[GitHub] [spark] AmplabJenkins removed a comment on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
AmplabJenkins removed a comment on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network URL: https://github.com/apache/spark/pull/25500#issuecomment-523713916 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14595/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
AmplabJenkins commented on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network URL: https://github.com/apache/spark/pull/25500#issuecomment-523713914 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
AmplabJenkins commented on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network URL: https://github.com/apache/spark/pull/25500#issuecomment-523713916 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14595/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
cloud-fan commented on issue #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema URL: https://github.com/apache/spark/pull/25536#issuecomment-523713382 thanks for your reviews! merging to master This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
cloud-fan closed pull request #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema URL: https://github.com/apache/spark/pull/25536 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
AmplabJenkins removed a comment on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523713145 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] akirillov commented on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
akirillov commented on issue #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network URL: https://github.com/apache/spark/pull/25500#issuecomment-523713344 Thanks for the review, @srowen and @dongjoon-hyun. Probably @samvantran can take a look at this PR? Thanks This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
AmplabJenkins removed a comment on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523713149 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109529/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES]
Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r316467917
##
File path:
examples/src/main/java/org/apache/spark/examples/streaming/JavaDirectKerberizedKafkaWordCount.java
##
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.streaming;
+
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Arrays;
+import java.util.Map;
+import java.util.Set;
+import java.util.regex.Pattern;
+
+import scala.Tuple2;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.serialization.StringDeserializer;
+
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.api.java.*;
+import org.apache.spark.streaming.kafka010.ConsumerStrategies;
+import org.apache.spark.streaming.kafka010.KafkaUtils;
+import org.apache.spark.streaming.kafka010.LocationStrategies;
+import org.apache.spark.streaming.Durations;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaDirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ * Yarn client:
+ *$ bin/run-example --files
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_driver_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * --master yarn
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ * Yarn cluster:
+ *$ bin/run-example --files \
+ *
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab,${krb5_path}/krb5.conf
\
+ * --driver-java-options \
+ * "-Djava.security.auth.login.config=./kafka_jaas.conf \
+ * -Djava.security.krb5.conf=./krb5.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * --master yarn --deploy-mode cluster \
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ *
+ * kafka_jaas.conf can manually create, template as:
+ * KafkaClient {
+ * com.sun.security.auth.module.Krb5LoginModule required
+ * keyTab="./kafka.service.keytab"
+ * useKeyTab=true
+ * storeKey=true
+ * useTicketCache=false
+ * serviceName="kafka"
+ * principal="kafka/h...@example.com";
+ * };
+ * kafka_driver_jaas.conf (used by yarn client) and kafka_jaas.conf are
basically the same
Review comment:
> If `--files` used for keytab and jaas file then both driver and executor
can pick up the same jaas (in keytab file `./kafka.service.keytab` has to be
set). Please see
https://github.com/gaborgsomogyi/spark-structured-secure-kafka-app#spark-submit
Is that not working somehow?
I thought dirver can pick up the jaas, but it can't pick up files upload by
`--files` after my test.
It can just work on cluster mode.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] akirillov commented on a change in pull request #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
akirillov commented on a change in pull request #25500: [SPARK-28778][MESOS]
Fixed executors advertised address when running in virtual network
URL: https://github.com/apache/spark/pull/25500#discussion_r316467832
##
File path:
resource-managers/mesos/src/test/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackendSuite.scala
##
@@ -587,6 +587,30 @@ class MesosCoarseGrainedSchedulerBackendSuite extends
SparkFunSuite
assert(networkInfos.get(0).getLabels.getLabels(1).getValue == "val2")
}
+ test("scheduler backend doesn't set '--hostname' for executor when virtual
network is enabled") {
Review comment:
Thanks, @dongjoon-hyun. Added Jira ticket reference
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
AmplabJenkins commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523713145 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] akirillov commented on a change in pull request #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
akirillov commented on a change in pull request #25500: [SPARK-28778][MESOS]
Fixed executors advertised address when running in virtual network
URL: https://github.com/apache/spark/pull/25500#discussion_r316467859
##
File path:
resource-managers/mesos/src/test/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtilSuite.scala
##
@@ -42,12 +44,28 @@ class MesosSchedulerBackendUtilSuite extends SparkFunSuite
{
val containerInfo = MesosSchedulerBackendUtil.buildContainerInfo(
conf)
val params = containerInfo.getDocker.getParametersList
-assert(params.size() == 3)
-assert(params.get(0).getKey == "a")
-assert(params.get(0).getValue == "1")
-assert(params.get(1).getKey == "b")
-assert(params.get(1).getValue == "2")
-assert(params.get(2).getKey == "c")
-assert(params.get(2).getValue == "3")
+assert(params.size() === 3)
+assert(params.get(0).getKey === "a")
+assert(params.get(0).getValue === "1")
+assert(params.get(1).getKey === "b")
+assert(params.get(1).getValue === "2")
+assert(params.get(2).getKey === "c")
+assert(params.get(2).getValue === "3")
+ }
+
+ test("ContainerInfo respects Docker network configuration") {
Review comment:
Updated
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
AmplabJenkins commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523713149 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109529/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
SparkQA removed a comment on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523670203 **[Test build #109529 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109529/testReport)** for PR 25247 at commit [`6e13c96`](https://github.com/apache/spark/commit/6e13c9681d88a9deb93e5abffb5c5e23313d0d7f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
SparkQA commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523712809 **[Test build #109529 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109529/testReport)** for PR 25247 at commit [`6e13c96`](https://github.com/apache/spark/commit/6e13c9681d88a9deb93e5abffb5c5e23313d0d7f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
AmplabJenkins removed a comment on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507#issuecomment-523712431 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14594/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
AmplabJenkins removed a comment on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507#issuecomment-523712425 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] akirillov commented on a change in pull request #25500: [SPARK-28778][MESOS] Fixed executors advertised address when running in virtual network
akirillov commented on a change in pull request #25500: [SPARK-28778][MESOS]
Fixed executors advertised address when running in virtual network
URL: https://github.com/apache/spark/pull/25500#discussion_r316467338
##
File path:
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala
##
@@ -268,27 +268,19 @@ private[spark] class MesosCoarseGrainedSchedulerBackend(
.getOrElse {
throw new SparkException(s"Executor Spark home `$EXECUTOR_HOME` is
not set!")
}
- val runScript = new File(executorSparkHome, "./bin/spark-class").getPath
- command.setValue(
-"%s \"%s\" org.apache.spark.executor.CoarseGrainedExecutorBackend"
- .format(prefixEnv, runScript) +
-s" --driver-url $driverURL" +
-s" --executor-id $taskId" +
-s" --hostname ${executorHostname(offer)}" +
-s" --cores $numCores" +
-s" --app-id $appId")
+ val executable = new File(executorSparkHome, "./bin/spark-class").getPath
+ val runScript = "%s \"%s\"
org.apache.spark.executor.CoarseGrainedExecutorBackend"
Review comment:
There was a problem with interpolation - checkstyle was failing on the
following string:
```
val runScript = s"$prefixEnv \"$executable\"
org.apache.spark.executor.CoarseGrainedExecutorBackend"
```
Error:
```
error
file=/Users/akirillov/projects/mesosphere/spark/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala
message=Expected token SEMI but got Token(STRING_LITERAL,"
org.apache.spark.executor.CoarseGrainedExecutorBackend",10094,"
org.apache.spark.executor.CoarseGrainedExecutorBackend")
```
The working variant with interpolation looks as following:
```
val runScript =
s"""$prefixEnv "$executable"
| org.apache.spark.executor.CoarseGrainedExecutorBackend
|""".stripMargin.replaceAll("\n", " ")
```
not sure if it's better than `String.format`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
AmplabJenkins commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507#issuecomment-523712431 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14594/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
AmplabJenkins commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507#issuecomment-523712425 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
srowen commented on a change in pull request #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#discussion_r31649 ## File path: docs/sql-ref-syntax-aux-cache-cache-table.md ## @@ -19,4 +19,34 @@ license: | limitations under the License. --- -**This page is under construction** +### Description +`CACHE TABLE` caches the table's contents in the RDD cache within memory. This reduces scanning of the original files in future queries. Review comment: memory or disk, right? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
srowen commented on a change in pull request #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#discussion_r316466742 ## File path: docs/sql-ref-syntax-aux-cache-uncache-table.md ## @@ -19,4 +19,21 @@ license: | limitations under the License. --- -**This page is under construction** +### Description +Removes the specified table from the in-memory cache. Review comment: Likewise, in-memory or on-disk, just to be technically correct. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
SparkQA commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507#issuecomment-523711333 **[Test build #109538 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109538/testReport)** for PR 25507 at commit [`30e2b0f`](https://github.com/apache/spark/commit/30e2b0f3941cbdb0983f724881edd57cf209). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES]
Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r316465282
##
File path:
examples/src/main/java/org/apache/spark/examples/streaming/JavaDirectKerberizedKafkaWordCount.java
##
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.streaming;
+
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Arrays;
+import java.util.Map;
+import java.util.Set;
+import java.util.regex.Pattern;
+
+import scala.Tuple2;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.serialization.StringDeserializer;
+
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.api.java.*;
+import org.apache.spark.streaming.kafka010.ConsumerStrategies;
+import org.apache.spark.streaming.kafka010.KafkaUtils;
+import org.apache.spark.streaming.kafka010.LocationStrategies;
+import org.apache.spark.streaming.Durations;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaDirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ * Yarn client:
+ *$ bin/run-example --files
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_driver_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * --master yarn
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ * Yarn cluster:
+ *$ bin/run-example --files \
+ *
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab,${krb5_path}/krb5.conf
\
+ * --driver-java-options \
+ * "-Djava.security.auth.login.config=./kafka_jaas.conf \
+ * -Djava.security.krb5.conf=./krb5.conf" \
Review comment:
@gaborgsomogyi , Client mode, driver run on client which usually has
environment of kerberos, so it's not need. Cluster mode, driver run in a random
executor which not contain
krb5.conf and it will throw exception:
```
Caused by: javax.security.auth.login.LoginException: Cannot locate KDC
at
com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:804)
at
com.sun.security.auth.module.Krb5LoginModule.login(Krb5LoginModule.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
javax.security.auth.login.LoginContext.invoke(LoginContext.java:755)
at
javax.security.auth.login.LoginContext.access$000(LoginContext.java:195)
at
javax.security.auth.login.LoginContext$4.run(LoginContext.java:682)
at
javax.security.auth.login.LoginContext$4.run(LoginContext.java:680)
at java.security.AccessController.doPrivileged(Native Method)
at
javax.security.auth.login.LoginContext.invokePriv(LoginContext.java:680)
at
javax.security.auth.login.LoginContext.login(LoginContext.java:587)
at
org.apache.kafka.common.security.authenticator.AbstractLogin.login(AbstractLogin.java:60)
at
org.apache.kafka.common.security.kerberos.KerberosLogin.login(KerberosLogin.java:103)
at
org.apache.kafka.common.security.authenticator.LoginManager.(LoginManager.java:64)
at
org.apache.kafka.common.security.authenticator.LoginManager.acquireLoginManager(LoginManager.java:114)
[GitHub] [spark] hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES] Add Java/Scala DirectKerberizedKafkaWordCount examples
hddong commented on a change in pull request #25412: [SPARK-28691][EXAMPLES]
Add Java/Scala DirectKerberizedKafkaWordCount examples
URL: https://github.com/apache/spark/pull/25412#discussion_r316465282
##
File path:
examples/src/main/java/org/apache/spark/examples/streaming/JavaDirectKerberizedKafkaWordCount.java
##
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.streaming;
+
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Arrays;
+import java.util.Map;
+import java.util.Set;
+import java.util.regex.Pattern;
+
+import scala.Tuple2;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.consumer.ConsumerRecord;
+import org.apache.kafka.common.serialization.StringDeserializer;
+
+import org.apache.spark.SparkConf;
+import org.apache.spark.streaming.api.java.*;
+import org.apache.spark.streaming.kafka010.ConsumerStrategies;
+import org.apache.spark.streaming.kafka010.KafkaUtils;
+import org.apache.spark.streaming.kafka010.LocationStrategies;
+import org.apache.spark.streaming.Durations;
+
+/**
+ * Consumes messages from one or more topics in Kafka and does wordcount.
+ * Usage: JavaDirectKerberizedKafkaWordCount
+ *is a list of one or more Kafka brokers
+ *is a consumer group name to consume from topics
+ *is a list of one or more kafka topics to consume from
+ *
+ * Example:
+ * Yarn client:
+ *$ bin/run-example --files
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab \
+ * --driver-java-options
"-Djava.security.auth.login.config=${path}/kafka_driver_jaas.conf" \
+ * --conf \
+ *
"spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./kafka_jaas.conf"
\
+ * --master yarn
+ * streaming.JavaDirectKerberizedKafkaWordCount
broker1-host:port,broker2-host:port \
+ * consumer-group topic1,topic2
+ * Yarn cluster:
+ *$ bin/run-example --files \
+ *
${jaas_path}/kafka_jaas.conf,${keytab_path}/kafka.service.keytab,${krb5_path}/krb5.conf
\
+ * --driver-java-options \
+ * "-Djava.security.auth.login.config=./kafka_jaas.conf \
+ * -Djava.security.krb5.conf=./krb5.conf" \
Review comment:
@gaborgsomogyi , Client mode, driver run on client which usually has
environment of kerberos, so it's not need. Cluster mode, driver run in a random
executor which not contain
krb5.conf and it will throw exception:
···
Caused by: javax.security.auth.login.LoginException: Cannot locate KDC
at
com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:804)
at
com.sun.security.auth.module.Krb5LoginModule.login(Krb5LoginModule.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
javax.security.auth.login.LoginContext.invoke(LoginContext.java:755)
at
javax.security.auth.login.LoginContext.access$000(LoginContext.java:195)
at
javax.security.auth.login.LoginContext$4.run(LoginContext.java:682)
at
javax.security.auth.login.LoginContext$4.run(LoginContext.java:680)
at java.security.AccessController.doPrivileged(Native Method)
at
javax.security.auth.login.LoginContext.invokePriv(LoginContext.java:680)
at
javax.security.auth.login.LoginContext.login(LoginContext.java:587)
at
org.apache.kafka.common.security.authenticator.AbstractLogin.login(AbstractLogin.java:60)
at
org.apache.kafka.common.security.kerberos.KerberosLogin.login(KerberosLogin.java:103)
at
org.apache.kafka.common.security.authenticator.LoginManager.(LoginManager.java:64)
at
org.apache.kafka.common.security.authenticator.LoginManager.acquireLoginManager(LoginManager.java:114)
[GitHub] [spark] AmplabJenkins removed a comment on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python.
AmplabJenkins removed a comment on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python. URL: https://github.com/apache/spark/pull/25545#issuecomment-523709657 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python.
AmplabJenkins removed a comment on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python. URL: https://github.com/apache/spark/pull/25545#issuecomment-523709663 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109531/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python.
AmplabJenkins commented on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python. URL: https://github.com/apache/spark/pull/25545#issuecomment-523709663 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109531/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python.
AmplabJenkins commented on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python. URL: https://github.com/apache/spark/pull/25545#issuecomment-523709657 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python.
SparkQA removed a comment on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python. URL: https://github.com/apache/spark/pull/25545#issuecomment-523681992 **[Test build #109531 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109531/testReport)** for PR 25545 at commit [`7ffd6e4`](https://github.com/apache/spark/commit/7ffd6e4e51eaa8d909320bee4efe64c924802d0f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3
AmplabJenkins removed a comment on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3 URL: https://github.com/apache/spark/pull/25544#issuecomment-523709128 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109532/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python.
SparkQA commented on issue #25545: NETFLIX-BUILD: Set OMP_NUM_THREADS to executor cores for python. URL: https://github.com/apache/spark/pull/25545#issuecomment-523709291 **[Test build #109531 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109531/testReport)** for PR 25545 at commit [`7ffd6e4`](https://github.com/apache/spark/commit/7ffd6e4e51eaa8d909320bee4efe64c924802d0f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3
AmplabJenkins removed a comment on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3 URL: https://github.com/apache/spark/pull/25544#issuecomment-523709123 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3
AmplabJenkins commented on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3 URL: https://github.com/apache/spark/pull/25544#issuecomment-523709123 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3
AmplabJenkins commented on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3 URL: https://github.com/apache/spark/pull/25544#issuecomment-523709128 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109532/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3
SparkQA removed a comment on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3 URL: https://github.com/apache/spark/pull/25544#issuecomment-523681967 **[Test build #109532 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109532/testReport)** for PR 25544 at commit [`fa3bdf6`](https://github.com/apache/spark/commit/fa3bdf6d16ca8b77943ed166733d33411ae80492). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3
SparkQA commented on issue #25544: [SPARK-17875][CORE][BUILD] Remove dependency on Netty 3 URL: https://github.com/apache/spark/pull/25544#issuecomment-523708762 **[Test build #109532 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109532/testReport)** for PR 25544 at commit [`fa3bdf6`](https://github.com/apache/spark/commit/fa3bdf6d16ca8b77943ed166733d33411ae80492). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
maropu commented on a change in pull request #25536: [SPARK-28837][SQL]
CTAS/RTAS should use nullable schema
URL: https://github.com/apache/spark/pull/25536#discussion_r316463260
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2Exec.scala
##
@@ -81,11 +81,12 @@ case class CreateTableAsSelectExec(
}
Utils.tryWithSafeFinallyAndFailureCallbacks({
+ val schema = query.schema.asNullable
Review comment:
Ah, I see. Thanks. Looks ok to me.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
ulysses-you commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-523707693 Thanks for review this. Make hint consistent with repartition api is a good idea. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
rdblue commented on a change in pull request #25536: [SPARK-28837][SQL]
CTAS/RTAS should use nullable schema
URL: https://github.com/apache/spark/pull/25536#discussion_r316462996
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2Exec.scala
##
@@ -81,11 +81,12 @@ case class CreateTableAsSelectExec(
}
Utils.tryWithSafeFinallyAndFailureCallbacks({
+ val schema = query.schema.asNullable
Review comment:
I think it would be incorrect to change the logical plan. The behavior of
CTAS should be that tables are created with nullable types. The query used by
CTAS should not be changed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins
HyukjinKwon commented on a change in pull request #25443: [WIP][SPARK-28723][test-hadoop3.2][test-maven] Test JDK 11 with Hadoop-3.2/Hive 2.3.6 on jenkins URL: https://github.com/apache/spark/pull/25443#discussion_r316462160 ## File path: pom.xml ## @@ -253,6 +253,18 @@ false + + + staged + staged-releases + https://repository.apache.org/content/repositories/staging/ Review comment: FYI, Hive 2.3.6 is being voted at https://www.mail-archive.com/dev@hive.apache.org/msg137043.html This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #20965: [SPARK-21870][SQL] Split aggregation code into small functions
maropu commented on a change in pull request #20965: [SPARK-21870][SQL] Split
aggregation code into small functions
URL: https://github.com/apache/spark/pull/20965#discussion_r316461971
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala
##
@@ -267,29 +302,81 @@ case class HashAggregateExec(
e.aggregateFunction.asInstanceOf[DeclarativeAggregate].mergeExpressions
}
}
-ctx.currentVars = bufVars ++ input
-val boundUpdateExpr = bindReferences(updateExpr, inputAttrs)
-val subExprs =
ctx.subexpressionEliminationForWholeStageCodegen(boundUpdateExpr)
-val effectiveCodes = subExprs.codes.mkString("\n")
-val aggVals = ctx.withSubExprEliminationExprs(subExprs.states) {
- boundUpdateExpr.map(_.genCode(ctx))
-}
-// aggregate buffer should be updated atomic
-val updates = aggVals.zipWithIndex.map { case (ev, i) =>
+
+if (!conf.codegenSplitAggregateFunc) {
+ ctx.currentVars = bufVars ++ input
+ val boundUpdateExpr = updateExpr.map(BindReferences.bindReference(_,
inputAttrs))
+ val subExprs =
ctx.subexpressionEliminationForWholeStageCodegen(boundUpdateExpr)
+ val effectiveCodes = subExprs.codes.mkString("\n")
+ val aggVals = ctx.withSubExprEliminationExprs(subExprs.states) {
+boundUpdateExpr.map(_.genCode(ctx))
+ }
+ // aggregate buffer should be updated atomic
+ val updates = aggVals.zipWithIndex.map { case (ev, i) =>
+s"""
+ | ${bufVars(i).isNull} = ${ev.isNull};
+ | ${bufVars(i).value} = ${ev.value};
+ """.stripMargin
+ }
+ s"""
+ | // do aggregate
Review comment:
I think there is no reason for that (I just followed the other parts, too).
I can fix them in this pr though, I think the fix makes this pr have unrelated
changes. So, If no problem, I'll do follow-up for that later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
cloud-fan commented on a change in pull request #25536: [SPARK-28837][SQL]
CTAS/RTAS should use nullable schema
URL: https://github.com/apache/spark/pull/25536#discussion_r316461201
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2Exec.scala
##
@@ -81,11 +81,12 @@ case class CreateTableAsSelectExec(
}
Utils.tryWithSafeFinallyAndFailureCallbacks({
+ val schema = query.schema.asNullable
Review comment:
I think it's too much work if we need to transform the logical plan and add
an extra Project to change the nullability.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users
AmplabJenkins commented on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users URL: https://github.com/apache/spark/pull/25517#issuecomment-523703280 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109526/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users
AmplabJenkins commented on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users URL: https://github.com/apache/spark/pull/25517#issuecomment-523703279 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users
AmplabJenkins removed a comment on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users URL: https://github.com/apache/spark/pull/25517#issuecomment-523703279 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users
AmplabJenkins removed a comment on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users URL: https://github.com/apache/spark/pull/25517#issuecomment-523703280 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109526/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users
SparkQA commented on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users URL: https://github.com/apache/spark/pull/25517#issuecomment-523703074 **[Test build #109526 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109526/testReport)** for PR 25517 at commit [`3249de3`](https://github.com/apache/spark/commit/3249de327f7372341dd66b7070123215329db561). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users
SparkQA removed a comment on issue #25517: [SPARK-26895][CORE][branch-2.3] prepareSubmitEnvironment should be called within doAs for proxy users URL: https://github.com/apache/spark/pull/25517#issuecomment-523645178 **[Test build #109526 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109526/testReport)** for PR 25517 at commit [`3249de3`](https://github.com/apache/spark/commit/3249de327f7372341dd66b7070123215329db561). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] keypointt commented on a change in pull request #25104: [WIP][SPARK-28341][SQL] refine the v2 session catalog config
keypointt commented on a change in pull request #25104: [WIP][SPARK-28341][SQL] refine the v2 session catalog config URL: https://github.com/apache/spark/pull/25104#discussion_r316457679 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala ## @@ -111,6 +112,35 @@ class Analyzer( override protected def defaultCatalogName: Option[String] = conf.defaultV2Catalog + private lazy val v2SessionCatalog = new V2SessionCatalog(catalog, conf) Review comment: minor and not a propose to change, just a quick check that the naming `V2SessionCatalog` or `SessionCatalogV2` ? I find V2 at the end like `WriteToDataSourceV2` or `CatalogV2Implicits` or `DataSourceV2Relation` in current code space, but also sometimes `V2SessionCatalog`, so I guess either way is ok? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu edited a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
maropu edited a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-523700271 I personally think that, if the current mismatching errors confuse users, we should fix them, first? (btw, I think you'd be better to describe more concrete examples in the PR description as you did in the JIRA description, too. That will make commit messages more understandable...) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directorie
AmplabJenkins removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523700440 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109528/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories
AmplabJenkins commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523700431 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories
AmplabJenkins commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523700440 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109528/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directorie
AmplabJenkins removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523700431 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories
SparkQA commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523700292 **[Test build #109528 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109528/testReport)** for PR 25514 at commit [`9a92b5e`](https://github.com/apache/spark/commit/9a92b5e8a3606e97286c36b3e5f8d364e9943d13). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
maropu commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-523700271 Yea, I have the same opinion with @srowen; if the current mismatching errors confuse users, we should fix them, first? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu edited a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
maropu edited a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-523700271 I personally think that, if the current mismatching errors confuse users, we should fix them, first? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories
SparkQA removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523665836 **[Test build #109528 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109528/testReport)** for PR 25514 at commit [`9a92b5e`](https://github.com/apache/spark/commit/9a92b5e8a3606e97286c36b3e5f8d364e9943d13). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316455428
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/SortMergeJoinExec.scala
##
@@ -45,6 +45,27 @@ case class SortMergeJoinExec(
override lazy val metrics = Map(
"numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output
rows"))
+ override def simpleString(maxFields: Int): String = {
Review comment:
@cloud-fan Oh.. boy... many thanks for catching this. I will remove.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316454665
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/basicPhysicalOperators.scala
##
@@ -682,6 +699,28 @@ abstract class BaseSubqueryExec extends SparkPlan {
override def outputPartitioning: Partitioning = child.outputPartitioning
override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def generateTreeString(
+ depth: Int,
+ lastChildren: Seq[Boolean],
+ append: String => Unit,
+ verbose: Boolean,
+ prefix: String = "",
+ addSuffix: Boolean = false,
+ maxFields: Int,
+ printNodeId: Boolean): Unit = {
+if (!printNodeId) {
Review comment:
@cloud-fan Oh.. because we don't show these SubqueryExec ops in the new
format. Here is an example:
** SQL **
```
explain select * from explain_temp1 where key = (select max(key) from
explain_temp2);
```
** Old output **
```
== Physical Plan ==
*(1) Project [key#33776, val#33777]
+- *(1) Filter (isnotnull(key#33776) AND (key#33776 = Subquery
scalar-subquery#33790))
: +- Subquery scalar-subquery#33790
: +- *(2) HashAggregate(keys=[], functions=[max(key#33778)])
:+- Exchange SinglePartition, true
: +- *(1) HashAggregate(keys=[],
functions=[partial_max(key#33778)])
: +- *(1) ColumnarToRow
: +- FileScan parquet default.explain_temp2[key#33778]
Batched: true, DataFilters: [], Format: Parquet, Location:
InMemoryFileIndex[file:/user/hive/warehouse/explain_temp2], PartitionFilters:
[], PushedFilters: [], ReadSchema: struct
+- *(1) ColumnarToRow
+- FileScan parquet default.explain_temp1[key#33776,val#33777]
Batched: true, DataFilters: [isnotnull(key#33776)], Format: Parquet, Location:
InMemoryFileIndex[file:/user/hive/warehouse/explain_temp1], PartitionFilters:
[], PushedFilters: [IsNotNull(key)], ReadSchema: struct
```
The line `Subquery scalar-subquery#33790` does not show up in the new plan
as we only show the actual plan and not the containing operator.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
maropu commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523698132 > Totally agree. I prefer using the ANSI mode as default as well. Disallowing the legacy mode in V2 also makes sense. I am glad that we come to agreement on this :) +1; the approach looks pretty reasonable to me, too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution
AmplabJenkins removed a comment on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution URL: https://github.com/apache/spark/pull/25456#issuecomment-523697028 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109525/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution
AmplabJenkins removed a comment on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution URL: https://github.com/apache/spark/pull/25456#issuecomment-523697024 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution
AmplabJenkins commented on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution URL: https://github.com/apache/spark/pull/25456#issuecomment-523697024 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution
AmplabJenkins commented on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution URL: https://github.com/apache/spark/pull/25456#issuecomment-523697028 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109525/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution
SparkQA removed a comment on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution URL: https://github.com/apache/spark/pull/25456#issuecomment-523633692 **[Test build #109525 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109525/testReport)** for PR 25456 at commit [`a40c8b9`](https://github.com/apache/spark/commit/a40c8b92c829817fd31a43a967f28f81d14c49ee). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution
SparkQA commented on issue #25456: [SPARK-28739][SQL] Add a simple cost check for Adaptive Query Execution URL: https://github.com/apache/spark/pull/25456#issuecomment-523696708 **[Test build #109525 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109525/testReport)** for PR 25456 at commit [`a40c8b9`](https://github.com/apache/spark/commit/a40c8b92c829817fd31a43a967f28f81d14c49ee). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shrutig removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories
shrutig removed a comment on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523693327 Checking the tests. The tests seemed to have passed on my local machine This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
maropu commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523695857 > Spark needs to follow SQL standard but not Postgres, so making Spark behave the same with Postgres is not a strong reason to me. > I 100% agree on that. Yea, the opinion looks reasonable to me, too. > How about we only use decimal as sum buffer? But, I feel a bit uncomfortable to add a new flag only for this sum behaviour change and I personally think most users might not notice this option. The change to support decimal sum buffer itself looks nice to me, but I think we'd like a coarser flag for that. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523695454 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109537/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523695450 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
SparkQA removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523693196 **[Test build #109537 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109537/testReport)** for PR 25540 at commit [`b3d2e6c`](https://github.com/apache/spark/commit/b3d2e6c328dd8a54b2676fe74a1c139a5684dd05). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
SparkQA commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523695392 **[Test build #109537 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109537/testReport)** for PR 25540 at commit [`b3d2e6c`](https://github.com/apache/spark/commit/b3d2e6c328dd8a54b2676fe74a1c139a5684dd05). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523695450 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523695454 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109537/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316450745
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/QueryExecution.scala
##
@@ -127,10 +128,16 @@ class QueryExecution(
ReuseExchange(sparkSession.sessionState.conf),
ReuseSubquery(sparkSession.sessionState.conf))
- def simpleString: String = withRedaction {
+ def simpleString: String = simpleString(false)
+
+ def simpleString(formatted: Boolean): String = withRedaction {
Review comment:
@cloud-fan Yeah.. actually there are quite a few callers of simpleString
from test suites and other places like Dataset.explain(). They invoke the
function like :
```
queryExecution.simpleString
```
so i wanted to avoid changing all the callers..
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523694346 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109536/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
SparkQA removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523691720 **[Test build #109536 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109536/testReport)** for PR 25532 at commit [`e1f55b3`](https://github.com/apache/spark/commit/e1f55b32c988b84f22b62c9f6d3734e9b4d08f9f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523694341 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523694355 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14593/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523694354 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523694341 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523694346 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109536/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523694355 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14593/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523694354 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
SparkQA commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523694277 **[Test build #109536 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109536/testReport)** for PR 25532 at commit [`e1f55b3`](https://github.com/apache/spark/commit/e1f55b32c988b84f22b62c9f6d3734e9b4d08f9f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ueshin commented on issue #24232: [SPARK-27297] [SQL] Add higher order functions to scala API
ueshin commented on issue #24232: [SPARK-27297] [SQL] Add higher order functions to scala API URL: https://github.com/apache/spark/pull/24232#issuecomment-523693984 @nvander1 Thanks for moving tests to Java tests. Btw, I don't think we need to have the whole tests in Java tests but just need to check whether the lambda works or not because we already check various patterns in Scala tests. Maybe one test per function usage should be fine (two for transform and aggregate, one for others). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shrutig commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories
shrutig commented on issue #25514: [SPARK-28784][SS]StreamExecution and StreamingQueryManager should utilize CheckpointFileManager to interact with checkpoint directories URL: https://github.com/apache/spark/pull/25514#issuecomment-523693327 Checking the tests. The tests seemed to have passed on my local machine This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
SparkQA commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523693196 **[Test build #109537 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109537/testReport)** for PR 25540 at commit [`b3d2e6c`](https://github.com/apache/spark/commit/b3d2e6c328dd8a54b2676fe74a1c139a5684dd05). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference
huaxingao commented on issue #25540: [SPARK-28830][DOC][SQL]Document UNCACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25540#issuecomment-523693037 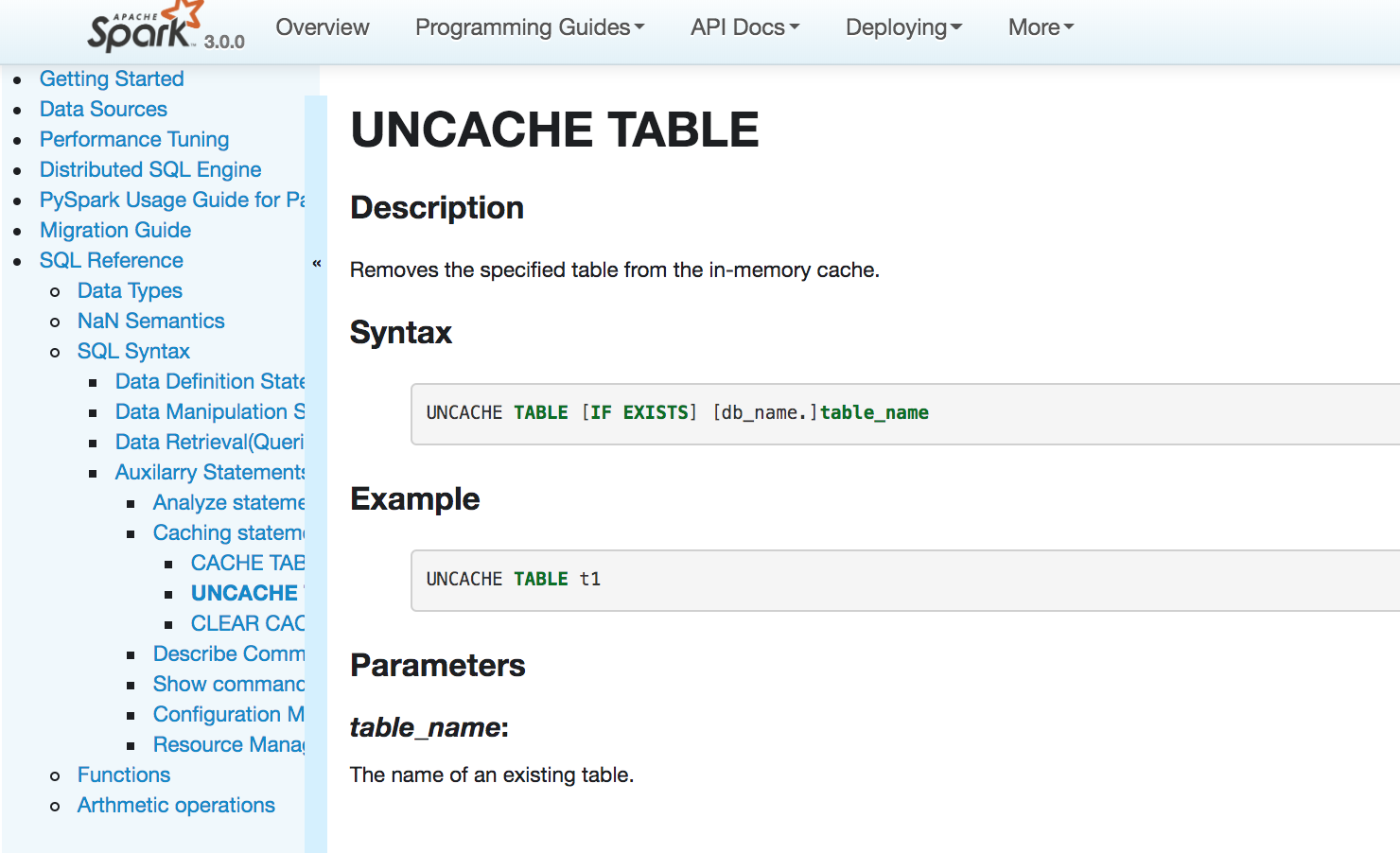 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
maropu commented on issue #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema URL: https://github.com/apache/spark/pull/25536#issuecomment-523692881 +1; the change looks reasonable to me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25536: [SPARK-28837][SQL] CTAS/RTAS should use nullable schema
maropu commented on a change in pull request #25536: [SPARK-28837][SQL]
CTAS/RTAS should use nullable schema
URL: https://github.com/apache/spark/pull/25536#discussion_r316448667
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2Exec.scala
##
@@ -81,11 +81,12 @@ case class CreateTableAsSelectExec(
}
Utils.tryWithSafeFinallyAndFailureCallbacks({
+ val schema = query.schema.asNullable
Review comment:
We don't need to update the schema nullability of the corresponding logical
plans, `CreateTableAsSelect` and `ReplaceTable`, in the analyzer phase? Any
reason to directly update the nullability of physical plans?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316448584
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/QueryPlan.scala
##
@@ -179,6 +180,20 @@ abstract class QueryPlan[PlanType <: QueryPlan[PlanType]]
extends TreeNode[PlanT
override def verboseString(maxFields: Int): String = simpleString(maxFields)
+ override def simpleStringWithNodeId(): String = {
+val operatorId = getTagValue(QueryPlan.OP_ID_TAG).map(id =>
s"$id").getOrElse("unknown")
Review comment:
@cloud-fan Actually i had tried.. but ExplainUtils is in execution package
:-). I couldn't move it to catalyst as it refers to physical operator classes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316448199
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
##
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import scala.collection.mutable
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.{Expression, PlanExpression}
+import org.apache.spark.sql.catalyst.plans.QueryPlan
+import org.apache.spark.sql.catalyst.trees.TreeNodeTag
+
+object ExplainUtils {
+ /**
+ * Given a input physical plan, performs the following tasks.
+ * 1. Computes the operator id for current operator and records it in the
operaror
+ * by setting a tag.
+ * 2. Computes the whole stage codegen id for current operator and records
it in the
+ * operator by setting a tag.
+ * 3. Generate the two part explain output for this plan.
+ * 1. First part explains the operator tree with each operator tagged
with an unique
+ * identifier.
+ * 2. Second part explans each operator in a verbose manner.
+ *
+ * Note : This function skips over subqueries. They are handled by its
caller.
+ *
+ * @param plan Input query plan to process
+ * @param append function used to append the explain output
+ * @startOperationID The start value of operation id. The subsequent
operations will
+ * be assigned higher value.
+ *
+ * @return The last generated operation id for this input plan. This is to
ensure we
+ * always assign incrementing unique id to each operator.
+ *
+ */
+ private def processPlanSkippingSubqueries[T <: QueryPlan[T]](
+ plan: => QueryPlan[T],
+ append: String => Unit,
+ startOperatorID: Int): Int = {
+
+// ReusedSubqueryExecs are skipped over
+if (plan.isInstanceOf[BaseSubqueryExec]) {
+ return startOperatorID
+}
+
+val operationIDs = new mutable.ArrayBuffer[(Int, QueryPlan[_])]()
+var currentOperatorID = startOperatorID
+try {
+ currentOperatorID = generateOperatorIDs(plan, currentOperatorID,
operationIDs)
+ generateWholeStageCodegenIds(plan)
+
+ QueryPlan.append(
+plan,
+append,
+verbose = false,
+addSuffix = false,
+printOperatorId = true)
+
+ append("\n")
+ var i: Integer = 0
+ for ((opId, curPlan) <- operationIDs) {
+append(curPlan.verboseStringWithOperatorId())
+ }
+} catch {
+ case e: AnalysisException => append(e.toString)
+}
+currentOperatorID
+ }
+
+ /**
+ * Given a input physical plan, performs the following tasks.
+ * 1. Generates the explain output for the input plan excluding the
subquery plans.
+ * 2. Generates the explain output for each subquery referenced in the
plan.
+ */
+ def processPlan[T <: QueryPlan[T]](
+ plan: => QueryPlan[T],
+ append: String => Unit): Unit = {
+try {
+ val subqueries = ArrayBuffer.empty[(SparkPlan, Expression, SparkPlan)]
+ var currentOperatorID = 0
+ currentOperatorID = processPlanSkippingSubqueries(plan, append,
currentOperatorID)
+ getSubqueries(plan, subqueries)
+ var i = 0
+
+ // Process all the subqueries in the plan.
+ for (sub <- subqueries) {
+if (i == 0) {
+ append("\n= Subqueries =\n\n")
+}
+i = i + 1
Review comment:
@cloud-fan actually i need that variable to print the subquery number ? I
print like :
```
subquery:1
subquery:2
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mai
[GitHub] [spark] SparkQA commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
SparkQA commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523691720 **[Test build #109536 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109536/testReport)** for PR 25532 at commit [`e1f55b3`](https://github.com/apache/spark/commit/e1f55b32c988b84f22b62c9f6d3734e9b4d08f9f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316447655
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
##
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import scala.collection.mutable
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.{Expression, PlanExpression}
+import org.apache.spark.sql.catalyst.plans.QueryPlan
+import org.apache.spark.sql.catalyst.trees.TreeNodeTag
+
+object ExplainUtils {
+ /**
+ * Given a input physical plan, performs the following tasks.
+ * 1. Computes the operator id for current operator and records it in the
operaror
+ * by setting a tag.
+ * 2. Computes the whole stage codegen id for current operator and records
it in the
+ * operator by setting a tag.
+ * 3. Generate the two part explain output for this plan.
+ * 1. First part explains the operator tree with each operator tagged
with an unique
+ * identifier.
+ * 2. Second part explans each operator in a verbose manner.
+ *
+ * Note : This function skips over subqueries. They are handled by its
caller.
+ *
+ * @param plan Input query plan to process
+ * @param append function used to append the explain output
+ * @startOperationID The start value of operation id. The subsequent
operations will
+ * be assigned higher value.
+ *
+ * @return The last generated operation id for this input plan. This is to
ensure we
+ * always assign incrementing unique id to each operator.
+ *
+ */
+ private def processPlanSkippingSubqueries[T <: QueryPlan[T]](
+ plan: => QueryPlan[T],
+ append: String => Unit,
+ startOperatorID: Int): Int = {
+
+// ReusedSubqueryExecs are skipped over
+if (plan.isInstanceOf[BaseSubqueryExec]) {
+ return startOperatorID
+}
+
+val operationIDs = new mutable.ArrayBuffer[(Int, QueryPlan[_])]()
+var currentOperatorID = startOperatorID
+try {
+ currentOperatorID = generateOperatorIDs(plan, currentOperatorID,
operationIDs)
+ generateWholeStageCodegenIds(plan)
+
+ QueryPlan.append(
+plan,
+append,
+verbose = false,
+addSuffix = false,
+printOperatorId = true)
+
+ append("\n")
+ var i: Integer = 0
+ for ((opId, curPlan) <- operationIDs) {
+append(curPlan.verboseStringWithOperatorId())
+ }
+} catch {
+ case e: AnalysisException => append(e.toString)
+}
+currentOperatorID
+ }
+
+ /**
+ * Given a input physical plan, performs the following tasks.
+ * 1. Generates the explain output for the input plan excluding the
subquery plans.
+ * 2. Generates the explain output for each subquery referenced in the
plan.
+ */
+ def processPlan[T <: QueryPlan[T]](
+ plan: => QueryPlan[T],
+ append: String => Unit): Unit = {
+try {
+ val subqueries = ArrayBuffer.empty[(SparkPlan, Expression, SparkPlan)]
+ var currentOperatorID = 0
+ currentOperatorID = processPlanSkippingSubqueries(plan, append,
currentOperatorID)
+ getSubqueries(plan, subqueries)
+ var i = 0
+
+ // Process all the subqueries in the plan.
+ for (sub <- subqueries) {
+if (i == 0) {
+ append("\n= Subqueries =\n\n")
+}
+i = i + 1
+append(s"Subquery:$i Hosting operator id = " +
+ s"${getOpId(sub._1)} Hosting Expression = ${sub._2}\n")
+
+// For each subquery expression in the parent plan, process its child
plan to compute
+// the explain output.
+currentOperatorID = processPlanSkippingSubqueries(
+ sub._3,
+ append,
+ currentOperatorID)
+append("\n")
+ }
+} finally {
+ removeTags(plan)
+}
+ }
+
+ /**
+ * Traverses the supplied input plan in a bottem-up fashion does the
following :
+ *1. produces a map : operator identifier -> oper
[GitHub] [spark] dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL] Improve EXPLAIN command
dilipbiswal commented on a change in pull request #24759: [SPARK-27395][SQL]
Improve EXPLAIN command
URL: https://github.com/apache/spark/pull/24759#discussion_r316447614
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
##
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import scala.collection.mutable
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.expressions.{Expression, PlanExpression}
+import org.apache.spark.sql.catalyst.plans.QueryPlan
+import org.apache.spark.sql.catalyst.trees.TreeNodeTag
+
+object ExplainUtils {
+ /**
+ * Given a input physical plan, performs the following tasks.
+ * 1. Computes the operator id for current operator and records it in the
operaror
+ * by setting a tag.
+ * 2. Computes the whole stage codegen id for current operator and records
it in the
+ * operator by setting a tag.
+ * 3. Generate the two part explain output for this plan.
+ * 1. First part explains the operator tree with each operator tagged
with an unique
+ * identifier.
+ * 2. Second part explans each operator in a verbose manner.
+ *
+ * Note : This function skips over subqueries. They are handled by its
caller.
+ *
+ * @param plan Input query plan to process
+ * @param append function used to append the explain output
+ * @startOperationID The start value of operation id. The subsequent
operations will
+ * be assigned higher value.
+ *
+ * @return The last generated operation id for this input plan. This is to
ensure we
+ * always assign incrementing unique id to each operator.
+ *
+ */
+ private def processPlanSkippingSubqueries[T <: QueryPlan[T]](
+ plan: => QueryPlan[T],
+ append: String => Unit,
+ startOperatorID: Int): Int = {
+
+// ReusedSubqueryExecs are skipped over
+if (plan.isInstanceOf[BaseSubqueryExec]) {
+ return startOperatorID
+}
+
+val operationIDs = new mutable.ArrayBuffer[(Int, QueryPlan[_])]()
+var currentOperatorID = startOperatorID
+try {
+ currentOperatorID = generateOperatorIDs(plan, currentOperatorID,
operationIDs)
+ generateWholeStageCodegenIds(plan)
+
+ QueryPlan.append(
+plan,
+append,
+verbose = false,
+addSuffix = false,
+printOperatorId = true)
+
+ append("\n")
+ var i: Integer = 0
+ for ((opId, curPlan) <- operationIDs) {
+append(curPlan.verboseStringWithOperatorId())
+ }
+} catch {
+ case e: AnalysisException => append(e.toString)
+}
+currentOperatorID
+ }
+
+ /**
+ * Given a input physical plan, performs the following tasks.
+ * 1. Generates the explain output for the input plan excluding the
subquery plans.
+ * 2. Generates the explain output for each subquery referenced in the
plan.
+ */
+ def processPlan[T <: QueryPlan[T]](
+ plan: => QueryPlan[T],
+ append: String => Unit): Unit = {
+try {
+ val subqueries = ArrayBuffer.empty[(SparkPlan, Expression, SparkPlan)]
+ var currentOperatorID = 0
+ currentOperatorID = processPlanSkippingSubqueries(plan, append,
currentOperatorID)
+ getSubqueries(plan, subqueries)
+ var i = 0
+
+ // Process all the subqueries in the plan.
+ for (sub <- subqueries) {
+if (i == 0) {
+ append("\n= Subqueries =\n\n")
+}
+i = i + 1
+append(s"Subquery:$i Hosting operator id = " +
+ s"${getOpId(sub._1)} Hosting Expression = ${sub._2}\n")
+
+// For each subquery expression in the parent plan, process its child
plan to compute
+// the explain output.
+currentOperatorID = processPlanSkippingSubqueries(
+ sub._3,
+ append,
+ currentOperatorID)
+append("\n")
+ }
+} finally {
+ removeTags(plan)
+}
+ }
+
+ /**
+ * Traverses the supplied input plan in a bottem-up fashion does the
following :
+ *1. produces a map : operator identifier -> oper
[GitHub] [spark] AmplabJenkins removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
AmplabJenkins removed a comment on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523691240 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14592/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference
AmplabJenkins commented on issue #25532: [SPARK-28790][DOC][SQL]Document CACHE TABLE statement in SQL Reference URL: https://github.com/apache/spark/pull/25532#issuecomment-523691240 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14592/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org