[GitHub] [flink] alpreu commented on a diff in pull request #19655: [FLINK-27527] Create a file-based upsert sink for testing internal components
alpreu commented on code in PR #19655:
URL: https://github.com/apache/flink/pull/19655#discussion_r868882875
##
flink-connectors/flink-connector-upsert-test/src/test/java/org/apache/flink/connector/upserttest/sink/UpsertTestSinkWriterITCase.java:
##
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connector.upserttest.sink;
+
+import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
+import org.apache.flink.api.common.serialization.DeserializationSchema;
+import org.apache.flink.api.common.serialization.SerializationSchema;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.util.TestLoggerExtension;
+
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.ExtendWith;
+import org.junit.jupiter.api.io.TempDir;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Map;
+
+import static org.assertj.core.api.Assertions.assertThat;
+
+/** Tests for {@link UpsertTestSinkWriter}. */
+@ExtendWith(TestLoggerExtension.class)
+class UpsertTestSinkWriterITCase {
+
+@Test
+public void testWrite(@TempDir File tempDir) throws Exception {
Review Comment:
I had the misconception that the test would then share the directory, but
this is only the case if its declared as static. I'll change it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] fapaul commented on pull request #19661: [FLINK-27487][kafka] Only forward measurable Kafka metrics and ignore others
fapaul commented on PR #19661: URL: https://github.com/apache/flink/pull/19661#issuecomment-1122003731 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] gyfora opened a new pull request, #199: [FLINK-27551] Update status manually instead of relying on updatecontrol
gyfora opened a new pull request, #199: URL: https://github.com/apache/flink-kubernetes-operator/pull/199 This PR reworks how status updates of Flink resources are updated in kubernetes. This is necessary due to https://github.com/java-operator-sdk/java-operator-sdk/issues/1198 Based on offline discussion with the JOSDK team this seems to be the safest short term solution. The caching of the latest status is necessary to avoid race condition between spec updates and status patches that are made by us. Tests have been updated with some init logic to enable patching them through the kubernetes client + removed the reliance of mutating status. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27543) Hide column statistics inside the file format writer.
[ https://issues.apache.org/jira/browse/FLINK-27543?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zheng Hu updated FLINK-27543: - Summary: Hide column statistics inside the file format writer. (was: Introduce StatsProducer to refactor code in DataFileWriter ) > Hide column statistics inside the file format writer. > - > > Key: FLINK-27543 > URL: https://issues.apache.org/jira/browse/FLINK-27543 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Reporter: Jingsong Lee >Assignee: Zheng Hu >Priority: Major > Fix For: table-store-0.2.0 > > > Lots of `fileStatsExtractor == null` looks bad. > I think we can have a `StatsProducer` to unify `StatsExtractor` and > `StatsCollector`. To reduce caller complexity. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (FLINK-27543) Hide column statistics collector inside the file format writer.
[ https://issues.apache.org/jira/browse/FLINK-27543?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zheng Hu updated FLINK-27543: - Summary: Hide column statistics collector inside the file format writer. (was: Hide column statistics inside the file format writer.) > Hide column statistics collector inside the file format writer. > --- > > Key: FLINK-27543 > URL: https://issues.apache.org/jira/browse/FLINK-27543 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Reporter: Jingsong Lee >Assignee: Zheng Hu >Priority: Major > Fix For: table-store-0.2.0 > > > Lots of `fileStatsExtractor == null` looks bad. > I think we can have a `StatsProducer` to unify `StatsExtractor` and > `StatsCollector`. To reduce caller complexity. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #83: [FLINK-27170] Add Transformer and Estimator for OnlineLogisticRegression
zhipeng93 commented on code in PR #83:
URL: https://github.com/apache/flink-ml/pull/83#discussion_r868872809
##
flink-ml-lib/src/main/java/org/apache/flink/ml/common/param/HasL2.java:
##
@@ -0,0 +1,37 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.common.param;
+
+import org.apache.flink.ml.param.DoubleParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.WithParams;
+
+/** Interface for the shared L2 param. */
+public interface HasL2 extends WithParams {
+Param L_2 = new DoubleParam("l2", "The l2 param.", 0.1,
ParamValidators.gt(0.0));
Review Comment:
After some offline discussion, @weibozhao and I agree that we could reuse
the exising `HasReg` and `HasElasticNet` param, without introducing `HasL1` and
`HasL2`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on a diff in pull request #83: [FLINK-27170] Add Transformer and Estimator for OnlineLogisticRegression
zhipeng93 commented on code in PR #83:
URL: https://github.com/apache/flink-ml/pull/83#discussion_r868872809
##
flink-ml-lib/src/main/java/org/apache/flink/ml/common/param/HasL2.java:
##
@@ -0,0 +1,37 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.common.param;
+
+import org.apache.flink.ml.param.DoubleParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.WithParams;
+
+/** Interface for the shared L2 param. */
+public interface HasL2 extends WithParams {
+Param L_2 = new DoubleParam("l2", "The l2 param.", 0.1,
ParamValidators.gt(0.0));
Review Comment:
After some offline discussion, @weibozhao and I agree that we could reuse
the exising `HasReg` and `HasElasticNet` param, without introducing `HasL1` and
`HasL2` in this implementation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] alpreu commented on a diff in pull request #19655: [FLINK-27527] Create a file-based upsert sink for testing internal components
alpreu commented on code in PR #19655:
URL: https://github.com/apache/flink/pull/19655#discussion_r868873968
##
flink-connectors/flink-connector-upsert-test/src/main/java/org/apache/flink/connector/upserttest/sink/BinaryFileUtil.java:
##
@@ -0,0 +1,155 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connector.upserttest.sink;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.serialization.DeserializationSchema;
+
+import java.io.BufferedInputStream;
+import java.io.BufferedOutputStream;
+import java.io.File;
+import java.io.FileInputStream;
+import java.io.IOException;
+import java.nio.ByteBuffer;
+import java.util.HashMap;
+import java.util.Iterator;
+import java.util.Map;
+
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/** Collection uf utility methods for tests using the {@link UpsertTestSink}.
*/
+@Internal
+public class BinaryFileUtil {
+private static final byte MAGIC_BYTE = 13;
+
+/**
+ * Reads records that were written using the {@link
BinaryFileUtil#readRecords} method from the
+ * given InputStream.
+ *
+ * @param bis The BufferedInputStream to read from
+ * @return Map containing the read ByteBuffer key-value pairs
+ * @throws IOException
+ */
+public static Map readRecords(BufferedInputStream
bis)
+throws IOException {
+checkNotNull(bis);
+Map records = new HashMap<>();
Review Comment:
Where do you see this? The one I found is iterates through the contents
individual bytes:
```
public int hashCode() {
int h = 1;
int p = position();
for (int i = limit() - 1; i >= p; i--)
h = 31 * h + (int)get(i);
return h;
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] alpreu commented on a diff in pull request #19655: [FLINK-27527] Create a file-based upsert sink for testing internal components
alpreu commented on code in PR #19655:
URL: https://github.com/apache/flink/pull/19655#discussion_r868878917
##
flink-connectors/flink-connector-upsert-test/src/main/java/org/apache/flink/connector/upserttest/sink/BinaryFileUtil.java:
##
@@ -0,0 +1,155 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connector.upserttest.sink;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.serialization.DeserializationSchema;
+
+import java.io.BufferedInputStream;
+import java.io.BufferedOutputStream;
+import java.io.File;
+import java.io.FileInputStream;
+import java.io.IOException;
+import java.nio.ByteBuffer;
+import java.util.HashMap;
+import java.util.Iterator;
+import java.util.Map;
+
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/** Collection uf utility methods for tests using the {@link UpsertTestSink}.
*/
+@Internal
+public class BinaryFileUtil {
Review Comment:
I previously wanted to use the SimpleVersionedSerializer and
SimpleVersionedSerialization. However implementing this interface adds the same
kind of code we already have in place. Also the SimpleVersionedSerialization
only takes single byte arrays as input so then we would have to write another
method around that to allow both key and value as input. And finally it does
not provide a simple entrypoint for reading back all elements so I decided
against that
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-27557) Create the empty writer for 'ALTER TABLE ... COMPACT'
[
https://issues.apache.org/jira/browse/FLINK-27557?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534178#comment-17534178
]
Jingsong Lee commented on FLINK-27557:
--
Can we just use overwrite?
* overwrite specific manifest entries.
* overwrite whole table or some whole partition. (eg: when rescale in
compaction)
> Create the empty writer for 'ALTER TABLE ... COMPACT'
> -
>
> Key: FLINK-27557
> URL: https://issues.apache.org/jira/browse/FLINK-27557
> Project: Flink
> Issue Type: Sub-task
> Components: Table Store
>Affects Versions: table-store-0.2.0
>Reporter: Jane Chan
>Priority: Major
> Fix For: table-store-0.2.0
>
>
> Currently, FileStoreWrite only creates an empty writer for the \{{INSERT
> OVERWRITE}} clause. We should also create the empty writer for manual
> compaction.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] alpreu commented on a diff in pull request #19655: [FLINK-27527] Create a file-based upsert sink for testing internal components
alpreu commented on code in PR #19655:
URL: https://github.com/apache/flink/pull/19655#discussion_r868869814
##
flink-connectors/flink-connector-upsert-test/pom.xml:
##
@@ -0,0 +1,151 @@
+
+
+http://maven.apache.org/POM/4.0.0";
+xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
+xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd";>
+
+ flink-connectors
+ org.apache.flink
+ 1.16-SNAPSHOT
+
+ 4.0.0
+
+ flink-connector-upsert-test
+ Flink : Connectors : Upsert Test
+
+ jar
+
+
+
+
+
+
+ org.apache.flink
+ flink-connector-base
+ ${project.version}
+
+
+
+ org.apache.flink
+ flink-streaming-java
+ ${project.version}
+ provided
+
+
+
+ org.apache.flink
+ flink-table-api-java-bridge
+ ${project.version}
+ provided
+ true
+
+
+
+
+
+ org.apache.flink
+ flink-test-utils
+ ${project.version}
+ test
+
+
+
+ org.apache.flink
+ flink-connector-test-utils
+ ${project.version}
+ test
+
+
+
+ org.apache.flink
+ flink-streaming-java
+ ${project.version}
+ test-jar
+ test
+
+
+
+ org.apache.flink
+ flink-table-common
+ ${project.version}
+ test-jar
+ test
+
+
+
+ org.apache.flink
+
flink-table-planner_${scala.binary.version}
+ ${project.version}
+ test
+
+
+
+ org.apache.flink
+ flink-json
+ ${project.version}
+ test
+
+
+
+
+
+ org.apache.flink
+ flink-architecture-tests-test
+ test
+
+
+
+
+
+
+
+ org.apache.maven.plugins
+ maven-jar-plugin
+
+
+
+ test-jar
Review Comment:
Oops, missed that on copying over some pom details
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] snuyanzin commented on a diff in pull request #19667: [FLINK-27501][tests] Migrate SerializerTestBase to JUnit5
snuyanzin commented on code in PR #19667:
URL: https://github.com/apache/flink/pull/19667#discussion_r868869212
##
flink-core/src/test/java/org/apache/flink/api/java/typeutils/runtime/PojoSerializerTest.java:
##
@@ -48,10 +47,7 @@
import java.util.Objects;
import java.util.Random;
-import static org.hamcrest.CoreMatchers.instanceOf;
-import static org.hamcrest.MatcherAssert.assertThat;
-import static org.junit.Assert.assertEquals;
-import static org.junit.Assert.assertTrue;
+import static org.assertj.core.api.Assertions.assertThat;
/** A test for the {@link PojoSerializer}. */
public class PojoSerializerTest extends
SerializerTestBase {
Review Comment:
```suggestion
class PojoSerializerTest extends
SerializerTestBase {
```
?
\+ there are 3-4 more tests within this class which are public and could be
made as package-private (GitHub does not allow to comment on them since they
were not touched)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #116: [FLINK-27558] Introduce a new optional option for TableStoreFactory to represent planned manifest entries
JingsongLi commented on code in PR #116:
URL: https://github.com/apache/flink-table-store/pull/116#discussion_r868862749
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreFactoryOptions.java:
##
@@ -39,6 +39,14 @@ public class TableStoreFactoryOptions {
+ "By default, compaction does not adjust
the bucket number "
+ "of a partition/table.");
+public static final ConfigOption COMPACTION_SCANNED_MANIFEST =
Review Comment:
Add a internal annotation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #116: [FLINK-27558] Introduce a new optional option for TableStoreFactory to represent planned manifest entries
JingsongLi commented on code in PR #116:
URL: https://github.com/apache/flink-table-store/pull/116#discussion_r868862596
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreFactoryOptions.java:
##
@@ -39,6 +39,14 @@ public class TableStoreFactoryOptions {
+ "By default, compaction does not adjust
the bucket number "
+ "of a partition/table.");
+public static final ConfigOption COMPACTION_SCANNED_MANIFEST =
Review Comment:
Can you add format information in description? (how to serialize manifest
entry to string?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] snuyanzin commented on a diff in pull request #19667: [FLINK-27501][tests] Migrate SerializerTestBase to JUnit5
snuyanzin commented on code in PR #19667:
URL: https://github.com/apache/flink/pull/19667#discussion_r868862351
##
flink-core/src/test/java/org/apache/flink/api/common/typeutils/base/array/StringArraySerializerTest.java:
##
@@ -91,6 +91,6 @@ protected String[][] getTestData() {
@Test
public void arrayTypeIsMutable() {
Review Comment:
```suggestion
void arrayTypeIsMutable() {
```
##
flink-core/src/test/java/org/apache/flink/api/common/typeutils/base/array/StringArraySerializerTest.java:
##
@@ -91,6 +91,6 @@ protected String[][] getTestData() {
@Test
public void arrayTypeIsMutable() {
Review Comment:
```suggestion
void arrayTypeIsMutable() {
```
?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-ml] zhipeng93 commented on pull request #96: [hotfix] Bucketizer split point search
zhipeng93 commented on PR #96: URL: https://github.com/apache/flink-ml/pull/96#issuecomment-1121980771 Thanks for the fix @mumuhhh ! LGTM. Two minor comments: - Could you add a unit test that the number of inputCols is not the same as number splits? - Could you re-polish the commit message, such as `[hotfix] Fix finding buckets error in Bucketizer`? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-27558) Introduce a new optional option for TableStoreFactory to represent planned manifest entries
[
https://issues.apache.org/jira/browse/FLINK-27558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee reassigned FLINK-27558:
Assignee: Jane Chan
> Introduce a new optional option for TableStoreFactory to represent planned
> manifest entries
> ---
>
> Key: FLINK-27558
> URL: https://issues.apache.org/jira/browse/FLINK-27558
> Project: Flink
> Issue Type: Sub-task
> Components: Table Store
>Affects Versions: table-store-0.2.0
>Reporter: Jane Chan
>Assignee: Jane Chan
>Priority: Major
> Labels: pull-request-available
> Fix For: table-store-0.2.0
>
>
> When
> {code:java}
> TableStoreFactory.onCompactTable
> {code}
> gets called, the planned manifest entries need to be injected back into the
> enriched options, and we need a new key to represent it.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] wangyang0918 commented on pull request #19675: [FLINK-27550] Remove checking yarn queues before submitting job to Yarn
wangyang0918 commented on PR #19675: URL: https://github.com/apache/flink/pull/19675#issuecomment-1121972802 Maybe we could check the scheduler type first. If it is capacity scheduler, `checkYarnQueues` only takes the leaf queue name. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27498) Add E2E tests to cover Flink 1.15
[ https://issues.apache.org/jira/browse/FLINK-27498?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534160#comment-17534160 ] Yang Wang commented on FLINK-27498: --- We could close this ticket since it is already covered by FLINK-27412. Now the e2e tests are run against with 1.13, 1.14, 1.15. > Add E2E tests to cover Flink 1.15 > - > > Key: FLINK-27498 > URL: https://issues.apache.org/jira/browse/FLINK-27498 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.0.0 >Reporter: Gyula Fora >Priority: Blocker > > We should extend our e2e test coverage to test all supported Flink versions, > initially that will be 1.14 and 1.15 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Closed] (FLINK-27412) Allow flinkVersion v1_13 in flink-kubernetes-operator
[ https://issues.apache.org/jira/browse/FLINK-27412?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yang Wang closed FLINK-27412. - Resolution: Fixed Fixed via: main: 6ce3d96937849c70e00ef5f3837bc08ed31d9952 ab1893c61adddb580116186500297cb954f6f6cc > Allow flinkVersion v1_13 in flink-kubernetes-operator > - > > Key: FLINK-27412 > URL: https://issues.apache.org/jira/browse/FLINK-27412 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Yang Wang >Assignee: Nicholas Jiang >Priority: Critical > Labels: pull-request-available, starter > Fix For: kubernetes-operator-1.0.0 > > > The core k8s related features: > * native k8s integration for session cluster, 1.10 > * native k8s integration for application cluster, 1.11 > * Flink K8s HA, 1.12 > * pod template, 1.13 > So we could set required the minimum version to 1.13. This will allow more > users to have a try on flink-kubernetes-operator. > > BTW, we need to update the e2e tests to cover all the supported versions. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-kubernetes-operator] wangyang0918 merged pull request #197: [FLINK-27412] Allow flinkVersion v1_13 in flink-kubernetes-operator
wangyang0918 merged PR #197: URL: https://github.com/apache/flink-kubernetes-operator/pull/197 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27495) Observer should update last savepoint information directly from cluster too
[ https://issues.apache.org/jira/browse/FLINK-27495?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534153#comment-17534153 ] Gyula Fora commented on FLINK-27495: [~thw] you are completely right. This is specifically intended to cover the case when the job goes into a globally terminal state and HA data is cleaned up: - Job has been cancelled with a savepoint (but maybe the operator failed before recording the final savepoint after the rest call) - Job fatally failed for any reason (restart strat exhausted, user throws restart supress error etc.) - Job Finishes You are right that in other cases this does not bring any value in terms of recording checkpoints so I will probably change the logic to only execute in terminal states. > Observer should update last savepoint information directly from cluster too > --- > > Key: FLINK-27495 > URL: https://issues.apache.org/jira/browse/FLINK-27495 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.0.0 >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Critical > > The observer should fetch the list checkpoints from the observed job and > store the last savepoint into the status directly. > This is especially useful for terminal job states in Flink 1.15 as it allows > us to avoid cornercases such as the operator failing after calling > cancel-with-savepoint but before updating the status. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27551) Consider implementing our own status update logic
[
https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534152#comment-17534152
]
Yang Wang commented on FLINK-27551:
---
I agree with you that we could have our own status update logic. How to deal
with the {{updateErrorStatus}}?
> Consider implementing our own status update logic
> -
>
> Key: FLINK-27551
> URL: https://issues.apache.org/jira/browse/FLINK-27551
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: Gyula Fora
>Assignee: Gyula Fora
>Priority: Critical
>
> If a custom resource version is applied while in the middle of a reconcile
> loop (for the same resource but previous version) the status update will
> throw an error and re-trigger reconciliation.
> In our case this might be problematic as it would mean we would retry
> operations that are not necessarily retriable and might require manual user
> intervention.
> Please see:
> [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198]
> I think we should consider implementing our own status update logic that is
> independent of the current resource version to make the flow more robust.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] zuston commented on pull request #19675: [FLINK-27550] Remove checking yarn queues before submitting job to Yarn
zuston commented on PR #19675: URL: https://github.com/apache/flink/pull/19675#issuecomment-1121953341 > IIRC, the leaf queue name in capacity scheduler should be unique, which means you could use `-Dyarn.application.queue=streaming/batch`. However, for fair scheduler, you need to specify a full path queue name. All in all, I do not think the `checkYarnQueues` is useless. However, the full queue name also can be used in capacity scheduler, but the method of `checkYarnQueues` can't be compatible with this. @wangyang0918 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-23143) Support state migration
[ https://issues.apache.org/jira/browse/FLINK-23143?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534149#comment-17534149 ] Hangxiang Yu commented on FLINK-23143: -- > I like the simplicity of your solution, but I think the concern I expressed > above (about creation of multiple state objects) is valid. The added methods we implement just mock what we do when restore (from rocksdb or hashmap). They will judge before adding new state. And judging will also works when users access. (We don't implement them by createInternalState) So I think it's not a problem ? > Besides that, RegisteredKeyValueStateBackendMetaInfo seems implementation > detail of a state backend, so it shouldn't be exposed. You are right. Maybe we could introduce a new more universal class to wrap these information, WDYT? > Regarding the key serializer upgrade, I think it's [not > supported|https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/fault-tolerance/serialization/schema_evolution/] > currently and therefore is out of the scope of this ticket. I agree. But we haven't implement the logic of compatibility check for key serializer as you could see in rocksdb and heap. What I describe above about key serializer is the difficulty of implementing the logic of compatibility check for key serializer. It will also works even if we lack it. Do you think it doesn't matter ? > Support state migration > --- > > Key: FLINK-23143 > URL: https://issues.apache.org/jira/browse/FLINK-23143 > Project: Flink > Issue Type: Sub-task > Components: Runtime / State Backends >Reporter: Roman Khachatryan >Priority: Minor > Labels: pull-request-available > Fix For: 1.16.0 > > > ChangelogKeyedStateBackend.getOrCreateKeyedState is currently used during > recovery; on 1st user access, it doesn't update metadata nor migrate state > (as opposed to other backends). > > The proposed solution is to > # wrap serializers (and maybe other objects) in getOrCreateKeyedState > # store wrapping objects in a new map keyed by state name > # pass wrapped objects to delegatedBackend.createInternalState > # on 1st user access, lookup wrapper and upgrade its wrapped serializer > This should be done for both KV/PQ states. > > See also [https://github.com/apache/flink/pull/15420#discussion_r656934791] > > cc: [~yunta] -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: Hmm, this is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut` teamed up with `numRecordsSend` and `numRecordsSendErrors`. 3. the information of using `numRecordsSend` has been described in the first part. From now on, it is actually mandatory for connector developers to use all of them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for details. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Even with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut` teamed up with `numRecordsSend` and `numRecordsSendErrors`. 3. the information of using `numRecordsSend` has been described in the first part. From now on, it is actually mandatory for connector developers to use all of them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for details. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Even with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut` teamed up with `numRecordsSend` and `numRecordsSendErrors`. 3. the information of using `numRecordsSend` has been described in the first part. From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for details. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Even with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27495) Observer should update last savepoint information directly from cluster too
[ https://issues.apache.org/jira/browse/FLINK-27495?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534131#comment-17534131 ] Thomas Weise commented on FLINK-27495: -- [~gyfora] is this for the case of a successfully completed job when the HA store was already removed? In other cases when the job isn't healthy the REST API may also be unavailable. And if we rely on polling the REST API, we may miss the latest checkpoint? Isn't reading from the HA store at the time when the path is required the only reliable method? > Observer should update last savepoint information directly from cluster too > --- > > Key: FLINK-27495 > URL: https://issues.apache.org/jira/browse/FLINK-27495 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.0.0 >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Critical > > The observer should fetch the list checkpoints from the observed job and > store the last savepoint into the status directly. > This is especially useful for terminal job states in Flink 1.15 as it allows > us to avoid cornercases such as the operator failing after calling > cancel-with-savepoint but before updating the status. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] fredia commented on pull request #19502: [FLINK-27260][Runtime/REST] Expose changelog configurations in Rest API and Web UI
fredia commented on PR #19502: URL: https://github.com/apache/flink/pull/19502#issuecomment-1121904893 Sure. I run `SocketWindowWordCount` to get WEB UI. Here are pictures: - when changelog enable, display `changelog_storage` and `changelog_periodic_materialization_interval` in checkpoint configuration tab: 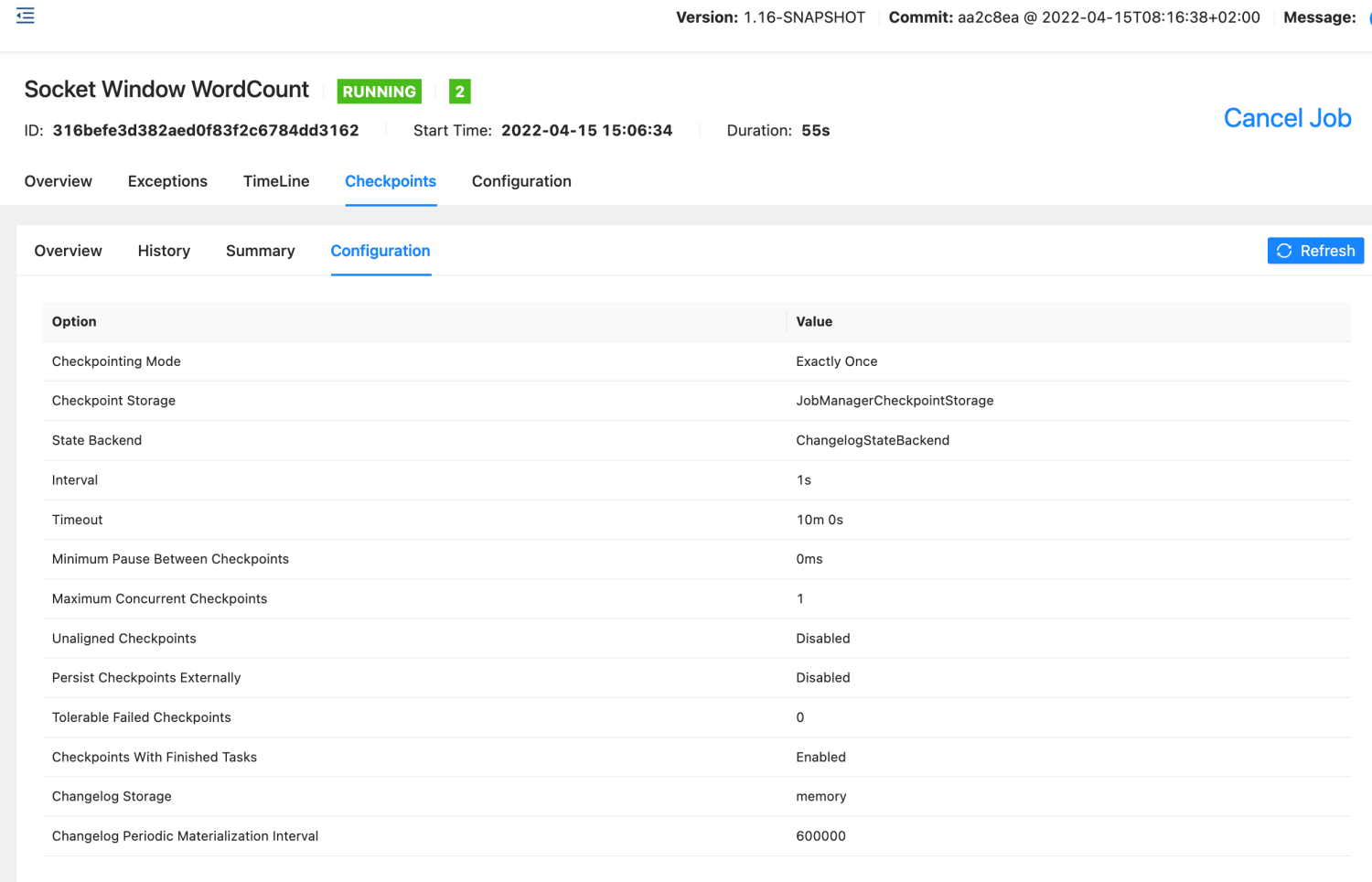 - when changelog disable, don't show `changelog_storage` and `changelog_periodic_materialization_interval`: 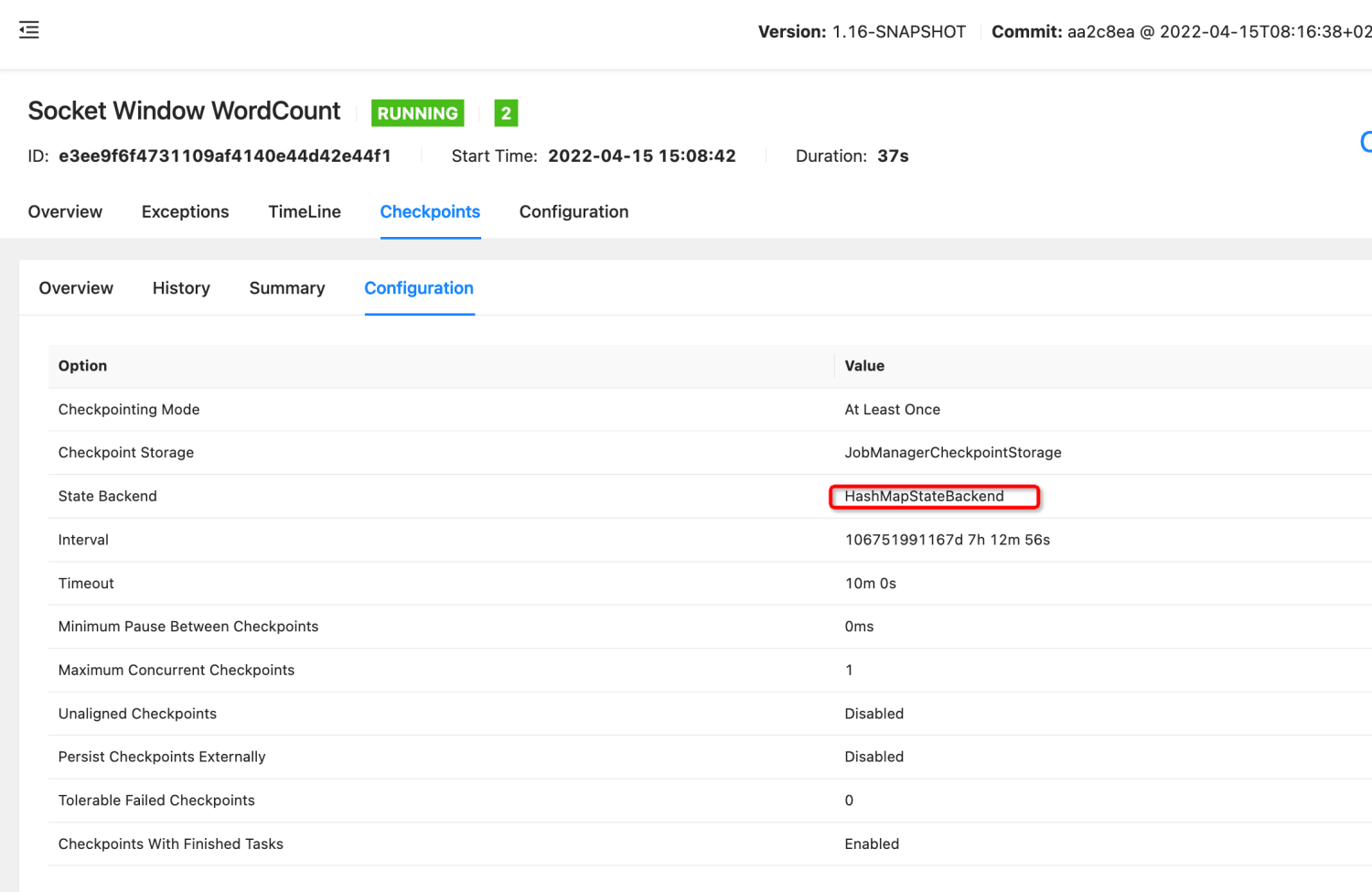 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] (FLINK-27555) Performance regression in schedulingDownstreamTasks on 02.05.2022
[ https://issues.apache.org/jira/browse/FLINK-27555 ] Guowei Ma deleted comment on FLINK-27555: --- was (Author: maguowei): Thanks [~roman] for letting this. I notice that [~zhuzh] have make some changed recently. So would you like to have a look! > Performance regression in schedulingDownstreamTasks on 02.05.2022 > - > > Key: FLINK-27555 > URL: https://issues.apache.org/jira/browse/FLINK-27555 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Coordination >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-33-11.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=5&ben=schedulingDownstreamTasks.BATCH&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27555) Performance regression in schedulingDownstreamTasks on 02.05.2022
[ https://issues.apache.org/jira/browse/FLINK-27555?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534120#comment-17534120 ] Guowei Ma commented on FLINK-27555: --- Thanks [~roman] for letting this. I notice that [~zhuzh] have make some changed recently. So would you like to have a look! > Performance regression in schedulingDownstreamTasks on 02.05.2022 > - > > Key: FLINK-27555 > URL: https://issues.apache.org/jira/browse/FLINK-27555 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Coordination >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-33-11.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=5&ben=schedulingDownstreamTasks.BATCH&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27555) Performance regression in schedulingDownstreamTasks on 02.05.2022
[ https://issues.apache.org/jira/browse/FLINK-27555?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534119#comment-17534119 ] Zhu Zhu commented on FLINK-27555: - This benchmark result is how much time it takes to do the scheduling. Therefore, it is actually an improvement instead of a regression. The improvement is caused by FLINK-27460 which removed some logics which are no longer needed. I can see it is the description on the left of the dashboard that is causing the confusion. But I'm not sure whether there is a way to change the description for certain benchmarks to clearly show that it is "Time cost (less is better)". > Performance regression in schedulingDownstreamTasks on 02.05.2022 > - > > Key: FLINK-27555 > URL: https://issues.apache.org/jira/browse/FLINK-27555 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Coordination >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-33-11.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=5&ben=schedulingDownstreamTasks.BATCH&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-ml] weibozhao commented on a diff in pull request #83: [FLINK-27170] Add Transformer and Estimator for OnlineLogisticRegression
weibozhao commented on code in PR #83:
URL: https://github.com/apache/flink-ml/pull/83#discussion_r868785218
##
flink-ml-lib/src/test/java/org/apache/flink/ml/classification/OnlineLogisticRegressionTest.java:
##
@@ -0,0 +1,444 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.classification;
+
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.restartstrategy.RestartStrategies;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.common.typeinfo.Types;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.configuration.Configuration;
+import
org.apache.flink.ml.classification.logisticregression.LogisticRegression;
+import
org.apache.flink.ml.classification.logisticregression.OnlineLogisticRegression;
+import
org.apache.flink.ml.classification.logisticregression.OnlineLogisticRegressionModel;
+import org.apache.flink.ml.feature.MinMaxScalerTest;
+import org.apache.flink.ml.linalg.DenseVector;
+import org.apache.flink.ml.linalg.SparseVector;
+import org.apache.flink.ml.linalg.Vectors;
+import org.apache.flink.ml.util.StageTestUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import
org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.streaming.api.functions.source.SourceFunction;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.table.api.internal.TableImpl;
+import org.apache.flink.test.util.AbstractTestBase;
+import org.apache.flink.types.Row;
+
+import org.apache.commons.collections.IteratorUtils;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import static junit.framework.TestCase.assertEquals;
+
+/** Tests {@link OnlineLogisticRegression} and {@link
OnlineLogisticRegressionModel}. */
+public class OnlineLogisticRegressionTest extends AbstractTestBase {
+@Rule public final TemporaryFolder tempFolder = new TemporaryFolder();
+private StreamExecutionEnvironment env;
+private StreamTableEnvironment tEnv;
+private Table trainDenseTable;
+private static final String LABEL_COL = "label";
+private static final String PREDICT_COL = "prediction";
+private static final String FEATURE_COL = "features";
+private static final String MODEL_VERSION_COL = "modelVersion";
+private static final double[] ONE_ARRAY = new double[] {1.0, 1.0, 1.0};
+private static final List TRAIN_DENSE_ROWS =
+Arrays.asList(
+Row.of(Vectors.dense(0.1, 2.), 0.),
+Row.of(Vectors.dense(0.2, 2.), 0.),
+Row.of(Vectors.dense(0.3, 2.), 0.),
+Row.of(Vectors.dense(0.4, 2.), 0.),
+Row.of(Vectors.dense(0.5, 2.), 0.),
+Row.of(Vectors.dense(11., 12.), 1.),
+Row.of(Vectors.dense(12., 11.), 1.),
+Row.of(Vectors.dense(13., 12.), 1.),
+Row.of(Vectors.dense(14., 12.), 1.),
+Row.of(Vectors.dense(15., 12.), 1.));
+
+private static final List PREDICT_DENSE_ROWS =
+Arrays.asList(
+Row.of(Vectors.dense(0.8, 2.7), 0.),
+Row.of(Vectors.dense(0.8, 2.4), 0.),
+Row.of(Vectors.dense(0.7, 2.3), 0.),
+Row.of(Vectors.dense(0.4, 2.7), 0.),
+Row.of(Vectors.dense(0.5, 2.8), 0.),
+Row.of(Vectors.dense(10.2, 12.1), 1.),
+Row.of(Vectors.dense(13.3, 13.1), 1.),
+Row.of(Vectors.dense(13.5, 12.2), 1.),
+Row.of(Vectors.dense(14.9, 12.5), 1.),
+Row.of(Vectors.dense(15.5, 11.2), 1.));
+
+private sta
[GitHub] [flink] wangyang0918 commented on pull request #19675: [FLINK-27550] Remove checking yarn queues before submitting job to Yarn
wangyang0918 commented on PR #19675: URL: https://github.com/apache/flink/pull/19675#issuecomment-1121849688 IIRC, the leaf queue name in capacity scheduler should be unique, which means you could use `-Dyarn.application.queue=streaming/batch`. However, for fair scheduler, you need to specify a full path queue name. All in all, I do not think the `checkYarnQueues` is useless. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
LadyForest commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868777111
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -182,4 +219,102 @@ public FileStoreSourceSplitSerializer
getSplitSerializer() {
public PendingSplitsCheckpointSerializer
getEnumeratorCheckpointSerializer() {
return new PendingSplitsCheckpointSerializer(getSplitSerializer());
}
+
+private void writeObject(ObjectOutputStream out) throws IOException {
+out.defaultWriteObject();
+if (specifiedManifestEntries != null) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+DataOutputViewStreamWrapper view = new
DataOutputViewStreamWrapper(out);
+view.writeInt(specifiedManifestEntries.size());
+for (Map.Entry>>
partEntry :
+specifiedManifestEntries.entrySet()) {
+partSerializer.serialize(partEntry.getKey(), view);
+Map> bucketEntry =
partEntry.getValue();
+view.writeInt(bucketEntry.size());
+for (Map.Entry> entry :
bucketEntry.entrySet()) {
+view.writeInt(entry.getKey());
+view.writeInt(entry.getValue().size());
+for (DataFileMeta meta : entry.getValue()) {
+metaSerializer.serialize(meta, view);
+}
+}
+}
+}
+}
+
+private void readObject(ObjectInputStream in) throws IOException,
ClassNotFoundException {
+in.defaultReadObject();
+if (in.available() > 0) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+DataInputViewStreamWrapper view = new
DataInputViewStreamWrapper(in);
+specifiedManifestEntries = new HashMap<>();
+int partitionCtr = view.readInt();
Review Comment:
> What's the meaning of suffix ctr ? partition number or partition count ?
So why not just use partitionNum ?
`ctr` is abbr. for the counter, stands for the size of the
`Map>>` .
(>). Put `ctr` as a suffix is due to this
value is mutable, while `partitionNum` should be a kind of immutable concept I
think. Do you feel this is better?
```java
int partitionNum = view.readInt();
int partitionCtr = partitionNum;
while(partitionCtr > 0) {
...
partitionCtr--;
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on a diff in pull request #197: [FLINK-27412] Allow flinkVersion v1_13 in flink-kubernetes-operator
wangyang0918 commented on code in PR #197: URL: https://github.com/apache/flink-kubernetes-operator/pull/197#discussion_r868774483 ## e2e-tests/data/sessionjob-cr.yaml: ## @@ -22,8 +22,8 @@ metadata: namespace: default name: session-cluster-1 spec: - image: flink:1.14.3 - flinkVersion: v1_14 + image: flink:1. Review Comment: I got it. It is due to the `sed`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] mumuhhh opened a new pull request, #96: [hotfix] Bucketizer split point search
mumuhhh opened a new pull request, #96: URL: https://github.com/apache/flink-ml/pull/96 Using variable repair -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on a diff in pull request #197: [FLINK-27412] Allow flinkVersion v1_13 in flink-kubernetes-operator
wangyang0918 commented on code in PR #197: URL: https://github.com/apache/flink-kubernetes-operator/pull/197#discussion_r868772741 ## e2e-tests/data/sessionjob-cr.yaml: ## @@ -22,8 +22,8 @@ metadata: namespace: default name: session-cluster-1 spec: - image: flink:1.14.3 - flinkVersion: v1_14 + image: flink:1. Review Comment: Same as above. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on a diff in pull request #197: [FLINK-27412] Allow flinkVersion v1_13 in flink-kubernetes-operator
wangyang0918 commented on code in PR #197: URL: https://github.com/apache/flink-kubernetes-operator/pull/197#discussion_r868772648 ## e2e-tests/data/flinkdep-cr.yaml: ## @@ -22,8 +22,8 @@ metadata: namespace: default name: flink-example-statemachine spec: - image: flink:1.14.3 - flinkVersion: v1_14 + image: flink:1. + flinkVersion: v1_ Review Comment: It is strange that the e2e test does not fail with this typo. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
LadyForest commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868771446
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -122,6 +150,17 @@ public SplitEnumerator restoreEnu
SplitEnumeratorContext context,
PendingSplitsCheckpoint checkpoint) {
FileStoreScan scan = fileStore.newScan();
+Long snapshotId;
+Collection splits;
+if (specifiedSnapshotId != null) {
+Preconditions.checkNotNull(
+specifiedManifestEntries,
+"The manifest entries cannot be null for manual
compaction.");
Review Comment:
Let me give a detailed explanation about
> `ALTER TABLE ... COMPACT` will pre-scan the latest snapshot during the
planning phase
`ALTER TABLE ... COMPACT` will be first converted to a `SinkModifyOperation`
with `SourceQueryOperation` as the only child (on the Flink side). And then the
`ManagedTableFactory#onCompactTable` is invoked, the impl(back to the
TableStore) will perform a scan, collect manifest entries and the corresponding
snapshot id, and serialize as a string. It will be put back to enriched
options. So at the runtime, when the source is initialized, the splits can be
directly generated from the options. This PR aims to pave the way for skipping
runtime scans for this condition.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
LadyForest commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868771446
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -122,6 +150,17 @@ public SplitEnumerator restoreEnu
SplitEnumeratorContext context,
PendingSplitsCheckpoint checkpoint) {
FileStoreScan scan = fileStore.newScan();
+Long snapshotId;
+Collection splits;
+if (specifiedSnapshotId != null) {
+Preconditions.checkNotNull(
+specifiedManifestEntries,
+"The manifest entries cannot be null for manual
compaction.");
Review Comment:
Let me give a detailed explanation about
> `ALTER TABLE ... COMPACT` will pre-scan the latest snapshot during the
planning phase
`ALTER TABLE ... COMPACT` will be first converted to a `SinkModifyOperation`
with `SourceQueryOperation` as the only child (on the Flink side). And then the
`ManagedTableFactory#onCompactTable` is invoked, the impl(back to the
TableStore) will perform a scan, collected manifest entries and the
corresponding snapshot id, and serialized as a string. It will be put back to
enriched options. So at the runtime, when the source is initialized, the splits
can be directly generated from the options. This PR aims to pave the way for
skipping runtime scans for this condition.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-27504) State compaction not happening with sliding window and incremental RocksDB backend
[ https://issues.apache.org/jira/browse/FLINK-27504?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534105#comment-17534105 ] Yun Tang commented on FLINK-27504: -- I think you'd better to read RocksDB docs on compaction to know how RocksDB trigger compaction at each level: https://github.com/facebook/rocksdb/wiki/Leveled-Compaction The number of levels is not important in your case. As I said above, this is more related with the implementation of RocksDB instead of Flink. For the state size, I think refer to the metrics of [total-sst-files-size|https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/config/#state-backend-rocksdb-metrics-total-sst-files-size] is much more accurate. > State compaction not happening with sliding window and incremental RocksDB > backend > -- > > Key: FLINK-27504 > URL: https://issues.apache.org/jira/browse/FLINK-27504 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Affects Versions: 1.14.4 > Environment: Local Flink cluster on Arch Linux. >Reporter: Alexis Sarda-Espinosa >Priority: Major > Attachments: duration_trend_52ca77c.png, duration_trend_67c76bb.png, > image-2022-05-06-10-34-35-007.png, size_growth_52ca77c.png, > size_growth_67c76bb.png > > > Hello, > I'm trying to estimate an upper bound for RocksDB's state size in my > application. For that purpose, I have created a small job with faster timings > whose code you can find on GitHub: > [https://github.com/asardaes/flink-rocksdb-ttl-test]. You can see some of the > results there, but I summarize here as well: > * Approximately 20 events per second, 10 unique keys for partitioning are > pre-specified. > * Sliding window of 11 seconds with a 1-second slide. > * Allowed lateness of 11 seconds. > * State TTL configured to 1 minute and compaction after 1000 entries. > * Both window-specific and window-global state used. > * Checkpoints every 2 seconds. > * Parallelism of 4 in stateful tasks. > The goal is to let the job run and analyze state compaction behavior with > RocksDB. I should note that global state is cleaned manually inside the > functions, TTL for those is in case some keys are no longer seen in the > actual production environment. > I have been running the job on a local cluster (outside IDE), the > configuration YAML is also available in the repository. After running for > approximately 1.6 days, state size is currently 2.3 GiB (see attachments). I > understand state can retain expired data for a while, but since TTL is 1 > minute, this seems excessive to me. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-web] JingsongLi commented on a diff in pull request #531: Add Table Store 0.1.0 release
JingsongLi commented on code in PR #531:
URL: https://github.com/apache/flink-web/pull/531#discussion_r868769686
##
_posts/2022-05-01-release-table-store-0.1.0.md:
##
@@ -0,0 +1,110 @@
+---
+layout: post
+title: "Apache Flink Table Store 0.1.0 Release Announcement"
+subtitle: "Unified streaming and batch store for building dynamic tables on
Apache Flink."
+date: 2022-05-01T08:00:00.000Z
+categories: news
+authors:
+- Jingsong Lee:
+ name: "Jingsong Lee"
+
+---
+
+The Apache Flink community is pleased to announce the preview release of the
+[Apache Flink Table Store](https://github.com/apache/flink-table-store)
(0.1.0).
+
+Flink Table Store is a unified streaming and batch store for building dynamic
tables
+on Apache Flink. It uses a full Log-Structured Merge-Tree (LSM) structure for
high speed
+and a large amount of data update & query capability.
+
+Please check out the full
[documentation]({{site.DOCS_BASE_URL}}flink-table-store-docs-release-0.1/) for
detailed information and user guides.
+
+Note: Flink Table Store is still in beta status and undergoing rapid
development,
+we do not recommend that you use it directly in a production environment.
+
+## What is Flink Table Store
+
+Open [Flink official website](https://flink.apache.org/), you can see the
following line:
+`Apache Flink - Stateful Computations over Data Streams.` Flink focuses on
distributed computing,
+which brings real-time big data computing. Users need to combine Flink with
some kind of external storage.
+
+The message queue will be used in both source & intermediate stages in
streaming pipeline, to guarantee the
+latency stay within seconds. There will also be a real-time OLAP system
receiving processed data in streaming
+fashion and serving user’s ad-hoc queries.
+
+Everything works fine as long as users only care about the aggregated results.
But when users start to care
+about the intermediate data, they will immediately hit a blocker: Intermediate
kafka tables are not queryable.
+
+Therefore, users use multiple systems. Writing to a lake store like Apache
Hudi, Apache Iceberg while writing to Queue,
+the lake store keeps historical data at a lower cost.
+
+There are two main issues with doing this:
+- High understanding bar for users: It’s also not easy for users to understand
all the SQL connectors,
+ learn the capabilities and restrictions for each of those. Users may also
want to play around with
+ streaming & batch unification, but don't really know how, given the
connectors are most of the time different
+ in batch and streaming use cases.
+- Increasing architecture complexity: It’s hard to choose the most suited
external systems when the requirements
+ include streaming pipelines, offline batch jobs, ad-hoc queries. Multiple
systems will increase the operation
+ and maintenance complexity. Users at least need to coordinate between the
queue system and file system of each
+ table, which is error-prone.
+
+The Flink Table Store aims to provide a unified storage abstraction:
+- Table Store provides storage of historical data while providing queue
abstraction.
+- Table Store provides competitive historical storage with lake storage
capability, using LSM file structure
+ to store data on DFS, providing real-time updates and queries at a lower
cost.
Review Comment:
> I think the object storage is also another kind of DFS...
Yes, I think too... we can also add more description
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (FLINK-27559) Some question about flink operator state
[ https://issues.apache.org/jira/browse/FLINK-27559?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yun Tang closed FLINK-27559. Resolution: Information Provided > Some question about flink operator state > > > Key: FLINK-27559 > URL: https://issues.apache.org/jira/browse/FLINK-27559 > Project: Flink > Issue Type: New Feature > Environment: Flink 1.14.4 >Reporter: Underwood >Priority: Major > > I hope to get two answers to Flink's maintenance status: > > 1. Does custompartition support saving status? In my usage scenario, the > partition strategy is dynamically adjusted, which depends on the data in > datastream. I hope to make different partition strategies according to > different data conditions. > > For a simple example, I want the first 100 pieces of data in datastream to be > range partitioned and the rest of the data to be hash partitioned. At this > time, I may need a count to identify the number of pieces of data that have > been processed. However, in custompartition, this is only a local variable, > so there seem to be two problems: declaring variables in this way can only be > used in single concurrency, and it seems that they cannot be counted across > slots; In this way, the count data will be lost during fault recovery. > > Although Flink already has operator state and key value state, > custompartition is not an operator, so I don't think it can solve this > problem through state. I've considered introducing a zookeeper to save the > state, but the introduction of new components will make the system bloated. I > don't know whether there is a better way to solve this problem. > > 2. How to make multiple operators share the same state, and even all parallel > subtasks of different operators share the same state? > > For a simple example, my stream processing is divided into four stages: > source - > mapa - > mapb - > sink. I hope to have a status count to count the > total amount of data processed by all operators. For example, if the source > receives one piece of data, then count + 1 when mapa is processed and count + > 1 when mapb is processed. Finally, after this piece of data is processed, the > value of count is 2. > > I don't know if there is such a state saving mechanism in Flink, which can > meet my scenario and recover from failure at the same time. At present, we > can still think of using zookeeper. I don't know if there is a better way. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27559) Some question about flink operator state
[ https://issues.apache.org/jira/browse/FLINK-27559?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534103#comment-17534103 ] Yun Tang commented on FLINK-27559: -- [~Underwood] Flink's JIRA is not a place to ask questions, please ask these questions in the mailing list: https://flink.apache.org/community.html#mailing-lists > Some question about flink operator state > > > Key: FLINK-27559 > URL: https://issues.apache.org/jira/browse/FLINK-27559 > Project: Flink > Issue Type: New Feature > Environment: Flink 1.14.4 >Reporter: Underwood >Priority: Major > > I hope to get two answers to Flink's maintenance status: > > 1. Does custompartition support saving status? In my usage scenario, the > partition strategy is dynamically adjusted, which depends on the data in > datastream. I hope to make different partition strategies according to > different data conditions. > > For a simple example, I want the first 100 pieces of data in datastream to be > range partitioned and the rest of the data to be hash partitioned. At this > time, I may need a count to identify the number of pieces of data that have > been processed. However, in custompartition, this is only a local variable, > so there seem to be two problems: declaring variables in this way can only be > used in single concurrency, and it seems that they cannot be counted across > slots; In this way, the count data will be lost during fault recovery. > > Although Flink already has operator state and key value state, > custompartition is not an operator, so I don't think it can solve this > problem through state. I've considered introducing a zookeeper to save the > state, but the introduction of new components will make the system bloated. I > don't know whether there is a better way to solve this problem. > > 2. How to make multiple operators share the same state, and even all parallel > subtasks of different operators share the same state? > > For a simple example, my stream processing is divided into four stages: > source - > mapa - > mapb - > sink. I hope to have a status count to count the > total amount of data processed by all operators. For example, if the source > receives one piece of data, then count + 1 when mapa is processed and count + > 1 when mapb is processed. Finally, after this piece of data is processed, the > value of count is 2. > > I don't know if there is such a state saving mechanism in Flink, which can > meet my scenario and recover from failure at the same time. At present, we > can still think of using zookeeper. I don't know if there is a better way. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (FLINK-27560) Refactor SimpleStateRequestHandler for PyFlink state
Juntao Hu created FLINK-27560: - Summary: Refactor SimpleStateRequestHandler for PyFlink state Key: FLINK-27560 URL: https://issues.apache.org/jira/browse/FLINK-27560 Project: Flink Issue Type: Improvement Components: API / Python Affects Versions: 1.15.0 Reporter: Juntao Hu Fix For: 1.16.0 Currently SimpleStateRequestHandler.java for handling beam state request from python side is coupled with keyed-state logic, which could be refactored to reduce code duplication when implementing operator state (list/broadcast state can be fit into bag/map logic). -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
LadyForest commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868767988
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -182,4 +219,102 @@ public FileStoreSourceSplitSerializer
getSplitSerializer() {
public PendingSplitsCheckpointSerializer
getEnumeratorCheckpointSerializer() {
return new PendingSplitsCheckpointSerializer(getSplitSerializer());
}
+
+private void writeObject(ObjectOutputStream out) throws IOException {
+out.defaultWriteObject();
+if (specifiedManifestEntries != null) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+DataOutputViewStreamWrapper view = new
DataOutputViewStreamWrapper(out);
+view.writeInt(specifiedManifestEntries.size());
+for (Map.Entry>>
partEntry :
+specifiedManifestEntries.entrySet()) {
+partSerializer.serialize(partEntry.getKey(), view);
+Map> bucketEntry =
partEntry.getValue();
+view.writeInt(bucketEntry.size());
+for (Map.Entry> entry :
bucketEntry.entrySet()) {
+view.writeInt(entry.getKey());
+view.writeInt(entry.getValue().size());
+for (DataFileMeta meta : entry.getValue()) {
+metaSerializer.serialize(meta, view);
+}
+}
+}
+}
+}
+
+private void readObject(ObjectInputStream in) throws IOException,
ClassNotFoundException {
+in.defaultReadObject();
+if (in.available() > 0) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+DataInputViewStreamWrapper view = new
DataInputViewStreamWrapper(in);
+specifiedManifestEntries = new HashMap<>();
+int partitionCtr = view.readInt();
+while (partitionCtr > 0) {
+BinaryRowData partition = partSerializer.deserialize(view);
+Map> bucketEntry = new HashMap<>();
+int bucketCtr = view.readInt();
+while (bucketCtr > 0) {
+int bucket = view.readInt();
+int entryCtr = view.readInt();
+if (entryCtr == 0) {
+bucketEntry.put(bucket, Collections.emptyList());
+} else {
+List metas = new ArrayList<>();
+while (entryCtr > 0) {
+metas.add(metaSerializer.deserialize(view));
+entryCtr--;
+}
+bucketEntry.put(bucket, metas);
+}
+bucketCtr--;
+}
+specifiedManifestEntries.put(partition, bucketEntry);
+partitionCtr--;
+}
+}
+}
+
+@Override
+public boolean equals(Object o) {
+if (this == o) {
+return true;
+}
+if (!(o instanceof FileStoreSource)) {
+return false;
+}
+FileStoreSource that = (FileStoreSource) o;
+return valueCountMode == that.valueCountMode
+&& isContinuous == that.isContinuous
+&& discoveryInterval == that.discoveryInterval
+&& latestContinuous == that.latestContinuous
+&& fileStore.equals(that.fileStore)
+&& Arrays.equals(projectedFields, that.projectedFields)
Review Comment:
Thanks for the reporting. This code snippet is auto-generated by Intellij. I
should check more carefully. Blame on me, and I'll fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] Myasuka commented on pull request #19502: [FLINK-27260][Runtime/REST] Expose changelog configurations in Rest API and Web UI
Myasuka commented on PR #19502: URL: https://github.com/apache/flink/pull/19502#issuecomment-1121834299 @fredia would you please share the picture that how the UI looks like with this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
LadyForest commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868767378
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -69,7 +92,10 @@ public FileStoreSource(
boolean latestContinuous,
@Nullable int[][] projectedFields,
@Nullable Predicate partitionPredicate,
-@Nullable Predicate fieldPredicate) {
+@Nullable Predicate fieldPredicate,
+@Nullable Long specifiedSnapshotId,
+@Nullable
+Map>>
specifiedManifestEntries) {
Review Comment:
> What's the case that we will set those two fields with non-null values ? I
see all of them will be set to be `null` in the `buildFileStore`.
For `ALTER TABLE ... COMPACT`, the `buildFileStore` will be modified in the
following PR
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
LadyForest commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868767106
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -122,6 +150,17 @@ public SplitEnumerator restoreEnu
SplitEnumeratorContext context,
PendingSplitsCheckpoint checkpoint) {
FileStoreScan scan = fileStore.newScan();
+Long snapshotId;
+Collection splits;
+if (specifiedSnapshotId != null) {
+Preconditions.checkNotNull(
+specifiedManifestEntries,
+"The manifest entries cannot be null for manual
compaction.");
Review Comment:
> The error message looks quite strange for me because I'm just curious : Is
it the only case that we will set `specifiedSnapshotId` and
`specifiedManifestEntries` for manual compaction ? Will be other case that we
will set the two fields ?
So far, only manually invoked compaction (triggered by `ALTER TABLE ...
COMPACT`) will specify the snapshot id and manifest entries. Other conditions
will perform a scan during the runtime.
The reason is that `ALTER TABLE ... COMPACT` will pre-scan the latest
snapshot during the planning phase, serialize the info as a string, and put it
back to enriched options. Therefore, at the runtime, the source does not need
to perform a scan anymore.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] schumiyi commented on pull request #18914: [FLINK-26259][table-planner]Partial insert and partition insert canno…
schumiyi commented on PR #18914: URL: https://github.com/apache/flink/pull/18914#issuecomment-1121831473 Appreciate if you can help take a look. @godfreyhe @wuchong @twalthr -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27559) Some question about flink operator state
Underwood created FLINK-27559: - Summary: Some question about flink operator state Key: FLINK-27559 URL: https://issues.apache.org/jira/browse/FLINK-27559 Project: Flink Issue Type: New Feature Environment: Flink 1.14.4 Reporter: Underwood I hope to get two answers to Flink's maintenance status: 1. Does custompartition support saving status? In my usage scenario, the partition strategy is dynamically adjusted, which depends on the data in datastream. I hope to make different partition strategies according to different data conditions. For a simple example, I want the first 100 pieces of data in datastream to be range partitioned and the rest of the data to be hash partitioned. At this time, I may need a count to identify the number of pieces of data that have been processed. However, in custompartition, this is only a local variable, so there seem to be two problems: declaring variables in this way can only be used in single concurrency, and it seems that they cannot be counted across slots; In this way, the count data will be lost during fault recovery. Although Flink already has operator state and key value state, custompartition is not an operator, so I don't think it can solve this problem through state. I've considered introducing a zookeeper to save the state, but the introduction of new components will make the system bloated. I don't know whether there is a better way to solve this problem. 2. How to make multiple operators share the same state, and even all parallel subtasks of different operators share the same state? For a simple example, my stream processing is divided into four stages: source - > mapa - > mapb - > sink. I hope to have a status count to count the total amount of data processed by all operators. For example, if the source receives one piece of data, then count + 1 when mapa is processed and count + 1 when mapb is processed. Finally, after this piece of data is processed, the value of count is 2. I don't know if there is such a state saving mechanism in Flink, which can meet my scenario and recover from failure at the same time. At present, we can still think of using zookeeper. I don't know if there is a better way. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] luoyuxia commented on a diff in pull request #19656: [FLINK-26371][hive] Support variable substitution for sql statement while using Hive dialect
luoyuxia commented on code in PR #19656:
URL: https://github.com/apache/flink/pull/19656#discussion_r868761997
##
flink-connectors/flink-connector-hive/src/test/java/org/apache/flink/connectors/hive/HiveDialectITCase.java:
##
@@ -807,6 +807,29 @@ public void testShowPartitions() throws Exception {
assertTrue(partitions.toString().contains("dt=2020-04-30
01:02:03/country=china"));
}
+@Test
+public void testStatementVariableSubstitution() {
+// test system variable for substitution
+System.setProperty("k1", "v1");
+List result =
+CollectionUtil.iteratorToList(
+tableEnv.executeSql("select
'${system:k1}'").collect());
+assertEquals("[+I[v1]]", result.toString());
+
+// test env variable for substitution
+String classPath = System.getenv("CLASSPATH");
+result =
+CollectionUtil.iteratorToList(
+tableEnv.executeSql("select
'${env:CLASSPATH}'").collect());
+assertEquals(String.format("[+I[%s]]", classPath), result.toString());
+
+// test hive conf variable for substitution
+result =
+CollectionUtil.iteratorToList(
+tableEnv.executeSql("select
'${hiveconf:common-key}'").collect());
Review Comment:
Currently, we have no way to dynamically set hiveconf variables in the flink
table api. AFAK, hive only supports set hiveconf variables in cli or init a
hive session with hiveconf variables.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] openinx commented on a diff in pull request #111: [FLINK-27540] Let FileStoreSource accept pre-planned manifest entries
openinx commented on code in PR #111:
URL: https://github.com/apache/flink-table-store/pull/111#discussion_r868754349
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -69,7 +92,10 @@ public FileStoreSource(
boolean latestContinuous,
@Nullable int[][] projectedFields,
@Nullable Predicate partitionPredicate,
-@Nullable Predicate fieldPredicate) {
+@Nullable Predicate fieldPredicate,
+@Nullable Long specifiedSnapshotId,
+@Nullable
+Map>>
specifiedManifestEntries) {
Review Comment:
What's the case that we will set those two fields with non-null values ? I
see all of them will be set to be `null` in the `buildFileStore`.
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -122,6 +150,17 @@ public SplitEnumerator restoreEnu
SplitEnumeratorContext context,
PendingSplitsCheckpoint checkpoint) {
FileStoreScan scan = fileStore.newScan();
+Long snapshotId;
+Collection splits;
+if (specifiedSnapshotId != null) {
+Preconditions.checkNotNull(
+specifiedManifestEntries,
+"The manifest entries cannot be null for manual
compaction.");
Review Comment:
The error message looks quite strange for me because I'm just curious : Is
it the only case that we will set `specifiedSnapshotId` and
`specifiedManifestEntries` for manual compaction ? Will be other case that we
will set the two fields ?
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -182,4 +219,102 @@ public FileStoreSourceSplitSerializer
getSplitSerializer() {
public PendingSplitsCheckpointSerializer
getEnumeratorCheckpointSerializer() {
return new PendingSplitsCheckpointSerializer(getSplitSerializer());
}
+
+private void writeObject(ObjectOutputStream out) throws IOException {
+out.defaultWriteObject();
+if (specifiedManifestEntries != null) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+DataOutputViewStreamWrapper view = new
DataOutputViewStreamWrapper(out);
+view.writeInt(specifiedManifestEntries.size());
+for (Map.Entry>>
partEntry :
+specifiedManifestEntries.entrySet()) {
+partSerializer.serialize(partEntry.getKey(), view);
+Map> bucketEntry =
partEntry.getValue();
+view.writeInt(bucketEntry.size());
+for (Map.Entry> entry :
bucketEntry.entrySet()) {
+view.writeInt(entry.getKey());
+view.writeInt(entry.getValue().size());
+for (DataFileMeta meta : entry.getValue()) {
+metaSerializer.serialize(meta, view);
+}
+}
+}
+}
+}
+
+private void readObject(ObjectInputStream in) throws IOException,
ClassNotFoundException {
+in.defaultReadObject();
+if (in.available() > 0) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+DataInputViewStreamWrapper view = new
DataInputViewStreamWrapper(in);
+specifiedManifestEntries = new HashMap<>();
+int partitionCtr = view.readInt();
Review Comment:
What's the meaning of suffix `ctr` ? partition number or partition count ?
So why not just use partitionNum ?
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/source/FileStoreSource.java:
##
@@ -182,4 +219,102 @@ public FileStoreSourceSplitSerializer
getSplitSerializer() {
public PendingSplitsCheckpointSerializer
getEnumeratorCheckpointSerializer() {
return new PendingSplitsCheckpointSerializer(getSplitSerializer());
}
+
+private void writeObject(ObjectOutputStream out) throws IOException {
+out.defaultWriteObject();
+if (specifiedManifestEntries != null) {
+BinaryRowDataSerializer partSerializer =
+new
BinaryRowDataSerializer(fileStore.partitionType().getFieldCount());
+DataFileMetaSerializer metaSerializer =
+new DataFileMetaSerializer(fileStore.keyType(),
fileStore.valueType());
+
[GitHub] [flink-ml] yunfengzhou-hub commented on pull request #95: Migrated to flink 1.15.0.
yunfengzhou-hub commented on PR #95: URL: https://github.com/apache/flink-ml/pull/95#issuecomment-1121813951 Hi @dotbg , thanks for contributing to Flink ML. I tried running `mvn clean install` on this PR, and it seems that there are still errors during compilation. Could you please fix them and push to this PR again? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-26588) Translate the new CAST documentation to Chinese
[ https://issues.apache.org/jira/browse/FLINK-26588?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu updated FLINK-26588: --- Fix Version/s: 1.15.1 > Translate the new CAST documentation to Chinese > --- > > Key: FLINK-26588 > URL: https://issues.apache.org/jira/browse/FLINK-26588 > Project: Flink > Issue Type: Sub-task > Components: Documentation, Table SQL / API >Affects Versions: 1.15.0 >Reporter: Martijn Visser >Assignee: Chengkai Yang >Priority: Major > Labels: chinese-translation, pull-request-available, > stale-assigned > Fix For: 1.15.1 > > > Since FLINK-26125 is now merged, this content change should also be > translated to Chinese. Relevant PR is > https://github.com/apache/flink/pull/18813 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-26588) Translate the new CAST documentation to Chinese
[ https://issues.apache.org/jira/browse/FLINK-26588?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534087#comment-17534087 ] Leonard Xu commented on FLINK-26588: Fixed in master: a9605906aa0a4c9157717b7221ef38eeb70f5525 release-1.15: TODO > Translate the new CAST documentation to Chinese > --- > > Key: FLINK-26588 > URL: https://issues.apache.org/jira/browse/FLINK-26588 > Project: Flink > Issue Type: Sub-task > Components: Documentation, Table SQL / API >Affects Versions: 1.15.0 >Reporter: Martijn Visser >Assignee: Chengkai Yang >Priority: Major > Labels: chinese-translation, pull-request-available, > stale-assigned > Fix For: 1.15.1 > > > Since FLINK-26125 is now merged, this content change should also be > translated to Chinese. Relevant PR is > https://github.com/apache/flink/pull/18813 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] leonardBang commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
leonardBang commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1121808405 @ChengkaiYang2022 Could you also open a backport PR for branch `release-1.15` ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] leonardBang merged pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
leonardBang merged PR #19498: URL: https://github.com/apache/flink/pull/19498 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zuston commented on pull request #19675: [FLINK-27550] Remove checking yarn queues before submitting job to Yarn
zuston commented on PR #19675:
URL: https://github.com/apache/flink/pull/19675#issuecomment-1121805622
@wangyang0918 Thanks for your quick reply.
Yes, you are right. If using the two levels queue naming policy, the leaf
queue name(`-Dyarn.application.queue=default`) or full
queue(`-Dyarn.application.queue=root.default`) name can work in
capacity-scheduler when checking the queues.
But when using three levels naming policy, like `root.job.streaming /
root.job.batch`, it will be invalid. When i remote debug with our internal job,
i found that the QueueInfo.getQueuePath will only return the simple queue name.
So let's see the example in the following yarn queue configuration.
> Yarn Queue:
> 1. root.job.streaming
> 2. root.job.batch
>
> When retrieving all queues by using YarnClient.getAllQueues, it will
return the list of QueueInfo. And the returning list of QueueInfo.getQueuePath
is [root, job, streaming, batch].
>
>
So when the flink job queue is specified as root.job.streaming and in the
method of `checkYarnQueues` , it will not find the corresponding the queue in
the existing above Yarn queues and will print out the incorrect message.
And why the queue can work in two level naming policy? I think it just add
the extra special handler to avoid misusing the api of getQueuePath in the
below code.
```
for (QueueInfo queue : queues) {
if (queue.getQueueName().equals(this.yarnQueue)
// 特殊处理:queue.getQueueName().equals("root." +
this.yarnQueue)
|| queue.getQueueName().equals("root." +
this.yarnQueue)) {
queueFound = true;
break;
}
}
```
And returning to this issue, to solve above problem, we have to use the api
of `getQueuePath`, but it's introduced in the Hadoop latest version.
So i think more about why introducing this method of `checkYarnQueues`? Just
to give user a tip and will not exit directly when the queue dont exist in the
cluster yarn queues? If only so, i think there is no need to use this method,
the error message will be shown in the Flink Yarn application master diagnostic
message.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] openinx commented on a diff in pull request #99: [FLINK-27307] Flink table store support append-only ingestion without primary keys.
openinx commented on code in PR #99:
URL: https://github.com/apache/flink-table-store/pull/99#discussion_r868744983
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/operation/FileStoreWriteImpl.java:
##
@@ -82,18 +95,41 @@ public FileStoreWriteImpl(
public RecordWriter createWriter(
BinaryRowData partition, int bucket, ExecutorService
compactExecutor) {
Long latestSnapshotId = pathFactory.latestSnapshotId();
-if (latestSnapshotId == null) {
-return createEmptyWriter(partition, bucket, compactExecutor);
-} else {
-return createMergeTreeWriter(
-partition,
-bucket,
-scan.withSnapshot(latestSnapshotId)
-
.withPartitionFilter(Collections.singletonList(partition))
-.withBucket(bucket).plan().files().stream()
-.map(ManifestEntry::file)
-.collect(Collectors.toList()),
-compactExecutor);
+List existingFileMetas = Lists.newArrayList();
+if (latestSnapshotId != null) {
+// Concat all the DataFileMeta of existing files into
existingFileMetas.
+scan.withSnapshot(latestSnapshotId)
+
.withPartitionFilter(Collections.singletonList(partition)).withBucket(bucket)
+.plan().files().stream()
+.map(ManifestEntry::file)
+.forEach(existingFileMetas::add);
+}
+
+switch (writeMode) {
+case APPEND_ONLY:
+DataFilePathFactory factory =
+pathFactory.createDataFilePathFactory(partition,
bucket);
+FileStatsExtractor fileStatsExtractor =
+
fileFormat.createStatsExtractor(writeSchema).orElse(null);
+
+return new AppendOnlyWriter(
+fileFormat,
+options.targetFileSize,
+writeSchema,
+existingFileMetas,
+factory,
+fileStatsExtractor);
+
+case CHANGE_LOG:
+if (latestSnapshotId == null) {
+return createEmptyWriter(partition, bucket,
compactExecutor);
+} else {
+return createMergeTreeWriter(
+partition, bucket, existingFileMetas,
compactExecutor);
+}
Review Comment:
Make sense for me !
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/operation/FileStoreWriteImpl.java:
##
@@ -34,30 +36,38 @@
import org.apache.flink.table.store.file.mergetree.compact.CompactStrategy;
import org.apache.flink.table.store.file.mergetree.compact.MergeFunction;
import org.apache.flink.table.store.file.mergetree.compact.UniversalCompaction;
+import org.apache.flink.table.store.file.stats.FileStatsExtractor;
import org.apache.flink.table.store.file.utils.FileStorePathFactory;
import org.apache.flink.table.store.file.utils.RecordReaderIterator;
+import org.apache.flink.table.store.file.writer.AppendOnlyWriter;
import org.apache.flink.table.store.file.writer.RecordWriter;
import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
+
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.function.Supplier;
-import java.util.stream.Collectors;
/** Default implementation of {@link FileStoreWrite}. */
public class FileStoreWriteImpl implements FileStoreWrite {
private final DataFileReader.Factory dataFileReaderFactory;
private final DataFileWriter.Factory dataFileWriterFactory;
+private final WriteMode writeMode;
+private final FileFormat fileFormat;
+private final RowType writeSchema;
private final Supplier> keyComparatorSupplier;
private final MergeFunction mergeFunction;
private final FileStorePathFactory pathFactory;
private final FileStoreScan scan;
private final MergeTreeOptions options;
public FileStoreWriteImpl(
+WriteMode writeMode,
+RowType writeSchema,
RowType keyType,
RowType valueType,
Review Comment:
The `writeSchema` can be removed now. In the previous version, I was
thinking that valueType would be some customized table schema (instead of the
original table schema), such as `int _VALUE_COUNT` or some other type. But in
fact, for append-only table the `valueType` will always be `tableSchema`. So
we don't have an extra `writeSchema` any more. Thanks for the comment.
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,176 @@
+/*
+ * License
[GitHub] [flink-table-store] openinx commented on a diff in pull request #115: [FLINK-27546] Add append only writer which implements the RecordWriter interface
openinx commented on code in PR #115:
URL: https://github.com/apache/flink-table-store/pull/115#discussion_r868723547
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,173 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.table.store.file.writer;
+
+import org.apache.flink.api.common.serialization.BulkWriter;
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.store.file.ValueKind;
+import org.apache.flink.table.store.file.data.DataFileMeta;
+import org.apache.flink.table.store.file.data.DataFilePathFactory;
+import org.apache.flink.table.store.file.format.FileFormat;
+import org.apache.flink.table.store.file.mergetree.Increment;
+import org.apache.flink.table.store.file.stats.FieldStats;
+import org.apache.flink.table.store.file.stats.FieldStatsCollector;
+import org.apache.flink.table.store.file.stats.FileStatsExtractor;
+import org.apache.flink.table.store.file.utils.FileUtils;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
+
+import java.io.IOException;
+import java.util.List;
+import java.util.concurrent.atomic.AtomicLong;
+import java.util.function.Supplier;
+
+/**
+ * A {@link RecordWriter} implementation that only accepts records which are
always insert
+ * operations and don't have any unique keys or sort keys.
+ */
+public class AppendOnlyWriter implements RecordWriter {
+private final BulkWriter.Factory writerFactory;
+private final RowType writeSchema;
+private final long targetFileSize;
+private final DataFilePathFactory pathFactory;
+private final FileStatsExtractor fileStatsExtractor;
+
+private final AtomicLong nextSeqNum;
+
+private RowRollingWriter writer;
+
+public AppendOnlyWriter(
+FileFormat fileFormat,
+long targetFileSize,
+RowType writeSchema,
+long maxWroteSeqNumber,
+DataFilePathFactory pathFactory) {
+
+this.writerFactory = fileFormat.createWriterFactory(writeSchema);
+this.writeSchema = writeSchema;
+this.targetFileSize = targetFileSize;
+
+this.pathFactory = pathFactory;
+this.fileStatsExtractor =
fileFormat.createStatsExtractor(writeSchema).orElse(null);
+
+this.nextSeqNum = new AtomicLong(maxWroteSeqNumber + 1);
+
+this.writer = createRollingRowWriter();
+}
+
+@Override
+public void write(ValueKind valueKind, RowData key, RowData value) throws
Exception {
+Preconditions.checkArgument(
+valueKind == ValueKind.ADD,
+"Append-only writer cannot accept ValueKind: " + valueKind);
+
+writer.write(value);
+}
+
+@Override
+public Increment prepareCommit() throws Exception {
+List newFiles = Lists.newArrayList();
+
+if (writer != null) {
+writer.close();
+
+// Reopen the writer to accept further records.
+newFiles.addAll(writer.result());
+writer = createRollingRowWriter();
+}
+
+return new Increment(Lists.newArrayList(newFiles));
+}
+
+@Override
+public void sync() throws Exception {
+// Do nothing here, as this writer don't introduce any async
compaction thread currently.
+}
+
+@Override
+public List close() throws Exception {
+sync();
+
+List result = Lists.newArrayList();
+if (writer != null) {
+// Abort this writer to clear uncommitted files.
+writer.abort();
Review Comment:
Filed a separate issue for this:
https://issues.apache.org/jira/browse/FLINK-27553
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] openinx commented on a diff in pull request #115: [FLINK-27546] Add append only writer which implements the RecordWriter interface
openinx commented on code in PR #115:
URL: https://github.com/apache/flink-table-store/pull/115#discussion_r868723542
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,173 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.table.store.file.writer;
+
+import org.apache.flink.api.common.serialization.BulkWriter;
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.store.file.ValueKind;
+import org.apache.flink.table.store.file.data.DataFileMeta;
+import org.apache.flink.table.store.file.data.DataFilePathFactory;
+import org.apache.flink.table.store.file.format.FileFormat;
+import org.apache.flink.table.store.file.mergetree.Increment;
+import org.apache.flink.table.store.file.stats.FieldStats;
+import org.apache.flink.table.store.file.stats.FieldStatsCollector;
+import org.apache.flink.table.store.file.stats.FileStatsExtractor;
+import org.apache.flink.table.store.file.utils.FileUtils;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
+
+import java.io.IOException;
+import java.util.List;
+import java.util.concurrent.atomic.AtomicLong;
+import java.util.function.Supplier;
+
+/**
+ * A {@link RecordWriter} implementation that only accepts records which are
always insert
+ * operations and don't have any unique keys or sort keys.
+ */
+public class AppendOnlyWriter implements RecordWriter {
+private final BulkWriter.Factory writerFactory;
+private final RowType writeSchema;
+private final long targetFileSize;
+private final DataFilePathFactory pathFactory;
+private final FileStatsExtractor fileStatsExtractor;
+
+private final AtomicLong nextSeqNum;
+
+private RowRollingWriter writer;
+
+public AppendOnlyWriter(
+FileFormat fileFormat,
+long targetFileSize,
+RowType writeSchema,
+long maxWroteSeqNumber,
+DataFilePathFactory pathFactory) {
+
+this.writerFactory = fileFormat.createWriterFactory(writeSchema);
+this.writeSchema = writeSchema;
+this.targetFileSize = targetFileSize;
+
+this.pathFactory = pathFactory;
+this.fileStatsExtractor =
fileFormat.createStatsExtractor(writeSchema).orElse(null);
+
+this.nextSeqNum = new AtomicLong(maxWroteSeqNumber + 1);
+
+this.writer = createRollingRowWriter();
+}
+
+@Override
+public void write(ValueKind valueKind, RowData key, RowData value) throws
Exception {
+Preconditions.checkArgument(
+valueKind == ValueKind.ADD,
+"Append-only writer cannot accept ValueKind: " + valueKind);
+
+writer.write(value);
+}
+
+@Override
+public Increment prepareCommit() throws Exception {
+List newFiles = Lists.newArrayList();
+
+if (writer != null) {
+writer.close();
+
+// Reopen the writer to accept further records.
+newFiles.addAll(writer.result());
+writer = createRollingRowWriter();
+}
+
+return new Increment(Lists.newArrayList(newFiles));
+}
+
+@Override
+public void sync() throws Exception {
+// Do nothing here, as this writer don't introduce any async
compaction thread currently.
+}
+
+@Override
+public List close() throws Exception {
+sync();
+
+List result = Lists.newArrayList();
+if (writer != null) {
+// Abort this writer to clear uncommitted files.
+writer.abort();
Review Comment:
Filed a separate issue for this:
https://issues.apache.org/jira/browse/FLINK-27553
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,173 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF license
[jira] [Assigned] (FLINK-27297) Add the StreamExecutionEnvironment#getExecutionEnvironment(Configuration) method in PyFlink
[ https://issues.apache.org/jira/browse/FLINK-27297?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dian Fu reassigned FLINK-27297: --- Assignee: LuNng Wang > Add the StreamExecutionEnvironment#getExecutionEnvironment(Configuration) > method in PyFlink > --- > > Key: FLINK-27297 > URL: https://issues.apache.org/jira/browse/FLINK-27297 > Project: Flink > Issue Type: Improvement > Components: API / Python >Reporter: Huang Xingbo >Assignee: LuNng Wang >Priority: Major > Fix For: 1.16.0 > > > StreamExecutionEnvironment#getExecutionEnvironment(Configuration) method has > been added in Java side since release-1.12, we need to add this method in > Python too -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27297) Add the StreamExecutionEnvironment#getExecutionEnvironment(Configuration) method in PyFlink
[ https://issues.apache.org/jira/browse/FLINK-27297?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534071#comment-17534071 ] Dian Fu commented on FLINK-27297: - [~ana4] Thanks for taking this. Have assigned it to you~ > Add the StreamExecutionEnvironment#getExecutionEnvironment(Configuration) > method in PyFlink > --- > > Key: FLINK-27297 > URL: https://issues.apache.org/jira/browse/FLINK-27297 > Project: Flink > Issue Type: Improvement > Components: API / Python >Reporter: Huang Xingbo >Assignee: LuNng Wang >Priority: Major > Fix For: 1.16.0 > > > StreamExecutionEnvironment#getExecutionEnvironment(Configuration) method has > been added in Java side since release-1.12, we need to add this method in > Python too -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27297) Add the StreamExecutionEnvironment#getExecutionEnvironment(Configuration) method in PyFlink
[ https://issues.apache.org/jira/browse/FLINK-27297?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534070#comment-17534070 ] LuNng Wang commented on FLINK-27297: [~dianfu] [~hxbks2ks] I would like to try this. > Add the StreamExecutionEnvironment#getExecutionEnvironment(Configuration) > method in PyFlink > --- > > Key: FLINK-27297 > URL: https://issues.apache.org/jira/browse/FLINK-27297 > Project: Flink > Issue Type: Improvement > Components: API / Python >Reporter: Huang Xingbo >Priority: Major > Fix For: 1.16.0 > > > StreamExecutionEnvironment#getExecutionEnvironment(Configuration) method has > been added in Java side since release-1.12, we need to add this method in > Python too -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] hililiwei commented on pull request #17798: [hotfix] Fix comment typos in AsyncIOExample
hililiwei commented on PR #17798: URL: https://github.com/apache/flink/pull/17798#issuecomment-1121765967 > @hililiwei You haven't updated the commit message, you have updated the PR title updated. thx. 😄 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27558) Introduce a new optional option for TableStoreFactory to represent planned manifest entries
[
https://issues.apache.org/jira/browse/FLINK-27558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-27558:
---
Labels: pull-request-available (was: )
> Introduce a new optional option for TableStoreFactory to represent planned
> manifest entries
> ---
>
> Key: FLINK-27558
> URL: https://issues.apache.org/jira/browse/FLINK-27558
> Project: Flink
> Issue Type: Sub-task
> Components: Table Store
>Affects Versions: table-store-0.2.0
>Reporter: Jane Chan
>Priority: Major
> Labels: pull-request-available
> Fix For: table-store-0.2.0
>
>
> When
> {code:java}
> TableStoreFactory.onCompactTable
> {code}
> gets called, the planned manifest entries need to be injected back into the
> enriched options, and we need a new key to represent it.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink-table-store] LadyForest opened a new pull request, #116: [FLINK-27558] Introduce a new optional option for TableStoreFactory to represent planned manifest entries
LadyForest opened a new pull request, #116: URL: https://github.com/apache/flink-table-store/pull/116 When `TableStoreFactory.onCompactTable`gets called, the planned manifest entries need to be injected back into the enriched options, and we need a new key to represent it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] weibozhao commented on a diff in pull request #86: [FLINK-27294] Add Transformer for BinaryClassificationEvaluator
weibozhao commented on code in PR #86:
URL: https://github.com/apache/flink-ml/pull/86#discussion_r868690036
##
flink-ml-lib/src/test/java/org/apache/flink/ml/evaluation/binaryeval/BinaryClassificationEvaluatorTest.java:
##
@@ -0,0 +1,210 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.evaluation.binaryeval;
+
+import org.apache.flink.api.common.restartstrategy.RestartStrategies;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.ml.linalg.Vectors;
+import org.apache.flink.ml.util.StageTestUtils;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import
org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
+import org.apache.flink.types.Row;
+
+import org.apache.commons.collections.IteratorUtils;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+
+import java.util.Arrays;
+import java.util.List;
+
+import static org.junit.Assert.assertArrayEquals;
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertNull;
+
+/** Tests {@link BinaryClassificationEvaluator}. */
+public class BinaryClassificationEvaluatorTest {
Review Comment:
OK, I will add these test case.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
ChengkaiYang2022 commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1121710303 CI test passed.[link](https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=35507&view=results) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] haizhou-zhao commented on a diff in pull request #19645: [FLINK-27255] [flink-avro] flink-avro does not support ser/de of large avro schema
haizhou-zhao commented on code in PR #19645:
URL: https://github.com/apache/flink/pull/19645#discussion_r868618419
##
flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/GenericRecordAvroTypeInfo.java:
##
@@ -104,10 +105,15 @@ public boolean canEqual(Object obj) {
}
private void writeObject(ObjectOutputStream oos) throws IOException {
-oos.writeUTF(schema.toString());
+byte[] schemaStrInBytes =
schema.toString(false).getBytes(StandardCharsets.UTF_8);
Review Comment:
@tweise @stevenzwu I think the avro serializer snapshot (which is used for
de/ser operator state if the state include Avro record) already takes care of
de/ser of large Avro schema: Code
[link](https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/test/java/org/apache/flink/formats/avro/typeutils/AvroSerializerSnapshotTest.java#L155).
Since the serialization of avro serializer and typeinfo is only used when
constructing edge and vertices of stream graph, maybe we don't need to take
care of backward compatibility here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-23633) HybridSource: Support dynamic stop position in FileSource
[ https://issues.apache.org/jira/browse/FLINK-23633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534050#comment-17534050 ] Thomas Weise commented on FLINK-23633: -- Hi [~binh] , of course. Perhaps you can start with a short description how you would like to go about it? Do you want me to assign this ticket to you? > HybridSource: Support dynamic stop position in FileSource > - > > Key: FLINK-23633 > URL: https://issues.apache.org/jira/browse/FLINK-23633 > Project: Flink > Issue Type: Sub-task > Components: Connectors / FileSystem >Reporter: Thomas Weise >Priority: Major > > As of FLINK-22670 FileSource can be used with HybridSource with fixed end > position. To support the scenario where the switch position isn't known ahead > of time, FileSource needs to have a hook to decide when it is time to stop > with continuous polling and then expose the end position through the > enumerator. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-23633) HybridSource: Support dynamic stop position in FileSource
[ https://issues.apache.org/jira/browse/FLINK-23633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534048#comment-17534048 ] Xinbin Huang commented on FLINK-23633: -- Hi [~thw] , may I try to implement this? > HybridSource: Support dynamic stop position in FileSource > - > > Key: FLINK-23633 > URL: https://issues.apache.org/jira/browse/FLINK-23633 > Project: Flink > Issue Type: Sub-task > Components: Connectors / FileSystem >Reporter: Thomas Weise >Priority: Major > > As of FLINK-22670 FileSource can be used with HybridSource with fixed end > position. To support the scenario where the switch position isn't known ahead > of time, FileSource needs to have a hook to decide when it is time to stop > with continuous polling and then expose the end position through the > enumerator. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-23143) Support state migration
[ https://issues.apache.org/jira/browse/FLINK-23143?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17534026#comment-17534026 ] Roman Khachatryan commented on FLINK-23143: --- Thanks a lot for sharing the prototype. I like the simplicity of your solution, but I think the concern I expressed above (about creation of multiple state objects) is valid. Besides that, RegisteredKeyValueStateBackendMetaInfo seems implementation detail of a state backend, so it shouldn't be exposed. Regarding the key serializer upgrade, I think it's [not supported|https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/fault-tolerance/serialization/schema_evolution/] currently and therefore is out of the scope of this ticket. > Support state migration > --- > > Key: FLINK-23143 > URL: https://issues.apache.org/jira/browse/FLINK-23143 > Project: Flink > Issue Type: Sub-task > Components: Runtime / State Backends >Reporter: Roman Khachatryan >Priority: Minor > Labels: pull-request-available > Fix For: 1.16.0 > > > ChangelogKeyedStateBackend.getOrCreateKeyedState is currently used during > recovery; on 1st user access, it doesn't update metadata nor migrate state > (as opposed to other backends). > > The proposed solution is to > # wrap serializers (and maybe other objects) in getOrCreateKeyedState > # store wrapping objects in a new map keyed by state name > # pass wrapped objects to delegatedBackend.createInternalState > # on 1st user access, lookup wrapper and upgrade its wrapped serializer > This should be done for both KV/PQ states. > > See also [https://github.com/apache/flink/pull/15420#discussion_r656934791] > > cc: [~yunta] -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-ml] dotbg opened a new pull request, #95: Migrated to flink 1.15.0.
dotbg opened a new pull request, #95: URL: https://github.com/apache/flink-ml/pull/95 * Flink 1.15.0 * Scala binary version used in test artifacts only. Hence artifact names were changed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] snuyanzin commented on pull request #19538: [FLINK-27323][flink-table-api-java][tests] Migrate tests to JUnit5
snuyanzin commented on PR #19538: URL: https://github.com/apache/flink/pull/19538#issuecomment-1121530098 merge conflicts resolved and rebased -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19684: Add support to pass Datadog API Key as environment variable
flinkbot commented on PR #19684: URL: https://github.com/apache/flink/pull/19684#issuecomment-1121463902 ## CI report: * 90ea579c38f9a5f3de805c8dd1b74ba7fc2d6a26 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] pinxiu opened a new pull request, #19684: Add support to pass Datadog API Key as environment variable
pinxiu opened a new pull request, #19684: URL: https://github.com/apache/flink/pull/19684 ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* Add support to pass Datadog API Key as environment variable to avoid explicitly adding API key in plain text config file. ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] snuyanzin commented on pull request #17564: [FLINK-24640][table] CEIL, FLOOR built-in functions for Timestamp should res…
snuyanzin commented on PR #17564: URL: https://github.com/apache/flink/pull/17564#issuecomment-1121413777 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27492) Flink table scala example does not including the scala-api jars
[ https://issues.apache.org/jira/browse/FLINK-27492?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533908#comment-17533908 ] Yun Gao commented on FLINK-27492: - For another thing, perhaps we could also including the two Table Scala API artifacts in the binary distribution package, like in the opt/ directory? Currently the document asks users to download the missing artifacts and put them into lib, but currently it seems we do not present the download links for these artifacts. > Flink table scala example does not including the scala-api jars > --- > > Key: FLINK-27492 > URL: https://issues.apache.org/jira/browse/FLINK-27492 > Project: Flink > Issue Type: Bug > Components: Table SQL / API >Affects Versions: 1.15.0, 1.16.0 >Reporter: Yun Gao >Assignee: Timo Walther >Priority: Critical > Fix For: 1.16.0, 1.15.1 > > > Currently it seems the flink-scala-api, flink-table-api-scala-bridge is not > including from the binary package[1]. However, currently the scala table > examples seems not include the scala-api classes in the generated jar, If we > start a standalone cluster from the binary distribution package and then > submit a table / sql job in scala, it would fail due to not found the > StreamTableEnvironment class. > > [1] > https://nightlies.apache.org/flink/flink-docs-master/docs/dev/configuration/advanced/#anatomy-of-table-dependencies -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut` teamed up with `numRecordsSend` and `numRecordsSendErrors`. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for details. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Even with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27506) update playgrounds for Flink 1.14
[ https://issues.apache.org/jira/browse/FLINK-27506?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533873#comment-17533873 ] Shubham Bansal commented on FLINK-27506: Thanks, David. I will take a look at the previous commit and return back shortly with the list of changes. > update playgrounds for Flink 1.14 > - > > Key: FLINK-27506 > URL: https://issues.apache.org/jira/browse/FLINK-27506 > Project: Flink > Issue Type: Improvement > Components: Documentation / Training / Exercises >Affects Versions: 1.14.4 >Reporter: David Anderson >Priority: Major > Labels: starter > > All of the flink-playgrounds need to be updated for 1.14. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut` teamed up with `numRecordsSend` and `numRecordsSendErrors`. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for details. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Event with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] HuangZhenQiu commented on pull request #14678: [FLINK-20833][runtime] Add pluggable failure listener in job manager
HuangZhenQiu commented on PR #14678: URL: https://github.com/apache/flink/pull/14678#issuecomment-1121273392 @zentol Would you please help to review this RP? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut`. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for details. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Event with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut`. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building sink connectors. Please refer to the new Kafka Sink for more information. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Event with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut`. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage of these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building your sink connectors. Please refer to the new Kafka Sink for more information. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Event with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. Connectors still use `numRecordsOut`. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building your sink connectors. Please refer to the new Kafka Sink for more information. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Event with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on code in PR #19664: URL: https://github.com/apache/flink/pull/19664#discussion_r868138403 ## docs/content/release-notes/flink-1.15.md: ## @@ -406,6 +406,18 @@ updating the client dependency to a version >= 7.14.0 is required due to interna The old JDBC connector (indicated by `connector.type=jdbc` in DDL) has been removed. If not done already, users need to upgrade to the newer stack (indicated by `connector=jdbc` in DDL). + + Extensible unified Sink uses new metric to capture outgoing records + +# [FLINK-26126](https://issues.apache.org/jira/browse/FLINK-26126) + +New metrics `numRecordsSend` and `numRecordsSendErrors` has been introduced for users to monitor the number of +records sent to the external system. The `numRecordsOut` should be used to monitor the number of records +transferred between sink tasks. + +Connector developers should Consider using the new metric `numRecordsSendErrors` to monitor errors, +since `numRecordsOut` has a different and more general meaning, and `numRecordsOutErrors` is therefore deprecated. Review Comment: This is confused for users and connector developers, tbh. 1. `numRecordsOut` will ONLY count the records(technically Commitables) sent between sink tasks. 2. the information about the deprecated metric `numRecordsOutErrors` is missing. 3. the information of using `numRecordsSend` has been described in the first part and there is no use case for "changing the connector"(all connectors that used `numRecordsOut` in a wrong way have been changed). From now on, it is actually mandatory for connector developers to use them except `numRecordsOutErrors`. How about this version: Connector developers should pay attention to the usage these metrics `numRecordsOut`, `numRecordsSend` and `numRecordsSendErrors` while building your sink connectors. Please refer to the new Kafka Sink for more information. Additionally since `numRecordsOut` now only counts the records sent between sink tasks and `numRecordsOutErrors` was designed for counting the records sent to the external system, we deprecated `numRecordsOutErrors` and recommend using `numRecordsSendErrors` instead. Event with this description, it is still unclear, since `numRecordsOut` is still used, why is `numRecordsOutErrors` deprecated? It should be used to monitor errors happened while Commitables were send between sink tasks. WDYT? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533852#comment-17533852
]
João Boto commented on FLINK-27552:
---
I was testing with a job that was a KafkaSink (sorry)
disabling kafkasink metrics works..
this could be closed
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] afedulov commented on a diff in pull request #19660: [FLINK-27185][connectors] Convert connector modules to assertj
afedulov commented on code in PR #19660:
URL: https://github.com/apache/flink/pull/19660#discussion_r868113102
##
flink-connectors/flink-connector-cassandra/src/test/java/org/apache/flink/streaming/connectors/cassandra/CassandraConnectorITCase.java:
##
@@ -723,11 +721,11 @@ public void testCassandraBatchPojoFormat() throws
Exception {
final List pojos =
writePojosWithOutputFormat(annotatedPojoClass);
ResultSet rs = session.execute(injectTableName(SELECT_DATA_QUERY));
-Assert.assertEquals(20, rs.all().size());
+assertThat(rs.all()).hasSize(20);
final List result =
readPojosWithInputFormat(annotatedPojoClass);
-Assert.assertEquals(20, result.size());
-assertThat(result, samePropertyValuesAs(pojos));
+assertThat(result).hasSize(20);
+assertThat(result).satisfies(matching(samePropertyValuesAs(pojos)));
Review Comment:
Can we find a native, non-hamcrest, assertj equivalent?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (FLINK-26112) Port getRestEndpoint method to the specific service type subclass
[ https://issues.apache.org/jira/browse/FLINK-26112?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yang Wang closed FLINK-26112. - Resolution: Fixed Fixed via: master: f24dc6da25246fdaf278f4b2ce88892ec79d1b8b ab3eb40d920fa609f49164a0bbb5fcbb3004a808 ff7d61954cad97e3e52df0c006f130de39a6a5c2 > Port getRestEndpoint method to the specific service type subclass > - > > Key: FLINK-26112 > URL: https://issues.apache.org/jira/browse/FLINK-26112 > Project: Flink > Issue Type: Sub-task >Reporter: Aitozi >Assignee: Aitozi >Priority: Major > Fix For: 1.16.0 > > > In the [FLINK-20830|https://issues.apache.org/jira/browse/FLINK-20830], we > introduce serval subclass to deal with the service build and query, This > ticket is meant to move the related code to the proper class -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (FLINK-27558) Introduce a new optional option for TableStoreFactory to represent planned manifest entries
Jane Chan created FLINK-27558:
-
Summary: Introduce a new optional option for TableStoreFactory to
represent planned manifest entries
Key: FLINK-27558
URL: https://issues.apache.org/jira/browse/FLINK-27558
Project: Flink
Issue Type: Sub-task
Components: Table Store
Affects Versions: table-store-0.2.0
Reporter: Jane Chan
Fix For: table-store-0.2.0
When
{code:java}
TableStoreFactory.onCompactTable
{code}
gets called, the planned manifest entries need to be injected back into the
enriched options, and we need a new key to represent it.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (FLINK-26112) Port getRestEndpoint method to the specific service type subclass
[ https://issues.apache.org/jira/browse/FLINK-26112?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yang Wang updated FLINK-26112: -- Fix Version/s: 1.16.0 > Port getRestEndpoint method to the specific service type subclass > - > > Key: FLINK-26112 > URL: https://issues.apache.org/jira/browse/FLINK-26112 > Project: Flink > Issue Type: Sub-task >Reporter: Aitozi >Assignee: Aitozi >Priority: Major > Fix For: 1.16.0 > > > In the [FLINK-20830|https://issues.apache.org/jira/browse/FLINK-20830], we > introduce serval subclass to deal with the service build and query, This > ticket is meant to move the related code to the proper class -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] wangyang0918 merged pull request #18762: [FlINK-26112][k8s]Port getRestEndpoint method to the specific service type subclass
wangyang0918 merged PR #18762: URL: https://github.com/apache/flink/pull/18762 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] afedulov commented on a diff in pull request #19660: [FLINK-27185][connectors] Convert connector modules to assertj
afedulov commented on code in PR #19660:
URL: https://github.com/apache/flink/pull/19660#discussion_r868090797
##
flink-connectors/flink-connector-base/src/test/java/org/apache/flink/connector/base/source/reader/SourceMetricsITCase.java:
##
@@ -169,45 +168,47 @@ private void assertSourceMetrics(
boolean hasTimestamps) {
List groups =
reporter.findOperatorMetricGroups(jobId,
"MetricTestingSource");
-assertThat(groups, hasSize(parallelism));
+assertThat(groups).hasSize(parallelism);
int subtaskWithMetrics = 0;
for (OperatorMetricGroup group : groups) {
Map metrics = reporter.getMetricsByGroup(group);
// there are only 2 splits assigned; so two groups will not update
metrics
if (group.getIOMetricGroup().getNumRecordsInCounter().getCount()
== 0) {
// assert that optional metrics are not initialized when no
split assigned
-assertThat(
-metrics.get(MetricNames.CURRENT_EMIT_EVENT_TIME_LAG),
-
isGauge(equalTo(InternalSourceReaderMetricGroup.UNDEFINED)));
-assertThat(metrics.get(MetricNames.WATERMARK_LAG),
nullValue());
+
assertThat(metrics.get(MetricNames.CURRENT_EMIT_EVENT_TIME_LAG))
+.satisfies(
+matching(
+isGauge(
+equalTo(
+
InternalSourceReaderMetricGroup
+.UNDEFINED;
+assertThat(metrics.get(MetricNames.WATERMARK_LAG)).isNull();
continue;
}
subtaskWithMetrics++;
// I/O metrics
-assertThat(
-group.getIOMetricGroup().getNumRecordsInCounter(),
-isCounter(equalTo(processedRecordsPerSubtask)));
-assertThat(
-group.getIOMetricGroup().getNumBytesInCounter(),
-isCounter(
-equalTo(
-processedRecordsPerSubtask
-*
MockRecordEmitter.RECORD_SIZE_IN_BYTES)));
+assertThat(group.getIOMetricGroup().getNumRecordsInCounter())
+
.satisfies(matching(isCounter(equalTo(processedRecordsPerSubtask;
+assertThat(group.getIOMetricGroup().getNumBytesInCounter())
+.satisfies(
+matching(
+isCounter(
+equalTo(
+processedRecordsPerSubtask
+* MockRecordEmitter
+
.RECORD_SIZE_IN_BYTES;
// MockRecordEmitter is just incrementing errors every even record
-assertThat(
-metrics.get(MetricNames.NUM_RECORDS_IN_ERRORS),
-isCounter(equalTo(processedRecordsPerSubtask / 2)));
+assertThat(metrics.get(MetricNames.NUM_RECORDS_IN_ERRORS))
+
.satisfies(matching(isCounter(equalTo(processedRecordsPerSubtask / 2;
Review Comment:
It seems that those matchers are used extensively and the readability really
suffers. The `isGauge`, `isCounter` etc. helper methods have pretty simple
logic. I think we should move away from hamcrest as much as possible. This
`.satisfies(matching(...)` really diminishes the purpose of introducing
matchers for the fluent API.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] afedulov commented on a diff in pull request #19660: [FLINK-27185][connectors] Convert connector modules to assertj
afedulov commented on code in PR #19660:
URL: https://github.com/apache/flink/pull/19660#discussion_r868080704
##
flink-connectors/flink-connector-base/src/test/java/org/apache/flink/connector/base/source/hybrid/HybridSourceTest.java:
##
@@ -29,9 +29,8 @@
import java.util.List;
-import static org.junit.Assert.assertEquals;
-import static org.junit.Assert.assertNotNull;
-import static org.junit.Assert.fail;
+import static org.assertj.core.api.Assertions.assertThat;
+import static org.assertj.core.api.Assertions.fail;
Review Comment:
Usage could be substituted by assertThatThrownBy.
##
flink-connectors/flink-connector-base/src/test/java/org/apache/flink/connector/base/source/hybrid/HybridSourceSplitEnumeratorTest.java:
##
@@ -158,7 +154,7 @@ public void
testHandleSplitRequestAfterSwitchAndReaderReset() {
enumerator.addSplitsBack(Collections.singletonList(splitFromSource0),
SUBTASK0);
try {
enumerator.handleSplitRequest(SUBTASK0, "fakehostname");
-Assert.fail("expected exception");
+fail("expected exception");
Review Comment:
How about assertThatThrownBy?
##
flink-connectors/flink-connector-base/src/test/java/org/apache/flink/connector/base/source/reader/SourceMetricsITCase.java:
##
@@ -169,45 +168,47 @@ private void assertSourceMetrics(
boolean hasTimestamps) {
List groups =
reporter.findOperatorMetricGroups(jobId,
"MetricTestingSource");
-assertThat(groups, hasSize(parallelism));
+assertThat(groups).hasSize(parallelism);
int subtaskWithMetrics = 0;
for (OperatorMetricGroup group : groups) {
Map metrics = reporter.getMetricsByGroup(group);
// there are only 2 splits assigned; so two groups will not update
metrics
if (group.getIOMetricGroup().getNumRecordsInCounter().getCount()
== 0) {
// assert that optional metrics are not initialized when no
split assigned
-assertThat(
-metrics.get(MetricNames.CURRENT_EMIT_EVENT_TIME_LAG),
-
isGauge(equalTo(InternalSourceReaderMetricGroup.UNDEFINED)));
-assertThat(metrics.get(MetricNames.WATERMARK_LAG),
nullValue());
+
assertThat(metrics.get(MetricNames.CURRENT_EMIT_EVENT_TIME_LAG))
+.satisfies(
+matching(
+isGauge(
+equalTo(
+
InternalSourceReaderMetricGroup
+.UNDEFINED;
+assertThat(metrics.get(MetricNames.WATERMARK_LAG)).isNull();
continue;
}
subtaskWithMetrics++;
// I/O metrics
-assertThat(
-group.getIOMetricGroup().getNumRecordsInCounter(),
-isCounter(equalTo(processedRecordsPerSubtask)));
-assertThat(
-group.getIOMetricGroup().getNumBytesInCounter(),
-isCounter(
-equalTo(
-processedRecordsPerSubtask
-*
MockRecordEmitter.RECORD_SIZE_IN_BYTES)));
+assertThat(group.getIOMetricGroup().getNumRecordsInCounter())
+
.satisfies(matching(isCounter(equalTo(processedRecordsPerSubtask;
+assertThat(group.getIOMetricGroup().getNumBytesInCounter())
+.satisfies(
+matching(
+isCounter(
+equalTo(
+processedRecordsPerSubtask
+* MockRecordEmitter
+
.RECORD_SIZE_IN_BYTES;
// MockRecordEmitter is just incrementing errors every even record
-assertThat(
-metrics.get(MetricNames.NUM_RECORDS_IN_ERRORS),
-isCounter(equalTo(processedRecordsPerSubtask / 2)));
+assertThat(metrics.get(MetricNames.NUM_RECORDS_IN_ERRORS))
+
.satisfies(matching(isCounter(equalTo(processedRecordsPerSubtask / 2;
Review Comment:
It seems that those matchers are used extensively and the readability really
suffers. Those `isGauge`, `isCounter` methods helper methods have pretty simple
logic. I think we should move away from hamcrest as much as possible. This
`.satisfies(matching(...)` really diminishes the purpose of introducing
matchers for the fluent API.
##
flink-connectors/flink-connector-base/src/test/java/org/apache/flink/connector/base/source/reader/f
[GitHub] [flink-web] liuzhuang2017 commented on pull request #528: [hotfix][docs] Delete the redundant content of "downloads.zh.md" file.
liuzhuang2017 commented on PR #528: URL: https://github.com/apache/flink-web/pull/528#issuecomment-1121172421 @MartijnVisser , Thank you very much for your review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org