[jira] [Updated] (HDDS-3957) Fix mixed use of Longs.toByteArray and Ints.fromByteArray
[ https://issues.apache.org/jira/browse/HDDS-3957?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-3957: - Labels: pull-request-available (was: ) > Fix mixed use of Longs.toByteArray and Ints.fromByteArray > - > > Key: HDDS-3957 > URL: https://issues.apache.org/jira/browse/HDDS-3957 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang opened a new pull request #1199: HDDS-3957. Fix mixed use of Longs.toByteArray and Ints.fromByteArray
runzhiwang opened a new pull request #1199: URL: https://github.com/apache/hadoop-ozone/pull/1199 ## What changes were proposed in this pull request? **What's the problem ?** When write `DB_PENDING_DELETE_BLOCK_COUNT_KEY` to rocksdb, most code convert value to byte array by Longs.toByteArray. But when read, `parseKVContainerData` use Ints.fromByteArray. The result is always wrong, unless the value is zero. 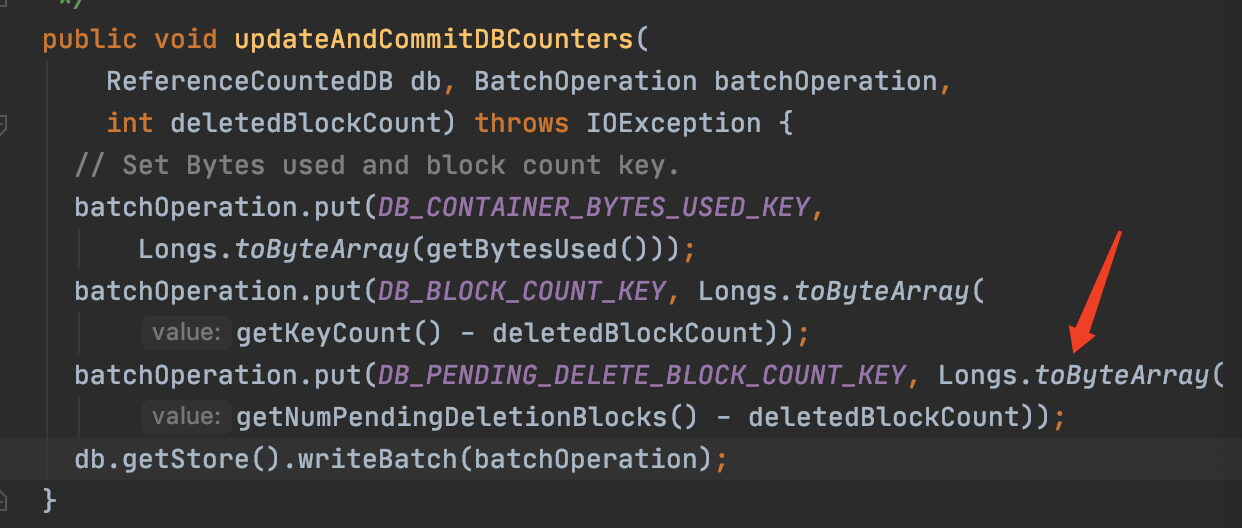 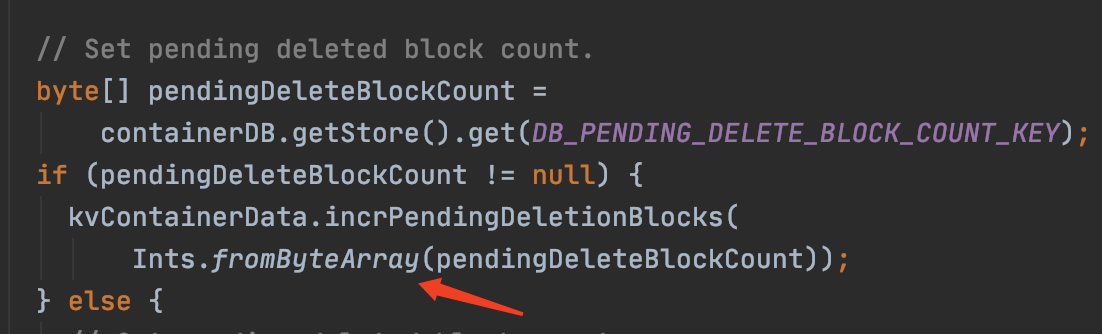 For example, Longs.toByteArray(1) return byte array in which only byte[7] is 1, but Ints.fromByteArray only parse the first 4 bytes of byte array. So write 1, but read out 0. 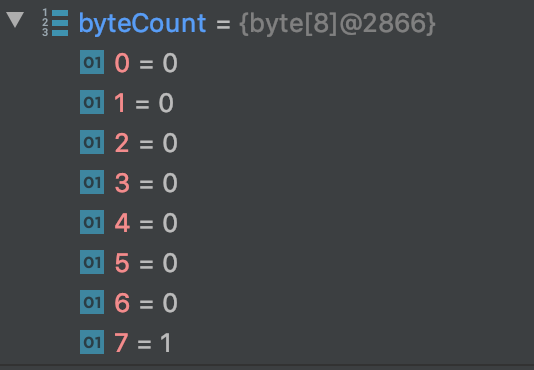 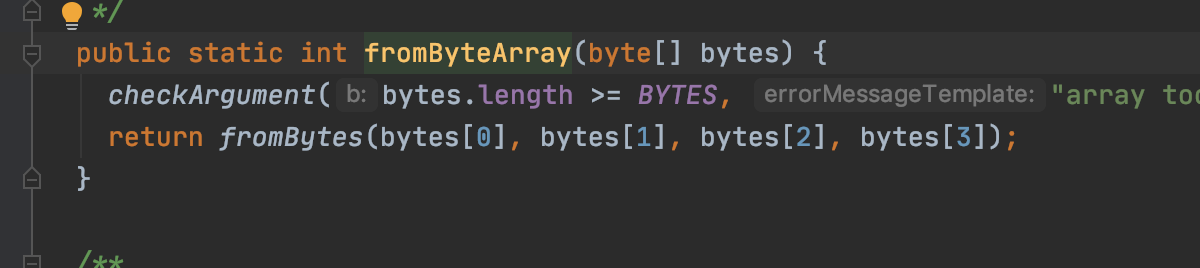 ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3957 ## How was this patch tested? add assert in current ut. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3957) Fix mixed use of Longs.toByteArray and Ints.fromByteArray
[ https://issues.apache.org/jira/browse/HDDS-3957?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] runzhiwang updated HDDS-3957: - Summary: Fix mixed use of Longs.toByteArray and Ints.fromByteArray (was: Fix error use Longs.toByteArray and Ints.fromByteArray of DB_PENDING_DELETE_BLOCK_COUNT_KEY) > Fix mixed use of Longs.toByteArray and Ints.fromByteArray > - > > Key: HDDS-3957 > URL: https://issues.apache.org/jira/browse/HDDS-3957 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454107185
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
+ByteBuffer.allocate(4096);
+result.order(ByteOrder.BIG_ENDIAN);
+try {
+ result.putLong(getIssueDate());
+ result.putInt(getMasterKeyId());
+ result.putInt(getSequenceNumber());
+
+ result.putLong(getMaxDate());
+
+ result.putInt(getOwner().toString().length());
+ result.put(getOwner().toString().getBytes(StandardCharsets.UTF_8));
+
+ result.putInt(getRealUser().toString().length());
+ result.put(getRealUser().toString().getBytes(StandardCharsets.UTF_8));
+
+ result.putInt(getRenewer().toString().length());
+ result.put(getRenewer().toString().getBytes(StandardCharsets.UTF_8));
+
+ result.putInt(getTokenType().getNumber());
+ // Set s3 specific fields.
+ if (getTokenType().equals(S3AUTHINFO)) {
+result.putInt(getAwsAccessId().length());
+result.put(getAwsAccessId().getBytes(StandardCharsets.UTF_8));
+
+result.putInt(getSignature().length());
+result.put(getSignature().getBytes(StandardCharsets.UTF_8));
+
+result.putInt(getStrToSign().length());
+result.put(getStrToSign().getBytes(StandardCharsets.UTF_8));
+ } else {
+result.putInt(getOmCertSerialId().length());
+result.put(getOmCertSerialId().getBytes(StandardCharsets.UTF_8));
+if (getOmServiceId() != null) {
+ result.putInt(getOmServiceId().length());
+ result.put(getOmServiceId().getBytes(StandardCharsets.UTF_8));
+} else {
+ result.putInt(0);
+}
+ }
+} catch (IndexOutOfBoundsException e) {
+ throw new IllegalArgumentException(
+ "Can't encode the the raw data ", e);
+}
+return result.array();
+ }
+
+ /** Instead of relying on proto deserialization, this
+ * provides explicit deserialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public static OzoneTokenIdentifier fromUniqueSerializedKey(byte[] rawData) {
+OzoneTokenIdentifier result = newInstance();
Review comment:
Earlier I wanted to do explicit serialization, but your suggestion looks
simpler. I will try this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454106901
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
Review comment:
I wanted to do explicit serialization. But this also looks safe
serialization.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454107032
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
+ByteBuffer.allocate(4096);
+result.order(ByteOrder.BIG_ENDIAN);
+try {
+ result.putLong(getIssueDate());
+ result.putInt(getMasterKeyId());
+ result.putInt(getSequenceNumber());
+
+ result.putLong(getMaxDate());
+
+ result.putInt(getOwner().toString().length());
Review comment:
this will change after I use super.write()
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454106592
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
Review comment:
didn't try this. This looks simpler. Let me try this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] rakeshadr commented on pull request #1164: HDDS-3824: OM read requests should make SCM#refreshPipeline outside BUCKET_LOCK
rakeshadr commented on pull request #1164: URL: https://github.com/apache/hadoop-ozone/pull/1164#issuecomment-657969627 Thanks @xiaoyuyao for the comments. I have updated PR, kindly review it again. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] rakeshadr commented on a change in pull request #1164: HDDS-3824: OM read requests should make SCM#refreshPipeline outside BUCKET_LOCK
rakeshadr commented on a change in pull request #1164:
URL: https://github.com/apache/hadoop-ozone/pull/1164#discussion_r454104113
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/KeyManagerImpl.java
##
@@ -1877,26 +1897,18 @@ public OmKeyInfo lookupFile(OmKeyArgs args, String
clientAddress)
String volumeName = args.getVolumeName();
String bucketName = args.getBucketName();
String keyName = args.getKeyName();
-
-metadataManager.getLock().acquireReadLock(BUCKET_LOCK, volumeName,
-bucketName);
-try {
- OzoneFileStatus fileStatus = getFileStatus(args);
- if (fileStatus.isFile()) {
-if (args.getRefreshPipeline()) {
- refreshPipeline(fileStatus.getKeyInfo());
-}
-if (args.getSortDatanodes()) {
- sortDatanodeInPipeline(fileStatus.getKeyInfo(), clientAddress);
-}
-return fileStatus.getKeyInfo();
- }
+OzoneFileStatus fileStatus = getOzoneFileStatus(volumeName, bucketName,
+keyName, false);
//if key is not of type file or if key is not found we throw an exception
-} finally {
- metadataManager.getLock().releaseReadLock(BUCKET_LOCK, volumeName,
- bucketName);
+if (fileStatus != null && fileStatus.isFile()) {
+ if (args.getRefreshPipeline()) {
+refreshPipeline(fileStatus.getKeyInfo());
+ }
+ if (args.getSortDatanodes()) {
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] rakeshadr commented on a change in pull request #1164: HDDS-3824: OM read requests should make SCM#refreshPipeline outside BUCKET_LOCK
rakeshadr commented on a change in pull request #1164:
URL: https://github.com/apache/hadoop-ozone/pull/1164#discussion_r454104041
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/KeyManagerImpl.java
##
@@ -1877,26 +1897,18 @@ public OmKeyInfo lookupFile(OmKeyArgs args, String
clientAddress)
String volumeName = args.getVolumeName();
String bucketName = args.getBucketName();
String keyName = args.getKeyName();
-
-metadataManager.getLock().acquireReadLock(BUCKET_LOCK, volumeName,
-bucketName);
-try {
- OzoneFileStatus fileStatus = getFileStatus(args);
- if (fileStatus.isFile()) {
-if (args.getRefreshPipeline()) {
- refreshPipeline(fileStatus.getKeyInfo());
-}
-if (args.getSortDatanodes()) {
- sortDatanodeInPipeline(fileStatus.getKeyInfo(), clientAddress);
-}
-return fileStatus.getKeyInfo();
- }
+OzoneFileStatus fileStatus = getOzoneFileStatus(volumeName, bucketName,
+keyName, false);
//if key is not of type file or if key is not found we throw an exception
-} finally {
- metadataManager.getLock().releaseReadLock(BUCKET_LOCK, volumeName,
- bucketName);
+if (fileStatus != null && fileStatus.isFile()) {
+ if (args.getRefreshPipeline()) {
+refreshPipeline(fileStatus.getKeyInfo());
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1196: Keyput
bharatviswa504 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r454102604
##
File path:
hadoop-ozone/ozone-manager/src/test/java/org/apache/hadoop/ozone/om/request/key/TestOMKeyCreateRequest.java
##
@@ -328,6 +342,73 @@ private OMRequest createKeyRequest(boolean isMultipartKey,
int partNumber) {
.setCmdType(OzoneManagerProtocolProtos.Type.CreateKey)
.setClientId(UUID.randomUUID().toString())
.setCreateKeyRequest(createKeyRequest).build();
+ }
+
+ @Test
+ public void testKeyCreateWithIntermediateDir() throws Exception {
+
+String keyName = "a/b/c/file1";
+OMRequest omRequest = createKeyRequest(false, 0, keyName);
+
+OzoneConfiguration configuration = new OzoneConfiguration();
+configuration.setBoolean(OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY, true);
+when(ozoneManager.getConfiguration()).thenReturn(configuration);
+OMKeyCreateRequest omKeyCreateRequest = new OMKeyCreateRequest(omRequest);
+
+omRequest = omKeyCreateRequest.preExecute(ozoneManager);
+
+omKeyCreateRequest = new OMKeyCreateRequest(omRequest);
+
+// Add volume and bucket entries to DB.
+addVolumeAndBucketToDB(volumeName, bucketName,
+omMetadataManager);
+
+OMClientResponse omClientResponse =
+omKeyCreateRequest.validateAndUpdateCache(ozoneManager,
+100L, ozoneManagerDoubleBufferHelper);
+
+Assert.assertEquals(omClientResponse.getOMResponse().getStatus(), OK);
+
+Path keyPath = Paths.get(keyName);
+
+// Check intermediate paths are created
+keyPath = keyPath.getParent();
+while(keyPath != null) {
+ Assert.assertNotNull(omMetadataManager.getKeyTable().get(
Review comment:
Added test
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1196: Keyput
bharatviswa504 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r454102550
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeyCreateRequest.java
##
@@ -221,8 +233,45 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OmBucketInfo bucketInfo = omMetadataManager.getBucketTable().get(
omMetadataManager.getBucketKey(volumeName, bucketName));
+ boolean createIntermediateDir =
+ ozoneManager.getConfiguration().getBoolean(
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY,
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY_DEFAULT);
+
+ // If FILE_EXISTS we just override like how we used to do for Key Create.
+ List< OzoneAcl > inheritAcls;
+ if (createIntermediateDir) {
+OMFileRequest.OMPathInfo pathInfo =
+OMFileRequest.verifyFilesInPath(omMetadataManager, volumeName,
+bucketName, keyName, Paths.get(keyName));
+OMFileRequest.OMDirectoryResult omDirectoryResult =
+pathInfo.getDirectoryResult();
+inheritAcls = pathInfo.getAcls();
+
+// Check if a file or directory exists with same key name.
+if (omDirectoryResult == DIRECTORY_EXISTS) {
+ throw new OMException("Can not write to directory: " + keyName,
Review comment:
Done
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/om/OMConfigKeys.java
##
@@ -239,4 +239,11 @@ private OMConfigKeys() {
"ozone.om.keyname.character.check.enabled";
public static final boolean OZONE_OM_KEYNAME_CHARACTER_CHECK_ENABLED_DEFAULT
=
false;
+
+ // This config needs to be enabled, when S3G created objects will be used
+ // FileSystem.
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3861) Fix handlePipelineFailure throw exception if role is follower
[ https://issues.apache.org/jira/browse/HDDS-3861?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shashikant Banerjee resolved HDDS-3861. --- Fix Version/s: 0.6.0 Resolution: Fixed > Fix handlePipelineFailure throw exception if role is follower > - > > Key: HDDS-3861 > URL: https://issues.apache.org/jira/browse/HDDS-3861 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > Labels: pull-request-available > Fix For: 0.6.0 > > Attachments: screenshot-1.png > > > !screenshot-1.png! -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bshashikant merged pull request #1122: HDDS-3861. Fix handlePipelineFailure throw exception if role is follower
bshashikant merged pull request #1122: URL: https://github.com/apache/hadoop-ozone/pull/1122 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3957) Fix error use Longs.toByteArray and Ints.fromByteArray of DB_PENDING_DELETE_BLOCK_COUNT_KEY
runzhiwang created HDDS-3957: Summary: Fix error use Longs.toByteArray and Ints.fromByteArray of DB_PENDING_DELETE_BLOCK_COUNT_KEY Key: HDDS-3957 URL: https://issues.apache.org/jira/browse/HDDS-3957 Project: Hadoop Distributed Data Store Issue Type: Bug Reporter: runzhiwang Assignee: runzhiwang -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi closed pull request #1193: HDDS-3953. Audit LOG action misused in OzoneManager.commitMultipartUp…
ChenSammi closed pull request #1193: URL: https://github.com/apache/hadoop-ozone/pull/1193 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1193: HDDS-3953. Audit LOG action misused in OzoneManager.commitMultipartUp…
ChenSammi commented on pull request #1193: URL: https://github.com/apache/hadoop-ozone/pull/1193#issuecomment-657941211 Thanks @bharatviswa504 . Close this MR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3953) Audit LOG action misused in OzoneManager.commitMultipartUploadPart
[ https://issues.apache.org/jira/browse/HDDS-3953?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sammi Chen resolved HDDS-3953. -- Resolution: Duplicate > Audit LOG action misused in OzoneManager.commitMultipartUploadPart > -- > > Key: HDDS-3953 > URL: https://issues.apache.org/jira/browse/HDDS-3953 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: Sammi Chen >Assignee: Sammi Chen >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3953) Audit LOG action misused in OzoneManager.commitMultipartUploadPart
[ https://issues.apache.org/jira/browse/HDDS-3953?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17157113#comment-17157113 ] Sammi Chen commented on HDDS-3953: -- Close this JIRA as it will be covered by HDDS-2353. > Audit LOG action misused in OzoneManager.commitMultipartUploadPart > -- > > Key: HDDS-3953 > URL: https://issues.apache.org/jira/browse/HDDS-3953 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: Sammi Chen >Assignee: Sammi Chen >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3956) Cleanup old write-path of MPU requests in OM
Bharat Viswanadham created HDDS-3956: Summary: Cleanup old write-path of MPU requests in OM Key: HDDS-3956 URL: https://issues.apache.org/jira/browse/HDDS-3956 Project: Hadoop Distributed Data Store Issue Type: Sub-task Reporter: YiSheng Lien Assignee: YiSheng Lien -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on pull request #1193: HDDS-3953. Audit LOG action misused in OzoneManager.commitMultipartUp…
bharatviswa504 commented on pull request #1193: URL: https://github.com/apache/hadoop-ozone/pull/1193#issuecomment-657929043 This is the parent Jira https://issues.apache.org/jira/browse/HDDS-2353 for the cleanup. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] maobaolong commented on pull request #1187: HDDS-3951. Rename the num.write.chunk.thread key.
maobaolong commented on pull request #1187: URL: https://github.com/apache/hadoop-ozone/pull/1187#issuecomment-657919706 @ChenSammi @xiaoyuyao Thank you for your review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang commented on pull request #1122: HDDS-3861. Fix handlePipelineFailure throw exception if role is follower
runzhiwang commented on pull request #1122: URL: https://github.com/apache/hadoop-ozone/pull/1122#issuecomment-657909810 @adoroszlai Could you help merge it ? The comment is just about the message of reason, I have updated it, I think it does not matter. But if without this PR, the cluster is very unstable. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang edited a comment on pull request #1122: HDDS-3861. Fix handlePipelineFailure throw exception if role is follower
runzhiwang edited a comment on pull request #1122: URL: https://github.com/apache/hadoop-ozone/pull/1122#issuecomment-657909810 @adoroszlai Could you help merge it ? The comment is just about the message of reason, I have updated it, I think it does not matter. But if without this PR, the cluster is very unstable. Thank you very much. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] fapifta commented on pull request #1197: HDDS-3925. SCM Pipeline DB should directly use UUID bytes for key rather than rely on proto serialization for key.
fapifta commented on pull request #1197: URL: https://github.com/apache/hadoop-ozone/pull/1197#issuecomment-657903257 Hi @avijayanhwx, thank you for the review, I have pushed the requested test, and a bit more. At the end of the day, I have added tests to verify the behaviour and interactions of RDBStoreIterator with the underlying RockIterator, and the RocksDBTable. I hope this should sufficiently address the test request, let me know if you thought about something different. As the TypedTable.TypedTableIterator class purely delegates to the raw RDbStoreIterator, I think that does not require too much tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3685) Remove replay logic from actual request logic
[ https://issues.apache.org/jira/browse/HDDS-3685?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bharat Viswanadham updated HDDS-3685: - Fix Version/s: 0.6.0 Resolution: Fixed Status: Resolved (was: Patch Available) > Remove replay logic from actual request logic > - > > Key: HDDS-3685 > URL: https://issues.apache.org/jira/browse/HDDS-3685 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: OM HA >Reporter: Bharat Viswanadham >Assignee: Bharat Viswanadham >Priority: Blocker > Labels: pull-request-available > Fix For: 0.6.0 > > > HDDS-3476 used the transaction info persisted in OM DB during double buffer > flush when OM is restarted. This transaction info log index and the term are > used as a snapshot index. So, we can remove the replay logic from actual > request logic. (As now we shall never have the transaction which is applied > to OM DB will never be again replayed to DB) -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 edited a comment on pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
bharatviswa504 edited a comment on pull request #1082: URL: https://github.com/apache/hadoop-ozone/pull/1082#issuecomment-657898158 Thank You @hanishakoneru for the review and @avijayanhwx for the confirmation on proto changes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 merged pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
bharatviswa504 merged pull request #1082: URL: https://github.com/apache/hadoop-ozone/pull/1082 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
bharatviswa504 commented on pull request #1082: URL: https://github.com/apache/hadoop-ozone/pull/1082#issuecomment-657898158 Thank You @hanishakoneru for the review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
xiaoyuyao commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454011791
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
+ByteBuffer.allocate(4096);
+result.order(ByteOrder.BIG_ENDIAN);
+try {
+ result.putLong(getIssueDate());
+ result.putInt(getMasterKeyId());
+ result.putInt(getSequenceNumber());
+
+ result.putLong(getMaxDate());
+
+ result.putInt(getOwner().toString().length());
+ result.put(getOwner().toString().getBytes(StandardCharsets.UTF_8));
+
+ result.putInt(getRealUser().toString().length());
+ result.put(getRealUser().toString().getBytes(StandardCharsets.UTF_8));
+
+ result.putInt(getRenewer().toString().length());
+ result.put(getRenewer().toString().getBytes(StandardCharsets.UTF_8));
+
+ result.putInt(getTokenType().getNumber());
+ // Set s3 specific fields.
+ if (getTokenType().equals(S3AUTHINFO)) {
+result.putInt(getAwsAccessId().length());
+result.put(getAwsAccessId().getBytes(StandardCharsets.UTF_8));
+
+result.putInt(getSignature().length());
+result.put(getSignature().getBytes(StandardCharsets.UTF_8));
+
+result.putInt(getStrToSign().length());
+result.put(getStrToSign().getBytes(StandardCharsets.UTF_8));
+ } else {
+result.putInt(getOmCertSerialId().length());
+result.put(getOmCertSerialId().getBytes(StandardCharsets.UTF_8));
+if (getOmServiceId() != null) {
+ result.putInt(getOmServiceId().length());
+ result.put(getOmServiceId().getBytes(StandardCharsets.UTF_8));
+} else {
+ result.putInt(0);
+}
+ }
+} catch (IndexOutOfBoundsException e) {
+ throw new IllegalArgumentException(
+ "Can't encode the the raw data ", e);
+}
+return result.array();
+ }
+
+ /** Instead of relying on proto deserialization, this
+ * provides explicit deserialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public static OzoneTokenIdentifier fromUniqueSerializedKey(byte[] rawData) {
+OzoneTokenIdentifier result = newInstance();
Review comment:
We could simplify the code by leveraging the readFields from parent
class to deserialize non-protoc token id.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
xiaoyuyao commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454011179
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
+ByteBuffer.allocate(4096);
+result.order(ByteOrder.BIG_ENDIAN);
+try {
+ result.putLong(getIssueDate());
+ result.putInt(getMasterKeyId());
+ result.putInt(getSequenceNumber());
+
+ result.putLong(getMaxDate());
+
+ result.putInt(getOwner().toString().length());
Review comment:
NIT: The Text class is a UTF-8 bytes + length wrapper class. You can use
getLength()/getBytes() without toString() conversion. Same apply to owner,
realuser and renewer.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
xiaoyuyao commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r454009691
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
Review comment:
Thanks @prashantpogde for working on this. The patch LGTM overall. Have
a few questions:
Have you consider leverage the readFields from parent class to handle the
basic non-protoc serialization which seems to be much simpler.
```
public byte[] toUniqueSerializedKey() throws IOException {
DataOutputBuffer buf = new DataOutputBuffer();
super.write(buf);
WritableUtils.writeEnum(buf, getTokenType());
// Set s3 specific fields.
if (getTokenType().equals(S3AUTHINFO)) {
WritableUtils.writeString(buf, getAwsAccessId());
WritableUtils.writeString(buf, getSignature());
WritableUtils.writeString(buf, getStrToSign());
} else {
WritableUtils.writeString(buf, getOmCertSerialId());
}
return buf.getData();
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1196: Keyput
bharatviswa504 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r454001878
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeyCreateRequest.java
##
@@ -221,8 +233,45 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OmBucketInfo bucketInfo = omMetadataManager.getBucketTable().get(
omMetadataManager.getBucketKey(volumeName, bucketName));
+ boolean createIntermediateDir =
+ ozoneManager.getConfiguration().getBoolean(
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY,
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY_DEFAULT);
+
+ // If FILE_EXISTS we just override like how we used to do for Key Create.
+ List< OzoneAcl > inheritAcls;
+ if (createIntermediateDir) {
+OMFileRequest.OMPathInfo pathInfo =
+OMFileRequest.verifyFilesInPath(omMetadataManager, volumeName,
+bucketName, keyName, Paths.get(keyName));
+OMFileRequest.OMDirectoryResult omDirectoryResult =
+pathInfo.getDirectoryResult();
+inheritAcls = pathInfo.getAcls();
+
+// Check if a file or directory exists with same key name.
+if (omDirectoryResult == DIRECTORY_EXISTS) {
+ throw new OMException("Can not write to directory: " + keyName,
+ NOT_A_FILE);
+} else
+ if (omDirectoryResult == FILE_EXISTS_IN_GIVENPATH) {
+throw new OMException("Can not create file: " + keyName +
+" as there is already file in the given path", NOT_A_FILE);
+ }
+
+missingParentInfos = OMDirectoryCreateRequest
+.getAllParentInfo(ozoneManager, keyArgs,
+pathInfo.getMissingParents(), inheritAcls, trxnLogIndex);
+
+// Add cache entries for the prefix directories.
Review comment:
Yes, there will be some intermediate directories left in DB, key commit
failed. There will be intermediate directories created.
But I don't see that causing an issue. But cleaner thing is cleaning up
entries.
But this is a common issue for FileCreate and KeyCreate.
And in the case lets say key create itself failed in DB flush, we terminate
DB.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] hanishakoneru commented on pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
hanishakoneru commented on pull request #1082: URL: https://github.com/apache/hadoop-ozone/pull/1082#issuecomment-657824863 Thanks @bharatviswa504 for working on this. +1 pending CI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] avijayanhwx edited a comment on pull request #1197: HDDS-3925. SCM Pipeline DB should directly use UUID bytes for key rather than rely on proto serialization for key.
avijayanhwx edited a comment on pull request #1197: URL: https://github.com/apache/hadoop-ozone/pull/1197#issuecomment-657780236 Thank you working on this pifta. I have verified the working using docker based testing. LGTM +1. Can we add a unit test for to verify that removeFromDb actually removes the entry? I am OK with adding it through a follow up JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] avijayanhwx edited a comment on pull request #1197: HDDS-3925. SCM Pipeline DB should directly use UUID bytes for key rather than rely on proto serialization for key.
avijayanhwx edited a comment on pull request #1197: URL: https://github.com/apache/hadoop-ozone/pull/1197#issuecomment-657780236 Thank you working on this pifta. The patch looks good to me. I have verified the working using docker based testing. Can we add a unit test for to verify that removeFromDb actually removes the entry? I am OK with adding it through a follow up JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1164: HDDS-3824: OM read requests should make SCM#refreshPipeline outside BUCKET_LOCK
xiaoyuyao commented on a change in pull request #1164:
URL: https://github.com/apache/hadoop-ozone/pull/1164#discussion_r453918089
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/KeyManagerImpl.java
##
@@ -1877,26 +1897,18 @@ public OmKeyInfo lookupFile(OmKeyArgs args, String
clientAddress)
String volumeName = args.getVolumeName();
String bucketName = args.getBucketName();
String keyName = args.getKeyName();
-
-metadataManager.getLock().acquireReadLock(BUCKET_LOCK, volumeName,
-bucketName);
-try {
- OzoneFileStatus fileStatus = getFileStatus(args);
- if (fileStatus.isFile()) {
-if (args.getRefreshPipeline()) {
- refreshPipeline(fileStatus.getKeyInfo());
-}
-if (args.getSortDatanodes()) {
- sortDatanodeInPipeline(fileStatus.getKeyInfo(), clientAddress);
-}
-return fileStatus.getKeyInfo();
- }
+OzoneFileStatus fileStatus = getOzoneFileStatus(volumeName, bucketName,
+keyName, false);
//if key is not of type file or if key is not found we throw an exception
-} finally {
- metadataManager.getLock().releaseReadLock(BUCKET_LOCK, volumeName,
- bucketName);
+if (fileStatus != null && fileStatus.isFile()) {
+ if (args.getRefreshPipeline()) {
+refreshPipeline(fileStatus.getKeyInfo());
+ }
+ if (args.getSortDatanodes()) {
Review comment:
NIT: sortDatanodes can be handled similarly in getOzoneFileStatus?
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/KeyManagerImpl.java
##
@@ -1877,26 +1897,18 @@ public OmKeyInfo lookupFile(OmKeyArgs args, String
clientAddress)
String volumeName = args.getVolumeName();
String bucketName = args.getBucketName();
String keyName = args.getKeyName();
-
-metadataManager.getLock().acquireReadLock(BUCKET_LOCK, volumeName,
-bucketName);
-try {
- OzoneFileStatus fileStatus = getFileStatus(args);
- if (fileStatus.isFile()) {
-if (args.getRefreshPipeline()) {
- refreshPipeline(fileStatus.getKeyInfo());
-}
-if (args.getSortDatanodes()) {
- sortDatanodeInPipeline(fileStatus.getKeyInfo(), clientAddress);
-}
-return fileStatus.getKeyInfo();
- }
+OzoneFileStatus fileStatus = getOzoneFileStatus(volumeName, bucketName,
+keyName, false);
//if key is not of type file or if key is not found we throw an exception
-} finally {
- metadataManager.getLock().releaseReadLock(BUCKET_LOCK, volumeName,
- bucketName);
+if (fileStatus != null && fileStatus.isFile()) {
+ if (args.getRefreshPipeline()) {
+refreshPipeline(fileStatus.getKeyInfo());
Review comment:
The last parameter of getOzoneFileStatus() should have refreshPipeline
handled already. Can we pass args.getRefreshPipeline() on line 1901?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] avijayanhwx commented on pull request #1197: HDDS-3925. SCM Pipeline DB should directly use UUID bytes for key rather than rely on proto serialization for key.
avijayanhwx commented on pull request #1197: URL: https://github.com/apache/hadoop-ozone/pull/1197#issuecomment-657780236 Thank you working on this pifta. The patch looks good to me. I have verified the working using docker based testing. Can we add a unit test for to verify that removeFromDb actually removes the entry? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3903) OzoneRpcClient support batch rename keys.
[ https://issues.apache.org/jira/browse/HDDS-3903?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Siyao Meng updated HDDS-3903: - Status: Patch Available (was: Open) > OzoneRpcClient support batch rename keys. > - > > Key: HDDS-3903 > URL: https://issues.apache.org/jira/browse/HDDS-3903 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: Ozone Manager >Reporter: mingchao zhao >Assignee: mingchao zhao >Priority: Major > Labels: pull-request-available > > Currently rename folder is to get all the keys, and then rename them one by > one. This makes for poor performance. > HDDS-2939 can able to optimize this part, but at present the HDDS-2939 is > slow and still a long way to go. So we optimized the batch operation based on > the current interface. We were able to get better performance with this PR > before the HDDS-2939 came in. > This patch is a subtask of Batch Rename and first makes OzoneRpcClient > Support Batch Rename Keys. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on a change in pull request #1184: HDDS-2767. security/SecuringTDE.md
xiaoyuyao commented on a change in pull request #1184: URL: https://github.com/apache/hadoop-ozone/pull/1184#discussion_r453834375 ## File path: hadoop-hdds/docs/content/security/SecuringTDE.zh.md ## @@ -0,0 +1,56 @@ +--- +title: "透明数据加密" +date: "2019-April-03" +summary: 透明数据加密(Transparent Data Encryption,TDE)以密文形式在磁盘上保存数据,但可以在用户访问的时候自动进行解密。TDE 以键或桶为单位进行加密。 Review comment: Can we remove this "TDE 以键或桶为单位进行加密"? Also please remove the EN part as well. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] prashantpogde commented on a change in pull request #1182: HDDS-3926. OM Token Identifier table should use in-house serialization.
prashantpogde commented on a change in pull request #1182:
URL: https://github.com/apache/hadoop-ozone/pull/1182#discussion_r453829216
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/security/OzoneTokenIdentifier.java
##
@@ -77,6 +80,122 @@ public Text getKind() {
return KIND_NAME;
}
+ /** Instead of relying on proto serialization, this
+ * provides explicit serialization for OzoneTokenIdentifier.
+ * @return byte[]
+ */
+ public byte[] toUniqueSerializedKey() {
+ByteBuffer result =
+ByteBuffer.allocate(4096);
Review comment:
> I see there is StrToSign if it's S3 auth. I 'm curious about how big
this StrToSign can be? And whether 4096 bytes can hold all these.
It should not be too big and not cause overflow.
https://docs.aws.amazon.com/general/latest/gr/sigv4-create-string-to-sign.html
I saw something similar in other places too e.g.
org/apache/hadoop/security/token/TokenIdentifier.class with 4096 bytes
limit.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3951) Rename the num.write.chunk.thread key
[ https://issues.apache.org/jira/browse/HDDS-3951?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Xiaoyu Yao resolved HDDS-3951. -- Fix Version/s: 0.6.0 Resolution: Fixed > Rename the num.write.chunk.thread key > - > > Key: HDDS-3951 > URL: https://issues.apache.org/jira/browse/HDDS-3951 > Project: Hadoop Distributed Data Store > Issue Type: Improvement > Components: Ozone Datanode >Affects Versions: 0.5.0 >Reporter: maobaolong >Assignee: maobaolong >Priority: Major > Labels: pull-request-available > Fix For: 0.6.0 > > > dfs.container.ratis.num.write.chunk.thread -> > dfs.container.ratis.num.write.chunk.thread.per.disk -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao merged pull request #1187: HDDS-3951. Rename the num.write.chunk.thread key.
xiaoyuyao merged pull request #1187: URL: https://github.com/apache/hadoop-ozone/pull/1187 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on pull request #1187: HDDS-3951. Rename the num.write.chunk.thread key.
xiaoyuyao commented on pull request #1187: URL: https://github.com/apache/hadoop-ozone/pull/1187#issuecomment-657701542 LGTM, +1. Thanks @maobaolong for the contribution and all for the reviews. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on pull request #1162: HDDS-3921. IllegalArgumentException triggered in SCMContainerPlacemen…
xiaoyuyao commented on pull request #1162: URL: https://github.com/apache/hadoop-ozone/pull/1162#issuecomment-657697063 LGTM, +1. Thanks @ChenSammi for the contribution and all for the reviews. I will merge the PR shortly. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] avijayanhwx commented on a change in pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
avijayanhwx commented on a change in pull request #1082:
URL: https://github.com/apache/hadoop-ozone/pull/1082#discussion_r453811018
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/om/exceptions/OMException.java
##
@@ -223,6 +223,6 @@ public String toString() {
INVALID_VOLUME_NAME,
-REPLAY // When ratis logs are replayed.
+REPLAY
Review comment:
The general guideline is breaking API changes are allowed pre-GA, but
not after that.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
bharatviswa504 commented on pull request #1082: URL: https://github.com/apache/hadoop-ozone/pull/1082#issuecomment-657686679 Thank You @hanishakoneru for the review. OMKeysDeleteRequest will be fixed by HDDS-3930. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on a change in pull request #1082: HDDS-3685. Remove replay logic from actual request logic.
bharatviswa504 commented on a change in pull request #1082:
URL: https://github.com/apache/hadoop-ozone/pull/1082#discussion_r453806643
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/om/exceptions/OMException.java
##
@@ -223,6 +223,6 @@ public String toString() {
INVALID_VOLUME_NAME,
-REPLAY // When ratis logs are replayed.
+REPLAY
Review comment:
Initially, the reason was because proto.lock file, if any breaking
changes, it will fail to compile. I have removed this, as anyway HA is part of
this release, and we can remove this field.
cc @avijayanhwx
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3955) Unable to list intermediate paths on keys created using S3G.
[ https://issues.apache.org/jira/browse/HDDS-3955?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Aravindan Vijayan updated HDDS-3955: Description: Keys created via the S3 Gateway currently use the createKey OM API to create the ozone key. Hence, when using a hdfs client to list intermediate directories in the key, OM returns key not found error. This was encountered while using fluentd to write Hive logs to Ozone via the s3 gateway. cc [~bharat] was: Keys created using the s3g currently use the createKey OM API to create the ozone key. Hence, when using a hdfs client to list intermediate directories in the key, OM returns key not found error. This was encountered while using fluentd to write Hive logs to Ozone via the s3 gateway. cc [~bharat] > Unable to list intermediate paths on keys created using S3G. > > > Key: HDDS-3955 > URL: https://issues.apache.org/jira/browse/HDDS-3955 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: Ozone Manager >Reporter: Aravindan Vijayan >Priority: Blocker > > Keys created via the S3 Gateway currently use the createKey OM API to create > the ozone key. Hence, when using a hdfs client to list intermediate > directories in the key, OM returns key not found error. This was encountered > while using fluentd to write Hive logs to Ozone via the s3 gateway. > cc [~bharat] -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3955) Unable to list intermediate paths on keys created using S3G.
Aravindan Vijayan created HDDS-3955: --- Summary: Unable to list intermediate paths on keys created using S3G. Key: HDDS-3955 URL: https://issues.apache.org/jira/browse/HDDS-3955 Project: Hadoop Distributed Data Store Issue Type: Bug Reporter: Aravindan Vijayan Keys created using the s3g currently use the createKey OM API to create the ozone key. Hence, when using a hdfs client to list intermediate directories in the key, OM returns key not found error. This was encountered while using fluentd to write Hive logs to Ozone via the s3 gateway. cc [~bharat] -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3955) Unable to list intermediate paths on keys created using S3G.
[ https://issues.apache.org/jira/browse/HDDS-3955?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Aravindan Vijayan updated HDDS-3955: Component/s: Ozone Manager > Unable to list intermediate paths on keys created using S3G. > > > Key: HDDS-3955 > URL: https://issues.apache.org/jira/browse/HDDS-3955 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: Ozone Manager >Reporter: Aravindan Vijayan >Priority: Blocker > > Keys created using the s3g currently use the createKey OM API to create the > ozone key. Hence, when using a hdfs client to list intermediate directories > in the key, OM returns key not found error. This was encountered while using > fluentd to write Hive logs to Ozone via the s3 gateway. > cc [~bharat] -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3955) Unable to list intermediate paths on keys created using S3G.
[ https://issues.apache.org/jira/browse/HDDS-3955?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Aravindan Vijayan updated HDDS-3955: Target Version/s: 0.6.0 > Unable to list intermediate paths on keys created using S3G. > > > Key: HDDS-3955 > URL: https://issues.apache.org/jira/browse/HDDS-3955 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: Aravindan Vijayan >Priority: Blocker > > Keys created using the s3g currently use the createKey OM API to create the > ozone key. Hence, when using a hdfs client to list intermediate directories > in the key, OM returns key not found error. This was encountered while using > fluentd to write Hive logs to Ozone via the s3 gateway. > cc [~bharat] -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on pull request #1195: HDDS-3930. Fix OMKeyDeletesRequest.
bharatviswa504 commented on pull request #1195: URL: https://github.com/apache/hadoop-ozone/pull/1195#issuecomment-657670868 Thank You @adoroszlai for the review. I have addressed review comments. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] mukul1987 commented on a change in pull request #1196: Keyput
mukul1987 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r453779672
##
File path:
hadoop-ozone/ozone-manager/src/test/java/org/apache/hadoop/ozone/om/request/key/TestOMKeyCreateRequest.java
##
@@ -328,6 +342,73 @@ private OMRequest createKeyRequest(boolean isMultipartKey,
int partNumber) {
.setCmdType(OzoneManagerProtocolProtos.Type.CreateKey)
.setClientId(UUID.randomUUID().toString())
.setCreateKeyRequest(createKeyRequest).build();
+ }
+
+ @Test
+ public void testKeyCreateWithIntermediateDir() throws Exception {
+
+String keyName = "a/b/c/file1";
+OMRequest omRequest = createKeyRequest(false, 0, keyName);
+
+OzoneConfiguration configuration = new OzoneConfiguration();
+configuration.setBoolean(OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY, true);
+when(ozoneManager.getConfiguration()).thenReturn(configuration);
+OMKeyCreateRequest omKeyCreateRequest = new OMKeyCreateRequest(omRequest);
+
+omRequest = omKeyCreateRequest.preExecute(ozoneManager);
+
+omKeyCreateRequest = new OMKeyCreateRequest(omRequest);
+
+// Add volume and bucket entries to DB.
+addVolumeAndBucketToDB(volumeName, bucketName,
+omMetadataManager);
+
+OMClientResponse omClientResponse =
+omKeyCreateRequest.validateAndUpdateCache(ozoneManager,
+100L, ozoneManagerDoubleBufferHelper);
+
+Assert.assertEquals(omClientResponse.getOMResponse().getStatus(), OK);
+
+Path keyPath = Paths.get(keyName);
+
+// Check intermediate paths are created
+keyPath = keyPath.getParent();
+while(keyPath != null) {
+ Assert.assertNotNull(omMetadataManager.getKeyTable().get(
Review comment:
Can we change this to fs.getFileStatus(keypath) so that returns
status.isDir() ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on a change in pull request #1196: Keyput
arp7 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r453761889
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/om/OMConfigKeys.java
##
@@ -239,4 +239,11 @@ private OMConfigKeys() {
"ozone.om.keyname.character.check.enabled";
public static final boolean OZONE_OM_KEYNAME_CHARACTER_CHECK_ENABLED_DEFAULT
=
false;
+
+ // This config needs to be enabled, when S3G created objects will be used
+ // FileSystem.
Review comment:
used via FileSystem API (reword comment).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on pull request #1196: Keyput
arp7 commented on pull request #1196: URL: https://github.com/apache/hadoop-ozone/pull/1196#issuecomment-657661338 The approach looks really good. It is surprisingly concise and elegant because I was expecting it to be a lot more code! Added a few review comments. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on a change in pull request #1196: Keyput
arp7 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r453775722
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeyCreateRequest.java
##
@@ -221,8 +233,45 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OmBucketInfo bucketInfo = omMetadataManager.getBucketTable().get(
omMetadataManager.getBucketKey(volumeName, bucketName));
+ boolean createIntermediateDir =
+ ozoneManager.getConfiguration().getBoolean(
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY,
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY_DEFAULT);
+
+ // If FILE_EXISTS we just override like how we used to do for Key Create.
+ List< OzoneAcl > inheritAcls;
+ if (createIntermediateDir) {
+OMFileRequest.OMPathInfo pathInfo =
+OMFileRequest.verifyFilesInPath(omMetadataManager, volumeName,
+bucketName, keyName, Paths.get(keyName));
+OMFileRequest.OMDirectoryResult omDirectoryResult =
+pathInfo.getDirectoryResult();
+inheritAcls = pathInfo.getAcls();
+
+// Check if a file or directory exists with same key name.
+if (omDirectoryResult == DIRECTORY_EXISTS) {
+ throw new OMException("Can not write to directory: " + keyName,
+ NOT_A_FILE);
+} else
+ if (omDirectoryResult == FILE_EXISTS_IN_GIVENPATH) {
+throw new OMException("Can not create file: " + keyName +
+" as there is already file in the given path", NOT_A_FILE);
+ }
+
+missingParentInfos = OMDirectoryCreateRequest
+.getAllParentInfo(ozoneManager, keyArgs,
+pathInfo.getMissingParents(), inheritAcls, trxnLogIndex);
+
+// Add cache entries for the prefix directories.
Review comment:
@bharatviswa504 , one q. We are adding cache entries right away instead
of at the end on success. Could this be a potential issue on the failure path?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on a change in pull request #1196: Keyput
arp7 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r453775722
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeyCreateRequest.java
##
@@ -221,8 +233,45 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OmBucketInfo bucketInfo = omMetadataManager.getBucketTable().get(
omMetadataManager.getBucketKey(volumeName, bucketName));
+ boolean createIntermediateDir =
+ ozoneManager.getConfiguration().getBoolean(
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY,
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY_DEFAULT);
+
+ // If FILE_EXISTS we just override like how we used to do for Key Create.
+ List< OzoneAcl > inheritAcls;
+ if (createIntermediateDir) {
+OMFileRequest.OMPathInfo pathInfo =
+OMFileRequest.verifyFilesInPath(omMetadataManager, volumeName,
+bucketName, keyName, Paths.get(keyName));
+OMFileRequest.OMDirectoryResult omDirectoryResult =
+pathInfo.getDirectoryResult();
+inheritAcls = pathInfo.getAcls();
+
+// Check if a file or directory exists with same key name.
+if (omDirectoryResult == DIRECTORY_EXISTS) {
+ throw new OMException("Can not write to directory: " + keyName,
+ NOT_A_FILE);
+} else
+ if (omDirectoryResult == FILE_EXISTS_IN_GIVENPATH) {
+throw new OMException("Can not create file: " + keyName +
+" as there is already file in the given path", NOT_A_FILE);
+ }
+
+missingParentInfos = OMDirectoryCreateRequest
+.getAllParentInfo(ozoneManager, keyArgs,
+pathInfo.getMissingParents(), inheritAcls, trxnLogIndex);
+
+// Add cache entries for the prefix directories.
Review comment:
@bharatviswa504 , one q. We are adding intermediate cache entries right
away instead of at the end on success. Could this be a potential issue on the
failure path?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on a change in pull request #1196: Keyput
arp7 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r453774238
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/key/OMKeyCreateRequest.java
##
@@ -221,8 +233,45 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
OmBucketInfo bucketInfo = omMetadataManager.getBucketTable().get(
omMetadataManager.getBucketKey(volumeName, bucketName));
+ boolean createIntermediateDir =
+ ozoneManager.getConfiguration().getBoolean(
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY,
+ OZONE_OM_CREATE_INTERMEDIATE_DIRECTORY_DEFAULT);
+
+ // If FILE_EXISTS we just override like how we used to do for Key Create.
+ List< OzoneAcl > inheritAcls;
+ if (createIntermediateDir) {
+OMFileRequest.OMPathInfo pathInfo =
+OMFileRequest.verifyFilesInPath(omMetadataManager, volumeName,
+bucketName, keyName, Paths.get(keyName));
+OMFileRequest.OMDirectoryResult omDirectoryResult =
+pathInfo.getDirectoryResult();
+inheritAcls = pathInfo.getAcls();
+
+// Check if a file or directory exists with same key name.
+if (omDirectoryResult == DIRECTORY_EXISTS) {
+ throw new OMException("Can not write to directory: " + keyName,
Review comment:
Let's make the exception message slightly more descriptive to explain
what is really going on. We can mention that createIntermediateDirs behavior is
enabled and hence `/` has special interpretation.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on pull request #1196: Keyput
arp7 commented on pull request #1196: URL: https://github.com/apache/hadoop-ozone/pull/1196#issuecomment-657658582 Can you update the PR template a bit to describe the high-level approach (was fix made in OM or S3G)? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDDS-3907) Topology related acceptance test is flaky
[
https://issues.apache.org/jira/browse/HDDS-3907?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Xiaoyu Yao reassigned HDDS-3907:
Assignee: Xiaoyu Yao
> Topology related acceptance test is flaky
> -
>
> Key: HDDS-3907
> URL: https://issues.apache.org/jira/browse/HDDS-3907
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
>Reporter: Marton Elek
>Assignee: Xiaoyu Yao
>Priority: Blocker
>
> Examples:
> https://github.com/elek/ozone-build-results/tree/master/2020/06/30/1318/acceptance
> https://github.com/elek/ozone-build-results/tree/master/2020/06/30/1321/acceptance
> https://github.com/elek/ozone-build-results/tree/master/2020/06/30/1334/acceptance
> Some strange errors:
> {code}
> scm_1 | 2020-06-30 19:17:50,787 [RatisPipelineUtilsThread] ERROR
> pipeline.SCMPipelineManager: Failed to create pipeline of type RATIS and
> factor ONE. Exception: Cannot create pipeline of factor 1 using 0 nodes. Used
> 6 nodes. Healthy nodes 6
> scm_1 | 2020-06-30 19:17:50,788 [RatisPipelineUtilsThread] ERROR
> pipeline.SCMPipelineManager: Failed to create pipeline of type RATIS and
> factor THREE. Exception: Pipeline creation failed because nodes are engaged
> in other pipelines and every node can only be engaged in max 2 pipelines.
> Required 3. Found 0
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3925) SCM Pipeline DB should directly use UUID bytes for key rather than rely on proto serialization for key.
[ https://issues.apache.org/jira/browse/HDDS-3925?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Aravindan Vijayan updated HDDS-3925: Status: Patch Available (was: Open) > SCM Pipeline DB should directly use UUID bytes for key rather than rely on > proto serialization for key. > --- > > Key: HDDS-3925 > URL: https://issues.apache.org/jira/browse/HDDS-3925 > Project: Hadoop Distributed Data Store > Issue Type: Sub-task > Components: SCM >Reporter: Aravindan Vijayan >Assignee: Istvan Fajth >Priority: Major > Labels: pull-request-available, upgrade-p0 > > Relying on Protobuf serialization for exact match is unreliable according to > the docs. Hence, we have to move away from using proto.toByteArray() for on > disk RocksDB keys. For more details, check parent JIRA. > cc [~nanda619] -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDDS-3509) Closing container with unhealthy replica on open pipeline
[ https://issues.apache.org/jira/browse/HDDS-3509?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Mukul Kumar Singh reassigned HDDS-3509: --- Assignee: Lokesh Jain (was: Nanda kumar) > Closing container with unhealthy replica on open pipeline > - > > Key: HDDS-3509 > URL: https://issues.apache.org/jira/browse/HDDS-3509 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: Ozone Datanode >Affects Versions: 0.5.0 >Reporter: Nilotpal Nandi >Assignee: Lokesh Jain >Priority: Major > > When a container replica of an OPEN container is marked as UNHEALTHY, SCM > tries to close the container. > If the pipeline is still healthy, we try to close the container via Ratis. > We could run into a scenario where the datanode which marked the container > replica as UNHEALTHY is the pipeline leader. In such case that datanode > (leader) should process the close container command even though the container > replica is in UNHEALTHY state. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] arp7 commented on a change in pull request #1196: Keyput
arp7 commented on a change in pull request #1196:
URL: https://github.com/apache/hadoop-ozone/pull/1196#discussion_r453761889
##
File path:
hadoop-ozone/common/src/main/java/org/apache/hadoop/ozone/om/OMConfigKeys.java
##
@@ -239,4 +239,11 @@ private OMConfigKeys() {
"ozone.om.keyname.character.check.enabled";
public static final boolean OZONE_OM_KEYNAME_CHARACTER_CHECK_ENABLED_DEFAULT
=
false;
+
+ // This config needs to be enabled, when S3G created objects will be used
+ // FileSystem.
Review comment:
used via FileSystem API.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] codecov-commenter commented on pull request #1198: HDDS-3789. Fix TestOzoneRpcClientAbstract#testDeletedKeyForGDPR.
codecov-commenter commented on pull request #1198: URL: https://github.com/apache/hadoop-ozone/pull/1198#issuecomment-657510256 # [Codecov](https://codecov.io/gh/apache/hadoop-ozone/pull/1198?src=pr=h1) Report > Merging [#1198](https://codecov.io/gh/apache/hadoop-ozone/pull/1198?src=pr=desc) into [master](https://codecov.io/gh/apache/hadoop-ozone/commit/2af6198686d81daa3ad0513f723118637d2945cf=desc) will **decrease** coverage by `0.19%`. > The diff coverage is `55.76%`. [](https://codecov.io/gh/apache/hadoop-ozone/pull/1198?src=pr=tree) ```diff @@ Coverage Diff @@ ## master#1198 +/- ## - Coverage 73.64% 73.45% -0.20% + Complexity1006310035 -28 Files 974 974 Lines 4972549749 +24 Branches 4893 4900 +7 - Hits 3662136543 -78 - Misses1078610871 +85 - Partials 2318 2335 +17 ``` | [Impacted Files](https://codecov.io/gh/apache/hadoop-ozone/pull/1198?src=pr=tree) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...che/hadoop/hdds/scm/block/DeletedBlockLogImpl.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvc2VydmVyLXNjbS9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL2hkZHMvc2NtL2Jsb2NrL0RlbGV0ZWRCbG9ja0xvZ0ltcGwuamF2YQ==) | `71.23% <0.00%> (-1.37%)` | `21.00 <0.00> (-1.00)` | | | [...m/container/IncrementalContainerReportHandler.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvc2VydmVyLXNjbS9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL2hkZHMvc2NtL2NvbnRhaW5lci9JbmNyZW1lbnRhbENvbnRhaW5lclJlcG9ydEhhbmRsZXIuamF2YQ==) | `52.77% <37.50%> (-2.07%)` | `6.00 <3.00> (ø)` | | | [.../hadoop/hdds/scm/container/ReplicationManager.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvc2VydmVyLXNjbS9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL2hkZHMvc2NtL2NvbnRhaW5lci9SZXBsaWNhdGlvbk1hbmFnZXIuamF2YQ==) | `87.35% <40.00%> (-0.76%)` | `102.00 <8.00> (ø)` | | | [...oop/hdds/scm/container/ContainerReportHandler.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvc2VydmVyLXNjbS9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL2hkZHMvc2NtL2NvbnRhaW5lci9Db250YWluZXJSZXBvcnRIYW5kbGVyLmphdmE=) | `86.31% <50.00%> (-2.58%)` | `16.00 <1.00> (ø)` | | | [...on/scm/ReconIncrementalContainerReportHandler.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLW96b25lL3JlY29uL3NyYy9tYWluL2phdmEvb3JnL2FwYWNoZS9oYWRvb3Avb3pvbmUvcmVjb24vc2NtL1JlY29uSW5jcmVtZW50YWxDb250YWluZXJSZXBvcnRIYW5kbGVyLmphdmE=) | `60.00% <50.00%> (-1.12%)` | `4.00 <2.00> (ø)` | | | [...rg/apache/hadoop/hdds/scm/node/SCMNodeManager.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvc2VydmVyLXNjbS9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL2hkZHMvc2NtL25vZGUvU0NNTm9kZU1hbmFnZXIuamF2YQ==) | `85.53% <68.00%> (-1.76%)` | `56.00 <4.00> (+1.00)` | :arrow_down: | | [...g/apache/hadoop/hdds/protocol/DatanodeDetails.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvY29tbW9uL3NyYy9tYWluL2phdmEvb3JnL2FwYWNoZS9oYWRvb3AvaGRkcy9wcm90b2NvbC9EYXRhbm9kZURldGFpbHMuamF2YQ==) | `88.97% <100.00%> (+0.08%)` | `31.00 <0.00> (ø)` | | | [...ds/scm/node/states/NodeAlreadyExistsException.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvc2VydmVyLXNjbS9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL2hkZHMvc2NtL25vZGUvc3RhdGVzL05vZGVBbHJlYWR5RXhpc3RzRXhjZXB0aW9uLmphdmE=) | `0.00% <0.00%> (-50.00%)` | `0.00% <0.00%> (-1.00%)` | | | [...doop/ozone/om/exceptions/OMNotLeaderException.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLW96b25lL2NvbW1vbi9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaGFkb29wL296b25lL29tL2V4Y2VwdGlvbnMvT01Ob3RMZWFkZXJFeGNlcHRpb24uamF2YQ==) | `48.48% <0.00%> (-18.19%)` | `3.00% <0.00%> (-2.00%)` | | | [.../transport/server/ratis/ContainerStateMachine.java](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree#diff-aGFkb29wLWhkZHMvY29udGFpbmVyLXNlcnZpY2Uvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2hhZG9vcC9vem9uZS9jb250YWluZXIvY29tbW9uL3RyYW5zcG9ydC9zZXJ2ZXIvcmF0aXMvQ29udGFpbmVyU3RhdGVNYWNoaW5lLmphdmE=) | `71.74% <0.00%> (-8.30%)` | `63.00% <0.00%> (-6.00%)` | | | ... and [25 more](https://codecov.io/gh/apache/hadoop-ozone/pull/1198/diff?src=pr=tree-more) | | -- [Continue to review full
[jira] [Updated] (HDDS-3789) Fix TestOzoneRpcClientAbstract#testDeletedKeyForGDPR
[
https://issues.apache.org/jira/browse/HDDS-3789?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HDDS-3789:
-
Labels: pull-request-available (was: )
> Fix TestOzoneRpcClientAbstract#testDeletedKeyForGDPR
>
>
> Key: HDDS-3789
> URL: https://issues.apache.org/jira/browse/HDDS-3789
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
>Reporter: Shashikant Banerjee
>Assignee: Lokesh Jain
>Priority: Major
> Labels: pull-request-available
>
> {code:java}
> [ERROR] Tests run: 67, Failures: 0, Errors: 1, Skipped: 1, Time elapsed:
> 36.615 s <<< FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClientWithRatis
> 3053[ERROR]
> testDeletedKeyForGDPR(org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClientWithRatis)
> Time elapsed: 0.165 s <<< ERROR!
> 3054java.lang.NullPointerException
> 3055 at
> org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClientAbstract.testDeletedKeyForGDPR(TestOzoneRpcClientAbstract.java:2730)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] lokeshj1703 opened a new pull request #1198: HDDS-3789. Fix TestOzoneRpcClientAbstract#testDeletedKeyForGDPR.
lokeshj1703 opened a new pull request #1198: URL: https://github.com/apache/hadoop-ozone/pull/1198 ## What changes were proposed in this pull request? Enables TestOzoneRpcClientAbstract#testDeletedKeyForGDPR. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3789 ## How was this patch tested? Test passes 20 times when run locally This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDDS-3789) Fix TestOzoneRpcClientAbstract#testDeletedKeyForGDPR
[
https://issues.apache.org/jira/browse/HDDS-3789?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lokesh Jain reassigned HDDS-3789:
-
Assignee: Lokesh Jain
> Fix TestOzoneRpcClientAbstract#testDeletedKeyForGDPR
>
>
> Key: HDDS-3789
> URL: https://issues.apache.org/jira/browse/HDDS-3789
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
>Reporter: Shashikant Banerjee
>Assignee: Lokesh Jain
>Priority: Major
>
> {code:java}
> [ERROR] Tests run: 67, Failures: 0, Errors: 1, Skipped: 1, Time elapsed:
> 36.615 s <<< FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClientWithRatis
> 3053[ERROR]
> testDeletedKeyForGDPR(org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClientWithRatis)
> Time elapsed: 0.165 s <<< ERROR!
> 3054java.lang.NullPointerException
> 3055 at
> org.apache.hadoop.ozone.client.rpc.TestOzoneRpcClientAbstract.testDeletedKeyForGDPR(TestOzoneRpcClientAbstract.java:2730)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1185: HDDS-3933. Fix memory leak because of too many Datanode State Machine Thread
ChenSammi commented on pull request #1185: URL: https://github.com/apache/hadoop-ozone/pull/1185#issuecomment-657437337 Don't find any unit tests here. Would you please add some? @runzhiwang This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] timmylicheng closed pull request #1191: HDDS-3837 Add isLeader check in SCMHAManager.
timmylicheng closed pull request #1191: URL: https://github.com/apache/hadoop-ozone/pull/1191 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] maobaolong commented on pull request #1187: HDDS-3951. Rename the num.write.chunk.thread key.
maobaolong commented on pull request #1187: URL: https://github.com/apache/hadoop-ozone/pull/1187#issuecomment-657397401 @ChenSammi Thanks for your suggestion,I have addressed your comment,PTAL This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3509) Closing container with unhealthy replica on open pipeline
[ https://issues.apache.org/jira/browse/HDDS-3509?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17156517#comment-17156517 ] Sammi Chen commented on HDDS-3509: -- Hi [~nanda], do you plan to fix this issue in 0.6.0, or move to 0.7.0? > Closing container with unhealthy replica on open pipeline > - > > Key: HDDS-3509 > URL: https://issues.apache.org/jira/browse/HDDS-3509 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: Ozone Datanode >Affects Versions: 0.5.0 >Reporter: Nilotpal Nandi >Assignee: Nanda kumar >Priority: Major > > When a container replica of an OPEN container is marked as UNHEALTHY, SCM > tries to close the container. > If the pipeline is still healthy, we try to close the container via Ratis. > We could run into a scenario where the datanode which marked the container > replica as UNHEALTHY is the pipeline leader. In such case that datanode > (leader) should process the close container command even though the container > replica is in UNHEALTHY state. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3920) Too many redudant replications due to fail to get node's ancestor in ReplicationManager
[
https://issues.apache.org/jira/browse/HDDS-3920?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sammi Chen resolved HDDS-3920.
--
Resolution: Fixed
> Too many redudant replications due to fail to get node's ancestor in
> ReplicationManager
> ---
>
> Key: HDDS-3920
> URL: https://issues.apache.org/jira/browse/HDDS-3920
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Reporter: Sammi Chen
>Assignee: Sammi Chen
>Priority: Blocker
> Labels: pull-request-available
> Attachments: over-replicated-container-list.txt
>
>
> In our production cluster, we turn on the network topology configuraiton.
> Due to fail to get the node's ancestor(the datanode object used doesn't have
> parent corrently set) in ReplicationManager during the under-replicate and
> over-replicate check, ReplicationManager think the replicas of the container
> doean't meet the acrossing more than one rack requirement, then treat the
> container as under-replicate although it already has many replicas, and send
> command to datanodes to replicate the container again and again.
> 2020-07-03 16:26:45,200 [ReplicationMonitor] INFO
> org.apache.hadoop.hdds.scm.container.ReplicationManager: Container #105228 is
> over replicated. Expected replica count is 3, but found 31.
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: Handling
> underreplicated container: 210413
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: deletionInFlight of
> container {}#210413
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: replicationInFlight
> of container {}#210413
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.20.43
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: source of container
> {}#210413
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.5.41
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.179.142.251
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.8.85
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.179.142.250
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.8.35
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.8.67
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.179.142.135
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.179.144.104
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.20.58
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.179.142.198
> 2020-07-03 10:48:00,161 [ReplicationMonitor] DEBUG
> org.apache.hadoop.hdds.scm.container.ReplicationManager: 9.180.20.222
> 2020-07-03 10:48:00,161 [ReplicationMonitor] WARN
> org.apache.hadoop.hdds.scm.container.ReplicationManager: Process container
> #210413 error:
> java.lang.IllegalArgumentException
> at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:128)
> at
> org.apache.hadoop.hdds.scm.container.placement.algorithms.SCMContainerPlacementRackAware.chooseDatanodes(SCMContainerPlacementRackAware.java:101)
> at
> org.apache.hadoop.hdds.scm.container.ReplicationManager.handleUnderReplicatedContainer(ReplicationManager.java:568)
> at
> org.apache.hadoop.hdds.scm.container.ReplicationManager.processContainer(ReplicationManager.java:331)
> 2020-07-03 10:48:00,161 [ReplicationMonitor] WARN
> org.apache.hadoop.hdds.scm.net.NetUtils: Fail to get ancestor generation 1 of
> node :f8d9ccf6-20c6-4dfa-8a49-012f43a1b27e{ip: 9.179.142.251, host: host251,
> networkLocation: /rack3, certSerialId: null}
> 2020-07-03 10:48:00,161 [ReplicationMonitor] WARN
> org.apache.hadoop.hdds.scm.net.NetUtils: Fail to get ancestor generation 1 of
> node :826dda09-1259-4c5c-9a80-56b985665dc4{ip: 9.180.6.157, host:
> host-9-180-6-157, networkLocation: /rack10, certSerialId: null}
> 2020-07-03 10:48:00,161 [ReplicationMonitor] WARN
> org.apache.hadoop.hdds.scm.net.NetUtils: Fail to get ancestor
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1163: HDDS-3920. Too many redudant replications due to fail to get node's a…
ChenSammi commented on pull request #1163: URL: https://github.com/apache/hadoop-ozone/pull/1163#issuecomment-657391415 Thanks @xiaoyuyao for the review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi merged pull request #1163: HDDS-3920. Too many redudant replications due to fail to get node's a…
ChenSammi merged pull request #1163: URL: https://github.com/apache/hadoop-ozone/pull/1163 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1187: HDDS-3951. Rename the num.write.chunk.thread key.
ChenSammi commented on pull request #1187: URL: https://github.com/apache/hadoop-ozone/pull/1187#issuecomment-657389570 @maobaolong, suggest change from " per disk" to " per volume" to be consistent with other datanode property naming style. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3937) Update jquery to v3.5.1
[ https://issues.apache.org/jira/browse/HDDS-3937?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17156509#comment-17156509 ] Attila Doroszlai commented on HDDS-3937: CC [~Sammi] for cherry-pick to 0.6.0. > Update jquery to v3.5.1 > > > Key: HDDS-3937 > URL: https://issues.apache.org/jira/browse/HDDS-3937 > Project: Hadoop Distributed Data Store > Issue Type: Task > Components: website >Affects Versions: 0.5.0 >Reporter: Vivek Ratnavel Subramanian >Assignee: Vivek Ratnavel Subramanian >Priority: Major > Labels: pull-request-available > Fix For: 0.7.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi merged pull request #1186: HDDS-3941. Enable core dump when crash in C++
ChenSammi merged pull request #1186: URL: https://github.com/apache/hadoop-ozone/pull/1186 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1186: HDDS-3941. Enable core dump when crash in C++
ChenSammi commented on pull request #1186: URL: https://github.com/apache/hadoop-ozone/pull/1186#issuecomment-657388589 The patch looks good to me. + 1. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] adoroszlai commented on pull request #1177: HDDS-3937. Update jquery to v3.5.1
adoroszlai commented on pull request #1177: URL: https://github.com/apache/hadoop-ozone/pull/1177#issuecomment-657388082 Thanks @vivekratnavel for the upgrade and @bharatviswa504 for reviewing it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3937) Update jquery to v3.5.1
[ https://issues.apache.org/jira/browse/HDDS-3937?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Attila Doroszlai updated HDDS-3937: --- Fix Version/s: 0.7.0 > Update jquery to v3.5.1 > > > Key: HDDS-3937 > URL: https://issues.apache.org/jira/browse/HDDS-3937 > Project: Hadoop Distributed Data Store > Issue Type: Task > Components: website >Affects Versions: 0.5.0 >Reporter: Vivek Ratnavel Subramanian >Assignee: Vivek Ratnavel Subramanian >Priority: Major > Labels: pull-request-available > Fix For: 0.7.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on pull request #1162: HDDS-3921. IllegalArgumentException triggered in SCMContainerPlacemen…
ChenSammi commented on pull request #1162: URL: https://github.com/apache/hadoop-ozone/pull/1162#issuecomment-657387772 Thanks @sodonnel and @xiaoyuyao for the review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org