[GitHub] [flink] liyafan82 commented on issue #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
liyafan82 commented on issue #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink URL: https://github.com/apache/flink/pull/8682#issuecomment-501976712 > > Can you please provide the benchmark that produces the 10x performance improvement? > > You can find the case in `SortAggITCase.testBigDataSimpleArrayUDAF`. > If you want to test previous code, you can modify `PrimitiveLongArrayConverter.toInternalImpl` to use `return BinaryArray.fromPrimitiveArray(value);`. > The difference is so obvious, both in generated code and performance. Good job. Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] sunjincheng121 edited a comment on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots
sunjincheng121 edited a comment on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots URL: https://github.com/apache/flink/pull/7227#issuecomment-501973070  I fond that `DefaultExecutionSlotAllocator` is merged 9 hours ago(https://github.com/apache/flink/commit/8a39c84e29c9ad64febbd850c99b40d28b5359d1), so I think may CI cache problem, restart all CI stage. If we still can not pass the CI, I think we should rebase the code. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on issue #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on issue #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink URL: https://github.com/apache/flink/pull/8682#issuecomment-501973780 > Can you please provide the benchmark that produces the 10x performance improvement? You can find the case in `SortAggITCase.testBigDataSimpleArrayUDAF`. If you want to test previous code, you can modify `PrimitiveLongArrayConverter.toInternalImpl` to use `return BinaryArray.fromPrimitiveArray(value);`. The difference is so obvious, both in generated code and performance. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] sunjincheng121 edited a comment on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots
sunjincheng121 edited a comment on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots URL: https://github.com/apache/flink/pull/7227#issuecomment-501973070  I fond that `DefaultExecutionSlotAllocator` is merged 9 hours ago(https://github.com/apache/flink/commit/8a39c84e29c9ad64febbd850c99b40d28b5359d1), so I think may CI cache problem, restart all CI stage. (Maybe some bug in Travis script, but not relate this PR) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] sunjincheng121 commented on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots
sunjincheng121 commented on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots URL: https://github.com/apache/flink/pull/7227#issuecomment-501973070  I did not find `DefaultExecutionSlotAllocator` in our code base, so I think may CI cache problem, restart all CI stage. (Maybe some bug in Travis script, but not relate this PR) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] docete commented on issue #8707: [FLINK-12815] [table-planner-blink] Supports CatalogManager in blink planner
docete commented on issue #8707: [FLINK-12815] [table-planner-blink] Supports CatalogManager in blink planner URL: https://github.com/apache/flink/pull/8707#issuecomment-501971743 +1 LGTM, leave a comment about CatalogView expanding. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] docete commented on a change in pull request #8707: [FLINK-12815] [table-planner-blink] Supports CatalogManager in blink planner
docete commented on a change in pull request #8707: [FLINK-12815]
[table-planner-blink] Supports CatalogManager in blink planner
URL: https://github.com/apache/flink/pull/8707#discussion_r293660477
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/plan/util/RelShuttles.scala
##
@@ -97,14 +97,15 @@ class ExpandTableScanShuttle extends RelShuttleImpl {
}
/**
-* Converts [[LogicalTableScan]] the result [[RelNode]] tree by calling
[[RelTable]]#toRel
+* Converts [[LogicalTableScan]] the result [[RelNode]] tree
+* by calling [[QueryOperationCatalogViewTable]]#toRel
*/
override def visit(scan: TableScan): RelNode = {
scan match {
case tableScan: LogicalTableScan =>
-val relTable = tableScan.getTable.unwrap(classOf[RelTable])
-if (relTable != null) {
- val rel =
relTable.toRel(RelOptUtil.getContext(tableScan.getCluster), tableScan.getTable)
+val viewTable =
tableScan.getTable.unwrap(classOf[QueryOperationCatalogViewTable])
Review comment:
AbstractCatalogView from Catalog has no QueryOperation. We must get the
underlie QueryOperation and convert to QueryOperationCatalogViewTable somewhere.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293656023
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ReleaseOnConsumptionResultPartition.java
##
@@ -0,0 +1,102 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.io.network.partition;
+
+import org.apache.flink.runtime.io.network.buffer.BufferPool;
+import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
+import org.apache.flink.util.function.FunctionWithException;
+
+import java.io.IOException;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkState;
+
+/**
+ * ResultPartition that releases itself once all subpartitions have been
consumed.
+ */
+public class ReleaseOnConsumptionResultPartition extends ResultPartition {
+
+ /**
+* The total number of references to subpartitions of this result. The
result partition can be
+* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
+* result partition has been released.
+*/
+ private final AtomicInteger pendingReferences = new AtomicInteger();
+
+ ReleaseOnConsumptionResultPartition(
+ String owningTaskName,
+ ResultPartitionID partitionId,
+ ResultPartitionType partitionType,
+ ResultSubpartition[] subpartitions,
+ int numTargetKeyGroups,
+ ResultPartitionManager partitionManager,
+ FunctionWithException bufferPoolFactory) {
+ super(owningTaskName, partitionId, partitionType,
subpartitions, numTargetKeyGroups, partitionManager, bufferPoolFactory);
+ }
+
+ @Override
+ void pin() {
+ while (true) {
Review comment:
I created [FLINK-12842](https://issues.apache.org/jira/browse/FLINK-12842)
and [FLINK-12843](https://issues.apache.org/jira/browse/FLINK-12843) for the
ref-counter issues which could be solved separately after this PR merged,
because these issues already exist before and are not in the scope of this PR.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (FLINK-12843) Refactor the pin logic in ResultPartition
zhijiang created FLINK-12843:
Summary: Refactor the pin logic in ResultPartition
Key: FLINK-12843
URL: https://issues.apache.org/jira/browse/FLINK-12843
Project: Flink
Issue Type: Sub-task
Components: Runtime / Network
Reporter: zhijiang
Assignee: zhijiang
The pin logic is for adding the reference counter based on number of
subpartitions in {{ResultPartition}}. It seems not necessary to do it in while
loop as now, because the atomic counter would not be accessed by other threads
during pin. If the `ResultPartition` is not created yet, the
{{ResultPartition#createSubpartitionView}} would not be called and it would
response {{ResultPartitionNotFoundException}} in {{ResultPartitionManager}}.
So we could simple increase the reference counter in {{ResultPartition}}
constructor directly.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs
sunjincheng121 commented on a change in pull request #8732:
[FLINK-12720][python] Add the Python Table API Sphinx docs
URL: https://github.com/apache/flink/pull/8732#discussion_r293653787
##
File path: flink-python/docs/conf.py
##
@@ -0,0 +1,208 @@
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import sys
+
+# -- Path setup --
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+sys.path.insert(0, os.path.abspath('.'))
+sys.path.insert(0, os.path.abspath('..'))
+
+# -- Project information -
+
+# project = u'Flink Python Table API'
+project = u'PyFlink'
+copyright = u''
+author = u'Author'
+
+# The short X.Y version
+version = '1.0'
Review comment:
The version should same as :
https://github.com/apache/flink/blob/master/flink-python/pyflink/version.py
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (FLINK-12842) Fix invalid check released state during ResultPartition#createSubpartitionView
zhijiang created FLINK-12842:
Summary: Fix invalid check released state during
ResultPartition#createSubpartitionView
Key: FLINK-12842
URL: https://issues.apache.org/jira/browse/FLINK-12842
Project: Flink
Issue Type: Sub-task
Components: Runtime / Network
Reporter: zhijiang
Assignee: zhijiang
Currently in {{ResultPartition#createSubpartitionView}} it would check whether
this partition is released before creating view. But this check is based on
{{refCnt != -1}} which seems invalid, because the reference counter would not
always reflect the released state.
In the case of {{ResultPartition#release/fail}}, the reference counter is not
set to -1. Even if in the case of {{ResultPartition#onConsumedSubpartition}},
the reference counter seems also no chance to be -1.
So we could check the real {{isReleased}} state during creating view instead of
reference counter.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293653903
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseMapSerializer.java
##
@@ -0,0 +1,273 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.TypeSerializerSchemaCompatibility;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.java.typeutils.runtime.DataInputViewStream;
+import org.apache.flink.api.java.typeutils.runtime.DataOutputViewStream;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+import org.apache.flink.table.dataformat.BaseMap;
+import org.apache.flink.table.dataformat.BinaryArray;
+import org.apache.flink.table.dataformat.BinaryArrayWriter;
+import org.apache.flink.table.dataformat.BinaryMap;
+import org.apache.flink.table.dataformat.BinaryWriter;
+import org.apache.flink.table.dataformat.GenericMap;
+import org.apache.flink.table.types.InternalSerializers;
+import org.apache.flink.table.types.logical.LogicalType;
+import org.apache.flink.table.util.SegmentsUtil;
+import org.apache.flink.util.InstantiationUtil;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Serializer for {@link BaseMap}.
+ */
+public class BaseMapSerializer extends TypeSerializer {
+
+ private final LogicalType keyType;
+ private final LogicalType valueType;
+
+ private final TypeSerializer keySerializer;
+ private final TypeSerializer valueSerializer;
+
+ private transient BinaryArray reuseKeyArray;
+ private transient BinaryArray reuseValueArray;
+ private transient BinaryArrayWriter reuseKeyWriter;
+ private transient BinaryArrayWriter reuseValueWriter;
+
+ public BaseMapSerializer(LogicalType keyType, LogicalType valueType) {
+ this.keyType = keyType;
+ this.valueType = valueType;
+
+ this.keySerializer = InternalSerializers.create(keyType, new
ExecutionConfig());
+ this.valueSerializer = InternalSerializers.create(valueType,
new ExecutionConfig());
+ }
+
+ @Override
+ public boolean isImmutableType() {
+ return false;
+ }
+
+ @Override
+ public TypeSerializer duplicate() {
+ return new BaseMapSerializer(keyType, valueType);
+ }
+
+ @Override
+ public BaseMap createInstance() {
+ return new BinaryMap();
+ }
+
+ @Override
+ public BaseMap copy(BaseMap from) {
+ if (from instanceof GenericMap) {
+ Map fromMap = ((GenericMap)
from).getMap();
+ HashMap toMap = new HashMap<>();
Review comment:
You are right,
`DataFormatConverter` is not wrong, but `copy` maybe have some trouble.
In fact, Runtime `MapSerializer` also has this problem.
I will add some comment.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] dianfu commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs
dianfu commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs URL: https://github.com/apache/flink/pull/8732#discussion_r293650042 ## File path: flink-python/docs/pyflink.rst ## @@ -0,0 +1,33 @@ +.. + Licensed to the Apache Software Foundation (ASF) under one + or more contributor license agreements. See the NOTICE file + distributed with this work for additional information + regarding copyright ownership. The ASF licenses this file + to you under the Apache License, Version 2.0 (the + "License"); you may not use this file except in compliance + with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and +limitations under the License. + + +pyflink package +=== + +Subpackages +--- + +.. toctree:: +:maxdepth: 1 + +pyflink.table + Review comment: Add the following text here to indicate that the following classes are the content of package pyflink: ```suggestion Contents ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] dianfu commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs
dianfu commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs URL: https://github.com/apache/flink/pull/8732#discussion_r293646408 ## File path: flink-python/docs/index.rst ## @@ -0,0 +1,39 @@ +.. + Licensed to the Apache Software Foundation (ASF) under one + or more contributor license agreements. See the NOTICE file + distributed with this work for additional information + regarding copyright ownership. The ASF licenses this file + to you under the Apache License, Version 2.0 (the + "License"); you may not use this file except in compliance + with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and +limitations under the License. + + +Welcome to Flink Python API Docs! +== + +.. toctree:: + :maxdepth: 2 + :caption: Contents + + pyflink + pyflink.table + + +Core Classes: +--- + +:class:`pyflink.table.TableEnvironment` + +Main entry point for Flink functionality. Review comment: What about `Main entry point for Flink Table functionality.` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] dianfu commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs
dianfu commented on a change in pull request #8732: [FLINK-12720][python] Add the Python Table API Sphinx docs URL: https://github.com/apache/flink/pull/8732#discussion_r293652965 ## File path: flink-python/docs/pyflink.table.rst ## @@ -0,0 +1,29 @@ +.. + Licensed to the Apache Software Foundation (ASF) under one + or more contributor license agreements. See the NOTICE file + distributed with this work for additional information + regarding copyright ownership. The ASF licenses this file + to you under the Apache License, Version 2.0 (the + "License"); you may not use this file except in compliance + with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and +limitations under the License. + + +pyflink.table package += + +Module contents +--- + +.. automodule:: pyflink.table +:members: +:undoc-members: +:show-inheritance: Review comment: One empty line at the end of the file This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] liyafan82 commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
liyafan82 commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293652318
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseMapSerializer.java
##
@@ -0,0 +1,273 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.TypeSerializerSchemaCompatibility;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.java.typeutils.runtime.DataInputViewStream;
+import org.apache.flink.api.java.typeutils.runtime.DataOutputViewStream;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+import org.apache.flink.table.dataformat.BaseMap;
+import org.apache.flink.table.dataformat.BinaryArray;
+import org.apache.flink.table.dataformat.BinaryArrayWriter;
+import org.apache.flink.table.dataformat.BinaryMap;
+import org.apache.flink.table.dataformat.BinaryWriter;
+import org.apache.flink.table.dataformat.GenericMap;
+import org.apache.flink.table.types.InternalSerializers;
+import org.apache.flink.table.types.logical.LogicalType;
+import org.apache.flink.table.util.SegmentsUtil;
+import org.apache.flink.util.InstantiationUtil;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Serializer for {@link BaseMap}.
+ */
+public class BaseMapSerializer extends TypeSerializer {
+
+ private final LogicalType keyType;
+ private final LogicalType valueType;
+
+ private final TypeSerializer keySerializer;
+ private final TypeSerializer valueSerializer;
+
+ private transient BinaryArray reuseKeyArray;
+ private transient BinaryArray reuseValueArray;
+ private transient BinaryArrayWriter reuseKeyWriter;
+ private transient BinaryArrayWriter reuseValueWriter;
+
+ public BaseMapSerializer(LogicalType keyType, LogicalType valueType) {
+ this.keyType = keyType;
+ this.valueType = valueType;
+
+ this.keySerializer = InternalSerializers.create(keyType, new
ExecutionConfig());
+ this.valueSerializer = InternalSerializers.create(valueType,
new ExecutionConfig());
+ }
+
+ @Override
+ public boolean isImmutableType() {
+ return false;
+ }
+
+ @Override
+ public TypeSerializer duplicate() {
+ return new BaseMapSerializer(keyType, valueType);
+ }
+
+ @Override
+ public BaseMap createInstance() {
+ return new BinaryMap();
+ }
+
+ @Override
+ public BaseMap copy(BaseMap from) {
+ if (from instanceof GenericMap) {
+ Map fromMap = ((GenericMap)
from).getMap();
+ HashMap toMap = new HashMap<>();
Review comment:
The user can provide a "correct" Map, but when the key value is wrapped in a
HashMap, it can be a "wrong" Map.
Let me illustrate with an example. Suppose the key type does not implement
"hashCode" and "equals" functions correctly (suppose for simplicity, hashCode
always returns 0, and equals always returns true).
The input GenericMap can be based on a TreeMap, with a proper comparator to
test key equality.
The input map is a "correct" map, because it implements get/put methods
correctly.
However, when we insert the key/value pairs of the TreeMap into a HashMap,
problems will occur. For this example, only one key/value pair will finally
exist in the HashMap, which is an unexpected behavior.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For
[GitHub] [flink] eaglewatcherwb commented on a change in pull request #8688: [FLINK-12760] [runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter
eaglewatcherwb commented on a change in pull request #8688: [FLINK-12760]
[runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter
URL: https://github.com/apache/flink/pull/8688#discussion_r293652038
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/scheduler/EGBasedInputsLocationsRetrieverTest.java
##
@@ -0,0 +1,134 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.scheduler;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.runtime.execution.ExecutionState;
+import org.apache.flink.runtime.executiongraph.ExecutionGraph;
+import org.apache.flink.runtime.executiongraph.ExecutionGraphTestUtils;
+import org.apache.flink.runtime.executiongraph.TestingSlotProvider;
+import org.apache.flink.runtime.executiongraph.restart.NoRestartStrategy;
+import org.apache.flink.runtime.io.network.partition.ResultPartitionType;
+import org.apache.flink.runtime.jobgraph.DistributionPattern;
+import org.apache.flink.runtime.jobgraph.JobVertex;
+import org.apache.flink.runtime.jobmaster.TestingLogicalSlot;
+import org.apache.flink.runtime.jobmaster.slotpool.SlotProvider;
+import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID;
+import org.apache.flink.runtime.taskmanager.TaskManagerLocation;
+import org.apache.flink.util.TestLogger;
+
+import org.junit.Test;
+
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Optional;
+import java.util.concurrent.CompletableFuture;
+
+import static org.hamcrest.CoreMatchers.is;
+import static org.hamcrest.Matchers.contains;
+import static org.hamcrest.Matchers.empty;
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.assertThat;
+
+/**
+ * Tests for {@link EGBasedInputsLocationsRetriever}.
+ */
+public class EGBasedInputsLocationsRetrieverTest extends TestLogger {
+
+ /**
+* Tests that can get the producers of consumed result partitions.
+*/
+ @Test
+ public void testGetConsumedResultPartitionsProducers() throws Exception
{
+ final JobVertex producer1 =
ExecutionGraphTestUtils.createNoOpVertex(1);
+ final JobVertex producer2 =
ExecutionGraphTestUtils.createNoOpVertex(1);
+ final JobVertex consumer =
ExecutionGraphTestUtils.createNoOpVertex(1);
+ consumer.connectNewDataSetAsInput(producer1,
DistributionPattern.ALL_TO_ALL, ResultPartitionType.PIPELINED);
+ consumer.connectNewDataSetAsInput(producer2,
DistributionPattern.ALL_TO_ALL, ResultPartitionType.PIPELINED);
+
+ final ExecutionGraph eg =
ExecutionGraphTestUtils.createSimpleTestGraph(new JobID(), producer1,
producer2, consumer);
+ final EGBasedInputsLocationsRetriever inputsLocationsRetriever
= new EGBasedInputsLocationsRetriever(eg);
+
+ ExecutionVertexID evIdOfProducer1 = new
ExecutionVertexID(producer1.getID(), 0);
+ ExecutionVertexID evIdOfProducer2 = new
ExecutionVertexID(producer2.getID(), 0);
+ ExecutionVertexID evIdOfConsumer = new
ExecutionVertexID(consumer.getID(), 0);
+
+ Collection> producersOfProducer1 =
+
inputsLocationsRetriever.getConsumedResultPartitionsProducers(evIdOfProducer1);
+ Collection> producersOfProducer2 =
+
inputsLocationsRetriever.getConsumedResultPartitionsProducers(evIdOfProducer2);
+ Collection> producersOfConsumer =
+
inputsLocationsRetriever.getConsumedResultPartitionsProducers(evIdOfConsumer);
+
+ assertThat(producersOfProducer1, is(empty()));
+ assertThat(producersOfProducer2, is(empty()));
+ assertThat(producersOfConsumer,
contains(Arrays.asList(evIdOfProducer1), Arrays.asList(evIdOfProducer2)));
Review comment:
`Arrays.asList` with only one argument could be replaced with
`Collections.singletonList`
This is an automated message from the Apache Git Service.
To respond to the message, please log
[GitHub] [flink] eaglewatcherwb commented on a change in pull request #8688: [FLINK-12760] [runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter
eaglewatcherwb commented on a change in pull request #8688: [FLINK-12760]
[runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter
URL: https://github.com/apache/flink/pull/8688#discussion_r293651290
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/scheduler/EGBasedInputsLocationsRetrieverTest.java
##
@@ -0,0 +1,134 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.scheduler;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.runtime.execution.ExecutionState;
+import org.apache.flink.runtime.executiongraph.ExecutionGraph;
+import org.apache.flink.runtime.executiongraph.ExecutionGraphTestUtils;
+import org.apache.flink.runtime.executiongraph.TestingSlotProvider;
+import org.apache.flink.runtime.executiongraph.restart.NoRestartStrategy;
+import org.apache.flink.runtime.io.network.partition.ResultPartitionType;
+import org.apache.flink.runtime.jobgraph.DistributionPattern;
+import org.apache.flink.runtime.jobgraph.JobVertex;
+import org.apache.flink.runtime.jobmaster.TestingLogicalSlot;
+import org.apache.flink.runtime.jobmaster.slotpool.SlotProvider;
+import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID;
+import org.apache.flink.runtime.taskmanager.TaskManagerLocation;
+import org.apache.flink.util.TestLogger;
+
+import org.junit.Test;
+
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Optional;
+import java.util.concurrent.CompletableFuture;
+
+import static org.hamcrest.CoreMatchers.is;
+import static org.hamcrest.Matchers.contains;
+import static org.hamcrest.Matchers.empty;
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.assertThat;
+
+/**
+ * Tests for {@link EGBasedInputsLocationsRetriever}.
+ */
+public class EGBasedInputsLocationsRetrieverTest extends TestLogger {
+
+ /**
+* Tests that can get the producers of consumed result partitions.
+*/
+ @Test
+ public void testGetConsumedResultPartitionsProducers() throws Exception
{
+ final JobVertex producer1 =
ExecutionGraphTestUtils.createNoOpVertex(1);
+ final JobVertex producer2 =
ExecutionGraphTestUtils.createNoOpVertex(1);
+ final JobVertex consumer =
ExecutionGraphTestUtils.createNoOpVertex(1);
+ consumer.connectNewDataSetAsInput(producer1,
DistributionPattern.ALL_TO_ALL, ResultPartitionType.PIPELINED);
+ consumer.connectNewDataSetAsInput(producer2,
DistributionPattern.ALL_TO_ALL, ResultPartitionType.PIPELINED);
+
+ final ExecutionGraph eg =
ExecutionGraphTestUtils.createSimpleTestGraph(new JobID(), producer1,
producer2, consumer);
+ final EGBasedInputsLocationsRetriever inputsLocationsRetriever
= new EGBasedInputsLocationsRetriever(eg);
+
+ ExecutionVertexID evIdOfProducer1 = new
ExecutionVertexID(producer1.getID(), 0);
+ ExecutionVertexID evIdOfProducer2 = new
ExecutionVertexID(producer2.getID(), 0);
+ ExecutionVertexID evIdOfConsumer = new
ExecutionVertexID(consumer.getID(), 0);
+
+ Collection> producersOfProducer1 =
+
inputsLocationsRetriever.getConsumedResultPartitionsProducers(evIdOfProducer1);
+ Collection> producersOfProducer2 =
+
inputsLocationsRetriever.getConsumedResultPartitionsProducers(evIdOfProducer2);
+ Collection> producersOfConsumer =
+
inputsLocationsRetriever.getConsumedResultPartitionsProducers(evIdOfConsumer);
+
+ assertThat(producersOfProducer1, is(empty()));
+ assertThat(producersOfProducer2, is(empty()));
+ assertThat(producersOfConsumer,
contains(Arrays.asList(evIdOfProducer1), Arrays.asList(evIdOfProducer2)));
+ }
+
+ /**
+* Tests that when execution is not scheduled, getting task manager
location will return null.
+*/
+ @Test
+ public void testGetNullTaskManagerLocationIfNotScheduled() throws
Exception {
+ final JobVertex
[GitHub] [flink] zjuwangg commented on issue #8636: [FLINK-12237][hive]Support Hive table stats related operations in HiveCatalog
zjuwangg commented on issue #8636: [FLINK-12237][hive]Support Hive table stats related operations in HiveCatalog URL: https://github.com/apache/flink/pull/8636#issuecomment-501958031 ccc @xuefuz again to review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #8687: [FLINK-12612][coordination] Track stored partition on the TaskExecutor
zhijiangW commented on a change in pull request #8687:
[FLINK-12612][coordination] Track stored partition on the TaskExecutor
URL: https://github.com/apache/flink/pull/8687#discussion_r293651140
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/taskexecutor/partition/JobAwareShuffleEnvironmentImpl.java
##
@@ -0,0 +1,194 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.taskexecutor.partition;
+
+import org.apache.flink.api.common.JobID;
+import org.apache.flink.metrics.MetricGroup;
+import org.apache.flink.runtime.deployment.InputGateDeploymentDescriptor;
+import org.apache.flink.runtime.deployment.ResultPartitionDeploymentDescriptor;
+import org.apache.flink.runtime.executiongraph.ExecutionAttemptID;
+import org.apache.flink.runtime.executiongraph.PartitionInfo;
+import org.apache.flink.runtime.io.network.api.writer.ResultPartitionWriter;
+import
org.apache.flink.runtime.io.network.partition.PartitionProducerStateProvider;
+import org.apache.flink.runtime.io.network.partition.ResultPartitionID;
+import org.apache.flink.runtime.io.network.partition.consumer.InputGate;
+import org.apache.flink.runtime.shuffle.ShuffleEnvironment;
+import org.apache.flink.util.Preconditions;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.function.Consumer;
+import java.util.stream.Collectors;
+
+/**
+ * Wraps a {@link ShuffleEnvironment} to allow tracking of partitions per job.
+ */
+public class JobAwareShuffleEnvironmentImpl implements
JobAwareShuffleEnvironment {
+
+ private static final Consumer NO_OP_NOTIFIER =
partitionId -> {};
+
+ private final ShuffleEnvironment backingShuffleEnvironment;
+ private final PartitionTable inProgressPartitionTable = new
PartitionTable();
+ private final PartitionTable finishedPartitionTable = new
PartitionTable();
+
+ /** Tracks which jobs are still being monitored, to ensure cleanup
in cases where tasks are finishing while
+* the jobmanager connection is being terminated. This is a concurrent
map since it is modified by both the
+* Task (via {@link #notifyPartitionFinished(JobID,
ResultPartitionID)}} and
+* TaskExecutor (via {@link
#releaseAllFinishedPartitionsForJobAndMarkJobInactive(JobID)}) thread. */
+ private final Set activeJobs = ConcurrentHashMap.newKeySet();
+
+ public JobAwareShuffleEnvironmentImpl(ShuffleEnvironment
backingShuffleEnvironment) {
+ this.backingShuffleEnvironment =
Preconditions.checkNotNull(backingShuffleEnvironment);
+ }
+
+ @Override
+ public boolean hasPartitionsOccupyingLocalResources(JobID jobId) {
+ return inProgressPartitionTable.hasTrackedPartitions(jobId) ||
finishedPartitionTable.hasTrackedPartitions(jobId);
+ }
+
+ @Override
+ public void markJobActive(JobID jobId) {
+ activeJobs.add(jobId);
+ }
+
+ @Override
+ public void releaseFinishedPartitions(JobID jobId,
Collection resultPartitionIds) {
+ finishedPartitionTable.stopTrackingPartitions(jobId,
resultPartitionIds);
+ backingShuffleEnvironment.releasePartitions(resultPartitionIds);
+ }
+
+ @Override
+ public void releaseAllFinishedPartitionsForJobAndMarkJobInactive(JobID
jobId) {
+ activeJobs.remove(jobId);
+ Collection finishedPartitionsForJob =
finishedPartitionTable.stopTrackingPartitions(jobId);
+
backingShuffleEnvironment.releasePartitions(finishedPartitionsForJob);
+ }
+
+ /**
+* This method wraps partition writers for externally managed
partitions and introduces callbacks into the lifecycle
+* methods of the {@link ResultPartitionWriter}.
+*/
+ @Override
+ public Collection
createResultPartitionWriters(
+ JobID jobId,
+ String taskName,
+ ExecutionAttemptID executionAttemptID,
+ Collection
[GitHub] [flink] gaoyunhaii commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
gaoyunhaii commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions URL: https://github.com/apache/flink/pull/8654#discussion_r293650869 ## File path: flink-runtime/src/test/java/org/apache/flink/runtime/io/network/partition/ResultPartitionFactoryTest.java ## @@ -0,0 +1,86 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.runtime.io.network.partition; + +import org.apache.flink.runtime.deployment.ResultPartitionDeploymentDescriptor; +import org.apache.flink.runtime.executiongraph.ExecutionAttemptID; +import org.apache.flink.runtime.io.disk.iomanager.NoOpIOManager; +import org.apache.flink.runtime.io.network.buffer.BufferPool; +import org.apache.flink.runtime.io.network.buffer.BufferPoolFactory; +import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner; Review comment: It seems there are unused imports here. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293650003
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseMapSerializer.java
##
@@ -0,0 +1,273 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.TypeSerializerSchemaCompatibility;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.java.typeutils.runtime.DataInputViewStream;
+import org.apache.flink.api.java.typeutils.runtime.DataOutputViewStream;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+import org.apache.flink.table.dataformat.BaseMap;
+import org.apache.flink.table.dataformat.BinaryArray;
+import org.apache.flink.table.dataformat.BinaryArrayWriter;
+import org.apache.flink.table.dataformat.BinaryMap;
+import org.apache.flink.table.dataformat.BinaryWriter;
+import org.apache.flink.table.dataformat.GenericMap;
+import org.apache.flink.table.types.InternalSerializers;
+import org.apache.flink.table.types.logical.LogicalType;
+import org.apache.flink.table.util.SegmentsUtil;
+import org.apache.flink.util.InstantiationUtil;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Serializer for {@link BaseMap}.
+ */
+public class BaseMapSerializer extends TypeSerializer {
+
+ private final LogicalType keyType;
+ private final LogicalType valueType;
+
+ private final TypeSerializer keySerializer;
+ private final TypeSerializer valueSerializer;
+
+ private transient BinaryArray reuseKeyArray;
+ private transient BinaryArray reuseValueArray;
+ private transient BinaryArrayWriter reuseKeyWriter;
+ private transient BinaryArrayWriter reuseValueWriter;
+
+ public BaseMapSerializer(LogicalType keyType, LogicalType valueType) {
+ this.keyType = keyType;
+ this.valueType = valueType;
+
+ this.keySerializer = InternalSerializers.create(keyType, new
ExecutionConfig());
+ this.valueSerializer = InternalSerializers.create(valueType,
new ExecutionConfig());
+ }
+
+ @Override
+ public boolean isImmutableType() {
+ return false;
+ }
+
+ @Override
+ public TypeSerializer duplicate() {
+ return new BaseMapSerializer(keyType, valueType);
+ }
+
+ @Override
+ public BaseMap createInstance() {
+ return new BinaryMap();
+ }
+
+ @Override
+ public BaseMap copy(BaseMap from) {
+ if (from instanceof GenericMap) {
+ Map fromMap = ((GenericMap)
from).getMap();
+ HashMap toMap = new HashMap<>();
Review comment:
This has nothing to do with `GenericMap`. If the user gives a wrong `Map`,
it's wrong to turn it into a `BinaryMap` too. It is totally wrong...
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293649615
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseRowSerializer.java
##
@@ -165,49 +168,33 @@ public int getArity() {
/**
* Convert base row to binary row.
-* TODO modify it to code gen, and reuse BinaryRow
+* TODO modify it to code gen.
Review comment:
This is a method comments, it mean move this method implement to code gen
instead of using `BinaryWriter.write` and `TypeGetterSetters.get`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] gaoyunhaii commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
gaoyunhaii commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293649558
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ReleaseOnConsumptionResultPartition.java
##
@@ -0,0 +1,102 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.io.network.partition;
+
+import org.apache.flink.runtime.io.network.buffer.BufferPool;
+import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
+import org.apache.flink.util.function.FunctionWithException;
+
+import java.io.IOException;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkState;
+
+/**
+ * ResultPartition that releases itself once all subpartitions have been
consumed.
+ */
+public class ReleaseOnConsumptionResultPartition extends ResultPartition {
+
+ /**
+* The total number of references to subpartitions of this result. The
result partition can be
+* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
+* result partition has been released.
+*/
+ private final AtomicInteger pendingReferences = new AtomicInteger();
+
+ ReleaseOnConsumptionResultPartition(
+ String owningTaskName,
+ ResultPartitionID partitionId,
+ ResultPartitionType partitionType,
+ ResultSubpartition[] subpartitions,
+ int numTargetKeyGroups,
+ ResultPartitionManager partitionManager,
+ FunctionWithException bufferPoolFactory) {
+ super(owningTaskName, partitionId, partitionType,
subpartitions, numTargetKeyGroups, partitionManager, bufferPoolFactory);
+ }
+
+ @Override
+ void pin() {
+ while (true) {
Review comment:
Follow Zhijiang's thought, I think we can now remove the pin method from the
ResultPartition, since it is only the implementation detail of the
ReleaseOnConsumptionResultPartiton. Then we can move the initialization of the
pending reference to the Constructor to ensure no concurrent access to the
variable, then we can use pendingReferences.set(subpartitions.length) to
initialize the variable.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] liyafan82 commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
liyafan82 commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293648291
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseRowSerializer.java
##
@@ -165,49 +168,33 @@ public int getArity() {
/**
* Convert base row to binary row.
-* TODO modify it to code gen, and reuse BinaryRow
+* TODO modify it to code gen.
Review comment:
I see the code gen related logic is already modified. You mean more changes
are needed?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] stevenzwu opened a new pull request #8665: [FLINK-12781] [Runtime/REST] include the whole stack trace in response payload
stevenzwu opened a new pull request #8665: [FLINK-12781] [Runtime/REST] include the whole stack trace in response payload URL: https://github.com/apache/flink/pull/8665 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] stevenzwu closed pull request #8665: [FLINK-12781] [Runtime/REST] include the whole stack trace in response payload
stevenzwu closed pull request #8665: [FLINK-12781] [Runtime/REST] include the whole stack trace in response payload URL: https://github.com/apache/flink/pull/8665 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] liyafan82 commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
liyafan82 commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293648012
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseMapSerializer.java
##
@@ -0,0 +1,273 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.TypeSerializerSchemaCompatibility;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.java.typeutils.runtime.DataInputViewStream;
+import org.apache.flink.api.java.typeutils.runtime.DataOutputViewStream;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+import org.apache.flink.table.dataformat.BaseMap;
+import org.apache.flink.table.dataformat.BinaryArray;
+import org.apache.flink.table.dataformat.BinaryArrayWriter;
+import org.apache.flink.table.dataformat.BinaryMap;
+import org.apache.flink.table.dataformat.BinaryWriter;
+import org.apache.flink.table.dataformat.GenericMap;
+import org.apache.flink.table.types.InternalSerializers;
+import org.apache.flink.table.types.logical.LogicalType;
+import org.apache.flink.table.util.SegmentsUtil;
+import org.apache.flink.util.InstantiationUtil;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Serializer for {@link BaseMap}.
+ */
+public class BaseMapSerializer extends TypeSerializer {
+
+ private final LogicalType keyType;
+ private final LogicalType valueType;
+
+ private final TypeSerializer keySerializer;
+ private final TypeSerializer valueSerializer;
+
+ private transient BinaryArray reuseKeyArray;
+ private transient BinaryArray reuseValueArray;
+ private transient BinaryArrayWriter reuseKeyWriter;
+ private transient BinaryArrayWriter reuseValueWriter;
+
+ public BaseMapSerializer(LogicalType keyType, LogicalType valueType) {
+ this.keyType = keyType;
+ this.valueType = valueType;
+
+ this.keySerializer = InternalSerializers.create(keyType, new
ExecutionConfig());
+ this.valueSerializer = InternalSerializers.create(valueType,
new ExecutionConfig());
+ }
+
+ @Override
+ public boolean isImmutableType() {
+ return false;
+ }
+
+ @Override
+ public TypeSerializer duplicate() {
+ return new BaseMapSerializer(keyType, valueType);
+ }
+
+ @Override
+ public BaseMap createInstance() {
+ return new BinaryMap();
+ }
+
+ @Override
+ public BaseMap copy(BaseMap from) {
+ if (from instanceof GenericMap) {
+ Map fromMap = ((GenericMap)
from).getMap();
+ HashMap toMap = new HashMap<>();
Review comment:
"Just wrap user Map, users need to guarantee their logic."
-> the users just guarantee that their Map works correctly according to the
Map interface, but it does not mean their Map would work correctly when wrapped
in a HashMap. Right?
When that is the case, it may cause some weird problem which is hard to
locate and debug. So this is not a reliable solution.
At the very least, we should write some comment in the JavaDoc about this
explicitly.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on issue #7435: [FLINK-11226] Lack of getKeySelector in Scala KeyedStream API unlike Java KeyedStream
yanghua commented on issue #7435: [FLINK-11226] Lack of getKeySelector in Scala KeyedStream API unlike Java KeyedStream URL: https://github.com/apache/flink/pull/7435#issuecomment-501953286 @sunjincheng121 I have a small PR holds a long time, can you have a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-12836) Allow retained checkpoints to be persisted on success
[
https://issues.apache.org/jira/browse/FLINK-12836?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863647#comment-16863647
]
vinoyang commented on FLINK-12836:
--
Hi [~klion26] I think {{CHECKPOINT_RETAINED_ON_CANCELLATION}} has a flag:
{{discardSubsumed}} its value is {{true}}. A checkpoint is subsumed when the
maximum number of retained checkpoints is reached and a more recent checkpoint
completes. Maybe this point is [~andreweduffy]'s thought.
> Allow retained checkpoints to be persisted on success
> -
>
> Key: FLINK-12836
> URL: https://issues.apache.org/jira/browse/FLINK-12836
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Checkpointing
>Reporter: Andrew Duffy
>Assignee: vinoyang
>Priority: Major
>
> Currently, retained checkpoints are persisted with one of 3 strategies:
> * {color:#33}CHECKPOINT_NEVER_RETAINED:{color} Retained checkpoints are
> never persisted
> * {color:#33}CHECKPOINT_RETAINED_ON_FAILURE:{color}{color:#33}
> Latest retained checkpoint{color} is persisted in the face of job failures
> * {color:#33}CHECKPOINT_RETAINED_ON_CANCELLATION{color}: Latest retained
> checkpoint is persisted when job is canceled externally (e.g. via the REST
> API)
>
> I'm proposing a third persistence mode: _CHECKPOINT_RETAINED_ALWAYS_. This
> mode would ensure that retained checkpoints are retained on successful
> completion of the job, and can be resumed from later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] zjuwangg commented on a change in pull request #8703: [FLINK-12807][hive]Support Hive table columnstats related operations in HiveCatalog
zjuwangg commented on a change in pull request #8703:
[FLINK-12807][hive]Support Hive table columnstats related operations in
HiveCatalog
URL: https://github.com/apache/flink/pull/8703#discussion_r293647266
##
File path:
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/table/catalog/hive/HiveCatalog.java
##
@@ -1079,7 +1100,27 @@ public void alterPartitionStatistics(ObjectPath
tablePath, CatalogPartitionSpec
@Override
public void alterPartitionColumnStatistics(ObjectPath tablePath,
CatalogPartitionSpec partitionSpec, CatalogColumnStatistics columnStatistics,
boolean ignoreIfNotExists) throws PartitionNotExistException, CatalogException {
+ try {
+ Partition hivePartition = getHivePartition(tablePath,
partitionSpec);
+ Table hiveTable = getHiveTable(tablePath);
+ String partName = getPartitionName(tablePath,
partitionSpec, hiveTable);
Review comment:
Yes, we can not just obtain partition keys from hive Partition
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on issue #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on issue #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions URL: https://github.com/apache/flink/pull/8654#issuecomment-501951296 Thanks for the updates @zentol and the reviews @tillrohrmann . I like the current way and it looks pretty good now. I only left several nit comments. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293644729
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/partition/ResultPartitionBuilder.java
##
@@ -112,13 +114,19 @@ public ResultPartitionBuilder setBufferPoolFactory(
return this;
}
+ public ResultPartitionBuilder isReleasedOnConsumption(boolean
releasedOnConsumption) {
+ this.releasedOnConsumption = releasedOnConsumption;
+ return this;
+ }
+
public ResultPartition build() {
ResultPartitionFactory resultPartitionFactory = new
ResultPartitionFactory(
partitionManager,
ioManager,
networkBufferPool,
networkBuffersPerChannel,
- floatingNetworkBuffersPerGate);
+ floatingNetworkBuffersPerGate,
+ true);
Review comment:
After this value is set true, it seems no way to generate `ResultPartition`
atm via builder no matter with `releasedOnConsumption` is set true or false.
Another option is make this value false, and let `releasedOnConsumption`
default value is true, then the final tag could also be changed via
`ResultPartitionBuilder#isReleasedOnConsumption(false)`.
I am not sure whether to adjust this issue atm or fix when required future.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293645376
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ReleaseOnConsumptionResultPartition.java
##
@@ -0,0 +1,102 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.io.network.partition;
+
+import org.apache.flink.runtime.io.network.buffer.BufferPool;
+import org.apache.flink.runtime.io.network.buffer.BufferPoolOwner;
+import org.apache.flink.util.function.FunctionWithException;
+
+import java.io.IOException;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkState;
+
+/**
+ * ResultPartition that releases itself once all subpartitions have been
consumed.
+ */
+public class ReleaseOnConsumptionResultPartition extends ResultPartition {
+
+ /**
+* The total number of references to subpartitions of this result. The
result partition can be
+* safely released, iff the reference count is zero. A reference count
of -1 denotes that the
+* result partition has been released.
+*/
+ private final AtomicInteger pendingReferences = new AtomicInteger();
+
+ ReleaseOnConsumptionResultPartition(
+ String owningTaskName,
+ ResultPartitionID partitionId,
+ ResultPartitionType partitionType,
+ ResultSubpartition[] subpartitions,
+ int numTargetKeyGroups,
+ ResultPartitionManager partitionManager,
+ FunctionWithException bufferPoolFactory) {
+ super(owningTaskName, partitionId, partitionType,
subpartitions, numTargetKeyGroups, partitionManager, bufferPoolFactory);
+ }
+
+ @Override
+ void pin() {
+ while (true) {
Review comment:
Actually I am not sure why it needs `while` loop here before.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Reopened] (FLINK-12541) Add deploy a Python Flink job and session cluster on Kubernetes support.
[ https://issues.apache.org/jira/browse/FLINK-12541?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sunjincheng reopened FLINK-12541: - Hi [~till.rohrmann] Thanks for helping review and merge the #8609, And #8609 is relating the FLINK-12788. So, I'll close the FLINK-12788, and reopen this JIRA. If I miss something, please correct me. :) > Add deploy a Python Flink job and session cluster on Kubernetes support. > > > Key: FLINK-12541 > URL: https://issues.apache.org/jira/browse/FLINK-12541 > Project: Flink > Issue Type: Sub-task > Components: API / Python, Runtime / REST >Affects Versions: 1.9.0 >Reporter: sunjincheng >Assignee: Dian Fu >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > Time Spent: 0.5h > Remaining Estimate: 0h > > Add deploy a Python Flink job and session cluster on Kubernetes support. > We need to have the same deployment step as the Java job. Please see: > [https://ci.apache.org/projects/flink/flink-docs-stable/ops/deployment/kubernetes.html] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] zhijiangW commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293644729
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/io/network/partition/ResultPartitionBuilder.java
##
@@ -112,13 +114,19 @@ public ResultPartitionBuilder setBufferPoolFactory(
return this;
}
+ public ResultPartitionBuilder isReleasedOnConsumption(boolean
releasedOnConsumption) {
+ this.releasedOnConsumption = releasedOnConsumption;
+ return this;
+ }
+
public ResultPartition build() {
ResultPartitionFactory resultPartitionFactory = new
ResultPartitionFactory(
partitionManager,
ioManager,
networkBufferPool,
networkBuffersPerChannel,
- floatingNetworkBuffersPerGate);
+ floatingNetworkBuffersPerGate,
+ true);
Review comment:
After this value is set true, it seems no way to generate `ResultPartition`
atm via builder no matter with `releasedOnConsumption` is set true or false.
Another option is make this value false, and let `releasedOnConsumption`
default value is true, then the final tag could also be changed via
`ResultPartitionBuilder#isReleasedOnConsumption(false)`.
I am not sure whether to adjust this issue atm or fix when required future.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Closed] (FLINK-12788) Add support to run a Python job-specific cluster on Kubernetes
[ https://issues.apache.org/jira/browse/FLINK-12788?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sunjincheng closed FLINK-12788. --- Resolution: Fixed Fix Version/s: 1.9.0 Fixed in master: 00d90a4fe3ff93d19ff6be3ed7b9cf9d0f5b0dfd > Add support to run a Python job-specific cluster on Kubernetes > -- > > Key: FLINK-12788 > URL: https://issues.apache.org/jira/browse/FLINK-12788 > Project: Flink > Issue Type: Sub-task > Components: API / Python, Deployment / Docker >Reporter: Dian Fu >Assignee: Dian Fu >Priority: Major > Labels: pull-request-available > Fix For: 1.9.0 > > > As discussed in FLINK-12541, we need to support to run a Python job-specific > cluster on Kubernetes. To support this, we need to improve the job specific > docker image build scripts to support Python Table API jobs. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293644286
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseMapSerializer.java
##
@@ -0,0 +1,273 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.TypeSerializerSchemaCompatibility;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.java.typeutils.runtime.DataInputViewStream;
+import org.apache.flink.api.java.typeutils.runtime.DataOutputViewStream;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+import org.apache.flink.table.dataformat.BaseMap;
+import org.apache.flink.table.dataformat.BinaryArray;
+import org.apache.flink.table.dataformat.BinaryArrayWriter;
+import org.apache.flink.table.dataformat.BinaryMap;
+import org.apache.flink.table.dataformat.BinaryWriter;
+import org.apache.flink.table.dataformat.GenericMap;
+import org.apache.flink.table.types.InternalSerializers;
+import org.apache.flink.table.types.logical.LogicalType;
+import org.apache.flink.table.util.SegmentsUtil;
+import org.apache.flink.util.InstantiationUtil;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * Serializer for {@link BaseMap}.
+ */
+public class BaseMapSerializer extends TypeSerializer {
+
+ private final LogicalType keyType;
+ private final LogicalType valueType;
+
+ private final TypeSerializer keySerializer;
+ private final TypeSerializer valueSerializer;
+
+ private transient BinaryArray reuseKeyArray;
+ private transient BinaryArray reuseValueArray;
+ private transient BinaryArrayWriter reuseKeyWriter;
+ private transient BinaryArrayWriter reuseValueWriter;
+
+ public BaseMapSerializer(LogicalType keyType, LogicalType valueType) {
+ this.keyType = keyType;
+ this.valueType = valueType;
+
+ this.keySerializer = InternalSerializers.create(keyType, new
ExecutionConfig());
+ this.valueSerializer = InternalSerializers.create(valueType,
new ExecutionConfig());
+ }
+
+ @Override
+ public boolean isImmutableType() {
+ return false;
+ }
+
+ @Override
+ public TypeSerializer duplicate() {
+ return new BaseMapSerializer(keyType, valueType);
+ }
+
+ @Override
+ public BaseMap createInstance() {
+ return new BinaryMap();
+ }
+
+ @Override
+ public BaseMap copy(BaseMap from) {
+ if (from instanceof GenericMap) {
+ Map fromMap = ((GenericMap)
from).getMap();
+ HashMap toMap = new HashMap<>();
Review comment:
No,
First: only `IdentityConverter` will use `GenericMap`, others will use
`BinaryMap`.
Second: Just wrap user `Map`, users need to guarantee their logic.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293640776
##
File path:
flink-python/src/main/java/org/apache/flink/python/client/PythonShellParser.java
##
@@ -0,0 +1,322 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.python.client;
+
+import org.apache.flink.util.Preconditions;
+
+import org.apache.commons.cli.CommandLine;
+import org.apache.commons.cli.DefaultParser;
+import org.apache.commons.cli.HelpFormatter;
+import org.apache.commons.cli.Option;
+import org.apache.commons.cli.Options;
+import org.apache.commons.cli.ParseException;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * Command line parser for Python shell.
+ */
+public class PythonShellParser {
+ private static final Option OPTION_HELP = Option
+ .builder("h")
+ .required(false)
+ .longOpt("help")
+ .desc("Show the help message with descriptions of all options.")
+ .build();
+
+ private static final Option OPTION_CONTAINER = Option
+ .builder("n")
+ .required(false)
+ .longOpt("container")
+ .hasArg()
+ .desc("Number of YARN container to allocate (=Number of Task
Managers)")
+ .build();
+
+ private static final Option OPTION_JM_MEMORY = Option
+ .builder("jm")
+ .required(false)
+ .longOpt("jobManagerMemory")
+ .hasArg()
+ .desc("Memory for JobManager Container with optional unit
(default: MB)")
+ .build();
+
+ private static final Option OPTION_NAME = Option
+ .builder("nm")
+ .required(false)
+ .longOpt("name")
+ .hasArg()
+ .desc("Set a custom name for the application on YARN")
+ .build();
+
+ private static final Option OPTION_QUEUE = Option
+ .builder("qu")
+ .required(false)
+ .longOpt("queue")
+ .hasArg()
+ .desc("Specify YARN queue.")
+ .build();
+
+ private static final Option OPTION_SLOTS = Option
+ .builder("s")
+ .required(false)
+ .longOpt("slots")
+ .hasArg()
+ .desc("Number of slots per TaskManager")
+ .build();
+
+ private static final Option OPTION_TM_MEMORY = Option
+ .builder("tm")
+ .required(false)
+ .longOpt("taskManagerMemory")
+ .hasArg()
+ .desc("Memory per TaskManager Container with optional unit
(default: MB)")
+ .build();
+
+ // cluster types
+ private static final String LOCAL_RUN = "local";
+ private static final String REMOTE_RUN = "remote";
+ private static final String YARN_RUN = "yarn";
+
+ // Options that will be used in mini cluster.
+ private static final Options LOCAL_OPTIONS = getLocalOptions(new
Options());
+
+ // Options that will be used in remote cluster.
+ private static final Options REMOTE_OPTIONS = getRemoteOptions(new
Options());
+
+ // Options that will be used in yarn cluster.
+ private static final Options YARN_OPTIONS = getYarnOptions(new
Options());
+
+ public static void main(String[] args) {
+ if (args.length < 1) {
+ printError("You should specify cluster type or -h |
--help option");
+ System.exit(1);
+ }
+ String command = args[0];
+ List commandOptions = null;
+ try {
+ switch (command) {
+ case LOCAL_RUN:
+ commandOptions = parseLocal(args);
+ break;
+ case REMOTE_RUN:
+ commandOptions = parseRemote(args);
+
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293642907
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够运行在本地启动的local模式,也能够运行在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
+
+## 使用
+
+当前Python shell支持Table API的功能。
+在启动之后,Table Environment的相关内容将会被自动加载。
+可以通过变量"bt_env"来使用BatchTableEnvironment,通过变量"st_env"来使用StreamTableEnvironment。
+
+### Table API
+
+下面的内容是关于如何通过Python Table API来实现一个简单的作业:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = bt_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> bt_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("batch_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("batch_sink")
+>>> bt_env.execute()
+{% endhighlight %}
+
+
+
+## 启动
+
+为了概览Python Shell提供的可选参数,可以使用:
+
+{% highlight bash %}
+bin/pyflink-shell.sh --help
+{% endhighlight %}
+
+### Local
+
+可以指定Python Shell运行在local模式下,只需要执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+
+### Remote
+
+可以指定Python Shell运行在一个指定的JobManager上,通过关键字`remote`和对应的JobManager
Review comment:
We can delete `可以指定`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293638255
##
File path: docs/ops/python_shell.md
##
@@ -0,0 +1,185 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink comes with an integrated interactive Python Shell.
+It can be used in a local setup as well as in a cluster setup.
+
+To use the shell with an integrated Flink cluster just execute:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+in the root directory of your binary Flink directory. To run the Shell on a
+cluster, please see the Setup section below.
+
+## Usage
+
+The shell only supports Table API currently.
+The Table Environments are automatically prebound after startup.
+Use "bt_env" and "st_env" to access BatchTableEnvironment and
StreamTableEnvironment respectively.
+
+### Table API
+
+The example below is a simple program using Table API:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
Review comment:
I think we can set the `set_parallelism(1)`, then we can check the result
easily, What to do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293642567
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够运行在本地启动的local模式,也能够运行在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
Review comment:
`关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容` ->
`关于如何在一个Cluster集群上运行Python shell,可以参考启动章节介绍。`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293643657
##
File path: flink-python/pyflink/shell.py
##
@@ -0,0 +1,128 @@
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import platform
+
+from pyflink.table import *
+
+print("Using Python version %s (%s, %s)" % (
+platform.python_version(),
+platform.python_build()[0],
+platform.python_build()[1]))
+
+welcome_msg = u'''
+ \u2592\u2593\u2588\u2588\u2593\u2588\u2588\u2592
+ \u2593\u2588\u2588\u2588\u2588\u2592\u2592\u2588\u2593 \
+ \u2592\u2593\u2588\u2588\u2588\u2593\u2592
+ \u2593\u2588\u2588\u2588\u2593\u2591\u2591\u2592 \
+ \u2592\u2592\u2593\u2588\u2588\u2592 \u2592
+\u2591\u2588\u2588\u2592 \u2592\u2592\u2593\u2593\u2588 \
+\u2593\u2593\u2592\u2591 \u2592\u2588\u2588\u2588\u2588
+\u2588\u2588\u2592 \u2591\u2592\u2593\u2588\u2588 \
+\u2588\u2592\u2592\u2588\u2592\u2588\u2592
+ \u2591\u2593\u2588\u2588\u2588\u2588 \u2593 \
+ \u2591\u2592\u2588\u2588
+\u2593\u2588
\u2592\u2592\u2592\u2592\u2592\u2593\u2588\u2588\u2593\u2591\u2592\u2591\u2593\u2593\u2588
+ \u2588\u2591 \u2588 \u2592\u2592\u2591
\u2588\u2588\u2588\u2593\u2593\u2588 \u2592\u2588\u2592\u2592\u2592
+ \u2588\u2588\u2588\u2588\u2591 \u2592\u2593\u2588\u2593
\u2588\u2588\u2592\u2592\u2592 \u2593\u2588\u2588\u2588\u2592
+ \u2591\u2592\u2588\u2593\u2593\u2588\u2588
\u2593\u2588\u2592\u2593\u2588\u2592\u2593\u2588\u2588\u2593
\u2591\u2588\u2591
+ \u2593\u2591\u2592\u2593\u2588\u2588\u2588\u2588\u2592 \u2588\u2588
\u2592\u2588
\u2588\u2593\u2591\u2592\u2588\u2592\u2591\u2592\u2588\u2592
+\u2588\u2588\u2588\u2593\u2591\u2588\u2588\u2593 \u2593\u2588
\u2588 \u2588\u2593 \u2592\u2593\u2588\u2593\u2593\u2588\u2592
+ \u2591\u2588\u2588\u2593 \u2591\u2588\u2591\u2588
\u2588\u2592 \u2592\u2588\u2588\u2588\u2588\u2588\u2593\u2592
\u2588\u2588\u2593\u2591\u2592
+ \u2588\u2588\u2588\u2591 \u2591 \u2588\u2591 \u2593 \u2591\u2588
\u2588\u2588\u2588\u2588\u2588\u2592\u2591\u2591\u2591\u2588\u2591\u2593
\u2593\u2591
+\u2588\u2588\u2593\u2588 \u2592\u2592\u2593\u2592
\u2593\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2593\u2591
\u2592\u2588\u2592 \u2592\u2593 \u2593\u2588\u2588\u2593
+ \u2592\u2588\u2588\u2593 \u2593\u2588 \u2588\u2593\u2588
\u2591\u2592\u2588\u2588\u2588\u2588\u2588\u2593\u2593\u2592\u2591
\u2588\u2588\u2592\u2592 \u2588 \u2592 \u2593\u2588\u2592
+ \u2593\u2588\u2593 \u2593\u2588 \u2588\u2588\u2593
\u2591\u2593\u2593\u2593\u2593\u2593\u2593\u2593\u2592
\u2592\u2588\u2588\u2593 \u2591\u2588\u2592
+ \u2593\u2588\u2588 \u2593\u2588\u2588\u2588\u2593\u2592\u2591
\u2591\u2593\u2593\u2593\u2588\u2588\u2588\u2593 \u2591\u2592\u2591
\u2593\u2588
+ \u2588\u2588\u2593\u2588\u2588\u2592
\u2591\u2592\u2593\u2593\u2588\u2588\u2588\u2593\u2593\u2593\u2593\u2593\u2588\u2588\u2588\u2588\u2588\u2588\u2593\u2592
\u2593\u2588\u2588\u2588 \u2588
+\u2593\u2588\u2588\u2588\u2592 \u2588\u2588\u2588
\u2591\u2593\u2593\u2592\u2591\u2591
\u2591\u2593\u2588\u2588\u2588\u2588\u2593\u2591
\u2591\u2592\u2593\u2592 \u2588\u2593
+\u2588\u2593\u2592\u2592\u2593\u2593\u2588\u2588
\u2591\u2592\u2592\u2591\u2591\u2591\u2592\u2592\u2592\u2592\u2593\u2588\u2588\u2593\u2591
\u2588\u2593
+\u2588\u2588 \u2593\u2591\u2592\u2588
\u2593\u2593\u2593\u2593\u2592\u2591\u2591 \u2592\u2588\u2593
\u2592\u2593\u2593\u2588\u2588\u2593\u2593\u2592
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293638505
##
File path: docs/ops/python_shell.md
##
@@ -0,0 +1,185 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink comes with an integrated interactive Python Shell.
+It can be used in a local setup as well as in a cluster setup.
+
+To use the shell with an integrated Flink cluster just execute:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+in the root directory of your binary Flink directory. To run the Shell on a
+cluster, please see the Setup section below.
+
+## Usage
+
+The shell only supports Table API currently.
+The Table Environments are automatically prebound after startup.
+Use "bt_env" and "st_env" to access BatchTableEnvironment and
StreamTableEnvironment respectively.
+
+### Table API
+
+The example below is a simple program using Table API:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
Review comment:
It's better to tell the user how to check the result. currently, I think we
can give the user some example to read the sink file, What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293643067
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够运行在本地启动的local模式,也能够运行在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
+
+## 使用
+
+当前Python shell支持Table API的功能。
+在启动之后,Table Environment的相关内容将会被自动加载。
+可以通过变量"bt_env"来使用BatchTableEnvironment,通过变量"st_env"来使用StreamTableEnvironment。
+
+### Table API
+
+下面的内容是关于如何通过Python Table API来实现一个简单的作业:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = bt_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> bt_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("batch_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("batch_sink")
+>>> bt_env.execute()
+{% endhighlight %}
+
+
+
+## 启动
+
+为了概览Python Shell提供的可选参数,可以使用:
+
+{% highlight bash %}
+bin/pyflink-shell.sh --help
+{% endhighlight %}
+
+### Local
+
+可以指定Python Shell运行在local模式下,只需要执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+
+### Remote
+
+可以指定Python Shell运行在一个指定的JobManager上,通过关键字`remote`和对应的JobManager
+的地址和端口号来进行指定:
+
+{% highlight bash %}
+bin/pyflink-shell.sh remote
+{% endhighlight %}
+
+### Yarn Python Shell cluster
+
+可以指定Python Shell运行在YARN集群之上。YARN的container的数量可以通过参数`-n `进行
Review comment:
`可以指定Python Shell运行在YARN集群之上` -> `Python Shell可以运行在YARN集群之上。`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293642713
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够运行在本地启动的local模式,也能够运行在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
+
+## 使用
+
+当前Python shell支持Table API的功能。
+在启动之后,Table Environment的相关内容将会被自动加载。
+可以通过变量"bt_env"来使用BatchTableEnvironment,通过变量"st_env"来使用StreamTableEnvironment。
+
+### Table API
+
+下面的内容是关于如何通过Python Table API来实现一个简单的作业:
Review comment:
下面是一个通过Python Shell 运行的简单示例。
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293641314
##
File path: docs/ops/python_shell.md
##
@@ -0,0 +1,185 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink comes with an integrated interactive Python Shell.
+It can be used in a local setup as well as in a cluster setup.
+
+To use the shell with an integrated Flink cluster just execute:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+in the root directory of your binary Flink directory. To run the Shell on a
+cluster, please see the Setup section below.
+
+## Usage
+
+The shell only supports Table API currently.
+The Table Environments are automatically prebound after startup.
+Use "bt_env" and "st_env" to access BatchTableEnvironment and
StreamTableEnvironment respectively.
+
+### Table API
+
+The example below is a simple program using Table API:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = bt_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> bt_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("batch_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("batch_sink")
+>>> bt_env.execute()
+{% endhighlight %}
+
+
+
+## Setup
+
+To get an overview of what options the Python Shell provides, please use
+
+{% highlight bash %}
+bin/pyflink-shell.sh --help
+{% endhighlight %}
+
+### Local
+
+To use the shell with an integrated Flink cluster just execute:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+
+### Remote
+
+To use it with a running cluster, please start the Python shell with the
keyword `remote`
+and supply the host and port of the JobManager with:
+
+{% highlight bash %}
+bin/pyflink-shell.sh remote
+{% endhighlight %}
+
+### Yarn Python Shell cluster
+
+The shell can deploy a Flink cluster to YARN, which is used exclusively by the
+shell. The number of YARN containers can be controlled by the parameter `-n
`.
+The shell deploys a new Flink cluster on YARN and connects the
+cluster. You can also specify options for YARN cluster such as memory for
+JobManager, name of YARN application, etc.
+
+For example, to start a Yarn cluster for the Python Shell with two TaskManagers
+use the following:
+
+{% highlight bash %}
+ bin/pyflink-shell.sh yarn -n 2
+{% endhighlight %}
+
+For all other options, see the full reference at the bottom.
+
+
+### Yarn Session
+
+If you have previously deployed a Flink cluster using the Flink Yarn Session,
+the Python shell can connect with it using the following command:
+
+{% highlight bash %}
+ bin/pyflink-shell.sh yarn
+{% endhighlight %}
+
+
+## Full Reference
Review comment:
The doc of the `full reference` should some as the command line output`:
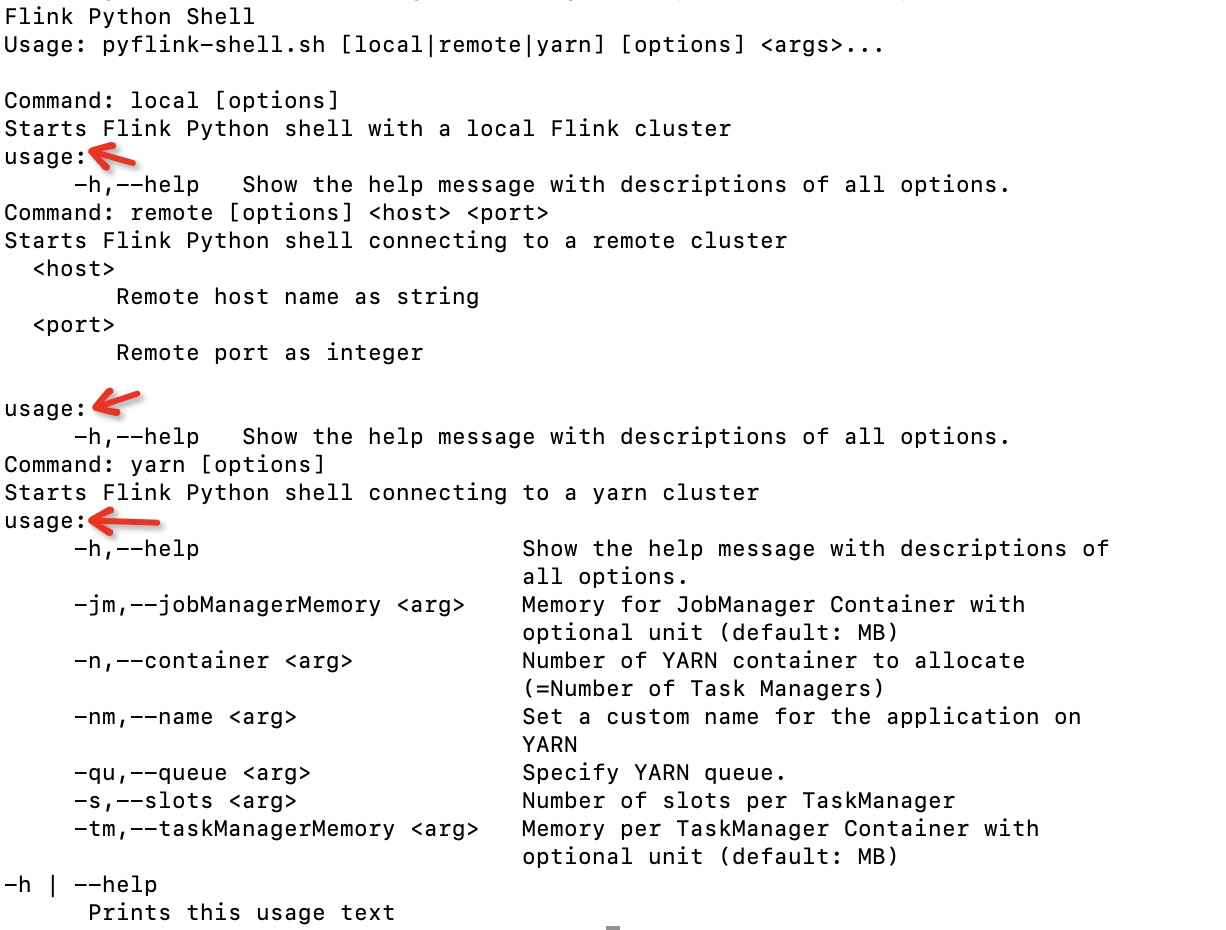
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293642161
##
File path: docs/ops/python_shell.md
##
@@ -0,0 +1,185 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink comes with an integrated interactive Python Shell.
+It can be used in a local setup as well as in a cluster setup.
+
+To use the shell with an integrated Flink cluster just execute:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+in the root directory of your binary Flink directory. To run the Shell on a
+cluster, please see the Setup section below.
+
+## Usage
+
+The shell only supports Table API currently.
+The Table Environments are automatically prebound after startup.
+Use "bt_env" and "st_env" to access BatchTableEnvironment and
StreamTableEnvironment respectively.
+
+### Table API
+
+The example below is a simple program using Table API:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
Review comment:
I think we should not only remove the file, but alos need delete the folder
by `shutil.rmtree(result_path)`, What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293642781
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够运行在本地启动的local模式,也能够运行在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
+
+## 使用
+
+当前Python shell支持Table API的功能。
+在启动之后,Table Environment的相关内容将会被自动加载。
+可以通过变量"bt_env"来使用BatchTableEnvironment,通过变量"st_env"来使用StreamTableEnvironment。
+
+### Table API
+
+下面的内容是关于如何通过Python Table API来实现一个简单的作业:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = bt_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> bt_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("batch_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("batch_sink")
+>>> bt_env.execute()
+{% endhighlight %}
+
+
+
+## 启动
+
+为了概览Python Shell提供的可选参数,可以使用:
Review comment:
查看Python Shell提供的可选参数,可以使用:
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293642820
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够运行在本地启动的local模式,也能够运行在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
+
+## 使用
+
+当前Python shell支持Table API的功能。
+在启动之后,Table Environment的相关内容将会被自动加载。
+可以通过变量"bt_env"来使用BatchTableEnvironment,通过变量"st_env"来使用StreamTableEnvironment。
+
+### Table API
+
+下面的内容是关于如何通过Python Table API来实现一个简单的作业:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = bt_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> bt_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("batch_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("batch_sink")
+>>> bt_env.execute()
+{% endhighlight %}
+
+
+
+## 启动
+
+为了概览Python Shell提供的可选参数,可以使用:
+
+{% highlight bash %}
+bin/pyflink-shell.sh --help
+{% endhighlight %}
+
+### Local
+
+可以指定Python Shell运行在local模式下,只需要执行:
Review comment:
Python Shell运行在local模式下,只需要执行:
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293262036
##
File path: docs/ops/python_shell.zh.md
##
@@ -0,0 +1,179 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink附带了一个集成的交互式Python Shell。
+它既能够用在本地启动的local模式,也能够用在集群启动的cluster模式下。
+
+为了使用Flink的Python Shell,你只需要在Flink的binary目录下执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+关于如何在一个Cluster集群上运行Python shell,可以参考下面的启动那一节的内容
+
+## 使用
+
+当前Python shell支持Table API的功能。
+在启动之后,Table Environment的相关内容将会被自动加载。
+可以通过变量"bt_env"来使用BatchTableEnvironment,通过变量"st_env"来使用StreamTableEnvironment。
+
+### Table API
+
+下面的内容是关于如何通过Table API来实现一个wordcount的作业:
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/streaming.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> st_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("stream_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("stream_sink")
+>>> st_env.execute()
+{% endhighlight %}
+
+
+{% highlight python %}
+>>> import tempfile
+>>> import os
+>>> sink_path = tempfile.gettempdir() + '/batch.csv'
+>>> if os.path.isfile(sink_path):
+>>> os.remove(sink_path)
+>>> t = bt_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a',
'b', 'c'])
+>>> bt_env.connect(FileSystem().path(sink_path))\
+>>> .with_format(OldCsv()
+>>> .field_delimiter(',')
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .with_schema(Schema()
+>>> .field("a", DataTypes.BIGINT())
+>>> .field("b", DataTypes.STRING())
+>>> .field("c", DataTypes.STRING()))\
+>>> .register_table_sink("batch_sink")
+>>> t.select("a + 1, b, c")\
+>>> .insert_into("batch_sink")
+>>> bt_env.execute()
+{% endhighlight %}
+
+
+
+## 启动
+
+为了概览Python Shell提供的可选参数,可以使用:
+
+{% highlight bash %}
+bin/pyflink-shell.sh --help
+{% endhighlight %}
+
+### Local
+
+可以指定Python Shell运行在local本地,只需要执行:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+
+### Remote
+
+可以指定Python Shell运行在一个指定的JobManager上,通过关键字`remote`和对应的JobManager
+的地址和端口号来进行指定:
+
+{% highlight bash %}
+bin/pyflink-shell.sh remote
+{% endhighlight %}
+
+### Yarn Python Shell cluster
+
+可以指定Python Shell运行在YARN集群之上。YARN的container的数量可以通过参数`-n `进行
+指定。Python shell在Yarn上部署一个新的Flink集群,并进行连接。除了指定container数量,你也
+可以指定JobManager的内存,YARN应用的名字等参数。
+例如,运行Python Shell部署一个包含两个TaskManager的Yarn集群:
+
+{% highlight bash %}
+ bin/pyflink-shell.sh yarn -n 2
+{% endhighlight %}
+
+关于所有可选的参数,可以查看本页面底部的完整说明。
+
+
+### Yarn Session
+
+如果你已经通过Flink Yarn Session部署了一个Flink集群,能够通过以下的命令连接到这个集群:
+
+{% highlight bash %}
+ bin/pyflink-shell.sh yarn
+{% endhighlight %}
+
+
+## 完整的参考
+
+{% highlight bash %}
+Flink Python Shell
+使用: pyflink-shell.sh [local|remote|yarn] [options] ...
+
+命令: local [选项]
+启动一个部署在local本地的Flink Python shell
Review comment:
`local本地` -> `local`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293643766
##
File path: flink-python/pyflink/shell.py
##
@@ -0,0 +1,128 @@
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import platform
+
+from pyflink.table import *
+
+print("Using Python version %s (%s, %s)" % (
+platform.python_version(),
+platform.python_build()[0],
+platform.python_build()[1]))
+
+welcome_msg = u'''
+ \u2592\u2593\u2588\u2588\u2593\u2588\u2588\u2592
+ \u2593\u2588\u2588\u2588\u2588\u2592\u2592\u2588\u2593 \
+ \u2592\u2593\u2588\u2588\u2588\u2593\u2592
+ \u2593\u2588\u2588\u2588\u2593\u2591\u2591\u2592 \
+ \u2592\u2592\u2593\u2588\u2588\u2592 \u2592
+\u2591\u2588\u2588\u2592 \u2592\u2592\u2593\u2593\u2588 \
+\u2593\u2593\u2592\u2591 \u2592\u2588\u2588\u2588\u2588
+\u2588\u2588\u2592 \u2591\u2592\u2593\u2588\u2588 \
+\u2588\u2592\u2592\u2588\u2592\u2588\u2592
+ \u2591\u2593\u2588\u2588\u2588\u2588 \u2593 \
+ \u2591\u2592\u2588\u2588
+\u2593\u2588
\u2592\u2592\u2592\u2592\u2592\u2593\u2588\u2588\u2593\u2591\u2592\u2591\u2593\u2593\u2588
+ \u2588\u2591 \u2588 \u2592\u2592\u2591
\u2588\u2588\u2588\u2593\u2593\u2588 \u2592\u2588\u2592\u2592\u2592
+ \u2588\u2588\u2588\u2588\u2591 \u2592\u2593\u2588\u2593
\u2588\u2588\u2592\u2592\u2592 \u2593\u2588\u2588\u2588\u2592
+ \u2591\u2592\u2588\u2593\u2593\u2588\u2588
\u2593\u2588\u2592\u2593\u2588\u2592\u2593\u2588\u2588\u2593
\u2591\u2588\u2591
+ \u2593\u2591\u2592\u2593\u2588\u2588\u2588\u2588\u2592 \u2588\u2588
\u2592\u2588
\u2588\u2593\u2591\u2592\u2588\u2592\u2591\u2592\u2588\u2592
+\u2588\u2588\u2588\u2593\u2591\u2588\u2588\u2593 \u2593\u2588
\u2588 \u2588\u2593 \u2592\u2593\u2588\u2593\u2593\u2588\u2592
+ \u2591\u2588\u2588\u2593 \u2591\u2588\u2591\u2588
\u2588\u2592 \u2592\u2588\u2588\u2588\u2588\u2588\u2593\u2592
\u2588\u2588\u2593\u2591\u2592
+ \u2588\u2588\u2588\u2591 \u2591 \u2588\u2591 \u2593 \u2591\u2588
\u2588\u2588\u2588\u2588\u2588\u2592\u2591\u2591\u2591\u2588\u2591\u2593
\u2593\u2591
+\u2588\u2588\u2593\u2588 \u2592\u2592\u2593\u2592
\u2593\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2593\u2591
\u2592\u2588\u2592 \u2592\u2593 \u2593\u2588\u2588\u2593
+ \u2592\u2588\u2588\u2593 \u2593\u2588 \u2588\u2593\u2588
\u2591\u2592\u2588\u2588\u2588\u2588\u2588\u2593\u2593\u2592\u2591
\u2588\u2588\u2592\u2592 \u2588 \u2592 \u2593\u2588\u2592
+ \u2593\u2588\u2593 \u2593\u2588 \u2588\u2588\u2593
\u2591\u2593\u2593\u2593\u2593\u2593\u2593\u2593\u2592
\u2592\u2588\u2588\u2593 \u2591\u2588\u2592
+ \u2593\u2588\u2588 \u2593\u2588\u2588\u2588\u2593\u2592\u2591
\u2591\u2593\u2593\u2593\u2588\u2588\u2588\u2593 \u2591\u2592\u2591
\u2593\u2588
+ \u2588\u2588\u2593\u2588\u2588\u2592
\u2591\u2592\u2593\u2593\u2588\u2588\u2588\u2593\u2593\u2593\u2593\u2593\u2588\u2588\u2588\u2588\u2588\u2588\u2593\u2592
\u2593\u2588\u2588\u2588 \u2588
+\u2593\u2588\u2588\u2588\u2592 \u2588\u2588\u2588
\u2591\u2593\u2593\u2592\u2591\u2591
\u2591\u2593\u2588\u2588\u2588\u2588\u2593\u2591
\u2591\u2592\u2593\u2592 \u2588\u2593
+\u2588\u2593\u2592\u2592\u2593\u2593\u2588\u2588
\u2591\u2592\u2592\u2591\u2591\u2591\u2592\u2592\u2592\u2592\u2593\u2588\u2588\u2593\u2591
\u2588\u2593
+\u2588\u2588 \u2593\u2591\u2592\u2588
\u2593\u2593\u2593\u2593\u2592\u2591\u2591 \u2592\u2588\u2593
\u2592\u2593\u2593\u2588\u2588\u2593\u2593\u2592
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675:
[FLINK-12716][python] Add an interactive shell for Python Table API
URL: https://github.com/apache/flink/pull/8675#discussion_r293634615
##
File path: docs/ops/python_shell.md
##
@@ -0,0 +1,185 @@
+---
+title: "Python REPL"
+nav-parent_id: ops
+nav-pos: 7
+---
+
+
+Flink comes with an integrated interactive Python Shell.
+It can be used in a local setup as well as in a cluster setup.
+
+To use the shell with an integrated Flink cluster just execute:
+
+{% highlight bash %}
+bin/pyflink-shell.sh local
+{% endhighlight %}
+
+in the root directory of your binary Flink directory. To run the Shell on a
+cluster, please see the Setup section below.
+
+## Usage
+
+The shell only supports Table API currently.
+The Table Environments are automatically prebound after startup.
+Use "bt_env" and "st_env" to access BatchTableEnvironment and
StreamTableEnvironment respectively.
+
+### Table API
+
+The example below is a simple program using Table API:
Review comment:
`The example below is a simple program using Table API` -> `The example
below is a simple program in the Python shell`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API
sunjincheng121 commented on a change in pull request #8675: [FLINK-12716][python] Add an interactive shell for Python Table API URL: https://github.com/apache/flink/pull/8675#discussion_r293634271 ## File path: flink-dist/src/main/flink-bin/bin/pyflink-shell.sh ## @@ -0,0 +1,79 @@ +#!/bin/bash Review comment: Can we rename `pyflink-shell.sh` to `start-python-shell.sh`? jsut like `start-scala-shell.sh` :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293643294
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseRowSerializer.java
##
@@ -165,49 +168,33 @@ public int getArity() {
/**
* Convert base row to binary row.
-* TODO modify it to code gen, and reuse BinaryRow
+* TODO modify it to code gen.
Review comment:
We still need take this logical to code gen.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] shuai-xu commented on issue #8688: [FLINK-12760] [runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter
shuai-xu commented on issue #8688: [FLINK-12760] [runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter URL: https://github.com/apache/flink/pull/8688#issuecomment-501947360 @GJL Of course, I have rebased it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-11879) Add JobGraph validators for the uses of InputSelectable, BoundedOneInput and BoundedMultiInput
[ https://issues.apache.org/jira/browse/FLINK-11879?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Haibo Sun updated FLINK-11879: -- Description: - Rejects the jobs containing operators which were implemented `InputSelectable` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `BoundedInput` or `BoundedMultiInput` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `InputSelectable` in case that credit-based flow control is disabled. was: - Rejects the jobs containing operators which were implemented `TwoInputSelectable` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `BoundedInput` or `BoundedMultiInput` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `TwoInputSelectable` in case that credit-based flow control is disabled. > Add JobGraph validators for the uses of InputSelectable, BoundedOneInput and > BoundedMultiInput > -- > > Key: FLINK-11879 > URL: https://issues.apache.org/jira/browse/FLINK-11879 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Task >Reporter: Haibo Sun >Assignee: Haibo Sun >Priority: Major > > - Rejects the jobs containing operators which were implemented > `InputSelectable` in case of enabled checkpointing. > - Rejects the jobs containing operators which were implemented > `BoundedInput` or `BoundedMultiInput` in case of enabled checkpointing. > - Rejects the jobs containing operators which were implemented > `InputSelectable` in case that credit-based flow control is disabled. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-11879) Add JobGraph validators for the uses of InputSelectable, BoundedOneInput and BoundedMultiInput
[ https://issues.apache.org/jira/browse/FLINK-11879?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Haibo Sun updated FLINK-11879: -- Description: - Rejects the jobs containing operators which were implemented `TwoInputSelectable` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `BoundedInput` or `BoundedMultiInput` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `TwoInputSelectable` in case that credit-based flow control is disabled. was: - Rejects the jobs containing operators which were implemented `TwoInputSelectable` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `BoundedInput` or `BoundedTwoInput` in case of enabled checkpointing. - Rejects the jobs containing operators which were implemented `TwoInputSelectable` in case that credit-based flow control is disabled. > Add JobGraph validators for the uses of InputSelectable, BoundedOneInput and > BoundedMultiInput > -- > > Key: FLINK-11879 > URL: https://issues.apache.org/jira/browse/FLINK-11879 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Task >Reporter: Haibo Sun >Assignee: Haibo Sun >Priority: Major > > - Rejects the jobs containing operators which were implemented > `TwoInputSelectable` in case of enabled checkpointing. > - Rejects the jobs containing operators which were implemented > `BoundedInput` or `BoundedMultiInput` in case of enabled checkpointing. > - Rejects the jobs containing operators which were implemented > `TwoInputSelectable` in case that credit-based flow control is disabled. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [flink] shuai-xu commented on a change in pull request #8688: [FLINK-12760] [runtime] Implement ExecutionGraph to InputsLocationsRetriever Adapter
shuai-xu commented on a change in pull request #8688: [FLINK-12760] [runtime]
Implement ExecutionGraph to InputsLocationsRetriever Adapter
URL: https://github.com/apache/flink/pull/8688#discussion_r293643179
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/EGBasedInputsLocationsRetriever.java
##
@@ -0,0 +1,87 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.scheduler;
+
+import org.apache.flink.runtime.execution.ExecutionState;
+import org.apache.flink.runtime.executiongraph.ExecutionEdge;
+import org.apache.flink.runtime.executiongraph.ExecutionGraph;
+import org.apache.flink.runtime.executiongraph.ExecutionJobVertex;
+import org.apache.flink.runtime.executiongraph.ExecutionVertex;
+import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID;
+import org.apache.flink.runtime.taskmanager.TaskManagerLocation;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.List;
+import java.util.Optional;
+import java.util.concurrent.CompletableFuture;
+
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/**
+ * An implementation of {@link InputsLocationsRetriever} based on the {@link
ExecutionGraph}.
+ */
+public class EGBasedInputsLocationsRetriever implements
InputsLocationsRetriever {
+
+ private final ExecutionGraph executionGraph;
+
+ public EGBasedInputsLocationsRetriever(ExecutionGraph executionGraph) {
+ this.executionGraph = checkNotNull(executionGraph);
+ }
+
+ @Override
+ public Collection>
getConsumedResultPartitionsProducers(
+ ExecutionVertexID executionVertexId) {
+ ExecutionVertex ev = getExecutionVertex(executionVertexId);
+
+ List> resultPartitionProducers =
new ArrayList<>(ev.getNumberOfInputs());
+ for (int i = 0 ; i < ev.getNumberOfInputs(); i++) {
+ ExecutionEdge[] inputEdges = ev.getInputEdges(i);
+ List producers = new
ArrayList<>(inputEdges.length);
+ for (ExecutionEdge inputEdge : inputEdges) {
+ ExecutionVertex producer =
inputEdge.getSource().getProducer();
+ producers.add(new
ExecutionVertexID(producer.getJobvertexId(),
producer.getParallelSubtaskIndex()));
+ }
+ resultPartitionProducers.add(producers);
+
+ }
+ return resultPartitionProducers;
+ }
+
+ @Override
+ public Optional>
getTaskManagerLocation(ExecutionVertexID executionVertexId) {
+ ExecutionVertex ev = getExecutionVertex(executionVertexId);
+
+ if (ev.getExecutionState() != ExecutionState.CREATED) {
+ return
Optional.of(ev.getCurrentTaskManagerLocationFuture());
+ } else {
+ return Optional.empty();
+ }
+ }
+
+ private ExecutionVertex getExecutionVertex(ExecutionVertexID
executionVertexId) {
+
+ ExecutionJobVertex ejv =
executionGraph.getJobVertex(executionVertexId.getJobVertexId());
+ if (ejv == null || ejv.getParallelism() <=
executionVertexId.getSubtaskIndex()) {
+ throw new
IllegalArgumentException(String.format("Failed to find execution {} in
execution graph.", executionVertexId));
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] lirui-apache commented on a change in pull request #8695: [FLINK-12805][FLINK-12808][FLINK-12809][table-api] Introduce PartitionableTableSource and PartitionableTableSink and Overwrit
lirui-apache commented on a change in pull request #8695: [FLINK-12805][FLINK-12808][FLINK-12809][table-api] Introduce PartitionableTableSource and PartitionableTableSink and OverwritableTableSink URL: https://github.com/apache/flink/pull/8695#discussion_r293642748 ## File path: flink-table/flink-table-common/src/main/java/org/apache/flink/table/sinks/PartitionableTableSink.java ## @@ -0,0 +1,71 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.table.sinks; + +import java.util.List; +import java.util.Map; + +/** + * An abstract class with trait about partitionable table sink. This is mainly used for Review comment: Yes we do. Actually the example in this very doc suggests it supports dynamic partitioning. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-9854) Allow passing multi-line input to SQL Client CLI
[
https://issues.apache.org/jira/browse/FLINK-9854?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863636#comment-16863636
]
vinoyang commented on FLINK-9854:
-
[~docete] yes, you are right. Please feel free to open a new issue for you
purpose.
> Allow passing multi-line input to SQL Client CLI
>
>
> Key: FLINK-9854
> URL: https://issues.apache.org/jira/browse/FLINK-9854
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / Client
>Reporter: Timo Walther
>Assignee: vinoyang
>Priority: Major
> Labels: pull-request-available
> Time Spent: 20m
> Remaining Estimate: 0h
>
> We should support {{flink-cli < query01.sql}} or {{echo "INSERT INTO bar
> SELECT * FROM foo" | flink-cli}} for convenience. I'm not sure how well we
> support multilines and EOF right now. Currenlty, with the experimental {{-u}}
> flag the user also gets the correct error code after the submission, with
> {{flink-cli < query01.sql}} the CLI would either stay in interactive mode or
> always return success.
> We should also discuss which statements are allowed. Actually, only DDL and
> {{INSERT INTO}} statements make sense so far.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] shuai-xu commented on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots
shuai-xu commented on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots URL: https://github.com/apache/flink/pull/7227#issuecomment-501946385 Thank you, @tillrohrmann This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (FLINK-12229) Implement Lazy Scheduling Strategy
[
https://issues.apache.org/jira/browse/FLINK-12229?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
BoWang closed FLINK-12229.
--
> Implement Lazy Scheduling Strategy
> --
>
> Key: FLINK-12229
> URL: https://issues.apache.org/jira/browse/FLINK-12229
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / Coordination
>Reporter: Gary Yao
>Assignee: BoWang
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.9.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> Implement a {{SchedulingStrategy}} that covers the functionality of
> {{ScheduleMode.LAZY_FROM_SOURCES}}, i.e., vertices are scheduled when all the
> input data are available.
> Acceptance Criteria:
> * New strategy is tested in isolation using test implementations (i.e.,
> without having to submit a job)
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] JingsongLi commented on issue #8718: [FLINK-12824][table-planner-blink] Set parallelism for stream SQL
JingsongLi commented on issue #8718: [FLINK-12824][table-planner-blink] Set parallelism for stream SQL URL: https://github.com/apache/flink/pull/8718#issuecomment-501946257 This calculation method basically completely reuses batch code. LGTM +1 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293642164
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ResultPartition.java
##
@@ -350,18 +336,6 @@ public String toString() {
* operation.
*/
void pin() {
Review comment:
The above javadoc `The partition can only be released after each
subpartition has been consumed once per pin
operation` might also be adjusted.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zhijiangW commented on a change in pull request #8654: [FLINK-12647][network] Add feature flag to disable release of consumed blocking partitions
zhijiangW commented on a change in pull request #8654: [FLINK-12647][network]
Add feature flag to disable release of consumed blocking partitions
URL: https://github.com/apache/flink/pull/8654#discussion_r293641912
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/io/network/partition/ResultPartition.java
##
@@ -337,8 +324,7 @@ public boolean isReleased() {
@Override
public String toString() {
return "ResultPartition " + partitionId.toString() + " [" +
partitionType + ", "
- + subpartitions.length + " subpartitions, "
- + pendingReferences + " pending references]";
+ + subpartitions.length + " subpartitions";
Review comment:
nit: left `]` in the end.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #8695: [FLINK-12805][FLINK-12808][FLINK-12809][table-api] Introduce PartitionableTableSource and PartitionableTableSink and OverwritableT
wuchong commented on a change in pull request #8695: [FLINK-12805][FLINK-12808][FLINK-12809][table-api] Introduce PartitionableTableSource and PartitionableTableSink and OverwritableTableSink URL: https://github.com/apache/flink/pull/8695#discussion_r293641738 ## File path: flink-table/flink-table-common/src/main/java/org/apache/flink/table/sinks/PartitionableTableSink.java ## @@ -0,0 +1,71 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.table.sinks; + +import java.util.List; +import java.util.Map; + +/** + * An abstract class with trait about partitionable table sink. This is mainly used for Review comment: I'm not sure, this is the current design in Blink. Do we support dynamic partition for sink in Blink? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293641180
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/types/InternalSerializers.java
##
@@ -71,10 +75,12 @@ public static TypeSerializer create(LogicalType type,
ExecutionConfig config) {
DecimalType decimalType = (DecimalType) type;
return new
DecimalSerializer(decimalType.getPrecision(), decimalType.getScale());
case ARRAY:
- return BinaryArraySerializer.INSTANCE;
+ return new BaseArraySerializer(((ArrayType)
type).getElementType(), config);
Review comment:
InternalSerializers.create is used to create serializers. runtime per record
process should not invoke it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #8682: [FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce conversion overhead to blink
JingsongLi commented on a change in pull request #8682:
[FLINK-12796][table-planner-blink] Introduce BaseArray and BaseMap to reduce
conversion overhead to blink
URL: https://github.com/apache/flink/pull/8682#discussion_r293640912
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/typeutils/BaseArraySerializer.java
##
@@ -0,0 +1,280 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License.You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.typeutils;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.TypeSerializerSchemaCompatibility;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.java.typeutils.runtime.DataInputViewStream;
+import org.apache.flink.api.java.typeutils.runtime.DataOutputViewStream;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.core.memory.MemorySegmentFactory;
+import org.apache.flink.table.dataformat.BaseArray;
+import org.apache.flink.table.dataformat.BinaryArray;
+import org.apache.flink.table.dataformat.BinaryArrayWriter;
+import org.apache.flink.table.dataformat.BinaryWriter;
+import org.apache.flink.table.dataformat.GenericArray;
+import org.apache.flink.table.dataformat.TypeGetterSetters;
+import org.apache.flink.table.types.InternalSerializers;
+import org.apache.flink.table.types.logical.LogicalType;
+import org.apache.flink.table.util.SegmentsUtil;
+import org.apache.flink.util.InstantiationUtil;
+
+import java.io.IOException;
+import java.lang.reflect.Array;
+import java.util.Arrays;
+
+import static
org.apache.flink.table.types.ClassLogicalTypeConverter.getInternalClassForType;
+
+/**
+ * Serializer for {@link BaseArray}.
+ */
+public class BaseArraySerializer extends TypeSerializer {
+
+ private final LogicalType eleType;
+ private final TypeSerializer eleSer;
+
+ private transient BinaryArray reuseArray;
+ private transient BinaryArrayWriter reuseWriter;
+
+ public BaseArraySerializer(LogicalType eleType, ExecutionConfig conf) {
+ this.eleType = eleType;
+ this.eleSer = InternalSerializers.create(eleType, conf);
+ }
+
+ private BaseArraySerializer(LogicalType eleType, TypeSerializer eleSer)
{
+ this.eleType = eleType;
+ this.eleSer = eleSer;
+ }
+
+ @Override
+ public boolean isImmutableType() {
+ return false;
+ }
+
+ @Override
+ public TypeSerializer duplicate() {
+ return new BaseArraySerializer(eleType, eleSer.duplicate());
+ }
+
+ @Override
+ public BaseArray createInstance() {
+ return new BinaryArray();
+ }
+
+ @Override
+ public BaseArray copy(BaseArray from) {
+ return from instanceof GenericArray ?
+ copyGenericArray((GenericArray) from) :
+ ((BinaryArray) from).copy();
+ }
+
+ @Override
+ public BaseArray copy(BaseArray from, BaseArray reuse) {
+ return copy(from);
+ }
+
+ private GenericArray copyGenericArray(GenericArray array) {
+ Object arr;
+ if (array.isPrimitiveArray()) {
+ switch (eleType.getTypeRoot()) {
+ case BOOLEAN:
+ arr = Arrays.copyOf((boolean[])
array.getArray(), array.numElements());
+ break;
+ case TINYINT:
+ arr = Arrays.copyOf((byte[])
array.getArray(), array.numElements());
+ break;
+ case SMALLINT:
Review comment:
we don't support logicalType char now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
[GitHub] [flink] lirui-apache commented on a change in pull request #8695: [FLINK-12805][FLINK-12808][FLINK-12809][table-api] Introduce PartitionableTableSource and PartitionableTableSink and Overwrit
lirui-apache commented on a change in pull request #8695: [FLINK-12805][FLINK-12808][FLINK-12809][table-api] Introduce PartitionableTableSource and PartitionableTableSink and OverwritableTableSink URL: https://github.com/apache/flink/pull/8695#discussion_r293640156 ## File path: flink-table/flink-table-common/src/main/java/org/apache/flink/table/sinks/PartitionableTableSink.java ## @@ -0,0 +1,71 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.table.sinks; + +import java.util.List; +import java.util.Map; + +/** + * An abstract class with trait about partitionable table sink. This is mainly used for Review comment: Why is it mainly used for static partition? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] docete commented on a change in pull request #8729: [FLINK-12831][table-planner][table-api-java] Split FunctionCatalog into Flink & Calcite specific parts
docete commented on a change in pull request #8729:
[FLINK-12831][table-planner][table-api-java] Split FunctionCatalog into Flink &
Calcite specific parts
URL: https://github.com/apache/flink/pull/8729#discussion_r293638486
##
File path:
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/catalog/FunctionCatalogOperatorTable.java
##
@@ -0,0 +1,139 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.catalog;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.table.calcite.FlinkTypeFactory;
+import org.apache.flink.table.expressions.AggregateFunctionDefinition;
+import org.apache.flink.table.expressions.FunctionDefinition;
+import org.apache.flink.table.expressions.ScalarFunctionDefinition;
+import org.apache.flink.table.expressions.TableFunctionDefinition;
+import org.apache.flink.table.functions.utils.UserDefinedFunctionUtils;
+
+import org.apache.calcite.sql.SqlFunction;
+import org.apache.calcite.sql.SqlFunctionCategory;
+import org.apache.calcite.sql.SqlIdentifier;
+import org.apache.calcite.sql.SqlOperator;
+import org.apache.calcite.sql.SqlOperatorTable;
+import org.apache.calcite.sql.SqlSyntax;
+
+import java.util.List;
+import java.util.Optional;
+
+/**
+ * Thin adapter between {@link SqlOperatorTable} and {@link FunctionCatalog}.
+ */
+@Internal
+public class FunctionCatalogOperatorTable implements SqlOperatorTable {
+
+ private final FunctionCatalog functionCatalog;
+ private final FlinkTypeFactory typeFactory;
+
+ public FunctionCatalogOperatorTable(
+ FunctionCatalog functionCatalog,
+ FlinkTypeFactory typeFactory) {
+ this.functionCatalog = functionCatalog;
+ this.typeFactory = typeFactory;
+ }
+
+ @Override
+ public void lookupOperatorOverloads(
+ SqlIdentifier opName,
+ SqlFunctionCategory category,
+ SqlSyntax syntax,
+ List operatorList) {
+ if (!opName.isSimple()) {
+ return;
+ }
+
+ // We lookup only user functions via CatalogOperatorTable.
Built in functions should
+ // go through BasicOperatorTable
+ if (isUserFunction(category)) {
+ return;
+ }
+
+ String name = opName.getSimple();
+ Optional candidateFunction =
functionCatalog.lookupFunction(name);
+
+ candidateFunction.flatMap(functionDefinition ->
+ convertToSqlFunction(category, name, functionDefinition)
+ ).ifPresent(operatorList::add);
+ }
+
+ private boolean isUserFunction(SqlFunctionCategory category) {
Review comment:
Use 'isNotUserFunction' for more clear and less misleading
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] zjuwangg commented on a change in pull request #8703: [FLINK-12807][hive]Support Hive table columnstats related operations in HiveCatalog
zjuwangg commented on a change in pull request #8703:
[FLINK-12807][hive]Support Hive table columnstats related operations in
HiveCatalog
URL: https://github.com/apache/flink/pull/8703#discussion_r293639722
##
File path:
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/table/catalog/hive/HiveCatalog.java
##
@@ -1069,7 +1075,22 @@ public void alterTableStatistics(ObjectPath tablePath,
CatalogTableStatistics ta
@Override
public void alterTableColumnStatistics(ObjectPath tablePath,
CatalogColumnStatistics columnStatistics, boolean ignoreIfNotExists) throws
TableNotExistException, CatalogException {
-
+ try {
+ Table hiveTable = getHiveTable(tablePath);
+ // Set table column stats. This only works for
non-partitioned tables.
+ if (!isTablePartitioned(hiveTable)) {
+
client.updateTableColumnStatistics(HiveCatalogUtil.createTableColumnStats(hiveTable,
columnStatistics.getColumnStatisticsData()));
+ } else {
+ throw new
CatalogException(String.format("Failed to alter partition table column stats of
table %s",
Review comment:
exactly
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-12829) jobmaster log taskmanger address when task transition state to failed with error
[
https://issues.apache.org/jira/browse/FLINK-12829?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863623#comment-16863623
]
Congxian Qiu(klion26) commented on FLINK-12829:
---
Hi, do you think FLINK-11165 is enough for your case?
> jobmaster log taskmanger address when task transition state to failed with
> error
>
>
> Key: FLINK-12829
> URL: https://issues.apache.org/jira/browse/FLINK-12829
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Task
>Reporter: zhaoshijie
>Assignee: zhaoshijie
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> when look over jobmaster log to find why job failed, log is like that:
> {code:java}
> // code placeholder
> 2019-06-13 10:13:28,066 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> Socket Stream -> Flat Map -> (Flat Map, Flat Map, Flat Map -> Sink: Unnamed)
> (1/1) (dc39ce18d3f1b4aa15198151e7544162) switched from RUNNING to FAILED.
> java.net.ConnectException: Connection refused
> at java.net.PlainSocketImpl.socketConnect(Native Method)
> at
> java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
> at
> java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
> at
> java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
> at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
> at java.net.Socket.connect(Socket.java:589)
> at
> org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction.run(SocketTextStreamFunction.java:96)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:112)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:74)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:94)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:299)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718)
> at java.lang.Thread.run(Thread.java:745)
> 2
> {code}
> I know why job failed from this log, but when i want to find out where the
> failed task(Lead to job failed) is located, i find it is not obvious. however
> some environment problems actully needs to know taskmanger address, so we can
> add this on log
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] sunjincheng121 commented on issue #8280: [FLINK-12297]Harden ClosureCleaner to handle the wrapped function
sunjincheng121 commented on issue #8280: [FLINK-12297]Harden ClosureCleaner to handle the wrapped function URL: https://github.com/apache/flink/pull/8280#issuecomment-501940453 The CI failed, I restarted the CI due to It looks the EVN problem. :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-12841) Unify catalog meta-objects implementations and remove their interfaces
[
https://issues.apache.org/jira/browse/FLINK-12841?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863617#comment-16863617
]
Jark Wu commented on FLINK-12841:
-
+1 to the change
> Unify catalog meta-objects implementations and remove their interfaces
> --
>
> Key: FLINK-12841
> URL: https://issues.apache.org/jira/browse/FLINK-12841
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Hive, Table SQL / API
>Affects Versions: 1.9.0
>Reporter: Bowen Li
>Assignee: Bowen Li
>Priority: Major
> Fix For: 1.9.0
>
>
> We've been evaluating the original design in FLIP-30 that proposed creating
> catalog meta object interfaces and individual impl of those interfaces in
> each catalog. Interfaces we have so far are: {{CatalogDatabase}},
> {{CatalogTable}}, {{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}},
> and e.g. for {{CatalogTable}} interface, we have impls of
> {{GenericCatalogTable}} and {{HiveCatalogTable}}, etc.
> Well, we have gone pretty far on FLIP-30 now. When we look back and
> re-evaluate this design, we actually found there are not many differences
> between, e.g. {{GenericCatalogTable}} and {{HiveCatalogTable}}. And having
> this class hierarchy complicates situations and development. E.g. this
> requires sql client to have a hard dependency on flink-connector-hive in
> order to create {{HiveCatalogTable}} from DDL, which I don't think is
> necessary.
> On the other side in Blink, we don't have this hierarchy and have been just
> using a single meta-object class (e.g. just {{CatalogTable}}) to represent
> data in different catalogs, it has been fine without any problem and all the
> difference among catalogs can be stored as properties.
> Thus we propose removing the inheritance hierarchy and impl of the
> meta-object interfaces for each individual catalog. To be more specific, take
> table classes for example, we will replace {{CatalogTable}} with existing
> {{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
> {{HiveCatalogTable}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-12836) Allow retained checkpoints to be persisted on success
[
https://issues.apache.org/jira/browse/FLINK-12836?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863613#comment-16863613
]
Congxian Qiu(klion26) commented on FLINK-12836:
---
Hi [~andreweduffy], Could you please share why
{{CHECKPOINT_RETAINED_ON_CANCELLATION}} is not enough for your case?
> Allow retained checkpoints to be persisted on success
> -
>
> Key: FLINK-12836
> URL: https://issues.apache.org/jira/browse/FLINK-12836
> Project: Flink
> Issue Type: Improvement
> Components: Runtime / Checkpointing
>Reporter: Andrew Duffy
>Assignee: vinoyang
>Priority: Major
>
> Currently, retained checkpoints are persisted with one of 3 strategies:
> * {color:#33}CHECKPOINT_NEVER_RETAINED:{color} Retained checkpoints are
> never persisted
> * {color:#33}CHECKPOINT_RETAINED_ON_FAILURE:{color}{color:#33}
> Latest retained checkpoint{color} is persisted in the face of job failures
> * {color:#33}CHECKPOINT_RETAINED_ON_CANCELLATION{color}: Latest retained
> checkpoint is persisted when job is canceled externally (e.g. via the REST
> API)
>
> I'm proposing a third persistence mode: _CHECKPOINT_RETAINED_ALWAYS_. This
> mode would ensure that retained checkpoints are retained on successful
> completion of the job, and can be resumed from later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-12355) KafkaITCase.testTimestamps is unstable
[
https://issues.apache.org/jira/browse/FLINK-12355?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863590#comment-16863590
]
leesf commented on FLINK-12355:
---
Another instance:[https://api.travis-ci.org/v3/job/545241400/log.txt]
> KafkaITCase.testTimestamps is unstable
> --
>
> Key: FLINK-12355
> URL: https://issues.apache.org/jira/browse/FLINK-12355
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Tests
>Affects Versions: 1.9.0
>Reporter: Yu Li
>Priority: Critical
> Labels: test-stability
> Fix For: 1.9.0
>
>
> The {{KafkaITCase.testTimestamps}} failed on Travis because it timed out.
> https://api.travis-ci.org/v3/job/525503117/log.txt
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] sunjincheng121 edited a comment on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots
sunjincheng121 edited a comment on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots URL: https://github.com/apache/flink/pull/7227#issuecomment-501931581 The CI failed, and I restarted the connector CI stage due to I think it's maybe the ENV problem. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] sunjincheng121 commented on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots
sunjincheng121 commented on issue #7227: [FLINK-11059] [runtime] do not add releasing failed slot to free slots URL: https://github.com/apache/flink/pull/7227#issuecomment-501931581 The CI failed, and I restarted the connector CI state due to I think it's maybe the ENV problem. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293623628
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/tasks/CheckpointCoordinatorConfiguration.java
##
@@ -63,11 +65,13 @@ public CheckpointCoordinatorConfiguration(
int maxConcurrentCheckpoints,
CheckpointRetentionPolicy checkpointRetentionPolicy,
boolean isExactlyOnce,
- boolean isPerfetCheckpointForRecovery) {
+ boolean isPerfetCheckpointForRecovery,
+ int tolerableCpFailureNumber) {
// sanity checks
- if (checkpointInterval < 1 || checkpointTimeout < 1 ||
- minPauseBetweenCheckpoints < 0 ||
maxConcurrentCheckpoints < 1) {
+ if (checkpointInterval < 10 || checkpointTimeout < 10 ||
Review comment:
Yes, I have a good reason. `ExecutionGraph#enableCheckpointing`(see
[here](https://github.com/apache/flink/blob/master/flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java#L536))
consider the illegal value is (`< 10`) and the [test
case](https://github.com/apache/flink/blob/master/flink-tests/src/test/java/org/apache/flink/test/checkpointing/ZooKeeperHighAvailabilityITCase.java#L189)
also know this. So we'd better have the same criterion.
From a realistic point of view, I also think that 10 is a meaningful value.
If the interval is allowed to be 1 ms, the frequency is too high and therefore
has no practical significance.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293628893
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/CheckpointFailureManager.java
##
@@ -0,0 +1,131 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.checkpoint;
+
+import org.apache.flink.util.FlinkRuntimeException;
+
+import java.util.Set;
+import java.util.concurrent.ConcurrentHashMap;
+import java.util.concurrent.atomic.AtomicInteger;
+
+import static org.apache.flink.util.Preconditions.checkArgument;
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/**
+ * The checkpoint failure manager which centralized manage checkpoint failure
processing logic.
+ */
+public class CheckpointFailureManager {
+
+ private final static int UNLIMITED_TOLERABLE_FAILURE_NUMBER =
Integer.MAX_VALUE;
+
+ private final int tolerableCpFailureNumber;
+ private final FailJobCallback failureCallback;
+ private final AtomicInteger continuousFailureCounter;
+ private final Set countedCheckpointIds;
+
+ public CheckpointFailureManager(int tolerableCpFailureNumber,
FailJobCallback failureCallback) {
+ checkArgument(tolerableCpFailureNumber >= 0,
+ "The tolerable checkpoint failure number is illegal, " +
+ "it must be greater than or equal to 0 .");
+ this.tolerableCpFailureNumber = tolerableCpFailureNumber;
+ this.continuousFailureCounter = new AtomicInteger(0);
+ this.failureCallback = checkNotNull(failureCallback);
+ this.countedCheckpointIds = ConcurrentHashMap.newKeySet();
+ }
+
+ /**
+* Handle checkpoint exception with a handler callback.
+*
+* @param exception the checkpoint exception.
+* @param checkpointId the failed checkpoint id used to count the
continuous failure number based on
+* checkpoint id sequence. In trigger phase, we may
not get the checkpoint id when the failure
+* happens before the checkpoint id generation. In
this case, it will be specified a negative
+* latest generated checkpoint id as a special
flag.
+*/
+ public void handleCheckpointException(CheckpointException exception,
long checkpointId) {
+ CheckpointFailureReason reason =
exception.getCheckpointFailureReason();
+ switch (reason) {
+ case PERIODIC_SCHEDULER_SHUTDOWN:
+ case ALREADY_QUEUED:
+ case TOO_MANY_CONCURRENT_CHECKPOINTS:
+ case MINIMUM_TIME_BETWEEN_CHECKPOINTS:
+ case NOT_ALL_REQUIRED_TASKS_RUNNING:
+ case CHECKPOINT_SUBSUMED:
+ case CHECKPOINT_COORDINATOR_SUSPEND:
+ case CHECKPOINT_COORDINATOR_SHUTDOWN:
+ case JOB_FAILURE:
+ case JOB_FAILOVER_REGION:
+ //for compatibility purposes with user job behavior
+ case CHECKPOINT_DECLINED_TASK_NOT_READY:
+ case CHECKPOINT_DECLINED_TASK_NOT_CHECKPOINTING:
+ case CHECKPOINT_DECLINED_ALIGNMENT_LIMIT_EXCEEDED:
+ case CHECKPOINT_DECLINED_ON_CANCELLATION_BARRIER:
+ case CHECKPOINT_DECLINED_SUBSUMED:
+ case CHECKPOINT_DECLINED_INPUT_END_OF_STREAM:
+
+ case EXCEPTION:
+ case CHECKPOINT_EXPIRED:
+ case TASK_CHECKPOINT_FAILURE:
+ case TRIGGER_CHECKPOINT_FAILURE:
+ case FINALIZE_CHECKPOINT_FAILURE:
+ //ignore
+ break;
+
+ case CHECKPOINT_DECLINED:
+ //we should make sure one checkpoint only be
counted once
+
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293627636
##
File path:
flink-tests/src/test/java/org/apache/flink/test/streaming/runtime/IterateITCase.java
##
@@ -618,7 +618,7 @@ public void testWithCheckPointing() throws Exception {
// expected behaviour
}
- env.enableCheckpointing(1,
CheckpointingMode.EXACTLY_ONCE, true);
+ env.enableCheckpointing(10,
CheckpointingMode.EXACTLY_ONCE, true);
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293627605
##
File path:
flink-tests/src/test/java/org/apache/flink/test/streaming/runtime/IterateITCase.java
##
@@ -609,7 +609,7 @@ public void testWithCheckPointing() throws Exception {
// Test force checkpointing
try {
- env.enableCheckpointing(1,
CheckpointingMode.EXACTLY_ONCE, false);
+ env.enableCheckpointing(10,
CheckpointingMode.EXACTLY_ONCE, false);
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293627519
##
File path:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/graph/StreamingJobGraphGenerator.java
##
@@ -583,7 +583,7 @@ private void configureCheckpointing() {
CheckpointConfig cfg = streamGraph.getCheckpointConfig();
long interval = cfg.getCheckpointInterval();
- if (interval > 0) {
+ if (interval >= 10) {
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293627478
##
File path:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/CheckpointConfig.java
##
@@ -125,8 +128,8 @@ public long getCheckpointInterval() {
* @param checkpointInterval The checkpoint interval, in milliseconds.
*/
public void setCheckpointInterval(long checkpointInterval) {
- if (checkpointInterval <= 0) {
- throw new IllegalArgumentException("Checkpoint interval
must be larger than zero");
+ if (checkpointInterval < 10) {
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293627503
##
File path:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/CheckpointConfig.java
##
@@ -146,8 +149,8 @@ public long getCheckpointTimeout() {
* @param checkpointTimeout The checkpoint timeout, in milliseconds.
*/
public void setCheckpointTimeout(long checkpointTimeout) {
- if (checkpointTimeout <= 0) {
- throw new IllegalArgumentException("Checkpoint timeout
must be larger than zero");
+ if (checkpointTimeout < 10) {
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293625337
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/checkpoint/CheckpointCoordinatorTest.java
##
@@ -1367,13 +1503,18 @@ public void testMinTimeBetweenCheckpointsInterval()
throws Exception {
final long delay = 50;
+ CheckpointCoordinatorConfiguration chkConfig = new
CheckpointCoordinatorConfiguration(
+ 12, // periodic interval is 12 ms
Review comment:
Yes, it is required. Just like the prior comment, I have changed the
condition of sanity checks in `CheckpointCoordinatorConfiguration.java`. We
should have the same criterion with `ExecutionGraph`, the correct condition is
interval must be larger than or equal to 10.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293623628
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/tasks/CheckpointCoordinatorConfiguration.java
##
@@ -63,11 +65,13 @@ public CheckpointCoordinatorConfiguration(
int maxConcurrentCheckpoints,
CheckpointRetentionPolicy checkpointRetentionPolicy,
boolean isExactlyOnce,
- boolean isPerfetCheckpointForRecovery) {
+ boolean isPerfetCheckpointForRecovery,
+ int tolerableCpFailureNumber) {
// sanity checks
- if (checkpointInterval < 1 || checkpointTimeout < 1 ||
- minPauseBetweenCheckpoints < 0 ||
maxConcurrentCheckpoints < 1) {
+ if (checkpointInterval < 10 || checkpointTimeout < 10 ||
Review comment:
Yes, I have a good reason. `ExecutionGraph#enableCheckpointing`(see
[here](https://github.com/apache/flink/blob/master/flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java#L536))
consider the illegal value is (`< 10`) and the [test
case](https://github.com/apache/flink/blob/master/flink-tests/src/test/java/org/apache/flink/test/checkpointing/ZooKeeperHighAvailabilityITCase.java#L189)
also know this. So we'd better have the same criterion.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293625337
##
File path:
flink-runtime/src/test/java/org/apache/flink/runtime/checkpoint/CheckpointCoordinatorTest.java
##
@@ -1367,13 +1503,18 @@ public void testMinTimeBetweenCheckpointsInterval()
throws Exception {
final long delay = 50;
+ CheckpointCoordinatorConfiguration chkConfig = new
CheckpointCoordinatorConfiguration(
+ 12, // periodic interval is 12 ms
Review comment:
Yes, it is required. Just like the prior comment, I have changed the
condition of sanity checks in `CheckpointCoordinatorConfiguration.java`. We
should have the same criterion, the correct condition is interval must be
larger than or equal to 10.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a CheckpointFailureManager to centralized manage checkpoint failure
yanghua commented on a change in pull request #8322: [FLINK-12364] Introduce a
CheckpointFailureManager to centralized manage checkpoint failure
URL: https://github.com/apache/flink/pull/8322#discussion_r293623628
##
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/tasks/CheckpointCoordinatorConfiguration.java
##
@@ -63,11 +65,13 @@ public CheckpointCoordinatorConfiguration(
int maxConcurrentCheckpoints,
CheckpointRetentionPolicy checkpointRetentionPolicy,
boolean isExactlyOnce,
- boolean isPerfetCheckpointForRecovery) {
+ boolean isPerfetCheckpointForRecovery,
+ int tolerableCpFailureNumber) {
// sanity checks
- if (checkpointInterval < 1 || checkpointTimeout < 1 ||
- minPauseBetweenCheckpoints < 0 ||
maxConcurrentCheckpoints < 1) {
+ if (checkpointInterval < 10 || checkpointTimeout < 10 ||
Review comment:
Yes, I have a good reason. `CheckpointConfig#setCheckpointInterval` and
`CheckpointConfig#setCheckpointTimeout` consider the illegal value is (`< 10`).
So we'd better have the same criterion.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] bowenli86 commented on a change in pull request #8700: [FLINK-12657][hive] Integrate Flink with Hive UDF
bowenli86 commented on a change in pull request #8700: [FLINK-12657][hive]
Integrate Flink with Hive UDF
URL: https://github.com/apache/flink/pull/8700#discussion_r293615802
##
File path:
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/table/functions/hive/conversion/HiveInspectors.java
##
@@ -0,0 +1,248 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.functions.hive.conversion;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.table.catalog.hive.util.HiveTypeUtil;
+import org.apache.flink.table.functions.hive.FlinkHiveUDFException;
+import org.apache.flink.table.types.DataType;
+
+import org.apache.hadoop.hive.serde2.io.ByteWritable;
+import org.apache.hadoop.hive.serde2.io.DoubleWritable;
+import org.apache.hadoop.hive.serde2.io.ShortWritable;
+import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
+import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.BooleanObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.ByteObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.DoubleObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.FloatObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.IntObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaBooleanObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaByteObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaDoubleObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaFloatObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaIntObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaLongObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaShortObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaStringObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.LongObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.ShortObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
+import
org.apache.hadoop.hive.serde2.objectinspector.primitive.VoidObjectInspector;
+import org.apache.hadoop.hive.serde2.typeinfo.PrimitiveTypeInfo;
+import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
+import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoFactory;
+import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
+import org.apache.hadoop.io.BooleanWritable;
+import org.apache.hadoop.io.FloatWritable;
+import org.apache.hadoop.io.IntWritable;
+import org.apache.hadoop.io.LongWritable;
+import org.apache.hadoop.io.Text;
+
+
+/**
+ * Util for any ObjectInspector related inspection and conversion of Hive data
to/from Flink data.
+ *
+ * Hive ObjectInspector is a group of flexible APIs to inspect value in
different data representation,
+ * and developers can extend those API as needed, so technically, object
inspector supports arbitrary data type in java.
+ */
+@Internal
+public class HiveInspectors {
+
+ /**
+* Get conversion for converting Flink object to Hive object from an
ObjectInspector.
+*/
+ public static HiveObjectConversion getConversion(ObjectInspector
inspector) {
+ if (inspector instanceof PrimitiveObjectInspector) {
+ if (inspector instanceof JavaBooleanObjectInspector) {
+ if (((JavaBooleanObjectInspector)
inspector).preferWritable()) {
+ return o -> new
BooleanWritable((Boolean) o);
+ } else {
+ return IdentityConversion.INSTANCE;
+ }
+ } else if (inspector instanceof
[jira] [Updated] (FLINK-12841) Unify catalog meta-objects implementations and remove their interfaces
[
https://issues.apache.org/jira/browse/FLINK-12841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bowen Li updated FLINK-12841:
-
Description:
We've been evaluating the original design in FLIP-30 that proposed creating
catalog meta object interfaces and individual impl of those interfaces in each
catalog. Interfaces we have so far are: {{CatalogDatabase}}, {{CatalogTable}},
{{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}}, and e.g. for
{{CatalogTable}} interface, we have impls of {{GenericCatalogTable}} and
{{HiveCatalogTable}}, etc.
Well, we have gone pretty far on FLIP-30 now. When we look back and re-evaluate
this design, we actually found there are not many differences between, e.g.
{{GenericCatalogTable}} and {{HiveCatalogTable}}. And having this class
hierarchy complicates situations and development. E.g. this requires sql client
to have a hard dependency on flink-connector-hive in order to create
{{HiveCatalogTable}} from DDL, which I don't think is necessary.
On the other side in Blink, we don't have this hierarchy and have been just
using a single meta-object class (e.g. just {{CatalogTable}}) to represent data
in different catalogs, it has been fine without any problem and all the
difference among catalogs can be stored as properties.
Thus we propose removing the inheritance hierarchy and impl of the meta-object
interfaces for each individual catalog. To be more specific, take table classes
for example, we will replace {{CatalogTable}} with existing
{{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
{{HiveCatalogTable}}.
was:
We've been evaluating the original design in FLIP-30 that proposed creating
catalog meta object interfaces and individual impl of those interfaces in each
catalog. Interfaces we have so far are: {{CatalogDatabase}}, {{CatalogTable}},
{{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}}, and e.g. for
{{CatalogTable}} interface, we have impls of {{GenericCatalogTable}} and
{{HiveCatalogTable}}, etc.
Well, we have gone pretty far on FLIP-30 now. When we look back and re-evaluate
this design, we actually found there are not many differences between, e.g.
{{GenericCatalogTable}} and {{HiveCatalogTable}}. And having this class
hierarchy complicates situations and development. E.g. this requires sql client
to have a hard dependency on flink-connector-hive in order to create
{{HiveCatalogTable}} from DDL.
On the other side in Blink, we don't have this hierarchy and have been just
using a single meta-object class (e.g. just {{CatalogTable}}) to represent data
in different catalogs, it has been fine without any problem and all the
difference among catalogs can be stored as properties.
Thus we propose removing the inheritance hierarchy and impl of the meta-object
interfaces for each individual catalog. To be more specific, take table classes
for example, we will replace {{CatalogTable}} with existing
{{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
{{HiveCatalogTable}}.
> Unify catalog meta-objects implementations and remove their interfaces
> --
>
> Key: FLINK-12841
> URL: https://issues.apache.org/jira/browse/FLINK-12841
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Hive, Table SQL / API
>Affects Versions: 1.9.0
>Reporter: Bowen Li
>Assignee: Bowen Li
>Priority: Major
> Fix For: 1.9.0
>
>
> We've been evaluating the original design in FLIP-30 that proposed creating
> catalog meta object interfaces and individual impl of those interfaces in
> each catalog. Interfaces we have so far are: {{CatalogDatabase}},
> {{CatalogTable}}, {{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}},
> and e.g. for {{CatalogTable}} interface, we have impls of
> {{GenericCatalogTable}} and {{HiveCatalogTable}}, etc.
> Well, we have gone pretty far on FLIP-30 now. When we look back and
> re-evaluate this design, we actually found there are not many differences
> between, e.g. {{GenericCatalogTable}} and {{HiveCatalogTable}}. And having
> this class hierarchy complicates situations and development. E.g. this
> requires sql client to have a hard dependency on flink-connector-hive in
> order to create {{HiveCatalogTable}} from DDL, which I don't think is
> necessary.
> On the other side in Blink, we don't have this hierarchy and have been just
> using a single meta-object class (e.g. just {{CatalogTable}}) to represent
> data in different catalogs, it has been fine without any problem and all the
> difference among catalogs can be stored as properties.
> Thus we propose removing the inheritance hierarchy and impl of the
> meta-object interfaces for each individual catalog. To be more specific, take
> table classes for example, we will
[jira] [Updated] (FLINK-12841) Unify catalog meta-objects implementations and remove their interfaces
[
https://issues.apache.org/jira/browse/FLINK-12841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bowen Li updated FLINK-12841:
-
Description:
We've been evaluating the original design in FLIP-30 that proposed creating
catalog meta object interfaces and individual impl of those interfaces in each
catalog. Interfaces we have so far are: {{CatalogDatabase}}, {{CatalogTable}},
{{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}}, and e.g. for
{{CatalogTable}} interface, we have impls of {{GenericCatalogTable}} and
{{HiveCatalogTable}}, etc.
Well, we have gone pretty far on FLIP-30 now. When we look back and re-evaluate
this design, we actually found there are not many differences between, e.g.
{{GenericCatalogTable}} and {{HiveCatalogTable}}. And having this class
hierarchy complicates situations and development. E.g. this requires sql client
to have a hard dependency on flink-connector-hive in order to create
{{HiveCatalogTable}} from DDL.
On the other side in Blink, we don't have this hierarchy and have been just
using a single meta-object class (e.g. just {{CatalogTable}}) to represent data
in different catalogs, it has been fine without any problem and all the
difference among catalogs can be stored as properties.
Thus we propose removing the inheritance hierarchy and impl of the meta-object
interfaces for each individual catalog. To be more specific, take table classes
for example, we will replace {{CatalogTable}} with existing
{{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
{{HiveCatalogTable}}.
was:
We've been evaluating the original design in FLIP-30 that proposed creating
catalog meta object interfaces and individual impl of those interfaces in each
catalog. Interfaces we have so far are: {{CatalogDatabase}}, {{CatalogTable}},
{{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}}, and e.g. for
{{CatalogTable}} interface, we have impls of {{GenericCatalogTable}} and
{{HiveCatalogTable}}, etc.
Well, we have gone pretty far on FLIP-30 now. When we look back and re-evaluate
this design, we actually found there are not many differences between, e.g.
{{GenericCatalogTable}} and {{HiveCatalogTable}}. And having this class
hierarchy complicates situations and development. On the other side in Blink,
we don't have this hierarchy and have been just using a single meta-object
class (e.g. just {{CatalogTable}}) to represent data in different catalogs, it
has been fine without any problem and all the difference among catalogs can be
stored as properties.
Thus we propose removing the inheritance hierarchy and impl of the meta-object
interfaces for each individual catalog. To be more specific, take table classes
for example, we will replace {{CatalogTable}} with existing
{{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
{{HiveCatalogTable}}.
> Unify catalog meta-objects implementations and remove their interfaces
> --
>
> Key: FLINK-12841
> URL: https://issues.apache.org/jira/browse/FLINK-12841
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Hive, Table SQL / API
>Affects Versions: 1.9.0
>Reporter: Bowen Li
>Assignee: Bowen Li
>Priority: Major
> Fix For: 1.9.0
>
>
> We've been evaluating the original design in FLIP-30 that proposed creating
> catalog meta object interfaces and individual impl of those interfaces in
> each catalog. Interfaces we have so far are: {{CatalogDatabase}},
> {{CatalogTable}}, {{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}},
> and e.g. for {{CatalogTable}} interface, we have impls of
> {{GenericCatalogTable}} and {{HiveCatalogTable}}, etc.
> Well, we have gone pretty far on FLIP-30 now. When we look back and
> re-evaluate this design, we actually found there are not many differences
> between, e.g. {{GenericCatalogTable}} and {{HiveCatalogTable}}. And having
> this class hierarchy complicates situations and development. E.g. this
> requires sql client to have a hard dependency on flink-connector-hive in
> order to create {{HiveCatalogTable}} from DDL.
> On the other side in Blink, we don't have this hierarchy and have been just
> using a single meta-object class (e.g. just {{CatalogTable}}) to represent
> data in different catalogs, it has been fine without any problem and all the
> difference among catalogs can be stored as properties.
> Thus we propose removing the inheritance hierarchy and impl of the
> meta-object interfaces for each individual catalog. To be more specific, take
> table classes for example, we will replace {{CatalogTable}} with existing
> {{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
> {{HiveCatalogTable}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-12841) Unify catalog meta-objects implementations and remove their interfaces
[
https://issues.apache.org/jira/browse/FLINK-12841?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16863541#comment-16863541
]
Bowen Li commented on FLINK-12841:
--
[~twalthr] [~dawidwys] what do you think?
> Unify catalog meta-objects implementations and remove their interfaces
> --
>
> Key: FLINK-12841
> URL: https://issues.apache.org/jira/browse/FLINK-12841
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Hive, Table SQL / API
>Affects Versions: 1.9.0
>Reporter: Bowen Li
>Assignee: Bowen Li
>Priority: Major
> Fix For: 1.9.0
>
>
> We've been evaluating the original design in FLIP-30 that proposed creating
> catalog meta object interfaces and individual impl of those interfaces in
> each catalog. Interfaces we have so far are: {{CatalogDatabase}},
> {{CatalogTable}}, {{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}},
> and e.g. for {{CatalogTable}} interface, we have impls of
> {{GenericCatalogTable}} and {{HiveCatalogTable}}, etc.
> Well, we have gone pretty far on FLIP-30 now. When we look back and
> re-evaluate this design, we actually found there are not many differences
> between, e.g. {{GenericCatalogTable}} and {{HiveCatalogTable}}. And having
> this class hierarchy complicates situations and development. E.g. this
> requires sql client to have a hard dependency on flink-connector-hive in
> order to create {{HiveCatalogTable}} from DDL, which I don't think is
> necessary.
> On the other side in Blink, we don't have this hierarchy and have been just
> using a single meta-object class (e.g. just {{CatalogTable}}) to represent
> data in different catalogs, it has been fine without any problem and all the
> difference among catalogs can be stored as properties.
> Thus we propose removing the inheritance hierarchy and impl of the
> meta-object interfaces for each individual catalog. To be more specific, take
> table classes for example, we will replace {{CatalogTable}} with existing
> {{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
> {{HiveCatalogTable}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] xuefuz commented on a change in pull request #8703: [FLINK-12807][hive]Support Hive table columnstats related operations in HiveCatalog
xuefuz commented on a change in pull request #8703: [FLINK-12807][hive]Support
Hive table columnstats related operations in HiveCatalog
URL: https://github.com/apache/flink/pull/8703#discussion_r293611339
##
File path:
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/table/catalog/hive/HiveCatalog.java
##
@@ -1069,7 +1075,22 @@ public void alterTableStatistics(ObjectPath tablePath,
CatalogTableStatistics ta
@Override
public void alterTableColumnStatistics(ObjectPath tablePath,
CatalogColumnStatistics columnStatistics, boolean ignoreIfNotExists) throws
TableNotExistException, CatalogException {
-
+ try {
+ Table hiveTable = getHiveTable(tablePath);
+ // Set table column stats. This only works for
non-partitioned tables.
+ if (!isTablePartitioned(hiveTable)) {
+
client.updateTableColumnStatistics(HiveCatalogUtil.createTableColumnStats(hiveTable,
columnStatistics.getColumnStatisticsData()));
+ } else {
+ throw new
CatalogException(String.format("Failed to alter partition table column stats of
table %s",
Review comment:
Yeah. I think TableNotPartitioned makes sense.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (FLINK-12841) Unify catalog meta-objects implementations and remove their interfaces
Bowen Li created FLINK-12841:
Summary: Unify catalog meta-objects implementations and remove
their interfaces
Key: FLINK-12841
URL: https://issues.apache.org/jira/browse/FLINK-12841
Project: Flink
Issue Type: Sub-task
Components: Connectors / Hive, Table SQL / API
Affects Versions: 1.9.0
Reporter: Bowen Li
Assignee: Bowen Li
Fix For: 1.9.0
We've been evaluating the original design in FLIP-30 that proposed creating
catalog meta object interfaces and individual impl of those interfaces in each
catalog. Interfaces we have so far are: {{CatalogDatabase}}, {{CatalogTable}},
{{CatalogView}}, {{CatalogPartition}}, {{CatalogFunction}}, and e.g. for
{{CatalogTable}} interface, we have impls of {{GenericCatalogTable}} and
{{HiveCatalogTable}}, etc.
Well, we have gone pretty far on FLIP-30 now. When we look back and re-evaluate
this design, we actually found there are not many differences between, e.g.
{{GenericCatalogTable}} and {{HiveCatalogTable}}. And having this class
hierarchy complicates situations and development. On the other side in Blink,
we don't have this hierarchy and have been just using a single meta-object
class (e.g. just {{CatalogTable}}) to represent data in different catalogs, it
has been fine without any problem and all the difference among catalogs can be
stored as properties.
Thus we propose removing the inheritance hierarchy and impl of the meta-object
interfaces for each individual catalog. To be more specific, take table classes
for example, we will replace {{CatalogTable}} with existing
{{AbstractCatalogTable}}, and remove {{GenericCatalogTable}} and
{{HiveCatalogTable}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [flink] xuefuz commented on a change in pull request #8720: [FLINK-12771][hive] Support ConnectorCatalogTable in HiveCatalog
xuefuz commented on a change in pull request #8720: [FLINK-12771][hive] Support
ConnectorCatalogTable in HiveCatalog
URL: https://github.com/apache/flink/pull/8720#discussion_r293600489
##
File path:
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/table/catalog/hive/HiveCatalog.java
##
@@ -332,11 +359,24 @@ public void renameTable(ObjectPath tablePath, String
newTableName, boolean ignor
checkNotNull(tablePath, "tablePath cannot be null");
checkArgument(!StringUtils.isNullOrWhitespaceOnly(newTableName), "newTableName
cannot be null or empty");
+ ObjectPath newPath = new
ObjectPath(tablePath.getDatabaseName(), newTableName);
+
+ ConnectorCatalogTable connectorTable =
connectorTables.remove(tablePath);
+
+ if (connectorTable != null) {
+ if (connectorTables.containsKey(newPath)) {
+ throw new TableAlreadyExistException(getName(),
newPath);
Review comment:
If we get here because of this exception, the table is already dropped,
which doesn't seem right.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot commented on issue #8734: [FLINK-12840] fix network utils to work with ipv6 correctly
flinkbot commented on issue #8734: [FLINK-12840] fix network utils to work with ipv6 correctly URL: https://github.com/apache/flink/pull/8734#issuecomment-501899832 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] bowenli86 commented on a change in pull request #8703: [FLINK-12807][hive]Support Hive table columnstats related operations in HiveCatalog
bowenli86 commented on a change in pull request #8703:
[FLINK-12807][hive]Support Hive table columnstats related operations in
HiveCatalog
URL: https://github.com/apache/flink/pull/8703#discussion_r293598734
##
File path:
flink-table/flink-table-common/src/test/java/org/apache/flink/table/catalog/CatalogTestUtil.java
##
@@ -58,7 +58,7 @@ static void checkEquals(CatalogTableStatistics ts1,
CatalogTableStatistics ts2)
assertEquals(ts1.getProperties(), ts2.getProperties());
}
- static void checkEquals(CatalogColumnStatistics cs1,
CatalogColumnStatistics cs2) {
+ public static void checkEquals(CatalogColumnStatistics cs1,
CatalogColumnStatistics cs2) {
Review comment:
move this to CatalogTestBase, rather than changing its signature?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] bowenli86 commented on a change in pull request #8703: [FLINK-12807][hive]Support Hive table columnstats related operations in HiveCatalog
bowenli86 commented on a change in pull request #8703:
[FLINK-12807][hive]Support Hive table columnstats related operations in
HiveCatalog
URL: https://github.com/apache/flink/pull/8703#discussion_r293598734
##
File path:
flink-table/flink-table-common/src/test/java/org/apache/flink/table/catalog/CatalogTestUtil.java
##
@@ -58,7 +58,7 @@ static void checkEquals(CatalogTableStatistics ts1,
CatalogTableStatistics ts2)
assertEquals(ts1.getProperties(), ts2.getProperties());
}
- static void checkEquals(CatalogColumnStatistics cs1,
CatalogColumnStatistics cs2) {
+ public static void checkEquals(CatalogColumnStatistics cs1,
CatalogColumnStatistics cs2) {
Review comment:
move this to CatalogTestBase?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services