[GitHub] [kafka] chia7712 commented on pull request #9767: KAFKA-10047: Remove unnecessary widening of (int to long) scope in FloatSerializer.
chia7712 commented on pull request #9767: URL: https://github.com/apache/kafka/pull/9767#issuecomment-748433375 Also, KAFKA-10047 already has a PR (https://github.com/apache/kafka/pull/9351). If you want to create a PR for it, it would be better to ask the author of PR (or reporter of jira) if they don't work on it anymore. If so, it is ok to take over the issue. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9767: KAFKA-10047: Remove unnecessary widening of (int to long) scope in FloatSerializer.
chia7712 commented on pull request #9767: URL: https://github.com/apache/kafka/pull/9767#issuecomment-748432898 @tguruprasad It would be better to ping author or kafka active committers to review code :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9520: MINOR: replace test "expected" parameter by assertThrows
chia7712 commented on pull request #9520: URL: https://github.com/apache/kafka/pull/9520#issuecomment-748432641 @ijuma Any thoughts to this PR? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9758: MINOR: remove FetchResponse.AbortedTransaction and redundant construc…
chia7712 commented on a change in pull request #9758: URL: https://github.com/apache/kafka/pull/9758#discussion_r546203915 ## File path: core/src/main/scala/kafka/server/KafkaApis.scala ## @@ -777,12 +775,12 @@ class KafkaApis(val requestChannel: RequestChannel, } def maybeConvertFetchedData(tp: TopicPartition, Review comment: @ijuma This is the only case that we create ```LazyDownConversionRecords``` in production. Through this PR, this case can get rid of generic ```FetchResponse.PartitionData```. Hence, we can remove generic from ```FetchResponse.PartitionData``` after this PR goes in trunk. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 opened a new pull request #9768: HOTFIX: fix failed ControllerChannelManagerTest#testUpdateMetadataReq…
chia7712 opened a new pull request #9768: URL: https://github.com/apache/kafka/pull/9768 as title ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tguruprasad commented on pull request #9767: KAFKA-10047: Remove unnecessary widening of (int to long) scope in FloatSerializer.
tguruprasad commented on pull request #9767: URL: https://github.com/apache/kafka/pull/9767#issuecomment-748423867 Apologizes for spamming folks who are tagged. As mentioned in [this wiki](https://cwiki.apache.org/confluence/display/KAFKA/Contributing+Code+Changes), I selected GitHub's automatic suggestions to tag the folks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (KAFKA-10547) Add topic IDs to MetadataResponse
[ https://issues.apache.org/jira/browse/KAFKA-10547?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] dengziming resolved KAFKA-10547. Resolution: Done > Add topic IDs to MetadataResponse > - > > Key: KAFKA-10547 > URL: https://issues.apache.org/jira/browse/KAFKA-10547 > Project: Kafka > Issue Type: Sub-task >Reporter: Justine Olshan >Assignee: dengziming >Priority: Major > > Will be able to use TopicDescription to identify the topic ID -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dengziming commented on pull request #9766: KAFKA-10864: Convert end txn marker schema to use auto-generated protocol
dengziming commented on pull request #9766: URL: https://github.com/apache/kafka/pull/9766#issuecomment-748414238 > Thanks for the PR, one high level question I have is that whether the new auto generated protocol format is exactly the same as old hard-coded schema format, since this field is used inter-broker. Could you write a test to prove that they could translate between each other? Thank you, I tested that the 2 schemas could translate between each other locally, now I add the code to `EndTransactionMarkerTest`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dengziming commented on a change in pull request #9766: KAFKA-10864: Convert end txn marker schema to use auto-generated protocol
dengziming commented on a change in pull request #9766:
URL: https://github.com/apache/kafka/pull/9766#discussion_r546185834
##
File path: clients/src/main/resources/common/message/EndTxnMarker.json
##
@@ -0,0 +1,23 @@
+// Licensed to the Apache Software Foundation (ASF) under one or more
+// contributor license agreements. See the NOTICE file distributed with
+// this work for additional information regarding copyright ownership.
+// The ASF licenses this file to You under the Apache License, Version 2.0
+// (the "License"); you may not use this file except in compliance with
+// the License. You may obtain a copy of the License at
+//
+//http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+{
+ "type": "data",
+ "name": "EndTxnMarker",
+ "validVersions": "0",
+ "fields": [
+{ "name": "CoordinatorEpoch", "type": "int32", "versions": "0+"}
Review comment:
Firstly I tried to use flexible version here, but it's not the same as
the old hard-coded schema format. Could we bump the version and support
flexible version from version 1 ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9712: KAFKA-10822 Force some stdout from downgrade_test.py/upgrade_test.py for Travis
chia7712 commented on pull request #9712: URL: https://github.com/apache/kafka/pull/9712#issuecomment-748409302 > Looks like the build is still in error? Thanks for your reviews. The main purpose of this PR is to avoid timeout from downgrade_test.py/upgrade_test.py. I browse the test results and the timeout does not happen on downgrade_test.py/upgrade_test.py again. After fixing the timeout issue, I will go back to dead with the true failure of system tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10687) Produce request should be bumped for new error code PRODUCE_FENCED
[ https://issues.apache.org/jira/browse/KAFKA-10687?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jason Gustafson updated KAFKA-10687: Description: In https://issues.apache.org/jira/browse/KAFKA-9911, we missed a case where the ProduceRequest needs to be bumped to return the new error code PRODUCE_FENCED. This gap needs to be addressed as a blocker since it is shipping in 2.7. (was: In https://issues.apache.org/jira/browse/KAFKA-9910, we missed a case where the ProduceRequest needs to be bumped to return the new error code PRODUCE_FENCED. This gap needs to be addressed as a blocker since it is shipping in 2.7.) > Produce request should be bumped for new error code PRODUCE_FENCED > -- > > Key: KAFKA-10687 > URL: https://issues.apache.org/jira/browse/KAFKA-10687 > Project: Kafka > Issue Type: Bug >Reporter: Boyang Chen >Assignee: Boyang Chen >Priority: Blocker > Fix For: 2.7.0 > > > In https://issues.apache.org/jira/browse/KAFKA-9911, we missed a case where > the ProduceRequest needs to be bumped to return the new error code > PRODUCE_FENCED. This gap needs to be addressed as a blocker since it is > shipping in 2.7. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10870) Consumer should handle REBALANCE_IN_PROGRESS from JoinGroup
[
https://issues.apache.org/jira/browse/KAFKA-10870?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jason Gustafson updated KAFKA-10870:
Description:
We hit a timeout when persisting group metadata to the __consumer_offsets topic:
{code}
[2020-12-18 18:06:08,209] DEBUG [GroupMetadataManager brokerId=1] Metadata from
group test_group_id with generation 1 failed when appending to log due to
org.apache.kafka.common.errors.TimeoutException
(kafka.coordinator.group.GroupMetadataManager)
[2020-12-18 18:06:08,210] WARN [GroupCoordinator 1]: Failed to persist metadata
for group test_group_id: The group is rebalancing, so a rejoin is needed.
(kafka.coordinator.group.GroupCoordinator)
{code}
This in turn resulted in a REBALANCE_IN_PROGRESS being returned from the
JoinGroup:
{code}
[2020-12-18 18:06:08,211] INFO Completed
request:RequestHeader(apiKey=JOIN_GROUP, apiVersion=7,
clientId=consumer-test_group_id-test_group_id-instance-1, correlationId=3) --
{group_id=test_group_id,session_timeout_ms=6,rebalance_timeout_ms=30,member_id=,group_instance_id=test_group_id-instance-1,protocol_type=consumer,protocols=[{name=range,metadata=java.nio.HeapByteBuffer[pos=0
lim=26
cap=26],_tagged_fields={}}],_tagged_fields={}},response:{throttle_time_ms=0,error_code=27,generation_id=1,protocol_type=consumer,protocol_name=range,leader=test_group_id-instance-2-32e72316-2c3f-40d6-bc34-8ec23d633d34,member_id=,members=[],_tagged_fields={}}
from connection
172.31.46.222:9092-172.31.44.169:41310-6;totalTime:5014.825,requestQueueTime:0.193,localTime:11.575,remoteTime:5002.195,throttleTime:0.66,responseQueueTime:0.105,sendTime:0.094,sendIoTime:0.038,securityProtocol:PLAINTEXT,principal:User:ANONYMOUS,listener:PLAINTEXT,clientInformation:ClientInformation(softwareName=apache-kafka-java,
softwareVersion=5.5.3-ce) (kafka.request.logger)
{code}
The consumer has no logic to handle REBALANCE_IN_PROGRESS from JoinGroup.
{code}
[2020-12-18 18:06:08,210] ERROR [Consumer instanceId=test_group_id-instance-1,
clientId=consumer-test_group_id-test_group_id-instance-1,
groupId=test_group_id] Attempt to join group failed due to unexpected error
: The group is rebalancing, so a rejoin is needed.
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2020-12-18 18:06:08,211] INFO [Consumer instanceId=test_group_id-instance-1,
clientId=consumer-test_group_id-test_group_id-instance-1,
groupId=test_group_id] Join group failed with org.apache.kafka.common.KafkaE
xception: Unexpected error in join group response: The group is rebalancing, so
a rejoin is needed.
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2020-12-18 18:06:08,211] ERROR Error during processing, terminating consumer
process: (org.apache.kafka.tools.VerifiableConsumer)
org.apache.kafka.common.KafkaException: Unexpected error in join group
response: The group is rebalancing, so a rejoin is needed.
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$JoinGroupResponseHandler.handle(AbstractCoordinator.java:653)
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$JoinGroupResponseHandler.handle(AbstractCoordinator.java:574)
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:1096)
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:1076)
at
org.apache.kafka.clients.consumer.internals.RequestFuture$1.onSuccess(RequestFuture.java:204)
{code}
was:
We hit a timeout when persisting group metadata to the __consumer_offsets topic:
{code}
[2020-12-18 18:06:07,889] DEBUG Created a new incremental FetchContext for
session id 5832, epoch 53: added 0 partition(s), updated 0 partition(s),
removed 0 partition(s) (kafka.server.FetchManager)
[2020-12-18 18:06:08,209] DEBUG [GroupMetadataManager brokerId=1] Metadata from
group test_group_id with generation 1 failed when appending to log due to
org.apache.kafka.common.errors.TimeoutException
(kafka.coordinator.group.GroupMetadataManager)
[2020-12-18 18:06:08,210] WARN [GroupCoordinator 1]: Failed to persist metadata
for group test_group_id: The group is rebalancing, so a rejoin is needed.
(kafka.coordinator.group.GroupCoordinator)
{code}
This in turn resulted in a REBALANCE_IN_PROGRESS being returned from the
JoinGroup:
{code}
[2020-12-18 18:06:08,211] INFO Completed
request:RequestHeader(apiKey=JOIN_GROUP, apiVersion=7,
clientId=consumer-test_group_id-test_group_id-instance-1, correlationId=3) --
{group_id=test_group_id,session_timeout_ms=6,rebalance_timeout_ms=30,member_id=,group_instance_id=test_group_id-instance-1,protocol_type=consumer,protocols=[{name=range,metadata=java.nio.HeapByteBuffer[pos=0
lim=26
[jira] [Created] (KAFKA-10870) Consumer should handle REBALANCE_IN_PROGRESS from JoinGroup
Jason Gustafson created KAFKA-10870:
---
Summary: Consumer should handle REBALANCE_IN_PROGRESS from
JoinGroup
Key: KAFKA-10870
URL: https://issues.apache.org/jira/browse/KAFKA-10870
Project: Kafka
Issue Type: Bug
Reporter: Jason Gustafson
We hit a timeout when persisting group metadata to the __consumer_offsets topic:
{code}
[2020-12-18 18:06:07,889] DEBUG Created a new incremental FetchContext for
session id 5832, epoch 53: added 0 partition(s), updated 0 partition(s),
removed 0 partition(s) (kafka.server.FetchManager)
[2020-12-18 18:06:08,209] DEBUG [GroupMetadataManager brokerId=1] Metadata from
group test_group_id with generation 1 failed when appending to log due to
org.apache.kafka.common.errors.TimeoutException
(kafka.coordinator.group.GroupMetadataManager)
[2020-12-18 18:06:08,210] WARN [GroupCoordinator 1]: Failed to persist metadata
for group test_group_id: The group is rebalancing, so a rejoin is needed.
(kafka.coordinator.group.GroupCoordinator)
{code}
This in turn resulted in a REBALANCE_IN_PROGRESS being returned from the
JoinGroup:
{code}
[2020-12-18 18:06:08,211] INFO Completed
request:RequestHeader(apiKey=JOIN_GROUP, apiVersion=7,
clientId=consumer-test_group_id-test_group_id-instance-1, correlationId=3) --
{group_id=test_group_id,session_timeout_ms=6,rebalance_timeout_ms=30,member_id=,group_instance_id=test_group_id-instance-1,protocol_type=consumer,protocols=[{name=range,metadata=java.nio.HeapByteBuffer[pos=0
lim=26
cap=26],_tagged_fields={}}],_tagged_fields={}},response:{throttle_time_ms=0,error_code=27,generation_id=1,protocol_type=consumer,protocol_name=range,leader=test_group_id-instance-2-32e72316-2c3f-40d6-bc34-8ec23d633d34,member_id=,members=[],_tagged_fields={}}
from connection
172.31.46.222:9092-172.31.44.169:41310-6;totalTime:5014.825,requestQueueTime:0.193,localTime:11.575,remoteTime:5002.195,throttleTime:0.66,responseQueueTime:0.105,sendTime:0.094,sendIoTime:0.038,securityProtocol:PLAINTEXT,principal:User:ANONYMOUS,listener:PLAINTEXT,clientInformation:ClientInformation(softwareName=apache-kafka-java,
softwareVersion=5.5.3-ce) (kafka.request.logger)
{code}
The consumer has no logic to handle REBALANCE_IN_PROGRESS from JoinGroup.
{code}
[2020-12-18 18:06:08,210] ERROR [Consumer instanceId=test_group_id-instance-1,
clientId=consumer-test_group_id-test_group_id-instance-1,
groupId=test_group_id] Attempt to join group failed due to unexpected error
: The group is rebalancing, so a rejoin is needed.
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2020-12-18 18:06:08,211] INFO [Consumer instanceId=test_group_id-instance-1,
clientId=consumer-test_group_id-test_group_id-instance-1,
groupId=test_group_id] Join group failed with org.apache.kafka.common.KafkaE
xception: Unexpected error in join group response: The group is rebalancing, so
a rejoin is needed.
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2020-12-18 18:06:08,211] ERROR Error during processing, terminating consumer
process: (org.apache.kafka.tools.VerifiableConsumer)
org.apache.kafka.common.KafkaException: Unexpected error in join group
response: The group is rebalancing, so a rejoin is needed.
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$JoinGroupResponseHandler.handle(AbstractCoordinator.java:653)
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$JoinGroupResponseHandler.handle(AbstractCoordinator.java:574)
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:1096)
at
org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:1076)
at
org.apache.kafka.clients.consumer.internals.RequestFuture$1.onSuccess(RequestFuture.java:204)
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] glasser commented on pull request #9767: KAFKA-10047: Remove unnecessary widening of (int to long) scope in FloatSerializer.
glasser commented on pull request #9767: URL: https://github.com/apache/kafka/pull/9767#issuecomment-748376004 I'm not sure why I'm tagged; did you mean somebody else? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (KAFKA-10545) Create topic IDs and propagate to brokers
[ https://issues.apache.org/jira/browse/KAFKA-10545?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Justine Olshan resolved KAFKA-10545. Resolution: Done > Create topic IDs and propagate to brokers > - > > Key: KAFKA-10545 > URL: https://issues.apache.org/jira/browse/KAFKA-10545 > Project: Kafka > Issue Type: Sub-task >Reporter: Justine Olshan >Assignee: Justine Olshan >Priority: Major > > First step for KIP-516 > The goals are: > * Create and store topic IDs in a ZK Node and controller memory. > * Propagate topic ID to brokers with updated LeaderAndIsrRequest, > UpdateMetadata > * Store topic ID in memory on broker, persistent file in log -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] rajinisivaram merged pull request #9626: KAFKA-10545: Create topic IDs and propagate to brokers
rajinisivaram merged pull request #9626: URL: https://github.com/apache/kafka/pull/9626 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on pull request #9626: KAFKA-10545: Create topic IDs and propagate to brokers
rajinisivaram commented on pull request #9626: URL: https://github.com/apache/kafka/pull/9626#issuecomment-748345741 @jolshan Thanks for the PR, the last build was good, so merging to trunk This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram merged pull request #9622: KAFKA-10547; add topicId in MetadataResp
rajinisivaram merged pull request #9622: URL: https://github.com/apache/kafka/pull/9622 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on pull request #9622: KAFKA-10547; add topicId in MetadataResp
rajinisivaram commented on pull request #9622: URL: https://github.com/apache/kafka/pull/9622#issuecomment-748328137 @dengziming Thanks for the PR, merging to trunk. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tguruprasad opened a new pull request #9767: KAFKA-10047: Remove unnecessary widening of (int to long) scope in FloatSerializer.
tguruprasad opened a new pull request #9767: URL: https://github.com/apache/kafka/pull/9767 @halorgium @astubbs @alexism @glasser @rhardouin This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe merged pull request #9736: Add configurable workloads and E2E latency tracking to Trogdor.
cmccabe merged pull request #9736: URL: https://github.com/apache/kafka/pull/9736 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on pull request #9736: Add configurable workloads and E2E latency tracking to Trogdor.
cmccabe commented on pull request #9736: URL: https://github.com/apache/kafka/pull/9736#issuecomment-748317827 > I wanted this timestamp to live outside the Kafka broker/client, as that is what customers will see. We can also validate the numbers within Kafka on this if we want, I just wanted to make sure we captured every bit of latency available. We're running this test on systems that are millisecond synced to get an accurate reading. OK. > The Throttle architecture didn't exactly work for the variable throughput generation. In order to add partition-specific testing I had to limit the test to 1 topic. I am by no means an experienced Java engineer and I couldn't find a way of modifying the original, or even subclassing it, without forcing the spec to change. Hmm. We could probably do some more work to share code, but in the meantime, this is a nice improvement. LGTM. Thanks, @scott-hendricks This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10869) Gate topic IDs behind IBP 2.8
[ https://issues.apache.org/jira/browse/KAFKA-10869?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Justine Olshan updated KAFKA-10869: --- Priority: Blocker (was: Major) > Gate topic IDs behind IBP 2.8 > - > > Key: KAFKA-10869 > URL: https://issues.apache.org/jira/browse/KAFKA-10869 > Project: Kafka > Issue Type: Sub-task >Reporter: Justine Olshan >Assignee: Justine Olshan >Priority: Blocker > > We want to do this so we don't lose topic IDs upon downgrades. If we > downgrade and write to topic node in ZK, the topic ID will be lost. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-10869) Gate topic IDs behind IBP 2.8
Justine Olshan created KAFKA-10869: -- Summary: Gate topic IDs behind IBP 2.8 Key: KAFKA-10869 URL: https://issues.apache.org/jira/browse/KAFKA-10869 Project: Kafka Issue Type: Sub-task Reporter: Justine Olshan Assignee: Justine Olshan We want to do this so we don't lose topic IDs upon downgrades. If we downgrade and write to topic node in ZK, the topic ID will be lost. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] hachikuji commented on a change in pull request #9713: KAFKA-10825 ZK ISR manager
hachikuji commented on a change in pull request #9713:
URL: https://github.com/apache/kafka/pull/9713#discussion_r546044857
##
File path: core/src/main/scala/kafka/cluster/Partition.scala
##
@@ -1374,46 +1314,29 @@ class Partition(val topicPartition: TopicPartition,
}
}
- private def shrinkIsrWithZk(newIsr: Set[Int]): Unit = {
-val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch,
newIsr.toList, zkVersion)
-val zkVersionOpt = stateStore.shrinkIsr(controllerEpoch, newLeaderAndIsr)
-if (zkVersionOpt.isDefined) {
- isrChangeListener.markShrink()
-}
-maybeUpdateIsrAndVersionWithZk(newIsr, zkVersionOpt)
- }
-
- private def maybeUpdateIsrAndVersionWithZk(isr: Set[Int], zkVersionOpt:
Option[Int]): Unit = {
-zkVersionOpt match {
- case Some(newVersion) =>
-isrState = CommittedIsr(isr)
-zkVersion = newVersion
-info("ISR updated to [%s] and zkVersion updated to
[%d]".format(isr.mkString(","), zkVersion))
-
- case None =>
-info(s"Cached zkVersion $zkVersion not equal to that in zookeeper,
skip updating ISR")
-isrChangeListener.markFailed()
-}
- }
-
private def sendAlterIsrRequest(proposedIsrState: IsrState): Unit = {
val isrToSend: Set[Int] = proposedIsrState match {
case PendingExpandIsr(isr, newInSyncReplicaId) => isr +
newInSyncReplicaId
case PendingShrinkIsr(isr, outOfSyncReplicaIds) => isr --
outOfSyncReplicaIds
case state =>
+isrChangeListener.markFailed()
throw new IllegalStateException(s"Invalid state $state for `AlterIsr`
request for partition $topicPartition")
}
val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch,
isrToSend.toList, zkVersion)
-val alterIsrItem = AlterIsrItem(topicPartition, newLeaderAndIsr,
handleAlterIsrResponse(proposedIsrState))
+val alterIsrItem = AlterIsrItem(topicPartition, newLeaderAndIsr,
handleAlterIsrResponse(proposedIsrState), controllerEpoch)
-if (!alterIsrManager.enqueue(alterIsrItem)) {
+val oldState = isrState
+isrState = proposedIsrState
+
+if (!alterIsrManager.submit(alterIsrItem)) {
+ // If the ISR manager did not accept our update, we need to revert back
to previous state
+ isrState = oldState
isrChangeListener.markFailed()
throw new IllegalStateException(s"Failed to enqueue `AlterIsr` request
with state " +
s"$newLeaderAndIsr for partition $topicPartition")
}
-isrState = proposedIsrState
debug(s"Sent `AlterIsr` request to change state to $newLeaderAndIsr after
transition to $proposedIsrState")
Review comment:
Should we generalize this log message as well? Also the couple
`IllegalStateException` messages above.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #9713: KAFKA-10825 ZK ISR manager
hachikuji commented on a change in pull request #9713:
URL: https://github.com/apache/kafka/pull/9713#discussion_r546044857
##
File path: core/src/main/scala/kafka/cluster/Partition.scala
##
@@ -1374,46 +1314,29 @@ class Partition(val topicPartition: TopicPartition,
}
}
- private def shrinkIsrWithZk(newIsr: Set[Int]): Unit = {
-val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch,
newIsr.toList, zkVersion)
-val zkVersionOpt = stateStore.shrinkIsr(controllerEpoch, newLeaderAndIsr)
-if (zkVersionOpt.isDefined) {
- isrChangeListener.markShrink()
-}
-maybeUpdateIsrAndVersionWithZk(newIsr, zkVersionOpt)
- }
-
- private def maybeUpdateIsrAndVersionWithZk(isr: Set[Int], zkVersionOpt:
Option[Int]): Unit = {
-zkVersionOpt match {
- case Some(newVersion) =>
-isrState = CommittedIsr(isr)
-zkVersion = newVersion
-info("ISR updated to [%s] and zkVersion updated to
[%d]".format(isr.mkString(","), zkVersion))
-
- case None =>
-info(s"Cached zkVersion $zkVersion not equal to that in zookeeper,
skip updating ISR")
-isrChangeListener.markFailed()
-}
- }
-
private def sendAlterIsrRequest(proposedIsrState: IsrState): Unit = {
val isrToSend: Set[Int] = proposedIsrState match {
case PendingExpandIsr(isr, newInSyncReplicaId) => isr +
newInSyncReplicaId
case PendingShrinkIsr(isr, outOfSyncReplicaIds) => isr --
outOfSyncReplicaIds
case state =>
+isrChangeListener.markFailed()
throw new IllegalStateException(s"Invalid state $state for `AlterIsr`
request for partition $topicPartition")
}
val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch,
isrToSend.toList, zkVersion)
-val alterIsrItem = AlterIsrItem(topicPartition, newLeaderAndIsr,
handleAlterIsrResponse(proposedIsrState))
+val alterIsrItem = AlterIsrItem(topicPartition, newLeaderAndIsr,
handleAlterIsrResponse(proposedIsrState), controllerEpoch)
-if (!alterIsrManager.enqueue(alterIsrItem)) {
+val oldState = isrState
+isrState = proposedIsrState
+
+if (!alterIsrManager.submit(alterIsrItem)) {
+ // If the ISR manager did not accept our update, we need to revert back
to previous state
+ isrState = oldState
isrChangeListener.markFailed()
throw new IllegalStateException(s"Failed to enqueue `AlterIsr` request
with state " +
s"$newLeaderAndIsr for partition $topicPartition")
}
-isrState = proposedIsrState
debug(s"Sent `AlterIsr` request to change state to $newLeaderAndIsr after
transition to $proposedIsrState")
Review comment:
Should we generalize this log message as well? Also the
`IllegalStateException` message above.
##
File path: core/src/main/scala/kafka/server/ZkIsrManager.scala
##
@@ -0,0 +1,109 @@
+/**
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package kafka.server
+
+import kafka.utils.{Logging, ReplicationUtils, Scheduler}
+import kafka.zk.KafkaZkClient
+import org.apache.kafka.common.TopicPartition
+import org.apache.kafka.common.protocol.Errors
+import org.apache.kafka.common.utils.Time
+
+import java.util.concurrent.TimeUnit
+import java.util.concurrent.atomic.AtomicLong
+import scala.collection.mutable
+
+/**
+ * @param checkIntervalMs How often to check for ISR
+ * @param maxDelayMs Maximum time that an ISR change may be delayed before
sending the notification
+ * @param lingerMs Maximum time to await additional changes before sending
the notification
+ */
+case class IsrChangePropagationConfig(checkIntervalMs: Long, maxDelayMs: Long,
lingerMs: Long)
+
+object ZkIsrManager {
+ // This field is mutable to allow overriding change notification behavior in
test cases
+ @volatile var DefaultIsrPropagationConfig: IsrChangePropagationConfig =
IsrChangePropagationConfig(
+checkIntervalMs = 2500,
+lingerMs = 5000,
+maxDelayMs = 6,
+ )
+}
+
+class ZkIsrManager(scheduler: Scheduler, time: Time, zkClient: KafkaZkClient)
extends AlterIsrManager with Logging {
+
+ private val isrChangeNotificationConfig =
ZkIsrManager.DefaultIsrPropagationConfig
+ // Visible for testing
+ private[server]
[GitHub] [kafka] JimGalasyn commented on pull request #9670: DOCS-6076: Clarify config names for EOS versions 1 and 2
JimGalasyn commented on pull request #9670: URL: https://github.com/apache/kafka/pull/9670#issuecomment-748281814 @abbccdda cool, does this work? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10843) Kafka Streams metadataForKey method returns null but allMetadata has the details
[
https://issues.apache.org/jira/browse/KAFKA-10843?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251960#comment-17251960
]
Matthias J. Sax commented on KAFKA-10843:
-
{quote}You want me to update the Kafka-streams version to 2.6.0?
{quote}
I might be worth a try.
{quote}With regards to using allMetadata(), this wont still give me the
particular store where my key is right? It would give all the hosts where the
store is present, but my key could be on any of them.
{quote}
Well, yes, but you see the partition information, and thus you could hash the
key yourself to find the right instance.
Curious to hear your answer to Bruno's questions. – If you use custom
partitioning, you would need to hand in a custom `StreamsPartitioner` to allow
KafkaStreams to compute the right partitions to find the right instance.
> Kafka Streams metadataForKey method returns null but allMetadata has the
> details
>
>
> Key: KAFKA-10843
> URL: https://issues.apache.org/jira/browse/KAFKA-10843
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.5.1
>Reporter: Maria Thomas
>Priority: Major
>
> Our application runs on multiple instances and to enable us to use get the
> key information from the state store we use "metadataForKey" method to
> retrieve the StreamMetadata and using the hostname do an RPC call to the host
> to get the value associated with the key.
> This call was working fine in our DEV and TEST environments, however, it is
> failing one our production clusters from the start. On further debugging, I
> noticed the allMetadata() method was returning the state stores with the host
> details as expected. However, it would not be feasible to go through each
> store explicitly to get the key details.
> To note, the cluster I am using is a stretch cluster.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-10868) Avoid double wrapping KafkaException
[ https://issues.apache.org/jira/browse/KAFKA-10868?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Boyang Chen updated KAFKA-10868: Description: Today certain exceptions get double wraps of KafkaException. We should remove those cases > Avoid double wrapping KafkaException > > > Key: KAFKA-10868 > URL: https://issues.apache.org/jira/browse/KAFKA-10868 > Project: Kafka > Issue Type: Sub-task >Reporter: Boyang Chen >Priority: Major > > Today certain exceptions get double wraps of KafkaException. We should remove > those cases -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-10868) Avoid double wrapping KafkaException
Boyang Chen created KAFKA-10868: --- Summary: Avoid double wrapping KafkaException Key: KAFKA-10868 URL: https://issues.apache.org/jira/browse/KAFKA-10868 Project: Kafka Issue Type: Sub-task Reporter: Boyang Chen -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] ncliang commented on a change in pull request #9765: KAFKA-10763: Fix incomplete cooperative rebalances preventing connector/task revocations
ncliang commented on a change in pull request #9765:
URL: https://github.com/apache/kafka/pull/9765#discussion_r546001555
##
File path:
connect/runtime/src/test/java/org/apache/kafka/connect/runtime/distributed/DistributedHerderTest.java
##
@@ -566,6 +566,112 @@ public Boolean answer() throws Throwable {
PowerMock.verifyAll();
}
+@Test
+public void testRevoke() throws TimeoutException {
+revokeAndReassign(false);
+}
+
+@Test
+public void testIncompleteRebalanceBeforeRevoke() throws TimeoutException {
+revokeAndReassign(true);
+}
+
+public void revokeAndReassign(boolean incompleteRebalance) throws
TimeoutException {
Review comment:
It's hard to tell if this actually reproduces the issue or not due to
the heavy mocking required. Is there a more direct way to reproduce? Maybe in
`RebalanceSourceConnectorsIntegrationTest` or similar? Even if the IT ends up
being flaky, having that repro would boost confidence in this fix.
##
File path:
connect/runtime/src/main/java/org/apache/kafka/connect/runtime/distributed/DistributedHerder.java
##
@@ -1740,7 +1741,7 @@ public void onRevoked(String leader, Collection
connectors, Collection=
CONNECT_PROTOCOL_V1) {
Review comment:
Maybe add a comment explaining why the additional check is needed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] d8tltanc commented on pull request #9485: KAKFA-10619: Idempotent producer will get authorized once it has a WRITE access to at least one topic
d8tltanc commented on pull request #9485: URL: https://github.com/apache/kafka/pull/9485#issuecomment-748242438 Thank you @rajinisivaram This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram commented on pull request #9622: KAFKA-10547; add topicId in MetadataResp
rajinisivaram commented on pull request #9622: URL: https://github.com/apache/kafka/pull/9622#issuecomment-748239592 There is a compilation failure in the Java 8 build because the PR uses an API not available in Scala 2.12. Will push a fix. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rajinisivaram merged pull request #9485: KAKFA-10619: Idempotent producer will get authorized once it has a WRITE access to at least one topic
rajinisivaram merged pull request #9485: URL: https://github.com/apache/kafka/pull/9485 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] abbccdda commented on a change in pull request #9766: KAFKA-10864: Convert end txn marker schema to use auto-generated protocol
abbccdda commented on a change in pull request #9766:
URL: https://github.com/apache/kafka/pull/9766#discussion_r545985013
##
File path:
clients/src/main/java/org/apache/kafka/common/record/MemoryRecords.java
##
@@ -618,8 +618,7 @@ public static MemoryRecords withEndTransactionMarker(long
timestamp, long produc
public static MemoryRecords withEndTransactionMarker(long initialOffset,
long timestamp, int partitionLeaderEpoch,
long producerId,
short producerEpoch,
EndTransactionMarker
marker) {
-int endTxnMarkerBatchSize = DefaultRecordBatch.RECORD_BATCH_OVERHEAD +
-EndTransactionMarker.CURRENT_END_TXN_SCHEMA_RECORD_SIZE;
+int endTxnMarkerBatchSize = DefaultRecordBatch.RECORD_BATCH_OVERHEAD +
marker.endTnxMarkerValueSize();
Review comment:
s/endTnxMarkerValueSize/endTxnMarkerValueSize
##
File path: clients/src/main/resources/common/message/EndTxnMarker.json
##
@@ -0,0 +1,23 @@
+// Licensed to the Apache Software Foundation (ASF) under one or more
+// contributor license agreements. See the NOTICE file distributed with
+// this work for additional information regarding copyright ownership.
+// The ASF licenses this file to You under the Apache License, Version 2.0
+// (the "License"); you may not use this file except in compliance with
+// the License. You may obtain a copy of the License at
+//
+//http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+{
+ "type": "data",
+ "name": "EndTxnMarker",
+ "validVersions": "0",
+ "fields": [
+{ "name": "CoordinatorEpoch", "type": "int32", "versions": "0+"}
Review comment:
Add a comment for the field. Also do you think we need flexible version
support here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #9508: KAFKA-10648: Add Prefix Scan support to State Stores
cadonna commented on a change in pull request #9508:
URL: https://github.com/apache/kafka/pull/9508#discussion_r545986204
##
File path:
streams/src/main/java/org/apache/kafka/streams/state/internals/RocksDBPrefixIterator.java
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.state.internals;
+
+import org.apache.kafka.common.utils.Bytes;
+import org.apache.kafka.streams.KeyValue;
+import org.apache.kafka.streams.state.KeyValueIterator;
+import org.rocksdb.RocksIterator;
+
+import java.nio.ByteBuffer;
+import java.util.Set;
+
+class RocksDBPrefixIterator extends RocksDbIterator {
Review comment:
Could you not use the same technique as you use in the in-memory
key-value state store and the cache?
```
final Bytes from = Bytes.wrap(prefixKeySerializer.serialize(null,
prefix));
final Bytes to = Bytes.increment(from);
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (KAFKA-10867) Implement improved semantics using the ConsumerRecords meta
John Roesler created KAFKA-10867: Summary: Implement improved semantics using the ConsumerRecords meta Key: KAFKA-10867 URL: https://issues.apache.org/jira/browse/KAFKA-10867 Project: Kafka Issue Type: Sub-task Components: streams Reporter: John Roesler Assignee: John Roesler Fix For: 2.8.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-10866) Add fetched metadata to ConsumerRecords
John Roesler created KAFKA-10866: Summary: Add fetched metadata to ConsumerRecords Key: KAFKA-10866 URL: https://issues.apache.org/jira/browse/KAFKA-10866 Project: Kafka Issue Type: Sub-task Components: consumer Reporter: John Roesler Assignee: John Roesler Fix For: 2.8.0 Consumer-side changes for KIP-695 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] mumrah commented on a change in pull request #9713: KAFKA-10825 ZK ISR manager
mumrah commented on a change in pull request #9713:
URL: https://github.com/apache/kafka/pull/9713#discussion_r545964382
##
File path: core/src/main/scala/kafka/cluster/Partition.scala
##
@@ -1374,47 +1314,28 @@ class Partition(val topicPartition: TopicPartition,
}
}
- private def shrinkIsrWithZk(newIsr: Set[Int]): Unit = {
-val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch,
newIsr.toList, zkVersion)
-val zkVersionOpt = stateStore.shrinkIsr(controllerEpoch, newLeaderAndIsr)
-if (zkVersionOpt.isDefined) {
- isrChangeListener.markShrink()
-}
-maybeUpdateIsrAndVersionWithZk(newIsr, zkVersionOpt)
- }
-
- private def maybeUpdateIsrAndVersionWithZk(isr: Set[Int], zkVersionOpt:
Option[Int]): Unit = {
-zkVersionOpt match {
- case Some(newVersion) =>
-isrState = CommittedIsr(isr)
-zkVersion = newVersion
-info("ISR updated to [%s] and zkVersion updated to
[%d]".format(isr.mkString(","), zkVersion))
-
- case None =>
-info(s"Cached zkVersion $zkVersion not equal to that in zookeeper,
skip updating ISR")
-isrChangeListener.markFailed()
-}
- }
-
private def sendAlterIsrRequest(proposedIsrState: IsrState): Unit = {
val isrToSend: Set[Int] = proposedIsrState match {
case PendingExpandIsr(isr, newInSyncReplicaId) => isr +
newInSyncReplicaId
case PendingShrinkIsr(isr, outOfSyncReplicaIds) => isr --
outOfSyncReplicaIds
case state =>
+isrChangeListener.markFailed()
throw new IllegalStateException(s"Invalid state $state for `AlterIsr`
request for partition $topicPartition")
}
val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch,
isrToSend.toList, zkVersion)
-val alterIsrItem = AlterIsrItem(topicPartition, newLeaderAndIsr,
handleAlterIsrResponse(proposedIsrState))
+val alterIsrItem = AlterIsrItem(topicPartition, newLeaderAndIsr,
handleAlterIsrResponse(proposedIsrState), controllerEpoch)
-if (!alterIsrManager.enqueue(alterIsrItem)) {
- isrChangeListener.markFailed()
- throw new IllegalStateException(s"Failed to enqueue `AlterIsr` request
with state " +
-s"$newLeaderAndIsr for partition $topicPartition")
-}
-
-isrState = proposedIsrState
-debug(s"Sent `AlterIsr` request to change state to $newLeaderAndIsr after
transition to $proposedIsrState")
+alterIsrManager.submit(alterIsrItem, (wasSubmitted: Boolean) => {
+ if (wasSubmitted) {
+isrState = proposedIsrState
Review comment:
Yea, this seems simpler than the callback thing. I've made this change
in the latest commit
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vamossagar12 commented on a change in pull request #9508: KAFKA-10648: Add Prefix Scan support to State Stores
vamossagar12 commented on a change in pull request #9508:
URL: https://github.com/apache/kafka/pull/9508#discussion_r545958971
##
File path:
streams/src/main/java/org/apache/kafka/streams/state/internals/RocksDBPrefixIterator.java
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.streams.state.internals;
+
+import org.apache.kafka.common.utils.Bytes;
+import org.apache.kafka.streams.KeyValue;
+import org.apache.kafka.streams.state.KeyValueIterator;
+import org.rocksdb.RocksIterator;
+
+import java.nio.ByteBuffer;
+import java.util.Set;
+
+class RocksDBPrefixIterator extends RocksDbIterator {
Review comment:
Well the only reason i chose to add a separate iterator is that for
prefix scan there is no end key which could be known upfront. We could pass a
null end key but that's prohibited in RocksDBRangeIterator constructor and i
don't think we should be changing that condition or we could pass in the same
value or from and to and add a condition in makeNext() for prefix scan. i
thought having a separate iterator might be cleaner. You have some other
approach in mind?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10865) Improve trace-logging for Transformations (including Predicates)
[
https://issues.apache.org/jira/browse/KAFKA-10865?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251851#comment-17251851
]
Randall Hauch commented on KAFKA-10865:
---
We currently trace-log the record passed into a transformation, but it looks
like we don't trace-log the record just before it is passed to the connector.
We may want to have slightly different log messages for source and sink
connectors. If so, that would make it difficult to add all of the log messages
in `TransformationChain`. So we might also need to think about the trace-log
messages in `WorkerSourceTask` and `WorkerSinkTask` near where the
transformation chain is called.
We need to be careful about changing existing log messages, in case users are
relying upon specific log messages for any automated tooling. Trace messages
are probably a bit easier to change if necessary, since it's unlikely those
would be enabled in production, but we should still strive for minimally
changing existing log messages.
[~govi20], thank you for volunteering to take this ticket. You assigned
yourself, so +1. Looking forward to a PR. :-)
> Improve trace-logging for Transformations (including Predicates)
>
>
> Key: KAFKA-10865
> URL: https://issues.apache.org/jira/browse/KAFKA-10865
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Robin Moffatt
>Assignee: Govinda Sakhare
>Priority: Major
> Labels: newbie
>
> I've been spending [a bunch of time poking around
> SMTs|https://rmoff.net/categories/twelvedaysofsmt/] recently, and one common
> challenge I've had is being able to debug when things don't behave as I
> expect.
>
> I know that there is the {{TransformationChain}} logger, but this only gives
> (IIUC) the input record
> {code:java}
> [2020-12-17 09:38:58,057] TRACE [sink-simulator-day12-00|task-0] Applying
> transformation io.confluent.connect.transforms.Filter$Value to
> SinkRecord{kafkaOffset=10551, timestampType=CreateTime}
> ConnectRecord{topic='day12-sys01', kafkaPartition=0,
> key=2c2ceb9b-8b31-4ade-a757-886ebfb7a398, keySchema=Schema{STRING},
> value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01},
> valueSchema=Schema{io.mdrogalis.Gen0:STRUCT}, timestamp=1608197938054,
> headers=ConnectHeaders(headers=)}
> (org.apache.kafka.connect.runtime.TransformationChain:47)
> {code}
>
> I think it would be really useful to also have trace level logging that
> included:
> - the _output_ of *each* transform
> - the evaluation and result of any `predicate`s
> I have been using
> {{com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector}}
> which is really useful for seeing the final record:
> {code:java}
> [2020-12-17 09:38:58,057] INFO [sink-simulator-day12-00|task-0]
> record.value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01}
> (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50)
> {code}
>
> But doesn't include things like topic name (which is often changed by common
> SMTs)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] rajinisivaram commented on pull request #9485: KAKFA-10619: Idempotent producer will get authorized once it has a WRITE access to at least one topic
rajinisivaram commented on pull request #9485: URL: https://github.com/apache/kafka/pull/9485#issuecomment-748190567 @d8tltanc Thanks for your patience with this PR, builds look good, merging to trunk. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (KAFKA-10100) LiveLeaders field in LeaderAndIsrRequest is not used anymore
[ https://issues.apache.org/jira/browse/KAFKA-10100?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David Jacot resolved KAFKA-10100. - Resolution: Won't Fix This is not worthwhile. > LiveLeaders field in LeaderAndIsrRequest is not used anymore > > > Key: KAFKA-10100 > URL: https://issues.apache.org/jira/browse/KAFKA-10100 > Project: Kafka > Issue Type: Improvement >Reporter: David Jacot >Assignee: David Jacot >Priority: Major > > We have noticed that the `LiveLeaders` field in the LeaderAndIsrRequest is > not used anywhere but still populated by the controller. > It seems that that field was introduced in AK `0.8.0` and was supposed to be > removed in AK `0.8.1`: > [https://github.com/apache/kafka/blob/0.8.0/core/src/main/scala/kafka/cluster/Partition.scala#L194.] > I think that we can safely deprecate the field and stop populating it for all > versions > 0. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dajac commented on pull request #8801: KAFKA-10100; LiveLeaders field in LeaderAndIsrRequest is not used anymore
dajac commented on pull request #8801: URL: https://github.com/apache/kafka/pull/8801#issuecomment-748177193 Won't proceed with this one. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac closed pull request #8801: KAFKA-10100; LiveLeaders field in LeaderAndIsrRequest is not used anymore
dajac closed pull request #8801: URL: https://github.com/apache/kafka/pull/8801 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (KAFKA-10865) Improve trace-logging for Transformations (including Predicates)
[
https://issues.apache.org/jira/browse/KAFKA-10865?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tom Bentley reassigned KAFKA-10865:
---
Assignee: Govinda Sakhare
> Improve trace-logging for Transformations (including Predicates)
>
>
> Key: KAFKA-10865
> URL: https://issues.apache.org/jira/browse/KAFKA-10865
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Robin Moffatt
>Assignee: Govinda Sakhare
>Priority: Major
> Labels: newbie
>
> I've been spending [a bunch of time poking around
> SMTs|https://rmoff.net/categories/twelvedaysofsmt/] recently, and one common
> challenge I've had is being able to debug when things don't behave as I
> expect.
>
> I know that there is the {{TransformationChain}} logger, but this only gives
> (IIUC) the input record
> {code:java}
> [2020-12-17 09:38:58,057] TRACE [sink-simulator-day12-00|task-0] Applying
> transformation io.confluent.connect.transforms.Filter$Value to
> SinkRecord{kafkaOffset=10551, timestampType=CreateTime}
> ConnectRecord{topic='day12-sys01', kafkaPartition=0,
> key=2c2ceb9b-8b31-4ade-a757-886ebfb7a398, keySchema=Schema{STRING},
> value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01},
> valueSchema=Schema{io.mdrogalis.Gen0:STRUCT}, timestamp=1608197938054,
> headers=ConnectHeaders(headers=)}
> (org.apache.kafka.connect.runtime.TransformationChain:47)
> {code}
>
> I think it would be really useful to also have trace level logging that
> included:
> - the _output_ of *each* transform
> - the evaluation and result of any `predicate`s
> I have been using
> {{com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector}}
> which is really useful for seeing the final record:
> {code:java}
> [2020-12-17 09:38:58,057] INFO [sink-simulator-day12-00|task-0]
> record.value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01}
> (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50)
> {code}
>
> But doesn't include things like topic name (which is often changed by common
> SMTs)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] APaMio commented on pull request #9750: MINOR: Change toArray usage for Increase efficiency
APaMio commented on pull request #9750: URL: https://github.com/apache/kafka/pull/9750#issuecomment-748161493 Roger that, Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] APaMio removed a comment on pull request #9750: MINOR: Change toArray usage for Increase efficiency
APaMio removed a comment on pull request #9750: URL: https://github.com/apache/kafka/pull/9750#issuecomment-748159574 Roger ,Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] APaMio commented on pull request #9750: MINOR: Change toArray usage for Increase efficiency
APaMio commented on pull request #9750: URL: https://github.com/apache/kafka/pull/9750#issuecomment-748159574 Roger ,Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10865) Improve trace-logging for Transformations (including Predicates)
[
https://issues.apache.org/jira/browse/KAFKA-10865?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251805#comment-17251805
]
Govinda Sakhare commented on KAFKA-10865:
-
Should I work on this?
> Improve trace-logging for Transformations (including Predicates)
>
>
> Key: KAFKA-10865
> URL: https://issues.apache.org/jira/browse/KAFKA-10865
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Robin Moffatt
>Priority: Major
> Labels: newbie
>
> I've been spending [a bunch of time poking around
> SMTs|https://rmoff.net/categories/twelvedaysofsmt/] recently, and one common
> challenge I've had is being able to debug when things don't behave as I
> expect.
>
> I know that there is the {{TransformationChain}} logger, but this only gives
> (IIUC) the input record
> {code:java}
> [2020-12-17 09:38:58,057] TRACE [sink-simulator-day12-00|task-0] Applying
> transformation io.confluent.connect.transforms.Filter$Value to
> SinkRecord{kafkaOffset=10551, timestampType=CreateTime}
> ConnectRecord{topic='day12-sys01', kafkaPartition=0,
> key=2c2ceb9b-8b31-4ade-a757-886ebfb7a398, keySchema=Schema{STRING},
> value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01},
> valueSchema=Schema{io.mdrogalis.Gen0:STRUCT}, timestamp=1608197938054,
> headers=ConnectHeaders(headers=)}
> (org.apache.kafka.connect.runtime.TransformationChain:47)
> {code}
>
> I think it would be really useful to also have trace level logging that
> included:
> - the _output_ of *each* transform
> - the evaluation and result of any `predicate`s
> I have been using
> {{com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector}}
> which is really useful for seeing the final record:
> {code:java}
> [2020-12-17 09:38:58,057] INFO [sink-simulator-day12-00|task-0]
> record.value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01}
> (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50)
> {code}
>
> But doesn't include things like topic name (which is often changed by common
> SMTs)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10865) Improve trace-logging for Transformations (including Predicates)
[
https://issues.apache.org/jira/browse/KAFKA-10865?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251805#comment-17251805
]
Govinda Sakhare edited comment on KAFKA-10865 at 12/18/20, 3:04 PM:
would it fine if I take this ticket?
was (Author: govi20):
Should I work on this?
> Improve trace-logging for Transformations (including Predicates)
>
>
> Key: KAFKA-10865
> URL: https://issues.apache.org/jira/browse/KAFKA-10865
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Robin Moffatt
>Priority: Major
> Labels: newbie
>
> I've been spending [a bunch of time poking around
> SMTs|https://rmoff.net/categories/twelvedaysofsmt/] recently, and one common
> challenge I've had is being able to debug when things don't behave as I
> expect.
>
> I know that there is the {{TransformationChain}} logger, but this only gives
> (IIUC) the input record
> {code:java}
> [2020-12-17 09:38:58,057] TRACE [sink-simulator-day12-00|task-0] Applying
> transformation io.confluent.connect.transforms.Filter$Value to
> SinkRecord{kafkaOffset=10551, timestampType=CreateTime}
> ConnectRecord{topic='day12-sys01', kafkaPartition=0,
> key=2c2ceb9b-8b31-4ade-a757-886ebfb7a398, keySchema=Schema{STRING},
> value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01},
> valueSchema=Schema{io.mdrogalis.Gen0:STRUCT}, timestamp=1608197938054,
> headers=ConnectHeaders(headers=)}
> (org.apache.kafka.connect.runtime.TransformationChain:47)
> {code}
>
> I think it would be really useful to also have trace level logging that
> included:
> - the _output_ of *each* transform
> - the evaluation and result of any `predicate`s
> I have been using
> {{com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector}}
> which is really useful for seeing the final record:
> {code:java}
> [2020-12-17 09:38:58,057] INFO [sink-simulator-day12-00|task-0]
> record.value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01}
> (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50)
> {code}
>
> But doesn't include things like topic name (which is often changed by common
> SMTs)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10865) Improve trace-logging for Transformations (including Predicates)
[
https://issues.apache.org/jira/browse/KAFKA-10865?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251805#comment-17251805
]
Govinda Sakhare edited comment on KAFKA-10865 at 12/18/20, 3:04 PM:
would it be fine if I take this ticket?
was (Author: govi20):
would it fine if I take this ticket?
> Improve trace-logging for Transformations (including Predicates)
>
>
> Key: KAFKA-10865
> URL: https://issues.apache.org/jira/browse/KAFKA-10865
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Robin Moffatt
>Priority: Major
> Labels: newbie
>
> I've been spending [a bunch of time poking around
> SMTs|https://rmoff.net/categories/twelvedaysofsmt/] recently, and one common
> challenge I've had is being able to debug when things don't behave as I
> expect.
>
> I know that there is the {{TransformationChain}} logger, but this only gives
> (IIUC) the input record
> {code:java}
> [2020-12-17 09:38:58,057] TRACE [sink-simulator-day12-00|task-0] Applying
> transformation io.confluent.connect.transforms.Filter$Value to
> SinkRecord{kafkaOffset=10551, timestampType=CreateTime}
> ConnectRecord{topic='day12-sys01', kafkaPartition=0,
> key=2c2ceb9b-8b31-4ade-a757-886ebfb7a398, keySchema=Schema{STRING},
> value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01},
> valueSchema=Schema{io.mdrogalis.Gen0:STRUCT}, timestamp=1608197938054,
> headers=ConnectHeaders(headers=)}
> (org.apache.kafka.connect.runtime.TransformationChain:47)
> {code}
>
> I think it would be really useful to also have trace level logging that
> included:
> - the _output_ of *each* transform
> - the evaluation and result of any `predicate`s
> I have been using
> {{com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector}}
> which is really useful for seeing the final record:
> {code:java}
> [2020-12-17 09:38:58,057] INFO [sink-simulator-day12-00|task-0]
> record.value=Struct{units=16,product=Founders Breakfast
> Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01}
> (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50)
> {code}
>
> But doesn't include things like topic name (which is often changed by common
> SMTs)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-10865) Improve trace-logging for Transformations (including Predicates)
Robin Moffatt created KAFKA-10865:
-
Summary: Improve trace-logging for Transformations (including
Predicates)
Key: KAFKA-10865
URL: https://issues.apache.org/jira/browse/KAFKA-10865
Project: Kafka
Issue Type: Improvement
Components: KafkaConnect
Reporter: Robin Moffatt
I've been spending [a bunch of time poking around
SMTs|https://rmoff.net/categories/twelvedaysofsmt/] recently, and one common
challenge I've had is being able to debug when things don't behave as I expect.
I know that there is the {{TransformationChain}} logger, but this only gives
(IIUC) the input record
{code:java}
[2020-12-17 09:38:58,057] TRACE [sink-simulator-day12-00|task-0] Applying
transformation io.confluent.connect.transforms.Filter$Value to
SinkRecord{kafkaOffset=10551, timestampType=CreateTime}
ConnectRecord{topic='day12-sys01', kafkaPartition=0,
key=2c2ceb9b-8b31-4ade-a757-886ebfb7a398, keySchema=Schema{STRING},
value=Struct{units=16,product=Founders Breakfast
Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01},
valueSchema=Schema{io.mdrogalis.Gen0:STRUCT}, timestamp=1608197938054,
headers=ConnectHeaders(headers=)}
(org.apache.kafka.connect.runtime.TransformationChain:47)
{code}
I think it would be really useful to also have trace level logging that
included:
- the _output_ of *each* transform
- the evaluation and result of any `predicate`s
I have been using
{{com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector}}
which is really useful for seeing the final record:
{code:java}
[2020-12-17 09:38:58,057] INFO [sink-simulator-day12-00|task-0]
record.value=Struct{units=16,product=Founders Breakfast
Stout,amount=30.41,txn_date=Sat Dec 12 18:21:18 GMT 2020,source=SYS01}
(com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50)
{code}
But doesn't include things like topic name (which is often changed by common
SMTs)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] bertber edited a comment on pull request #9761: KAFKA-10768 Add a test for ByteBufferInputStream to ByteBufferLogInputStreamTest
bertber edited a comment on pull request #9761: URL: https://github.com/apache/kafka/pull/9761#issuecomment-748028169 > Is `kafka.server.ControllerMutationQuotaTest.testPermissiveDeleteTopicsRequest` related to this PR? No, I don't think it is related to this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] bertber commented on pull request #9761: KAFKA-10768 Add a test for ByteBufferInputStream to ByteBufferLogInputStreamTest
bertber commented on pull request #9761: URL: https://github.com/apache/kafka/pull/9761#issuecomment-748028169 > Is `kafka.server.ControllerMutationQuotaTest.testPermissiveDeleteTopicsRequest` related to this PR? Yes, I think it is related to this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-10843) Kafka Streams metadataForKey method returns null but allMetadata has the details
[
https://issues.apache.org/jira/browse/KAFKA-10843?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251690#comment-17251690
]
Bruno Cadonna edited comment on KAFKA-10843 at 12/18/20, 11:02 AM:
---
I had another look at the code and I see two options {{metadataForKey()}} might
return {{null}}.
1. There are no source topics in the topology for the given state store (see
[code|https://github.com/apache/kafka/blob/0efa8fb0f4c73d92b6e55a112fa45417a67a7dc2/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetadataState.java#L165]).
2. Kafka Streams finds the wrong source topic partition for the given key (see
[code|https://github.com/apache/kafka/blob/0efa8fb0f4c73d92b6e55a112fa45417a67a7dc2/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetadataState.java#L411]).
I guess, option 1 does not apply since the same topology worked in your other
environments.
Is your data partitioned differently in your PROD environment than in your
other environments? Do you use a custom partitioner for the data in your PROD
environment?
was (Author: cadonna):
I had another look at the code and I see two options {{metadataForKey()}} might
return {{null}}.
1. There are no source topics in the topology for the given state store (see
[code|https://github.com/apache/kafka/blob/0efa8fb0f4c73d92b6e55a112fa45417a67a7dc2/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetadataState.java#L165]).
2. Kafka Streams finds the wrong source topic partition for the given key (see
[code|https://github.com/apache/kafka/blob/0efa8fb0f4c73d92b6e55a112fa45417a67a7dc2/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetadataState.java#L411]).
I guess, option 1 does not apply since the same topology worked in your other
environments.
Is your data partitioned differently in your PROD environment than in your
other environments?
> Kafka Streams metadataForKey method returns null but allMetadata has the
> details
>
>
> Key: KAFKA-10843
> URL: https://issues.apache.org/jira/browse/KAFKA-10843
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.5.1
>Reporter: Maria Thomas
>Priority: Major
>
> Our application runs on multiple instances and to enable us to use get the
> key information from the state store we use "metadataForKey" method to
> retrieve the StreamMetadata and using the hostname do an RPC call to the host
> to get the value associated with the key.
> This call was working fine in our DEV and TEST environments, however, it is
> failing one our production clusters from the start. On further debugging, I
> noticed the allMetadata() method was returning the state stores with the host
> details as expected. However, it would not be feasible to go through each
> store explicitly to get the key details.
> To note, the cluster I am using is a stretch cluster.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-10843) Kafka Streams metadataForKey method returns null but allMetadata has the details
[
https://issues.apache.org/jira/browse/KAFKA-10843?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251690#comment-17251690
]
Bruno Cadonna commented on KAFKA-10843:
---
I had another look at the code and I see two options {{metadataForKey()}} might
return {{null}}.
1. There are no source topics in the topology for the given state store (see
[code|https://github.com/apache/kafka/blob/0efa8fb0f4c73d92b6e55a112fa45417a67a7dc2/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetadataState.java#L165]).
2. Kafka Streams finds the wrong source topic partition for the given key (see
[code|https://github.com/apache/kafka/blob/0efa8fb0f4c73d92b6e55a112fa45417a67a7dc2/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetadataState.java#L411]).
I guess, option 1 does not apply since the same topology worked in your other
environments.
Is your data partitioned differently in your PROD environment than in your
other environments?
> Kafka Streams metadataForKey method returns null but allMetadata has the
> details
>
>
> Key: KAFKA-10843
> URL: https://issues.apache.org/jira/browse/KAFKA-10843
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.5.1
>Reporter: Maria Thomas
>Priority: Major
>
> Our application runs on multiple instances and to enable us to use get the
> key information from the state store we use "metadataForKey" method to
> retrieve the StreamMetadata and using the hostname do an RPC call to the host
> to get the value associated with the key.
> This call was working fine in our DEV and TEST environments, however, it is
> failing one our production clusters from the start. On further debugging, I
> noticed the allMetadata() method was returning the state stores with the host
> details as expected. However, it would not be feasible to go through each
> store explicitly to get the key details.
> To note, the cluster I am using is a stretch cluster.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-9837) New RPC for notifying controller of failed replica
[ https://issues.apache.org/jira/browse/KAFKA-9837?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251619#comment-17251619 ] dengziming commented on KAFKA-9837: --- [GitHub Pull Request #9577|https://github.com/apache/kafka/pull/9577] is ready for review! > New RPC for notifying controller of failed replica > -- > > Key: KAFKA-9837 > URL: https://issues.apache.org/jira/browse/KAFKA-9837 > Project: Kafka > Issue Type: Sub-task > Components: controller, core >Reporter: David Arthur >Assignee: dengziming >Priority: Major > Fix For: 2.8.0 > > > This is the tracking ticket for > [KIP-589|https://cwiki.apache.org/confluence/display/KAFKA/KIP-589+Add+API+to+update+Replica+state+in+Controller]. > For the bridge release, brokers should no longer use ZooKeeper to notify the > controller that a log dir has failed. It should instead use an RPC mechanism. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10843) Kafka Streams metadataForKey method returns null but allMetadata has the details
[ https://issues.apache.org/jira/browse/KAFKA-10843?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17251609#comment-17251609 ] Maria Thomas commented on KAFKA-10843: -- [~cadonna] The stretch cluster is a multiple data center deployment so, our topics are not on different clusters but replicated across different datacenters. So, I didn't get the second question. We have 6 bootstrap servers specified, 3 in each datacenter. [~mjsax] You want me to update the Kafka-streams version to 2.6.0? With regards to using allMetadata(), this wont still give me the particular store where my key is right? It would give all the hosts where the store is present, but my key could be on any of them. > Kafka Streams metadataForKey method returns null but allMetadata has the > details > > > Key: KAFKA-10843 > URL: https://issues.apache.org/jira/browse/KAFKA-10843 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.5.1 >Reporter: Maria Thomas >Priority: Major > > Our application runs on multiple instances and to enable us to use get the > key information from the state store we use "metadataForKey" method to > retrieve the StreamMetadata and using the hostname do an RPC call to the host > to get the value associated with the key. > This call was working fine in our DEV and TEST environments, however, it is > failing one our production clusters from the start. On further debugging, I > noticed the allMetadata() method was returning the state stores with the host > details as expected. However, it would not be feasible to go through each > store explicitly to get the key details. > To note, the cluster I am using is a stretch cluster. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] tombentley commented on pull request #9735: KAFKA-10846: Grow buffer in FileSourceStreamTask only when needed
tombentley commented on pull request #9735: URL: https://github.com/apache/kafka/pull/9735#issuecomment-747954608 @chia7712 thank _you_ for the reviews. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] Montyleo commented on pull request #9675: KAFKA-10794 Replica leader election is too slow in the case of too many partitions
Montyleo commented on pull request #9675: URL: https://github.com/apache/kafka/pull/9675#issuecomment-747942928 > @chia7712 does the patch can resolve the issue ? I find the only differences is that controllerContext.allPartitions can be invoked once or the number of partition times . please correct me if I am wrong. thanks. Hi,lqjack Thanks for your question. There is a saying that: quantitative change leads to qualitative change. when the function controllerContext.allPartitions was called too many time, the rebalance will become too slow. I'll show you the effect after the PR published,1.3ms VS 35541ms 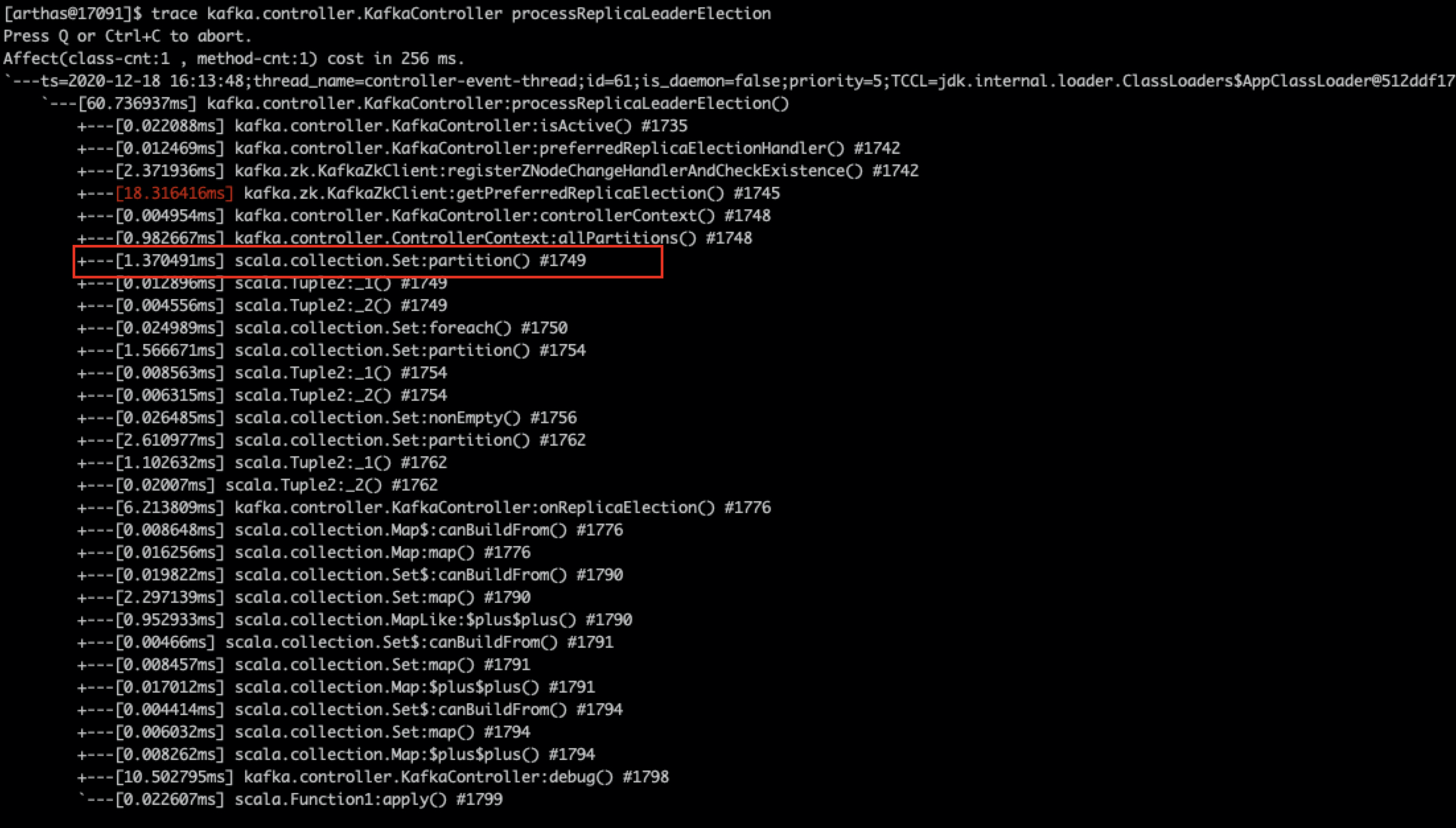 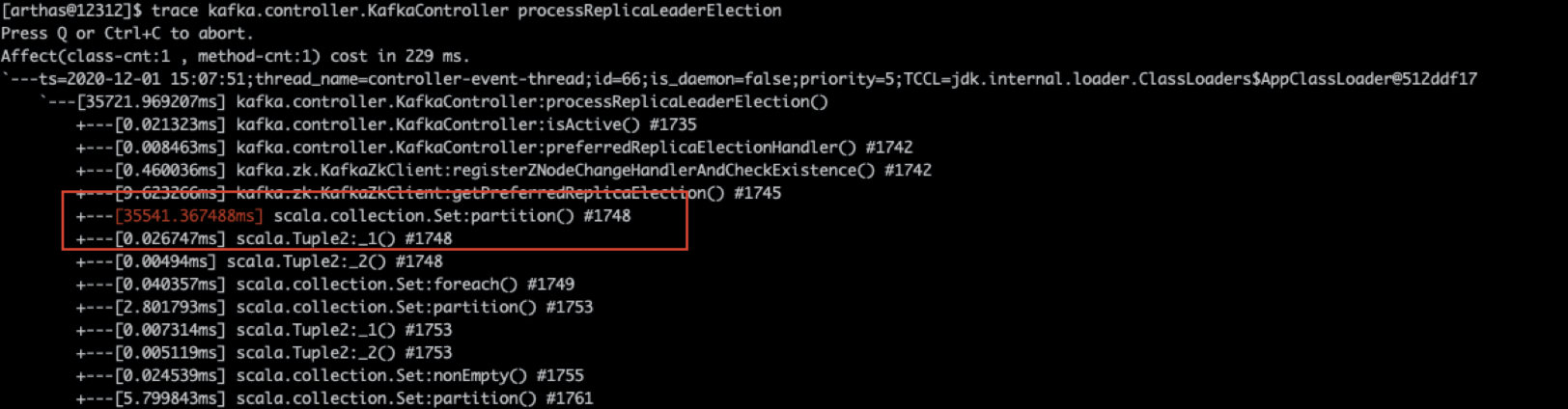 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9761: KAFKA-10768 Add a test for ByteBufferInputStream to ByteBufferLogInputStreamTest
chia7712 commented on pull request #9761: URL: https://github.com/apache/kafka/pull/9761#issuecomment-747942346 Is ```kafka.server.ControllerMutationQuotaTest.testPermissiveDeleteTopicsRequest``` related to this PR? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org