[GitHub] [spark] AmplabJenkins removed a comment on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only
AmplabJenkins removed a comment on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only URL: https://github.com/apache/spark/pull/25834#issuecomment-532978569 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only
AmplabJenkins removed a comment on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only URL: https://github.com/apache/spark/pull/25834#issuecomment-532978575 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16077/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only
AmplabJenkins commented on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only URL: https://github.com/apache/spark/pull/25834#issuecomment-532978575 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16077/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only
AmplabJenkins commented on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only URL: https://github.com/apache/spark/pull/25834#issuecomment-532978569 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT
AmplabJenkins removed a comment on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT URL: https://github.com/apache/spark/pull/25835#issuecomment-532978425 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT
AmplabJenkins removed a comment on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT URL: https://github.com/apache/spark/pull/25835#issuecomment-532978435 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110953/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT
AmplabJenkins commented on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT URL: https://github.com/apache/spark/pull/25835#issuecomment-532978425 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only
SparkQA commented on issue #25834: [WIP][SPARK-29155][SQL] Support special date/timestamp values in the PostgreSQL dialect only URL: https://github.com/apache/spark/pull/25834#issuecomment-532978223 **[Test build #110973 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110973/testReport)** for PR 25834 at commit [`b8ed08b`](https://github.com/apache/spark/commit/b8ed08b53655648caeb5df19f2ae6c90d62f63ec). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT
AmplabJenkins commented on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT URL: https://github.com/apache/spark/pull/25835#issuecomment-532978435 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110953/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT
SparkQA removed a comment on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT URL: https://github.com/apache/spark/pull/25835#issuecomment-532922053 **[Test build #110953 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110953/testReport)** for PR 25835 at commit [`d836138`](https://github.com/apache/spark/commit/d836138d256bf0b429cab7d6706547d4b2bc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on a change in pull request #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
sarutak commented on a change in pull request #25846: [SPARK-29168][WebUI] Fix
the appearance issue on timeline view
URL: https://github.com/apache/spark/pull/25846#discussion_r325998724
##
File path: core/src/main/resources/org/apache/spark/ui/static/timeline-view.css
##
@@ -223,8 +223,8 @@ rect.getting-result-time-proportion {
}
.vis-timeline .vis-item.executor.vis-selected {
- background-color: #A2FCC0;
- border-color: #36F572;
+ background-color: #A0DFFF;
+ border-color: #3EC0FF;
z-index: 2;
}
Review comment:
How about just removing this directive rather than modifying the color
settings?
I've tried removing it and seems to works fine.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT
SparkQA commented on issue #25835: [SPARK-29165][SQL][TEST] Set log level of log generated code as ERROR in case of compile error on generated code in UT URL: https://github.com/apache/spark/pull/25835#issuecomment-532977764 **[Test build #110953 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110953/testReport)** for PR 25835 at commit [`d836138`](https://github.com/apache/spark/commit/d836138d256bf0b429cab7d6706547d4b2bc). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-532975834 @cloud-fan I noticed that three hive-thriftserver related tests were failing after this change because of `SELECT current_database()`. Basically it was getting current database from `SessionCatalog` directly. https://github.com/apache/spark/blob/c1bb3316bd7e992897ebb48f7f648194db4d06f1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/finishAnalysis.scala#L81-L85 The fix is to use the `currentNamespace` from `CatalogManager`, but I wasn't sure what the best way to pass the `CatalogManger` around. I can just change `Optimizer` to take in `CatalogManager` instead of `SessionCatalog`. What do you think? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on issue #25708: [SPARK-28141][SQL] Support special date values
MaxGekk commented on issue #25708: [SPARK-28141][SQL] Support special date values URL: https://github.com/apache/spark/pull/25708#issuecomment-532975906 I have rebased this on the master with merged https://github.com/apache/spark/pull/25716 . @HyukjinKwon Could you take a look at this, please. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#discussion_r325994572 ## File path: sql/core/benchmarks/DataSourceReadBenchmark-results.txt ## @@ -2,251 +2,251 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26366 / 26562 0.6 1676.3 1.0X -SQL Json 8709 / 8724 1.8 553.7 3.0X -SQL Parquet Vectorized 166 / 187 94.8 10.5 159.0X -SQL Parquet MR1706 / 1720 9.2 108.4 15.5X -SQL ORC Vectorized 167 / 174 94.2 10.6 157.9X -SQL ORC MR1433 / 1465 11.0 91.1 18.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 200 / 207 78.7 12.7 1.0X -ParquetReader Vectorized -> Row117 / 119134.7 7.4 1.7X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26489 / 26547 0.6 1684.1 1.0X -SQL Json 8990 / 8998 1.7 571.5 2.9X -SQL Parquet Vectorized 209 / 221 75.1 13.3 126.5X -SQL Parquet MR1949 / 1949 8.1 123.9 13.6X -SQL ORC Vectorized 221 / 228 71.3 14.0 120.1X -SQL ORC MR1527 / 1549 10.3 97.1 17.3X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 286 / 296 54.9 18.2 1.0X -ParquetReader Vectorized -> Row249 / 253 63.1 15.8 1.1X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 27701 / 27744 0.6 1761.2 1.0X -SQL Json 9703 / 9733 1.6 616.9 2.9X -SQL Parquet Vectorized 176 / 182 89.2 11.2 157.0X -SQL Parquet MR2164 / 2173 7.3 137.6 12.8X -SQL ORC Vectorized 307 / 314 51.2 19.5 90.2X -SQL ORC MR1690 / 1700 9.3 107.4 16.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 259 / 277 60.7 16.5 1.0X -ParquetReader Vectorized -> Row261 / 265 60.3 16.6 1.0X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single BIGINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative
[GitHub] [spark] MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#discussion_r325994572 ## File path: sql/core/benchmarks/DataSourceReadBenchmark-results.txt ## @@ -2,251 +2,251 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26366 / 26562 0.6 1676.3 1.0X -SQL Json 8709 / 8724 1.8 553.7 3.0X -SQL Parquet Vectorized 166 / 187 94.8 10.5 159.0X -SQL Parquet MR1706 / 1720 9.2 108.4 15.5X -SQL ORC Vectorized 167 / 174 94.2 10.6 157.9X -SQL ORC MR1433 / 1465 11.0 91.1 18.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 200 / 207 78.7 12.7 1.0X -ParquetReader Vectorized -> Row117 / 119134.7 7.4 1.7X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26489 / 26547 0.6 1684.1 1.0X -SQL Json 8990 / 8998 1.7 571.5 2.9X -SQL Parquet Vectorized 209 / 221 75.1 13.3 126.5X -SQL Parquet MR1949 / 1949 8.1 123.9 13.6X -SQL ORC Vectorized 221 / 228 71.3 14.0 120.1X -SQL ORC MR1527 / 1549 10.3 97.1 17.3X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 286 / 296 54.9 18.2 1.0X -ParquetReader Vectorized -> Row249 / 253 63.1 15.8 1.1X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 27701 / 27744 0.6 1761.2 1.0X -SQL Json 9703 / 9733 1.6 616.9 2.9X -SQL Parquet Vectorized 176 / 182 89.2 11.2 157.0X -SQL Parquet MR2164 / 2173 7.3 137.6 12.8X -SQL ORC Vectorized 307 / 314 51.2 19.5 90.2X -SQL ORC MR1690 / 1700 9.3 107.4 16.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 259 / 277 60.7 16.5 1.0X -ParquetReader Vectorized -> Row261 / 265 60.3 16.6 1.0X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single BIGINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative
[GitHub] [spark] gatorsmile closed pull request #25693: [SPARK-28989][SQL] Add a SQLConf `spark.sql.ansi.enabled`
gatorsmile closed pull request #25693: [SPARK-28989][SQL] Add a SQLConf `spark.sql.ansi.enabled` URL: https://github.com/apache/spark/pull/25693 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on issue #25693: [SPARK-28989][SQL] Add a SQLConf `spark.sql.ansi.enabled`
gatorsmile commented on issue #25693: [SPARK-28989][SQL] Add a SQLConf `spark.sql.ansi.enabled` URL: https://github.com/apache/spark/pull/25693#issuecomment-532972576 LGTM Thanks! Merged to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
dongjoon-hyun commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#discussion_r325994228 ## File path: sql/core/benchmarks/DataSourceReadBenchmark-results.txt ## @@ -2,251 +2,251 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26366 / 26562 0.6 1676.3 1.0X -SQL Json 8709 / 8724 1.8 553.7 3.0X -SQL Parquet Vectorized 166 / 187 94.8 10.5 159.0X -SQL Parquet MR1706 / 1720 9.2 108.4 15.5X -SQL ORC Vectorized 167 / 174 94.2 10.6 157.9X -SQL ORC MR1433 / 1465 11.0 91.1 18.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 200 / 207 78.7 12.7 1.0X -ParquetReader Vectorized -> Row117 / 119134.7 7.4 1.7X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26489 / 26547 0.6 1684.1 1.0X -SQL Json 8990 / 8998 1.7 571.5 2.9X -SQL Parquet Vectorized 209 / 221 75.1 13.3 126.5X -SQL Parquet MR1949 / 1949 8.1 123.9 13.6X -SQL ORC Vectorized 221 / 228 71.3 14.0 120.1X -SQL ORC MR1527 / 1549 10.3 97.1 17.3X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 286 / 296 54.9 18.2 1.0X -ParquetReader Vectorized -> Row249 / 253 63.1 15.8 1.1X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 27701 / 27744 0.6 1761.2 1.0X -SQL Json 9703 / 9733 1.6 616.9 2.9X -SQL Parquet Vectorized 176 / 182 89.2 11.2 157.0X -SQL Parquet MR2164 / 2173 7.3 137.6 12.8X -SQL ORC Vectorized 307 / 314 51.2 19.5 90.2X -SQL ORC MR1690 / 1700 9.3 107.4 16.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 259 / 277 60.7 16.5 1.0X -ParquetReader Vectorized -> Row261 / 265 60.3 16.6 1.0X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single BIGINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative
[GitHub] [spark] MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#discussion_r325994058 ## File path: sql/core/benchmarks/DataSourceReadBenchmark-results.txt ## @@ -2,251 +2,251 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26366 / 26562 0.6 1676.3 1.0X -SQL Json 8709 / 8724 1.8 553.7 3.0X -SQL Parquet Vectorized 166 / 187 94.8 10.5 159.0X -SQL Parquet MR1706 / 1720 9.2 108.4 15.5X -SQL ORC Vectorized 167 / 174 94.2 10.6 157.9X -SQL ORC MR1433 / 1465 11.0 91.1 18.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 200 / 207 78.7 12.7 1.0X -ParquetReader Vectorized -> Row117 / 119134.7 7.4 1.7X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26489 / 26547 0.6 1684.1 1.0X -SQL Json 8990 / 8998 1.7 571.5 2.9X -SQL Parquet Vectorized 209 / 221 75.1 13.3 126.5X -SQL Parquet MR1949 / 1949 8.1 123.9 13.6X -SQL ORC Vectorized 221 / 228 71.3 14.0 120.1X -SQL ORC MR1527 / 1549 10.3 97.1 17.3X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 286 / 296 54.9 18.2 1.0X -ParquetReader Vectorized -> Row249 / 253 63.1 15.8 1.1X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 27701 / 27744 0.6 1761.2 1.0X -SQL Json 9703 / 9733 1.6 616.9 2.9X -SQL Parquet Vectorized 176 / 182 89.2 11.2 157.0X -SQL Parquet MR2164 / 2173 7.3 137.6 12.8X -SQL ORC Vectorized 307 / 314 51.2 19.5 90.2X -SQL ORC MR1690 / 1700 9.3 107.4 16.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 259 / 277 60.7 16.5 1.0X -ParquetReader Vectorized -> Row261 / 265 60.3 16.6 1.0X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single BIGINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative
[GitHub] [spark] HyukjinKwon commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
HyukjinKwon commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845#issuecomment-532971687 @HeartSaVioR, if you concern about compatibility, you could leave a note in migration guide at https://github.com/apache/spark/blob/master/docs/core-migration-guide.md . I guess most of machines use UTF-8 by default though. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532971416 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16076/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532971411 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532971416 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16076/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532971411 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
SparkQA commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532971146 **[Test build #110972 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110972/testReport)** for PR 25846 at commit [`41ac897`](https://github.com/apache/spark/commit/41ac8975d11f42b2de5eac54fae2063123c8a337). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #25802: [SPARK-29095][ML] add extractInstances
zhengruifeng commented on a change in pull request #25802: [SPARK-29095][ML]
add extractInstances
URL: https://github.com/apache/spark/pull/25802#discussion_r325993291
##
File path: mllib/src/main/scala/org/apache/spark/ml/Predictor.scala
##
@@ -62,6 +62,40 @@ private[ml] trait PredictorParams extends Params
}
SchemaUtils.appendColumn(schema, $(predictionCol), DoubleType)
}
+
+ /**
+ * Extract [[labelCol]], weightCol(if any) and [[featuresCol]] from the
given dataset,
+ * and put it in an RDD with strong types.
+ */
+ protected def extractInstances(dataset: Dataset[_]): RDD[Instance] = {
+val w = this match {
+ case p: HasWeightCol =>
+if (isDefined(p.weightCol) && $(p.weightCol).nonEmpty) {
+ col($(p.weightCol)).cast(DoubleType)
+} else {
+ lit(1.0)
+}
+ case _ => lit(1.0)
Review comment:
You are right, if an alg do not have `weightCol`, it should not deal with
weighting.
So, what about raising an exception instead of assign it to 1.0?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
MaxGekk commented on a change in pull request #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#discussion_r325993197 ## File path: sql/core/benchmarks/DataSourceReadBenchmark-results.txt ## @@ -2,251 +2,251 @@ SQL Single Numeric Column Scan -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26366 / 26562 0.6 1676.3 1.0X -SQL Json 8709 / 8724 1.8 553.7 3.0X -SQL Parquet Vectorized 166 / 187 94.8 10.5 159.0X -SQL Parquet MR1706 / 1720 9.2 108.4 15.5X -SQL ORC Vectorized 167 / 174 94.2 10.6 157.9X -SQL ORC MR1433 / 1465 11.0 91.1 18.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single TINYINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 200 / 207 78.7 12.7 1.0X -ParquetReader Vectorized -> Row117 / 119134.7 7.4 1.7X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 26489 / 26547 0.6 1684.1 1.0X -SQL Json 8990 / 8998 1.7 571.5 2.9X -SQL Parquet Vectorized 209 / 221 75.1 13.3 126.5X -SQL Parquet MR1949 / 1949 8.1 123.9 13.6X -SQL ORC Vectorized 221 / 228 71.3 14.0 120.1X -SQL ORC MR1527 / 1549 10.3 97.1 17.3X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single SMALLINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 286 / 296 54.9 18.2 1.0X -ParquetReader Vectorized -> Row249 / 253 63.1 15.8 1.1X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -SQL CSV 27701 / 27744 0.6 1761.2 1.0X -SQL Json 9703 / 9733 1.6 616.9 2.9X -SQL Parquet Vectorized 176 / 182 89.2 11.2 157.0X -SQL Parquet MR2164 / 2173 7.3 137.6 12.8X -SQL ORC Vectorized 307 / 314 51.2 19.5 90.2X -SQL ORC MR1690 / 1700 9.3 107.4 16.4X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -Parquet Reader Single INT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative - -ParquetReader Vectorized 259 / 277 60.7 16.5 1.0X -ParquetReader Vectorized -> Row261 / 265 60.3 16.6 1.0X - -OpenJDK 64-Bit Server VM 1.8.0_191-b12 on Linux 3.10.0-862.3.2.el7.x86_64 -Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz -SQL Single BIGINT Column Scan: Best/Avg Time(ms)Rate(M/s) Per Row(ns) Relative
[GitHub] [spark] dongjoon-hyun commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
dongjoon-hyun commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532970669 Thank you, @srowen and @HyukjinKwon . Since there is no other option, we had better merge this PR~ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
dongjoon-hyun edited a comment on issue #25836: [SPARK-29159][BUILD] Increase
ReservedCodeCacheSize to 1G
URL: https://github.com/apache/spark/pull/25836#issuecomment-532970077
@srowen . I took a look. `UseCodeCacheFlushing` was introduced at JDK6 by
default `false`, but was changed at JDK7 by default `true`. We are already
`true`. I checked with the following.
```
$ java -XX:+PrintFlagsFinal -version | grep UseCodeCacheFlushing
bool UseCodeCacheFlushing = true
{product}
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)
```
Oracle Website is also inconsistent.
-
https://docs.oracle.com/javase/8/embedded/develop-apps-platforms/codecache.htm
1. In the table, the default value is `false`.
2. In the sentence, the default value is `true`.
> The UseCodeCacheFlushing option turns codecache flushing on and off. By
default it is on. You can disable this feature by specifying
XX:-UseCodeCacheFlushing.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532969772 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
dongjoon-hyun commented on issue #25836: [SPARK-29159][BUILD] Increase
ReservedCodeCacheSize to 1G
URL: https://github.com/apache/spark/pull/25836#issuecomment-532970077
@srowen . I took a look. `UseCodeCacheFlushing` was introduced at JDK6 by
default `false`, but was changed at JDK7 by default `true`. We are already
`true`. I checked with the following.
```
$ java -XX:+PrintFlagsFinal -version | grep UseCodeCacheFlushing
bool UseCodeCacheFlushing = true
{product}
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
sarutak commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532970022 ok to test. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins removed a comment on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532969485 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532969772 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25214: [SPARK-28461][SQL] Pad Decimal numbers with trailing zeros to the scale of the column
wangyum commented on issue #25214: [SPARK-28461][SQL] Pad Decimal numbers with trailing zeros to the scale of the column URL: https://github.com/apache/spark/pull/25214#issuecomment-532969472 @tooptoop4 I think it's different things. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
AmplabJenkins commented on issue #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846#issuecomment-532969485 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern
dongjoon-hyun commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern URL: https://github.com/apache/spark/pull/25842#issuecomment-532968870 Thank you for review. I transformed the test cases, too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] TomokoKomiyama opened a new pull request #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view
TomokoKomiyama opened a new pull request #25846: [SPARK-29168][WebUI] Fix the appearance issue on timeline view URL: https://github.com/apache/spark/pull/25846 ### What changes were proposed in this pull request? Changed color settings in .vis-timeline .vis-item.executor.vis-selected (timeline-view.css) ### Why are the changes needed? In WebUI, executor bar's color changes blue to green with no meaning when you click it. [Before Click] 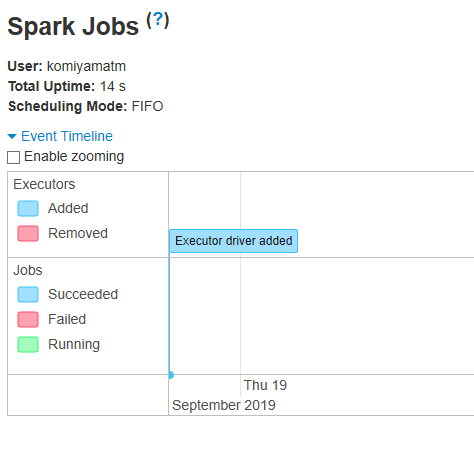 [After Click] 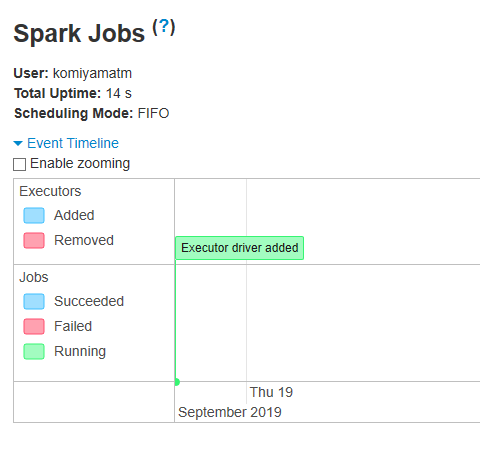 ### Does this PR introduce any user-facing change? No ### How was this patch tested? tested manually This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern
AmplabJenkins removed a comment on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern URL: https://github.com/apache/spark/pull/25842#issuecomment-532968476 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25844: [SPARK-29167][SQL] Make Metrics of Analyzer/Optimizer use Scientific counting human readable
AngersZh commented on a change in pull request #25844: [SPARK-29167][SQL]
Make Metrics of Analyzer/Optimizer use Scientific counting human readable
URL: https://github.com/apache/spark/pull/25844#discussion_r325991432
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules/QueryExecutionMetering.scala
##
@@ -85,10 +85,11 @@ case class QueryExecutionMetering() {
s"$ruleName $runtimeValue $numRunValue"
}.mkString("\n", "\n", "")
+val format = new java.text.DecimalFormat("#,##0.#")
s"""
|=== Metrics of Analyzer/Optimizer Rules ===
|Total number of runs: $totalNumRuns
- |Total time: ${totalTime / NANOS_PER_SECOND.toDouble} seconds
+ |Total time: ${format.format(totalTime / NANOS_PER_SECOND.toDouble)}
seconds
Review comment:
> How about this?
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/ui/UIUtils.scala#L50
`UIUtils.formatDuration(totalTime / NANOS_PER_MICROS)`
Use this method will lose precision, if you don's mind, it's ok.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern
AmplabJenkins removed a comment on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern URL: https://github.com/apache/spark/pull/25842#issuecomment-532968479 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16075/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern
AmplabJenkins commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern URL: https://github.com/apache/spark/pull/25842#issuecomment-532968479 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16075/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern
AmplabJenkins commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern URL: https://github.com/apache/spark/pull/25842#issuecomment-532968476 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern
SparkQA commented on issue #25842: [SPARK-28208][SQL][FOLLOWUP] Use `tryWithResource` pattern URL: https://github.com/apache/spark/pull/25842#issuecomment-532968268 **[Test build #110970 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110970/testReport)** for PR 25842 at commit [`9c20556`](https://github.com/apache/spark/commit/9c20556fa9705a9678826e01b0159fbea542d3da). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold
SparkQA commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold URL: https://github.com/apache/spark/pull/25829#issuecomment-532968269 **[Test build #110971 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110971/testReport)** for PR 25829 at commit [`190c3b8`](https://github.com/apache/spark/commit/190c3b891387e2a137964c0cc3b5670dede23a25). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325990343
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -60,22 +60,10 @@ object SimpleAnalyzer extends Analyzer(
},
new SQLConf().copy(SQLConf.CASE_SENSITIVE -> true))
-object FakeV2SessionCatalog extends TableCatalog {
+object FakeV2SessionCatalog extends CatalogPlugin {
private def fail() = throw new UnsupportedOperationException
- override def listTables(namespace: Array[String]): Array[Identifier] = fail()
- override def loadTable(ident: Identifier): Table = {
-throw new NoSuchTableException(ident.toString)
- }
- override def createTable(
- ident: Identifier,
- schema: StructType,
- partitions: Array[Transform],
- properties: util.Map[String, String]): Table = fail()
- override def alterTable(ident: Identifier, changes: TableChange*): Table =
fail()
- override def dropTable(ident: Identifier): Boolean = fail()
- override def renameTable(oldIdent: Identifier, newIdent: Identifier): Unit =
fail()
override def initialize(name: String, options: CaseInsensitiveStringMap):
Unit = fail()
- override def name(): String = fail()
+ override def name(): String = "fake_v2_session"
Review comment:
OK, I will change it. I thought it was more clear this way to indicate that
`FakeV2SessionCatalog` was being used instead of `V2SessionCatalog`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold
AmplabJenkins removed a comment on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold URL: https://github.com/apache/spark/pull/25829#issuecomment-532967138 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold
AmplabJenkins removed a comment on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold URL: https://github.com/apache/spark/pull/25829#issuecomment-532967140 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16074/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold
AmplabJenkins commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold URL: https://github.com/apache/spark/pull/25829#issuecomment-532967138 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold
AmplabJenkins commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold URL: https://github.com/apache/spark/pull/25829#issuecomment-532967140 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16074/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold
zhengruifeng commented on issue #25829: [SPARK-29144][ML] Binarizer handle sparse vectors incorrectly with negative threshold URL: https://github.com/apache/spark/pull/25829#issuecomment-532966941 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
AmplabJenkins removed a comment on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#issuecomment-532965921 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
AmplabJenkins removed a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532965987 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
AmplabJenkins removed a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532965992 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110957/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
AmplabJenkins removed a comment on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#issuecomment-532965925 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110947/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25844: [SPARK-29167][SQL] Make Metrics of Analyzer/Optimizer use Scientific counting human readable
maropu commented on a change in pull request #25844: [SPARK-29167][SQL] Make
Metrics of Analyzer/Optimizer use Scientific counting human readable
URL: https://github.com/apache/spark/pull/25844#discussion_r325989089
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules/QueryExecutionMetering.scala
##
@@ -85,10 +85,11 @@ case class QueryExecutionMetering() {
s"$ruleName $runtimeValue $numRunValue"
}.mkString("\n", "\n", "")
+val format = new java.text.DecimalFormat("#,##0.#")
s"""
|=== Metrics of Analyzer/Optimizer Rules ===
|Total number of runs: $totalNumRuns
- |Total time: ${totalTime / NANOS_PER_SECOND.toDouble} seconds
+ |Total time: ${format.format(totalTime / NANOS_PER_SECOND.toDouble)}
seconds
Review comment:
How about this?
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/ui/UIUtils.scala#L50
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
AmplabJenkins commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532965987 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
AmplabJenkins commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532965992 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110957/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532965766 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532965773 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16073/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
AmplabJenkins commented on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#issuecomment-532965925 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110947/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
AmplabJenkins commented on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#issuecomment-532965921 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
AmplabJenkins removed a comment on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845#issuecomment-532964191 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532965766 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
SparkQA removed a comment on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#issuecomment-532905800 **[Test build #110947 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110947/testReport)** for PR 25828 at commit [`9c665a6`](https://github.com/apache/spark/commit/9c665a6fe0a08304a61577da93179d7f1a09880e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532965773 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16073/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
SparkQA removed a comment on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532930208 **[Test build #110957 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110957/testReport)** for PR 25836 at commit [`04d2b61`](https://github.com/apache/spark/commit/04d2b616f0528b948d44bd324831a2471fb53b42). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
SparkQA commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532965537 **[Test build #110969 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110969/testReport)** for PR 25843 at commit [`c8d8ff5`](https://github.com/apache/spark/commit/c8d8ff5523c93dec6888c72492da7e9e4fd4c6aa). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G
SparkQA commented on issue #25836: [SPARK-29159][BUILD] Increase ReservedCodeCacheSize to 1G URL: https://github.com/apache/spark/pull/25836#issuecomment-532965604 **[Test build #110957 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110957/testReport)** for PR 25836 at commit [`04d2b61`](https://github.com/apache/spark/commit/04d2b616f0528b948d44bd324831a2471fb53b42). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks
SparkQA commented on issue #25828: [SPARK-29141][SQL][TEST] Use SqlBasedBenchmark in SQL benchmarks URL: https://github.com/apache/spark/pull/25828#issuecomment-532965588 **[Test build #110947 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110947/testReport)** for PR 25828 at commit [`9c665a6`](https://github.com/apache/spark/commit/9c665a6fe0a08304a61577da93179d7f1a09880e). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
SparkQA commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845#issuecomment-532965539 **[Test build #110968 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110968/testReport)** for PR 25845 at commit [`71bf026`](https://github.com/apache/spark/commit/71bf026586c81880941b31b4a771c2178564dfd2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS] Port window.sql (Part 1)
maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS] Port window.sql (Part 1) URL: https://github.com/apache/spark/pull/25816#discussion_r325983692 ## File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/window_part1.sql ## @@ -0,0 +1,343 @@ +-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group +-- +-- Window Functions Testing +-- https://github.com/postgres/postgres/blob/REL_12_BETA3/src/test/regress/sql/window.sql Review comment: Can you add line numbers?: https://github.com/apache/spark/blob/a6a663c4379390217443bc5b6f75873fb1c38c73/sql/core/src/test/resources/sql-tests/inputs/pgSQL/aggregates_part1.sql#L6 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS] Port window.sql (Part 1)
maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS]
Port window.sql (Part 1)
URL: https://github.com/apache/spark/pull/25816#discussion_r325988295
##
File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/window_part1.sql
##
@@ -0,0 +1,343 @@
+-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group
+--
+-- Window Functions Testing
+--
https://github.com/postgres/postgres/blob/REL_12_BETA3/src/test/regress/sql/window.sql
+
+CREATE TEMPORARY VIEW tenk2 AS SELECT * FROM tenk1;
+
+CREATE TABLE empsalary (
+depname string,
+empno integer,
+salary int,
+enroll_date date
+) USING parquet;
+
+INSERT INTO empsalary VALUES
+('develop', 10, 5200, '2007-08-01'),
+('sales', 1, 5000, '2006-10-01'),
+('personnel', 5, 3500, '2007-12-10'),
+('sales', 4, 4800, '2007-08-08'),
+('personnel', 2, 3900, '2006-12-23'),
+('develop', 7, 4200, '2008-01-01'),
+('develop', 9, 4500, '2008-01-01'),
+('sales', 3, 4800, '2007-08-01'),
+('develop', 8, 6000, '2006-10-01'),
+('develop', 11, 5200, '2007-08-15');
+
+SELECT depname, empno, salary, sum(salary) OVER (PARTITION BY depname) FROM
empsalary ORDER BY depname, salary;
+
+SELECT depname, empno, salary, rank() OVER (PARTITION BY depname ORDER BY
salary) FROM empsalary;
+
+-- with GROUP BY
+SELECT four, ten, SUM(SUM(four)) OVER (PARTITION BY four), AVG(ten) FROM tenk1
+GROUP BY four, ten ORDER BY four, ten;
+
+SELECT depname, empno, salary, sum(salary) OVER w FROM empsalary WINDOW w AS
(PARTITION BY depname);
+
+-- [SPARK-28064] Order by does not accept a call to rank()
+-- SELECT depname, empno, salary, rank() OVER w FROM empsalary WINDOW w AS
(PARTITION BY depname ORDER BY salary) ORDER BY rank() OVER w;
+
+-- empty window specification
+SELECT COUNT(*) OVER () FROM tenk1 WHERE unique2 < 10;
+
+SELECT COUNT(*) OVER w FROM tenk1 WHERE unique2 < 10 WINDOW w AS ();
+
+-- no window operation
+SELECT four FROM tenk1 WHERE FALSE WINDOW w AS (PARTITION BY ten);
+
+-- cumulative aggregate
+SELECT sum(four) OVER (PARTITION BY ten ORDER BY unique2) AS sum_1, ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT row_number() OVER (ORDER BY unique2) FROM tenk1 WHERE unique2 < 10;
+
+SELECT rank() OVER (PARTITION BY four ORDER BY ten) AS rank_1, ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT dense_rank() OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT percent_rank() OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT cume_dist() OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+SELECT ntile(3) OVER (ORDER BY ten, four), ten, four FROM tenk1 WHERE unique2
< 10;
+
+-- [SPARK-28065] ntile does not accept NULL as input
+-- SELECT ntile(NULL) OVER (ORDER BY ten, four), ten, four FROM tenk1 LIMIT 2;
+
+SELECT lag(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+-- [SPARK-28068] `lag` second argument must be a literal in Spark
+-- SELECT lag(ten, four) OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+-- [SPARK-28068] `lag` second argument must be a literal in Spark
+-- SELECT lag(ten, four, 0) OVER (PARTITION BY four ORDER BY ten), ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT lead(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+SELECT lead(ten * 2, 1) OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT lead(ten * 2, 1, -1) OVER (PARTITION BY four ORDER BY ten), ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT first(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+-- last returns the last row of the frame, which is CURRENT ROW in ORDER BY
window.
+SELECT last(four) OVER (ORDER BY ten), ten, four FROM tenk1 WHERE unique2 < 10;
+
+SELECT last(ten) OVER (PARTITION BY four), ten, four FROM
+(SELECT * FROM tenk1 WHERE unique2 < 10 ORDER BY four, ten)s
+ORDER BY four, ten;
+
+-- [SPARK-27951] ANSI SQL: NTH_VALUE function
+-- SELECT nth_value(ten, four + 1) OVER (PARTITION BY four), ten, four
+-- FROM (SELECT * FROM tenk1 WHERE unique2 < 10 ORDER BY four, ten)s;
+
+SELECT ten, two, sum(hundred) AS gsum, sum(sum(hundred)) OVER (PARTITION BY
two ORDER BY ten) AS wsum
+FROM tenk1 GROUP BY ten, two;
+
+SELECT count(*) OVER (PARTITION BY four), four FROM (SELECT * FROM tenk1 WHERE
two = 1)s WHERE unique2 < 10;
+
+SELECT (count(*) OVER (PARTITION BY four ORDER BY ten) +
+ sum(hundred) OVER (PARTITION BY four ORDER BY ten)) AS cntsum
+ FROM tenk1 WHERE unique2 < 10;
+
+-- opexpr with different windows evaluation.
+SELECT * FROM(
+ SELECT count(*) OVER (PARTITION BY four ORDER BY ten) +
+sum(hundred) OVER (PARTITION BY two ORDER BY ten) AS total,
+count(*) OVER (PARTITION BY four ORDER BY ten) AS fourcount,
+sum(hundred) OVER (PARTITION BY two ORDER BY ten) AS twosum
+FROM tenk1
+)sub
[GitHub] [spark] maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS] Port window.sql (Part 1)
maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS]
Port window.sql (Part 1)
URL: https://github.com/apache/spark/pull/25816#discussion_r325987766
##
File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/window_part1.sql
##
@@ -0,0 +1,343 @@
+-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group
+--
+-- Window Functions Testing
+--
https://github.com/postgres/postgres/blob/REL_12_BETA3/src/test/regress/sql/window.sql
+
+CREATE TEMPORARY VIEW tenk2 AS SELECT * FROM tenk1;
+
+CREATE TABLE empsalary (
+depname string,
+empno integer,
+salary int,
+enroll_date date
+) USING parquet;
+
+INSERT INTO empsalary VALUES
+('develop', 10, 5200, '2007-08-01'),
+('sales', 1, 5000, '2006-10-01'),
+('personnel', 5, 3500, '2007-12-10'),
+('sales', 4, 4800, '2007-08-08'),
+('personnel', 2, 3900, '2006-12-23'),
+('develop', 7, 4200, '2008-01-01'),
+('develop', 9, 4500, '2008-01-01'),
+('sales', 3, 4800, '2007-08-01'),
+('develop', 8, 6000, '2006-10-01'),
+('develop', 11, 5200, '2007-08-15');
+
+SELECT depname, empno, salary, sum(salary) OVER (PARTITION BY depname) FROM
empsalary ORDER BY depname, salary;
+
+SELECT depname, empno, salary, rank() OVER (PARTITION BY depname ORDER BY
salary) FROM empsalary;
+
+-- with GROUP BY
+SELECT four, ten, SUM(SUM(four)) OVER (PARTITION BY four), AVG(ten) FROM tenk1
+GROUP BY four, ten ORDER BY four, ten;
+
+SELECT depname, empno, salary, sum(salary) OVER w FROM empsalary WINDOW w AS
(PARTITION BY depname);
+
+-- [SPARK-28064] Order by does not accept a call to rank()
+-- SELECT depname, empno, salary, rank() OVER w FROM empsalary WINDOW w AS
(PARTITION BY depname ORDER BY salary) ORDER BY rank() OVER w;
+
+-- empty window specification
+SELECT COUNT(*) OVER () FROM tenk1 WHERE unique2 < 10;
+
+SELECT COUNT(*) OVER w FROM tenk1 WHERE unique2 < 10 WINDOW w AS ();
+
+-- no window operation
+SELECT four FROM tenk1 WHERE FALSE WINDOW w AS (PARTITION BY ten);
+
+-- cumulative aggregate
+SELECT sum(four) OVER (PARTITION BY ten ORDER BY unique2) AS sum_1, ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT row_number() OVER (ORDER BY unique2) FROM tenk1 WHERE unique2 < 10;
+
+SELECT rank() OVER (PARTITION BY four ORDER BY ten) AS rank_1, ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT dense_rank() OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT percent_rank() OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT cume_dist() OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+SELECT ntile(3) OVER (ORDER BY ten, four), ten, four FROM tenk1 WHERE unique2
< 10;
+
+-- [SPARK-28065] ntile does not accept NULL as input
+-- SELECT ntile(NULL) OVER (ORDER BY ten, four), ten, four FROM tenk1 LIMIT 2;
+
+SELECT lag(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+-- [SPARK-28068] `lag` second argument must be a literal in Spark
+-- SELECT lag(ten, four) OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+-- [SPARK-28068] `lag` second argument must be a literal in Spark
+-- SELECT lag(ten, four, 0) OVER (PARTITION BY four ORDER BY ten), ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT lead(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+SELECT lead(ten * 2, 1) OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT lead(ten * 2, 1, -1) OVER (PARTITION BY four ORDER BY ten), ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT first(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+-- last returns the last row of the frame, which is CURRENT ROW in ORDER BY
window.
+SELECT last(four) OVER (ORDER BY ten), ten, four FROM tenk1 WHERE unique2 < 10;
+
+SELECT last(ten) OVER (PARTITION BY four), ten, four FROM
+(SELECT * FROM tenk1 WHERE unique2 < 10 ORDER BY four, ten)s
+ORDER BY four, ten;
+
+-- [SPARK-27951] ANSI SQL: NTH_VALUE function
+-- SELECT nth_value(ten, four + 1) OVER (PARTITION BY four), ten, four
+-- FROM (SELECT * FROM tenk1 WHERE unique2 < 10 ORDER BY four, ten)s;
+
+SELECT ten, two, sum(hundred) AS gsum, sum(sum(hundred)) OVER (PARTITION BY
two ORDER BY ten) AS wsum
+FROM tenk1 GROUP BY ten, two;
+
+SELECT count(*) OVER (PARTITION BY four), four FROM (SELECT * FROM tenk1 WHERE
two = 1)s WHERE unique2 < 10;
+
+SELECT (count(*) OVER (PARTITION BY four ORDER BY ten) +
+ sum(hundred) OVER (PARTITION BY four ORDER BY ten)) AS cntsum
+ FROM tenk1 WHERE unique2 < 10;
+
+-- opexpr with different windows evaluation.
+SELECT * FROM(
+ SELECT count(*) OVER (PARTITION BY four ORDER BY ten) +
+sum(hundred) OVER (PARTITION BY two ORDER BY ten) AS total,
+count(*) OVER (PARTITION BY four ORDER BY ten) AS fourcount,
+sum(hundred) OVER (PARTITION BY two ORDER BY ten) AS twosum
+FROM tenk1
+)sub
[GitHub] [spark] maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS] Port window.sql (Part 1)
maropu commented on a change in pull request #25816: [SPARK-29107][SQL][TESTS]
Port window.sql (Part 1)
URL: https://github.com/apache/spark/pull/25816#discussion_r325986810
##
File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/window_part1.sql
##
@@ -0,0 +1,343 @@
+-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group
+--
+-- Window Functions Testing
+--
https://github.com/postgres/postgres/blob/REL_12_BETA3/src/test/regress/sql/window.sql
+
+CREATE TEMPORARY VIEW tenk2 AS SELECT * FROM tenk1;
+
+CREATE TABLE empsalary (
+depname string,
+empno integer,
+salary int,
+enroll_date date
+) USING parquet;
+
+INSERT INTO empsalary VALUES
+('develop', 10, 5200, '2007-08-01'),
+('sales', 1, 5000, '2006-10-01'),
+('personnel', 5, 3500, '2007-12-10'),
+('sales', 4, 4800, '2007-08-08'),
+('personnel', 2, 3900, '2006-12-23'),
+('develop', 7, 4200, '2008-01-01'),
+('develop', 9, 4500, '2008-01-01'),
+('sales', 3, 4800, '2007-08-01'),
+('develop', 8, 6000, '2006-10-01'),
+('develop', 11, 5200, '2007-08-15');
+
+SELECT depname, empno, salary, sum(salary) OVER (PARTITION BY depname) FROM
empsalary ORDER BY depname, salary;
+
+SELECT depname, empno, salary, rank() OVER (PARTITION BY depname ORDER BY
salary) FROM empsalary;
+
+-- with GROUP BY
+SELECT four, ten, SUM(SUM(four)) OVER (PARTITION BY four), AVG(ten) FROM tenk1
+GROUP BY four, ten ORDER BY four, ten;
+
+SELECT depname, empno, salary, sum(salary) OVER w FROM empsalary WINDOW w AS
(PARTITION BY depname);
+
+-- [SPARK-28064] Order by does not accept a call to rank()
+-- SELECT depname, empno, salary, rank() OVER w FROM empsalary WINDOW w AS
(PARTITION BY depname ORDER BY salary) ORDER BY rank() OVER w;
+
+-- empty window specification
+SELECT COUNT(*) OVER () FROM tenk1 WHERE unique2 < 10;
+
+SELECT COUNT(*) OVER w FROM tenk1 WHERE unique2 < 10 WINDOW w AS ();
+
+-- no window operation
+SELECT four FROM tenk1 WHERE FALSE WINDOW w AS (PARTITION BY ten);
+
+-- cumulative aggregate
+SELECT sum(four) OVER (PARTITION BY ten ORDER BY unique2) AS sum_1, ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT row_number() OVER (ORDER BY unique2) FROM tenk1 WHERE unique2 < 10;
+
+SELECT rank() OVER (PARTITION BY four ORDER BY ten) AS rank_1, ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT dense_rank() OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT percent_rank() OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT cume_dist() OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+SELECT ntile(3) OVER (ORDER BY ten, four), ten, four FROM tenk1 WHERE unique2
< 10;
+
+-- [SPARK-28065] ntile does not accept NULL as input
+-- SELECT ntile(NULL) OVER (ORDER BY ten, four), ten, four FROM tenk1 LIMIT 2;
+
+SELECT lag(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+-- [SPARK-28068] `lag` second argument must be a literal in Spark
+-- SELECT lag(ten, four) OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+-- [SPARK-28068] `lag` second argument must be a literal in Spark
+-- SELECT lag(ten, four, 0) OVER (PARTITION BY four ORDER BY ten), ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT lead(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+SELECT lead(ten * 2, 1) OVER (PARTITION BY four ORDER BY ten), ten, four FROM
tenk1 WHERE unique2 < 10;
+
+SELECT lead(ten * 2, 1, -1) OVER (PARTITION BY four ORDER BY ten), ten, four
FROM tenk1 WHERE unique2 < 10;
+
+SELECT first(ten) OVER (PARTITION BY four ORDER BY ten), ten, four FROM tenk1
WHERE unique2 < 10;
+
+-- last returns the last row of the frame, which is CURRENT ROW in ORDER BY
window.
+SELECT last(four) OVER (ORDER BY ten), ten, four FROM tenk1 WHERE unique2 < 10;
+
+SELECT last(ten) OVER (PARTITION BY four), ten, four FROM
+(SELECT * FROM tenk1 WHERE unique2 < 10 ORDER BY four, ten)s
+ORDER BY four, ten;
+
+-- [SPARK-27951] ANSI SQL: NTH_VALUE function
+-- SELECT nth_value(ten, four + 1) OVER (PARTITION BY four), ten, four
+-- FROM (SELECT * FROM tenk1 WHERE unique2 < 10 ORDER BY four, ten)s;
+
+SELECT ten, two, sum(hundred) AS gsum, sum(sum(hundred)) OVER (PARTITION BY
two ORDER BY ten) AS wsum
+FROM tenk1 GROUP BY ten, two;
+
+SELECT count(*) OVER (PARTITION BY four), four FROM (SELECT * FROM tenk1 WHERE
two = 1)s WHERE unique2 < 10;
+
+SELECT (count(*) OVER (PARTITION BY four ORDER BY ten) +
+ sum(hundred) OVER (PARTITION BY four ORDER BY ten)) AS cntsum
+ FROM tenk1 WHERE unique2 < 10;
+
+-- opexpr with different windows evaluation.
+SELECT * FROM(
+ SELECT count(*) OVER (PARTITION BY four ORDER BY ten) +
+sum(hundred) OVER (PARTITION BY two ORDER BY ten) AS total,
+count(*) OVER (PARTITION BY four ORDER BY ten) AS fourcount,
+sum(hundred) OVER (PARTITION BY two ORDER BY ten) AS twosum
+FROM tenk1
+)sub
[GitHub] [spark] dongjoon-hyun commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
dongjoon-hyun commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532964914 Retest this please. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25841: [SPARK-28683][BUILD][FOLLOW-UP][2.4] Fix javadoc generation issue after upgrading genjavadoc to 0.14
dongjoon-hyun closed pull request #25841: [SPARK-28683][BUILD][FOLLOW-UP][2.4] Fix javadoc generation issue after upgrading genjavadoc to 0.14 URL: https://github.com/apache/spark/pull/25841 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
HeartSaVioR commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845#issuecomment-532964896 We might be able to remedy the backward incompatible change via having new option to let ReplayListenerBus use default character set to read file, though I'm not 100% sure it's a good workaround. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325987967
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -60,22 +60,10 @@ object SimpleAnalyzer extends Analyzer(
},
new SQLConf().copy(SQLConf.CASE_SENSITIVE -> true))
-object FakeV2SessionCatalog extends TableCatalog {
+object FakeV2SessionCatalog extends CatalogPlugin {
private def fail() = throw new UnsupportedOperationException
- override def listTables(namespace: Array[String]): Array[Identifier] = fail()
- override def loadTable(ident: Identifier): Table = {
-throw new NoSuchTableException(ident.toString)
- }
- override def createTable(
- ident: Identifier,
- schema: StructType,
- partitions: Array[Transform],
- properties: util.Map[String, String]): Table = fail()
- override def alterTable(ident: Identifier, changes: TableChange*): Table =
fail()
- override def dropTable(ident: Identifier): Boolean = fail()
- override def renameTable(oldIdent: Identifier, newIdent: Identifier): Unit =
fail()
override def initialize(name: String, options: CaseInsensitiveStringMap):
Unit = fail()
- override def name(): String = fail()
+ override def name(): String = "fake_v2_session"
Review comment:
so that you don't need to rely on the fake name at
https://github.com/apache/spark/pull/25771/files#diff-c3084f55edbba87c6eca641c135a2e79R32
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25841: [SPARK-28683][BUILD][FOLLOW-UP][2.4] Fix javadoc generation issue after upgrading genjavadoc to 0.14
dongjoon-hyun commented on issue #25841: [SPARK-28683][BUILD][FOLLOW-UP][2.4] Fix javadoc generation issue after upgrading genjavadoc to 0.14 URL: https://github.com/apache/spark/pull/25841#issuecomment-532964585 I'll merge this because this is verified manually and currently blocks the other backporting PR. Merged to branch-2.4. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
AmplabJenkins commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845#issuecomment-532964191 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
HeartSaVioR commented on issue #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845#issuecomment-532964064 As I commented in `Does this PR introduce any user-facing change?` section, it may not be backward compatible change for some users. Please take this into consideration. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR opened a new pull request #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file
HeartSaVioR opened a new pull request #25845: [SPARK-29160][CORE] Use UTF-8 explicitly for reading/writing event log file URL: https://github.com/apache/spark/pull/25845 ### What changes were proposed in this pull request? Credit to @vanzin as he found and commented on this while reviewing #25670 - [comment](https://github.com/apache/spark/pull/25670#discussion_r325383512). This patch proposes to specify UTF-8 explicitly while reading/writer event log file. ### Why are the changes needed? The event log file is being read/written as default character set of JVM process which may open the chance to bring some problems on reading event log files from another machines. Spark's de facto standard character set is UFT-8, so it should be explicitly set to ### Does this PR introduce any user-facing change? Yes, if end users have been running Spark process with different default charset than "UTF-8", especially their driver JVM processes. No otherwise. ### How was this patch tested? Existing UTs, as ReplayListenerSuite contains "end-to-end" event logging/reading tests (both uncompressed/compressed). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25844: [SPARK-29167][SQL] Make Metrics of Analyzer/Optimizer use Scientific counting human readable
AngersZh commented on a change in pull request #25844: [SPARK-29167][SQL]
Make Metrics of Analyzer/Optimizer use Scientific counting human readable
URL: https://github.com/apache/spark/pull/25844#discussion_r325987334
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules/QueryExecutionMetering.scala
##
@@ -85,10 +85,11 @@ case class QueryExecutionMetering() {
s"$ruleName $runtimeValue $numRunValue"
}.mkString("\n", "\n", "")
+val format = new java.text.DecimalFormat("#,##0.#")
s"""
|=== Metrics of Analyzer/Optimizer Rules ===
|Total number of runs: $totalNumRuns
- |Total time: ${totalTime / NANOS_PER_SECOND.toDouble} seconds
+ |Total time: ${format.format(totalTime / NANOS_PER_SECOND.toDouble)}
seconds
Review comment:
> Just use `String.format`?
`String.format("%.9f, args)` can't handle extra 0 in the end.
Such as `String.format("%.9f, (100/ 10D))` = `0.000100`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty
AmplabJenkins removed a comment on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty URL: https://github.com/apache/spark/pull/25837#issuecomment-532962979 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110956/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty
AmplabJenkins removed a comment on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty URL: https://github.com/apache/spark/pull/25837#issuecomment-532962975 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty
AmplabJenkins commented on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty URL: https://github.com/apache/spark/pull/25837#issuecomment-532962975 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty
AmplabJenkins commented on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty URL: https://github.com/apache/spark/pull/25837#issuecomment-532962979 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110956/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty
SparkQA removed a comment on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty URL: https://github.com/apache/spark/pull/25837#issuecomment-532928842 **[Test build #110956 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110956/testReport)** for PR 25837 at commit [`769c1ee`](https://github.com/apache/spark/commit/769c1ee7aaf030b27e7293b19d9b6be08f77ad5c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty
SparkQA commented on issue #25837: [SPARK-29161][CORE][SQL][STREAMING] Unify default wait time for waitUntilEmpty URL: https://github.com/apache/spark/pull/25837#issuecomment-532962592 **[Test build #110956 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110956/testReport)** for PR 25837 at commit [`769c1ee`](https://github.com/apache/spark/commit/769c1ee7aaf030b27e7293b19d9b6be08f77ad5c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LantaoJin commented on a change in pull request #25840: [SPARK-29166][SQL] Add a parameter to limit the number of dynamic partitions for data source table
LantaoJin commented on a change in pull request #25840: [SPARK-29166][SQL] Add
a parameter to limit the number of dynamic partitions for data source table
URL: https://github.com/apache/spark/pull/25840#discussion_r325985789
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/SQLHadoopMapReduceCommitProtocol.scala
##
@@ -66,4 +68,18 @@ class SQLHadoopMapReduceCommitProtocol(
logInfo(s"Using output committer class
${committer.getClass.getCanonicalName}")
committer
}
+
+ override def newTaskTempFile(
+ taskContext: TaskAttemptContext, dir: Option[String], ext: String):
String = {
+val path = super.newTaskTempFile(taskContext, dir, ext)
+if (dynamicPartitionOverwrite) {
+ val numParts = partitionPaths.size
+ if (numParts > maxDynamicPartitions) {
Review comment:
Oh, you are right. `partitionPaths` may be similar to
`hive.exec.max.dynamic.partitions.pernode`. And the implementation of total
limitation has to add a `var totalPartitions: Int` for checking.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25022: [SPARK-24695][SQL] Move `CalendarInterval` to org.apache.spark.sql.types package
wangyum commented on issue #25022: [SPARK-24695][SQL] Move `CalendarInterval` to org.apache.spark.sql.types package URL: https://github.com/apache/spark/pull/25022#issuecomment-532961590 @MaxGekk WDYT? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #25817: [SPARK-29108][SQL][TESTS] Port window.sql (Part 2)
wangyum commented on issue #25817: [SPARK-29108][SQL][TESTS] Port window.sql (Part 2) URL: https://github.com/apache/spark/pull/25817#issuecomment-532960337 Yes. We also need to drop `numerics`: https://github.com/apache/spark/pull/25817/files#diff-67dcfa1c6f3eddf7e1f24e5cfa300302R205 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532959780 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110966/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532959777 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
SparkQA removed a comment on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532955059 **[Test build #110966 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110966/testReport)** for PR 25843 at commit [`c8d8ff5`](https://github.com/apache/spark/commit/c8d8ff5523c93dec6888c72492da7e9e4fd4c6aa). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532959777 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
SparkQA commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532959757 **[Test build #110966 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110966/testReport)** for PR 25843 at commit [`c8d8ff5`](https://github.com/apache/spark/commit/c8d8ff5523c93dec6888c72492da7e9e4fd4c6aa). * This patch **fails to generate documentation**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25843: [SPARK-29101][SQL][2.4] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25843#issuecomment-532959780 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110966/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org