[GitHub] [flink] godfreyhe commented on a change in pull request #13742: [FLINK-19626][table-planner-blink] Introduce multi-input operator construction algorithm
godfreyhe commented on a change in pull request #13742:
URL: https://github.com/apache/flink/pull/13742#discussion_r512431935
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/planner/plan/processor/utils/TopologyGraph.java
##
@@ -0,0 +1,206 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.planner.plan.processor.utils;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import
org.apache.flink.table.planner.plan.nodes.exec.AbstractExecNodeExactlyOnceVisitor;
+import org.apache.flink.table.planner.plan.nodes.exec.ExecNode;
+import
org.apache.flink.table.planner.plan.nodes.physical.batch.BatchExecBoundedStreamScan;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.LinkedList;
+import java.util.List;
+import java.util.Map;
+import java.util.Queue;
+import java.util.Set;
+
+/**
+ * A data structure storing the topological and input priority information of
an {@link ExecNode} graph.
+ */
+@Internal
+class TopologyGraph {
+
+ private final Map, TopologyNode> nodes;
+
+ TopologyGraph(List> roots) {
+ this(roots, Collections.emptySet());
+ }
+
+ TopologyGraph(List> roots, Set>
boundaries) {
+ this.nodes = new HashMap<>();
+
+ // we first link all edges in the original exec node graph
+ AbstractExecNodeExactlyOnceVisitor visitor = new
AbstractExecNodeExactlyOnceVisitor() {
+ @Override
+ protected void visitNode(ExecNode node) {
+ if (boundaries.contains(node)) {
+ return;
+ }
+ for (ExecNode input :
node.getInputNodes()) {
+ link(input, node);
+ }
+ visitInputs(node);
+ }
+ };
+ roots.forEach(n -> n.accept(visitor));
+ }
+
+ /**
+* Link an edge from `from` node to `to` node if no loop will occur
after adding this edge.
+* Returns if this edge is successfully added.
+*/
+ boolean link(ExecNode from, ExecNode to) {
+ TopologyNode fromNode = getTopologyNode(from);
+ TopologyNode toNode = getTopologyNode(to);
+
+ if (canReach(toNode, fromNode)) {
+ // invalid edge, as `to` is the predecessor of `from`
+ return false;
+ } else {
+ // link `from` and `to`
+ fromNode.outputs.add(toNode);
+ toNode.inputs.add(fromNode);
+ return true;
+ }
+ }
+
+ /**
+* Remove the edge from `from` node to `to` node. If there is no edge
between them then do nothing.
+*/
+ void unlink(ExecNode from, ExecNode to) {
+ TopologyNode fromNode = getTopologyNode(from);
+ TopologyNode toNode = getTopologyNode(to);
+
+ fromNode.outputs.remove(toNode);
+ toNode.inputs.remove(fromNode);
+ }
+
+ /**
+* Calculate the maximum distance of the currently added nodes from the
nodes without inputs.
+* The smallest distance is 0 (which are exactly the nodes without
inputs) and the distances of
+* other nodes are the largest distances in their inputs plus 1.
+*/
+ Map, Integer> calculateDistance() {
Review comment:
give `distance` a definition ?
##
File path:
flink-table/flink-table-planner-blink/src/main/java/org/apache/flink/table/planner/plan/processor/MultipleInputNodeCreationProcessor.java
##
@@ -0,0 +1,484 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional
[GitHub] [flink] wuchong commented on a change in pull request #13669: [FLINK-19684][Connector][jdbc] Fix the Jdbc-connector's 'lookup.max-retries' option implementation
wuchong commented on a change in pull request #13669:
URL: https://github.com/apache/flink/pull/13669#discussion_r512405731
##
File path:
flink-connectors/flink-connector-jdbc/src/test/java/org/apache/flink/connector/jdbc/table/JdbcDynamicTableSourceITCase.java
##
@@ -125,6 +125,45 @@ public void testJdbcSource() throws Exception {
assertEquals(expected, result);
}
+ @Test
+ public void testJdbcSourceWithLookupMaxRetries() throws Exception {
+ StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
+ EnvironmentSettings envSettings =
EnvironmentSettings.newInstance()
+ .useBlinkPlanner()
+ .inStreamingMode()
+ .build();
+ StreamTableEnvironment tEnv =
StreamTableEnvironment.create(env, envSettings);
+
+ tEnv.executeSql(
+ "CREATE TABLE " + INPUT_TABLE + "(" +
+ "id BIGINT," +
+ "timestamp6_col TIMESTAMP(6)," +
+ "timestamp9_col TIMESTAMP(9)," +
+ "time_col TIME," +
+ "real_col FLOAT," +
+ "double_col DOUBLE," +
+ "decimal_col DECIMAL(10, 4)" +
+ ") WITH (" +
+ " 'connector'='jdbc'," +
+ " 'url'='" + DB_URL + "'," +
+ " 'lookup.max-retries'='0'," +
+ " 'table-name'='" + INPUT_TABLE + "'" +
+ ")"
+ );
+
+ Iterator collected = tEnv.executeSql("SELECT id FROM " +
INPUT_TABLE).collect();
Review comment:
`SELECT *` can't test lookup ability.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-19820) TableEnvironment init fails with JDK9
[
https://issues.apache.org/jira/browse/FLINK-19820?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Timo Walther updated FLINK-19820:
-
Affects Version/s: 1.11.2
> TableEnvironment init fails with JDK9
> -
>
> Key: FLINK-19820
> URL: https://issues.apache.org/jira/browse/FLINK-19820
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API
>Affects Versions: 1.11.2
>Reporter: Timo Walther
>Priority: Major
>
> I haven't verified the issue myself. But it seems that TableEnvironment
> cannot be properly initialized when using JDK9:
> Stack trace:
> {code}
> Exception in thread "main" java.lang.ExceptionInInitializerError
> at
> org.apache.flink.table.planner.calcite.FlinkRelFactories$.(FlinkRelFactories.scala:51)
> at
> org.apache.flink.table.planner.calcite.FlinkRelFactories$.(FlinkRelFactories.scala)
> at
> org.apache.flink.table.planner.calcite.FlinkRelFactories.FLINK_REL_BUILDER(FlinkRelFactories.scala)
> at
> org.apache.flink.table.planner.delegation.PlannerContext.lambda$getSqlToRelConverterConfig$2(PlannerContext.java:279)
> at
> java.util.Optional.orElseGet(java.base@9-internal/Optional.java:344)
> at
> org.apache.flink.table.planner.delegation.PlannerContext.getSqlToRelConverterConfig(PlannerContext.java:273)
> at
> org.apache.flink.table.planner.delegation.PlannerContext.createFrameworkConfig(PlannerContext.java:137)
> at
> org.apache.flink.table.planner.delegation.PlannerContext.(PlannerContext.java:113)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.(PlannerBase.scala:112)
> at
> org.apache.flink.table.planner.delegation.StreamPlanner.(StreamPlanner.scala:48)
> at
> org.apache.flink.table.planner.delegation.BlinkPlannerFactory.create(BlinkPlannerFactory.java:50)
> at
> org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.create(StreamTableEnvironmentImpl.java:130)
> at
> org.apache.flink.table.api.bridge.java.StreamTableEnvironment.create(StreamTableEnvironment.java:111)
> at
> org.apache.flink.table.api.bridge.java.StreamTableEnvironment.create(StreamTableEnvironment.java:82)
> at com.teavaro.cep.modules.ml.CEPMLInit.runUseCase(CEPMLInit.java:57)
> at com.teavaro.cep.modules.ml.CEPMLInit.start(CEPMLInit.java:43)
> at
> com.teavaro.cep.modules.ml.CEPMLInit.prepareUseCase(CEPMLInit.java:35)
> at com.teavaro.cep.pipelines.CEPInit.start(CEPInit.java:47)
> at com.teavaro.cep.StreamingJob.runCEP(StreamingJob.java:121)
> at com.teavaro.cep.StreamingJob.prepareJob(StreamingJob.java:106)
> at com.teavaro.cep.StreamingJob.main(StreamingJob.java:64)
> Caused by: java.lang.RuntimeException: while binding method public default
> org.apache.calcite.tools.RelBuilder$ConfigBuilder
> org.apache.calcite.tools.RelBuilder$Config.toBuilder()
> at
> org.apache.calcite.util.ImmutableBeans.create(ImmutableBeans.java:215)
> at
> org.apache.calcite.tools.RelBuilder$Config.(RelBuilder.java:3074)
> ... 21 more
> Caused by: java.lang.IllegalAccessException: access to public member failed:
> org.apache.calcite.tools.RelBuilder$Config.toBuilder()ConfigBuilder/invokeSpecial,
> from org.apache.calcite.tools.RelBuilder$Config/2 (unnamed module @2cc03cd1)
> at
> java.lang.invoke.MemberName.makeAccessException(java.base@9-internal/MemberName.java:908)
> at
> java.lang.invoke.MethodHandles$Lookup.checkAccess(java.base@9-internal/MethodHandles.java:1839)
> at
> java.lang.invoke.MethodHandles$Lookup.checkMethod(java.base@9-internal/MethodHandles.java:1779)
> at
> java.lang.invoke.MethodHandles$Lookup.getDirectMethodCommon(java.base@9-internal/MethodHandles.java:1928)
> at
> java.lang.invoke.MethodHandles$Lookup.getDirectMethodNoSecurityManager(java.base@9-internal/MethodHandles.java:1922)
> at
> java.lang.invoke.MethodHandles$Lookup.unreflectSpecial(java.base@9-internal/MethodHandles.java:1480)
> at
> org.apache.calcite.util.ImmutableBeans.create(ImmutableBeans.java:213)
> {code}
> This might be fixed in later JDK versions but we should track the issue
> nevertheless. The full discussion can be found here:
> https://stackoverflow.com/questions/64544422/illegal-access-to-create-streamtableenvironment-with-jdk-9-in-debian
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-19820) TableEnvironment init fails with JDK9
Timo Walther created FLINK-19820:
Summary: TableEnvironment init fails with JDK9
Key: FLINK-19820
URL: https://issues.apache.org/jira/browse/FLINK-19820
Project: Flink
Issue Type: Bug
Components: Table SQL / API
Reporter: Timo Walther
I haven't verified the issue myself. But it seems that TableEnvironment cannot
be properly initialized when using JDK9:
Stack trace:
{code}
Exception in thread "main" java.lang.ExceptionInInitializerError
at
org.apache.flink.table.planner.calcite.FlinkRelFactories$.(FlinkRelFactories.scala:51)
at
org.apache.flink.table.planner.calcite.FlinkRelFactories$.(FlinkRelFactories.scala)
at
org.apache.flink.table.planner.calcite.FlinkRelFactories.FLINK_REL_BUILDER(FlinkRelFactories.scala)
at
org.apache.flink.table.planner.delegation.PlannerContext.lambda$getSqlToRelConverterConfig$2(PlannerContext.java:279)
at java.util.Optional.orElseGet(java.base@9-internal/Optional.java:344)
at
org.apache.flink.table.planner.delegation.PlannerContext.getSqlToRelConverterConfig(PlannerContext.java:273)
at
org.apache.flink.table.planner.delegation.PlannerContext.createFrameworkConfig(PlannerContext.java:137)
at
org.apache.flink.table.planner.delegation.PlannerContext.(PlannerContext.java:113)
at
org.apache.flink.table.planner.delegation.PlannerBase.(PlannerBase.scala:112)
at
org.apache.flink.table.planner.delegation.StreamPlanner.(StreamPlanner.scala:48)
at
org.apache.flink.table.planner.delegation.BlinkPlannerFactory.create(BlinkPlannerFactory.java:50)
at
org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.create(StreamTableEnvironmentImpl.java:130)
at
org.apache.flink.table.api.bridge.java.StreamTableEnvironment.create(StreamTableEnvironment.java:111)
at
org.apache.flink.table.api.bridge.java.StreamTableEnvironment.create(StreamTableEnvironment.java:82)
at com.teavaro.cep.modules.ml.CEPMLInit.runUseCase(CEPMLInit.java:57)
at com.teavaro.cep.modules.ml.CEPMLInit.start(CEPMLInit.java:43)
at
com.teavaro.cep.modules.ml.CEPMLInit.prepareUseCase(CEPMLInit.java:35)
at com.teavaro.cep.pipelines.CEPInit.start(CEPInit.java:47)
at com.teavaro.cep.StreamingJob.runCEP(StreamingJob.java:121)
at com.teavaro.cep.StreamingJob.prepareJob(StreamingJob.java:106)
at com.teavaro.cep.StreamingJob.main(StreamingJob.java:64)
Caused by: java.lang.RuntimeException: while binding method public default
org.apache.calcite.tools.RelBuilder$ConfigBuilder
org.apache.calcite.tools.RelBuilder$Config.toBuilder()
at
org.apache.calcite.util.ImmutableBeans.create(ImmutableBeans.java:215)
at
org.apache.calcite.tools.RelBuilder$Config.(RelBuilder.java:3074)
... 21 more
Caused by: java.lang.IllegalAccessException: access to public member failed:
org.apache.calcite.tools.RelBuilder$Config.toBuilder()ConfigBuilder/invokeSpecial,
from org.apache.calcite.tools.RelBuilder$Config/2 (unnamed module @2cc03cd1)
at
java.lang.invoke.MemberName.makeAccessException(java.base@9-internal/MemberName.java:908)
at
java.lang.invoke.MethodHandles$Lookup.checkAccess(java.base@9-internal/MethodHandles.java:1839)
at
java.lang.invoke.MethodHandles$Lookup.checkMethod(java.base@9-internal/MethodHandles.java:1779)
at
java.lang.invoke.MethodHandles$Lookup.getDirectMethodCommon(java.base@9-internal/MethodHandles.java:1928)
at
java.lang.invoke.MethodHandles$Lookup.getDirectMethodNoSecurityManager(java.base@9-internal/MethodHandles.java:1922)
at
java.lang.invoke.MethodHandles$Lookup.unreflectSpecial(java.base@9-internal/MethodHandles.java:1480)
at
org.apache.calcite.util.ImmutableBeans.create(ImmutableBeans.java:213)
{code}
This might be fixed in later JDK versions but we should track the issue
nevertheless. The full discussion can be found here:
https://stackoverflow.com/questions/64544422/illegal-access-to-create-streamtableenvironment-with-jdk-9-in-debian
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] xintongsong closed pull request #13584: [hotfix][typo] Fix typo in MiniCluster
xintongsong closed pull request #13584: URL: https://github.com/apache/flink/pull/13584 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-19654) Improve the execution time of PyFlink end-to-end tests
[ https://issues.apache.org/jira/browse/FLINK-19654?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221148#comment-17221148 ] Dian Fu commented on FLINK-19654: - - Set the parallelism to 2 to reduce the execution time: merged to master via 16ed892245fa0ccd0319597f26f0ec193d5021c8 > Improve the execution time of PyFlink end-to-end tests > -- > > Key: FLINK-19654 > URL: https://issues.apache.org/jira/browse/FLINK-19654 > Project: Flink > Issue Type: Bug > Components: API / Python, Tests >Affects Versions: 1.12.0 >Reporter: Dian Fu >Assignee: Huang Xingbo >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > Attachments: image (7).png > > > Thanks for the sharing from [~rmetzger], currently the test duration for > PyFlink end-to-end test is as following: > ||test case||average execution-time||maximum execution-time|| > |PyFlink Table end-to-end test|1340s|1877s| > |PyFlink DataStream end-to-end test|387s|575s| > |Kubernetes PyFlink application test|606s|694s| > We need to investigate how to improve them to reduce the execution time. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-19768) The shell "./yarn-session.sh " not use log4j-session.properties , it use log4j.properties
[
https://issues.apache.org/jira/browse/FLINK-19768?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221147#comment-17221147
]
Xintong Song commented on FLINK-19768:
--
[~YUJIANBO],
I don't think you can easily separate logs for different jobs in the same Flink
session cluster. Since the jobs share the same Flink cluster, some of the
framework activities cannot be separated.
You can only separated the logs generated by user codes. To achieve that, you
would need to set the environment variable {{FLINK_CONF_DIR}}, pointing to
different directories containing different {{log4j.properties}} when submitting
the jobs
> The shell "./yarn-session.sh " not use log4j-session.properties , it use
> log4j.properties
> --
>
> Key: FLINK-19768
> URL: https://issues.apache.org/jira/browse/FLINK-19768
> Project: Flink
> Issue Type: Bug
> Components: Client / Job Submission, Deployment / YARN
>Affects Versions: 1.11.2
>Reporter: YUJIANBO
>Priority: Major
>
> The shell "./yarn-session.sh " not use log4j-session.properties , it use
> log4j.properties
> My Flink Job UI shows the $internal.yarn.log-config-file is
> "/usr/local/flink-1.11.2/conf/log4j.properties",is it a bug?
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] dianfu closed pull request #13736: [FLINK-19654][python][e2e] Reduce pyflink e2e test parallelism
dianfu closed pull request #13736: URL: https://github.com/apache/flink/pull/13736 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dianfu commented on a change in pull request #13736: [FLINK-19654][python][e2e] Reduce pyflink e2e test parallelism
dianfu commented on a change in pull request #13736:
URL: https://github.com/apache/flink/pull/13736#discussion_r512419927
##
File path: flink-end-to-end-tests/test-scripts/test_pyflink.sh
##
@@ -110,6 +110,7 @@ echo "pytest==4.4.1" > "${REQUIREMENTS_PATH}"
echo "Test submitting python job with 'pipeline.jars':\n"
PYFLINK_CLIENT_EXECUTABLE=${PYTHON_EXEC} "${FLINK_DIR}/bin/flink" run \
+ -p 2 \
Review comment:
format is incorrect.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] curcur edited a comment on pull request #13648: [FLINK-19632] Introduce a new ResultPartitionType for Approximate Local Recovery
curcur edited a comment on pull request #13648: URL: https://github.com/apache/flink/pull/13648#issuecomment-716973831 Hey @rkhachatryan and @pnowojski , thanks for the response. > We realized that if we check view reference in subpartition (or null out view.parent) then the downstream which view was overwritten by an older thread, will sooner or later be fenced by the upstream (or checkpoint will time out). > FLINK-19774 then becomes only an optimization. 1. Do you have preferences on `check view reference` vs `null out view.parent`? I would slightly prefer to set view.parent -> null; Conceptually, it breaks the connection between the old view and its parent; Implementation wise, it can limit the (parent == null) handling mostly within `PipelinedApproximateSubpartitionView`. Notice that not just `pollNext()` needs the check, I think everything that touches view.parent needs a check. 2. How this can solve the problem of a new view is replaced by an old one? Let's say downstream reconnects, asking for a new view; the new view is created; replaced by an old view that is triggered by an old handler event. The new view's parent is null-out. Then what will happen? I do not think "fenced by the upstream (or checkpoint will time out)" can **solve** this problem, it just ends with more failures caused by this problem. > So we can prevent most of the issues without touching deployment descriptors. > Therefore, I think it makes sense to implement it in this PR. Sorry for changing the decision. I am overall fine to put the check within this PR. However, may I ask how it is different from we have this PR as it is, and I do a follow-up one to null-out the parent? In this PR, my main purpose is to introduce a different result partition type, and scheduler changes are based upon this new type. That's the main reason I prefer to do it in a follow-up PR otherwise the scheduler part is blocked. It is easier to review as well. > Another concern is a potential resource leak if downstream continuously fail without notifying the upstream (instances of CreditBasedSequenceNumberingViewReader will accumulate). Can you create a follow-up ticket for that? > This can be addressed by firing user event (see PartitionRequestQueue.userEventTriggered). Yes, that's a good point. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13626: [FLINK-19594][web] Make subtask index start from zero
flinkbot edited a comment on pull request #13626: URL: https://github.com/apache/flink/pull/13626#issuecomment-708171532 ## CI report: * 1f6974a2251daef826687b981fd5a5fb428fe66c Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=7857) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=7571) * bcea64faf14e9261ae2cb6b996701b844bf876d3 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8342) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] curcur edited a comment on pull request #13648: [FLINK-19632] Introduce a new ResultPartitionType for Approximate Local Recovery
curcur edited a comment on pull request #13648: URL: https://github.com/apache/flink/pull/13648#issuecomment-716973831 Hey @rkhachatryan and @pnowojski , thanks for the response. > We realized that if we check view reference in subpartition (or null out view.parent) then the downstream which view was overwritten by an older thread, will sooner or later be fenced by the upstream (or checkpoint will time out). > FLINK-19774 then becomes only an optimization. 1. Do you have preferences on `check view reference` vs `null out view.parent`? I have evaluated these two methods before, and I feel set view.parent -> null may be a cleaner way (that's why I proposed null out parent). Conceptually, it breaks the connection between the old view and its parent; Implementation wise, it can limit the (parent == null) handling mostly within `PipelinedApproximateSubpartition` or probably a little bit in `PipelinedSubpartition`, while in the reference check way, we have to change the interface and touch all the subpartitions that implements `PipelinedSubpartition`. Notice that not just `pollNext()` needs the check, everything that touches parent needs a check. 2. How this can solve the problem of a new view is replaced by an old one? Let's say downstream reconnects, asking for a new view; the new view is created; replaced by an old view that is triggered by an old handler event. The new view's parent is null-out. Then what will happen? I do not think "fenced by the upstream (or checkpoint will time out)" can **solve** this problem, it just ends with more failures caused by this problem. > So we can prevent most of the issues without touching deployment descriptors. > Therefore, I think it makes sense to implement it in this PR. Sorry for changing the decision. I am overall fine to put the check within this PR. However, may I ask how it is different from we have this PR as it is, and I do a follow-up one to null-out the parent? In this PR, my main purpose is to introduce a different result partition type, and scheduler changes are based upon this new type. That's the main reason I prefer to do it in a follow-up PR otherwise the scheduler part is blocked. And also, it is easier to review, and for me to focus on tests after null-out parent as well. > Another concern is a potential resource leak if downstream continuously fail without notifying the upstream (instances of CreditBasedSequenceNumberingViewReader will accumulate). Can you create a follow-up ticket for that? > This can be addressed by firing user event (see PartitionRequestQueue.userEventTriggered). Yes, that's a good point. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] curcur edited a comment on pull request #13648: [FLINK-19632] Introduce a new ResultPartitionType for Approximate Local Recovery
curcur edited a comment on pull request #13648: URL: https://github.com/apache/flink/pull/13648#issuecomment-716973831 Hey @rkhachatryan and @pnowojski , thanks for the response. > We realized that if we check view reference in subpartition (or null out view.parent) then the downstream which view was overwritten by an older thread, will sooner or later be fenced by the upstream (or checkpoint will time out). > FLINK-19774 then becomes only an optimization. 1. Do you have preferences on `check view reference` vs `null out view.parent`? I have evaluated these two methods before, and I feel set view.parent -> null may be a cleaner way (that's why I proposed null out parent). Conceptually, it breaks the connection between the old view and the new view; Implementation wise, it can limit the (parent == null) handling mostly within `PipelinedApproximateSubpartition` or probably a little bit in `PipelinedSubpartition`, while in the reference check way, we have to change the interface and touch all the subpartitions that implements `PipelinedSubpartition`. Notice that not just `pollNext()` needs the check, everything that touches parent needs a check. 2. How this can solve the problem of a new view is replaced by an old one? Let's say downstream reconnects, asking for a new view; the new view is created; replaced by an old view that is triggered by an old handler event. The new view's parent is null-out. Then what will happen? I do not think "fenced by the upstream (or checkpoint will time out)" can **solve** this problem, it just ends with more failures caused by this problem. > So we can prevent most of the issues without touching deployment descriptors. > Therefore, I think it makes sense to implement it in this PR. Sorry for changing the decision. I am overall fine to put the check within this PR. However, may I ask how it is different from we have this PR as it is, and I do a follow-up one to null-out the parent? In this PR, my main purpose is to introduce a different result partition type, and scheduler changes are based upon this new type. That's the main reason I prefer to do it in a follow-up PR otherwise the scheduler part is blocked. And also, it is easier to review, and for me to focus on tests after null-out parent as well. > Another concern is a potential resource leak if downstream continuously fail without notifying the upstream (instances of CreditBasedSequenceNumberingViewReader will accumulate). Can you create a follow-up ticket for that? > This can be addressed by firing user event (see PartitionRequestQueue.userEventTriggered). Yes, that's a good point. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] curcur edited a comment on pull request #13648: [FLINK-19632] Introduce a new ResultPartitionType for Approximate Local Recovery
curcur edited a comment on pull request #13648: URL: https://github.com/apache/flink/pull/13648#issuecomment-716973831 Hey @rkhachatryan and @pnowojski , thanks for the response. > We realized that if we check view reference in subpartition (or null out view.parent) then the downstream which view was overwritten by an older thread, will sooner or later be fenced by the upstream (or checkpoint will time out). > FLINK-19774 then becomes only an optimization. 1. Do you have preferences on `check view reference` vs `null out view.parent`? I have evaluated these two methods before, and I feel set view.parent -> null may be a cleaner way (that's why I proposed null out parent). Conceptually, it breaks the cut between the old view and the new view; Implementation wise, it can limit the (parent == null) handling mostly within `PipelinedApproximateSubpartition` or probably a little bit in `PipelinedSubpartition`, while in the reference check way, we have to change the interface and touch all the subpartitions that implements `PipelinedSubpartition`. Notice that not just `pollNext()` needs the check, everything that touches parent needs a check. 2. How this can solve the problem of a new view is replaced by an old one? Let's say downstream reconnects, asking for a new view; the new view is created; replaced by an old view that is triggered by an old handler event. The new view's parent is null-out. Then what will happen? I do not think "fenced by the upstream (or checkpoint will time out)" can **solve** this problem, it just ends with more failures caused by this problem. > So we can prevent most of the issues without touching deployment descriptors. > Therefore, I think it makes sense to implement it in this PR. Sorry for changing the decision. I am overall fine to put the check within this PR. However, may I ask how it is different from we have this PR as it is, and I do a follow-up one to null-out the parent? In this PR, my main purpose is to introduce a different result partition type, and scheduler changes are based upon this new type. That's the main reason I prefer to do it in a follow-up PR otherwise the scheduler part is blocked. And also, it is easier to review, and for me to focus on tests after null-out parent as well. > Another concern is a potential resource leak if downstream continuously fail without notifying the upstream (instances of CreditBasedSequenceNumberingViewReader will accumulate). Can you create a follow-up ticket for that? > This can be addressed by firing user event (see PartitionRequestQueue.userEventTriggered). Yes, that's a good point. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] shizhengchao commented on pull request #13717: [FLINK-19723][Connector/JDBC] Solve the problem of repeated data submission in the failure retry
shizhengchao commented on pull request #13717: URL: https://github.com/apache/flink/pull/13717#issuecomment-716976670 > Could you add an unit test in `JdbcDynamicOutputFormatTest` to verify this bug fix? Thanks for review, i will add unit tests soon This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on a change in pull request #13612: [FLINK-19587][table-planner-blink] Fix error result when casting binary as varchar
wuchong commented on a change in pull request #13612:
URL: https://github.com/apache/flink/pull/13612#discussion_r512412637
##
File path:
flink-table/flink-table-planner-blink/src/test/scala/org/apache/flink/table/planner/expressions/ScalarOperatorsTest.scala
##
@@ -62,6 +62,26 @@ class ScalarOperatorsTest extends ScalarOperatorsTestBase {
)
}
+ @Test
+ def testCast(): Unit = {
+
+// binary -> varchar
+testSqlApi(
+ "CAST (f18 as varchar)",
+ "hello world")
+
+// varbinary -> varchar
+testSqlApi(
+ "CAST (f19 as varchar)",
+ "hello flink")
+
+// null case
+testSqlApi("CAST (NULL AS INT)", "null")
+testSqlApi(
+ "CAST (NULL AS VARCHAR) = ''",
+ "null")
Review comment:
Would be better to add a test for cast binary literal to varchar.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] curcur commented on pull request #13648: [FLINK-19632] Introduce a new ResultPartitionType for Approximate Local Recovery
curcur commented on pull request #13648: URL: https://github.com/apache/flink/pull/13648#issuecomment-716973831 Hey @rkhachatryan and @pnowojski , thanks for the response. > We realized that if we check view reference in subpartition (or null out view.parent) then the downstream which view was overwritten by an older thread, will sooner or later be fenced by the upstream (or checkpoint will time out). > FLINK-19774 then becomes only an optimization. 1. Do you have preferences on `check view reference` vs `null out view.parent`? I have evaluated these two methods before, and I feel set view.parent -> null may be a cleaner way (that's why I proposed null out parent). Conceptually, it breaks the cut between the old view and the new view; Implementation wise, it can limit the (parent == null) handling mostly within `PipelinedApproximateSubpartition` or probably a little bit in `PipelinedSubpartition`, while in the reference check way, we have to change the interface and touch all the subpartitions that implements `PipelinedSubpartition`. Notice that not just `pollNext()` needs the check, everything that touches parent needs a check. 2. How this can solve the problem of a new view is replaced by an old one? Let's say downstream reconnects, asking for a new view; the new view is created; replaced by an old view that is triggered by an old handler event. The new view's parent is null-out. Then what will happen? I do not think "fenced by the upstream (or checkpoint will time out)" can **solve** this problem, it just ends with more failures caused by this problem. > So we can prevent most of the issues without touching deployment descriptors. > Therefore, I think it makes sense to implement it in this PR. Sorry for changing the decision. I am overall fine to put the check within this PR. However, may I ask how it is different from we have this PR as it is, and I fire a follow-up one to null-out the parent? In this PR, my main purpose is to introduce a different result partition type, and scheduler changes are based upon this new type. That's the main reason I prefer to do it in a follow-up PR otherwise the scheduler part is blocked. And also, it is easier to review, and for me to focus on tests after null-out parent as well. > Another concern is a potential resource leak if downstream continuously fail without notifying the upstream (instances of CreditBasedSequenceNumberingViewReader will accumulate). Can you create a follow-up ticket for that? > This can be addressed by firing user event (see PartitionRequestQueue.userEventTriggered). Yes, that's a good point. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #13802: [FLINK-19793][connector-kafka] Harden KafkaTableITCase.testKafkaSourceSinkWithMetadata
flinkbot commented on pull request #13802: URL: https://github.com/apache/flink/pull/13802#issuecomment-716973857 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 25256d07a44b5e60b2f699a73220d6ea4a5d44f1 (Tue Oct 27 04:32:20 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-19793) KafkaTableITCase.testKafkaSourceSinkWithMetadata fails on AZP
[
https://issues.apache.org/jira/browse/FLINK-19793?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-19793:
---
Labels: pull-request-available test-stability (was: test-stability)
> KafkaTableITCase.testKafkaSourceSinkWithMetadata fails on AZP
> -
>
> Key: FLINK-19793
> URL: https://issues.apache.org/jira/browse/FLINK-19793
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Table SQL / Ecosystem
>Affects Versions: 1.12.0
>Reporter: Till Rohrmann
>Assignee: Timo Walther
>Priority: Blocker
> Labels: pull-request-available, test-stability
> Fix For: 1.12.0
>
>
> The {{KafkaTableITCase.testKafkaSourceSinkWithMetadata}} seems to fail on AZP:
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=8197=logs=c5f0071e-1851-543e-9a45-9ac140befc32=1fb1a56f-e8b5-5a82-00a0-a2db7757b4f5
> {code}
> Expected: k2=[B@7c9ecd9e},0,metadata_topic_avro,true>
> 2,2,CreateTime,2020-03-09T13:12:11.123,1,0,{},0,metadata_topic_avro,false>
> k2=[B@4af44e42},0,metadata_topic_avro,true>
> but: was 1,1,CreateTime,2020-03-08T13:12:11.123,0,0,{k1=[B@4ea4e0f3,
> k2=[B@7c9ecd9e},0,metadata_topic_avro,true>
> 2,2,CreateTime,2020-03-09T13:12:11.123,1,0,{},0,metadata_topic_avro,false>
> k2=[B@4af44e42},0,metadata_topic_avro,true>
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] twalthr opened a new pull request #13802: [FLINK-19793][connector-kafka] Harden KafkaTableITCase.testKafkaSourceSinkWithMetadata
twalthr opened a new pull request #13802: URL: https://github.com/apache/flink/pull/13802 ## What is the purpose of the change Hardens the KafkaTableITCase by further improving the new test utilities and ignoring non-deterministic metadata columns. ## Brief change log - Offer an unordered list of row deep equals with matcher - Remove offset from test ## Verifying this change This change added tests and can be verified as follows: `RowTest` ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: yes - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-19684) The Jdbc-connector's 'lookup.max-retries' option implementation is different from the meaning
[
https://issues.apache.org/jira/browse/FLINK-19684?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu reassigned FLINK-19684:
---
Assignee: CaoZhen
> The Jdbc-connector's 'lookup.max-retries' option implementation is different
> from the meaning
> --
>
> Key: FLINK-19684
> URL: https://issues.apache.org/jira/browse/FLINK-19684
> Project: Flink
> Issue Type: Bug
> Components: Connectors / JDBC
>Reporter: CaoZhen
>Assignee: CaoZhen
>Priority: Minor
> Labels: pull-request-available
>
>
> The code of 'lookup.max-retries' option :
> {code:java}
> for (int retry = 1; retry <= maxRetryTimes; retry++) {
> statement.clearParameters();
> .
> }
> {code}
> From the code, If this option is set to 0, the JDBC query will not be
> executed.
>
> From documents, the max retry times if lookup database failed. [1]
> When set to 0, there is a query, but no retry.
>
> So,the code of 'lookup.max-retries' option should be:
> {code:java}
> for (int retry = 0; retry <= maxRetryTimes; retry++) {
> statement.clearParameters();
> .
> }
> {code}
>
>
> [1]
> https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/connectors/jdbc.html#lookup-max-retries
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-19819) SourceReaderBase supports limit push down
Jingsong Lee created FLINK-19819: Summary: SourceReaderBase supports limit push down Key: FLINK-19819 URL: https://issues.apache.org/jira/browse/FLINK-19819 Project: Flink Issue Type: Improvement Components: Connectors / Common Reporter: Jingsong Lee Fix For: 1.12.0 User requirement: Users need to look at a few random pieces of data in a table to see what the data looks like. So users often use the SQL: "select * from table limit 10" For a large table, expect to end soon because only a few pieces of data are queried. For DataStream or BoundedStream, they are push based execution models, so the downstream cannot control the end of source operator. We need push down limit to source operator, so that source operator can end early. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] godfreyhe commented on pull request #13793: [FLINK-19811][table-planner-blink] Simplify SEARCHes in conjunctions in FlinkRexUtil#simplify
godfreyhe commented on pull request #13793: URL: https://github.com/apache/flink/pull/13793#issuecomment-716967458 update the title as "Simplify SEARCHes in FlinkRexUtil#simplify" This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] vthinkxie edited a comment on pull request #13786: [FLINK-19764] Add More Metrics to TaskManager in Web UI
vthinkxie edited a comment on pull request #13786: URL: https://github.com/apache/flink/pull/13786#issuecomment-716966483 Hi @XComp fixed, thanks for your comments new screenshot 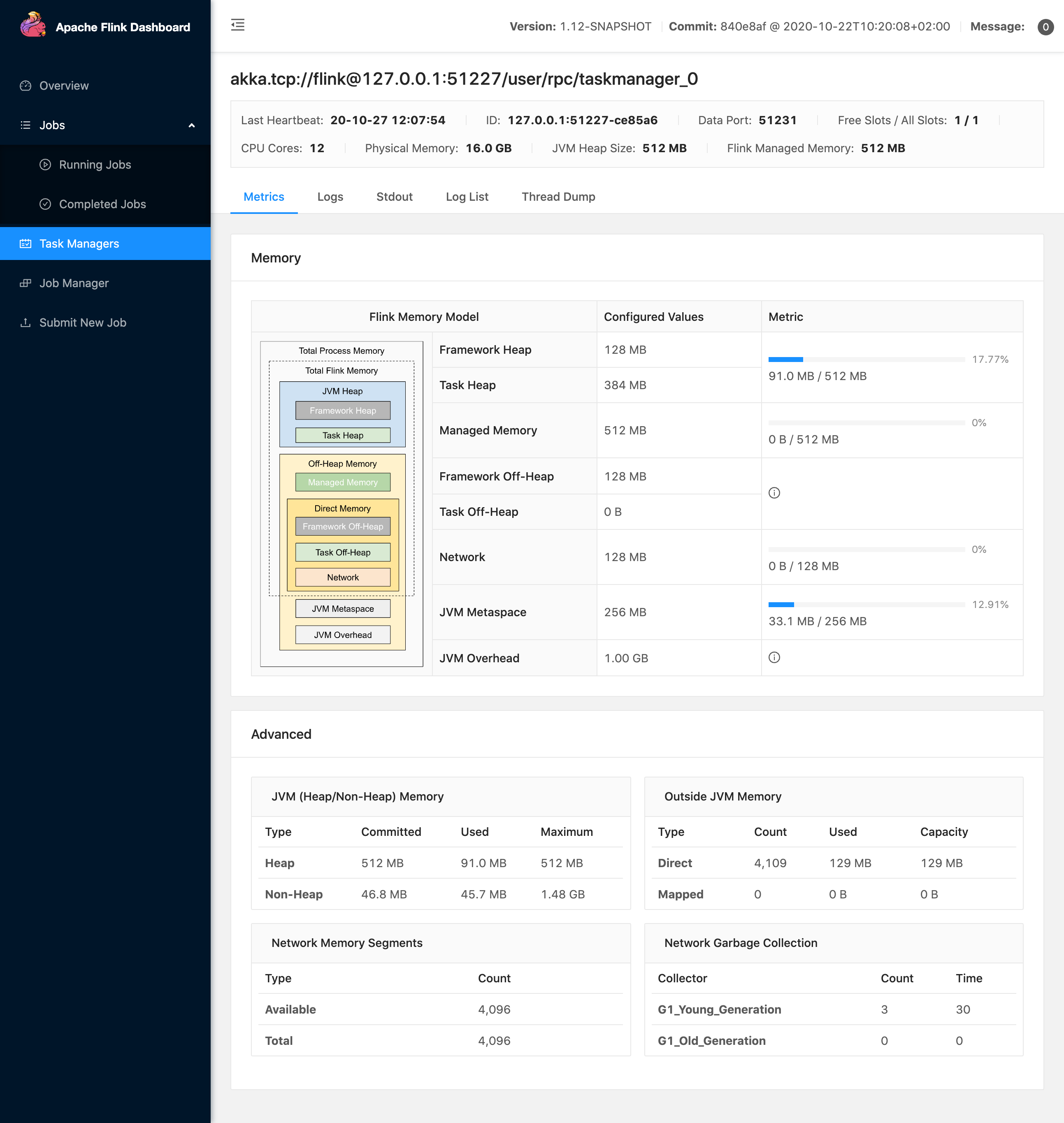 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] vthinkxie commented on pull request #13786: [FLINK-19764] Add More Metrics to TaskManager in Web UI
vthinkxie commented on pull request #13786: URL: https://github.com/apache/flink/pull/13786#issuecomment-716966483 Hi @XComp fixed, thanks for your comments This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on pull request #13717: [FLINK-19723][Connector/JDBC] Solve the problem of repeated data submission in the failure retry
wuchong commented on pull request #13717: URL: https://github.com/apache/flink/pull/13717#issuecomment-716965007 Could you add an unit test in `JdbcDynamicOutputFormatTest` to verify this bug fix? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on pull request #13721: [FLINK-19694][table] Support Upsert ChangelogMode for ScanTableSource
wuchong commented on pull request #13721: URL: https://github.com/apache/flink/pull/13721#issuecomment-716944858 Hi @godfreyhe , I have added the plan test as we discussed offline, and I did find a bug. Appreciate if you can have another look . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-19793) KafkaTableITCase.testKafkaSourceSinkWithMetadata fails on AZP
[
https://issues.apache.org/jira/browse/FLINK-19793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221093#comment-17221093
]
Timo Walther commented on FLINK-19793:
--
Will take care of this.
> KafkaTableITCase.testKafkaSourceSinkWithMetadata fails on AZP
> -
>
> Key: FLINK-19793
> URL: https://issues.apache.org/jira/browse/FLINK-19793
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Table SQL / Ecosystem
>Affects Versions: 1.12.0
>Reporter: Till Rohrmann
>Assignee: Timo Walther
>Priority: Blocker
> Labels: test-stability
> Fix For: 1.12.0
>
>
> The {{KafkaTableITCase.testKafkaSourceSinkWithMetadata}} seems to fail on AZP:
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=8197=logs=c5f0071e-1851-543e-9a45-9ac140befc32=1fb1a56f-e8b5-5a82-00a0-a2db7757b4f5
> {code}
> Expected: k2=[B@7c9ecd9e},0,metadata_topic_avro,true>
> 2,2,CreateTime,2020-03-09T13:12:11.123,1,0,{},0,metadata_topic_avro,false>
> k2=[B@4af44e42},0,metadata_topic_avro,true>
> but: was 1,1,CreateTime,2020-03-08T13:12:11.123,0,0,{k1=[B@4ea4e0f3,
> k2=[B@7c9ecd9e},0,metadata_topic_avro,true>
> 2,2,CreateTime,2020-03-09T13:12:11.123,1,0,{},0,metadata_topic_avro,false>
> k2=[B@4af44e42},0,metadata_topic_avro,true>
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (FLINK-19793) KafkaTableITCase.testKafkaSourceSinkWithMetadata fails on AZP
[
https://issues.apache.org/jira/browse/FLINK-19793?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Timo Walther reassigned FLINK-19793:
Assignee: Timo Walther
> KafkaTableITCase.testKafkaSourceSinkWithMetadata fails on AZP
> -
>
> Key: FLINK-19793
> URL: https://issues.apache.org/jira/browse/FLINK-19793
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka, Table SQL / Ecosystem
>Affects Versions: 1.12.0
>Reporter: Till Rohrmann
>Assignee: Timo Walther
>Priority: Blocker
> Labels: test-stability
> Fix For: 1.12.0
>
>
> The {{KafkaTableITCase.testKafkaSourceSinkWithMetadata}} seems to fail on AZP:
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=8197=logs=c5f0071e-1851-543e-9a45-9ac140befc32=1fb1a56f-e8b5-5a82-00a0-a2db7757b4f5
> {code}
> Expected: k2=[B@7c9ecd9e},0,metadata_topic_avro,true>
> 2,2,CreateTime,2020-03-09T13:12:11.123,1,0,{},0,metadata_topic_avro,false>
> k2=[B@4af44e42},0,metadata_topic_avro,true>
> but: was 1,1,CreateTime,2020-03-08T13:12:11.123,0,0,{k1=[B@4ea4e0f3,
> k2=[B@7c9ecd9e},0,metadata_topic_avro,true>
> 2,2,CreateTime,2020-03-09T13:12:11.123,1,0,{},0,metadata_topic_avro,false>
> k2=[B@4af44e42},0,metadata_topic_avro,true>
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-19818) ArrayIndexOutOfBoundsException occus when the source table have nest json
[
https://issues.apache.org/jira/browse/FLINK-19818?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
shizhengchao updated FLINK-19818:
-
Description:
I get an *ArrayIndexOutOfBoundsException* , when my table source have nest
json. as the follows is my test:
{code:sql}
CREATE TABLE Orders (
nest ROW<
idBIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
>,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE TABLE print (
orderId BIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
) WITH (
'connector' = 'print'
);
CREATE VIEW testView AS
SELECT
id,
consumerName,
price,
productName
FROM (
SELECT * FROM Orders
);
INSERT INTO print
SELECT
*
FROM testView;
{code}
The following is the exception of flink:
{code}
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
at java.util.ArrayList.elementData(ArrayList.java:422)
at java.util.ArrayList.get(ArrayList.java:435)
at
org.apache.calcite.sql.validate.SelectNamespace.getMonotonicity(SelectNamespace.java:73)
at
org.apache.calcite.sql.SqlIdentifier.getMonotonicity(SqlIdentifier.java:375)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectList(SqlToRelConverter.java:4132)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:685)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:642)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3345)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:568)
at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:164)
at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:151)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:789)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convertViewQuery(SqlToOperationConverter.java:696)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convertCreateView(SqlToOperationConverter.java:665)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:228)
at
org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:78)
at
org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:684)
at
com.fcbox.streaming.sql.submit.StreamingJob.callExecuteSql(StreamingJob.java:239)
at
com.fcbox.streaming.sql.submit.StreamingJob.callCommand(StreamingJob.java:207)
at
com.fcbox.streaming.sql.submit.StreamingJob.run(StreamingJob.java:133)
at
com.fcbox.streaming.sql.submit.StreamingJob.main(StreamingJob.java:77)
{code}
was:
I get an *ArrayIndexOutOfBoundsException* , when my table source have nest
json. as the follows is my test:
{code:sql}
CREATE TABLE Orders (
nest ROW<
idBIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
>,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE TABLE print (
orderId BIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
) WITH (
'connector' = 'print'
);
CREATE VIEW testView AS
SELECT
id,
consumerName,
price,
productName
FROM (
SELECT * FROM Orders
);
INSERT INTO print
SELECT
*
FROM testView;
{code}
The following is the exception of flink:
{code}
Unable to find source-code formatter for language: log. Available languages
are: actionscript, ada, applescript, bash, c, c#, c++, cpp, css, erlang, go,
groovy, haskell, html, java, javascript, js, json, lua, none, nyan, objc, perl,
php, python, r, rainbow, ruby, scala, sh, sql, swift, visualbasic, xml,
yamlException in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
at java.util.ArrayList.elementData(ArrayList.java:422)
at java.util.ArrayList.get(ArrayList.java:435)
at
org.apache.calcite.sql.validate.SelectNamespace.getMonotonicity(SelectNamespace.java:73)
at
org.apache.calcite.sql.SqlIdentifier.getMonotonicity(SqlIdentifier.java:375)
at
[jira] [Updated] (FLINK-19818) ArrayIndexOutOfBoundsException occus when the source table have nest json
[
https://issues.apache.org/jira/browse/FLINK-19818?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
shizhengchao updated FLINK-19818:
-
Description:
I get an *ArrayIndexOutOfBoundsException* , when my table source have nest
json. as the follows is my test:
{code:sql}
CREATE TABLE Orders (
nest ROW<
idBIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
>,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE TABLE print (
orderId BIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
) WITH (
'connector' = 'print'
);
CREATE VIEW testView AS
SELECT
id,
consumerName,
price,
productName
FROM (
SELECT * FROM Orders
);
INSERT INTO print
SELECT
*
FROM testView;
{code}
The following is the exception of flink:
{code}
Unable to find source-code formatter for language: log. Available languages
are: actionscript, ada, applescript, bash, c, c#, c++, cpp, css, erlang, go,
groovy, haskell, html, java, javascript, js, json, lua, none, nyan, objc, perl,
php, python, r, rainbow, ruby, scala, sh, sql, swift, visualbasic, xml,
yamlException in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
at java.util.ArrayList.elementData(ArrayList.java:422)
at java.util.ArrayList.get(ArrayList.java:435)
at
org.apache.calcite.sql.validate.SelectNamespace.getMonotonicity(SelectNamespace.java:73)
at
org.apache.calcite.sql.SqlIdentifier.getMonotonicity(SqlIdentifier.java:375)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectList(SqlToRelConverter.java:4132)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:685)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:642)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3345)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:568)
at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:164)
at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:151)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:789)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convertViewQuery(SqlToOperationConverter.java:696)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convertCreateView(SqlToOperationConverter.java:665)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:228)
at
org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:78)
at
org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:684)
at
com.fcbox.streaming.sql.submit.StreamingJob.callExecuteSql(StreamingJob.java:239)
at
com.fcbox.streaming.sql.submit.StreamingJob.callCommand(StreamingJob.java:207)
at
com.fcbox.streaming.sql.submit.StreamingJob.run(StreamingJob.java:133)
at
com.fcbox.streaming.sql.submit.StreamingJob.main(StreamingJob.java:77)
{code}
was:
I get an *ArrayIndexOutOfBoundsException* in *Interval Joins*, when my table
source have nest json. as the follows is my test:
{code:sql}
CREATE TABLE Orders (
nest ROW<
idBIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
>,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
DROP TABLE IF EXISTS Shipments;
CREATE TABLE Shipments (
idBIGINT,
orderId BIGINT,
originSTRING,
destnationSTRING,
isArrived BOOLEAN,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Shipments',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
DROP TABLE IF EXISTS print;
CREATE TABLE print (
orderId BIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING,
originSTRING,
destnationSTRING,
isArrived BOOLEAN
) WITH (
'connector' = 'print'
);
DROP VIEW IF EXISTS IntervalJoinView;
CREATE VIEW IntervalJoinView AS
SELECT
o.id,
o.consumerName,
o.price,
o.productName,
[jira] [Commented] (FLINK-19768) The shell "./yarn-session.sh " not use log4j-session.properties , it use log4j.properties
[ https://issues.apache.org/jira/browse/FLINK-19768?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221121#comment-17221121 ] YUJIANBO commented on FLINK-19768: -- Thank you for your reply! I want to ask a question. Our company plans to use yarn-session model, but we don't know how to Distinguish between different task logs on JobManager Log. I'm looking forward to your reply。 Thank you! > The shell "./yarn-session.sh " not use log4j-session.properties , it use > log4j.properties > -- > > Key: FLINK-19768 > URL: https://issues.apache.org/jira/browse/FLINK-19768 > Project: Flink > Issue Type: Bug > Components: Client / Job Submission, Deployment / YARN >Affects Versions: 1.11.2 >Reporter: YUJIANBO >Priority: Major > > The shell "./yarn-session.sh " not use log4j-session.properties , it use > log4j.properties > My Flink Job UI shows the $internal.yarn.log-config-file is > "/usr/local/flink-1.11.2/conf/log4j.properties",is it a bug? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Issue Comment Deleted] (FLINK-19768) The shell "./yarn-session.sh " not use log4j-session.properties , it use log4j.properties
[ https://issues.apache.org/jira/browse/FLINK-19768?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] YUJIANBO updated FLINK-19768: - Comment: was deleted (was: Thank you for your reply! I want to ask a question. Our company plans to use yarn-session model, but we don't know how to Distinguish between different task logs on JobManager Log. I'm looking forward to your reply。 Thank you!) > The shell "./yarn-session.sh " not use log4j-session.properties , it use > log4j.properties > -- > > Key: FLINK-19768 > URL: https://issues.apache.org/jira/browse/FLINK-19768 > Project: Flink > Issue Type: Bug > Components: Client / Job Submission, Deployment / YARN >Affects Versions: 1.11.2 >Reporter: YUJIANBO >Priority: Major > > The shell "./yarn-session.sh " not use log4j-session.properties , it use > log4j.properties > My Flink Job UI shows the $internal.yarn.log-config-file is > "/usr/local/flink-1.11.2/conf/log4j.properties",is it a bug? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-19818) ArrayIndexOutOfBoundsException occus when the source table have nest json
[
https://issues.apache.org/jira/browse/FLINK-19818?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
shizhengchao updated FLINK-19818:
-
Summary: ArrayIndexOutOfBoundsException occus when the source table have
nest json (was: ArrayIndexOutOfBoundsException occus in 'Interval Joins' when
the source table have nest json)
> ArrayIndexOutOfBoundsException occus when the source table have nest json
> --
>
> Key: FLINK-19818
> URL: https://issues.apache.org/jira/browse/FLINK-19818
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.11.2
>Reporter: shizhengchao
>Priority: Major
>
> I get an *ArrayIndexOutOfBoundsException* in *Interval Joins*, when my table
> source have nest json. as the follows is my test:
> {code:sql}
> CREATE TABLE Orders (
> nest ROW<
> idBIGINT,
> consumerName STRING,
> price DECIMAL(10, 5),
> productName STRING
> >,
> proctime AS PROCTIME()
> ) WITH (
> 'connector' = 'kafka-0.11',
> 'topic' = 'Orders',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'latest-offset',
> 'format' = 'json'
> );
> DROP TABLE IF EXISTS Shipments;
> CREATE TABLE Shipments (
> idBIGINT,
> orderId BIGINT,
> originSTRING,
> destnationSTRING,
> isArrived BOOLEAN,
> proctime AS PROCTIME()
> ) WITH (
> 'connector' = 'kafka-0.11',
> 'topic' = 'Shipments',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'latest-offset',
> 'format' = 'json'
> );
> DROP TABLE IF EXISTS print;
> CREATE TABLE print (
> orderId BIGINT,
> consumerName STRING,
> price DECIMAL(10, 5),
> productName STRING,
> originSTRING,
> destnationSTRING,
> isArrived BOOLEAN
> ) WITH (
> 'connector' = 'print'
> );
> DROP VIEW IF EXISTS IntervalJoinView;
> CREATE VIEW IntervalJoinView AS
> SELECT
> o.id,
> o.consumerName,
> o.price,
> o.productName,
> s.origin,
> s.destnation,
> s.isArrived
> FROM
> (SELECT * FROM Orders) o,
> (SELECT * FROM Shipments) s
> WHERE s.orderId = o.id AND o.proctime BETWEEN s.proctime - INTERVAL '4' HOUR
> AND s.proctime;
> INSERT INTO print
> SELECT
> id,
> consumerName,
> price,
> productName,
> origin,
> destnation,
> isArrived
> FROM IntervalJoinView;
> {code}
> The following is the exception of flink:
> {code:log}
> Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
> at java.util.ArrayList.elementData(ArrayList.java:422)
> at java.util.ArrayList.get(ArrayList.java:435)
> at
> org.apache.calcite.sql.validate.SelectNamespace.getMonotonicity(SelectNamespace.java:73)
> at
> org.apache.calcite.sql.SqlIdentifier.getMonotonicity(SqlIdentifier.java:375)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectList(SqlToRelConverter.java:4132)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:685)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:642)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3345)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:568)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:164)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:151)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:789)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convertViewQuery(SqlToOperationConverter.java:696)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convertCreateView(SqlToOperationConverter.java:665)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:228)
> at
> org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:78)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:684)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.callExecuteSql(StreamingJob.java:239)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.callCommand(StreamingJob.java:207)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.run(StreamingJob.java:133)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.main(StreamingJob.java:77)
> {code}
[jira] [Commented] (FLINK-19768) The shell "./yarn-session.sh " not use log4j-session.properties , it use log4j.properties
[ https://issues.apache.org/jira/browse/FLINK-19768?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221120#comment-17221120 ] YUJIANBO commented on FLINK-19768: -- Thank you for your reply! I want to ask a question. Our company plans to use yarn-session model, but we don't know how to Distinguish between different task logs on JobManager Log. I'm looking forward to your reply。 Thank you! > The shell "./yarn-session.sh " not use log4j-session.properties , it use > log4j.properties > -- > > Key: FLINK-19768 > URL: https://issues.apache.org/jira/browse/FLINK-19768 > Project: Flink > Issue Type: Bug > Components: Client / Job Submission, Deployment / YARN >Affects Versions: 1.11.2 >Reporter: YUJIANBO >Priority: Major > > The shell "./yarn-session.sh " not use log4j-session.properties , it use > log4j.properties > My Flink Job UI shows the $internal.yarn.log-config-file is > "/usr/local/flink-1.11.2/conf/log4j.properties",is it a bug? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #13801: [FLINK-19213][docs-zh] Update the Chinese documentation
flinkbot commented on pull request #13801: URL: https://github.com/apache/flink/pull/13801#issuecomment-716960915 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 08c397aefda24ff450869e60acfadff81859e669 (Tue Oct 27 03:46:54 UTC 2020) ✅no warnings Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-19213) Update the Chinese documentation
[ https://issues.apache.org/jira/browse/FLINK-19213?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-19213: --- Labels: pull-request-available (was: ) > Update the Chinese documentation > > > Key: FLINK-19213 > URL: https://issues.apache.org/jira/browse/FLINK-19213 > Project: Flink > Issue Type: Sub-task > Components: chinese-translation, Documentation >Reporter: Dawid Wysakowicz >Assignee: jiawen xiao >Priority: Trivial > Labels: pull-request-available > Time Spent: 168h > > We should update the Chinese documentation with the changes introduced in > FLINK-18802 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] xiaoHoly opened a new pull request #13801: [FLINK-19213][docs-zh] Update the Chinese documentation
xiaoHoly opened a new pull request #13801: URL: https://github.com/apache/flink/pull/13801 ## What is the purpose of the change I will translate document avro-confluent.md under formats into document avro-confluent.zh.md. We should update the Chinese documentation with the changes introduced in FLINK-18802 ## Brief change log -translate flink/docs/dev/table/connectors/formats/avro-confluent.zh.md ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (no) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on a change in pull request #13081: [FLINK-18590][json] Support json array explode to multi messages
wuchong commented on a change in pull request #13081:
URL: https://github.com/apache/flink/pull/13081#discussion_r512399078
##
File path:
flink-formats/flink-json/src/main/java/org/apache/flink/formats/json/JsonRowDataDeserializationSchema.java
##
@@ -130,6 +133,39 @@ public RowData deserialize(byte[] message) throws
IOException {
}
}
+ @Override
Review comment:
I still prefer to only keep one implementation, otherwise it's hard to
maintain in the future. We should update the json tests to use collector
methods to have full test coverage.
The Kinesis should migrate to collector method ASAP, rather than hacking
JSON format for Kinesis. What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #13800: [FLINK-19650][connectors jdbc]Support the limit push down for the Jdb…
flinkbot commented on pull request #13800: URL: https://github.com/apache/flink/pull/13800#issuecomment-716959806 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit d03e417c4b828ffb3e3b8061d0a9b5dd9a38b018 (Tue Oct 27 03:43:08 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-19650).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-19650) Support the limit push down for the Jdbc connector
[
https://issues.apache.org/jira/browse/FLINK-19650?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-19650:
---
Labels: pull-request-available (was: )
> Support the limit push down for the Jdbc connector
> --
>
> Key: FLINK-19650
> URL: https://issues.apache.org/jira/browse/FLINK-19650
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / JDBC, Table SQL / API
>Reporter: Shengkai Fang
>Priority: Major
> Labels: pull-request-available
>
> Currently the blink planner has already supported rule
> {{PushLimitIntoLegacyTableSourceScanRule}}. It's ready to add this feature
> for the jdbc connector.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] fsk119 opened a new pull request #13800: [FLINK-19650][connectors jdbc]Support the limit push down for the Jdb…
fsk119 opened a new pull request #13800: URL: https://github.com/apache/flink/pull/13800 …c connector ## What is the purpose of the change *Support the limit push down for the jdbc connectors* ## Brief change log - *The jdbc connector extends the `SupportsLimitPushDown` interface* ## Verifying this change This change added tests and can be verified as follows: - *Added IT case to verify the results.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (**yes** / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / **not documented**) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] TsReaper commented on a change in pull request #13742: [FLINK-19626][table-planner-blink] Introduce multi-input operator construction algorithm
TsReaper commented on a change in pull request #13742:
URL: https://github.com/apache/flink/pull/13742#discussion_r512391340
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/planner/plan/nodes/physical/batch/BatchExecMultipleInputNode.scala
##
@@ -99,6 +100,14 @@ class BatchExecMultipleInputNode(
val memoryKB = generator.getManagedMemoryWeight
ExecNode.setManagedMemoryWeight(multipleInputTransform, memoryKB * 1024)
+if (withSourceChaining) {
+ // set chaining strategy for source chaining
+
multipleInputTransform.setChainingStrategy(ChainingStrategy.HEAD_WITH_SOURCES)
Review comment:
It's OK. I just want to be more precise.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] wuchong commented on a change in pull request #13081: [FLINK-18590][json] Support json array explode to multi messages
wuchong commented on a change in pull request #13081:
URL: https://github.com/apache/flink/pull/13081#discussion_r512397979
##
File path:
flink-formats/flink-json/src/main/java/org/apache/flink/formats/json/JsonRowDataDeserializationSchema.java
##
@@ -130,6 +133,39 @@ public RowData deserialize(byte[] message) throws
IOException {
}
}
+ @Override
Review comment:
Could you create an issue for this and add comment in the
`deserialize(byte[] message)` method?
I think the problem is that some connector doesn't migrate to
`deserialize(byte[] message, Collector out)` yet, for example,
Kinesis. If we remove the implementation of `deserialize(byte[] message)`, the
upcoming Kinesis SQL connector will not support JSON format.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-19818) ArrayIndexOutOfBoundsException occus in 'Interval Joins' when the source table have nest json
[
https://issues.apache.org/jira/browse/FLINK-19818?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221118#comment-17221118
]
shizhengchao commented on FLINK-19818:
--
After my test, only `select * from Orders` will report an error, while use
`select id, consumerName, price, productName, proctime from Orders` will be
OK
> ArrayIndexOutOfBoundsException occus in 'Interval Joins' when the source
> table have nest json
> -
>
> Key: FLINK-19818
> URL: https://issues.apache.org/jira/browse/FLINK-19818
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.11.2
>Reporter: shizhengchao
>Priority: Major
>
> I get an *ArrayIndexOutOfBoundsException* in *Interval Joins*, when my table
> source have nest json. as the follows is my test:
> {code:sql}
> CREATE TABLE Orders (
> nest ROW<
> idBIGINT,
> consumerName STRING,
> price DECIMAL(10, 5),
> productName STRING
> >,
> proctime AS PROCTIME()
> ) WITH (
> 'connector' = 'kafka-0.11',
> 'topic' = 'Orders',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'latest-offset',
> 'format' = 'json'
> );
> DROP TABLE IF EXISTS Shipments;
> CREATE TABLE Shipments (
> idBIGINT,
> orderId BIGINT,
> originSTRING,
> destnationSTRING,
> isArrived BOOLEAN,
> proctime AS PROCTIME()
> ) WITH (
> 'connector' = 'kafka-0.11',
> 'topic' = 'Shipments',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'latest-offset',
> 'format' = 'json'
> );
> DROP TABLE IF EXISTS print;
> CREATE TABLE print (
> orderId BIGINT,
> consumerName STRING,
> price DECIMAL(10, 5),
> productName STRING,
> originSTRING,
> destnationSTRING,
> isArrived BOOLEAN
> ) WITH (
> 'connector' = 'print'
> );
> DROP VIEW IF EXISTS IntervalJoinView;
> CREATE VIEW IntervalJoinView AS
> SELECT
> o.id,
> o.consumerName,
> o.price,
> o.productName,
> s.origin,
> s.destnation,
> s.isArrived
> FROM
> (SELECT * FROM Orders) o,
> (SELECT * FROM Shipments) s
> WHERE s.orderId = o.id AND o.proctime BETWEEN s.proctime - INTERVAL '4' HOUR
> AND s.proctime;
> INSERT INTO print
> SELECT
> id,
> consumerName,
> price,
> productName,
> origin,
> destnation,
> isArrived
> FROM IntervalJoinView;
> {code}
> The following is the exception of flink:
> {code:log}
> Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
> at java.util.ArrayList.elementData(ArrayList.java:422)
> at java.util.ArrayList.get(ArrayList.java:435)
> at
> org.apache.calcite.sql.validate.SelectNamespace.getMonotonicity(SelectNamespace.java:73)
> at
> org.apache.calcite.sql.SqlIdentifier.getMonotonicity(SqlIdentifier.java:375)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectList(SqlToRelConverter.java:4132)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:685)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:642)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3345)
> at
> org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:568)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:164)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:151)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:789)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convertViewQuery(SqlToOperationConverter.java:696)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convertCreateView(SqlToOperationConverter.java:665)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:228)
> at
> org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:78)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:684)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.callExecuteSql(StreamingJob.java:239)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.callCommand(StreamingJob.java:207)
> at
> com.fcbox.streaming.sql.submit.StreamingJob.run(StreamingJob.java:133)
> at
>
[GitHub] [flink] flinkbot edited a comment on pull request #13744: [FLINK-19766][table-runtime] Introduce File streaming compaction operators
flinkbot edited a comment on pull request #13744: URL: https://github.com/apache/flink/pull/13744#issuecomment-714369975 ## CI report: * 074ab07749ff798563e785d2c2fafeee1302ac74 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8262) * 22d42a57852d0a240e2abb6bf1a4c2ade682601f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-19817) Is FileSystem source unsupported?
[
https://issues.apache.org/jira/browse/FLINK-19817?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221117#comment-17221117
]
Jingsong Lee commented on FLINK-19817:
--
Hi [~ZhuShang], the reason is
Complex types not supported
> Is FileSystem source unsupported?
> -
>
> Key: FLINK-19817
> URL: https://issues.apache.org/jira/browse/FLINK-19817
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / FileSystem
>Reporter: CloseRiver
>Priority: Minor
>
> When I create a table with filesystem connector + parquet format.Then read
> from the table and received the following exception.
>
> {code:java}
> java.lang.UnsupportedOperationException: Complex types not supported.at
> org.apache.flink.formats.parquet.vector.ParquetColumnarRowSplitReader.checkSchema(ParquetColumnarRowSplitReader.java:226)
> at
> org.apache.flink.formats.parquet.vector.ParquetColumnarRowSplitReader.(ParquetColumnarRowSplitReader.java:144)
> at
> org.apache.flink.formats.parquet.vector.ParquetSplitReaderUtil.genPartColumnarRowReader(ParquetSplitReaderUtil.java:131)
> at
> org.apache.flink.formats.parquet.ParquetFileSystemFormatFactory$ParquetInputFormat.open(ParquetFileSystemFormatFactory.java:204)
> at
> org.apache.flink.formats.parquet.ParquetFileSystemFormatFactory$ParquetInputFormat.open(ParquetFileSystemFormatFactory.java:159)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:85)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:201)
> {code}
> Then I found the description in official document
>
> `File system sources for streaming is still under development. In the future,
> the community will add support for common streaming use cases, i.e.,
> partition and directory monitoring.`
> means that read from flilesystem is not supported currently.
> But the above exception make users confused.If there is a msg about reading
> from filesystem is unsupported will be friendly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (FLINK-19553) The format of checkpoint Completion Time and Failure Time should be changed from HH:mm:ss to yyyy-MM-dd HH:mm:ss
[ https://issues.apache.org/jira/browse/FLINK-19553?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yun Tang resolved FLINK-19553. -- Resolution: Fixed > The format of checkpoint Completion Time and Failure Time should be changed > from HH:mm:ss to -MM-dd HH:mm:ss > > > Key: FLINK-19553 > URL: https://issues.apache.org/jira/browse/FLINK-19553 > Project: Flink > Issue Type: Improvement > Components: Runtime / Web Frontend >Reporter: liufangliang >Assignee: liufangliang >Priority: Minor > Labels: pull-request-available > Fix For: 1.12.0 > > Attachments: image-2020-10-09-15-14-42-491.png, > image-2020-10-09-15-15-27-768.png > > > As shown in the picture below, The latest completed checkpoint ID is 3, > but the latest failed checkpoint ID is 5370. The two IDs are too far apart > .The failure time in HH:mm:ss format is difficult to determine the specific > failure date of the checkpoint. > > !image-2020-10-09-15-15-27-768.png|width=980,height=90! > !image-2020-10-09-15-14-42-491.png|width=981,height=80! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-19553) The format of checkpoint Completion Time and Failure Time should be changed from HH:mm:ss to yyyy-MM-dd HH:mm:ss
[ https://issues.apache.org/jira/browse/FLINK-19553?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221098#comment-17221098 ] Yun Tang commented on FLINK-19553: -- Merged into master with commit 8e6b04a103771f4f50654933af05e47bb937f5b5 > The format of checkpoint Completion Time and Failure Time should be changed > from HH:mm:ss to -MM-dd HH:mm:ss > > > Key: FLINK-19553 > URL: https://issues.apache.org/jira/browse/FLINK-19553 > Project: Flink > Issue Type: Improvement > Components: Runtime / Web Frontend >Reporter: liufangliang >Assignee: liufangliang >Priority: Minor > Labels: pull-request-available > Fix For: 1.12.0 > > Attachments: image-2020-10-09-15-14-42-491.png, > image-2020-10-09-15-15-27-768.png > > > As shown in the picture below, The latest completed checkpoint ID is 3, > but the latest failed checkpoint ID is 5370. The two IDs are too far apart > .The failure time in HH:mm:ss format is difficult to determine the specific > failure date of the checkpoint. > > !image-2020-10-09-15-15-27-768.png|width=980,height=90! > !image-2020-10-09-15-14-42-491.png|width=981,height=80! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #13721: [FLINK-19694][table] Support Upsert ChangelogMode for ScanTableSource
flinkbot edited a comment on pull request #13721: URL: https://github.com/apache/flink/pull/13721#issuecomment-713489063 ## CI report: * 709d07f21f4b5be3b49901baf57a5a16179a50c7 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8275) * abcd6adcb7094de11bf46b06d9d68d69035293d2 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13718: [FLINK-18811] Pick another tmpDir if an IOException occurs when creating spill file
flinkbot edited a comment on pull request #13718: URL: https://github.com/apache/flink/pull/13718#issuecomment-713418812 ## CI report: * 61d088bc24fa8610f1c03cef9b94197107f91b04 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8002) * 5c96af1117f6f6ac03ba38c20af505fe7a6bae4f Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8338) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13626: [FLINK-19594][web] Make subtask index start from zero
flinkbot edited a comment on pull request #13626: URL: https://github.com/apache/flink/pull/13626#issuecomment-708171532 ## CI report: * 1f6974a2251daef826687b981fd5a5fb428fe66c Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=7857) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=7571) * bcea64faf14e9261ae2cb6b996701b844bf876d3 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-19818) ArrayIndexOutOfBoundsException occus in 'Interval Joins' when the source table have nest json
shizhengchao created FLINK-19818:
Summary: ArrayIndexOutOfBoundsException occus in 'Interval Joins'
when the source table have nest json
Key: FLINK-19818
URL: https://issues.apache.org/jira/browse/FLINK-19818
Project: Flink
Issue Type: Bug
Components: Table SQL / Planner
Affects Versions: 1.11.2
Reporter: shizhengchao
I get an *ArrayIndexOutOfBoundsException* in *Interval Joins*, when my table
source have nest json. as the follows is my test:
{code:sql}
CREATE TABLE Orders (
nest ROW<
idBIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING
>,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
DROP TABLE IF EXISTS Shipments;
CREATE TABLE Shipments (
idBIGINT,
orderId BIGINT,
originSTRING,
destnationSTRING,
isArrived BOOLEAN,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'Shipments',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
DROP TABLE IF EXISTS print;
CREATE TABLE print (
orderId BIGINT,
consumerName STRING,
price DECIMAL(10, 5),
productName STRING,
originSTRING,
destnationSTRING,
isArrived BOOLEAN
) WITH (
'connector' = 'print'
);
DROP VIEW IF EXISTS IntervalJoinView;
CREATE VIEW IntervalJoinView AS
SELECT
o.id,
o.consumerName,
o.price,
o.productName,
s.origin,
s.destnation,
s.isArrived
FROM
(SELECT * FROM Orders) o,
(SELECT * FROM Shipments) s
WHERE s.orderId = o.id AND o.proctime BETWEEN s.proctime - INTERVAL '4' HOUR
AND s.proctime;
INSERT INTO print
SELECT
id,
consumerName,
price,
productName,
origin,
destnation,
isArrived
FROM IntervalJoinView;
{code}
The following is the exception of flink:
{code:log}
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
at java.util.ArrayList.elementData(ArrayList.java:422)
at java.util.ArrayList.get(ArrayList.java:435)
at
org.apache.calcite.sql.validate.SelectNamespace.getMonotonicity(SelectNamespace.java:73)
at
org.apache.calcite.sql.SqlIdentifier.getMonotonicity(SqlIdentifier.java:375)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectList(SqlToRelConverter.java:4132)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:685)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:642)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3345)
at
org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:568)
at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:164)
at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:151)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:789)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convertViewQuery(SqlToOperationConverter.java:696)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convertCreateView(SqlToOperationConverter.java:665)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:228)
at
org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:78)
at
org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:684)
at
com.fcbox.streaming.sql.submit.StreamingJob.callExecuteSql(StreamingJob.java:239)
at
com.fcbox.streaming.sql.submit.StreamingJob.callCommand(StreamingJob.java:207)
at
com.fcbox.streaming.sql.submit.StreamingJob.run(StreamingJob.java:133)
at
com.fcbox.streaming.sql.submit.StreamingJob.main(StreamingJob.java:77)
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #13799: [FLINK-19201][python] Set conda install retries to avoid network problems
flinkbot commented on pull request #13799: URL: https://github.com/apache/flink/pull/13799#issuecomment-716956912 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit a024fb24774e040339371f3a2c5ac71c6831d187 (Tue Oct 27 03:33:36 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-19201).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-19817) Is FileSystem source unsupported?
CloseRiver created FLINK-19817:
--
Summary: Is FileSystem source unsupported?
Key: FLINK-19817
URL: https://issues.apache.org/jira/browse/FLINK-19817
Project: Flink
Issue Type: Improvement
Components: Connectors / FileSystem
Reporter: CloseRiver
When I create a table with filesystem connector + parquet format.Then read from
the table and received the following exception.
{code:java}
java.lang.UnsupportedOperationException: Complex types not supported.at
org.apache.flink.formats.parquet.vector.ParquetColumnarRowSplitReader.checkSchema(ParquetColumnarRowSplitReader.java:226)
at
org.apache.flink.formats.parquet.vector.ParquetColumnarRowSplitReader.(ParquetColumnarRowSplitReader.java:144)
at
org.apache.flink.formats.parquet.vector.ParquetSplitReaderUtil.genPartColumnarRowReader(ParquetSplitReaderUtil.java:131)
at
org.apache.flink.formats.parquet.ParquetFileSystemFormatFactory$ParquetInputFormat.open(ParquetFileSystemFormatFactory.java:204)
at
org.apache.flink.formats.parquet.ParquetFileSystemFormatFactory$ParquetInputFormat.open(ParquetFileSystemFormatFactory.java:159)
at
org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:85)
at
org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100)
at
org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63)
at
org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:201)
{code}
Then I found the description in official document
`File system sources for streaming is still under development. In the future,
the community will add support for common streaming use cases, i.e., partition
and directory monitoring.`
means that read from flilesystem is not supported currently.
But the above exception make users confused.If there is a msg about reading
from filesystem is unsupported will be friendly.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-19201) PyFlink e2e tests is instable and failed with "Connection broken: OSError"
[
https://issues.apache.org/jira/browse/FLINK-19201?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-19201:
---
Labels: pull-request-available test-stability (was: test-stability)
> PyFlink e2e tests is instable and failed with "Connection broken: OSError"
> --
>
> Key: FLINK-19201
> URL: https://issues.apache.org/jira/browse/FLINK-19201
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.11.0, 1.12.0
>Reporter: Dian Fu
>Priority: Major
> Labels: pull-request-available, test-stability
>
> [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=6452=logs=ff2e2ea5-07e3-5521-7b04-a4fc3ad765e9=6945d9e3-ebef-5993-0c44-838d8ad079c0]
> {code}
> 2020-09-10T21:37:42.9988117Z install conda ... [SUCCESS]
> 2020-09-10T21:37:43.0018449Z install miniconda... [SUCCESS]
> 2020-09-10T21:37:43.0082244Z installing python environment...
> 2020-09-10T21:37:43.0100408Z installing python3.5...
> 2020-09-10T21:37:58.7214400Z install python3.5... [SUCCESS]
> 2020-09-10T21:37:58.7253792Z installing python3.6...
> 2020-09-10T21:38:06.5855143Z install python3.6... [SUCCESS]
> 2020-09-10T21:38:06.5903358Z installing python3.7...
> 2020-09-10T21:38:11.5444706Z
> 2020-09-10T21:38:11.5484852Z ('Connection broken: OSError("(104,
> \'ECONNRESET\')")', OSError("(104, 'ECONNRESET')"))
> 2020-09-10T21:38:11.5513130Z
> 2020-09-10T21:38:11.8044086Z conda install 3.7 failed.You can
> retry to exec the script.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #13214: [FLINK-18938][tableSQL/API] Throw better exception message for quering sink-only connector
flinkbot edited a comment on pull request #13214: URL: https://github.com/apache/flink/pull/13214#issuecomment-678119788 ## CI report: * 8c8fcc0f241851849e0b3faefa88aea5d6649662 UNKNOWN * 86fd7ea0db4fc5c6e62f2aa259592b510677c874 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8299) * 985c2d40aec3e20a402998b16d7eaf8d73ad9738 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] Shawn-Hx commented on pull request #13584: [hotfix][typo] Fix typo in MiniCluster
Shawn-Hx commented on pull request #13584: URL: https://github.com/apache/flink/pull/13584#issuecomment-716948087 Hi, @xintongsong Could you help to review this PR at your convenience ? Thank you~ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] HuangXingBo opened a new pull request #13799: [FLINK-19201][python] Set conda install retries to avoid network problems
HuangXingBo opened a new pull request #13799: URL: https://github.com/apache/flink/pull/13799 ## What is the purpose of the change *This pull request will set conda install retries to avoid network problems* ## Brief change log - *set conda install retries to install python environment* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-19232) Support MapState and MapView for Python UDAF
[ https://issues.apache.org/jira/browse/FLINK-19232?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17218200#comment-17218200 ] Dian Fu edited comment on FLINK-19232 at 10/27/20, 3:29 AM: Merged "Basic support of MapState and MapView" to master via 079bbacd1754a766198e4b7e22644845baaef51b was (Author: dian.fu): Merged to master via 079bbacd1754a766198e4b7e22644845baaef51b > Support MapState and MapView for Python UDAF > > > Key: FLINK-19232 > URL: https://issues.apache.org/jira/browse/FLINK-19232 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Reporter: Wei Zhong >Assignee: Wei Zhong >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] Myasuka commented on pull request #13626: [FLINK-19594][web] Make subtask index start from zero
Myasuka commented on pull request #13626: URL: https://github.com/apache/flink/pull/13626#issuecomment-716947546 @zlzhang0122 Could you rename your commit title also as `[FLINK-19594][web] Make subtask index start from zero`? We don't have component as `[flink-runtime-web]`. Moreover, don't leave spaces between `[FLINK-19594]` and `[web]`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-19232) Support MapState and MapView for Python UDAF
[ https://issues.apache.org/jira/browse/FLINK-19232?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221112#comment-17221112 ] Dian Fu commented on FLINK-19232: - Merged "Support iterating MapState and MapView" to master via d30e52380b1dc6bdffb75cb13d1af7b8d6999196 > Support MapState and MapView for Python UDAF > > > Key: FLINK-19232 > URL: https://issues.apache.org/jira/browse/FLINK-19232 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Reporter: Wei Zhong >Assignee: Wei Zhong >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] tzulitai edited a comment on pull request #13761: [FLINK-19741] Allow AbstractStreamOperator to skip restoring timers if subclasses are using raw keyed state
tzulitai edited a comment on pull request #13761: URL: https://github.com/apache/flink/pull/13761#issuecomment-716945671 @pnowojski since the root cause of this issue is that the timer services are incorrectly assuming that whatever written in raw keyed state is written by them (please see details in the description of this PR), the ideal solution is to include as metadata in checkpoints / savepoints a header indicating what was used to write to raw keyed state. This way, the timer service can know to safely skip restoring from raw keyed state if it wasn't written by them (there is only ever one writer to raw keyed state streams). However, we decided not to go with that approach because: - Adding such a header would require some backwards compatibility path for savepoint formats - Raw keyed state is not intended or advertised to be used by users at the moment. Moreover, if some user is really using raw keyed state right now, restoring from checkpoints would have always failed due to this issue. - In the long term, the heap-based timers should eventually by moved to the state backends as well and no longer used raw keyed state anyways. That's why we came up with this temporary workaround, with a flag that we expect power-users to set if they are using raw keyed state. Since the Stateful Functions project bumped into this, and this is the first time ever the issue was reported, we're expecting that StateFun is currently the only Flink user with raw keyed state and needs to set this flag. As an alternative to the `isUsingCustomRawKeyedState()` method in this PR, I also considered a configuration flag, say `state.backend.rocksdb.migrate-timers` to provide the exact same functionality across all operators in a job. I chose to go with `isUsingCustomRawKeyedState()` in the end because: - the flag is set closer to where it is needed - we ONLY skip timer restores for operators that are using custom raw keyed state and set the flag - otherwise, using the global config flag, _all_ operators will either try to skip or read from raw keyed state. Either way, this is meant as an undocumented internal flag that is supposedly only used by StateFun. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lirui-apache commented on a change in pull request #13744: [FLINK-19766][table-runtime] Introduce File streaming compaction operators
lirui-apache commented on a change in pull request #13744:
URL: https://github.com/apache/flink/pull/13744#discussion_r512388323
##
File path:
flink-table/flink-table-runtime-blink/src/test/java/org/apache/flink/table/filesystem/stream/compact/CompactCoordinatorTest.java
##
@@ -0,0 +1,130 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.filesystem.stream.compact;
+
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.runtime.checkpoint.OperatorSubtaskState;
+import org.apache.flink.streaming.util.OneInputStreamOperatorTestHarness;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CompactionUnit;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CoordinatorInput;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CoordinatorOutput;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.EndCompaction;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.EndInputFile;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.InputFile;
+import org.apache.flink.util.function.ThrowingConsumer;
+
+import org.junit.Assert;
+import org.junit.Test;
+
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.concurrent.atomic.AtomicReference;
+import java.util.stream.Collectors;
+
+/**
+ * Test for {@link CompactCoordinator}.
+ */
+public class CompactCoordinatorTest extends AbstractCompactTestBase {
+
+ @Test
+ public void testCoordinatorCrossCheckpoints() throws Exception {
+ AtomicReference state = new
AtomicReference<>();
+ runCoordinator(harness -> {
+ harness.setup();
+ harness.open();
+
+ harness.processElement(new InputFile("p0",
newFile("f0", 3)), 0);
+ harness.processElement(new InputFile("p0",
newFile("f1", 2)), 0);
+
+ harness.processElement(new InputFile("p1",
newFile("f2", 2)), 0);
+
+ harness.processElement(new InputFile("p0",
newFile("f3", 5)), 0);
+ harness.processElement(new InputFile("p0",
newFile("f4", 1)), 0);
+
+ harness.processElement(new InputFile("p1",
newFile("f5", 5)), 0);
+ harness.processElement(new InputFile("p1",
newFile("f6", 4)), 0);
+
+ state.set(harness.snapshot(1, 0));
+ });
+
+ runCoordinator(harness -> {
+ harness.setup();
+ harness.initializeState(state.get());
+ harness.open();
+
+ harness.processElement(new InputFile("p0",
newFile("f7", 3)), 0);
+ harness.processElement(new InputFile("p0",
newFile("f8", 2)), 0);
+
+ state.set(harness.snapshot(2, 0));
+ });
+
+ runCoordinator(harness -> {
+ harness.setup();
+ harness.initializeState(state.get());
+ harness.open();
+
+ harness.processElement(new EndInputFile(2, 0, 1), 0);
+
+ List outputs =
harness.extractOutputValues();
+
+ Assert.assertEquals(7, outputs.size());
+
+ assertUnit(outputs.get(0), 0, "p0", Arrays.asList("f0",
"f1", "f4"));
Review comment:
Yeah... but then how could we assert the first output is for `p0`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] wuchong merged pull request #13753: [FLINK-19765][flink-table-planner] refactor SqlToOperationConverter a…
wuchong merged pull request #13753: URL: https://github.com/apache/flink/pull/13753 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #13798: [BP-1.11][FLINK-19777][table-runtime-blink] Fix NullPointException for WindowOperator.close()
flinkbot commented on pull request #13798: URL: https://github.com/apache/flink/pull/13798#issuecomment-716946611 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit dbd064dbef9e76b88f1633b79f5e771ecf072678 (Tue Oct 27 02:59:24 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dianfu closed pull request #13739: [FLINK-19232][python] support iterating MapState and MapView
dianfu closed pull request #13739: URL: https://github.com/apache/flink/pull/13739 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13793: [FLINK-19811][table-planner-blink] Simplify SEARCHes in conjunctions in FlinkRexUtil#simplify
flinkbot edited a comment on pull request #13793: URL: https://github.com/apache/flink/pull/13793#issuecomment-716625439 ## CI report: * dbd532ce6d9cb6bb713eb794fdb10e79ba2e3856 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8314) * 2320004768e00086c264056f67bddb21613374db UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-19799) Make FileSource extensible
[
https://issues.apache.org/jira/browse/FLINK-19799?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221102#comment-17221102
]
Steven Zhen Wu edited comment on FLINK-19799 at 10/27/20, 3:17 AM:
---
We just went through a similar exercise with the [Iceberg source
PoC|https://github.com/stevenzwu/iceberg/pull/2/files]. We want to make
assigner pluggable (no order/locale guarantee, some ordering guarantee, local
aware etc.). Different assigner may have different state type for checkpoint.
That is why we have to add generic types for assigner state and serializer too.
We did make IcebergSource generic
{code}
public class IcebergSource<
T,
SplitAssignerStateT extends SplitAssignerState,
SplitAssignerT extends SplitAssigner,
SplitAssignerStateSerializerT extends
SplitAssignerStateSerializer>
{code}
We simplified the construction in builder.
{code}
public static Builder useSimpleAssigner(TableLoader
tableLoader) {
SimpleSplitAssignerFactory assignerFactory = new
SimpleSplitAssignerFactory();
return new Builder<>(tableLoader, assignerFactory);
}
{code}
The end result is still simple for users if they don't need to keep a reference
to the IcebergSource object.
{code}
final DataStream stream = env.fromSource(
IcebergSource.useSimpleAssigner(tableLoader())
.iteratorFactory(new RowDataIteratorFactory())
.config(config)
.scanContext(scanContext)
.build(),
...
{code}
was (Author: stevenz3wu):
We just went through a similar exercise with the [Iceberg source
PoC|https://github.com/stevenzwu/iceberg/pull/2/files]. We want to make
assigner pluggable (no order/locale guarantee, some ordering guarantee, local
aware etc.). Different assigner may have different state type for checkpoint.
That is why we have to add generic types for assigner state and serializer too.
We did make IcebergSource generic
{code}
public class IcebergSource,
SplitAssignerStateSerializerT extends
SplitAssignerStateSerializer>
{code}
We simplified the construction in builder.
{code}
public static Builder useSimpleAssigner(TableLoader
tableLoader) {
SimpleSplitAssignerFactory assignerFactory = new
SimpleSplitAssignerFactory();
return new Builder<>(tableLoader, assignerFactory);
}
{code}
The end result is still simple for users if they don't need to keep a reference
to the IcebergSource object.
{code}
final DataStream stream = env.fromSource(
IcebergSource.useSimpleAssigner(tableLoader())
.iteratorFactory(new RowDataIteratorFactory())
.config(config)
.scanContext(scanContext)
.build(),
...
{code}
> Make FileSource extensible
> --
>
> Key: FLINK-19799
> URL: https://issues.apache.org/jira/browse/FLINK-19799
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / FileSystem
>Reporter: Stephan Ewen
>Assignee: Stephan Ewen
>Priority: Major
> Fix For: 1.12.0
>
>
> The File System Source currently assumes all formats can represent their work
> units as {{FileSourceSplit}}. If that is not the case, the formats cannot be
> implemented using the {{FileSource}}.
> We need to support extending the splits to carry additional information in
> the splits, and to use that information when creating bulk readers and
> handling split state.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] tzulitai edited a comment on pull request #13761: [FLINK-19741] Allow AbstractStreamOperator to skip restoring timers if subclasses are using raw keyed state
tzulitai edited a comment on pull request #13761: URL: https://github.com/apache/flink/pull/13761#issuecomment-716945671 @pnowojski since the root cause of this issue is that the timer services are incorrectly assuming that whatever written in raw keyed state is written by them (please see details in the description of this PR), the ideal solution is to include as metadata in checkpoints / savepoints a header indicating what was used to write to raw keyed state. This way, the timer service can know to safely skip restoring from raw keyed state if it wasn't written by them (there is only ever one writer to raw keyed state streams). However, we decided not to go with that approach because: - Adding such a header would require some backwards compatibility path for savepoint formats - Raw keyed state is not intended or advertised to be used by users at the moment. Moreover, if some user is really using raw keyed state right now, restoring from checkpoints would have always failed due to this issue. - In the long term, the heap-based timers should eventually by moved to the state backends as well and no longer used raw keyed state anyways. That's why we came up with this temporary workaround, with a flag that we expect power-users to set if they are using raw keyed state. Since the Stateful Functions project bumped into this, and this is the first time ever the issue was reported, we're expecting that StateFun is currently the only Flink user with raw keyed state and needs to set this flag. As an alternative to the `isUsingCustomRawKeyedState()` method in this PR, I also considered a configuration flag, say `state.backend.rocksdb.migrate-timers` to provide the exact same functionality across all operators in a job. I chose to go with `isUsingCustomRawKeyedState()` so that: - the flag is set closer to where it is needed - we ONLY skip timer restores for operators that are using custom raw keyed state and set the flag - otherwise, using the global config flag, _all_ operators will either try to skip or read from raw keyed state. Either way, this is meant as an undocumented internal flag that is supposedly only used by StateFun. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-19799) Make FileSource extensible
[
https://issues.apache.org/jira/browse/FLINK-19799?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221102#comment-17221102
]
Steven Zhen Wu edited comment on FLINK-19799 at 10/27/20, 3:17 AM:
---
We just went through a similar exercise with the [Iceberg source
PoC|https://github.com/stevenzwu/iceberg/pull/2/files]. We want to make
assigner pluggable (no order/locale guarantee, some ordering guarantee, local
aware etc.). Different assigner may have different state type for checkpoint.
That is why we have to add generic types for assigner state and serializer too.
We did make IcebergSource generic
{code}
public class IcebergSource,
SplitAssignerStateSerializerT extends
SplitAssignerStateSerializer>
{code}
We simplified the construction in builder.
{code}
public static Builder useSimpleAssigner(TableLoader
tableLoader) {
SimpleSplitAssignerFactory assignerFactory = new
SimpleSplitAssignerFactory();
return new Builder<>(tableLoader, assignerFactory);
}
{code}
The end result is still simple for users if they don't need to keep a reference
to the IcebergSource object.
{code}
final DataStream stream = env.fromSource(
IcebergSource.useSimpleAssigner(tableLoader())
.iteratorFactory(new RowDataIteratorFactory())
.config(config)
.scanContext(scanContext)
.build(),
...
{code}
was (Author: stevenz3wu):
We just went through a similar exercise with the Iceberg source PoC. We want to
make assigner pluggable (no order/locale guarantee, some ordering guarantee,
local aware etc.). Different assigner may have different state type for
checkpoint. That is why we have to add generic types for assigner state and
serializer too.
We did make IcebergSource generic
{code}
public class IcebergSource,
SplitAssignerStateSerializerT extends
SplitAssignerStateSerializer>
{code}
We simplified the construction in builder.
{code}
public static Builder useSimpleAssigner(TableLoader
tableLoader) {
SimpleSplitAssignerFactory assignerFactory = new
SimpleSplitAssignerFactory();
return new Builder<>(tableLoader, assignerFactory);
}
{code}
The end result is still simple for users if they don't need to keep a reference
to the IcebergSource object.
{code}
final DataStream stream = env.fromSource(
IcebergSource.useSimpleAssigner(tableLoader())
.iteratorFactory(new RowDataIteratorFactory())
.config(config)
.scanContext(scanContext)
.build(),
...
{code}
> Make FileSource extensible
> --
>
> Key: FLINK-19799
> URL: https://issues.apache.org/jira/browse/FLINK-19799
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / FileSystem
>Reporter: Stephan Ewen
>Assignee: Stephan Ewen
>Priority: Major
> Fix For: 1.12.0
>
>
> The File System Source currently assumes all formats can represent their work
> units as {{FileSourceSplit}}. If that is not the case, the formats cannot be
> implemented using the {{FileSource}}.
> We need to support extending the splits to carry additional information in
> the splits, and to use that information when creating bulk readers and
> handling split state.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] JingsongLi commented on a change in pull request #13744: [FLINK-19766][table-runtime] Introduce File streaming compaction operators
JingsongLi commented on a change in pull request #13744:
URL: https://github.com/apache/flink/pull/13744#discussion_r512392582
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/filesystem/stream/compact/CompactMessages.java
##
@@ -0,0 +1,155 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.filesystem.stream.compact;
+
+import org.apache.flink.core.fs.Path;
+
+import java.io.Serializable;
+import java.net.URI;
+import java.util.Arrays;
+import java.util.List;
+import java.util.stream.Collectors;
+
+/**
+ * Util class for all compaction messages.
+ *
+ * The compaction operator graph is:
+ * TempFileWriter|parallel ---(InputFile)--->
CompactCoordinator|non-parallel
+ *
---(CompactionUnit)--->CompactOperator|parallel---(PartitionCommitInfo)--->
+ * PartitionCommitter|non-parallel
+ *
+ * Because the end message is a kind of barrier of record messages, they
can only be transmitted
+ * in the way of full broadcast in the link from coordinator to compact
operator.
+ */
+public class CompactMessages {
+ private CompactMessages() {}
+
+ /**
+* The input of compact coordinator.
+*/
+ public interface CoordinatorInput extends Serializable {}
+
+ /**
+* A partitioned input file.
+*/
+ public static class InputFile implements CoordinatorInput {
+ private final String partition;
+ private final Path file;
+
+ public InputFile(String partition, Path file) {
+ this.partition = partition;
+ this.file = file;
+ }
+
+ public String getPartition() {
+ return partition;
+ }
+
+ public Path getFile() {
+ return file;
+ }
+ }
+
+ /**
+* A flag to end file input.
+*/
+ public static class EndInputFile implements CoordinatorInput {
+ private final long checkpointId;
+ private final int taskId;
+ private final int numberOfTasks;
+
+ public EndInputFile(long checkpointId, int taskId, int
numberOfTasks) {
+ this.checkpointId = checkpointId;
+ this.taskId = taskId;
+ this.numberOfTasks = numberOfTasks;
+ }
+
+ public long getCheckpointId() {
+ return checkpointId;
+ }
+
+ public int getTaskId() {
+ return taskId;
+ }
+
+ public int getNumberOfTasks() {
+ return numberOfTasks;
+ }
+ }
+
+ /**
+* The output of compact coordinator.
+*/
+ public interface CoordinatorOutput extends Serializable {}
+
+ /**
+* The unit of a single compaction.
+*/
+ public static class CompactionUnit implements CoordinatorOutput {
+
+ private final int unitId;
+ private final String partition;
+
+ // Store strings to improve serialization performance.
+ private final String[] pathStrings;
+
+ public CompactionUnit(int unitId, String partition, List
unit) {
+ this.unitId = unitId;
+ this.partition = partition;
+ this.pathStrings = unit.stream()
+ .map(Path::toUri)
+ .map(URI::toString)
+ .toArray(String[]::new);
+ }
+
+ public boolean isTaskMessage(int taskId) {
Review comment:
Good catch, there is a bug here, should be:
```
public boolean isTaskMessage(int taskNumber, int taskId) {
return unitId % taskNumber == taskId;
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries
[jira] [Commented] (FLINK-19799) Make FileSource extensible
[
https://issues.apache.org/jira/browse/FLINK-19799?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221102#comment-17221102
]
Steven Zhen Wu commented on FLINK-19799:
We just went through a similar exercise with the Iceberg source PoC. We want to
make assigner pluggable (no order/locale guarantee, some ordering guarantee,
local aware etc.). Different assigner may have different state type for
checkpoint. That is why we have to add generic types for assigner state and
serializer too.
We did make IcebergSource generic
{code}
public class IcebergSource,
SplitAssignerStateSerializerT extends
SplitAssignerStateSerializer>
{code}
We simplified the construction in builder.
{code}
public static Builder useSimpleAssigner(TableLoader
tableLoader) {
SimpleSplitAssignerFactory assignerFactory = new
SimpleSplitAssignerFactory();
return new Builder<>(tableLoader, assignerFactory);
}
{code}
The end result is still simple for users if they don't need to keep a reference
to the IcebergSource object.
{code}
final DataStream stream = env.fromSource(
IcebergSource.useSimpleAssigner(tableLoader())
.iteratorFactory(new RowDataIteratorFactory())
.config(config)
.scanContext(scanContext)
.build(),
...
{code}
> Make FileSource extensible
> --
>
> Key: FLINK-19799
> URL: https://issues.apache.org/jira/browse/FLINK-19799
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / FileSystem
>Reporter: Stephan Ewen
>Assignee: Stephan Ewen
>Priority: Major
> Fix For: 1.12.0
>
>
> The File System Source currently assumes all formats can represent their work
> units as {{FileSourceSplit}}. If that is not the case, the formats cannot be
> implemented using the {{FileSource}}.
> We need to support extending the splits to carry additional information in
> the splits, and to use that information when creating bulk readers and
> handling split state.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] tzulitai edited a comment on pull request #13761: [FLINK-19741] Allow AbstractStreamOperator to skip restoring timers if subclasses are using raw keyed state
tzulitai edited a comment on pull request #13761: URL: https://github.com/apache/flink/pull/13761#issuecomment-716945671 @pnowojski since the root cause of this issue is that the timer services are incorrectly assuming that whatever written in raw keyed state is written by them (please see details in the description of this PR), the ideal solution is to include as metadata in checkpoints / savepoints a header indicating what was used to write to raw keyed state. This way, the timer service can know to safely skip restoring from raw keyed state if it wasn't written by them (there is only ever one writer to raw keyed state streams). However, we decided not to go with that approach because: - Adding such a header would require some backwards compatibility path for savepoint formats - Raw keyed state is not intended or advertised to be used by users at the moment. Moreover, if some user is really using raw keyed state right now, restoring from checkpoints would have always failed due to this issue. - In the long term, the heap-based timers should eventually by moved to the state backends as well and no longer used raw keyed state anyways. That's why we came up with this temporary workaround, with a flag that we expect power-users to set if they are using raw keyed state. Since the Stateful Functions project bumped into this, and this is the first time ever the issue was reported, we're expecting that StateFun is currently the only Flink user with raw keyed state and needs to set this flag. As an alternative to the `isUsingCustomRawKeyedState()` method in this PR, I also considered a configuration flag, say `state.backend.rocksdb.migrate-timers` to provide the exact same functionality across all operators in a job. I chose to go with `isUsingCustomRawKeyedState()` so that: - the flag is set closer to where it is needed - only operators that are using custom raw keyed state should skip timer restores - otherwise, using the global config flag, _all_ operators will either try to skip or read from raw keyed state. Either way, this is meant as an undocumented internal flag that is supposedly only used by StateFun. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-19816) Flink restored from a wrong checkpoint (a very old one and not the last completed one)
[
https://issues.apache.org/jira/browse/FLINK-19816?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Steven Zhen Wu updated FLINK-19816:
---
Description:
h2. Summary
Upon failure, it seems that Flink didn't restore from the last completed
checkpoint. Instead, it restored from a very old checkpoint. As a result, Kafka
offsets are invalid and caused the job to replay from the beginning as Kafka
consumer "auto.offset.reset" was set to "EARLIEST".
This is an embarrassingly parallel stateless job. Parallelism is over 1,000. I
have the full log file from jobmanager at INFO level.
h2. Sequence of events from the logs
Just before the failure, checkpoint *210768* completed.
{code}
2020-10-25 02:35:05,970 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator
[jobmanager-future-thread-5] - Completed checkpoint 210768 for job
233b4938179c06974e4535ac8a868675 (4623776 bytes in 120402 ms).
{code}
During restart, somehow it decided to restore from a very old checkpoint
*203531*.
{code:java}
2020-10-25 02:36:03,301 INFO
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
[cluster-io-thread-3] - Start SessionDispatcherLeaderProcess.
2020-10-25 02:36:03,302 INFO
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
[cluster-io-thread-5] - Recover all persisted job graphs.
2020-10-25 02:36:03,304 INFO com.netflix.bdp.s3fs.BdpS3FileSystem
[cluster-io-thread-25] - Deleting path:
s3:///checkpoints/XM3B/clapp_avro-clapp_avro_nontvui/1593/233b4938179c06974e4535ac8a868675/chk-210758/c31aec1e-07a7-4193-aa00-3fbe83f9e2e6
2020-10-25 02:36:03,307 INFO
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
[cluster-io-thread-5] - Trying to recover job with job id
233b4938179c06974e4535ac8a868675.
2020-10-25 02:36:03,381 INFO com.netflix.bdp.s3fs.BdpS3FileSystem
[cluster-io-thread-25] - Deleting path:
s3:///checkpoints/Hh86/clapp_avro-clapp_avro_nontvui/1593/233b4938179c06974e4535ac8a868675/chk-210758/4ab92f70-dfcd-4212-9b7f-bdbecb9257fd
...
2020-10-25 02:36:03,427 INFO
org.apache.flink.runtime.checkpoint.ZooKeeperCompletedCheckpointStore
[flink-akka.actor.default-dispatcher-82003] - Recovering checkpoints from
ZooKeeper.
2020-10-25 02:36:03,432 INFO
org.apache.flink.runtime.checkpoint.ZooKeeperCompletedCheckpointStore
[flink-akka.actor.default-dispatcher-82003] - Found 0 checkpoints in ZooKeeper.
2020-10-25 02:36:03,432 INFO
org.apache.flink.runtime.checkpoint.ZooKeeperCompletedCheckpointStore
[flink-akka.actor.default-dispatcher-82003] - Trying to fetch 0 checkpoints
from storage.
2020-10-25 02:36:03,432 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator
[flink-akka.actor.default-dispatcher-82003] - Starting job
233b4938179c06974e4535ac8a868675 from savepoint
s3:///checkpoints/metadata/clapp_avro-clapp_avro_nontvui/1113/47e2a25a8d0b696c7d0d423722bb6f54/chk-203531/_metadata
()
{code}
was:
h2. Summary
Upon failure, it seems that Flink didn't restore from the last completed
checkpoint. Instead, it restored from a very old checkpoint. As a result, Kafka
offsets are invalid and caused the job to replay from the beginning as Kafka
consumer "auto.offset.reset" was set to "EARLIEST".
This is an embarrassingly parallel stateless job. Parallelism is over 1,000. I
have the full log file from jobmanager.
h2. Sequence of events from the logs
Just before the failure, checkpoint *210768* completed.
{code}
2020-10-25 02:35:05,970 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator
[jobmanager-future-thread-5] - Completed checkpoint 210768 for job
233b4938179c06974e4535ac8a868675 (4623776 bytes in 120402 ms).
{code}
During restart, somehow it decided to restore from a very old checkpoint
*203531*.
{code:java}
2020-10-25 02:36:03,301 INFO
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
[cluster-io-thread-3] - Start SessionDispatcherLeaderProcess.
2020-10-25 02:36:03,302 INFO
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
[cluster-io-thread-5] - Recover all persisted job graphs.
2020-10-25 02:36:03,304 INFO com.netflix.bdp.s3fs.BdpS3FileSystem
[cluster-io-thread-25] - Deleting path:
s3:///checkpoints/XM3B/clapp_avro-clapp_avro_nontvui/1593/233b4938179c06974e4535ac8a868675/chk-210758/c31aec1e-07a7-4193-aa00-3fbe83f9e2e6
2020-10-25 02:36:03,307 INFO
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
[cluster-io-thread-5] - Trying to recover job with job id
233b4938179c06974e4535ac8a868675.
2020-10-25 02:36:03,381 INFO com.netflix.bdp.s3fs.BdpS3FileSystem
[cluster-io-thread-25] - Deleting path:
s3:///checkpoints/Hh86/clapp_avro-clapp_avro_nontvui/1593/233b4938179c06974e4535ac8a868675/chk-210758/4ab92f70-dfcd-4212-9b7f-bdbecb9257fd
[GitHub] [flink] tzulitai commented on pull request #13761: [FLINK-19741] Allow AbstractStreamOperator to skip restoring timers if subclasses are using raw keyed state
tzulitai commented on pull request #13761: URL: https://github.com/apache/flink/pull/13761#issuecomment-716945671 @pnowojski since the root cause of this issue is that the timer services are incorrectly assuming that whatever written in raw keyed state is written by them (please see details in the description of this PR), the ideal solution is to include as metadata in checkpoints / savepoints a header indicating what was used to write to raw keyed state. This way, the timer service can know to safely skip restoring from raw keyed state if it wasn't written by them (there is only ever one writer to raw keyed state streams). However, we decided not to go with that approach because: - Adding such a header would require some backwards compatibility path for savepoint formats - Raw keyed state is not intended or advertised to be used by users at the moment. Moreover, if some user is really using raw keyed state right now, restoring from checkpoints would have always failed due to this issue. - In the long term, the heap-based timers should eventually by moved to the state backends as well and no longer used raw keyed state anyways. That's why we came up with this temporary workaround, with a flag that we expect power-users to set if they are using raw keyed state. Since the Stateful Functions project bumped into this, and this is the first time ever the issue was reported, we're expecting that StateFun is currently the only Flink user with raw keyed state and needs to set this flag. As an alternative to the `isUsingCustomRawKeyedState()` method in this PR, I also considered a configuration flag, say `state.backend.rocksdb.migrate-timers` to provide the exact same functionality across all operators in a job. I chose to go with `isUsingCustomRawKeyedState()` so that: - the flag is set closer to where it is needed - only operators that are using custom raw keyed state should skip timer restores - otherwise, using the global config flag, _all_ operators will either try to skip or read from raw keyed state. Either way, this is meant as an undocumented internal flag that is supposedly only used by StateFun. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong opened a new pull request #13798: [BP-1.11][FLINK-19777][table-runtime-blink] Fix NullPointException for WindowOperator.close()
wuchong opened a new pull request #13798: URL: https://github.com/apache/flink/pull/13798 This is a cherry pick for release-1.11 branch. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-19765) flink SqlUseCatalog.getCatalogName is not unified with SqlCreateCatalog and SqlDropCatalog
[ https://issues.apache.org/jira/browse/FLINK-19765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-19765: Issue Type: Improvement (was: Bug) > flink SqlUseCatalog.getCatalogName is not unified with SqlCreateCatalog and > SqlDropCatalog > -- > > Key: FLINK-19765 > URL: https://issues.apache.org/jira/browse/FLINK-19765 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.11.0 >Reporter: jackylau >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > > when i develop flink ranger plugin at operation level, i find this method not > unified. > And SqlToOperationConverter.convert needs has the good order for user to find > code. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (FLINK-19765) flink SqlUseCatalog.getCatalogName is not unified with SqlCreateCatalog and SqlDropCatalog
[ https://issues.apache.org/jira/browse/FLINK-19765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu closed FLINK-19765. --- Assignee: jackylau Resolution: Fixed Fixed in master: 2e60d04b170ad9900d486b1e88fae750fc9995fc > flink SqlUseCatalog.getCatalogName is not unified with SqlCreateCatalog and > SqlDropCatalog > -- > > Key: FLINK-19765 > URL: https://issues.apache.org/jira/browse/FLINK-19765 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Reporter: jackylau >Assignee: jackylau >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > > when i develop flink ranger plugin at operation level, i find this method not > unified. > And SqlToOperationConverter.convert needs has the good order for user to find > code. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-19765) flink SqlUseCatalog.getCatalogName is not unified with SqlCreateCatalog and SqlDropCatalog
[ https://issues.apache.org/jira/browse/FLINK-19765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-19765: Affects Version/s: (was: 1.11.0) > flink SqlUseCatalog.getCatalogName is not unified with SqlCreateCatalog and > SqlDropCatalog > -- > > Key: FLINK-19765 > URL: https://issues.apache.org/jira/browse/FLINK-19765 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Reporter: jackylau >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > > when i develop flink ranger plugin at operation level, i find this method not > unified. > And SqlToOperationConverter.convert needs has the good order for user to find > code. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] QingdongZeng3 commented on pull request #13690: [FLINK-16595][YARN]support more HDFS nameServices in yarn mode when security enabled. Is…
QingdongZeng3 commented on pull request #13690: URL: https://github.com/apache/flink/pull/13690#issuecomment-716951090 Thanks for the review and Merging! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13772: [FLINK-19748] Iterating key groups in raw keyed stream on restore fails if some key groups weren't written
flinkbot edited a comment on pull request #13772: URL: https://github.com/apache/flink/pull/13772#issuecomment-715366899 ## CI report: * 3abd2ed382cbb3d875ed0ad4754bf34b26da78fc Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8305) Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8340) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13767: [FLINK-19787][table-runtime] Migrate Filesystem connector to new table source sink interface
flinkbot edited a comment on pull request #13767: URL: https://github.com/apache/flink/pull/13767#issuecomment-715256450 ## CI report: * 11330173d2fcaeead16e067e1f7d31c50081c2e1 UNKNOWN * afd866cd911131de15dfe3a2d3ec80b93ea78da7 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8282) * bf0d914e9559cdfb49695af72933911fa83bbb26 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8339) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] Myasuka merged pull request #13680: [FLINK-19553][web] Make timestamp of checkpoints shown with date format
Myasuka merged pull request #13680: URL: https://github.com/apache/flink/pull/13680 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13755: [FLINK-19700][k8s] Make Kubernetes Client in KubernetesResourceManagerDriver use io executor
flinkbot edited a comment on pull request #13755: URL: https://github.com/apache/flink/pull/13755#issuecomment-714883306 ## CI report: * 8fffb4f4aeb5080f0ed028bfa744ff5f9acaf5ca Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8313) * 04e4ab123cfd0a95dc6ebc2a5316d35fb8f65e65 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-18044) Add the subtask index information to the SourceReaderContext.
[
https://issues.apache.org/jira/browse/FLINK-18044?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17133852#comment-17133852
]
liufangliang edited comment on FLINK-18044 at 10/27/20, 2:44 AM:
-
Hi [~becket_qin],
can i pack this issue?
my solution is to add a methed named indexOfSubtask to interface
SourceReaderContext,as following
{code:java}
/**
* @return The index of this subtask
*/
int getIndexOfSubtask();{code}
And then ,implement this method in the open() method of class SourceOperator,as
following
{code:java}
@Override
public int getIndexOfSubtask(){
return getRuntimeContext().getIndexOfThisSubtask();
}
{code}
what do you think of it ?
was (Author: liufangliang):
Hi [~becket_qin],
can i pack this issue?
my solution is to add a methed named indexOfSubtask to interface
SourceReaderContext,as following
{code:java}
/**
* @return The index of this subtask
*/
int indexOfSubtask();{code}
And then ,implement this method in the open() method of class SourceOperator,as
following
{code:java}
@Override
public int indexOfSubtask(){
return getRuntimeContext().getIndexOfThisSubtask();
}
{code}
what do you think of it ?
> Add the subtask index information to the SourceReaderContext.
> -
>
> Key: FLINK-18044
> URL: https://issues.apache.org/jira/browse/FLINK-18044
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Common
>Reporter: Jiangjie Qin
>Priority: Major
> Labels: pull-request-available
>
> It is useful for the `SourceReader` to retrieve its subtask id. For example,
> Kafka readers can create a consumer with proper client id.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #13767: [FLINK-19787][table-runtime] Migrate Filesystem connector to new table source sink interface
flinkbot edited a comment on pull request #13767: URL: https://github.com/apache/flink/pull/13767#issuecomment-715256450 ## CI report: * 11330173d2fcaeead16e067e1f7d31c50081c2e1 UNKNOWN * afd866cd911131de15dfe3a2d3ec80b93ea78da7 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8282) * bf0d914e9559cdfb49695af72933911fa83bbb26 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] xintongsong commented on pull request #13755: [FLINK-19700][k8s] Make Kubernetes Client in KubernetesResourceManagerDriver use io executor
xintongsong commented on pull request #13755: URL: https://github.com/apache/flink/pull/13755#issuecomment-716941855 @SteNicholas I've updated the PR: - Rebased onto latest `master` branch - Your original changes are squashed into one main commit. - My new changes are in the hotfix and fixup commits. Please take a look at the changes. It there's no objections, I'll merge this once AZP gives green light. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13718: [FLINK-18811] Pick another tmpDir if an IOException occurs when creating spill file
flinkbot edited a comment on pull request #13718: URL: https://github.com/apache/flink/pull/13718#issuecomment-713418812 ## CI report: * 61d088bc24fa8610f1c03cef9b94197107f91b04 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=8002) * 5c96af1117f6f6ac03ba38c20af505fe7a6bae4f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] RocMarshal commented on pull request #13791: [FLINK-19749][docs] Improve documentation in 'Table API' page
RocMarshal commented on pull request #13791: URL: https://github.com/apache/flink/pull/13791#issuecomment-716940547 ping @dianfu This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13680: [FLINK-19553][web] Make timestamp of checkpoints shown with date format
flinkbot edited a comment on pull request #13680: URL: https://github.com/apache/flink/pull/13680#issuecomment-711592132 ## CI report: * a040eaf5fdc1858602290024370747ee7d2c8e13 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=7979) * 746d30c0758aa6b5f80cf826f084780a33a57de0 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] tzulitai commented on pull request #13772: [FLINK-19748] Iterating key groups in raw keyed stream on restore fails if some key groups weren't written
tzulitai commented on pull request #13772: URL: https://github.com/apache/flink/pull/13772#issuecomment-716939458 @flinkbot run azure This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-19777) Fix NullPointException for WindowOperator.close()
[
https://issues.apache.org/jira/browse/FLINK-19777?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17221076#comment-17221076
]
Jark Wu commented on FLINK-19777:
-
Fixed in
- master: 1bdac236eb0eb19ab2125bf70ebb1099e0bca468
- 1.11: TODO
> Fix NullPointException for WindowOperator.close()
> -
>
> Key: FLINK-19777
> URL: https://issues.apache.org/jira/browse/FLINK-19777
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.11.2
> Environment: jdk 1.8.0_262
> flink 1.11.1
>Reporter: frank wang
>Assignee: Jark Wu
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.12.0, 1.11.3
>
>
> i use flink sql run a job,the sql and metadata is :
> meta :
> 1>soure: kafka
> create table metric_source_window_table(
> `metricName` String,
> `namespace` String,
> `timestamp` BIGINT,
> `doubleValue` DOUBLE,
> `longValue` BIGINT,
> `metricsValue` String,
> `tags` MAP,
> `meta` Map,
> t as TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`/1000,'-MM-dd HH:mm:ss')),
> WATERMARK FOR t AS t) WITH (
> 'connector' = 'kafka',
> 'topic' = 'ai-platform',
> 'properties.bootstrap.servers' = 'xxx',
> 'properties.group.id' = 'metricgroup',
> 'scan.startup.mode'='earliest-offset',
> 'format' = 'json',
> 'json.fail-on-missing-field' = 'false',
> 'json.ignore-parse-errors' = 'true')
> 2>sink to clickhouse(the clickhouse-connector was developed by ourself)
> create table flink_metric_window_table(
> `timestamp` BIGINT,
> `longValue` BIGINT,
> `metricName` String,
> `metricsValueSum` DOUBLE,
> `metricsValueMin` DOUBLE,
> `metricsValueMax` DOUBLE,
> `tag_record_id` String,
> `tag_host_ip` String,
> `tag_instance` String,
> `tag_job_name` String,
> `tag_ai_app_name` String,
> `tag_namespace` String,
> `tag_ai_type` String,
> `tag_host_name` String,
> `tag_alarm_domain` String) WITH (
> 'connector.type' = 'clickhouse',
> 'connector.property-version' = '1',
> 'connector.url' = 'jdbc:clickhouse://xxx:8123/dataeye',
> 'connector.cluster'='ck_cluster',
> 'connector.write.flush.max-rows'='6000',
> 'connector.write.flush.interval'='1000',
> 'connector.table' = 'flink_metric_table_all')
> my sql is :
> insert into
> hive.temp_vipflink.flink_metric_window_table
> select
> cast(HOP_ROWTIME(t, INTERVAL '60' SECOND, INTERVAL '15' MINUTE) AS BIGINT)
> AS `timestamps`,
> sum(COALESCE( `longValue`, 0)) AS longValue,
> metricName,
> sum(IF(IS_DIGIT(metricsValue), cast(metricsValue AS DOUBLE), 0)) AS
> metricsValueSum,
> min(IF(IS_DIGIT(metricsValue), cast(metricsValue AS DOUBLE), 0)) AS
> metricsValueMin,
> max(IF(IS_DIGIT(metricsValue), cast(metricsValue AS DOUBLE), 0)) AS
> metricsValueMax,
> tags ['record_id'],
> tags ['host_ip'],
> tags ['instance'],
> tags ['job_name'],
> tags ['ai_app_name'],
> tags ['namespace'],
> tags ['ai_type'],
> tags ['host_name'],
> tags ['alarm_domain']
> from
> hive.temp_vipflink.metric_source_window_table
> group by
> metricName,
> tags ['record_id'],
> tags ['host_ip'],
> tags ['instance'],
> tags ['job_name'],
> tags ['ai_app_name'],
> tags ['namespace'],
> tags ['ai_type'],
> tags ['host_name'],
> tags ['alarm_domain'],
> HOP(t, INTERVAL '60' SECOND, INTERVAL '15' MINUTE)
>
> when i run this sql for a long hours, it will appear a exception like this:
> [2020-10-22 20:54:52.089] [ERROR] [GroupWindowAggregate(groupBy=[metricName,
> $f1, $f2, $f3, $f4, $f5, $f6, $f7, $f8, $f9], window=[SlidingGroupWindow('w$,
> t, 90, 6)], properties=[w$start, w$end, w$rowtime, w$proctime],
> select=[metricName, $f1, $f2, $f3, $f4, $f5, $f6, $f7, $f8, $f9, SUM($f11) AS
> longValue, SUM($f12) AS metricsValueSum, MIN($f12) AS metricsValueMin,
> MAX($f12) AS metricsValueMax, start('w$) AS w$start, end('w$) AS w$end,
> rowtime('w$) AS w$rowtime, proctime('w$) AS w$proctime]) ->
> Calc(select=[CAST(CAST(w$rowtime)) AS timestamps, longValue, metricName,
> metricsValueSum, metricsValueMin, metricsValueMax, $f1 AS EXPR$6, $f2 AS
> EXPR$7, $f3 AS EXPR$8, $f4 AS EXPR$9, $f5 AS EXPR$10, $f6 AS EXPR$11, $f7 AS
> EXPR$12, $f8 AS EXPR$13, $f9 AS EXPR$14]) -> SinkConversionToTuple2 -> Sink:
> JdbcUpsertTableSink(timestamp, longValue, metricName, metricsValueSum,
> metricsValueMin, metricsValueMax, tag_record_id, tag_host_ip, tag_instance,
> tag_job_name, tag_ai_app_name, tag_namespace, tag_ai_type, tag_host_name,
> tag_alarm_domain) (23/44)]
> [org.apache.flink.streaming.runtime.tasks.StreamTask] >>> Error during
> disposal of stream operator. java.lang.NullPointerException: null at
> org.apache.flink.table.runtime.operators.window.WindowOperator.dispose(WindowOperator.java:318)
> ~[flink-table-blink_2.11-1.11-SNAPSHOT.jar:1.11-SNAPSHOT] at
>
[GitHub] [flink] TsReaper commented on a change in pull request #13793: [FLINK-19811][table-planner-blink] Simplify SEARCHes in conjunctions in FlinkRexUtil#simplify
TsReaper commented on a change in pull request #13793:
URL: https://github.com/apache/flink/pull/13793#discussion_r512380855
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/planner/plan/utils/FlinkRexUtil.scala
##
@@ -196,14 +196,23 @@ object FlinkRexUtil {
* 4. (a > b OR c < 10) OR b < a -> a > b OR c < 10
* 5. a = a, a >= a, a <= a -> true
* 6. a <> a, a > a, a < a -> false
+* 7. a = 2020 AND SEARCH(a, [2020, 2021]) -> a = 2020
Review comment:
This should be simplified as `SEARCH(a, [2020, 2021])`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] TsReaper commented on a change in pull request #13793: [FLINK-19811][table-planner-blink] Simplify SEARCHes in conjunctions in FlinkRexUtil#simplify
TsReaper commented on a change in pull request #13793:
URL: https://github.com/apache/flink/pull/13793#discussion_r512101883
##
File path:
flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/planner/plan/utils/FlinkRexUtil.scala
##
@@ -196,14 +196,23 @@ object FlinkRexUtil {
* 4. (a > b OR c < 10) OR b < a -> a > b OR c < 10
* 5. a = a, a >= a, a <= a -> true
* 6. a <> a, a > a, a < a -> false
+* 7. a = 2020 AND SEARCH(a, [2020, 2021]) -> a = 2020
Review comment:
Obviously it can't.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] wuchong merged pull request #13768: [FLINK-19777][table-runtime-blink] Fix NullPointException for WindowOperator.close()
wuchong merged pull request #13768: URL: https://github.com/apache/flink/pull/13768 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on pull request #13768: [FLINK-19777][table-runtime-blink] Fix NullPointException for WindowOperator.close()
wuchong commented on pull request #13768: URL: https://github.com/apache/flink/pull/13768#issuecomment-716938309 Thanks @leonardBang , will merge this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingsongLi commented on a change in pull request #13744: [FLINK-19766][table-runtime] Introduce File streaming compaction operators
JingsongLi commented on a change in pull request #13744:
URL: https://github.com/apache/flink/pull/13744#discussion_r512378461
##
File path:
flink-table/flink-table-runtime-blink/src/test/java/org/apache/flink/table/filesystem/stream/compact/CompactCoordinatorTest.java
##
@@ -0,0 +1,130 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.filesystem.stream.compact;
+
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.runtime.checkpoint.OperatorSubtaskState;
+import org.apache.flink.streaming.util.OneInputStreamOperatorTestHarness;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CompactionUnit;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CoordinatorInput;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CoordinatorOutput;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.EndCompaction;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.EndInputFile;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.InputFile;
+import org.apache.flink.util.function.ThrowingConsumer;
+
+import org.junit.Assert;
+import org.junit.Test;
+
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.concurrent.atomic.AtomicReference;
+import java.util.stream.Collectors;
+
+/**
+ * Test for {@link CompactCoordinator}.
+ */
+public class CompactCoordinatorTest extends AbstractCompactTestBase {
+
+ @Test
+ public void testCoordinatorCrossCheckpoints() throws Exception {
+ AtomicReference state = new
AtomicReference<>();
+ runCoordinator(harness -> {
+ harness.setup();
+ harness.open();
+
+ harness.processElement(new InputFile("p0",
newFile("f0", 3)), 0);
+ harness.processElement(new InputFile("p0",
newFile("f1", 2)), 0);
+
+ harness.processElement(new InputFile("p1",
newFile("f2", 2)), 0);
+
+ harness.processElement(new InputFile("p0",
newFile("f3", 5)), 0);
+ harness.processElement(new InputFile("p0",
newFile("f4", 1)), 0);
+
+ harness.processElement(new InputFile("p1",
newFile("f5", 5)), 0);
+ harness.processElement(new InputFile("p1",
newFile("f6", 4)), 0);
+
+ state.set(harness.snapshot(1, 0));
+ });
+
+ runCoordinator(harness -> {
+ harness.setup();
+ harness.initializeState(state.get());
+ harness.open();
+
+ harness.processElement(new InputFile("p0",
newFile("f7", 3)), 0);
+ harness.processElement(new InputFile("p0",
newFile("f8", 2)), 0);
+
+ state.set(harness.snapshot(2, 0));
+ });
+
+ runCoordinator(harness -> {
+ harness.setup();
+ harness.initializeState(state.get());
+ harness.open();
+
+ harness.processElement(new EndInputFile(2, 0, 1), 0);
+
+ List outputs =
harness.extractOutputValues();
+
+ Assert.assertEquals(7, outputs.size());
+
+ assertUnit(outputs.get(0), 0, "p0", Arrays.asList("f0",
"f1", "f4"));
Review comment:
You mean the order of partitions? There is no relationship between
partitions, so there is no need to guarantee this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] JingsongLi commented on a change in pull request #13744: [FLINK-19766][table-runtime] Introduce File streaming compaction operators
JingsongLi commented on a change in pull request #13744:
URL: https://github.com/apache/flink/pull/13744#discussion_r512378183
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/filesystem/stream/compact/CompactOperator.java
##
@@ -0,0 +1,276 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.table.filesystem.stream.compact;
+
+import org.apache.flink.api.common.state.ListState;
+import org.apache.flink.api.common.state.ListStateDescriptor;
+import org.apache.flink.api.common.typeutils.base.ListSerializer;
+import org.apache.flink.api.common.typeutils.base.LongSerializer;
+import org.apache.flink.api.common.typeutils.base.MapSerializer;
+import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.connector.file.src.reader.BulkFormat;
+import org.apache.flink.core.fs.FSDataInputStream;
+import org.apache.flink.core.fs.FileSystem;
+import org.apache.flink.core.fs.FileSystemKind;
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.core.fs.RecoverableFsDataOutputStream;
+import org.apache.flink.core.fs.RecoverableWriter;
+import org.apache.flink.runtime.state.StateInitializationContext;
+import org.apache.flink.runtime.state.StateSnapshotContext;
+import org.apache.flink.streaming.api.functions.sink.filesystem.BucketWriter;
+import org.apache.flink.streaming.api.operators.AbstractStreamOperator;
+import org.apache.flink.streaming.api.operators.BoundedOneInput;
+import org.apache.flink.streaming.api.operators.OneInputStreamOperator;
+import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
+import org.apache.flink.table.filesystem.stream.PartitionCommitInfo;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CompactionUnit;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.CoordinatorOutput;
+import
org.apache.flink.table.filesystem.stream.compact.CompactMessages.EndCompaction;
+import org.apache.flink.util.IOUtils;
+import org.apache.flink.util.Preconditions;
+import org.apache.flink.util.function.SupplierWithException;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.NavigableMap;
+import java.util.Set;
+import java.util.TreeMap;
+
+/**
+ * Receives compaction units to do compaction. Send partition commit
information after
+ * compaction finished.
+ *
+ * Use {@link BulkFormat} to read and use {@link BucketWriter} to write.
+ *
+ * STATE: This operator stores expired files in state, after the checkpoint
completes successfully,
+ * We can ensure that these files will not be used again and they
can be deleted from the
+ * file system.
+ */
+public class CompactOperator extends
AbstractStreamOperator
+ implements OneInputStreamOperator, BoundedOneInput {
+
+ private static final long serialVersionUID = 1L;
+
+ private static final String UNCOMPACTED_PREFIX = ".uncompacted-";
+
+ private static final String COMPACTED_PREFIX = "compacted-";
+
+ private final SupplierWithException fsFactory;
+ private final CompactReader.Factory readerFactory;
+ private final CompactWriter.Factory writerFactory;
+
+ private transient FileSystem fileSystem;
+
+ private transient ListState>> expiredFilesState;
+ private transient TreeMap> expiredFiles;
+ private transient List currentExpiredFiles;
+
+ private transient Set partitions;
+
+ public CompactOperator(
+ SupplierWithException
fsFactory,
+ CompactReader.Factory readerFactory,
+ CompactWriter.Factory writerFactory) {
+ this.fsFactory = fsFactory;
+ this.readerFactory = readerFactory;
+ this.writerFactory = writerFactory;
+ }
+
+ @Override
+ public void initializeState(StateInitializationContext context) throws
Exception {
+ super.initializeState(context);
+ this.partitions = new HashSet<>();
+
[jira] [Updated] (FLINK-19795) Fix Flink SQL throws exception when changelog source contains duplicate change events
[
https://issues.apache.org/jira/browse/FLINK-19795?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-19795:
Summary: Fix Flink SQL throws exception when changelog source contains
duplicate change events (was: Flink SQL throws exception when changelog source
contains duplicate change events)
> Fix Flink SQL throws exception when changelog source contains duplicate
> change events
> -
>
> Key: FLINK-19795
> URL: https://issues.apache.org/jira/browse/FLINK-19795
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / Runtime
>Affects Versions: 1.11.2
>Reporter: jinxin
>Assignee: Jark Wu
>Priority: Major
> Fix For: 1.12.0
>
>
> We are using Canal to synchornize MySQL data into Kafka, the synchornization
> delivery is not exactly-once, so there might be dupcliate
> INSERT/UPDATE/DELETE messages for the same primary key. We are using
> {{'connecotr' = 'kafka', 'format' = 'canal-json'}} to consume such topic.
> However, when appling TopN query on this created source table, the TopN
> operator will thrown exception: {{Caused by: java.lang.RuntimeException: Can
> not retract a non-existent record. This should never happen.}}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)