[GitHub] spark issue #22951: [SPARK-25945][SQL] Support locale while parsing date/tim...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22951 **[Test build #98583 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98583/testReport)** for PR 22951 at commit [`8834b4b`](https://github.com/apache/spark/commit/8834b4b804f99d2a31654a4700359bb4f32e6dba). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22972: [SPARK-25971][SQL] Ignore partition byte-size statistics...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22972 **[Test build #98582 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98582/testReport)** for PR 22972 at commit [`ea768d0`](https://github.com/apache/spark/commit/ea768d03d1577d5ed265bcac175522d3e63a34e2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231790964
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
This is the reason i asked why in some flow we are initializing the stats
and for some flow we are not because of which stats will be none and
refreshTable will be never called.
in my PR i told the flow where i saw in insert flow we are not nitializing
the stats because of which refreshTable () flow will never be executed.
But before insert command you execute a select statement where stats will
be intialized and the relation will be cached, now if you execute insert query
refreshTable() will be called as this time the stats will be nonempty
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22972: [SPARK-25971][SQL] Ignore partition byte-size sta...
GitHub user dongjoon-hyun opened a pull request: https://github.com/apache/spark/pull/22972 [SPARK-25971][SQL] Ignore partition byte-size statistics in SQLQueryTestSuite ## What changes were proposed in this pull request? Currently, `SQLQueryTestSuite` is sensitive in terms of the bytes of parquet files in table partitions. If we change the default file format (from Parquet to ORC) or update the metadata of them, the test case should be changed accordingly. This PR aims to make `SQLQueryTestSuite` more robust by ignoring the partition byte statistics. ``` -Partition Statistics 1144 bytes, 2 rows +Partition Statistics [not included in comparison] bytes, 2 rows ``` ## How was this patch tested? Pass the Jenkins with the newly updated test cases. You can merge this pull request into a Git repository by running: $ git pull https://github.com/dongjoon-hyun/spark SPARK-25971 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22972.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22972 commit ea768d03d1577d5ed265bcac175522d3e63a34e2 Author: Dongjoon Hyun Date: 2018-11-08T07:56:23Z [SPARK-25971][SQL] Ignore partition byte-size statistics in SQLQueryTestSuite --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789742
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
might be the way i explained was not clear to all
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789510
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
yep... so it wont execute this flow... this is what i want to say in my PR
https://github.com/apache/spark/pull/22758
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789027
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
Good catch. new created table's stats is empty, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22970 The failures are irrelevant to this PR because this PR only updates benchmark code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22951: [SPARK-25945][SQL] Support locale while parsing date/tim...
Github user MaxGekk commented on the issue: https://github.com/apache/spark/pull/22951 > OMG, what does Ð½Ð¾Ñ 2018 mean BTW? haha It is 3 letters prefix of `ÐоÑбÑÑ` which is November in Russian. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22970 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98578/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22970 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22970 **[Test build #98578 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98578/testReport)** for PR 22970 at commit [`770cc33`](https://github.com/apache/spark/commit/770cc33752f657472010b34262ec10e1612098a2). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231785137
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
Already in CommandUtils.updateTableStats(sparkSession, catalogTable.get)
flow we are invalidating table relation cache, then do we need to call
invalidate here also? May i know the difference between these two statements
Thanks.
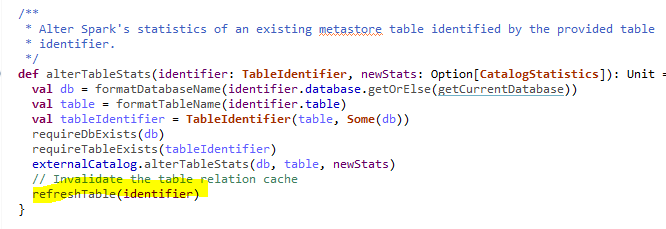
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231783302
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
Let me try to take a look as well this weekends.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMe...
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/22969#discussion_r231783323
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala
---
@@ -787,7 +789,7 @@ case class HashAggregateExec(
|$unsafeRowKeys, ${hashEval.value});
| if ($unsafeRowBuffer == null) {
|// failed to allocate the first page
- |throw new OutOfMemoryError("No enough memory for
aggregation");
+ |throw new $oomeClassName("No enough memory for aggregation");
--- End diff --
Yes, I think so based on my investigation. I grep-ed with
"OutOfMemoryError" and checked the suspicious places.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231783339
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
adding @JoshRosen
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22938: [SPARK-25935][SQL] Prevent null rows from JSON pa...
Github user MaxGekk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22938#discussion_r231783277
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
---
@@ -550,15 +550,33 @@ case class JsonToStructs(
s"Input schema ${nullableSchema.catalogString} must be a struct, an
array or a map.")
}
- // This converts parsed rows to the desired output by the given schema.
@transient
- lazy val converter = nullableSchema match {
-case _: StructType =>
- (rows: Iterator[InternalRow]) => if (rows.hasNext) rows.next() else
null
-case _: ArrayType =>
- (rows: Iterator[InternalRow]) => if (rows.hasNext)
rows.next().getArray(0) else null
-case _: MapType =>
- (rows: Iterator[InternalRow]) => if (rows.hasNext)
rows.next().getMap(0) else null
+ private lazy val castRow = nullableSchema match {
+case _: StructType => (row: InternalRow) => row
+case _: ArrayType => (row: InternalRow) =>
+ if (row.isNullAt(0)) {
+new GenericArrayData(Array())
--- End diff --
I also thought what is better to return here - `null` or empty
`Array`/`MapData`. In the case of `StructType` we return `Row` in the
`PERMISSIVE` mode. For consistency should we return empty array/map in this
mode too?
Maybe we can consider special mode when we can return `null` for the bad
record? For now it is easy to do since we use `FailureSafeParser`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231783212
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
I am not an expert but just know a bit. The mima change look right from a
cursory look.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22971: [SPARK-25970][ML] Add Instrumentation to PrefixSpan
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22971 **[Test build #98581 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98581/testReport)** for PR 22971 at commit [`fd15a57`](https://github.com/apache/spark/commit/fd15a57823efc2c8d3c4fa0883452c0e1815bd73). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22971: [SPARK-25970][ML] Add Instrumentation to PrefixSpan
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22971 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22971: [SPARK-25970][ML] Add Instrumentation to PrefixSpan
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22971 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/4835/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user dbtsai commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231781938
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
Get you.
BTW, are you familiar with Mima? I still can not figure out why it's still
failing.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22971: [SPARK-25970][ML] Add Instrumentation to PrefixSp...
GitHub user zhengruifeng opened a pull request: https://github.com/apache/spark/pull/22971 [SPARK-25970][ML] Add Instrumentation to PrefixSpan ## What changes were proposed in this pull request? Add Instrumentation to PrefixSpan ## How was this patch tested? existing tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/zhengruifeng/spark log_PrefixSpan Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22971.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22971 commit fd15a57823efc2c8d3c4fa0883452c0e1815bd73 Author: zhengruifeng Date: 2018-11-08T06:45:36Z init --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231781880
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
I mean it's related with using external package, it looks so but Avro is
kind of internal source now .. so it's out of date.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user dbtsai commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231781635
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
I am not familiar with R. Can you elaborate? Thanks.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231781676
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
oh, but the problem is other packages probably wouldn't have _2.12
distribution. hm, I think this can be left as was for now.
At least I am going to release spark-xml before Spark 3.0.0 anyway. I can
try to include 2.12 distribution as well and fix it here later.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22967: [SPARK-25956] Make Scala 2.12 as default Scala ve...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22967#discussion_r231780839
--- Diff: docs/sparkr.md ---
@@ -133,7 +133,7 @@ specifying `--packages` with `spark-submit` or `sparkR`
commands, or if initiali
{% highlight r %}
-sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")
+sparkR.session()
--- End diff --
Eh, @dbtsai, I think you can just switch this to other datasources like
`spark-redshift` or `spark-xml`, and fix the description above `you can find
data source connectors for popular file formats like Avro`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22967 **[Test build #98580 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98580/testReport)** for PR 22967 at commit [`2eea387`](https://github.com/apache/spark/commit/2eea387d93dd99365f3b7e79d9c67f87347159b2). * This patch **fails MiMa tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98580/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22960: [SPARK-25955][TEST] Porting JSON tests for CSV fu...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22960 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22958: [SPARK-25952][SQL] Passing actual schema to Jacks...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22958 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMe...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22969#discussion_r231779387
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala
---
@@ -787,7 +789,7 @@ case class HashAggregateExec(
|$unsafeRowKeys, ${hashEval.value});
| if ($unsafeRowBuffer == null) {
|// failed to allocate the first page
- |throw new OutOfMemoryError("No enough memory for
aggregation");
+ |throw new $oomeClassName("No enough memory for aggregation");
--- End diff --
Hi, @ueshin . Is this the final place? If not, can we have a separate JIRA
issue for this?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22960: [SPARK-25955][TEST] Porting JSON tests for CSV functions
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22960 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22967 **[Test build #98580 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98580/testReport)** for PR 22967 at commit [`2eea387`](https://github.com/apache/spark/commit/2eea387d93dd99365f3b7e79d9c67f87347159b2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/4834/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22958: [SPARK-25952][SQL] Passing actual schema to JacksonParse...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22958 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22958: [SPARK-25952][SQL] Passing actual schema to JacksonParse...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22958 @MaxGekk, BTW, can you call `verifyColumnNameOfCorruptRecord` here and datasource as well for JSON and CSV? Of course in a separate PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22958: [SPARK-25952][SQL] Passing actual schema to JacksonParse...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22958 For CSV, looks we are already doing so: https://github.com/apache/spark/blob/76813cfa1e2607ea3b669a79e59b568e96395b2e/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/csvExpressions.scala#L109-L111 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22932: [SPARK-25102][SQL] Write Spark version to ORC/Par...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22932#discussion_r231777190 --- Diff: sql/core/src/test/resources/sql-tests/results/describe-part-after-analyze.sql.out --- @@ -93,7 +93,7 @@ Partition Values [ds=2017-08-01, hr=10] Location [not included in comparison]sql/core/spark-warehouse/t/ds=2017-08-01/hr=10 Created Time [not included in comparison] Last Access [not included in comparison] -Partition Statistics 1121 bytes, 3 rows +Partition Statistics 1229 bytes, 3 rows --- End diff -- Hmmm .. yea, I think we should avoid .. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22951: [SPARK-25945][SQL] Support locale while parsing d...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22951#discussion_r231776739 --- Diff: python/pyspark/sql/readwriter.py --- @@ -349,7 +353,7 @@ def csv(self, path, schema=None, sep=None, encoding=None, quote=None, escape=Non negativeInf=None, dateFormat=None, timestampFormat=None, maxColumns=None, maxCharsPerColumn=None, maxMalformedLogPerPartition=None, mode=None, columnNameOfCorruptRecord=None, multiLine=None, charToEscapeQuoteEscaping=None, -samplingRatio=None, enforceSchema=None, emptyValue=None): +samplingRatio=None, enforceSchema=None, emptyValue=None, locale=None): --- End diff -- Let's add `emptyValue` in `streaming.py` in the same separate PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22951: [SPARK-25945][SQL] Support locale while parsing d...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22951#discussion_r231776568 --- Diff: python/pyspark/sql/readwriter.py --- @@ -267,7 +270,8 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None, mode=mode, columnNameOfCorruptRecord=columnNameOfCorruptRecord, dateFormat=dateFormat, timestampFormat=timestampFormat, multiLine=multiLine, allowUnquotedControlChars=allowUnquotedControlChars, lineSep=lineSep, -samplingRatio=samplingRatio, dropFieldIfAllNull=dropFieldIfAllNull, encoding=encoding) +samplingRatio=samplingRatio, dropFieldIfAllNull=dropFieldIfAllNull, encoding=encoding, --- End diff -- @MaxGekk, let's also add `dropFieldIfAllNull` and `encoding` in `sql/streaming.py` in a separate PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22951: [SPARK-25945][SQL] Support locale while parsing d...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22951#discussion_r231776396 --- Diff: python/pyspark/sql/readwriter.py --- @@ -267,7 +270,8 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None, mode=mode, columnNameOfCorruptRecord=columnNameOfCorruptRecord, dateFormat=dateFormat, timestampFormat=timestampFormat, multiLine=multiLine, allowUnquotedControlChars=allowUnquotedControlChars, lineSep=lineSep, -samplingRatio=samplingRatio, dropFieldIfAllNull=dropFieldIfAllNull, encoding=encoding) +samplingRatio=samplingRatio, dropFieldIfAllNull=dropFieldIfAllNull, encoding=encoding, +locale=locale) --- End diff -- @MaxGekk, looks `sql/streaming.py` is missed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22951: [SPARK-25945][SQL] Support locale while parsing d...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22951#discussion_r231775987 --- Diff: python/pyspark/sql/readwriter.py --- @@ -446,6 +450,9 @@ def csv(self, path, schema=None, sep=None, encoding=None, quote=None, escape=Non If None is set, it uses the default value, ``1.0``. :param emptyValue: sets the string representation of an empty value. If None is set, it uses the default value, empty string. +:param locale: sets a locale as language tag in IETF BCP 47 format. If None is set, + it uses the default value, ``en-US``. For instance, ``locale`` is used while + parsing dates and timestamps. --- End diff -- I think ideally we should apply to decimal parsing too actually. But yea we can leave it separate. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22951: [SPARK-25945][SQL] Support locale while parsing date/tim...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22951 OMG, what does `Ð½Ð¾Ñ 2018` mean BTW? haha --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22932: [SPARK-25102][SQL] Write Spark version to ORC/Par...
Github user dongjoon-hyun commented on a diff in the pull request: https://github.com/apache/spark/pull/22932#discussion_r231775619 --- Diff: sql/core/src/test/resources/sql-tests/results/describe-part-after-analyze.sql.out --- @@ -93,7 +93,7 @@ Partition Values [ds=2017-08-01, hr=10] Location [not included in comparison]sql/core/spark-warehouse/t/ds=2017-08-01/hr=10 Created Time [not included in comparison] Last Access [not included in comparison] -Partition Statistics 1121 bytes, 3 rows +Partition Statistics 1229 bytes, 3 rows --- End diff -- Nice catch! Hmm. I think we should not measure the bytes in the test case. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22932: [SPARK-25102][SQL] Write Spark version to ORC/Par...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/22932#discussion_r231775020 --- Diff: sql/core/src/test/resources/sql-tests/results/describe-part-after-analyze.sql.out --- @@ -93,7 +93,7 @@ Partition Values [ds=2017-08-01, hr=10] Location [not included in comparison]sql/core/spark-warehouse/t/ds=2017-08-01/hr=10 Created Time [not included in comparison] Last Access [not included in comparison] -Partition Statistics 1121 bytes, 3 rows +Partition Statistics 1229 bytes, 3 rows --- End diff -- Hm, does it mean that basically the tests will be failed or fixed for official releases (since it doesn't have `-SNAPSHOT`)? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22966: [SPARK-25965][SQL][TEST] Add avro read benchmark
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/22966 Cool, could you introduce it to Spark? That would be very helpful :) @dbtsai @jleach4 and @aokolnychyi --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes (/ spo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/19045 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes (/ spo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/19045 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98573/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes (/ spo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/19045 **[Test build #98573 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98573/testReport)** for PR 19045 at commit [`8d504b2`](https://github.com/apache/spark/commit/8d504b23f95722be9eb53aeef84ee71d44a6013e). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user dongjoon-hyun commented on the issue:
https://github.com/apache/spark/pull/22967
At this time, this is MiMa issue.
```
[error] * method compressed()org.apache.spark.ml.linalg.Matrix in trait
org.apache.spark.ml.linalg.Matrix does not have a correspondent in current
version
[error]filter with:
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.ml.linalg.Matrix.compressed")
[error] * method compressedRowMajor()org.apache.spark.ml.linalg.Matrix in
trait org.apache.spark.ml.linalg.Matrix does not have a correspondent in
current version
[error]filter with:
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.ml.linalg.Matrix.compressedRowMajor")
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22967 **[Test build #98579 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98579/testReport)** for PR 22967 at commit [`eb10e5a`](https://github.com/apache/spark/commit/eb10e5a7d25881982f2d13423531969234b1c27c). * This patch **fails MiMa tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98579/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22966: [PARK-25965][SQL][TEST] Add avro read benchmark
Github user dbtsai commented on the issue: https://github.com/apache/spark/pull/22966 jmh is a framework to write benchmark that can generate standardized reports to be consumed by Jenkins. Here is an example, https://github.com/pvillega/jmh-scala-test/blob/master/src/main/scala/com/perevillega/JMHTest.scala --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22967 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/4833/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 bui...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22970 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22967 **[Test build #98579 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98579/testReport)** for PR 22967 at commit [`eb10e5a`](https://github.com/apache/spark/commit/eb10e5a7d25881982f2d13423531969234b1c27c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22970 Thank you, @dbtsai ! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user dbtsai commented on the issue: https://github.com/apache/spark/pull/22967 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user dbtsai commented on the issue: https://github.com/apache/spark/pull/22970 Merged into master as the compilation finished. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22932: [SPARK-25102][SQL] Write Spark version to ORC/Parquet fi...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22932 Yes. It does. If you use `spark.sql.orc.impl=hive`. It has a different version number like the following. ``` File Version: 0.12 with HIVE_8732 ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22823: [SPARK-25676][SQL][TEST] Rename and refactor Benc...
Github user yucai commented on a diff in the pull request:
https://github.com/apache/spark/pull/22823#discussion_r231771399
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/WideTableBenchmark.scala
---
@@ -0,0 +1,52 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.benchmark
+
+import org.apache.spark.benchmark.Benchmark
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * Benchmark to measure performance for wide table.
+ * {{{
+ * To run this benchmark:
+ * 1. without sbt: bin/spark-submit --class
+ *--jars ,
+ * 2. build/sbt "sql/test:runMain "
+ * 3. generate result: SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt
"sql/test:runMain "
+ * Results will be written to
"benchmarks/WideTableBenchmark-results.txt".
+ * }}}
+ */
+object WideTableBenchmark extends SqlBasedBenchmark {
+
+ override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
+runBenchmark("projection on wide table") {
+ val N = 1 << 20
+ val df = spark.range(N)
+ val columns = (0 until 400).map{ i => s"id as id$i"}
+ val benchmark = new Benchmark("projection on wide table", N, output
= output)
+ Seq("10", "100", "1024", "2048", "4096", "8192", "65536").foreach {
n =>
+benchmark.addCase(s"split threshold $n", numIters = 5) { iter =>
+ withSQLConf(SQLConf.CODEGEN_METHOD_SPLIT_THRESHOLD.key -> n) {
+df.selectExpr(columns: _*).foreach(identity(_))
--- End diff --
I see, thanks!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22951: [SPARK-25945][SQL] Support locale while parsing date/tim...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22951 Could you take a look once more, @HyukjinKwon ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22932: [SPARK-25102][SQL] Write Spark version to ORC/Parquet fi...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/22932 Does it have different values for new native ORC writer, old Hive ORC writer --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22966: [PARK-25965][SQL][TEST] Add avro read benchmark
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/22966 @dbtsai Great! I was thinking the benchmark in this PR is kind of simple, so I didn't add it for over months.. The benchmark you mentioned should also workable for other data sources, right? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21679: [SPARK-24695] [SQL]: To add support to return Calendar i...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21679 I think we should close this for now then. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22970 **[Test build #98578 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98578/testReport)** for PR 22970 at commit [`770cc33`](https://github.com/apache/spark/commit/770cc33752f657472010b34262ec10e1612098a2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user dbtsai commented on the issue: https://github.com/apache/spark/pull/22970 LGTM. Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22970 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22970 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/4832/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22823: [SPARK-25676][SQL][TEST] Rename and refactor Benc...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22823#discussion_r231769889
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/WideTableBenchmark.scala
---
@@ -0,0 +1,52 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.benchmark
+
+import org.apache.spark.benchmark.Benchmark
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * Benchmark to measure performance for wide table.
+ * {{{
+ * To run this benchmark:
+ * 1. without sbt: bin/spark-submit --class
+ *--jars ,
+ * 2. build/sbt "sql/test:runMain "
+ * 3. generate result: SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt
"sql/test:runMain "
+ * Results will be written to
"benchmarks/WideTableBenchmark-results.txt".
+ * }}}
+ */
+object WideTableBenchmark extends SqlBasedBenchmark {
+
+ override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
+runBenchmark("projection on wide table") {
+ val N = 1 << 20
+ val df = spark.range(N)
+ val columns = (0 until 400).map{ i => s"id as id$i"}
+ val benchmark = new Benchmark("projection on wide table", N, output
= output)
+ Seq("10", "100", "1024", "2048", "4096", "8192", "65536").foreach {
n =>
+benchmark.addCase(s"split threshold $n", numIters = 5) { iter =>
+ withSQLConf(SQLConf.CODEGEN_METHOD_SPLIT_THRESHOLD.key -> n) {
+df.selectExpr(columns: _*).foreach(identity(_))
--- End diff --
Hi, All.
It turns out that this breaks Scala-2.12 build. I made a PR to fix that.
https://github.com/apache/spark/pull/22970
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22966: [PARK-25965][SQL][TEST] Add avro read benchmark
Github user dbtsai commented on the issue: https://github.com/apache/spark/pull/22966 cc @jleach4 and @aokolnychyi We have a great success using [jmh](http://openjdk.java.net/projects/code-tools/jmh/) for this type of benchmarking; the benchmarks can be written in the unit test. This framework handles JVM warn-up, computes the latency, and throughput, etc, and then generates reports that can be consumed in Jenkins. We also use Jenkins to visualize the trend of performance changes which is very useful to find regressions. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build erro...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22970 @dbtsai . The PR is ready. Could you review this? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22970: [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 bui...
GitHub user dongjoon-hyun opened a pull request: https://github.com/apache/spark/pull/22970 [SPARK-25676][FOLLOWUP][BUILD] Fix Scala 2.12 build error ## What changes were proposed in this pull request? This PR fixes the Scala-2.12 build. ## How was this patch tested? Pass the Jenkins. You can merge this pull request into a Git repository by running: $ git pull https://github.com/dongjoon-hyun/spark SPARK-25676-2.12 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22970.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22970 commit 770cc33752f657472010b34262ec10e1612098a2 Author: Dongjoon Hyun Date: 2018-11-08T03:57:08Z fix scala 2.12 build error --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22967: [SPARK-25956] Make Scala 2.12 as default Scala version i...
Github user dbtsai commented on the issue: https://github.com/apache/spark/pull/22967 @dongjoon-hyun Yeah, seems https://github.com/apache/spark/commit/63ca4bbe792718029f6d6196e8a6bb11d1f20fca breaks the Scala 2.12 build. I'll re-trigger the build once Scala 2.12 build is fixed. Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMemoryErr...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22969 **[Test build #98577 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98577/testReport)** for PR 22969 at commit [`f07ab09`](https://github.com/apache/spark/commit/f07ab0938563fe63dd20fa756543b14478a27c2f). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use weight...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/17086 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98575/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMemoryErr...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22969 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use weight...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/17086 **[Test build #98575 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98575/testReport)** for PR 17086 at commit [`88b4bad`](https://github.com/apache/spark/commit/88b4bad15f525c4dbeb8c6881f5e1246e958a1cf). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `class MulticlassMetrics @Since(\"1.1.0\") (predAndLabelsWithOptWeight: RDD[_ <: Product]) ` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17086: [SPARK-24101][ML][MLLIB] ML Evaluators should use weight...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/17086 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMemoryErr...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22969 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/4831/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMemoryErr...
Github user ueshin commented on the issue: https://github.com/apache/spark/pull/22969 cc @sitalkedia @cloud-fan @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22969: [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMe...
GitHub user ueshin opened a pull request: https://github.com/apache/spark/pull/22969 [SPARK-22827][SQL][FOLLOW-UP] Throw `SparkOutOfMemoryError` in `HashAggregateExec`, too. ## What changes were proposed in this pull request? This is a follow-up pr of #20014 which introduced `SparkOutOfMemoryError` to avoid killing the entire executor when an `OutOfMemoryError` is thrown. We should throw `SparkOutOfMemoryError` in `HashAggregateExec`, too. ## How was this patch tested? Existing tests. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ueshin/apache-spark issues/SPARK-22827/oome Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22969.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22969 commit f07ab0938563fe63dd20fa756543b14478a27c2f Author: Takuya UESHIN Date: 2018-11-08T04:59:35Z Throw `SparkOutOfMemoryError` in `HashAggregateExec`, too. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22965: [SPARK-25964][SQL][Minor] Revise OrcReadBenchmark/DataSo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22965 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22965: [SPARK-25964][SQL][Minor] Revise OrcReadBenchmark/DataSo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22965 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/4830/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22965: [SPARK-25964][SQL][Minor] Revise OrcReadBenchmark...
Github user gengliangwang commented on a diff in the pull request: https://github.com/apache/spark/pull/22965#discussion_r231766852 --- Diff: sql/core/benchmarks/DataSourceReadBenchmark-results.txt --- @@ -2,268 +2,268 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +Java HotSpot(TM) 64-Bit Server VM 1.8.0_131-b11 on Mac OS X 10.13.6 +Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative -SQL CSV 21508 / 22112 0.7 1367.5 1.0X -SQL Json 8705 / 8825 1.8 553.4 2.5X -SQL Parquet Vectorized 157 / 186100.0 10.0 136.7X -SQL Parquet MR1789 / 1794 8.8 113.8 12.0X -SQL ORC Vectorized 156 / 166100.9 9.9 138.0X -SQL ORC Vectorized with copy 218 / 225 72.1 13.9 98.6X -SQL ORC MR1448 / 1492 10.9 92.0 14.9X - -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +SQL CSV 15974 / 16222 1.0 1015.6 1.0X +SQL Json 5917 / 6174 2.7 376.2 2.7X +SQL Parquet Vectorized 115 / 128136.8 7.3 138.9X +SQL Parquet MR1459 / 1571 10.8 92.8 10.9X +SQL ORC Vectorized 164 / 194 95.8 10.4 97.3X +SQL ORC Vectorized with copy 204 / 303 77.2 12.9 78.4X +SQL ORC MR1095 / 1143 14.4 69.6 14.6X + +Java HotSpot(TM) 64-Bit Server VM 1.8.0_131-b11 on Mac OS X 10.13.6 +Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative -ParquetReader Vectorized 202 / 211 77.7 12.9 1.0X -ParquetReader Vectorized -> Row118 / 120133.5 7.5 1.7X +ParquetReader Vectorized 139 / 156113.1 8.8 1.0X +ParquetReader Vectorized -> Row 83 / 89188.7 5.3 1.7X -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +Java HotSpot(TM) 64-Bit Server VM 1.8.0_131-b11 on Mac OS X 10.13.6 +Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative -SQL CSV 23282 / 23312 0.7 1480.2 1.0X -SQL Json 9187 / 9189 1.7 584.1 2.5X -SQL Parquet Vectorized 204 / 218 77.0 13.0 114.0X -SQL Parquet MR1941 / 1953 8.1 123.4 12.0X -SQL ORC Vectorized 217 / 225 72.6 13.8 107.5X -SQL ORC Vectorized with copy 279 / 289 56.3 17.8 83.4X -SQL ORC MR1541 / 1549 10.2 98.0 15.1X - -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +SQL CSV 16394 / 16643 1.0 1042.3 1.0X +SQL Json 6014 / 6020 2.6 382.4 2.7X +SQL Parquet Vectorized 147 / 155106.9 9.4 111.4X +SQL Parquet MR1575 / 1581 10.0 100.1 10.4X +SQL ORC Vectorized 168 / 173 93.9 10.7 97.9X +SQL ORC Vectorized with copy
[GitHub] spark issue #22965: [SPARK-25964][SQL][Minor] Revise OrcReadBenchmark/DataSo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22965 **[Test build #98576 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98576/testReport)** for PR 22965 at commit [`3067a6d`](https://github.com/apache/spark/commit/3067a6d1f63c93b4295425d90e5894d27c840995). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22965: [SPARK-25964][SQL][Minor] Revise OrcReadBenchmark...
Github user gengliangwang commented on a diff in the pull request: https://github.com/apache/spark/pull/22965#discussion_r231765680 --- Diff: sql/core/benchmarks/DataSourceReadBenchmark-results.txt --- @@ -2,268 +2,268 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +Java HotSpot(TM) 64-Bit Server VM 1.8.0_131-b11 on Mac OS X 10.13.6 +Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative -SQL CSV 21508 / 22112 0.7 1367.5 1.0X -SQL Json 8705 / 8825 1.8 553.4 2.5X -SQL Parquet Vectorized 157 / 186100.0 10.0 136.7X -SQL Parquet MR1789 / 1794 8.8 113.8 12.0X -SQL ORC Vectorized 156 / 166100.9 9.9 138.0X -SQL ORC Vectorized with copy 218 / 225 72.1 13.9 98.6X -SQL ORC MR1448 / 1492 10.9 92.0 14.9X - -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +SQL CSV 15974 / 16222 1.0 1015.6 1.0X +SQL Json 5917 / 6174 2.7 376.2 2.7X +SQL Parquet Vectorized 115 / 128136.8 7.3 138.9X +SQL Parquet MR1459 / 1571 10.8 92.8 10.9X +SQL ORC Vectorized 164 / 194 95.8 10.4 97.3X +SQL ORC Vectorized with copy 204 / 303 77.2 12.9 78.4X +SQL ORC MR1095 / 1143 14.4 69.6 14.6X + +Java HotSpot(TM) 64-Bit Server VM 1.8.0_131-b11 on Mac OS X 10.13.6 +Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative -ParquetReader Vectorized 202 / 211 77.7 12.9 1.0X -ParquetReader Vectorized -> Row118 / 120133.5 7.5 1.7X +ParquetReader Vectorized 139 / 156113.1 8.8 1.0X +ParquetReader Vectorized -> Row 83 / 89188.7 5.3 1.7X -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +Java HotSpot(TM) 64-Bit Server VM 1.8.0_131-b11 on Mac OS X 10.13.6 +Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative -SQL CSV 23282 / 23312 0.7 1480.2 1.0X -SQL Json 9187 / 9189 1.7 584.1 2.5X -SQL Parquet Vectorized 204 / 218 77.0 13.0 114.0X -SQL Parquet MR1941 / 1953 8.1 123.4 12.0X -SQL ORC Vectorized 217 / 225 72.6 13.8 107.5X -SQL ORC Vectorized with copy 279 / 289 56.3 17.8 83.4X -SQL ORC MR1541 / 1549 10.2 98.0 15.1X - -OpenJDK 64-Bit Server VM 1.8.0_181-b13 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz +SQL CSV 16394 / 16643 1.0 1042.3 1.0X +SQL Json 6014 / 6020 2.6 382.4 2.7X +SQL Parquet Vectorized 147 / 155106.9 9.4 111.4X +SQL Parquet MR1575 / 1581 10.0 100.1 10.4X +SQL ORC Vectorized 168 / 173 93.9 10.7 97.9X +SQL ORC Vectorized with copy
[GitHub] spark issue #21679: [SPARK-24695] [SQL]: To add support to return Calendar i...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21679 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22921: [SPARK-25908][CORE][SQL] Remove old deprecated it...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22921 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22921: [SPARK-25908][CORE][SQL] Remove old deprecated items in ...
Github user srowen commented on the issue: https://github.com/apache/spark/pull/22921 Merged to master --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22087: [SPARK-25097][ML] Support prediction on single instance ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22087 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22087: [SPARK-25097][ML] Support prediction on single instance ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22087 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98574/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22087: [SPARK-25097][ML] Support prediction on single instance ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22087 **[Test build #98574 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98574/testReport)** for PR 22087 at commit [`01b726f`](https://github.com/apache/spark/commit/01b726f850d5f987a0b1de15f8c4d94a694541b0). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22963: [SPARK-25962][BUILD][PYTHON] Specify minimum vers...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22963 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22938: [SPARK-25935][SQL] Prevent null rows from JSON pa...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22938#discussion_r231762733
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
---
@@ -550,15 +550,33 @@ case class JsonToStructs(
s"Input schema ${nullableSchema.catalogString} must be a struct, an
array or a map.")
}
- // This converts parsed rows to the desired output by the given schema.
@transient
- lazy val converter = nullableSchema match {
-case _: StructType =>
- (rows: Iterator[InternalRow]) => if (rows.hasNext) rows.next() else
null
-case _: ArrayType =>
- (rows: Iterator[InternalRow]) => if (rows.hasNext)
rows.next().getArray(0) else null
-case _: MapType =>
- (rows: Iterator[InternalRow]) => if (rows.hasNext)
rows.next().getMap(0) else null
+ private lazy val castRow = nullableSchema match {
+case _: StructType => (row: InternalRow) => row
+case _: ArrayType => (row: InternalRow) =>
+ if (row.isNullAt(0)) {
+new GenericArrayData(Array())
--- End diff --
I think this is the place `from_json` is different from json data source. A
data source must produce data as rows, while the `from_json` can return array
or map.
I think the previous behavior also makes sense. For array/map, we don't
have the corrupted column, and returning null is reasonable. Actually I prefer
null over empty array/map, but we need more discussion about this behavior.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org