[jira] [Updated] (HDDS-3951) Rename the num.write.chunk.thread key
[ https://issues.apache.org/jira/browse/HDDS-3951?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-3951: - Labels: pull-request-available (was: ) > Rename the num.write.chunk.thread key > - > > Key: HDDS-3951 > URL: https://issues.apache.org/jira/browse/HDDS-3951 > Project: Hadoop Distributed Data Store > Issue Type: Improvement > Components: Ozone Datanode >Affects Versions: 0.5.0 >Reporter: maobaolong >Assignee: maobaolong >Priority: Major > Labels: pull-request-available > > dfs.container.ratis.num.write.chunk.thread -> > dfs.container.ratis.num.write.chunk.thread.per.disk -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] maobaolong opened a new pull request #1187: HDDS-3951. Rename the num.write.chunk.thread key.
maobaolong opened a new pull request #1187: URL: https://github.com/apache/hadoop-ozone/pull/1187 ## What changes were proposed in this pull request? Reanme `dfs.container.ratis.num.write.chunk.thread` to `dfs.container.ratis.num.write.chunk.thread.per.disk ` to clearly express the meaning of this key, if it configured to 10, then the thread num would be 10 * numOfDisk. ## What is the link to the Apache JIRA HDDS-3951 ## How was this patch tested? NO Need, just rename config key. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3951) Rename the num.write.chunk.thread key
[ https://issues.apache.org/jira/browse/HDDS-3951?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3951: - Description: dfs.container.ratis.num.write.chunk.thread -> dfs.container.ratis.num.write.chunk.thread.per.disk (was: dfs.container.ratis.num.write.chunk.thread -> dfs.container.ratis.num.write.chunk.thread.per.volume ) > Rename the num.write.chunk.thread key > - > > Key: HDDS-3951 > URL: https://issues.apache.org/jira/browse/HDDS-3951 > Project: Hadoop Distributed Data Store > Issue Type: Improvement > Components: Ozone Datanode >Affects Versions: 0.5.0 >Reporter: maobaolong >Assignee: maobaolong >Priority: Major > > dfs.container.ratis.num.write.chunk.thread -> > dfs.container.ratis.num.write.chunk.thread.per.disk -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] captainzmc commented on a change in pull request #1150: HDDS-3903. OzoneRpcClient support batch rename keys.
captainzmc commented on a change in pull request #1150:
URL: https://github.com/apache/hadoop-ozone/pull/1150#discussion_r452634999
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/response/key/OMKeysRenameResponse.java
##
@@ -0,0 +1,135 @@
+/**
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hadoop.ozone.om.response.key;
+
+import com.google.common.annotations.VisibleForTesting;
+import com.google.common.base.Optional;
+import org.apache.hadoop.hdds.utils.db.BatchOperation;
+import org.apache.hadoop.hdds.utils.db.Table;
+import org.apache.hadoop.hdds.utils.db.cache.CacheKey;
+import org.apache.hadoop.hdds.utils.db.cache.CacheValue;
+import org.apache.hadoop.ozone.om.OMMetadataManager;
+import org.apache.hadoop.ozone.om.OmRenameKeyInfo;
+import org.apache.hadoop.ozone.om.helpers.OmKeyInfo;
+import org.apache.hadoop.ozone.om.response.CleanupTableInfo;
+import org.apache.hadoop.ozone.om.response.OMClientResponse;
+import
org.apache.hadoop.ozone.protocol.proto.OzoneManagerProtocolProtos.OMResponse;
+
+import javax.annotation.Nonnull;
+import java.io.IOException;
+import java.util.List;
+
+import static org.apache.hadoop.ozone.om.OmMetadataManagerImpl.KEY_TABLE;
+import static
org.apache.hadoop.ozone.om.lock.OzoneManagerLock.Resource.BUCKET_LOCK;
+
+/**
+ * Response for RenameKeys request.
+ */
+@CleanupTableInfo(cleanupTables = {KEY_TABLE})
+public class OMKeysRenameResponse extends OMClientResponse {
+
+ private List renameKeyInfoList;
+ private long trxnLogIndex;
+ private String fromKeyName = null;
+ private String toKeyName = null;
+
+ public OMKeysRenameResponse(@Nonnull OMResponse omResponse,
+ List renameKeyInfoList,
+ long trxnLogIndex) {
+super(omResponse);
+this.renameKeyInfoList = renameKeyInfoList;
+this.trxnLogIndex = trxnLogIndex;
+ }
+
+
+ /**
+ * For when the request is not successful or it is a replay transaction.
+ * For a successful request, the other constructor should be used.
+ */
+ public OMKeysRenameResponse(@Nonnull OMResponse omResponse) {
+super(omResponse);
+checkStatusNotOK();
+ }
+
+ @Override
+ public void addToDBBatch(OMMetadataManager omMetadataManager,
+ BatchOperation batchOperation) throws IOException {
+boolean acquiredLock = false;
+for (OmRenameKeyInfo omRenameKeyInfo : renameKeyInfoList) {
+ String volumeName = omRenameKeyInfo.getNewKeyInfo().getVolumeName();
+ String bucketName = omRenameKeyInfo.getNewKeyInfo().getBucketName();
+ fromKeyName = omRenameKeyInfo.getFromKeyName();
+ OmKeyInfo newKeyInfo = omRenameKeyInfo.getNewKeyInfo();
+ toKeyName = newKeyInfo.getKeyName();
+ Table keyTable = omMetadataManager
+ .getKeyTable();
+ try {
+acquiredLock =
+omMetadataManager.getLock().acquireWriteLock(BUCKET_LOCK,
+volumeName, bucketName);
+// If toKeyName is null, then we need to only delete the fromKeyName
+// from KeyTable. This is the case of replay where toKey exists but
+// fromKey has not been deleted.
+if (deleteFromKeyOnly()) {
Review comment:
Thanks Bharat for the suggestion, I have taken a close look at the
implementation of #1169 with some very nice changes. In this PR I will
synchronize the #1169 changes here to make sure they are implemented the same.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3951) Rename the num.write.chunk.thread key
maobaolong created HDDS-3951: Summary: Rename the num.write.chunk.thread key Key: HDDS-3951 URL: https://issues.apache.org/jira/browse/HDDS-3951 Project: Hadoop Distributed Data Store Issue Type: Improvement Components: Ozone Datanode Affects Versions: 0.5.0 Reporter: maobaolong Assignee: maobaolong dfs.container.ratis.num.write.chunk.thread -> dfs.container.ratis.num.write.chunk.thread.per.volume -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3813) Integrate with ratis 1.0.0 release binaries for ozone 0.6.0 release
[ https://issues.apache.org/jira/browse/HDDS-3813?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaoyu Yao updated HDDS-3813: - Summary: Integrate with ratis 1.0.0 release binaries for ozone 0.6.0 release (was: Integrate with ratis 0.6.0 release binaries for ozone 0.6.0 release) > Integrate with ratis 1.0.0 release binaries for ozone 0.6.0 release > --- > > Key: HDDS-3813 > URL: https://issues.apache.org/jira/browse/HDDS-3813 > Project: Hadoop Distributed Data Store > Issue Type: Improvement >Reporter: Sammi Chen >Assignee: Lokesh Jain >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3833) Use Pipeline choose policy to choose pipeline from exist pipeline list
[ https://issues.apache.org/jira/browse/HDDS-3833?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3833: - Target Version/s: 0.7.0 > Use Pipeline choose policy to choose pipeline from exist pipeline list > -- > > Key: HDDS-3833 > URL: https://issues.apache.org/jira/browse/HDDS-3833 > Project: Hadoop Distributed Data Store > Issue Type: New Feature >Reporter: maobaolong >Assignee: maobaolong >Priority: Major > Labels: pull-request-available > > With this policy driven mode, we can develop various pipeline choosing policy > to satisfy complex production environment. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3885) Create Datanode home page
[ https://issues.apache.org/jira/browse/HDDS-3885?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaoyu Yao updated HDDS-3885: - Target Version/s: 0.6.0 Affects Version/s: (was: 0.6.0) 0.5.0 > Create Datanode home page > - > > Key: HDDS-3885 > URL: https://issues.apache.org/jira/browse/HDDS-3885 > Project: Hadoop Distributed Data Store > Issue Type: Improvement > Components: Ozone Datanode >Affects Versions: 0.5.0 >Reporter: maobaolong >Assignee: maobaolong >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3941) Enable core dump when crash in C++
[ https://issues.apache.org/jira/browse/HDDS-3941?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-3941: - Labels: pull-request-available (was: ) > Enable core dump when crash in C++ > -- > > Key: HDDS-3941 > URL: https://issues.apache.org/jira/browse/HDDS-3941 > Project: Hadoop Distributed Data Store > Issue Type: Improvement >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang opened a new pull request #1186: HDDS-3941. Enable core dump when crash in C++
runzhiwang opened a new pull request #1186: URL: https://github.com/apache/hadoop-ozone/pull/1186 ## What changes were proposed in this pull request? **What's the problem ?** This PR is related to HDDS-3933. Fix memory leak because of too many Datanode State Machine Thread. When memory leak, Datanode most time generates core.pid because it crash in Rocksdb when create new thread, as the image shows, and generates crash log rarely. 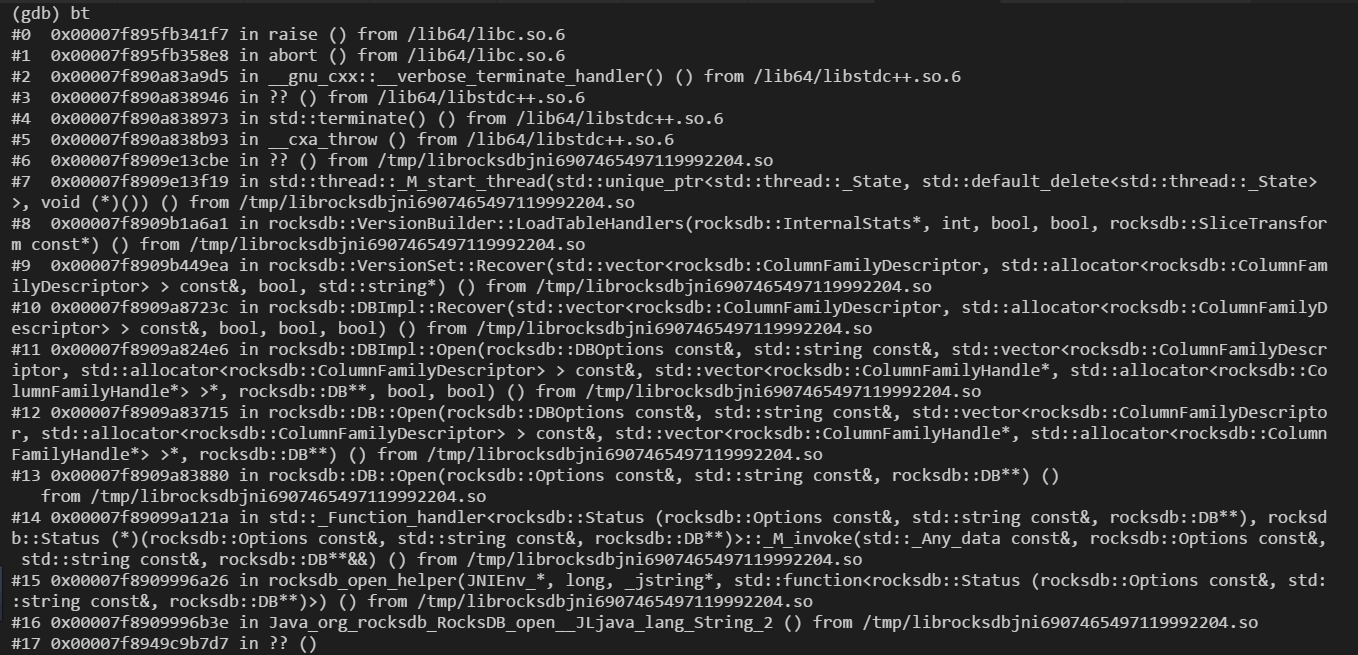 But because the default value of `core file size` if zero, so core.pid can not be generated. So when Datanode crash in Rocksdb, we can not get any information about why it crashed. **How to fix ?** Set `ulimit -c unlimited` to enable core dump when crash in RocksDB. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3941 ## How was this patch tested? Existed UT. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3933) Fix memory leak because of too many Datanode State Machine Thread
[ https://issues.apache.org/jira/browse/HDDS-3933?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-3933: - Labels: pull-request-available (was: ) > Fix memory leak because of too many Datanode State Machine Thread > - > > Key: HDDS-3933 > URL: https://issues.apache.org/jira/browse/HDDS-3933 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > Labels: pull-request-available > Attachments: jstack.txt, screenshot-1.png, screenshot-2.png, > screenshot-3.png > > > When create 22345th Datanode State Machine Thread, OOM happened. > !screenshot-1.png! > !screenshot-2.png! > !screenshot-3.png! -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang opened a new pull request #1185: HDDS-3933. Fix memory leak because of too many Datanode State Machine Thread
runzhiwang opened a new pull request #1185: URL: https://github.com/apache/hadoop-ozone/pull/1185 ## What changes were proposed in this pull request? **What's problem ?** Datanode creates more than 20K Datanode State Machine Thread, then OOM happened. 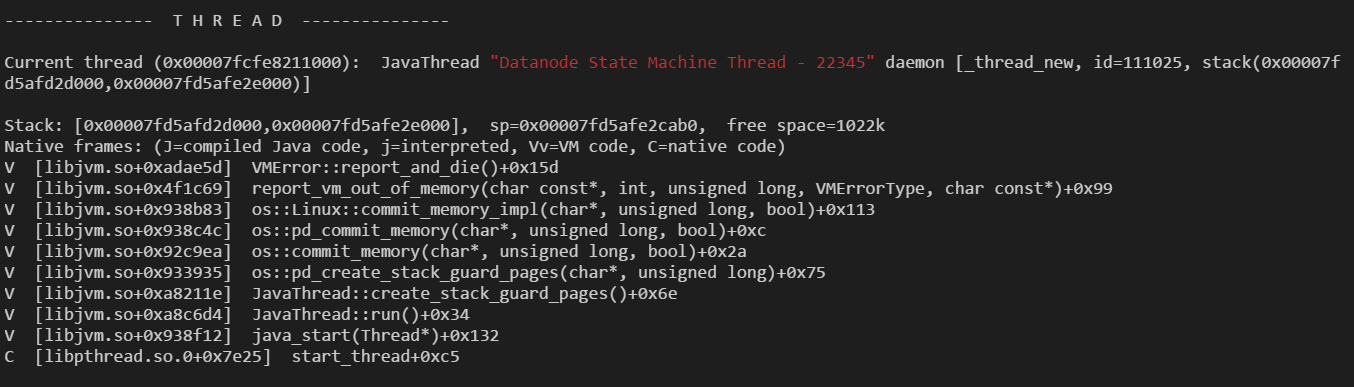 **What's the reason ?** 20K Datanode State Machine Thread were created by newCachedThreadPool  Almost all of them were wait lock.  Only one Datanode State Machine Thread got the lock, and block when submitRequest. Because this thread was blocked and can not free the lock, newCachedThreadPool will create new thread infinitely. 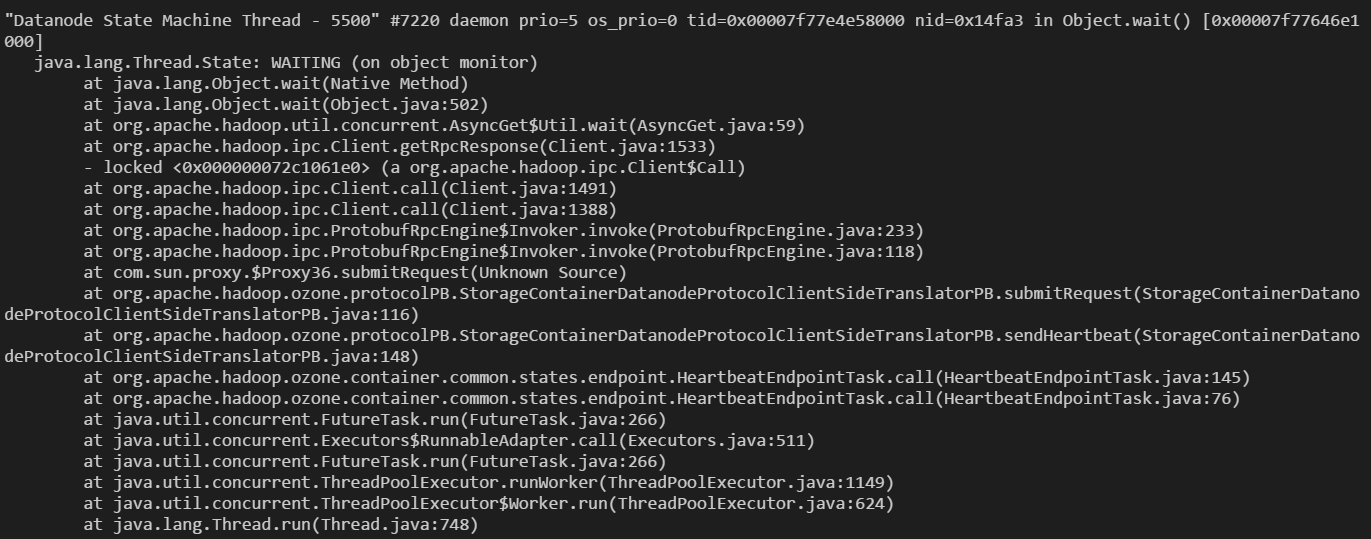 **How to fix ?** 1. Avoid use newCachedThreadPool, because it will create new thread infinitely, if no thread available in pool. 2. Cancel future when task time out. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3933 ## How was this patch tested? Existed UT. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452613394
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -848,7 +850,18 @@ message DeleteKeyRequest {
}
message DeleteKeysRequest {
-repeated KeyArgs keyArgs = 1;
+optional DeleteKeyArgs deleteKeys = 1;
Review comment:
From proto 3 onwards all fields are optional.
So, followed that approach and declared optional. (In future if something is
changed, we can still be backward compatible)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452613394
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -848,7 +850,18 @@ message DeleteKeyRequest {
}
message DeleteKeysRequest {
-repeated KeyArgs keyArgs = 1;
+optional DeleteKeyArgs deleteKeys = 1;
Review comment:
In proto 3 onwards all fields are optional.
So, followed that approach and declared optional. (In future if something is
changed, we can still be backward compatible)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Issue Comment Deleted] (HDDS-3841) FLAKY-UT: TestSecureOzoneRpcClient timeout
[ https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3841: - Comment: was deleted (was: [WARNING] Tests run: 68, Failures: 0, Errors: 0, Skipped: 3, Time elapsed: 58.105 s - in org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient [INFO] [INFO] Results: [INFO] [ERROR] Failures: [ERROR] TestDeleteWithSlowFollower.testDeleteKeyWithSlowFollower:225) > FLAKY-UT: TestSecureOzoneRpcClient timeout > -- > > Key: HDDS-3841 > URL: https://issues.apache.org/jira/browse/HDDS-3841 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Affects Versions: 0.7.0 >Reporter: maobaolong >Priority: Major > > [WARNING] Tests run: 68, Failures: 0, Errors: 0, Skipped: 3, Time elapsed: > 58.105 s - in org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient > [INFO] > [INFO] Results: > [INFO] > [ERROR] Failures: > [ERROR] TestDeleteWithSlowFollower.testDeleteKeyWithSlowFollower:225 -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3841) FLAKY-UT: TestSecureOzoneRpcClient timeout
[ https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3841: - Description: [WARNING] Tests run: 68, Failures: 0, Errors: 0, Skipped: 3, Time elapsed: 58.105 s - in org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient [INFO] [INFO] Results: [INFO] [ERROR] Failures: [ERROR] TestDeleteWithSlowFollower.testDeleteKeyWithSlowFollower:225 was:If a failure test appeared in your CI checks, and you are sure it is not relation with your PR, so, paste the stale test log here. > FLAKY-UT: TestSecureOzoneRpcClient timeout > -- > > Key: HDDS-3841 > URL: https://issues.apache.org/jira/browse/HDDS-3841 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Affects Versions: 0.7.0 >Reporter: maobaolong >Priority: Major > > [WARNING] Tests run: 68, Failures: 0, Errors: 0, Skipped: 3, Time elapsed: > 58.105 s - in org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient > [INFO] > [INFO] Results: > [INFO] > [ERROR] Failures: > [ERROR] TestDeleteWithSlowFollower.testDeleteKeyWithSlowFollower:225 -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3841) FLAKY-UT: TestSecureOzoneRpcClient timeout
[ https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3841: - Summary: FLAKY-UT: TestSecureOzoneRpcClient timeout (was: Stale tests(timeout or other reason)) > FLAKY-UT: TestSecureOzoneRpcClient timeout > -- > > Key: HDDS-3841 > URL: https://issues.apache.org/jira/browse/HDDS-3841 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Affects Versions: 0.7.0 >Reporter: maobaolong >Priority: Major > > If a failure test appeared in your CI checks, and you are sure it is not > relation with your PR, so, paste the stale test log here. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Issue Comment Deleted] (HDDS-3841) FLAKY-UT: TestSecureOzoneRpcClient timeout
[
https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
maobaolong updated HDDS-3841:
-
Comment: was deleted
(was: {code:}
[INFO] Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[INFO]
Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 94.969 s <<<
FAILURE! - in
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
testPipelineExclusionWithPipelineFailure(org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay)
Time elapsed: 94.881 s <<< FAILURE!java.lang.AssertionError at
org.junit.Assert.fail(Assert.java:86) at
org.junit.Assert.assertTrue(Assert.java:41) at
org.junit.Assert.assertTrue(Assert.java:52) at
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay.testPipelineExclusionWithPipelineFailure(TestFailureHandlingByClientFlushDelay.java:200)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498) at
org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at
org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at
org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at
org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at
org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
{code}
)
> FLAKY-UT: TestSecureOzoneRpcClient timeout
> --
>
> Key: HDDS-3841
> URL: https://issues.apache.org/jira/browse/HDDS-3841
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.7.0
>Reporter: maobaolong
>Priority: Major
>
> If a failure test appeared in your CI checks, and you are sure it is not
> relation with your PR, so, paste the stale test log here.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDDS-3841) FLAKY-UT: TestSecureOzoneRpcClient timeout
[
https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17141235#comment-17141235
]
maobaolong edited comment on HDDS-3841 at 7/10/20, 4:13 AM:
{code:}
[INFO] Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[INFO]
Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 94.969 s <<<
FAILURE! - in
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
testPipelineExclusionWithPipelineFailure(org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay)
Time elapsed: 94.881 s <<< FAILURE!java.lang.AssertionError at
org.junit.Assert.fail(Assert.java:86) at
org.junit.Assert.assertTrue(Assert.java:41) at
org.junit.Assert.assertTrue(Assert.java:52) at
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay.testPipelineExclusionWithPipelineFailure(TestFailureHandlingByClientFlushDelay.java:200)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498) at
org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at
org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at
org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at
org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at
org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
{code}
was (Author: maobaolong):
{code:}
[INFO] Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[INFO]
Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 94.969 s <<<
FAILURE! - in
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
testPipelineExclusionWithPipelineFailure(org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay)
Time elapsed: 94.881 s <<< FAILURE!java.lang.AssertionError at
org.junit.Assert.fail(Assert.java:86) at
org.junit.Assert.assertTrue(Assert.java:41) at
org.junit.Assert.assertTrue(Assert.java:52) at
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay.testPipelineExclusionWithPipelineFailure(TestFailureHandlingByClientFlushDelay.java:200)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498) at
org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at
org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at
org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at
org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at
org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
{code}
> FLAKY-UT: TestSecureOzoneRpcClient timeout
> --
>
> Key: HDDS-3841
> URL: https://issues.apache.org/jira/browse/HDDS-3841
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.7.0
>Reporter: maobaolong
>Priority: Major
>
> If a failure test appeared in your CI checks, and you are sure it is not
> relation with your PR, so, paste the stale test log here.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
xiaoyuyao commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452612030
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -867,10 +867,10 @@ message DeletedKeys {
}
message DeleteKeysResponse {
-repeated KeyInfo deletedKeys = 1;
-repeated KeyInfo unDeletedKeys = 2;
Review comment:
Looks good to me.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
xiaoyuyao commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452611714
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -848,7 +850,18 @@ message DeleteKeyRequest {
}
message DeleteKeysRequest {
-repeated KeyArgs keyArgs = 1;
+optional DeleteKeyArgs deleteKeys = 1;
Review comment:
Should this be required?
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -848,7 +850,18 @@ message DeleteKeyRequest {
}
message DeleteKeysRequest {
-repeated KeyArgs keyArgs = 1;
+optional DeleteKeyArgs deleteKeys = 1;
Review comment:
Should this be required instead of optional?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on pull request #1163: HDDS-3920. Too many redudant replications due to fail to get node's a…
xiaoyuyao commented on pull request #1163: URL: https://github.com/apache/hadoop-ozone/pull/1163#issuecomment-656470926 LGTM, +1 pending CI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1444) Allocate block fails in MiniOzoneChaosCluster because of InsufficientDatanodesException
[
https://issues.apache.org/jira/browse/HDDS-1444?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1444:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Allocate block fails in MiniOzoneChaosCluster because of
> InsufficientDatanodesException
> ---
>
> Key: HDDS-1444
> URL: https://issues.apache.org/jira/browse/HDDS-1444
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: SCM
>Affects Versions: 0.3.0
>Reporter: Mukul Kumar Singh
>Priority: Major
> Labels: TriagePending
>
> MiniOzoneChaosCluster is failing with InsufficientDatanodesException while
> writing keys to the Ozone Cluster
> {code}
> org.apache.hadoop.hdds.scm.pipeline.InsufficientDatanodesException: Cannot
> create pipeline of factor 3 using 2 nodes.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1163: HDDS-3920. Too many redudant replications due to fail to get node's a…
xiaoyuyao commented on a change in pull request #1163:
URL: https://github.com/apache/hadoop-ozone/pull/1163#discussion_r452609872
##
File path:
hadoop-hdds/server-scm/src/main/java/org/apache/hadoop/hdds/scm/container/ContainerReportHandler.java
##
@@ -102,8 +102,15 @@ public ContainerReportHandler(final NodeManager
nodeManager,
public void onMessage(final ContainerReportFromDatanode reportFromDatanode,
final EventPublisher publisher) {
-final DatanodeDetails datanodeDetails =
+final DatanodeDetails dnFromReport =
reportFromDatanode.getDatanodeDetails();
+DatanodeDetails datanodeDetails =
Review comment:
That's a good catch. Thanks for the details.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2039) Some ozone unit test takes too long to finish.
[
https://issues.apache.org/jira/browse/HDDS-2039?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2039:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Test)
> Some ozone unit test takes too long to finish.
> --
>
> Key: HDDS-2039
> URL: https://issues.apache.org/jira/browse/HDDS-2039
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Xiaoyu Yao
>Priority: Major
>
> Here are a few
> {code}
> [INFO] Running org.apache.hadoop.ozone.om.TestOzoneManagerHA
> [INFO] Tests run: 15, Failures: 0, Errors: 0, Skipped: 0, Time elapsed:
> 436.08 s - in org.apache.hadoop.ozone.om.TestOzoneManagerHA
> [INFO] Running org.apache.hadoop.ozone.om.TestOzoneManager
> [INFO] Tests run: 26, Failures: 0, Errors: 0, Skipped: 0, Time elapsed:
> 259.566 s - in org.apache.hadoop.ozone.om.TestOzoneManager
> [INFO] Running org.apache.hadoop.ozone.om.TestScmSafeMode
> [INFO] Tests run: 5, Failures: 0, Errors: 0, Skipped: 0, Time elapsed:
> 129.653 s - in org.apache.hadoop.ozone.om.TestScmSafeMode
> [INFO] Running org.apache.hadoop.ozone.om.TestOzoneManagerRestart
> [INFO] Tests run: 3, Failures: 0, Errors: 0, Skipped: 0, Time elapsed:
> 843.129 s - in org.apache.hadoop.ozone.om.TestOzoneManagerRestart
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2643) TestOzoneDelegationTokenSecretManager#testRenewTokenFailureRenewalTime fails intermittently
[
https://issues.apache.org/jira/browse/HDDS-2643?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2643:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Test)
> TestOzoneDelegationTokenSecretManager#testRenewTokenFailureRenewalTime fails
> intermittently
> ---
>
> Key: HDDS-2643
> URL: https://issues.apache.org/jira/browse/HDDS-2643
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Lokesh Jain
>Priority: Major
> Labels: TriagePending
>
> TestOzoneDelegationTokenSecretManager.testRenewTokenFailureRenewalTime fails
> intermittently with the following error.
> {code:java}
> [ERROR] Failures:
> [ERROR]
> TestOzoneDelegationTokenSecretManager.testRenewTokenFailureRenewalTime:253
> Expecting java.io.IOException with text is expired but got : Expected to
> find 'is expired' but got unexpected exception:
> org.apache.hadoop.security.token.SecretManager$InvalidToken: token
> (OzoneToken owner=testUser, renewer=testUser, realUser=testUser,
> issueDate=1574938955794, maxDate=1574938965794, sequenceNumber=1,
> masterKeyId=1, strToSign=null, signature=null, awsAccessKeyId=null) can't be
> found in cache
> at
> org.apache.hadoop.ozone.security.OzoneDelegationTokenSecretManager.validateToken(OzoneDelegationTokenSecretManager.java:362)
> at
> org.apache.hadoop.ozone.security.OzoneDelegationTokenSecretManager.renewToken(OzoneDelegationTokenSecretManager.java:244)
> at
> org.apache.hadoop.ozone.security.TestOzoneDelegationTokenSecretManager.lambda$testRenewTokenFailureRenewalTime$2(TestOzoneDelegationTokenSecretManager.java:254)
> at
> org.apache.hadoop.test.LambdaTestUtils.lambda$intercept$0(LambdaTestUtils.java:527)
> at
> org.apache.hadoop.test.LambdaTestUtils.intercept(LambdaTestUtils.java:491)
> at
> org.apache.hadoop.test.LambdaTestUtils.intercept(LambdaTestUtils.java:522)
> at
> org.apache.hadoop.ozone.security.TestOzoneDelegationTokenSecretManager.testRenewTokenFailureRenewalTime(TestOzoneDelegationTokenSecretManager.java:253)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.rules.ExternalResource$1.evaluate(ExternalResource.java:48)
> at org.junit.rules.RunRules.evaluate(RunRules.java:20)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail:
[jira] [Updated] (HDDS-2644) TestTableCacheImpl#testPartialTableCacheWithOverrideAndDelete fails intermittently
[
https://issues.apache.org/jira/browse/HDDS-2644?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2644:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Test)
> TestTableCacheImpl#testPartialTableCacheWithOverrideAndDelete fails
> intermittently
> --
>
> Key: HDDS-2644
> URL: https://issues.apache.org/jira/browse/HDDS-2644
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Lokesh Jain
>Priority: Major
> Labels: TriagePending
>
> {code:java}
> [ERROR] Tests run: 10, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 2.87
> s <<< FAILURE! - in org.apache.hadoop.hdds.utils.db.cache.TestTableCacheImpl
> [ERROR]
> testPartialTableCacheWithOverrideAndDelete[0](org.apache.hadoop.hdds.utils.db.cache.TestTableCacheImpl)
> Time elapsed: 0.044 s <<< FAILURE!
> java.lang.AssertionError: expected:<2> but was:<6>
> at org.junit.Assert.fail(Assert.java:88)
> at org.junit.Assert.failNotEquals(Assert.java:743)
> at org.junit.Assert.assertEquals(Assert.java:118)
> at org.junit.Assert.assertEquals(Assert.java:555)
> at org.junit.Assert.assertEquals(Assert.java:542)
> at
> org.apache.hadoop.hdds.utils.db.cache.TestTableCacheImpl.testPartialTableCacheWithOverrideAndDelete(TestTableCacheImpl.java:308)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at org.junit.runners.Suite.runChild(Suite.java:127)
> at org.junit.runners.Suite.runChild(Suite.java:26)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2649) TestOzoneManagerHttpServer#testHttpPolicy fails intermittently
[
https://issues.apache.org/jira/browse/HDDS-2649?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2649:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Test)
> TestOzoneManagerHttpServer#testHttpPolicy fails intermittently
> --
>
> Key: HDDS-2649
> URL: https://issues.apache.org/jira/browse/HDDS-2649
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Lokesh Jain
>Priority: Major
> Labels: TriagePending
>
> TestOzoneManagerHttpServer#testHttpPolicy fails with the following exception.
> {code:java}
> [ERROR] Tests run: 3, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 3.42
> s <<< FAILURE! - in org.apache.hadoop.ozone.om.TestOzoneManagerHttpServer
> [ERROR]
> testHttpPolicy[1](org.apache.hadoop.ozone.om.TestOzoneManagerHttpServer)
> Time elapsed: 0.343 s <<< FAILURE!
> java.lang.AssertionError
> at org.junit.Assert.fail(Assert.java:86)
> at org.junit.Assert.assertTrue(Assert.java:41)
> at org.junit.Assert.assertTrue(Assert.java:52)
> at
> org.apache.hadoop.ozone.om.TestOzoneManagerHttpServer.testHttpPolicy(TestOzoneManagerHttpServer.java:110)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at org.junit.runners.Suite.runChild(Suite.java:127)
> at org.junit.runners.Suite.runChild(Suite.java:26)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1249) Fix TestOzoneManagerHttpServer & TestStorageContainerManagerHttpServer
[
https://issues.apache.org/jira/browse/HDDS-1249?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1249:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Fix TestOzoneManagerHttpServer & TestStorageContainerManagerHttpServer
> --
>
> Key: HDDS-1249
> URL: https://issues.apache.org/jira/browse/HDDS-1249
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: Ozone Manager, SCM
>Affects Versions: 0.4.0
>Reporter: Mukul Kumar Singh
>Assignee: Nanda kumar
>Priority: Major
> Labels: TriagePending
>
> Fix the following unit test failures
> {code}
> java.lang.AssertionError
> at org.junit.Assert.fail(Assert.java:86)
> at org.junit.Assert.assertTrue(Assert.java:41)
> at org.junit.Assert.assertTrue(Assert.java:52)
> at
> org.apache.hadoop.hdds.scm.TestStorageContainerManagerHttpServer.testHttpPolicy(TestStorageContainerManagerHttpServer.java:114)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at org.junit.runners.Suite.runChild(Suite.java:127)
> at org.junit.runners.Suite.runChild(Suite.java:26)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
> and
> {code}
> java.lang.AssertionError
> at org.junit.Assert.fail(Assert.java:86)
> at org.junit.Assert.assertTrue(Assert.java:41)
> at org.junit.Assert.assertTrue(Assert.java:52)
> at
> org.apache.hadoop.hdds.scm.TestStorageContainerManagerHttpServer.testHttpPolicy(TestStorageContainerManagerHttpServer.java:109)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
>
[jira] [Updated] (HDDS-1537) TestContainerPersistence#testDeleteBlockTwice is failing
[
https://issues.apache.org/jira/browse/HDDS-1537?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1537:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Improvement)
> TestContainerPersistence#testDeleteBlockTwice is failing
> -
>
> Key: HDDS-1537
> URL: https://issues.apache.org/jira/browse/HDDS-1537
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: Ozone Datanode
>Reporter: Mukul Kumar Singh
>Priority: Major
> Labels: TriagePending
>
> The test is failing with the following exception.
> {code}
> [ERROR] Tests run: 18, Failures: 1, Errors: 0, Skipped: 0, Time elapsed:
> 4.132 s <<< FAILURE! - in
> org.apache.hadoop.ozone.container.common.impl.TestContainerPersistence
> [ERROR]
> testDeleteBlockTwice(org.apache.hadoop.ozone.container.common.impl.TestContainerPersistence)
> Time elapsed: 0.058 s <<< FAILURE!
> java.lang.AssertionError: Expected test to throw (an instance of
> org.apache.hadoop.hdds.scm.container.common.helpers.StorageContainerException
> and exception with message a string containing "Unable to find the block.")
> at org.junit.Assert.fail(Assert.java:88)
> at
> org.junit.rules.ExpectedException.failDueToMissingException(ExpectedException.java:184)
> at
> org.junit.rules.ExpectedException.access$100(ExpectedException.java:85)
> at
> org.junit.rules.ExpectedException$ExpectedExceptionStatement.evaluate(ExpectedException.java:170)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1342) TestOzoneManagerHA#testOMProxyProviderFailoverOnConnectionFailure fails intermittently
[
https://issues.apache.org/jira/browse/HDDS-1342?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1342:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestOzoneManagerHA#testOMProxyProviderFailoverOnConnectionFailure fails
> intermittently
> --
>
> Key: HDDS-1342
> URL: https://issues.apache.org/jira/browse/HDDS-1342
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Lokesh Jain
>Assignee: Hanisha Koneru
>Priority: Major
> Labels: TriagePending
>
> The test fails intermittently. The link to the test report can be found below.
> [https://builds.apache.org/job/PreCommit-HDDS-Build/2582/testReport/]
> {code:java}
> java.net.ConnectException: Call From ea902c1cb730/172.17.0.3 to
> localhost:10174 failed on connection exception: java.net.ConnectException:
> Connection refused; For more details see:
> http://wiki.apache.org/hadoop/ConnectionRefused
> at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
> at
> sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
> at
> sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
> at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
> at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:831)
> at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:755)
> at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1515)
> at org.apache.hadoop.ipc.Client.call(Client.java:1457)
> at org.apache.hadoop.ipc.Client.call(Client.java:1367)
> at
> org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
> at
> org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
> at com.sun.proxy.$Proxy34.submitRequest(Unknown Source)
> at sun.reflect.GeneratedMethodAccessor30.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
> at
> org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
> at
> org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
> at
> org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
> at
> org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
> at com.sun.proxy.$Proxy34.submitRequest(Unknown Source)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.hadoop.hdds.tracing.TraceAllMethod.invoke(TraceAllMethod.java:66)
> at com.sun.proxy.$Proxy34.submitRequest(Unknown Source)
> at
> org.apache.hadoop.ozone.om.protocolPB.OzoneManagerProtocolClientSideTranslatorPB.submitRequest(OzoneManagerProtocolClientSideTranslatorPB.java:310)
> at
> org.apache.hadoop.ozone.om.protocolPB.OzoneManagerProtocolClientSideTranslatorPB.createVolume(OzoneManagerProtocolClientSideTranslatorPB.java:343)
> at
> org.apache.hadoop.ozone.client.rpc.RpcClient.createVolume(RpcClient.java:275)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.hadoop.ozone.client.OzoneClientInvocationHandler.invoke(OzoneClientInvocationHandler.java:54)
> at com.sun.proxy.$Proxy86.createVolume(Unknown Source)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.hadoop.hdds.tracing.TraceAllMethod.invoke(TraceAllMethod.java:66)
> at com.sun.proxy.$Proxy86.createVolume(Unknown Source)
> at
>
[jira] [Updated] (HDDS-1316) TestContainerStateManagerIntegration#testReplicaMap fails with ChillModePrecheck
[
https://issues.apache.org/jira/browse/HDDS-1316?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1316:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestContainerStateManagerIntegration#testReplicaMap fails with
> ChillModePrecheck
>
>
> Key: HDDS-1316
> URL: https://issues.apache.org/jira/browse/HDDS-1316
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.4.0
>Reporter: Mukul Kumar Singh
>Priority: Major
> Labels: Triaged
>
> TestContainerStateManagerIntegration#testReplicaMap fails with
> ChillModePrecheck
> {code}
> [ERROR] Tests run: 8, Failures: 0, Errors: 1, Skipped: 1, Time elapsed:
> 41.475 s <<< FAILURE! - in
> org.apache.hadoop.hdds.scm.container.TestContainerStateManagerIntegration
> [ERROR]
> testReplicaMap(org.apache.hadoop.hdds.scm.container.TestContainerStateManagerIntegration)
> Time elapsed: 4.589 s <<< ERROR!
> org.apache.hadoop.hdds.scm.exceptions.SCMException: ChillModePrecheck failed
> for allocateContainer
> at
> org.apache.hadoop.hdds.scm.chillmode.ChillModePrecheck.check(ChillModePrecheck.java:51)
> at
> org.apache.hadoop.hdds.scm.chillmode.ChillModePrecheck.check(ChillModePrecheck.java:31)
> at org.apache.hadoop.hdds.scm.ScmUtils.preCheck(ScmUtils.java:53)
> at
> org.apache.hadoop.hdds.scm.server.SCMClientProtocolServer.allocateContainer(SCMClientProtocolServer.java:180)
> at
> org.apache.hadoop.hdds.scm.container.TestContainerStateManagerIntegration.testReplicaMap(TestContainerStateManagerIntegration.java:386)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2934) OM HA S3 test failure
[
https://issues.apache.org/jira/browse/HDDS-2934?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2934:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> OM HA S3 test failure
> -
>
> Key: HDDS-2934
> URL: https://issues.apache.org/jira/browse/HDDS-2934
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: Ozone Manager
>Reporter: Attila Doroszlai
>Priority: Major
> Labels: Triaged, intermittent
> Attachments: docker-ozone-om-ha-s3-ozone-om-ha-s3-s3-scm.log,
> robot-ozone-om-ha-s3-ozone-om-ha-s3-s3-scm.xml
>
>
> OM HA S3 test ({{ozone-om-ha-s3}}) failed in one CI run at the following test
> case, then most subsequent test cases failed, too:
> {code}
> 2020-01-22T06:33:16.7322540Z Test Multipart Upload Put With Copy and range
> | FAIL |
> 2020-01-22T06:33:16.7323058Z 255 != 0
> {code}
> Docker log has several of the following exception starting around above time:
> {code}
> OMNotLeaderException: OM:om1 is not the leader. Suggested leader is OM:om3.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on pull request #1174: HDDS-3918. ConcurrentModificationException in ContainerReportHandler.…
xiaoyuyao commented on pull request #1174: URL: https://github.com/apache/hadoop-ozone/pull/1174#issuecomment-656465017 Thanks @adoroszlai for the review and @ChenSammi for reporting the issue. PR has been merged. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3918) ConcurrentModificationException in ContainerReportHandler.onMessage
[ https://issues.apache.org/jira/browse/HDDS-3918?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaoyu Yao resolved HDDS-3918. -- Fix Version/s: 0.6.0 Resolution: Fixed > ConcurrentModificationException in ContainerReportHandler.onMessage > --- > > Key: HDDS-3918 > URL: https://issues.apache.org/jira/browse/HDDS-3918 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: Sammi Chen >Assignee: Xiaoyu Yao >Priority: Major > Labels: pull-request-available > Fix For: 0.6.0 > > Attachments: TestCME.java > > > 2020-07-03 14:51:45,489 [EventQueue-ContainerReportForContainerReportHandler] > ERROR org.apache.hadoop.hdds.server.events.SingleThreadExecutor: Error on > execution message > org.apache.hadoop.hdds.scm.server.SCMDatanodeHeartbeatDispatcher$ContainerReportFromDatanode@8f6e7cb > java.util.ConcurrentModificationException > at java.util.HashMap$HashIterator.nextNode(HashMap.java:1445) > at java.util.HashMap$KeyIterator.next(HashMap.java:1469) > at > java.util.Collections$UnmodifiableCollection$1.next(Collections.java:1044) > at java.util.AbstractCollection.addAll(AbstractCollection.java:343) > at java.util.HashSet.(HashSet.java:120) > at > org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:127) > at > org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:50) > at > org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) > 2020-07-03 14:51:45,648 [EventQueue-ContainerReportForContainerReportHandler] > ERROR org.apache.hadoop.hdds.server.events.SingleThreadExecutor: Error on > execution message > org.apache.hadoop.hdds.scm.server.SCMDatanodeHeartbeatDispatcher$ContainerReportFromDatanode@49d2b84b > java.util.ConcurrentModificationException > at java.util.HashMap$HashIterator.nextNode(HashMap.java:1445) > at java.util.HashMap$KeyIterator.next(HashMap.java:1469) > at > java.util.Collections$UnmodifiableCollection$1.next(Collections.java:1044) > at java.util.AbstractCollection.addAll(AbstractCollection.java:343) > at java.util.HashSet.(HashSet.java:120) > at > org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:127) > at > org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:50) > at > org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao merged pull request #1174: HDDS-3918. ConcurrentModificationException in ContainerReportHandler.…
xiaoyuyao merged pull request #1174: URL: https://github.com/apache/hadoop-ozone/pull/1174 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1166: HDDS-3914. Remove LevelDB configuration option for DN Metastore
xiaoyuyao commented on a change in pull request #1166:
URL: https://github.com/apache/hadoop-ozone/pull/1166#discussion_r452605910
##
File path:
hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/keyvalue/KeyValueContainerCheck.java
##
@@ -186,8 +186,8 @@ private void checkContainerFile() throws IOException {
}
dbType = onDiskContainerData.getContainerDBType();
-if (!dbType.equals(OZONE_METADATA_STORE_IMPL_ROCKSDB) &&
-!dbType.equals(OZONE_METADATA_STORE_IMPL_LEVELDB)) {
+if (!dbType.equals(CONTAINER_DB_TYPE_ROCKSDB) &&
Review comment:
That makes sense to me.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1681) TestNodeReportHandler failing because of NPE
[
https://issues.apache.org/jira/browse/HDDS-1681?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1681:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestNodeReportHandler failing because of NPE
>
>
> Key: HDDS-1681
> URL: https://issues.apache.org/jira/browse/HDDS-1681
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Mukul Kumar Singh
>Assignee: Nanda kumar
>Priority: Major
> Labels: TriagePending
>
> {code}
> [INFO] Running org.apache.hadoop.hdds.scm.node.TestNodeReportHandler
> [ERROR] Tests run: 1, Failures: 0, Errors: 1, Skipped: 0, Time elapsed: 0.469
> s <<< FAILURE! - in org.apache.hadoop.hdds.scm.node.TestNodeReportHandler
> [ERROR] testNodeReport(org.apache.hadoop.hdds.scm.node.TestNodeReportHandler)
> Time elapsed: 0.31 s <<< ERROR!
> java.lang.NullPointerException
> at
> org.apache.hadoop.hdds.scm.node.SCMNodeManager.(SCMNodeManager.java:122)
> at
> org.apache.hadoop.hdds.scm.node.TestNodeReportHandler.resetEventCollector(TestNodeReportHandler.java:53)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:24)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2011) TestRandomKeyGenerator fails due to timeout
[
https://issues.apache.org/jira/browse/HDDS-2011?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2011:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestRandomKeyGenerator fails due to timeout
> ---
>
> Key: HDDS-2011
> URL: https://issues.apache.org/jira/browse/HDDS-2011
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
> Attachments:
> org.apache.hadoop.ozone.freon.TestRandomKeyGenerator-output.txt
>
>
> {{TestRandomKeyGenerator#bigFileThan2GB}} is failing intermittently due to
> timeout in Ratis {{appendEntries}}. Commit on pipeline fails, and new
> pipeline cannot be created with 2 nodes (there are 5 nodes total).
> Most recent one:
> https://github.com/elek/ozone-ci/tree/master/trunk/trunk-nightly-pz9vg/integration/hadoop-ozone/tools
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1343) TestNodeFailure times out intermittently
[
https://issues.apache.org/jira/browse/HDDS-1343?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1343:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestNodeFailure times out intermittently
>
>
> Key: HDDS-1343
> URL: https://issues.apache.org/jira/browse/HDDS-1343
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Lokesh Jain
>Priority: Major
> Labels: TriagePending
>
> TestNodeFailure times out while waiting for cluster to be ready. This is done
> in cluster setup.
> {code:java}
> java.lang.Thread.State: WAITING (on object monitor)
> at sun.misc.Unsafe.park(Native Method)
> at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
> at
> java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
> at
> java.util.concurrent.ArrayBlockingQueue.take(ArrayBlockingQueue.java:403)
> at
> java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> at
> org.apache.hadoop.test.GenericTestUtils.waitFor(GenericTestUtils.java:389)
> at
> org.apache.hadoop.ozone.MiniOzoneClusterImpl.waitForClusterToBeReady(MiniOzoneClusterImpl.java:140)
> at
> org.apache.hadoop.hdds.scm.pipeline.TestNodeFailure.init(TestNodeFailure.java:74)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:24)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
> 5 datanodes out of 6 are able to heartbeat in the test result
> [https://builds.apache.org/job/PreCommit-HDDS-Build/2582/testReport/].
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2083) Fix TestQueryNode#testStaleNodesCount
[ https://issues.apache.org/jira/browse/HDDS-2083?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen updated HDDS-2083: - Parent: HDDS-1127 Issue Type: Sub-task (was: Bug) > Fix TestQueryNode#testStaleNodesCount > - > > Key: HDDS-2083 > URL: https://issues.apache.org/jira/browse/HDDS-2083 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Reporter: Dinesh Chitlangia >Priority: Major > Labels: TriagePending > Attachments: stacktrace.rtf > > > It appears this test is failing due to several threads in waiting state. > Attached complete stack trace. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1960) TestMiniChaosOzoneCluster may run until OOME
[
https://issues.apache.org/jira/browse/HDDS-1960?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1960:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestMiniChaosOzoneCluster may run until OOME
>
>
> Key: HDDS-1960
> URL: https://issues.apache.org/jira/browse/HDDS-1960
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Critical
> Labels: MiniOzoneChaosCluster
>
> {{TestMiniChaosOzoneCluster}} runs load generator on a cluster for supposedly
> 1 minute, but it may run indefinitely until JVM crashes due to
> OutOfMemoryError.
> In 0.4.1 nightly build it crashed 29/30 times (and no tests were executed in
> the remaining one run due to some other error).
> Latest:
> https://github.com/elek/ozone-ci/blob/3f553ed6ad358ba61a302967617de737d7fea01a/byscane/byscane-nightly-wggqd/integration/output.log#L5661-L5662
> When it crashes, it leaves GBs of data lying around.
> HDDS-1952 disabled this test in CI runs. It can still be run manually (eg.
> {{mvn -Phdds -pl :hadoop-ozone-integration-test
> -Dtest=TestMiniChaosOzoneCluster test}}). The goal of this task is to
> investigate the root cause of the runaway nature of this test.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2085) TestBlockManager#testMultipleBlockAllocationWithClosedContainer timed out
[
https://issues.apache.org/jira/browse/HDDS-2085?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2085:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestBlockManager#testMultipleBlockAllocationWithClosedContainer timed out
> -
>
> Key: HDDS-2085
> URL: https://issues.apache.org/jira/browse/HDDS-2085
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Dinesh Chitlangia
>Priority: Major
> Labels: TriagePending, ozone-flaky-test
>
> {code:java}
> ---
> Test set: org.apache.hadoop.hdds.scm.block.TestBlockManager
> ---
> Tests run: 8, Failures: 0, Errors: 1, Skipped: 0, Time elapsed: 7.697 s <<<
> FAILURE! - in org.apache.hadoop.hdds.scm.block.TestBlockManager
> testMultipleBlockAllocationWithClosedContainer(org.apache.hadoop.hdds.scm.block.TestBlockManager)
> Time elapsed: 3.619 s <<< ERROR!
> java.util.concurrent.TimeoutException:
> Timed out waiting for condition. Thread diagnostics:
> Timestamp: 2019-09-03 08:46:46,870
> "Socket Reader #1 for port 32840" prio=5 tid=14 runnable
> java.lang.Thread.State: RUNNABLE
> at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
> at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
> at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
> at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
> at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
> at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
> at
> org.apache.hadoop.ipc.Server$Listener$Reader.doRunLoop(Server.java:1097)
> at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:1076)
> "Socket Reader #1 for port 43576" prio=5 tid=22 runnable
> java.lang.Thread.State: RUNNABLE
> at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
> at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
> at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
> at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
> at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
> at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
> at
> org.apache.hadoop.ipc.Server$Listener$Reader.doRunLoop(Server.java:1097)
> at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:1076)
> "surefire-forkedjvm-command-thread" daemon prio=5 tid=8 runnable
> java.lang.Thread.State: RUNNABLE
> at java.io.FileInputStream.readBytes(Native Method)
> at java.io.FileInputStream.read(FileInputStream.java:255)
> at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
> at java.io.BufferedInputStream.read(BufferedInputStream.java:265)
> at java.io.DataInputStream.readInt(DataInputStream.java:387)
> at
> org.apache.maven.surefire.booter.MasterProcessCommand.decode(MasterProcessCommand.java:115)
> at
> org.apache.maven.surefire.booter.CommandReader$CommandRunnable.run(CommandReader.java:390)
> at java.lang.Thread.run(Thread.java:748)
> "surefire-forkedjvm-ping-30s" daemon prio=5 tid=9 timed_waiting
> java.lang.Thread.State: TIMED_WAITING
> at sun.misc.Unsafe.park(Native Method)
> at
> java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
> at
> java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
> at
> java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> "Thread-15" daemon prio=5 tid=30 timed_waiting
> java.lang.Thread.State: TIMED_WAITING
> at java.lang.Thread.sleep(Native Method)
> at
> org.apache.hadoop.hdds.scm.safemode.SafeModeHandler.lambda$onMessage$0(SafeModeHandler.java:114)
> at
> org.apache.hadoop.hdds.scm.safemode.SafeModeHandler$$Lambda$33/1541519391.run(Unknown
> Source)
> at java.lang.Thread.run(Thread.java:748)
> "process reaper" daemon prio=10 tid=10 timed_waiting
> java.lang.Thread.State: TIMED_WAITING
>
[jira] [Updated] (HDDS-1936) ozonesecure s3 test fails intermittently
[
https://issues.apache.org/jira/browse/HDDS-1936?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1936:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> ozonesecure s3 test fails intermittently
>
>
> Key: HDDS-1936
> URL: https://issues.apache.org/jira/browse/HDDS-1936
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
> Labels: TriagePending
>
> Sometimes acceptance tests fail at ozonesecure s3 test, starting with:
> {code:title=https://ci.anzix.net/job/ozone/17607/artifact/hadoop-ozone/dist/target/ozone-0.5.0-SNAPSHOT/compose/result/log.html#s1-s18-s1-t1-k3-k1-k2}
> Completed 29 Bytes/29 Bytes (6 Bytes/s) with 1 file(s) remaining
> upload failed: ../../tmp/testfile to s3://bucket-07853/testfile An error
> occurred (500) when calling the PutObject operation (reached max retries: 4):
> Internal Server Error
> {code}
> followed by:
> {code:title=https://ci.anzix.net/job/ozone/17607/artifact/hadoop-ozone/dist/target/ozone-0.5.0-SNAPSHOT/compose/result/log.html#s1-s18-s5-t1}
> ('Connection aborted.', error(32, 'Broken pipe'))
> {code}
> in subsequent test cases.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2263) Intermittent failure in TestOzoneContainer#testContainerCreateDiskFull
[
https://issues.apache.org/jira/browse/HDDS-2263?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2263:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in TestOzoneContainer#testContainerCreateDiskFull
> --
>
> Key: HDDS-2263
> URL: https://issues.apache.org/jira/browse/HDDS-2263
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Minor
>
> {code:title=https://github.com/elek/ozone-ci-q4/blob/9bdc8cbd50e9a46c193da288ebea74de8aaea094/pr/pr-hdds-2239-kl4xt/unit/hadoop-hdds/container-service/org.apache.hadoop.ozone.container.ozoneimpl.TestOzoneContainer.txt#L4-L11}
> Tests run: 2, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 16.246 s <<<
> FAILURE! - in org.apache.hadoop.ozone.container.ozoneimpl.TestOzoneContainer
> testContainerCreateDiskFull(org.apache.hadoop.ozone.container.ozoneimpl.TestOzoneContainer)
> Time elapsed: 11.562 s <<< FAILURE!
> java.lang.AssertionError: expected: but was:
> ...
> at
> org.apache.hadoop.ozone.container.ozoneimpl.TestOzoneContainer.testContainerCreateDiskFull(TestOzoneContainer.java:176)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2961) Intermittent failure in TestSCMContainerPlacementPolicyMetrics
[
https://issues.apache.org/jira/browse/HDDS-2961?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2961:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in TestSCMContainerPlacementPolicyMetrics
> --
>
> Key: HDDS-2961
> URL: https://issues.apache.org/jira/browse/HDDS-2961
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
>
> TestSCMContainerPlacementPolicyMetrics fails intermittently, probably due to
> usage of {{Thread.sleep}}.
> {code:title=https://github.com/adoroszlai/hadoop-ozone/runs/417318332}
> 2020-01-30T14:46:16.2217714Z [INFO] Running
> org.apache.hadoop.ozone.scm.TestSCMContainerPlacementPolicyMetrics
> 2020-01-30T14:47:46.5509550Z [ERROR] Tests run: 1, Failures: 0, Errors: 1,
> Skipped: 0, Time elapsed: 90.285 s <<< FAILURE! - in
> org.apache.hadoop.ozone.scm.TestSCMContainerPlacementPolicyMetrics
> 2020-01-30T14:47:46.5532268Z [ERROR]
> test(org.apache.hadoop.ozone.scm.TestSCMContainerPlacementPolicyMetrics)
> Time elapsed: 90.147 s <<< ERROR!
> 2020-01-30T14:47:46.5584246Z java.lang.Exception: test timed out after 6
> milliseconds
> 2020-01-30T14:47:46.5588764Z at java.lang.Thread.sleep(Native Method)
> 2020-01-30T14:47:46.5605748Z at
> org.apache.hadoop.ozone.scm.TestSCMContainerPlacementPolicyMetrics.test(TestSCMContainerPlacementPolicyMetrics.java:135)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2986) MiniOzoneChaosCluster exits because of datanode shutdown
[
https://issues.apache.org/jira/browse/HDDS-2986?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2986:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> MiniOzoneChaosCluster exits because of datanode shutdown
>
>
> Key: HDDS-2986
> URL: https://issues.apache.org/jira/browse/HDDS-2986
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: Ozone Datanode
>Reporter: Mukul Kumar Singh
>Assignee: Siddharth Wagle
>Priority: Major
> Labels: MiniOzoneChaosCluster
> Attachments: HDDS-2986.test.patch
>
>
> MiniOzoneChaosCluster exits because of datanode shutdown
> {code}
> 2020-02-06 18:50:50,760 [Datanode State Machine Thread - 0] ERROR
> statemachine.DatanodeStateMachine (DatanodeStateMachine.java:start(219)) -
> DatanodeStateMachine Shutdown due to an critical error
> 2020-02-06 18:50:50,772 [RatisApplyTransactionExecutor 0] INFO
> interfaces.Container (KeyValueContainer.java:flushAndSyncDB(400)) - Container
> 30 is synced with bcsId 7490.
> 2020-02-06 18:50:50,774 [RatisApplyTransactionExecutor 0] INFO
> interfaces.Container (KeyValueContainer.java:close(338)) - Container 30 is
> closed with bcsId 7490.
> 2020-02-06 18:50:50,774 [Datanode State Machine Thread - 0] ERROR
> report.ReportManager (ReportManager.java:shutdown(82)) - Failed to shutdown
> Report Manager
> java.lang.InterruptedException
> at
> java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.reportInterruptAfterWait(AbstractQueuedSynchronizer.java:2014)
> at
> java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2088)
> at
> java.util.concurrent.ThreadPoolExecutor.awaitTermination(ThreadPoolExecutor.java:1475)
> at
> org.apache.hadoop.ozone.container.common.report.ReportManager.shutdown(ReportManager.java:80)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.stopDaemon(DatanodeStateMachine.java:411)
> at
> org.apache.hadoop.ozone.HddsDatanodeService.stop(HddsDatanodeService.java:474)
> at
> org.apache.hadoop.ozone.HddsDatanodeService.terminateDatanode(HddsDatanodeService.java:454)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.start(DatanodeStateMachine.java:220)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.lambda$startDaemon$0(DatanodeStateMachine.java:365)
> at java.lang.Thread.run(Thread.java:748)
> 2020-02-06 18:50:50,774 [Datanode State Machine Thread - 0] ERROR
> statemachine.DatanodeStateMachine (DatanodeStateMachine.java:close(272)) -
> Error attempting to shutdown.
> java.lang.InterruptedException
> at
> java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2067)
> at
> java.util.concurrent.ThreadPoolExecutor.awaitTermination(ThreadPoolExecutor.java:1475)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.close(DatanodeStateMachine.java:264)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.stopDaemon(DatanodeStateMachine.java:412)
> at
> org.apache.hadoop.ozone.HddsDatanodeService.stop(HddsDatanodeService.java:474)
> at
> org.apache.hadoop.ozone.HddsDatanodeService.terminateDatanode(HddsDatanodeService.java:454)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.start(DatanodeStateMachine.java:220)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.lambda$startDaemon$0(DatanodeStateMachine.java:365)
> at java.lang.Thread.run(Thread.java:748)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3039) SCM sometimes cannot exit safe mode
[
https://issues.apache.org/jira/browse/HDDS-3039?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3039:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> SCM sometimes cannot exit safe mode
> ---
>
> Key: HDDS-3039
> URL: https://issues.apache.org/jira/browse/HDDS-3039
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: SCM
>Reporter: Attila Doroszlai
>Priority: Critical
> Labels: Triaged
>
> Sometimes SCM cannot exit safe mode:
> {code:title=https://github.com/apache/hadoop-ozone/pull/563/checks?check_run_id=453543576}
> 2020-02-18T19:12:28.1108180Z [ERROR] Tests run: 1, Failures: 0, Errors: 1,
> Skipped: 0, Time elapsed: 139.821 s <<< FAILURE! - in
> org.apache.hadoop.ozone.fsck.TestContainerMapper
> 2020-02-18T19:12:28.1169327Z [ERROR]
> org.apache.hadoop.ozone.fsck.TestContainerMapper Time elapsed: 139.813 s
> <<< ERROR!
> 2020-02-18T19:12:28.1202534Z java.util.concurrent.TimeoutException:
> ...
> at
> org.apache.hadoop.ozone.MiniOzoneClusterImpl.waitForClusterToBeReady(MiniOzoneClusterImpl.java:164)
> at
> org.apache.hadoop.ozone.fsck.TestContainerMapper.init(TestContainerMapper.java:71)
> {code}
> despite nodes and pipeline being ready:
> {code}
> 2020-02-18 19:10:18,045 [main] INFO ozone.MiniOzoneClusterImpl
> (MiniOzoneClusterImpl.java:lambda$waitForClusterToBeReady$0(169)) - Nodes are
> ready. Got 3 of 3 DN Heartbeats.
> ...
> 2020-02-18 19:10:18,847 [RatisPipelineUtilsThread] INFO
> pipeline.PipelineStateManager (PipelineStateManager.java:addPipeline(54)) -
> Created pipeline Pipeline[ Id: b56478a3-8816-459e-a007-db5ee4a5572e, Nodes:
> 86e97873-2dbd-4f1b-b418-cf9fba405476{ip: 172.17.0.2, host: bedb6e0ff851,
> networkLocation: /default-rack, certSerialId:
> null}0fb407c1-4cda-4b3e-8e64-20c845872684{ip: 172.17.0.2, host: bedb6e0ff851,
> networkLocation: /default-rack, certSerialId:
> null}31baa82d-441c-41be-94c9-8dd7468b728e{ip: 172.17.0.2, host: bedb6e0ff851,
> networkLocation: /default-rack, certSerialId: null}, Type:RATIS,
> Factor:THREE, State:ALLOCATED, leaderId:null ]
> ...
> 2020-02-18 19:12:17,108 [main] INFO ozone.MiniOzoneClusterImpl
> (MiniOzoneClusterImpl.java:lambda$waitForClusterToBeReady$0(169)) - Nodes are
> ready. Got 3 of 3 DN Heartbeats.
> 2020-02-18 19:12:17,108 [main] INFO ozone.MiniOzoneClusterImpl
> (MiniOzoneClusterImpl.java:lambda$waitForClusterToBeReady$0(172)) - Waiting
> for cluster to exit safe mode
> 2020-02-18 19:12:17,151 [main] INFO ozone.MiniOzoneClusterImpl
> (MiniOzoneClusterImpl.java:shutdown(370)) - Shutting down the Mini Ozone
> Cluster
> {code}
> [~shashikant] also noticed this in other integration tests.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3131) TestMiniChaosOzoneCluster timeout
[ https://issues.apache.org/jira/browse/HDDS-3131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen updated HDDS-3131: - Parent: HDDS-1127 Issue Type: Sub-task (was: Bug) > TestMiniChaosOzoneCluster timeout > - > > Key: HDDS-3131 > URL: https://issues.apache.org/jira/browse/HDDS-3131 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Reporter: Attila Doroszlai >Priority: Critical > Attachments: unit (1).zip, unit (2).zip > > Time Spent: 20m > Remaining Estimate: 0h > > TestMiniChaosOzoneCluster times out in CI runs rather frequently: > https://github.com/apache/hadoop-ozone/runs/486890736 > https://github.com/apache/hadoop-ozone/runs/486890004 > https://github.com/apache/hadoop-ozone/runs/486836962 > Logs are available in "unit" artifacts. > CC [~msingh] -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3145) Intermittent failure in TestEndPoint#testGetVersionAssertRpcTimeOut
[
https://issues.apache.org/jira/browse/HDDS-3145?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3145:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in TestEndPoint#testGetVersionAssertRpcTimeOut
> ---
>
> Key: HDDS-3145
> URL: https://issues.apache.org/jira/browse/HDDS-3145
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
>
> {{TestEndPoint#testGetVersionAssertRpcTimeOut}} is intermittently failing due
> to too slow response:
> {code:title=https://github.com/adoroszlai/hadoop-ozone/runs/495215641}
> [ERROR] Tests run: 15, Failures: 1, Errors: 0, Skipped: 0, Time elapsed:
> 6.898 s <<< FAILURE! - in
> org.apache.hadoop.ozone.container.common.TestEndPoint
> 2020-03-09T13:57:54.6010903Z [ERROR]
> testGetVersionAssertRpcTimeOut(org.apache.hadoop.ozone.container.common.TestEndPoint)
> Time elapsed: 1.168 s <<< FAILURE!
> Expected: a value less than or equal to <1100L>
> but: <1107L> was greater than <1100L>
> ...
> at
> org.apache.hadoop.ozone.container.common.TestEndPoint.testGetVersionAssertRpcTimeOut(TestEndPoint.java:261)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3146) Intermittent timeout in TestOzoneRpcClient
[
https://issues.apache.org/jira/browse/HDDS-3146?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3146:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent timeout in TestOzoneRpcClient
> --
>
> Key: HDDS-3146
> URL: https://issues.apache.org/jira/browse/HDDS-3146
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
> Attachments:
> org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClient-output.txt
>
>
> {code:title=https://github.com/apache/hadoop-ozone/runs/495197228}
> [ERROR] Failed to execute goal
> org.apache.maven.plugins:maven-surefire-plugin:3.0.0-M1:test (default-test)
> on project hadoop-ozone-integration-test: There was a timeout or other error
> in the fork
> ...
> org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClient
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3265) Intermittent timeout in TestRatisPipelineLeader
[
https://issues.apache.org/jira/browse/HDDS-3265?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3265:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent timeout in TestRatisPipelineLeader
> ---
>
> Key: HDDS-3265
> URL: https://issues.apache.org/jira/browse/HDDS-3265
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Assignee: Siddharth Wagle
>Priority: Major
> Attachments:
> TEST-org.apache.hadoop.hdds.scm.TestRatisPipelineLeader.xml,
> org.apache.hadoop.hdds.scm.TestRatisPipelineLeader-output.txt,
> org.apache.hadoop.hdds.scm.TestRatisPipelineLeader-output.txt,
> org.apache.hadoop.hdds.scm.TestRatisPipelineLeader.txt
>
>
> TestRatisPipelineLeader sometimes times out waiting to create container:
> {code:title=https://github.com/apache/hadoop-ozone/runs/527779039}
> [ERROR] Tests run: 2, Failures: 0, Errors: 1, Skipped: 0, Time elapsed:
> 174.712 s <<< FAILURE! - in org.apache.hadoop.hdds.scm.TestRatisPipelineLeader
> [ERROR]
> testLeaderIdUsedOnFirstCall(org.apache.hadoop.hdds.scm.TestRatisPipelineLeader)
> Time elapsed: 120.01 s <<< ERROR!
> java.lang.Exception: test timed out after 12 milliseconds
> ...
> at
> org.apache.hadoop.hdds.scm.XceiverClientSpi.sendCommand(XceiverClientSpi.java:134)
> at
> org.apache.hadoop.hdds.scm.storage.ContainerProtocolCalls.createContainer(ContainerProtocolCalls.java:406)
> at
> org.apache.hadoop.hdds.scm.TestRatisPipelineLeader.testLeaderIdUsedOnFirstCall(TestRatisPipelineLeader.java:100)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3950) FLAKY-UT: TestFailureHandlingByClientFlushDelay timeout
[
https://issues.apache.org/jira/browse/HDDS-3950?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3950:
-
Target Version/s: 0.7.0
> FLAKY-UT: TestFailureHandlingByClientFlushDelay timeout
> ---
>
> Key: HDDS-3950
> URL: https://issues.apache.org/jira/browse/HDDS-3950
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.6.0
>Reporter: maobaolong
>Priority: Major
>
> {code:java}
> [INFO] Running
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[INFO]
> Running
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
> Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 94.969 s <<<
> FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
>
> testPipelineExclusionWithPipelineFailure(org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay)
> Time elapsed: 94.881 s <<< FAILURE!java.lang.AssertionError at
> org.junit.Assert.fail(Assert.java:86) at
> org.junit.Assert.assertTrue(Assert.java:41) at
> org.junit.Assert.assertTrue(Assert.java:52) at
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay.testPipelineExclusionWithPipelineFailure(TestFailureHandlingByClientFlushDelay.java:200)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498) at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3841) Stale tests(timeout or other reason)
[ https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen updated HDDS-3841: - Parent: HDDS-1127 Issue Type: Sub-task (was: Test) > Stale tests(timeout or other reason) > > > Key: HDDS-3841 > URL: https://issues.apache.org/jira/browse/HDDS-3841 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Affects Versions: 0.7.0 >Reporter: maobaolong >Priority: Major > > If a failure test appeared in your CI checks, and you are sure it is not > relation with your PR, so, paste the stale test log here. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3841) Stale tests(timeout or other reason)
[ https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3841: - Summary: Stale tests(timeout or other reason) (was: FLAKY-UT: TestSecureOzoneRpcClient timeout) > Stale tests(timeout or other reason) > > > Key: HDDS-3841 > URL: https://issues.apache.org/jira/browse/HDDS-3841 > Project: Hadoop Distributed Data Store > Issue Type: Test > Components: test >Affects Versions: 0.7.0 >Reporter: maobaolong >Priority: Major > > If a failure test appeared in your CI checks, and you are sure it is not > relation with your PR, so, paste the stale test log here. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3950) FLAKY-UT: TestFailureHandlingByClientFlushDelay timeout
[
https://issues.apache.org/jira/browse/HDDS-3950?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3950:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Improvement)
> FLAKY-UT: TestFailureHandlingByClientFlushDelay timeout
> ---
>
> Key: HDDS-3950
> URL: https://issues.apache.org/jira/browse/HDDS-3950
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.6.0
>Reporter: maobaolong
>Priority: Major
>
> {code:java}
> [INFO] Running
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[INFO]
> Running
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
> Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 94.969 s <<<
> FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
>
> testPipelineExclusionWithPipelineFailure(org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay)
> Time elapsed: 94.881 s <<< FAILURE!java.lang.AssertionError at
> org.junit.Assert.fail(Assert.java:86) at
> org.junit.Assert.assertTrue(Assert.java:41) at
> org.junit.Assert.assertTrue(Assert.java:52) at
> org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay.testPipelineExclusionWithPipelineFailure(TestFailureHandlingByClientFlushDelay.java:200)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498) at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3950) FLAKY-UT: TestFailureHandlingByClientFlushDelay timeout
maobaolong created HDDS-3950:
Summary: FLAKY-UT: TestFailureHandlingByClientFlushDelay timeout
Key: HDDS-3950
URL: https://issues.apache.org/jira/browse/HDDS-3950
Project: Hadoop Distributed Data Store
Issue Type: Improvement
Components: test
Affects Versions: 0.6.0
Reporter: maobaolong
{code:java}
[INFO] Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[INFO]
Running
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 94.969 s <<<
FAILURE! - in
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay[ERROR]
testPipelineExclusionWithPipelineFailure(org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay)
Time elapsed: 94.881 s <<< FAILURE!java.lang.AssertionError at
org.junit.Assert.fail(Assert.java:86) at
org.junit.Assert.assertTrue(Assert.java:41) at
org.junit.Assert.assertTrue(Assert.java:52) at
org.apache.hadoop.ozone.client.rpc.TestFailureHandlingByClientFlushDelay.testPipelineExclusionWithPipelineFailure(TestFailureHandlingByClientFlushDelay.java:200)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498) at
org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at
org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at
org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at
org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at
org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3907) Topology related acceptance test is flaky
[
https://issues.apache.org/jira/browse/HDDS-3907?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3907:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Topology related acceptance test is flaky
> -
>
> Key: HDDS-3907
> URL: https://issues.apache.org/jira/browse/HDDS-3907
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
>Reporter: Marton Elek
>Priority: Blocker
>
> Examples:
> https://github.com/elek/ozone-build-results/tree/master/2020/06/30/1318/acceptance
> https://github.com/elek/ozone-build-results/tree/master/2020/06/30/1321/acceptance
> https://github.com/elek/ozone-build-results/tree/master/2020/06/30/1334/acceptance
> Some strange errors:
> {code}
> scm_1 | 2020-06-30 19:17:50,787 [RatisPipelineUtilsThread] ERROR
> pipeline.SCMPipelineManager: Failed to create pipeline of type RATIS and
> factor ONE. Exception: Cannot create pipeline of factor 1 using 0 nodes. Used
> 6 nodes. Healthy nodes 6
> scm_1 | 2020-06-30 19:17:50,788 [RatisPipelineUtilsThread] ERROR
> pipeline.SCMPipelineManager: Failed to create pipeline of type RATIS and
> factor THREE. Exception: Pipeline creation failed because nodes are engaged
> in other pipelines and every node can only be engaged in max 2 pipelines.
> Required 3. Found 0
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1435) ITestOzoneContractOpen.testOpenFileTwice is flaky
[
https://issues.apache.org/jira/browse/HDDS-1435?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1435:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> ITestOzoneContractOpen.testOpenFileTwice is flaky
> -
>
> Key: HDDS-1435
> URL: https://issues.apache.org/jira/browse/HDDS-1435
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Marton Elek
>Priority: Major
> Labels: TriagePending, ozone-flaky-test
> Attachments: ci.log, ci2.log
>
>
> It is failed with:
> {code}
> java.lang.Exception: test timed out after 3 milliseconds
> at java.lang.Thread.sleep(Native Method)
> at
> org.apache.hadoop.test.GenericTestUtils.waitFor(GenericTestUtils.java:382)
> at
> org.apache.hadoop.hdds.scm.pipeline.TestRatisPipelineUtils.waitForPipelines(TestRatisPipelineUtils.java:125)
> at
> org.apache.hadoop.hdds.scm.pipeline.TestRatisPipelineUtils.testPipelineCreationOnNodeRestart(TestRatisPipelineUtils.java:120)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
> Log file is uploaded.
> AFAIK the problem is that RatisPipelineUtils.createPipeline connected to a
> non-leader node.
> But it's not clear for me how is it possible. According to the log (attached)
> the leader election continued after the NonLeaderException. It can be just
> the sign that one datanode was missing from the pipeline...
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3841) FLAKY-UT: TestSecureOzoneRpcClient timeout
[ https://issues.apache.org/jira/browse/HDDS-3841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] maobaolong updated HDDS-3841: - Summary: FLAKY-UT: TestSecureOzoneRpcClient timeout (was: Stale tests(timeout or other reason)) > FLAKY-UT: TestSecureOzoneRpcClient timeout > -- > > Key: HDDS-3841 > URL: https://issues.apache.org/jira/browse/HDDS-3841 > Project: Hadoop Distributed Data Store > Issue Type: Test > Components: test >Affects Versions: 0.7.0 >Reporter: maobaolong >Priority: Major > > If a failure test appeared in your CI checks, and you are sure it is not > relation with your PR, so, paste the stale test log here. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1967) TestBlockOutputStreamWithFailures is flaky
[
https://issues.apache.org/jira/browse/HDDS-1967?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1967:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestBlockOutputStreamWithFailures is flaky
> --
>
> Key: HDDS-1967
> URL: https://issues.apache.org/jira/browse/HDDS-1967
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Nanda kumar
>Priority: Major
> Labels: TriagePending, ozone-flaky-test
> Attachments:
> TEST-org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures.xml,
>
> org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures-output.txt,
> org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures.txt
>
>
> {{TestBlockOutputStreamWithFailures}} is flaky.
> {noformat}
> [ERROR]
> test2DatanodesFailure(org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures)
> Time elapsed: 23.816 s <<< FAILURE!
> java.lang.AssertionError: expected:<4> but was:<8>
> at org.junit.Assert.fail(Assert.java:88)
> at org.junit.Assert.failNotEquals(Assert.java:743)
> at org.junit.Assert.assertEquals(Assert.java:118)
> at org.junit.Assert.assertEquals(Assert.java:555)
> at org.junit.Assert.assertEquals(Assert.java:542)
> at
> org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures.test2DatanodesFailure(TestBlockOutputStreamWithFailures.java:425)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {noformat}
> {noformat}
> [ERROR]
> testWatchForCommitDatanodeFailure(org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures)
> Time elapsed: 30.895 s <<< FAILURE!
> java.lang.AssertionError: expected:<2> but was:<3>
> at org.junit.Assert.fail(Assert.java:88)
> at org.junit.Assert.failNotEquals(Assert.java:743)
> at org.junit.Assert.assertEquals(Assert.java:118)
> at org.junit.Assert.assertEquals(Assert.java:555)
> at org.junit.Assert.assertEquals(Assert.java:542)
> at
> org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures.testWatchForCommitDatanodeFailure(TestBlockOutputStreamWithFailures.java:366)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
>
[jira] [Updated] (HDDS-1656) Fix flaky test TestWatchForCommit#testWatchForCommitWithKeyWrite
[ https://issues.apache.org/jira/browse/HDDS-1656?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen updated HDDS-1656: - Parent: HDDS-1127 Issue Type: Sub-task (was: Bug) > Fix flaky test TestWatchForCommit#testWatchForCommitWithKeyWrite > > > Key: HDDS-1656 > URL: https://issues.apache.org/jira/browse/HDDS-1656 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Reporter: Ajay Kumar >Priority: Major > Labels: TriagePending > > TestWatchForCommit#testWatchForCommitWithKeyWrite behavior is not consistent. > In multiple runs sometimes it passes while on other occasions it fails with > different assertion/DN related errors. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-1409) TestOzoneClientRetriesOnException is flaky
[
https://issues.apache.org/jira/browse/HDDS-1409?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-1409:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Test)
> TestOzoneClientRetriesOnException is flaky
> --
>
> Key: HDDS-1409
> URL: https://issues.apache.org/jira/browse/HDDS-1409
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Nanda kumar
>Priority: Major
> Labels: TriagePending, ozone-flaky-test
>
> TestOzoneClientRetriesOnException is flaky, we get the below exception when
> it fails.
> {noformat}
> [ERROR]
> testMaxRetriesByOzoneClient(org.apache.hadoop.ozone.client.rpc.TestOzoneClientRetriesOnException)
> Time elapsed: 16.227 s <<< FAILURE!
> java.lang.AssertionError
> at org.junit.Assert.fail(Assert.java:86)
> at org.junit.Assert.assertTrue(Assert.java:41)
> at org.junit.Assert.assertTrue(Assert.java:52)
> at
> org.apache.hadoop.ozone.client.rpc.TestOzoneClientRetriesOnException.testMaxRetriesByOzoneClient(TestOzoneClientRetriesOnException.java:197)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {noformat}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2082) Fix flaky TestContainerStateMachineFailures#testApplyTransactionFailure
[
https://issues.apache.org/jira/browse/HDDS-2082?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2082:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Fix flaky TestContainerStateMachineFailures#testApplyTransactionFailure
> ---
>
> Key: HDDS-2082
> URL: https://issues.apache.org/jira/browse/HDDS-2082
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Dinesh Chitlangia
>Priority: Major
> Labels: TriagePending, ozone-flaky-test
>
> {code:java}
> ---
> Test set: org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailures
> ---
> Tests run: 3, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 102.615 s <<<
> FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailures
> testApplyTransactionFailure(org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailures)
> Time elapsed: 15.677 s <<< FAILURE!
> java.lang.AssertionError
> at org.junit.Assert.fail(Assert.java:86)
> at org.junit.Assert.assertTrue(Assert.java:41)
> at org.junit.Assert.assertTrue(Assert.java:52)
> at
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailures.testApplyTransactionFailure(TestContainerStateMachineFailures.java:349)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:365)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
> at
> org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
> at
> org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
> at
> org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
> at
> org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
> at
> org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3151) Intermittent timeout in TestCloseContainerHandlingByClient#testMultiBlockWrites3
[
https://issues.apache.org/jira/browse/HDDS-3151?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3151:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent timeout in
> TestCloseContainerHandlingByClient#testMultiBlockWrites3
>
>
> Key: HDDS-3151
> URL: https://issues.apache.org/jira/browse/HDDS-3151
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
> Attachments:
> org.apache.hadoop.ozone.client.rpc.TestCloseContainerHandlingByClient-output.txt,
> org.apache.hadoop.ozone.client.rpc.TestCloseContainerHandlingByClient.txt
>
>
> {code:title=https://github.com/apache/hadoop-ozone/runs/495906854}
> Tests run: 8, Failures: 0, Errors: 1, Skipped: 1, Time elapsed: 210.963 s <<<
> FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestCloseContainerHandlingByClient
> testMultiBlockWrites3(org.apache.hadoop.ozone.client.rpc.TestCloseContainerHandlingByClient)
> Time elapsed: 108.777 s <<< ERROR!
> java.util.concurrent.TimeoutException:
> ...
> at
> org.apache.hadoop.ozone.container.TestHelper.waitForContainerClose(TestHelper.java:251)
> at
> org.apache.hadoop.ozone.container.TestHelper.waitForContainerClose(TestHelper.java:151)
> at
> org.apache.hadoop.ozone.client.rpc.TestCloseContainerHandlingByClient.waitForContainerClose(TestCloseContainerHandlingByClient.java:342)
> at
> org.apache.hadoop.ozone.client.rpc.TestCloseContainerHandlingByClient.testMultiBlockWrites3(TestCloseContainerHandlingByClient.java:310)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3313) OM HA acceptance test is flaky
[
https://issues.apache.org/jira/browse/HDDS-3313?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3313:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> OM HA acceptance test is flaky
> --
>
> Key: HDDS-3313
> URL: https://issues.apache.org/jira/browse/HDDS-3313
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Assignee: Hanisha Koneru
>Priority: Critical
> Attachments: acceptance.zip
>
>
> {{ozone-om-ha}} test is failing intermittently. Example on master:
> https://github.com/apache/hadoop-ozone/runs/549544110
> {code:title=failure 1}
> 2020-03-31T19:34:02.3757399Z
> ==
> 2020-03-31T19:34:02.3762775Z ozone-om-ha-testOMHA :: Smoketest ozone cluster
> startup
> 2020-03-31T19:34:02.3763313Z
> ==
> 2020-03-31T19:34:07.9174050Z Stop Leader OM and Verify Failover
> | FAIL |
> 2020-03-31T19:34:07.9174675Z 255 != 0
> 2020-03-31T19:34:07.9176048Z
> --
> 2020-03-31T19:34:37.4682717Z Test Multiple Failovers
> | FAIL |
> 2020-03-31T19:34:37.4682899Z 1 != 0
> 2020-03-31T19:34:37.4683766Z
> --
> 2020-03-31T19:35:24.9569154Z Restart OM and Verify Ratis Logs
> | FAIL |
> 2020-03-31T19:35:24.9569529Z 255 != 0
> 2020-03-31T19:35:24.9574925Z
> --
> 2020-03-31T19:35:24.9575613Z ozone-om-ha-testOMHA :: Smoketest ozone cluster
> startup | FAIL |
> 2020-03-31T19:35:24.9575952Z 3 critical tests, 0 passed, 3 failed
> 2020-03-31T19:35:24.9576076Z 3 tests total, 0 passed, 3 failed
> {code}
> {code:title=failure 2}
> 2020-03-31T20:36:29.5715868Z
> ==
> 2020-03-31T20:36:29.5743517Z ozone-om-ha-testOMHA :: Smoketest ozone cluster
> startup
> 2020-03-31T20:36:29.5744025Z
> ==
> 2020-03-31T20:37:08.4625840Z Stop Leader OM and Verify Failover
> | PASS |
> 2020-03-31T20:37:08.4626644Z
> --
> 2020-03-31T20:39:47.9721513Z Test Multiple Failovers
> | PASS |
> 2020-03-31T20:39:47.9723424Z
> --
> 2020-03-31T21:25:29.1203036Z Restart OM and Verify Ratis Logs
> | FAIL |
> 2020-03-31T21:25:29.1204001Z Test timeout 8 minutes exceeded.
> 2020-03-31T21:25:29.1204954Z
> --
> 2020-03-31T21:25:29.1220689Z ozone-om-ha-testOMHA :: Smoketest ozone cluster
> startup | FAIL |
> 2020-03-31T21:25:29.1224446Z 3 critical tests, 2 passed, 1 failed
> 2020-03-31T21:25:29.1224833Z 3 tests total, 2 passed, 1 failed
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2760) Intermittent timeout in TestCloseContainerEventHandler
[
https://issues.apache.org/jira/browse/HDDS-2760?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-2760:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent timeout in TestCloseContainerEventHandler
> --
>
> Key: HDDS-2760
> URL: https://issues.apache.org/jira/browse/HDDS-2760
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Minor
> Labels: TriagePending, ozone-flaky-test
>
> TestCloseContainerEventHandler depends on wall clock and fails intermittently:
> {code}
> 2019-12-17T11:29:56.1873334Z [INFO] Running
> org.apache.hadoop.hdds.scm.container.TestCloseContainerEventHandler
> 2019-12-17T11:31:10.0593259Z [ERROR] Tests run: 4, Failures: 1, Errors: 0,
> Skipped: 0, Time elapsed: 71.343 s <<< FAILURE! - in
> org.apache.hadoop.hdds.scm.container.TestCloseContainerEventHandler
> 2019-12-17T11:31:10.0604096Z [ERROR]
> testCloseContainerEventWithRatis(org.apache.hadoop.hdds.scm.container.TestCloseContainerEventHandler)
> Time elapsed: 66.214 s <<< FAILURE!
> 2019-12-17T11:31:10.0604347Z java.lang.AssertionError: Messages are not
> processed in the given timeframe. Queued: 5 Processed: 0
> 2019-12-17T11:31:10.0614937Z at
> org.apache.hadoop.hdds.server.events.EventQueue.processAll(EventQueue.java:238)
> 2019-12-17T11:31:10.0616610Z at
> org.apache.hadoop.hdds.scm.container.TestCloseContainerEventHandler.testCloseContainerEventWithRatis(TestCloseContainerEventHandler.java:149)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3294) Flaky test TestContainerStateMachineFailureOnRead#testReadStateMachineFailureClosesPipeline
[
https://issues.apache.org/jira/browse/HDDS-3294?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3294:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Flaky test
> TestContainerStateMachineFailureOnRead#testReadStateMachineFailureClosesPipeline
> ---
>
> Key: HDDS-3294
> URL: https://issues.apache.org/jira/browse/HDDS-3294
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Siyao Meng
>Priority: Major
> Labels: TriagePending, flaky-test, ozone-flaky-test
> Attachments:
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead-output.txt,
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead.txt
>
>
> Shows up in a PR: https://github.com/apache/hadoop-ozone/runs/540133363
> {code:title=log}
> [INFO] Running
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead
> [ERROR] Tests run: 1, Failures: 0, Errors: 1, Skipped: 0, Time elapsed:
> 49.766 s <<< FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead
> [ERROR]
> testReadStateMachineFailureClosesPipeline(org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead)
> Time elapsed: 49.623 s <<< ERROR!
> java.lang.NullPointerException
> at
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead.testReadStateMachineFailureClosesPipeline(TestContainerStateMachineFailureOnRead.java:204)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
> {code:title=Location of NPE at
> TestContainerStateMachineFailureOnRead.java:204}
> // delete the container dir from leader
> FileUtil.fullyDelete(new File(
> leaderDn.get().getDatanodeStateMachine()
> .getContainer().getContainerSet()
>
> .getContainer(omKeyLocationInfo.getContainerID()).getContainerData() <-- this
> line
> .getContainerPath()));
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] timmylicheng commented on a change in pull request #1049: HDDS-3662 Decouple finalizeAndDestroyPipeline.
timmylicheng commented on a change in pull request #1049:
URL: https://github.com/apache/hadoop-ozone/pull/1049#discussion_r452602085
##
File path:
hadoop-hdds/server-scm/src/main/java/org/apache/hadoop/hdds/scm/pipeline/PipelineManagerV2Impl.java
##
@@ -410,18 +399,29 @@ public void scrubPipeline(ReplicationType type,
ReplicationFactor factor)
ScmConfigKeys.OZONE_SCM_PIPELINE_ALLOCATED_TIMEOUT,
ScmConfigKeys.OZONE_SCM_PIPELINE_ALLOCATED_TIMEOUT_DEFAULT,
TimeUnit.MILLISECONDS);
-List needToSrubPipelines = stateManager.getPipelines(type,
factor,
-Pipeline.PipelineState.ALLOCATED).stream()
-.filter(p -> currentTime.toEpochMilli() - p.getCreationTimestamp()
-.toEpochMilli() >= pipelineScrubTimeoutInMills)
-.collect(Collectors.toList());
-for (Pipeline p : needToSrubPipelines) {
- LOG.info("Scrubbing pipeline: id: " + p.getId().toString() +
- " since it stays at ALLOCATED stage for " +
- Duration.between(currentTime, p.getCreationTimestamp()).toMinutes() +
- " mins.");
- finalizeAndDestroyPipeline(p, false);
+
+List candidates = stateManager.getPipelines(type, factor);
+
+for (Pipeline p : candidates) {
+ // scrub pipelines who stay ALLOCATED for too long.
+ if (p.getPipelineState() == Pipeline.PipelineState.ALLOCATED &&
+ (currentTime.toEpochMilli() - p.getCreationTimestamp()
+ .toEpochMilli() >= pipelineScrubTimeoutInMills)) {
+LOG.info("Scrubbing pipeline: id: " + p.getId().toString() +
+" since it stays at ALLOCATED stage for " +
+Duration.between(currentTime, p.getCreationTimestamp())
+.toMinutes() + " mins.");
+closePipeline(p, false);
+ }
+ // scrub pipelines who stay CLOSED for too long.
+ if (p.getPipelineState() == Pipeline.PipelineState.CLOSED) {
Review comment:
I updated with the scheduler to schedule removing pipeline after closing
contaienrs.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3297) TestOzoneClientKeyGenerator is flaky
[ https://issues.apache.org/jira/browse/HDDS-3297?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen updated HDDS-3297: - Parent: HDDS-1127 Issue Type: Sub-task (was: Bug) > TestOzoneClientKeyGenerator is flaky > > > Key: HDDS-3297 > URL: https://issues.apache.org/jira/browse/HDDS-3297 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: test >Reporter: Marton Elek >Priority: Critical > Labels: TriagePending, flaky-test, ozone-flaky-test > Attachments: > org.apache.hadoop.ozone.freon.TestOzoneClientKeyGenerator-output.txt > > > Sometimes it's hanging and stopped after a timeout. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3338) TestOzoneManagerRocksDBLogging.shutdown times out
[
https://issues.apache.org/jira/browse/HDDS-3338?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3338:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestOzoneManagerRocksDBLogging.shutdown times out
> -
>
> Key: HDDS-3338
> URL: https://issues.apache.org/jira/browse/HDDS-3338
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
>Reporter: Siyao Meng
>Priority: Major
> Labels: TriagePending
>
> Failed in it-hdds-om:
> {code}
> [INFO] Running org.apache.hadoop.ozone.om.TestKeyPurging
> [INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 36.933
> s - in org.apache.hadoop.ozone.om.TestKeyPurging
> [INFO] Running org.apache.hadoop.ozone.om.TestOzoneManagerRocksDBLogging
> [ERROR] Tests run: 1, Failures: 0, Errors: 1, Skipped: 0, Time elapsed: 60.44
> s <<< FAILURE! - in org.apache.hadoop.ozone.om.TestOzoneManagerRocksDBLogging
> [ERROR]
> testOMRocksDBLoggingEnabled(org.apache.hadoop.ozone.om.TestOzoneManagerRocksDBLogging)
> Time elapsed: 60.023 s <<< ERROR!
> java.lang.Exception: test timed out after 6 milliseconds
> at java.lang.Object.wait(Native Method)
> at
> java.util.concurrent.ForkJoinTask.externalAwaitDone(ForkJoinTask.java:334)
> at java.util.concurrent.ForkJoinTask.doInvoke(ForkJoinTask.java:405)
> at java.util.concurrent.ForkJoinTask.invoke(ForkJoinTask.java:734)
> at
> java.util.stream.ForEachOps$ForEachOp.evaluateParallel(ForEachOps.java:159)
> at
> java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateParallel(ForEachOps.java:173)
> at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:233)
> at
> java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:485)
> at
> java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:650)
> at
> org.apache.hadoop.ozone.MiniOzoneClusterImpl.stopDatanodes(MiniOzoneClusterImpl.java:463)
> at
> org.apache.hadoop.ozone.MiniOzoneClusterImpl.stop(MiniOzoneClusterImpl.java:404)
> at
> org.apache.hadoop.ozone.MiniOzoneClusterImpl.shutdown(MiniOzoneClusterImpl.java:391)
> at
> org.apache.hadoop.ozone.om.TestOzoneManagerRocksDBLogging.shutdown(TestOzoneManagerRocksDBLogging.java:63)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> {code}
> {code}
> [INFO] Results:
> [INFO]
> [ERROR] Errors:
> [ERROR] TestOzoneManagerRocksDBLogging.shutdown:63->Object.wait:-2 ? test
> timed out a...
> [INFO]
> [ERROR] Tests run: 62, Failures: 0, Errors: 1, Skipped: 12
> {code}
> Output is FLOODED with the same message:
> {code:title=org.apache.hadoop.ozone.om.TestOzoneManagerRocksDBLogging-output.txt}
> 2020-04-01 20:52:54,072 [Datanode State Machine Thread - 0] ERROR
> statemachine.DatanodeStateMachine (DatanodeStateMachine.java:start(232)) -
> Unable to finish the execution.
> java.util.concurrent.RejectedExecutionException: Task
> java.util.concurrent.ExecutorCompletionService$QueueingFuture@24ae1cc8
> rejected from
> org.apache.hadoop.util.concurrent.HadoopThreadPoolExecutor@24ed6a81[Terminated,
> pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 35]
> at
> java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
> at
> java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
> at
> java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
> at
> java.util.concurrent.ExecutorCompletionService.submit(ExecutorCompletionService.java:181)
> at
> org.apache.hadoop.ozone.container.common.states.datanode.RunningDatanodeState.execute(RunningDatanodeState.java:144)
> at
> org.apache.hadoop.ozone.container.common.statemachine.StateContext.execute(StateContext.java:419)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.start(DatanodeStateMachine.java:219)
> at
> org.apache.hadoop.ozone.container.common.statemachine.DatanodeStateMachine.lambda$startDaemon$0(DatanodeStateMachine.java:386)
> at java.lang.Thread.run(Thread.java:748)
> {code}
> Artifact:
> https://github.com/apache/hadoop-ozone/suites/565485547/artifacts/3737405
> Could be related to HDDS-2866 ?
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3358) Intermittent test failure related to a race conditon during PipelineManager close
[
https://issues.apache.org/jira/browse/HDDS-3358?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3358:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Improvement)
> Intermittent test failure related to a race conditon during PipelineManager
> close
> -
>
> Key: HDDS-3358
> URL: https://issues.apache.org/jira/browse/HDDS-3358
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Marton Elek
>Assignee: Marton Elek
>Priority: Major
> Labels: TriagePending, flaky-test, ozone-flaky-test
> Attachments:
> org.apache.hadoop.hdds.scm.node.TestSCMNodeManager-output.txt
>
>
> The test which is failed:
> TestSCMNodeManager
> The end of the log is:
> {code}
> 2020-04-08 10:49:44,544 ERROR events.SingleThreadExecutor
> (SingleThreadExecutor.java:lambda$onMessage$1(84)) - Error on execution
> message 19844615-0d70-4172-8c34-96e5b7295ef2{ip: 196.189.243.187, host:
> localhost-196.189.243.187, networkLocation: /default-rack, certSerialId: null}
> java.lang.NullPointerException
> at
> org.apache.hadoop.hdds.scm.pipeline.SCMPipelineManager.finalizeAndDestroyPipeline(SCMPipelineManager.java:380)
> at
> org.apache.hadoop.hdds.scm.node.StaleNodeHandler.onMessage(StaleNodeHandler.java:63)
> at
> org.apache.hadoop.hdds.scm.node.StaleNodeHandler.onMessage(StaleNodeHandler.java:38)
> at
> org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> 2020-04-08 10:49:44,544 INFO node.StaleNodeHandler
> (StaleNodeHandler.java:onMessage(58)) - Datanode
> 0914e56d-c7f8-4e0a-8fd1-845a9806172b{ip: 57.46.156.17, host:
> localhost-57.46.156.17, networkLocation: /default-rack, certSerialId: null}
> moved to stale state. Finalizing its pipelines
> [PipelineID=fd1f9e92-2f90-43e7-8406-94ba6ac356b0,
> PipelineID=8d380e3c-b632-4bda-aa7a-554774fba09d]
> 2020-04-08 10:49:44,544 INFO pipeline.SCMPipelineManager
> (SCMPipelineManager.java:finalizeAndDestroyPipeline(373)) - Destroying
> pipeline:Pipeline[ Id: fd1f9e92-2f90-43e7-8406-94ba6ac356b0, Nodes:
> 0914e56d-c7f8-4e0a-8fd1-845a9806172b{ip: 57.46.156.17, host:
> localhost-57.46.156.17, networkLocation: /default-rack, certSerialId: null},
> Type:RATIS, Factor:ONE, State:ALLOCATED, leaderId:null,
> CreationTimestamp2020-04-08T10:49:37.441Z]
> 2020-04-08 10:49:44,544 INFO pipeline.PipelineStateManager
> (PipelineStateManager.java:finalizePipeline(120)) - Pipeline Pipeline[ Id:
> fd1f9e92-2f90-43e7-8406-94ba6ac356b0, Nodes:
> 0914e56d-c7f8-4e0a-8fd1-845a9806172b{ip: 57.46.156.17, host:
> localhost-57.46.156.17, networkLocation: /default-rack, certSerialId: null},
> Type:RATIS, Factor:ONE, State:CLOSED, leaderId:null,
> CreationTimestamp2020-04-08T10:49:37.441Z] moved to CLOSED state
> 2020-04-08 10:49:44,544 ERROR events.SingleThreadExecutor
> (SingleThreadExecutor.java:lambda$onMessage$1(84)) - Error on execution
> message 0914e56d-c7f8-4e0a-8fd1-845a9806172b{ip: 57.46.156.17, host:
> localhost-57.46.156.17, networkLocation: /default-rack, certSerialId: null}
> java.lang.NullPointerException
> at
> org.apache.hadoop.hdds.scm.pipeline.SCMPipelineManager.finalizeAndDestroyPipeline(SCMPipelineManager.java:380)
> at
> org.apache.hadoop.hdds.scm.node.StaleNodeHandler.onMessage(StaleNodeHandler.java:63)
> at
> org.apache.hadoop.hdds.scm.node.StaleNodeHandler.onMessage(StaleNodeHandler.java:38)
> at
> org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> 2020-04-08 10:49:44,544 INFO pipeline.RatisPipelineProvider
> (RatisPipelineProvider.java:lambda$close$4(208)) - Send
> pipeline:PipelineID=e0e155c6-9fbe-46a7-b742-e805ea9baacf close command to
> datanode 30a24b04-1289-4c30-a28a-034edfe29e3d
> 2020-04-08 10:49:44,545 WARN events.EventQueue
> (EventQueue.java:fireEvent(151)) - Processing of
> TypedEvent{payloadType=CommandForDatanode, name='Datanode_Command'} is
> skipped, EventQueue is not running
> 2020-04-08 10:49:44,544 INFO node.StaleNodeHandler
> (StaleNodeHandler.java:onMessage(58)) - Datanode
> 59bdd26b-05da-47d1-8c3f-8350d55d7299{ip: 248.147.58.17, host:
>
[GitHub] [hadoop-ozone] iamabug commented on pull request #1184: HDDS-2767. security/SecuringTDE.md
iamabug commented on pull request #1184: URL: https://github.com/apache/hadoop-ozone/pull/1184#issuecomment-656459321 @cxorm @smengcl @xiaoyuyao Please help review this if available, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3363) Intermittent failure in testContainerImportExport
[
https://issues.apache.org/jira/browse/HDDS-3363?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3363:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in testContainerImportExport
> -
>
> Key: HDDS-3363
> URL: https://issues.apache.org/jira/browse/HDDS-3363
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
>
> {code:title=https://github.com/adoroszlai/hadoop-ozone/runs/571992849}
> 2020-04-08T20:30:49.0510599Z [ERROR] Tests run: 22, Failures: 0, Errors: 1,
> Skipped: 0, Time elapsed: 3.669 s <<< FAILURE! - in
> org.apache.hadoop.ozone.container.keyvalue.TestKeyValueContainer
> 2020-04-08T20:30:49.0535678Z [ERROR]
> testContainerImportExport[1](org.apache.hadoop.ozone.container.keyvalue.TestKeyValueContainer)
> Time elapsed: 0.079 s <<< ERROR!
> 2020-04-08T20:30:49.0552584Z java.io.IOException: request to write '4096'
> bytes exceeds size in header of '19906' bytes for entry 'db/LOG'
> 2020-04-08T20:30:49.0572746Z at
> org.apache.commons.compress.archivers.tar.TarArchiveOutputStream.write(TarArchiveOutputStream.java:385)
> 2020-04-08T20:30:49.0572897Z at
> org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:2147)
> 2020-04-08T20:30:49.0582579Z at
> org.apache.commons.io.IOUtils.copy(IOUtils.java:2102)
> 2020-04-08T20:30:49.0593659Z at
> org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:2123)
> 2020-04-08T20:30:49.0603340Z at
> org.apache.commons.io.IOUtils.copy(IOUtils.java:2078)
> 2020-04-08T20:30:49.0613502Z at
> org.apache.hadoop.ozone.container.keyvalue.TarContainerPacker.includeFile(TarContainerPacker.java:225)
> 2020-04-08T20:30:49.0631425Z at
> org.apache.hadoop.ozone.container.keyvalue.TarContainerPacker.includePath(TarContainerPacker.java:215)
> 2020-04-08T20:30:49.0637525Z at
> org.apache.hadoop.ozone.container.keyvalue.TarContainerPacker.pack(TarContainerPacker.java:155)
> 2020-04-08T20:30:49.0648504Z at
> org.apache.hadoop.ozone.container.keyvalue.KeyValueContainer.exportContainerData(KeyValueContainer.java:549)
> 2020-04-08T20:30:49.0659852Z at
> org.apache.hadoop.ozone.container.keyvalue.TestKeyValueContainer.testContainerImportExport(TestKeyValueContainer.java:233)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3506) TestOzoneFileInterfaces is flaky
[
https://issues.apache.org/jira/browse/HDDS-3506?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3506:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> TestOzoneFileInterfaces is flaky
>
>
> Key: HDDS-3506
> URL: https://issues.apache.org/jira/browse/HDDS-3506
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Marton Elek
>Assignee: Istvan Fajth
>Priority: Critical
> Labels: TriagePending, flaky-test, ozone-flaky-test
> Attachments:
> TEST-org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.xml
>
>
> TestOzoneFileInterfaces.testOzoneManagerLocatedFileStatusBlockOffsetsWithMultiBlockFile
> is flaky and failed multiple times on master:
> {code}
> ./2020/04/24/822/it-filesystem/hadoop-ozone/integration-test/org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.txt
> ./2020/04/24/822/it-filesystem/hadoop-ozone/integration-test/TEST-org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.xml
> ./2020/04/24/822/it-filesystem/output.log
> ./2020/04/27/830/it-filesystem/hadoop-ozone/integration-test/org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.txt
> ./2020/04/27/830/it-filesystem/hadoop-ozone/integration-test/TEST-org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.xml
> ./2020/04/27/830/it-filesystem/output.log
> ./2020/04/28/831/it-filesystem/hadoop-ozone/integration-test/org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.txt
> ./2020/04/28/831/it-filesystem/hadoop-ozone/integration-test/TEST-org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.xml
> ./2020/04/28/831/it-filesystem/output.log
> ./2020/04/28/833/it-filesystem/hadoop-ozone/integration-test/org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.txt
> ./2020/04/28/833/it-filesystem/hadoop-ozone/integration-test/TEST-org.apache.hadoop.fs.ozone.TestOzoneFileInterfaces.xml
> ./2020/04/28/833/it-filesystem/output.log
> {code}
> I am disabling it until the fix
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3762) Intermittent failure in TestDeleteWithSlowFollower
[
https://issues.apache.org/jira/browse/HDDS-3762?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3762:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in TestDeleteWithSlowFollower
> --
>
> Key: HDDS-3762
> URL: https://issues.apache.org/jira/browse/HDDS-3762
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.6.0
>Reporter: Attila Doroszlai
>Priority: Major
>
> TestDeleteWithSlowFollower failed soon after it was re-enabled in HDDS-3330.
> {code:title=https://github.com/apache/hadoop-ozone/runs/753363338}
> [INFO] Running org.apache.hadoop.ozone.client.rpc.TestDeleteWithSlowFollower
> [ERROR] Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed:
> 28.647 s <<< FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestDeleteWithSlowFollower
> [ERROR]
> testDeleteKeyWithSlowFollower(org.apache.hadoop.ozone.client.rpc.TestDeleteWithSlowFollower)
> Time elapsed: 0.163 s <<< FAILURE!
> java.lang.AssertionError
> ...
> at org.junit.Assert.assertNotNull(Assert.java:631)
> at
> org.apache.hadoop.ozone.client.rpc.TestDeleteWithSlowFollower.testDeleteKeyWithSlowFollower(TestDeleteWithSlowFollower.java:225)
> {code}
> CC [~shashikant] [~elek]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3516) Intermittent failure in TestReadRetries
[
https://issues.apache.org/jira/browse/HDDS-3516?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3516:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in TestReadRetries
> ---
>
> Key: HDDS-3516
> URL: https://issues.apache.org/jira/browse/HDDS-3516
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
> Labels: TriagePending, flaky-test, ozone-flaky-test
>
> {code:title=https://github.com/apache/hadoop-ozone/runs/626422906}
> ---
> Test set: org.apache.hadoop.ozone.client.rpc.TestReadRetries
> ---
> Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 56.35 s <<<
> FAILURE! - in org.apache.hadoop.ozone.client.rpc.TestReadRetries
> testPutKeyAndGetKeyThreeNodes(org.apache.hadoop.ozone.client.rpc.TestReadRetries)
> Time elapsed: 10.265 s <<< FAILURE!
> java.lang.AssertionError
> ...
> at
> org.apache.hadoop.ozone.client.rpc.TestReadRetries.testPutKeyAndGetKeyThreeNodes(TestReadRetries.java:181)
> {code}
> https://github.com/elek/ozone-build-results/tree/master/2020/04/28/836/it-client
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2767) security/SecuringTDE.md
[ https://issues.apache.org/jira/browse/HDDS-2767?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-2767: - Labels: pull-request-available (was: ) > security/SecuringTDE.md > --- > > Key: HDDS-2767 > URL: https://issues.apache.org/jira/browse/HDDS-2767 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task >Reporter: Xiang Zhang >Assignee: Xiang Zhang >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] iamabug opened a new pull request #1184: HDDS-2767. security/SecuringTDE.md
iamabug opened a new pull request #1184: URL: https://github.com/apache/hadoop-ozone/pull/1184 ## What changes were proposed in this pull request? translation to https://hadoop.apache.org/ozone/docs/0.5.0-beta/security/securingtde.html ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-2767 ## How was this patch tested? hugo server This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3874) ITestRootedOzoneContract tests are flaky
[
https://issues.apache.org/jira/browse/HDDS-3874?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3874:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> ITestRootedOzoneContract tests are flaky
>
>
> Key: HDDS-3874
> URL: https://issues.apache.org/jira/browse/HDDS-3874
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
>Reporter: Marton Elek
>Assignee: Siyao Meng
>Priority: Blocker
>
> Different tests are failed with similar reasons:
> {code}
> java.lang.Exception: test timed out after 18 milliseconds
> at sun.misc.Unsafe.park(Native Method)
> at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
> at
> java.util.concurrent.CompletableFuture$Signaller.block(CompletableFuture.java:1707)
> at
> java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3323)
> at
> java.util.concurrent.CompletableFuture.waitingGet(CompletableFuture.java:1742)
> at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
> at
> org.apache.hadoop.hdds.scm.storage.BlockOutputStream.waitOnFlushFutures(BlockOutputStream.java:537)
> at
> org.apache.hadoop.hdds.scm.storage.BlockOutputStream.handleFlush(BlockOutputStream.java:499)
> at
> org.apache.hadoop.hdds.scm.storage.BlockOutputStream.close(BlockOutputStream.java:514)
> at
> org.apache.hadoop.ozone.client.io.BlockOutputStreamEntry.close(BlockOutputStreamEntry.java:149)
> at
> org.apache.hadoop.ozone.client.io.KeyOutputStream.handleStreamAction(KeyOutputStream.java:483)
> at
> org.apache.hadoop.ozone.client.io.KeyOutputStream.handleFlushOrClose(KeyOutputStream.java:457)
> at
> org.apache.hadoop.ozone.client.io.KeyOutputStream.close(KeyOutputStream.java:510)
> at
> org.apache.hadoop.fs.ozone.OzoneFSOutputStream.close(OzoneFSOutputStream.java:56)
> at
> org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
> at
> org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:101)
> at
> org.apache.hadoop.fs.contract.ContractTestUtils.createFile(ContractTestUtils.java:638)
> at
> org.apache.hadoop.fs.contract.AbstractContractOpenTest.testOpenFileTwice(AbstractContractOpenTest.java:135)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:55)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
> Example:
> https://github.com/elek/ozone-build-results/blob/master/2020/06/16/1051/it-filesystem-contract/hadoop-ozone/integration-test/org.apache.hadoop.fs.ozone.contract.rooted.ITestRootedOzoneContractOpen.txt
> But same problem here:
> https://github.com/elek/hadoop-ozone/runs/810175295?check_suite_focus=true
> (contract)
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3873) Intermittent failure in Recon acceptance test due to too many pipelines
[
https://issues.apache.org/jira/browse/HDDS-3873?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3873:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Intermittent failure in Recon acceptance test due to too many pipelines
> ---
>
> Key: HDDS-3873
> URL: https://issues.apache.org/jira/browse/HDDS-3873
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Reporter: Attila Doroszlai
>Assignee: Attila Doroszlai
>Priority: Minor
>
> Recon API acceptance test has too strict check on number of pipelines:
> {code}
> Check if Recon picks up DN heartbeats | FAIL |
> ...
> {"pipelines":5,...' does not contain '"pipelines":4'
> {code}
> https://github.com/apache/hadoop-ozone/pull/1050/checks?check_run_id=810139657
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3938) Flaky TestWatchForCommit#test2WayCommitForTimeoutException
[
https://issues.apache.org/jira/browse/HDDS-3938?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3938:
-
Parent: HDDS-1127
Issue Type: Sub-task (was: Bug)
> Flaky TestWatchForCommit#test2WayCommitForTimeoutException
> --
>
> Key: HDDS-3938
> URL: https://issues.apache.org/jira/browse/HDDS-3938
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.6.0
>Reporter: Siyao Meng
>Priority: Major
>
> In PR#1255
> https://github.com/apache/hadoop-ozone/runs/813994346?check_suite_focus=true:
> {code:title=https://github.com/elek/ozone-build-results/blob/master/2020/06/27/1255/it-client/hadoop-ozone/integration-test/org.apache.hadoop.ozone.client.rpc.TestWatchForCommit-output.txt}
> java.util.concurrent.ExecutionException:
> org.apache.ratis.protocol.GroupMismatchException:
> a498c7dc-27d9-4ae8-a233-895baee1c3ae: group-C4714E1CC0B9 not found.
> at
> java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
> at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
> at
> org.apache.hadoop.hdds.scm.XceiverClientRatis.watchForCommit(XceiverClientRatis.java:262)
> at
> org.apache.hadoop.ozone.client.rpc.TestWatchForCommit.testWatchForCommitForGroupMismatchException(TestWatchForCommit.java:351)
> {code}
> In PR#1459
> https://github.com/apache/hadoop-ozone/runs/844177861?check_suite_focus=true:
> {code:title=https://github.com/elek/ozone-build-results/blob/master/2020/07/07/1459/it-client/hadoop-ozone/integration-test/org.apache.hadoop.ozone.client.rpc.TestWatchForCommit-output.txt}
> java.util.concurrent.ExecutionException:
> org.apache.ratis.protocol.GroupMismatchException:
> a7b8b74b-f98f-42e2-9f4c-7068bd51e221: group-DCED9E4CDB5B not found.
> at
> java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
> at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
> at
> org.apache.hadoop.hdds.scm.XceiverClientRatis.watchForCommit(XceiverClientRatis.java:262)
> at
> org.apache.hadoop.ozone.client.rpc.TestWatchForCommit.testWatchForCommitForGroupMismatchException(TestWatchForCommit.java:348)
> {code}
> And there are two more instances that can be found in
> https://elek.github.io/ozone-build-results/.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3938) Flaky TestWatchForCommit#test2WayCommitForTimeoutException
[
https://issues.apache.org/jira/browse/HDDS-3938?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen updated HDDS-3938:
-
Labels: 0.7.0 (was: )
> Flaky TestWatchForCommit#test2WayCommitForTimeoutException
> --
>
> Key: HDDS-3938
> URL: https://issues.apache.org/jira/browse/HDDS-3938
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: test
>Affects Versions: 0.6.0
>Reporter: Siyao Meng
>Priority: Major
> Labels: 0.7.0
>
> In PR#1255
> https://github.com/apache/hadoop-ozone/runs/813994346?check_suite_focus=true:
> {code:title=https://github.com/elek/ozone-build-results/blob/master/2020/06/27/1255/it-client/hadoop-ozone/integration-test/org.apache.hadoop.ozone.client.rpc.TestWatchForCommit-output.txt}
> java.util.concurrent.ExecutionException:
> org.apache.ratis.protocol.GroupMismatchException:
> a498c7dc-27d9-4ae8-a233-895baee1c3ae: group-C4714E1CC0B9 not found.
> at
> java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
> at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
> at
> org.apache.hadoop.hdds.scm.XceiverClientRatis.watchForCommit(XceiverClientRatis.java:262)
> at
> org.apache.hadoop.ozone.client.rpc.TestWatchForCommit.testWatchForCommitForGroupMismatchException(TestWatchForCommit.java:351)
> {code}
> In PR#1459
> https://github.com/apache/hadoop-ozone/runs/844177861?check_suite_focus=true:
> {code:title=https://github.com/elek/ozone-build-results/blob/master/2020/07/07/1459/it-client/hadoop-ozone/integration-test/org.apache.hadoop.ozone.client.rpc.TestWatchForCommit-output.txt}
> java.util.concurrent.ExecutionException:
> org.apache.ratis.protocol.GroupMismatchException:
> a7b8b74b-f98f-42e2-9f4c-7068bd51e221: group-DCED9E4CDB5B not found.
> at
> java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
> at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
> at
> org.apache.hadoop.hdds.scm.XceiverClientRatis.watchForCommit(XceiverClientRatis.java:262)
> at
> org.apache.hadoop.ozone.client.rpc.TestWatchForCommit.testWatchForCommitForGroupMismatchException(TestWatchForCommit.java:348)
> {code}
> And there are two more instances that can be found in
> https://elek.github.io/ozone-build-results/.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3949) Flaky test cases
[ https://issues.apache.org/jira/browse/HDDS-3949?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen resolved HDDS-3949. -- Resolution: Duplicate > Flaky test cases > > > Key: HDDS-3949 > URL: https://issues.apache.org/jira/browse/HDDS-3949 > Project: Hadoop Distributed Data Store > Issue Type: New Feature >Reporter: Sammi Chen >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3949) Flaky test cases
Sammi Chen created HDDS-3949: Summary: Flaky test cases Key: HDDS-3949 URL: https://issues.apache.org/jira/browse/HDDS-3949 Project: Hadoop Distributed Data Store Issue Type: New Feature Reporter: Sammi Chen -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3912) Change SCM ContainerDB key to proto structure to support backward compatibility.
[
https://issues.apache.org/jira/browse/HDDS-3912?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17155061#comment-17155061
]
Sammi Chen commented on HDDS-3912:
--
Hi [~pifta] and [~avijayan], do we need to put this into 0.6.0 to fix the
compatibility issue ASAP?
> Change SCM ContainerDB key to proto structure to support backward
> compatibility.
>
>
> Key: HDDS-3912
> URL: https://issues.apache.org/jira/browse/HDDS-3912
> Project: Hadoop Distributed Data Store
> Issue Type: Task
>Reporter: Aravindan Vijayan
>Assignee: Istvan Fajth
>Priority: Major
>
> Currently, the 'key' type of the SCM container DB is
> org.apache.hadoop.hdds.scm.container.ContainerID which is not backed up by a
> proto equivalent. Hence, we use a long codec to serialize and deserialize the
> key from long to byte[ ] and back.
> {code}
> public static final DBColumnFamilyDefinition
> CONTAINERS =
> new DBColumnFamilyDefinition(
> "containers",
> ContainerID.class,
> new ContainerIDCodec(),
> ContainerInfo.class,
> new ContainerInfoCodec());
> {code}
> In the future if we have to support a container id type that is more than
> just a long, then changing the ContainerID class will break backward
> compatibility. To handle this incompatibility in the future, we have to
> either migrate old data or provide fallback conversion codecs for the old
> data type. Hence, it is good to wrap this long into a proto structure.
> cc [~nanda619] / [~arp].
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3916) Change the return type in DeleteKeys and renameKeys in om client side.
[ https://issues.apache.org/jira/browse/HDDS-3916?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17155059#comment-17155059 ] Sammi Chen commented on HDDS-3916: -- Hi [~micahzhao],will this break the API level backword compatibility? > Change the return type in DeleteKeys and renameKeys in om client side. > -- > > Key: HDDS-3916 > URL: https://issues.apache.org/jira/browse/HDDS-3916 > Project: Hadoop Distributed Data Store > Issue Type: Improvement > Components: Ozone Manager >Reporter: mingchao zhao >Priority: Major > > Currently all delete and rename operations in OzoneBucket.java are void. > We had putted the List of unDeletedKeys and unRenamedKeys into Response. We > also need to change the return type in client side。Make sure the user can get > collection of keys for unsuccessful operations. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3933) Fix memory leak because of too many Datanode State Machine Thread
[ https://issues.apache.org/jira/browse/HDDS-3933?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] runzhiwang updated HDDS-3933: - Summary: Fix memory leak because of too many Datanode State Machine Thread (was: memory leak because of too many Datanode State Machine Thread) > Fix memory leak because of too many Datanode State Machine Thread > - > > Key: HDDS-3933 > URL: https://issues.apache.org/jira/browse/HDDS-3933 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > Attachments: jstack.txt, screenshot-1.png, screenshot-2.png, > screenshot-3.png > > > When create 22345th Datanode State Machine Thread, OOM happened. > !screenshot-1.png! > !screenshot-2.png! > !screenshot-3.png! -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1162: HDDS-3921. IllegalArgumentException triggered in SCMContainerPlacemen…
ChenSammi commented on pull request #1162: URL: https://github.com/apache/hadoop-ozone/pull/1162#issuecomment-656443918 testDeleteKeyWithSlowFollower failed at leader membership check step. The test passed locally. It seems a timing issue, not relevant to this patch. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r452573445
##
File path: hadoop-hdds/interface-client/src/main/proto/proto.lock
##
@@ -1476,6 +1476,21 @@
}
],
"messages": [
+ {
Review comment:
Integration test failure seems unrelated to the changes here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r452573311
##
File path: hadoop-hdds/interface-client/src/main/proto/proto.lock
##
@@ -1476,6 +1476,21 @@
}
],
"messages": [
+ {
Review comment:
It was auto generated. I did not modify anything here in this file.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] iamabug commented on a change in pull request #1175: HDDS-2766. security/SecuringDataNodes.md
iamabug commented on a change in pull request #1175: URL: https://github.com/apache/hadoop-ozone/pull/1175#discussion_r452569796 ## File path: hadoop-hdds/docs/content/security/SecuringDatanodes.zh.md ## @@ -0,0 +1,53 @@ +--- +title: "安全化 Datanode" +date: "2019-April-03" +weight: 2 +summary: 解释安全化 datanode 的不同模式,包括 Kerberos、证书的手动颁发和自动颁发等。 +icon: th +--- + + + +过去,Hadoop 中 datanode 的安全机制是通过在节点上创建 Keytab 文件实现的,而 Ozone 改用 datanode 证书,在安全的 Ozone 集群中,datanode 不再需要 Kerberos。 + +但是我们也支持传统的基于 Kerberos 的认证来方便现有用户,用户只需要在 hdfs-site.xml 里配置下面参数即可: + +参数名|描述 +|-- +dfs.datanode.kerberos.principal| datanode 的服务主体名 比如:dn/_h...@realm.com +dfs.datanode.keytab.file| datanode 进程所使用的 keytab 文件 +hdds.datanode.http.kerberos.principal| datanode http 服务器的服务主体名 Review comment: Thanks for the link and commit. @smengcl This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452561831
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeysDeleteRequest.java
##
@@ -116,93 +111,116 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OMResponse.Builder omResponse = OmResponseUtil.getOMResponseBuilder(
getOmRequest());
OMMetadataManager omMetadataManager = ozoneManager.getMetadataManager();
+
+// As right now, only client exposed API is for a single volume and
+// bucket. So, all entries will have same volume name and bucket name.
+// So, we can validate once.
+if (deleteKeyArgsList.size() > 0) {
+ volumeName = deleteKeyArgsList.get(0).getVolumeName();
+ bucketName = deleteKeyArgsList.get(0).getBucketName();
+}
+
+boolean acquiredLock =
+omMetadataManager.getLock().acquireWriteLock(BUCKET_LOCK, volumeName,
+bucketName);
+
+int indexFailed = 0;
try {
- for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
+
+ // Validate bucket and volume exists or not.
+ if (deleteKeyArgsList.size() > 0) {
+validateBucketAndVolume(omMetadataManager, volumeName, bucketName);
+ }
+
+
+ // Check if any of the key in the batch cannot be deleted. If exists the
+ // batch delete will be failed.
+
+ for (indexFailed = 0; indexFailed < deleteKeyArgsList.size();
+ indexFailed++) {
+KeyArgs deleteKeyArgs = deleteKeyArgsList.get(indexFailed);
+auditMap = buildKeyArgsAuditMap(deleteKeyArgs);
volumeName = deleteKeyArgs.getVolumeName();
bucketName = deleteKeyArgs.getBucketName();
keyName = deleteKeyArgs.getKeyName();
String objectKey = omMetadataManager.getOzoneKey(volumeName,
bucketName,
keyName);
OmKeyInfo omKeyInfo = omMetadataManager.getKeyTable().get(objectKey);
-omKeyInfoList.add(omKeyInfo);
-unDeletedKeys.add(omKeyInfo);
- }
- // Check if any of the key in the batch cannot be deleted. If exists the
- // batch will delete failed.
- for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
-volumeName = deleteKeyArgs.getVolumeName();
-bucketName = deleteKeyArgs.getBucketName();
-keyName = deleteKeyArgs.getKeyName();
-auditMap = buildKeyArgsAuditMap(deleteKeyArgs);
+
+// Do we need to fail the batch if one of the key does not exist?
+// For now following the previous code behavior. If this code changes
+// behavior, this will be incompatible change across upgrades, and we
+// need to version the Requests and do logic accordingly.
+
+if (omKeyInfo == null) {
+ LOG.error("Key does not exist {}", objectKey);
+ throw new OMException("Key Not Found " + objectKey, KEY_NOT_FOUND);
+}
+
// check Acl
checkKeyAcls(ozoneManager, volumeName, bucketName, keyName,
Review comment:
Done
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/response/key/OMKeysDeleteResponse.java
##
@@ -69,65 +64,36 @@ public OMKeysDeleteResponse(@Nonnull OMResponse omResponse)
{
public void addToDBBatch(OMMetadataManager omMetadataManager,
BatchOperation batchOperation) throws IOException {
+String volumeName = "";
+String bucketName = "";
+String keyName = "";
for (OmKeyInfo omKeyInfo : omKeyInfoList) {
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452561712
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeysDeleteRequest.java
##
@@ -116,89 +111,112 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OMResponse.Builder omResponse = OmResponseUtil.getOMResponseBuilder(
getOmRequest());
OMMetadataManager omMetadataManager = ozoneManager.getMetadataManager();
+
+// As right now, only client exposed API is for a single volume and
+// bucket. So, all entries will have same volume name and bucket name.
+// So, we can validate once.
+if (deleteKeyArgsList.size() > 0) {
+ volumeName = deleteKeyArgsList.get(0).getVolumeName();
+ bucketName = deleteKeyArgsList.get(0).getBucketName();
+}
+
+boolean acquiredLock =
+omMetadataManager.getLock().acquireWriteLock(BUCKET_LOCK, volumeName,
+bucketName);
+
+int indexFailed = 0;
try {
- for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
+
+ // Validate bucket and volume exists or not.
+ if (deleteKeyArgsList.size() > 0) {
+validateBucketAndVolume(omMetadataManager, volumeName, bucketName);
+ }
+
+
+ // Check if any of the key in the batch cannot be deleted. If exists the
+ // batch delete will be failed.
+
+ for (indexFailed = 0; indexFailed < deleteKeyArgsList.size();
+ indexFailed++) {
+KeyArgs deleteKeyArgs = deleteKeyArgsList.get(0);
+auditMap = buildKeyArgsAuditMap(deleteKeyArgs);
volumeName = deleteKeyArgs.getVolumeName();
bucketName = deleteKeyArgs.getBucketName();
keyName = deleteKeyArgs.getKeyName();
String objectKey = omMetadataManager.getOzoneKey(volumeName,
bucketName,
keyName);
OmKeyInfo omKeyInfo = omMetadataManager.getKeyTable().get(objectKey);
-omKeyInfoList.add(omKeyInfo);
-unDeletedKeys.add(omKeyInfo);
- }
- // Check if any of the key in the batch cannot be deleted. If exists the
- // batch will delete failed.
- for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
-volumeName = deleteKeyArgs.getVolumeName();
-bucketName = deleteKeyArgs.getBucketName();
-keyName = deleteKeyArgs.getKeyName();
-auditMap = buildKeyArgsAuditMap(deleteKeyArgs);
+
+// Do we need to fail the batch if one of the key does not exist?
+// For now following the previous code behavior. If this code changes
+// behavior, this will be incompatible change across upgrades, and we
+// need to version the Requests and do logic accordingly.
+
+if (omKeyInfo == null) {
+ LOG.error("Key does not exist {}", objectKey);
+ throw new OMException("Key Not Found " + objectKey, KEY_NOT_FOUND);
+}
+
// check Acl
checkKeyAcls(ozoneManager, volumeName, bucketName, keyName,
IAccessAuthorizer.ACLType.DELETE, OzoneObj.ResourceType.KEY);
-String objectKey = omMetadataManager.getOzoneKey(
-volumeName, bucketName, keyName);
-
-// Validate bucket and volume exists or not.
-validateBucketAndVolume(omMetadataManager, volumeName, bucketName);
-
-OmKeyInfo omKeyInfo = omMetadataManager.getKeyTable().get(objectKey);
+omKeyInfoList.add(omKeyInfo);
+ }
-if (omKeyInfo == null) {
- throw new OMException("Key not found: " + keyName, KEY_NOT_FOUND);
-}
-// Check if this transaction is a replay of ratis logs.
-if (isReplay(ozoneManager, omKeyInfo, trxnLogIndex)) {
- // Replay implies the response has already been returned to
- // the client. So take no further action and return a dummy
- // OMClientResponse.
- throw new OMReplayException();
-}
+ // Mark all keys in cache as deleted.
+ for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
+volumeName = deleteKeyArgs.getVolumeName();
+bucketName = deleteKeyArgs.getBucketName();
+keyName = deleteKeyArgs.getKeyName();
+omMetadataManager.getKeyTable().addCacheEntry(
+new CacheKey<>(omMetadataManager.getOzoneKey(volumeName,
bucketName,
+keyName)),
+new CacheValue<>(Optional.absent(), trxnLogIndex));
}
+
omClientResponse = new OMKeysDeleteResponse(omResponse
- .setDeleteKeysResponse(DeleteKeysResponse.newBuilder()).build(),
- omKeyInfoList, trxnLogIndex, ozoneManager.isRatisEnabled());
+ .setDeleteKeysResponse(DeleteKeysResponse.newBuilder()
+ .setStatus(true)).build(), omKeyInfoList, trxnLogIndex,
+ ozoneManager.isRatisEnabled());
result = Result.SUCCESS;
+
} catch (IOException ex) {
- if (ex instanceof OMReplayException) {
-
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452561797
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeysDeleteRequest.java
##
@@ -116,93 +111,116 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OMResponse.Builder omResponse = OmResponseUtil.getOMResponseBuilder(
getOmRequest());
OMMetadataManager omMetadataManager = ozoneManager.getMetadataManager();
+
+// As right now, only client exposed API is for a single volume and
+// bucket. So, all entries will have same volume name and bucket name.
+// So, we can validate once.
+if (deleteKeyArgsList.size() > 0) {
+ volumeName = deleteKeyArgsList.get(0).getVolumeName();
+ bucketName = deleteKeyArgsList.get(0).getBucketName();
+}
+
+boolean acquiredLock =
+omMetadataManager.getLock().acquireWriteLock(BUCKET_LOCK, volumeName,
+bucketName);
+
+int indexFailed = 0;
try {
- for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
+
+ // Validate bucket and volume exists or not.
+ if (deleteKeyArgsList.size() > 0) {
+validateBucketAndVolume(omMetadataManager, volumeName, bucketName);
+ }
+
+
+ // Check if any of the key in the batch cannot be deleted. If exists the
+ // batch delete will be failed.
+
+ for (indexFailed = 0; indexFailed < deleteKeyArgsList.size();
+ indexFailed++) {
+KeyArgs deleteKeyArgs = deleteKeyArgsList.get(indexFailed);
+auditMap = buildKeyArgsAuditMap(deleteKeyArgs);
volumeName = deleteKeyArgs.getVolumeName();
bucketName = deleteKeyArgs.getBucketName();
keyName = deleteKeyArgs.getKeyName();
String objectKey = omMetadataManager.getOzoneKey(volumeName,
bucketName,
keyName);
OmKeyInfo omKeyInfo = omMetadataManager.getKeyTable().get(objectKey);
-omKeyInfoList.add(omKeyInfo);
-unDeletedKeys.add(omKeyInfo);
- }
- // Check if any of the key in the batch cannot be deleted. If exists the
- // batch will delete failed.
- for (KeyArgs deleteKeyArgs : deleteKeyArgsList) {
-volumeName = deleteKeyArgs.getVolumeName();
-bucketName = deleteKeyArgs.getBucketName();
-keyName = deleteKeyArgs.getKeyName();
-auditMap = buildKeyArgsAuditMap(deleteKeyArgs);
+
+// Do we need to fail the batch if one of the key does not exist?
+// For now following the previous code behavior. If this code changes
+// behavior, this will be incompatible change across upgrades, and we
+// need to version the Requests and do logic accordingly.
+
+if (omKeyInfo == null) {
Review comment:
Done. For now, made it simple returning unDeletedKeys.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3948) Release/reacquire lock for OMKeysDeleteRequest
Bharat Viswanadham created HDDS-3948: Summary: Release/reacquire lock for OMKeysDeleteRequest Key: HDDS-3948 URL: https://issues.apache.org/jira/browse/HDDS-3948 Project: Hadoop Distributed Data Store Issue Type: Bug Reporter: Bharat Viswanadham This is created based on the comment from @xiaoyu during review of PR #1169 https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452474846 Also holding the bucket lock once for all may not be a good idea to large delete as that will prevent other clients operation on the same bucket. grab and release individual or in small batches give other clients opportunities to access buckets. This might be helpful for non-HA without ratis enabled. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452560417
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -867,10 +867,10 @@ message DeletedKeys {
}
message DeleteKeysResponse {
-repeated KeyInfo deletedKeys = 1;
-repeated KeyInfo unDeletedKeys = 2;
Review comment:
Created https://issues.apache.org/jira/browse/HDDS-3948 for this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1169: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on a change in pull request #1169:
URL: https://github.com/apache/hadoop-ozone/pull/1169#discussion_r452559759
##
File path: hadoop-ozone/interface-client/src/main/proto/OmClientProtocol.proto
##
@@ -867,10 +867,10 @@ message DeletedKeys {
}
message DeleteKeysResponse {
-repeated KeyInfo deletedKeys = 1;
-repeated KeyInfo unDeletedKeys = 2;
Review comment:
As in HA, and when ratis is enabled as default for non-HA, it is a
single thread executor now. So, this optimization is not really required. For
non-HA, it might help, I will open a new Jira for this improvement.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3944) OM StateMachine unpause fails with NPE
[
https://issues.apache.org/jira/browse/HDDS-3944?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bharat Viswanadham resolved HDDS-3944.
--
Fix Version/s: 0.6.0
Resolution: Fixed
> OM StateMachine unpause fails with NPE
> --
>
> Key: HDDS-3944
> URL: https://issues.apache.org/jira/browse/HDDS-3944
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: OM HA
>Affects Versions: 0.6.0
>Reporter: Attila Doroszlai
>Assignee: Attila Doroszlai
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 0.6.0
>
>
> Noticed this NPE in OM logs for OM HA [acceptance
> test|https://github.com/apache/hadoop-ozone/pull/1173/checks?check_run_id=847204159]:
> {code}
> 2020-07-07 20:54:23 WARN RaftServerImpl:1247 - om2@group-D66704EFC61C:
> Failed to notify StateMachine to InstallSnapshot. Exception:
> java.lang.NullPointerException: When ratis is enabled indexToTerm should not
> be null
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on pull request #1183: HDDS-3944. OM StateMachine unpause fails with NPE
bharatviswa504 commented on pull request #1183: URL: https://github.com/apache/hadoop-ozone/pull/1183#issuecomment-656398721 Thank You @adoroszlai for the contribution and @hanishakoneru for the review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org