[jira] [Updated] (FLINK-25123) Improve expression description in SQL operator
[ https://issues.apache.org/jira/browse/FLINK-25123?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-25123: --- Labels: pull-request-available (was: ) > Improve expression description in SQL operator > -- > > Key: FLINK-25123 > URL: https://issues.apache.org/jira/browse/FLINK-25123 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / Planner >Reporter: Wenlong Lyu >Assignee: Wenlong Lyu >Priority: Major > Labels: pull-request-available > Fix For: 1.15.0 > > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #18110: [FLINK-25310][Documentation] Fix the incorrect description for output network buffers in buffer debloat documenation
flinkbot edited a comment on pull request #18110: URL: https://github.com/apache/flink/pull/18110#issuecomment-994244366 ## CI report: * c7ce675ebbb98339bc05e357623ced593df8efa3 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28138) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wenlong88 opened a new pull request #18127: [FLINK-25123][table-planner] Improve description of expression in ExecNode
wenlong88 opened a new pull request #18127: URL: https://github.com/apache/flink/pull/18127 ## What is the purpose of the change this is part of This PR is part of https://cwiki.apache.org/confluence/display/FLINK/FLIP-195%3A+Improve+the+name+and+structure+of+vertex+and+operator+name+for+job , aims at to improve description of sql job operator. ## Brief change log - *simplify literal presentation in explain* - *add target type for cast in explain* - *introduce ExpressionDetail to distinguish target format of explain[digest or explain]* ## Verifying this change This change is already covered by existing tests. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #18110: [FLINK-25310][Documentation] Fix the incorrect description for output network buffers in buffer debloat documenation
MartijnVisser commented on pull request #18110: URL: https://github.com/apache/flink/pull/18110#issuecomment-995526705 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-24348) Kafka ITCases (e.g. KafkaTableITCase) fail with "ContainerLaunch Container startup failed"
[
https://issues.apache.org/jira/browse/FLINK-24348?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460466#comment-17460466
]
Yun Gao edited comment on FLINK-24348 at 12/16/21, 7:53 AM:
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=28157=logs=c5f0071e-1851-543e-9a45-9ac140befc32=15a22db7-8faa-5b34-3920-d33c9f0ca23c=35599
Hi [~MartijnVisser] it seems reproduced, could you have a double look~?
was (Author: gaoyunhaii):
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=28157=logs=c5f0071e-1851-543e-9a45-9ac140befc32=15a22db7-8faa-5b34-3920-d33c9f0ca23c=35599
> Kafka ITCases (e.g. KafkaTableITCase) fail with "ContainerLaunch Container
> startup failed"
> --
>
> Key: FLINK-24348
> URL: https://issues.apache.org/jira/browse/FLINK-24348
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0, 1.15.0
>Reporter: Dawid Wysakowicz
>Assignee: Martijn Visser
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.15.0, 1.14.3
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=24338=logs=b0097207-033c-5d9a-b48c-6d4796fbe60d=8338a7d2-16f7-52e5-f576-4b7b3071eb3d=7140
> {code}
> Sep 21 02:44:33 org.testcontainers.containers.ContainerLaunchException:
> Container startup failed
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.doStart(GenericContainer.java:334)
> Sep 21 02:44:33 at
> org.testcontainers.containers.KafkaContainer.doStart(KafkaContainer.java:97)
> Sep 21 02:44:33 at
> org.apache.flink.streaming.connectors.kafka.table.KafkaTableTestBase$1.doStart(KafkaTableTestBase.java:71)
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.start(GenericContainer.java:315)
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.starting(GenericContainer.java:1060)
> Sep 21 02:44:33 at
> org.testcontainers.containers.FailureDetectingExternalResource$1.evaluate(FailureDetectingExternalResource.java:29)
> Sep 21 02:44:33 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> Sep 21 02:44:33 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> Sep 21 02:44:33 at org.junit.rules.RunRules.evaluate(RunRules.java:20)
> Sep 21 02:44:33 at
> org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> Sep 21 02:44:33 at
> org.junit.runners.ParentRunner.run(ParentRunner.java:413)
> Sep 21 02:44:33 at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
> Sep 21 02:44:33 at org.junit.runner.JUnitCore.run(JUnitCore.java:115)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.execution.RunnerExecutor.execute(RunnerExecutor.java:43)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:183)
> Sep 21 02:44:33 at
> java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
> Sep 21 02:44:33 at
> java.util.Iterator.forEachRemaining(Iterator.java:116)
> Sep 21 02:44:33 at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:150)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:173)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
> Sep 21 02:44:33 at
> java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:485)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.VintageTestEngine.executeAllChildren(VintageTestEngine.java:82)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.VintageTestEngine.execute(VintageTestEngine.java:73)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:220)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.lambda$execute$6(DefaultLauncher.java:188)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.withInterceptedStreams(DefaultLauncher.java:202)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:181)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:128)
> Sep 21 02:44:33 at
>
[jira] [Commented] (FLINK-24348) Kafka ITCases (e.g. KafkaTableITCase) fail with "ContainerLaunch Container startup failed"
[
https://issues.apache.org/jira/browse/FLINK-24348?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460466#comment-17460466
]
Yun Gao commented on FLINK-24348:
-
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=28157=logs=c5f0071e-1851-543e-9a45-9ac140befc32=15a22db7-8faa-5b34-3920-d33c9f0ca23c=35599
> Kafka ITCases (e.g. KafkaTableITCase) fail with "ContainerLaunch Container
> startup failed"
> --
>
> Key: FLINK-24348
> URL: https://issues.apache.org/jira/browse/FLINK-24348
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0, 1.15.0
>Reporter: Dawid Wysakowicz
>Assignee: Martijn Visser
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.15.0, 1.14.3
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=24338=logs=b0097207-033c-5d9a-b48c-6d4796fbe60d=8338a7d2-16f7-52e5-f576-4b7b3071eb3d=7140
> {code}
> Sep 21 02:44:33 org.testcontainers.containers.ContainerLaunchException:
> Container startup failed
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.doStart(GenericContainer.java:334)
> Sep 21 02:44:33 at
> org.testcontainers.containers.KafkaContainer.doStart(KafkaContainer.java:97)
> Sep 21 02:44:33 at
> org.apache.flink.streaming.connectors.kafka.table.KafkaTableTestBase$1.doStart(KafkaTableTestBase.java:71)
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.start(GenericContainer.java:315)
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.starting(GenericContainer.java:1060)
> Sep 21 02:44:33 at
> org.testcontainers.containers.FailureDetectingExternalResource$1.evaluate(FailureDetectingExternalResource.java:29)
> Sep 21 02:44:33 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> Sep 21 02:44:33 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> Sep 21 02:44:33 at org.junit.rules.RunRules.evaluate(RunRules.java:20)
> Sep 21 02:44:33 at
> org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> Sep 21 02:44:33 at
> org.junit.runners.ParentRunner.run(ParentRunner.java:413)
> Sep 21 02:44:33 at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
> Sep 21 02:44:33 at org.junit.runner.JUnitCore.run(JUnitCore.java:115)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.execution.RunnerExecutor.execute(RunnerExecutor.java:43)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:183)
> Sep 21 02:44:33 at
> java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
> Sep 21 02:44:33 at
> java.util.Iterator.forEachRemaining(Iterator.java:116)
> Sep 21 02:44:33 at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:150)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:173)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
> Sep 21 02:44:33 at
> java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:485)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.VintageTestEngine.executeAllChildren(VintageTestEngine.java:82)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.VintageTestEngine.execute(VintageTestEngine.java:73)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:220)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.lambda$execute$6(DefaultLauncher.java:188)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.withInterceptedStreams(DefaultLauncher.java:202)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:181)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:128)
> Sep 21 02:44:33 at
> org.apache.maven.surefire.junitplatform.JUnitPlatformProvider.invokeAllTests(JUnitPlatformProvider.java:150)
> Sep 21 02:44:33 at
> org.apache.maven.surefire.junitplatform.JUnitPlatformProvider.invoke(JUnitPlatformProvider.java:120)
> Sep 21 02:44:33 at
>
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770295193
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/typeinfo/SparseVectorSerializer.java
##
@@ -0,0 +1,151 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.ml.linalg.typeinfo;
+
+import org.apache.flink.api.common.typeutils.SimpleTypeSerializerSnapshot;
+import org.apache.flink.api.common.typeutils.TypeSerializerSnapshot;
+import org.apache.flink.api.common.typeutils.base.TypeSerializerSingleton;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputView;
+import org.apache.flink.ml.linalg.SparseVector;
+
+import java.io.IOException;
+import java.util.Arrays;
+
+/** Specialized serializer for {@link SparseVector}. */
+public final class SparseVectorSerializer extends
TypeSerializerSingleton {
Review comment:
Ok. I'll add the test.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18068: [FLINK-25105][checkpoint] Enables final checkpoint by default
flinkbot edited a comment on pull request #18068: URL: https://github.com/apache/flink/pull/18068#issuecomment-989975508 ## CI report: * 6832524d7d78de814cbeadb44fa8037da5c10ca9 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28200) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-25336) Kafka connector compatible problem in Flink sql
[
https://issues.apache.org/jira/browse/FLINK-25336?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460465#comment-17460465
]
Martijn Visser commented on FLINK-25336:
[~straw] This version is not supported anymore per
https://docs.confluent.io/platform/current/installation/versions-interoperability.html
We always try to have as much backwards compatibility, but in order to support
newer versions with specific features or bug fixes, there is a point where we
can't support older versions anymore.
> Kafka connector compatible problem in Flink sql
> ---
>
> Key: FLINK-25336
> URL: https://issues.apache.org/jira/browse/FLINK-25336
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0
> Environment: Flink 1.14.0
> Kafka 0.10.2.1
>Reporter: Yuan Zhu
>Priority: Minor
> Labels: Flink-sql, Kafka, flink
> Attachments: log.jpg
>
>
> When I use sql to query kafka table, like
> {code:java}
> create table `kfk`
> (
> user_id VARCHAR
> ) with (
> 'connector' = 'kafka',
> 'topic' = 'test',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'format' = 'json',
> 'scan.startup.mode' = 'timestamp',
> 'scan.startup.timestamp-millis' = '163941120',
> 'properties.group.id' = 'test'
> );
> CREATE TABLE print_table (user_id varchar) WITH ('connector' = 'print');
> insert into print_table select user_id from kfk;{code}
> It will encounter an exception:
> org.apache.kafka.common.errors.UnsupportedVersionException: MetadataRequest
> versions older than 4 don't support the allowAutoTopicCreation field !log.jpg!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Reopened] (FLINK-24348) Kafka ITCases (e.g. KafkaTableITCase) fail with "ContainerLaunch Container startup failed"
[
https://issues.apache.org/jira/browse/FLINK-24348?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yun Gao reopened FLINK-24348:
-
> Kafka ITCases (e.g. KafkaTableITCase) fail with "ContainerLaunch Container
> startup failed"
> --
>
> Key: FLINK-24348
> URL: https://issues.apache.org/jira/browse/FLINK-24348
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0, 1.15.0
>Reporter: Dawid Wysakowicz
>Assignee: Martijn Visser
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.15.0, 1.14.3
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=24338=logs=b0097207-033c-5d9a-b48c-6d4796fbe60d=8338a7d2-16f7-52e5-f576-4b7b3071eb3d=7140
> {code}
> Sep 21 02:44:33 org.testcontainers.containers.ContainerLaunchException:
> Container startup failed
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.doStart(GenericContainer.java:334)
> Sep 21 02:44:33 at
> org.testcontainers.containers.KafkaContainer.doStart(KafkaContainer.java:97)
> Sep 21 02:44:33 at
> org.apache.flink.streaming.connectors.kafka.table.KafkaTableTestBase$1.doStart(KafkaTableTestBase.java:71)
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.start(GenericContainer.java:315)
> Sep 21 02:44:33 at
> org.testcontainers.containers.GenericContainer.starting(GenericContainer.java:1060)
> Sep 21 02:44:33 at
> org.testcontainers.containers.FailureDetectingExternalResource$1.evaluate(FailureDetectingExternalResource.java:29)
> Sep 21 02:44:33 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> Sep 21 02:44:33 at
> org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:54)
> Sep 21 02:44:33 at org.junit.rules.RunRules.evaluate(RunRules.java:20)
> Sep 21 02:44:33 at
> org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> Sep 21 02:44:33 at
> org.junit.runners.ParentRunner.run(ParentRunner.java:413)
> Sep 21 02:44:33 at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
> Sep 21 02:44:33 at org.junit.runner.JUnitCore.run(JUnitCore.java:115)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.execution.RunnerExecutor.execute(RunnerExecutor.java:43)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:183)
> Sep 21 02:44:33 at
> java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
> Sep 21 02:44:33 at
> java.util.Iterator.forEachRemaining(Iterator.java:116)
> Sep 21 02:44:33 at
> java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:150)
> Sep 21 02:44:33 at
> java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:173)
> Sep 21 02:44:33 at
> java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
> Sep 21 02:44:33 at
> java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:485)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.VintageTestEngine.executeAllChildren(VintageTestEngine.java:82)
> Sep 21 02:44:33 at
> org.junit.vintage.engine.VintageTestEngine.execute(VintageTestEngine.java:73)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:220)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.lambda$execute$6(DefaultLauncher.java:188)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.withInterceptedStreams(DefaultLauncher.java:202)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:181)
> Sep 21 02:44:33 at
> org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:128)
> Sep 21 02:44:33 at
> org.apache.maven.surefire.junitplatform.JUnitPlatformProvider.invokeAllTests(JUnitPlatformProvider.java:150)
> Sep 21 02:44:33 at
> org.apache.maven.surefire.junitplatform.JUnitPlatformProvider.invoke(JUnitPlatformProvider.java:120)
> Sep 21 02:44:33 at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> Sep 21 02:44:33 at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> Sep 21 02:44:33 at
>
[GitHub] [flink] flinkbot edited a comment on pull request #18068: [FLINK-25105][checkpoint] Enables final checkpoint by default
flinkbot edited a comment on pull request #18068: URL: https://github.com/apache/flink/pull/18068#issuecomment-989975508 ## CI report: * 6832524d7d78de814cbeadb44fa8037da5c10ca9 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28200) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] mbalassi commented on pull request #17582: [FLINK-24674][kubernetes] Create corresponding resouces for task manager Pods
mbalassi commented on pull request #17582: URL: https://github.com/apache/flink/pull/17582#issuecomment-995521569 I see, @viirya. Sent you an email to address this separately from the PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaoyunhaii commented on pull request #18068: [FLINK-25105][checkpoint] Enables final checkpoint by default
gaoyunhaii commented on pull request #18068: URL: https://github.com/apache/flink/pull/18068#issuecomment-995519603 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18119: [FLINK-24947] Support hostNetwork for native K8s integration on session mode
flinkbot edited a comment on pull request #18119: URL: https://github.com/apache/flink/pull/18119#issuecomment-994734000 ## CI report: * Unknown: [CANCELED](TBD) * d2242677110bbd6b38963379d4f8624f13c7 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28224) * e2088d07438a6944276bf720f9bd18722554facc Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28234) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] spoon-lz commented on pull request #18119: [FLINK-24947] Support hostNetwork for native K8s integration on session mode
spoon-lz commented on pull request #18119: URL: https://github.com/apache/flink/pull/18119#issuecomment-995518247 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18119: [FLINK-24947] Support hostNetwork for native K8s integration on session mode
flinkbot edited a comment on pull request #18119: URL: https://github.com/apache/flink/pull/18119#issuecomment-994734000 ## CI report: * Unknown: [CANCELED](TBD) * d2242677110bbd6b38963379d4f8624f13c7 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28224) * e2088d07438a6944276bf720f9bd18722554facc UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770286109
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java
##
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.linalg;
+
+import org.apache.flink.api.common.typeinfo.TypeInfo;
+import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Arrays;
+import java.util.Objects;
+
+/** A sparse vector of double values. */
+@TypeInfo(SparseVectorTypeInfoFactory.class)
+public class SparseVector implements Vector {
+public final int n;
+public final int[] indices;
+public final double[] values;
+
+public SparseVector(int n, int[] indices, double[] values) {
+this.n = n;
+this.indices = indices;
+this.values = values;
+if (!isIndicesSorted()) {
+sortIndices();
+}
+validateSortedData();
+}
+
+@Override
+public int size() {
+return n;
+}
+
+@Override
+public double get(int i) {
+int pos = Arrays.binarySearch(indices, i);
+if (pos >= 0) {
+return values[pos];
+}
+return 0.;
+}
+
+@Override
+public double[] toArray() {
+double[] result = new double[n];
+for (int i = 0; i < indices.length; i++) {
+result[indices[i]] = values[i];
+}
+return result;
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (o == null || getClass() != o.getClass()) {
+return false;
+}
+SparseVector that = (SparseVector) o;
+return n == that.n
+&& Arrays.equals(indices, that.indices)
+&& Arrays.equals(values, that.values);
+}
+
+@Override
+public int hashCode() {
+int result = Objects.hash(n);
+result = 31 * result + Arrays.hashCode(indices);
+result = 31 * result + Arrays.hashCode(values);
+return result;
+}
+
+/**
+ * Check whether input data is validate.
+ *
+ * This function does the following checks:
+ *
+ *
+ * The indices array and values array are of the same size.
+ * vector indices are in valid range.
+ * vector indices are unique.
+ *
+ *
+ * This function works as expected only when indices are sorted.
+ */
+private void validateSortedData() {
+Preconditions.checkArgument(
+indices.length == values.length,
+"Indices size and values size should be the same.");
+if (this.indices.length > 0) {
+Preconditions.checkArgument(
+this.indices[0] >= 0 && this.indices[this.indices.length -
1] < this.n,
+"Index out of bound.");
+}
+for (int i = 1; i < this.indices.length; i++) {
+Preconditions.checkArgument(
+this.indices[i] > this.indices[i - 1], "Indices
duplicated.");
+}
+}
+
+private boolean isIndicesSorted() {
+for (int i = 1; i < this.indices.length; i++) {
+if (this.indices[i] < this.indices[i - 1]) {
+return false;
+}
+}
+return true;
+}
+
+/** Sort the indices and values. */
+private void sortIndices() {
+sortImpl(this.indices, this.values, 0, this.indices.length - 1);
+}
+
+/** Sort the indices and values using quick sort. */
+private static void sortImpl(int[] indices, double[] values, int low, int
high) {
+int pivotPos = (low + high) / 2;
+int pivot = indices[pivotPos];
+indices[pivotPos] = indices[high];
+indices[high] = pivot;
+double t = values[pivotPos];
+values[pivotPos] = values[high];
+values[high] = t;
+
+int pos = low - 1;
+for (int i = low; i <= high; i++) {
+if (indices[i] <= pivot) {
+pos++;
+int tempI = indices[pos];
+
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770285422
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java
##
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.linalg;
+
+import org.apache.flink.api.common.typeinfo.TypeInfo;
+import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Arrays;
+import java.util.Objects;
+
+/** A sparse vector of double values. */
+@TypeInfo(SparseVectorTypeInfoFactory.class)
+public class SparseVector implements Vector {
+public final int n;
+public final int[] indices;
+public final double[] values;
+
+public SparseVector(int n, int[] indices, double[] values) {
+this.n = n;
+this.indices = indices;
+this.values = values;
+if (!isIndicesSorted()) {
+sortIndices();
+}
+validateSortedData();
+}
+
+@Override
+public int size() {
+return n;
+}
+
+@Override
+public double get(int i) {
+int pos = Arrays.binarySearch(indices, i);
+if (pos >= 0) {
+return values[pos];
+}
+return 0.;
+}
+
+@Override
+public double[] toArray() {
+double[] result = new double[n];
+for (int i = 0; i < indices.length; i++) {
+result[indices[i]] = values[i];
+}
+return result;
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (o == null || getClass() != o.getClass()) {
+return false;
+}
+SparseVector that = (SparseVector) o;
+return n == that.n
+&& Arrays.equals(indices, that.indices)
+&& Arrays.equals(values, that.values);
+}
+
+@Override
+public int hashCode() {
+int result = Objects.hash(n);
+result = 31 * result + Arrays.hashCode(indices);
+result = 31 * result + Arrays.hashCode(values);
+return result;
+}
+
+/**
+ * Check whether input data is validate.
+ *
+ * This function does the following checks:
+ *
+ *
+ * The indices array and values array are of the same size.
+ * vector indices are in valid range.
+ * vector indices are unique.
+ *
+ *
+ * This function works as expected only when indices are sorted.
+ */
+private void validateSortedData() {
+Preconditions.checkArgument(
+indices.length == values.length,
+"Indices size and values size should be the same.");
+if (this.indices.length > 0) {
+Preconditions.checkArgument(
+this.indices[0] >= 0 && this.indices[this.indices.length -
1] < this.n,
+"Index out of bound.");
+}
+for (int i = 1; i < this.indices.length; i++) {
+Preconditions.checkArgument(
+this.indices[i] > this.indices[i - 1], "Indices
duplicated.");
+}
+}
+
+private boolean isIndicesSorted() {
+for (int i = 1; i < this.indices.length; i++) {
+if (this.indices[i] < this.indices[i - 1]) {
+return false;
+}
+}
+return true;
+}
+
+/** Sort the indices and values. */
+private void sortIndices() {
+sortImpl(this.indices, this.values, 0, this.indices.length - 1);
+}
+
+/** Sort the indices and values using quick sort. */
+private static void sortImpl(int[] indices, double[] values, int low, int
high) {
+int pivotPos = (low + high) / 2;
+int pivot = indices[pivotPos];
+indices[pivotPos] = indices[high];
+indices[high] = pivot;
+double t = values[pivotPos];
+values[pivotPos] = values[high];
+values[high] = t;
+
+int pos = low - 1;
+for (int i = low; i <= high; i++) {
+if (indices[i] <= pivot) {
+pos++;
+int tempI = indices[pos];
+
[GitHub] [flink] shenzhu commented on pull request #17793: [FLINK-21565][Table SQL/API] Support more integer types in TIMESTAMPADD
shenzhu commented on pull request #17793: URL: https://github.com/apache/flink/pull/17793#issuecomment-995513366 Hey @zentol , would you mind taking a look at this PR when you have a moment? Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-25339) Moving to the hadoop-free flink runtime.
[ https://issues.apache.org/jira/browse/FLINK-25339?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David Morávek updated FLINK-25339: -- Summary: Moving to the hadoop-free flink runtime. (was: Moving to hadoop-free flink runtime.) > Moving to the hadoop-free flink runtime. > > > Key: FLINK-25339 > URL: https://issues.apache.org/jira/browse/FLINK-25339 > Project: Flink > Issue Type: Technical Debt > Components: Runtime / Coordination >Reporter: David Morávek >Priority: Major > > Only remaining reason for having hadoop dependencies (even though these are > _provided_) in `flink-runtime` is the Security / Kerberos setup, which is > already hidden behind a service loader. This should be fairly straightforward > to move into the separate module. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Created] (FLINK-25339) Moving to hadoop-free flink runtime.
David Morávek created FLINK-25339: - Summary: Moving to hadoop-free flink runtime. Key: FLINK-25339 URL: https://issues.apache.org/jira/browse/FLINK-25339 Project: Flink Issue Type: Technical Debt Components: Runtime / Coordination Reporter: David Morávek Only remaining reason for having hadoop dependencies (even though these are _provided_) in `flink-runtime` is the Security / Kerberos setup, which is already hidden behind a service loader. This should be fairly straightforward to move into the separate module. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25311) DelimitedInputFormat cannot read compressed files correctly
[
https://issues.apache.org/jira/browse/FLINK-25311?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460446#comment-17460446
]
Jinxin.Tang commented on FLINK-25311:
-
Thanks for your issue, work correct in spark, I will try fix it in flink.
> DelimitedInputFormat cannot read compressed files correctly
> ---
>
> Key: FLINK-25311
> URL: https://issues.apache.org/jira/browse/FLINK-25311
> Project: Flink
> Issue Type: Bug
> Components: API / Core
>Affects Versions: 1.14.2
>Reporter: Caizhi Weng
>Priority: Major
> Attachments: gao.gz, gao.json
>
>
> This is reported from the [user mailing
> list|https://lists.apache.org/thread/y854gjxyomtypcs8x4f88pttnl9k0j9q].
> Run the following test to reproduce this bug.
> {code:java}
> import org.apache.flink.table.api.EnvironmentSettings;
> import org.apache.flink.table.api.TableEnvironment;
> import org.apache.flink.table.api.internal.TableEnvironmentImpl;
> import org.junit.Test;
> public class MyTest {
> @Test
> public void myTest() throws Exception {
> EnvironmentSettings settings = EnvironmentSettings.inBatchMode();
> TableEnvironment tEnv = TableEnvironmentImpl.create(settings);
> tEnv.executeSql(
> "create table T1 ( a INT ) with ( 'connector' =
> 'filesystem', 'format' = 'json', 'path' = '/tmp/gao.json' )")
> .await();
> tEnv.executeSql(
> "create table T2 ( a INT ) with ( 'connector' =
> 'filesystem', 'format' = 'json', 'path' = '/tmp/gao.gz' )")
> .await();
> tEnv.executeSql("select count(*) from T1 UNION ALL select count(*)
> from T2").print();
> }
> }
> {code}
> Data files used are attached in the attachment.
> The result is
> {code}
> +--+
> | EXPR$0 |
> +--+
> | 100 |
> | 24 |
> +--+
> {code}
> which is obviously incorrect.
> This is because {{DelimitedInputFormat#fillBuffer}} cannot deal with
> compressed files correctly. It limits the number of (uncompressed) bytes read
> with {{splitLength}}, while {{splitLength}} is the length of compressed
> bytes, so they cannot match.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #18125: [FLINK-25210][pulsar][e2e][tests] add resource file to test jar
flinkbot edited a comment on pull request #18125: URL: https://github.com/apache/flink/pull/18125#issuecomment-995378571 ## CI report: * 5a3c5da78c91fe870a07d38b0683e725893c1fc7 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28220) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18086: [FLINK-25192][checkpointing] Implement no-claim mode support
flinkbot edited a comment on pull request #18086: URL: https://github.com/apache/flink/pull/18086#issuecomment-991936309 ## CI report: * fc2b8b343e1400f86d2d300408829cb4a9bb8672 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28198) * 1c15ed7a1a50b92b15924e3851114f88d039fa9e Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28233) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18118: [FLINK-24907] Support side out late data for interval join
flinkbot edited a comment on pull request #18118: URL: https://github.com/apache/flink/pull/18118#issuecomment-994686917 ## CI report: * d8e09a1643cb2fffc9bf3c836dbfb20a9114f26b Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28178) * 1468790353855f4b2560b6fad69aa46567925ddb Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28223) * 9d02e023335be853fd7dd6616ae20b7612746410 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28232) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18086: [FLINK-25192][checkpointing] Implement no-claim mode support
flinkbot edited a comment on pull request #18086: URL: https://github.com/apache/flink/pull/18086#issuecomment-991936309 ## CI report: * fc2b8b343e1400f86d2d300408829cb4a9bb8672 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28198) * 1c15ed7a1a50b92b15924e3851114f88d039fa9e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a change in pull request #18086: [FLINK-25192][checkpointing] Implement no-claim mode support
dawidwys commented on a change in pull request #18086: URL: https://github.com/apache/flink/pull/18086#discussion_r770273532 ## File path: flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/snapshot/RocksIncrementalSnapshotStrategy.java ## @@ -179,6 +180,8 @@ public IncrementalRocksDBSnapshotResources syncPrepareResources(long checkpointI return new RocksDBIncrementalSnapshotOperation( checkpointId, +checkpointOptions.getCheckpointType().getSharingFilesStrategy() +== CheckpointType.SharingFilesStrategy.FORWARD_BACKWARD, checkpointStreamFactory, snapshotResources.snapshotDirectory, snapshotResources.baseSstFiles, Review comment: Sure it works. My goal was to already provide a solution that could be easier changed to `duplicate` instead of reupload, but as the change is so small it can be done as part of https://issues.apache.org/jira/browse/FLINK-25195. I changed to passing an empty set for now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18118: [FLINK-24907] Support side out late data for interval join
flinkbot edited a comment on pull request #18118: URL: https://github.com/apache/flink/pull/18118#issuecomment-994686917 ## CI report: * d8e09a1643cb2fffc9bf3c836dbfb20a9114f26b Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28178) * 1468790353855f4b2560b6fad69aa46567925ddb Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28223) * 9d02e023335be853fd7dd6616ae20b7612746410 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #16108: [FLINK-22821][core] Stabilize NetUtils#getAvailablePort in order to avoid wrongly allocating any used ports
flinkbot edited a comment on pull request #16108: URL: https://github.com/apache/flink/pull/16108#issuecomment-856641884 ## CI report: * 03e33a13e8826f6cda49070c16679533f1223e94 Azure: [CANCELED](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28137) * b77db664216ddf6e88f2f663e08e7390809a24df Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28231) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] chenyuzhi459 commented on pull request #18118: [FLINK-24907] Support side out late data for interval join
chenyuzhi459 commented on pull request #18118: URL: https://github.com/apache/flink/pull/18118#issuecomment-995499315 @flinkbot re-run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] chenyuzhi459 removed a comment on pull request #18118: [FLINK-24907] Support side out late data for interval join
chenyuzhi459 removed a comment on pull request #18118: URL: https://github.com/apache/flink/pull/18118#issuecomment-995390917 @flinkbot re-run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #16108: [FLINK-22821][core] Stabilize NetUtils#getAvailablePort in order to avoid wrongly allocating any used ports
flinkbot edited a comment on pull request #16108: URL: https://github.com/apache/flink/pull/16108#issuecomment-856641884 ## CI report: * 03e33a13e8826f6cda49070c16679533f1223e94 Azure: [CANCELED](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28137) * b77db664216ddf6e88f2f663e08e7390809a24df UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17938: [FLINK-25073][streaming] Introduce TreeMode description for vertices
flinkbot edited a comment on pull request #17938: URL: https://github.com/apache/flink/pull/17938#issuecomment-981363546 ## CI report: * ef63c831770e3921d33c30c410a903e6614acb78 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28221) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] paul8263 commented on a change in pull request #16108: [FLINK-22821][core] Stabilize NetUtils#getAvailablePort in order to avoid wrongly allocating any used ports
paul8263 commented on a change in pull request #16108:
URL: https://github.com/apache/flink/pull/16108#discussion_r770268401
##
File path:
flink-clients/src/test/java/org/apache/flink/client/program/ClientTest.java
##
@@ -102,10 +102,11 @@ public void setUp() throws Exception {
env.generateSequence(1, 1000).output(new DiscardingOutputFormat<>());
plan = env.createProgramPlan();
-final int freePort = NetUtils.getAvailablePort();
config = new Configuration();
config.setString(JobManagerOptions.ADDRESS, "localhost");
-config.setInteger(JobManagerOptions.PORT, freePort);
+try (NetUtils.Port port = NetUtils.getAvailablePort()) {
Review comment:
Thanks. I'll do it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-25286) Improve connector testing framework to support more scenarios
[ https://issues.apache.org/jira/browse/FLINK-25286?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460438#comment-17460438 ] ZhuoYu Chen commented on FLINK-25286: - Hi [~renqs], I've done a lot of custom work on connectors at work and I'm very interested in the issues you mentioned. Is there any work I can be involved in with this current isues > Improve connector testing framework to support more scenarios > - > > Key: FLINK-25286 > URL: https://issues.apache.org/jira/browse/FLINK-25286 > Project: Flink > Issue Type: Improvement > Components: Test Infrastructure >Reporter: Qingsheng Ren >Priority: Major > Fix For: 1.15.0 > > > Currently connector testing framework only support tests for DataStream > sources, and available scenarios are quite limited by current interface > design. > This ticket proposes to made improvements to connector testing framework for > supporting more test scenarios, and add test suites for sink and Table/SQL > API. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] paul8263 commented on a change in pull request #16108: [FLINK-22821][core] Stabilize NetUtils#getAvailablePort in order to avoid wrongly allocating any used ports
paul8263 commented on a change in pull request #16108:
URL: https://github.com/apache/flink/pull/16108#discussion_r770266892
##
File path: flink-core/src/main/java/org/apache/flink/util/NetUtils.java
##
@@ -498,4 +503,33 @@ public static boolean isValidClientPort(int port) {
public static boolean isValidHostPort(int port) {
return 0 <= port && port <= 65535;
}
+
+/**
+ * Port wrapper class which holds a {@link FileLock} until it releases.
Used to avoid race
+ * condition among multiple threads/processes.
+ */
+public static class Port implements AutoCloseable {
+private final int port;
+private final FileLock fileLock;
+
+public Port(int port, FileLock fileLock) throws IOException {
+Preconditions.checkNotNull(fileLock, "FileLock should not be
null");
+Preconditions.checkState(fileLock.isValid(), "FileLock should be
locked");
+this.port = port;
+this.fileLock = fileLock;
+}
+
+public int getPort() {
+return port;
+}
+
+public void release() throws IOException {
+fileLock.unlockAndDestroy();
+}
Review comment:
OK. I'll inline it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-25338) Improvement of connection from TM to JM in session cluster
[ https://issues.apache.org/jira/browse/FLINK-25338?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shammon updated FLINK-25338: Description: When taskmanager receives slot request from resourcemanager for the specify job, it will connect to the jobmaster with given job address. Taskmanager register itself, monitor the heartbeat of job and update task's state by this connection. There's no need to create connections in one taskmanager for each job, and when the taskmanager is busy, it will increase the latency of job. One idea is that taskmanager manages the connection to `Dispatcher`, sends events such as heartbeat, state update to `Dispatcher`, and `Dispatcher` tell the local `JobMaster`. The main problem is that `Dispatcher` is an actor and can only be executed in one thread, it may be the performance bottleneck for deserialize event. The other idea is to create a netty service in `SessionClusterEntrypoint`, it can receive and deserialize events from taskmanagers in a threadpool, and send the event to the `Dispatcher` or `JobMaster`. Taskmanagers manager the connection to the netty service when it start. Thus a service can also receive the result of a job from taskmanager later. [~xtsong] What do you think? THX was: When taskmanager receives slot request from resourcemanager for the specify job, it will connect to the jobmaster with given job address. Taskmanager register itself, monitor the heartbeat of job and update task's state by this connection. There's no need to create connections in one taskmanager for each job, and when the taskmanager is busy, it will increase the latency of job. One idea is that taskmanager manages the connection to `Dispatcher`, sends events such as heartbeat, state update to `Dispatcher`, and `Dispatcher` tell the local `JobMaster`. The main problem is that `Dispatcher` is an actor and can only be executed in one thread, it may be the performance bottleneck for deserialize event. The other idea it to create a netty service in `SessionClusterEntrypoint`, it can receive and deserialize events from taskmanagers in a threadpool, and send the event to the `Dispatcher` or `JobMaster`. Taskmanagers manager the connection to the netty service when it start. Thus a service can also receive the result of a job from taskmanager later. [~xtsong] What do you think? THX > Improvement of connection from TM to JM in session cluster > -- > > Key: FLINK-25338 > URL: https://issues.apache.org/jira/browse/FLINK-25338 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Affects Versions: 1.12.7, 1.13.5, 1.14.2 >Reporter: Shammon >Priority: Major > > When taskmanager receives slot request from resourcemanager for the specify > job, it will connect to the jobmaster with given job address. Taskmanager > register itself, monitor the heartbeat of job and update task's state by this > connection. There's no need to create connections in one taskmanager for each > job, and when the taskmanager is busy, it will increase the latency of job. > One idea is that taskmanager manages the connection to `Dispatcher`, sends > events such as heartbeat, state update to `Dispatcher`, and `Dispatcher` > tell the local `JobMaster`. The main problem is that `Dispatcher` is an actor > and can only be executed in one thread, it may be the performance bottleneck > for deserialize event. > The other idea is to create a netty service in `SessionClusterEntrypoint`, it > can receive and deserialize events from taskmanagers in a threadpool, and > send the event to the `Dispatcher` or `JobMaster`. Taskmanagers manager the > connection to the netty service when it start. Thus a service can also > receive the result of a job from taskmanager later. > [~xtsong] What do you think? THX -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #18126: [FLINK-25036][runtime] Add stage wise scheduling strategy
flinkbot edited a comment on pull request #18126: URL: https://github.com/apache/flink/pull/18126#issuecomment-995489268 ## CI report: * f769f988700610398b4c9d1e6ad0210a28a07a16 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28230) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #18126: [FLINK-25036][runtime] Add stage wise scheduling strategy
flinkbot commented on pull request #18126: URL: https://github.com/apache/flink/pull/18126#issuecomment-995489535 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit f769f988700610398b4c9d1e6ad0210a28a07a16 (Thu Dec 16 06:47:33 UTC 2021) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #18126: [FLINK-25036][runtime] Add stage wise scheduling strategy
flinkbot commented on pull request #18126: URL: https://github.com/apache/flink/pull/18126#issuecomment-995489268 ## CI report: * f769f988700610398b4c9d1e6ad0210a28a07a16 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-25036) Introduce stage-wised scheduling strategy
[ https://issues.apache.org/jira/browse/FLINK-25036?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-25036: --- Labels: pull-request-available (was: ) > Introduce stage-wised scheduling strategy > - > > Key: FLINK-25036 > URL: https://issues.apache.org/jira/browse/FLINK-25036 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Reporter: Lijie Wang >Assignee: Lijie Wang >Priority: Major > Labels: pull-request-available > > The scheduling of the adaptive batch job scheduler should be stage > granularity, because the information for deciding parallelism can only be > collected after the upstream stage is fully finished, so we need to introduce > a new scheduling strategy: Stage-wised Scheduling Strategy. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] wanglijie95 opened a new pull request #18126: [FLINK-25036][runtime] Add stage wise scheduling strategy
wanglijie95 opened a new pull request #18126: URL: https://github.com/apache/flink/pull/18126 ## What is the purpose of the change Add stage wise scheduling strategy for adaptive batch scheduler. ## Brief change log f769f988700610398b4c9d1e6ad0210a28a07a16 Add stage wise scheduling strategy for adaptive batch scheduler. ## Verifying this change Add unit test `StagewiseSchedulingStrategyTest` ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (**no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (**no**) - The serializers: (**no**) - The runtime per-record code paths (performance sensitive): (**no**) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (**no**) - The S3 file system connector: (**no**) ## Documentation - Does this pull request introduce a new feature? (**no**) - If yes, how is the feature documented? (**not applicable**) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-25338) Improvement of connection from TM to JM in session cluster
Shammon created FLINK-25338: --- Summary: Improvement of connection from TM to JM in session cluster Key: FLINK-25338 URL: https://issues.apache.org/jira/browse/FLINK-25338 Project: Flink Issue Type: Sub-task Components: Runtime / Coordination Affects Versions: 1.14.2, 1.13.5, 1.12.7 Reporter: Shammon When taskmanager receives slot request from resourcemanager for the specify job, it will connect to the jobmaster with given job address. Taskmanager register itself, monitor the heartbeat of job and update task's state by this connection. There's no need to create connections in one taskmanager for each job, and when the taskmanager is busy, it will increase the latency of job. One idea is that taskmanager manages the connection to `Dispatcher`, sends events such as heartbeat, state update to `Dispatcher`, and `Dispatcher` tell the local `JobMaster`. The main problem is that `Dispatcher` is an actor and can only be executed in one thread, it may be the performance bottleneck for deserialize event. The other idea it to create a netty service in `SessionClusterEntrypoint`, it can receive and deserialize events from taskmanagers in a threadpool, and send the event to the `Dispatcher` or `JobMaster`. Taskmanagers manager the connection to the netty service when it start. Thus a service can also receive the result of a job from taskmanager later. [~xtsong] What do you think? THX -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Comment Edited] (FLINK-25330) Flink SQL doesn't retract all versions of Hbase data
[ https://issues.apache.org/jira/browse/FLINK-25330?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460432#comment-17460432 ] Bruce Wong edited comment on FLINK-25330 at 12/16/21, 6:11 AM: --- Hi, [~wenlong.lwl] In my opinion, if the user deletes data in mysql, even the old version of HBase data should not be retained if it is not, because it will cause incorrect semantics to join HBase data before and after HBase flush. was (Author: bruce wong): Hi, Wenlong Lyu In my opinion, if the user deletes data in mysql, even the old version of HBase data should not be retained if it is not, because it will cause incorrect semantics to join HBase data before and after HBase flush. > Flink SQL doesn't retract all versions of Hbase data > > > Key: FLINK-25330 > URL: https://issues.apache.org/jira/browse/FLINK-25330 > Project: Flink > Issue Type: Bug > Components: Connectors / HBase >Affects Versions: 1.14.0 >Reporter: Bruce Wong >Priority: Critical > Labels: pull-request-available > Attachments: image-2021-12-15-20-05-18-236.png > > > h2. Background > When we use CDC to synchronize mysql data to HBase, we find that HBase > deletes only the last version of the specified rowkey when deleting mysql > data. The data of the old version still exists. You end up using the wrong > data. And I think its a bug of HBase connector. > The following figure shows Hbase data changes before and after mysql data is > deleted. > !image-2021-12-15-20-05-18-236.png|width=910,height=669! > > h2. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25330) Flink SQL doesn't retract all versions of Hbase data
[ https://issues.apache.org/jira/browse/FLINK-25330?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460432#comment-17460432 ] Bruce Wong commented on FLINK-25330: Hi, Wenlong Lyu In my opinion, if the user deletes data in mysql, even the old version of HBase data should not be retained if it is not, because it will cause incorrect semantics to join HBase data before and after HBase flush. > Flink SQL doesn't retract all versions of Hbase data > > > Key: FLINK-25330 > URL: https://issues.apache.org/jira/browse/FLINK-25330 > Project: Flink > Issue Type: Bug > Components: Connectors / HBase >Affects Versions: 1.14.0 >Reporter: Bruce Wong >Priority: Critical > Labels: pull-request-available > Attachments: image-2021-12-15-20-05-18-236.png > > > h2. Background > When we use CDC to synchronize mysql data to HBase, we find that HBase > deletes only the last version of the specified rowkey when deleting mysql > data. The data of the old version still exists. You end up using the wrong > data. And I think its a bug of HBase connector. > The following figure shows Hbase data changes before and after mysql data is > deleted. > !image-2021-12-15-20-05-18-236.png|width=910,height=669! > > h2. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28229) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-25336) Kafka connector compatible problem in Flink sql
[
https://issues.apache.org/jira/browse/FLINK-25336?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460431#comment-17460431
]
Yuan Zhu commented on FLINK-25336:
--
[~JasonLee] Why not make it configurable to support more versions? Upgrading
kafka version is troublesome.
> Kafka connector compatible problem in Flink sql
> ---
>
> Key: FLINK-25336
> URL: https://issues.apache.org/jira/browse/FLINK-25336
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0
> Environment: Flink 1.14.0
> Kafka 0.10.2.1
>Reporter: Yuan Zhu
>Priority: Minor
> Labels: Flink-sql, Kafka, flink
> Attachments: log.jpg
>
>
> When I use sql to query kafka table, like
> {code:java}
> create table `kfk`
> (
> user_id VARCHAR
> ) with (
> 'connector' = 'kafka',
> 'topic' = 'test',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'format' = 'json',
> 'scan.startup.mode' = 'timestamp',
> 'scan.startup.timestamp-millis' = '163941120',
> 'properties.group.id' = 'test'
> );
> CREATE TABLE print_table (user_id varchar) WITH ('connector' = 'print');
> insert into print_table select user_id from kfk;{code}
> It will encounter an exception:
> org.apache.kafka.common.errors.UnsupportedVersionException: MetadataRequest
> versions older than 4 don't support the allowAutoTopicCreation field !log.jpg!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770243747
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java
##
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.linalg;
+
+import org.apache.flink.api.common.typeinfo.TypeInfo;
+import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Arrays;
+import java.util.Objects;
+
+/** A sparse vector of double values. */
+@TypeInfo(SparseVectorTypeInfoFactory.class)
+public class SparseVector implements Vector {
+public final int n;
+public final int[] indices;
+public final double[] values;
+
+public SparseVector(int n, int[] indices, double[] values) {
+this.n = n;
+this.indices = indices;
+this.values = values;
+if (!isIndicesSorted()) {
+sortIndices();
+}
+validateSortedData();
+}
+
+@Override
+public int size() {
+return n;
+}
+
+@Override
+public double get(int i) {
+int pos = Arrays.binarySearch(indices, i);
+if (pos >= 0) {
+return values[pos];
+}
+return 0.;
+}
+
+@Override
+public double[] toArray() {
+double[] result = new double[n];
+for (int i = 0; i < indices.length; i++) {
+result[indices[i]] = values[i];
+}
+return result;
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (o == null || getClass() != o.getClass()) {
+return false;
+}
+SparseVector that = (SparseVector) o;
+return n == that.n
+&& Arrays.equals(indices, that.indices)
+&& Arrays.equals(values, that.values);
+}
+
+@Override
+public int hashCode() {
+int result = Objects.hash(n);
+result = 31 * result + Arrays.hashCode(indices);
+result = 31 * result + Arrays.hashCode(values);
+return result;
+}
+
+/**
+ * Check whether input data is validate.
+ *
+ * This function does the following checks:
+ *
+ *
+ * The indices array and values array are of the same size.
+ * vector indices are in valid range.
+ * vector indices are unique.
+ *
+ *
+ * This function works as expected only when indices are sorted.
+ */
+private void validateSortedData() {
+Preconditions.checkArgument(
+indices.length == values.length,
+"Indices size and values size should be the same.");
+if (this.indices.length > 0) {
+Preconditions.checkArgument(
+this.indices[0] >= 0 && this.indices[this.indices.length -
1] < this.n,
+"Index out of bound.");
+}
+for (int i = 1; i < this.indices.length; i++) {
+Preconditions.checkArgument(
+this.indices[i] > this.indices[i - 1], "Indices
duplicated.");
+}
+}
+
+private boolean isIndicesSorted() {
+for (int i = 1; i < this.indices.length; i++) {
+if (this.indices[i] < this.indices[i - 1]) {
+return false;
+}
+}
+return true;
+}
+
+/** Sort the indices and values. */
+private void sortIndices() {
+sortImpl(this.indices, this.values, 0, this.indices.length - 1);
+}
+
+/** Sort the indices and values using quick sort. */
+private static void sortImpl(int[] indices, double[] values, int low, int
high) {
Review comment:
OK. I'll add more tests in reference to Alink and Spark.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770243574
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java
##
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.linalg;
+
+import org.apache.flink.api.common.typeinfo.TypeInfo;
+import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Arrays;
+import java.util.Objects;
+
+/** A sparse vector of double values. */
+@TypeInfo(SparseVectorTypeInfoFactory.class)
+public class SparseVector implements Vector {
+public final int n;
+public final int[] indices;
+public final double[] values;
+
+public SparseVector(int n, int[] indices, double[] values) {
+this.n = n;
+this.indices = indices;
+this.values = values;
+if (!isIndicesSorted()) {
+sortIndices();
+}
+validateSortedData();
+}
+
+@Override
+public int size() {
+return n;
+}
+
+@Override
+public double get(int i) {
+int pos = Arrays.binarySearch(indices, i);
+if (pos >= 0) {
+return values[pos];
+}
+return 0.;
+}
+
+@Override
+public double[] toArray() {
+double[] result = new double[n];
+for (int i = 0; i < indices.length; i++) {
+result[indices[i]] = values[i];
+}
+return result;
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (o == null || getClass() != o.getClass()) {
+return false;
+}
+SparseVector that = (SparseVector) o;
+return n == that.n
+&& Arrays.equals(indices, that.indices)
+&& Arrays.equals(values, that.values);
+}
+
+@Override
+public int hashCode() {
+int result = Objects.hash(n);
+result = 31 * result + Arrays.hashCode(indices);
+result = 31 * result + Arrays.hashCode(values);
+return result;
+}
+
+/**
+ * Check whether input data is validate.
+ *
+ * This function does the following checks:
+ *
+ *
+ * The indices array and values array are of the same size.
+ * vector indices are in valid range.
+ * vector indices are unique.
+ *
+ *
+ * This function works as expected only when indices are sorted.
+ */
+private void validateSortedData() {
+Preconditions.checkArgument(
+indices.length == values.length,
+"Indices size and values size should be the same.");
+if (this.indices.length > 0) {
+Preconditions.checkArgument(
+this.indices[0] >= 0 && this.indices[this.indices.length -
1] < this.n,
+"Index out of bound.");
+}
+for (int i = 1; i < this.indices.length; i++) {
+Preconditions.checkArgument(
+this.indices[i] > this.indices[i - 1], "Indices
duplicated.");
+}
+}
+
+private boolean isIndicesSorted() {
+for (int i = 1; i < this.indices.length; i++) {
+if (this.indices[i] < this.indices[i - 1]) {
+return false;
+}
+}
+return true;
+}
+
+/** Sort the indices and values. */
+private void sortIndices() {
+sortImpl(this.indices, this.values, 0, this.indices.length - 1);
+}
+
+/** Sort the indices and values using quick sort. */
+private static void sortImpl(int[] indices, double[] values, int low, int
high) {
+int pivotPos = (low + high) / 2;
+int pivot = indices[pivotPos];
+indices[pivotPos] = indices[high];
+indices[high] = pivot;
+double t = values[pivotPos];
+values[pivotPos] = values[high];
+values[high] = t;
+
+int pos = low - 1;
+for (int i = low; i <= high; i++) {
+if (indices[i] <= pivot) {
+pos++;
+int tempI = indices[pos];
+
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770243498
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java
##
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.linalg;
+
+import org.apache.flink.api.common.typeinfo.TypeInfo;
+import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Arrays;
+import java.util.Objects;
+
+/** A sparse vector of double values. */
+@TypeInfo(SparseVectorTypeInfoFactory.class)
+public class SparseVector implements Vector {
+public final int n;
+public final int[] indices;
+public final double[] values;
+
+public SparseVector(int n, int[] indices, double[] values) {
+this.n = n;
+this.indices = indices;
+this.values = values;
+if (!isIndicesSorted()) {
+sortIndices();
+}
+validateSortedData();
+}
+
+@Override
+public int size() {
+return n;
+}
+
+@Override
+public double get(int i) {
+int pos = Arrays.binarySearch(indices, i);
+if (pos >= 0) {
+return values[pos];
+}
+return 0.;
+}
+
+@Override
+public double[] toArray() {
+double[] result = new double[n];
+for (int i = 0; i < indices.length; i++) {
+result[indices[i]] = values[i];
+}
+return result;
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (o == null || getClass() != o.getClass()) {
+return false;
+}
+SparseVector that = (SparseVector) o;
+return n == that.n
+&& Arrays.equals(indices, that.indices)
+&& Arrays.equals(values, that.values);
+}
+
+@Override
+public int hashCode() {
+int result = Objects.hash(n);
+result = 31 * result + Arrays.hashCode(indices);
+result = 31 * result + Arrays.hashCode(values);
+return result;
+}
+
+/**
+ * Check whether input data is validate.
+ *
+ * This function does the following checks:
+ *
+ *
+ * The indices array and values array are of the same size.
+ * vector indices are in valid range.
+ * vector indices are unique.
+ *
+ *
+ * This function works as expected only when indices are sorted.
+ */
+private void validateSortedData() {
+Preconditions.checkArgument(
+indices.length == values.length,
+"Indices size and values size should be the same.");
+if (this.indices.length > 0) {
+Preconditions.checkArgument(
+this.indices[0] >= 0 && this.indices[this.indices.length -
1] < this.n,
+"Index out of bound.");
+}
+for (int i = 1; i < this.indices.length; i++) {
+Preconditions.checkArgument(
+this.indices[i] > this.indices[i - 1], "Indices
duplicated.");
+}
+}
+
+private boolean isIndicesSorted() {
+for (int i = 1; i < this.indices.length; i++) {
+if (this.indices[i] < this.indices[i - 1]) {
+return false;
+}
+}
+return true;
+}
+
+/** Sort the indices and values. */
+private void sortIndices() {
+sortImpl(this.indices, this.values, 0, this.indices.length - 1);
+}
+
+/** Sort the indices and values using quick sort. */
+private static void sortImpl(int[] indices, double[] values, int low, int
high) {
+int pivotPos = (low + high) / 2;
+int pivot = indices[pivotPos];
Review comment:
OK. I'll try to make the change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770243384
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/typeinfo/SparseVectorTypeInfo.java
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.ml.linalg.typeinfo;
+
+import org.apache.flink.api.common.ExecutionConfig;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.ml.linalg.SparseVector;
+
+/** A {@link TypeInformation} for the {@link SparseVector} type. */
+public class SparseVectorTypeInfo extends TypeInformation {
+public static final SparseVectorTypeInfo INSTANCE = new
SparseVectorTypeInfo();
Review comment:
Yes, it is unused for now. `Kmeans` uses `DenseVectorTypeInfo.INSTANCE`
in its algorithm, and similarly other algorithms may also use this instance in
their implementations. Thus I created this instance in advance.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770241491
##
File path:
flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java
##
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.linalg;
+
+import org.apache.flink.api.common.typeinfo.TypeInfo;
+import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory;
+import org.apache.flink.util.Preconditions;
+
+import java.util.Arrays;
+import java.util.Objects;
+
+/** A sparse vector of double values. */
+@TypeInfo(SparseVectorTypeInfoFactory.class)
+public class SparseVector implements Vector {
+public final int n;
+public final int[] indices;
+public final double[] values;
+
+public SparseVector(int n, int[] indices, double[] values) {
+this.n = n;
+this.indices = indices;
+this.values = values;
+if (!isIndicesSorted()) {
+sortIndices();
+}
+validateSortedData();
+}
+
+@Override
+public int size() {
+return n;
+}
+
+@Override
+public double get(int i) {
+int pos = Arrays.binarySearch(indices, i);
+if (pos >= 0) {
+return values[pos];
+}
+return 0.;
+}
+
+@Override
+public double[] toArray() {
+double[] result = new double[n];
+for (int i = 0; i < indices.length; i++) {
+result[indices[i]] = values[i];
+}
+return result;
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (o == null || getClass() != o.getClass()) {
+return false;
+}
+SparseVector that = (SparseVector) o;
+return n == that.n
+&& Arrays.equals(indices, that.indices)
+&& Arrays.equals(values, that.values);
+}
+
+@Override
+public int hashCode() {
+int result = Objects.hash(n);
+result = 31 * result + Arrays.hashCode(indices);
+result = 31 * result + Arrays.hashCode(values);
+return result;
+}
+
+/**
+ * Check whether input data is validate.
+ *
+ * This function does the following checks:
+ *
+ *
+ * The indices array and values array are of the same size.
+ * vector indices are in valid range.
+ * vector indices are unique.
+ *
+ *
+ * This function works as expected only when indices are sorted.
+ */
+private void validateSortedData() {
+Preconditions.checkArgument(
+indices.length == values.length,
+"Indices size and values size should be the same.");
+if (this.indices.length > 0) {
+Preconditions.checkArgument(
+this.indices[0] >= 0 && this.indices[this.indices.length -
1] < this.n,
+"Index out of bound.");
+}
+for (int i = 1; i < this.indices.length; i++) {
+Preconditions.checkArgument(
+this.indices[i] > this.indices[i - 1], "Indices
duplicated.");
+}
+}
+
+private boolean isIndicesSorted() {
+for (int i = 1; i < this.indices.length; i++) {
+if (this.indices[i] < this.indices[i - 1]) {
+return false;
+}
+}
+return true;
+}
+
+/** Sort the indices and values. */
Review comment:
OK. I'll make the change here and for other comments.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37: URL: https://github.com/apache/flink-ml/pull/37#discussion_r770241406 ## File path: flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoderModelData.java ## @@ -0,0 +1,106 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.ml.feature.onehotencoder; + +import org.apache.flink.api.common.functions.MapFunction; +import org.apache.flink.api.common.serialization.Encoder; +import org.apache.flink.api.common.typeinfo.TypeInformation; +import org.apache.flink.api.common.typeinfo.Types; +import org.apache.flink.api.java.tuple.Tuple2; +import org.apache.flink.configuration.Configuration; +import org.apache.flink.connector.file.src.reader.SimpleStreamFormat; +import org.apache.flink.core.fs.FSDataInputStream; +import org.apache.flink.streaming.api.datastream.DataStream; +import org.apache.flink.table.api.Table; +import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; +import org.apache.flink.table.api.internal.TableImpl; +import org.apache.flink.types.Row; + +import com.esotericsoftware.kryo.io.Input; +import com.esotericsoftware.kryo.io.Output; + +import java.io.IOException; +import java.io.OutputStream; + +/** Provides classes to save/load model data. */ Review comment: OK. I'll make the change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770241084
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoder.java
##
@@ -0,0 +1,146 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.onehotencoder;
+
+import org.apache.flink.api.common.functions.FlatMapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.api.common.typeinfo.Types;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.MapPartitionFunctionWrapper;
+import org.apache.flink.ml.common.param.HasHandleInvalid;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * An Estimator which implements the one-hot encoding algorithm.
+ *
+ * See https://en.wikipedia.org/wiki/One-hot.
+ */
+public class OneHotEncoder
+implements Estimator,
+OneHotEncoderParams {
+private final Map, Object> paramMap = new HashMap<>();
+
+public OneHotEncoder() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public OneHotEncoderModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+
Preconditions.checkArgument(getHandleInvalid().equals(HasHandleInvalid.ERROR_INVALID));
+
+final String[] inputCols = getInputCols();
+
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+DataStream> modelData =
+tEnv.toDataStream(inputs[0])
+.flatMap(new ExtractInputColsValueFunction(inputCols))
+.keyBy(x -> x.f0)
+.transform(
+"findMaxIndex",
+Types.TUPLE(Types.INT, Types.INT),
+new MapPartitionFunctionWrapper<>(new
FindMaxIndexFunction()));
+
+OneHotEncoderModel model =
+new OneHotEncoderModel()
+
.setModelData(OneHotEncoderModelData.getModelDataTable(modelData));
+ReadWriteUtils.updateExistingParams(model, paramMap);
+return model;
+}
+
+@Override
+public void save(String path) throws IOException {
+ReadWriteUtils.saveMetadata(this, path);
+}
+
+public static OneHotEncoder load(StreamExecutionEnvironment env, String
path)
+throws IOException {
+return ReadWriteUtils.loadStageParam(path);
+}
+
+@Override
+public Map, Object> getParamMap() {
+return paramMap;
+}
+
+/**
+ * Extract values of input columns of input data.
+ *
+ * Input: rows of input data containing designated input columns
+ *
+ * Output: Pairs of column index and value stored in those columns
+ */
+private static class ExtractInputColsValueFunction
+implements FlatMapFunction> {
+private final String[] inputCols;
+
+private ExtractInputColsValueFunction(String[] inputCols) {
+this.inputCols = inputCols;
+}
+
+@Override
+public void flatMap(Row row, Collector>
collector) {
+for (int i = 0; i < inputCols.length; i++) {
+Number number = (Number) row.getField(inputCols[i]);
+Preconditions.checkArgument(
+number.intValue() == number.doubleValue(),
+
[GitHub] [flink] chenyuzhi459 edited a comment on pull request #18118: [FLINK-24907] Support side out late data for interval join
chenyuzhi459 edited a comment on pull request #18118: URL: https://github.com/apache/flink/pull/18118#issuecomment-995390917 @flinkbot re-run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770239537
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoder.java
##
@@ -0,0 +1,146 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.onehotencoder;
+
+import org.apache.flink.api.common.functions.FlatMapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.api.common.typeinfo.Types;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.MapPartitionFunctionWrapper;
+import org.apache.flink.ml.common.param.HasHandleInvalid;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * An Estimator which implements the one-hot encoding algorithm.
+ *
+ * See https://en.wikipedia.org/wiki/One-hot.
+ */
+public class OneHotEncoder
+implements Estimator,
+OneHotEncoderParams {
+private final Map, Object> paramMap = new HashMap<>();
+
+public OneHotEncoder() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public OneHotEncoderModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+
Preconditions.checkArgument(getHandleInvalid().equals(HasHandleInvalid.ERROR_INVALID));
+
+final String[] inputCols = getInputCols();
+
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+DataStream> modelData =
+tEnv.toDataStream(inputs[0])
+.flatMap(new ExtractInputColsValueFunction(inputCols))
+.keyBy(x -> x.f0)
+.transform(
+"findMaxIndex",
+Types.TUPLE(Types.INT, Types.INT),
+new MapPartitionFunctionWrapper<>(new
FindMaxIndexFunction()));
+
+OneHotEncoderModel model =
+new OneHotEncoderModel()
+
.setModelData(OneHotEncoderModelData.getModelDataTable(modelData));
+ReadWriteUtils.updateExistingParams(model, paramMap);
+return model;
+}
+
+@Override
+public void save(String path) throws IOException {
+ReadWriteUtils.saveMetadata(this, path);
+}
+
+public static OneHotEncoder load(StreamExecutionEnvironment env, String
path)
+throws IOException {
+return ReadWriteUtils.loadStageParam(path);
+}
+
+@Override
+public Map, Object> getParamMap() {
+return paramMap;
+}
+
+/**
+ * Extract values of input columns of input data.
+ *
+ * Input: rows of input data containing designated input columns
+ *
+ * Output: Pairs of column index and value stored in those columns
+ */
+private static class ExtractInputColsValueFunction
+implements FlatMapFunction> {
+private final String[] inputCols;
+
+private ExtractInputColsValueFunction(String[] inputCols) {
+this.inputCols = inputCols;
+}
+
+@Override
+public void flatMap(Row row, Collector>
collector) {
+for (int i = 0; i < inputCols.length; i++) {
+Number number = (Number) row.getField(inputCols[i]);
Review comment:
The current implementation aligns with Spark, in which the One Hot
Encoder also only supports indexed integer values. In order
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770238699
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/common/param/HasDropLast.java
##
@@ -0,0 +1,37 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.common.param;
+
+import org.apache.flink.ml.param.BooleanParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.WithParams;
+
+/** Interface for the shared dropLast param. */
+public interface HasDropLast extends WithParams {
Review comment:
Yes, this is exactly true at least for Spark. Alink also uses
`HasDropLast` in Quantile Discretizer and
`tree.Preprocessing.VectorPredictParams`, but those usages are similar to
OneHotEncoder and I agree that we can put `HasDropLast` a class member of
`OneHotEncoderParams`. I'll make the change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770238822
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoderModelData.java
##
@@ -0,0 +1,106 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.onehotencoder;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.serialization.Encoder;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.common.typeinfo.Types;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.connector.file.src.reader.SimpleStreamFormat;
+import org.apache.flink.core.fs.FSDataInputStream;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+
+import java.io.IOException;
+import java.io.OutputStream;
+
+/** Provides classes to save/load model data. */
+public class OneHotEncoderModelData {
+/** Converts the provided modelData Datastream into corresponding Table. */
+public static Table getModelDataTable(DataStream>
stream) {
Review comment:
OK. I'll make the change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r770238761
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoder.java
##
@@ -0,0 +1,146 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.onehotencoder;
+
+import org.apache.flink.api.common.functions.FlatMapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.api.common.typeinfo.Types;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.MapPartitionFunctionWrapper;
+import org.apache.flink.ml.common.param.HasHandleInvalid;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * An Estimator which implements the one-hot encoding algorithm.
+ *
+ * See https://en.wikipedia.org/wiki/One-hot.
+ */
+public class OneHotEncoder
+implements Estimator,
+OneHotEncoderParams {
+private final Map, Object> paramMap = new HashMap<>();
+
+public OneHotEncoder() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public OneHotEncoderModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+
Preconditions.checkArgument(getHandleInvalid().equals(HasHandleInvalid.ERROR_INVALID));
+
+final String[] inputCols = getInputCols();
+
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+DataStream> modelData =
+tEnv.toDataStream(inputs[0])
+.flatMap(new ExtractInputColsValueFunction(inputCols))
+.keyBy(x -> x.f0)
Review comment:
OK. I'll make the change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37: URL: https://github.com/apache/flink-ml/pull/37#discussion_r770237425 ## File path: flink-ml-lib/src/main/java/org/apache/flink/ml/common/param/HasHandleInvalid.java ## @@ -0,0 +1,54 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.ml.common.param; + +import org.apache.flink.ml.param.Param; +import org.apache.flink.ml.param.ParamValidators; +import org.apache.flink.ml.param.StringParam; +import org.apache.flink.ml.param.WithParams; + +/** + * Interface for the shared handleInvalid param. + * + * Supported options and the corresponding behavior to handle invalid entries of each of them is + * as follows. + * + * + * error: raise an exception. + * + */ Review comment: OK. I'll make the change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-25332) When using Pyflink Table API, 'where' clause seems to work incorrectly
[ https://issues.apache.org/jira/browse/FLINK-25332?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460425#comment-17460425 ] TongMeng commented on FLINK-25332: -- [~dianfu] ,I posted the sql explain to the appendix [^sql_explain.txt]. writeData() is my UDF and the parameters is my json data from kafka. > When using Pyflink Table API, 'where' clause seems to work incorrectly > -- > > Key: FLINK-25332 > URL: https://issues.apache.org/jira/browse/FLINK-25332 > Project: Flink > Issue Type: Bug > Components: Table SQL / API >Affects Versions: 1.13.0 > Environment: Python 3.6.9, Pyflink 1.13.0, kafka2.12-2.4.0 >Reporter: TongMeng >Priority: Major > Attachments: sql_explain.txt > > > The UDF I used just returns a float, the first four data it returns 1.0, 2.0, > 3.0 and 4.0, then it returns 0.0. I use 'where' in the sql to filter the 0.0 > result. So the expected result I want to see in the kafka should be 1.0, 2.0, > 3.0 and 4.0. However kafka consumer gives four 0.0. > The sql is as follow: > "insert into algorithmsink select dt.my_result from(select udf1(a) AS > my_result from mysource) AS dt where dt.my_result > 0.0" (udf1 is my UDF) > After I removed the 'where dt.my_result > 0.0' part, it workd well. Kafka > gave 1.0, 2.0, 3.0, 4.0, 0.0, 0.0, 0.0…… -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink-ml] yunfengzhou-hub commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
yunfengzhou-hub commented on a change in pull request #37: URL: https://github.com/apache/flink-ml/pull/37#discussion_r770236389 ## File path: flink-ml-core/src/main/java/org/apache/flink/ml/linalg/SparseVector.java ## @@ -0,0 +1,174 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.ml.linalg; + +import org.apache.flink.api.common.typeinfo.TypeInfo; +import org.apache.flink.ml.linalg.typeinfo.SparseVectorTypeInfoFactory; +import org.apache.flink.util.Preconditions; + +import java.util.Arrays; +import java.util.Objects; + +/** A sparse vector of double values. */ +@TypeInfo(SparseVectorTypeInfoFactory.class) Review comment: Currently we have not encountered an algorithm that needs BLAS operation on SparseVectors. Maybe we can add such support when there is such need from algorithms. As for the second suggestion, I agree that in high dimension model's case we may need more than integer can express. For now I believe having integer implementation as the default for vector classes is enough. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-25332) When using Pyflink Table API, 'where' clause seems to work incorrectly
[ https://issues.apache.org/jira/browse/FLINK-25332?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] TongMeng updated FLINK-25332: - Attachment: sql_explain.txt > When using Pyflink Table API, 'where' clause seems to work incorrectly > -- > > Key: FLINK-25332 > URL: https://issues.apache.org/jira/browse/FLINK-25332 > Project: Flink > Issue Type: Bug > Components: Table SQL / API >Affects Versions: 1.13.0 > Environment: Python 3.6.9, Pyflink 1.13.0, kafka2.12-2.4.0 >Reporter: TongMeng >Priority: Major > Attachments: sql_explain.txt > > > The UDF I used just returns a float, the first four data it returns 1.0, 2.0, > 3.0 and 4.0, then it returns 0.0. I use 'where' in the sql to filter the 0.0 > result. So the expected result I want to see in the kafka should be 1.0, 2.0, > 3.0 and 4.0. However kafka consumer gives four 0.0. > The sql is as follow: > "insert into algorithmsink select dt.my_result from(select udf1(a) AS > my_result from mysource) AS dt where dt.my_result > 0.0" (udf1 is my UDF) > After I removed the 'where dt.my_result > 0.0' part, it workd well. Kafka > gave 1.0, 2.0, 3.0, 4.0, 0.0, 0.0, 0.0…… -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0bd3d46af5cfb0923f3e15db55d57e25b08e3bb UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28228) * a0119a5e1cfd5ddaf8beed6960483e5ca17eec48 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #17990: [FLINK-25142][Connectors / Hive]Fix user-defined hive udtf initialize exception in hive dialect
flinkbot edited a comment on pull request #17990: URL: https://github.com/apache/flink/pull/17990#issuecomment-984420447 ## CI report: * 892dbf12c5dbdb02d17d936faa2cce06fe8ea4f8 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=27574) * f7e133a173e8b89a105307f0773c1f1d8c039fee UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wenlong88 commented on pull request #17938: [FLINK-25073][streaming] Introduce TreeMode description for vertices
wenlong88 commented on pull request #17938: URL: https://github.com/apache/flink/pull/17938#issuecomment-995422266 this is a comparison example:  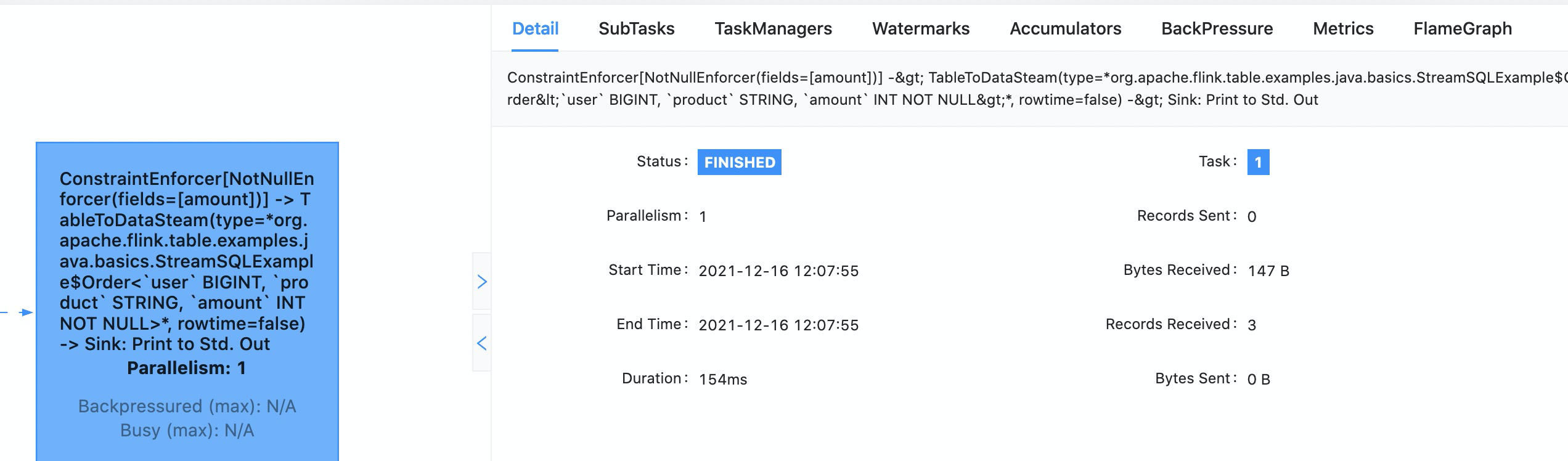 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-25330) Flink SQL doesn't retract all versions of Hbase data
[ https://issues.apache.org/jira/browse/FLINK-25330?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460396#comment-17460396 ] Wenlong Lyu commented on FLINK-25330: - hi, [~Bruce Wong] I have a concern on deleting all of the version when receive a retract message. IMO, users who uses HBase in production track changes by enabling multi-version, so it maybe not actually needed by users to delete all of the version when receiving a retract message, instead, they may want to translate the retract message to a flag column such as is_deleted or set all columns to be empty. WDYT? > Flink SQL doesn't retract all versions of Hbase data > > > Key: FLINK-25330 > URL: https://issues.apache.org/jira/browse/FLINK-25330 > Project: Flink > Issue Type: Bug > Components: Connectors / HBase >Affects Versions: 1.14.0 >Reporter: Bruce Wong >Priority: Critical > Labels: pull-request-available > Attachments: image-2021-12-15-20-05-18-236.png > > > h2. Background > When we use CDC to synchronize mysql data to HBase, we find that HBase > deletes only the last version of the specified rowkey when deleting mysql > data. The data of the old version still exists. You end up using the wrong > data. And I think its a bug of HBase connector. > The following figure shows Hbase data changes before and after mysql data is > deleted. > !image-2021-12-15-20-05-18-236.png|width=910,height=669! > > h2. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25336) Kafka connector compatible problem in Flink sql
[
https://issues.apache.org/jira/browse/FLINK-25336?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460395#comment-17460395
]
JasonLee commented on FLINK-25336:
--
[~straw] In fact, this is because the version of Kafka is too low. Just upgrade
to a higher version.
> Kafka connector compatible problem in Flink sql
> ---
>
> Key: FLINK-25336
> URL: https://issues.apache.org/jira/browse/FLINK-25336
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0
> Environment: Flink 1.14.0
> Kafka 0.10.2.1
>Reporter: Yuan Zhu
>Priority: Minor
> Labels: Flink-sql, Kafka, flink
> Attachments: log.jpg
>
>
> When I use sql to query kafka table, like
> {code:java}
> create table `kfk`
> (
> user_id VARCHAR
> ) with (
> 'connector' = 'kafka',
> 'topic' = 'test',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'format' = 'json',
> 'scan.startup.mode' = 'timestamp',
> 'scan.startup.timestamp-millis' = '163941120',
> 'properties.group.id' = 'test'
> );
> CREATE TABLE print_table (user_id varchar) WITH ('connector' = 'print');
> insert into print_table select user_id from kfk;{code}
> It will encounter an exception:
> org.apache.kafka.common.errors.UnsupportedVersionException: MetadataRequest
> versions older than 4 don't support the allowAutoTopicCreation field !log.jpg!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot edited a comment on pull request #18044: [FLINK-25215][table] ISODOW, ISOYEAR fail and DECADE gives wrong result for timestamps with timezones
flinkbot edited a comment on pull request #18044: URL: https://github.com/apache/flink/pull/18044#issuecomment-987951721 ## CI report: * 5724a6b4e5c9f7706fa0f27ba05fe95aa34df198 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28214) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
zhipeng93 commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r769422262
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoderModel.java
##
@@ -0,0 +1,190 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.onehotencoder;
+
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.ml.api.Model;
+import org.apache.flink.ml.common.broadcast.BroadcastUtils;
+import org.apache.flink.ml.common.datastream.TableUtils;
+import org.apache.flink.ml.common.param.HasHandleInvalid;
+import org.apache.flink.ml.linalg.Vectors;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.table.runtime.typeutils.ExternalTypeInfo;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.commons.lang3.ArrayUtils;
+
+import java.io.IOException;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+import java.util.Vector;
+import java.util.function.Function;
+
+/**
+ * A Model which encodes data into one-hot format using the model data
computed by {@link
+ * OneHotEncoder}.
+ */
+public class OneHotEncoderModel
+implements Model,
OneHotEncoderParams {
+private final Map, Object> paramMap = new HashMap<>();
+private Table modelDataTable;
+
+public OneHotEncoderModel() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public Table[] transform(Table... inputs) {
+final String[] inputCols = getInputCols();
+final String[] outputCols = getOutputCols();
+final boolean dropLast = getDropLast();
+final String broadcastModelKey = "OneHotModelStream";
+
+
Preconditions.checkArgument(getHandleInvalid().equals(HasHandleInvalid.ERROR_INVALID));
+Preconditions.checkArgument(inputs.length == 1);
+Preconditions.checkArgument(inputCols.length == outputCols.length);
+
+RowTypeInfo inputTypeInfo =
TableUtils.getRowTypeInfo(inputs[0].getResolvedSchema());
+RowTypeInfo outputTypeInfo =
+new RowTypeInfo(
+ArrayUtils.addAll(
+inputTypeInfo.getFieldTypes(),
+Collections.nCopies(
+outputCols.length,
+
ExternalTypeInfo.of(Vector.class))
+.toArray(new TypeInformation[0])),
+ArrayUtils.addAll(inputTypeInfo.getFieldNames(),
outputCols));
+
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
modelDataTable).getTableEnvironment();
+DataStream input = tEnv.toDataStream(inputs[0]);
+DataStream> modelStream =
+OneHotEncoderModelData.getModelDataStream(modelDataTable);
+
+Map> broadcastMap = new HashMap<>();
Review comment:
nits: How about using new HashMap(1) or `Collections.singleMap()`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
zhipeng93 commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r769401955
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/feature/onehotencoder/OneHotEncoder.java
##
@@ -0,0 +1,146 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.feature.onehotencoder;
+
+import org.apache.flink.api.common.functions.FlatMapFunction;
+import org.apache.flink.api.common.functions.MapPartitionFunction;
+import org.apache.flink.api.common.typeinfo.Types;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.ml.api.Estimator;
+import org.apache.flink.ml.common.datastream.MapPartitionFunctionWrapper;
+import org.apache.flink.ml.common.param.HasHandleInvalid;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.util.ParamUtils;
+import org.apache.flink.ml.util.ReadWriteUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.Collector;
+import org.apache.flink.util.Preconditions;
+
+import java.io.IOException;
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * An Estimator which implements the one-hot encoding algorithm.
+ *
+ * See https://en.wikipedia.org/wiki/One-hot.
+ */
+public class OneHotEncoder
+implements Estimator,
+OneHotEncoderParams {
+private final Map, Object> paramMap = new HashMap<>();
+
+public OneHotEncoder() {
+ParamUtils.initializeMapWithDefaultValues(paramMap, this);
+}
+
+@Override
+public OneHotEncoderModel fit(Table... inputs) {
+Preconditions.checkArgument(inputs.length == 1);
+
Preconditions.checkArgument(getHandleInvalid().equals(HasHandleInvalid.ERROR_INVALID));
+
+final String[] inputCols = getInputCols();
+
+StreamTableEnvironment tEnv =
+(StreamTableEnvironment) ((TableImpl)
inputs[0]).getTableEnvironment();
+DataStream> modelData =
+tEnv.toDataStream(inputs[0])
+.flatMap(new ExtractInputColsValueFunction(inputCols))
+.keyBy(x -> x.f0)
Review comment:
x -> `columnIdAndValue`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a change in pull request #37: [FLINK-24955] Add Estimator and Transformer for One Hot Encoder
zhipeng93 commented on a change in pull request #37:
URL: https://github.com/apache/flink-ml/pull/37#discussion_r769397742
##
File path:
flink-ml-lib/src/main/java/org/apache/flink/ml/common/param/HasDropLast.java
##
@@ -0,0 +1,37 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.common.param;
+
+import org.apache.flink.ml.param.BooleanParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.WithParams;
+
+/** Interface for the shared dropLast param. */
+public interface HasDropLast extends WithParams {
Review comment:
Should we make `HasDropLast` a class member of `OneHotEncoderParams`? I
am not aware of any other algorithms those are using this param.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-25336) Kafka connector compatible problem in Flink sql
[
https://issues.apache.org/jira/browse/FLINK-25336?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yuan Zhu updated FLINK-25336:
-
Docs Text: (was: Kafka connector compatible problem in Flink sql)
> Kafka connector compatible problem in Flink sql
> ---
>
> Key: FLINK-25336
> URL: https://issues.apache.org/jira/browse/FLINK-25336
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0
> Environment: Flink 1.14.0
> Kafka 0.10.2.1
>Reporter: Yuan Zhu
>Priority: Minor
> Labels: Flink-sql, Kafka, flink
> Attachments: log.jpg
>
>
> When I use sql to query kafka table, like
> {code:java}
> create table `kfk`
> (
> user_id VARCHAR
> ) with (
> 'connector' = 'kafka',
> 'topic' = 'test',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'format' = 'json',
> 'scan.startup.mode' = 'timestamp',
> 'scan.startup.timestamp-millis' = '163941120',
> 'properties.group.id' = 'test'
> );
> CREATE TABLE print_table (user_id varchar) WITH ('connector' = 'print');
> insert into print_table select user_id from kfk;{code}
> It will encounter an exception:
> org.apache.kafka.common.errors.UnsupportedVersionException: MetadataRequest
> versions older than 4 don't support the allowAutoTopicCreation field !log.jpg!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-25336) Kafka connector compatible problem in Flink sql
[
https://issues.apache.org/jira/browse/FLINK-25336?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460391#comment-17460391
]
Yuan Zhu commented on FLINK-25336:
--
Hi, [~becket_qin]. What's the purpose here? Can we make
ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG configurable?
> Kafka connector compatible problem in Flink sql
> ---
>
> Key: FLINK-25336
> URL: https://issues.apache.org/jira/browse/FLINK-25336
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0
> Environment: Flink 1.14.0
> Kafka 0.10.2.1
>Reporter: Yuan Zhu
>Priority: Minor
> Labels: Flink-sql, Kafka, flink
> Attachments: log.jpg
>
>
> When I use sql to query kafka table, like
> {code:java}
> create table `kfk`
> (
> user_id VARCHAR
> ) with (
> 'connector' = 'kafka',
> 'topic' = 'test',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'format' = 'json',
> 'scan.startup.mode' = 'timestamp',
> 'scan.startup.timestamp-millis' = '163941120',
> 'properties.group.id' = 'test'
> );
> CREATE TABLE print_table (user_id varchar) WITH ('connector' = 'print');
> insert into print_table select user_id from kfk;{code}
> It will encounter an exception:
> org.apache.kafka.common.errors.UnsupportedVersionException: MetadataRequest
> versions older than 4 don't support the allowAutoTopicCreation field !log.jpg!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] Myasuka commented on a change in pull request #17774: [FLINK-24611] Prevent JM from discarding state on checkpoint abortion
Myasuka commented on a change in pull request #17774:
URL: https://github.com/apache/flink/pull/17774#discussion_r770198103
##
File path:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/snapshot/RocksIncrementalSnapshotStrategy.java
##
@@ -97,12 +98,23 @@
/**
* Stores the materialized sstable files from all snapshots that build the
incremental history.
+ * Used to check whether {@link PlaceholderStreamStateHandle} can be sent
or the original {@link
+ * StreamStateHandle} must be used.
*/
-@Nonnull private final SortedMap>
materializedSstFiles;
+@Nonnull private final SortedMap>
uploadedStateIDs;
+
+/**
+ * Last uploaded but potentially not confirmed SST files. Used if {@link
#uploadedStateIDs}
+ * doesn't contain the corresponding {@link StateHandleID}.
+ */
+@Nonnull private final Map
lastUploadedSstFiles;
Review comment:
You are right, the `lastUploadedSstFiles` would only be cleared after
calling `createUploadFilePaths`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #18114: [FLINK-25173][table][hive] Introduce CatalogLock and implement HiveCatalogLock
flinkbot edited a comment on pull request #18114: URL: https://github.com/apache/flink/pull/18114#issuecomment-994556266 ## CI report: * 163245e6c628a06bc5ce593d014e1588262aae60 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28183) * 1568f5f4106b821cef0066ce2cae68a5a035c1fd Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=28227) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-25337) Check whether the target table is valid when SqlToOperationConverter.convertSqlInsert
vim-wang created FLINK-25337: Summary: Check whether the target table is valid when SqlToOperationConverter.convertSqlInsert Key: FLINK-25337 URL: https://issues.apache.org/jira/browse/FLINK-25337 Project: Flink Issue Type: Improvement Components: Table SQL / Planner Affects Versions: 1.14.0 Reporter: vim-wang when I execute insert sql like "insert into t1 select ...", If the t1 is not defined,sql will not throw an exception after SqlToOperationConverter.convertSqlInsert(), I think this is unreasonable, why not use catalogManager to check whether the target table is valid? -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-25336) Kafka connector compatible problem in Flink sql
[
https://issues.apache.org/jira/browse/FLINK-25336?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17460387#comment-17460387
]
Yuan Zhu commented on FLINK-25336:
--
The cause of this exception is invoked by the logic in
KafkaSourceEnumerator#getKafkaConsumer.
In line 420, properties will be overwrite.
{code:java}
private KafkaConsumer getKafkaConsumer() {
Properties consumerProps = new Properties();
deepCopyProperties(properties, consumerProps);
……
consumerProps.setProperty(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG,
"false");
return new KafkaConsumer<>(consumerProps);
} {code}
It leads to the invalidation of config in sql ddl.
> Kafka connector compatible problem in Flink sql
> ---
>
> Key: FLINK-25336
> URL: https://issues.apache.org/jira/browse/FLINK-25336
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.0
> Environment: Flink 1.14.0
> Kafka 0.10.2.1
>Reporter: Yuan Zhu
>Priority: Minor
> Labels: Flink-sql, Kafka, flink
> Attachments: log.jpg
>
>
> When I use sql to query kafka table, like
> {code:java}
> create table `kfk`
> (
> user_id VARCHAR
> ) with (
> 'connector' = 'kafka',
> 'topic' = 'test',
> 'properties.bootstrap.servers' = 'localhost:9092',
> 'format' = 'json',
> 'scan.startup.mode' = 'timestamp',
> 'scan.startup.timestamp-millis' = '163941120',
> 'properties.group.id' = 'test'
> );
> CREATE TABLE print_table (user_id varchar) WITH ('connector' = 'print');
> insert into print_table select user_id from kfk;{code}
> It will encounter an exception:
> org.apache.kafka.common.errors.UnsupportedVersionException: MetadataRequest
> versions older than 4 don't support the allowAutoTopicCreation field !log.jpg!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-25335) Improvement of task deployment by enable source split asynchronous enumerate
[ https://issues.apache.org/jira/browse/FLINK-25335?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] KevinyhZou updated FLINK-25335: --- Summary: Improvement of task deployment by enable source split asynchronous enumerate (was: Improvement of task deployment by enable source split Asynchronous enumerate) > Improvement of task deployment by enable source split asynchronous enumerate > > > Key: FLINK-25335 > URL: https://issues.apache.org/jira/browse/FLINK-25335 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Coordination >Affects Versions: 1.12.1 >Reporter: KevinyhZou >Priority: Major > Attachments: image-2021-12-16-11-14-36-030.png > > > When submit olap query by flink client to Flink Session Cluster, the > JobMaster will start scheduling and enumerate the hive source split by > `HiveSourceFileEnumerator`, and then deploy the query task and execute it. if > the source table has a lot of partition and the partition file is big, the > source split enumerate will cost a lot of time, which would block the task > deployment & execution for a long time, and the dashboard can not appear > !image-2021-12-16-11-14-36-030.png! > it would be better to Asynchronous enumerate the hive split, and meanwhile > deploy the query task and execute it. when the deployment is finished, source > operator fetch split and read data, and the split enumeration is also going > on. -- This message was sent by Atlassian Jira (v8.20.1#820001)