[GitHub] [spark] AmplabJenkins commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors
AmplabJenkins commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors URL: https://github.com/apache/spark/pull/25593#issuecomment-525150952 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14826/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors
AmplabJenkins commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors URL: https://github.com/apache/spark/pull/25593#issuecomment-525150947 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors
HyukjinKwon commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors URL: https://github.com/apache/spark/pull/25593#issuecomment-525150529 Otherwise, we should revert #21546 but ironically seems having a different fix from master will have less risk from my perspective because #21546 is too big and old. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525150265 Since I already reverted the first trial of your this PR, I'm honestly reluctant to revert this by myself again. Let me ping PMCs since we need to fix this in anyway urgently. Hi, @gatorsmile , @HyukjinKwon , @srowen . Could you make a decision to this? This is committed 16 hours ago and already caused at least 7 failures in various profiles (including PR builders) @wangyum is suggesting to add `@Ignore` tag. That would be one possible solution. In that case, one thing I'm not sure is that who will fix this later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525150265 Since I already reverted the first trial of your this PR, I'm honestly reluctant to revert this by myself again. Let me ping PMCs since we need to fix this in anyway. Hi, @gatorsmile , @HyukjinKwon , @srowen . Could you make a decision to this? This is committed 16 hours ago and already caused at least 7 failures in various profiles (including PR builders) @wangyum is suggesting to add `@Ignore` tag. That would be one possible solution. In that case, one thing I'm not sure is that who will fix this later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525150265 Since I already reverted the first trial of your this PR, I'm honestly reluctant to revert this by myself again. Let me ping PMCs since we need to fix this in anyway urgently. Hi, @gatorsmile , @cloud-fan , @HyukjinKwon , @srowen . Could you make a decision to this? This is committed 16 hours ago and already caused at least 7 failures in various profiles (including PR builders) @wangyum is suggesting to add `@Ignore` tag. That would be one possible solution. In that case, one thing I'm not sure is that who will fix this later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors
HyukjinKwon commented on issue #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors URL: https://github.com/apache/spark/pull/25593#issuecomment-525149871 cc @cloud-fan, @gatorsmile, @BryanCutler, Also cc @dongjoon-hyun, I think we should block Spark 2.4.4 RC2. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite
AmplabJenkins removed a comment on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite URL: https://github.com/apache/spark/pull/25592#issuecomment-525148945 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14824/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite
AmplabJenkins removed a comment on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite URL: https://github.com/apache/spark/pull/25592#issuecomment-525148939 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request #25593: [SPARK-27992][PYTHON][BRANCH-2.4] Allow Python to join with connection thread to propagate errors
HyukjinKwon opened a new pull request #25593: [SPARK-27992][PYTHON][BRANCH-2.4]
Allow Python to join with connection thread to propagate errors
URL: https://github.com/apache/spark/pull/25593
### What changes were proposed in this pull request?
This PR proposes to backport https://github.com/apache/spark/pull/24834 with
minimised changes. See
https://github.com/apache/spark/pull/24834/commits/519926f908fe3f54cd149a24a7e645c3e69347a8
It was not backported before because basically it targeted a better
exception by propagating the exception from JVM.
However, actually this PR fixed another problem accidentally (see
[SPARK-28881](https://issues.apache.org/jira/browse/SPARK-28881)). This
regression seems introduced by https://github.com/apache/spark/pull/21546.
Root cause is that, seems
https://github.com/apache/spark/blob/23bed0d3c08e03085d3f0c3a7d457eedd30bd67f/sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala#L3370-L3384
`runJob` with `resultHandler` seems able to write partial output.
JVM throws an exception but, since the JVM exception is not propagated into
Python process, Python process doesn't know if the exception is thrown or not
from JVM (it just closes the socket), which results as below:
```
./bin/pyspark --conf spark.driver.maxResultSize=1m
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled",True)
spark.range(1000).toPandas()
```
```
Empty DataFrame
Columns: [id]
Index: []
```
This PR let Python process catches exceptions from JVM.
### Why are the changes needed?
It returns incorrect data. And potentially it returns partial results when
an exception happens in JVM sides. This is a regression. The codes work fine in
Spark 2.3.3.
### Does this PR introduce any user-facing change?
Yes.
```
./bin/pyspark --conf spark.driver.maxResultSize=1m
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled",True)
spark.range(1000).toPandas()
```
```
Traceback (most recent call last):
File "", line 1, in
File "/.../pyspark/sql/dataframe.py", line 2122, in toPandas
batches = self._collectAsArrow()
File "/.../pyspark/sql/dataframe.py", line 2184, in _collectAsArrow
jsocket_auth_server.getResult() # Join serving thread and raise any
exceptions
File "/.../lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in
__call__
File "/.../pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/.../lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in
get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o42.getResult.
: org.apache.spark.SparkException: Exception thrown in awaitResult:
...
Caused by: org.apache.spark.SparkException: Job aborted due to stage
failure: Total size of serialized results of 1 tasks (6.5 MB) is bigger than
spark.driver.maxResultSize (1024.0 KB)
```
now throws an exception as expected.
### How was this patch tested?
Manually as described above. unittest will be added against SPARK-28881.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
SparkQA commented on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-525149497 **[Test build #109784 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109784/testReport)** for PR 25465 at commit [`d9f6644`](https://github.com/apache/spark/commit/d9f664438417ee8f4bb952d41f53c8c0b0e8d500). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite
SparkQA commented on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite URL: https://github.com/apache/spark/pull/25592#issuecomment-525149500 **[Test build #109783 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109783/testReport)** for PR 25592 at commit [`37196c0`](https://github.com/apache/spark/commit/37196c08ae19dd2b2f6862945f3b84c79e704495). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-525148992 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-525149004 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14825/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins commented on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-525149004 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14825/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins commented on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-525148992 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite
AmplabJenkins commented on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite URL: https://github.com/apache/spark/pull/25592#issuecomment-525148945 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14824/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
cloud-fan commented on a change in pull request #25584: [SPARK-28876][SQL]
fallBackToHdfs should not support Hive partitioned table
URL: https://github.com/apache/spark/pull/25584#discussion_r317903176
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala
##
@@ -1484,4 +1484,27 @@ class StatisticsSuite extends
StatisticsCollectionTestBase with TestHiveSingleto
}
}
}
+
+ test("fallBackToHdfs should not support Hive partitioned table") {
+Seq(true, false).foreach { fallBackToHdfs =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHdfs",
+HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
+withTempDir { tempDir =>
+ withTable("spark_28876") {
+sql(s"""
+ |CREATE EXTERNAL TABLE spark_28876(id bigint)
+ |PARTITIONED BY (ds STRING)
+ |STORED AS PARQUET
+ |LOCATION '${tempDir.toURI}'
+ """.stripMargin)
+sql("INSERT INTO TABLE spark_28876 PARTITION (ds='p1') SELECT 1")
Review comment:
can we use `ADD PARTITION` to test external partitions?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite
AmplabJenkins commented on issue #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite URL: https://github.com/apache/spark/pull/25592#issuecomment-525148939 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
wangyum commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525148529 I plan to ignore this test: https://github.com/apache/spark/pull/25592 We can run it manually. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite
wangyum opened a new pull request #25592: [SPARK-28527][SQL][TEST][FOLLOW-UP] Ignores Thrift server ThriftServerQueryTestSuite URL: https://github.com/apache/spark/pull/25592 ### What changes were proposed in this pull request? This PR ignores Thrift server `ThriftServerQueryTestSuite`. ### Why are the changes needed? This ThriftServerQueryTestSuite test case led to frequent Jenkins build failure. ### Does this PR introduce any user-facing change? Yes. ### How was this patch tested? N/A This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly
AmplabJenkins removed a comment on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly URL: https://github.com/apache/spark/pull/25591#issuecomment-525145367 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly
AmplabJenkins removed a comment on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly URL: https://github.com/apache/spark/pull/25591#issuecomment-525145371 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14823/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly
SparkQA commented on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly URL: https://github.com/apache/spark/pull/25591#issuecomment-525145861 **[Test build #109781 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109781/testReport)** for PR 25591 at commit [`4c1c467`](https://github.com/apache/spark/commit/4c1c467a2bc063d11b6fa2d318c04d7aace51135). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525145883 **[Test build #109782 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109782/testReport)** for PR 22138 at commit [`2ac46e4`](https://github.com/apache/spark/commit/2ac46e44253a11e755798372eebacf89a359987f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #24486: [SPARK-27592][SQL] Set the bucketed data source table SerDe correctly
wangyum commented on a change in pull request #24486: [SPARK-27592][SQL] Set
the bucketed data source table SerDe correctly
URL: https://github.com/apache/spark/pull/24486#discussion_r317900088
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveMetastoreCatalogSuite.scala
##
@@ -284,4 +284,40 @@ class DataSourceWithHiveMetastoreCatalogSuite
}
}
+
+ test("SPARK-27592 set the bucketed data source table SerDe correctly") {
+val provider = "parquet"
+withTable("t") {
+ spark.sql(
+s"""
+ |CREATE TABLE t
+ |USING $provider
+ |CLUSTERED BY (c1)
+ |SORTED BY (c1)
+ |INTO 2 BUCKETS
+ |AS SELECT 1 AS c1, 2 AS c2
Review comment:
https://github.com/apache/spark/pull/25591
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS]
Apply Apache Commons Pool to KafkaDataConsumer
URL: https://github.com/apache/spark/pull/22138#discussion_r317900033
##
File path:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/FetchedDataPool.scala
##
@@ -0,0 +1,190 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+import java.util.concurrent.{ScheduledFuture, TimeUnit}
+import java.util.concurrent.atomic.LongAdder
+
+import scala.collection.mutable
+import scala.util.control.NonFatal
+
+import org.apache.kafka.clients.consumer.ConsumerRecord
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.kafka010.KafkaDataConsumer.{CacheKey,
UNKNOWN_OFFSET}
+import org.apache.spark.util.ThreadUtils
+
+/**
+ * Provides object pool for [[FetchedData]] which is grouped by [[CacheKey]].
+ *
+ * Along with CacheKey, it receives desired start offset to find cached
FetchedData which
+ * may be stored from previous batch. If it can't find one to match, it will
create
+ * a new FetchedData.
+ */
+private[kafka010] class FetchedDataPool extends Logging {
+ import FetchedDataPool._
+
+ private val cache: mutable.Map[CacheKey, CachedFetchedDataList] =
mutable.HashMap.empty
Review comment:
Updated both javadoc and PR description.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly
AmplabJenkins commented on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly URL: https://github.com/apache/spark/pull/25591#issuecomment-525145367 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly
AmplabJenkins commented on issue #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly URL: https://github.com/apache/spark/pull/25591#issuecomment-525145371 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14823/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
wangyum commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525144852 Could we ignore this test on jenkins? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525144497 Also, the followings are the recent failures in `master` branch across various profiles. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/332/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/331/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/6380/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/6379/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-3.2/325/ In the PR builder, there will be more failures. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525144497 Also, the followings are the recent failures in `master` branch across various profiles. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/332/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-jdk-11/331/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/6380/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/6379/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-3.2/325/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly
wangyum opened a new pull request #25591: [SPARK-27592][SQL][TEST][FOLLOW-UP] Test set the partitioned bucketed data source table SerDe correctly URL: https://github.com/apache/spark/pull/25591 ### What changes were proposed in this pull request? This PR add test for set the partitioned bucketed data source table SerDe correctly. ### Why are the changes needed? Improve test. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? N/A This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS]
Apply Apache Commons Pool to KafkaDataConsumer
URL: https://github.com/apache/spark/pull/22138#discussion_r317897581
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/FetchedDataPoolSuite.scala
##
@@ -0,0 +1,337 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+
+import scala.collection.JavaConverters._
+import scala.collection.mutable
+
+import org.apache.kafka.clients.consumer.ConsumerRecord
+import org.apache.kafka.common.TopicPartition
+import org.scalatest.PrivateMethodTester
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.sql.kafka010.KafkaDataConsumer.CacheKey
+import org.apache.spark.sql.test.SharedSparkSession
+
+class FetchedDataPoolSuite extends SharedSparkSession with PrivateMethodTester
{
+ import FetchedDataPool._
+ type Record = ConsumerRecord[Array[Byte], Array[Byte]]
+
+ private val dummyBytes = "dummy".getBytes
+
+ // Helper private method accessors for FetchedDataPool
+ private type PoolCacheType = mutable.Map[CacheKey, CachedFetchedDataList]
+ private val _cache = PrivateMethod[PoolCacheType]('cache)
+
+ def getCache(pool: FetchedDataPool): PoolCacheType = {
+pool.invokePrivate(_cache())
+ }
+
+ test("acquire fresh one") {
+val dataPool = FetchedDataPool.build
+
+val cacheKey = CacheKey("testgroup", new TopicPartition("topic", 0))
+
+assert(getCache(dataPool).get(cacheKey).isEmpty)
+
+val data = dataPool.acquire(cacheKey, 0)
+
+assertFetchedDataPoolStatistic(dataPool, expectedNumCreated = 1,
expectedNumTotal = 1)
+assert(getCache(dataPool)(cacheKey).size === 1)
+assert(getCache(dataPool)(cacheKey).head.inUse)
+
+data.withNewPoll(testRecords(0, 5).listIterator, 5)
+
+dataPool.release(cacheKey, data)
+
+assertFetchedDataPoolStatistic(dataPool, expectedNumCreated = 1,
expectedNumTotal = 1)
+assert(getCache(dataPool)(cacheKey).size === 1)
+assert(!getCache(dataPool)(cacheKey).head.inUse)
+
+dataPool.shutdown()
+ }
+
+ test("acquire fetched data from multiple keys") {
+val dataPool = FetchedDataPool.build
+
+val cacheKeys = (0 until 10).map { partId =>
+ CacheKey("testgroup", new TopicPartition("topic", partId))
+}
+
+assert(getCache(dataPool).size === 0)
+cacheKeys.foreach { key => assert(getCache(dataPool).get(key).isEmpty) }
+
+val dataList = cacheKeys.map(key => (key, dataPool.acquire(key, 0)))
+
+assert(getCache(dataPool).size === cacheKeys.size)
+cacheKeys.map { key =>
+ assert(getCache(dataPool)(key).size === 1)
+ assert(getCache(dataPool)(key).head.inUse)
+}
+
+assertFetchedDataPoolStatistic(dataPool, expectedNumCreated = 10,
expectedNumTotal = 10)
+
+dataList.map { case (_, data) =>
+ data.withNewPoll(testRecords(0, 5).listIterator, 5)
+}
+
+dataList.foreach { case (key, data) =>
+ dataPool.release(key, data)
+}
+
+assert(getCache(dataPool).size === cacheKeys.size)
+cacheKeys.map { key =>
+ assert(getCache(dataPool)(key).size === 1)
+ assert(!getCache(dataPool)(key).head.inUse)
+}
+
+dataPool.shutdown()
+ }
+
+ test("continuous use of fetched data from single key") {
+val dataPool = FetchedDataPool.build
+
+val cacheKey = CacheKey("testgroup", new TopicPartition("topic", 0))
+
+assert(getCache(dataPool).get(cacheKey).isEmpty)
+
+val data = dataPool.acquire(cacheKey, 0)
+
+assertFetchedDataPoolStatistic(dataPool, expectedNumCreated = 1,
expectedNumTotal = 1)
+assert(getCache(dataPool)(cacheKey).size === 1)
+assert(getCache(dataPool)(cacheKey).head.inUse)
+
+data.withNewPoll(testRecords(0, 5).listIterator, 5)
+
+(0 to 3).foreach { _ => data.next() }
+
+dataPool.release(cacheKey, data)
+
+// suppose next batch
+
+val data2 = dataPool.acquire(cacheKey, data.nextOffsetInFetchedData)
+
+assert(data.eq(data2))
+
+assertFetchedDataPoolStatistic(dataPool, expectedNumCreated = 1,
expectedNumTotal = 1)
+assert(getCache(dataPool)(cacheKey).size === 1)
+
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525142261 **[Test build #109780 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109780/testReport)** for PR 22138 at commit [`9543745`](https://github.com/apache/spark/commit/9543745bc41b2adf258a8a91e3c5aab59c5d0cbd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
SparkQA commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525140444 **[Test build #109779 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109779/testReport)** for PR 25172 at commit [`41e20f8`](https://github.com/apache/spark/commit/41e20f8700a5cfd908523e454582ef5d90a4dc04). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
SparkQA commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-525140437 **[Test build #109778 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109778/testReport)** for PR 25464 at commit [`b0ae689`](https://github.com/apache/spark/commit/b0ae689fe86f36b6620d5709adeb429c514f40d4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525140044 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14822/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525140038 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-525140009 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-525140013 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14821/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-525140009 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-525140013 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14821/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525140038 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525140044 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14822/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #25561: [SPARK-28810][DOC][SQL] Document SHOW TABLES in SQL Reference.
sandeep-katta commented on a change in pull request #25561:
[SPARK-28810][DOC][SQL] Document SHOW TABLES in SQL Reference.
URL: https://github.com/apache/spark/pull/25561#discussion_r317895360
##
File path: docs/sql-ref-syntax-aux-show-tables.md
##
@@ -18,5 +18,34 @@ license: |
See the License for the specific language governing permissions and
limitations under the License.
---
+### Description
+Return all tables form the database. It shows databse name and whether a table
is temporary.
+
+### Syntax
+{% highlight sql %}
+SHOW TABLES [{FROM|IN} dbname] [LIKE 'pattern']
Review comment:
refer
[tables.scala](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala#L743)
for syntax
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
beliefer commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525139260 Retest this please. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
maropu commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-525138923 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
AmplabJenkins removed a comment on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table URL: https://github.com/apache/spark/pull/25584#issuecomment-525138340 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on issue #24983: [SPARK-27714][SQL][CBO] Support Genetic Algorithm based join reorder
xianyinxin commented on issue #24983: [SPARK-27714][SQL][CBO] Support Genetic Algorithm based join reorder URL: https://github.com/apache/spark/pull/24983#issuecomment-525138556 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
AmplabJenkins removed a comment on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table URL: https://github.com/apache/spark/pull/25584#issuecomment-525138345 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109772/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
AmplabJenkins commented on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table URL: https://github.com/apache/spark/pull/25584#issuecomment-525138345 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109772/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
AmplabJenkins commented on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table URL: https://github.com/apache/spark/pull/25584#issuecomment-525138340 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
SparkQA removed a comment on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table URL: https://github.com/apache/spark/pull/25584#issuecomment-525112280 **[Test build #109772 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109772/testReport)** for PR 25584 at commit [`8d6daca`](https://github.com/apache/spark/commit/8d6daca6fd5b9bfa8d4abd161b1f2e44ba54772f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
cloud-fan closed pull request #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table
SparkQA commented on issue #25584: [SPARK-28876][SQL] fallBackToHdfs should not support Hive partitioned table URL: https://github.com/apache/spark/pull/25584#issuecomment-525137970 **[Test build #109772 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109772/testReport)** for PR 25584 at commit [`8d6daca`](https://github.com/apache/spark/commit/8d6daca6fd5b9bfa8d4abd161b1f2e44ba54772f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
cloud-fan commented on issue #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog URL: https://github.com/apache/spark/pull/25507#issuecomment-525137858 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25507: [SPARK-28667][SQL] Support InsertInto through the V2SessionCatalog
cloud-fan commented on a change in pull request #25507: [SPARK-28667][SQL]
Support InsertInto through the V2SessionCatalog
URL: https://github.com/apache/spark/pull/25507#discussion_r317866727
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -770,40 +760,35 @@ class Analyzer(
object ResolveInsertInto extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators
{
- case i @ InsertIntoStatement(
- UnresolvedRelation(CatalogObjectIdentifier(Some(tableCatalog),
ident)), _, _, _, _)
- if i.query.resolved =>
-loadTable(tableCatalog, ident)
-.map(DataSourceV2Relation.create)
-.map(relation => {
- // ifPartitionNotExists is append with validation, but
validation is not supported
- if (i.ifPartitionNotExists) {
-throw new AnalysisException(
- s"Cannot write, IF NOT EXISTS is not supported for table:
${relation.table.name}")
- }
-
- val partCols = partitionColumnNames(relation.table)
- validatePartitionSpec(partCols, i.partitionSpec)
+ case i @ InsertIntoStatement(u: UnresolvedRelation, _, _, _, _) if
i.query.resolved =>
+lookupV2Relation(u) match {
+ case scala.Right(Some(v2Table: Table)) =>
+val relation = DataSourceV2Relation.create(v2Table)
+// ifPartitionNotExists is append with validation, but validation
is not supported
+if (i.ifPartitionNotExists) {
+ throw new AnalysisException(
+s"Cannot write, IF NOT EXISTS is not supported for table:
${relation.table.name}")
+}
- val staticPartitions =
i.partitionSpec.filter(_._2.isDefined).mapValues(_.get)
- val query = addStaticPartitionColumns(relation, i.query,
staticPartitions)
- val dynamicPartitionOverwrite = partCols.size >
staticPartitions.size &&
- conf.partitionOverwriteMode == PartitionOverwriteMode.DYNAMIC
+val partCols = partitionColumnNames(relation.table)
+validatePartitionSpec(partCols, i.partitionSpec)
- if (!i.overwrite) {
-AppendData.byPosition(relation, query)
- } else if (dynamicPartitionOverwrite) {
-OverwritePartitionsDynamic.byPosition(relation, query)
- } else {
-OverwriteByExpression.byPosition(
- relation, query, staticDeleteExpression(relation,
staticPartitions))
- }
-})
-.getOrElse(i)
+val staticPartitions =
i.partitionSpec.filter(_._2.isDefined).mapValues(_.get)
+val query = addStaticPartitionColumns(relation, i.query,
staticPartitions)
+val dynamicPartitionOverwrite = partCols.size >
staticPartitions.size &&
+ conf.partitionOverwriteMode == PartitionOverwriteMode.DYNAMIC
- case i @ InsertIntoStatement(UnresolvedRelation(AsTableIdentifier(_)),
_, _, _, _)
- if i.query.resolved =>
-InsertIntoTable(i.table, i.partitionSpec, i.query, i.overwrite,
i.ifPartitionNotExists)
+if (!i.overwrite) {
+ AppendData.byPosition(relation, query)
+} else if (dynamicPartitionOverwrite) {
+ OverwritePartitionsDynamic.byPosition(relation, query)
+} else {
+ OverwriteByExpression.byPosition(
+relation, query, staticDeleteExpression(relation,
staticPartitions))
+}
+ case _ =>
+InsertIntoTable(i.table, i.partitionSpec, i.query, i.overwrite,
i.ifPartitionNotExists)
Review comment:
ok let's leave it as it is and clean it up after ALTER TABLE.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command
AmplabJenkins removed a comment on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command URL: https://github.com/apache/spark/pull/25590#issuecomment-525133796 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command
AmplabJenkins commented on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command URL: https://github.com/apache/spark/pull/25590#issuecomment-525134185 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command
AmplabJenkins removed a comment on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command URL: https://github.com/apache/spark/pull/25590#issuecomment-525133700 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command
AmplabJenkins commented on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command URL: https://github.com/apache/spark/pull/25590#issuecomment-525133700 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command
AmplabJenkins commented on issue #25590: [SPARK-28791] [DOC] Documentation for Alter table Command URL: https://github.com/apache/spark/pull/25590#issuecomment-525133796 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525133496 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109773/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525133488 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] PavithraRamachandran opened a new pull request #25590: [SPARK-28791] [DOC] Documentation for Alter table Command
PavithraRamachandran opened a new pull request #25590: [SPARK-28791] [DOC] Documentation for Alter table Command URL: https://github.com/apache/spark/pull/25590 What changes were proposed in this pull request? Document ALTER TABLE statement in SQL Reference Guide. Why are the changes needed? Adding documentation for SQL reference. Does this PR introduce any user-facing change? yes Before: There was no documentation for this. After. 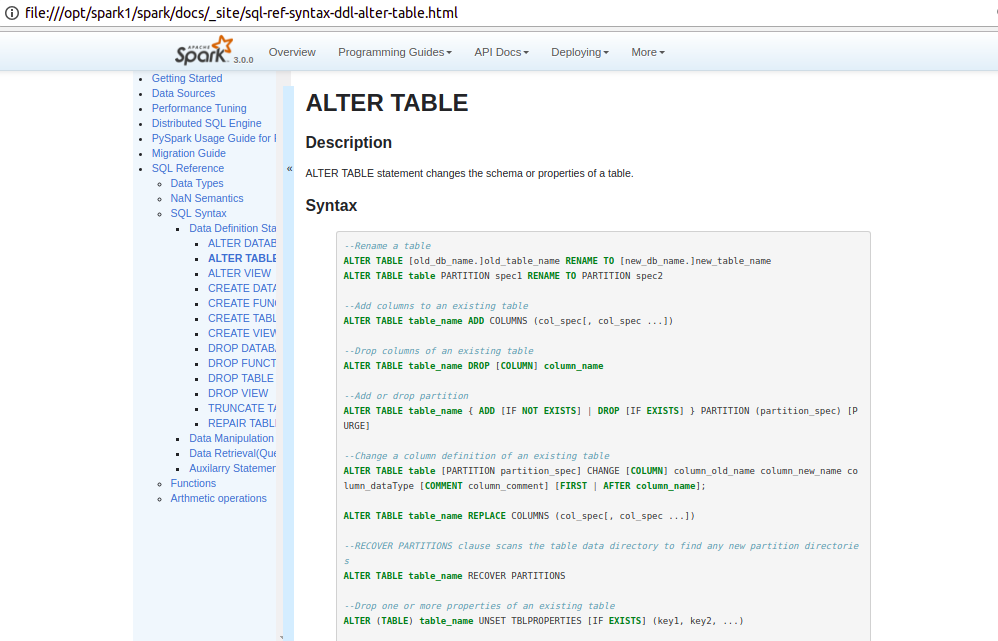 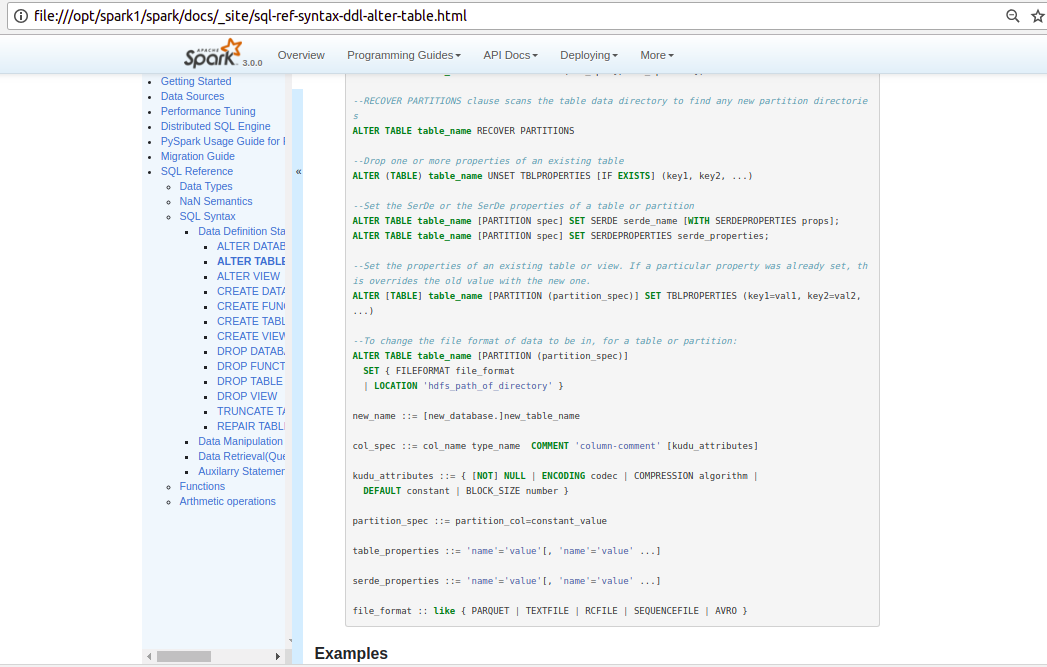 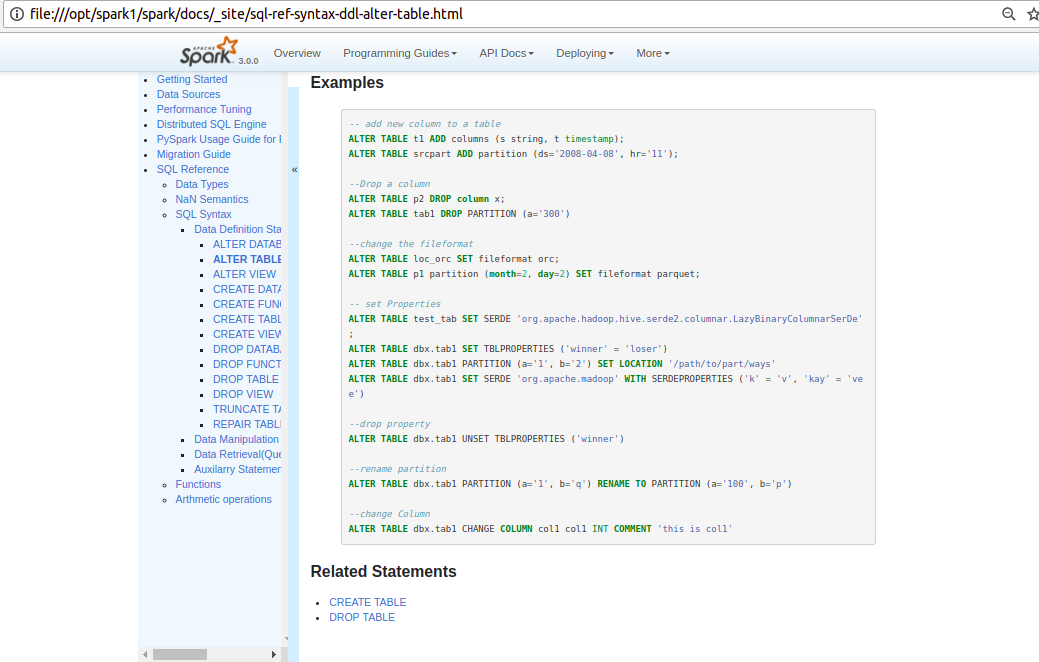 How was this patch tested? Used jekyll build and serve to verify. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525133488 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
AmplabJenkins commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525133496 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109773/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525133266 **[Test build #109773 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109773/testReport)** for PR 22138 at commit [`8cb52e3`](https://github.com/apache/spark/commit/8cb52e39092e74a1db35ee909c5f93ccda9d1e55). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
SparkQA removed a comment on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-525112281 **[Test build #109773 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109773/testReport)** for PR 22138 at commit [`8cb52e3`](https://github.com/apache/spark/commit/8cb52e39092e74a1db35ee909c5f93ccda9d1e55). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25439: [SPARK-28709][DSTREAMS] Fix StreamingContext leak through Streaming
dongjoon-hyun commented on issue #25439: [SPARK-28709][DSTREAMS] Fix StreamingContext leak through Streaming URL: https://github.com/apache/spark/pull/25439#issuecomment-525132625 Thank you all. Yes. This is a good backport candidate for `2.4.5`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25587: [SPARK-28877][PYSPARK][test-hadoop3.2][test-java11] Make jaxb-runtime compile-time dependency
dongjoon-hyun commented on issue #25587: [SPARK-28877][PYSPARK][test-hadoop3.2][test-java11] Make jaxb-runtime compile-time dependency URL: https://github.com/apache/spark/pull/25587#issuecomment-525132096 Technically, the UT failures here are irrelevant to this PR. Especially, last two failures seems to be due to the new test suite flakiness. (https://github.com/apache/spark/pull/25567#issuecomment-525131555) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525131555 Hi, @wangyum and @HyukjinKwon . Sorry, but #25587 failed two times consecutively due to `ThriftServerQueryTestSuite`. Since `ThriftServerQueryTestSuite` is irrelevant to that PR, it seems to be due to its flakiness. Could you take a look at that? - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109764/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/ (2 failures) - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109768/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/ (4 failures) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525131555 Hi, @wangyum and @HyukjinKwon . Sorry, but #25587 failed two times consecutively due to `ThriftServerQueryTestSuite`. Since `ThriftServerQueryTestSuite` is irrelevant to that PR, it seems to be due to its flakiness. Could you take a look at that? - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109764/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/sql/ - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109768/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun commented on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525131555 Hi, @wangyum and @HyukjinKwon . Sorry, but #25587 failed two times consecutively due to `ThriftServerQueryTestSuite`. Since `ThriftServerQueryTestSuite` is irrelevant to that PR, it seems to be due to its flakiness. Could you take a look at that? - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109764/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/sql/ - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109768/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/sql_2/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server
dongjoon-hyun edited a comment on issue #25567: [SPARK-28527][SQL][TEST] Re-run all the tests in SQLQueryTestSuite via Thrift Server URL: https://github.com/apache/spark/pull/25567#issuecomment-525131555 Hi, @wangyum and @HyukjinKwon . Sorry, but #25587 failed two times consecutively due to `ThriftServerQueryTestSuite`. Since `ThriftServerQueryTestSuite` is irrelevant to that PR, it seems to be due to its flakiness. Could you take a look at that? - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109764/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/sql/ - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109768/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/sql_3/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525131275 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109774/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525131273 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zzcclp commented on issue #25439: [SPARK-28709][DSTREAMS] Fix StreamingContext leak through Streaming
zzcclp commented on issue #25439: [SPARK-28709][DSTREAMS] Fix StreamingContext leak through Streaming URL: https://github.com/apache/spark/pull/25439#issuecomment-525131489 OK, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
SparkQA removed a comment on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525123038 **[Test build #109774 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109774/testReport)** for PR 25172 at commit [`41e20f8`](https://github.com/apache/spark/commit/41e20f8700a5cfd908523e454582ef5d90a4dc04). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zzcclp commented on issue #25511: [SPARK-22955][DSTREAMS] - graceful shutdown shouldn't lead to job gen…
zzcclp commented on issue #25511: [SPARK-22955][DSTREAMS] - graceful shutdown shouldn't lead to job gen… URL: https://github.com/apache/spark/pull/25511#issuecomment-525131462 OK, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
SparkQA commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525131245 **[Test build #109774 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109774/testReport)** for PR 25172 at commit [`41e20f8`](https://github.com/apache/spark/commit/41e20f8700a5cfd908523e454582ef5d90a4dc04). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525131273 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array
AmplabJenkins commented on issue #25172: [SPARK-28412][SQL] ANSI SQL: OVERLAY function support byte array URL: https://github.com/apache/spark/pull/25172#issuecomment-525131275 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109774/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25559: [WIP][DO-NOT-MERGE] Test updating Kinesis deps and current state of Kinesis Python tests
SparkQA removed a comment on issue #25559: [WIP][DO-NOT-MERGE] Test updating Kinesis deps and current state of Kinesis Python tests URL: https://github.com/apache/spark/pull/25559#issuecomment-525107118 **[Test build #4841 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4841/testReport)** for PR 25559 at commit [`e760ebb`](https://github.com/apache/spark/commit/e760ebbde9e304a3f3a9355ed12b61c6cfe16287). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25559: [WIP][DO-NOT-MERGE] Test updating Kinesis deps and current state of Kinesis Python tests
SparkQA commented on issue #25559: [WIP][DO-NOT-MERGE] Test updating Kinesis deps and current state of Kinesis Python tests URL: https://github.com/apache/spark/pull/25559#issuecomment-525130210 **[Test build #4841 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4841/testReport)** for PR 25559 at commit [`e760ebb`](https://github.com/apache/spark/commit/e760ebbde9e304a3f3a9355ed12b61c6cfe16287). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kiszk commented on a change in pull request #25470: [SPARK-28751][Core][WIP] Improve java serializer deserialization performance
kiszk commented on a change in pull request #25470: [SPARK-28751][Core][WIP]
Improve java serializer deserialization performance
URL: https://github.com/apache/spark/pull/25470#discussion_r317881044
##
File path: core/src/main/scala/org/apache/spark/rpc/netty/NettyRpcEnv.scala
##
@@ -261,20 +265,20 @@ private[netty] class NettyRpcEnv(
}
private[netty] def serialize(content: Any): ByteBuffer = {
-javaSerializerInstance.serialize(content)
+serializer.get().serialize(content)
}
/**
* Returns [[SerializationStream]] that forwards the serialized bytes to
`out`.
*/
private[netty] def serializeStream(out: OutputStream): SerializationStream =
{
-javaSerializerInstance.serializeStream(out)
+serializer.get.serializeStream(out)
}
private[netty] def deserialize[T: ClassTag](client: TransportClient, bytes:
ByteBuffer): T = {
NettyRpcEnv.currentClient.withValue(client) {
deserialize { () =>
-javaSerializerInstance.deserialize[T](bytes)
+serializer.get.deserialize[T](bytes)
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kiszk commented on a change in pull request #25470: [SPARK-28751][Core][WIP] Improve java serializer deserialization performance
kiszk commented on a change in pull request #25470: [SPARK-28751][Core][WIP]
Improve java serializer deserialization performance
URL: https://github.com/apache/spark/pull/25470#discussion_r317881031
##
File path: core/src/main/scala/org/apache/spark/rpc/netty/NettyRpcEnv.scala
##
@@ -261,20 +265,20 @@ private[netty] class NettyRpcEnv(
}
private[netty] def serialize(content: Any): ByteBuffer = {
-javaSerializerInstance.serialize(content)
+serializer.get().serialize(content)
}
/**
* Returns [[SerializationStream]] that forwards the serialized bytes to
`out`.
*/
private[netty] def serializeStream(out: OutputStream): SerializationStream =
{
-javaSerializerInstance.serializeStream(out)
+serializer.get.serializeStream(out)
Review comment:
nit: do we want to use the same style for `use`? Probably, `get`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions
SparkQA commented on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-525127394 **[Test build #109777 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109777/testReport)** for PR 20965 at commit [`e558d6b`](https://github.com/apache/spark/commit/e558d6beb5802ab9b3eb3e0cff1c6b2eb310834c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
SparkQA commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-525127385 **[Test build #109776 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109776/testReport)** for PR 25520 at commit [`9a49a6a`](https://github.com/apache/spark/commit/9a49a6a5397362951bb8d9c3c7af6a090b538552). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
AmplabJenkins removed a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-525126997 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
AmplabJenkins removed a comment on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-525127005 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14819/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins removed a comment on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-525126995 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins removed a comment on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-525127007 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14820/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins commented on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-525126995 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
AmplabJenkins commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-525127005 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14819/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions
AmplabJenkins commented on issue #20965: [WIP][SPARK-21870][SQL] Split aggregation code into small functions URL: https://github.com/apache/spark/pull/20965#issuecomment-525127007 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14820/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true
AmplabJenkins commented on issue #25520: [SPARK-28621][SQL] Make spark.sql.crossJoin.enabled default value true URL: https://github.com/apache/spark/pull/25520#issuecomment-525126997 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25512: [SPARK-28782][SQL] Support explode function on aggregate expressions
SparkQA commented on issue #25512: [SPARK-28782][SQL] Support explode function on aggregate expressions URL: https://github.com/apache/spark/pull/25512#issuecomment-525124529 **[Test build #109775 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109775/testReport)** for PR 25512 at commit [`48565b6`](https://github.com/apache/spark/commit/48565b674578d3e5cb4bcffad539e6f17ae2a4d3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on issue #25511: [SPARK-22955][DSTREAMS] - graceful shutdown shouldn't lead to job gen…
srowen commented on issue #25511: [SPARK-22955][DSTREAMS] - graceful shutdown shouldn't lead to job gen… URL: https://github.com/apache/spark/pull/25511#issuecomment-525124554 Yes I think that's OK. We're in a 'code freeze' for the 2.4.4 release at the moment, so I hesitate to merge anything but critical fixes until it's finalized. But it could go in for 2.4.5. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org