you please review on this? > KafkaAvroTableSource failed to work for map and array fields > > > Key: FLINK-9444 > URL: https://issues.apache.org/jira/browse/FLINK-9444 > Project: Flink > Issue Type: Bug > Components: Kafka Connector, Table API SQL >Affects Versions: 1.6.0 >Reporter: Jun Zhang >Priority: Blocker > Labels: patch > Fix For: 1.6.0 > > Attachments: flink-9444.patch > > > When some Avro schema has map/array fields and the corresponding TableSchema > declares *MapTypeInfo/ListTypeInfo* for these fields, an exception will be > thrown when registering the *KafkaAvroTableSource*, complaining like: > Exception in thread "main" org.apache.flink.table.api.ValidationException: > Type Map of table field 'event' does not match with type > GenericType of the field 'event' of the TableSource return > type. > at org.apache.flink.table.api.ValidationException$.apply(exceptions.scala:74) > at > org.apache.flink.table.sources.TableSourceUtil$$anonfun$validateTableSource$1.apply(TableSourceUtil.scala:92) > at > org.apache.flink.table.sources.TableSourceUtil$$anonfun$validateTableSource$1.apply(TableSourceUtil.scala:71) > at > scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33) > at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186) > at > org.apache.flink.table.sources.TableSourceUtil$.validateTableSource(TableSourceUtil.scala:71) > at > org.apache.flink.table.plan.schema.StreamTableSourceTable.(StreamTableSourceTable.scala:33) > at > org.apache.flink.table.api.StreamTableEnvironment.registerTableSourceInternal(StreamTableEnvironment.scala:124) > at > org.apache.flink.table.api.TableEnvironment.registerTableSource(TableEnvironment.scala:438) -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #6082: [FLINK-9444][table] KafkaAvroTableSource failed to work f...
Github user tragicjun commented on the issue: https://github.com/apache/flink/pull/6082 @twalthr @suez1224 would you please review on this? ---
[jira] [Commented] (FLINK-9257) End-to-end tests prints "All tests PASS" even if individual test-script returns non-zero exit code
[
https://issues.apache.org/jira/browse/FLINK-9257?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496710#comment-16496710
]
ASF GitHub Bot commented on FLINK-9257:
---
Github user florianschmidt1994 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6053#discussion_r192139268
--- Diff: flink-end-to-end-tests/test-scripts/test-runner-common.sh ---
@@ -0,0 +1,76 @@
+#!/usr/bin/env bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+source "$(pwd)"/test-scripts/common.sh
+
+###
+# Prints the given description, runs the given test and prints how long
the execution took.
+# Arguments:
+# $1: description of the test
+# $2: command to execute
+###
+function run_test {
+description="$1"
+command="$2"
+
+printf
"\n==\n"
+printf "Running '${description}'\n"
+printf
"==\n"
+start_timer
+${command}
+exit_code="$?"
+time_elapsed=$(end_timer)
+
+check_logs_for_errors
+check_logs_for_exceptions
+check_logs_for_non_empty_out_files
--- End diff --
We have been discussing about changing the semantics at some point to leave
it up to each individual test case to check the logs for errors and drop it
from the test runner, maybe even with a whitelist / blacklist approach of
expected exceptions. If we want to go that way I'd say leave it in common.sh
We could also say we're probably gonna stick with the current approach for
a while, then I'd say let's move them to test-runner-common.sh
> End-to-end tests prints "All tests PASS" even if individual test-script
> returns non-zero exit code
> --
>
> Key: FLINK-9257
> URL: https://issues.apache.org/jira/browse/FLINK-9257
> Project: Flink
> Issue Type: Bug
> Components: Tests
>Affects Versions: 1.5.0
>Reporter: Florian Schmidt
>Assignee: Florian Schmidt
>Priority: Critical
> Fix For: 1.6.0
>
>
> In some cases the test-suite exits with non-zero exit code but still prints
> "All tests PASS" to stdout. This happens because how the test runner works,
> which is roughly as follows
> # Either run-nightly-tests.sh or run-precommit-tests.sh executes a suite of
> tests consisting of one multiple bash scripts.
> # As soon as one of those bash scripts exists with non-zero exit code, the
> tests won't continue to run and the test-suite will also exit with non-zero
> exit code.
> # *During the cleanup hook (trap cleanup EXIT in common.sh) it will be
> checked whether there are non-empty out files or log files with certain
> exceptions. If a tests fails with non-zero exit code, but does not have any
> exceptions or .out files, this will still print "All tests PASS" to stdout,
> even though they don't*
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #6053: [FLINK-9257][E2E Tests] Fix wrong "All tests pass"...
Github user florianschmidt1994 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6053#discussion_r192139268
--- Diff: flink-end-to-end-tests/test-scripts/test-runner-common.sh ---
@@ -0,0 +1,76 @@
+#!/usr/bin/env bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+source "$(pwd)"/test-scripts/common.sh
+
+###
+# Prints the given description, runs the given test and prints how long
the execution took.
+# Arguments:
+# $1: description of the test
+# $2: command to execute
+###
+function run_test {
+description="$1"
+command="$2"
+
+printf
"\n==\n"
+printf "Running '${description}'\n"
+printf
"==\n"
+start_timer
+${command}
+exit_code="$?"
+time_elapsed=$(end_timer)
+
+check_logs_for_errors
+check_logs_for_exceptions
+check_logs_for_non_empty_out_files
--- End diff --
We have been discussing about changing the semantics at some point to leave
it up to each individual test case to check the logs for errors and drop it
from the test runner, maybe even with a whitelist / blacklist approach of
expected exceptions. If we want to go that way I'd say leave it in common.sh
We could also say we're probably gonna stick with the current approach for
a while, then I'd say let's move them to test-runner-common.sh
---
[jira] [Assigned] (FLINK-9353) End-to-end test: Kubernetes integration
[ https://issues.apache.org/jira/browse/FLINK-9353?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Aljoscha Krettek reassigned FLINK-9353: --- Assignee: Aljoscha Krettek > End-to-end test: Kubernetes integration > --- > > Key: FLINK-9353 > URL: https://issues.apache.org/jira/browse/FLINK-9353 > Project: Flink > Issue Type: Sub-task > Components: Tests >Reporter: Aljoscha Krettek >Assignee: Aljoscha Krettek >Priority: Blocker > Fix For: 1.6.0 > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-9482) Not applicable functions for TIME
[
https://issues.apache.org/jira/browse/FLINK-9482?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Viktor Vlasov updated FLINK-9482:
-
Component/s: Table API & SQL
> Not applicable functions for TIME
> -
>
> Key: FLINK-9482
> URL: https://issues.apache.org/jira/browse/FLINK-9482
> Project: Flink
> Issue Type: Bug
> Components: Table API SQL
>Reporter: Viktor Vlasov
>Priority: Minor
>
> Due to work on https://issues.apache.org/jira/browse/FLINK-9432 I have faced
> with question how to check DECADE function with tests in
> _org/apache/flink/table/expressions/validation/ScalarFunctionsValidationTest.scala._
>
> Because I have used CENTURY function as an example, first of all I have check
> it. During the test I figured out that when we use it with TIME it returns 0.
> I suppose arguments for such functions (also it works for YEAR, MONTH,
> MILLENNIUM, etc) need to be checked and throw some exception if type is not
> suitable.
> As an example, in Apache Calcite project (checked in sqlline shell), when I
> am trying to use CENTURY with TIME it throw:
> {code:java}
> java.lang.AssertionError: unexpected TIME
> {code}
> Need to determine, why such check is not exists and add it.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-9482) Not applicable functions for TIME
[
https://issues.apache.org/jira/browse/FLINK-9482?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Viktor Vlasov updated FLINK-9482:
-
Description:
Due to work on https://issues.apache.org/jira/browse/FLINK-9432 I have faced
with question how to check DECADE function with tests in
_org/apache/flink/table/expressions/validation/ScalarFunctionsValidationTest.scala._
Because I have used CENTURY function as an example, first of all I have check
it. During the test I figured out that when we use it with TIME it returns 0.
I suppose arguments for such functions (also it works for YEAR, MONTH,
MILLENNIUM, etc) need to be checked and throw some exception if type is not
suitable.
As an example, in Apache Calcite project (checked in sqlline shell), when I am
trying to use CENTURY with TIME it throw:
{code:java}
java.lang.AssertionError: unexpected TIME
{code}
Need to determine, why such check is not exists and add it.
> Not applicable functions for TIME
> -
>
> Key: FLINK-9482
> URL: https://issues.apache.org/jira/browse/FLINK-9482
> Project: Flink
> Issue Type: Bug
>Reporter: Viktor Vlasov
>Priority: Minor
>
> Due to work on https://issues.apache.org/jira/browse/FLINK-9432 I have faced
> with question how to check DECADE function with tests in
> _org/apache/flink/table/expressions/validation/ScalarFunctionsValidationTest.scala._
>
> Because I have used CENTURY function as an example, first of all I have check
> it. During the test I figured out that when we use it with TIME it returns 0.
> I suppose arguments for such functions (also it works for YEAR, MONTH,
> MILLENNIUM, etc) need to be checked and throw some exception if type is not
> suitable.
> As an example, in Apache Calcite project (checked in sqlline shell), when I
> am trying to use CENTURY with TIME it throw:
> {code:java}
> java.lang.AssertionError: unexpected TIME
> {code}
> Need to determine, why such check is not exists and add it.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (FLINK-9482) Not applicable functions for TIME
Viktor Vlasov created FLINK-9482: Summary: Not applicable functions for TIME Key: FLINK-9482 URL: https://issues.apache.org/jira/browse/FLINK-9482 Project: Flink Issue Type: Bug Reporter: Viktor Vlasov -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-9343) Add Async Example with External Rest API call
[ https://issues.apache.org/jira/browse/FLINK-9343?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496534#comment-16496534 ] ASF GitHub Bot commented on FLINK-9343: --- Github user medcv commented on the issue: https://github.com/apache/flink/pull/5996 @StephanEwen PR is updated as requested! I would appreciate if you review. > Add Async Example with External Rest API call > - > > Key: FLINK-9343 > URL: https://issues.apache.org/jira/browse/FLINK-9343 > Project: Flink > Issue Type: Improvement > Components: Examples >Affects Versions: 1.4.0, 1.4.1, 1.4.2 >Reporter: Yazdan Shirvany >Assignee: Yazdan Shirvany >Priority: Minor > > Async I/O is a good way to call External resources such as REST API and > enrich the stream with external data. > Adding example to simulate Async GET api call on an input stream. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #5996: [FLINK-9343] [Example] Add Async Example with External Re...
Github user medcv commented on the issue: https://github.com/apache/flink/pull/5996 @StephanEwen PR is updated as requested! I would appreciate if you review. ---
[jira] [Commented] (FLINK-8983) End-to-end test: Confluent schema registry
[ https://issues.apache.org/jira/browse/FLINK-8983?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496533#comment-16496533 ] ASF GitHub Bot commented on FLINK-8983: --- Github user medcv commented on the issue: https://github.com/apache/flink/pull/6083 @tillrohrmann I would appreciate if you review or assign a reviewer to this PR. > End-to-end test: Confluent schema registry > -- > > Key: FLINK-8983 > URL: https://issues.apache.org/jira/browse/FLINK-8983 > Project: Flink > Issue Type: Sub-task > Components: Kafka Connector, Tests >Reporter: Till Rohrmann >Assignee: Yazdan Shirvany >Priority: Critical > > It would be good to add an end-to-end test which verifies that Flink is able > to work together with the Confluent schema registry. In order to do that we > have to setup a Kafka cluster and write a Flink job which reads from the > Confluent schema registry producing an Avro type. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #6083: [FLINK-8983] End-to-end test: Confluent schema registry
Github user medcv commented on the issue: https://github.com/apache/flink/pull/6083 @tillrohrmann I would appreciate if you review or assign a reviewer to this PR. ---
[jira] [Commented] (FLINK-8654) Extend quickstart docs on how to submit jobs
[ https://issues.apache.org/jira/browse/FLINK-8654?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496530#comment-16496530 ] ASF GitHub Bot commented on FLINK-8654: --- Github user medcv commented on the issue: https://github.com/apache/flink/pull/6084 @zentol Please review > Extend quickstart docs on how to submit jobs > > > Key: FLINK-8654 > URL: https://issues.apache.org/jira/browse/FLINK-8654 > Project: Flink > Issue Type: Improvement > Components: Documentation, Quickstarts >Affects Versions: 1.5.0 >Reporter: Chesnay Schepler >Assignee: Yazdan Shirvany >Priority: Major > > The quickstart documentation explains how to setup the project, build the jar > and run things in the IDE, but neither explains how to submit the jar to a > cluster nor guides the user to where he could find this information (like the > CLI docs). > Additionally, the quickstart poms should also contain the commands for > submitting the jar to a cluster, in particular how to select a main-class if > it wasn't set in the pom. (-c CLI flag) -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-9451) End-to-end test: Scala Quickstarts
[
https://issues.apache.org/jira/browse/FLINK-9451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496529#comment-16496529
]
ASF GitHub Bot commented on FLINK-9451:
---
Github user medcv commented on the issue:
https://github.com/apache/flink/pull/6089
@zentol PR is updated with requested changes! Please review
> End-to-end test: Scala Quickstarts
> --
>
> Key: FLINK-9451
> URL: https://issues.apache.org/jira/browse/FLINK-9451
> Project: Flink
> Issue Type: Sub-task
> Components: Quickstarts
>Affects Versions: 1.5.0, 1.4.1, 1.4.2
>Reporter: Yazdan Shirvany
>Assignee: Yazdan Shirvany
>Priority: Blocker
>
> We could add an end-to-end test which verifies Flink's quickstarts scala. It
> should do the following:
> # create a new Flink project using the quickstarts archetype
> # add a new Flink dependency to the {{pom.xml}} (e.g. Flink connector or
> library)
> # run {{mvn clean package -Pbuild-jar}}
> # verify that no core dependencies are contained in the jar file
> # Run the program
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #6084: [FLINK-8654][Docs] Extend quickstart docs on how to submi...
Github user medcv commented on the issue: https://github.com/apache/flink/pull/6084 @zentol Please review ---
[GitHub] flink issue #6089: [FLINK-9451]End-to-end test: Scala Quickstarts
Github user medcv commented on the issue: https://github.com/apache/flink/pull/6089 @zentol PR is updated with requested changes! Please review ---
[jira] [Commented] (FLINK-9367) Truncate() in BucketingSink is only allowed after hadoop2.7
[ https://issues.apache.org/jira/browse/FLINK-9367?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496524#comment-16496524 ] ASF GitHub Bot commented on FLINK-9367: --- GitHub user zhangxinyu1 opened a pull request: https://github.com/apache/flink/pull/6108 [FLINK-9367] [Streaming Connectors] Allow to do truncate() in calss BucketingSink when hadoop version is lower than 2.7 ## What is the purpose of the change In the current implementation of class BucketingSink, we cannot use truncate() function if the hadoop version is lower than 2.7. Instead, it use a valid-length file to mark how much data is valid. However, users which reads data from HDFS may not or should not know how deal with this valid-length file. Hence, we need a configuration to decide whether use the valid-length file. If not, we should rewrite the valid file. ## Brief change log Add a function `enableForceTruncateInProgressFile()` for BucketingSink to decide whether use the valid-length file. If it's true, the valid-length file wouldn't be produced. Instead, the valid in-progress file will be rewritten. ## Verifying this change This change is a trivial work without any test coverage. You can merge this pull request into a Git repository by running: $ git pull https://github.com/zhangxinyu1/flink force-recovery-file-in-bucketingsink Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6108.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6108 commit 7c5ba6d54658916e65c40fbbed646efce2c40645 Author: unknown Date: 2018-05-31T12:52:09Z allow to do truncate() when hadoop version is lower than 2.7 > Truncate() in BucketingSink is only allowed after hadoop2.7 > --- > > Key: FLINK-9367 > URL: https://issues.apache.org/jira/browse/FLINK-9367 > Project: Flink > Issue Type: Improvement > Components: Streaming Connectors >Affects Versions: 1.5.0 >Reporter: zhangxinyu >Priority: Major > > When output to HDFS using BucketingSink, truncate() is only allowed after > hadoop2.7. > If some tasks failed, the ".valid-length" file is created for the lower > version hadoop. > The problem is, if other people want to use the data in HDFS, they must know > how to deal with the ".valid-length" file, otherwise, the data may be not > exactly-once. > I think it's not convenient for other people to use the data. Why not just > read the in-progress file and write a new file when restoring instead of > writing a ".valid-length" file. > In this way, others who use the data in HDFS don't need to know how to deal > with the ".valid-length" file. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #6108: [FLINK-9367] [Streaming Connectors] Allow to do tr...
GitHub user zhangxinyu1 opened a pull request: https://github.com/apache/flink/pull/6108 [FLINK-9367] [Streaming Connectors] Allow to do truncate() in calss BucketingSink when hadoop version is lower than 2.7 ## What is the purpose of the change In the current implementation of class BucketingSink, we cannot use truncate() function if the hadoop version is lower than 2.7. Instead, it use a valid-length file to mark how much data is valid. However, users which reads data from HDFS may not or should not know how deal with this valid-length file. Hence, we need a configuration to decide whether use the valid-length file. If not, we should rewrite the valid file. ## Brief change log Add a function `enableForceTruncateInProgressFile()` for BucketingSink to decide whether use the valid-length file. If it's true, the valid-length file wouldn't be produced. Instead, the valid in-progress file will be rewritten. ## Verifying this change This change is a trivial work without any test coverage. You can merge this pull request into a Git repository by running: $ git pull https://github.com/zhangxinyu1/flink force-recovery-file-in-bucketingsink Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6108.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6108 commit 7c5ba6d54658916e65c40fbbed646efce2c40645 Author: unknown Date: 2018-05-31T12:52:09Z allow to do truncate() when hadoop version is lower than 2.7 ---
[jira] [Commented] (FLINK-9366) Distribute Cache only works for client-accessible files
[ https://issues.apache.org/jira/browse/FLINK-9366?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496517#comment-16496517 ] ASF GitHub Bot commented on FLINK-9366: --- Github user dawidwys commented on the issue: https://github.com/apache/flink/pull/6107 Could you have a look @zentol @aljoscha ? > Distribute Cache only works for client-accessible files > --- > > Key: FLINK-9366 > URL: https://issues.apache.org/jira/browse/FLINK-9366 > Project: Flink > Issue Type: Bug > Components: Client, Local Runtime >Affects Versions: 1.6.0 >Reporter: Chesnay Schepler >Assignee: Dawid Wysakowicz >Priority: Blocker > Fix For: 1.6.0 > > > In FLINK-8620 the distributed cache was modified to the distribute files via > the blob store, instead of downloading them from a distributed filesystem. > Previously, taskmanagers would download requested files from the DFS. Now, > they retrieve it form the blob store. This requires the client to > preemptively upload all files used with distributed cache. > As a result it is no longer possible to use the distributed cache for files > that reside in a cluster-internal DFS, as the client cannot download it. This > is a regression from the previous behavior and may break existing setups. > [~aljoscha] [~dawidwys] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #6107: [FLINK-9366] DistributedCache works with Distributed File...
Github user dawidwys commented on the issue: https://github.com/apache/flink/pull/6107 Could you have a look @zentol @aljoscha ? ---
[jira] [Commented] (FLINK-9366) Distribute Cache only works for client-accessible files
[ https://issues.apache.org/jira/browse/FLINK-9366?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496516#comment-16496516 ] ASF GitHub Bot commented on FLINK-9366: --- GitHub user dawidwys opened a pull request: https://github.com/apache/flink/pull/6107 [FLINK-9366] DistributedCache works with Distributed File System ## What is the purpose of the change Allows to use DistributeCache to cache files from cluster internal DFS (reverted behaviour). ## Brief change log *(for example:)* - Local files (based on uri schema) are distributed via BlobServer - Files in DFS are cached from DFS ## Verifying this change * Added test for distributing files through DFS: org.apache.flink.hdfstests.DistributedCacheDfsTest * local files shipping covered by previous tests ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`:no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no You can merge this pull request into a Git repository by running: $ git pull https://github.com/dawidwys/flink FLINK-9366 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6107.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6107 commit cc1344d18e2b1d9953e21d5189f2813fdabd7b01 Author: Dawid Wysakowicz Date: 2018-05-31T12:35:44Z [FLINK-9366] DistributedCache works with Distributed File System > Distribute Cache only works for client-accessible files > --- > > Key: FLINK-9366 > URL: https://issues.apache.org/jira/browse/FLINK-9366 > Project: Flink > Issue Type: Bug > Components: Client, Local Runtime >Affects Versions: 1.6.0 >Reporter: Chesnay Schepler >Assignee: Dawid Wysakowicz >Priority: Blocker > Fix For: 1.6.0 > > > In FLINK-8620 the distributed cache was modified to the distribute files via > the blob store, instead of downloading them from a distributed filesystem. > Previously, taskmanagers would download requested files from the DFS. Now, > they retrieve it form the blob store. This requires the client to > preemptively upload all files used with distributed cache. > As a result it is no longer possible to use the distributed cache for files > that reside in a cluster-internal DFS, as the client cannot download it. This > is a regression from the previous behavior and may break existing setups. > [~aljoscha] [~dawidwys] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8160) Extend OperatorHarness to expose metrics
[ https://issues.apache.org/jira/browse/FLINK-8160?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496514#comment-16496514 ] ASF GitHub Bot commented on FLINK-8160: --- Github user wangtuo21 commented on the issue: https://github.com/apache/flink/pull/6047 @zentol , I misunderstood the request. Does it go in the right direction now? Thank you > Extend OperatorHarness to expose metrics > > > Key: FLINK-8160 > URL: https://issues.apache.org/jira/browse/FLINK-8160 > Project: Flink > Issue Type: Improvement > Components: Metrics, Streaming >Reporter: Chesnay Schepler >Assignee: Tuo Wang >Priority: Major > Fix For: 1.6.0 > > > To better test interactions between operators and metrics the harness should > expose the metrics registered by the operator. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #6107: [FLINK-9366] DistributedCache works with Distribut...
GitHub user dawidwys opened a pull request: https://github.com/apache/flink/pull/6107 [FLINK-9366] DistributedCache works with Distributed File System ## What is the purpose of the change Allows to use DistributeCache to cache files from cluster internal DFS (reverted behaviour). ## Brief change log *(for example:)* - Local files (based on uri schema) are distributed via BlobServer - Files in DFS are cached from DFS ## Verifying this change * Added test for distributing files through DFS: org.apache.flink.hdfstests.DistributedCacheDfsTest * local files shipping covered by previous tests ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`:no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no You can merge this pull request into a Git repository by running: $ git pull https://github.com/dawidwys/flink FLINK-9366 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6107.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6107 commit cc1344d18e2b1d9953e21d5189f2813fdabd7b01 Author: Dawid Wysakowicz Date: 2018-05-31T12:35:44Z [FLINK-9366] DistributedCache works with Distributed File System ---
[GitHub] flink issue #6047: [FLINK-8160]Extend OperatorHarness to expose...
Github user wangtuo21 commented on the issue: https://github.com/apache/flink/pull/6047 @zentol , I misunderstood the request. Does it go in the right direction now? Thank you ---
[GitHub] flink pull request #6106: [hotfix][table] Remove a println statement
Github user xccui closed the pull request at: https://github.com/apache/flink/pull/6106 ---
[GitHub] flink issue #6106: [hotfix][table] Remove a println statement
Github user xccui commented on the issue: https://github.com/apache/flink/pull/6106 Merging this. ---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496463#comment-16496463
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192082241
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
Ok
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192082241
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
Ok
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496462#comment-16496462
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192081960
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
Then let's just keep it simple for now, and we can still improve it if we
later find that the size can also be an indicator of the better initial db
state.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192081960
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
Then let's just keep it simple for now, and we can still improve it if we
later find that the size can also be an indicator of the better initial db
state.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496460#comment-16496460
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192081415
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
I think I'm a bit torn here.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192081415
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
I think I'm a bit torn here.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496458#comment-16496458
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192081137
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
That makes sense, will change it.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192081137
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
That makes sense, will change it.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496457#comment-16496457
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192080706
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
I think it make sense to also take the state size into the count. If we
take it into count, then the score may look like: `"handle's state size" *
"numberOfKeyGroups" / "handle's total key group"`. But you are right, I don't
know if a higher or the a lower size is better either, which make me not sure
whether we should take it into count now...
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192080706
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
I think it make sense to also take the state size into the count. If we
take it into count, then the score may look like: `"handle's state size" *
"numberOfKeyGroups" / "handle's total key group"`. But you are right, I don't
know if a higher or the a lower size is better either, which make me not sure
whether we should take it into count now...
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496454#comment-16496454
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192079420
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
I think the code will still look ok, it is just one more `if` (we even only
need if in the cases where we would clip something). If this allows us to
eliminate some amount of codes, test, move away from experimental features, and
may be faster then I think it is a good idea.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192079420
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
I think the code will still look ok, it is just one more `if` (we even only
need if in the cases where we would clip something). If this allows us to
eliminate some amount of codes, test, move away from experimental features, and
may be faster then I think it is a good idea.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496448#comment-16496448
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078870
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
--- End diff --
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496447#comment-16496447
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078846
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtilsTest.java
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.common.typeutils.base.IntSerializer;
+import org.apache.flink.core.memory.ByteArrayOutputStreamWithPos;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.junit.Assert;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.io.IOException;
+import java.util.Collections;
+
+/**
+ * Tests to guard {@link RocksDBIncrementalCheckpointUtils}.
+ */
+public class RocksDBIncrementalCheckpointUtilsTest {
--- End diff --
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496446#comment-16496446
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078816
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
Ah, I don't see a clear benefit either, but I think it makes the loop code
look cleaner to me. But If you think that we don't need to clip the database to
avoid prefix check, that's also good to me and I will change it.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078870
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
--- End diff --
ð
---
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078846
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtilsTest.java
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.common.typeutils.base.IntSerializer;
+import org.apache.flink.core.memory.ByteArrayOutputStreamWithPos;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.junit.Assert;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.io.IOException;
+import java.util.Collections;
+
+/**
+ * Tests to guard {@link RocksDBIncrementalCheckpointUtils}.
+ */
+public class RocksDBIncrementalCheckpointUtilsTest {
--- End diff --
ð
---
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078816
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
Ah, I don't see a clear benefit either, but I think it makes the loop code
look cleaner to me. But If you think that we don't need to clip the database to
avoid prefix check, that's also good to me and I will change it.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496441#comment-16496441
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078327
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtilsTest.java
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.common.typeutils.base.IntSerializer;
+import org.apache.flink.core.memory.ByteArrayOutputStreamWithPos;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.junit.Assert;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.io.IOException;
+import java.util.Collections;
+
+/**
+ * Tests to guard {@link RocksDBIncrementalCheckpointUtils}.
+ */
+public class RocksDBIncrementalCheckpointUtilsTest {
--- End diff --
Please add `extends TestLogger`
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192078327
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtilsTest.java
---
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.common.typeutils.base.IntSerializer;
+import org.apache.flink.core.memory.ByteArrayOutputStreamWithPos;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.junit.Assert;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.io.IOException;
+import java.util.Collections;
+
+/**
+ * Tests to guard {@link RocksDBIncrementalCheckpointUtils}.
+ */
+public class RocksDBIncrementalCheckpointUtilsTest {
--- End diff --
Please add `extends TestLogger`
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496439#comment-16496439
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192077816
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
One more thought: do you think it can make sense to also include the state
size of the handle in the evaluation score? Only problem here is, is a higher
or a lower size better? A higher size could also just mean that the initial
database was just not in a well compacted state.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192077816
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
One more thought: do you think it can make sense to also include the state
size of the handle in the evaluation score? Only problem here is, is a higher
or a lower size better? A higher size could also just mean that the initial
database was just not in a well compacted state.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496434#comment-16496434
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192076835
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
--- End diff --
I think this is a not so nice API of `RocksIterator`, a newly created
Iterator doesn't point to the header element by default, users need to
performance the `seek()` to make sure it is valid.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192076835
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
--- End diff --
I think this is a not so nice API of `RocksIterator`, a newly created
Iterator doesn't point to the header element by default, users need to
performance the `seek()` to make sure it is valid.
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496433#comment-16496433
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192076636
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
I wonder if clipping the database to avoid prefix check is an optimization
or not? If we don't clip, the must seek the iterator and apply a single if to
every key. This if is very predictable for the CPU because it always passed
except for when we terminate the loop. This sounds rather cheap. What are your
thoughts about why deleting ranges is the better approach?
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192076636
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
--- End diff --
I wonder if clipping the database to avoid prefix check is an optimization
or not? If we don't clip, the must seek the iterator and apply a single if to
every key. This if is very predictable for the CPU because it always passed
except for when we terminate the loop. This sounds rather cheap. What are your
thoughts about why deleting ranges is the better approach?
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496429#comment-16496429
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192076060
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
--- End diff --
typo: endKye
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192076060
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
--- End diff --
typo: endKye
---
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496427#comment-16496427
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075842
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
Yes, will change it.
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For: 1.6.0
>
>
> When there are multi state handle to be restored, we can improve the
> performance as follow:
> 1. Choose the best state handle to init the target db
> 2. Use the other state handles to create temp db, and clip the db according
> to the target key group range (via rocksdb.deleteRange()), this can help use
> get rid of the `key group check` in
> `data insertion loop` and also help us get rid of traversing the useless
> record.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075842
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBIncrementalCheckpointUtils.java
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.runtime.state.KeyGroupRange;
+
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+
+import java.util.List;
+
+/**
+ * Utils for RocksDB Incremental Checkpoint.
+ */
+public class RocksDBIncrementalCheckpointUtils {
+
+ public static void clipDBWithKeyGroupRange(
+ RocksDB db,
+ List columnFamilyHandles,
+ KeyGroupRange targetGroupRange,
+ KeyGroupRange currentGroupRange,
+ int keyGroupPrefixBytes) throws RocksDBException {
+
+ for (ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandles) {
+ if (currentGroupRange.getStartKeyGroup() <
targetGroupRange.getStartKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ currentGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ byte[] endKye =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getStartKeyGroup(),
keyGroupPrefixBytes);
+ db.deleteRange(columnFamilyHandle, beginKey,
endKye);
+ }
+
+ if (currentGroupRange.getEndKeyGroup() >
targetGroupRange.getEndKeyGroup()) {
+ byte[] beginKey =
RocksDBKeySerializationUtils.serializeKeyGroup(
+ targetGroupRange.getEndKeyGroup() + 1,
keyGroupPrefixBytes);
+
+ byte[] endKey = new byte[keyGroupPrefixBytes];
+ for (int i = 0; i < keyGroupPrefixBytes; ++i) {
+ endKey[i] = (byte) (0xFF);
+ }
+ db.deleteRange(columnFamilyHandle, beginKey,
endKey);
+ }
+ }
+ }
+
+ public static int evaluateGroupRange(KeyGroupRange range1,
KeyGroupRange range2) {
--- End diff --
Yes, will change it. ð
---
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075543
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
+ while
(iterator.isValid()) {
+ // DB has been
clip by target key group range, so we do not need to do key rang check in this
loop
+
stateBackend.db.put(targetColumnFamilyHandle, iterator.key(), iterator.value());
+ iterator.next();
+ }
+ } // releases native iterator
resources
+ }
+ } finally {
+ FileSystem restoreFileSystem =
temporaryRestoreInstancePath.getFileSystem();
+ if
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496424#comment-16496424
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075519
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
+ while
(iterator.isValid()) {
+ // DB has been
clip by target key group range, so we do not need to do key rang check in this
loop
+
stateBackend.db.put(targetColumnFamilyHandle, iterator.key(), iterator.value());
+ iterator.next();
+ }
+ } // releases native iterator
resources
+
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496425#comment-16496425
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075532
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
--- End diff --
If the DB is clipped, do we even need to seek or will the iterator already
begin at a useful key-group anyways?
> Improve performance for recovery from incremental checkpoint
>
>
> Key: FLINK-8790
> URL: https://issues.apache.org/jira/browse/FLINK-8790
> Project: Flink
> Issue Type: Improvement
> Components: State Backends, Checkpointing
>Affects Versions: 1.5.0
>Reporter: Sihua Zhou
>Assignee: Sihua Zhou
>Priority: Major
> Fix For:
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075532
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
--- End diff --
If the DB is clipped, do we even need to seek or will the iterator already
begin at a useful key-group anyways?
---
[GitHub] flink pull request #5582: [FLINK-8790][State] Improve performance for recove...
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075519
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
+ while
(iterator.isValid()) {
+ // DB has been
clip by target key group range, so we do not need to do key rang check in this
loop
+
stateBackend.db.put(targetColumnFamilyHandle, iterator.key(), iterator.value());
+ iterator.next();
+ }
+ } // releases native iterator
resources
+ }
+ } finally {
+ FileSystem restoreFileSystem =
temporaryRestoreInstancePath.getFileSystem();
+ if
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496426#comment-16496426
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192075543
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
+ while
(iterator.isValid()) {
+ // DB has been
clip by target key group range, so we do not need to do key rang check in this
loop
+
stateBackend.db.put(targetColumnFamilyHandle, iterator.key(), iterator.value());
+ iterator.next();
+ }
+ } // releases native iterator
resources
+
[jira] [Commented] (FLINK-8790) Improve performance for recovery from incremental checkpoint
[
https://issues.apache.org/jira/browse/FLINK-8790?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16496419#comment-16496419
]
ASF GitHub Bot commented on FLINK-8790:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5582#discussion_r192074489
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -791,20 +784,215 @@ private void restoreInstance(
}
/**
-* Recovery from local incremental state.
+* Recovery from multi incremental states.
+* In case of rescaling, this method creates a temporary
RocksDB instance for a key-groups shard. All contents
+* from the temporary instance are copied into the real restore
instance and then the temporary instance is
+* discarded.
*/
- private void restoreInstance(IncrementalLocalKeyedStateHandle
localKeyedStateHandle) throws Exception {
+ void restoreFromMultiHandles(Collection
restoreStateHandles) throws Exception {
+
+ KeyGroupRange targetKeyGroupRange =
stateBackend.keyGroupRange;
+
+ chooseTheBestStateHandleToInit(restoreStateHandles,
targetKeyGroupRange);
+
+ int targetStartKeyGroup =
stateBackend.getKeyGroupRange().getStartKeyGroup();
+ byte[] targetStartKeyGroupPrefixBytes = new
byte[stateBackend.keyGroupPrefixBytes];
+ for (int j = 0; j < stateBackend.keyGroupPrefixBytes;
++j) {
+ targetStartKeyGroupPrefixBytes[j] = (byte)
(targetStartKeyGroup >>> ((stateBackend.keyGroupPrefixBytes - j - 1) *
Byte.SIZE));
+ }
+
+ for (KeyedStateHandle rawStateHandle :
restoreStateHandles) {
+
+ if (!(rawStateHandle instanceof
IncrementalKeyedStateHandle)) {
+ throw new
IllegalStateException("Unexpected state handle type, " +
+ "expected " +
IncrementalKeyedStateHandle.class +
+ ", but found " +
rawStateHandle.getClass());
+ }
+
+ Path temporaryRestoreInstancePath = new
Path(stateBackend.instanceBasePath.getAbsolutePath() +
UUID.randomUUID().toString());
+ try (RestoredDBInfo tmpRestoreDBInfo =
restoreDBFromStateHandle(
+ (IncrementalKeyedStateHandle)
rawStateHandle,
+ temporaryRestoreInstancePath,
+ targetKeyGroupRange,
+
stateBackend.keyGroupPrefixBytes)) {
+
+ List
tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
+ List
tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
+
+ // iterating only the requested
descriptors automatically skips the default column family handle
+ for (int i = 0; i <
tmpColumnFamilyDescriptors.size(); ++i) {
+ ColumnFamilyHandle
tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
+ ColumnFamilyDescriptor
tmpColumnFamilyDescriptor = tmpColumnFamilyDescriptors.get(i);
+
+ ColumnFamilyHandle
targetColumnFamilyHandle = getOrRegisterColumnFamilyHandle(
+
tmpColumnFamilyDescriptor, null,
tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i));
+
+ try (RocksIterator iterator =
tmpRestoreDBInfo.db.newIterator(tmpColumnFamilyHandle)) {
+
+
iterator.seek(targetStartKeyGroupPrefixBytes);
+ while
(iterator.isValid()) {
+ // DB has been
clip by target key group range, so we do not need to do key rang check in this
loop
+
stateBackend.db.put(targetColumnFamilyHandle, iterator.key(), iterator.value());
+ iterator.next();
+ }
+ } // releases native iterator
resources
+