[GitHub] spark issue #22593: [Streaming][DOC] Fix typo & format in DataStreamWriter.s...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22593 **[Test build #96805 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96805/testReport)** for PR 22593 at commit [`c1a89f0`](https://github.com/apache/spark/commit/c1a89f0455995d9d20920a8b9b45d3b6a9dcd898). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [Streaming][DOC] Fix typo & format in DataStreamWriter.s...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22593 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96805/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [Streaming][DOC] Fix typo & format in DataStreamWriter.s...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22593 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [Streaming][DOC] Fix typo & format in DataStreamWriter.s...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22593 **[Test build #96805 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96805/testReport)** for PR 22593 at commit [`c1a89f0`](https://github.com/apache/spark/commit/c1a89f0455995d9d20920a8b9b45d3b6a9dcd898). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [Streaming][DOC] Fix typo & format in DataStreamWriter.s...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22593 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18457: [SPARK-21241][MLlib]- Add setIntercept to StreamingLinea...
Github user SoulGuedria commented on the issue: https://github.com/apache/spark/pull/18457 Can one of the admins verify this patch? Thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22586: [SPARK-25568][Core]Continue to update the remaining accu...
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/22586 Thanks! Merged to master/2.4/2.3/2.2 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22586: [SPARK-25568][Core]Continue to update the remaini...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22586 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22528: [SPARK-25513][SQL] Read zipped CSV and JSON
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/22528 We should stop returning a wrong result. Please fix it. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI...
Github user shahidki31 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22592#discussion_r221443587
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
---
@@ -206,11 +238,8 @@ private[ui] abstract class ExecutionTable(
}
def toNodeSeq(request: HttpServletRequest): Seq[Node] = {
-
- {tableName}
--- End diff --
> It's just a detail, but I was unclear why you don't need the table name
anymore.
Table name for running executions was 'Running Queries ({running.size})',
for completed executions was 'Completed Queries ({completed.size})' and for
failed executions was 'Failed Queries ({failed.size})'.
This is already there in the code, inside if condition.
```
Running Queries ({running.size})
```
So, the table name is no longer required in this case.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI suppor...
Github user shahidki31 commented on the issue: https://github.com/apache/spark/pull/22592 Thanks @srowen for reviewing. > I think it's OK. Do you need to collapse this one table though? It's the only thing on the page. There are 'Running', 'Completed' and 'Failed' tables in the SQL page. Similar to the Jobs page. Also, all the pages ( Jobs, stages etc.) supports hiding table, except SQL page. So, behavior should be same for SQL page also, right? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22581 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22581 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96804/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22581 **[Test build #96804 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96804/testReport)** for PR 22581 at commit [`bdbfbfe`](https://github.com/apache/spark/commit/bdbfbfe59da6f6ba2814e4816e556c296eab7f59). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [SQL][DOC] Fix typo & format in DataStreamWriter.scala
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22593 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [SQL][DOC] Fix typo & format in DataStreamWriter.scala
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22593 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22593: [SQL][DOC] Fix typo & format in DataStreamWriter.scala
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22593 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22593: Fix typo & format in DataStreamWriter.scala
GitHub user niofire opened a pull request: https://github.com/apache/spark/pull/22593 Fix typo & format in DataStreamWriter.scala ## What changes were proposed in this pull request? - Fixed typo for function outputMode - OutputMode.Complete(), changed `these is some updates` to `there are some updates` - Replaced hyphens by HTML unordered list tags in comments for - outputMode(String) - outputMode(OutputMode) - partitionBy(String*) Current render from most recent [Spark API Docs](https://spark.apache.org/docs/2.3.1/api/java/org/apache/spark/sql/streaming/DataStreamWriter.html): outputMode(OutputMode) - Typo + List formatted as a prose.  outputMode(String) - Typo + List formatted as a prose.  partitionBy(String*) - List formatted as a prose.  ## How was this patch tested? This PR contains a document patch ergo no functional testing is required. You can merge this pull request into a Git repository by running: $ git pull https://github.com/niofire/spark fix-typo-datastreamwriter Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22593.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22593 commit c1a89f0455995d9d20920a8b9b45d3b6a9dcd898 Author: Mathieu St-Louis Date: 2018-09-29T21:03:15Z Fix typo + replaced hyphens with html lists in DataStreamWriter --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22589: [SPARK-25572][SPARKR] test only if not cran
Github user shivaram commented on the issue: https://github.com/apache/spark/pull/22589 LGTM. Thanks @felixcheung --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/21669 like it, but we could also first support cluster mode and add client mode after. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22589: [SPARK-25572][SPARKR] test only if not cran
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22589 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/22592#discussion_r221440824
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
---
@@ -206,11 +238,8 @@ private[ui] abstract class ExecutionTable(
}
def toNodeSeq(request: HttpServletRequest): Seq[Node] = {
-
- {tableName}
--- End diff --
It's just a detail, but I was unclear why you don't need the table name
anymore. It's because all other code paths already render the table name, and
`UIUtils.listingTable` does the rest?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22589: [SPARK-25572][SPARKR] test only if not cran
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22589 merged to master/2.4 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22589: [SPARK-25572][SPARKR] test only if not cran
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/22589#discussion_r221440760
--- Diff: R/pkg/tests/run-all.R ---
@@ -18,50 +18,55 @@
library(testthat)
library(SparkR)
-# Turn all warnings into errors
-options("warn" = 2)
+# SPARK-25572
+if (identical(Sys.getenv("NOT_CRAN"), "true")) {
-if (.Platform$OS.type == "windows") {
- Sys.setenv(TZ = "GMT")
-}
+ # Turn all warnings into errors
+ options("warn" = 2)
-# Setup global test environment
-# Install Spark first to set SPARK_HOME
+ if (.Platform$OS.type == "windows") {
+Sys.setenv(TZ = "GMT")
+ }
-# NOTE(shivaram): We set overwrite to handle any old tar.gz files or
directories left behind on
-# CRAN machines. For Jenkins we should already have SPARK_HOME set.
-install.spark(overwrite = TRUE)
+ # Setup global test environment
+ # Install Spark first to set SPARK_HOME
-sparkRDir <- file.path(Sys.getenv("SPARK_HOME"), "R")
-sparkRWhitelistSQLDirs <- c("spark-warehouse", "metastore_db")
-invisible(lapply(sparkRWhitelistSQLDirs,
- function(x) { unlink(file.path(sparkRDir, x), recursive =
TRUE, force = TRUE)}))
-sparkRFilesBefore <- list.files(path = sparkRDir, all.files = TRUE)
+ # NOTE(shivaram): We set overwrite to handle any old tar.gz files or
directories left behind on
+ # CRAN machines. For Jenkins we should already have SPARK_HOME set.
+ install.spark(overwrite = TRUE)
-sparkRTestMaster <- "local[1]"
-sparkRTestConfig <- list()
-if (identical(Sys.getenv("NOT_CRAN"), "true")) {
- sparkRTestMaster <- ""
-} else {
- # Disable hsperfdata on CRAN
- old_java_opt <- Sys.getenv("_JAVA_OPTIONS")
- Sys.setenv("_JAVA_OPTIONS" = paste("-XX:-UsePerfData", old_java_opt))
- tmpDir <- tempdir()
- tmpArg <- paste0("-Djava.io.tmpdir=", tmpDir)
- sparkRTestConfig <- list(spark.driver.extraJavaOptions = tmpArg,
- spark.executor.extraJavaOptions = tmpArg)
-}
+ sparkRDir <- file.path(Sys.getenv("SPARK_HOME"), "R")
+ sparkRWhitelistSQLDirs <- c("spark-warehouse", "metastore_db")
+ invisible(lapply(sparkRWhitelistSQLDirs,
+ function(x) { unlink(file.path(sparkRDir, x), recursive
= TRUE, force = TRUE)}))
+ sparkRFilesBefore <- list.files(path = sparkRDir, all.files = TRUE)
-test_package("SparkR")
+ sparkRTestMaster <- "local[1]"
+ sparkRTestConfig <- list()
+ if (identical(Sys.getenv("NOT_CRAN"), "true")) {
+sparkRTestMaster <- ""
+ } else {
+# Disable hsperfdata on CRAN
+old_java_opt <- Sys.getenv("_JAVA_OPTIONS")
+Sys.setenv("_JAVA_OPTIONS" = paste("-XX:-UsePerfData", old_java_opt))
+tmpDir <- tempdir()
+tmpArg <- paste0("-Djava.io.tmpdir=", tmpDir)
+sparkRTestConfig <- list(spark.driver.extraJavaOptions = tmpArg,
+ spark.executor.extraJavaOptions = tmpArg)
+ }
-if (identical(Sys.getenv("NOT_CRAN"), "true")) {
- # set random seed for predictable results. mostly for base's sample() in
tree and classification
- set.seed(42)
- # for testthat 1.0.2 later, change reporter from "summary" to
default_reporter()
- testthat:::run_tests("SparkR",
- file.path(sparkRDir, "pkg", "tests", "fulltests"),
- NULL,
- "summary")
-}
+ test_package("SparkR")
+
+ if (identical(Sys.getenv("NOT_CRAN"), "true")) {
--- End diff --
We are trying this now - we can clean it up if this works
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22582 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22582 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96803/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22582 **[Test build #96803 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96803/testReport)** for PR 22582 at commit [`66206a1`](https://github.com/apache/spark/commit/66206a1f99a21bfac13056fc0e9d7ce3daed2619). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22586: [SPARK-25568][Core]Continue to update the remaini...
Github user zsxwing commented on a diff in the pull request:
https://github.com/apache/spark/pull/22586#discussion_r221438766
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -1880,6 +1880,26 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
assert(sc.parallelize(1 to 10, 2).count() === 10)
}
+ test("misbehaved accumulator should not impact other accumulators") {
--- End diff --
> Also verify the log message?
That's not in the core project.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22379 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22379 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96802/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22379 **[Test build #96802 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96802/testReport)** for PR 22379 at commit [`a5b6f69`](https://github.com/apache/spark/commit/a5b6f696c5f410d3be93299bb748799d37d04bb9). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI suppor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22592 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI suppor...
Github user shahidki31 commented on the issue: https://github.com/apache/spark/pull/22592 cc @srowen @dongjoon-hyun --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI suppor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22592 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI suppor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22592 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI suppor...
Github user shahidki31 commented on the issue: https://github.com/apache/spark/pull/22592 Jobs and stages page support hiding table. So to make it consistent, SQL tab also should behave the same.   --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22592: [SPARK-25575][WEBUI][SQL] SQL tab in the spark UI...
GitHub user shahidki31 opened a pull request:
https://github.com/apache/spark/pull/22592
[SPARK-25575][WEBUI][SQL] SQL tab in the spark UI support hide tables, to
make it consistent with other tabs.
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in
the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024
https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
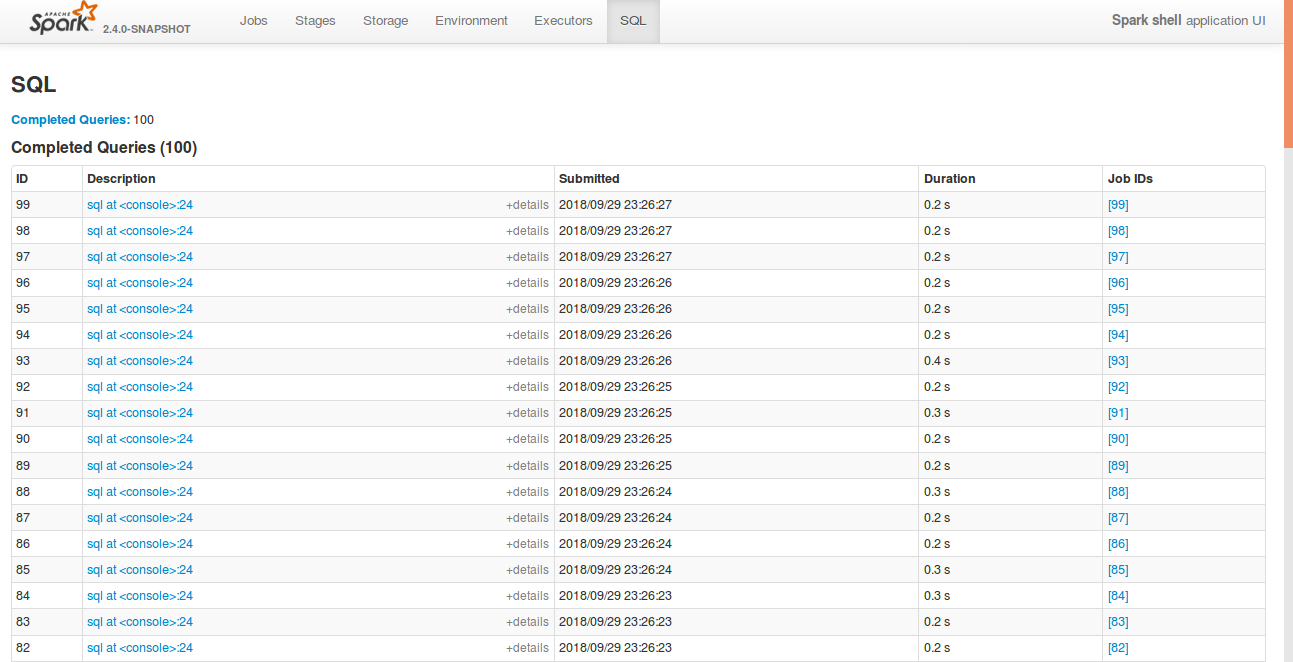
**After fix:**

(Please explain how this patch was tested. E.g. unit tests, integration
tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise,
remove this)
Please review http://spark.apache.org/contributing.html before opening a
pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/shahidki31/spark SPARK-25575
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22592.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22592
commit ef40698e107090d69e06f41194eb68673791b6d8
Author: Shahid
Date: 2018-09-29T16:48:07Z
Spark SQL ui about the contents of the form need to have hidden and show
features, when the table records very much.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21990: [SPARK-25003][PYSPARK] Use SessionExtensions in P...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/21990#discussion_r221436367 --- Diff: python/pyspark/sql/session.py --- @@ -212,13 +212,17 @@ def __init__(self, sparkContext, jsparkSession=None): self._sc = sparkContext self._jsc = self._sc._jsc self._jvm = self._sc._jvm + if jsparkSession is None: if self._jvm.SparkSession.getDefaultSession().isDefined() \ and not self._jvm.SparkSession.getDefaultSession().get() \ .sparkContext().isStopped(): jsparkSession = self._jvm.SparkSession.getDefaultSession().get() else: -jsparkSession = self._jvm.SparkSession(self._jsc.sc()) +extensions = self._sc._jvm.org.apache.spark.sql\ --- End diff -- tiny nit: just for consistency `extensions = self._sc._jvm.org.apache.spark.sql\` -> `extensions = self._sc._jvm.org.apache.spark.sql \` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22581 **[Test build #96804 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96804/testReport)** for PR 22581 at commit [`bdbfbfe`](https://github.com/apache/spark/commit/bdbfbfe59da6f6ba2814e4816e556c296eab7f59). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22581 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3597/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21990: [SPARK-25003][PYSPARK] Use SessionExtensions in Pyspark
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21990 Looks close to go. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22581 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21990: [SPARK-25003][PYSPARK] Use SessionExtensions in P...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/21990#discussion_r221436324 --- Diff: python/pyspark/sql/session.py --- @@ -212,13 +212,17 @@ def __init__(self, sparkContext, jsparkSession=None): self._sc = sparkContext self._jsc = self._sc._jsc self._jvm = self._sc._jvm + --- End diff -- really not a big deal but let's revert this newline to leave related changes only. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21990: [SPARK-25003][PYSPARK] Use SessionExtensions in P...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21990#discussion_r221436261
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/SparkSessionExtensions.scala ---
@@ -169,3 +178,29 @@ class SparkSessionExtensions {
parserBuilders += builder
}
}
+
+object SparkSessionExtensions extends Logging {
+
+ /**
+ * Initialize extensions if the user has defined a configurator class in
their SparkConf.
+ * This class will be applied to the extensions passed into this
function.
+ */
+ private[sql] def applyExtensionsFromConf(conf: SparkConf, extensions:
SparkSessionExtensions) {
--- End diff --
Can you just put this in `SparkSession` object and make it `private[spark]`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22581 just rebased to run the test to reflect the latest changes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22581 rebased to reflect the latest change. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21669: [SPARK-23257][K8S] Kerberos Support for Spark on K8S
Github user suryag10 commented on the issue: https://github.com/apache/spark/pull/21669 Hi Ilan, Point to note, this kerberos support for spark k8s is working only for the cluster mode deployment. As client mode is also supported now in spark K8S, we should plan for supporting the kerberos for client mode as well. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22587: [SPARK-25570][SQL][TEST] Replace 2.3.1 with 2.3.2...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22587#discussion_r221435024
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
---
@@ -206,7 +206,7 @@ class HiveExternalCatalogVersionsSuite extends
SparkSubmitTestUtils {
object PROCESS_TABLES extends QueryTest with SQLTestUtils {
// Tests the latest version of every release line.
- val testingVersions = Seq("2.1.3", "2.2.2", "2.3.1")
+ val testingVersions = Seq("2.1.3", "2.2.2", "2.3.2")
--- End diff --
https://github.com/apache/spark-website/pull/151 is created.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21990: [SPARK-25003][PYSPARK] Use SessionExtensions in Pyspark
Github user RussellSpitzer commented on the issue: https://github.com/apache/spark/pull/21990 I'm fine with anything really, I still think the ideal solution is probably not to tie the creation of the py4j gateway to the SparkContext, but that's probably a much bigger refactor. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22591: [SPARK-25571][SQL] Add withColumnsRenamed method to Data...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22591 Please take a look for PRs or JIRAs before creating them. It's an exact duplicate of SPARK-25430. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22591: [SPARK-25571][SQL] Add withColumnsRenamed method to Data...
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/22591
```
// before
ds.withColumnRenamed("first_name", "firstName")
.withColumnRenamed("last_name", "lastName")
.withColumnRenamed("postal_code", "postalCode")
// after
ds.withColumnsRenamed(
"first_name" -> "firstName",
"last_name" -> "lastName",
"postal_code" -> "postalCode"
)
// or
ds.withColumnsRenamed(Map(
"first_name" -> "firstName",
"last_name" -> "lastName",
"postal_code" -> "postalCode"
))
```
This doesn't looks useful or making the codes even shorter. I don't think
we should add this.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22316: [SPARK-25048][SQL] Pivoting by multiple columns in Scala...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22316 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96800/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22316: [SPARK-25048][SQL] Pivoting by multiple columns in Scala...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22316 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22316: [SPARK-25048][SQL] Pivoting by multiple columns in Scala...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22316 **[Test build #96800 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96800/testReport)** for PR 22316 at commit [`43972ef`](https://github.com/apache/spark/commit/43972ef4461451b346a0a4ba7191a8c7ed00afb9). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22587: [SPARK-25570][SQL][TEST] Replace 2.3.1 with 2.3.2...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22587#discussion_r221434222
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
---
@@ -206,7 +206,7 @@ class HiveExternalCatalogVersionsSuite extends
SparkSubmitTestUtils {
object PROCESS_TABLES extends QueryTest with SQLTestUtils {
// Tests the latest version of every release line.
- val testingVersions = Seq("2.1.3", "2.2.2", "2.3.1")
+ val testingVersions = Seq("2.1.3", "2.2.2", "2.3.2")
--- End diff --
Is it `release-process.md`, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22484: [SPARK-25476][SPARK-25510][TEST] Refactor Aggrega...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22484#discussion_r221434117
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/SqlBasedBenchmark.scala
---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.benchmark
+
+import org.apache.spark.benchmark.{Benchmark, BenchmarkBase}
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.plans.SQLHelper
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * Common base trait to run benchmark with the Dataset and DataFrame API.
+ */
+trait SqlBasedBenchmark extends BenchmarkBase with SQLHelper {
--- End diff --
Thank you, @gengliangwang and @wangyum . Let me think about this again.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22582 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3596/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22582 **[Test build #96803 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96803/testReport)** for PR 22582 at commit [`66206a1`](https://github.com/apache/spark/commit/66206a1f99a21bfac13056fc0e9d7ce3daed2619). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22582 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22582: [SPARK-25505][SQL][FOLLOWUP] Fix for attributes cosmetic...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/22582 thanks for the review @dongjoon-hyun and @viirya. I think I addressed your comments. Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22584: [SPARK-25262][DOC][FOLLOWUP] Fix missing markup tag
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22584 Thank you, @HyukjinKwon and @mgaido91 ! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22580: [SPARK-25508][SQL][TEST] Refactor OrcReadBenchmar...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22580 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22587: [SPARK-25570][SQL][TEST] Replace 2.3.1 with 2.3.2 in Hiv...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22587 Thank you, @HyukjinKwon and @wangyum . --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22587: [SPARK-25570][SQL][TEST] Replace 2.3.1 with 2.3.2...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22587#discussion_r221433361
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala
---
@@ -206,7 +206,7 @@ class HiveExternalCatalogVersionsSuite extends
SparkSubmitTestUtils {
object PROCESS_TABLES extends QueryTest with SQLTestUtils {
// Tests the latest version of every release line.
- val testingVersions = Seq("2.1.3", "2.2.2", "2.3.1")
+ val testingVersions = Seq("2.1.3", "2.2.2", "2.3.2")
--- End diff --
Sure!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22580: [SPARK-25508][SQL][TEST] Refactor OrcReadBenchmark to us...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22580 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22581 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22581 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96798/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22581: [SPARK-25565][BUILD] Add scalastyle rule to check add Lo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22581 **[Test build #96798 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96798/testReport)** for PR 22581 at commit [`d48825d`](https://github.com/apache/spark/commit/d48825d9469fa8c9d360620db9183f1ec949f67c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22589: [SPARK-25572][SPARKR] test only if not cran
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22589 We are tryin this now - we can clean it up if this works --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22591: [SPARK-25571][SQL] Add withColumnsRenamed method ...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22591#discussion_r221431453
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -2300,6 +2300,60 @@ class Dataset[T] private[sql](
}
}
+ /**
+ * (Scala-specific) Returns a new Dataset with renamed columns.
+ * This is a no-op if schema doesn't contain any columns in map.
+ *
+ * {{{
+ * ds.withColumnsRenamed(
+ * "exist_column1" -> "new_column1",
+ * "exist_column2" -> "new_column2"
+ * )
+ * }}}
+ *
+ * @group untypedrel
+ * @since 3.0.0
+ */
+ @scala.annotation.varargs
+ def withColumnsRenamed(columnMap: (String, String), columnMaps: (String,
String)*): DataFrame = {
+withColumnsRenamed((columnMap +: columnMaps).toMap)
+ }
+
+ /**
+ * (Scala-specific) Returns a new Dataset with renamed columns.
+ * This is a no-op if schema doesn't contain any columns in map.
+ *
+ * {{{
+ * ds.withColumnsRenamed(Map(
+ * "exist_column1" -> "new_column1",
+ * "exist_column2" -> "new_column2"
+ * ))
+ * }}}
+ *
+ * @group untypedrel
+ * @since 3.0.0
+ */
+ def withColumnsRenamed(columnMap: Map[String, String]): DataFrame = {
--- End diff --
These changes seem to be duplicated:
https://github.com/apache/spark/pull/22428/files#diff-7a46f10c3cedbf013cf255564d9483cdR2316
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22429: [SPARK-25440][SQL] Dumping query execution info to a fil...
Github user MaxGekk commented on the issue: https://github.com/apache/spark/pull/22429 @gatorsmile @zsxwing @hvanhovell @viirya @rednaxelafx @HyukjinKwon Please, take a look at the PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22379 **[Test build #96802 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96802/testReport)** for PR 22379 at commit [`a5b6f69`](https://github.com/apache/spark/commit/a5b6f696c5f410d3be93299bb748799d37d04bb9). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22461: [SPARK-25453][SQL][TEST] OracleIntegrationSuite IllegalA...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22461 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96795/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22461: [SPARK-25453][SQL][TEST] OracleIntegrationSuite IllegalA...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22461 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22461: [SPARK-25453][SQL][TEST] OracleIntegrationSuite IllegalA...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22461 **[Test build #96795 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96795/testReport)** for PR 22461 at commit [`f6274a5`](https://github.com/apache/spark/commit/f6274a50177e18be7b36d87913c44103f2fa02d2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22591: [SPARK-25571][SQL] Add withColumnsRenamed method to Data...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22591 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22591: [SPARK-25571][SQL] Add withColumnsRenamed method to Data...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22591 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22591: [SPARK-25571][SQL] Add withColumnsRenamed method to Data...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22591 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22591: [SPARK-25571][SQL] Add withColumnsRenamed method ...
GitHub user cryeo opened a pull request:
https://github.com/apache/spark/pull/22591
[SPARK-25571][SQL] Add withColumnsRenamed method to Dataset
## What changes were proposed in this pull request?
Add `withColumnsRenamed` method to rename multiple columns at a time as
follows.
```scala
// before
ds.withColumnRenamed("first_name", "firstName")
.withColumnRenamed("last_name", "lastName")
.withColumnRenamed("postal_code", "postalCode")
// after
ds.withColumnsRenamed(
"first_name" -> "firstName",
"last_name" -> "lastName",
"postal_code" -> "postalCode"
)
// or
ds.withColumnsRenamed(Map(
"first_name" -> "firstName",
"last_name" -> "lastName",
"postal_code" -> "postalCode"
))
```
## How was this patch tested?
This patch is tested by unit test.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cryeo/spark SPARK-25571
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22591.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22591
commit af9dabe3919ae3811c258e5dbf224fb7bde225be
Author: Chaerim YEO
Date: 2018-09-29T13:57:16Z
[SPARK-25571][SQL] Add withColumnsRenamed method to Dataset
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r221429353 --- Diff: python/pyspark/sql/session.py --- @@ -252,6 +253,22 @@ def newSession(self): """ return self.__class__(self._sc, self._jsparkSession.newSession()) +@since(2.5) +def getActiveSession(self): --- End diff -- I think the class method should initialize JVM if non existent (see functions.py). Probably Spark context too. If exists, it should use the existing one. Also, let's define this as a property since that's closer to Scala's usage. I know it's difficult to define a static property. You can refer https://github.com/graphframes/graphframes/pull/169/files#diff-e81e6b169c0aa35012a3263b2f31b330R381 or we should consider adding this as a function --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r221429200 --- Diff: python/pyspark/sql/session.py --- @@ -252,6 +253,22 @@ def newSession(self): """ return self.__class__(self._sc, self._jsparkSession.newSession()) +@since(2.5) +def getActiveSession(self): --- End diff -- Wait .. this should be class method. since the scala usage is `SparkSession. getActiveSession` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22295#discussion_r221429170
--- Diff: python/pyspark/sql/session.py ---
@@ -231,6 +231,7 @@ def __init__(self, sparkContext, jsparkSession=None):
or SparkSession._instantiatedSession._sc._jsc is None:
SparkSession._instantiatedSession = self
self._jvm.SparkSession.setDefaultSession(self._jsparkSession)
+self._jvm.SparkSession.setActiveSession(self._jsparkSession)
--- End diff --
Simialr. I was expecting something like:
```python
session1 = SparkSession.builder.config("key1", "value1").getOrCreate()
session2 = SparkSession.builder.config("key2", "value2").getOrCreate()
assert(session2 == SparkSession.getActiveSession())
session1.createDataFrame([(1, 'Alice')], ['age', 'name'])
assert(session1 == SparkSession.getActiveSession())
```
does this work?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22316: [SPARK-25048][SQL] Pivoting by multiple columns i...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22316 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22316: [SPARK-25048][SQL] Pivoting by multiple columns in Scala...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22316 I'm merging this. Last change is comment change and lint / unidoc check passed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22316: [SPARK-25048][SQL] Pivoting by multiple columns in Scala...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22316 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22379 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22379 **[Test build #96801 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96801/testReport)** for PR 22379 at commit [`2b7c268`](https://github.com/apache/spark/commit/2b7c2689bc0cbfd9671dc170d09a30ed6c2c1017). * This patch **fails to build**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class SchemaOfJson(` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22379 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96801/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22316: [SPARK-25048][SQL] Pivoting by multiple columns i...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22316#discussion_r221428797
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/RelationalGroupedDataset.scala ---
@@ -330,6 +330,15 @@ class RelationalGroupedDataset protected[sql](
* df.groupBy("year").pivot("course").sum("earnings")
* }}}
*
+ * From Spark 2.5.0, values can be literal columns, for instance,
struct. For pivoting by
+ * multiple columns, use the `struct` function to combine the columns
and values:
+ *
+ * {{{
+ * df.groupBy($"year")
--- End diff --
we can. just to match the examples with above except the difference. really
not a big deal at all.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22379 **[Test build #96801 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96801/testReport)** for PR 22379 at commit [`2b7c268`](https://github.com/apache/spark/commit/2b7c2689bc0cbfd9671dc170d09a30ed6c2c1017). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22316: [SPARK-25048][SQL] Pivoting by multiple columns in Scala...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22316 **[Test build #96800 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96800/testReport)** for PR 22316 at commit [`43972ef`](https://github.com/apache/spark/commit/43972ef4461451b346a0a4ba7191a8c7ed00afb9). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user MaxGekk commented on the issue: https://github.com/apache/spark/pull/22379 Something wrong with build, it takes old version of a class. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22316: [SPARK-25048][SQL] Pivoting by multiple columns i...
Github user MaxGekk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22316#discussion_r221427994
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/RelationalGroupedDataset.scala ---
@@ -330,6 +330,15 @@ class RelationalGroupedDataset protected[sql](
* df.groupBy("year").pivot("course").sum("earnings")
* }}}
*
+ * From Spark 2.5.0, values can be literal columns, for instance,
struct. For pivoting by
+ * multiple columns, use the `struct` function to combine the columns
and values:
+ *
+ * {{{
+ * df.groupBy($"year")
--- End diff --
Why cannot be grouping by `Column` type?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22316: [SPARK-25048][SQL] Pivoting by multiple columns i...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22316#discussion_r221427775
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/RelationalGroupedDataset.scala ---
@@ -330,6 +330,15 @@ class RelationalGroupedDataset protected[sql](
* df.groupBy("year").pivot("course").sum("earnings")
* }}}
*
+ * From Spark 2.5.0, values can be literal columns, for instance,
struct. For pivoting by
+ * multiple columns, use the `struct` function to combine the columns
and values:
+ *
+ * {{{
+ * df.groupBy($"year")
--- End diff --
nit: `$"year"` -> `"year"`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22379 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22379 **[Test build #96799 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96799/testReport)** for PR 22379 at commit [`826be4e`](https://github.com/apache/spark/commit/826be4e67221c9d2a4d904ff56db48073883715c). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22379 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96799/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22379 **[Test build #96799 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/96799/testReport)** for PR 22379 at commit [`826be4e`](https://github.com/apache/spark/commit/826be4e67221c9d2a4d904ff56db48073883715c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user MaxGekk commented on the issue: https://github.com/apache/spark/pull/22379 jenkins, retest this, please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22590: [SPARK-25574][SQL]Add an option `keepQuotes` for parsing...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22590 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/96793/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org